Область техники, к которой относится изобретение
Изобретение относится к информационным технологиям, в частности к устройству и способу для разметки жестов жестового языка.
Уровень техники
Традиционными и привычными средствами коммуникации для слышащих людей являются звуковые языки, которые лишь в качестве вспомогательной функции или для усиления самовыражения дополняются невербальными средствами. В отличие от звуковых языков, жестовый язык глухих является естественным языком, в котором жест, наоборот, является главной смысловой единицей. Между глухими и слышащими, как и между носителями разных жестовых и звуковых языков, существует языковой барьер. Кроме того, для звуковых языков разработано множество систем распознавания речи и ее преобразования в текст, тогда как жестовые языки пока не имеют таких широко доступных инструментов. Одна из важных социальных задач состоит в устранении подобных барьеров путем создания технических средств коммуникации, позволяющих быстро выполнять перевод с жестового языка на звуковой и обратно, а также перевод с жестового языка в текст и обратно. Для реализации этих задач необходимо разработать систему распознавания жестового языка. Настоящее изобретение нацелено на содействие созданию такой системы на основе методов машинного обучения. Поскольку жестовый язык является визуальным, для его распознавания необходима видеозапись или изображение говорящего. Соответственно, для обучения модели распознавания необходим набор данных, содержащий видеозаписи или изображения с разметкой записанных на них жестов жестового языка.
Известен раскрытый в RU 2737600 C1 способ формирования обучающих данных для нейронной сети в точке розничных продаж, заключающийся в том, что для каждого пользователя динамически формируют изображения набора товаров-покупок устройством регистрации изображения, которое осуществляет запись, хранение и передачу регистрируемого изображения товаров с меткой времени, а также кассовым аппаратом с возможностью формирования набора данных, при этом данные могут включать как позиции, регистрируемые кассовым аппаратом и содержащиеся в кассовых чеках, так и данные регистрации данных позиций, соответствующих объектам, размещаемым в области видимости устройства регистрации изображения, для отправки на сервер обработки данных. Данное решение позволяет формировать обучающие данные, однако оно неприменимо для разметки жестов жестового языка.
Известна раскрытая в RU 2754095 C1 методика подготовки наборов фотографий для машинного анализа для персональной идентификации животных по морде. Данное решение позволяет формировать набор фотографий для машинного анализа, однако оно неприменимо для разметки жестов жестового языка.
Известен раскрытый в WO 2022/226642 A1 способ генерации размеченного набора данных, в котором производится видеозапись человека, и затем пользователь выбирает временную метку в пределах видео и вводит разметку, соответствующую этой временной метке. Указывается, что данное решение применимо для разметки жестов жестового языка, однако оно не учитывает особенности жестового языка и не предусматривает особенности съемки. Так, необходимо отметить, что жесты в жестовом языке могут выполняться как правой или левой рукой отдельно, так и обеими руками вместе, и данное решение не дает ответ на то, как при разметке охватить все эти случаи, не усложняя процесс. Кроме того, при распознавании жестов существует проблема сегментации разных частей тела, но аналогичные трудности испытывает и пользователь, выполняющий разметку, а данное решение не обеспечивает пути упрощения интерпретации жестов.
Более того, для символьного представления жестового языка разработано несколько систем нотации, в которых запись жеста производится путем описания комбинации компонентов этого жеста с помощью специальных знаков. При этом, например, число знаков в одной из самых известных систем нотации SignWriting превышает 38 тысяч, и простое перечисление этих знаков на экране компьютера для того, чтобы пользователь выбрал из них нужный в качестве разметки, потребует от пользователя высокого уровня знания языка и даже при этом займет чрезвычайно много времени.
Таким образом, в уровне техники существует потребность в создании технических средств, позволяющих упростить процесс разметки жестов жестового языка.
Сущность изобретения
Настоящее изобретение направлено на создание устройств и систем, позволяющих устранить по меньшей мере некоторые из указанных выше недостатков предшествующего уровня техники.
В частности, предложен способ разметки жестов жестового языка, реализуемый с помощью компьютерного устройства, содержащего процессор, память, экран и средство управления экранным указателем, содержащий этапы, на которых:
- отображают в пользовательском интерфейсе видеофрагмент, содержащий один компонент жеста, жест или фразу жестового языка, при этом в кадре находится один говорящий в анфас, выполняющий в процессе видео по меньшей мере один жест жестового языка, при этом кадр полностью охватывает область пространства, в которой выполняется жест, и части тела говорящего, участвующие в выполнении жеста,
- предоставляют элемент интерфейса, обеспечивающий указание правой руки и левой руки,
- отображают в пользовательском интерфейсе набор визуальных представлений, характеризующих компоненты жестов, входящие в предварительно заданную систему нотации жестового языка, при этом набор визуальных представлений содержит по меньшей мере следующие блоки: блок визуальных представлений конфигурации руки, блок визуальных представлений ориентации руки,
причем визуальное представление представляет собой изображение, анимированное изображение или короткое видео, упрощенно характеризующее соответствующий компонент жеста,
причем по меньшей мере один блок визуальных представлений содержит подблоки визуальных представлений для каждой руки, причем подблоки сформированы согласно параметрам компонентов жеста,
причем параметры компонентов жеста включают в себя тип конфигурации руки или тип ориентации руки,
- принимают от пользователя для жеста, содержащегося в видеофрагменте, для каждой руки, участвующей в жесте, выполненное с помощью экранного указателя указание руки и указание одного или более визуальных представлений из каждого блока визуальных представлений,
- для каждой руки, участвующей в жесте, формируют идентификатор жеста, соответствующий нотации этого жеста в системе нотации, согласно принятым указаниям от пользователя, соответствующим этой руке, и
- формируют запись в файле разметки, содержащую указание видеофрагмента и для каждой руки, участвующей в жесте, идентификатор жеста,
причем набор данных, содержащий файл разметки и видеофрагменты, указанные в файле разметки, используется для машинного обучения модели распознавания жестов жестового языка, видеофрагменты используются в качестве обучающих данных, а идентификаторы жестов из файла разметки используются в качестве разметки.
В одном из вариантов осуществления способ дополнительно содержит этап, на котором:
- выполняют видеозапись человека, говорящего на жестовом языке.
В одном из вариантов осуществления говорящий одет в одежду, цвет которой является контрастным к цвету фона, к цвету лица и к цвету кисти или перчаток, одежда полностью закрывает тело до шеи говорящего и руки по меньшей мере в области плеч и не имеет элементов, выступающих выше шеи, одежда близко повторяет форму тела говорящего, цвет кисти или перчаток является контрастным к цвету одежды, цвет фона является контрастным к цвету лица и к цвету кисти или перчаток.
В одном из вариантов осуществления способ дополнительно содержит этапы, на которых:
- принимают и отображают в пользовательском интерфейсе входное видео, содержащее по меньшей мере один жест жестового языка,
- принимают ввод от пользователя, указывающий один или два момента времени в пределах длительности входного видео для выделения видеофрагмента,
- выделяют из входного видео видеофрагмент, содержащий один компонент жеста, жест или фразу, причем видеофрагмент содержит один или более последовательных видеокадров.
В одном из вариантов осуществления набор визуальных представлений дополнительно содержит блок визуальных представлений локализации жеста, блок визуальных представлений движения руки и блок визуальных представлений немануальных компонентов жеста,
параметры компонентов жеста дополнительно включают в себя место исполнения жеста, тип движения или немануальный объект, участвующий в жесте.
В одном из вариантов осуществления способ дополнительно содержит этап, на котором:
- формируют и сохраняют в памяти набор данных, содержащий файл разметки и видеофрагменты, указанные в файле разметки.
Кроме того, предложено устройство для разметки жестов жестового языка, содержащее процессор, память, экран и средство управления экранным указателем, причем устройство выполнено с возможностью:
- отображать в пользовательском интерфейсе видеофрагмент, содержащий один компонент жеста, жест или фразу жестового языка, при этом в кадре находится один говорящий в анфас, выполняющий в процессе видео по меньшей мере один жест жестового языка, при этом кадр полностью охватывает область пространства, в которой выполняется жест, и части тела говорящего, участвующие в выполнении жеста,
- предоставлять элемент интерфейса, обеспечивающий указание правой руки и левой руки,
- отображать в пользовательском интерфейсе набор визуальных представлений, характеризующих компоненты жестов, входящие в предварительно заданную систему нотации жестового языка, при этом набор визуальных представлений содержит по меньшей мере следующие блоки: блок визуальных представлений конфигурации руки, блок визуальных представлений ориентации руки,
причем визуальное представление представляет собой изображение, анимированное изображение или короткое видео, упрощенно характеризующее соответствующий компонент жеста,
причем по меньшей мере один блок визуальных представлений содержит подблоки визуальных представлений для каждой руки, причем подблоки сформированы согласно параметрам компонентов жеста,
причем параметры компонентов жеста включают в себя тип конфигурации руки или тип ориентации руки,
- принимать от пользователя для жеста, содержащегося в видеофрагменте, для каждой руки, участвующей в жесте, выполненное с помощью экранного указателя указание руки и указание одного или более визуальных представлений из каждого блока визуальных представлений,
- для каждой руки, участвующей в жесте, формировать идентификатор жеста, соответствующий нотации этого жеста в системе нотации, согласно принятым указаниям от пользователя, соответствующим этой руке,
- формировать запись в файле разметки, содержащую указание видеофрагмента и для каждой руки, участвующей в жесте, идентификатор жеста,
причем набор данных, содержащий файл разметки и видеофрагменты, используется для машинного обучения модели распознавания жестов жестового языка, видеофрагменты используются в качестве обучающих данных, а идентификаторы жестов из файла разметки используются в качестве разметки.
В одном из вариантов осуществления устройство дополнительно содержит камеру, выполненную с возможностью:
- выполнять видеозапись человека, говорящего на жестовом языке.
В одном из вариантов осуществления устройство дополнительно выполнено с возможностью:
- принимать и отображать в пользовательском интерфейсе входное видео, содержащее по меньшей мере один жест жестового языка,
- принимать ввод от пользователя, указывающий один или два момента времени в пределах длительности входного видео для выделения видеофрагмента,
- выделять из входного видео видеофрагмент, содержащий один компонент жеста, жест или фразу, причем видеофрагмент содержит один или более последовательных видеокадров.
В одном из вариантов осуществления набор визуальных представлений дополнительно содержит блок визуальных представлений локализации жеста, блок визуальных представлений движения руки и блок визуальных представлений немануальных компонентов жеста,
параметры компонентов жеста дополнительно включают в себя место исполнения жеста, тип движения или немануальный объект, участвующий в жесте.
В одном из вариантов осуществления устройство дополнительно выполнено с возможностью:
- формировать и сохранять в памяти набор данных, содержащий файл разметки и видеофрагменты, указанные в файле разметки.
Технический результат
Настоящее изобретение обеспечивает повышение скорости и точности разметки за счет упрощения интерпретации компонентов жеста.
Эти и другие преимущества настоящего изобретения станут понятны при прочтении нижеследующего подробного описания со ссылкой на сопроводительные чертежи.
Краткое описание чертежей
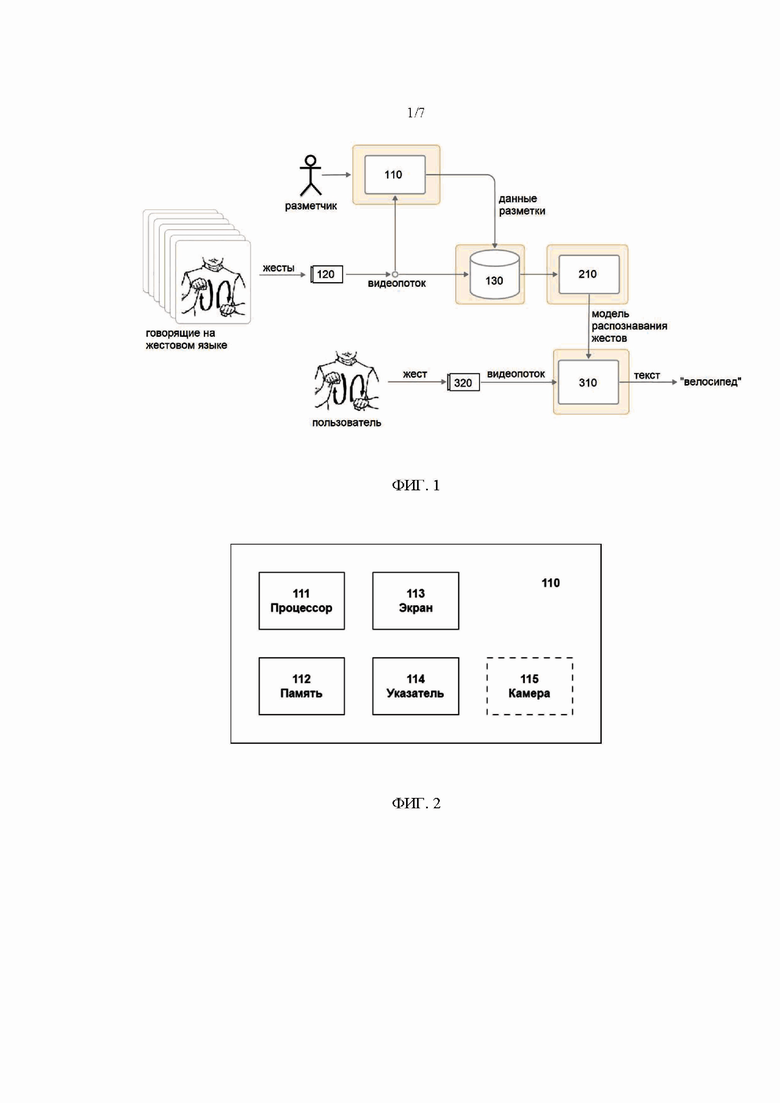
На Фиг. 1 показан пример системы разметки, обучения и распознавания жестов.
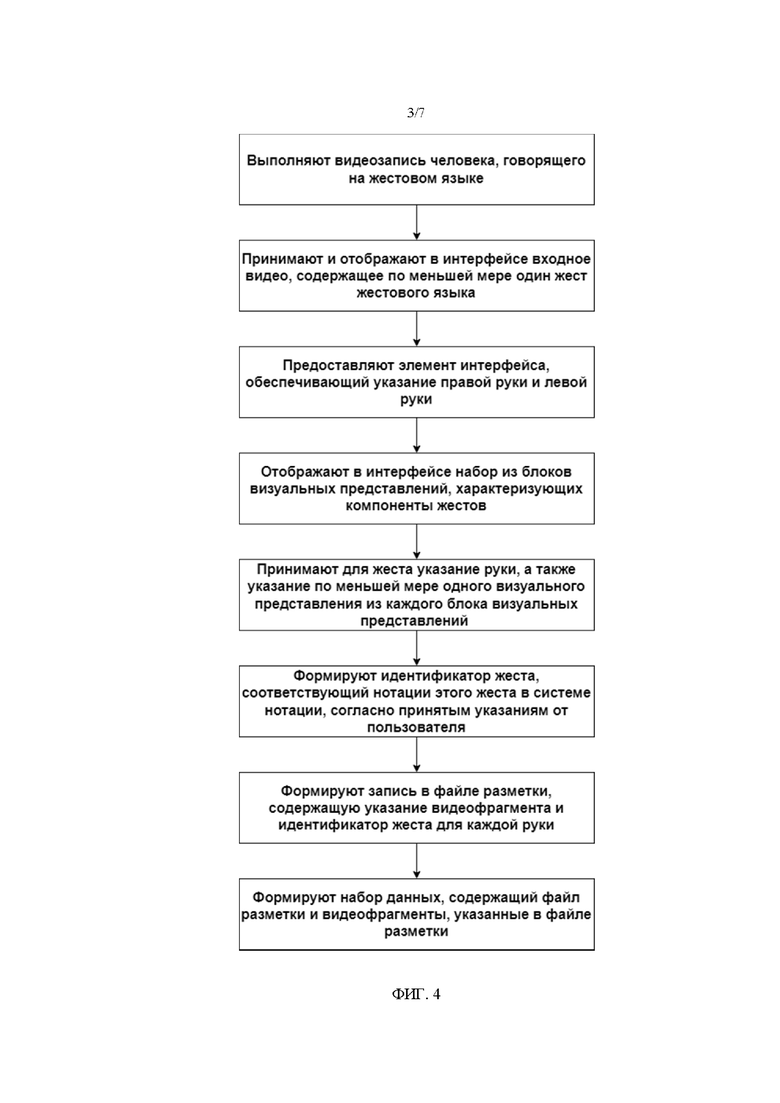
На Фиг. 2 показана блок-схема устройства для разметки жестов.
На Фиг. 3 показаны примеры записи нескольких жестов в разных системах нотации.
На Фиг. 4 показана блок-схема способа разметки жестов.
На Фиг. 5-6 показаны примеры интерфейса устройства для разметки жестов.
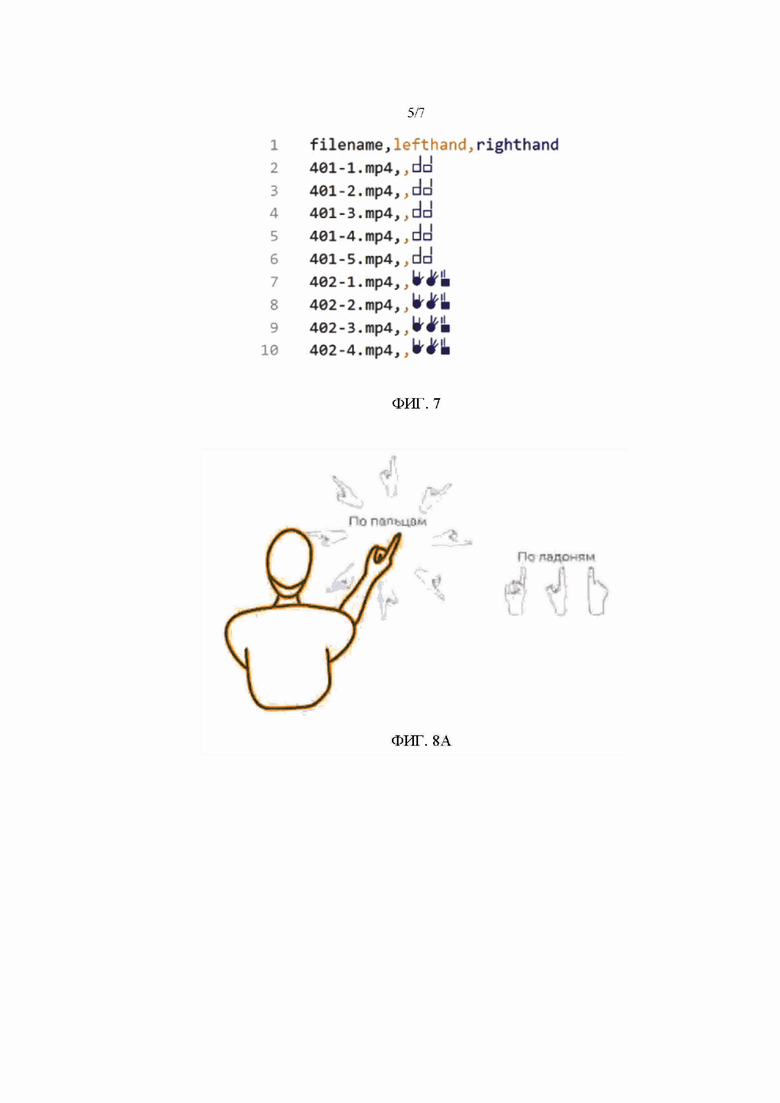
На Фиг. 7 показан пример файла разметки.
На Фиг. 8А-8B показаны дополнительные примеры блока визуальных представлений.
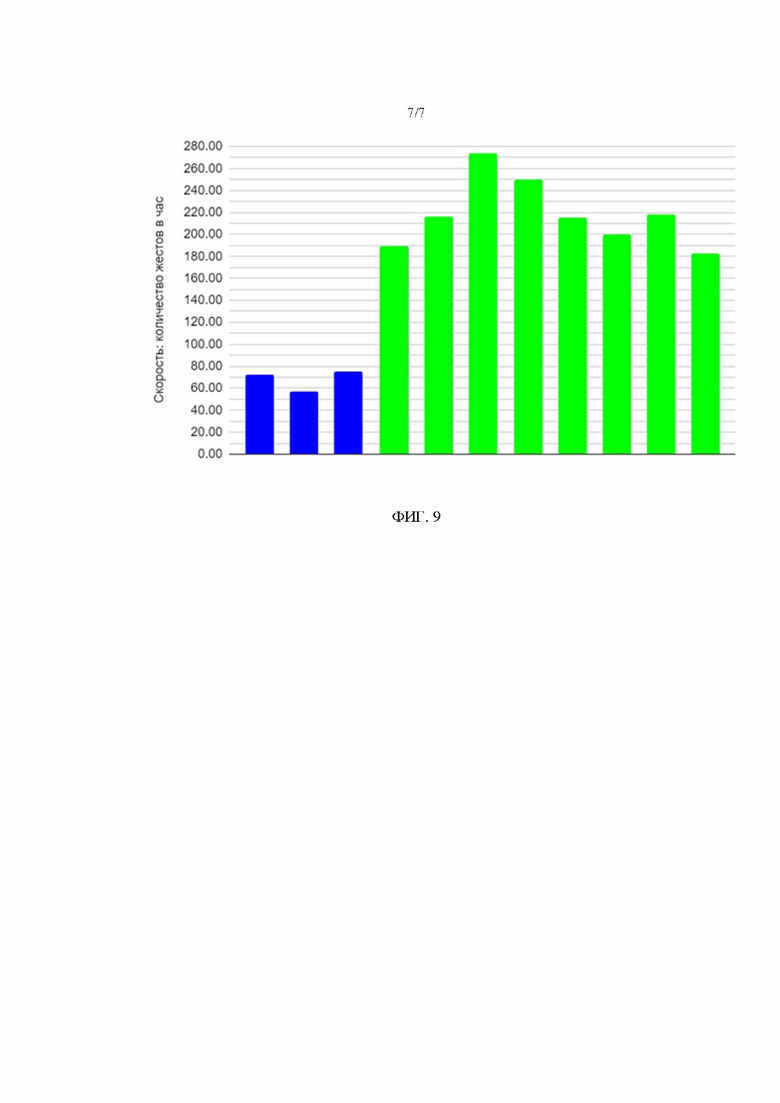
На Фиг. 9 приведены результаты испытаний настоящего изобретения.
Следует понимать, что фигуры могут быть представлены схематично и не в масштабе и предназначены, главным образом, для улучшения понимания настоящего изобретения.
Подробное описание
В структуре жестового языка основное внимание обращено на фокусную область, известную как «жестовое пространство»; все жесты по существу сконцентрированы в этой области. Область пространства вокруг тела жестикулирующего лица представляет собой «пузырь». Жестовое пространство простирается вперёд от груди жестикулирующего лица и включает пространство от талии до верха головы и всю ширину плеч. Именно в этой области жестикулирующие лица двигают руками при разговоре. Говорящие на жестовом языке знают о необходимости держать это пространство ясным и не блокировать его от тех, с кем они разговаривают. Жестовое пространство по существу является расширением тела жестикулирующего лица. Пространство вокруг тела человека активно создаётся независимо от тела и языка. Теория жестового пространства обращает внимание на то, что пространство является необходимым компонентом для общения в жестовом языке.
Область жеста может менять свой размер в зависимости от ситуации, в которой находится человек. В случаях, когда человек «кричит», его жестовое пространство будет охватывать гораздо большую область, чтобы учесть увеличенный размер движений знака. Напротив, когда жестикулирующий хочет «шептать», размер его или её жестового пространства будет уменьшаться и часто смещаться, бывает в области живота, чтобы удерживать жесты скрытыми от зрения. Независимо от размера жестового пространства, используемое пространство является важным расширением тела и необходимым для общения. Жестовое пространство увеличивает или уменьшает свой размер в зависимости от количества внимания, которое желает привлечь говорящий на жестовом языке.
В лингвистике жест – это элемент жестового языка, который состоит из пяти компонентов: конфигурации руки; ориентации руки; места исполнения жеста; движения; немануального компонента. В настоящем изобретении предлагается использовать данную модель для разметки жестов.
При изменении одного из компонентов жеста меняется его значение. Например, при изменении лишь одного компонента может измениться лексическое значение (направление сверху – вниз и справа – налево: ПАПА – МАМА; ориентация и движение: МОСКВА – БАБУШКА – СТАРЫЙ) или морфологическое (грамматическое) значение (направление движения: (я) ДАЮ – (мне) ДАЮТ; однократность – повторяемость движения: ВСПОМНИТЬ – ВСПОМИНАТЬ).
Важным свидетельством того, что то или иное различие является в заданном языке фонологическим (смыслоразличительным), является наличие минимальной пары. Минимальная пара – это две разных морфемы или словоформы, различающихся только одним компонентом в одной и той же позиции.
Далее компоненты жеста будут описаны более подробно.
1. Конфигурация руки
Конфигурация представляет собой форму кисти руки при исполнении жеста. Примером минимальной пары в русском жестовом языке, в которой жесты различаются только конфигурацией, являются жесты «Сибирь» и «Новосибирск»: в жесте «Сибирь» руки находятся в конфигурации «С» (С-образная рука), а в жесте «Новосибирск» – в конфигурации «Н». Место исполнения обоих жестов, ориентация рук и движение одни и те же.
2. Ориентация руки
Ориентация представляет собой положение ладони и пальцев в пространстве по отношению к корпусу тела говорящего и положение рук по отношению друг к другу. Ладонь может быть развернута вверх, вниз, вправо, влево, по направлению к говорящему или от говорящего, ребром к говорящему. Кончики пальцев могут быть направлены вверх, вниз, вправо, влево, к говорящему, от говорящего, по диагонали и т. д. В двуручных жестах ориентации рук могут быть симметричными, руки могут быть расположены параллельно друг другу, одна рука может быть расположена над другой рукой, позади или впереди нее, кисти рук могут быть скрещены, ладони могут касаться друг друга ребрами и т.д. Например, в жесте русского жестового языка ГОРЯЧИЙ кисть повернута кончиками пальцев вверх ладонью к говорящему, в жесте ТЕМА кисти рук повернуты кончиками пальцев вверх ладонями от говорящего, а в жесте СИДЕТЬ кисти рук развернуты ладонями вниз параллельно полу.
3. Локализация
Локализация жеста включает в себя два признака: место исполнения и сеттинг. Место исполнения – это несколько крупных областей в пределах жестового пространства, в которых может производиться жест: голова, корпус, нейтральное жестовое пространство и пассивная рука. Сеттинг уточняет местоположение жеста внутри этой крупной области. Например, в пределах места исполнения, обозначаемого как «голова», можно выделить такие сеттинги как «лоб», «подбородок», «нос», «ухо». минимальной пары жестов. Например, жесты МАЛЬЧИК и ДЕВОЧКА исполняются на уровне головы говорящего, при этом жест МАЛЬЧИК исполняется на уровне лба, а ДЕВОЧКА – на уровне щеки.
4. Движение
Движение является наиболее сложным и внутренне неоднородным параметром в структуре жеста. Выделяются два основных его типа: траекторное и локальное.
Траекторное движение – это перемещение руки от одной локализации к другой. В траекторном движении, в свою очередь, важны такие его признаки, как направление (перемещение руки относительно вертикальной, горизонтальной и сагиттальной осей) и характер (по прямой, по дуге, по зигзагу, по спирали, резкое, плавное и т.п.).
Например, в жесте русского жестового языка ОТЕЦ рука движется вертикально сверху вниз от локализации у лба к локализации у подбородка. В жесте ГОРА рука совершает плавное дугообразное движение по воображаемой плоскости, параллельной телу говорящего. При исполнении жеста РЕКА рука движется вперед в горизонтальной плоскости по зигзагу.
5. Немануальный компонент
Одно из распространенных заблуждений относительно жестовых языков состоит в том, что это «языки рук», то есть что лингвистические единицы артикулируются в них только руками. Мануальные артикуляторы – руки – играют важную роль в жестовой речи, однако не менее важны и другие артикуляторы – корпус тела, голова, плечи и части лица. Лингвистически значимые компоненты жестовой речи, исполняемые не руками, называются немануальными компонентами или немануальными маркерами.
В структуру многих жестов, помимо мануальных компонентов, рассмотренных выше, в качестве обязательной составляющей может входить и немануальный компонент – определенное движение головы и/или корпуса, мимика, маусинг и жесты рта. Такие жесты называются комбинированными. В русском жестовом языке многие жесты являются комбинированными. Например, жест БОЛЕТЬ обычно исполняется с поджатыми губами; жест НЕ ВЕРИТЬ сочетается с легкими поворотами головы вправо-влево; в жесте ПРОСНУТЬСЯ глаза в начальной фазе исполнения жеста закрыты, а в конечной – открыты; при исполнении жеста ДРАЗНИТЬ глаза немного прищурены.
Маусинг представляет собой беззвучную артикуляцию соответствующего слова (или его части) звукового языка. Например, в нидерландском жестовом языке мануальный жест ЦВЕТОК сопровождается артикуляцией соответствующего голландского слова BLOEM, а жест МАТЬ – артикуляцией слова MOEDER. В русском жестовом языке тоже имеются жесты, исполнение которых обычно сопровождается артикуляцией соответствующего русского слова или его части. Например, жесты ДЕТИ и ДОМ обычно включают беззвучную артикуляцию соответствующего слова, а жест УЧИТЬСЯ артикуляцию “учи”.
К жестам рта относятся различные движения или положения губ и языка, артикуляция некоторых звуков или их сочетаний, а также вдох или выдох ртом. В отличие от маусинга, жесты рта не связаны со звуковым языком и не являются результатом влияния звукового языка. Примеры жестов рта, сопровождающих движения рук, имеются и в русском жестовом языке. При исполнении жестов ЦЕЛОВАТЬ и КАЧЕСТВЕННЫЙ губы вытянуты вперед. Жест НИ ЗА ЧТО (указательный палец совершает резкое повторяющееся горизонтальное движение вдоль подбородка) исполняется с высунутым кончиком языка. В жесте СОВСЕМ НИЧЕГО (рука в конфигурации “- О ” подносится ко лбу) беззвучно артикулируется [u], в жесте ГОВОРИТЬ [a], а в жесте РАЗГОВАРИВАТЬ [vаvаvа]. Исполнение одного из жестов со значением ‘не мочь’ (обе руки в конфигурации “1”; указательный палец активной руки резко ударяет по указательному пальцу пассивной руки) сопровождается положением губ, напоминающим беззвучную артикуляцию звука [u] и резким выдохом.
Минимальные пары по немануальному компоненту имеются и в русском жестовом языке. Например, жесты БЕСПЛАТНЫЙ и БЕЗДЕЛЬНИЧАТЬ имеют одни и те же мануальные параметры, но БЕСПЛАТНЫЙ сопровождается беззвучной артикуляцией слога “бес”. Жесты СМЫСЛ и МЕЧТАТЬ отличаются тем, что при исполнении жеста МЕЧТАТЬ взгляд обычно направлен вверх, рот приоткрыт, а голова чуть отклонена назад.
Настоящее изобретение направлено на создание устройства и способа (инструмента) для разметки жестов жестового языка на видеозаписи и создания основанного на этом обучающего набора данных, с помощью которого можно обучить систему распознавания жестов.
Пример системы разметки, обучения и распознавания жестов представлен на Фиг. 1. Далее в данном документе
Система разметки, обучения и распознавания жестов содержит устройство 100 для разметки жестов, устройство 200 для обучения модели и устройство 300 для распознавания жестов.
В состав устройства 300 для распознавания жестов входят компьютерное устройство 310 и камера 320 – например, ПК с внешней веб-камерой или ноутбук/планшет/смартфон со встроенной камерой. Камера 320 захватывает изображение человека (пользователя), говорящего на жестовом языке, компьютер 310 с помощью алгоритма распознавания жестов определяет, какой жест был произведен говорящим, и выдает текст или звук, соответствующий этому жесту. Алгоритм распознавания жестов может работать на базе модели машинного обучения – например, нейронной сети.
Обучение модели производится заранее в устройстве 200 для обучения модели. Между тем, чтобы обучить такую модель, требуется наличие размеченного набора данных, содержащего множество видеофайлов или изображений с различными жестами.
Формирование размеченного набора данных и разметка жестов выполняется с помощью устройства 100 для разметки жестов согласно настоящему изобретению, примерная блок-схема которого представлена на Фиг. 2. Устройство 100 для разметки жестов содержит инструмент 110 разметки, камеру 120 и устройство 130 для хранения набора данных. Инструмент 110 разметки представляет собой компьютерное устройство, такое как компьютер, ноутбук, планшет и т.п., содержащее процессор 111, память 112, экран 113 и средство 114 управления экранным указателем. Например, в компьютере экраном может быть экран монитора, а средством управления экранным указателем может быть компьютерная мышь или клавиатура, в то время как в планшете экраном может быть сенсорный экран, а средством управления экранным указателем является встроенное в сенсорный экран средство сенсорного ввода. В необязательном варианте осуществления инструмент 110 разметки может содержать камеру 115 для захвата видео, в таком случае она может использоваться в качестве вышеуказанной камеры 120 или в дополнение к ней. Еще в одном необязательном варианте осуществления память 112 инструмента 110 разметки может обеспечивать хранение набора данных, в таком случае устройство 130 для хранения набора данных может рассматриваться как часть инструмента 110 разметки.
Быстрое создание размеченного набора данных с жестами жестового языка является нетривиальной задачей. Приведенная выше компонентная модель представления жестового языка позволяет охватить все возможные комбинации жестовых компонентов без потери значимых данных. Существуют различные систем нотации, основанные на этих принципах, такие как SignWriting, HamNoSys и т.д. В системе нотации запись жеста производится путем описания комбинации компонентов этого жеста с помощью специальных знаков. Примеры записи нескольких жестов в разных системах нотации показаны на Фиг. 3 и демонстрируют, что стандартными средствами сделать подобные записи невозможно, поэтому разметчику требуется инструмент, с помощью которого он мог бы вводить необходимые знаки. При этом, например, число знаков в одной из самых известных систем нотации SignWriting превышает 38 тысяч, поэтому простое перечисление этих знаков на экране компьютера во всем возможном множестве вариаций для того, чтобы пользователь выбрал из них нужную в качестве разметки, потребует от пользователя высокого уровня знания языка и даже при этом займет чрезвычайно много времени.
Во избежание излишних затрат времени и трудностей интерпретации в настоящем изобретении способ разметки жестов жестового языка предлагается выполнять следующим образом (см. блок-схему способа на Фиг. 4).
Сначала выполняется видеозапись человека, говорящего на жестовом языке, при этом в кадре находится один говорящий человек на жестовом языке в анфас, этот человек выполняет в процессе видео один или более жестов жестового языка, при этом кадр полностью охватывает жестовое пространство, то есть область пространства, в которой выполняется жест, а также части тела говорящего, участвующие в выполнении жеста. Например, видео может содержать область тела говорящего от головы до пояса, или область головы, или все тело от головы до ног. Для целей нормализации создаваемой базы данных видео может записываться таким образом, чтобы в кадр попадала только необходимая область – например, только область тела говорящего от головы до пояса. Камера может фокусироваться таким образом, чтобы расстояние от головы до верхней границы кадра было минимальным. Ориентация и соотношение сторон кадра выбирается в соответствии с размерами жестового пространства. Таким образом, обеспечивается максимальный охват различных вариантов жестов жестового языка, при этом границы жестового пространства, используемого для выполнения различных жестов, максимально приближены к границам кадра, за счет чего предотвращается потеря данных и обеспечивается упрощение интерпретации жестов как пользователю, выполняющему разметку, так и в дальнейшем модели машинного обучения, которая будет обучаться на этом наборе данных. В предпочтительном варианте осуществления используется горизонтальная ориентация кадра, говорящий человек на жестовом языке находится в центре кадра по пояс, расстояние от верха головы говорящего до верхней границы кадра минимизировано. Еще в одном варианте осуществления используется горизонтальная ориентация кадра, в центре кадра находится голова говорящего на жестовом языке, расстояние от верха головы говорящего до верхней границы кадра и от подбородка до нижней части кадра минимизировано.
Для упрощения интерпретации жестов как пользователю, выполняющему разметку, так и в дальнейшем модели машинного обучения, которая будет обучаться на этом наборе данных, говорящий на жестовом языке может быть одет в одежду, цвет которой является контрастным к цвету фона, к цвету лица и к цвету кисти или перчаток, одежда может полностью закрывать тело до шеи и руки по меньшей мере в области плеч (предпочтительно до запястья) и не иметь элементов, выступающих выше шеи (и предпочтительно от запястья в сторону кисти), одежда может близко повторять форму тела говорящего, цвет кисти или перчаток может быть контрастным к цвету одежды, цвет фона может быть контрастным к цвету лица и к цвету кисти или перчаток.
Записанное видео должно содержать по меньшей мере один жест жестового языка.
Записанное видео принимается компьютером и отображается в пользовательском интерфейсе, общий вид которого показан на Фиг. 5.
Пользователь просматривает (или иными словами, инструмент 110 разметки воспроизводит с помощью экрана 113) видео и указывает с помощью интерфейса временные границы в пределах этого видео, в рамках которых содержится видеофрагмент, содержащий один компонент жеста, жест или фразу, если она может быть размечена. При необходимости это может быть одиночный кадр, и тогда пользователь указывает один момент времени, соответствующий этому кадру в пределах длительности входного видео. Указание может выполняться путем остановки видео в необходимой точке и нажатия на кнопку фиксации момента времени. В другом варианте осуществления жест может выполняться в течение более чем одного кадра, и тогда пользователь может указывать начало и конец требуемого видеофрагмента (то есть указывать первый и последний кадр путем ввода времени, выбора соответствующих точек на шкале просмотра и т.д.). Следует понимать, что в зависимости от того, является ли видеофрагмент одним кадром или последовательностью кадров, меняется структура входных данных для обучения, поэтому для обработки разных видеофрагментов могут потребоваться разные модели.
На основании указания пользователя инструмент 110 разметки (в частности, процессор 111) выделяет из входного видео видеофрагмент.
В пользовательском интерфейсе также отображается окно с набором визуальных представлений, характеризующих компоненты жестов, входящие в предварительно заданную систему нотации жестового языка, такую как SignWriting. Набор визуальных представлений содержит по меньшей мере следующие блоки (по очереди или все одновременно): блок визуальных представлений конфигурации руки, блок визуальных представлений ориентации руки. Наличие соответствующей разметки позволяет обеспечить высокое качество обучения модели машинного обучения для распознавания жестов. Кроме того, в дополнительных вариантах осуществления набор визуальных представлений может также содержать блок визуальных представлений локализации жеста, блок визуальных представлений движения руки и блок визуальных представлений немануальных компонентов жеста, чтобы дополнительно повысить метрики обучения модели машинного обучения для распознавания жестов. При необходимости блоки могут пересекаться, чтобы сэкономить экранное пространство и иметь возможность увеличить размеры визуальных представлений. В другом варианте осуществления блоки не перекрывают друг друга, чтобы не затруднять поиск необходимого визуального представления, что бывает актуально, например, для случаев, когда ранее выбрано ошибочное визуальное представление, и в соответствующем предыдущем блоке необходимо изменить выбор, не закрывая текущий блок.
Визуальное представление представляет собой изображение, анимированное изображение или короткое видео, упрощенно характеризующее соответствующий компонент жеста. Например, визуальное представление может быть выполнено в виде изображения или контуров той части тела, которая участвует в жесте, в форме или ориентации, соответствующей данному варианту выбора в рамках данного компонента жеста, или может одним изображением описывать движение, совершаемое этой частью тела, или может одним изображением описывать место исполнения жеста. Таким образом, упрощается поиск и интерпретация необходимых вариантов выбора компонентов жеста для его корректной разметки.
В одном из дополнительных вариантов осуществления визуальное представление может быть выполнено в виде контуров, но при наведении на него указателя может воспроизводиться окрашивание элементов визуального представления для упрощения и ускорения его идентификации.
Также в одном из дополнительных вариантов осуществления визуальное представление может быть выполнено в виде статичного изображения или контуров, но при наведении на него указателя может воспроизводиться анимация, соответствующая данному компоненту жеста, для упрощения и ускорения его идентификации.
В одном из дополнительных вариантов осуществления каждое визуальное представление сразу в пределах блока может сопровождаться пояснительным текстом, для упрощения и ускорения его идентификации.
Еще в одном из дополнительных вариантов осуществления текстовая подсказка может появляться лишь при наведении указателя на визуальное представление, для упрощения и ускорения его идентификации, но без сокращения экранного пространства.
Из каждого блока визуальных представлений пользователь выбирает необходимое визуальное представление, соответствующее данному жесту. Выбор может производиться, например, путем непосредственного нажатия на это представление или на сопровождающий его текст. В другом варианте осуществления выбор производится, если нажатие на необходимое представление длится не менее чем в течение предварительно заданного промежутка времени – например, 1 сек. Еще в одном варианте осуществления выбор может производиться путем нажатия на поле указания (например, чекбокс), расположенное рядом с этим визуальным представлением.
В пользовательском интерфейсе также предоставляется элемент интерфейса, обеспечивающий указание правой руки и левой руки. Каждая рука может выполнять действия в процессе выполнения жеста, и эти действия могут быть несимметричны, поэтому необходимо отдельно указывать, какая рука выполняет какие действия. Пользователь выполняет разметку для руки и указывает эту руку, нажимая на соответствующую кнопку – например, «Сохранить правую». При этом в памяти сохраняется разметка для данной руки. Если в жесте участвует две руки, то пользователь выполняет разметку сначала для одной руки, а потом для другой. Устройство 100 для разметки жестов не требует от пользователя соблюдать порядок разметки, обеспечивая ему возможность произвольно определять, какие компоненты и какие руки в каком порядке указывать. Тем самым, пользователь имеет возможность выполнять разметку по мере интерпретации им тех или иных компонентов жеста, начиная с наиболее очевидных и понятных, за счет чего разметка упрощается и ускоряется, при этом учитываются особенности жестового языка.
В другом варианте осуществления у пользователя нет необходимости производить отдельное нажатие кнопки «Сохранить правую» или «Сохранить левую», вместо этого в интерфейсе отображается отдельно подблок визуальных представлений для правой руки и подблок визуальных представлений для левой руки. Такой вариант особенно применим, например, для визуальных представлений ориентации руки, когда вслед за выбором визуального представления конфигурации руки в интерфейсе отображается отдельно подблок визуальных представлений ориентации руки для правой руки и подблок визуальных представлений ориентации руки для левой руки, причем визуальные представления ориентации руки в каждом подблоке описывают выбранную конфигурацию руки с учетом того, правая это рука или левая. В частности, как показано в примере на Фиг. 6, визуальные представления ориентации руки в подблоке для правой руки, который отображается в правой части интерфейса, отличаются от визуальных представлений ориентации руки в подблоке для левой руки, который отображается в левой части интерфейса, потому что выбранная конфигурация руки выглядит по-разному при ее выполнении левой или правой рукой. Соответственно, пользователю (разметчику) проще сделать выбор, и он делает выбор сразу для нужной руки. Таким образом, разметка упрощается и ускоряется, при этом учитываются особенности жестового языка.
Когда выбор для жеста, содержащегося в видеофрагменте, для каждой руки, участвующей в жесте, сделан, инструмент 110 разметки с помощью средства 114 управления экранным указателем принимает от пользователя соответствующий ввод.
Для каждой руки, участвующей в жесте, инструмент 110 разметки с помощью процессора 111 формирует идентификатор жеста, соответствующий нотации этого жеста в системе нотации, согласно принятым указаниям от пользователя, соответствующим этой руке. Для этого каждому указанному визуальному представлению инструмент 110 разметки с помощью процессора 111 ставит в соответствие (буквенно-цифровой) идентификатор представления. В разных вариантах осуществления идентификатор может содержать буквы, цифры или другие символы или любые их комбинации. Далее путем конкатенации идентификаторов представления, соответствующих заданной руке, инструмент 110 разметки с помощью процессора 111 формирует идентификатор жеста. Конкатенация может производиться без разделителя или с разделителем, в качестве разделителя может использоваться пробел, дефис, символ подчеркивания и т.д.
После этого инструмент 110 разметки с помощью процессора 111 и памяти 112 формирует запись в файле разметки, содержащую указание видеофрагмента и для каждой руки, участвующей в жесте, идентификатор жеста. Пример файла разметки показан на Фиг. 7. В частности, файл на Фиг. 7 представляет собой csv-файл, содержащий три столбца. Столбец «filename» («имя файла») содержит указание видеофрагмента в виде соответствующего имени файла в папке, в которой хранятся видеофрагменты. Столбец «lefthand» («левая рука») содержит идентификатор жеста для левой руки, столбец «righthand» («правая рука») содержит идентификатор жеста для правой руки. Для каждого видеофрагмента в файле разметки создается отдельная запись (строка). Например, для видеофрагмента с именем файла «401-5.mp4» в файле разметки создана строка 6, в которой указано, что данный видеофрагмент содержит жест  , выполненный правой рукой. Пустое значение для левой руки означает, что левая рука не использовалась при выполнении этого жеста.
, выполненный правой рукой. Пустое значение для левой руки означает, что левая рука не использовалась при выполнении этого жеста.
Файл разметки вместе с соответствующими видеофрагментами представляет собой набор данных, который сохраняется в устройстве 130 для хранения набора данных.
Полученный в результате разметки множества видеофрагментов набор данных используется для машинного обучения модели распознавания жестов жестового языка, видеофрагменты используются в качестве обучающих данных, а идентификаторы жестов используются в качестве разметки.
В одном из дополнительных вариантов осуществления настоящего изобретения пользовательский интерфейс также может иметь элемент интерфейса, обеспечивающий одновременно указание руки с переходом к следующему видео. Для этого интерфейс может содержать кнопку, такую как «Сохранить и след» (что означает сохранить и перейти к следующему). Для примера на Фиг. 6 блок визуальных представлений ориентации руки рядом с кнопками «ОК» и «Отмена» может содержать кнопку «ОК и след». Соответственно, пользователь имеет возможность нажатием на одну кнопку зафиксировать результат разметки для текущего жеста и сразу перейти к следующему видео. Аналогичным образом, пользовательский интерфейс также может иметь элемент интерфейса, обеспечивающий одновременно указание руки с переходом к предыдущему видео.
Еще в одном варианте осуществления инструмент 110 разметки может содержать опцию настройки, чтобы при нажатии на кнопку «ОК» автоматически выполнялся переход к следующему жесту. Это позволяет ускорить процесс разметки, не загромождая интерфейс лишними элементами.
На Фиг. 8A-8B показаны дополнительные примеры блока визуальных представлений, где ориентация руки отображается относительно тела человека с учетом того, какой частью тела выполняется жест, при этом части тела человека схематически отображаются в выбранной ранее конфигурации жеста. Ориентации могут отображаться непосредственно вокруг той части тела, которая выполняет жест (Фиг. 8A), или около нее (Фиг. 8B). Таким образом, идентификация жеста и разметка упрощается и ускоряется, при этом учитываются особенности жестового языка.
Блоки визуальных представлений могут отображаться последовательно с помощью древовидной структуры. В частности, по меньшей мере один блок визуальных представлений может содержать несколько групп визуальных представлений, причем группы могут быть сформированы согласно параметрам компонентов жеста.
В одном из вариантов осуществления интерфейс может дополнительно содержать элементы, позволяющие копировать разметку из предыдущего размеченного жеста (см. Фиг. 5 внизу слева). Для этого при переходе к следующему жесту в соответствующих полях для правой и левой руки может отображаться результат разметки предыдущего жеста, и при нажатии на кнопку «Копировать» эти результаты могут быть скопированы в поля для правой и левой руки для текущего жеста. Таким образом, идентификация жеста и разметка упрощается и ускоряется.
Аналогично описанной ранее функции сохранения с переходом, в дополнительном варианте осуществления инструмент 110 разметки может содержать кнопку «Копировать и след» или опцию настройки, чтобы при нажатии на кнопку «Копировать» автоматически выполнялся переход к следующему жесту. Это позволяет ускорить процесс разметки.
Таким образом, обеспечивается повышение скорости разметки за счет упрощения интерпретации компонентов жеста как для пользователя, так и для модели машинного обучения. Кроме того, модель машинного обучения будет быстрее обучаться, и для ее обучения потребуется меньше данных, то есть предложенный способ формирования набора данных обеспечивает также уменьшение требуемого объема набора данных. Также снижаются требования к квалификации оператора/пользователя, выполняющего разметку, поскольку в предложенном способе с достаточной точностью может выполнять разметку даже человек, имеющий лишь первичное знакомство с жестовым языком и получивший инструктаж по пользованию данным устройством.
Пример
Настоящее изобретение было испытан на практике с использованием нескольких пользователей-разметчиков, имеющих разную квалификацию и разные уровни знания жестового языка. На Фиг. 9 приведены результаты испытаний. В частности, первые три столбца слева (синий цвет) показывают среднее количество жестов в час за день, которые были размечены разметчиками, когда в качестве инструмента разметки им было предоставлено простое перечисление знаков системы нотации на экране компьютера. Остальные столбцы справа (зеленый цвет) показывают среднее количество жестов в час за день, которые были размечены разметчиками, когда они пользовались предложенным в настоящем изобретении инструментом разметки, который был реализован в варианте осуществления, приведенном на Фиг. 5-6. Как можно видеть, предложенное изобретение позволяет объективно повысить скорость разметки.
Применение
Устройства и способы согласно настоящему изобретению можно использовать для создания базы данных, которая обеспечивает выполнение функций по хранению и сортировке данных о жестах и их компонентах жестового языка, и для разработки с помощью такой базы данных систем распознавания жестового языка, применяемых для обеспечения коммуникации глухих и слышащих.
Дополнительные особенности реализации
Различные иллюстративные блоки и модули, описанные в связи с раскрытием сущности в данном документе, могут реализовываться или выполняться с помощью процессора общего назначения, процессора цифровых сигналов (DSP), специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA) или другого программируемого логического устройства (PLD), дискретного логического элемента или транзисторной логики, дискретных аппаратных компонентов либо любой комбинации вышеозначенного, предназначенной для того, чтобы выполнять описанные в данном документе функции. Процессор общего назначения может представлять собой микропроцессор, но в альтернативном варианте, процессор может представлять собой любой традиционный процессор, контроллер, микроконтроллер или конечный автомат. Процессор также может реализовываться как комбинация вычислительных устройств (к примеру, комбинация DSP и микропроцессора, несколько микропроцессоров, один или более микропроцессоров вместе с DSP-ядром либо любая другая подобная конфигурация).
Некоторые блоки или модули по отдельности или вместе могут представлять собой, например, процессор, который сконфигурирован для вызова и выполнения компьютерных программ из памяти для выполнения этапов способа или функций блоков или модулей в соответствии с вариантами осуществления настоящего изобретения. Согласно вариантам осуществления, устройство может дополнительно включать в себя память. Процессор может вызывать и выполнять компьютерные программы из памяти для выполнения способа. Память может быть отдельным устройством, независимым от процессора, или может быть интегрирована в процессор. Память может хранить код, инструкции, команды и/или данные для исполнения на наборе из одного или более процессоров описанного устройства. Коды, инструкции, команды могут предписывать процессору выполнять этапы способа или функции устройства.
Функции, описанные в данном документе, могут реализовываться в аппаратном обеспечении, программном обеспечении, выполняемом посредством одного или более процессоров, микропрограммном обеспечении или в любой комбинации вышеозначенного, если это применимо. Аппаратные и программные средства, реализующие функции, также могут физически находиться в различных позициях, в том числе согласно такому распределению, что части функций реализуются в различных физических местоположениях, то есть может выполняться распределенная обработка или распределенные вычисления.
Вышеупомянутая память может быть энергозависимой или энергонезависимой памятью или может включать в себя как энергозависимую, так и энергонезависимую память. Специалисту в области техники должно быть также понятно, что, когда речь идет о памяти и о хранении данных, программ, кодов, инструкций, команд и т.п., подразумевается наличие машиночитаемого (или компьютерно-читаемого, процессорно-читаемого) запоминающего носителя. Машиночитаемый запоминающий носитель может представлять собой любой доступный носитель, который может использоваться для того, чтобы переносить или сохранять требуемое средство программного кода в форме инструкций или структур данных, и к которому можно осуществлять доступ посредством компьютера, процессора или иного устройства обработки общего назначения или специального назначения.
Следует понимать, что хотя в настоящем документе для описания различных элементов, компонентов, областей, слоев и/или секций могут использоваться такие термины, как "первый", "второй", "третий" и т.п., эти элементы, компоненты, области, слои и/или секции не должны ограничиваться этими терминами. Эти термины используются только для того, чтобы отличить один элемент, компонент, область, слой или секцию от другого элемента, компонента, области, слоя или секции. Так, первый элемент, компонент, область, слой или секция может быть назван вторым элементом, компонентом, областью, слоем или секцией без выхода за рамки объема настоящего изобретения. В настоящем описании термин "и/или" включает любые и все комбинации из одной или более из соответствующих перечисленных позиций. Элементы, упомянутые в единственном числе, не исключают множественности элементов, если отдельно не указано иное.
Функциональность элемента, указанного в описании или формуле изобретения как единый элемент, может быть реализована на практике посредством нескольких компонентов устройства, и наоборот, функциональность элементов, указанных в описании или формуле изобретения как несколько отдельных элементов, может быть реализована на практике посредством единого компонента.
Несмотря на то, что примерные варианты осуществления были подробно описаны и показаны на сопроводительных чертежах, следует понимать, что такие варианты осуществления являются лишь иллюстративными и не предназначены ограничивать настоящее изобретение, и что данное изобретение не должно ограничиваться конкретными показанными и описанными компоновками и конструкциями, поскольку специалисту в данной области техники на основе информации, изложенной в описании, и знаний уровня техники могут быть очевидны различные другие модификации и варианты осуществления изобретения, не выходящие за пределы сущности и объема данного изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| СПОСОБ ГЕНЕРАЦИИ И РАСПОЗНАВАНИЯ ЖЕСТОВ ЖЕСТОВОГО ЯЗЫКА И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2024 |
|
RU2836110C1 |
| ЖЕСТОВЫЕ СОКРАЩЕНИЯ | 2010 |
|
RU2574830C2 |
| ВЕРИФИКАЦИЯ ГОВОРЯЩЕГО | 2017 |
|
RU2697736C1 |
| ФРЕЙМВОРК ПРИЕМА ВИДЕО ДЛЯ ПЛАТФОРМЫ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2720536C1 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ЖЕСТОВ | 2024 |
|
RU2829441C1 |
| СПОСОБ ДЛЯ ОТОБРАЖЕНИЯ СУБТИТРОВ В ПРОЦЕССЕ ВОСПРОИЗВЕДЕНИЯ МЕДИАКОНТЕНТА (ВАРИАНТЫ) | 2017 |
|
RU2668721C1 |
| ЭЛЕКТРОННЫЙ СЕРВИС ДЛЯ ИЗУЧЕНИЯ ЛЕКСИКИ И СЕМАНТИКИ ЖЕСТОВЫХ ЯЗЫКОВ | 2022 |
|
RU2807015C1 |
| ОБНОВЛЕНИЕ ФАЙЛА МАНИФЕСТА ДЛЯ СЕТЕВОЙ ПОТОКОВОЙ ПЕРЕДАЧИ КОДИРОВАННЫХ ВИДЕОДАННЫХ | 2011 |
|
RU2558615C2 |



Группа изобретений относится к информационным технологиям, в частности к устройству и способу для разметки жестов жестового языка. Предложено устройство для реализации способа, который содержит этапы, на которых: отображают в пользовательском интерфейсе видеофрагмент, содержащий один компонент жеста, жест или фразу жестового языка, при этом в кадре находится один говорящий в анфас, выполняющий в процессе видео по меньшей мере один жест жестового языка, при этом кадр полностью охватывает область пространства, в которой выполняется жест, и части тела говорящего, участвующие в выполнении жеста, предоставляют элемент интерфейса, обеспечивающий указание правой руки и левой руки, отображают в пользовательском интерфейсе набор визуальных представлений, характеризующих компоненты жестов, входящие в предварительно заданную систему нотации жестового языка, при этом набор визуальных представлений содержит по меньшей мере следующие блоки: блок визуальных представлений конфигурации руки, блок визуальных представлений ориентации руки, причем визуальное представление представляет собой изображение, анимированное изображение или короткое видео, упрощенно характеризующее соответствующий компонент жеста, причем по меньшей мере один блок визуальных представлений содержит подблоки визуальных представлений для каждой руки, причем подблоки сформированы согласно параметрам компонентов жеста, причем параметры компонентов жеста включают в себя тип конфигурации руки или тип ориентации руки, принимают от пользователя для жеста, содержащегося в видеофрагменте, для каждой руки, участвующей в жесте, выполненное с помощью экранного указателя указание руки и указание одного или более визуальных представлений из каждого блока визуальных представлений, для каждой руки, участвующей в жесте, формируют идентификатор жеста, соответствующий нотации этого жеста в системе нотации, согласно принятым указаниям от пользователя, соответствующим этой руке, и формируют запись в файле разметки, содержащую указание видеофрагмента и для каждой руки, участвующей в жесте, идентификатор жеста, причем набор данных, содержащий файл разметки и видеофрагменты, указанные в файле разметки, используется для машинного обучения модели распознавания жестов жестового языка, видеофрагменты используются в качестве обучающих данных, а идентификаторы жестов из файла разметки используются в качестве разметки. Группа изобретений обеспечивает повышение скорости разметки за счет упрощения интерпретации компонентов жеста. 2 н. и 9 з.п. ф-лы, 10 ил.
1. Способ разметки жестов жестового языка, реализуемый с помощью компьютерного устройства, содержащего процессор, память, экран и средство управления экранным указателем, содержащий этапы, на которых:
- отображают в пользовательском интерфейсе видеофрагмент, содержащий один компонент жеста, жест или фразу жестового языка, при этом в кадре находится один говорящий в анфас, выполняющий в процессе видео по меньшей мере один жест жестового языка, при этом кадр полностью охватывает область пространства, в которой выполняется жест, и части тела говорящего, участвующие в выполнении жеста,
- предоставляют элемент интерфейса, обеспечивающий указание правой руки и левой руки для выполнения соответствующей разметки,
- отображают в пользовательском интерфейсе набор визуальных представлений, характеризующих компоненты жестов, входящие в предварительно заданную систему нотации жестового языка, для выполнения соответствующей разметки, при этом набор визуальных представлений содержит по меньшей мере следующие блоки: блок визуальных представлений конфигурации руки, блок визуальных представлений ориентации руки,
причем визуальное представление представляет собой изображение или анимированное изображение, упрощенно характеризующее соответствующий компонент жеста,
причем по меньшей мере один блок визуальных представлений содержит подблоки визуальных представлений для каждой руки, причем подблоки сформированы отдельно по каждому параметру компонентов жеста,
причем параметры компонентов жеста включают в себя тип конфигурации руки или тип ориентации руки,
- принимают от пользователя для жеста, содержащегося в видеофрагменте, для каждой руки, участвующей в жесте, выполненное с помощью экранного указателя указание руки и указание одного или более визуальных представлений из каждого блока визуальных представлений, в качестве разметки,
- для каждой руки, участвующей в жесте, формируют идентификатор жеста, соответствующий нотации этого жеста в системе нотации, согласно принятым указаниям от пользователя, соответствующим этой руке, и
- формируют запись в файле разметки, содержащую указание видеофрагмента и для каждой руки, участвующей в жесте, идентификатор жеста,
причем набор данных, содержащий файл разметки и видеофрагменты, указанные в файле разметки, используется для машинного обучения модели распознавания жестов жестового языка, видеофрагменты используются в качестве обучающих данных, а идентификаторы жестов из файла разметки используются в качестве разметки.
2. Способ по п. 1, дополнительно содержащий этап, на котором:
- выполняют видеозапись человека, говорящего на жестовом языке.
3. Способ по п. 1, в котором говорящий одет в одежду, цвет которой является контрастным к цвету фона, к цвету лица и к цвету кисти или перчаток, одежда полностью закрывает тело до шеи говорящего и руки по меньшей мере в области плеч и не имеет элементов, выступающих выше шеи, одежда повторяет форму тела говорящего, цвет кисти или перчаток является контрастным к цвету одежды, цвет фона является контрастным к цвету лица и к цвету кисти или перчаток.
4. Способ по п. 1, дополнительно содержащий этапы, на которых:
- принимают и отображают в пользовательском интерфейсе входное видео, содержащее по меньшей мере один жест жестового языка,
- принимают ввод от пользователя, указывающий один или два момента времени в пределах длительности входного видео для выделения видеофрагмента,
- выделяют из входного видео видеофрагмент, содержащий один компонент жеста, жест или фразу, причем видеофрагмент содержит один или более последовательных видеокадров.
5. Способ по п. 1, в котором набор визуальных представлений дополнительно содержит блок визуальных представлений локализации жеста, блок визуальных представлений движения руки и блок визуальных представлений немануальных компонентов жеста,
параметры компонентов жеста дополнительно включают в себя место исполнения жеста, тип движения или немануальный объект, участвующий в жесте.
6. Способ по п. 1, дополнительно содержащий этап, на котором:
- формируют и сохраняют в памяти набор данных, содержащий файл разметки и видеофрагменты, указанные в файле разметки.
7. Устройство для разметки жестов жестового языка, содержащее процессор, память, экран и средство управления экранным указателем, причем устройство выполнено с возможностью:
- отображать в пользовательском интерфейсе видеофрагмент, содержащий один компонент жеста, жест или фразу жестового языка, при этом в кадре находится один говорящий в анфас, выполняющий в процессе видео по меньшей мере один жест жестового языка, при этом кадр полностью охватывает область пространства, в которой выполняется жест, и части тела говорящего, участвующие в выполнении жеста,
- предоставлять элемент интерфейса, обеспечивающий указание правой руки и левой руки для выполнения соответствующей разметки,
- отображать в пользовательском интерфейсе набор визуальных представлений, характеризующих компоненты жестов, входящие в предварительно заданную систему нотации жестового языка, для выполнения соответствующей разметки, при этом набор визуальных представлений содержит по меньшей мере следующие блоки: блок визуальных представлений конфигурации руки, блок визуальных представлений ориентации руки,
причем визуальное представление представляет собой изображение или анимированное изображение, упрощенно характеризующее соответствующий компонент жеста,
причем по меньшей мере один блок визуальных представлений содержит подблоки визуальных представлений для каждой руки, причем подблоки сформированы отдельно по каждому параметру компонентов жеста,
причем параметры компонентов жеста включают в себя тип конфигурации руки или тип ориентации руки,
- принимать от пользователя для жеста, содержащегося в видеофрагменте, для каждой руки, участвующей в жесте, выполненное с помощью экранного указателя указание руки и указание одного или более визуальных представлений из каждого блока визуальных представлений, в качестве разметки,
- для каждой руки, участвующей в жесте, формировать идентификатор жеста, соответствующий нотации этого жеста в системе нотации, согласно принятым указаниям от пользователя, соответствующим этой руке,
- формировать запись в файле разметки, содержащую указание видеофрагмента и для каждой руки, участвующей в жесте, идентификатор жеста,
причем набор данных, содержащий файл разметки и видеофрагменты, используется для машинного обучения модели распознавания жестов жестового языка, видеофрагменты используются в качестве обучающих данных, а идентификаторы жестов из файла разметки используются в качестве разметки.
8. Устройство по п. 7, дополнительно содержащее камеру, выполненную с возможностью:
- выполнять видеозапись человека, говорящего на жестовом языке.
9. Устройство по п. 7, дополнительно выполненное с возможностью:
- принимать и отображать в пользовательском интерфейсе входное видео, содержащее по меньшей мере один жест жестового языка,
- принимать ввод от пользователя, указывающий один или два момента времени в пределах длительности входного видео для выделения видеофрагмента,
- выделять из входного видео видеофрагмент, содержащий один компонент жеста, жест или фразу, причем видеофрагмент содержит один или более последовательных видеокадров.
10. Устройство по п. 7, в котором набор визуальных представлений дополнительно содержит блок визуальных представлений локализации жеста, блок визуальных представлений движения руки и блок визуальных представлений немануальных компонентов жеста,
параметры компонентов жеста дополнительно включают в себя место исполнения жеста, тип движения или немануальный объект, участвующий в жесте.
11. Устройство по п. 7, дополнительно выполненное с возможностью:
- формировать и сохранять в памяти набор данных, содержащий файл разметки и видеофрагменты, указанные в файле разметки.
| US 2015049017 А1, 19.02.2015 | |||
| US 2021174034 А1, 10.06.2021 | |||
| ГРИФ и др | |||
| Распознавание русского и индийского жестовых языков на основе машинного обучения, Информатика и вычислительная техника, Системы анализа и обработки данных том 83, N 3, 2021, с | |||
| Веникодробильный станок | 1921 |
|
SU53A1 |
| М.Г | |||
| ГРИФ и др | |||
| Интерлингва в системах машинного перевода для жестовых языков, Тр | |||
| СПИИРАН, | |||

