Область техники, к которой относится изобретение
[001] Настоящая технология в целом относится к машинному переводу, а в частности - к способу и системе для формирования обучающего набора данных для обучения модели машинного обучения для перевода.
Уровень техники
[002] С увеличением количества пользователей сети Интернет возникло огромное количество интернет-сервисов. Такие сервисы, например, включают в себя поисковые системы (такие как поисковые системы Yandex™ и Google™), позволяющие пользователям получать информацию путем отправки запросов поисковой системе. Кроме того, благодаря социальным сетям и мультимедийным сервисам множество пользователей с разным социальным происхождением и разными культурными традициями могут общаться на унифицированных платформах с целью обмена контентом и информацией. Цифровой контент и другие данные, которыми обмениваются пользователи, могут быть представлены на множестве языков. При этом вследствие постоянно растущего объема информации, обмен которой осуществляется в сети Интернет, часто используются сервисы перевода, например, такие как Yandex.Translate™.
[003] Такой сервис особенно полезен, поскольку с его помощью пользователи могут легко переводить текст (или даже устную речь) с одного языка (т.е. с исходного языка), непонятного пользователю, на другой, понятный ему язык (т.е. на целевой язык). Это означает, что сервисы перевода обычно разрабатываются для предоставления переведенного варианта контента на понятном пользователю целевом языке, чтобы сделать контент доступным для пользователя.
[004] Системы перевода обычно содержат модель машинного обучения (ML, Machine-Learning) (далее называется ML-моделью перевода), которая обучается переводу текстов с исходного языка на целевой язык на основе большого количества примеров параллельных предложений на этих языках. При этом традиционные компьютерные системы, предоставляющие услуги перевода, по-прежнему имеют много недостатков, таких как неправильный перевод редких слов или слов, специфичных для конкретной области знаний.
[005] В частности, одна из проблем, связанных с обучением ML-модели перевода, заключается в том, что обучающие примеры параллельных предложений (т.е. пар, содержащих фразы на исходном языке и их переводы на целевом языке) обычно по меньшей мере частично сформированы другими ML-моделями перевода низкого качества. В результате данная ML-модель перевода может выучить неправильные соответствия между предложениями на исходном языке и на целевом языке, что приводит к формированию некачественных переводов.
[006] Для решения описанной выше технической проблемы предложены некоторые известные подходы.
[007] В патенте JP 5780670 B2 «Translation apparatus, method, and program, and translation model learning apparatus, method, and program» (Nippon Telegraph and Telephone Corp., выдан 16 сентября 2015 г.) описан обучающий элемент для предварительной обработки, формирующий перевод на промежуточном языке, в котором исходный язык заменяется с помощью словарей целевого языка с использованием близкого к исходному языку порядка слов. Первый обучающий элемент для перевода обучает первую модель перевода переводу с исходного языка в предложение промежуточного перевода с использованием корпуса параллельных текстов на исходном языке и на промежуточном языке. Последний обучающий элемент для перевода обучает последнюю модель перевода переводу предложения промежуточного перевода на целевой язык с использованием корпуса параллельных текстов на промежуточном языке и на целевом языке. Первый элемент для перевода соответствует первой модели перевода и переводит входное предложение в предложение промежуточного перевода. Последний элемент для перевода соответствует последней модели перевода и переводит предложение промежуточного перевода в предложение на целевом языке.
[008] В патентной заявке CN 114881051 A «Translation quality determination method, related device and computer program product» (Beijing Baidu Netcom Science and Technology Co Ltd., опубликована 9 августа 2022 г.) описан способ определения качества перевода. Способ включает в себя получение первого корпуса и второго корпуса, которые отличаются языком, но сходны по смысловому значению, замена ключевой информации во втором корпусе с использованием слов запроса, построение третьего корпуса, в котором структура предложения соответствует предложению запроса, формирование с использованием модели перевода четвертого корпуса, который соответствует смысловому значению первого корпуса, а по языку совпадает со вторым корпусом, определение в четвертом корпусе первой получаемой в результате информации, соответствующей запросу в третьем корпусе, формирование первой оценочной информации для оценивания качества перевода модели перевода на основе сходства между ключевой информацией и первой получаемой в результате информацией. Вариант осуществления изобретения обеспечивает способ определения качества перевода, при этом качество перевода модели перевода оценивается на основе способности понимания семантического уровня.
Раскрытие изобретения
[009] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений.
[010] Разработчики настоящей технологии установили, что качество обучающих примеров для обучения ML-модели перевода может быть повышено путем выявления в исходном и целевом корпусах текстов, используемых для формирования обучающих примеров, «непараллельных» предложений, т.е. тех, которые в отличие от «параллельных» предложений не соответствуют друг другу по значению на исходном и целевом языках и, следовательно, могут образовывать обучающие примеры неудовлетворительного качества.
[011] С этой целью в описанных здесь способах и системах используются две дополнительные ML-модели перевода. В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, (а) первая дополнительная ML-модель перевода обучена переводу текста с исходного языка на целевой язык и (б) вторая дополнительная ML-модель перевода, например, обучена переводу текста с исходного языка на промежуточный язык (отличный от исходного и от целевого языков) и с промежуточного языка на целевой язык.
[012] Таким образом, в по меньшей мере некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для формирования обучающих примеров предусмотрено следующее: (а) ввод исходного предложения из исходного корпуса текстов в первую и во вторую дополнительные ML-модели перевода для формирования первого варианта перевода и второго варианта перевода исходного предложения, соответственно; (б) определение для первого и второго вариантов перевода оценки достоверности, указывающей на их точность перевода; (в) определение того, превышает ли оценка из числа оценок достоверности, связанных с первым и вторым вариантами перевода, оценку достоверности, связанную с целевым предложением, которое первоначально соответствовало исходному предложению в целевом корпусе текстов. Если определено, что оценка из числа оценок достоверности, связанных с первым и вторым вариантами перевода исходного предложения, больше оценки достоверности, связанной с целевым предложением, то настоящие способы предусматривают замену в целевом корпусе текстов целевого предложения на первый или второй вариант перевода, связанный с большей оценкой достоверности.
[013] В результате, благодаря настоящим способам и системам, возможно уточнение целевого корпуса текстов с использованием предложений на целевом языке, которые ближе по смыслу к исходным предложениям. Затем уточненный таким образом корпус текстов может быть использован для формирования более качественных обучающих примеров для обучения ML-модели перевода, которая, в свою очередь, впоследствии способна обеспечивать более качественные переводы.
[014] В частности, согласно одному аспекту настоящей технологии реализован компьютерный способ формирования обучающего набора данных для обучения ML-модели перевода. Формирование включает в себя использование первой ML-модели перевода, предварительно обученной переводу текста с исходного языка на целевой язык, и второй ML-модели, предварительно обученной переводу текста с исходного языка на промежуточный язык и с промежуточного языка на целевой язык. Способ включает в себя: получение корпуса текстов на исходном языке, содержащего первое множество фраз на исходном языке, и корпуса текстов на целевом языке, содержащего второе множество фраз на целевом языке, при этом фраза на целевом языке из второго множества фраз представляет собой перевод фразы на исходном языке из первого множества фраз с исходного языка на целевой язык и связана с базовой оценкой достоверности, указывающей на точность перевода для фразы на целевом языке; ввод фразы на исходном языке в первую ML-модель перевода для формирования первого варианта перевода фразы на исходном языке на целевой язык и для формирования первой оценки достоверности, указывающей на точность перевода для первого варианта перевода; ввод фразы на исходном языке во вторую ML-модель перевода для формирования второго варианта перевода фразы на исходном языке на целевой язык и для формирования второй оценки достоверности, указывающей на точность перевода для второго варианта перевода; замену в корпусе на целевом языке фразы на целевом языке первым или вторым вариантом перевода фразы на исходном языке, если первая или вторая оценка достоверности превышает базовую оценку достоверности, связанную с фразой на целевом языке; формирование обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит фразу на исходном языке и первый или второй вариант перевода фразы на исходном языке; и обучение на основе обучающего набора данных ML-модели перевода переводу текста с исходного языка на целевой язык.
[015] В некоторых вариантах осуществления способа он дополнительно включает в себя сохранение фразы на целевом языке в корпусе на целевом языке, если первая и вторая оценки достоверности не превышают базовой оценки достоверности, связанной с фразой на целевом языке.
[016] В некоторых вариантах осуществления способа он дополнительно включает в себя определение базовой оценки достоверности, связанной с фразой на целевом языке.
[017] В некоторых вариантах осуществления способа определение базовой оценки достоверности включает в себя применение первой ML-модели перевода.
[018] В некоторых вариантах осуществления способа он дополнительно включает в себя использование третьей ML-модели перевода, предварительно обученной переводу текста с целевого языка на исходный язык, при этом формирование базовой, первой и второй оценок достоверности включает в себя: формирование прямой оценки достоверности для фразы на целевом языке, а также для первого и второго вариантов перевода фразы на исходном языке на целевой язык; ввод фразы на целевом языке, а также первого и второго вариантов перевода фразы на исходном языке в третью ML-модель перевода для формирования вариантов обратного перевода для фразы на целевом языке, связанной с фразой на исходном языке, на исходный язык и для формирования обратной оценки достоверности каждого варианта обратного перевода фразы на целевом языке на исходный язык; и объединение прямой и обратной оценок достоверности.
[019] В некоторых вариантах осуществления способа объединение включает в себя определение суммы прямого и обратного уровней достоверности.
[020] В некоторых вариантах осуществления способа ML-модель перевода отличается от первой и второй ML-моделей перевода.
[021] В некоторых вариантах осуществления способа ML-модель перевода представляет собой первую или вторую ML-модель перевода, а обучение ML-модели перевода включает в себя точную настройку первой или второй ML-модели перевода для перевода текста с исходного языка на целевой язык.
[022] В некоторых вариантах осуществления способа вторая ML-модель перевода содержит две ML-модели перевода: первую промежуточную ML-модель перевода, предварительно обученную переводу текста с исходного языка на промежуточный язык, и вторую промежуточную ML-модель перевода, предварительно обученную переводу текста с промежуточного языка на целевой язык.
[023] В некоторых вариантах осуществления способа первая или вторая ML-модель перевода представляет собой ML-модель на основе нейронной сети.
[024] В некоторых вариантах осуществления способа ML-модель на основе нейронной сети представляет собой ML-модель на основе трансформера.
[025] Согласно другому аспекту настоящей технологии реализован сервер для формирования обучающего набора данных для обучения ML-модели перевода. Формирование включает в себя использование первой ML-модели перевода, предварительно обученной переводу текста с исходного языка на целевой язык, и второй ML-модели, предварительно обученной переводу текста с исходного языка на промежуточный язык и с промежуточного языка на целевой язык. Сервер содержит по меньшей мере один процессор и по меньшей мере одну машиночитаемую физическую память, содержащую исполняемые команды, которые при их исполнении процессором инициируют выполнение сервером следующих действий: получение корпуса текстов на исходном языке, содержащего первое множество фраз на исходном языке, и корпуса текстов на целевом языке, содержащего второе множество фраз на целевом языке, при этом фраза на целевом языке из второго множества фраз представляет собой перевод фразы на исходном языке из первого множества фраз с исходного языка на целевой язык и связана с базовой оценкой достоверности, указывающей на точность перевода для фразы на целевом языке; ввод фразы на исходном языке в первую ML-модель перевода для формирования первого варианта перевода фразы на исходном языке на целевой язык и для формирования первой оценки достоверности, указывающей на точность перевода для первого варианта перевода; ввод фразы на исходном языке во вторую ML-модель перевода для формирования второго варианта перевода фразы на исходном языке на целевой язык и для формирования второй оценки достоверности, указывающей на точность перевода для второго варианта перевода; замена в корпусе на целевом языке фразы на целевом языке первым или вторым вариантом перевода фразы на исходном языке, если первая или вторая оценка достоверности превышает базовую оценку достоверности, связанную с фразой на целевом языке; формирование обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит фразу на исходном языке и первый или второй вариант перевода фразы на исходном языке; и обучение на основе обучающего набора данных ML-модели перевода переводу текста с исходного языка на целевой язык.
[026] В некоторых вариантах осуществления сервера по меньшей мере один процессор дополнительно инициирует сохранение сервером фразы на целевом языке в корпусе на целевом языке, если первая и вторая оценки достоверности не превышают базовой оценки достоверности, связанной с фразой на целевом языке.
[027] В некоторых вариантах осуществления сервера по меньшей мере один процессор дополнительно инициирует определение сервером базовой оценки достоверности, связанной с фразой на целевом языке.
[028] В некоторых вариантах осуществления сервера для определения базовой оценки достоверности по меньшей мере один процессор инициирует применение сервером первой ML-модели перевода.
[029] В некоторых вариантах осуществления сервера по меньшей мере один процессор дополнительно инициирует обращение сервера к третьей ML-модели перевода, предварительно обученной переводу текста с целевого языка на исходный язык, при этом для формирования базовой, первой и второй оценок достоверности по меньшей мере один процессор инициирует выполнение сервером следующих действий: формирование прямой оценки достоверности для фразы на целевом языке, а также для первого и второго вариантов перевода фразы на исходном языке на целевой язык; ввод фразы на целевом языке, а также первого и второго вариантов перевода фразы на исходном языке в третью ML-модель перевода для формирования вариантов обратного перевода фразы на целевом языке, связанной с фразой на исходном языке, на исходный язык и для формирования обратной оценки достоверности каждого варианта обратного перевода фразы на целевом языке на исходный язык; и объединение прямой и обратной оценок достоверности.
[030] В некоторых вариантах осуществления сервера для объединения прямой и обратной оценок достоверности по меньшей мере один процессор инициирует определение сервером суммы прямого и обратного уровней достоверности.
[031] В некоторых вариантах осуществления сервера ML-модель перевода отличается от первой и второй ML-моделей перевода.
[032] В некоторых вариантах осуществления сервера ML-модель перевода представляет собой первую или вторую ML-модель перевода, а обучение ML-модели перевода включает в себя точную настройку первой или второй ML-модели перевода для перевода текста с исходного языка на целевой язык.
[033] В некоторых вариантах осуществления сервера вторая ML-модель перевода содержит две ML-модели перевода: первую промежуточную ML-модель перевода, предварительно обученную переводу текста с исходного языка на промежуточный язык, и вторую промежуточную ML-модель перевода, предварительно обученную переводу текста с промежуточного языка на целевой язык.
[034] В контексте настоящего описания трансформерная модель представляет собой модель с архитектурой вида «кодер-декодер», в которой используются механизмы внимания. Механизмы внимания могут применяться при обработке данных кодером, при обработке данных декодером и при взаимодействиях кодер-декодер. В трансформерной модели может использоваться множество механизмов внимания.
[035] Один из компонентов трансформерной модели может представлять собой механизм самовнимания. Различие между механизмом внимания и механизмом самовнимания заключается в том, что механизм самовнимания работает между схожими представлениями, например, между всеми состояниями кодера в одном слое. Механизм самовнимания входит в состав трансформерной модели, в которой токены взаимодействуют друг с другом. Каждый токен, в известном смысле, «наблюдает» за другими токенами в предложении с помощью механизма внимания, собирает контекст и обновляет свое предыдущее представление. Каждый входной токен в механизме самовнимания получает три представления: запрос, ключ и значение. Запрос используется, когда токен наблюдает за другими токенами - он ищет информацию, чтобы лучше «понимать» себя. Ключ реагирует на запрос - он используется для расчета весов внимания. Значение используется для расчета выхода внимания - оно предоставляет информацию о токенах, которые сообщают, что им требуется внимание (т.е. этим токенам присваиваются большие веса).
[036] Другой компонент трансформерной модели может представлять собой механизм маскированного самовнимания. Декодер обычно содержит особый механизм самовнимания, который отличается от механизма самовнимания в кодере. Кодер получает все токены одновременно и токены могут наблюдать за всеми токенами во входном предложении, а в декодере токены формируются поодиночке, т.е. во время формирования модели неизвестно, какие токены будут сформированы в будущем. Чтобы запретить декодеру «забегать вперед», в трансформерной модели используется механизм маскированного самовнимания, т.е. будущие токены маскируются.
[037] Еще один компонент трансформерной модели может представлять собой механизм многоголового внимания. Следует отметить, что для понимания роли слова в предложении требуется понимание того, как оно связано с различными частями предложения. Это важно не только при обработке исходного предложения, но и при формировании целей. В результате благодаря механизму внимания этого вида трансформерная модель может «концентрироваться» на различных вещах. Механизм многоголового внимания вместо одного механизма внимания содержит несколько независимо работающих «голов». Он может быть реализован в виде нескольких механизмов внимания, результаты которых объединяются.
[038] Кодер трансформерной модели может содержать механизм самовнимания кодера и блок сети прямого распространения. Механизм самовнимания кодера может представлять собой механизм многоголового внимания, используемый для наблюдения токенами друг за другом. Запросы, ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[039] Декодер трансформерной модели может содержать механизм самовнимания (маскированного) декодера, механизм внимания декодер-кодер и сеть прямого распространения. Механизм маскированного самовнимания декодера может представлять собой механизм маскированного многоголового внимания, используемый для наблюдения токенами за предыдущими токенами. Запросы, ключи и значения рассчитываются на основе состояний декодера. Механизм внимания декодер-кодер может представлять собой механизм многоголового внимания, используемый для просмотра целевыми токенами исходной информации. Запросы рассчитываются на основе состояний декодера, а ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[040] Можно сказать, что токены в кодере поддерживают связь друг с другом и обновляют свои представления. Также можно сказать, что в декодере целевой токен сначала просматривает ранее сформированные целевые токены, затем источник и, наконец, обновляет свое представление. Это может повторяться в нескольких слоях. В одном не имеющем ограничительного характера варианте реализации изобретения это может повторяться шесть раз.
[041] Как упомянуто выше, в дополнение к механизму внимания слой содержит блок сети прямого распространения. Например, блок сети прямого распространения может быть представлен двумя линейными слоями с нелинейной связью вида «усеченное линейное преобразование» (ReLU, Rectifier Linear Unit) между ними. После просмотра других токенов с применением механизма внимания в модели используется блок сети прямого распространения для обработки этой новой информации. Трансформерная модель может дополнительно содержать остаточные связи для добавления входных данных блока к его выходным данным. Остаточные связи могут использоваться для объединения слоев. В трансформерной модели остаточные связи могут использоваться после механизма внимания и блока сети прямого распространения. Например, слою «Add & Norm» (суммирование и нормализация) могут предоставляться входные данные механизма внимания через остаточную связь и выходные данные механизма внимания. Затем результат этого слоя «Add & Norm» может предоставляться блоку сети прямого распространения или другому механизму внимания. В другом примере слою «Add & Norm» могут предоставляться входные данные блока сети прямого распространения через остаточную связь и выходные данные блока сети прямого распространения. Как описано выше, трансформерная модель может содержать слои «Add & Norm». В общем случае такой слой может независимо нормализовывать векторное представление каждого примера в пакете. Это выполняется для управления «потоком» в следующий слой. Нормализация слоя позволяет повышать устойчивость схождения и в некоторых случаях даже качество.
[042] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну физическую компьютерную систему, но это не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[043] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[044] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[045] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Эта информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[046] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[047] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[048] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. используются лишь для указания на различие между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - разные программные и/или аппаратные средства.
[049] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или к одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[050] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, на приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[051] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[052] На фиг. 1 представлена схема примера компьютерной системы для реализации некоторых не имеющих ограничительного характера вариантов осуществления систем и/или способов согласно настоящей технологии.
[053] На фиг. 2 представлена сетевая вычислительная среда, пригодная для некоторых вариантов реализации некоторых не имеющих ограничительного характера вариантов осуществления настоящей технологии.
[054] На фиг. 3 приведено схематическое изображение отображаемого на экране электронного устройства графического интерфейса пользователя (GUI, Graphical User Interface) системы перевода, размещенной на сервере в сетевой вычислительной среде, представленной на фиг. 2, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[055] На фиг. 4 представлена схема архитектуры модели машинного обучения, пригодной для использования в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии.
[056] На фиг. 5 приведено схематическое изображение шага для определения сервером из сетевой вычислительной среды, представленной на фиг. 2, с использованием двух дополнительных ML-моделей перевода обучающих переводов на целевом языке для фраз на исходном языке, которые впоследствии могут использоваться для обучения системы перевода, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[057] На фиг. 6 приведено схематическое изображение шага определения сервером из сетевой вычислительной среды, представленной на фиг. 2, оценок достоверности обучающих переводов на целевом языке, сформированных дополнительными ML-моделями, представленными фиг. 5, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[058] На фиг. 7 приведена блок-схема способа формирования сервером из сетевой вычислительной среды, представленной на фиг. 2, обучающего набора данных для обучения системы перевода согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Осуществление изобретения
[059] Представленные здесь примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[060] Чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалистам в данной области техники должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[061] В некоторых случаях приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области техники может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[062] Описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть понятно, что любые описанные здесь структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих основы настоящей технологии. Также должно быть понятно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор явно или нет.
[063] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также с использованием аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором и/или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и/или энергонезависимое запоминающее устройство. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[064] Программные модули или просто модули, реализация которых предполагается в виде программных средств, могут быть представлены здесь как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми.
[065] Далее с учетом вышеизложенных принципов рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
Компьютерная система
[066] На фиг. 1 представлена компьютерная система 100, пригодная для использования в некоторых вариантах осуществления настоящей технологии. Компьютерная система 100 содержит различные аппаратные элементы, включая один или несколько одноядерных или многоядерных процессоров, обобщенно представленных процессором 110, графический процессор 111, твердотельный накопитель 120, ОЗУ 130, интерфейс 140 дисплея и интерфейс 150 ввода-вывода.
[067] Связь между различными элементами компьютерной системы 100 может осуществляться через одну или несколько внутренних и/или внешних шин 160 (таких как шина PCI, шина USB, шина FireWire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д.), с которыми различные аппаратные элементы соединены электронными средствами.
[068] Интерфейс 150 ввода-вывода может соединяться с сенсорным экраном 190 и/или с одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может входить в состав дисплея. В некоторых вариантах реализации сенсорный экран 190 представляет собой дисплей. В представленных на фиг. 1 вариантах осуществления изобретения сенсорный экран 190 содержит сенсорные средства 194 (например, чувствительные к нажатию ячейки, встроенные в слой дисплея и позволяющие обнаруживать физическое взаимодействие между пользователем и дисплеем), и контроллер 192 сенсорных средств ввода-вывода, который обеспечивает связь с интерфейсом 140 дисплея и/или с одной или несколькими внутренними и/или внешними шинами 160. В некоторых вариантах осуществления изобретения интерфейс 150 ввода-вывода может соединяться с клавиатурой (не показана), мышью (не показана) или сенсорной площадкой (не показана), которые обеспечивают взаимодействие пользователя с компьютерной системой 100 в дополнение к сенсорному экрану 190 или вместо него. В некоторых вариантах осуществления изобретения компьютерная система 100 может содержать один или несколько микрофонов (не показаны). Микрофоны могут записывать звуковой сигнал, такой как речевые фрагменты пользователя. Речевые фрагменты пользователя могут преобразовываться в команды для управления компьютерной системой 100.
[069] Следует отметить, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии некоторые элементы компьютерной системы 100 могут отсутствовать. Например, может отсутствовать сенсорный экран 190, в частности, если компьютерная система реализована в виде «умной колонки», но не ограничиваясь этим.
[070] Согласно вариантам осуществления настоящей технологии, твердотельный накопитель 120 хранит программные команды, пригодные для загрузки в ОЗУ 130 и выполнения процессором 110 и/или графическим процессором 111. Программные команды могут, например, входить в состав библиотеки или приложения.
Сетевая вычислительная среда
[071] На фиг. 2 представлена схема сетевой вычислительной среды 200, пригодной для использования с некоторыми вариантами осуществления систем и/или способов согласно настоящей технологии. Сетевая вычислительная среда 200 содержит сервер 202, соединенный через сеть 208 связи с электронным устройством 204. В не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может быть связано с пользователем 206.
[072] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 реализован в виде традиционного компьютерного сервера и может содержать некоторые или все элементы компьютерной системы 100, представленной на фиг. 1. В одном не имеющем ограничительного характера примере сервер 202 реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™, но он также может быть реализован с использованием любых других подходящих аппаратных средств, прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны) функции сервера 202 могут быть распределены между несколькими серверами.
[073] Электронное устройство 204 может представлять собой любые компьютерные аппаратные средства, способные выполнять программы, подходящие для решения поставленной задачи. Таким образом, в качестве некоторых не имеющих ограничительного характера примеров электронного устройства 204 можно привести персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 также может содержать некоторые или все элементы компьютерной системы 100, представленной на фиг. 1.
[074] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сетевая вычислительная среда 200 способна обеспечивать сервисы машинного перевода для пользователей сети 208 связи, таких как пользователь 206.
[075] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, с этой целью на сервере 202 может быть размещена система 210 перевода, к которой пользователь 206 может обращаться с использованием сети 208 связи. Например, для доступа к системе 210 перевода пользователь 206 может отправлять универсальный указатель ресурсов (URL, Universal Resource Locator), связанный с системой 210 перевода, в адресной строке браузерного приложения (отдельно не обозначено) электронного устройства 204. В ответ сервер 202 может инициировать отображение электронным устройством 204 в его браузерном приложении интерфейса GUI системы 210 перевода.
[076] На фиг. 3 представлен интерфейс 300 GUI системы 210 перевода (см. фиг. 2), отображаемый на экране электронного устройства, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[077] В общем случае, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, система 210 перевода способна переводить части текста, такие как абзацы, предложения, словосочетания или отдельные слова, с исходного языка 302 (например, с английского языка) на целевой язык 304 (например, на русский язык). В частности, пользователь 206 с использованием электронного устройства 204 может с помощью интерфейса 300 GUI системы перевода предоставлять текстовое представление (например, путем ввода с клавиатуры) фразы 212 на исходном языке в текстовом поле (отдельно не обозначено), предназначенном для получения текста на исходном языке 302. В ответ электронное устройство 204 может отправлять фразу 212 на исходном языке серверу 202. В свою очередь, сервер 202 может получать фразу 212 на исходном языке, вводить ее в систему 210 перевода и таким образом инициировать формирование системой 210 перевода текстового представления фразы 214 на целевом языке, представляющей собой вариант перевода фразы 212 на исходном языке на целевой язык 304.
[078] Следует отметить, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии интерфейс 300 GUI системы перевода может обеспечивать пользователю 206 возможность предоставления фразы 212 на исходном языке иным образом. Например, благодаря интерфейсу 300 GUI системы перевода пользователь 206 может отправлять звуковое представление фразы 212 на исходном языке серверу 202 с использованием микрофона электронного устройства 204. С целью преобразования звукового представления фразы 212 на исходном языке в ее текстовое представление для дальнейшей обработки на сервере 202 может быть размещена модель преобразования речи в текст (STT, Speech-To-Text) (отдельно не показана), способная формировать текстовые представления вводимых пользователем речевых фрагментов.
[079] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии система 210 перевода может формировать не только текстовые представления фраз на целевом языке, такие как фраза 214 на целевом языке, но и звуковое представление фразы 214 на целевом языке. С этой целью в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии на сервере 202 может быть размещена модель преобразования текста в речь (TTS, Text-To-Speech), способная формировать звуковые представления входного текста. На реализацию моделей STT и TTS не накладывается ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии обе они могут быть реализованы на основе нейронных сетей, например, как описано в патентной заявке этого же заявителя US 18081634 «Method and system for recognizing a user utterance» (подана 14 февраля 2022 г.), содержание которой полностью включено в данное описание посредством ссылки.
[080] Сервер 202 может отправлять фразу 214 на целевом языке, сформированную системой 210 перевода, электронному устройству 204 для представления пользователю в текстовом поле (отдельно не обозначено) для вывода текстов на целевом языке 304.
[081] В конкретном не имеющем ограничительного характера примере система 210 перевода может быть реализована в виде системы перевода Yandex™ Translate™, предоставляемой компанией ООО «Яндекс» (ул. Льва Толстого, 16, Москва, 119021, Россия). Тем не менее, следует отметить, что система 210 перевода может быть реализована в виде любой другой коммерчески доступной или проприетарной системы перевода.
[082] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии система 210 перевода может содержать ML-модель перевода (такую как ML-модель на основе глубокой нейронной сети), обученную переводу частей текста с исходного языка 302 на целевой язык 304.
[083] Обычно ML-модель перевода системы 210 перевода может быть обучена на основе корпусов параллельных текстов, т.е. на основе первого корпуса текстов на исходном языке 302 и второго корпуса текстов на целевом языке 304. В частности, первый и второй корпусы текстов организованы так, чтобы обучающая фраза на исходном языке (такая как обучающая фраза 501 на исходном языке, схематически показанная на фиг. 5) из первого корпуса соответствовала обучающей фразе на целевом языке (такой как обучающая фраза 511, схематически показанная на фиг. 5) из второго корпуса, представляющей собой вариант перевода обучающей фразы 501 на исходном языке. На основе таких обучающих цифровых объектов, каждый из которых содержит (а) обучающую фразу 501 на исходном языке из первого корпуса текстов и (б) обучающую фразу 511 на целевом языке, ML-модель перевода может быть обучена формированию переводов на целевой язык 304 для вводимых пользователем текстов на исходном языке 302.
[084] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первый и второй корпусы текстов и, следовательно, обучающие цифровые объекты могут быть реализованы на основе текстов, сформированных людьми. Например, в этих вариантах осуществления изобретения соответствующие части обоих корпусов могут содержать по меньшей мере одно из следующего: (а) беллетристические литературные произведения; (б) новостные статьи; (в) научные работы; (г) учебные материалы и т.п., которые были переведены профессиональными переводчиками-людьми с исходного языка 302 на целевой язык 304 или наоборот. Обучающий цифровой объект, сформированный на основе таких текстов, может, например, содержать (а) обучающую фразу 501 на исходном языке «I recollect that wondrous meeting, that instant I encountered you...» и (б) обучающую фразу 511 на целевом языке «Я помню чудное мгновенье, передо мной явилась ты...». В этих вариантах осуществления изобретения сервер 202 может получать первый и второй корпусы текстов из ресурсов, доступных в сети 208 связи. Например, сервер 202 может выполнять обход некоторых ресурсов сети 208 связи с целью определения в них текстов и/или их частей, сформированных авторами-людьми и переводчиками-людьми.
[085] Тем не менее, по мере роста потребности в машинных переводах в различных отраслях, где требуются переводы текстов различных видов, для обучения ML-модели перевода может оказаться недостаточно обучающих примеров, сформированных исключительно на основе переведенных человеком текстов. Поэтому в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может (а) получать различные тексты на исходном языке 302 независимо от того, доступны для них выполненные человеком переводы или нет, и (б) отправлять эти тексты доступным серверу 202 сторонним системам перевода (не показаны) для формирования переводов полученных текстов на целевой язык 304. Затем на основе текстов на исходном языке 302 и сформированных таким образом переводов сервер 202 может формировать дополнительные обучающие цифровые объекты для обучения ML-модели перевода системы 210 перевода.
[086] Несмотря на то, что такие сторонние системы перевода могут быть сравнительно эффективными при предоставлении обучающих данных, один из недостатков их использования может заключаться в том, что предоставленные ими переводы фраз из первого корпуса могут быть неточными. В частности, обучающие цифровые объекты, сформированные на основе таких переводов, могут содержать «непараллельные» фразы, т.е. фразы на исходном и целевом языках 302, 304, которые не соответствуют друг другу по смыслу и/или по стилю. Например, для обучающей фразы 501 на исходном английском языке 302 «Please do not disturb» сторонняя система перевода может сформировать обучающую фразу 511 на целевом языке «Просьба не дистербировать». Носители русского языка, которые также знают английский язык, могут предположить, что правильный перевод для этой обучающей фразы 501 на исходном языке будет «Просьба не беспокоить». Тем не менее, сторонняя система перевода может быть неспособной определить правильный перевод на русский язык английского слова «disturb», что в результате может привести к представленному выше неправильному переводу. В другом примере с обучающей фразой 501 на исходном языке «Max found him bleeding like a pig» вследствие неправильного определения идиомы «bleed like a pig», означающей «истекать кровью», сторонняя система перевода может, например, сформировать для этой обучающей фразы 501 на исходном языке перевод «Макс увидел, что он кровоточил, как поросенок», что является буквальным и неправильным переводом представленной выше фразы на исходном языке, тогда как правильный перевод был бы, например, «Макс увидел его истекающим кровью».
[087] Можно предположить, что в результате использования такого обучающего цифрового объекта сервер 202 может инициировать заучивание ML-моделью перевода системы 210 перевода неправильных соответствий между обучающими фразами на исходном и целевом языках, а затем инициировать формирование обученной таким образом ML-моделью перевода при ее использовании неправильных и неточных переводов вводимых пользователем данных, что может негативно влиять на общую удовлетворенность пользователей от использования системы 210 перевода и других связанных с ней сервисов.
[088] С целью решения этой проблемы разработчики настоящей технологии разработали способы и системы для определения среди необработанных переводов на целевой язык обучающих фраз на исходном языке тех фраз на целевом языке, которые содержат неточные переводы обучающих фраз на исходном языке, и для замены этих фраз на целевом языке на более точные варианты перевода обучающих фраз на исходном языке. Таким образом, настоящие способы и системы предназначены для уточнения необработанных переводов на целевой язык обучающих фраз на исходном языке и для формирования таким образом обучающих данных высокого качества для обучения ML-модели перевода.
[089] Ниже со ссылкой на фиг. 4-6 описан пример ML-архитектуры ML-модели перевода, а также способ формирования обучающих данных и процесс обучения ML-модели перевода согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Сеть связи
[090] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи представляет собой сеть Интернет. В альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи может быть реализована в виде любой подходящей локальной сети (LAN, Local Area Network), глобальной сети (WAN, Wide Area Network), частной сети связи и т.п. Очевидно, что варианты реализации сети 208 связи приведены лишь в иллюстративных целях. Реализация соответствующих линий связи (отдельно не обозначены) между сервером 202 и электронным устройством 204 с одной стороны и сетью 208 связи с другой стороны зависит, среди прочего, от реализации сервера 202 и электронного устройства 204. В качестве не имеющего ограничительного характера примера, в тех вариантах осуществления настоящей технологии, где электронное устройство 204 реализовано в виде устройства беспроводной связи, такого как смартфон, линия связи может быть реализована в виде беспроводной линии связи. Примеры беспроводных линий связи включают в себя канал сети связи 3G, канал сети связи 4G и т.д. В сети 208 связи также может использоваться беспроводное соединение с сервером 202.
Архитектура модели машинного обучения
[091] На фиг. 4 представлена архитектура 400 ML-модели, пригодная для использования в по меньшей мере некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии архитектура 400 ML-модели основана на архитектуре модели нейронной сети на основе трансформера, как описано, например, в работе Vaswani et al. «Attention Is All You Need», Proceedings of 31st Conference on Neural Information Processing Systems (NIPS 2017), содержание которой полностью включено в данное описание посредством ссылки.
[092] Таким образом, архитектура 400 ML-модели может содержать стек 402 слоев кодера и стек 403 слоев декодера, способные обрабатывать входные данные 412 и целевые данные 417 архитектуры 400 ML-модели, соответственно.
[093] Кроме того, блок 404 кодера стека 402 слоев кодера содержит слой 406 многоголового внимания (MHA, Multi-Head Attention) кодера и слой 408 нейронной сети (NN, Neural Network) прямого распространения кодера. Слой 406 MHA кодера содержит зависимости между частями предоставленных ему входных данных 412. Например, если входные данные 412 содержат текстовые данные, такие как текстовое предложение, то слой 406 MHA кодера может содержать зависимости между словами предложения. В другом примере, где входные данные 412 стека 402 слоев кодера содержат звуковой сигнал, например, представляющий фрагмент устной человеческой речи, слой 406 MHA кодера может содержать зависимости между конкретными звуками и/или акустическими признаками фрагмента устной человеческой речи. Такие зависимости могут использоваться слоем 406 MHA кодера для определения контекстной информации части входных данных 412 стека 402 слоев кодера (например, представляющей слово из предложения), связанной с другой частью входных данных 412.
[094] Слой 408 сети NN прямого распространения кодера способен преобразовывать свои входные данные, поступающие из слоя 406 MHA кодера, в формат, принимаемый одним или несколькими следующими слоями архитектуры 400 ML-модели, такими как слой 409 MHA кодера-декодера (описано ниже). Слой 408 сети NN прямого распространения кодера обычно не содержит зависимостей слоя 406 MHA кодера, поэтому входные данные слоя 408 сети NN прямого распространения кодера могут обрабатываться параллельно.
[095] Кроме того, входные данные 412 стека 402 слоев кодера могут быть представлены множеством входных векторов 414, формируемых алгоритмом 410 векторизации входных данных. В общем случае алгоритм 410 векторизации входных данных способен формировать векторные представления фиксированной размерности для входных данных 412 в пространстве векторных представлений. Иными словами, если входные данные 412 содержат текстовые данные, то алгоритм 410 векторизации входных данных может формировать множество входных векторов 414, в котором координаты векторных представлений, представляющих слова текстового предложения со схожим значением, располагаются ближе друг к другу в пространстве векторных представлений. Таким образом, алгоритм 410 векторизации входных данных может быть реализован в виде алгоритма векторизации текста, включая, среди прочего, алгоритм векторизации текста «слово в вектор» (Word2Vec, Word to Vector), алгоритм векторизации текста на основе глобальных векторов для представления слов (GloVe, Global Vectors for Word Representation) и т.п.
[096] Вектор из множества входных векторов 414 может содержать числовые значения, например, 768 значений с плавающей запятой, представляющие часть входных данных 412, такую как слово, часть запроса 212 от человека и т.п.
[097] Формирование множества входных векторов 414 может также включать в себя применение позиционного алгоритма векторизации (не показан), способного регистрировать позиционные данные в частях входных данных 412. Например, если входные данные 412 содержат текстовое предложение, то позиционный алгоритм векторизации может формировать вектор, указывающий на позиционные данные слов в этом текстовом предложении. Иными словами, позиционный алгоритм векторизации может формировать вектор, содержащий контекстную информацию из входных данных 412, который может быть добавлен ко множеству входных векторов 414. На реализацию позиционного алгоритма векторизации не накладывается ограничений. Например, он, в числе прочего, может содержать позиционный алгоритм синусоидальной векторизации, позиционный алгоритм векторизации с объединением кадров и позиционный алгоритм сверточной векторизации.
[098] Следует отметить, что стек 402 слоев кодера может содержать несколько (например, 6 или 12) блоков кодера, реализованных подобно блоку 404 кодера.
[099] Блок 405 декодера стека 403 слоев декодера архитектуры 400 ML-модели содержит (а) слой 407 MHA декодера и (б) слой 411 сети NN прямого распространения декодера, которые в целом могут быть реализованы подобно слою 406 MHA кодера и слою 408 сети NN прямого распространения кодера, соответственно. При этом архитектура блока 405 декодера отличается от архитектуры блока 404 кодера тем, что блок 405 декодера дополнительно содержит слой 409 MHA кодера-декодера. Слой 409 MHA кодера-декодера способен (а) получать входные векторы из стека 402 слоев кодера и из слоя 407 MHA декодера и, следовательно, (б) определять в процессе обучения зависимости между входными данными 412 и целевыми данными 417 (такими, как текстовые данные) архитектуры 400 ML-модели, введенными в стек 403 слоев декодера. Иными словами, выходные данные слоя 409 MHA кодера-декодера представляют собой векторы внимания, содержащие данные, указывающие на взаимосвязи между соответствующими частями входных данных 412 и целевых данных 417.
[0100] Как и в случае входных данных 412, с целью подачи целевых данных 417 в блок 405 декодера алгоритм 415 векторизации целевых данных может применяться в отношении целевых данных 417 для формирования множества целевых векторов 419, содержащих числовые представления частей целевых данных 417.
[0101] Предполагается, что в тех вариантах осуществления изобретения, где целевые данные 417 представляют собой текстовые данные, алгоритм 415 векторизации целевых данных может быть реализован подобно алгоритму 410 векторизации входных данных. Кроме того, позиционный алгоритм также может применяться в отношении множества целевых векторов 419 для регистрации позиционных данных из частей целевых данных 417, как описано выше применительно ко множеству входных векторов 414.
[0102] Как описано ниже, архитектура 400 ML-модели может получать входные данные 412 и целевые данные 417 из цифрового объекта, такого как обучающий цифровой объект, содержащий обучающую фразу 501 на исходном языке и обучающую фразу 511 на целевом языке, как описано ниже со ссылкой на фиг. 5 и 6.
[0103] Следует отметить, что стек 403 слоев декодера может содержать несколько (например, 6 или 12) блоков декодера, реализованных подобно блоку 405 декодера. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии архитектура 400 ML-модели может содержать только стек 402 слоев кодера, т.е. не включать в себя блоки декодера, а содержать, например, 12, 24 или 36 блоков кодера, реализованных подобно блоку 404 кодера, описанному выше. В этом случае архитектура 400 ML-модели может называться моделью «представления двунаправленного кодера из трансформеров» (BERT, Bidirectional Encoder Representations from Transformers).
[0104] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии архитектура 400 ML-модели может содержать только стек 403 слоев декодера, т.е. может не включать в себя блоки кодера, а содержать, например, 12, 24 или 36 блоков декодера, реализованных подобно блоку 405 декодера, описанному выше. В этом случае архитектура 400 ML-модели может называться моделью предварительно обучаемого генеративного трансформера (GPT, Generative Pre-trained Transformer).
[0105] Предполагается, что после обучения архитектуры 400 ML-модели все блоки стека 402 слоев кодера и стека 403 слоев декодера имеют различные веса, используемые при формировании выходных данных 425. Для корректировки весов в процессе обучения в отношении архитектуры 400 ML-модели может применяться алгоритм обратного распространения, при этом могут определяться и оптимизироваться различия между входными данными 412 и выходными данными 425. Такие различия могут выражаться функцией потерь, такой как функция потерь кросс-энтропии.
[0106] Должно быть понятно, что в не имеющих ограничительного характера вариантах осуществления настоящей технологии также возможны и другие варианты реализации функции потерь, например, функция потерь среднеквадратичной ошибки, функция потерь по Губеру, кусочно-линейная функция потерь и т.д.
[0107] На способ оптимизации функции потерь сервером 202 не накладывается ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии он обычно зависит от дифференцируемости функции потерь. Например, если функция потерь является непрерывно дифференцируемой, то подходы к ее минимизации могут включать в себя алгоритм градиентного спуска, алгоритм оптимизации на основе метода Ньютона и т.д. В тех вариантах осуществления изобретения, где функция потерь является недифференцируемой, для ее минимизации сервер 202 может, например, применять прямые алгоритмы, стохастические алгоритмы и/или популяционные алгоритмы.
[0108] Выходные данные 425 архитектуры 400 ML-модели могут содержать выходной вектор, соответствующий вектору из множества входных векторов 414 и/или из множества целевых векторов 419. Например, как описано ниже, в тех вариантах осуществления изобретения, где входные данные 412 архитектуры 400 ML-модели содержат текстовое представление фразы 212 на исходном языке, выходной вектор может содержать вероятности, относящиеся к текстовому представлению фразы 214 на целевом языке.
[0109] Должно быть понятно, что архитектура 400 ML-модели, описанная со ссылкой на фиг. 4, значительно упрощена для лучшего понимания и что практический вариант реализации архитектуры 400 ML-модели может содержать дополнительные слои и/или блоки, например, как описано в вышеупомянутой работе Vaswani et al. Например, в некоторых вариантах реализации архитектуры 400 ML-модели блок 404 кодера и блок 405 декодера может также содержать слой операций нормализации. Кроме того, формирование выходных данных 425 может включать в себя применение функции нормализации softmax на выходе стека 403 слоев декодера и т.д. Специалистам в данной области техники должно быть понятно, что эти операции широко используются в нейронных сетях и в моделях глубокого обучения, таких как архитектура 400 ML-модели.
ML-модель перевода
[0110] Как описано выше, ML-модель перевода системы 210 перевода способна переводить вводимый пользователем текст с исходного языка 302 на целевой язык 304. В качестве примера можно привести фразу 214 на целевом языке для фразы 212 на исходном языке (см. фиг. 3).
[0111] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии ML-модель перевода может быть реализована на основе сети NN, такой как сеть NN с долгой краткосрочной памятью (LSTM, Long Short-Term Memory) или рекуррентная сеть NN. Тем не менее, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, ML-модель перевода может быть реализована в виде модели NN на основе трансформера. С этой целью ML-модель перевода может содержать некоторые или все компоненты архитектуры 400 ML-модели, описанной выше.
[0112] В общем случае, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может выполнять два процесса, относящихся к ML-модели перевода системы 210 перевода. Первый из этих двух процессов представляет собой процесс обучения, когда сервер 202 может на основе обучающего набора данных обучать ML-модель перевода формированию фразы 214 на целевом языке, как описано ниже. Второй процесс представляет собой процесс этапа использования, когда сервер 202 может применять обученную таким образом ML-модель перевода в отношении вводимых пользователем фраз на исходном языке, таких как фраза 212 на исходном языке, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, как описано еще ниже.
Процесс обучения
[0113] Как описано выше, сервер 202 может обучать ML-модель перевода формированию переводов вводимых пользователем фраз на исходном языке на основе обучающих цифровых объектов, каждый из которых содержит пару, состоящую из (а) обучающей фразы 501 на исходном языке и (б) экземпляра (варианта) перевода обучающей фразы 501 на исходном языке на целевой язык 304, такого как фраза 511 на целевом языке или другой вариант, как описано ниже.
[0114] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, с целью формирования обучающего набора данных для обучения ML-модели перевода сервер 202 может (а) получать первый корпус текстов на исходном языке 302, (б) получать второй корпус текстов на целевом языке 304, фразы из которого формируют параллельные пары с фразами из первого корпуса текстов, и (в) модифицировать второй корпус текстов путем выявления в нем «непараллельных» фраз и замены этих «непараллельных» фраз более точными вариантами перевода обучающих фраз на исходном языке из первого корпуса. С этой целью в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может содержать дополнительные ML-модели перевода (или иметь доступ к ним иным образом через сеть 208 связи).
[0115] На фиг. 5 представлена схема шага для формирования обучающего набора данных для обучения ML-модели перевода системы 210 перевода согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0116] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может содержать базу 510 входных данных (или иметь доступ к ней иным образом), где сервер 202 может хранить обучающие фразы на исходном языке из первого корпуса текстов на исходном языке 302, такие как обучающая фраза 501 на исходном языке. На способ наполнения сервером 202 базы входных данных не накладывается ограничений, например, он может включать в себя обход ресурсов сети 208 связи, содержащих текстовый контент на исходном языке 302, который, среди прочего, может содержать сообщения в социальных сетях (таких как социальная сеть VK.COM™); новостные и документальные статьи на новостных и информационных медиа-ресурсах (таких как новостной портал Yandex.News™, новостной портал Rambler™ и т.п.), статьи, опубликованные некоторыми справочными ресурсами (такими как онлайн-энциклопедия Wikipedia™, онлайн-энциклопедия Britannica™ и т.п.), беллетристические литературные произведения, доступ к которым предоставляют открытые онлайн-библиотеки (такие как онлайн-библиотека LIB.RU™, онлайн-библиотека Z-Library™ и т.п.), комментарии пользователей онлайн-платформ видеохостинга (таких как онлайн-платформа видеохостинга RUTUBE™) и онлайн-платформ аудиохостинга (таких как онлайн-платформа аудиохостинга Yandex.Music™) и т.д. Очевидно, что тексты на исходном зыке 302 других видов также могут быть включены в первый корпус текстов для формирования обучающего набора данных для ML-модели перевода без выхода за границы настоящей технологии.
[0117] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может содержать базу 520 выходных данных (или иметь доступ к ней иным образом), в которой могут храниться обучающие фразы на целевом языке из второго корпуса текстов на целевом языке 304. Как описано выше, каждая обучающая фраза на целевом языке, такая как обучающая фраза 511 на целевом языке, представляет собой перевод обучающей фразы на исходном языке, т.е. обучающей фразы 501 на исходном языке, с исходного языка 302 на целевой язык 304. Как также описано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии база 520 выходных данных может быть первоначально наполнена обучающими фразами на целевом языке, полученными в качестве переводов обучающих фраз на исходном языке, определенных людьми или сторонними системами переводов.
[0118] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может получать обучающую фразу 511 на целевом языке, связанную с базовой оценкой 521 достоверности, указывающей на точность перевода с исходного языка 302 для обучающей фразы 511 на целевом языке. Тем не менее, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может (а) получать обучающую фразу 511 на целевом языке, как описано выше, и (б) определять для нее базовую оценку 521 достоверности, как описано ниже.
[0119] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может иметь доступ не только к ML-модели перевода системы 210 перевода, но также и к первой ML-модели 502 перевода и ко второй ML-модели 504 перевода (см. фиг. 5). Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, первая и вторая ML-модели 502, 504 перевода предварительно обучены переводу текстов с исходного языка 302 на целевой язык 304 (или настроены иным образом). Например, первая и вторая ML-модели 502, 504 перевода могут быть предварительно обучены сторонней системой перевода, как описано выше со ссылкой на фиг. 3. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая и вторая ML-модели 502, 504 перевода могут быть обучены на основе обучающих наборов данных, которые по меньшей мере частично отличаются. На реализацию первой и второй ML-моделей 502, 504 перевода не накладывается ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая и вторая ML-модели перевода могут быть реализованы на основе архитектуры 400 ML-модели перевода, описанной выше.
[0120] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая ML-модель 502 перевода может формировать прямые переводы текстов с исходного языка 302 на целевой язык 304. В контексте настоящего документа под прямыми переводами понимаются переводы, выполняемые ML-моделью перевода, такой как первая ML-модель 502 перевода, с исходного языка 302 непосредственно на целевой язык 304 без формирования промежуточных переводов входных фраз на исходном языке на другие языки.
[0121] При этом в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии вторая ML-модель 504 перевода может формировать переводы через промежуточный целевой язык (отдельно не обозначен), который отличается от исходного и целевого языков 302, 304. В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, вторая ML-модель 504 перевода может переводить фразу 212 на исходном языке сначала с исходного языка 302 на промежуточный целевой язык, а затем с промежуточного целевого языка на целевой язык 304. Подобно исходному и целевому языкам 302, 304, промежуточный целевой язык может представлять собой любой естественный язык, который когда-либо использовался для человеческого общения, например, немецкий, французский, китайский язык и т.д.
[0122] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии вторая ML-модель 504 перевода может содержать две последовательно соединенных ML-модели перевода: первую модель, способную переводить входные тексты с исходного языка 302 на промежуточный целевой язык, и вторую модель, способную переводить входные тексты с промежуточного целевого языка на целевой язык 304. Например, эти компоненты второй ML-модели 504 перевода могут быть реализованы на основе архитектуры 400 ML-модели, описанной выше.
[0123] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая и вторая ML-модели 502, 504 перевода отличаются от ML-модели перевода системы 210 перевода. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии модель из числа первой и второй ML-моделей 502, 504 перевода, например, первая ML-модель 502 перевода, может быть той же, что и ML-модель перевода системы 210 перевода, предварительно обученная переводу вводимых пользователем фраз на исходном языке с исходного языка 302 на целевой язык 304. В этих вариантах осуществления изобретения вместо обучения такой ML-модели перевода «с нуля» сервер 202 может точно настраивать такую ML-модель перевода на основе обучающего набора данных для формирования более точных переводов на целевой язык 304.
[0124] Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может (а) обращаться к базе 510 входных данных для получения из нее обучающей фразы 501 на исходном языке, (б) вводить обучающую фразу 501 на исходном языке в первую ML-модель 502 перевода для формирования первого варианта 512 перевода на целевой язык обучающей фразы 501 на исходном языке для целевого языка 304 и (в) вводить обучающую фразу 501 на исходном языке во вторую ML-модель 504 перевода для формирования второго варианта 514 перевода на целевой язык обучающей фразы 501 на исходном языке для целевого языка 304. Кроме того, сервер 202 может (а) определять, имеет ли первый вариант 512 перевода на целевой язык или второй вариант 514 перевода на целевой язык более высокую точность, чем обучающая фраза 511 на целевом языке, и (б) заменять обучающую фразу 511 на целевом языке из второго корпуса текстов, который хранится в базе 520 выходных данных, на первый или второй варианты 512, 514 перевода на целевой язык, если точность первого или второго вариантов 512, 514 перевода на целевой язык оказывается выше, чем у обучающей фразы 511 на целевом языке. В противном случае в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может сохранять обучающую фразу 511 на целевом языке во втором корпусе текстов.
[0125] В результате сервер 202 может определять обучающие фразы на целевом языке, которые ближе по смыслу к обучающим фразам на исходном языке, и таким образом модифицировать второй корпус текстов на целевом языке 304. Кроме того, сервер 202 может использовать модифицированный таким образом корпус текстов для формирования обучающего набора данных для ML-модели перевода системы 210 перевода. При этом предполагается, что этот обучающий набор данных имеет более высокое качество, чем набор, сформированный на основе первоначально полученного второго корпуса текстов без определения и замены менее точных обучающих фраз на целевом языке.
[0126] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять более точную обучающую фразу на целевом языке из числа обучающей фразы 511 на целевом языке, первого и второго вариантов 512, 514 перевода на целевой язык для включения в состав второго корпуса на основе связанных с ними оценок достоверности, указывающих на точность каждого варианта перевода на целевой язык, т.е. на основе базовой оценки 521 достоверности, первой оценки 522 достоверности и второй оценки 524 достоверности, соответственно.
[0127] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять базовую, первую и вторую оценки 521, 522, 524 достоверности как прямые оценки достоверности, сформированные одной из ML-моделей перевода, способной переводить с исходного языка 302 на целевой язык 304, такой как первая ML-модель 502.
[0128] В частности, в тех вариантах осуществления изобретения, где первая ML-модель 502 перевода основана на архитектуре 400 ML-модели, чтобы, например, определить базовую прямую оценку 527 достоверности, указывающую на точность прямого перевода для обучающей фразы 511 на целевом языке, сервер 202 может использовать заранее созданный словарь токенов первой ML-модели 502 перевода с целью определения для языковой единицы из обучающей фразы 511 на целевом языке (такой как морфема, слово или словосочетание) значения вероятности того, что эта языковая единица наилучшим образом соответствует предыдущей языковой единице в обучающей фразе 511 на целевом языке. Иными словами, с использованием заранее созданного словаря токенов первой ML-модели 502 перевода сервер 202 может определять значения вероятности того, что каждая языковая единица, образующая обучающую фразу 511 на целевом языке, контекстуально и грамматически правильно размещена относительно других единиц языка в обучающей фразе 511 на целевом языке. Кроме того, для определения базовой прямой оценки достоверности сервер 202 может объединять (например, путем суммирования) значения вероятности, связанные с каждой языковой единицей из обучающей фразы 511 на целевом языке.
[0129] Подобным образом с использованием первой ML-модели 502 перевода сервер 202 может определять (а) первую прямую оценку 523 достоверности, указывающую на точность прямого перевода для первого варианта 512 перевода на целевой язык, и (б) вторую прямую оценку 525 достоверности, указывающую на точность прямого перевода для второго варианта 514 перевода на целевой язык. В качестве альтернативы в других не имеющих ограничительного характера вариантах осуществления настоящей технологии для определения второй прямой оценки 525 достоверности сервер 202 может использовать вторую ML-модель 504 перевода, как схематически показано на фиг. 5.
[0130] При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять базовую, первую и вторую оценки 521, 522 и 524 достоверности иным образом. На фиг. 6 приведено схематическое изображение для альтернативного не имеющего ограничительного характера варианта осуществления шага определения базовой, первой и второй оценок 521, 522 и 524 достоверности, связанных с обучающей фразой 511 на целевом языке, первым и вторым вариантами 512, 514 перевода на целевой язык, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0131] В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может определять оценку достоверности для базовой, первой и второй оценок 521, 522 и 524 достоверности как сочетание прямой и обратной оценок достоверности обучающей фразы 511 на целевом языке, первого и второго вариантов 512, 514 перевода на целевой язык, соответственно.
[0132] С этой целью в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может содержать третью ML-модель 602 перевода (или иметь доступ к ней иным образом) для формирования переводов текстов с целевого языка 304 на исходный язык 302. Очевидно, что третья ML-модель перевода может быть реализована подобно первой и второй ML-моделям 502, 504 перевода с необходимыми изменениями.
[0133] Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии после определения базовой прямой оценки 527 достоверности сервер 202 для определения базовой оценки 521 достоверности может вводить обучающую фразу 511 на целевом языке в третью ML-модель 602 перевода с целью формирования базового обратного варианта 611 перевода обучающей фразы 511 на целевом языке на исходный язык 302 и формирования базовой обратной оценки 627 достоверности базового обратного варианта 611 перевода. Например, в тех вариантах осуществления изобретения, где третья ML-модель 602 перевода реализована на основе архитектуры 400 ML-модели, сервер 202 может определять базовую обратную оценку 627 достоверности с использованием заранее созданного словаря токенов третьей ML-модели 602 перевода подобно тому, как это описано выше для определения базовой прямой оценки 527 достоверности.
[0134] Подобным образом в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии после определения первого и второго вариантов 512, 514 перевода на целевой язык и их первой и второй прямых оценок 523, 525 достоверности сервер 202 для определения первой и второй оценок 522, 524 достоверности может вводить первый и второй варианты 512, 514 перевода на целевой язык в третью ML-модель 602 перевода с целью формирования (а) первого обратного варианта 612 перевода на исходный язык 302 для первого варианта 512 перевода на целевой язык и первой обратной оценки 623 достоверности для первого обратного варианта 612 перевода и (б) второго обратного варианта 614 перевода на исходный язык 302 для второго варианта 514 перевода на целевой язык и второй обратной оценки 625 достоверности для второго обратного варианта 614 перевода.
[0135] Кроме того, сервер 202 может определять (а) базовую оценку 521 достоверности для обучающей фразы 511 на целевом языке как сочетание базовых прямой и обратной оценок 527, 627 достоверности, (б) первую оценку 522 достоверности первого варианта 512 перевода на целевой язык как сочетание первых прямой и обратной оценок 523, 623 достоверности и (в) вторую оценку 524 достоверности второго варианта 514 перевода на целевой язык как сочетание вторых прямой и обратной оценок 525, 625 достоверности. На определение сервером 202 сочетания для пары прямой и обратной оценок достоверности не накладывается ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии определение такого сочетания может включать в себя различные математические операции, такие как сумма, разность, произведение, сумма квадратов, разность квадратов, абсолютные суммы и разность и т.п.
[0136] Например, если имеется обучающая фраза 501 на исходном языке «London is the capital of Great Britain, a great modern city that inherits a spirit of old times» и связанная с ней обучающая фраза 511 на целевом языке «Лондон - столица Великобритании, великого современного города, который наследует дух старых времен». Сначала сервер 202 может определить базовую прямую оценку 521 достоверности, равную -5,56. Затем сервер 202 может ввести обучающую фразу 511 на целевом языке в третью ML-модель 602 перевода, чтобы сформировать базовый обратный вариант 611 перевода «London is the capital of Britain, a great modern city that inherits the spirit of old times» с базовой обратной оценкой 627 достоверности, равной -24,63.
[0137] Подобным образом на основе обучающей фразы 501 на исходном языке первая ML-модель 502 перевода может сформировать первый вариант 512 перевода на целевой язык «Лондон - столица Великобритании, великий современный город, унаследовавший дух древних времен» с первой прямой оценкой 523 достоверности, равной -4,47. Вторая ML-модель 504 перевода может сформировать второй вариант 514 перевода на целевой язык «Лондон - столица Великобритании, великий современный город, унаследовавший дух старины» со второй прямой оценкой 525 достоверности, равной -5,37. Затем сервер 202 может ввести первый и второй варианты 512, 514 перевода на целевой язык в третью ML-модель 602 перевода и инициировать формирование третьей ML-моделью 602 перевода (1) первого обратного варианта 612 перевода «London is the capital of Great Britain, a great modern city that has inherited the spirit of ancient times» с первой обратной оценкой 623 достоверности, равной -20,54; и (2) второго обратного варианта 614 перевода «London - the capital of Great Britain, a great modern city that has inherited the spirit of antiquity» со второй обратной оценкой 625 достоверности, равной -19,15.
[0138] Таким образом, сервер 202 может определить базовую, первую и вторую оценки 521, 522 и 524 достоверности, например, путем определения сумм прямых и обратных оценок достоверности. Иными словами, сервер 202 может определить: (а) базовую оценку 521 достоверности как сумму базовых прямой и обратной оценок 527, 627 достоверности, равную -30,19; (б) первую оценку 522 достоверности как сумму первых прямой и обратной оценок 523, 623 достоверности, равную -25,01; и (в) вторую оценку 524 достоверности как сумму вторых прямой и обратной оценок 525, 625 достоверности, равную -24,52.
[0139] Определив базовую, первую и вторую оценки 521, 522, 524 достоверности, связанные с обучающей фразой 511 на целевом языке, первым и вторым вариантами 512, 514 перевода на целевой язык, соответственно, сервер 202 может определить, имеется ли более точный вариант перевода на целевой язык для замены обучающей фразы 511 на целевом языке во втором корпусе текстов на целевом языке 304 (см. фиг. 5).
[0140] Например, сервер 202 может выбрать первую или вторую оценку 522, 524 достоверности для сравнения с базовой оценкой 521 достоверности. В данном примере с обучающей фразой 501 на исходном языке «London is the capital of Great Britain, a great modern city that inherits a spirit of old times» после определения того, что вторая оценка 524 достоверности (-24,52) больше первой оценки 522 достоверности (-25,01), сервер 202 может сравнить вторую оценку 524 достоверности с базовой оценкой 521 достоверности. Таким образом, в данном примере, если определено, что вторая оценка 524 достоверности (-24,52) больше базовой оценки 521 достоверности (-30,19), сервер 202 может заменить во втором корпусе текстов обучающую фразу 511 на целевом языке на второй вариант 514 перевода на целевой язык, поскольку он представляет собой более точный вариант перевода обучающей фразы 501 на исходном языке. Если же базовая оценка 521 достоверности оказывается большей или равной первой и второй оценке 522, 524 достоверности, сервер 202 может сохранить обучающую фразу 511 на целевом языке для последующего формирования обучающего набора данных.
[0141] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может заменять во втором корпусе текстов обучающую фразу 511 на целевом языке на первый или второй варианты 512, 514 перевода на целевой язык обучающей фразы 501 на исходном языке, если первая или вторая оценка 522, 524 достоверности превышает базовую оценку 521 достоверности на заранее заданное пороговое значение разности (например, на 3, 5 или 10).
[0142] Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии после модификации и сохранения в базе 520 выходных данных второго корпуса текстов, в котором каждая обучающая фраза на целевом языке представляет собой более точный перевод обучающей фразы на исходном языке из первого корпуса текстов с исходного языка 302 на целевой язык 304, сервер 202 может формировать множество обучающих цифровых объектов для обучения ML-модели перевода системы 210 перевода переводу на целевой язык 304 вводимых пользователем текстов на исходном языке 302, таких как вышеупомянутая фраза 212 на исходном языке. В представленном выше примере с обучающей фразой 501 на исходном языке «London is the capital of Great Britain, a great modern city that inherits a spirit of old times» сервер 202 может сформировать обучающий цифровой объект, содержащий (а) обучающую фразу 501 на исходном языке и (б) второй вариант 514 перевода на целевой язык.
[0143] Для обучения ML-модели перевода системы 210 перевода сервер 202 может вводить каждый объект из множества обучающих цифровых объектов в ML-модель перевода. Например, в тех вариантах осуществления изобретения, где ML-модель перевода реализована на основе описанной выше архитектуры 400 ML-модели, содержащей стеки 402, 403 слоев кодера и декодера, с целью ввода обучающего цифрового объекта в ML-модель перевода сервер 202 может (а) вводить обучающую фразу 501 на исходном языке в стек 402 слоев кодера как часть входных данных 412 и (б) вводить второй вариант 514 перевода на целевой язык в стек 403 слоев декодера как часть целевых данных 417.
[0144] На каждой итерации обучения сервер 202 может на основе обучающего цифрового объекта оптимизировать различие между вторым вариантом 514 перевода на целевой язык и текущим обучающим переводом фразы 501 на исходном языке из выходных данных 425, сформированным ML-моделью перевода. Как описано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии это различие может задаваться с помощью функции потерь, не исчерпывающий список примеров и подходов к оптимизации которой представлен выше. На каждой итерации обучения сервер 202 с использованием алгоритма обратного распространения может корректировать веса ML-модели перевода и таким образом обучать ML-модель перевода формированию переводов вводимых пользователем фраз на исходном языке с исходного языка 302 на целевой язык 304, например, фразы 214 на целевом языке, сформированной как перевод фразы 212 на исходном языке.
[0145] Как описано выше, в тех не имеющих ограничительного характера вариантах осуществления настоящей технологии, где ML-модель перевода системы 210 перевода представляет собой первую ML-модель 502 перевода, сервер 202 путем выполнения вышеупомянутых шагов ввода множества обучающих цифровых объектов в ML-модель перевода и последующей оптимизации функции потерь на каждой итерации обучения может точно настраивать ML-модель перевода для формирования переводов на целевой язык 304 вводимых пользователем фраз на исходном языке.
[0146] При выполнении описанного выше процесса обучения сервер 202 может модифицировать второй корпус текстов путем выявления в нем «непараллельных» предложений и замены таких предложений на более точные переводы обучающих фраз на исходном языке, что позволяет формировать более качественные обучающие цифровые объекты. Это создает возможность обучения ML-модели перевода формированию более точных переводов вводимых пользователем фраз на исходном языке по сравнению с предоставляемыми вышеупомянутой сторонней системой перевода, как описано ниже.
Процесс этапа использования
[0147] После обучения ML-модели перевода системы 210 перевода сервер 202 может использовать ее для формирования перевода на целевой язык 304 вводимых пользователем фраз на исходном языке, например, для формирования фразы 214 на целевом языке, соответствующей фразе 212 на исходном языке (описано выше со ссылкой на фиг. 3).
[0148] В частности, в тех вариантах осуществления изобретения, где ML-модель перевода основана на архитектуре 400 ML-модели, сервер 202 может вводить фразу 212 на исходном языке в стек 402 слоев кодера как часть входных данных 412 и таким образом инициировать формирование ML-моделью перевода выходных данных 425, содержащих выходной вектор, содержащий вероятности, относящиеся к текстовому представлению фразы 214 на целевом языке.
[0149] Предполагается, что сформированная таким образом фраза 214 на целевом языке точнее фразы, сформированной ML-моделью перевода, обученной на основе второго корпуса текстов без модификации, как описано выше. Это позволяет повышать удовлетворенность пользователя 206 от взаимодействия с системой 210 перевода.
Способ
[0150] Описанные выше архитектура и примеры позволяют выполнять способ формирования обучающего набора данных для обучения ML-модели перевода, например, в вышеупомянутой системе 210 перевода. На фиг. 7 представлена блок-схема способа 700 согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии. Способ 700 может выполняться сервером 202.
Шаг 702: получение (а) корпуса текстов на исходном языке, содержащего первое множество фраз на исходном языке, и (б) корпуса текстов на целевом языке, содержащего второе множество фраз на целевом языке.
[0151] Способ 700 начинается с шага 702, на котором сервер 202 способен получать первый корпус текстов на исходном языке 302 и второй корпус текстов на целевом языке 304. Например, как описано выше со ссылкой на фиг. 5 и 6, сервер 202 может получать первый и второй корпусы текстов из заранее наполненных баз 510, 520 входных и выходных данных, соответственно.
[0152] В частности, первый корпус текстов содержит обучающие фразы на исходном языке, такие как обучающая фраза 501 на исходном языке, а второй корпус текстов содержит обучающие фразы на целевом языке, такие как обучающая фраза 511 на целевом языке. Как описано выше, обучающая фраза 511 на целевом языке представляет собой вариант перевода обучающей фразы 501 на исходном языке с исходного языка 302 на целевой язык 304, который может быть получен от человека (такого как автор или человек-переводчик) или от одной из сторонних систем перевода.
[0153] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может получать обучающую фразу 511 на целевом языке с базовой оценкой 521 достоверности, указывающей на точность перевода для обучающей фразы 511 на целевом языке. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять базовую оценку 521 достоверности для обучающей фразы 511 на целевом языке с использованием одной из ML-моделей перевода, таких как первая ML-модель 502 перевода, способная выполнять прямой перевод текстов с исходного языка 302 на целевой язык 304 (как описано выше со ссылкой на фиг. 5 и 6).
[0154] Как подробно описано выше со ссылкой на фиг. 5, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может с использованием первой ML-модели 502 перевода определять базовую оценку 521 достоверности как базовую прямую оценку 527 достоверности. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202, как описано выше со ссылкой на фиг. 6, может (а) определять с использованием первой ML-модели 502 перевода базовую прямую оценку 527 достоверности, связанную с обучающей фразой 511 на целевом языке, (б) определять с использованием третьей ML-модели 602 перевода, способной формировать перевод текстов с целевого языка 304 на исходный язык 302, базовую обратную оценку 627 достоверности, связанную с базовым обратным вариантом 611 перевода обучающей фразы 511 на целевом языке, и (в) определять базовую оценку 521 достоверности как сочетание (например, сумму) базовых прямой и обратной оценок 527, 627 достоверности.
[0155] Далее способ 700 продолжается на шаге 704.
Шаг 704: ввод фразы на исходном языке в первую ML-модель перевода для формирования первого варианта перевода фразы на исходном языке на целевой язык и для формирования первой оценки достоверности, указывающей на точность перевода для первого варианта перевода.
[0156] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, на шаге 704 сервер 202 может вводить обучающую фразу 501 на исходном языке в первую ML-модель 502 перевода для формирования первого варианта 512 перевода на целевой язык обучающей фразы 501 на исходном языке. Как описано выше, первая ML-модель 502 перевода предварительно обучена прямому переводу текстов с исходного языка 302 на целевой язык 304. Иными словами, первая ML-модель 502 перевода может формировать перевод с исходного языка 302 на целевой язык 304 без промежуточного перевода на третий язык. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая ML-модель 502 перевода может быть реализована на основе архитектуры 400 ML-модели, подробно описанной выше со ссылкой на фиг. 4.
[0157] Кроме того, для первого варианта 512 перевода на целевой язык сервер 202 может определять первую оценку 522 достоверности, указывающую на точность перевода для первого варианта 512 перевода на целевой язык. Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может определять первую оценку 522 достоверности подобно определению базовой оценки 521 достоверности для обучающей фразы 511 на целевом языке.
[0158] Далее способ 700 продолжается на шаге 706.
Шаг 706: ввод фразы на исходном языке во вторую ML-модель перевода для формирования второго варианта перевода фразы на исходном языке на целевой язык и для формирования второй оценки достоверности, указывающей на точность перевода для второго варианта перевода.
[0159] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, на шаге 706 сервер 202 может вводить обучающую фразу 501 на исходном языке во вторую ML-модель 504 перевода для формирования второго варианта 514 перевода на целевой язык обучающей фразы 501 на исходном языке. Как описано выше, вторая ML-модель 504 перевода предварительно обучена переводу текстов с исходного языка 302 на целевой язык 304 через промежуточный язык, отличающийся от исходного и целевого языков 302, 304. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии вторая ML-модель 504 перевода, подобно первой ML-модели 502 перевода, может быть реализована на основе архитектуры 400 ML-модели.
[0160] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии вторая ML-модель 504 перевода может содержать две последовательно соединенных ML-модели перевода - первую модель, способную переводить тексты с исходного языка 302 на промежуточный язык, и вторую модель, способную переводить тексты с промежуточного языка на целевой язык 304.
[0161] Кроме того, для второго варианта 514 перевода на целевой язык сервер 202 может определять вторую оценку 524 достоверности, указывающую на точность перевода для второго варианта 514 перевода на целевой язык. Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может определять вторую оценку 524 достоверности подобно определению базовой оценки 521 достоверности.
[0162] Далее способ 700 продолжается на шаге 708.
Шаг 708: замена в корпусе на целевом языке фразы на целевом языке первым или вторым вариантом перевода фразы на исходном языке, если первая или вторая оценка достоверности превышает базовую оценку достоверности, связанную с фразой на целевом языке.
[0163] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, на шаге 708 сервер 202 может определять, содержит ли первый или второй вариант 512, 514 перевода на целевой язык более точный перевод обучающей фразы 501 на исходном языке, чем обучающая фраза 511 на целевом языке, первоначально содержащаяся во втором корпусе текстов фразе 501.
[0164] Как подробно описано выше со ссылкой на фиг. 5, с этой целью сервер 202 может сравнивать первую и вторую оценки 522, 524 достоверности с базовой оценкой 521 достоверности. Например, если определено, что вторая оценка 524 достоверности больше базовой оценки 521 достоверности, то сервер 202 может заменить во втором корпусе текстов обучающую фразу 511 на целевом языке на второй вариант 514 перевода на целевой язык обучающей фразы 501 на исходном языке, сформированный второй ML-моделью 504 перевода. В противном случае в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может сохранить обучающую фразу 511 на целевом языке во втором корпусе текстов.
[0165] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может заменять во втором корпусе текстов обучающую фразу 511 на целевом языке на первый или второй варианты 512, 514 перевода на целевой язык обучающей фразы 501 на исходном языке, если первая или вторая оценка 522, 524 достоверности больше базовой оценки 521 достоверности на заранее заданное пороговое значение разности (например, на 3, 5 или 10).
[0166] Путем выполнения шагов 704-708 сервер 202 может модифицировать второй корпус текстов путем (а) выявления в нем обучающих фраз на целевом языке, «непараллельных» обучающим фразам на исходном языке из первого корпуса текстов, и (б) замены этих «непараллельных» обучающих фраз на целевом языке на более точные варианты перевода на целевой язык обучающей фразы на исходном языке.
[0167] Далее способ 700 продолжается на шаге 710.
Шаг 710: формирование обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит (а) фразу на исходном языке и (б) первый или второй вариант перевода фразы на исходном языке.
[0168] На шаге 710 после уточнения второго корпуса текстов, как описано выше, сервер 202 может формировать обучающий набор данных для обучения ML-модели перевода системы 210 перевода формированию переводов вводимых пользователем текстов с исходного языка 302 на целевой язык 304, например, фразы 214 на целевом языке для фразы 212 на исходном языке, отправленной пользователем 206 системе 210 перевода.
[0169] Обучающий набор данных может содержать множество обучающих цифровых объектов, каждый из которых может содержать (а) обучающую фразу 501 на исходном языке и (б) первый или второй вариант 512, 514 перевода на целевой язык с оценкой из числа первой и второй оценок 522, 524 достоверности, большей базовой оценки 521 достоверности, связанной с обучающей фразой 511 на целевом языке, например, второй вариант 514 перевода на целевой язык, как показано в представленном выше примере.
[0170] Далее способ 700 продолжается на шаге 712.
Шаг 712: обучение ML-модели перевода переводу текста с исходного языка на целевой язык на основе обучающего набора данных.
[0171] Как подробно описано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии на шаге 712 сервер 202 может вводить сформированное таким образом множество обучающих цифровых объектов в ML-модель перевода системы 210 перевода с целью ее обучения формированию переводов вводимых пользователем текстов с исходного языка 302 на целевой язык 304.
[0172] На этом выполнение способа 700 завершается.
[0173] Некоторые не имеющие ограничительного характера варианты осуществления способа 700 позволяют формировать переводы вводимых пользователем на исходном языке 302 текстов на целевой язык 304 с большей точностью, что может способствовать повышению удовлетворенности пользователей от взаимодействия с системой 210 перевода.
[0174] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии.
[0175] Для специалиста в данной области техники могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2832419C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПЕРЕВОДУ | 2020 |
|
RU2770569C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке | 2017 |
|
RU2692049C1 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ТЕКСТОВЫХ ПОДСКАЗОК | 2024 |
|
RU2841233C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| Способ и сервер для выполнения контекстно-зависимого перевода | 2021 |
|
RU2812301C2 |
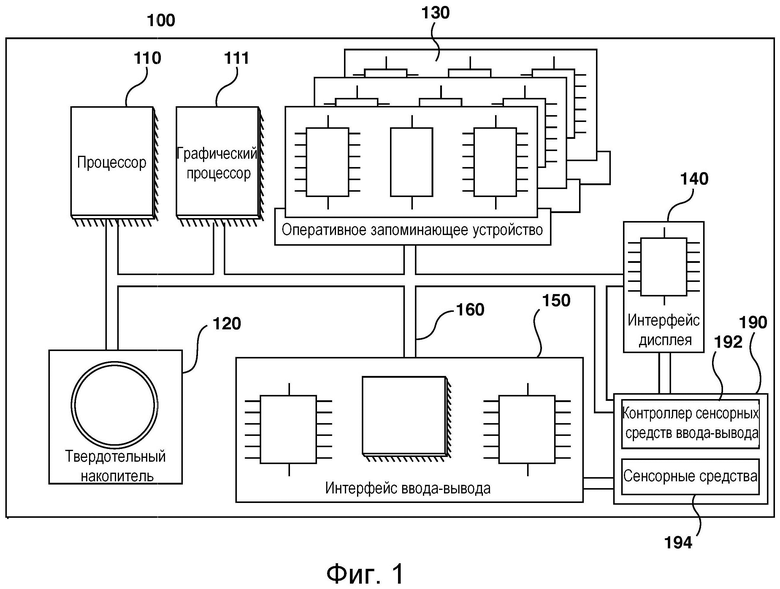
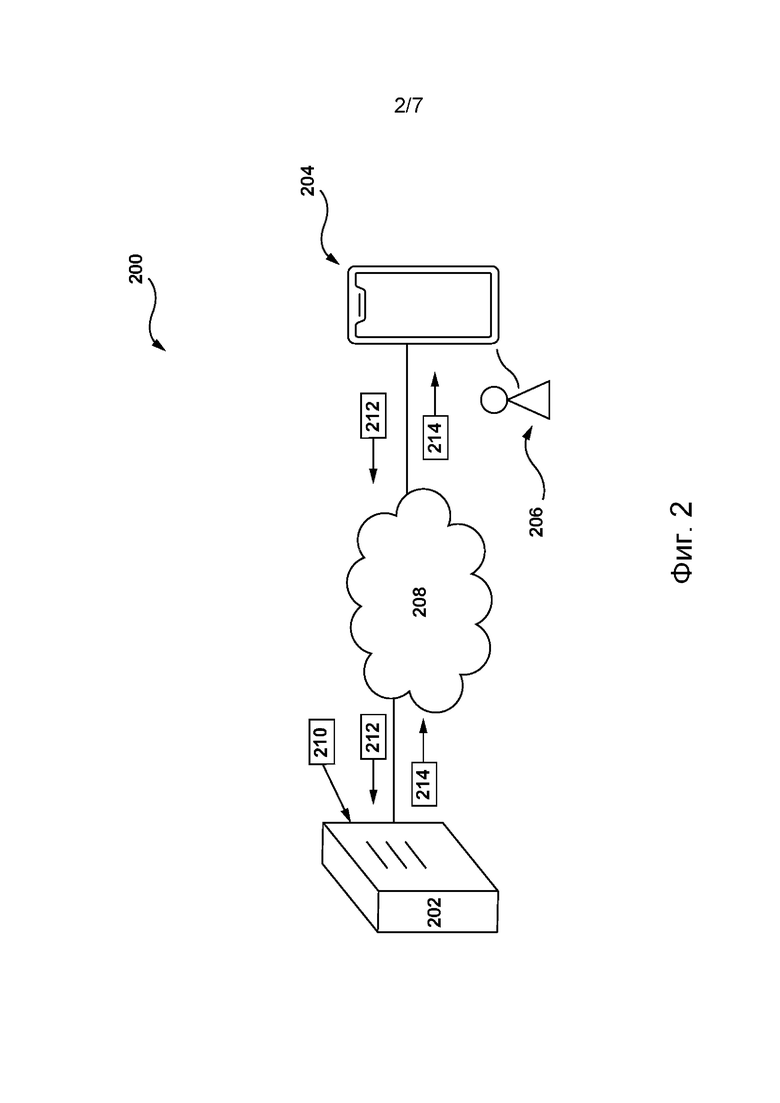
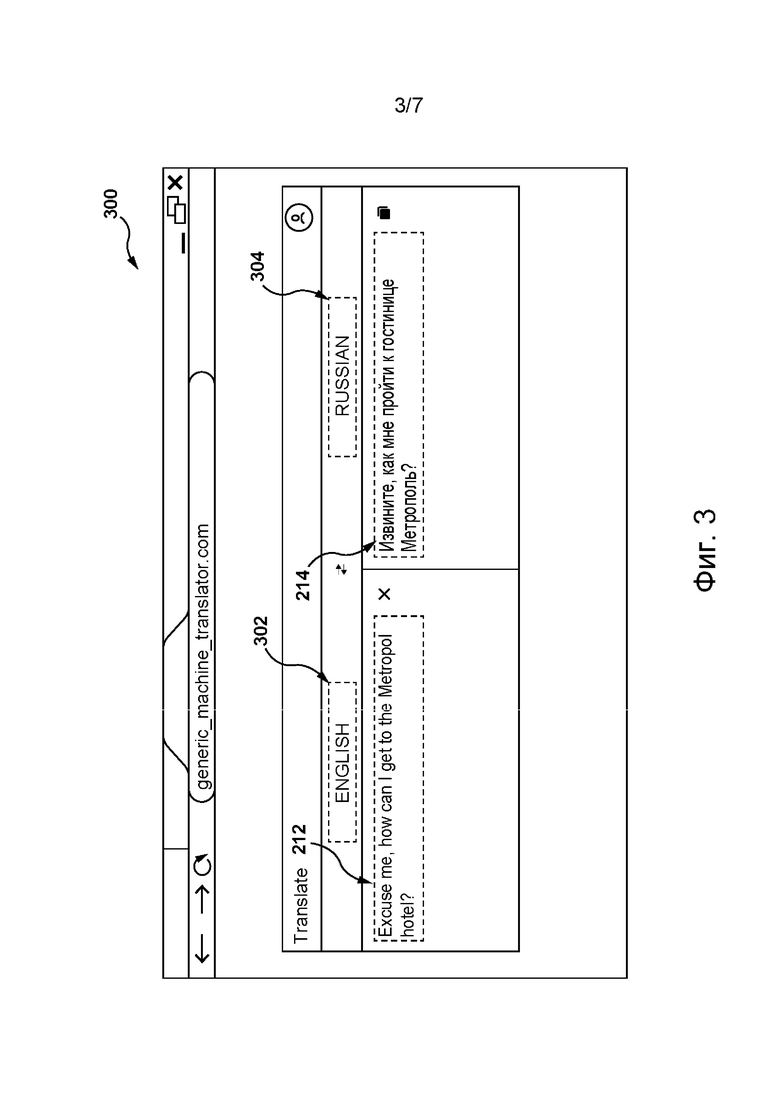
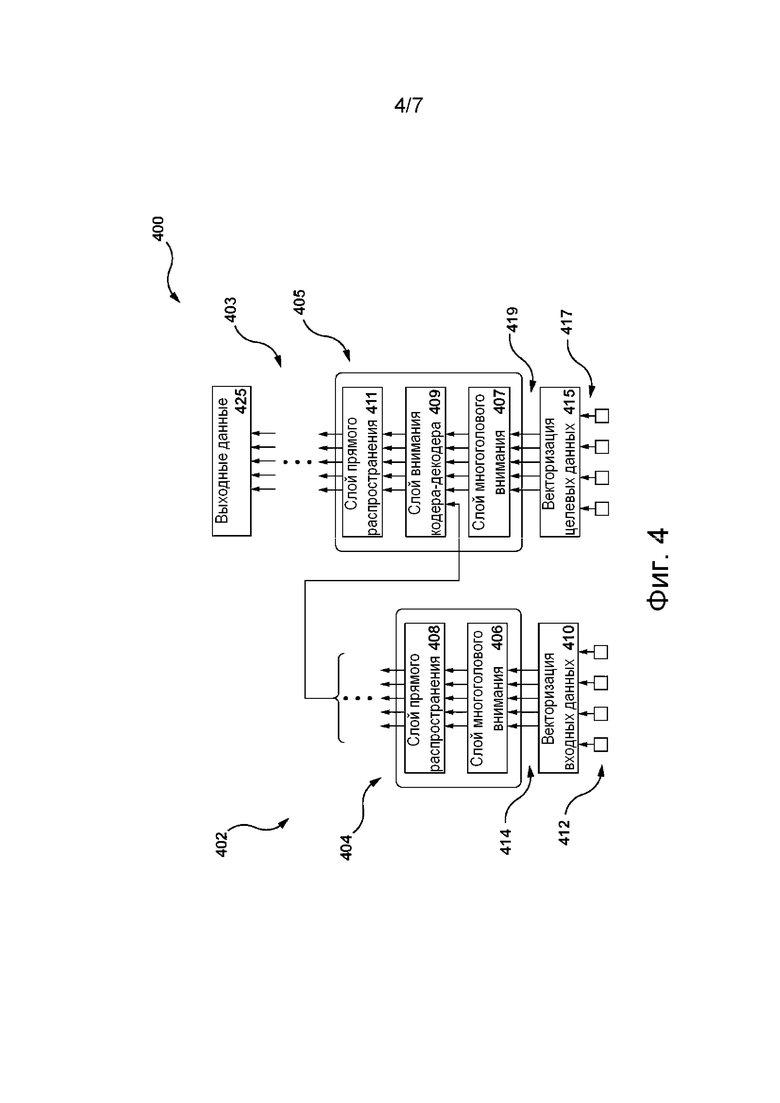
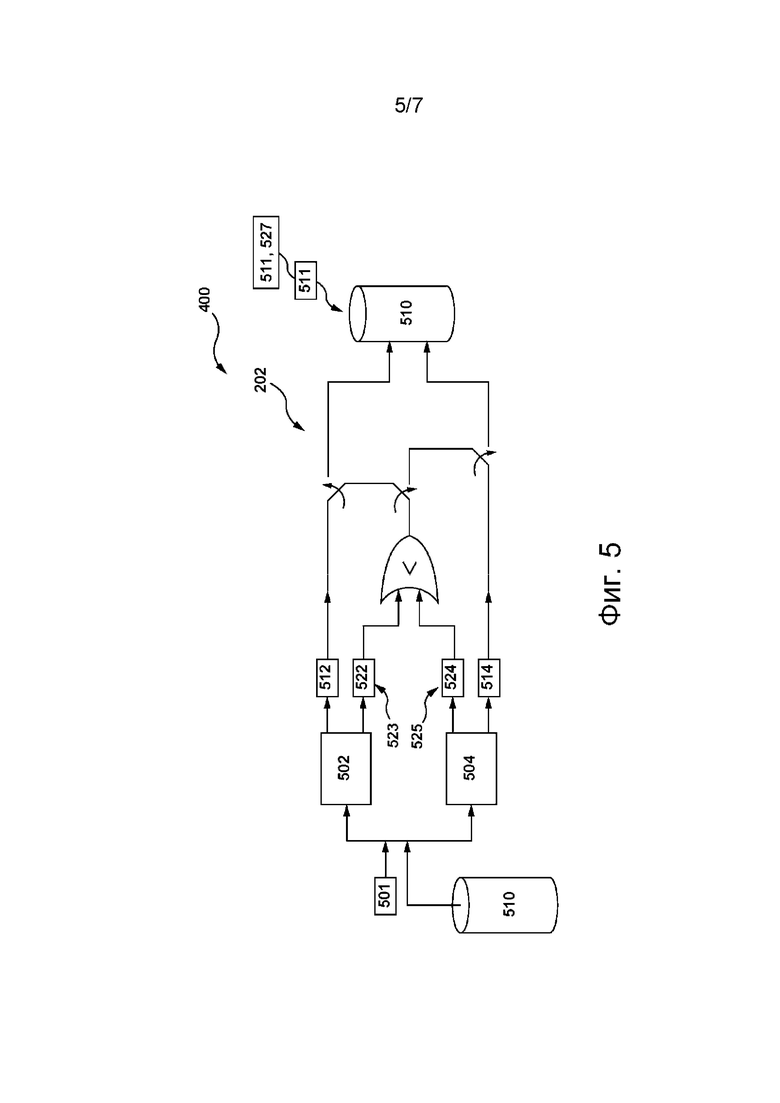
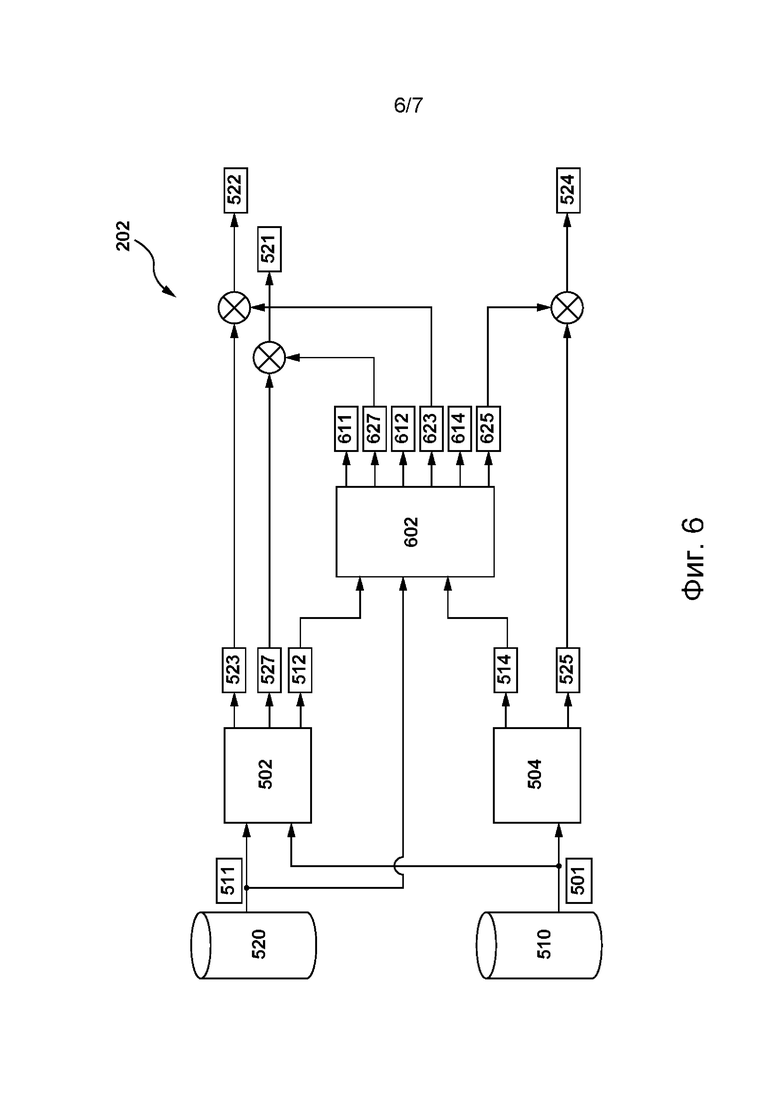
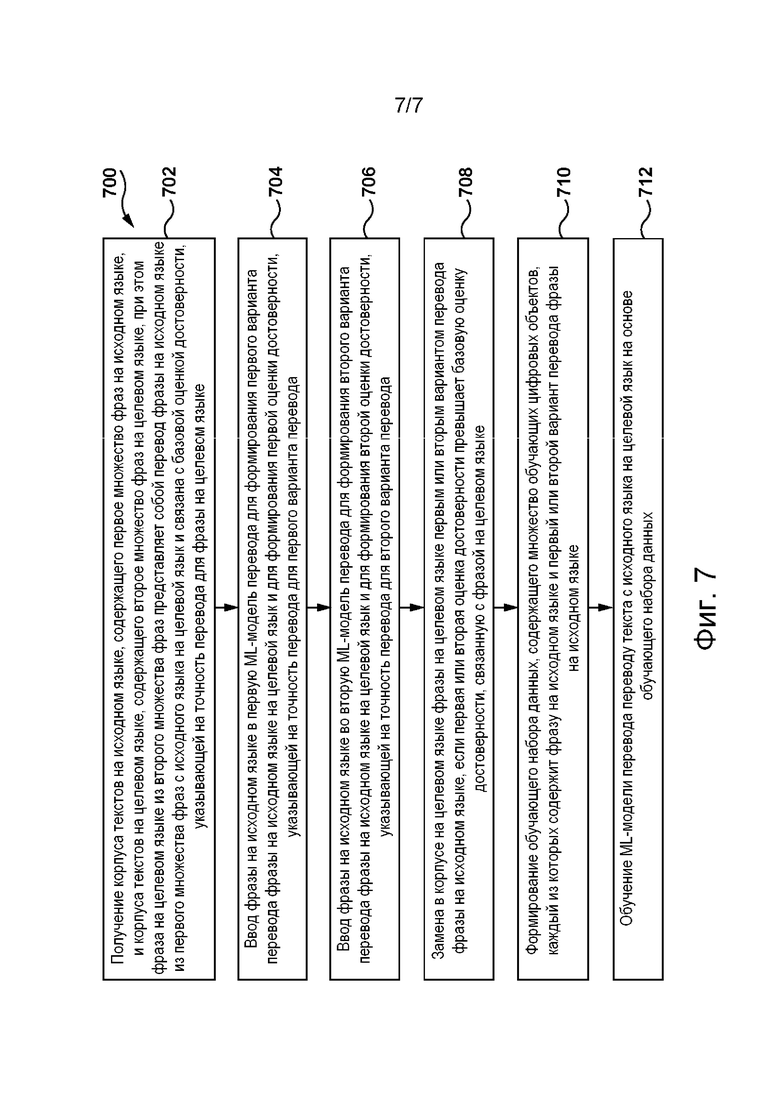
Заявленная группа изобретений относится к обучению модели машинного обучения перевода. Предложены способ и сервер для формирования обучающего набора данных для обучения модели машинного обучения для перевода. Способ включает в себя: получение корпуса текстов на исходном языке и корпуса текстов на целевом языке; формирование первого варианта перевода фразы на исходном языке из корпуса на исходном языке на целевой язык и его первой оценки достоверности; формирование второго варианта перевода фразы на исходном языке на целевой язык и его второй оценки достоверности; и замену фразы на целевом языке первым или вторым вариантом перевода, если первая или вторая оценка достоверности превышает базовую оценку достоверности, связанную с фразой на целевом языке из корпуса на целевом языке. Технический результат заключается в повышении точности целевого корпуса текстов с использованием предложений на целевом языке, повышении качества перевода. 2 н. и 18 з.п. ф-лы, 7 ил.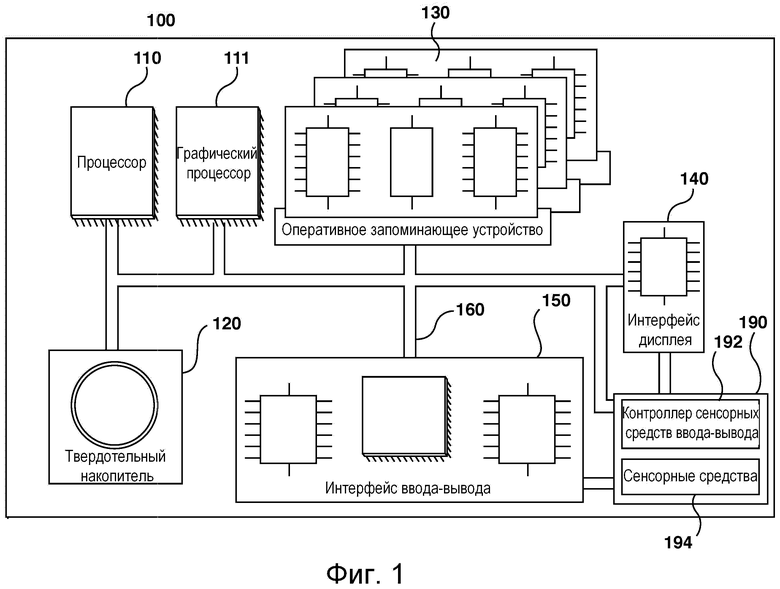
1. Компьютерный способ формирования обучающего набора данных для обучения модели машинного обучения (ML-модели) для перевода, в котором формирование включает в себя использование первой ML-модели перевода, предварительно обученной переводу текста с исходного языка на целевой язык, и второй ML-модели, предварительно обученной переводу текста с исходного языка на промежуточный язык и с промежуточного языка на целевой язык, при этом способ включает в себя:
- получение корпуса текстов на исходном языке, содержащего первое множество фраз на исходном языке, и корпуса текстов на целевом языке, содержащего второе множество фраз на целевом языке, при этом фраза на целевом языке из второго множества фраз представляет собой перевод фразы на исходном языке из первого множества фраз с исходного языка на целевой язык и связана с базовой оценкой достоверности, указывающей на точность перевода для фразы на целевом языке;
- ввод фразы на исходном языке в первую ML-модель перевода для формирования первого варианта перевода фразы на исходном языке на целевой язык и для формирования первой оценки достоверности, указывающей на точность перевода для первого варианта перевода;
- ввод фразы на исходном языке во вторую ML-модель перевода для формирования второго варианта перевода фразы на исходном языке на целевой язык и для формирования второй оценки достоверности, указывающей на точность перевода для второго варианта перевода;
- замену в корпусе на целевом языке фразы на целевом языке первым или вторым вариантом перевода фразы на исходном языке, если первая или вторая оценка достоверности превышает базовую оценку достоверности, связанную с фразой на целевом языке;
- формирование обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит фразу на исходном языке и первый или второй вариант перевода фразы на исходном языке; и
- обучение на основе обучающего набора данных ML-модели перевода переводу текста с исходного языка на целевой язык.
2. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя сохранение фразы на целевом языке в корпусе на целевом языке, если первая и вторая оценки достоверности меньше или равны базовой оценке достоверности, связанной с фразой на целевом языке.
3. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя определение базовой оценки достоверности, связанной с фразой на целевом языке.
4. Способ по п. 3, отличающийся тем, что определение базовой оценки достоверности включает в себя применение первой ML-модели перевода.
5. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя использование третьей ML-модели перевода, предварительно обученной переводу текста с целевого языка на исходный язык, при этом формирование базовой, первой и второй оценок достоверности включает в себя:
- формирование прямой оценки достоверности для фразы на целевом языке, а также для первого и второго вариантов перевода фразы на исходном языке на целевой язык;
- ввод фразы на целевом языке, а также первого и второго вариантов перевода фразы на исходном языке в третью ML-модель перевода для формирования вариантов обратного перевода фразы на целевом языке, связанной с фразой на исходном языке, на исходный язык и для формирования обратной оценки достоверности каждого варианта обратного перевода фразы на целевом языке на исходный язык; и
- объединение прямой и обратной оценок достоверности.
6. Способ по п. 5, отличающийся тем, что объединение включает в себя определение суммы прямого и обратного уровней достоверности.
7. Способ по п. 1, отличающийся тем, что ML-модель перевода отличается от первой и второй ML-моделей перевода.
8. Способ по п. 1, отличающийся тем, что ML-модель перевода представляет собой первую или вторую ML-модель перевода, а обучение ML-модели перевода включает в себя точную настройку первой или второй ML-модели перевода для перевода текста с исходного языка на целевой язык.
9. Способ по п. 1, отличающийся тем, что вторая ML-модель перевода содержит две ML-модели перевода: первую промежуточную ML-модель перевода, предварительно обученную переводу текста с исходного языка на промежуточный язык, и вторую промежуточную ML-модель перевода, предварительно обученную переводу текста с промежуточного языка на целевой язык.
10. Способ по п. 1, отличающийся тем, что первая или вторая ML-модель перевода представляет собой ML-модель на основе нейронной сети.
11. Способ по п. 10, отличающийся тем, что ML-модель на основе нейронной сети представляет собой ML-модель на основе трансформера.
12. Сервер для формирования обучающего набора данных для обучения ML-модели перевода, в котором формирование включает в себя использование первой ML-модели перевода, предварительно обученной переводу текста с исходного языка на целевой язык, и второй ML-модели, предварительно обученной переводу текста с исходного языка на промежуточный язык и с промежуточного языка на целевой язык, при этом сервер содержит по меньшей мере один процессор и по меньшей мере одну машиночитаемую физическую память, содержащую исполняемые команды, которые при их исполнении процессором инициируют выполнение сервером следующих действий:
- получение корпуса текстов на исходном языке, содержащего первое множество фраз на исходном языке и корпуса текстов на целевом языке, содержащего второе множество фраз на целевом языке, при этом фраза на целевом языке из второго множества фраз представляет собой перевод фразы на исходном языке из первого множества фраз с исходного языка на целевой язык и связана с базовой оценкой достоверности, указывающей на точность перевода для фразы на целевом языке;
- ввод фразы на исходном языке в первую ML-модель перевода для формирования первого варианта перевода фразы на исходном языке на целевой язык и для формирования первой оценки достоверности, указывающей на точность перевода для первого варианта перевода;
- ввод фразы на исходном языке во вторую ML-модель перевода для формирования второго варианта перевода фразы на исходном языке на целевой язык и для формирования второй оценки достоверности, указывающей на точность перевода для второго варианта перевода;
- замена в корпусе на целевом языке фразы на целевом языке первым или вторым вариантом перевода фразы на исходном языке, если первая или вторая оценка достоверности превышает базовую оценку достоверности, связанную с фразой на целевом языке;
- формирование обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит фразу на исходном языке и первый или второй вариант перевода фразы на исходном языке; и
- обучение на основе обучающего набора данных ML-модели перевода переводу текста с исходного языка на целевой язык.
13. Сервер по п. 12, отличающийся тем, что по меньшей мере один процессор дополнительно инициирует сохранение сервером фразы на целевом языке в корпусе на целевом языке, если первая и вторая оценки достоверности меньше или равны базовой оценке достоверности, связанной с фразой на целевом языке.
14. Сервер по п. 12, отличающийся тем, что по меньшей мере один процессор дополнительно инициирует определение сервером базовой оценки достоверности, связанной с фразой на целевом языке.
15. Сервер по п. 14, отличающийся тем, что для определения базовой оценки достоверности по меньшей мере один процессор инициирует применение сервером первой ML-модели перевода.
16. Сервер по п. 12, отличающийся тем, что по меньшей мере один процессор дополнительно инициирует обращение сервера к третьей ML-модели перевода, предварительно обученной переводу текста с целевого языка на исходный язык, при этом для формирования базовой, первой и второй оценок достоверности по меньшей мере один процессор инициирует выполнение сервером следующих действий:
- формирование прямой оценки достоверности для фразы на целевом языке, а также для первого и второго вариантов перевода фразы на исходном языке на целевой язык;
- ввод фразы на целевом языке, а также первого и второго вариантов перевода фразы на исходном языке в третью ML-модель перевода для формирования вариантов обратного перевода фразы на целевом языке, связанной с фразой на исходном языке, на исходный язык и для формирования обратной оценки достоверности каждого варианта обратного перевода фразы на целевом языке на исходный язык; и
- объединение прямой и обратной оценок достоверности.
17. Сервер по п. 16, отличающийся тем, что для объединения прямой и обратной оценок достоверности по меньшей мере один процессор инициирует определение сервером суммы прямого и обратного уровней достоверности.
18. Сервер по п. 12, отличающийся тем, что ML-модель перевода отличается от первой и второй ML-моделей перевода.
19. Сервер по п. 12, отличающийся тем, что ML-модель перевода представляет собой первую или вторую ML-модель перевода, а обучение ML-модели перевода включает в себя точную настройку первой или второй ML-модели перевода для перевода текста с исходного языка на целевой язык.
20. Сервер по п. 12, отличающийся тем, что вторая ML-модель перевода содержит две ML-модели перевода: первую промежуточную ML-модель перевода, предварительно обученную переводу текста с исходного языка на промежуточный язык, и вторую промежуточную ML-модель перевода, предварительно обученную переводу текста с промежуточного языка на целевой язык.
| Способ и сервер для обучения алгоритму машинного обучения для выполнения перевода | 2020 |
|
RU2789796C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПЕРЕВОДУ | 2020 |
|
RU2770569C2 |
| ЭЛЕКТРОННОЕ УСТРОЙСТВО ДЛЯ АВТОМАТИЧЕСКОГО ПЕРЕВОДА УСТНОЙ РЕЧИ С ОДНОГО ЯЗЫКА НА ДРУГОЙ | 2014 |
|
RU2571588C2 |
| JP 2015072509 A, 16.04.2015. | |||

