ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[001] Изобретение относится к способам и серверам для автоматического создания тезауруса.
УРОВЕНЬ ТЕХНИКИ
[002] С повышающимся количеством данных, хранящихся на различных серверах, задача эффективного получения информации становится еще более важной. Например, в сети Интернет присутствуют миллионы ресурсов и множество поисковых систем (например, GOOGLE, YAHOO!, YANDEX, BAIDU и так далее), которые предоставляют пользователям удобные инструменты поиска релевантной информации, которая соответствует поисковому намерению пользователя.
[003] Обычно сервер поисковой системы выполняет функцию поискового робота. Конкретнее, поисковая система выполняет функцию робота, который «посещает» различные ресурсы, доступные в Интернете и индексирует их содержимое. Конкретные алгоритмы и программы поисковых роботов могут быть различны, но на высшем уровне основной задачей поискового робота является: идентифицировать конкретный ресурс в Интернете, идентифицировать ключевые темы, связанные с конкретным ресурсом (темы представлены ключевыми словами и тому подобным), и индексировать ключевые темы по отношению к конкретному ресурсу.
[004] После того как поисковая система получает поисковый запрос от пользователя, она идентифицирует все просмотренные ресурсы, которые потенциально релевантны поисковому запросу пользователя. Поисковая система далее выполняет поисковое ранжирование для ранжирования идентифицированных потенциальных релевантных ресурсов. Ключевой задачей поискового ранжирования является организация идентифицированных результатов поиска путем расположения потенциально наиболее релевантных результатов в верхней части списка результатов поиска.
[005] Обычный поисковый запрос включает в себя строку слов, введенную пользователем. Тем не менее, пользователи часто не могут выбрать эффективные термины при вводе строки слов. Например, гурман, увлекающийся английской кухней, который желает расширить свои кулинарные познания, может ввести "японский гастропаб в Монреале", и при этом основная часть релевантных страниц была проиндексирована с помощью терминов "изакая", а не "гастропаб". Таким образом, документы, которые удовлетворяют информационным запросам пользователя, могут находиться по терминам, отличным от терминов, которые используются пользователем.
[006] В общем случае, существует несколько типов компьютерных подходов для модификации/расширения поисковых терминов с целью удовлетворения поискового намерения пользователя. Например, простой подход к использованию заранее созданной семантической базы данных, например, базы данных тезауруса. Тем не менее, создание базы данных тезауруса стоит дорого, занимает продолжительное время и, как правило, ограничивается одним языком.
[007] Патентная публикация US 7890521 (опубликовано 15 февраля 2011 г.) описывает систему, которая автоматически создает синонимы для слов из документов. Во время выполнения операции, эта система определяет частоту совместного вхождения пар слов в документах. Система также определяет оценку близости пар слов в документах, причем оценка близости указывает, расположена ли пара слов так близко друг к другу, что слова вероятно встречаются в одних и тех же предложениях или фразах. Наконец, система определяет, является ли пара слов синонимами на основе определенных частот совместного вхождения и определенных оценок близости. При этом определении, система может дополнительно учитывать корреляцию между словами в заголовке или якорем документа и словами в документе, а также оценки словоформы для пар слов в документах.
[008] Патентная публикация US 9158841 (опубликовано 13 октября 2015 г.) описывает способ оценки семантических различий между первым элементом в первом семантическом пространстве и вторым элементом во втором семантическом пространстве. Способ включает в себя: вычисление первого упорядоченного списка N ближайших соседей первого элемента в первом семантическом пространстве; вычисление второго упорядоченного списка N ближайших соседей второго элемента во втором семантическом пространстве; и вычисление множества показателей сходства между первыми n ближайшими соседями первого элемента и первыми n ближайшими соседями второго элемента, где n и N являются положительными целыми числами и n больше или равно 1, а также n меньше или равно N.
[009] Патентная публикация US 2015046152 (опубликовано 12 февраля 2015 г.) описывает способ создания набора концептуальных блоков, причем концептуальные блоки являются словами в корпусе документов, которые могут быть обработаны для выявления трендов, построения эффективного инвертированного индекса или создания краткого отчета по содержимому. Способ охватывает создание множества целевых слов из корпуса, определение строк контекста для целевых слов, получение типов паттерна, основанных на множестве слов и позиций слов в отношении целевых слов, и назначение весовых коэффициентов для каждой строки контекста, обладающей конкретным типом паттерна. Целевые слова далее выражаются как векторы, которые отражают весовые коэффициенты контекстных строк. Векторы сравниваются и группируются в кластеры на основе сходства. Целевые слова в получившихся кластерах являются концептуальными блоками. Подгруппа кластеров может быть выбрана для другой итерации процесса для поиска новых концептуальных блоков.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0010] Настоящее техническое решение может уменьшить по меньшей мере некоторые недостатки, присущие текущему уровню техники, в отношении автоматического создания тезауруса. Прежде всего настоящее решение решает задачу создания тезауруса, соответственно одним из технических результатов настоящего решения является достижение заявленного назначения решения.
[0011] Первым объектом настоящего технического решения является способ автоматического создания цифрового тезауруса. Способ выполняется на сервере, который соединен с базой данных семантических отношений. Способ включает в себя: получение сервером указания на цифровой текст; синтаксический анализ (парсинг) сервером цифрового текста и определение первого лексического элемента и второго лексического элемента; для каждой записи первого лексического элемента и второго лексического элемента: выбор сервером n-ного количества последовательных элементов, соседних с первым лексическим элементом; создание сервером первого контекстного параметра для первого лексического элемента, первый контекстный параметр включает в себя указание на каждый элемент из n-ного числа последовательных элементов и частоту совместных вхождений каждого элемента и первого лексического элемента в цифровом тексте; для каждой записи второго лексического элемента в цифровом тексте: выбор сервером n-ного количества последовательных элементов, соседних со вторым лексическим элементом; создание сервером второго контекстного параметра для второго лексического элемента, второй контекстный параметр включает в себя указание на каждый элемент из n-ного числа последовательных элементов и частоту совместных вхождений каждого элемента и второго лексического элемента в цифровом тексте; определение сервером параметра связи лексических элементов для первого лексического элемента и второго лексического элемента, параметр связи лексических элементов указывает на семантическую связь между первым лексическим элементом и вторым лексическим элементом, параметр связи лексических элементов определяется следующим образом: анализ взаимосвязи первого контекстного параметра и второго контекстного параметра; анализ совместного вхождения записей первого лексического элемента и второго лексического элемента в цифровом тексте; сохранение сервером параметра связи лексических элементов в базе данных семантических отношений.
[0012] В некоторых вариантах осуществления способа, указание на цифровой текст получают из базы данных, содержащей по меньшей мере один цифровой обучающий документ.
[0013] В некоторых вариантах осуществления способа, способ далее включает в себя присваивание грамматического типа каждому слову в цифровом тексте до определения первого лексического элемента и второго лексического элемента.
[0014] В некоторых вариантах осуществления способа, лексический элемент представляет собой одно из: слово, которое определено на основе его соответствующего грамматического типа; и фразу, которая является группой из двух или более слов, определенных на основе соответствующего грамматического типа одного из двух или более слов.
[0015] В некоторых вариантах осуществления способа, способ далее включает в себя лемматизацию первого и второго лексических элементов и слов цифрового текста до определения частоты совместного вхождения.
[0016] В некоторых вариантах осуществления способа, n-ное число последовательных элементов представляет собой по меньшей мере одно из: последовательные предшествующие, последовательные следующие или последовательные предшествующие и последовательные следующие элементы для первого и второго лексических элементов соответственно.
[0017] В некоторых вариантах осуществления способа, при определении того, что n-ное число последовательных элементов, соседних для данного вхождения первого лексического элемента охватывает дополнительное предложение, соседнее с ним, создание соответствующего первого контекстного параметра, связанного с данным вхождением, включает в себя использование подмножества n-ного числа последовательных элементов, подмножество представляет собой элементы предложения данного вхождения.
[0018] В некоторых вариантах осуществления способа, n-ное число последовательных элементов имеет заранее определенных грамматический тип.
[0019] В некоторых вариантах осуществления способа, анализ совместного вхождения записей включает в себя определение параметра совместного вхождения, указывающего на частоту первого лексического элемента и второго лексического элемента, которые содержатся в данном одном предложении цифрового текста.
[0020] В некоторых вариантах осуществления способа, анализ взаимосвязи включает в себя определение первого параметра сходства между первым контекстным параметром и вторым контекстным параметром.
[0021] В некоторых вариантах осуществления способа, анализ взаимосвязи далее включает в себя определение первого параметра включения, который указывает на включение первого контекстного параметра во второй контекстный параметр, и второго параметра включения, который указывает на включение второго контекстного параметра в первый контекстный параметр.
[0022] В некоторых вариантах осуществления способа, при определении того, что первый параметр включения и второй параметр включения находятся ниже первого порога, параметр связи лексических элементов для первого и второго лексических элементов: указывает на синонимические отношения, если первый параметр сходства находится выше второго порога, а параметр совместного вхождения находится ниже третьего порога; указывает на антонимические отношения, если первый параметр сходства находится выше четвертого порога, а параметр совместного вхождения находится выше пятого порога; и указывает на ассоциативную связь, если первый параметр сходства находится ниже шестого порога.
[0023] В некоторых вариантах осуществления способа, параметр связи лексических элементов для первого и второго лексических элементов указывает на отношения гипероним-гипоним, если один из первого параметра включения или второго параметра включения находится выше порога.
[0024] В некоторых вариантах осуществления способа, анализ взаимосвязи далее включает в себя: определение первого параметра включения первого контекстного параметра во второй контекстный параметр; определение второго параметра включения первого контекстного параметра в третий контекстный параметр, причем третий контекстный параметр определяется путем: дальнейшего парсинга цифрового текста сервером для определения третьего лексического элемента; для каждой записи третьего лексического элемента в цифровом тексте: выбор сервером n-ного числа последовательных элементов, соседних с третьим лексическим элементом; создание сервером третьего контекстного параметра для третьего лексического элемента, третий контекстный параметр содержит указание на каждый элемент из n-ного числа последовательных элементов и частоту совместного вхождения каждого слова с третьим лексическим элементом в цифровом тексте; и определение второго параметра сходства третьего контекстного параметра и второго контекстного параметра.
[0025] В некоторых вариантах осуществления способа, параметр связи лексических элементов для первого, второго и третьего лексических элементов указывает на отношения гипероним-гипоним, если первый параметр включения и второй параметр включения находятся выше первого порога, и второй параметр сходства находится ниже второго порога.
[0026] В некоторых вариантах осуществления способа, парсинг цифрового текста для определения первого лексического элемента и второго лексического элемента включает в себя разделение цифрового текста на множество предложений.
[0027] В некоторых вариантах осуществления способа, сервер является сервером поисковой системы.
[0028] В некоторых вариантах осуществления способа, цифровой текст представляет собой сетевой ресурс, который был ранее просмотрен приложением поискового робота.
[0029] В некоторых вариантах осуществления способа, в ответ на полученный поисковый запрос, сервер поисковой системы выполнен с возможностью получать доступ к базе данных семантических отношений и модифицировать поисковый запрос для получения релевантных сетевых ресурсов.
[0030] В контексте настоящего описания, если четко не указано иное, "электронное устройство", "пользовательское устройство", "сервер", "удаленный сервер" и "компьютерная система" подразумевают под собой аппаратное и/или системное обеспечение, подходящее к решению соответствующей задачи. Таким образом, некоторые неограничивающие примеры аппаратного и/или программного обеспечения включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и т.д.), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и так далее) и/или их комбинацию.
[0031] В контексте настоящего описания, если четко не указано иное, "машиночитаемый носитель" и "память" подразумевает под собой носитель абсолютно любого типа и характера, не ограничивающие примеры включают в себя ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB-ключи, флеш-карты, твердотельные накопители и накопители на магнитной ленте.
[0032] В контексте настоящего описания, если четко не указано иное, "указание" информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, указание файла может включать в себя сам файл (т.е. его содержимое), или же оно может являться уникальным дескриптором файла, идентифицирующим файл по отношению к конкретной файловой системе, или какими-то другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к файлу. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до установления связи между отправителем и получателем понятно, что признак информационного элемента принимает вид ключа базы данных для записи в конкретной таблице заранее установленной базы данных, содержащей информационный элемент, то передача ключа базы данных - это все, что необходимо для эффективной передачи информационного элемента получателю, несмотря на то, что сам по себе информационный элемент не передавался между отправителем и получателем указания.
[0033] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0034] Каждый вариант осуществления настоящей технологии включает по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут удовлетворять другим целям, отдельно не указанным здесь.
[0035] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0036] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[0037] На Фиг. 1 представлена система, которая подходит для реализации вариантов осуществления настоящей технологии и/или которая используется в сочетании с вариантами осуществления настоящей технологии.
[0038] На Фиг. 2 представлена схематическая иллюстрация приложения по обработке текста, относящегося к серверу поисковой системы, который показан на Фиг. 1.
[0039] На Фиг. 3 представлен снимок экрана с цифровым текстом, который включает в себя часть текста, обрабатываемого приложением по обработке текста, которое показано на Фиг. 2.
[0040] На Фиг. 4 представлена первая блок-схема идентификации фразы в цифровом тексте, показанного на Фиг. 3.
[0041] На Фиг. 5 представлена вторая блок-схема идентификации фразы в цифровом тексте, показанного на Фиг. 3.
[0042] На Фиг. 6 представлен пример контекстного параметра, полученного для лексического элемента.
[0043] На Фиг. 7 представлена блок-схема определения параметра сходства между двумя лексическими элементами с помощью контекстного параметра, показанного на Фиг. 6.
[0044] На Фиг. 8 представлена блок-схема определения параметра включения между двумя лексическими элементами с помощью контекстного параметра, показанного на Фиг. 6.
[0045] На Фиг. 9 представлена блок-схема определения неиерархической семантической связи между двумя лексическими элементами на основе параметра сходства, показанного на Фиг. 7.
[0046] На Фиг. 10 представлена блок-схема определения иерархической семантической связи между двумя или более лексическими элементами на основе параметра сходства, показанного на Фиг. 7, и параметра включения, показанного на Фиг. 8.
[0047] На Фиг. 11 представлена блок-схема способа автоматического создания тезауруса, способ выполняется сервером поисковой системы, изображенном на Фиг. 1, способ выполняется в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[0048] Также следует отметить, что чертежи выполнены не в масштабе, если не специально указано иное.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0049] На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание показательных вариантов осуществления настоящей технологии. Таким образом, все последующее описание
представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что-то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях представлена здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[0050] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящей технологии, а не для установления границ ее объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящей технологии и находятся в границах ее объема. Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящей технологии.
[0051] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящей технологии, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящей технологии. Аналогично, любые блок-схемы, диаграммы переходного состояния, псевдокоды и т.п. представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор или нет.
[0052] Функции различных элементов, показанных на фигурах, включая функциональный блок, обозначенный как "процессор", могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящей технологии, процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина "процессор" или "контроллер" не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[0053] С учетом этих примечаний, далее будут рассмотрены некоторые не ограничивающие варианты осуществления аспектов настоящей технологии.
[0054] Система 100 включает в себя электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и, таким образом, иногда может упоминаться как «клиентское устройство». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[0055] В контексте настоящего описания, если конкретно не указано иное, «электронное устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как электронное устройство в настоящем контексте, может вести себя как сервер по отношению к другим электронным устройствам. Использование выражения «электронное устройство» не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[0056] Электронное устройство 102 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования поискового приложения 104. В общем случае, задачей поискового приложения является предоставление пользователю, связанному с клиентским устройством 102, доступа к одному или нескольким веб-ресурсам. Реализация поискового приложения 104 никак конкретно не ограничена. Один из примеров поискового приложения 104 может быть реализован в вызове пользователем веб-сайта, соответствующего поисковой системе, для получения доступа к поисковому приложению 104. Например, поисковое приложение 104 может быть вызвано путем ввода URL www.yandex.ru, связанного с поисковой системой Yandex. Важно иметь в виду, что поисковое приложение 104 может быть доступно с помощью любой другой коммерчески доступной или собственной поисковой системы.
[0057] В общем случае, поисковое приложение 104 включает в себя интерфейс 106 веб-браузера и интерфейс 108 запроса. Основной задачей интерфейса 108 запроса является предоставление возможности пользователю, который связан с электронным устройством 102, вводить поисковый запрос или предоставлять «поисковую строку». Основной задачей интерфейса 106 веб-браузера является предоставление результатов поиска, отвечающих поисковому запросу, который был введен в интерфейс 108 запроса. То, как именно обрабатывается поисковый запрос и как происходит предоставление результатов, будет подробно описано ниже.
[0058] Электронное устройство 102 соединено с сетью 112 связи через линию 110 связи. В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 112 передачи данных (связи) может представлять собой Интернет. В других вариантах осуществления настоящей технологии, сеть 112 связи может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п.
[0059] Реализация линии 110 связи не ограничена, и будет зависеть от того, какое электронное устройство 102 используется. В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии, когда электронное устройство 102 представляет собой беспроводное устройство связи (например, смартфон), линия 110 передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных сети 3G, линия передачи данных сети 4G, беспроводной интернет Wireless Fidelity или коротко WiFi, Bluetooth и т.п.).
[0060] Важно иметь в виду, что варианты осуществления электронного устройства 102, линии 110 передачи данных и сети 112 передачи данных даны исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления электронного устройства 102, линии 110 передачи данных и сети 112 передачи данных. Таким образом, представленные здесь примеры не ограничивают объем настоящей технологии.
[0061] Система 100 далее включает в себя сервер 114, соединенный с сетью 112 передачи данных. Сервер 114 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения сервер 114 может представлять собой сервер Dell PowerEdge, на котором используется операционная система Microsoft Windows Server. Излишне говорить, что сервер 114 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 114 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 114 может быть разделена, и может выполняться с помощью нескольких серверов.
[0062] В некоторых вариантах осуществления настоящей технологии, и в общем случае, сервер 114 служит хранилищем для сетевого ресурса 116. В контексте настоящего описания термин «сетевой ресурс» относится к любому сетевому ресурсу (например, веб-странице, веб-сайту), который визуально может быть представлен на электронном устройстве 102, связанном с конкретным адресом веб-ресурса (например, Единый указатель ресурса (URL)). Сетевой ресурс 116 включает в себя цифровой текст, закодированный с помощью естественного языка. Например, цифровой текст сетевого ресурса 116 может быть связан с новостной статьей, записью в энциклопедии или любым другим текстом на естественном языке. Сетевой ресурс 116 доступен электронному устройству 102 через сеть 112 передачи данных, например, посредством ввода пользователем URL в браузерное приложение (не показано) или путем выполнения веб-поиска с помощью поискового приложения 104 на электронном устройстве 102. Несмотря на то, что в показанном неограничивающем варианте осуществления настоящей технологии, сервер 114 размещает только сетевой ресурс 116, это не является ограничением и, следовательно, он может содержать множество сетевых ресурсов.
[0063] С сетью 112 передачи данных также соединен сервер 118 поисковой системы. Достаточно сказать, что сервер 118 поисковой системы может быть (но не обязан быть) реализован тем же способом, что и сервер 114. В представленных неограничивающих вариантах осуществления настоящей технологии, сервер 118 поисковой системы является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих ее объем, функциональность сервера 118 хостинга содержимого может быть разделена, и может выполняться с помощью нескольких серверов.
[0064] Вариант осуществления сервера 118 поисковой системы хорошо известен. Тем не менее, сервер 118 поисковой системы содержит интерфейс передачи данных (не показан), который настроен и выполнен с возможностью обмениваться данными с различными элементами (например, электронным устройством 102) через сеть 112 передачи данных. Сервер 118 поисковой системы далее включает в себя по меньшей мере один компьютерный процессор (не показан), функционально соединенный с интерфейсом передачи данных, который структурирован и выполнен с возможностью выполнять заранее определенный набор исполняемых на компьютере операций в ответ на получение соответствующего машиночитаемого кода, выбранного из заранее определенного родного набора кодов, который хранится в памяти (не показано) - для выполнения различных описанных здесь процессов.
[0065] В некоторых вариантах осуществления настоящей технологии, сервер 118 поискового ранжирования находится под контролем и/или управлением поисковой системы, например, поисковой системы YANDEX компании ООО «Яндекс», расположенной по адресу: 119021, Москва, ул. Льва Толстого, дом 16. Тем не менее, сервер 118 поисковой системы может быть реализован иначе (например, через локальный поисковик и так далее). Сервер 118 поисковой системы выполнен с возможностью поддерживать индекс 120, который содержит указание на просмотренные поисковым роботом сетевые ресурсы (например, сетевой ресурс 116), доступные через сеть 112 передачи данных.
[0066] Процесс заполнения и поддержания индекса 120 в общем случае известен как «просмотр поисковым роботом», когда приложение 122 поискового робота, которое выполняется сервером 118 поисковой системы, выполнено с возможностью «посещать» один или более сетевых ресурсов (например, сетевой ресурс 116) через сеть 112 передачи данных и индексировать их содержимое (например, связывать данный веб-ресурс с одним или несколькими ключевыми словами). В некоторых вариантах осуществления настоящей технологии, приложение 122 поискового робота поддерживает индекс 120 как «инвертированный индекс». Следовательно, приложение 122 поискового робота сервера 118 поисковой системы выполнено с возможностью сохранять информацию о проиндексированных сетевых ресурсах в индексе 120.
[0067] Сервер 118 поисковой системы выполнен с возможностью поддерживать базу 124 данных семантических отношений. В некоторых вариантах осуществления настоящей технологии, база 124 данных семантических отношений содержит цифровой тезаурус (не показано), цифровой тезаурус является хранилищем семантических отношений между словами и/или фразами, как описано далее.
[0068] Наполнение и поддержка базы 124 данных семантических отношений выполняются приложением 126 по обработке текста. Как будет более подробно описано далее, приложение 126 по обработке текста содержит набор машиночитаемых кодов (как описано выше), выполняемых процессором (не показано) сервера 118 поисковой системы, для выполнения анализа цифрового текста (описано далее) для автоматического создания цифрового тезауруса.
[0069] Когда сервер 118 поисковой системы получает поисковый запрос из поискового приложения 104 (например, «как быть хорошим патентным специалистом»), сервер 118 поисковой системы выполнен с возможностью выполнять приложение 128 ранжирования. Приложение 128 ранжирования выполнено с возможностью получать доступ к индексу 120 для получения указания на множество сетевых ресурсов (например, сетевой ресурс 116), которые потенциально релевантны введенному поисковому запросу. В данном примере, приложение 128 ранжирования дополнительно выполнено с возможностью ранжировать таким образом полученные потенциальные релевантные сетевые ресурсы, чтобы они могли быть представлены в ранжированном порядке на странице результатов поиска (SERP) в интерфейсе 106 веб-браузера, причем на странице результатов поиска наиболее релевантные ранжированные сетевые ресурсы расположены в верхней части SERP.
[0070] В некоторых вариантах осуществления настоящей технологии, сервер 118 поисковой системы выполнен с возможностью модифицировать поисковый запрос с помощью цифрового тезауруса, расположенного в базе 124 данных семантических отношений. Тем не менее, следует иметь в виду, что приложение цифрового тезауруса, расположенное в базе 124 данных семантических отношений, не ограничивается созданием результатов поисковой системы. И, таким образом, цифровой тезаурус, расположенный в базе 124 данных семантических отношений, может быть использован для других целей, например, автоматического перевода текстов, представляющих информацию из тезауруса пользователю, для расширения / изменения текста и так далее.
[0071] Создание Цифрового Тезауруса
[0072] На Фиг. 3 представлен снимок экрана цифрового обучающего документа 300, цифровой обучающий документ 300 включает в себя цифровой текст 302. В некоторых вариантах осуществления настоящей технологии, цифровой обучающий документ 300 представляет собой цифровой носитель, закодированный с помощью естественного языка, например, сетевой ресурс 116 или другой цифровой носитель, который может быть использован для целей построения цифрового тезауруса.
[0073] Цифровой текст 302 создан из множества предложений 304, множество предложений 304 включает в себя ряд индивидуальных предложений 306, например, первое предложение 306, второе предложение 308 и третье предложение 310. Несмотря на то что в представленной иллюстрации множество предложений 304 полностью разделены (т.е. разделены точкой), специалисты в данной области техники поймут, что это не является обязательным, и разделять множество предложений 304 могут и другие знаки препинания, например, вопросительный знак, восклицательный знак и др. Первое предложение 306 включает в себя первый лексический элемент 312, второе предложение 308 включает в себя второй лексический элемент 314, и третье предложение 310 включает в себя третий лексический элемент 316. Во избежание сомнений, следует отметить, что цифровой текст 302 (и, конкретнее, каждая буква лексических элементов) представлена буквой «X», тем не менее, в реальности лексические элементы созданы из букв конкретного языка. Например, если конкретным языком является английский, первое предложение 306 может представлять собой: "Although not an athlete, the lawyer was having a leg day, as he was running away from all the deadlines" ("Даже не будучи спортсменом, адвокат накачал отличные мышцы на ногах, убегая от дедлайнов").
[0074] В некоторых вариантах осуществления настоящей технологии, лексические элементы (первый лексический элемент 312, второй лексический элемент 314 и третий лексический элемент 316) могут представлять собой слово, которое является наименьшим самостоятельным элементом речи, или фразу, которая является смысловой единицей, содержащей группу из двух или более слов (например, "современные компьютерные системы", "способы получения информации", "деревянный стул" и так далее) или комбинацию из слов и фраз.
[0075] Функции и процедуры различных компонентов приложения 126 по обработке текста будут более подробно описаны далее с использованием примера цифрового текста 302. На Фиг. 2 представлен схематический пример приложения 126 по обработке текста для автоматического создания цифрового тезауруса на основе цифрового текста 302. Приложение 216 по обработке текста выполняет (или иначе имеет доступ к): процедуру 202 получения текста, процедуру 204 парсинга, процедуру 206 определения лексического элемента, процедуру 208 создания контекстного параметра и процедуру 210 создания отношения лексического элемента.
[0076] В контексте настоящего описания термин "процедура" относится к подмножеству машиночитаемых кодов приложения 126 по обработке текста, которое выполняется процессором (не показано) сервера 118 поисковой системы для выполнения функции, которые описаны далее. Во избежание каких-либо сомнений, следует иметь в виду, что процедура 202 получения текста, процедура 204 парсинга, процедура 206 определения лексического элемента, процедура 208 создания контекстного параметра и процедура 210 создания отношения лексического элемента представлены здесь схематично в распределенном и разделенном виде для простоты понимания процессов, выполняемых приложением 126 по обработке текста. Считается, что некоторые или все из процедуры 202 получения текста, процедуры 204 парсинга, процедуры 206 определения лексического элемента, процедуры 208 создания контекстного параметра и процедуры 210 создания отношения лексического элемента могут быть выполнены как одна или несколько объединенных процедур.
[0077] Функции каждой из процедуры 202 получения текста, процедуры 204 парсинга, процедуры 206 определения лексического элемента, процедуры 208 создания контекстного параметра и процедуры 210 создания отношения лексического элемента, а также данных и/или обработанной или сохраненной информации будут описаны далее.
[0078] В соответствии с вариантами осуществления настоящего технического решения, процедура 202 получения текста выполнена с возможностью получать пакет 218 данных, включающий в себя указание на цифровой текст 302, который будет обработан.
[0079] То, как именно процедура 202 получения текста получает указание на цифровой текст 302, никак конкретно не ограничено. В некоторых вариантах осуществления настоящей технологии, пакет 218 данных, который включает в себя указание на цифровой текст 302, передается из соответствующего источника (не показано), например, базы данных, которая содержит по меньшей мере один цифровой обучающий документ.
[0080] Альтернативно, в некоторых вариантах осуществления настоящей технологии, индекс 120 выполнен с возможностью передавать пакет данных 218 процедуре 202 получения текста. В подобном случае, пакет 218 данных содержит указание на цифровой текст 302, который является текстовой частью одного или нескольких просмотренных поисковым роботом сетевых ресурсов.
[0081] Процедура 204 парсинга выполнена с возможностью парсить множество предложений 304 на одно или несколько отдельных предложений, например, первое предложение 306, второе предложение 308 и третье предложение 310. Способ, которым выполняется парсинг, хорошо известен в данной области техники и никак не ограничен, и может выполняться путем анализа знаков препинания и применения правил грамматики. В некоторых вариантах осуществления настоящей технологии, процедура 204 парсинга использует специфичные для языка правила (т.е. правила, специально выбранные для языка, на котором написан цифровой текст 302).
[0082] Процедура 206 определения лексического элемента относит каждое слово цифрового текста 302 к соответствующему грамматическому типу (например, существительное, глагол и т.д.). Способ, которым выполняется такая отметка, хорошо известен в данной области техники и никак не ограничен, и может быть выполнен путем анализа окончания соседних слов или окончания данного слова.
[0083] Процедура 206 определения лексического элемента далее выполнена с возможностью выбирать первый лексический элемент 312, второй лексический элемент 314, и третий лексический элемент 316.
[0084] Как указано выше, каждый лексический элемент может быть словом или фразой. Способ идентификации данной фразы описан далее.
[0085] На Фиг. 4 представлен вариант осуществления процесса идентификации данной фразы. На этапе 402, процедура 206. определения лексического элемента выполнена с возможностью анализировать цифровой текст 302 и идентифицировать по меньшей мере одну группу слов, каждая группа слов включает в себя по меньшей два слова, которые появляются вместе в цифровом тексте 302.
[0086] На этапе 404, для каждой идентифицированной группы слов, процедура 206 определения лексического элемента выполнена с возможностью определять, обладает ли логическим значением по меньшей мере одно слово из группы слов. В контексте настоящей технологии, термины "логическое значение" относится к семантике, содержащейся в лексической морфеме.
[0087] В некоторых вариантах осуществления настоящей технологии, процедура 206 определения лексического элемента выполнена с возможностью определить, обладает ли данное слово из группы слов логическим значением на основе грамматического типа данного слова. Например, процедура 206 определения лексического элемента выполнена с возможностью идентифицировать лексические морфемы, такие как глаголы, прилагательные и наречия, как обладающие логическим значением. С другой стороны, слова, которые являются грамматическими морфемами (которые указывают на отношения между другими морфемами, например, предлогами, артиклями, союзами и так далее), считаются не обладающими логическим значением при процедуре 206 определения лексического элемента.
[0088] Опционально, даже если данное слово из группы слов определено как обладающее логическим значением, процедура 206 определения лексического элемента также выполнена с возможностью считать данное слово не обладающим логическим значением, если определено, что данное слово является бессмысленным, неважным и/или создающим шум на основе эмпирического анализа, например, частое появление таких глаголов как, "быть" и "иметь" ("to be", "to have").
[0089] Далее на этапе 404, если есть по меньшей мере одно слово, обладающее логическим значением в рамках группы слов, способ переходит к этапу 412, где процедура 206 определения лексического элемента выполнена с возможностью идентифицировать группу слов как фразу. С другой стороны, если идентифицированная группа слов не обладает по меньшей мере одним словом с логическим значением, группа слов игнорируется на этапе 406.
[0090] Опционально, далее на этапе 404 и до перехода напрямую к этапу 412, процедура 206 определения лексического элемента выполнена с возможностью вычислять частоту записей данной группы слов в цифровом тексте 302 на этапе 408. Если частота записей находится ниже заранее заданного порога (который может быть определен эмпирически), данная группа слов игнорируется на этапе 410. Если группа слов обладает частотой записей, находящейся выше заранее заданного порога, способ переходит к этапу 412, где процедура 206 определения лексического элемента выполнена с возможностью идентифицировать группу слов как фразу.
[0091] На Фиг. 5 представлен другой вариант осуществления процесса для идентификации данной фразы для первого предложения 306, которое выглядит как "Не sat on the wooden chair of the captain" ("Он сидел на деревянном стуле капитана"). На этапе 502, процедура 206 определения лексического элемента выполнена с возможностью анализировать предложение и идентифицировать слова, ранее отмеченные как существительные (т.е. "chair" ("стул") и "captain" ("капитан")). На этапе 504, процедура 206 определения лексического элемента выполнена с возможностью анализировать слова, идентифицированные как существительные, и определять, являются ли слова, определенные как существительные, "кодовым словом", т.е. главным словом во фразе. Конкретные эвристические правила определения инициирующего слова могут изменяться (т.е. конкретные правила могут зависеть от языка). В русском языке, главное слово обычно является существительным, которое находится левее всего во фразе. В английском языке, это может быть существительное, которое стоит во фразе правее всего, если отсутствуют такие предлоги как «of», или же существительное, которое стоит во фразе левее всего до предлога. Таким образом, в представленном примере, слово "chair" ("стул") считается кодовым словом в результате процедуры 206 определения лексического элемента. На этапе 506, процедура 206 определения лексического элемента далее выполнена с возможностью анализировать соседние с кодовым словом слова, и определять, формируют ли одно или несколько соседних слов логическую запись с кодовым словом. Например, процедура 206 определения лексического элемента может быть выполнена с возможностью считать слова конкретного типа, например, прилагательные, существительные и так далее, расположенные рядом с кодовым словом, формирующими логическую запись с кодовым словом (например, "wooden chair" ("деревянный стул")). Если было определено, что одно или несколько окружающих слов формируют логическую запись с кодовым словом, одно или несколько окружающих слов и кодовое слово идентифицируются как фраза на этапе 508.
[0092] Излишне говорить, что другие средства идентификации фразы в цифровом тексте 302 известны в данной области техники, и представленные выше примеры не являются ограничивающими.
[0093] После того как одна или несколько фраз были идентифицированы с помощью вышеописанных неограничивающих вариантов осуществления технологии, процедура 206 определения лексического элемента выполнена с возможностью связывать каждую идентифицированную фразу в лексический элемент. Например, если процедура 206 определения лексического элемента идентифицирует в цифровом тексте 302 2 фразы, процедура 206 определения лексического элемента будет выбирать 2 фразы как первый лексический элемент 312 и второй лексический элемент 314.
[0094] После того как в процедуре 206 определения лексического элемента выбраны одна или несколько фраз в качестве лексических элементов, в качестве лексических элементов будут выбраны одно или несколько слов. Способ выбора слова в качестве лексического элемента будет описан далее.
[0095] В некоторых вариантах осуществления настоящей технологии, процедура 206 определения лексического элемента выполнена с возможностью исключать заранее идентифицированные фразы из цифрового текста 302 и идентифицировать отметку оставшихся слов цифрового текста 302 и выбирать слово, которое относится к одному конкретному грамматическому типу. В некоторых вариантах осуществления настоящей технологии, процедура 206 определения лексического элемента выполнена с возможностью выбирать слова, обладающие логическим значением, как описано выше (например, глагол, существительное, прилагательное, наречение и так далее, но не предлоги, союзы и тому подобное).
[0096] В некоторых вариантах осуществления настоящей технологии, процедура 206 определения лексического элемента далее выполнена с возможностью анализировать выбранные один или несколько лексических элементов для определения наличия лексического элемента, который является омонимом. Например, слово "bank" ("банк") может быть выбрано в качестве лексического элемента, несмотря на то, что априори может быть неизвестно, используется ли в цифровом тексте 302 это слово в значении финансового учреждения или в значении береговой линии, которая ограничивает естественное течение вод. Конечно, может быть и так, что в цифровом тексте 302 слово "bank" используется в значении финансового учреждения в одном случае, и в значении береговой линии, которая ограничивает естественное течение вод, в другом. Способ определения омонима никак не ограничен и может быть выполнен с использованием известных методов. Если было определено, что выбранный лексический элемент, который является омонимом, используется более чем в одном смысле в цифровом тексте 302, процедура 206 определения лексического элемента выполнена с возможностью выбирать слово (или фразу) как два или несколько лексических элементов. Например, продолжая с примером со словом "bank", слово "bank" в контексте финансового учреждения выбрано как первый лексический элемент, а слово "bank" в контексте береговой линии выбрано как другой лексический элемент.
[0097] После того как первый лексический элемент 312, второй лексический элемент 314 и третий лексический элемент 316 были выбраны, для каждого вхождения первого лексического элемента 312, второго лексического элемента 314 и третьего лексического элемента 316 в цифровом тексте 302, процедура 206 определения лексического элемента далее выполнена с возможностью выбирать n-ное число последовательных элементов, соседних для соответствующего первого лексического элемента 312, второго лексического элемента 314 и третьего лексического элемента 316. В некоторых вариантах осуществления настоящей технологии, n-ное число последовательных элементов может последовательно предшествовать и/или последовательно следовать за каждым первым лексическим элементом 312, вторым лексическим элементом 314 и третьим лексическим элементом 316. Способ, по которому определяется количество слов в n-ном числе последовательных элементов, никак не ограничен. Например, количество слов в n-ном числе последовательных элементов может быть заранее определено и/или определено эмпирически.
[0098] Для целей настоящей иллюстрации и без установления ограничений, предлагается следующий пример:
Первое предложение 306 выглядит следующим образом: "There are plenty of fishes swimming in the ocean" ("В океане плавает большое количество рыб");
Второе предложение 308 выглядит следующим образом: "In the ocean, the whale shark is one of the largest fish" ("Китовая акула - одна из самых больших рыб в океане");
Третье предложение 310 выглядит следующим образом: "A whale shark is not a mammal that swims, unlike the whale" ("Китовая акула не является плавающим млекопитающим, в отличие от кита");
Первым лексическим элементом 312 выбрано слово "fishes" ("рыбы");
Вторым лексическим элементом 314 выбрана фраза "whale shark" ("китовая акула");
Третьим лексическим элементом 316 выбрано слово "mammal" ("млекопитающее");
Процедура 206 определения лексического элемента выполнена с возможностью определять 3 слова, которые последовательно предшествуют (n-ное число последовательных элементов), и 3 слова, которые последовательно следуют (n-ное число последовательных элементов) за каждым из лексических элементов.
[0099] В некоторых вариантах осуществления настоящей технологии, процедура 206 определения лексического элемента выполнена с возможностью выполнять, после идентификации того, что n-ное число последовательных элементов захватывает предложение, отличное от предложения, в котором содержится данный лексический элемент, для идентификации только подмножества n-ного числа последовательных элементов, подмножество представляет собой подмножество слов/фраз из n-ного числа последовательных элементов, содержащихся в данном предложении.
[00100] В некоторых вариантах осуществления настоящей технологии, процедура 206 определения лексического элемента выполнена с возможностью лемматизации каждого выбранного лексического элемента. Например, первый лексический элемент 312 переводится в форму "fish" ("рыба"). В альтернативных вариантах осуществления технологии, процедура 206 определения лексического элемента выполнена с возможностью лемматизации всех слов цифрового текста 302 для идентификации вхождения данного лемматизированного лексического элемента в цифровом тексте 302.
[00101] Способ, в соответствии с которым лемматизируется слово, хорошо известен в данной области техники, достаточно будет упомянуть, что при лемматизации не необходимо использовать словарь, и это может быть сделано путем стемминга и анализа данного слова для создания леммы упомянутого слова, как известно в данной области техники. Излишне говорить, что использование словаря не исключается и он может быть использован для улучшения качестве лемматизации.
[00102] N-ное число последовательных элементов для первого лексического элемента 312 в первом предложении 306 представляет собой "be" (лемма глагола "are"), "plenty", "of, "swim" (лемма глагола "swimming"), "in" и "the". N-ное число последовательных элементов для первого лексического элемента 312 во втором предложении 308 представляет собой "of, "the", и "large" (лемма прилагательного "largest").
[00103] N-ное число последовательных элементов для второго лексического элемента 314 во втором предложении 308 представляет собой "the", "ocean", "the", "be" (лемма глагола "is"), "one", и "of. N-ное число последовательных элементов для второго лексического элемента 314 в третьем предложении представляет собой "a", "is" и "not".
[00104] N-ное число последовательных элементов для третьего лексического элемента 316 представляет собой "is", "not", "a", "swim" (лемма глагола "swims"), "unlike", и "the".
[00105] Несмотря на то, что в представленном выше примере, количество слов/фраз в n-ном числе последовательных элементов, соседних с каждым лексическим элементом, было одинаковым, это не является ограничением и может различаться для каждого лексического элемента.
[00106] В некоторых вариантах осуществления настоящей технологии, при идентификации n-ного числа последовательных элементов, процедура 206 определения лексического элемента выполнена для идентификации n-ного числа последовательных элементов, которые обладают логическим смыслом (например, глагол, существительные, наречия, прилагательные и так далее) и игнорирования последовательных элементов без логического смысла (например, местоимения, предлоги, союзы и так далее). Опционально, процедура 206 определения лексического элемента также выполнена с возможностью игнорировать последовательные элементы, обладающие логическим смыслом, которые встречаются часто (например, глаголы "to be", "to have", элементы такие как "one", и так далее) при определении n-ного числа последовательных элементов.
[00107] В таком случае, n-ное число последовательных элементов для первого лексического элемента 312 ("fish") в первом предложении 306 представляет собой "plenty", "swim" (лемма глагола "swimming") и "ocean". N-ное число последовательных элементов для первого лексического элемента 312 во втором предложении 308 представляет собой "large" (лемма прилагательного "largest"), "ocean" и фразу "whale shark".
[00108] N-ное число последовательных элементов для второго лексического элемента 314 ("whale shark") во втором предложении 308 представляет собой "ocean", "large" (лемма прилагательного "largest") и "fish". N-ное число последовательных элементов для второго лексического элемента 314 во втором предложении 310 представляет собой "mammal", "swim" (лемма глагола "swims") и "whale".
[00109] N-ное число последовательных элементов для третьего лексического элемента 316 ("mammal") представляет собой фразу "whale shark", слова "swim" (лемма глагола "swims") и "whale".
[00110] Возвращаясь к Фиг. 2, после идентификации n-ного числа последовательных элементов для каждого лексического элемента, процедура 208 создания контекстного параметра выполняется для создания первого контекстного параметра 212 для первого лексического элемента 312, второго контекстного параметра 214 для второго лексического элемента 314 и третьего контекстного параметра 216 для третьего лексического элемента 316.
[00111] В контексте настоящей технологии, термин "контекстный параметр" относится к указанию на каждое слово/фразу из n-ного числа последовательных элементов и частоты совместного вхождения в каждую запись данного лексического элемента в каждом из множества предложений 304.
[00112] На Фиг. 6 представлен неограничивающий пример первого контекстного параметра 212 для первого лексического элемента 312 (относится к слову/фразе "А" для удобства) в форме табличного списка 602.
[00113] Табличный список 602 включает в себя первый столбец 604. Каждая запись в первом столбце 604 соответствует каждому из лемматизированных n последовательных элементов лематизированного первого лексического элемента 312 (элементы "В", "С", "D", и "Е", каждый из которых может быть одним из слова или фразы).
[00114] В некоторых вариантах осуществления настоящей технологии, процедура 208 создания контекстного параметра выполняется с возможностью формировать элемент-пару, включающую в себя лемматизированный первый лексический элемент 312 и каждый из лематизированного n последовательных элементов в первом столбце 604, а также определять частоту совместного вхождения каждой элемент-пары, где первый лексический элемент 312 представляет собой запись в цифровом тексте 302. Следует иметь в виду, что процедура 206 определения лексического элемента может заранее лемматизировать все (или некоторые) слова цифрового текста 302, которые позволяют быстро идентифицировать частоту совместных вхождений каждой элемент-пары.
[00115] Во избежание сомнений, следует упомянуть, что, несмотря на то, что цифровой текст 302 на Фиг. 3 иллюстрирует конкретное число предложений, это сделано только для простоты понимания. Следует иметь в виду, что цифровой текст 302 включает большее число предложений, чем представлено, и выбранные лексические элементы (первый лексический элемент 312, второй лексический элемент 314 и третий лексический элемент 316) будут появляться еще много раз.
[00116] Например, в представленной иллюстрации, во втором столбце 606 определено, что цифровой текст 302 включает в себя только одно предложение, где совместно встречается элемент-пара "А - В". В другом примере, элемент-пара "А - Е" совместно встречается в 5 предложениях.
[00117] После определения контекстных параметров (первый контекстный параметр 212, второй контекстный параметр 214, третий контекстный параметр 216), процедура 210 создания связи лексических элементов выполнена с возможностью выполнять, одновременно или последовательно: анализ взаимосвязи первого контекстного параметра 212, второго контекстного параметра 214, и третьего контекстного параметра 216; и анализ совместного вхождения записей среди первого лексического элемента 312, второго лексического элемента 314 и третьего лексического элемента 316 в цифровом тексте 302.
[00118] С учетом примера с первым лексическим элементом 312 и вторым лексическим элементом 314, анализ совместного вхождения записей включает в себя определение параметра совместного вхождения, указывающего на частоту первого лексического элемента 312 и второго лексического элемента 314, которые содержатся в данном предложении цифрового текста 302.
[00119] В контексте настоящей технологии, термин "анализ взаимосвязи" относится к тому, что определяется относительный параметр сходства среди первого контекстного параметра 212, второго контекстного параметра 214 и третьего контекстного параметра 216, относительный параметр включения среди двух из первого контекстного параметра 212, второго контекстного параметра 214 и третьего контекстного параметра 216. Описание и функции параметра сходства и параметра включения будут представлены далее.
[00120] Параметр сходства
[00121] На Фиг. 7 представлен неограничивающий вариант осуществления процесса определения параметра сходства между первым контекстным параметром 212 и вторым контекстным параметром 214 в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00122] На этапе 702, процедура 210 создания связи лексических элементов выбирает первый контекстный параметр 212 и второй контекстный параметр 214.
[00123] В некоторых вариантах осуществления технологии, на этапе 704, процедура 210 создания связи лексических элементов выполнена с возможностью вычислять первый параметр сходства n-ного числа последовательных элементов между первым контекстным параметром 212 (т.е. первым столбцом 604 табличного списка 602) и вторым контекстным параметром 214. Способ, в соответствии с которым определяется первый параметр сходства, никак конкретно не ограничен, и может быть определен с помощью известных методов, например, коэффициента Сёренсена. Определение первого параметра сходства считается параметром сходства между первым контекстным параметром 212 и вторым контекстным параметром 214 на этапе 708.
[00124] Альтернативно, вместо вычисления первого параметра сходства на этапе 704, процедура 210 создания связи лексических элементов выполнена с возможностью вычислять второй параметр сходства на этапе 706, второй параметр сходства отражает то, насколько каждая элемент-пара и ее частота совместного вхождения сходны между первым контекстным параметром 212 и вторым контекстным параметром 214. Другими словами, в отличие от первого параметра сходства, который является сходством n-ного числа последовательных слов, второй параметр сходства является сходством элемент-пары контекстных параметров и их частоты совместного вхождения. Способ, в соответствии с которым определяется второй параметр сходства, никак конкретно не ограничен, и может быть определен с помощью известных методов, например, коэффициента корреляции Спирмана-Кендалла. Определение второго параметра сходства считается параметром сходства между первым контекстным параметром 212 и вторым контекстным параметром 214 на этапе 708.
[00125] Опционально, процедура 210 создания связи лексических элементов выполнена с возможностью вычислять первый параметр сходства на этапе 704 и второй параметр сходства на этапе 706, и вычислять третий параметр сходства как параметр сходства на этапе 708, третий параметр сходства является результатом первого параметра сходства и второго параметра сходства.
[00126] Параметр включения
[00127] На Фиг. 8 представлен неограничивающий вариант осуществления процесса определения параметра включения первого контекстного параметра 212 во второй контекстный параметр 214 в соответствии с некоторыми неограничивающими вариантами осуществления настоящей технологии.
[00128] На этапе 802, процедура 210 создания связи лексических элементов выбирает первый контекстный параметр 212 и второй контекстный параметр 214.
[00129] На этапе 804 процедура 210 создания связи лексических элементов идентифицирует каждое n-ное число последовательных элементов, связанных с первым лексическим элементом 312 (т.е. первого столбца 604 табличного списка 602).
[00130] На этапе 806 процедура 210 создания связи лексических элементов идентифицирует каждое n-ное число последовательных элементов, связанных со вторым лексическим элементом 314.
[00131] На этапе 808, процедура 210 создания связи лексических элементов вычисляет параметр включения. Способ, в соответствии с которым вычисляется параметр включения, никак не ограничен, и может быть определен путем идентификации n-ного числа последовательных элементов, связанных с первым лексическим элементом 314, включенного в n-ное число последовательных элементов, связанных со вторым лексическим элементом 316.
[00132] Варианты осуществления настоящей технологии основаны на том, что два контекстных параметра относятся друг к другу тем же образом, что и их соответствующие лексические элементы и, таким образом, семантическая связь между двумя лексическими элементами может быть определена путем анализа связи между соответствующими контекстными параметрами. Таким образом, способ, в соответствии с которым определяется семантическая связь, может основываться на одном или нескольких эвристических правилах.
[00133] Следовательно, в некоторых вариантах осуществления настоящей технологии, после выполнения анализа взаимосвязи и вычисления параметра совместного вхождения, процедура 210 создания связи лексических элементов выполняется с возможностью определить параметр связи лексических элементов, указывающий на семантическую связь между двумя или более лексическими элементами (например, первым лексическим элементом 312, вторым лексическим элементом 314 и третьим лексическим элементом 316). В некоторых вариантах осуществления настоящей технологии, семантическая связь может представлять собой одно из: неиерархическую связь (которая является одним из: ассоциативной связью, синонимическим отношением или антонимическим отношением), иерархическую связь (которая является одним из: связью гипероним-гипоним или связью холоним-мероним). В контексте настоящей технологии, термин "ассоциативная связь" относится к семантической связи между двумя или более лексическими элементами, пересекающимися по значению, которая не доходит до синонимических отношений.
[00134] Определение параметра связи лексических элементов
[00135] Далее будет описано определение параметра связи лексических элементов. Для простоты понимания и во избежание дублирования, предлагается следующее описание определения параметра связи лексических элементов для первого лексического элемента 312 в отношении других лексических параметров.
[00136] На первом этапе, процедура 210 создания связи лексических элементов выполнена с возможностью идентифицировать оставшиеся лексические элементы (т.е., второй лексический элемент 314, и третий элемент 316).
[00137] На втором этапе, процедура 210 создания связи лексических элементов выполнена с возможностью идентифицировать для каждого из оставшихся лексических элементов, два параметра включения, связанные с первым лексическим элементом 312: а именно, параметр включения первого контекстного параметра 212 в данные оставшиеся лексические элементы; и параметр включения данных оставшихся лексических элементов в первый контекстный параметр.
[00138] В некоторых вариантах осуществления технологии, если оба параметра включения находятся ниже заранее определенного порога (может быть определен эмпирически), процедура 210 создания связи лексических элементов выполнена с возможностью выполнять анализ неиерархической связи в отношении первого лексического элемента 312 и лексического элемента, связанного с данными параметрами включения, как описано далее со ссылкой на Фиг. 9.
[00139] И наоборот, если один из двух параметров включения находится выше заранее определенного порога, процедура 210 создания связи лексических элементов выполнена с возможностью выполнять анализ иерархической связи в отношении первого лексического элемента 312 и лексического элемента, связанного с данными параметрами включения, как описано далее со ссылкой на Фиг. 9.
[00140] Например, может быть определено, что параметр включения первого контекстного параметра 212 во второй контекстный параметр 214, а также параметр включения второго контекстного параметра 214 в первый контекстный параметр 212 находится ниже заранее определенного порога. Таким образом, процедура 210 создания связи лексических элементов выполнена с возможностью выполнять анализ неиерархической связи в отношении первого лексического элемента 312 и второго лексического элемента 314 (описано ниже).
[00141] В другом примере, может быть определено, что параметр включения первого контекстного параметра 212 в третий контекстный параметр 216 находится ниже заранее определенного порога, а параметр включения третьего контекстного параметра 216 в первый контекстный параметр 212 находится выше заранее определенного порога. Таким образом, процедура 210 создания связи лексических элементов выполнена с возможностью выполнять анализ иерархической связи в отношении первого лексического элемента 312 и третьего элемента 316 (описано ниже).
[00142] Анализ неиерархической связи
[00143] На Фиг. 9 представлен неограничивающий вариант осуществления процесса выполнения неиерархического анализа для определения того, является ли неиерархическая связь одним из: ассоциативной связью, синонимическими отношениями или антонимическими отношениями. Как было упомянуто ранее, представленный описанный вариант осуществления выполняется, когда параметр включения первого контекстного параметра 212 в данные оставшиеся лексические элементы; и параметр включения данных оставшихся лексических элементов в первый контекстный параметр оба находятся ниже заранее определенного порога. Для простоты настоящего описания, следующий процесс описан со ссылкой на первый контекстный параметр 212 и второй контекстный параметр 214.
[00144] На этапе 902, процедура 210 создания связи лексических элементов выполнена с возможностью анализировать параметр сходства между первым контекстным параметром 212 и вторым контекстным параметром 214, который был определен на этапе 708, и далее определять, находится ли параметр сходства выше первого порога (который может быть определен эмпирически).
[00145] Если определено, что параметр сходства находится ниже первого порога, первый лексический элемент 312 и второй лексический элемент 314 определены как не связанные друг с другом на этапе 904.
[00146] Если определено, что параметр сходства находится выше первого порога, процедура 210 создания связи лексических элементов переходит к этапу 906. На этапе 906, процедура 210 создания связи лексических элементов выполнена с возможностью определять, находится ли параметр сходства выше второго порога (который может быть определен эмпирически).
[00147] Если определено, что параметр сходства находится ниже второго порога, семантическая связь между первым лексическим элементом 312 и вторым лексическим элементом 314 определена как ассоциативная связь на этапе 908.
[00148] Если определено, что параметр сходства находится выше второго порога, процедура 210 создания связи лексических элементов переходит к этапу 910. На этапе 910, процедура 210 создания связи лексических элементов выполнена с возможностью определять, находится ли параметр совместного вхождения первого лексического элемента 312 и второго лексического элемента 314 выше третьего порога (который может быть определен эмпирически).
[00149] Если определено, что параметр совместного вхождения первого лексического элемента 312 и второго лексического элемента 314 находится ниже третьего порога, параметр связи лексических элементов для первого лексического элемента 312 и второго лексического элемента 314 определяется как синонимические отношения на этапе 912.
[00150] С другой стороны, если определено, что параметр совместного вхождения первого лексического элемента 312 и второго лексического элемента 314 находится выше третьего порога, параметр связи лексических элементов для первого лексического элемента 312 и второго лексического элемента 314 определяется как антонимические отношения на этапе 914.
[00151] Процедура 210 создания связи лексических элементов выполнена далее с возможностью передавать пакет 220 данных, содержащий определенный параметр связи лексических элементов с соответствующими лексическими элементами, в семантическую базу 124 данных отношений для заполнения хранящегося там цифрового тезауруса.
[00152] Анализ иерархической связи
[00153] На Фиг. 10 представлен неограничивающий вариант осуществления процесса иерархического анализа для определения того, является ли иерархическая связь одним из: отношениями гипероним-гипоним или отношениями холоним-мероним. Как было упомянуто ранее, представленный описанный вариант осуществления выполняется, когда по меньшей мере одно из параметр включения первого контекстного параметра 212 в данные оставшиеся лексические элементы; и параметр включения данных оставшихся лексических элементов в первый контекстный параметр определен как находящийся выше заранее определенного порога. Для простоты понимания, следующий процесс описан с учетом предположения о том, что параметр включения данного контекстного параметра (либо одного, либо обоих из второго контекстного параметра 214 и третьего контекстного параметра 216) в первый контекстный параметр 212 выше заранее определенного порога. Во избежание сомнений, несмотря на то, что ссылки с номерами продолжают ссылки с номерами, используемые для описания Фиг. 9, данный неограничивающий вариант является другим.
[00154] Настоящий вариант осуществления технологии начинается на этапе 916, причем процедура 210 создания связи лексических элементов выполняется для идентификации того, сколько параметров включения оставшихся лексических элементов в первый контекстный параметр 212 было определено как находящиеся выше заранее определенного порога.
[00155] Например, если определено, что только параметр включения второго контекстного параметра 214 в первый контекстный параметр 212 находится выше заранее определенного порога, процесс переходит к этапу 918, где определено, что первый лексический элемент 312 и второй лексический элемент 314 являются одними иерархическим отношениями. В некоторых вариантах осуществления настоящей технологии, одни иерархические отношения являются отношениями гипероним-гипоним. В этом случае, поскольку второй контекстный параметр 214 включен в первый контекстный параметр 212, первый лексический элемент 312 будет гиперонимом, а второй лексический элемент 314 будет гипонимом. Альтернативно, процедура 210 создания связи лексического элемента выполнена с возможностью определять, находится ли параметр совместного вхождения, связанный с первым оригинальным лексическим элементом 312 и вторым лексическим элементом 314, выше другого заранее определенного порога (который может быть определен эмпирически). Если было определено, что параметр совместного вхождения находится выше другого порога, одни иерархические отношения являются отношениями холоним-мероним.
[00156] С другой стороны, если определено, что в дополнении к параметру включения второго контекстного параметра 214 в первый контекстный параметр 212, есть параметр включения третьего контекстного параметра 214 в первый контекстный параметр 212, который находится выше заранее определенного порога, процесс переходит к этапу 920.
[00157] Продолжая приведенный пример, процедура 210 создания связи лексических элементов выполнена с возможностью определять, находится ли параметр сходства между вторым контекстным параметром 214 и третьим параметром 216 выше четвертого порога (может быть определен эмпирически).
[00158] Если определено, что параметр сходства между вторым контекстным параметром 214 и третьим контекстным параметром 216 находится ниже четвертого порога, процесс переходит к этапу 922, где определено, что первый лексический элемент 312, второй лексический элемент 314 и третий лексический элемент 316 находятся в отношении холоним-мероним. Например, определение отношений холоним-мероним происходит в ситуации, когда первый лексический элемент 314 является словом "wing" ("крыло"), второй элемент 314 является словом "bird" ("птица"), а третий элемент 316 является словом "plane" ("самолет"): первый лексический элемент 312 является меронимом для второго лексического элемента 314 и третьего лексического элемента 316, которые являются холонимами.
[00159] Если определено, что параметр сходства между вторым контекстным параметром 214 и третьим контекстным параметром 216 находится выше четвертого порога, процедура 210 создания связи лексических элементов переходит к этапу 924. На этапе 924, процедура 210 создания связи лексических элементов выполнена с возможностью определять, находится ли: параметр включения второго контекстного параметра 214 в третий контекстный параметр 216; и параметр включения третьего контекстного параметра 216 во второй контекстный параметр выше пятого порога.
[00160] Например, если определено, что параметр включения третьего контекстного параметра 216 во второй контекстный параметр 214 находится выше пятого порога, процесс переходит к этапу 926, где определено, что первый лексический элемент 312, второй лексический элемент 314 и третий лексический элемент 316 находятся в многоуровневых отношениях гипероним-гипоним. Другими словами, третий лексический элемент 316 будет гипонимом для второго лексического элемента 314, который будет гипонимом для первого лексического элемента 312 (который является гиперонимом).
[00161] Если определено, что параметр включения третьего контекстного параметра 216 во второй контекстный параметр 214 (и наоборот, параметр вхождения второго контекстного параметра 214 в третий контекстный параметр 216), процесс переходит к этапу 928, где определено, что первый лексический элемент 312, второй лексический элемент 314 и третий лексический элемент 316 находятся в двухуровневых отношениях гипероним-гипоним. Другими словами, первый лексический элемент 316 будет гипонимом, а второй лексический элемент 314 и третий лексический элемент 318 будут гиперонимами.
[00162] Процедура 210 создания связи лексических элементов выполнена далее с возможностью передавать пакет 220 данных, содержащий определенный параметр связи лексических элементов с соответствующими лексическими элементами, в семантическую базу 124 данных отношений для заполнения хранящегося там цифрового тезауруса.
[00163] Излишне говорить, что несмотря на то что настоящая технология была описана с использованием трех лексических элементов (первого лексического элемента 312, второго элемента 314 и третьего элемента 316) из одного цифрового текста (текста 302), это было сделано исключительно для облегчения понимания, а для не установления ограничений. Специалисту в данной области техники будет очевидно, что для правильного заполнения тезауруса, необходимо большое количество лексических элементов, а также цифровых текстов.
[00164] Использование цифрового тезауруса
[00165] Как было уже сказано ранее, сервер 118 поисковой системы выполнен с возможностью модифицировать поисковый запрос с помощью цифрового тезауруса, расположенного в базе 124 данных семантических отношений.
[00166] В общем случае, когда сервер 118 поисковой системы получает поисковый запрос, сервер 118 поисковой системы выполнен с возможностью получать доступ к индексу 120 и извлекать указание на множество просмотренных поисковым роботом поисковых ресурсов, которые потенциально релевантны введенному поисковому запросу.
[00167] В некоторых вариантах осуществления настоящей технологии, до извлечения указания на множество просмотренных поисковым роботом сетевых ресурсов, которые потенциально релевантны введенному поисковому запросу, сервер 118 поисковой системы выполнен с возможностью создавать один или несколько измененных запросов с помощью цифрового тезауруса.
[00168] В одном варианте осуществления технологии, сервер 118 поисковой системы выполнен с возможностью парсить поисковый запрос и создавать первый альтернативный запрос с помощью синонимических слов или фраз, идентифицированных цифровым тезаурусом.
[00169] В другом варианте осуществления технологии, сервер 118 поисковой системы выполнен с возможностью парсить поисковый запрос и создавать второй альтернативный запрос с помощью холонима (или гиперонима), связанного с одним или несколькими словами или фразами поискового запроса для расширения объема потенциально релевантных сетевых ресурсов.
[00170] В другом варианте осуществления технологии, сервер 118 поисковой системы выполнен с возможностью парсить поисковый запрос и идентифицировать один или несколько антонимов (как слово или фразу), связанных с одним или несколькими словами поискового запроса. С помощью идентифицированных антонимов, сервер 118 поисковой системы может быть выполнен для фильтрации или ранжирования таким образом извлеченных потенциальных релевантных сетевых ресурсов.
[00171] В еще одном другом варианте осуществления технологии, сервер 118 поисковой системы выполнен с возможностью парсить поисковый запрос и идентифицировать одно или несколько слов/фраз, которые находятся в ассоциативной связи с одним или несколькими словами/фразами поискового запроса. С помощью идентифицированных одного или нескольких слов/фраз, которые находятся в ассоциативной связи, сервер 118 поисковой системы может быть выполнен с возможностью создавать третий альтернативный запрос для идентификации сетевых ресурсов, которые косвенно релевантны для полученного поискового запроса.
[00172] После того как сервер 118 поисковой системы получает множество сетевых ресурсов на основе одного или нескольких вышеупомянутых альтернативных запросов (а также оригинального поискового запроса), сервер 118 поисковой системы далее выполнен с возможностью ранжировать (с помощью приложения 128 ранжирования) таким образом полученные потенциально релевантные сетевые ресурсы, что они могут быть представлены в ранжированном порядке на SERP, и SERP отображает указанным образом ранжированные наиболее релевантные ресурсы в верхней части списка.
[00173] С учетом представленных выше архитектуры и примеров, возможно выполнить исполняемый на компьютере способ автоматического создания цифрового тезауруса. На Фиг. 11 представлена блок-схема способа 1000, реализованного в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем. Процесс 1000 может выполняться сервером 118 поисковой системы.
[00174] Этап 1002 - получение сервером указания на цифровой текст
[00175] Способ 1000 начинается на этапе 1102, где приложение 126 по обработке текста, которое выполняется сервером 118 поисковой системы, получает указание на цифровой текст 302 через процедуру 202 получения текста.
[00176] В некотором варианте осуществления технологии, цифровой текст 302 получают от соответствующего ресурса, например, из базы данных, соединенной с сервером 118 поисковой системы, содержащей по меньшей мере один обучающий документ, или из индекса 120, и в этом случае цифровой текст является текстовой частью одного или нескольких просмотренных поисковым роботом сетевых ресурсов.
[00177] Этап 1004 - парсинг сервером цифрового текста и определение первого лексического элемента и второго лексического элемента
[00178] На этапе 1004 процедура 204 парсинга приложения 126 по обработке текста выполняет парсинг множества предложений 304 на одно или несколько отдельных предложений, например, первое предложение 306, второе предложение 308 и третье предложение 310.
[00179] Процедура 206 определения лексического элемента приложения 126 по обработке текста далее выполнена с возможностью выполнять первый лексический элемент 312 и второй лексический элемент 314.
[00180] Этап 1006 - для каждой записи о первом лексическом элементе в цифровом тексте: выбор сервером, n-ного числа последовательных элементов, соседних для первого лексического элемента
[00181] На этапе 1006 процедура 206 определения лексического элемента выполнена с возможностью идентифицировать каждое n-ное число последовательных элементов, соседних с первым лексическим элементом 314 для каждой записи о первом лексическом элементе 314 в цифровом тексте 302.
[00182] Этап 1008 - создание сервером первого контекстного параметра для первого лексического элемента, первый контекстный параметр включает указание на каждый элемент n-ного числа последовательных элементов и частоту совместного вхождения каждого элемента и первого лексического элемента в цифровом тексте
[00183] На этапе 1008 процедура 208 создания контекстного параметра выполнена с возможностью создавать первый контекстный параметр 212 для первого лексического элемента 314. Первый контекстный параметр 212 содержит указание на каждый элемент каждого из n-ного числа последовательных элементов, идентифицированных с помощью процедуры 206 определения лексического элемента и частоты совместного вхождения данного элемента и первого лексического элемента 314 в цифровой текст 302.
[00184] Этап 1010 - для каждой записи о втором лексическом элементе в цифровом тексте: выбор сервером, n-ного числа последовательных элементов, соседних для второго лексического элемента
[00185] На этапе 1010 процедура 206 определения лексического элемента выполнена с возможностью идентифицировать каждое n-ное число последовательных элементов, соседних со вторым лексическим элементом 316 для каждой записи о втором лексическом элементе 316 в цифровом тексте 302.
[00186] Этап 1012 - создание сервером второго контекстного параметра для второго лексического элемента, второй контекстный параметр включает указание на каждый элемент n-ного числа последовательных элементов и частоту совместного вхождения каждого элемента и второго лексического элемента в цифровом тексте
[00187] На этапе 1012 процедура 208 создания контекстного параметра выполнена с возможностью создавать второй контекстный параметр 214 для второго лексического элемента 316. Второй контекстный параметр 214 содержит указание на каждый элемент каждого из n-ного числа последовательных элементов, идентифицированных с помощью процедуры 206 определения лексического элемента и частоты совместного вхождения данного элемента и второго лексического элемента 316 в цифровой текст 302.
[00188] Этап 1014 - определение сервером параметра отношений лексических элементов для первого лексического элемента и второго лексического элемента, параметр отношений лексических элементов указывает на семантическую связь между первым лексическим элементом и вторым элементом, параметр отношений лексических элементов определяется путем: анализа взаимосвязи первого контекстного параметра и второго контекстного параметра; анализ совместного вхождения записей первого лексического элемента и второго лексического элемента в цифровом тексте
[00189] На этапе 1014 процедура 210 создания связи лексических элементов выполнена с возможностью выполнять одновременно или последовательно анализ взаимосвязи первого контекстного параметра 212 и второго параметра 214, а также анализа записей о совместном вхождении среди первого лексического элемента 312 и второго лексического элемента 314 в цифровом тексте 302.
[00190] На основе анализа взаимосвязи и анализа записей о совместном вхождении, процедура 210 создания связи лексических элементов выполнена с возможностью создавать параметр связи лексических элементов, указывающих на семантическую связь между первым лексическим элементом 312 и вторым лексическим элементом 314.
[00191] В некоторых вариантах осуществления технологии, семантическая связь может представлять собой одно из: неиерархическую связь (которая является одним из: синонимическим отношением или антонимическим отношением), иерархическую связь (которая является одним из: связью гипероним-гипоним или связью холоним-мероним) и ассоциативную связь.
[00192] Этап 1016 - сохранение сервером параметра связи лексических элементов в базу данных семантических отношений
[00193] На этапе 1016 процедура 210 создания связи лексических элементов выполнена с возможностью передавать пакет 220 данных, содержащий указание на первый лексический элемент 314 и второй лексический элемент 316 вместе с определенным параметром связи лексических элементов, в базу 124 данных семантических отношений для заполнения хранящегося там цифрового тезауруса.
[00194] Важно иметь в виду, что несмотря на то что вариант осуществления цифрового тезауруса был описан в отношении среды получения информации, это сделано для облегчения понимания и не предназначено для ограничения. Специалист в данной области техники поймет, что созданный цифровой тезаурус может быть использован для других целей, например, идентификации релевантной рекламы в среде получения информации, процесса перевода текста в речь, машинного перевода и так далее.
[00195] С учетом вышеописанных вариантов осуществления технологии, которые были описаны и показаны со ссылкой на конкретные этапы, выполненные в определенном порядке, следует иметь в виду, что эти этапы могут быть совмещены, разделены, обладать другим порядком выполнения - все это не выходит за границы настоящей технологии. Соответственно, порядок и группировка этапов не является ограничением для настоящей технологии.
[00196] Таким образом, по меньшей мере некоторые неограничивающие варианты осуществления настоящей технологии, описанные выше, можно изложить следующим образом в виде пронумерованных пунктов.
[00197] ПУНКТ 1 Способ автоматического создания цифрового тезауруса, способ выполняется на сервере (118), связанном с базой (124) данных семантических отношений, способ включает в себя:
получение (1002) сервером (118) указания на цифровой текст (302);
парсинг (1004) сервером (118) цифрового текста (302) и определение первого лексического элемента (312) и второго лексического элемента (314);
для каждой записи о первом лексическом элементе (312) в цифровом тексте (302);
выбор (1006) сервером (118) n-ного числа последовательных элементов, соседних с первым лексическим элементом (312);
создание (1006) сервером (118) первого контекстного параметра (212) для первого лексического элемента (312), первый контекстный параметр (212) включает указание на каждый элемент n-ного количества последовательных элементов и частоту совместного вхождения каждого элемента и первого лексического элемента (312) в цифровом тексте (302);
для каждой записи о втором лексическом элементе (314) в цифровом тексте (302):
выбор (1008) сервером (118) n-ного числа последовательных элементов, соседних со вторым лексическим элементом (314);
создание (1008) сервером (118) второго контекстного параметра (214) для второго лексического элемента (314), второй контекстный параметр (214) включает указание на каждый элемент n-ного количества последовательных элементов и частоту совместного вхождения каждого элемента и второго лексического элемента (314) в цифровом тексте (302);
определение (1010) сервером (118) параметра связи лексических элементов для первого лексического элемента (312) и второго лексического элемента (314), параметр связи лексических элементов указывает на семантическую связь между первым лексическим элементом (312) и вторым лексическим элементом (314), параметр связи лексических элементов определяется путем:
анализа взаимосвязи первого контекстного параметра (212) и второго контекстного параметра (214);
анализа совместного вхождения записей первого лексического элемента (312) и второго лексического элемента (314) в цифровом тексте (302);
сохранения (1012) сервером параметра связи лексических элементов в базу (124) данных семантических отношений.
[00198] ПУНКТ 2 Способ по п. 1, в котором указание на цифровой текст (302) получают из базы данных, содержащей по меньшей мере один цифровой обучающий документ.
[00199] ПУНКТ 3 Способ по любому из пп. 1-2, дополнительно включающий в себя присваивание грамматического типа каждому слову в цифровом тексте (302) до определения первого лексического элемента (312) и второго лексического элемента (314).
[00200] ПУНКТ 4 Способ по любому из пп. 1-3, в котором лексический элемент является одном из:
словом, которое было определено на основе соответствующего грамматического типа; и
фразой, которая является группой из двух или более слов, определенных на основе соответствующего грамматического типа одного из двух или более слов.
[00201] ПУНКТ 5 Способ по любому из пп. 1-4, дополнительно включающий в себя лемматизацию первого (312) и второго (314) лексических элементов и слов цифрового текста (302) до определения частоты совместного вхождения.
[00202] ПУНКТ 6 Способ по любому из пп. 1-5, в котором n-ное число последовательных элементов представляет собой по меньшей мере одно из: последовательные предшествующие, последовательные следующие или последовательные предшествующие и последовательные следующие элементы для первого (312) и второго (314) лексических элементов соответственно.
[00203] ПУНКТ 7 Способ по любому из пп. 1-6, в котором при определении того, что n-ное число последовательных элементов, соседних для данного вхождения первого лексического элемента (312) охватывает дополнительное предложение, соседнее с ним, создание соответствующего первого контекстного параметра (212), связанного с данным вхождением включает в себя использование подмножества n-ного числа последовательных элементов, подмножество представляет собой элементы предложения данного вхождения.
[00204] ПУНКТ 8 Способ по любому из пп. 1-7, в котором n-ное число последовательных элементов относятся к заранее определенному грамматическому типу.
[00205] ПУНКТ 9 Способ по любому из пп. 1-8, причем анализ совместного вхождения записей включает в себя определение параметра совместного вхождения, указывающего на частоту первого лексического элемента (312) и второго лексического элемента (314), которые содержатся в данном предложении цифрового текста (302).
[00206] ПУНКТ 10 Способ по любому из пп. 1-9, в котором анализ взаимосвязи включает в себя определение первого параметра сходства между первым контекстным параметром (212) и вторым контекстным параметром (214).
[00207] ПУНКТ 11 Способ по любому из пп. 1-10, в котором анализ взаимосвязи далее включает в себя определение первого параметра включения, который указывает на включение первого контекстного параметра (212) во второй контекстный параметр (214), и второго параметра включения (214), который указывает на включение второго контекстного параметра в первый контекстный параметр (212).
[00208] ПУНКТ 12 Способ по п. 11, в котором при определении того, что первый параметр включения и второй параметр включения находятся ниже первого порога, параметр связи лексических элементов для первого (312) и второго (314) лексических элементов является:
указанием на синонимические отношения, если первый параметр сходства выше второго порога, а параметр совместного вхождения ниже третьего порога;
указанием на антонимические отношения, если первый параметр сходства выше четвертого порога, а параметр совместного вхождения выше пятого порога; и
указанием на ассоциативную связь, если первый параметр сходства находится ниже шестого порога.
[00209] ПУНКТ 13 Способ по п. 12, в котором параметр связи лексических элементов для первого (312) и второго (314) лексических элементов указывает на связь гипероним-гипоним, если один из первого параметра включения или второго параметра включения находится выше порога.
[00210] ПУНКТ 14 Способ по любому из пп. 1-9, в котором анализ взаимосвязи дополнительно включает в себя:
определение первого параметра включения первого контекстного параметра (212) во второй контекстный параметр (214);
определение второго параметра включения первого контекстного параметра (212) в третий контекстный параметр (216), причем третий контекстный параметр (216) определен путем:
дальнейшего парсинга цифрового текста (302) сервером (118) для определения третьего лексического элемента (316);
для каждой записи о третьем лексическом элементе (316) в цифровом тексте (302):
выбор сервером (118) n-ного числа последовательных элементов, соседних с третьим лексическим элементом (316);
создание сервером (118) третьего контекстного параметра (216) для третьего лексического элемента (316), третий контекстный параметр (216) включает указание на каждый элемент n-ного количества последовательных элементов и частоту совместного вхождения каждого слова и третьего лексического элемента (316) в цифровом тексте (302); и
определение второго параметра сходства третьего контекстного параметра (216) со вторым контекстным параметром (212).
[00211] ПУНКТ 15 Способ по п. 14, в котором параметр связи лексических элементов для первого (312), второго (314) и третьего (316) лексических элементов указывает на связь гипероним-гипоним, если первый параметр включения и второй параметр включения находятся выше первого порога, и второй параметр сходства находится ниже второго порога.
[00212] ПУНКТ 16 Способ по любому из пп. 1-15, в котором парсинг цифрового текста (302) для определения первого лексического элемента (312) и второго лексического элемента включает в себя разделение цифрового текста (302) на множество предложений (304).
[00213] ПУНКТ 17 Способ по п. 1, в котором обучающий сервер (118) является сервером (118) поисковой системы.
[00214] ПУНКТ 18 Способ по п. 17, в котором цифровой текст (302) является веб-ресурсом (116), ранее просмотренным приложением (122) поискового робота.
[00215] ПУНКТ 19 Способ по п. 18, в котором в ответ на полученный поисковый запрос, сервер (118) поисковой системы выполнен с возможностью получать доступ к базе (124) данных семантических отношений и модифицировать поисковый запрос для получения релевантных веб-ресурсов (116).
[00216] ПУНКТ 20 Сервер (118) для автоматического создания цифрового тезауруса, сервер (118) содержит:
сетевой интерфейс для коммуникативного соединения сети (112) передачи данных;
процессор соединен с сетевым интерфейсом, процессор выполнен с возможностью выполнять способ по любому из пп. 1-18.
[00217] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом из вариантов осуществления настоящего технического решения. Например, варианты осуществления настоящего технического решения могут быть выполнены без проявления некоторых технических результатов, другие могут быть выполнены с проявлением и других технических результатов.
[00218] Некоторые из этих этапов, а также передача-получение сигнала хорошо известны в данной области техники и поэтому для упрощения были опущены в конкретных частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, опто-волоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00219] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ СОПОСТАВЛЕНИЯ ИСХОДНОГО ЛЕКСИЧЕСКОГО ЭЛЕМЕНТА ПЕРВОГО ЯЗЫКА С ЦЕЛЕВЫМ ЛЕКСИЧЕСКИМ ЭЛЕМЕНТОМ ВТОРОГО ЯЗЫКА | 2016 |
|
RU2682002C2 |
| СПОСОБ (ВАРИАНТЫ) И СЕРВЕР ОБРАБОТКИ ТЕКСТА | 2016 |
|
RU2642413C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке | 2017 |
|
RU2692049C1 |
| АННОТАЦИЯ ПОСРЕДСТВОМ ПОИСКА | 2007 |
|
RU2439686C2 |
| СПОСОБ И СИСТЕМА КОМПЬЮТЕРНОЙ ОБРАБОТКИ ОДНОЙ ИЛИ НЕСКОЛЬКИХ ЦИТАТ В ЦИФРОВЫХ ТЕКСТАХ ДЛЯ ОПРЕДЕЛЕНИЯ ИХ АВТОРА | 2018 |
|
RU2711123C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| Устройство для формирования лексических массивов | 1980 |
|
SU934487A1 |
| АВТОМАТИЧЕСКИЙ ПОИСК КОНТЕКСТНО-СВЯЗАННЫХ ЭЛЕМЕНТОВ ЗАДАЧИ | 2010 |
|
RU2573209C2 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
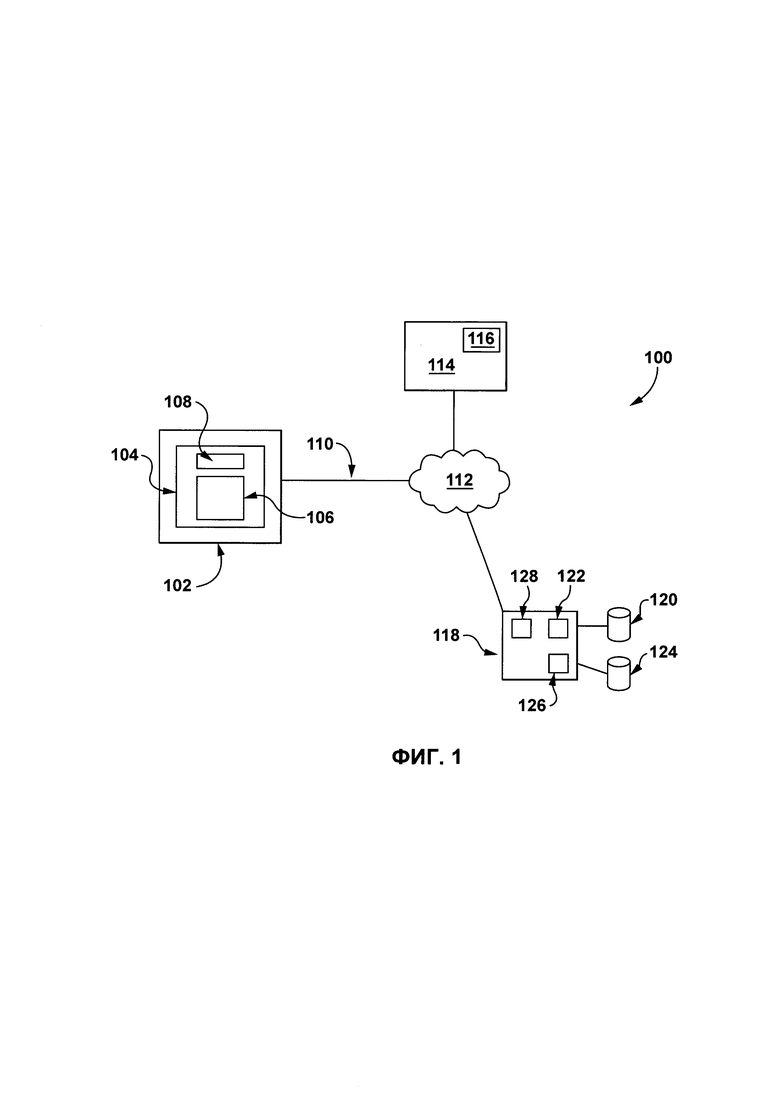
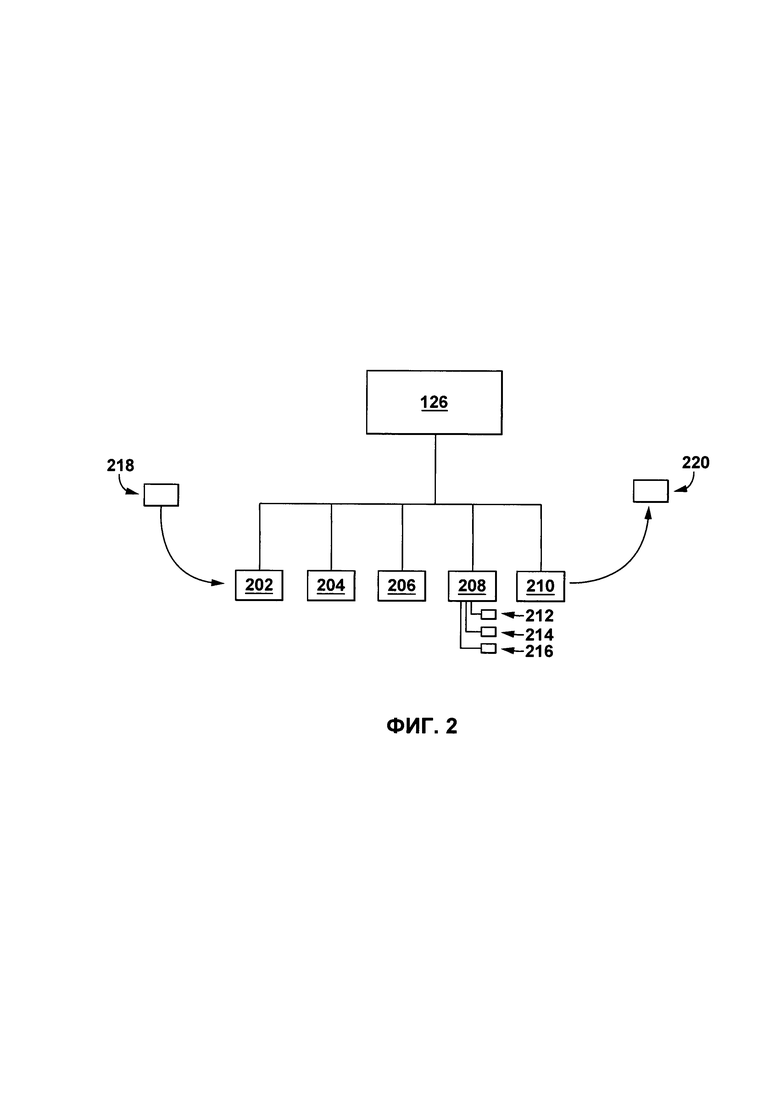
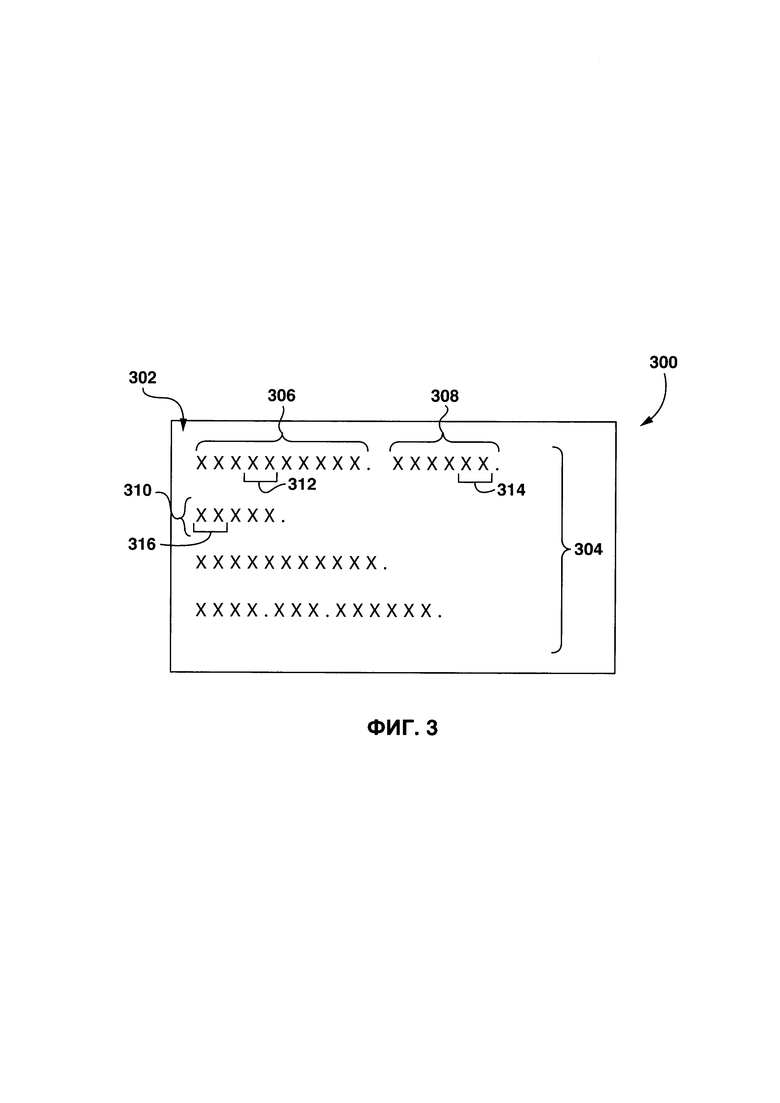
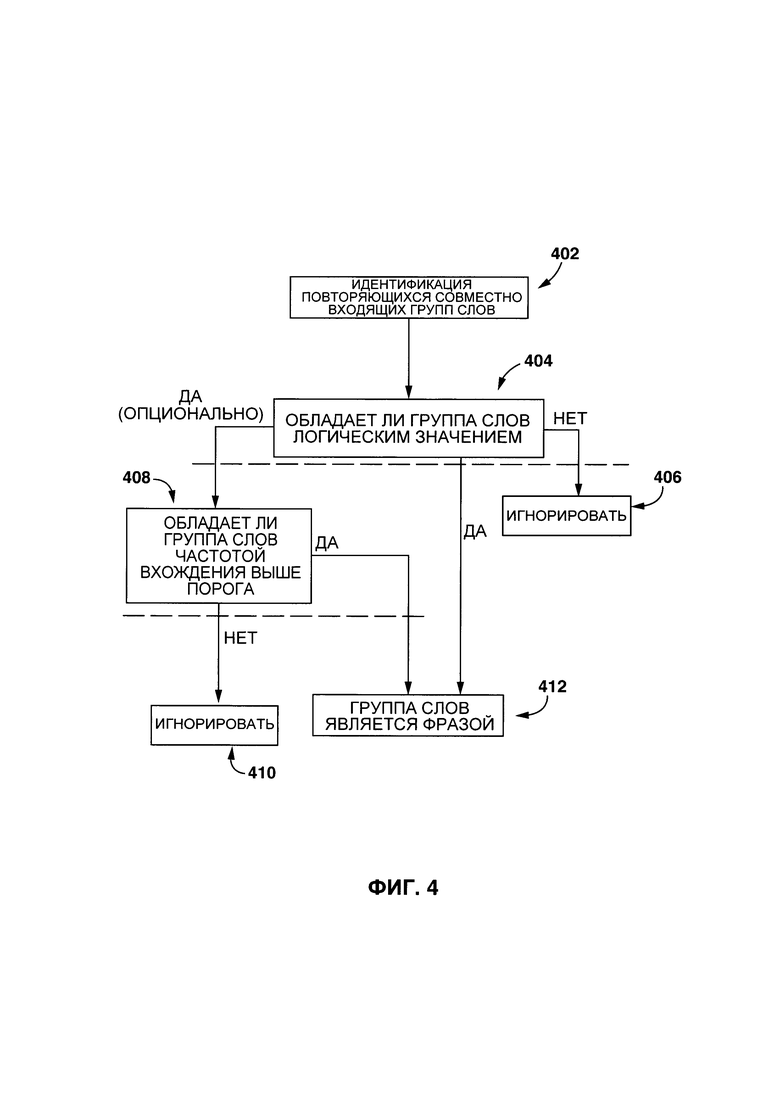
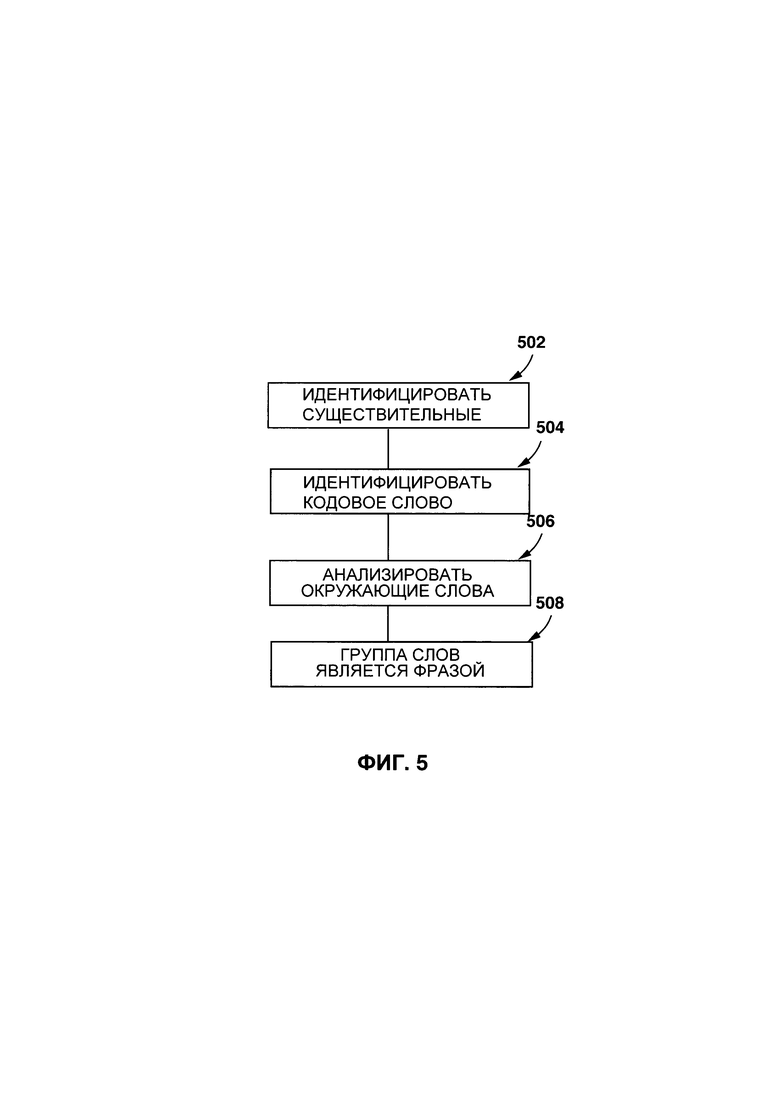
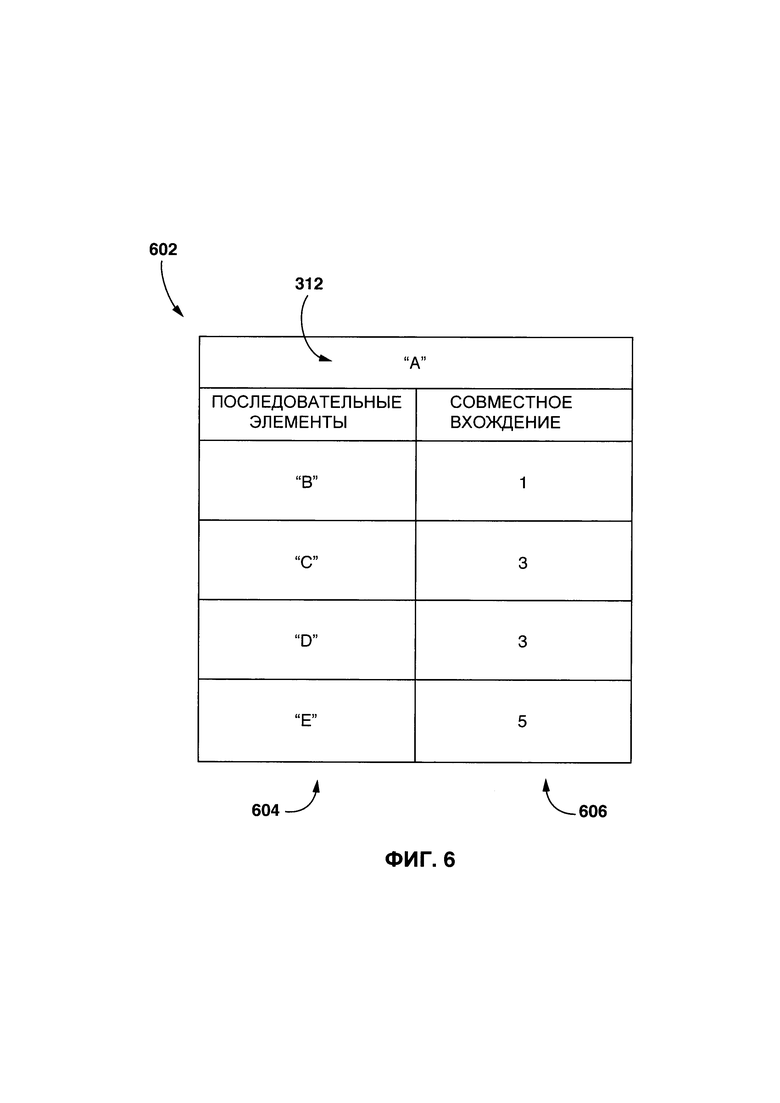
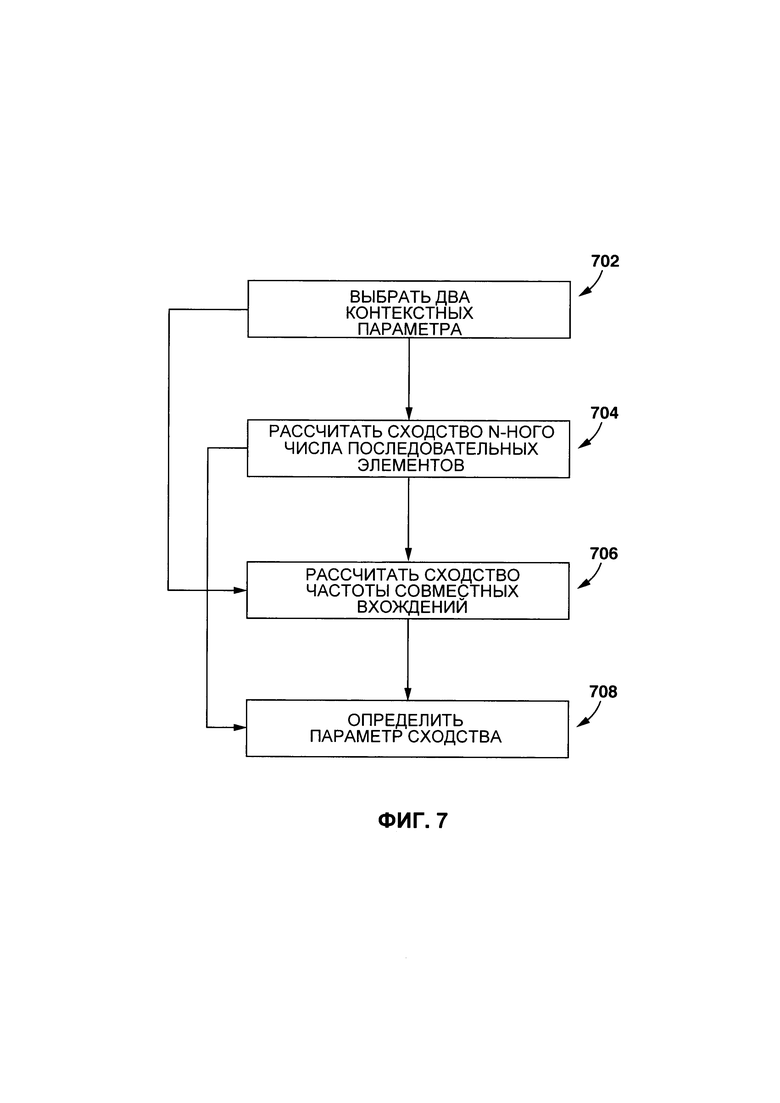
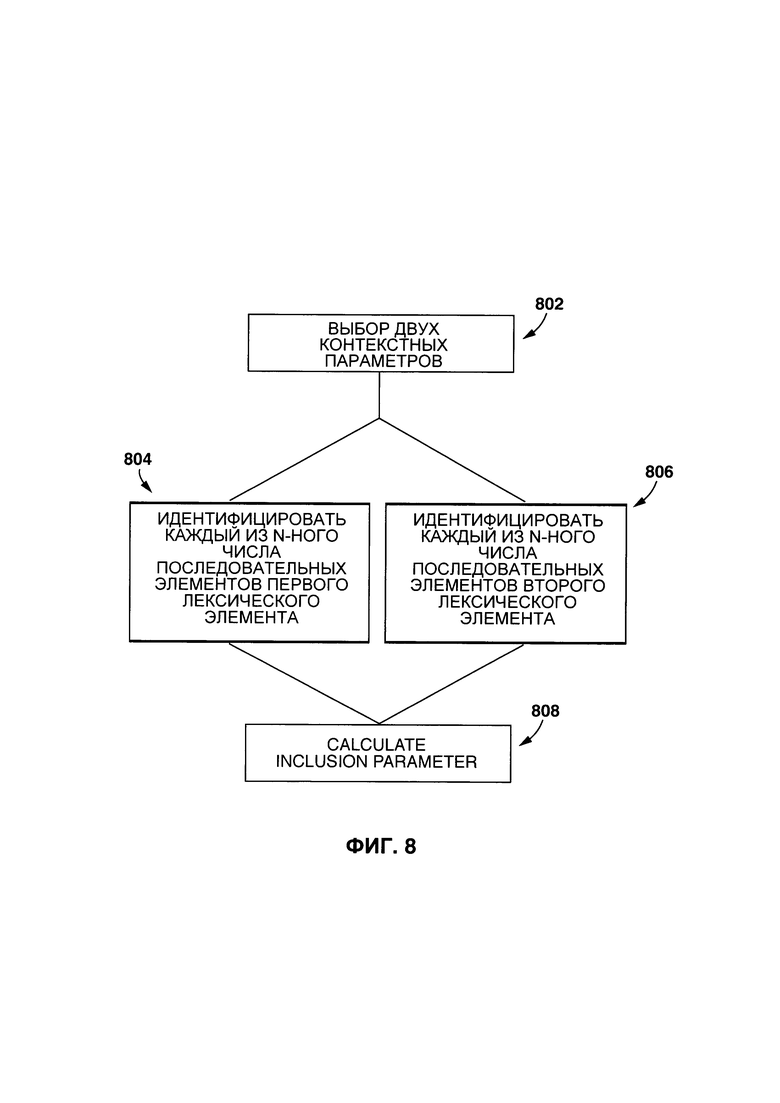
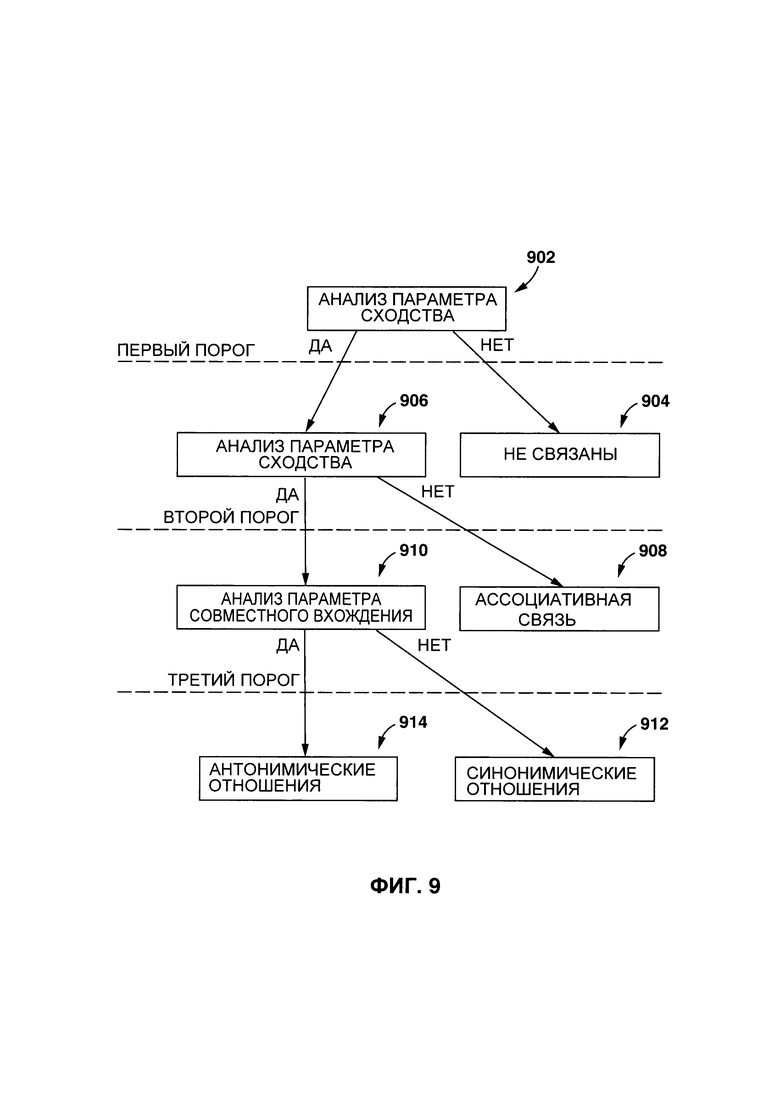
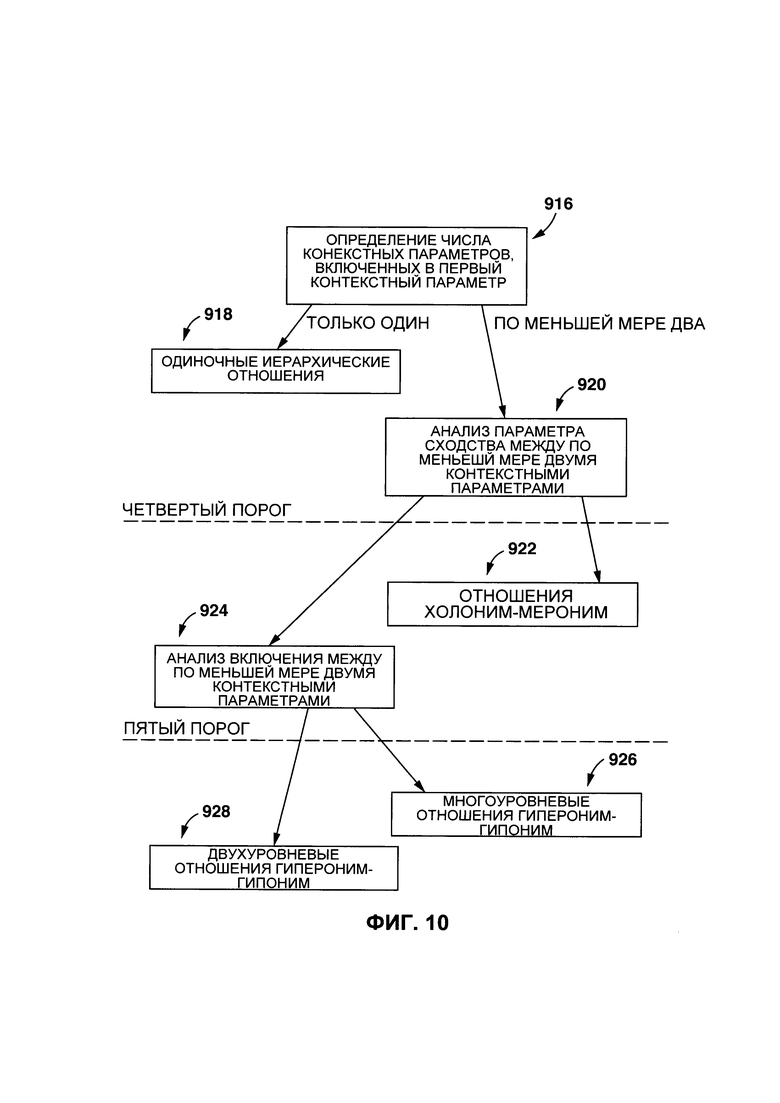
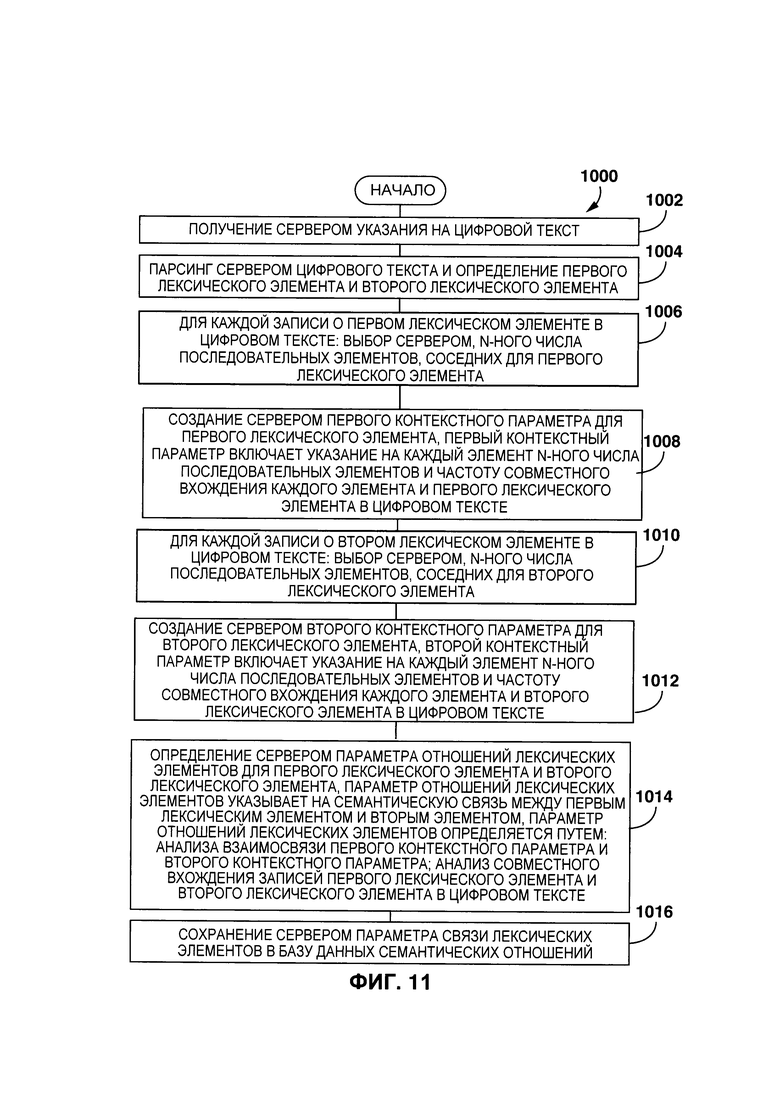
Изобретение относится к способам и серверам для автоматического создания тезауруса. Техническим результатом является расширение арсенала технических средств автоматического создания цифрового тезауруса. В способе автоматического создания цифрового тезауруса выполняют парсинг цифрового текста и определение первого и второго лексических элементов. Для каждой записи о первом элементе выбирают n-е число последовательных элементов, соседних с первым элементом, создают первый контекстный параметр для первого элемента, включающий указание на каждый элемент из n-го числа последовательных элементов и частоты совместного вхождения каждого элемента с первым элементов в цифровом тексте. Для каждой записи второго элемента выбирают n-е число последовательных элементов, соседних для второго элемента, создают второй контекстный параметр. Определяют параметр связи лексических элементов для первого элемента и второго элемента путем анализа взаимосвязи и анализа совместного вхождения записей. 2 н. и 18 з.п. ф-лы, 11 ил.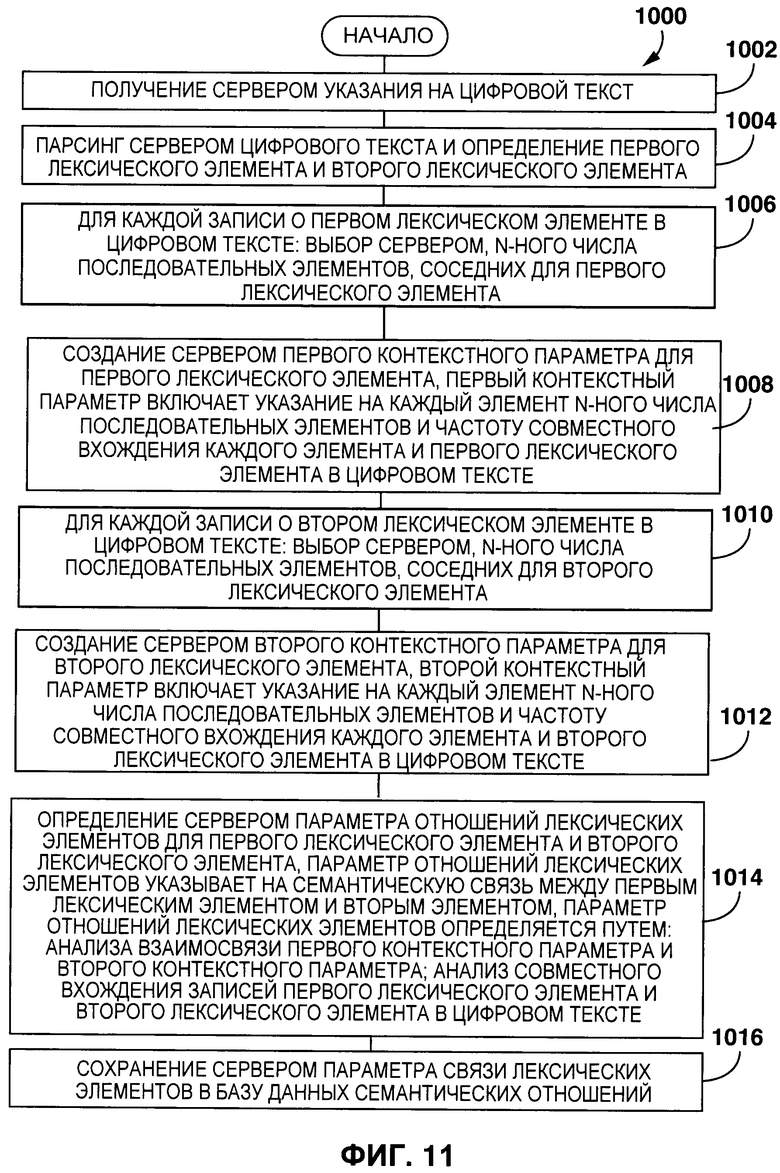
1. Способ автоматического создания цифрового тезауруса, выполняемый на сервере, связанном с базой данных семантических отношений, и включающий:
получение сервером указания на цифровой текст;
парсинг сервером цифрового текста и определение первого лексического элемента и второго лексического элемента;
для каждой записи о первом лексическом элементе в цифровом тексте:
выбор сервером n-го числа последовательных элементов, соседних с первым лексическим элементом;
создание сервером для первого лексического элемента первого контекстного параметра, включающего указание на каждый элемент n-го количества последовательных элементов и частоту совместного вхождения каждого элемента и первого лексического элемента в цифровом тексте;
для каждой записи о втором лексическом элементе в цифровом тексте:
выбор сервером n-го числа последовательных элементов, соседних со вторым лексическим элементом;
создание сервером для второго лексического элемента второго контекстного параметра, включающего указание на каждый элемент n-го количества последовательных элементов и частоту совместного вхождения каждого элемента и второго лексического элемента в цифровом тексте;
определение сервером для первого лексического элемента и второго лексического элемента параметра связи лексических элементов, указывающего на семантическую связь между первым лексическим элементом и вторым лексическим элементом и определяемого путем:
анализа взаимосвязи первого контекстного параметра и второго контекстного параметра;
анализа совместного вхождения записей первого лексического элемента и второго лексического элемента в цифровом тексте; и
сохранение сервером параметра связи лексических элементов в базу данных семантических отношений.
2. Способ по п. 1, который включает в себя присваивание грамматического типа каждому слову в цифровом тексте до определения первого лексического элемента и второго лексического элемента.
3. Способ по п. 2, в котором лексический элемент представляет собой одно из следующего:
слово, определенное на основе соответствующего грамматического типа; и
фразу, которая является группой из двух или более слов, определенных на основе соответствующего грамматического типа одного из двух или более слов.
4. Способ по п. 3, который включает в себя лемматизацию первого и второго лексических элементов и слов цифрового текста до определения частоты совместного вхождения.
5. Способ по п. 1, в котором n-е число последовательных элементов представляет собой по меньшей мере одно из: последовательные предшествующие, последовательные следующие или последовательные предшествующие и последовательные следующие элементы для первого и второго лексических элементов соответственно.
6. Способ по п. 1, в котором анализ совместного вхождения записей включает в себя определение параметра совместного вхождения, указывающего на частоту первого лексического элемента и второго лексического элемента, которые содержатся в одном и том же предложении цифрового текста.
7. Способ по п. 6, в котором анализ взаимосвязи включает в себя определение первого параметра сходства между первым контекстным параметром и вторым контекстным параметром.
8. Способ по п. 7, в котором анализ взаимосвязи далее включает в себя:
определение первого параметра включения, указывающего на включение первого контекстного параметра во второй контекстный параметр;
определение второго параметра включения, указывающего на включение второго контекстного параметра в первый контекстный параметр.
9. Способ по п. 8, в котором при определении того, что первый параметр включения и второй параметр включения находятся ниже первого порога, параметр связи лексических элементов для первого и второго лексических элементов является:
указанием на синонимические отношения, если первый параметр сходства выше второго порога, а параметр совместного вхождения ниже третьего порога;
указанием на антонимические отношения, если первый параметр сходства выше четвертого порога, а параметр совместного вхождения ниже пятого порога;
указанием на ассоциативную связь, если первый параметр сходства находится ниже шестого порога.
10. Способ по п. 8, в котором параметр связи лексических элементов для первого и второго лексических элементов указывает на связь гипероним-гипоним, если один из первого параметра включения или второго параметра включения находится выше порога.
11. Способ по п. 6, в котором анализ взаимосвязи далее включает в себя:
определение первого параметра включения первого контекстного параметра во второй контекстный параметр;
определение второго параметра включения первого контекстного параметра в третий контекстный параметр, причем третий контекстный параметр определен путем:
дальнейшего парсинга цифрового текста сервером для определения третьего лексического элемента;
для каждой записи о третьем лексическом элементе в тексте:
выбор сервером n-го числа последовательных элементов, соседних с третьим лексическим элементом;
создание сервером третьего контекстного параметра для третьего лексического элемента, третий контекстный параметр включает указание на каждый элемент n-го количества последовательных элементов и частоту совместного вхождения каждого слова и третьего лексического элемента в цифровом тексте; и
определение второго параметра сходства третьего контекстного параметра со вторым контекстным параметром.
12. Способ по п. 11, в котором параметр связи лексических элементов для первого, второго и третьего лексических элементов указывает на связь гипероним-гипоним, если первый параметр включения и второй параметр включения находятся выше первого порога, и второй параметр сходства находится ниже второго порога.
13. Сервер для автоматического создания цифрового тезауруса, содержащий:
сетевой интерфейс для коммуникативного соединения по сети передачи данных;
процессор, соединенный с сетевым интерфейсом и выполненный с возможностью осуществлять:
получение указания на цифровой текст;
парсинг цифрового текста и определение первого лексического элемента и второго лексического элемента;
для каждой записи о первом лексическом элементе в цифровом тексте:
выбор сервером n-го числа последовательных элементов, соседних с первым лексическим элементом;
создание для первого лексического элемента первого контекстного параметра, включающего указание на каждый элемент n-го числа последовательных элементов и частоту совместного вхождения каждого элемента и первого лексического элемента в цифровом тексте;
для каждой записи о втором лексическом элементе в цифровом тексте:
выбор сервером n-го числа последовательных элементов, соседних со вторым лексическим элементом;
создание для второго лексического элемента сервером второго контекстного параметра, включающего указание на каждый элемент n-го числа последовательных элементов и частоту совместного вхождения каждого элемента и второго лексического элемента в цифровом тексте;
определение для первого лексического элемента и второго лексического элемента параметра связи лексических элементов, указывающего на семантическую связь между первым лексическим элементом и вторым лексическим элементом и определяемого путем:
анализа взаимосвязи первого контекстного параметра и второго контекстного параметра;
анализа совместного вхождения записей первого лексического элемента и второго лексического элемента в цифровом тексте; и
сохранения параметра связи лексических элементов в базу данных семантических отношений.
14. Сервер по п. 13, который выполнен с возможностью осуществлять лемматизацию первого и второго лексических элементов и слов цифрового текста до определения частоты совместного вхождения.
15. Сервер по п. 13, в котором n-е число последовательных элементов представляет собой по меньшей мере одно из: последовательные предшествующие, последовательные следующие или последовательные предшествующие и последовательные следующие элементы для первого и второго лексических элементов соответственно.
16. Сервер по п. 15, который при определении того, что n-е число последовательных элементов, соседних для данного вхождения первого лексического элемента, охватывает дополнительное предложение, соседнее с ним, создает соответствующий первый контекстный параметр, связанный с данным вхождением, который включает в себя использование подмножества n-го числа последовательных элементов, подмножество представляет собой элементы предложения данного вхождения.
17. Сервер по п. 16, который:
до определения n-го числа последовательных элементов выполнен с возможностью назначать грамматический тип каждому слову цифрового текста; и
в котором n-е число последовательных элементов имеет заранее определенный грамматический тип.
18. Сервер по п. 13, в котором анализ взаимосвязи включает в себя одно из:
определение первого параметра включения, указывающего на включение первого контекстного параметра во второй контекстный параметр;
определение второго параметра включения, указывающего на включение второго контекстного параметра в первый контекстный параметр;
определение третьего параметра включения первого контекстного параметра в третий контекстный параметр, причем третий контекстный параметр определен путем:
дальнейшего парсинга цифрового текста сервером для определения третьего лексического элемента;
для каждой записи о третьем лексическом элементе в тексте:
выбор сервером n-го числа последовательных элементов, соседних с третьим лексическим элементом;
создание для третьего лексического элемента третьего контекстного параметра, включающего указание на каждый элемент n-го количества последовательных элементов и частоту совместного вхождения каждого слова и третьего лексического элемента в цифровом тексте;
определение первого параметра сходства между первым контекстным параметром и вторым контекстным параметром; и
определение второго параметра сходства между третьим контекстным параметром и вторым контекстным параметром.
19. Сервер по п. 18, в котором анализ совместного вхождения записей включает в себя определение параметра совместного вхождения, указывающего на частоту первого лексического элемента и второго лексического элемента, которые содержатся данном одном предложении цифрового текста.
20. Сервер по п. 19, в котором:
при определении того, что первый параметр включения и второй параметр включения находятся ниже первого порога, параметр связи лексических элементов для первого и второго лексических элементов является:
синонимическим отношением, если первый параметр сходства выше второго порога, а параметр совместного вхождения ниже третьего порога;
антонимическим отношением, если первый параметр сходства выше четвертого порога, а параметр совместного вхождения выше пятого порога;
ассоциативной связью, если первый параметр сходства находится ниже пятого порога;
при определении того, что первый параметр включения находится выше первого порога, параметр связи лексических элементов для первого и второго лексических элементов является:
отношением гипероним-гипоним, если параметр включения находится выше пятого порога; и
при определении того, что первый параметр включения и третий параметр включения находятся выше шестого порога, параметр связи лексических элементов для первого, второго и третьего лексических элементов является:
отношением холоним-мероним, если второй параметр сходства находится ниже седьмого порога.
| Токарный резец | 1924 |
|
SU2016A1 |
| US 9158841 B2, 13.10.2015 | |||
| US 7890521 B1, 15.02.2011 | |||
| US 6519586 B2, 11.02.2003 | |||
| US 5128865 A, 07.07.1992 | |||
| СПОСОБ ПОСТРОЕНИЯ СЕМАНТИЧЕСКОЙ МОДЕЛИ ДОКУМЕНТА | 2011 |
|
RU2487403C1 |

