Область техники
Настоящее техническое решение относится к области информационных технологий, а именно к способу и системе поиска информации.
Уровень техники
Одной из задач руководителей крупных корпораций является быстрый поиск решений на возникающие вызовы в современном обществе. Для этого, в частности, создаются ситуационные центры, задачей которых является обобщение и анализ в режиме реального времени поступающей от экспертов информации. Для решения этой задачи ситуационные центры оснащены всеми необходимыми техническими средствами и технологиями. Практика показала, что проблемным местом в работе ситуационных центров являются оперативный выбор экспертов для обсуждения исследуемой тематики и базовое представление руководителя ситуационного центра о предметной области. Зачастую, в число экспертов входят специалисты с глобальным представлением об обсуждаемой тематике. Они хорошо разбираются в стратегиях и концепциях, но, не работая непосредственно с рассматриваемыми системами или технологиями, не представляют всех нюансов и деталей, знание о которых часто играет решающую роль в реализации принятого решения. Кроме того, отсутствие, по крайней мере, базовых знаний у руководителя ситуационного центра о предметной области часто приводит к тому, что диалог с тем или иным экспертом сводится к популярному разъяснению экспертом основных категорий и принципов работы, навязыванию безальтернативных решений, на которых, как правило, каждый отдельный эксперт специализируется. Все это создает риски того, что принятое в результате обсуждения решение окажется неэффективным или вообще ошибочным.
Для эффективной работы ситуационных центров требуется наличие инструментов (способов и систем), предназначенных для оперативного и глубокого поиска информации с целью последующего описания (построения) предметных областей в виде онтологических моделей, например, в форме графа знаний, а также выявление авторитетных экспертов, непосредственно работающих в областях, соответствующих каждой тематике. Автоматизация и роботизация процесса сбора и обработки информации позволит получать независимое от точки зрения отдельных экспертов описание предметных областей.
Существующие способы автоматизации поиска информации, в основном, предназначены для построения семантических сетей и их использования для решения технических проблем, например, для повышения точности построения индексов текстов на естественных языках (RU 2518946 С1), повышения точности и скорости поиска технологических объектов за счет формирования классификации объектов и процессов посредством создания онтологий (RU 2639652 С1), для расширения функциональных возможностей семантической навигации по Веб-контенту за счет семантической разметки документов (RU 2442214 С2), ускорения процесса сравнения текстов (RU 2538303 С1) и в ряде других технологий. Построение семантических сетей в приведенных примерах предназначено для последующего использования и улучшения работы программных комплексов, но не для визуализации в познавательных целях пользователя. Автоматически построенные семантические сети, хотя часто и выглядят эффектно, не всегда пригодны для визуального анализа пользователя. Для неспециалиста паутина из сотен взаимосвязанных непонятных для него слов не является эффективным способом изучения предметной области.
Большинство патентов, раскрывающих создание онтологических моделей, описывают технические решения по созданию пользовательской онтологической модели с помощью аппаратного процессора, в который специалист/пользователь вводит данные о своем представлении о структуре предметной области, сформированном на основе собственных знаний и когнитивных способностей. Как правило, в этих случаях онтологические модели представлены в форме семантической сети или так называемых графов знаний (RU 2596599 С2, US 11,443,213, US 11,436,469, US 11,437,039). Во всех этих случаях используемые системы являются инструментом в руках пользователя, но не создают граф знаний автоматически.
Существуют программные средства, предназначенные для автоматизации рутинных процессов описания (построения) онтологий. К их числу следует отнести Ontolingua, Protégé, OntoEdit и ряд других. С помощью этих инструментов пользователь вводит данные о своей онтологической модели, предварительно созданной на когнитивном уровне. Представление об онтологической модели предметной области у разных пользователей часто может отличаться, особенно в деталях, что принципиально отличает такой подход от раскрытых в настоящей заявке системы и способа автоматизированного описания онтологии предметной области и формирования экспертного сообщества по заданной тематике, в которых на формальном уровне автоматически обобщаются материалы публикаций многочисленных авторов в заданной предметной области.
Наиболее близким прототипом заявленного решения является способ поиска и выборки информации с повышенной релевантностью и поисковая система для реализации данного способа (патент RU 2236699 С1). Система содержит следующие элементы: рабочее место пользователя (терминал компьютера), блоки «Преобразователь запросов», «Интегратор документов», «Сортировка документов», «Восстановления структуры предметной области», «Восстановления структуры», «Оценки пересечений», «Рейтинг», «Блок формирования результатов» и «Формирования рейтингов баз данных», а также базы данных «Стандарты баз данных, «Поисковые информационные ресурсы», «Единое хранилище», «Папки», «Объекты». Способ заключается в том, что проводят сортировку по отдельным папкам всех однородных документов из различных баз данных, определяют рейтинги каждого документа внутри папки, затем находят число совпадений признаков отдельных документов в различных папках, определяют окончательный рейтинг каждого документа с учетом числа пересечений, сортируют документы в соответствии с этим рейтингом и направляют эти документы на компьютер пользователя. Пользователю, чтобы составить представление о предметной области, достаточно просмотреть уже отобранные наиболее значимые материалы. Этот способ хорошо подходит для пользователей, обладающих значительным запасом времени для глубокого изучения этих материалов. Для оперативного поиска решения данный способ не пригоден, так как не позволяет получать визуальное представление о предметной области в виде графа знаний и формировать актуальный список экспертов, способных, при необходимости, проконсультировать по отдельным вопросам.
Раскрытие изобретения
Основной технической проблемой, на решение которой направлена заявленная группа изобретений, является автоматизация (роботизация) поиска информации, касающейся определенной тематики, с целью последующего описания (построения) онтологий предметных областей на основе формального выявления знаний и формирования экспертного сообщества по заданной тематике с использованием автоматизированных программных роботов и технологий искусственного интеллекта.
Техническим результатом группы изобретений является повышение точности поиска информации, что способствует повышению скорости и надежности описания онтологии предметной области, с последующим построением и визуализацией графа знаний и формированием сообщества экспертов, работающих в конкретной предметной области и внесших значимый вклад в ее развитие.
Получение технического результата обеспечивается в настоящем изобретении благодаря системе поиска информации, которая состоит из объединенных в коммуникационную сеть компьютеров, серверов и баз данных, причем серверами являются сервер управления поисковыми роботами, сервер машинного обучения, сервер хранения первоисточников, сервер парсинга, сервер ключевых слов, сервер построения графа знаний, сервер оплаты электронной копии публикации или продления подписки, базами данных являются публичные базы данных, база данных эмпирических правил, база данных первоисточников, база данных ключевых слов, база данных экспертов. Причем к серверу управления поисковыми роботами подключен компьютер оператора ситуационного центра, к серверу машинного обучения подключен компьютер эксперта по машинному обучению, к серверу построения графа знаний подключен монитор визуализации графа знаний. При этом компьютер оператора ситуационного центра формирует поисковый запрос, содержащий основное ключевое слово и дополнительное ключевое слово. Сервер управления поисковыми роботами получает поисковый запрос через коммуникационную сеть, определяет несколько поисковых роботов для выполнения одновременного поиска публикаций в сети Интернет и в публичных базах данных, посредством которых осуществляет проверку соответствия основного ключевого слова на соответствие критерию «Сообщество» согласно эмпирически заданным правилам, осуществляя поиск публикаций в сети Интернет и информации в публичных базах данных, при котором выполняется проверка присутствия во всех найденных документах основного ключевого слова в основной теме опубликованного материала, формирует в соответствии с эмпирическими правилами задание поисковым роботам, содержащее основное ключевое слово, дополнительное ключевое слово и два служебных ключевых слова, одно из которых определяет тип документа pdf или doc, а другое представляет собой фразу «ключевые слова», для осуществления поиска в публичных базах данных, формирует список ссылок по результатам работы поисковых роботов из публичных баз данных, направляет список авторов, хранящийся в базе данных экспертов, в библиографические базы данных сети Интернет, и формирует список экспертов на основании индексов активности авторов, найденных поисковыми роботами в библиографических базах данных сети Интернет. Сервер хранения первоисточников получает сформированный список ссылок, запрашивает и получает электронные копии публикаций, размещенных в публичных базах данных, и размещает указанные электронные копии публикаций в базе данных первоисточников, выполняет анализ первоисточников для исключения повторяющихся публикаций. Сервер парсинга выполняет парсинг первоисточников, формирует список авторов, извлекает из первоисточников ключевые слова, указанные авторами, передает в базу данных экспертов информацию об авторах. Сервер ключевых слов сохраняет в базе данных ключевых слов полученные ключевые слова, указанные авторами, вместе со ссылками на первоисточники, формирует кластеры ключевых слов для каждого автора и устанавливает связи между авторами через ключевые слова, указанные в публикациях этих авторов. Сервер построения графа знаний выполняет построение первичного графа знаний на основе выявленных взаимосвязей ключевых слов и с использованием технологий статистического и графового анализа, при этом вершинами первичного графа знаний являются основное и дополнительное ключевые слова, передает полученный первичный граф знаний в базу данных ключевых слов, выполняет форматирование данных о первичном графе знаний в один из графических форматов и выполняет отображение на мониторе визуализации графа знаний
Коммуникационная сеть может быть образована локальной сетью и сетью Интернет.
База данных эмпирических правил и сервер машинного обучения могут быть выполнены с возможностью хранения и пополнения эмпирических правил.
Публичными базами данных могут быть базы данных книг, базы данных статей, базы данных патентов, базы данных диссертаций, базы данных, размещенные на отдельных сайтах сети Интернет.
Кроме того, получение технического результата обеспечивается в настоящем изобретении посредством способа поиска информации, реализуемого вышеуказанной системой и включающего в себя следующие операции:
- ввод посредством компьютера оператора ситуационного центра поискового запроса, содержащего основное ключевое слово и дополнительное ключевое слово;
- поступление поискового запроса через коммуникационную сеть на сервер управления поисковыми роботами, который определяет несколько поисковых роботов для выполнения одновременного поиска публикаций в сети Интернет и в публичных базах данных;
- выполнение поисковыми роботами проверки соответствия основного ключевого слова на соответствие критерию «Сообщество» согласно эмпирически заданным правилам посредством поиска публикаций в сети Интернет и информации в публичных базах данных, при котором осуществляется проверка присутствия во всех найденных документах основного ключевого слова в основной теме опубликованного материала;
- формирование сервером управления поисковыми роботами в соответствии с эмпирическими правилами задания поисковым роботам, содержащего основное ключевое слово, дополнительное ключевое слово и два служебных ключевых слова, одно из которых определяет тип документа pdf или doc, а другое представляет собой фразу «ключевые слова» для осуществления поиска в публичных базах данных;
- формирование из публичных баз данных списка ссылок по результатам работы поисковых роботов;
- поступление списка ссылок на сервер хранения первоисточников, который запрашивает и получает электронные копии публикаций, размещенных в публичных базах данных, и размещает указанные электронные копии публикаций в базе данных первоисточников;
- проведение анализа первоисточников на сервере хранения первоисточников с целью исключения повторяющихся публикаций;
- проведение парсинга первоисточников на сервере парсинга, формирование списка авторов, извлечение из первоисточников ключевых слов, указанных авторами;
- передача на хранение в базу данных ключевых слов сервера ключевых слов ключевых слов, указанных авторами, вместе со ссылками на первоисточники;
- формирование кластеров ключевых слов для каждого автора на сервере ключевых слов и установление связи между авторами через ключевые слова, указанные в публикациях этих авторов;
- статистический и графовый анализ отобранных ключевых слов;
- поступление в базу данных экспертов из сервера парсинга информации об авторах;
- построение первичного графа знаний на сервере построения графа знаний на основе выявленных взаимосвязей ключевых слов и с использованием технологий статистического и графового анализа, при этом вершинами первичного графа знаний являются основное и дополнительное ключевые слова;
- отправка полученного первичного графа знаний на хранение в базу данных ключевых слов;
- форматирование данных о первичном графе знаний в один из графических форматов и отображение на мониторе визуализации графа знаний;
- направление сервером управления поисковыми роботами списка авторов, хранящегося в базе данных экспертов, в библиографические базы данных сети Интернет;
- формирование списка экспертов на основании индексов активности авторов, найденных поисковыми роботами в библиографических базах данных сети Интернет.
При этом основное, дополнительное и служебные ключевые слова могут быть определены на основании эмпирических правил, которые хранятся в базе данных эмпирических правил.
Основное ключевое слово может определять исследуемую технологию, дополнительное ключевое слово - область применения этой технологии, а служебные ключевые слова могут способствовать повышению релевантности списков найденных публикаций.
При этом служебными словами могут быть pdf и «ключевые слова» или doc и фраза «ключевые слова».
Если первоначально заданное основное ключевое слово не соответствует критерию «Сообщество», может проводиться поиск более общего понятия в соответствии с эмпирически заданным правилом посредством поиска публикаций в сети Интернет и информации в публичных базах данных.
Дополнительно эмпирически заданным правилом определения основного ключевого слова может быть:
- наличие в публикациях, размещенных в публичных базах данных, разделов, в которых основной темой является заданное ключевое слово;
- сравнение указанных авторами списков ключевых слов в разделах «Ключевые слова» с терминами, используемыми в текстах публикаций, размещенных в публичных базах данных;
- определение терминов, выделенных авторами специальными метками в текстах публикаций, размещенных в публичных базах данных. При этом специальными метками могут быть: подчеркивание текста, выделение текста курсивом, выделение текста жирным шрифтом, выделение текста заглавными буквами.
Дополнительно поиск статей из диссертационных работ авторов может осуществляться в следующем порядке:
- по основному и дополнительному ключевым словам находят диссертации, размещенные в базе данных диссертаций,
- получают электронные копии диссертаций,
- с использованием парсинга извлекают названия статей для каждого автора,
- по названиям статей проводят их поиск в базах публичных данных,
- получают электронные копии найденных статей.
При этом, если фамилия автора диссертации не совпадает с фамилией автора статьи, то такая статья отбирается в базу данных первоисточников, при этом в базе данных обе фамилии помечаются, как принадлежащие одному автору.
Дополнительно каждому ключевому слову, указанному автором в первоисточнике, присваивается весовой коэффициент, равный обратной величине порядкового номера ключевого слова в списке ключевых слов автора первоисточника, причем для каждого ключевого слова может рассчитываться его вес, равный сумме весовых коэффициентов общего числа упоминаний этого ключевого слова всеми авторами.
Для получения электронных копий первоисточников публикаций, размещенных в публичных базах данных, может производиться оплата посредством сервера оплаты электронной копии публикации или продления подписки, выполненного с возможностью автоматического пополнения денежных средств.
Дополнительно площадь узлов графа знаний может быть пропорциональна весам ключевых слов.
Дополнительно ветви графа знаний могут быть окрашены в различные цвета.
Дополнительно все узлы графа знаний могут иметь гиперссылки на список авторов, указавших ключевые слова данного графа знаний в первоисточниках.
Дополнительно взаимное размещение узлов графа знаний может коррелироваться с использованием технологий машинного обучения.
Дополнительно может быть определена характеристика активности автора нечетким множеством, состоящим из численных показателей индексов Хирши, количества патентов автора, его участие в публичных мероприятиях в предметной области по заданному основному ключевому слову. При этом системой для определения численных показателей индексов Хирши является РИНЦ, или SCOPUS, или Web of Science, или Google Scholar, а публичным мероприятием может быть конференция, съезд, семинар, форум.
В случае если отдельное ключевое слово, входящее в структуру первичного графа знаний, соответствует критерию «Сообщество», оно становится ключевым словом второго уровня, для которого может быть построен вторичный граф знаний, доступ к которому возможен по гиперссылке из первичного графа знаний.
Дополнительно по каждому входящему в состав графа знаний (первичному или вторичному) ключевому слову может быть проведена проверка на наличие патентов, для чего в базах данных патентов отбираются патенты, соответствующие основному ключевому слову и входящим в состав графа знаний ключевым словам.
Дополнительно граф знаний (первичный или вторичный) выполнен с возможностью корректировки с использованием технологий машинного обучения на сервере машинного обучения.
Таким образом, технический результат обеспечивается в настоящем изобретении посредством способа и системы автоматизированного описания онтологии предметной области и формирования экспертного сообщества по заданной тематике и эмпирически заданных правил ее работы, позволяющих с использованием автоматических программных роботов распознать в публикуемых материалах выделенные авторами ключевые слова и объединить их в кластеры с последующим построением графа знаний.
Краткое описание чертежей.
На фиг.1 представлена схема системы, пригодной для осуществления заявленного технического решения.
На фиг.2 представлена последовательность выполнения операций по заявленному способу поиска информации.
На фиг.3 представлена последовательность выполнения операций по извлечению ключевых слов из указанных в диссертациях статей.
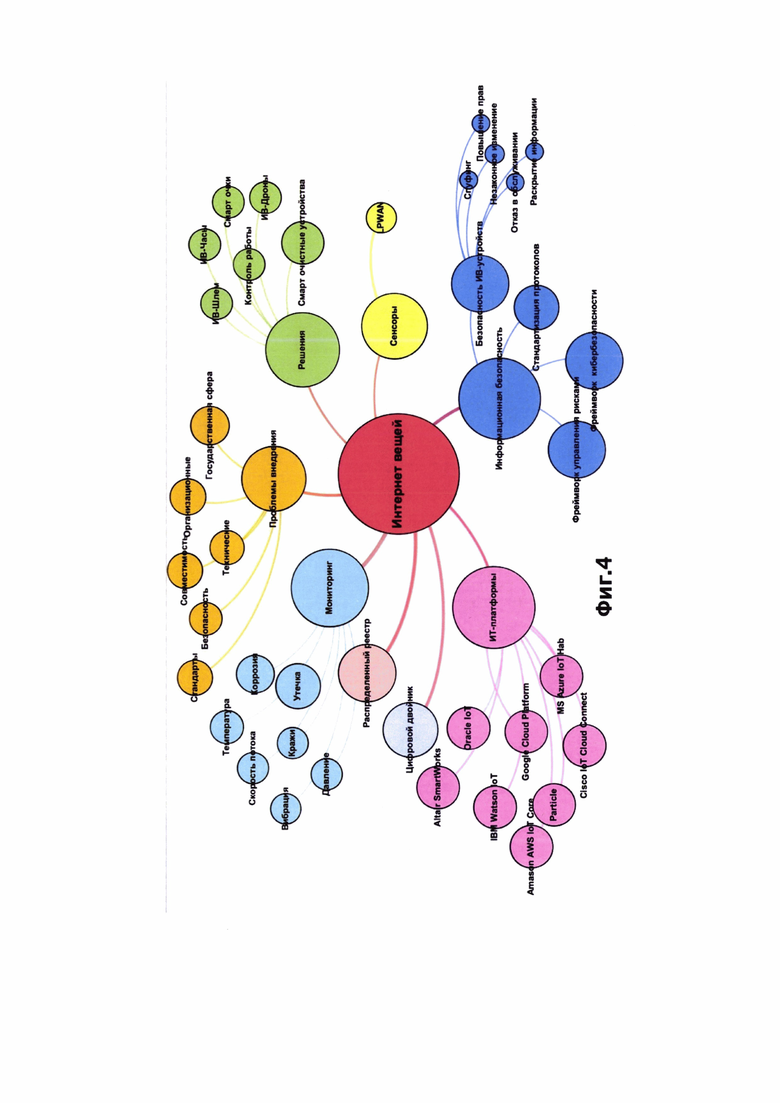
На фиг.4 представлен вариант визуализации предметной области первого уровня по ключевым словам «интернет вещей» и «трубопроводный транспорт нефти».
На фиг.5 представлен вариант визуализации предметной области второго уровня по ключевым словам «информационная безопасность» и «устройства интернет вещей».
Заявленная система включает в себя (фиг.1) компьютер оператора ситуационного центра (101), компьютер эксперта по машинному обучению (102), монитор визуализации графа знаний (103), сервер оплаты электронной копии публикации или продления подписки (106), сервер управления поисковыми роботами (107), сервер машинного обучения (108), сервер хранения первоисточников (109), сервер парсинга (110), сервер ключевых слов (111), сервер построения графа знаний (112), публичные базы данных, база данных эмпирических правил (116), база данных первоисточников (117), база данных ключевых слов (118), база данных экспертов (119). Причем публичными базами данных могут быть базы данных книг (113), базы данных статей (114), базы данных патентов (115), базы данных диссертаций (120), базы данных, размещенные на отдельных сайтах сети Интернет (121), и, при необходимости, иные базы данных. При этом база данных эмпирических правил и сервер машинного обучения выполнены с возможностью хранения и пополнения эмпирических правил.
Все устройства объединены в коммуникационную сеть с использованием локальной сети (104) и сети Интернет (105).
Система поиска информации позволяет производить выборку материалов из баз данных по оригинальной схеме с использованием эмпирических правил, анализировать тексты из выбранных материалов с целью выявления значимых структурных элементов (ключевых слов), устанавливать взаимосвязи между элементами, строить и корректировать граф знаний с использованием технологии машинного обучения, автоматизировать описание (построение) онтологии предметной области, визуализировать граф знаний, формировать списки экспертов на основе отобранных значимых материалов.
В контексте настоящей заявки под «сервером» подразумевают компьютерную программу, работающую на соответствующем оборудовании. Оборудование может представлять собой, например, один физический компьютер или одну физическую компьютерную систему.
В контексте настоящей заявки под «базой данных» подразумевают любой структурированный набор данных. При этом публичные базы данных могут быть как специализированными, такими как, например, Amazon, Litres (книги), cyberleninka, eLIBRARY, deepdyve (статьи), disserCat (диссертации), fips (патенты), так и предоставляемые поисковыми системами, например, Яндексом или Google.
В контексте настоящей заявки под первоисточниками статей, книг, диссертаций, патентов, материалов конференций и других материалов/документов подразумеваются их электронные копии.
В контексте настоящей заявки анализируемый «текст» представляет собой последовательность знаков, букв или цифр, каждый из которых представляет собой некую «картинку». Очевидно, что «картинка» является материальным объектом, а, следовательно, «текст», как совокупность «картинок» также является материальным объектом. При этом под анализом текстов подразумевается проведение различных манипуляций с текстом как материальным объектом, таких как разбиение на части, сравнение фрагментов текста с заданным эталоном, выделение фрагментов текста из первоисточника, хранение обработанных текстов.
В контексте настоящей заявки «авторы» и «эксперты» имеют равное значение. Тот или иной термин в описании используется в зависимости от контекста.
В контексте настоящей заявки под выборкой материалов (документов) из баз данных по оригинальной схеме подразумевается использование эмпирических правил отбора материалов, хранящихся в базе данных эмпирических правил (116) и периодически пополняемых в процессе машинного обучения на сервере машинного обучения (108). Примером эмпирического правила является, например, выбор ключевых слов. Так, в частности, для выбора оригинальных статей в сети Интернет используется триада ключевых слов, состоящая из основного ключевого слова и двух служебных, позволяющих при использовании поисковых систем получить в списке выдачи по запросу статьи только по заданной тематике, например, «разлив нефти» (основное ключевое слово) и (and) служебные ключевые слова pdf и «ключевые слова». В силу установленных правил и стандарта ГОСТ Р 7.0.7-2021, все публикуемые статьи содержат раздел «ключевые слова», а статьи, как правило, выкладываются в формате PDF; таким образом, удается отсечь в выборке все материалы, не являющиеся статьями. Используемый прием позволяет получить из сети Интернет материалы с низким индексом цитирования, которые, в силу алгоритмов работы поисковых систем, могут не попадать в список выдачи по запросу из-за установленных вендорами ограничений. Все эмпирические приемы и правила хранятся в базе данных, используются в заданной последовательности, дополняются и совершенствуются с использованием технологии машинного обучения.
В контексте настоящей заявки поисковые роботы представляют собой автоматизированные программные роботы, включающие в себя цепочки эмпирически найденных правил поиска информации.
В контексте настоящей заявки корректировка графа знаний с использованием технологии машинного обучения проводится на основе комплекса формальных и неформальных методов машинного обучения с акцентом на «обучение с учителем». Дополнительно используются аналитические методы статистического и графового анализа.
В контексте настоящей заявки запрос, как правило, содержит основное и дополнительное ключевые слова. Основное ключевое слово выбирается в соответствии с эмпирически найденным критерием «Сообщество». Критерий «Сообщество» устанавливает, является ли выбранное ключевое слово основным (определяющим) для данной предметной области или оно входит в состав более общего понятия. Формальными параметрами для критерия «Сообщество» являются наличие проводимых конференций, интернет-форумов, учебных курсов, существование разделов патентных классификаторов, книг и монографий, где во всех перечисленных материалах основной темой является заданное ключевое слово. Положительным результатом считается хотя бы одно совпадение темы материалов с заданным ключевым словом. Если в результате анализа получен отрицательный результат, то проводится поиск более общего понятия, соответствующего указанным критериям.
Отрицательным также считается результат, когда выбранное в качестве основного ключевое слово имеет слишком широкое применение (используется в различных областях). В этом случае область поиска сужается и в качестве основного выбирается сочетание основного и дополнительного ключевых слов.
Дополнительные ключевые слова выбираются из ключевых слов, относящихся к области применения основного ключевого слова, а также служебных ключевых слов из базы данных эмпирических правил.
В контексте настоящей заявки автоматизация описания онтологии предметной области включает в себя процесс построения (и, при необходимости, коррекции) графа знаний, преобразование полученного графа знаний (в том числе, в результате коррекции) в формат графического файла визуализации графа знаний. В зависимости от выбранной программы визуализации такими форматами могут быть, например, csv для Neo4J, gephi для Gephi, graphml для yEd и другие форматы и программы визуализации.
В контексте настоящей заявки список экспертов формируется на основе эмпирических правил, статистического и графового анализа, позволяющих выявлять наиболее активных и влиятельных участников сообщества в выбранной предметной области. По результатам собранной информации строится таблица, в которой по каждому автору отображаются показатели его профессиональной активности: индексы Хирша (РИНЦ, SCOPUS, Web of Science, Google Scholar), количество патентов и конференций, в которых автор принял участие.
Заявленные система и способ реализуются следующим образом. Оператор ситуационного центра со своего компьютера (101) вводит поисковый запрос (фиг.2), содержащий основное и дополнительное ключевые слова. Основным ключевым словом является изучаемая технология, дополнительным ключевым словом является область ее применения. Запрос через коммуникационную сеть (104 или 105) поступает на сервер управления поисковыми роботами (107), который по заданному основному и дополнительному ключевым словам определяет несколько поисковых роботов. Роботы с полученным заданием проверки на соответствие основного ключевого слова критерию «Сообщество» направляются в публичные базы данных (113-115, 120, 121). Если хотя бы в одном из запросов найден положительный результат, проверка считается законченной и выбранное ключевое слово признается основным. В случае отрицательного результата проводится поиск более общего понятия. С этой целью обобщаются ключевые слова из найденных материалов, где первоначально заданное как основное ключевое слово входит в состав множества ключевых слов. Например, близкие по смыслу ключевые слова и синонимы определяются по эмпирическому правилу, включающему в себя сравнение указанного автором списка ключевых слов в разделе «Ключевые слова» с используемыми терминами в тексте самой публикации. Затем по результатам статистического анализа выбирается более общее понятие (ключевое слово). Например, был задан запрос, состоящий из основного ключевого слова «адсорбент» и дополнительного ключевого слова «ликвидация разливов нефти». Проверка по критерию «Сообщество» показала, что основное ключевое слово «адсорбент» в сочетании с дополнительным ключевым словом «ликвидация разливов нефти» не соответствует критерию «Сообщество». Анализ перечней ключевых слов материалов/публикаций, включающих в себя заданные основное и дополнительное ключевые слова, показал, что основным ключевым словом в данном случае является «технологии ликвидации разливов нефти». Онтология более общих понятий представляет для ситуационных центров не менее полезную информацию, так как содержит в себе более широкое описание проблемы, включая альтернативные технологии.
Далее, определив основное и дополнительное ключевые слова, сервер управления поисковыми роботами (107) формирует задания поисковым роботам. При этом для поиска публикаций в сети Интернет сервер управления поисковыми роботами (107) формирует четыре ключевые слова: основное ключевое слово («технология»), дополнительное ключевое слово («область применения») и два служебных ключевых слова pdf или doc и фразу «ключевые слова». Такое сочетание ключевых слов позволяет найти более полную выборку ссылок на публикации в поисковых системах. Одновременно с поиском публикаций в сети Интернет с использованием поисковых систем, поисковые роботы направляются в специализированные базы данных, каковыми являются cyberleninka, eLIBRARY, SCOPUS, Google Scholar и другие. Во всех случаях запросы по ключевым словам проводятся как на русском, так и на английском языках.
В результате работы поисковых роботов формируется список ссылок на найденные публикации, который передается на сервер хранения первоисточников (109) для последующей обработки. Получив список ссылок, сервер хранения первоисточников (109) по этим ссылкам скачивает (получает) электронные копии публикаций и размещает их в базе данных первоисточников (117).
В отдельных случаях, чтобы получить электронную копию публикации, требуется оплата. Функция оплаты возложена на сервер оплаты электронной копии публикации или продления подписки (106), который работает с заранее определенными базами данных, имеющими функцию автоматического пополнения средств или продления подписки. Первоначальную регистрацию и первичный платеж проводит организация, эксплуатирующая заявленную систему.
Сервер хранения первоисточников (109) сортирует и анализирует полученные первоисточники публикаций по названию и удаляет одни и те же публикации, полученные из разных источников.
Для примера на фиг.3 показана последовательность выполнения операций по извлечению ключевых слов из статей, указанных в диссертациях и размещенных в базах данных диссертаций. С целью поиска статей сервер управления поисковыми роботами (107) формирует задание из основного и дополнительного ключевых слов и направляет поисковые роботы в базы данных диссертаций
Найденные соответствующие ключевым словам диссертации или их рефераты скачиваются и размещаются в базе данных первоисточников (117). Затем сервер парсинга (110) последовательно получает из базы данных первоисточников (117) тексты рефератов диссертаций и извлекает из них список публикаций автора. После этого список передается на сервер управления поисковыми роботами (107) для поиска первоисточников статей и патентов, найденных в рефератах диссертаций. Одним из эмпирических правил парсинга рефератов диссертаций является следующее: «Если в списке работ фамилия автора не совпадает с фамилией автора диссертации, то ссылки на такие работы также извлекаются, а к фамилии автора диссертации добавляется вторая указанная в статье фамилия». Подобные случаи встречаются довольно часто с авторами-женщинами, меняющими в процессе работы над диссертацией фамилию при изменении семейного положения.
Далее сервер управления поисковыми роботами (107) по полученным названиям статей и патентов, найденных в рефератах диссертаций публикаций, находит ссылки на полнотекстовые материалы и передает эту информацию серверу хранения первоисточников (109) для скачивания электронных копий первоисточников.
Первоисточники, собранные в соответствии со схемами, представленными на фиг.2 и фиг.3, направляются на сервер парсинга (110). Сервер парсинга (110) в каждой статье находит фрагмент текста «ключевые слова», выделяет указанные автором ключевые слова, и передает их в базу данных ключевых слов (118) сервера ключевых слов (111). Найденные по результатам работы сервера парсинга (110) авторские ключевые слова хранятся в базе данных ключевых слов (118) вместе со ссылками на первоисточники. Сервер ключевых слов (111) формирует кластер ключевых слов для каждого автора и устанавливает связи между авторами через ключевые слова, указанные в публикациях этих авторов. Каждому ключевому слову автора первоисточника (статьи, книги, патента, иной публикации) присваивается определенный весовой коэффициент, определяющийся как обратная величина порядковому номеру упоминания ключевого слова автором. Например, первое слово в списке имеет весовой коэффициент 1, второе слово 1/2, третье 1/3, и т.д.
Далее сервер парсинга (110) выделяет в текстах первоисточников фамилии и имена авторов и размещает их в базе данных экспертов (119).
После этого сервер построения графа знаний (112) строит иерархический граф знаний (первичный), получая данные о ключевых словах, статистики их использования с учетом весовых коэффициентов и взаимосвязей через авторов статей. Вершиной графа знаний являются основное и дополнительное ключевые слова. Полученный граф знаний хранится в базе данных ключевых слов (118) и может корректироваться с использованием технологий машинного обучения на сервере машинного обучения (108).
Данные о графе знаний форматируются в один из графических форматов и отображаются (например, как на фиг.4) на мониторе визуализации графа знаний (103), при этом площадь узлов графа знаний может быть, например, пропорциональна весам (весовым коэффициентам) ключевых слов, а ветви графа знаний могут быть окрашены в различные цвета. Все отображаемые вершины графа знаний имеют гиперссылки на списки материалов, содержащих заданное ключевое слово.
Отдельные ключевые слова, входящие в структуру первичного графа знаний, могут также соответствовать критерию «Сообщество». В этом случае весь цикл работ по схеме, приведенной на фиг.2 (или фиг.3), повторяется в отношении ключевых слов второго уровня и строится вторичный граф знаний (пример показан на фиг.5), доступ к которому возможен по гиперссылке из первичного графа знаний.
На завершающем этапе проводится сбор информации об активности авторов. Для этого в соответствии со списком авторов из базы данных экспертов (119) сервер управления поисковыми роботами (107) отправляет запросы в библиографические базы данных, например, РИНЦ, SCOPUS, Web of Science, Google Scholar, где указаны наукометрические показатели и индексы активности автора. Из полученных данных формируется список (например, в виде таблицы) активности авторов (Таблица 1). Дополнительно в этой таблице может указываться количество патентов автора, участие в конференциях и его место работы.
По каждому входящему в состав графа знаний ключевому слову также может осуществляться проверка на наличие патентов. С этой целью в базах данных патентов отбираются патенты, соответствующие основному ключевому слову и входящим в состав графа знаний ключевым словам (Таблица 2).
Пример осуществления изобретения
Перед ситуационным центром поставлена задача поиска информации с последующим построением онтологической модели с целью оперативного формирования группы экспертов и организации обсуждения проблемы использования устройств интернета вещей (Internet of Things, IoT) в трубопроводном транспорте нефти (Oil Pipeline).
В данном случае основным ключевым словом является «интернет вещей» (Internet of Things), а дополнительным - «трубопроводный транспорт нефти» (Oil Pipelines).
Проверка основного ключевого слова «интернет вещей» на соответствие критерию «Сообщество» показала, что оно является слишком общим понятием для целей проводимого исследования. В соответствии с заданными эмпирическими правилами для проверки на соответствие критерию «Сообщество» диапазон поиска был сужен за счет использования дополнительного ключевого слова «трубопроводный транспорт нефти». Проверка показала положительный результат на соответствие указанному критерию. В частности, автоматические поисковые роботы обнаружили нижеприведенные материалы.
Книги и монографии:
R.F. Hussain, A. Mokhtari, A. Ghalambor, М.A. Salehi. IoT for Smart Operations in the Oil and Gas Industry from Upstream to Downstream. Gulf Professional Publishing. 2022.
Учебные курсы:
1. Учебная дисциплина: «Интернет вещей» в Российском государственном университете нефти и газа имени И.М. Губкина
2. ITU Training on Building IoT solutions for e-applications. Internet of Things and the Future of Oil & Gas Industry. IoT Academia of Iran.
Компании:
1. Транснефть. Автоматизированная система коммерческого учета электроэнергии (АИИС КУЭ), собирающая данные удаленно. Автоматизированная система технического учета электроэнергии (АСТУЭ).
2. Группа компаний Цифра. Платформа Zyfra Industrial IoT Platform Oil&Gas.
3. AO «ЭР-ТЕЛЕКОМ ХОЛДИНГ. АСУ ТП upstream. Конференции:
1. 8th Annual IoT in Oil & Gas Conference, 12-13 September, Houston, USA.
2. The Oil and Gas IoT Summit 2023, 24-25 May - Lisbon, Portugal.
3. The Internet of Things for the Oil and Gas Industry, 19 June 2017, PTAC Conference Room, Calgary, Canada.
Всего в публичных базах данных было найдено более десятка конференций. Наличие конференций по исследуемой тематике явным образом указывает на существование профессионального сообщества в предметной области.
В соответствии с установленными эмпирическими правилами выбранные ключевые слова удовлетворяют критерию «Сообщество» по трем показателям: книги, учебные курсы и проводимые конференции.
Анализ близких по смыслу слов выявил два новых для поиска ключевых слова: «промышленный интернет вещей» (Industrial IoT) и «транспортировка нефти и газа» (Midstream). Эти ключевые слова использовались для расширения диапазона поиска.
По основному, дополнительному и служебным ключевым словам на русском языке («интернет вещей», «трубопроводный транспорт нефти», «ключевые слова», pdf), а также по их аналогам на английском языке было отобрано 127 статей.
Последующий парсинг статей с выделением авторских ключевых слов, их статистический и графовый анализ позволили построить и визуализировать первый уровень онтологии предметной области (фиг.4).
Затем по всем найденным ключевым словам в сочетании с основным и дополнительным ключевыми словами был проведен патентный анализ. Наибольшее число патентов было зафиксировано по ключевому слову «сенсор» («Sensor»). Фрагмент списка патентов приведен в Таблице 2.
Далее была проведена проверка всех найденных ключевых слов на соответствие критерию «Сообщество». Было установлено, что несколько ключевых слов соответствует этому критерию. По всем найденным соответствующим критерию «Сообщество» ключевым словам были построены вторичные графы знаний, переход к которым осуществлялся по гиперссылке из первичного графа знаний. На фиг.5 приведен пример вторичного графа знаний, построенного по ключевым словам «IoT» и «Device Cybersecurity».
По всем найденным авторам статей, книг, патентов и участникам профильных конференций проводился сбор информации об их активности, для чего использовались базы данных eLIBRARY, SCOPUS, Google Scholar, патентные базы данных, а также ранее полученные материалы конференций. Фрагмент таблицы активности авторов в предметной области «интернет вещей в трубопроводном транспорте нефти» показан в Таблице 1.
Интеграция информации по патентам позволила также определить список компаний-лидеров по числу патентов в области «интернет вещей» за последние 10 лет. В их число вошли Qualcomm Incorporated, Shenzhen Shenglu Iot Communication Technology, Chengdu Qinchuan Technology Development, Zte Corporation, Intel Corporation, Southeast University, Afero, Inc. и Shenzhen Shenglu Iot Communication Technology Co., Ltd.
Собранная и визуализированная информация позволила оперативно описать онтологическую модель предметной области, получить базовое представление о ее структуре и взаимосвязях входящих в ее состав технологий, сформировать группу из ведущих экспертов для дальнейшей работы.

| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ ИЗ РАЗЛИЧНЫХ БАЗ ДАННЫХ | 2006 |
|
RU2305314C1 |
| СПОСОБ ПРОВЕРКИ НАУЧНЫХ РАБОТ ОГРАНИЧЕННОГО РАСПРОСТРАНЕНИЯ НА ПЛАГИАТ | 2021 |
|
RU2774100C1 |
| УНИВЕРСАЛЬНАЯ СИСТЕМА МНОГОФУНКЦИОНАЛЬНОЙ КОММУНИКАЦИИ С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ И СЕРВИСНЫХ СЛУЖБ | 2010 |
|
RU2451992C2 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| СПОСОБ И СИСТЕМА КОМПЬЮТЕРНОЙ ОБРАБОТКИ ОДНОЙ ИЛИ НЕСКОЛЬКИХ ЦИТАТ В ЦИФРОВЫХ ТЕКСТАХ ДЛЯ ОПРЕДЕЛЕНИЯ ИХ АВТОРА | 2018 |
|
RU2711123C2 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| СПОСОБ ВВОДА И МНОГОУРОВНЕВОЙ ВЕРИФИКАЦИИ ИНТЕНСИВНО ПОСТУПАЮЩИХ ДАННЫХ В БОЛЬШИХ ИНФОРМАЦИОННО-АНАЛИТИЧЕСКИХ СИСТЕМАХ НАУКОМЕТРИЧЕСКОГО СОДЕРЖАНИЯ | 2020 |
|
RU2763458C1 |
| СПОСОБ ОТБОРА ИНФОРМАЦИИ В СЕТИ ИНТЕРНЕТ И ИСПОЛЬЗОВАНИЯ ЭТОЙ ИНФОРМАЦИИ В РАЗДЕЛЯЕМОМ ВЕБ-САЙТЕ И КОМПЬЮТЕРНЫЙ СЕРВЕР ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2009 |
|
RU2413278C1 |
| Способ и система автоматического создания тезауруса | 2016 |
|
RU2672393C2 |
| Способ и система определения параметра релевантность для элементов содержимого | 2018 |
|
RU2714594C1 |




Изобретение относится к системе и способу поиска информации. Технический результат заключается в повышении скорости и точности поиска информации. В способе выполняют ввод посредством компьютера оператора ситуационного центра поискового запроса, содержащего основное ключевое слово и дополнительное ключевое слово; поступление поискового запроса через коммуникационную сеть на сервер управления поисковыми роботами, который определяет несколько поисковых роботов для выполнения одновременного поиска публикаций в сети Интернет и в публичных базах данных; выполнение поисковыми роботами проверки соответствия основного ключевого слова на соответствие критерию «Сообщество» согласно эмпирически заданным правилам посредством поиска публикаций в сети Интернет и информации в публичных базах данных, при котором осуществляется проверка присутствия во всех найденных документах основного ключевого слова в основной теме опубликованного материала; формирование сервером управления поисковыми роботами в соответствии с эмпирическими правилами задания поисковым роботам, содержащего основное ключевое слово, дополнительное ключевое слово и два служебных ключевых слова, одно из которых определяет тип документа pdf или doc, а другое представляет собой фразу «ключевые слова» для осуществления поиска в публичных базах данных; формирование из публичных баз данных списка ссылок по результатам работы поисковых роботов; поступление списка ссылок на сервер хранения первоисточников, который запрашивает и получает электронные копии публикаций, размещенных в публичных базах данных, и размещает указанные электронные копии публикаций в базе данных первоисточников; проведение анализа первоисточников на сервере хранения первоисточников с целью исключения повторяющихся публикаций; проведение парсинга первоисточников на сервере парсинга, формирование списка авторов, извлечение из первоисточников ключевых слов, указанных авторами; передачу на хранение в базу данных ключевых слов сервера ключевых слов ключевых слов, указанных авторами, вместе со ссылками на первоисточники; формирование кластеров ключевых слов для каждого автора на сервере ключевых слов и установление связи между авторами через ключевые слова, указанные в публикациях этих авторов; статистический и графовый анализ отобранных ключевых слов; поступление в базу данных экспертов из сервера парсинга информации об авторах; построение первичного графа знаний на сервере построения графа знаний на основе выявленных взаимосвязей ключевых слов и с использованием технологий статистического и графового анализа, при этом вершинами первичного графа знаний являются основное и дополнительное ключевые слова; отправку полученного первичного графа знаний на хранение в базу данных ключевых слов; форматирование данных о первичном графе знаний в один из графических форматов и отображение на мониторе визуализации графа знаний; направление сервером управления поисковыми роботами списка авторов, хранящегося в базе данных экспертов, в библиографические базы данных сети Интернет; формирование списка экспертов на основании индексов активности авторов, найденных поисковыми роботами в библиографических базах данных сети Интернет. 2 н. и 27 з.п. ф-лы, 5 ил., 2 табл.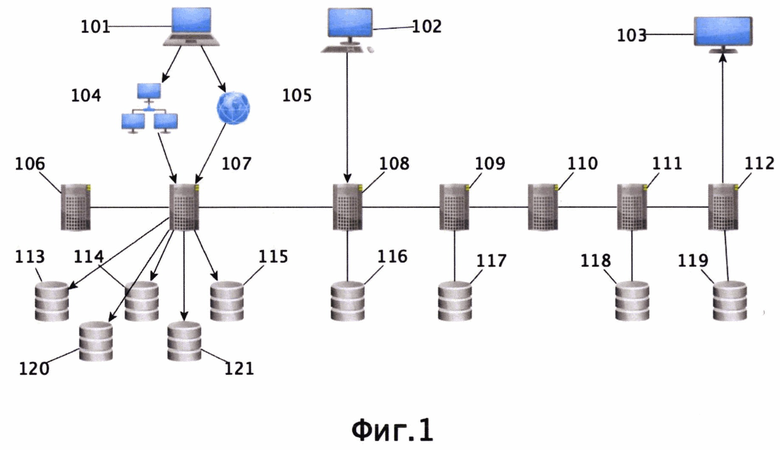
1. Система поиска информации, состоящая из
объединенных в коммуникационную сеть компьютеров, серверов и баз данных, отличающаяся тем, что
серверами являются сервер управления поисковыми роботами, сервер машинного обучения, сервер хранения первоисточников, сервер парсинга, сервер ключевых слов, сервер построения графа знаний, сервер оплаты электронной копии публикации или продления подписки,
базами данных являются публичные базы данных, база данных эмпирических правил, база данных первоисточников, база данных ключевых слов, база данных экспертов,
причем к серверу управления поисковыми роботами подключен компьютер оператора ситуационного центра, к серверу машинного обучения подключен компьютер эксперта по машинному обучению, к серверу построения графа знаний подключен монитор визуализации графа знаний, при этом
компьютер оператора ситуационного центра формирует поисковый запрос, содержащий основное ключевое слово и дополнительное ключевое слово,
сервер управления поисковыми роботами получает поисковый запрос через коммуникационную сеть, определяет несколько поисковых роботов для выполнения одновременного поиска публикаций в сети Интернет и в публичных базах данных, посредством которых осуществляет проверку соответствия основного ключевого слова на соответствие критерию «Сообщество» согласно эмпирически заданным правилам, осуществляя поиск публикаций в сети Интернет и информации в публичных базах данных, при котором выполняется проверка присутствия во всех найденных документах основного ключевого слова в основной теме опубликованного материала, формирует в соответствии с эмпирическими правилами задание поисковым роботам, содержащее основное ключевое слово, дополнительное ключевое слово и два служебных ключевых слова, одно из которых определяет тип документа pdf или doc, а другое представляет собой фразу «ключевые слова», для осуществления поиска в публичных базах данных, формирует список ссылок по результатам работы поисковых роботов из публичных баз данных, направляет список авторов, хранящийся в базе данных экспертов, в библиографические базы данных сети Интернет, и формирует список экспертов на основании индексов активности авторов, найденных поисковыми роботами в библиографических базах данных сети Интернет,
сервер хранения первоисточников получает сформированный список ссылок, запрашивает и получает электронные копии публикаций, размещенных в публичных базах данных, и размещает указанные электронные копии публикаций в базе данных первоисточников, выполняет анализ первоисточников для исключения повторяющихся публикаций,
сервер парсинга выполняет парсинг первоисточников, формирует список авторов, извлекает из первоисточников ключевые слова, указанные авторами, передает в базу данных экспертов информацию об авторах,
сервер ключевых слов сохраняет в базе данных ключевых слов полученные ключевые слова, указанные авторами, вместе со ссылками на первоисточники, формирует кластеры ключевых слов для каждого автора и устанавливает связи между авторами через ключевые слова, указанные в публикациях этих авторов,
сервер построения графа знаний выполняет построение первичного графа знаний на основе выявленных взаимосвязей ключевых слов и с использованием технологий статистического и графового анализа, при этом вершинами первичного графа знаний являются основное и дополнительное ключевые слова, передает полученный первичный граф знаний в базу данных ключевых слов, выполняет форматирование данных о первичном графе знаний в один из графических форматов и выполняет отображение на мониторе визуализации графа знаний.
2. Система по п. 1, отличающаяся тем, что коммуникационная сеть образована локальной сетью и сетью Интернет.
3. Система по п. 1, отличающаяся тем, что база данных эмпирических правил и сервер машинного обучения выполнены с возможностью хранения и пополнения эмпирических правил.
4. Система по п. 1, отличающаяся тем, что публичными базами данных являются базы данных книг, базы данных статей, базы данных патентов, базы данных диссертаций, базы данных, размещенные на отдельных сайтах сети Интернет.
5. Способ поиска информации, реализуемый системой по п. 1, включающий в себя:
- ввод посредством компьютера оператора ситуационного центра поискового запроса, содержащего основное ключевое слово и дополнительное ключевое слово;
- поступление поискового запроса через коммуникационную сеть на сервер управления поисковыми роботами, который определяет несколько поисковых роботов для выполнения одновременного поиска публикаций в сети Интернет и в публичных базах данных;
- выполнение поисковыми роботами проверки соответствия основного ключевого слова на соответствие критерию «Сообщество» согласно эмпирически заданным правилам посредством поиска публикаций в сети Интернет и информации в публичных базах данных, при котором осуществляется проверка присутствия во всех найденных документах основного ключевого слова в основной теме опубликованного материала;
- формирование сервером управления поисковыми роботами в соответствии с эмпирическими правилами задания поисковым роботам, содержащего основное ключевое слово, дополнительное ключевое слово и два служебных ключевых слова, одно из которых определяет тип документа pdf или doc, а другое представляет собой фразу «ключевые слова» для осуществления поиска в публичных базах данных;
- формирование из публичных баз данных списка ссылок по результатам работы поисковых роботов;
- поступление списка ссылок на сервер хранения первоисточников, который запрашивает и получает электронные копии публикаций, размещенных в публичных базах данных, и размещает указанные электронные копии публикаций в базе данных первоисточников;
- проведение анализа первоисточников на сервере хранения первоисточников с целью исключения повторяющихся публикаций;
- проведение парсинга первоисточников на сервере парсинга, формирование списка авторов, извлечение из первоисточников ключевых слов, указанных авторами;
- передачу на хранение в базу данных ключевых слов сервера ключевых слов ключевых слов, указанных авторами, вместе со ссылками на первоисточники;
- формирование кластеров ключевых слов для каждого автора на сервере ключевых слов и установление связи между авторами через ключевые слова, указанные в публикациях этих авторов;
- статистический и графовый анализ отобранных ключевых слов;
- поступление в базу данных экспертов из сервера парсинга информации об авторах;
- построение первичного графа знаний на сервере построения графа знаний на основе выявленных взаимосвязей ключевых слов и с использованием технологий статистического и графового анализа, при этом вершинами первичного графа знаний являются основное и дополнительное ключевые слова;
- отправку полученного первичного графа знаний на хранение в базу данных ключевых слов;
- форматирование данных о первичном графе знаний в один из графических форматов и отображение на мониторе визуализации графа знаний;
- направление сервером управления поисковыми роботами списка авторов, хранящегося в базе данных экспертов, в библиографические базы данных сети Интернет;
- формирование списка экспертов на основании индексов активности авторов, найденных поисковыми роботами в библиографических базах данных сети Интернет.
6. Способ по п. 5, отличающийся тем, что основное, дополнительное и служебные ключевые слова определяют на основании эмпирических правил, которые хранятся в базе данных эмпирических правил.
7. Способ по п. 6, отличающийся тем, что основное ключевое слово определяет исследуемую технологию, дополнительное ключевое слово определяет область применения этой технологии, а служебные ключевые слова способствуют повышению релевантности списков найденных публикаций.
8. Способ по п. 7, отличающийся тем, что служебными словами являются pdf и фраза «ключевые слова».
9. Способ по п. 7, отличающийся тем, что служебными словами являются doc и фраза «ключевые слова».
10. Способ по п. 5, отличающийся тем, что, в случае если первоначально заданное основное ключевое слово не соответствует критерию «Сообщество», проводится поиск более общего понятия в соответствии с эмпирически заданным правилом посредством поиска публикаций в сети Интернет и информации в публичных базах данных.
11. Способ по п. 10, отличающийся тем, что эмпирически заданным правилом определения основного ключевого слова является наличие в публикациях, размещенных в публичных базах данных, разделов, в которых основной темой является заданное ключевое слово.
12. Способ по п. 10, отличающийся тем, что эмпирически заданным правилом определения основного ключевого слова и его близких по смыслу синонимов является сравнение указанных авторами списков ключевых слов в разделах «Ключевые слова» с терминами, используемыми в текстах публикаций, размещенных в публичных базах данных.
13. Способ по п. 10, в котором эмпирически заданным правилом определения основного ключевого слова является определение терминов, выделенных авторами специальными метками в текстах публикаций, размещенных в публичных базах данных.
14. Способ по п. 13, отличающийся тем, что специальными метками являются подчеркивание текста, выделение текста курсивом, выделение текста жирным шрифтом, выделение текста заглавными буквами.
15. Способ по п. 5, отличающийся тем, что поиск статей из диссертационных работ авторов проводится в следующем порядке:
- по основному и дополнительному ключевым словам находят диссертации, размещенные в базе данных диссертаций,
- получают электронные копии диссертаций,
- с использованием парсинга извлекают названия статей для каждого автора,
- по названиям статей проводят их поиск в базах публичных данных,
- получают электронные копии найденных статей.
16. Способ по п. 15, отличающийся тем, что, в случае если фамилия автора диссертации не совпадает с фамилией автора статьи, такая статья отбирается в базу данных первоисточников, при этом в базе данных обе фамилии помечаются как принадлежащие одному автору.
17. Способ по п. 5, отличающийся тем, что каждому ключевому слову, указанному автором в первоисточнике, присваивается весовой коэффициент, равный обратной величине порядкового номера ключевого слова в списке ключевых слов автора первоисточника.
18. Способ по п. 17, в котором для каждого ключевого слова рассчитывается его вес, равный сумме весовых коэффициентов общего числа упоминаний этого ключевого слова всеми авторами.
19. Способ по п. 5, отличающийся тем, что для получения электронных копий первоисточников публикаций, размещенных в публичных базах данных, производят оплату посредством сервера оплаты электронной копии публикации или продления подписки, выполненного с возможностью автоматического пополнения денежных средств.
20. Способ по п. 18, отличающийся тем, что площадь узлов графа знаний пропорциональна весам ключевых слов.
21. Способ по п. 5, отличающийся тем, что ветви графа знаний окрашены в различные цвета.
22. Способ по п. 5, отличающийся тем, что все узлы графа знаний имеют гиперссылки на список авторов, указавших ключевые слова данного графа знаний в первоисточниках.
23. Способ по п. 5, отличающийся тем, что взаимное размещение узлов графа знаний коррелируется с использованием технологий машинного обучения.
24. Способ по п. 5, отличающийся тем, что определяется характеристика активности автора нечетким множеством, состоящим из численных показателей индексов Хирши, количества патентов автора, его участие в публичных мероприятиях в предметной области по заданному основному ключевому слову.
25. Способ по п. 24, отличающийся тем, что системой для определения численных показателей индексов Хирши является РИНЦ, или SCOPUS, или Web of Science, или Google Scholar.
26. Способ по п. 24, отличающийся тем, что публичным мероприятием является конференция, съезд, семинар, форум.
27. Способ по п. 5, отличающийся тем, что, в случае если отдельное ключевое слово, входящее в структуру первичного графа знаний, соответствует критерию «Сообщество», оно становится ключевым словом второго уровня, для которого строится вторичный граф знаний, доступ к которому возможен по гиперссылке из первичного графа знаний.
28. Способ по п. 5 или 27, отличающийся тем, что по каждому входящему в состав графа знаний ключевому слову проводится проверка на наличие патентов, для чего в базах данных патентов отбираются патенты, соответствующие основному ключевому слову и входящим в состав графа знаний ключевым словам.
29. Способ по п. 5 или 27, отличающийся тем, что граф знаний выполнен с возможностью корректировки с использованием технологий машинного обучения на сервере машинного обучения.

