Область техники, к которой относится изобретение
Настоящее изобретение относится к кодированию двоичных чисел, в частности, с целью подготовки адресов пакетов для эффективной классификации пакетов, и к соответствующей системе классификации пакетов.
Уровень техники
Троичная память, ориентированная на содержание (Ternary Content Aware Memory, TCAM), широко используется для классификации пакетов в сетевых чипах. TCAM может параллельно и с высокой производительностью искать правила классификации. Однако TCAM имеет ряд недостатков, например, необходимая площадь чипа для каждого бита TCAM намного больше, чем у SRAM. Кроме того, стоимость TCAM является очень высокой. Нагревание также является серьезной проблемой. Что еще более важно, TCAM поддерживает только значения «0», «1», «*», «*», указывающие «не важно» для сопоставления. Она не может поддерживать сопоставление диапазонов. Как правило, диапазоны могут быть преобразованы в соответствующий набор префиксов, при этом каждый префикс может храниться в отдельной записи TCAM. Одно правило диапазона, занимающее множество записей TCAM, называется расширением диапазона. Однако новые способы кодирования для кодирования диапазонов с помощью «0», «1», «*» позволяют уменьшить количество необходимых записей TCAM.
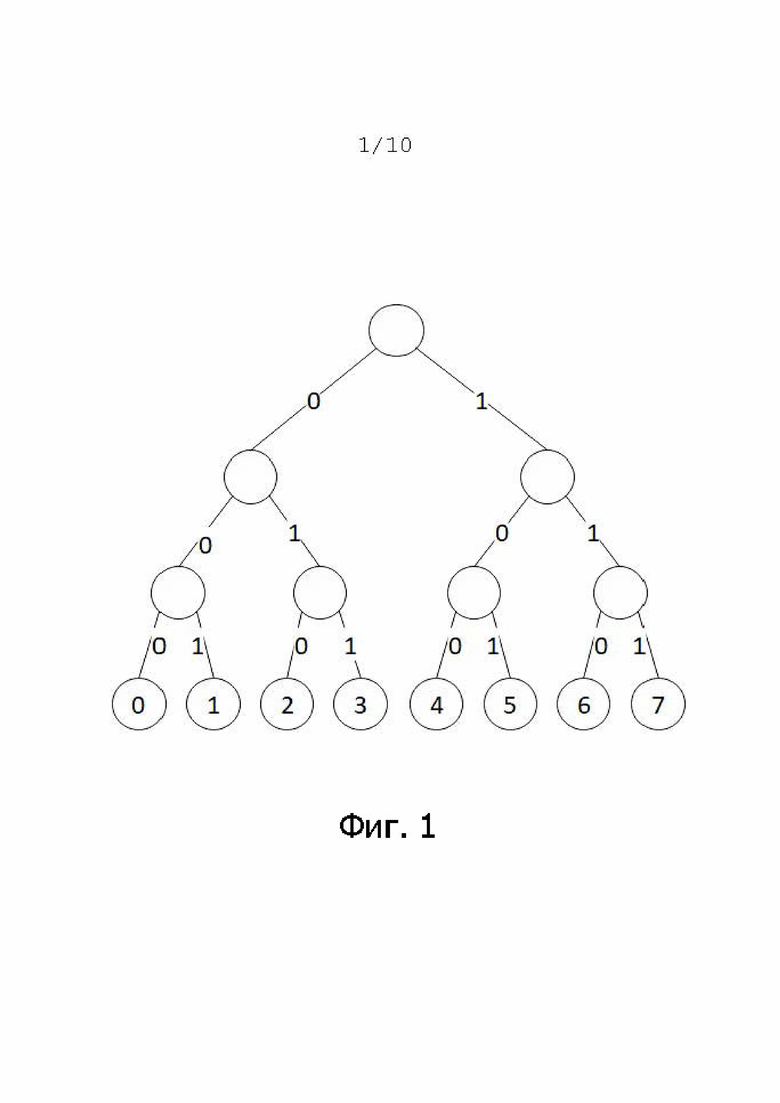
Первым примером известной схемы кодирования является двоичное кодирование. Двоичный код, как правило, используется в электронике. На фиг. 1 показано примерное двоичное кодирование. Хотя значения 0–7 в нижних восьми кругах представляют значения, подлежащие кодированию в десятичной системе, соответствующее дерево кодирования показано выше.
Для того чтобы закодировать, например, диапазон [1,6], необходимы четыре записи (001, 01*, 10*, 110).
TCAM в нем использует значения «0», «1», «*» записей для отдельных цифр.
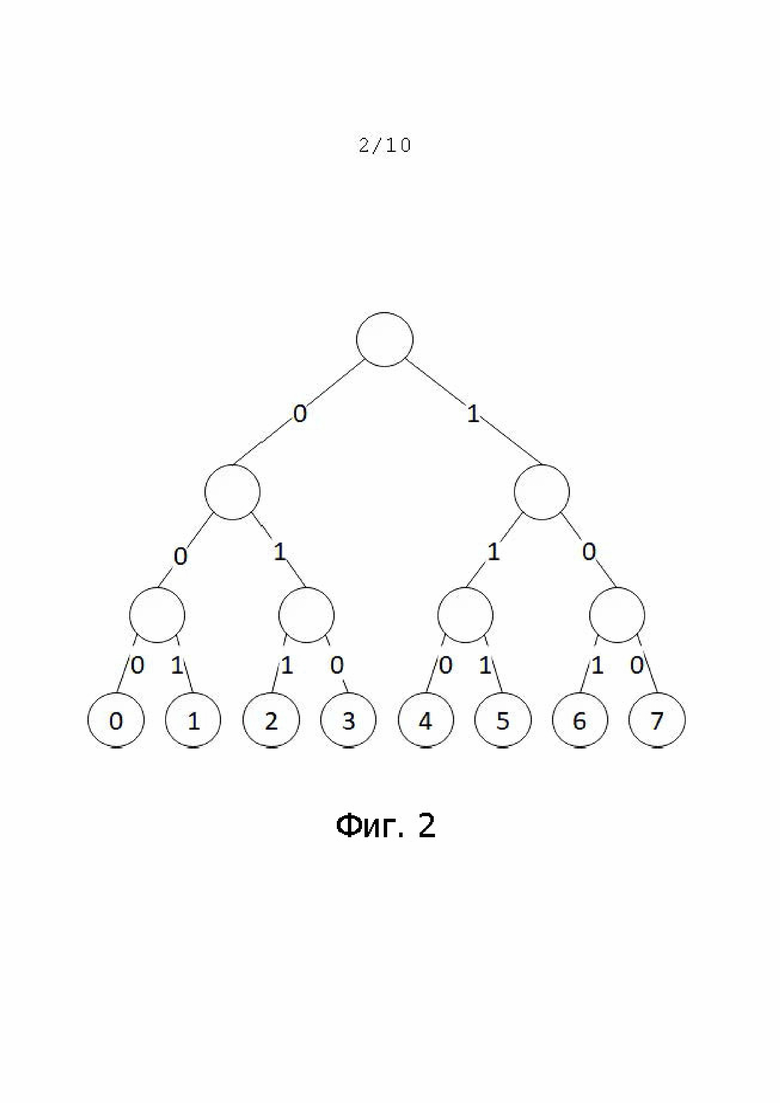
Еще одной примерной схемой кодирования является кодирование по Грею для коротких диапазонов. Примерное дерево кодирования показано на фиг. 2.
Кодирование по Грею для коротких диапазонов (Short Range Grey Encoding, SRGE) основано на кодах Грея, первоначально разработанных для исправления ошибок таким образом, чтобы кодировки каждых двух целочисленных значений, следующих друг за другом, отличались только одним битом. Для коротких диапазонов требуется меньше записей по сравнению с двоичным кодированием. Например, для диапазона [1, 6], выраженного в коде Грея, требуется только 2 записи: *01, *1*, тогда как для двоичного кодирования требуется 4 записи, как показано выше.
Еще одной примерной схемой кодирования является предварительное кодирование диапазона, независимого от базы данных (Database Independent Range Pre-Encoding, DIRPE).
В DIRPE для выражения произвольного w-битовго диапазона необходимо по меньшей мере 2w - 1 битов. Например, для 16-битового поля порта, для кодирования необходимо 65535 битов. Однако разделение w-битового поля на несколько фрагментов и реализация ограничительного кодирования (Fence Encoding) в каждом фрагменте позволяет легко сократить количество записей для выражения диапазонов.
В приведенной ниже таблице представлен пример ограничительного кодирования:
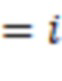
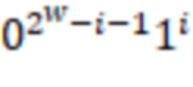
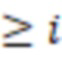
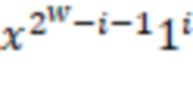
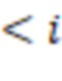
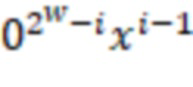
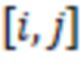
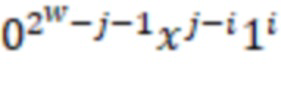
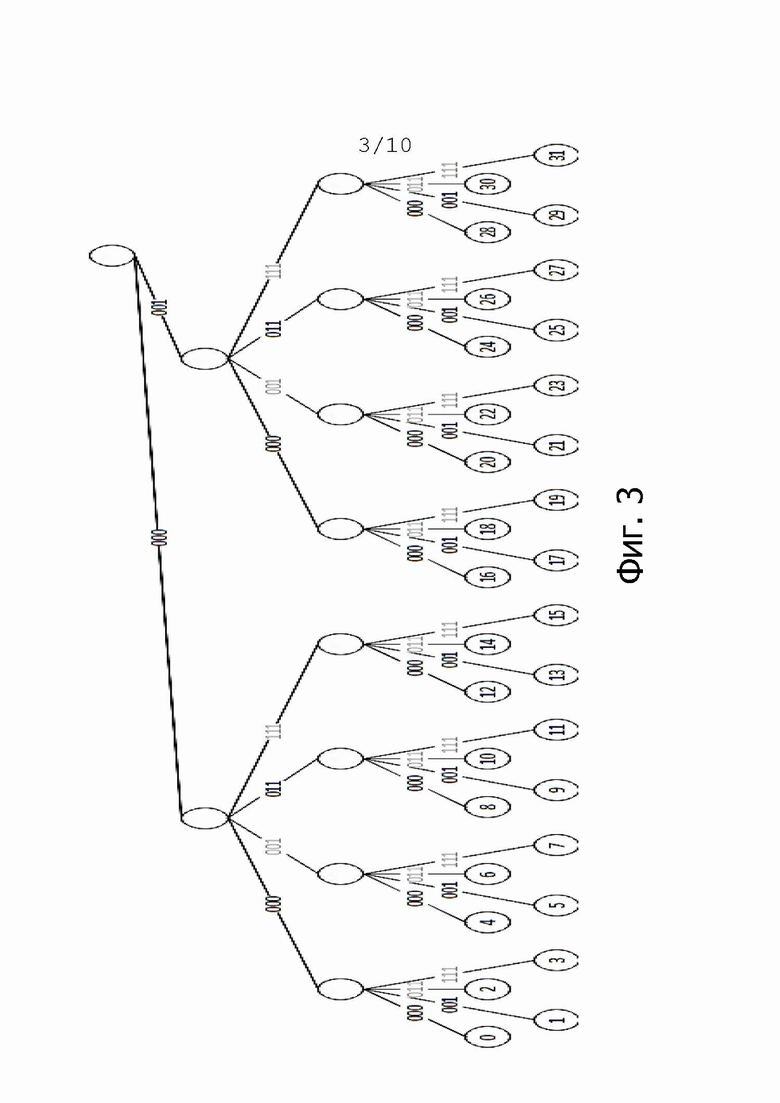
Пример DIRPE показан на фиг. 3. Тридцать два кружка в нижней части чертежа, помеченные цифрами 0-31, показывают здесь снова некодированные значения в десятичной форме. Сверху над этими числами показано дерево кодирования. Здесь легко увидеть, что для каждого уровня кодирования, соответствующего фрагментам, используется одно и то же правило кодирования. Это означает, что еще не закодированное двоичное значение фрагмента всегда кодируется в один и тот же кодированный фрагмент.
Хотя DIRPE позволяет значительно сократить количество необходимых записей TCAM, по-прежнему требуется большое количество записей.
Раскрытие сущности изобретения
Соответственно, задача настоящего изобретения состоит в том, чтобы обеспечить кодер и способ кодирования, обеспечивающие эффективное кодирование, и систему классификации пакетов, которая обеспечивает эффективную классификацию пакетов.
Задача решается с помощью признаков независимых пунктов формулы изобретения. Зависимые пункты формулы изобретения содержат дополнительные усовершенствования. Аспекты, показанные ниже, следует понимать как примеры, полезные для понимания изобретения, а не как варианты осуществления изобретения.
Согласно первому аспекту изобретения предусмотрен кодер для кодирования двоичного входного числа в двоичное выходное число. Кодер содержит разделитель фрагментов, выполненный с возможностью разделения двоичного входного числа на фрагменты длиной n битов, и кодер фрагментов, выполненный с возможностью кодирования каждого из фрагментов в кодированный фрагмент длиной m в соответствии с правилом кодирования фрагментов. Правило кодирования фрагментов содержит кодирование фрагмента с использованием первого правила кодирования частичных фрагментов, если значение предыдущего фрагмента является четным, и кодирование фрагмента с использованием второго правила кодирования частичных фрагментов, если значение предыдущего фрагмента является нечетным. Более того, кодер содержит конкатенатор фрагментов, выполненный с возможностью конкатенации кодированных фрагментов, в результате чего получается двоичное выходное число. Использование различных правил кодирования частичных фрагментов в зависимости от значения предыдущего фрагмента позволяет значительно сократить количество необходимых записей TCAM для выражения диапазона. Таким образом, возможно очень эффективное кодирование и, в частности, дополнительная эффективная обработка соответствующим образом кодированных чисел и правил классификации пакетов.
Согласно первой форме реализации первого аспекта, второе правило кодирования частичных фрагментов является зеркальным отображением первого правила кодирования частичных фрагментов. Дополнительно или альтернативно, второе правило кодирования частичных фрагментов содержит кодирование фрагмента со значением x в том же самом кодированном фрагменте, в котором первое правило кодирования фрагментов кодирует фрагмент со значением 2n-1-x. Оба эти варианта значительно уменьшаю количество необходимых записей TCAM.
Согласно второй форме реализации первого аспекта, первое правило кодирования частичных фрагментов и второе правило кодирования частичных фрагментов содержат каждое по отдельности то, что соседние значения кодируются таким образом, чтобы кодированные числа отличались только на один бит. Это дополнительно уменьшает количество необходимых записей TCAM для выражения диапазонов.
Согласно третьей форме реализации первого аспекта, m больше, чем n. Это позволяет обеспечить, в частности, эффективную структуру кода.
Согласно четвертой форме реализации первого аспекта, если n=2, и m=3,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 000,
○ 01 кодируется в кодированный фрагмент значения 001,
○ 10 кодируется в кодированный фрагмент значения 011,
○ 11 кодируется в кодированный фрагмент значения 111,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 111,
○ 01 кодируется в кодированный фрагмент значения 011,
○ 10 кодируется в кодированный фрагмент значения 001,
○ 11 кодируется в кодированный фрагмент значения 000, или
- где, если n=2, и m=3,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 000,
○ 01 кодируется в кодированный фрагмент значения 001,
○ 10 кодируется в кодированный фрагмент значения 011,
○ 11 кодируется в кодированный фрагмент значения 111,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 111,
○ 01 кодируется в кодированный фрагмент значения 011,
○ 10 кодируется в кодированный фрагмент значения 001,
○ 11 кодируется в кодированный фрагмент значения 000.
Альтернативно, если n=2, и m=4,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 0001,
○ 01 кодируется в кодированный фрагмент значения 0111,
○ 10 кодируется в кодированный фрагмент значения 1011,
○ 11 кодируется в кодированный фрагмент значения 1110,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 1110,
○ 01 кодируется в кодированный фрагмент значения 1011,
○ 10 кодируется в кодированный фрагмент значения 0111,
○ 11 кодируется в кодированный фрагмент значения 0001, или
- где, если n=2, и m=4,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 0001,
○ 01 кодируется в кодированный фрагмент значения 0111,
○ 10 кодируется в кодированный фрагмент значения 1011,
○ 11 кодируется в кодированный фрагмент значения 1110,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 1110,
○ 01 кодируется в кодированный фрагмент значения 1011,
○ 10 кодируется в кодированный фрагмент значения 0111,
○ 11 кодируется в кодированный фрагмент значения 0001.
Эти альтернативные варианты позволяют обеспечить очень эффективное кодирование для кодов различной длины.
Согласно второму аспекту изобретения, предусмотрена система классификации пакетов для классификации входных пакетов, каждый из которых содержит по меньшей мере один параметр классификации, согласно по меньшей мере одному правилу классификации, на основе по меньшей мере одного параметра классификации. Система классификации пакетов содержит описанный выше кодер, выполненный с возможностью кодирования по меньшей мере одного параметра классификации по меньшей мере в один кодированный параметр классификации, и классификатор пакетов, выполненный с возможностью классификации входных пакетов, согласно по меньшей мере одному правилу классификации, на основе по меньшей мере одного кодированного параметра классификации. Это позволяет обеспечить очень эффективную классификацию пакетов.
Согласно первой форме реализации второго аспекта, классификатор пакетов содержит кодер правил классификации, выполненный с возможностью определения по меньшей мере одного кодированного правила классификации по меньшей мере из одного правила классификации, и устройство классификации, выполненное с возможностью классификации входных пакетов, согласно по меньшей мере одному кодированному правилу классификации, на основе по меньшей мере одного кодированного параметра классификации. Это позволяет автоматически определять кодированные правила классификации и, таким образом, выполнять очень простую операцию.
Согласно второй форме реализации второго аспекта, устройство классификации представляет собой троичную память, ориентированную на содержание (Ternary Content-Aware Memory, TCAM). Кодер правил классификации выполнен с возможностью программирования TCAM с использованием по меньшей мере одного кодированного правила классификации. Это позволяет обеспечить особенно эффективную классификацию пакетов.
Следует отметить, что аббревиатура TCAM также используется для термина «троичная адресуемая по содержимому память», который является синонимом троичной памяти, ориентированной на содержание.
Согласно третьей форме реализации второго аспекта, система классификации содержит множество выходных портов. По меньшей мере один параметр классификации содержит адрес. По меньшей мере одно правило классификации содержит множество сопоставлений каждого из диапазона адресов с одним из множества выходных портов. Это дополнительно повышает эффективность классификации пакетов.
Согласно четвертой реализации второго аспекта, каждый из диапазонов адресов содержит адрес между первым адресом l и последним адресом r. Кодер правил классификации выполнен с возможностью кодирования каждого диапазона адресов в несколько записей TCAM. Кроме того, это повышает эффективность классификации.
Согласно пятой форме реализации второго аспекта, кодер правил классификации содержит разделитель наиболее значащего фрагмента, выполненный с возможностью определения наиболее значащего фрагмента адреса x (MSC(x)) и количества транковых фрагментов адреса x (TC(x)) как оставшейся части адреса без наиболее значащего фрагмента. Это дополнительно повышает эффективность кодирования.
Согласно шестой форме реализации второго аспекта, кодер (111) правил классификации содержит определитель (1111) записи, выполненный таким образом, чтобы:
- если TC(l) = 0, и если TC(r) = 2n-2-1, определить одну запись TCAM как единственную запись для этого диапазона адресов,
- если TC(l) = 0, и если TC(r) |= 2n-2-1,
○ разбить I на два диапазона I1 = [l, x-1] и I2 = [x, r], где x = MSC(r)*2n-2,
○ для I1 определить одну запись TCAM и
○ для I2 рекурсивно построить диапазон,
- если диапазон [l, r1-1] адресов уже закодирован, выбрать значение l1 в качестве начального значения для кодирования оставшейся части диапазона [l, r1-1], чтобы минимизировать размер кодирования диапазона [l1, r] следующим образом:
○ если MSC(r1) > MSC(r), вернуть нулевое значение,
○ если MSC(r1) = MSC(r), рекурсивно найти кодировку (n-2)-битового диапазона [0, TC(r)] адресов, и
○ если MSC(r1) < MSC(r), разбить диапазон I на 3 диапазона: I1 = [0, r1-1], I2 = [r1, x-1], и I3 = [x, r], где x = MSC(r)*2n-2, причем
● если size(I3) >= size (I2), зеркальное отображение I3 охватывает I2
● если size(I3) < size(I2), определить одну запись TCAM для диапазона I2 в виде [0, x],
- если TC(l) > 0, TC(r) < 2n-2-1, и MSC(l) != MSC(r)
○ если MSC(l) + 1 = MSC(r):
● определить I1 = [l, x-1] и определить верхний диапазон I2 = [x, r], где x = MSC(r)*2n-2 при условии, что size(I1) <= size(I2)
● кодировать и зеркально отобразить I1,
● кодировать последний из I2 путем частичного кодирования нижних диапазонов,
● если MSC(l) + 2 = MSC(r):
● определить I1 = [l, (MSC(l)+1)*2n-2-1],
● определить I2 = [(MSC(l)+1)*2n-2, MSC(r)*2n-2-1],
● определить I3 = [MSC(r)*2n-2, r],
● кодировать I1 и I3,
● если size(I1) + size(I3) > size(I2), зеркально отобразить диапазоны I1 и I3
● если size(I1) + size(I3) <= size(I2), использовать запись 1 для кодирования I2,
○ если MSC(l) + 3 = MSC(r):
● определить I1 = [l, 2n-2-1],
● определить I2 = [2n-2, 3*2n-2-1],
● определить I3 = [3*2n-2, r] при условии, что size(I1) <= size(I2), без ограничения общности,
● кодировать I1 и I3 таким же образом, как и для MSC(l) + 1 = MSC(r), с модификацией, которая состоит в добавлении [0, 3] двух наиболее значащих битов.
Это позволяет обеспечить, в частности, высокую эффективность кодирования.
Согласно третьему аспекту изобретения предусмотрен способ кодирования двоичного входного числа в двоичное выходное число. Способ содержит разделение двоичного входного числа на фрагменты длиной n битов, кодирование каждого из фрагментов в кодированный фрагмент длиной m в соответствии с правилом кодирования фрагментов. Правило кодирования фрагментов содержит кодирование фрагмента с использованием первого правила кодирования частичных фрагментов, если значение предыдущего фрагмента является четным, и кодирование фрагмента с использованием второго правила кодирования частичных фрагментов, если значение предыдущего фрагмента является нечетным. Более того, способ содержит конкатенацию кодированных фрагментов, в результате чего получается двоичное выходное число. Это позволяет обеспечить, в частности, эффективное кодирование. Кроме того, адреса, закодированные с использованием этого способа, позволяют использовать очень небольшое количество записей TCAM для классификации пакетов.
Согласно четвертому аспекту изобретения предусмотрен машиночитаемый носитель данных. Машиночитаемый носитель данных хранит компьютерную программу, которая при исполнении компьютером предписывает компьютеру выполнять описанный выше способ согласно третьему аспекту. Это позволяет обеспечить особенно эффективное кодирование.
В общем, следует отметить, что все компоновки, устройства, элементы, блоки и средства и т.д., описанные в настоящей заявке, могут быть реализованы с помощью программных или аппаратных элементов или любого их сочетания. Кроме того, устройства могут быть процессорами или могут содержать процессоры, при этом функции элементов, блоков и средств, описанных в настоящей заявке, могут быть реализованы в одном или более процессорах. Все этапы, которые выполняются различными объектами, описанными в настоящей заявке, а также функциональность, описанная как подлежащая выполнению различными объектами, подразумевают, что соответствующий объект адаптирован или сконфигурирован для выполнения соответствующих этапов и функциональностей. Даже если в последующем описании или конкретных вариантах осуществления конкретная функциональность (или этап), которая должна выполнять общий объект, не отражена в описании конкретного подробного элемента этого объекта, который выполняет этот конкретный этап или функциональность, специалисту в данной области техники должно быть понятно, что эти способы и функциональности могут быть реализованы в отношении элементов программного обеспечения или аппаратных средств или любого их сочетания.
Краткое описание чертежей
Настоящее изобретение подробно поясняется ниже в отношении вариантов осуществления изобретения со ссылкой на сопроводительные чертежи, на которых:
фиг. 1 – первая примерная схема кодирования;
фиг. 2 – вторая примерная схема кодирования;
фиг. 3 – третья примерная схема кодирования;
фиг. 4 – схема кодирования, используемая в первом варианте осуществления кодера согласно изобретению;
фиг. 5 – дополнительная схема кодирования, используемая во втором варианте осуществления кодера согласно изобретению;
фиг. 6 – примерная схема классификации пакетов;
фиг. 7 – первый вариант осуществления системы классификации пакетов согласно изобретению, содержащей третий вариант осуществления кодера согласно изобретению;
фиг. 8 – четвертый вариант осуществления кодера согласно изобретению;
фиг. 9 – детальное представление второго варианта осуществления системы классификации пакетов согласно изобретению;
фиг. 10 – вариант осуществления способа кодирования согласно изобретению, представленного в виде блок-схемы последовательности операций.
Осуществление изобретения
Со ссылкой на фиг. 1 - фиг. 3 были описаны различные примерные схемы кодирования. На фиг. 4 показана базовая структура схемы кодирования, используемой в различных вариантах осуществления настоящего изобретения. На фиг. 5 показана альтернативная схема кодирования. На фиг. 6 показана общая функция классификации пакетов. На фиг. 7-9 показаны и описаны структура и функции различных вариантов осуществления системы классификации пакетов и кодера согласно изобретению. Наконец, со ссылкой на фиг. 10 подробно описана функция варианта осуществления способа кодирования согласно изобретению. На различных фигурах аналогичные объекты и ссылочные позиции частично опущены.
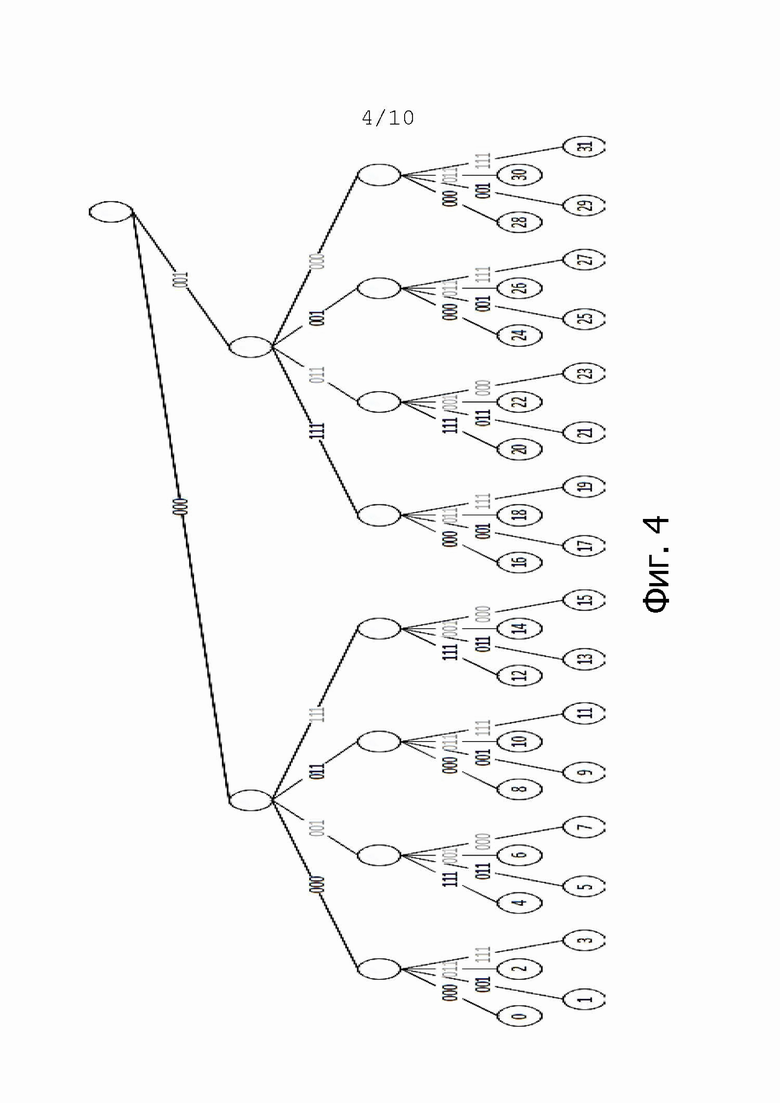
На фиг. 4 показана схема кодирования согласно изобретению. Эта схема кодирования будет называться четвертичным ограничительным кодированием по Грею (Quaternary Gray Fence Encoding, QGFE).
QGFE представляет собой новую схему кодирования, которая объединяет в себе кодирование DIRPE и кодирование SRGE. В базовом случае используется 2-битовых фрагмента, поэтому мы называем его четвертичным. Однако применима любая другая длина фрагмента. Битовое кодирование всех чисел от 0 до 2w – 1 для поля длиной w выглядит следующим образом:
1) Разделить битовую строку длиной w с битами, пронумерованными от 0 до w-1, на 2-битовые фрагменты;
2) Рекурсивно повторить для i = 1, 2, …, w/2, взять i-й 2-битовый фрагмент справа, биты w-2i и w-2i+1 (начиная отсчет от нуля); чтобы получить кодирование битов от w-2i до w-1:
a) кодировать биты w-2i и w-2i+1 с использованием DIRPE-кодирования, это превращает их в 3 бита;
b) для битов от w-2(i-1) до w-1, использовать рекурсивно предыдущее кодирование, но отразить его аналогично SRGE, то есть кодировать числа от 0 до 22i - 1 следующим образом:
(1) кодировать число 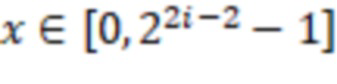 как 000, объединенное с предыдущим кодированием x mod
как 000, объединенное с предыдущим кодированием x mod 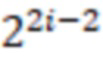 (то есть x без первых двух битов);
(то есть x без первых двух битов);
(2) кодировать число 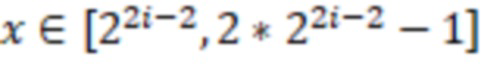 как 001, объединенное с отраженным предыдущим кодированием x mod ;
как 001, объединенное с отраженным предыдущим кодированием x mod ;
(3) кодировать число 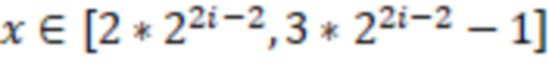 как 011, объединенное с предыдущим кодированием x mod ;
как 011, объединенное с предыдущим кодированием x mod ;
(4) кодировать число 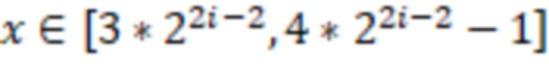 как 111, объединенное с отраженным предыдущим кодированием x mod
как 111, объединенное с отраженным предыдущим кодированием x mod 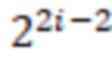 .
.
Например, входное число длиной w = 16 бит может быть разделено на фрагменты следующим образом:

На фиг. 4 показано QGFE для фрагмента длиной n=2. Длина кодированного фрагмента m=3. Здесь легко увидеть, что в зависимости от значения предыдущего фрагмента используется одно из двух правил кодирования фрагментов. Например, последние фрагменты с номерами 0–3, 8–11, 16–19, 24–27 кодируются с использованием правила кодирования первого частичного фрагмента, и последние фрагменты с номерами 4-7, 12-15, 20-23 и 28-31 кодируются с использованием второго правила кодирования частичных фрагментов. Если значение предыдущего фрагмента является четным, используется первое правило кодирования частичных фрагментов, и если значение предыдущего фрагмента является нечетным, используется второе правило кодирования частичных фрагментов. Второе правило кодирования фрагментов является зеркальным отображением первого правила кодирования фрагментов. Например, это можно легко увидеть по номерам 0-7. Последний фрагмент с номером 3 кодируется под тем же номером, что и последний фрагмент с номером 4. Последний фрагмент с номером 2 кодируется под тем же номером, что и последний фрагмент с номером 5 и т.д.
Это зеркальное отображение повторяется на каждом уровне, то есть для всех последовательных фрагментов. Например, предпоследний фрагмент со значениями 12–15 кодируется с тем же значением, что и предпоследний фрагмент с номерами 16–19.
QGFE основана на DIRPE, поэтому количество записей, необходимых в QGFE, никогда не превышает количество записей, необходимое при использовании DIRPE. Более того, благодаря зеркальному отображению между соседними числами, расширенному из кода Грея (Grey Code), производительность QGFE намного выше, чем в случае DIRPE для коротких диапазонов. Смотри следующие примеры:
● Для диапазона [1, 14] DIRPE требуется 3 записи (000 **1, 0*1 ***, 111 0**), QGFE требуется только 2 записи (*** **1, 0*1 ***)
● Для диапазона [11, 21] DIRPE требуется 4 записи (000 011 111, 000 111 ***, 001 000 ***, 001 001 00*), QGFE требуется только 3 записи (00* 011 111, 00* 111 ***, 001 011 011)
● Для диапазона [2, 9] DIRPE требуется 3 записи (000 *11, 001 ***, 011 00*), QGFE требуется только 2 записи (00* *11, 0*1 00*).
Чтобы обеспечить баланс между преимуществами и недостатками ограничительного кодирования, DIRPE разбивает двоичную строку длиной n, представляющую значение поля, на фрагменты, кодирует отдельно каждый фрагмент с использованием ограничительного кодирования и затем конкатенирует результаты. Например, DIRPE может закодировать x = 01001101 следующим образом:
1) разбить x на фрагменты 01, 00, 11, 01;
2) закодировать эти фрагменты в 001, 000, 111 и 001, соответственно, используя ограничительное кодирование;
3) конкатенировать кодировки фрагментов в результирующую двоичную строку 001000111001.
QGFE имеет некоторые сходства. Для упрощения объяснения ниже предполагается, что длина каждой кодированной двоичной строки является четной, и как DIRPE, так и QGFE разделяют каждое значение x на 2-битовые фрагменты. Для каждого значения x фрагменты нумеруются, начиная с фрагмента, содержащего два наиболее значащих бита x.
Основное различие между DIRPE-кодированием и QGFE-кодированием значения x состоит в следующем:
Если значение i-го фрагмента равно 1 (012) или 3 (112), QGFE кодирует i-1-ый фрагмент со значением a с помощью Fence(3-a) вместо Fence(a).
Например, QGFE кодирует x = 010011012 следующим образом:
1) разбить x на фрагменты 01, 00, 11, 01;
2) закодировать эти фрагменты числами 001, 111, 111 и 011, соответственно; следует отметить, что второй фрагмент 00 и последний фрагмент 01 кодируются с использованием Fence(3-0) = Fence(3) и Fence(2) = Fence(3-1), соответственно, а не Fence(0) и Fence(1);
3) конкатенировать кодировки фрагментов в результирующую двоичную строку 001111111011.
Кодирование диапазонов дополнительно поясняется со ссылкой на фиг. 6-9.
До сих пор была описана длина фрагмента при n=2.
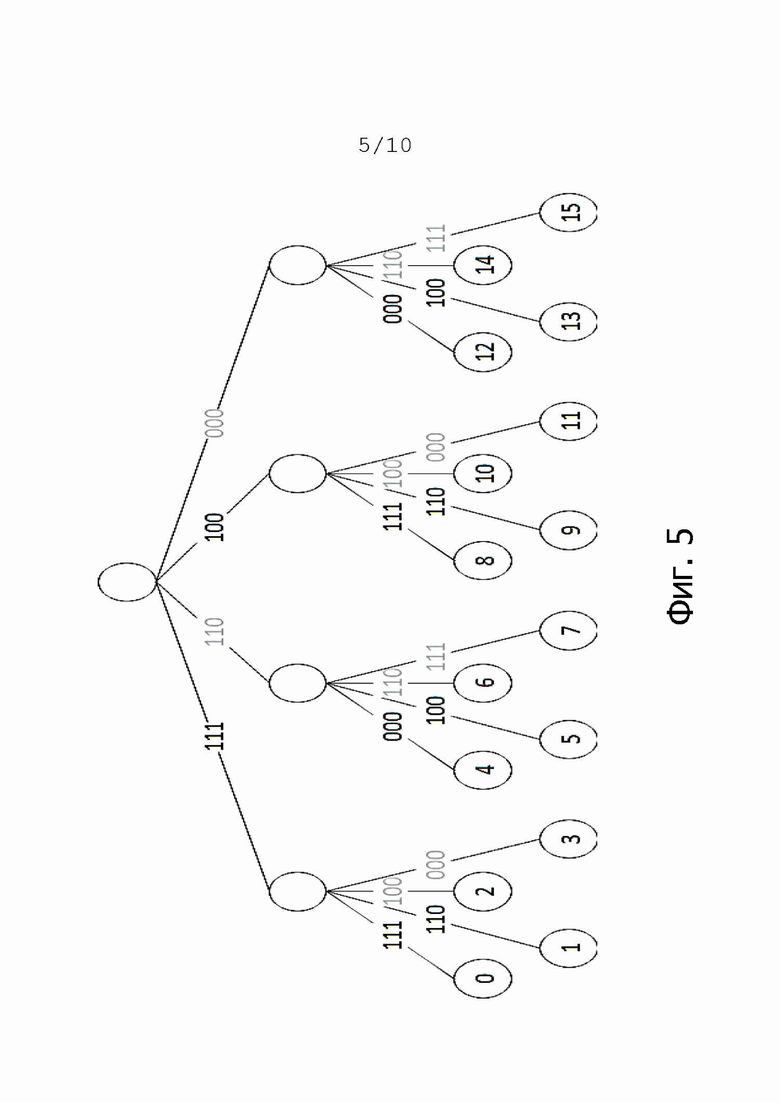
Также возможно использование фрагментов различной длины. Например, возможно n=3. Также возможно любое другое число n. Кроме того, возможно использование разных чисел для отдельных значений фрагментов. Например, такая разная нумерация значений фрагментов показана в схеме кодирования на фиг. 5. Здесь n=2, тогда как для отдельных значений фрагментов используются разные номера.
Кроме того, возможно кодирование в кодированный фрагмент длиной m≠3. Например, возможно m=4 или любое другое число, большее m.
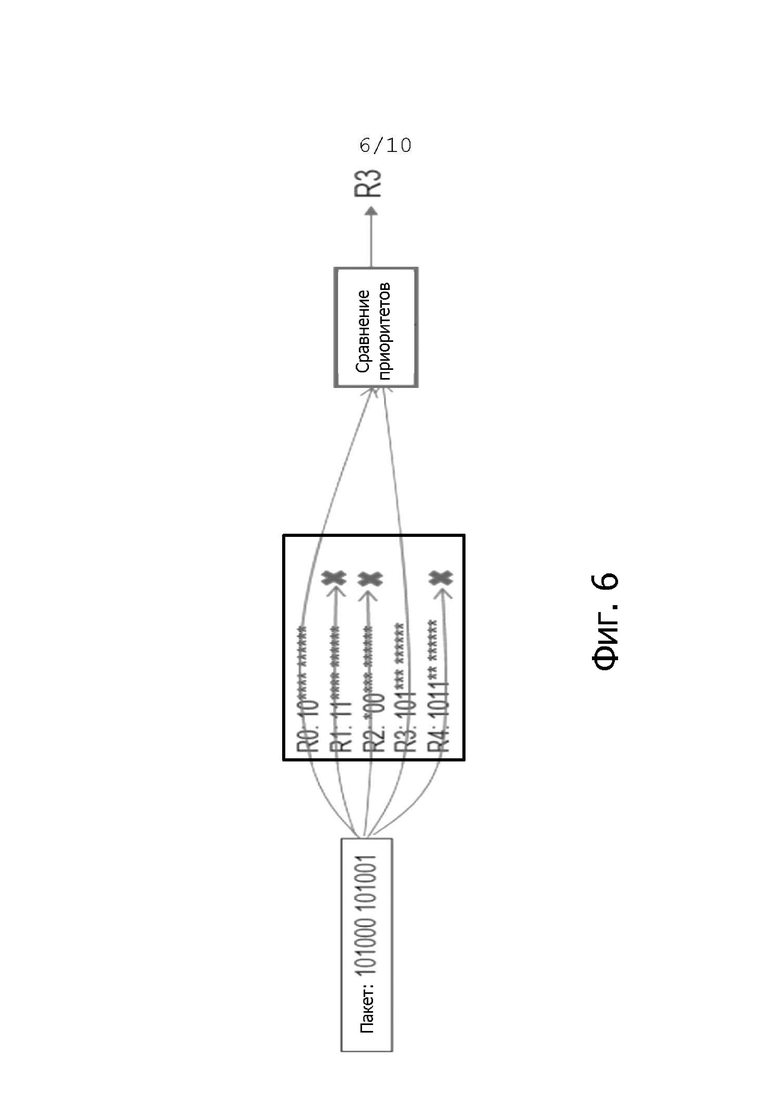
Чтобы понять диапазон и кодирование в контексте настоящего изобретения, на фиг. 6 показан пример схемы классификации пакетов. Пакет содержит параметр классификации, например адрес назначения. В примере, показанном на фиг. 6, адресом назначения является 101000 101001. Этот пакет классифицируется по меньшей мере в соответствии с одним правилом классификации. Здесь показано пять правил R0 – R4 классификации. Значение 1 определенного бита в правиле классификации указывает то, что бит в этой позиции параметра классификации пакета должен соответствовать значению 1 для того, чтобы выполнялось это правило классификации. Значение 0 для бита правила классификации указывает то, что значение бита в той же позиции параметра классификации пакета должно соответствовать значению 0 для того, чтобы выполнялось соответствующее правило классификации. Значение * указывает то, что для этой позиции бита значение параметра классификации пакета, подлежащего классификации, не имеет значения.
В показанном примере правило R0 классификации соблюдено, так как первые два бита параметра классификации имеют значения 10, которые заданы правилом R0 классификации. Значения остальных восьми бит не имеют значения. Таким образом, правило R0 классификации выполнено.
Правило R1 классификации не выполняется, так как правило R1 классификации указывает то, что второй бит должен иметь значение 1, тогда как второй бит параметра классификации пакета имеет здесь значение 0.
Правило R2 классификации не соблюдается, так как в соответствии с правилом R2 классификации третий бит должен иметь значение 0, в то время как третий бит параметра классификации имеет значение 1.
Правило R3 классификации выполняется, так как первые три бита имеют значение 101, которое задано R3.
Правило R4 классификации не выполняется, так как четвертый бит имеет значение 0, хотя R4 указывает на необходимость значения 1.
Таким образом, правила R0 и R3 классификации выполняются, тогда как правила R1, R2 и R4 классификации не выполняются.
Так как выполняется более одного правила классификации, выполняется приоритезация правила классификации. В данном случае, чем выше номер правила классификации, тем выше правило классификации в расчете на приоритет. Таким образом, выполненное правило R3 классификации имеет наивысший приоритет, и пакет классифицируется как пакет, соответствующий правилу R3 классификации.
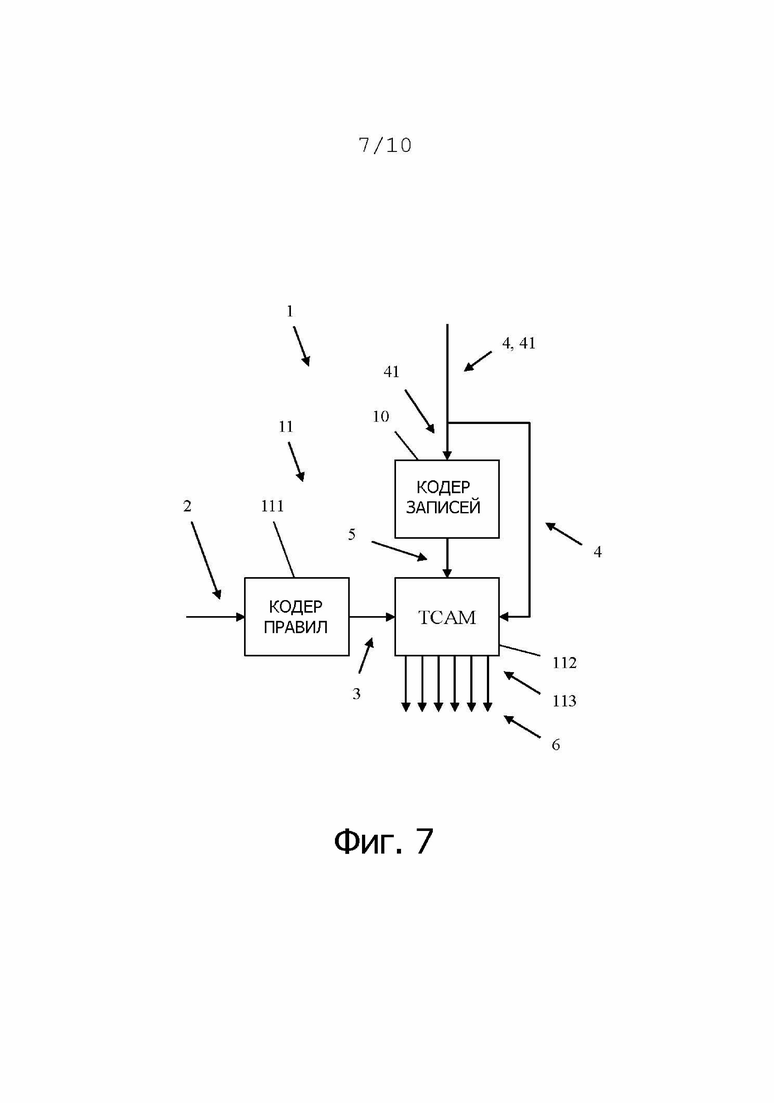
На фиг. 7 показан первый вариант осуществления системы 1 классификации пакетов согласно изобретению. Система классификации пакетов содержит кодер 10, подключенный к классификатору 11 пакетов, который содержит кодер 111 правил классификации и устройство 112 классификации. Устройством 112 классификации является, например, TCAM 112. Ряд пакетов 4, каждый из которых содержит по меньшей мере один параметр 41 классификации, например, адрес источника, или адрес назначения, или порт источника, или порт назначения или любой другой параметр, по которому пакет должен быть классифицирован. По меньшей мере один параметр 41 классификации передается в кодер 10, который выполняет ранее описанное кодирование. Более подробная информация об этом кодировании будет представлена в подробном описании кодера, показанного на фиг. 8.
Результирующий кодированный параметр 5 классификации передается классификатору 11 пакетов, в частности, устройству 112 классификации. Устройство 112 классификации классифицирует пакеты 4 согласно по меньшей мере одному кодированному правилу 3 классификации на основе по меньшей мере одного кодированного параметра 5 классификации. Классификатор 11 пакетов в нем принимает кодированное правило 3 классификации из кодера 111 правил, который вырабатывает кодированное правило 3 классификации по меньшей мере из одного правила 2 классификации. Правило 2 классификации может быть, например, одним из правил R0-R4, показанных на фиг. 6.
Классификатор 11 пакетов, в частности, устройство 112 классификации, подключен к множеству выходных портов 113. Пакеты 4 классифицируются и выводятся в отдельные выходные порты 113 в качестве классифицированных пакетов 6.
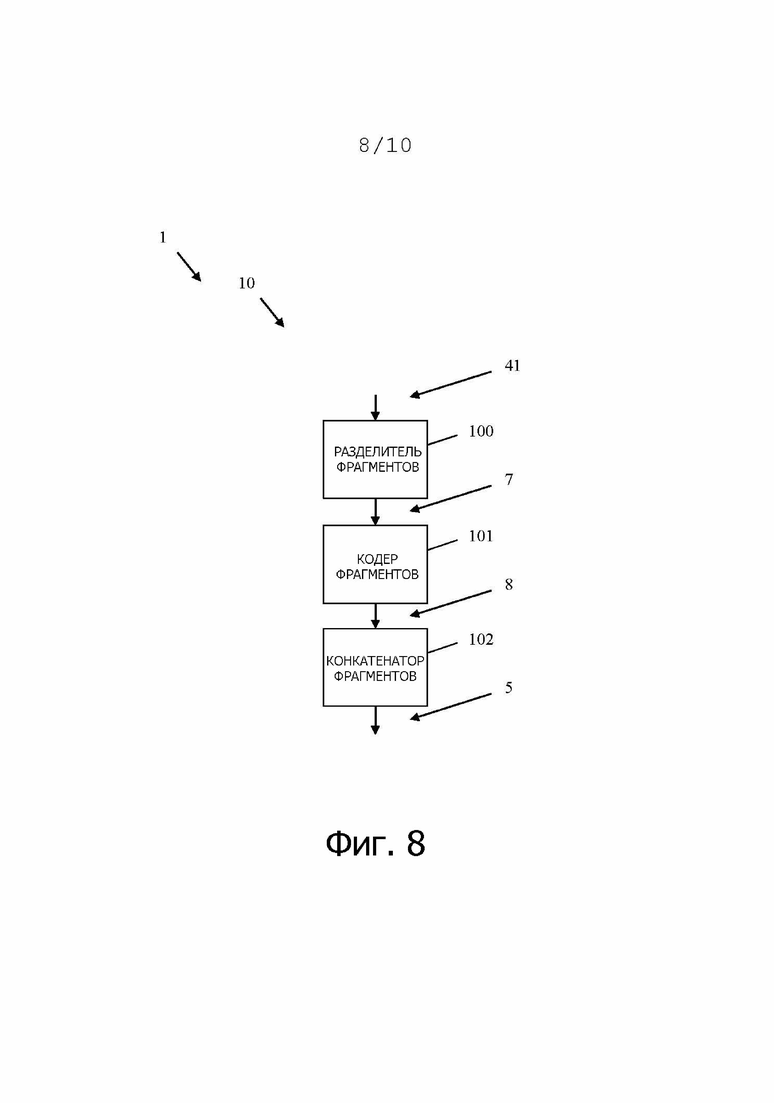
На фиг. 8 приведены дополнительные подробности, касающиеся кодирования кодером 10. Кодер 10 содержит разделитель 100 фрагментов, соединенный с кодером 101 фрагментов, который, в свою очередь, соединен с конкатенатором 102 фрагментов.
Разделитель фрагментов разделяет двоичное входное число 41, в частности, параметр 41 классификации, на фрагменты 7 длиной n битов. Эти фрагменты 7 передаются в кодер 101 фрагментов. Кодер 101 фрагментов кодирует каждый из фрагментов 7 в кодированный фрагмент 8 длиной m в соответствии с правилом кодирования фрагментов. Правило кодирования фрагментов содержит кодирование фрагмента 7 с использованием первого правила кодирования частичных фрагментов, если значение предыдущего фрагмента является четным, и кодирование фрагмента 7 с использованием второго правила кодирования частичных фрагментов, если значение предыдущего фрагмента является нечетным.
Второе правило кодирования фрагментов в нем является зеркальным отображением первого правила кодирования фрагментов. Дополнительно или альтернативно, второе правило кодирования частичных фрагментов содержит кодирование фрагмента со значением x в том же самом кодированном фрагменте, в котором первое правило кодирования фрагментов кодирует фрагмент со значением 2n-1-x. Соседние значения предпочтительно кодируются таким образом, чтобы кодированные фрагменты отличались только на один бит. Длина m кодированного фрагмента в нем предпочтительно всегда больше длины n фрагмента 7.
Кодированные фрагменты 8 передаются в конкатенатор фрагментов, который выполнен с возможностью конкатенации кодированных фрагментов 8, в результате чего получается двоичное выходное число 5, в частности, кодированный параметр 5 классификации.
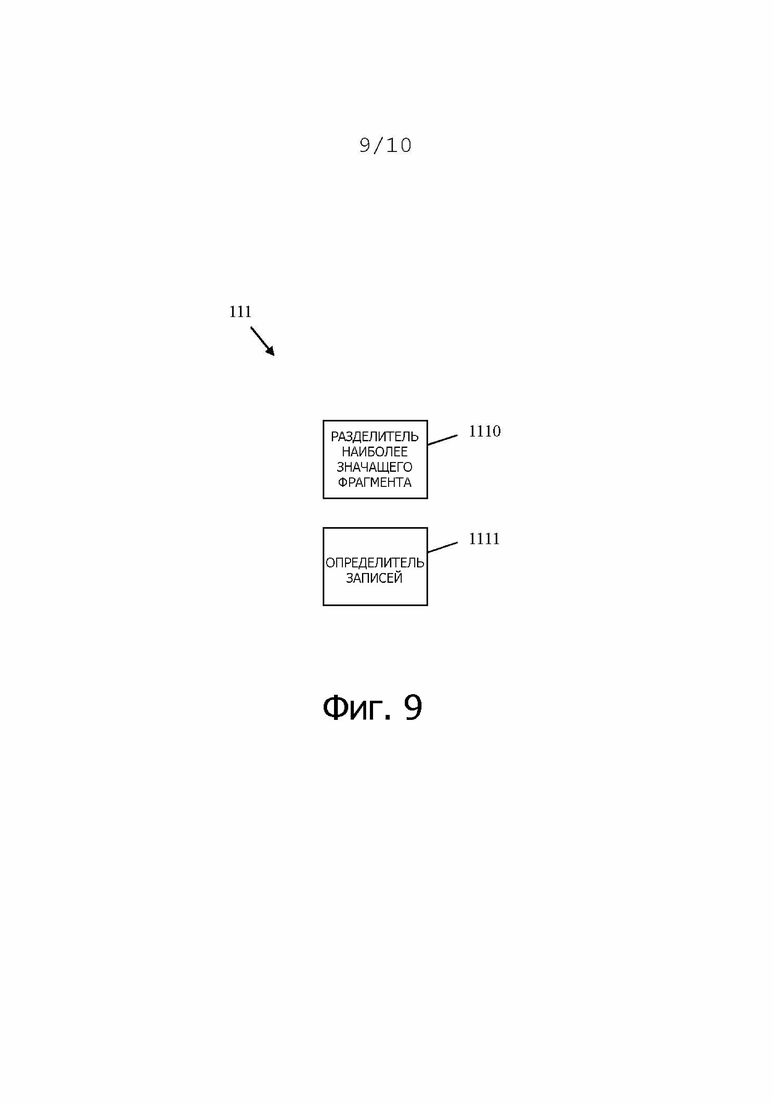
На фиг. 9 показана некоторая внутренняя структура кодера 111 правил классификации. Кодер 111 правил классификации содержит разделитель 1110 наиболее значащего фрагмента, который выполнен с возможностью определения наиболее значащего фрагмента адреса x (MSC(x)) и количества транковых фрагментов адреса x (TC(x)) как оставшейся части адреса без наиболее значащего фрагмента. Кроме того, кодер 111 правил классификации содержит определитель 1111 записей, который выполнен с возможностью определения записей для устройства 112 классификации, в частности, TCAM 112. Записи определяются следующим образом:
- если TC(l) = 0, и если TC(r) = 2n-2-1, определить одну запись TCAM как единственную запись для этого диапазона адресов,
- если TC(l) = 0, и если TC(r) |= 2n-2-1,
○ разбить I на два диапазона I1 = [l, x-1] и I2 = [x, r], где x = MSC(r)*2n-2,
○ для I1 определить одну запись TCAM и
○ для I2 рекурсивно построить диапазон,
- если диапазон [l, r1-1] адресов уже закодирован, выбрать значение l1 в качестве начального значения для кодирования оставшейся части диапазона [l, r1-1], чтобы минимизировать размер кодирования диапазона [l1, r] следующим образом:
○ если MSC(r1) > MSC(r), вернуть нулевое значение,
○ если MSC(r1) = MSC(r), рекурсивно найти кодировку (n-2)-битового диапазона [0, TC(r)] адресов, и
○ если MSC(r1) < MSC(r), разбить диапазон I на 3 диапазона: I1 = [0, r1-1], I2 = [r1, x-1], и I3 = [x, r], где x = MSC(r)*2n-2, причем
● если size(I3) >= size (I2), зеркальное отображение I3 охватывает I2
● если size(I3) < size(I2), определить одну запись TCAM для диапазона I2 в виде [0, x],
- если TC(l) > 0, TC(r) < 2n-2-1, и MSC(l) != MSC(r)
○ если MSC(l) + 1 = MSC(r):
● определить I1 = [l, x-1] и определить верхний диапазон I2 = [x, r], где x = MSC(r)*2n-2 при условии, что size(I1) <= size(I2)
● кодировать и зеркально отобразить I1,
● кодировать последний из I2 путем частичного кодирования нижних диапазонов,
○ если MSC(l) + 2 = MSC(r):
● определить I1 = [l, (MSC(l)+1)*2n-2-1],
● определить I2 = [(MSC(l)+1)*2n-2, MSC(r)*2n-2-1],
● определить I3 = [MSC(r)*2n-2, r],
● кодировать I1 и I3,
● если size(I1) + size(I3) > size(I2), зеркально отобразить диапазоны I1 и I3
● если size(I1) + size(I3) <= size(I2), использовать запись 1 для кодирования I2,
○ если MSC(l) + 3 = MSC(r):
● определить I1 = [l, 2n-2-1],
● определить I2 = [2n-2, 3*2n-2-1],
● определить I3 = [3*2n-2, r] при условии, что size(I1) <= size(I2), без ограничения общности,
● кодировать I1 и I3 таким же образом, как и для MSC(l) + 1 = MSC(r), с модификацией, которая состоит в добавлении [0, 3] двух наиболее значащих битов.
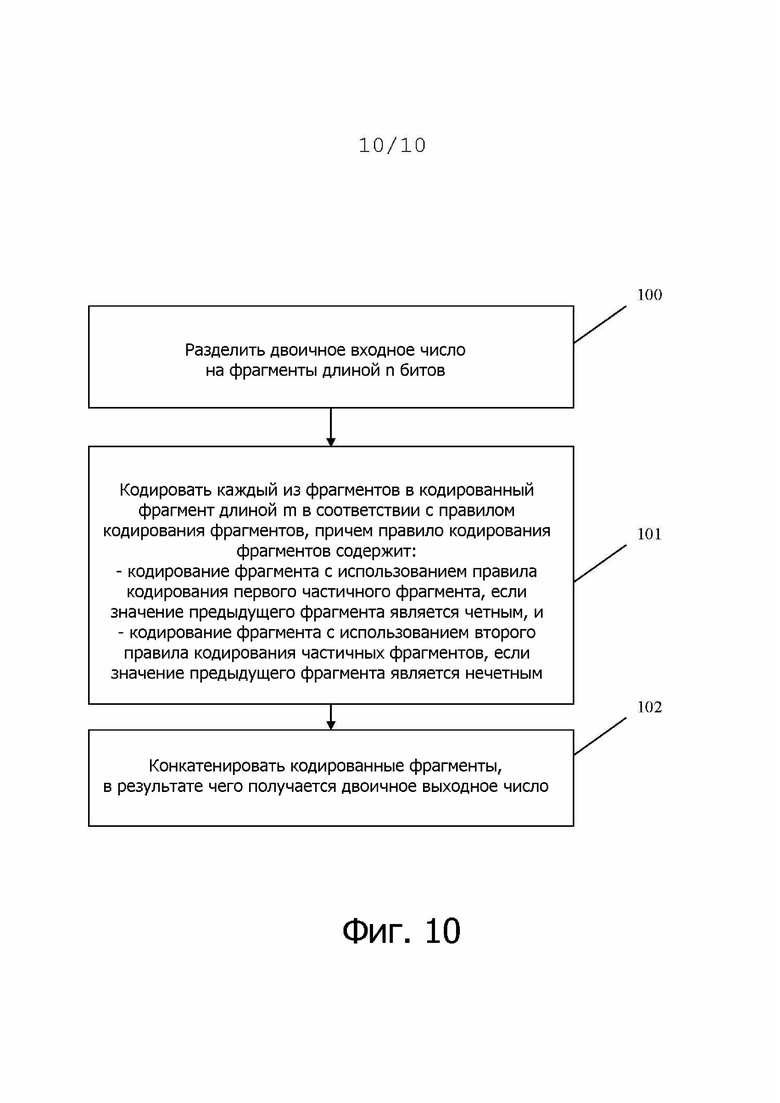
Наконец, на фиг. 10 показан вариант осуществления способа кодирования согласно изобретению. На первом этапе 100 входное двоичное число разделяется на фрагменты длиной n битов. На втором этапе 101 каждый фрагмент кодируется в кодированный фрагмент длиной m в соответствии с правилом кодирования фрагментов. Правило кодирования фрагментов содержит кодирование фрагмента с использованием первого правила кодирования частичных фрагментов, если значение предыдущего фрагмента является четным, и кодирование фрагмента с использованием второго правила кодирования частичных фрагментов, если значение предыдущего фрагмента является нечетным. Наконец, способ содержит третий этап 102, на котором кодированные фрагменты конкатенируются, в результате чего получается двоичное выходное число.
Изобретение не ограничивается примерами и, в частности, длиной фрагмента и длиной кодированного фрагмента. Кроме того, конкретные правила кодирования фрагментов, показанные в примерах, не следует понимать как ограничивающие. Характеристики примерных вариантов осуществления можно использовать в любой выгодной комбинации.
Настоящее изобретение было описано в связи с различными вариантами осуществления. Однако другие варианты раскрытых вариантов осуществления могут быть поняты и реализованы специалистами в данной области техники при практическом применении заявленного изобретения на основе изучения чертежей, описания и прилагаемой формулы изобретения. В формуле изобретения слово «содержащий» не исключает другие элементы или этапы, и форма единственного числа не исключает форму множественного числа. Один процессор или другой блок может выполнять функции нескольких объектов, указанных в формуле изобретения. Тот факт, что определенные меры упоминаются, как правило, в различных зависимых пунктах формулы изобретения, не означает, что сочетание этих мер не может быть использовано с пользой. Компьютерная программа может храниться/распространяться на подходящем носителе информации, таком как оптический носитель информации или твердотельный носитель информации, поставляемый вместе с другим оборудованием или как его часть, но также может распространяться и в других формах, например, через Интернет или другие проводные или беспроводные системы связи.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДЕР И СПОСОБ КОДИРОВАНИЯ, ОБЕСПЕЧИВАЮЩИЕ ПОСЛЕДОВАТЕЛЬНОЕ ПРИРАЩЕНИЕ ИЗБЫТОЧНОСТИ | 2012 |
|
RU2541174C1 |
| СПОСОБ И УСТРОЙСТВО ЭФФЕКТИВНОЙ МАСКИРОВКИ СТИРАНИЯ КАДРОВ В РЕЧЕВЫХ КОДЕКАХ | 2006 |
|
RU2419891C2 |
| УПРАВЛЕНИЕ МАКСИМАЛЬНЫМ РАЗМЕРОМ ПРЕОБРАЗОВАНИЯ | 2020 |
|
RU2778250C1 |
| УКАЗАНИЕ ИСПОЛЬЗОВАНИЯ ПАРАЛЛЕЛЬНОЙ ВОЛНОВОЙ ОБРАБОТКИ В КОДИРОВАНИИ ВИДЕО | 2012 |
|
RU2609073C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2018 |
|
RU2699677C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2018 |
|
RU2758981C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2642373C1 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ВКЛЮЧЕНИЯ ИДЕНТИФИКАТОРА В ПАКЕТ, АССОЦИАТИВНО СВЯЗАННЫЙ С РЕЧЕВЫМ СИГНАЛОМ | 2007 |
|
RU2421828C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |
Изобретение относится к кодерам для кодирования двоичного входного числа в двоичное выходное число. Технический результат – повышение эффективности кодирования. Кодер содержит разделитель фрагментов, выполненный с возможностью разделения двоичного входного числа на фрагменты длиной n битов, и кодер фрагментов, выполненный с возможностью кодирования каждого из фрагментов в кодированный фрагмент длиной m в соответствии с правилом кодирования фрагментов. Правило кодирования фрагментов содержит кодирование фрагмента с использованием первого правила кодирования частичных фрагментов, если значение предыдущего фрагмента является четным, и кодирование фрагмента с использованием второго правила кодирования частичных фрагментов, если значение предыдущего фрагмента является нечетным. Кроме того, кодер содержит конкатенатор фрагментов, выполненный с возможностью конкатенации кодированных фрагментов, в результате чего получается двоичное выходное число. 4 н. и 10 з.п. ф-лы, 10 ил.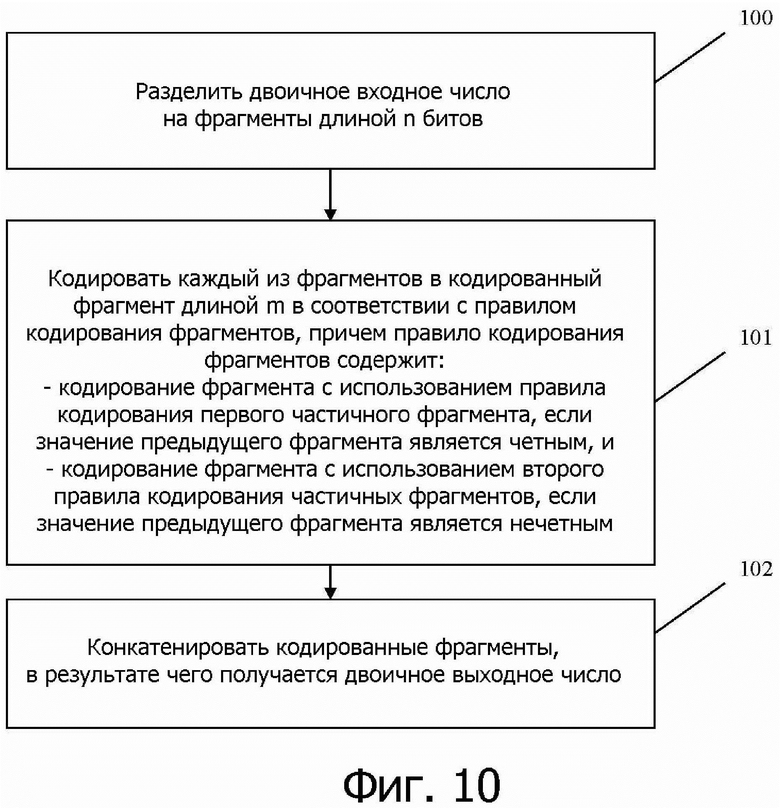
1. Кодер (10) кодирования двоичного входного числа (41) в двоичное выходное число (5), содержащий:
- разделитель (100) фрагментов, выполненный с возможностью разделения двоичного входного числа (41) на фрагменты (7) длиной n битов,
- кодер (101) фрагментов, выполненный с возможностью кодирования каждого из фрагментов (7) в кодированный фрагмент (8) длиной m в соответствии с правилом кодирования фрагментов, причем правило кодирования фрагментов содержит то, что:
- кодируют фрагмент (7) с использованием правила кодирования первого частичного фрагмента, если значение предыдущего фрагмента является четным, и
- кодируют фрагмент (7) с использованием второго правила кодирования частичных фрагментов, если значение предыдущего фрагмента является нечетным,
- конкатенатор (102) фрагментов, выполненный с возможностью конкатенации кодированных фрагментов (8), для получения двоичного выходного числа (5), причем
второе правило кодирования частичных фрагментов является зеркальным отображением первого правила кодирования частичных фрагментов, и/или
второе правило кодирования частичных фрагментов содержит кодирование фрагмента со значением x в том же самом кодированном фрагменте, в котором первое правило кодирования фрагментов кодирует фрагмент со значением 2n-1-x.
2. Кодер по п. 1, в котором
первое правило кодирования частичных фрагментов и второе правило кодирования частичных фрагментов содержат каждое по отдельности то, что соседние значения кодируются таким образом, чтобы кодированное число отличалось только на один бит.
3. Кодер по п. 1 или 2,
в котором m больше n.
4. Кодер по любому из пп. 1-3,
в котором, если n=2, и m=3,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 000,
○ 01 кодируется в кодированный фрагмент значения 001,
○ 10 кодируется в кодированный фрагмент значения 011,
○ 11 кодируется в кодированный фрагмент значения 111,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 111,
○ 01 кодируется в кодированный фрагмент значения 011,
○ 10 кодируется в кодированный фрагмент значения 001,
○ 11 кодируется в кодированный фрагмент значения 000, или
- в котором, если n=2, и m=3,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 000,
○ 01 кодируется в кодированный фрагмент значения 001,
○ 10 кодируется в кодированный фрагмент значения 011,
○ 11 кодируется в кодированный фрагмент значения 111,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 111,
○ 01 кодируется в кодированный фрагмент значения 011,
○ 10 кодируется в кодированный фрагмент значения 001,
○ 11 кодируется в кодированный фрагмент значения 000.
5. Кодер по любому из пп. 1-3,
в котором, если n=2, и m=4,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 0001,
○ 01 кодируется в кодированный фрагмент значения 0111,
○ 10 кодируется в кодированный фрагмент значения 1011,
○ 11 кодируется в кодированный фрагмент значения 1110,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 1110,
○ 01 кодируется в кодированный фрагмент значения 1011,
○ 10 кодируется в кодированный фрагмент значения 0111,
○ 11 кодируется в кодированный фрагмент значения 0001, или
- в котором, если n=2, и m=4,
- согласно второму правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 0001,
○ 01 кодируется в кодированный фрагмент значения 0111,
○ 10 кодируется в кодированный фрагмент значения 1011,
○ 11 кодируется в кодированный фрагмент значения 1110,
- согласно первому правилу кодирования фрагментов, значение фрагмента
○ 00 кодируется в кодированный фрагмент значения 1110,
○ 01 кодируется в кодированный фрагмент значения 1011,
○ 10 кодируется в кодированный фрагмент значения 0111,
○ 11 кодируется в кодированный фрагмент значения 0001.
6. Система классификации пакетов (1) для классификации входных пакетов (4), каждый из которых содержит по меньшей мере один параметр (41) классификации, согласно по меньшей мере одному правилу (2) классификации, на основе по меньшей мере одного параметра (41) классификации, содержащая:
- кодер (10) по любому из пп. 1-5, выполненный с возможностью кодирования по меньшей мере одного параметра (41) классификации по меньшей мере в один кодированный параметр (5) классификации, и
- классификатор (11) пакетов, выполненный с возможностью классификации входных пакетов (4), согласно по меньшей мере одному правилу (2) классификации, на основе по меньшей мере одного кодированного параметра (5) классификации.
7. Система классификации пакетов (1) по п. 6,
в которой классификатор (11) пакетов содержит:
- кодер (111) правил классификации, выполненный с возможностью определения по меньшей мере одного кодированного правила (3) классификации по меньшей мере из одного правила (2) классификации, и
- устройство (112) классификации, выполненное с возможностью классификации входных пакетов (4), согласно по меньшей мере одному кодированному правилу классификации (3), на основе по меньшей мере одного кодированного параметра (5) классификации.
8. Система классификации пакетов (1) по п. 7,
в которой устройство (112) классификации представляет собой троичную память (112), ориентированную на содержание (TCAM), и
в которой кодер (111) правил классификации выполнен с возможностью программирования TCAM (112) с использованием по меньшей мере одного кодированного правила (3) классификации.
9. Система (1) классификации пакетов по любому из пп. 6-8,
в которой система (1) классификации содержит множество выходных портов (113),
в которой по меньшей мере один параметр (41) классификации содержит адрес, и
в которой по меньшей мере одно правило (2) классификации содержит множество сопоставлений каждого из диапазона адресов с одним из множества выходных портов (113).
10. Система классификации пакетов по п. 8 или 9, в которой
каждый из диапазонов I[l, r] адресов содержит все адреса между первым адресом l и последним адресом r, при этом
кодер (111) правил классификации выполнен с возможностью кодирования каждого диапазона адресов в числовые записи TCAM.
11. Система (1) классификации пакетов по п. 10, в которой
кодер (111) правил классификации содержит разделитель (1110) наиболее значащего фрагмента, выполненный с возможностью определения
- наиболее значащего фрагмента адреса x (MSC(x)), и
- количества транковых фрагментов адреса x (TC(x)) в качестве оставшейся части адреса без наиболее значащего фрагмента.
12. Система классификации пакетов по п. 11,
в которой кодер (111) правил классификации содержит определитель (1111) записи, выполненный таким образом, чтобы:
- если TC(l) = 0, и если TC(r) = 2n-2-1, определить одну запись TCAM как единственную запись для этого диапазона адресов,
- если TC(l) = 0, и если TC(r) |= 2n-2-1,
○ разбить I на два диапазона I1 = [l, x-1] и I2 = [x, r], где x = MSC(r)*2n-2,
○ для I1 определить одну запись TCAM и
○ для I2 рекурсивно построить диапазон,
- если диапазон [l, r1-1] адресов уже закодирован, выбрать значение l1 в качестве начального значения для кодирования оставшейся части диапазона [l, r1-1], чтобы минимизировать размер кодирования диапазона [l1, r] следующим образом:
○ если MSC(r1) > MSC(r), вернуть нулевое значение,
○ если MSC(r1) = MSC(r), рекурсивно найти кодировку (n-2)-битового диапазона [0, TC(r)] адресов, и
○ если MSC(r1) < MSC(r), разбить диапазон I на 3 диапазона: I1 = [0, r1-1], I2 = [r1, x-1], и I3 = [x, r], где x = MSC(r)*2n-2, причем
● если size(I3) >= size (I2), зеркальное отображение I3 охватывает I2
● если size(I3) < size(I2), определить одну запись TCAM для диапазона I2 в виде [0, x],
- если TC(l) > 0, TC(r) < 2n-2-1, и MSC(l) != MSC(r)
○ если MSC(l) + 1 = MSC(r):
● определить I1 = [l, x-1] и определить верхний диапазон I2 = [x, r], где x = MSC(r)*2n-2 при условии, что size(I1) <= size(I2)
● кодировать и зеркально отобразить I1,
● кодировать последний из I2 путем частичного кодирования нижних диапазонов,
○ если MSC(l) + 2 = MSC(r):
● определить I1 = [l, (MSC(l)+1)*2n-2-1],
● определить I2 = [(MSC(l)+1)*2n-2, MSC(r)*2n-2-1],
● определить I3 = [MSC(r)*2n-2, r],
● кодировать I1 и I3,
● если size(I1) + size(I3) > size(I2), зеркально отобразить I1 и I3
● если size(I1) + size(I3) <= size(I2), использовать запись 1 для кодирования I2,
○ если MSC(l) + 3 = MSC(r):
● определить I1 = [l, 2n-2-1],
● определить I2 = [2n-2, 3*2n-2-1],
● определить I3 = [3*2n-2, r] при условии, что size(I1) <= size(I2), без ограничения общности,
● кодировать I1 и I3 таким же образом, как и для MSC(l) + 1 = MSC(r), с модификацией, которая состоит в добавлении [0, 3] двух наиболее значащих битов.
13. Способ кодирования двоичного входного числа в двоичное выходное число, содержащий этапы, на которых:
- разделяют двоичное входное число на фрагменты длиной n битов,
- кодируют каждый из фрагментов в кодированный фрагмент длиной m в соответствии с правилом кодирования фрагментов, причем правило кодирования фрагментов содержит то, что:
- кодируют фрагмент с использованием правила кодирования первого частичного фрагмента, если значение предыдущего фрагмента является четным, и
- кодируют фрагмент с использованием второго правила кодирования частичных фрагментов, если значение предыдущего фрагмента является нечетным,
- осуществляют конкатенацию кодированных фрагментов, для получения двоичного выходного числа, причем
второе правило кодирования частичных фрагментов является зеркальным отображением первого правила кодирования частичных фрагментов, и/или
второе правило кодирования частичных фрагментов содержит кодирование фрагмента со значением x в том же самом кодированном фрагменте, в котором первое правило кодирования фрагментов кодирует фрагмент со значением 2n-1-x.
14. Машиночитаемый носитель информации, хранящий компьютерную программу, вызывающую, при исполнении компьютером, выполнение, компьютером, способа по п. 13.
| Anat Bremler-Barr et al., Encoding Short Ranges in TCAM Without Expansion: Efficient Algorithm and Applications, IEEE/ACM TRANSACTIONS ON NETWORKING, EEE / ACM, NEW YORK, NY, US, vol | |||
| Прибор для получения стереоскопических впечатлений от двух изображений различного масштаба | 1917 |
|
SU26A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| US 9608913 B1, 28.03.2017 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ | 2006 |
|
RU2321946C1 |

