Область техники
Настоящее изобретение относится к кодированию многоканального аудио и, в частности, к концепции объединения параметрически кодированных аудиопотоков гибким и эффективным образом.
Уровень техники
Недавнее развитие технологий в области кодирования аудио выдвинуло на первый план несколько технологий параметрического кодирования аудио для совместного кодирования многоканального аудиосигнала (например, каналов 5.1) в один (или более) каналов понижающего микширования плюс поток дополнительной информации. Обычно поток дополнительной информации содержит параметры, относящиеся к свойствам исходных каналов многоканального сигнала относительно других исходных каналов многоканального сигнала или относительно канала понижающего микширования. Конкретное определение параметров опорного канала, к которым относятся эти параметры, зависит от конкретной реализации. Некоторыми из технологий, известных в данной области техники, являются «кодирование стереофоническими контрольными сигналами», «кодирование пространственного аудио» и «параметрическая стереофония».
Для указания подробностей об этих конкретных реализациях в настоящем документе приведена ссылка на соответствующие публикации. Кодирование стереофоническими контрольными сигналами, например, подробно описано в публикациях: C. Faller and F. Baumgarte, ”Efficient representation of spatial audio using perceptual parametrization”, IEEE WASPAA, Mohonk, NY, October 2001; F. Baumgarte and C. Faller, ”Estimation of auditory spatial cues for binaural cue coding”, ICASSP, Orlando, FL, May 2002; C. Faller and F. Baumgarte, ”Binaural cue coding: a novel and efficient representation of spatial audio”, ICASSP, Orlando, FL, May 2002; C. Faller and F. Baumgarte, ”Binaural cue coding applied to audio compression with flexible rendering”, AES 113th Convention, Los Angeles, Preprint 5686, October 2002; C. Faller and F. Baumgarte, ”Binaural Cue Coding - Part II: Schemes and applications”, IEEE Trans. on Speech and Audio Proc., vol. 11, no. 6, Nov. 2003; J. Herre, C. Faller et al., ”Spatial Audio Coding: Next-generation efficient and compatible coding of multi-channel audio”, Audio Engineering Society Convention Paper, Oct. 28, 2004, San Francisco, CA, USA.
В то время как при кодировании стереофоническими контрольными сигналами используют множество исходных каналов, параметрическая стереофония является связанной технологией для параметрического кодирования двухканального стереофонического сигнала, дающей в результате передаваемые монофонический сигнал и параметрическую дополнительную информацию, например, как описано в следующих публикациях: J. Breebaart, S. van de Par, A. Kohlrausch, E. Schuijers, ”High-Quality Parametric Spatial Audio Coding at Low Bitrates”, AES 116th Convention, Berlin, Preprint 6072, May 2004; E. Schuijers, J. Breebaart, H. Purnhagen, J. Engdegard, ”Low Complexity Parametric Stereo Coding”, AES 116th Convention, Berlin, Preprint 6073, May 2004.
Другие технологии основаны на мультиплексировании произвольных количеств аудиоисточников или объектов в единый аудиоканал передачи. Схемы, основанные на мультиплексировании, например, введены в качестве «гибкого воспроизведения» в связанные с BCC (кодированием стереофоническими контрольными сигналами) публикации или, в более позднее время, схемой, названной «совместным кодированием источников» (JSC). Например, связанными публикациями являются: C. Faller, ”Parametric Joint Coding of Audio Sources”, Convention Paper 6752, 120th AES Convention, Paris, May 2006. Подобно схемам параметрической стереофонии и стереофонического кодирования контрольными сигналами эти технологии предназначены для кодирования множества исходных аудиообъектов (каналов) для передачи посредством меньшего количества каналов понижающего микширования. Посредством дополнительного выведения основанных на объектах параметров для каждого входного канала, которые могут кодироваться при очень низких скоростях передачи данных и которые также передаются на приемник, на стороне приемника эти объекты могут быть разделены и интерпретированы (микшированы) для определенного количества устройств вывода, например, как наушники, двухканальные стереофонические громкоговорители или многоканальные установки громкоговорителей. Этот подход предусматривает настройку уровня и перераспределение (панорамирование) разных звуковых объектов по различным местоположениям в установке воспроизведения, то есть на стороне приемника.
В основном такие технологии работают как передатчик M-k-N, причем M является количеством аудиообъектов на входе, k является количеством передаваемых каналов понижающего микширования, обычно k≤2, N является количеством аудиоканалов на выходе интерпретатора, то есть, например, количеством громкоговорителей. То есть N=2 для стереофонического интерпретатора, N=5 для многоканальной акустической установки 5.1. С точки зрения эффективности сжатия типовыми значениями являются, например, 64 кбит/с для перцепционно кодированного канала понижающего микширования (состоящего из k аудиоканалов) и приблизительно 3 кбит/с для параметров объектов на каждый передаваемый аудиообъект.
Примерами применения для вышеприведенных технологий, например, являются кодирование сцен пространственного аудио, имеющих отношение к кинематографической продукции, для обеспечения возможности пространственного воспроизведения аудио в системе домашнего кинотеатра. Распространенными примерами являются широко известные звуковые дорожки объемного звучания 5.1 и 7.1 на носителях кинофильмов, таких как DVD (многофункциональный цифровой диск), и тому подобное. Кинопродукция становится все более и более сложной в том, что касается аудиосцен, которые предназначены для обеспечения впечатления пространственного прослушивания и поэтому должны микшироваться с большой тщательностью. Микширование разных источников звука или звуковых эффектов может быть поручено разным звукооператорам, а потому желательна передача параметрически кодированных многоканальных сценариев между отдельными звукооператорами для эффективной транспортировки аудиопотоков отдельных звукооператоров.
Еще одним примером применения такой технологии является проведение телеконференций с множеством говорящих абонентов на каждом конце двухточечного соединения. Для экономии ширины полосы большинство установок проведения телеконференций работают с монофонической передачей. Например, с использованием совместного кодирования источников или одной из других технологий многоканального кодирования для передачи может достигаться перераспределение и выравнивание уровней разных говорящих абонентов на приемном конце (каждом конце), и таким образом разборчивость речи и баланс говорящих абонентов улучшаются за счет использования незначительно повышенной скорости передачи битов по сравнению с монофонической системой. Преимущество повышенной разборчивости речи становится особенно очевидным в частном случае назначения каждого отдельного участника конференции на одиночный канал (и, таким образом, говорящего абонента) многоканальной акустической установки на приемном конце. Это, однако, является частным случаем. Вообще количество участников не будет соответствовать количеству говорящих абонентов на приемном конце. Однако с использованием существующей акустической установки можно воспроизводить сигнал, связанный с каждым участником так, чтобы он казался исходящим из любого заданного положения. То есть отдельный участник распознается не только по его/ее собственному голосу, но также по местоположению аудиоисточника, относящегося к говорящему участнику.
Несмотря на то, что современные технологии реализуют концепции, относящиеся к эффективному кодированию множества каналов или аудиообъектов, все известные в настоящее время технологии не имеют возможности эффективно объединять два или более из этих передаваемых аудиопотоков, чтобы получать выходной поток (выходной сигнал), который является представлением всех входных аудиопотоков (входных аудиосигналов).
Например, возникает проблема в случае проведения телеконференций с более чем двумя местоположениями, причем в каждом местоположении имеется один или более говорящих абонентов. В таком случае требуется промежуточный этап приема входных аудиосигналов отдельных источников и формирования выходных аудиосигналов для каждого местоположения проведения телеконференции, содержащих информацию только оставшихся местоположений проведения телеконференции. То есть на промежуточном этапе должен формироваться выходной сигнал, который выводится из комбинации двух или более входных аудиосигналов, и который предусматривает воспроизведение отдельных аудио каналов или аудиообъектов двух или более входных сигналов.
Похожая ситуация может иметь место в случае, когда два звукооператора в кинематографическом производстве желают объединить свои пространственные аудиосигналы для проверки впечатления от прослушивания, формируемого обоими сигналами. В таком случае может быть желательным непосредственное объединение двух кодированных многоканальных сигналов для проверки общего впечатления от прослушивания. То есть необходимо, чтобы объединенный сигнал имел сходство со всеми аудиообъектами (источниками) двух звукооператоров.
Однако согласно технологиям из уровня техники такое объединение осуществимо только посредством декодирования аудиосигналов (потоков). В таком случае декодированные аудиосигналы могут вновь повторно кодироваться многоканальными кодерами уровня техники для формирования объединенного сигнала, в котором надлежащим образом представлены все исходные аудиоканалы или аудиообъекты.
Это имеет недостаток, заключающийся в высокой вычислительной сложности, что приводит к затратам большого количества энергии, а иногда и вовсе исключает возможность применения концепции, особенно в сценариях реального времени. Более того, объединение посредством последовательного декодирования и повторного кодирования аудио может вызывать значительную задержку, обусловленную двумя этапами обработки, что является неприемлемым для некоторых применений, таких как проведение телеконференций/телекоммуникации.
Сущность изобретения
Задача настоящего изобретения состоит в том, чтобы предложить концепцию эффективного объединения множества параметрически кодированных аудиосигналов.
В соответствии с первым аспектом настоящего изобретения эта задача выполняется генератором аудиосигнала для формирования выходного аудиосигнала, при этом генератор аудиосигнала содержит: приемник аудиосигнала для приема первого аудиосигнала, содержащего первый канал понижающего микширования, содержащий информацию о двух или более первых исходных каналах, и содержащего исходный параметр, связанный с одним из первых исходных каналов и описывающий свойство одного из первых исходных каналов относительно опорного канала; и второго аудиосигнала, содержащего второй канал понижающего микширования, содержащий информацию о по меньшей мере одном втором исходном канале; объединитель каналов для получения объединенного канала понижающего микширования объединением первого канала понижающего микширования и второго канала понижающего микширования; вычислитель параметров для получения первого обобщенного параметра, описывающего свойство одного из первых исходных каналов относительно общего опорного канала, и второго обобщенного параметра, описывающего свойство другого одного из первых исходных каналов или по меньшей мере одного второго исходного канала относительно общего опорного канала; и выходной интерфейс для вывода выходного аудиосигнала, содержащего объединенный канал понижающего микширования, первый и второй обобщенные параметры.
В соответствии со вторым аспектом настоящего изобретения эта задача выполняется способом формирования выходного аудиосигнала, причем способ содержит прием первого аудиосигнала, содержащего первый канал понижающего микширования, содержащий информацию о двух или более первых исходных каналах, и содержащего исходный параметр, связанный с одним из первых исходных каналов, описывающий свойство одного из первых исходных каналов относительно опорного канала, и второй аудиосигнал, содержащий второй канал понижающего микширования, содержащий информацию о по меньшей мере одном втором исходном канале; получение объединенного канала понижающего микширования объединением первого канала понижающего микширования и второго канала понижающего микширования; получение первого обобщенного параметра, описывающего свойство одного из первых исходных каналов относительно общего опорного канала, и второго обобщенного параметра, описывающего свойство другого канала из первых исходных каналов или по меньшей мере одного второго исходного канала относительно общего опорного канала; и вывод выходного аудиосигнала, содержащего объединенный канал понижающего микширования, а также первый и второй обобщенные параметры.
В соответствии с третьим аспектом настоящего изобретения эта задача выполняется представлением трех или более аудиоканалов, содержащим: объединенный канал понижающего микширования, являющийся комбинацией первого канала понижающего микширования, содержащего информацию о по меньшей мере двух первых исходных каналах, и второго канала понижающего микширования, содержащего информацию о по меньшей мере одном втором исходном канале; первый параметр, описывающий свойство одного из по меньшей мере двух первых исходных каналов относительно опорного канала; и второй параметр, описывающий свойство другого канала из первых исходных каналов или свойство по меньшей мере одного второго исходного канала относительно опорного канала.
В соответствии с четвертым аспектом настоящего изобретения эта задача выполняется компьютерной программой, реализующей способ формирования выходного аудиосигнала, содержащий прием первого аудиосигнала, содержащего первый канал понижающего микширования, содержащий информацию о двух или более первых исходных каналах, и содержащий исходный параметр, связанный с одним из первых исходных каналов, описывающий свойство одного из первых исходных каналов относительно опорного канала, и второго аудиосигнала, содержащего второй канал понижающего микширования, содержащий информацию о по меньшей мере одном втором исходном канале; получение объединенного канала понижающего микширования объединением первого канала понижающего микширования и второго канала понижающего микширования; получение первого обобщенного параметра, описывающего свойство одного из первых исходных каналов относительно общего опорного канала, и второго обобщенного параметра, описывающего свойство другого канала из первых исходных каналов или по меньшей мере одного второго исходного канала относительно общего опорного канала; и вывод выходного аудиосигнала, содержащего объединенный канал понижающего микширования, а также первый и второй обобщенные параметры.
В соответствии с пятым аспектом настоящего изобретения эта задача выполняется системой конференц-связи, содержащей генератор аудиосигнала для формирования выходного аудиосигнала, содержащий приемник аудиосигнала для приема первого аудиосигнала, содержащего первый канал понижающего микширования, содержащий информацию о двух или более первых исходных каналах, и содержащего исходный параметр, связанный с одним из первых исходных каналов, описывающий свойство одного из первых исходных каналов относительно опорного канала; и второго аудиосигнала, содержащего второй канал понижающего микширования, содержащий информацию о по меньшей мере одном втором исходном канале; объединитель каналов для получения объединенного канала понижающего микширования объединением первого канала понижающего микширования и второго канала понижающего микширования; вычислитель параметров для получения первого обобщенного параметра, описывающего свойство одного из первых исходных каналов относительно общего опорного канала, и второго обобщенного параметра, описывающего свойство другого одного из первых исходных каналов или по меньшей мере одного второго исходного канала относительно общего опорного канала; и выходной интерфейс для вывода выходного аудиосигнала, содержащего объединенный канал понижающего микширования, первый и второй обобщенный параметр.
Настоящее изобретение основано на обнаружении того, что множество параметрически кодированных аудиосигналов могут эффективно объединяться с использованием генератора аудиосигнала или объединителя аудиосигнала, который формирует выходной аудиосигнал путем объединения каналов понижающего микширования и связанных с ними параметров входных аудиосигналов непосредственно в пределах области значений параметров, то есть без реконструкции или декодирования отдельных входных аудиосигналов перед формированием выходного аудиосигнала. Более конкретно, это достигается непосредственным микшированием связанных каналов понижающего микширования отдельных входных сигналов, например суммированием или формированием их линейной комбинации. Ключевой признак настоящего изобретения состоит в том, что объединение каналов понижающего микширования достигается простыми вычислительно экономными арифметическими операциями, такими как суммирование.
То же самое справедливо для объединения параметров, связывающих каналы понижающего микширования. Так как обычно во время объединения входных аудиосигналов должно будет изменяться по меньшей мере подмножество связанных параметров, наиболее важно, во-первых, чтобы расчеты, выполняемые для изменения параметров, были простыми и поэтому не нуждались ни в значительной вычислительной мощности, и, во-вторых, чтобы расчеты не вызывали дополнительной задержки, например, посредством использования блоков фильтров или других операций, использующих память.
Согласно одному из вариантов осуществления настоящего изобретения реализован генератор аудиосигнала для формирования выходного звукового сигнала для объединения первого и второго аудиосигнала, причем оба сигнала являются параметрически кодированными. Для формирования выходного аудиосигнала генератор аудиосигнала согласно настоящему изобретению извлекает каналы понижающего микширования из входных аудиосигналов и формирует объединенный канал понижающего микширования, образуя линейную комбинацию двух каналов понижающего микширования. То есть отдельные каналы складываются с применением дополнительных весов.
В предпочтительном варианте осуществления настоящего изобретения применяемые веса выводятся путем крайне простых операций, например, посредством использования в качестве основы для расчета количества каналов, представленных первым аудиосигналом и вторым аудиосигналом.
В дополнительном предпочтительном варианте осуществления расчет весов выполняется исходя из предположения, что каждый исходный аудиоканал входных сигналов вносит вклад в полную энергию сигнала с одинаковой долей. То есть применяемые веса являются простыми отношениями количеств каналов входных сигналов и общего количества каналов.
В дополнительном предпочтительном варианте осуществления настоящего изобретения веса отдельных каналов понижающего микширования рассчитываются на основании энергии, содержащейся в каналах понижающего микширования для обеспечения возможности более достоверного воспроизведения объединенного канала понижающего микширования, включенного в формируемый выходной аудиосигнал.
В дополнительном предпочтительном варианте осуществления настоящего изобретения вычислительная работа дополнительно сокращается за счет того, что изменяются только параметры, связанные с одним из двух аудиосигналов. То есть параметры другого аудиосигнала передаются неизменными, не вызывая никаких вычислений и таким образом сводя к минимуму нагрузку на генератор аудиосигнала согласно настоящему изобретению.
В последующих разделах концепция согласно настоящему изобретению будет подробно описана, главным образом, в отношении схемы кодирования, использующей совместное кодирование источников (JSC). В этом смысле настоящее изобретение расширяет эту технологию для соединения множества монофонических или наделенных возможностью JSC приемопередатчиков с удаленными станциями посредством микширования сигналов понижающего микширования JSC и информации об объектах в пределах области значений параметров. Как показали вышеприведенные соображения, концепция согласно настоящему изобретению никоим образом не ограничена использованием кодирования JSC, но также может быть реализована с помощью кодирования BCC или других многоканальных схем кодирования, таких как кодирование пространственного аудиоMPEG (стандарта Экспертной группы по киноизображению) (объемного звучания MPEG), и тому подобное.
Так как концепция согласно настоящему изобретению будет подробно описана главным образом в отношении использования кодирования JSC, кодирование JSC будет кратко рассмотрено в последующих разделах, для более четкой демонстрации гибкости концепции согласно настоящему изобретению и усовершенствований, достигаемых по сравнению с уровнем техники при применении концепции согласно настоящему изобретению к существующим многоканальным схемам кодирования аудио.
Краткое описание чертежей
На фиг.1 показан пример схемы кодирования JSC;
на фиг.2 показан пример устройства воспроизведения JSC;
на фиг.3 показан пример проведения телеконференций между двумя местоположениями;
на фиг.4 показан пример проведения телеконференций между тремя местоположениями;
на фиг.5 показан пример проведения телеконференции с использованием генератора аудиосигнала согласно настоящему изобретению;
на фиг.6А показан дополнительный пример проведения телеконференции с использованием генератора аудиосигнала согласно настоящему изобретению;
на фиг.6B показана обратная совместимость концепции согласно настоящему изобретению; и
на фиг.7 показан пример генератора аудиосигнала согласно настоящему изобретению.
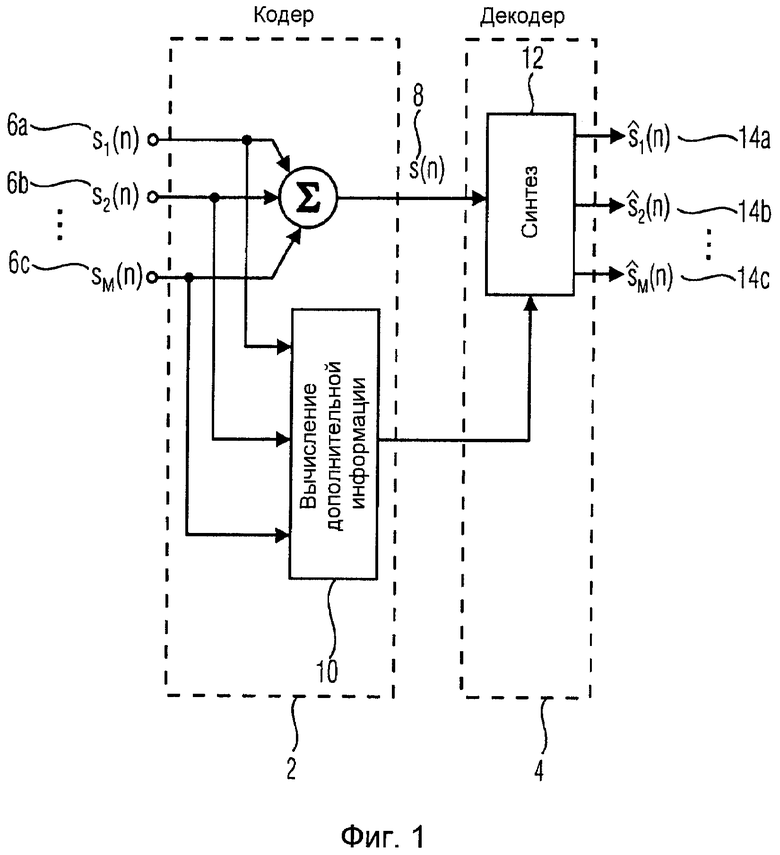
Кодирование JSC будет далее разъяснено со ссылкой на фиг. 1 и 2. На чертежах функционально идентичные компоненты будут иметь одинаковые ссылочные позиции, указывающие, что отдельные компоненты, обеспечивающие идентичные функциональные возможности, могут взаимно заменяться между отдельными вариантами осуществления настоящего изобретения без ослабления или ограничения функциональных возможностей и без ограничения объема настоящего изобретения.
На фиг.1 показана блок-схема совместного кодирования источников, соответствующий кодер 2 и соответствующий декодер 4.
Кодер 2 принимает отдельные входные сигналы si(n) 6a, 6b и 6c и создает сигнал s(n) 8 понижающего микширования, например, посредством суммирования форм сигналов.
В качестве дополнения выделитель 10 параметров в составе кодера 2 извлекает дополнительную параметрическую информацию для каждого одиночного объекта (сигнала 6a, 6b и 6c). Хотя это не показано на фиг.1, сигнал 8 понижающего микширования может дополнительно сжиматься речевым или аудиокодером и передаваться со смежной дополнительной параметрической информацией в декодер 4JSC. Модуль 12 синтеза в декодере 4 восстанавливает оценки 14a, 14b и 14c (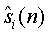 ) входных объектов (каналов 6a, 6b и 6c).
) входных объектов (каналов 6a, 6b и 6c).
Для того чтобы реконструировать оценки 14a, 14b и 14c, являющиеся перцепционно подобными отдельным входным объектам (входным каналам) 6a, 6b и 6c, следует извлекать надлежащую дополнительную параметрическую информацию для каждого канала. Так как отдельные каналы суммируются для формирования сигнала 8 понижающего микширования, такими надлежащими величинами являются отношения мощностей между каналами. Поэтому параметрическая информация для разных объектов или каналов состоит из отношений мощностей Δp каждого объекта относительно первого объекта (опорного объекта).
Эта информация выводится в частотной области в неравномерно разнесенных полосах (поддиапазонах) частот, соответствующих разрешению ключевых полос частот человеческого слухового восприятия. Это концепция более подробно описана, например, в публикации: J. Blauert, ”Spatial Hearing: The Psychophysics of Human Sound Localization”, The MIT Press, Cambridge, MA, revised edition 1997.
Таким образом, широкополосные входные аудиоканалы фильтруются в несколько полос частот конечной ширины полосы, и для каждой из отдельных полос частот выполняются следующие расчеты. Как уже было указано, полосовая мощность первого объекта (опорного объекта или опорного канала) действует в качестве опорного значения.
Уравнение 1
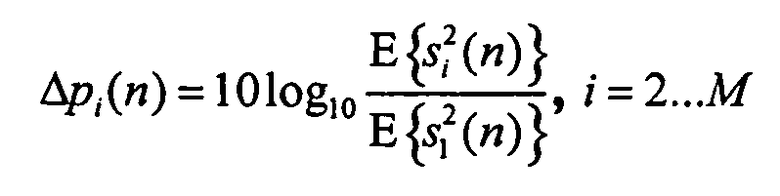
Чтобы избежать дополнительных артефактов, например, привнесенных делением на ноль, эти отношения мощности (в логарифмическом представлении) могут дополнительно ограничиваться максимальным значением, например, в 24 дБ в каждом поддиапазоне. Отношение мощности, кроме того, может квантоваться перед представлением, чтобы дополнительно сэкономить ширину полосы передачи.
Необязательно передавать мощность первого объекта явным образом. Вместо этого, это значение может выводиться из допущения, что для статистически независимых объектов сумма мощностей синтезированных сигналов равна мощности сигнала s(n) понижающего микширования. Математически это выражается следующим образом:
Уравнение 2
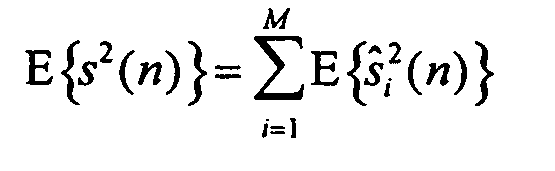
На основании этого допущения и уравнения могут быть реконструированы мощности поддиапазонов для первого объекта (опорного объекта или опорного канала), как будет дополнительно описано ниже при подробном описании концепции согласно настоящему изобретению.
Подытоживая вышесказанное, аудиосигнал или аудиопоток согласно JSC содержит канал понижающего микширования и связанные параметры, при этом параметры описывают отношения мощностей исходных каналов по отношению к одному исходному опорному каналу. Можно отметить, что в этот пример могут быть легко внесены изменения, так как в качестве опорного канала могут быть выбраны другие каналы. Например, опорным каналом может быть сам канал понижающего микширования, что требует передачи дополнительного параметра, соотносящего мощность первого упомянутого выше опорного канала с мощностью канала понижающего микширования. К тому же может быть выбран изменяемый опорный канал посредством выбора в качестве опорного канала одного из каналов, имеющего наибольшую мощность. Поэтому, так как мощность в пределах отдельных каналов может изменяться со временем, опорный канал также может меняться со временем. К тому же, вследствие того обстоятельства, что вся обработка обычно выполняется частотно избирательным образом, опорный канал может быть разным для разных полос частот.
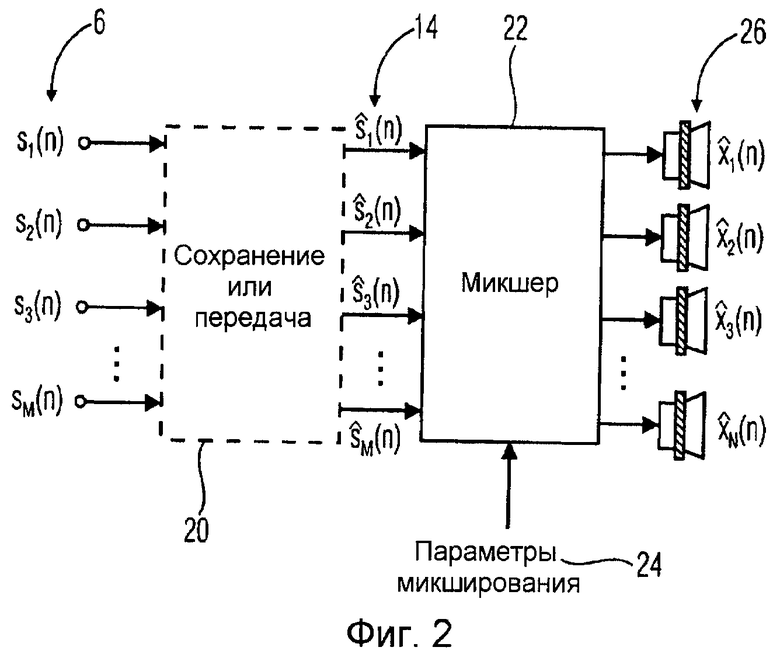
На фиг.2 показаны дополнительно усовершенствованные схемы кодирования JSC, основанные на схеме по фиг.1. Признаки, подробно описанные относительно фиг.1, относятся к блоку 20 сохранения и передачи, принимающему входные каналы 6, которые следует кодировать, и выводящему оценки 14 входных каналов 6. Схема по фиг.2 улучшена за счет того, что она дополнительно содержит микшер 22, принимающий оценки. То есть синтезированные объекты 14 не выводятся непосредственно в качестве одиночных аудиосигналов, а воспроизводятся в N выходных каналов в модуле микшера. Такой микшер может быть реализован разными способами, например, путем приема дополнительных параметров 24 микширования в качестве входного сигнала для управления микшированием синтезированных объектов 14. Только в качестве примера можно рассмотреть пример проведения телеконференции, в котором каждый из выходных каналов 26 приписан одному участнику конференции. Таким образом участник на приемном конце имеет возможность виртуально разделять других участников, связывая их голоса с отдельными местоположениями. Таким образом, в качестве критерия для проведения различия между разными участниками телефонной конференции может служить не только речь, но также и направление, с которого слушатель принимает голос участника. Более того, слушатель может компоновать выходной канал таким образом, чтобы все участники из одного и того же местоположения проведения телеконференции группировались в одном и том же направлении, тем самым в еще большей степени улучшая впечатление от восприятия.
Как показано на фиг.2, s1(n)... sM(n) обозначают отдельные аудиообъекты на входе кодера JSC. На выходе декодера JSC 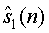 ...
... 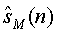 представляют «виртуально» разделенные аудиообъекты, которые подаются в микшер. Параметры 24 микширования могут интерактивно модифицироваться на стороне приемника для размещения разных объектов в звуковой сцене, которая воспроизводятся выходными каналами
представляют «виртуально» разделенные аудиообъекты, которые подаются в микшер. Параметры 24 микширования могут интерактивно модифицироваться на стороне приемника для размещения разных объектов в звуковой сцене, которая воспроизводятся выходными каналами 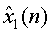 ...
... 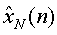 .
.
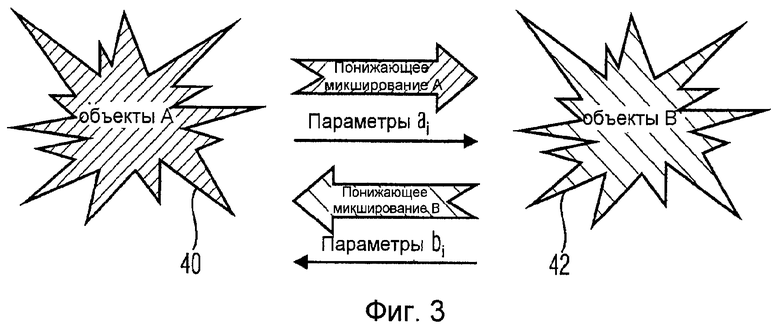
На фиг.3 показано применение многоканальных схем аудиокодирования для базового примера проведения телеконференции, происходящей между двумя местоположениями. В данном примере первое местоположение 40 осуществляет связь со вторым местоположением 42. Первое местоположение может иметь A участников, то есть A аудиообъектов, второе местоположение имеет B участников или аудиообъектов. При проведении двухточечной телеконференции описанная технология кодирования JSC может применяться непосредственно для передачи аудиосигналов множества объектов в каждом местоположении на соответствующую удаленную станцию. То есть (A-1) параметров ai и связанное с ними понижающее микширование передаются в местоположение 42. В противоположном направлении (B-1) параметров bi передаются вместе со связанным с ними понижающим микшированием в местоположение 40.
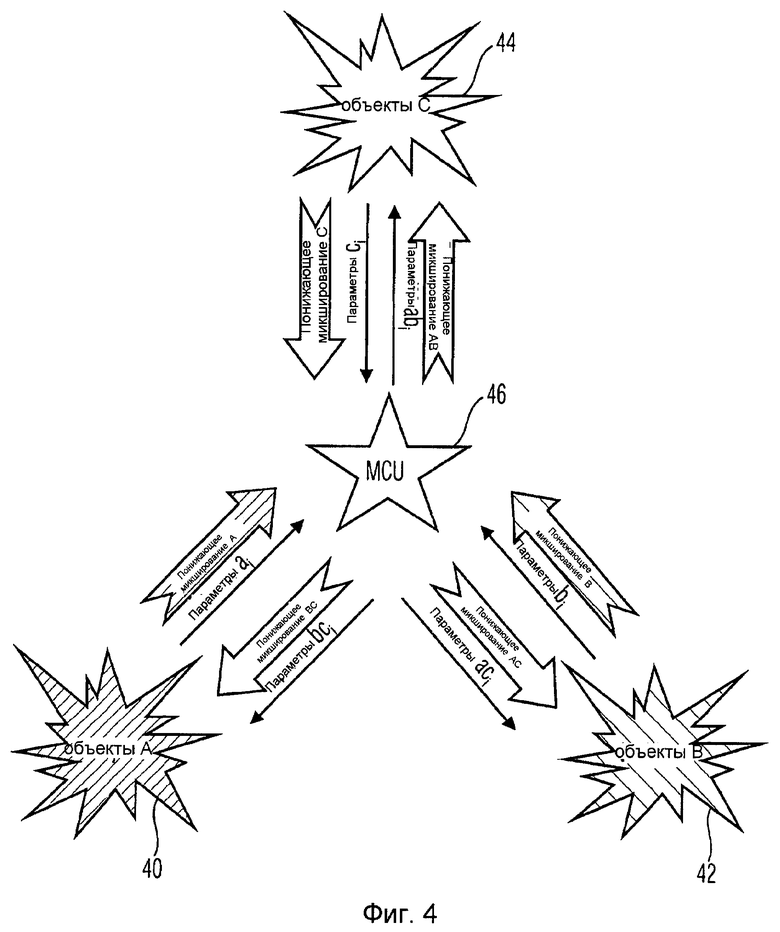
Для проведения телеконференции с более чем двумя конечными точками ситуация является совершенно иной, как проиллюстрировано на фиг.4.
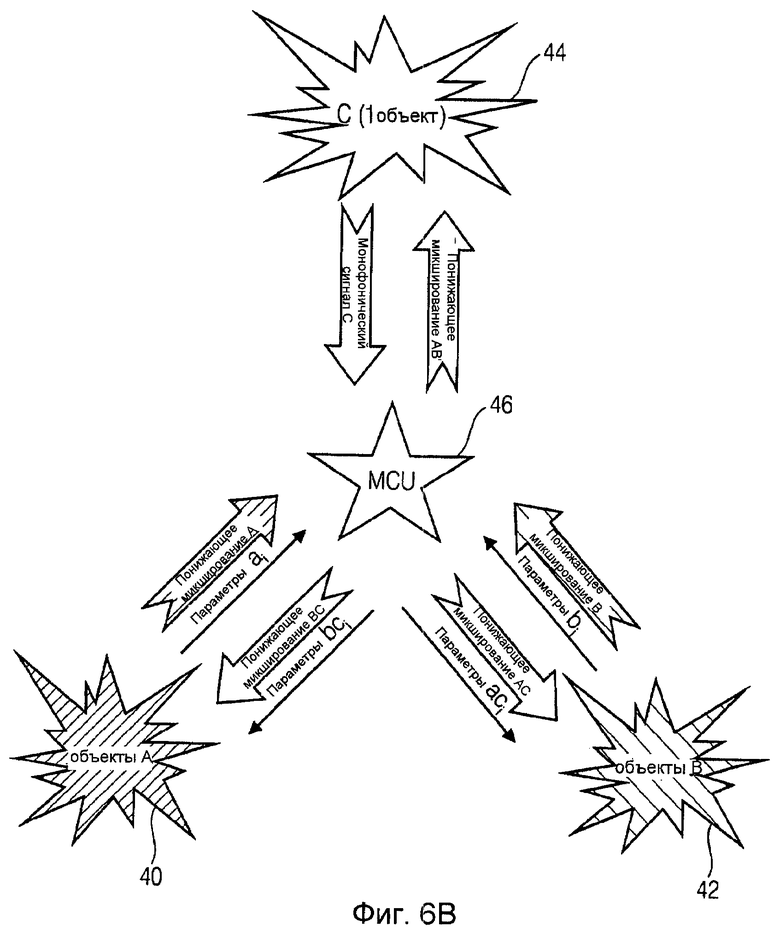
На фиг.4 кроме местоположений 40 и 42 показано третье местоположение 44. Как можно увидеть на фиг.4, такому сценарию необходим центральный распределитель для ассоциированных аудиосигналов, обычно называемый многоточечным устройством управления, MCU. Каждое из местоположений (абонентских пунктов) 40, 42 и 44 соединено с MCU 46. Каждому абонентскому пункту 40, 42 и 44 соответствует одиночный восходящий поток в MCU, содержащий сигнал из абонентского пункта. Так как каждому отдельному абонентскому пункту необходимо принимать сигналы из остальных абонентских пунктов, нисходящий поток в каждый абонентский пункт 40, 42 и 44 является смесью сигналов других абонентских пунктов, исключая собственный сигнал абонентского пункта, который также обозначен как сигнал (N-1). Как правило, для удовлетворения требований установки и для сохранения приемлемо малой ширины полосы передачи передача N-1 кодированных посредством JSC потоков из MCU в каждый абонентский пункт неосуществима. Это, конечно, было бы простым вариантом выбора.
Современный подход к получению отдельных нисходящих потоков состоит в том, чтобы повторно синтезировать все входящие потоки (объекты) в MCU 46 с использованием декодера JSC. В таком случае повторно синтезированные аудиообъекты могли бы группироваться и повторно кодироваться, например, чтобы снабжать каждый абонентский пункт аудиопотоками, содержащими требуемые аудиообъекты или аудиоканалы. Даже в этом простом примере это означало бы три задачи декодирования и три задачи кодирования, которые должны одновременно выполняться в MCU 46. Несмотря на значительные вычислительные потребности, от этого процесса параметрического «тандемного кодирования» (повторного кодирования/декодирования) можно ожидать дополнительных слышимых артефактов. Увеличение количества абонентских пунктов, кроме того, увеличило бы количество потоков и, следовательно, количество требуемых процессов кодирования или декодирования, не обеспечивая ни одного из простых подходов, осуществимых для сценариев реального времени.
Поэтому согласно настоящему изобретению для такого сценария типа MCU разработана схема микширования разных параметрически кодированных потоков (в этом конкретном примере - потоков JSC) непосредственно в пределах области значений параметров понижающего микширования и объектов, создающая требуемые выходные сигналы (выходные аудиопотоки) при минимальной вычислительной работе и потере качества.
В последующих разделах концепция непосредственного микширования многоканальных параметрически кодированных аудиопотоков согласно настоящему изобретению в пределах области значений параметров подробно описана для аудиопотоков, кодированных посредством JSC.
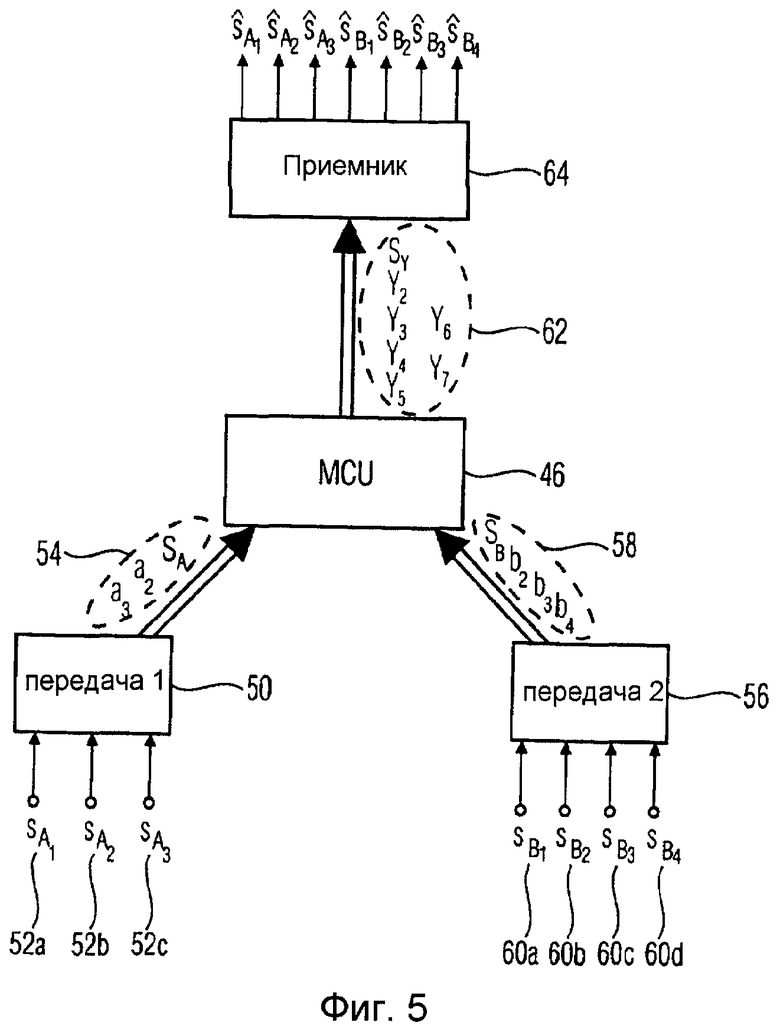
Концепция согласно настоящему изобретению пояснена на примере объединения двух исходных аудиосигналов (потоков) в один выходной сигнал. Соединение трех или более потоков может быть легко выведено из случая объединения двух потоков. Следующие математические соображения проиллюстрированы посредством фиг.5, на которой показан случай, когда три аудиоканала абонентского пункта A должны объединяться с четырьмя аудиоканалами абонентского пункта B. Конечно, это только пример для визуализации концепции согласно настоящему изобретению.
При использовании кодирования JSC абонентский пункт 50 (A), имеющий трех участников с 52a по 52c конференции (говорящих абонентов), формирующих сигналы sAx, передает аудиопоток или аудиосигнал 54. Аудиосигнал 54 содержит канал sA и параметры a2 и a3, относящие мощность каналов 52b и 52c к мощности канала 52a. Равным образом абонентский пункт 56 (B) передает аудиосигнал 58, содержащий канал SB понижающего микширования и три параметра b2, b3 и b4, представляющий собой кодированное посредством JSC представление четырех говорящих абонентов с 60a по 60d. MCU 46 объединяет аудиосигналы 54 и 58 для получения выходного сигнала 62, содержащего объединенный канал sY понижающего микширования и 6 параметров y2, ..., y7.
На приемной стороне приемник 64 декодирует выходной сигнал 62 для получения представлений 7 аудиообъектов или аудиоканалов абонентских пунктов 50 и 56.
В общих чертах задача состоит в формировании одиночного объединенного представления 62 двух потоков 54 и 58 JSC, каждый из которых представляет некоторое количество объектов, посредством одного общего сигнала sY понижающего микширования и одного набора параметров объектов, характеризующих объекты. В идеальном варианте объединенное представление JSC должно быть идентично такому представлению, которое получалось бы в результате кодирования полного набора исходных сигналов источников, лежащих в основе обоих потоков JSC, в одиночный поток JSC на одном этапе.
Для сохранения простоты следующих уравнений допустим, что отношения относительных мощностей из уравнения 1 доступны не в логарифмической области, а непосредственно в качестве отношений мощности. Каждый параметр ri(n) объекта для определенного объекта i может быть получен в виде
Уравнение 3
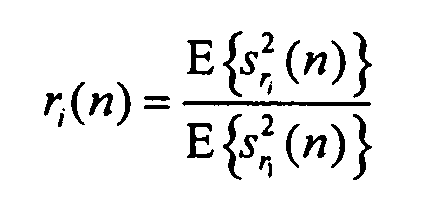
Преобразование в логарифмической области может затем применяться к каждому параметру для обеспечения возможности квантования с использованием логарифмической шкалы мощностей.
Предполагается, что все сигналы, приведенные ниже, преобразованы в представление поддиапазонов, и поэтому каждый из расчетов применяется отдельно для каждого поддиапазона.
Мы имеем поток A с его сигналом sA понижающего микширования и параметрами (отношениями относительных мощностей) для U объектов a2 ...aU. Поток B состоит из сигнала sB понижающего микширования и параметров для V объектов b2 ...bV.
Объединенный сигнал sY понижающего микширования может формироваться в качестве линейной комбинации обоих сигналов sA и sB понижающего микширования. Для обеспечения правильной регулировки уровня вкладов разных объектов могут применяться коэффициенты gA и gB усиления
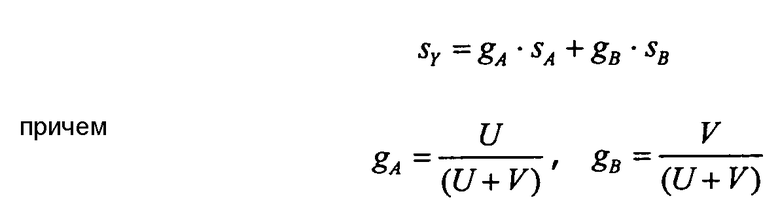
Этот вид масштабирования может быть показательным, если одиночные аудиоисточники равной средней мощности были суммированы и нормированы в полном объеме процесса понижающего микширования.
В качестве альтернативы можно использовать позволяющий экономить мощность подход для коэффициентов усиления с
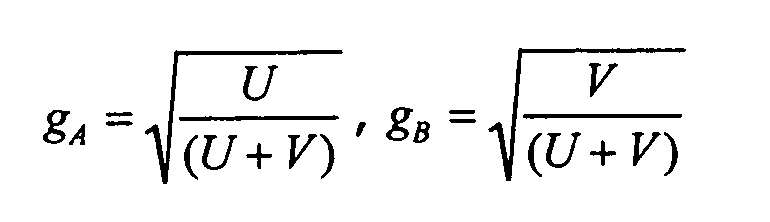
Другая возможность состоит в выборе коэффициента усиления таким образом, чтобы оба сигнала понижающего микширования привносили одинаковую среднюю энергию в объединенное понижающее микширование, то есть посредством выбора
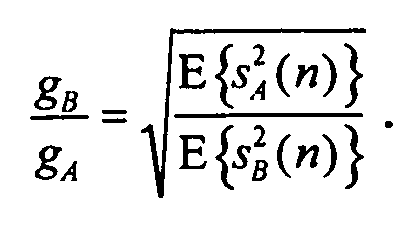
Параметры yi объектов для объединенного потока sY будут представлять все U + V объектов.
Поскольку параметры, связанные с каналами понижающего микширования, являются отношениями относительных мощностей, параметры a2, ..., aU могут использоваться, как они есть (неизменными), а параметры для объектов B могут объединяться с параметрами a2, ..., aU. Как только первый объект сигнала A выбран опорным объектом или опорным каналом, исходные параметры bi должны преобразовываться, чтобы соотноситься с таким опорным каналом. Следует отметить, что необходимо повторно рассчитывать параметры только одного потока, за счет чего дополнительно снижается вычислительная нагрузка в MCU 46.
Кроме того, можно отметить, что никоим образом не является обязательным использование в качестве нового опорного канала опорного канала одного из исходных аудиопотоков. Концепция объединения параметрически кодированных аудиопотоков в пределах области значений параметров согласно настоящему изобретению также вполне может быть реализована с другими опорными каналами, выбранными из числа исходных каналов абонентских пунктов A или B. Дополнительная возможность состоит в использовании в качестве нового опорного канала объединенного канала понижающего микширования.
Следуя этому подходу использования исходного опорного канала абонентского пункта A в качестве опорного канала (объединенного опорного канала), нужно прежде всего рассчитывать энергию (мощность) первого объекта (канала) каждого сигнала A и B, поскольку упомянутые данные доступны лишь в неявном виде.
Сохранение мощности для сигнала A понижающего микширования, при условии статистически независимых источников, дает:
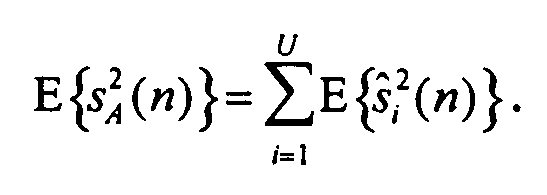
Мощности E{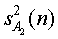 }... E{
}... E{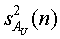 } сигналов определены с помощью их относительных мощностей a2 ... aU по отношению к E{
} сигналов определены с помощью их относительных мощностей a2 ... aU по отношению к E{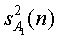 }:
}:
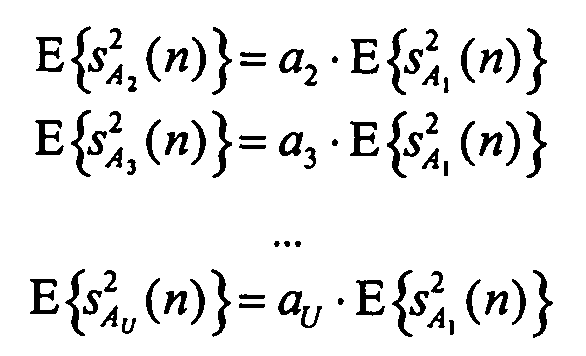
Это приводит к мощности  в виде:
в виде:
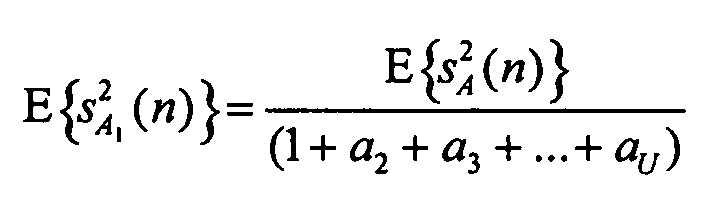
Применяя то же самое для сигнала sB понижающего микширования, можно рассчитать мощность объекта 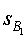 в виде:
в виде:
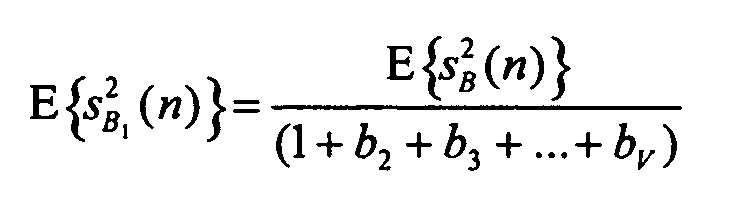
Теперь можно построить новый набор параметров для всех объектов сигнала sY:
y1: (не передаваемый опорный объект, имеющийся в распоряжении неявным образом)
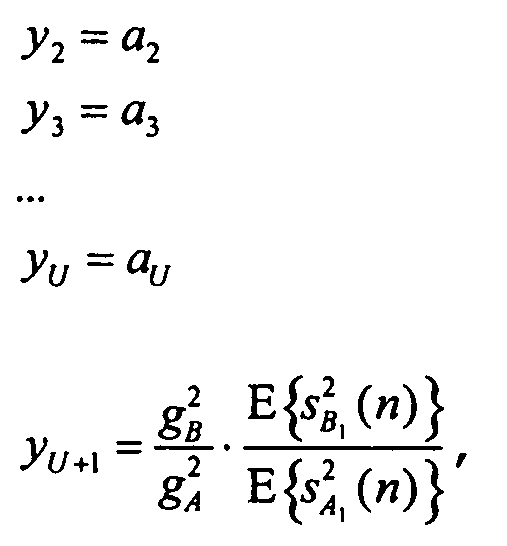
(отношение мощности первого объекта сигнала B относительно опорного объекта A1)
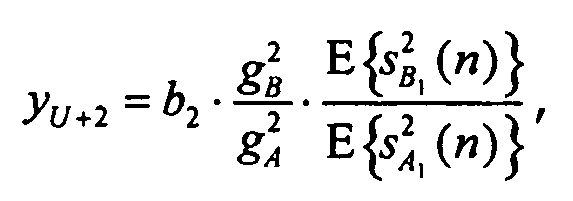
(отношение мощности второго объекта сигнала B, повторно нормированного к мощности опорного объекта A1)
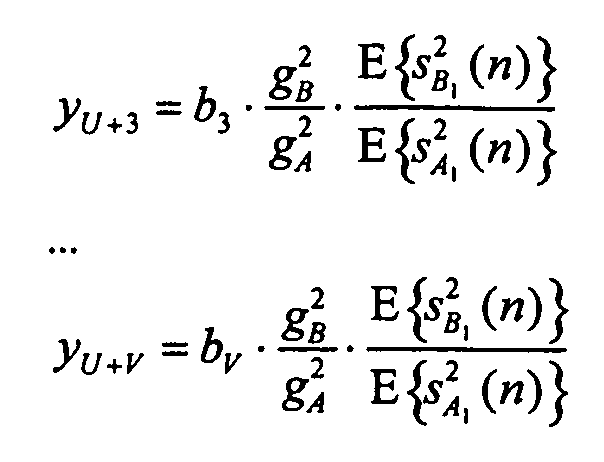
Как указано в предыдущих абзацах, концепция согласно настоящему изобретению предусматривает формирование объединенного аудиопотока с использованием исключительно простых арифметических операций, за счет чего она является чрезвычайно эффективной с точки зрения вычислений. Таким образом, объединение множества параметрически кодированных аудиопотоков может выполняться в режиме реального времени.
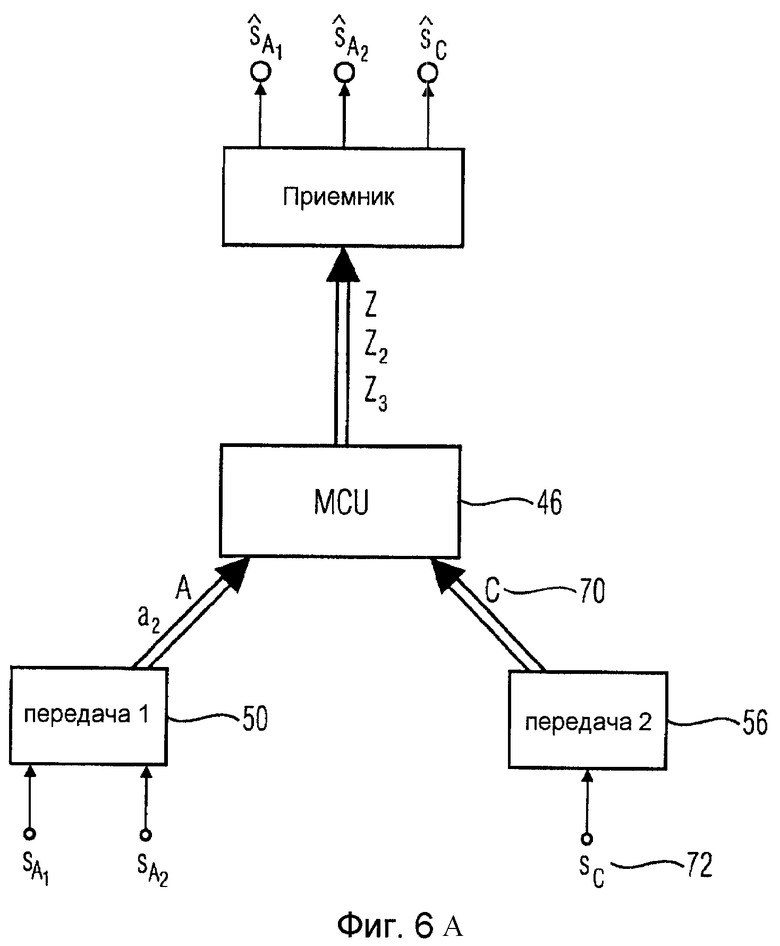
Чтобы дополнительно подчеркнуть большую гибкость концепции согласно настоящему изобретению, на фиг.6А показано, каким образом монофонический сигнал 70, вызванный одиночным говорящим абонентом в абонентском пункте 56, может объединяться согласно изобретению с двумя или более кодированными посредством JSC сигналами говорящих абонентов в абонентском пункте 50. То есть вследствие гибкости концепции согласно настоящему изобретению монофонические сигналы произвольной системы телеконференцсвязи могут объединяться согласно изобретению с параметрически кодированными многоканальными (многообъектными) источниками для формирования кодированного посредством JSC аудиосигнала, представляющего все исходные аудиоканалы (объекты).
Расширяя совместимость также с удаленными станциями, которые способны передавать не объекты JSC, а лишь обычные монофонические сигналы, эта технология также применима для вставки монофонического объекта, например, из обычного устройства проведения конференций в основанный на объектах поток.
Вышеприведенный пример с потоком A JSC (понижающим микшированием sA, параметрами a2...aU) и монофоническим объектом C (понижающим микшированием sC) приводит к объединенному сигналу Z с сигналом понижающего микширования

с коэффициентами усиления, которые описаны ранее, и своими параметрами объектов:
y1: не передаваемый (опорный канал, имеющийся в распоряжении неявным образом)
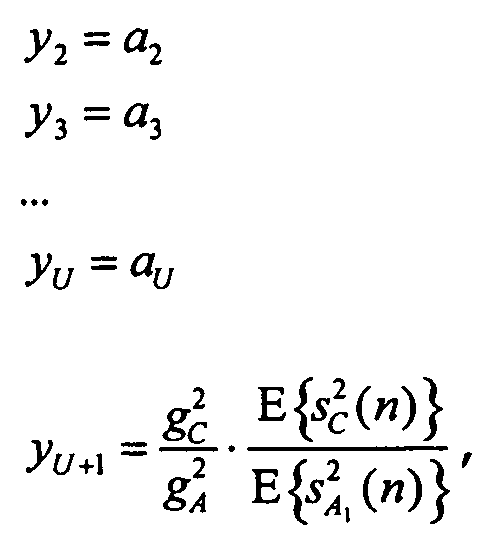
(отношение мощности сигнала C относительно опорного объекта A1)
Вышеупомянутый пример перекодировки/слияния двух потоков JSC зависит от представления мощности объектов, как задано в уравнении 1. Однако та же схема согласно настоящему изобретению также может применяться и к другим способам представления этой информации.
Фиг.6B вновь подчеркивает большую гибкость концепции согласно настоящему изобретению с включением в состав одного монофонического аудиоисточника. Фиг.6B основана на многоканальном примере по фиг.4 и дополнительно показывает, насколько легко монофонический аудиокодер уровня техники, присутствующий в аудиоисточнике C(44), может быть интегрирован в многоканальную аудиоконференцию с использованием MCU 46 согласно настоящему изобретению.
Как упомянуто ранее, концепция согласно настоящему изобретению не ограничена кодированием JSC, имеющим определенный фиксированный опорный канал. Поэтому в альтернативном примере отношение мощностей может вычисляться относительно опорного канала, который изменяется со временем, при этом опорный канал является одним из каналов, имеющим наибольшую энергию в пределах данного определенного временного интервала.
Вместо нормирования значений полосовой мощности сигнала к мощности соответствующей полосы фиксированного опорного канала (объекта) и преобразования результата в логарифмическую область (дБ), как показано в уравнении 1, может иметь место нормирование относительно максимальной мощности по всем объектам в определенной полосе частот:
Уравнение 4

Эти нормированные значения мощности (которые приведены в линейном представлении) не нуждаются ни в каком дополнительном ограничении определенной верхней границей, поскольку они по своей природе могут принимать значения только между 0 и 1. Это преимущество влечет за собой недостаток, заключающийся в необходимости передачи одного дополнительного параметра для уже неизвестного априори опорного канала.
Последовательность операций микширования для этого сценария может включать в себя следующие этапы (которые вновь должны выполняться отдельно для каждого поддиапазона):
Мы имеем поток A с его сигналом sA понижающего микширования и параметрами (нормированными значениями мощности, уравнение 3, уравнение 1) для U объектов a1 ...aU.
Поток B состоит из сигнала sB понижающего микширования и параметров для V объектов b1 ...bV.
Объединенный сигнал понижающего микширования может формироваться согласно одному из уже показанных вариантов выбора:
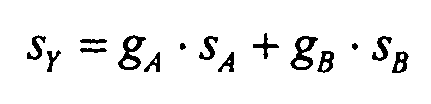
Все нормированные значения мощности для объединенного представления yi должны устанавливаться относительно объекта с наибольшей мощностью из всех объектов сигнала Y. Есть два кандидата для занятия места этого «максимального объекта» из Y - максимальный объект из A или максимальный объект из B, причем оба могут быть определены за счет обладания нормированным отношением мощности в '1'.
Это решение может быть принято путем сравнения абсолютной мощности обоих кандидатов. Снова можно использовать соотношение для мощности сигналов понижающего микширования (уравнение 2), чтобы получить
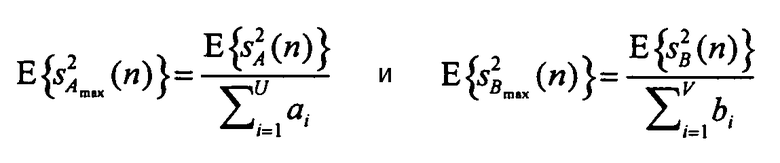
Теперь можно сравнить максимальные мощности объектов, взвешенные коэффициентами усиления обработки понижающим микшированием:
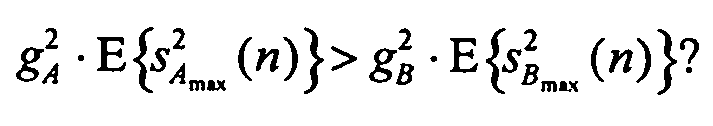
Вне зависимости от того, какой объект имеет более высокую мощность, этот объект будет служить в качестве «максимального объекта» для обобщенных параметров yi.
В качестве примера пусть a2 будет общим объектом amax максимальной мощности обоих сигналов, A и B, тогда все другие параметры могут обобщаться в качестве:
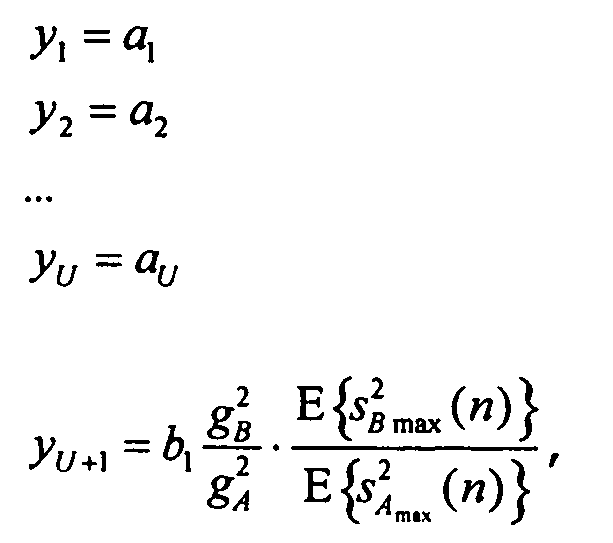
(отношение мощности первого объекта сигнала B относительно 'максимального объекта', здесь, a2)
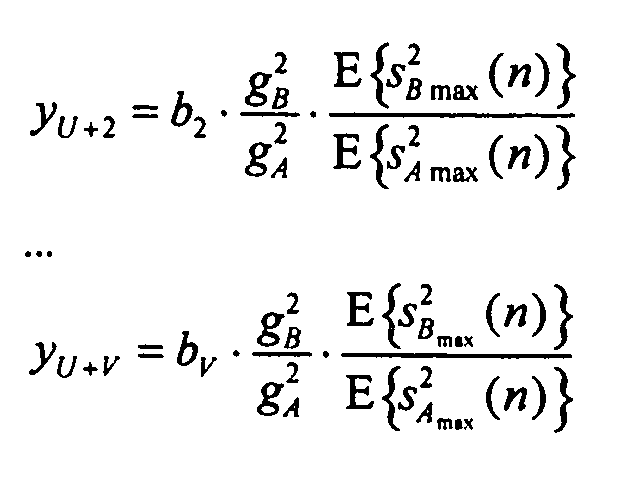
Что касается этого примера, все параметры для объектов из A могут оставаться неизменными, поскольку сигнал A несет общий максимальный объект.
К тому же в этом представлении может соответствующим образом быть выполнена вставка монофонического объекта, например, при условии, что V=1.
Как правило, процесс перекодировки выполняется таким образом, чтобы его результат приближался к результату, который был бы достигнут, если бы все исходные объекты для обоих потоков с самого начала были закодированы в единственный поток JSC.
На фиг.7 показан пример генератора аудиосигнала согласно настоящему изобретению для формирования выходного аудиосигнала, который может быть использован в MCU 46 для реализации концепции согласно настоящему изобретению.
Генератор 100 аудиосигнала содержит приемник 102 аудиосигнала, объединитель 104 каналов, вычислитель 106 параметров и выходной интерфейс 108.
Приемник 102 аудиосигнала принимает первый аудиосигнал 110, содержащий первый канал 110a понижающего микширования, содержащий информацию о двух или более первых исходных каналах, и содержащий исходный параметр 110b, связанный с одним из первых исходных каналов и описывающий свойство одного из первых исходных каналов относительно опорного канала. Приемник 102 аудиосигнала, кроме того, принимает второй аудиосигнал 112, содержащий второй канал 112a понижающего микширования, содержащий информацию по меньшей мере об одном втором исходном канале.
Приемник аудиосигнала выводит первый канал 110a понижающего микширования и второй канал 112a понижающего микширования на вход объединителя 104 каналов, и первый канал 110a понижающего микширования, второй канал 112a понижающего микширования и исходный параметр 110b в вычислитель 106 параметров.
Объединитель 104 каналов получает объединенный канал 114 понижающего микширования путем объединения первого канала 110a понижающего микширования и второго канала 112b понижающего микширования, т.е. путем непосредственного объединения каналов понижающего микширования без реконструкции лежащих в их основе исходных аудиоканалов.
Вычислитель 106 параметров получает первый обобщенный параметр 116a, описывающий свойство одного из первых исходных каналов относительно общего опорного канала, и второй обобщенный параметр 116b, описывающий свойство другого канала из первых исходных каналов или по меньшей мере одного второго исходного канала относительно того же самого общего опорного канала. Первый и второй обобщенные параметры вводятся в выходной интерфейс 108, который, кроме того, принимает объединенный канал 114 понижающего микширования из объединителя 104 каналов. В заключение, выходной интерфейс выводит выходной сигнал 120, содержащий объединенный канал 114 понижающего микширования, а также первый и второй обобщенные параметры 116a и 116b.
Таким образом, выходной аудиосигнал был получен без полной реконструкции входных аудиосигналов, и, как следствие, без операций, требующих слишком большого объема вычислений.
Выше была описана общая концепция микширования двух или более сигналов, каждый из которых основан на параметрическом подходе JSC. Более точно, вышеприведенные уравнения показывают, каким образом следует применять эту технологию для случая, когда параметрическая информация состоит из отношений относительных мощностей. Однако эта технология не ограничивается определенным представлением параметров объектов. Поэтому также могут использоваться параметры, описывающие амплитудные показатели или другие свойства отдельных аудиоканалов, такие как корреляции. Отношения мощности также могут вычисляться по отношению к объединенному каналу понижающего микширования за счет передачи одного дополнительного параметра. С другой стороны, преимущество этого альтернативного примера заключается в пониженной вычислительной сложности микширования аудиопотоков, поскольку более не требуется воссоздания мощности опорного канала, которая не передается явным образом в «базовом» JSC.
Более того, изобретение не ограничено примером проведения телеконференции, но может применяться в любой ситуации, в которой требуется мультиплексирование параметрических объектов в одиночный поток. Это, например, может иметь место в схемах кодирования BCC, пространственного объемного звучания MPEG и в других случаях.
Как было показано, концепция согласно настоящему изобретению даже обеспечивает возможность беспрепятственного включения обычных удаленных станций, выдающих одиночный монофонический сигнал, в пример, основанный на объектах. Кроме объединения разных объектных потоков концепция согласно настоящему изобретению также показывает, как разные виды представления параметрических данных могут формироваться таким образом, чтобы они были пригодными для обеспечения возможности последовательностей операций объединения, которые являются рациональными с точки зрения вычислений. По существу обладающая преимуществом характеристика синтаксиса параметрического битового потока согласно настоящему изобретению состоит в выражении свойств объектов таким образом, чтобы два потока могли объединяться исключительно за счет выполнения простых операций.
Поэтому концепция согласно настоящему изобретению также описывает то, каким образом можно создавать надлежащие битовые потоки, или форматы битовых потоков, для параметрического кодирования множества исходных аудиоканалов (аудиообъектов), придерживаясь следующих критериев:
• Объединенный сигнал понижающего микширования формируется простым образом из отдельных сигналов понижающего микширования
• Обобщенная дополнительная параметрическая информация формируется из объединения отдельной дополнительной параметрической информации и некоторых простых в вычислении признаков сигналов понижающего микширования (например, энергии)
• Ни в коем случае не следует выполнять сложную операцию, такую как этап декодирования/повторного кодирования для аудиообъектов.
Таким образом, параметрическое представление, описывающее объекты, должно выбираться так, чтобы объединение («сложение») двух или более объектных потоков было возможным с использованием только полей битовых потоков, которые имеются в распоряжении в качестве части дополнительной параметрической информации, а также по возможности простых в вычислении параметров сигналов понижающего микширования (например, энергии, пикового значения).
Примером такого представления может быть использование нормированных значений мощности (уравнение 4) для каждого объекта. Упомянутые значения могут преобразовываться в логарифмическое представление (дБ), а затем квантоваться в некоторое количество ступеней квантователя или соответствующих им показателей квантователя. Синтаксис битового потока должен предусматривать легкое увеличение (или уменьшение) количества параметров объектов в потоке, например, простым объединением, вставкой или удалением параметров.
Подводя итог, концепция согласно настоящему изобретению предусматривает наиболее гибкое и эффективное по вычислениям объединение симметрично кодированных аудиопотоков. Вследствие высокой вычислительной эффективности концепция согласно настоящему изобретению не имеет ограничения в отношении максимального количества каналов, которые необходимо объединить. В основных чертах, каналы, которые можно объединять в режиме реального времени, могут выдаваться в генератор аудиосигнала согласно настоящему изобретению в произвольных количествах. К тому же точное параметрическое представление (JSC), использованное для иллюстрации концепции согласно настоящему изобретению, не является обязательным. Более того, как уже было указано выше, основой для применения концепции согласно настоящему изобретению могут быть другие схемы параметрического кодирования, такие как широко известные схемы объемного звучания.
Более того, необходимые вычисления не обязательно должны применяться в программном обеспечении. Аппаратные реализации, например, использующие ЦСП (цифровые сигнальные процессоры, DSP), ASIC (специализированные интегральные схемы) и другие интегральные схемы, также могут использоваться для выполнения расчетов, что даже в большей степени повысит быстродействие концепции согласно настоящему изобретению, позволяя применять концепцию согласно настоящему изобретению в ситуациях в режиме реального времени.
Вследствие гибкости концепции согласно настоящему изобретению аудиопотоки согласно настоящему изобретению могут быть основаны на разных параметрических представлениях. Параметры, которые следует передавать, например, также могут представлять собой показатели амплитуды, разности времени между исходными аудиоканалами, показатели когерентности и другие показатели.
Таким образом, была показана общая концепция микширования двух или более сигналов, каждый из которых является основанным на параметрическом подходе типа JSC.
Вышеприведенные уравнения показывают, как эту технологию следует применять в случае, когда параметрическая информация состоит из отношений относительных мощностей. Однако эта технология не ограничивается конкретным представлением параметров объектов.
Более того, изобретение не ограничено ситуацией проведения телеконференции, но может применяться в любом случае, где полезно мультиплексирование параметрических объектов в одиночный поток JSC.
В качестве дополнения эта технология позволяет беспрепятственно включать в основанный на объектах пример обычные удаленные станции, формирующие одиночный монофонический сигнал.
Кроме собственно последовательности операций объединения разных объектных потоков изобретение также показывает, каким образом для использования этого процесса объединения пригодны разные способы представления параметрических данных. Поскольку не все возможные параметрические представления допускают такой описанный процесс объединения без полного декодирования/повторного кодирования объектов, обеспечивающая преимущество характеристика синтаксиса параметрического битового потока состоит в выражении свойств объектов таким образом, чтобы два потока могли объединяться путем выполнения только простых операций.
В зависимости от определенных требований реализации способов согласно настоящему изобретению эти способы могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового запоминающего носителя, в частности диска, DVD или CD (компакт-диска), на котором сохранены считываемые электронным образом управляющие сигналы, которые взаимодействуют с программируемой компьютерной системой для выполнения способов согласно настоящему изобретению. Таким образом, настоящее изобретение в общем является компьютерным программным продуктом с программным кодом, сохраненным на машиночитаемом носителе, при этом программный код выполнен с возможностью выполнения способов согласно настоящему изобретению при исполнении компьютерного программного продукта на компьютере. Другими словами, способы согласно настоящему изобретению таким образом представляют собой компьютерную программу, содержащую программный код для выполнения по меньшей мере одного из способов согласно настоящему изобретению при исполнении компьютерной программы на компьютере.
Хотя вышеизложенное было подробно показано и описано со ссылкой на конкретные варианты осуществления, специалистам в данной области техники следует понимать, что могут быть внесены различные другие изменения по форме и содержанию без отклонения от объема настоящего изобретения. Следует понимать, что при адаптации к различным вариантам осуществления могут быть внесены различные изменения без отклонения от более широких концепций, раскрытых здесь и содержащихся в нижеследующей формуле изобретения.
Изобретение относится к кодированию многоканального аудиосигнала и, в частности, к концепции объединения параметрически кодированных аудиопотоков гибким и эффективным образом. Множество параметрически кодированных аудиосигналов объединяют с использованием генератора (100) аудиосигнала, который формирует выходной аудиосигнал (120) объединением каналов (110а, 112а) понижающего микширования и связанных с ними параметров (110b, 112b) аудиосигналов непосредственно в пределах области значений параметров, то есть без реконструкции или декодирования отдельных входных аудиосигналов перед формированием выходного аудиосигнала (120). Это достигается непосредственным микшированием связанных каналов (110а, 112а) понижающего микширования отдельных входных сигналов. Один из ключевых признаков настоящего изобретения состоит в том, что объединение каналов (110а, 112а) понижающего микширования достигается простыми вычислительно экономными арифметическими операциями. Технический результат - возможность эффективного объединения передаваемых аудиопотоков. 4 н. и 16 з.п. ф-лы, 8 ил.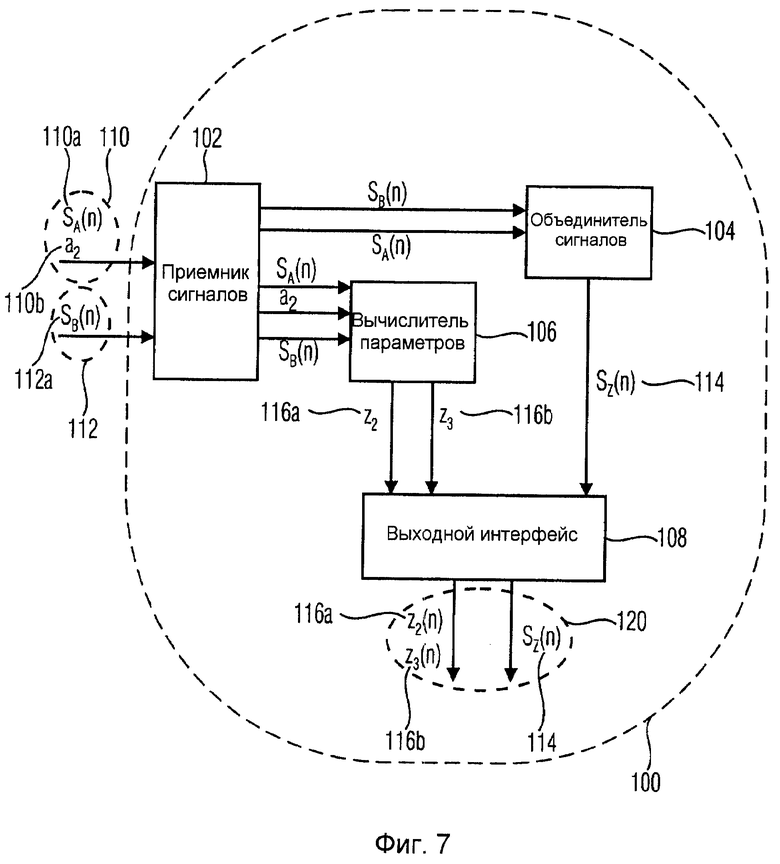
1. Генератор (100) аудиосигнала для формирования выходного аудиосигнала, содержащий
приемник (102) аудиосигналов для приема
первого аудиосигнала (110), содержащего первый канал (110а) понижающего микширования, имеющий информацию о двух или более первых исходных каналах, и содержащего, по меньшей мере, один исходный параметр (110b), связанный с одним из первых исходных каналов, описывающий свойство одного из первых исходных каналов относительно опорного канала; и
второго аудиосигнала (112), содержащего второй канал (112а) понижающего микширования, имеющий информацию, по меньшей мере, об одном втором исходном канале;
объединитель (104) каналов для получения объединенного канала (114) понижающего микширования путем объединения первого канала (110а) понижающего микширования и второго канала (112а) понижающего микширования;
вычислитель (106) параметров для получения первого обобщенного параметра (116а), описывающего свойство одного из первых исходных каналов относительно общего опорного канала, и второго обобщенного параметра (116b), описывающего свойство другого канала из первых исходных каналов или, по меньшей мере, одного второго исходного канала относительно общего опорного канала; и
выходной интерфейс для вывода выходного аудиосигнала (120), содержащего объединенный канал (114) понижающего микширования, первый (116а) и второй обобщенные параметры (116b).
2. Генератор (100) аудиосигнала по п.1, в котором объединитель (104) каналов выполнен с возможностью получения объединенного канала (114) понижающего микширования с использованием линейной комбинации первого канала (110а) и второго канала (110b) понижающего микширования.
3. Генератор (100) аудиосигнала по п.2, в котором объединитель (104) каналов выполнен с возможностью использования линейной комбинации, имеющей коэффициенты, зависящие от энергии E(sA 2(n)) в первом канале (110а) понижающего микширования и от энергии E(sB 2(n)) во втором канале (112а) понижающего микширования.
4. Генератор (100) аудиосигнала по п.3, в котором объединитель (104) каналов выполнен с возможностью использования линейной комбинации, имеющей коэффициент gA для первого канала понижающего микширования и коэффициент gB для второго канала понижающего микширования, выведенные с использованием следующего уравнения:
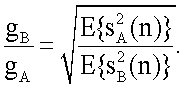
5. Генератор (100) аудиосигнала по п.2, в котором объединитель (104) каналов выполнен с возможностью использования линейной комбинации, имеющей коэффициенты, зависящие от количества U первых исходных каналов и количества V вторых исходных каналов.
6. Генератор (100) аудиосигнала по п.5, в котором объединитель (104) каналов выполнен с возможностью использования линейной комбинации, имеющей коэффициент gA первого канала (110а) понижающего микширования и коэффициент gB второго канала (112а) понижающего микширования, выведенные согласно одному из следующих уравнений:
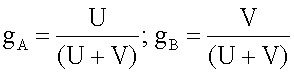
или
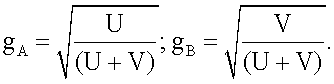
7. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью использования определенного канала из первых исходных каналов или по меньшей мере одного второго исходного канала в качестве общего опорного канала.
8. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью использования опорного канала первого аудиосигнала (110) в качестве общего опорного канала.
9. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью использования объединенного канала (114) понижающего микширования в качестве общего опорного канала.
10. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью использования исходного канала в качестве общего опорного канала, который имеет наибольшую энергию.
11. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью расчета энергии 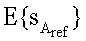 опорного канала путем получения энергии E{sA 2} первого канала (110а) понижающего микширования и параметров ai{i=1, …, n}, связанных с каналами, иными, чем опорный канал, согласно уравнению
опорного канала путем получения энергии E{sA 2} первого канала (110а) понижающего микширования и параметров ai{i=1, …, n}, связанных с каналами, иными, чем опорный канал, согласно уравнению
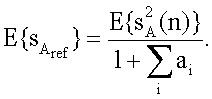
12. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью использования опорного канала в качестве общего опорного канала, а исходного параметра а2 в качестве первого обобщенного параметра уU, и для получения второго обобщенного параметра yU+1 для по меньшей мере одного второго исходного канала относительно опорного канала.
13. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью получения обобщенных параметров с использованием энергии E{sA 2(n)} первого канала (110а) понижающего микширования и энергии E{sB 2(n)} второго канала (112b) понижающего микширования.
14. Генератор (100) аудиосигнала по п.13, в котором вычислитель (106) параметров выполнен с возможностью дополнительного использования коэффициентов gA, связанных с первым каналом (110а) понижающего микширования, и gB, связанных со вторым каналом (112а) понижающего микширования, причем коэффициенты используются для линейной комбинации первого и второго понижающего микширования, используемых объединителем (104) каналов.
15. Генератор (100) аудиосигнала по п.14, в котором вычислитель (106) параметров выполнен с возможностью расчета второго обобщенного параметра yU+1 для по меньшей мере одного второго исходного канала согласно следующему уравнению:
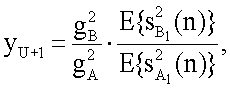
при этом 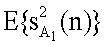 - энергия опорного канала, полученная с использованием энергии
- энергия опорного канала, полученная с использованием энергии 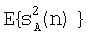 первого канала понижающего микширования согласно следующей формуле:
первого канала понижающего микширования согласно следующей формуле:
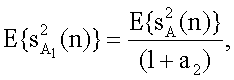
при этом a2 - исходный параметр, относящий первый исходный канал к опорному каналу.
16. Генератор (100) аудиосигнала по любому из пп.1-6, в котором вычислитель (106) параметров выполнен с возможностью обработки частотных участков первого и второго каналов понижающего микширования, связанных с дискретными интервалами частот таким образом, что обобщенные параметры выводятся для каждого дискретного интервала частот.
17. Генератор (100) аудиосигнала по любому из пп.1-6, в котором приемник аудиосигналов выполнен с возможностью приема аудиосигналов (110, 112), содержащих каналы (110а, 112а) понижающего микширования, представленные дискретизацией параметров, дискретизированных с определенной частотой выборки.
18. Способ формирования выходного аудиосигнала, причем способ содержит
прием первого аудиосигнала (110), содержащего первый канал (110а) понижающего микширования, имеющий информацию о двух или более первых исходных каналах, и содержащего по меньшей мере один исходный параметр (110b), связанный с одним из первых исходных каналов, описывающий свойство одного из первых исходных каналов относительно опорного канала, и второго аудиосигнала (112), содержащего второй канал (112а) понижающего микширования, имеющий информацию о по меньшей мере одном втором исходном канале;
получение объединенного канала (114) понижающего микширования объединением первого канала (110) понижающего микширования и второго канала (112) понижающего микширования;
получение первого обобщенного параметра (116а), описывающего свойство одного из первых исходных каналов относительно общего опорного канала, и второго обобщенного параметра (116b), описывающего свойство другого канала из первых исходных каналов или по меньшей мере одного второго исходного канала относительно общего опорного канала; и
вывод выходного аудиосигнала (120), содержащего объединенный канал (114) понижающего микширования, а также первый (116а) и второй (116b) обобщенные параметры.
19. Система конференц-связи, содержащая генератор (100) аудиосигнала для формирования выходного аудиосигнала по п.1.
20. Машиночитаемый цифровой носитель, на котором сохранена компьютерная программа для реализации при исполнении на компьютере способа формирования выходного аудиосигнала, причем способ содержит
прием первого аудиосигнала, содержащего первый канал понижающего микширования, имеющий информацию о двух или более первых исходных каналах, и содержащего, по меньшей мере, один исходный параметр, связанный с одним из первых исходных каналов, описывающий свойство одного из первых исходных каналов относительно опорного канала, и второго аудиосигнала, содержащего второй канал понижающего микширования, имеющий информацию о по меньшей мере одном втором исходном канале;
получение объединенного канала понижающего микширования путем объединения первого канала понижающего микширования и второго канала понижающего микширования;
получение первого обобщенного параметра, описывающего свойство одного из первых исходных каналов относительно общего опорного канала, и второго обобщенного параметра, описывающего свойство другого канала из первых исходных каналов или, по меньшей мере, одного второго исходного канала относительно общего опорного канала; и
вывод выходного аудиосигнала, содержащего объединенный канал понижающего микширования, а также первый и второй обобщенные параметры.
| US 2005062843 A1, 24.03.2005 | |||
| СПОСОБ И УСТРОЙСТВО МАСШТАБИРУЕМОГО КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ СТЕРЕОФОНИЧЕСКОГО ЗВУКОВОГО СИГНАЛА (ВАРИАНТЫ) | 1998 |
|
RU2197776C2 |
| US 2005074127 A1, 07.04.2005 | |||
| EP 1881486 B1, 22.04.2003 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Кишечный интубатор | 1986 |
|
SU1377123A2 |
| СПОСОБ ПЕРЕДАЧИ И/ИЛИ ЗАПОМИНАНИЯ ЦИФРОВЫХ СИГНАЛОВ НЕСКОЛЬКИХ КАНАЛОВ | 1993 |
|
RU2129336C1 |

