Область техники
[01] Настоящая технология относится к обработке звука и, в частности, к способу и серверу для генерирования модифицированного звука для видео.
УРОВЕНЬ ТЕХНИКИ
[02] Перевод речи в видео с изначально записанного языка на другой язык может потребовать трудоемких усилий по голосовому дублированию переведенных аудиофрагментов на исходное видео. Как правило, голосовое дублирование означает объединение вспомогательных или дополнительных записей (дублированной речи) с исходно записанной речью для создания законченного саундтрека к видео. Однако дублированная речь может отличаться от первоначально записанной речи и может не совпадать с временем начала и окончания исходно записанной речи. В результате переведенное аудио может показаться несинхронизированным и не понравиться зрителям.
[03] Патент США 9,734,820 раскрывает способ перевода речи в реальном времени, который уравновешивает задержку и точность машинного перевода путем сегментации речи при обнаружении соединения.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[04] Разработчики настоящей технологии оценили некоторые технические недостатки, связанные с существующими услугами дублирования. Целью настоящей технологии является устранение по меньшей мере некоторых неудобств, имеющихся в предшествующем уровне техники.
Общий алгоритм
[05] Разработчики поняли, что некоторые алгоритмы могут смещать начальные временные метки аудиосегментов и изменять скорость аудиосегментов, чтобы лучше соответствовать исходным аудиосегментам в видеофайле. В некоторых случаях такие алгоритмы могут применяться после того, как MEL спектрограммы были сгенерированы для переведенных частей текста. Однако в других случаях такие алгоритмы могут применяться после того, как сгенерированы формы сигналов для переведенных частей текста.
[06] Пусть 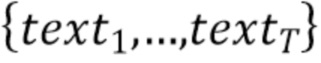 будет представлением входного текста. Для texti алгоритм
будет представлением входного текста. Для texti алгоритм 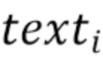 принимает временную метку начала gt_starti и продолжительность сгенерированного аудио
принимает временную метку начала gt_starti и продолжительность сгенерированного аудио 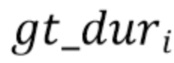 , например, в секундах. Продолжительность может быть рассчитана из продолжительности, ассоциированной с соответствующей спектрограммой MEL. Алгоритм выводит новую временную метку начала new_starti и коэффициент изменения скорости аудио speed_coefi.
, например, в секундах. Продолжительность может быть рассчитана из продолжительности, ассоциированной с соответствующей спектрограммой MEL. Алгоритм выводит новую временную метку начала new_starti и коэффициент изменения скорости аудио speed_coefi.
[07] Следует отметить, что вся длина аудио может быть разбита на сегменты фиксированной длины 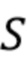 и пусть
и пусть 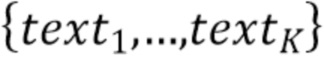 соответствуют начальным временным меткам результирующих сегментов. Пусть
соответствуют начальным временным меткам результирующих сегментов. Пусть 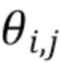 соответствует затратам на оптимизацию первого texti до timej. В некоторых случаях потеря может быть комбинацией различных параметров потерь. Другими словами, соответствует затратам для всех оптимизированных текстов от 1 до i до момента j.
соответствует затратам на оптимизацию первого texti до timej. В некоторых случаях потеря может быть комбинацией различных параметров потерь. Другими словами, соответствует затратам для всех оптимизированных текстов от 1 до i до момента j.
[08] Например, параметр потери может представлять смещение временной метки начала аудио куска относительно начальной временной метки начала:
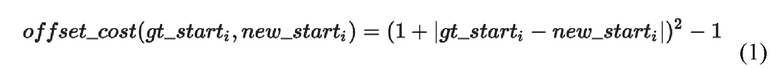
[09] В том же примере другой параметр потери может отражать увеличение скорости звука:
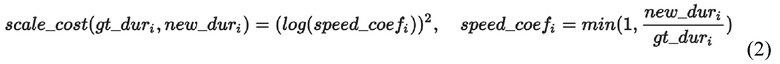 [10] Таким образом, значение потери может быть рекурсивно рассчитано через предыдущие во времени как:
[10] Таким образом, значение потери может быть рекурсивно рассчитано через предыдущие во времени как:
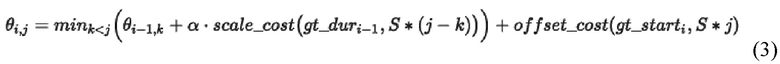
[11] Цель состоит в том, чтобы найти компоновку, соответствующую минимальному накопленному суммарному значению потери minjθT,j. В течение одной итерации вычисляются значения i столбца θi: на основе значений предыдущего столбца θi-1,:, и для каждой пары (i,j) сохраняется оптимальный индекс временной метки начала предыдущего текста k из уравнения (3).
[12] После вычисления значений всей матрицы θ, 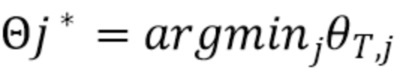 вычисляется для последнего столбца, получается начальная временная метка последней текстовой части, и, используя сохраненные значения k из уравнения (3), можно управлять обратным прослеживаением. Разработчики настоящей технологии поняли, что сложность полученного алгоритма составляет
вычисляется для последнего столбца, получается начальная временная метка последней текстовой части, и, используя сохраненные значения k из уравнения (3), можно управлять обратным прослеживаением. Разработчики настоящей технологии поняли, что сложность полученного алгоритма составляет 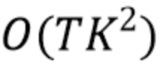 .
.
[13] В некоторых вариантах осуществления можно сказать, что может быть получена матрица (таблица), в которой каждый столбец ассоциирован с аудио частью и включает в себя все возможные значения . Матрица считает столбец за столбцом, и в каждом последующем столбце рассчитывается на основе элементов из предыдущего столбца. Цель состоит в том, чтобы найти оптимальное решение. Информацию об оптимальном «укладывании» аудио можно получить, имея конечное значение, поскольку оно ассоциировано со значением в предыдущем столбце, которое, в свою очередь, ассоциировано со значением в столбце перед этим, и так далее. По этой причине может быть выполнена операция обратного прослеживания.
[14] Задумано, что при постановке задачи предполагается, что текст начинается в любой из дискретных точек. Оптимизация синхронизации новой аудио части за произвольное время является слишком сложной задачей и требует значительных ресурсов для запуска алгоритма. По меньшей мере, в некоторых вариантах осуществления настоящей технологии временная составляющая квантуется в форме «временной сетки». Можно сказать, что каждая переведенная аудио часть может быть расположена на этой временной сетке. Квантование можно выполнять на временной сетке, например, с точками, расположенными примерно на 50 миллисекундах. После того как временная сетка сгенерирована, вычисляются потери за смещение начальной временной метки времени аудио куска и увеличение скорости аудио.
Вариант реализации алгоритма
[15] Разработчики поняли, что перемещение начальных временных меток аудиосегментов может быть нежелательным. В некоторых вариантах осуществления может быть выбран размер максимально допустимого смещения L (измеряемого количеством аудио кусков), и возможные значения 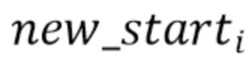 могут рассматриваться в диапазоне:
могут рассматриваться в диапазоне:
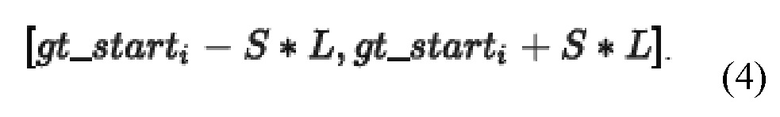
[16] Тогда в формулу расчета потери можно добавить потерю за выход за границы всего аудио:
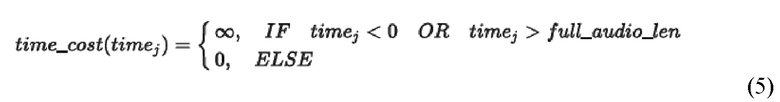
что приводит к следующему:
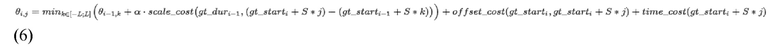
[17] Разработчики настоящей технологии поняли, что сложность результирующего алгоритма равна 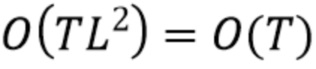 и, следовательно, линейна по отношению к количеству текстовых частей.
и, следовательно, линейна по отношению к количеству текстовых частей.
[18] В этом варианте осуществления значение 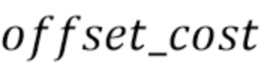 зависит только от размера смещения начальной временной метки текстовой части и одинаково для всех столбцов матрицы. Разработчики поняли, что эти значения можно вычислить один раз и использовать повторно.
зависит только от размера смещения начальной временной метки текстовой части и одинаково для всех столбцов матрицы. Разработчики поняли, что эти значения можно вычислить один раз и использовать повторно.
[19] При расчете 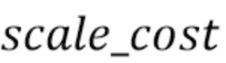
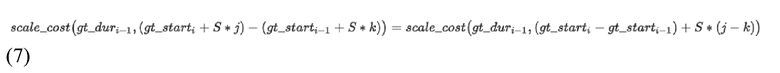
при фиксированном i выражение требует не L2, а 4L различных значений, так как 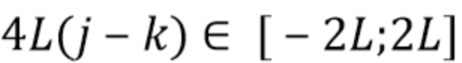 . Таким образом, можно рассчитать матрицу всех возможных значений и использовать ее для индексации.
. Таким образом, можно рассчитать матрицу всех возможных значений и использовать ее для индексации.
[20] Вместо того, чтобы сохранять всю матрицу θ можно сохранить последний столбец, сохраняя при этом временную метку начала оптимального индекса k предыдущей текстовой части для каждой пары (i,j). Кроме того, в некоторых вариантах осуществления можно взвешивать параметры потери.
[21] В первом широком аспекте настоящей технологии предоставляется способ генерирования модифицированных аудиоданных для видеофайла, при этом видеофайл ассоциируется с аудиоданными, способ, исполняемый сервером. Способ включает в себя получение сервером последовательности первых аудиофрагментов, причем данный фрагмент из последовательности первых аудиофрагментов представляет данное предложение на первом языке и связан с временной меткой в видеофайле. Способ содержит получение сервером последовательности вторых аудиофрагментов, причем данный фрагмент из последовательности вторых аудиофрагментов представляет другое данное предложение на втором языке и ассоциирован с временной продолжительностью, причем другое данное предложение является переводом данного предложения. Способ содержит генерирование сервером множества возможных компоновок последовательности вторых аудиофрагментов, при этом данная возможная компоновка ассоциирована с возможными временными метками в видеофайле и возможными коэффициентами сжатия для соответствующих из последовательности вторых аудиофрагментов. Способ содержит выбор целевой компоновки для последовательности вторых аудиофрагментов из множества возможных компоновок, причем выбор основан на целевой компоновке, имеющей минимальный балл потери среди баллов потери, ассоциированных с соответствующими баллами из множества возможных компоновок. Данная оценка потери для данной возможной компоновки генерируется на основе: (i) комбинации различий между временными метками, ассоциированными с соответствующими из последовательности первых аудиофрагментов и соответствующими метками из данной возможной компоновки, (ii) наличия перекрытия между заданной парой вторых аудиофрагментов, если: вторые аудиофрагменты из последовательности вторых аудиофрагментов расположены в видеофайле в соответствии с возможными временными метками и возможными коэффициентами сжатия. Способ содержит генерирование по меньшей мере одного модифицированного аудиофрагмента для видеофайла в качестве перевода аудиоданных с использованием целевой компоновки.
[22] В некоторых вариантах осуществления способа данный фрагмент из последовательности первых аудиофрагментов представляет собой аудио сигнал формы волны.
[23] В некоторых вариантах осуществления способа данная из последовательности первых звуковых фрагментов представляет собой мел-спектрограмму.
[24] В некоторых вариантах осуществления способ дополнительно содержит генерирование сервером последовательности вторых аудиофрагментов на основе последовательности первых аудиофрагментов.
[25] В некоторых вариантах осуществления способа временная метка, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, является временной меткой начала. Данный фрагмент из последовательности первых аудиофрагментов дополнительно ассоциирован с временной меткой окончания в видеофайле. Возможные временные метки данной возможной компоновки включают в себя возможные временные метки начала и возможные временные метки окончания для соответствующих вторых аудиофрагментов из данной возможной компоновки. Заданная оценка потерь дополнительно сгенерирована на основе: комбинации различий между метками времени начала, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими возможными временными метками начала из данной возможной компоновки, а также комбинацией различий между временными метками окончания, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими временными метками окончания из данной возможной компоновки.
[26] В некоторых вариантах осуществления способа метка времени, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, является центральной временной меткой. Возможные временные метки данной возможной компоновки включают в себя центральные возможные временные метки для соответствующих вторых аудиофрагментов из данной возможной компоновки. Данная оценка потери дополнительно сгенерирована на основе комбинации разностей между центральными временными метками, ассоциированными с соответствующими метками из последовательности первых аудиофрагментов, и соответствующими центральными возможными временными метками из данной возможной компоновки.
[27] В некоторых вариантах осуществления способа оценка потери дополнительно сгенерирована на основе комбинации возможных коэффициентов сжатия для данной возможной компоновки.
[28] В некоторых вариантах осуществления способа генерирование по меньшей мере одного модифицированного аудиофрагмента выполняется сервером в автономном режиме. Способ дополнительно содержит сохранение сервером видеофайла с по меньшей мере одним модифицированным аудиофрагментом в хранилище.
[29] В некоторых вариантах осуществления способа генерирование по меньшей мере одного модифицированного аудиофрагмента выполняется сервером в потоковом режиме. Способ дополнительно содержит передачу сервером видеофрагмента видеофайла с по меньшей мере одним модифицированным аудиофрагментом на пользовательское устройство.
[30] В некоторых вариантах осуществления способа, способ дополнительно содержит получение сервером нового первого аудиофрагмента, представляющего дополнительное предложение на первом языке. Способ дополнительно содержит получение сервером нового второго аудиофрагмента, представляющего другое дополнительное предложение на втором языке, причем другое дополнительное предложение является переводом дополнительного предложения. Новый второй аудиофрагмент и подмножество вторых аудиофрагментов из последовательности вторых аудиофрагментов образуют новую последовательность вторых аудиофрагментов. Подмножество вторых аудиофрагментов исключает первую из последовательности вторых аудиофрагментов, которые использовались для создания по меньшей мере одного модифицированного фрагмента. Способ дополнительно содержит генерирование сервером нового множества возможных компоновок для новой последовательности вторых аудиофрагментов. Способ дополнительно содержит выбор сервером новой целевой компоновки для новой последовательности вторых аудиофрагментов из нового множества возможных компоновок. Способ дополнительно содержит генерирование сервером нового модифицированного аудиофрагмента путем модификации первого из новой последовательности вторых аудиофрагментов в соответствии с новой целевой компоновкой. Способ дополнительно содержит передачу сервером другого фрагмента видеофайла с новым модифицированным аудиофрагментом на пользовательское устройство.
[31] Во втором широком аспекте настоящей технологии предоставляется сервер для генерирования модифицированных аудиоданных для видеофайла, при этом видеофайл ассоциирован с аудиоданными. Сервер сконфигурирован для получения последовательности первых аудиофрагментов, причем данный фрагмент из последовательности первых аудиофрагментов представляет данное предложение на первом языке и ассоциирован с временной меткой в видеофайле. Сервер сконфигурирован для получения последовательности вторых аудиофрагментов, причем данный фрагмент из последовательности вторых аудиофрагментов представляет собой другое данное предложение на втором языке и ассоциирован с временной продолжительностью, причем другое данное предложение является переводом данного предложения. Сервер сконфигурирован для генерирования множества возможных компоновок для последовательности вторых аудиофрагментов, при этом данная возможная компоновка ассоциирована с возможными временными метками в видеофайле и возможными коэффициентами сжатия для соответствующих из последовательности вторых аудиофрагментов. Сервер сконфигурирован для выбора целевой компоновки для последовательности вторых аудиофрагментов из множества возможных компоновок. Сервер сконфигурирован для выбора на основе целевой компоновки, имеющей минимальный балл потери из числа баллов потери, ассоциированных с соответствующими компоновками из множества возможных компоновок. Данный балл потери для данной возможной компоновки генерируется на основе: (i) различия между временными метками, ассоциированными с соответствующими из последовательности первых аудиофрагментов и соответствующими метками из данной возможной компоновки, и (ii) наличием перекрытия между данной парой вторых аудиофрагментов, если: вторые аудиофрагменты из последовательности вторых аудиофрагментов расположены в видеофайле в соответствии с возможными временными метками и возможными степенями сжатия. Сервер сконфигурирован для генерирования по меньшей мере одного модифицированного аудиофрагмента для видеофайла в качестве перевода аудиоданных с использованием целевой компоновки.
[32] В некоторых вариантах осуществления сервера данный из последовательности первых аудиофрагментов представляет собой звуковой сигнал формы волны.
[33] В некоторых вариантах осуществления сервера данный из последовательности первых аудиофрагментов представляет собой мел-спектрограмму.
[34] В некоторых вариантах осуществления сервер дополнительно сконфигурирован для генерирования последовательности вторых аудиофрагментов на основе последовательности первых аудиофрагментов.
[35] В некоторых вариантах осуществления сервера временная метка, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, является временной меткой начала, и данный фрагмент из последовательности первых аудиофрагментов дополнительно ассоциирован с временной меткой окончания в видеофайле. Возможные временные метки данной возможной компоновки включают в себя возможные временные метки начала и возможные временные метки окончания для соответствующих вторых аудиофрагментов. Данная оценка потери дополнительно генерируется на основе: комбинации различий между временными метками начала, ассоциированными с соответствующими фрагментами из последовательности первых аудиофрагментов, и соответствующими возможными временными метками начала из данной возможной компоновки, и комбинации различий между временными метками окончания, ассоциированными с соответствующими фрагментами из последовательности первых аудиофрагментов, и соответствующими временными метками окончания из данной возможной компоновки.
[36] В некоторых вариантах осуществления сервера временная метка, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, является центральной временной меткой. Возможные временные метки данной возможной компоновки включают в себя возможные центральные временные метки для соответствующих вторых аудиофрагментов. Данная оценка потери дополнительно генерируется на основе комбинации различий между центральными временными метками, ассоциированными с соответствующими фрагментами из последовательности первых аудиофрагментов, и соответствующими центральными возможными временными метками из данной возможной компоновки.
[37] В некоторых вариантах осуществления сервера оценка потери дополнительно генерируется на основе комбинации возможных степеней сжатия данной подходящей компоновки.
[38] В некоторых вариантах осуществления сервер сконфигурирован для генерирования по меньшей мере одного модифицированного аудиофрагмента в автономном режиме и дополнительно сконфигурирован для хранения видеофайла с по меньшей мере одним модифицированным аудиофрагментом в хранилище.
[39] В некоторых вариантах осуществления сервер сконфигурирован для генерирования по меньшей мере одного модифицированного аудиофрагмента в потоковом режиме и дополнительно сконфигурирован для передачи видеофрагмента видеофайла с по меньшей мере одним модифицированным аудиофрагментом на пользовательское устройство.
[40] В некоторых вариантах осуществления сервер дополнительно сконфигурирован для получения нового первого аудиофрагмента, представляющего дополнительное предложение на первом языке. Сервер дополнительно сконфигурирован для получения нового второго аудиофрагмента, представляющего другое дополнительное предложение на втором языке, причем другое дополнительное предложение является переводом дополнительного предложения. Новый второй аудиофрагмент и подмножество вторых аудиофрагментов из последовательности вторых аудиофрагментов образуют новую последовательность вторых аудиофрагментов. Подмножество вторых аудиофрагментов исключает первый из последовательности вторых аудиофрагментов, которые использовались для генерирования по меньшей мере одного модифицированного фрагмента. Сервер дополнительно сконфигурирован для генерирования нового множества возможных компоновок для новой последовательности вторых аудиофрагментов. Сервер дополнительно сконфигурирован для выбора новой целевой компоновки для новой последовательности вторых аудиофрагментов из нового множества возможных компоновок. Сервер дополнительно сконфигурирован для создания нового модифицированного аудиофрагмента путем модификации первого из новой последовательности вторых аудиофрагментов в соответствии с новой целевой компоновкой. Сервер дополнительно сконфигурирован для передачи другого фрагмента видеофайла с новым модифицированным аудиофрагментом на пользовательское устройство.
[41] В контексте настоящего описания «сервер» представляет собой компьютерную программу, которая работает на надлежащем аппаратном обеспечении и способна принимать запросы (например, от клиентских устройств) по сети и выполнять эти запросы, или вызывать выполнение этих запросов. Аппаратное обеспечение может быть одним физическим компьютером или одной физической компьютерной системой, но ни то, ни другое не является обязательным для настоящей технологии. В настоящем контексте использование выражения "сервер" не предполагает, что каждая задача (например, принятые инструкции или запросы) или какая-либо конкретная задача будут приняты, выполнены или вызваны для выполнения одним и тем же сервером (т.е. тем же самым программным обеспечением и/или аппаратным обеспечением); данное выражение предполагает, что любое количество программных элементов или аппаратных устройств может быть задействовано в приеме/отправке, выполнении или вызове для выполнения любой задачи или запроса, или последствий любой задачи или запроса; и все это программное обеспечение и аппаратное обеспечение может быть одним сервером или многочисленными серверами, причем оба данных случая включены в выражение "по меньшей мере один сервер".
[42] В контексте настоящего описания "клиентское устройство" представляет собой любое компьютерное оборудование, которое способно выполнять программное обеспечение, которое является надлежащим для релевантной поставленной задачи. Таким образом, некоторые (неограничивающие) примеры клиентских устройств включают в себя персональные компьютеры (настольные ПК, ноутбуки, нетбуки и т.д.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что устройство, выступающее в качестве клиентского устройства в настоящем контексте, не исключается из возможности выступать в качестве сервера для других клиентских устройств. Использование выражения "клиентское устройство" не исключает использования многочисленных клиентских устройств при приеме/отправке, выполнении или вызове для выполнения какой-либо задачи или запроса, или последствий любой задачи или запроса, или этапов любого описанного в данном документе способа.
[43] В контексте настоящего описания "база данных" представляет собой любую структурированную совокупность данных, независимо от ее конкретной структуры, программное обеспечение для администрирования базы данных, или компьютерное оборудование, на котором данные хранятся, реализуются или их делают доступными для использования иным образом. База данных может находиться на том же оборудовании, что и процесс, который хранит или использует информацию, хранящуюся в базе данных, или она может находиться на отдельном оборудовании, например на выделенном сервере или множестве серверов.
[44] В контексте настоящего описания выражение "информация" включает в себя информацию любого характера или вида, который способен храниться в базе данных любым образом. Таким образом, информация включает в себя, но без ограничения, аудиовизуальные произведения (изображения, фильмы, звуковые записи, презентации и т.д.), данные (данные о местоположении, численные данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д.
[45] В контексте настоящего описания, если специально не указано иное, подразумевается, что термин «компонент» включает в себя программное обеспечение (соответствующее конкретному аппаратному контексту), которое является как необходимым, так и достаточным для реализации конкретной функции (функций), на которую ссылаются.
[46] В контексте настоящего описания предполагается, что выражение "используемый компьютером носитель хранения информации" включает в себя носители любого характера и вида, в том числе RAM, ROM, диски (CD-ROM, DVD, дискеты, накопители на жестких дисках и т.д.), USB-ключи, твердотельные накопители, ленточные накопители и т.д.
[47] В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в качестве прилагательных только для того, чтобы позволить отличать существительные, которые они модифицируют, друг от друга, а не для описания какой-либо особой взаимосвязи между такими существительными. Таким образом, например, следует понимать, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо конкретного порядка, типа, хронологии, иерархии или ранжирования (например) таких серверов, равно как и их использование (само по себе) не означает, что какой-либо "второй сервер" должен обязательно существовать в любой данной ситуации. Кроме того, как обсуждается в других контекстах данного документа, ссылка на "первый" элемент и "второй" элемент не исключает того, что эти два элемента фактически являются одним и тем же элементом реального мира. Таким образом, например, в некоторых случаях "первый" сервер и "второй" сервер могут быть одним и тем же программным обеспечением и/или аппаратным обеспечением, в других случаях они могут представлять собой разное программное обеспечение и/или аппаратное обеспечение.
[48] Каждая из реализаций настоящей технологии обладает по меньшей мере одним из вышеупомянутых аспектов и/или цели, но не обязательно имеет их все. Следует понимать, что некоторые аспекты настоящей технологии, которые возникли в попытке достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или удовлетворять другим целям, которые не описаны в данном документе явным образом.
[49] Дополнительные и/или альтернативные признаки, аспекты и преимущества реализаций настоящей технологии станут очевидными из нижеследующего описания, сопроводительных чертежей и приложенной формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[50] Для лучшего понимания настоящей технологии, а также других аспектов и ее дополнительных признаков, ссылка приводится на нижеследующее описание, которое должно использоваться в сочетании с сопроводительными чертежами, на которых:
[51] на Фиг. 1 изображена система, пригодная для реализации неограничивающих вариантов осуществления настоящей технологии.
[52] на Фиг. 2 показан конвейер обработки, выполняемый сервером по фиг. 1 для генерации модифицированного аудио на основе исходного аудио из видеофайла в соответствии по меньшей мере с некоторыми вариантами осуществления настоящей технологии.
[53] на Фиг. 3 показан конвейер обработки, выполняемый сервером для генерации модифицированного аудио на основе фонем, в соответствии по меньшей мере с некоторыми вариантами осуществления настоящей технологии.
[54] на Фиг. 4 изображен входной набор, содержащий последовательность первых аудиофрагментов и последовательность вторых аудиофрагментов, а также множество возможных компоновок для последовательности вторых аудиофрагментов в соответствии по меньшей мере с некоторыми вариантами осуществления настоящей технологии.
[55] Фиг. 5 представляет собой схематическое представление последовательности первых аудиофрагментов и последовательности вторых аудиофрагментов с фиг. 4.
[56] Фиг. 6 является схематическим представлением оценки потери для соответствующих из множества возможных компоновок по фиг. 4.
[57] Фиг. 7 является схематическим представлением генерации модифицированных аудиофрагментов в потоковом режиме.
[58] Фиг. 8 представляет собой блок-схему последовательности операций способа, выполняемого в соответствии с некоторыми неограничивающими вариантами осуществления настоящей технологии.
ПОДРОБНОЕ ОПИСАНИЕ
[59] Со ссылкой на Фигуру 1 проиллюстрировано схематичное представление системы 100, причем система 100 подходит для реализации неограничивающих вариантов осуществления настоящей технологии. Следует четко понимать, что изображенная система 100 является лишь иллюстративной реализацией настоящей технологии. Таким образом, нижеследующее описание предназначено лишь для того, чтобы использоваться в качестве описания иллюстративных примеров настоящей технологии. Это описание не предназначено для определения объема или ограничения настоящей технологии. В некоторых случаях то, что считается полезными примерами модификаций системы 100, также может быть изложено ниже. Это делается лишь для содействия пониманию и опять же не для строгого определения объема или очерчивания границ настоящей технологии. Эти модификации не являются исчерпывающим списком и, как будет понятно специалисту в данной области техники, возможны другие модификации. Кроме того, те случаи, когда этого не было сделано (т.е. когда не было представлено примеров модификаций), не следует интерпретировать так, что никакие модификации не возможны и/или что описанное является единственным способом реализации такого элемента в настоящей технологии. Специалисту в данной области будет понятно, что это, вероятно, не так. Кроме того, следует понимать, что система 100 может предоставлять в некоторых случаях простые реализации настоящей технологии, и что в таком случае они были представлены для помощи в понимании. Специалисты в данной области поймут, что различные реализации настоящей технологии могут иметь большую сложность.
[60] Вообще говоря, система 100 сконфигурирована для предоставления услуг электронного дублирования для пользователя 102 электронного устройства 104. Например, система 100 может быть сконфигурирована для получения видеофайла с аудио на первом языке, генерирования аудио на втором языке и предоставления пользователю видеофайла со вторым языком. Теперь будут описаны по меньшей мере некоторые компоненты системы 100, однако следует понимать, что другие компоненты, помимо тех, что проиллюстрированы на Фигуре 1, могут быть частью системы 100, не выходя за рамки объема настоящей технологии.
Сеть связи
[61] Электронное устройство 104 коммуникативно связано с сетью 110 связи для связи с сервером 112. Например, электронное устройство 104 может быть коммуникативно связано с сервером 112 через сеть 110 связи для предоставления пользователю 102 онлайновых услуг, таких как, например, механизмы потокового видео. Сеть 110 связи сконфигурирована для передачи, среди прочего, данных между электронным устройством 104 и сервером 112 в виде одного или нескольких пакетов данных.
[62] В некоторых неограничивающих вариантах осуществления настоящей технологии сеть 110 связи может быть реализована как Интернет. В других неограничивающих вариантах осуществления настоящей технологии сеть 110 связи может быть реализована иначе, например как какая-либо глобальная сеть связи, локальная сеть связи, частная сеть связи и тому подобное. То, как реализована линия связи (отдельно не пронумерована) между электронным устройством 104 и сетью 110 связи, будет зависеть, в частности, от того, как реализовано электронное устройство 104.
[63] Просто как пример, а не как ограничение, в тех вариантах осуществления настоящей технологии, в которых электронное устройство 104 реализовано как устройство беспроводной связи (например как смартфон), линия связи может быть реализована как линия беспроводной связи (такая как, но без ограничения, линия сети связи 3G, линия сети связи 4G, Wireless Fidelity или WiFi для краткости, Bluetooth® и тому подобные). В тех примерах, где электронное устройство 104 реализовано как ноутбук, линия связи может быть либо беспроводной (такой как Wireless Fidelity или WiFi® для краткости, Bluetooth® или тому подобное), либо проводной (такой как Ethernet-соединение).
ЭЛЕКТРОННОЕ УСТРОЙСТВО
[64] Система 100 содержит электронное устройство 104, причем электронное устройство 104 ассоциировано с пользователем 102. Как таковое, электронное устройство 104 иногда может именоваться «клиентским устройством», «конечным пользовательским устройством», «клиентским электронным устройством» или просто «устройством». Следует отметить, что связь электронного устройства 104 с пользователем 102 не обязательно предполагает или подразумевает какой-либо режим работы - например необходимость входа в систему, необходимость регистрации или тому подобное.
[65] Реализация электронного устройства 104 конкретным образом не ограничивается, но в качестве примера электронное устройство 104 может быть реализовано как персональный компьютер (настольные компьютеры, ноутбуки, нетбуки и т.д.), устройство беспроводной связи (такое как смартфон, сотовый телефон, планшет и подобное), а также сетевое оборудование (например, маршрутизаторы, коммутаторы и шлюзы). Электронное устройство 104 содержит аппаратное обеспечение и/или программное обеспечение и/или микропрограммное обеспечение (или их комбинацию), которое известно в данной области техники, для исполнения приложения браузера.
[66] Вообще говоря, назначением приложения браузера является предоставление пользователю 102 возможности доступа к одному или более сетевым ресурсам, таким как, например, веб-страницы. То, как приложение браузера реализуется, конкретным образом не ограничено. Один пример приложения браузера может быть воплощен как браузер Яндекс™ (Yandex™).
[67] Пользователь 102 может использовать приложение браузера для доступа к платформе потокового видео для потоковой передачи видеоконтента. Например, электронное устройство 104 может быть сконфигурировано для генерирования запроса, указывающего видеоконтент, который пользователь 102 желает просмотреть. В некоторых вариантах осуществления запрос от электронного устройства 104 может дополнительно указывать желаемый язык для аудио, сопровождающего видеоконтент. Кроме того, электронное устройство 104 может быть настроено на получение ответа (не показано) для воспроизведения видеоконтента и аудио на выбранном языке пользователю 102. Обычно запрос и ответ могут передаваться от электронного устройства 104 и на него через сеть 110 связи. Содержание запроса и ответа может зависеть, среди прочего, от того, транслируются ли видео- и аудиоконтент в режиме реального времени или нет.
База данных
[68] Система 100 также содержит базу 150 данных, которая коммуникативно связана с сервером 112 и выполнена с возможностью хранения информации, извлекаемой, или иным образом определяемой или генерируемой сервером 112. Вообще говоря, база 150 данных может принимать данные от сервера 112, которые были извлечены, или иным образом определены или сгенерированы сервером 112 во время обработки, для их временного и/или постоянного хранения, и может предоставлять сохраненные данные серверу 112 для их использования. Предполагается, что база 150 данных может быть разделена на несколько распределенных баз данных без выхода за рамки объема настоящей технологии.
[69] База данных 150 может быть сконфигурирована для хранения данных для поддержки механизмов потокового видео сервера 112. С этой целью база 150 данных может хранить среди прочего множество элементов цифрового контента, включая видео- и аудиофайлы, представляющие медиа-контент, потребляемый пользователем 102. Примеры элементов цифрового контента могут включать, помимо прочего, цифровое видео, цифровые фильмы, цифровое аудио, цифровую музыку, контент веб-сайта, контент социальных сетей и т.п.
Сервер
[70] Система 100 также содержит сервер 112, который может быть реализован как традиционный компьютерный сервер. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 112 является единственным сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 112 могут быть распределены и могут быть реализованы посредством многочисленных серверов. Сервер 112 может включать в себя один или более процессоров, одно или более энергонезависимых запоминающих устройств, считываемые компьютером инструкции и/или дополнительные аппаратные компоненты, дополнительные программные компоненты и/или их комбинацию для реализации различных функциональных возможностей сервера 112, не выходя за рамки объема настоящей технологии.
[71] Вообще говоря, сервер 112 может находиться под контролем и/или управлением поставщика видеоуслуг (не показан), такого как, например, оператор платформы потокового видео Yandex™. Предполагается, что провайдер услуг потокового видео и провайдер приложения браузера могут быть одним и тем же провайдером. Например, приложение браузера (например, браузер Yandex™) и механизмы потоковой передачи видео (например, механизмы потоковой передачи видео Yandex™) могут предоставляться, контролироваться и/или управляться одним и тем же оператором или организацией.
[72] Как упоминалось выше, на сервере 112 размещен механизм потоковой передачи видео (не показан). Вообще говоря, механизм потоковой передачи видео реализован как множество реализуемых компьютером процедур, которые используются для предоставления видеоконтента пользователю 102 в сопровождении аудиоконтента на одном или нескольких языках.
[73] Разработчики настоящей технологии осознали, что большой объем медиаконтента, транслируемого онлайн, например, изначально создается на английском языке, хотя многие пользователи не говорят по-английски. Чтобы сделать такой медиаконтент доступным для большого количества пользователей, традиционные решения предусматривают либо субтитры на разных языках, либо дублирование аудиоконтента на разных языках. Разработчики разработали способы и системы, сконфигурированные для предоставления услуг дублирования видео, в которых аудиоконтент на одном или нескольких языках генерируется сервером 112 без необходимости вмешательства человека для создания аудиоконтента на одном или нескольких языках.
[74] В некоторых вариантах осуществления сервер 112 сконфигурирован для предоставления услуг автоматического дублирования, при которых исходный аудиоконтент переводится на один или несколько языков и воспроизводится мужским или женским голосом, и который может быть наложен на исходный видеоконтент для потребления пользователем 102.
[75] Как будет более подробно описано ниже, услуги автоматического дублирования могут быть реализованы с использованием нескольких нейронных сетей, которые могут быть сконфигурированы чтобы: (i) распознавать речь (преобразовывать аудио в текст), разбивать распознанный текст на отдельные сегменты (например, предложения), переводить сегменты на целевой язык и генерировать дублированный контент, который накладывается поверх исходного видеоконтента. Система может дополнительно определять пол говорящего и синтезировать соответствующие голосовые характеристики.
[76] Со ссылкой на фиг. 2 изображен конвейер 200 обработки, выполняемый сервером 112 в некоторых вариантах осуществления настоящей технологии. Первая процедура конвейера 200 обработки выполняется модулем 202 распознавания речи над исходным аудиоконтентом. В широком смысле первая процедура используется для приема исходного аудиоконтента 251 и создания данных 252 распознавания речи.
[77] Данные 252 распознавания речи могут представлять автоматически распознаваемую речь или другое аудио из элемента видеоконтента. Данные 252 распознавания речи могут включать в себя множество сгенерированных строк символов, где каждая отдельная сгенерированная строка символов представляет слово, фразу или набор символов, произнесенных говорящим в элементе видеоконтента. Каждая сгенерированная строка символов в данных 252 распознавания речи может быть ассоциирована с информацией о времени, которая представляет конкретное время, когда сгенерированная строка символов была произнесена в видео. Например, информация о времени для фразы «Доброе утро» может включать в себя время, когда произносится слово «Доброе», и время, когда произносится слово «утро». Информация о времени может включать в себя конкретное время начала и окончания (например, временные метки) для каждой сгенерированной строки символов или может включать в себя информацию о конкретном времени начала и продолжительности для каждой сгенерированной строки символов.
[78] В некоторых вариантах осуществления модуль 202 распознавания речи может быть сконфигурирован для дополнительной обработки исходного аудиоконтента для удаления артефактов, не связанных с речью, таких как, например, звуки музыки. В дополнительных вариантах осуществления модуль 202 распознавания речи может быть сконфигурирован для вставки знаков препинания и/или может дополнительно разделять слова на сегменты подслов.
[79] В некоторых вариантах осуществления модуль 202 распознавания речи может содержать модель преобразования речи в текст (STT). Модель STT может быть моделью машинного обучения, такой как модель нейронной сети (NN). Неограничивающие примеры моделей NN, которые можно использовать для реализации настоящей технологии, могут включать в себя модель рекуррентной NN и/или модель NN с долговременной кратковременной памятью. В дополнительных вариантах осуществления модель машинного обучения может быть реализована как модель преобразователя.
[80] По меньшей мере, в некоторых вариантах осуществления предусмотрена модель автоматического распознавания речи (ASR). ASR может быть реализован как комбинация модели seq2seq и сверточной нейронной сети (CNN). Модель seq2seq может быть реализована как модель VGGTransformer. Дополнительно или необязательно преобразователь СТС также может использоваться для промежуточных распознаваний (например, частичных). По меньшей мере, в некоторых вариантах осуществления модель ASR может быть реализована аналогично модели ASR, раскрытой в совместном владении патентом США 11,145,305, содержание которого полностью включено в настоящее описание посредством ссылки.
[81] Вторая процедура конвейера 200 обработки выполняется модулем 204 перевода над данными 252 распознавания речи. В широком смысле вторая процедура используется для приема данных распознавания речи и создания данных перевода 253.
[82] Данные 253 перевода представляют собой перевод строк символов из данных 252 распознавания речи (которые находятся на исходном языке исходного аудиоконтента) на второй язык. Модуль 204 перевода также может принимать информацию о поле, ассоциированном с человеком, говорящим в исходном аудиоконтенте. В некоторых случаях модуль 204 перевода может генерировать разные данные 253 перевода в зависимости, среди прочего, от того, говорит ли мужчина или женщина.
[83] Предполагается, что модуль 204 перевода может быть сконфигурирован для выполнения множества моделей перевода для перевода строк символов с исходного языка на один или несколько вторых языков.
[84] То, как реализуется данная модель перевода модуля 204 перевода, не является особым ограничением. В одном варианте осуществления модель перевода может быть реализована как модель статистического машинного перевода (SMT), обученная переводить предложения с первого языка на второй язык.
[85] В широком смысле SMT имеет дело с автоматическим преобразованием предложений одного человеческого языка (например, французского) в другой человеческий язык (например, английский). Первый язык называется исходным, а второй язык называется целевым. Этот процесс можно рассматривать как стохастический процесс. Существует много вариантов SMT, в зависимости от того, как моделируется перевод. Некоторые подходы основаны на преобразовании строки в строку, некоторые используют деревья в строки, а некоторые используют модели дерева в дерево. Модель SMT оценивается по параллельным корпусам (пары исходный-целевой) и/или по одноязычным корпусам (примеры целевых предложений). Предполагается, что сервер 112 может быть сконфигурирован для генерирования данной функции перевода путем обучения модели SMT на основе выровненных корпусов текстов между соответствующей парой языков. Предполагается, что данная модель перевода может быть реализована как модель типа кодер-декодер, не выходя за рамки настоящей технологии.
[86] В некоторых вариантах осуществления модель перевода может быть воплощена как NN с архитектурой преобразователя. Способность архитектур-преобразователей учитывать широкий контекст, появившийся в сетях с долговременной кратковременной памятью (LS™), а затем с помощью механизма внимания, может оказаться полезной для использования в качестве модели перевода. Предполагается, что модель перевода может быть снабжена дополнительными признаками, такими как, например, пол говорящего.
[87] Третья процедура конвейера 200 обработки выполняется модулем 204 синтеза речи над данными 253 перевода. В общем, третья процедура используется для приема данных 253 перевода и создания данных 254 синтеза речи.
[88] Данные 254 синтеза речи содержат переведенный аудиоконтент, сгенерированный на основе, среди прочего, данных 253 перевода, где переведенный аудиоконтент представляет предложения, произносимые на одном (или более) других языках. Модуль 206 синтеза речи может содержать акустическую модель 214 и вокодер 212.
[89] Предполагается, что синтез речи может быть достигнут за счет использования глубоких нейронных моделей, которые иногда называют «акустическими моделями» и «вокодерами». Следует отметить, что акустическая модель может генерировать мел-спектрограммы на основе, например, фонем, а вокодер может синтезировать формы сигналов во временной области, которые могут быть обусловлены мел-спектрограммами из модели текст-в-спектрограмма.
[90] В некоторых вариантах осуществления настоящей технологии акустическая модель может быть реализована как известная модель Tacotron 2. В широком смысле, Tacotron 2 представляет собой рекуррентную сеть предсказания признаков от последовательности к последовательности с механизмом(ами) внимания, который предсказывает последовательность кадров мел-спектрограммы из входной последовательности символов. В других вариантах осуществления вокодер может быть реализован как известная модель HiFi-GAN. В широком смысле архитектура HiFi-GAN может содержать один генератор и два дискриминатора: многомасштабный и многопериодный дискриминаторы. Генератор представляет собой полностью сверточную нейронную сеть. Он использует мел-спектрограмму в качестве входных данных и увеличивает ее дискретность с помощью транспонированных сверток до тех пор, пока длина выходной последовательности не совпадет с временным разрешением необработанных сигналов. Каждая транспонированная свертка сопровождается модулем мультирецепторного слияния полей (MRF). В других вариантах осуществления вокодер может быть реализован аналогично модели, описанной в находящейся в совместном владении заявке на патент США US 2022/084499 под названием «Способ и сервер для преобразования текста в речь», опубликованной 17 марта 2022 г., содержание которой полностью включено в настоящее описание посредством ссылки.
[91] В контексте настоящей технологии сервер 112 сконфигурирован для выполнения операции 208 выравнивания и/или операции 210 выравнивания. Следует отметить, что выравнивание может использоваться, поскольку переведенный аудиоконтент может отличаться от исходного аудиоконтента, например, по продолжительности, и может не «выравниваться» с видеоконтентом таким же образом. Например, без выравнивания переведенный аудиоконтент может выглядеть несинхронизированным с видеоконтентом и может не понравиться зрителям.
[92] Разработчики поняли, что некоторые традиционные решения могут использоваться для ускорения или замедления аудиосегментов и/или добавления пауз, если это необходимо. Однако такие решения приводят к тому, что аудиосегменты переводятся либо слишком быстро, либо слишком медленно, либо содержат слишком много пауз, что отрицательно сказывается на удовлетворенности пользователей.
[93] В некоторых вариантах осуществления операция 208 выравнивания может выполняться для сигналов формы волны во временной области, генерируемых вокодером 212. В других вариантах осуществления операция 210 выравнивания может выполняться на мел-спектрограммах, сгенерированных акустической моделью 214. Например, со ссылкой на фиг. 3 изображен конвейер 300 обработки, выполняемый сервером 112. Сервер 112 сконфигурирован для предоставления сгенерированных фонем 302 в акустическую модель 214. Акустическая модель 214 сконфигурирована для генерации MEL-спектрограмм 304, представляющих фонемы 302. Сервер 112 сконфигурирован для ввода MEL-спектрограмм 304 в вокодер 212 для генерирования сигналов 306 формы волны. В некоторых вариантах осуществления сервер 112 выполнен с возможностью выполнения операции 210 выравнивания MEL-спектрограмм 304, сгенерированных акустической моделью 214. Однако в других вариантах осуществления сервер 112 может быть сконфигурирован для выполнения операции 208 выравнивания над сигналами 254 формы волны. Теперь будет более подробно описано, как сервер 112 сконфигурирован для выполнения 208 операции выравнивания и/или операции 210 выравнивания.
[94] Со ссылкой на фиг. 4 показано представление 400 того, как сервер 112 сконфигурирован для генерирования модифицированных аудиофрагментов. Сервер 112 сконфигурирован для получения входного набора 402, содержащего последовательность первых аудиофрагментов 410 и последовательность вторых аудиофрагментов 420.
[95] В некоторых вариантах осуществления последовательность первых аудиофрагментов 410 может быть последовательностью первых спектрограмм MEL, а последовательность вторых аудиофрагментов 420 может быть последовательностью вторых спектрограмм MEL. В этих вариантах осуществления сервер 112 сконфигурирован для выполнения операции 210 выравнивания. В других вариантах осуществления последовательность первых аудиофрагментов 410 может быть последовательностью первых сигналов формы волны, а последовательность вторых аудиофрагментов 420 может быть последовательностью вторых сигналов формы волны. В этих других вариантах осуществления сервер 112 сконфигурирован для выполнения операции 208 выравнивания.
[96] Следует отметить, что данный один из последовательности первых аудиофрагментов 410 представляет данное предложение на первом языке. Таким образом, последовательность первых аудиофрагментов 410 содержит первые аудиофрагменты 412, 414 и 416, которые представляют собой три последовательных предложения на первом языке. Каждая из последовательности первых аудиофрагментов 410 ассоциирована с данными временной метки. Например, первый аудиофрагмент 412 ассоциирован с временными данными 413, первый аудиофрагмент 414 ассоциирвоан с временными данными 415, а первый аудиофрагмент 416 ассоциирован с временными данными 417. Временные данные 413 могут содержать временную метку начала и временную метку окончания первого аудиофрагмента 412 в видеофайле. Временные данные 415 могут содержать временную метку начала и временную метку окончания первого аудиофрагмента 414 в видеофайле. Временные данные 417 могут содержать временную метку начала и временную метку окончания первого аудиофрагмента 416 в видеофайле.
[97] Следует отметить, что данный один из последовательности вторых аудиофрагментов 420 представляет данное предложение на втором языке. Таким образом, последовательность вторых аудиофрагментов 420 содержит вторые аудиофрагменты 422, 424 и 426, которые представляют три последовательных предложения на втором языке и которые являются соответствующими переводами трех последовательных предложений на первом языке, представленном первыми аудиофрагментами 412, 414 и 416.
[98] Каждый из последовательности вторых аудиофрагментов 420 ассоциирован с данными временной метки. Например, второй аудиофрагмент 422 ассоциирован с временными данными 423, второй аудиофрагмент 424 ассоциирован с временными данными 425, а второй аудиофрагмент 426 ассоциирован с временными данными 427. Временные данные 423 могут содержать продолжительность второго аудиофрагмента 422. Временные данные 425 могут содержать продолжительность второго аудиофрагмента 424. Временные данные 427 могут содержать продолжительность второго аудиофрагмента 426. Предполагается, что в тех вариантах осуществления, где вторые звуковые части являются соответствующими MEL спектрограммами, продолжительность времени может быть извлечена из соответствующей спектрограммы MEL. В тех вариантах осуществления, где вторые звуковые части представляют собой соответствующие сигналы формы волны, продолжительность времени может соответствовать продолжительности времени соответствующего сигнала формы волны.
[99] С краткой ссылкой на фиг. 5 изображена временная шкала 502, ассоциированная с видеофайлом. Первая звуковая часть 412 ассоциирована с временной меткой t0 начала и временной меткой t3 окончания, первый аудиофрагмент 414 ассоциирован с временной меткой t4 окончания и временной меткой t7 окончания, а первый аудиофрагмент 416 ассоциирован с временной меткой t9 начала и временной меткой t11 окончания. Также изображен второй аудиофрагмент 422, имеющий продолжительность 523, второй аудиофрагмент 424, имеющий продолжительность 525, и второй аудиофрагмент 426, имеющий продолжительность 527.
[100] Сервер 112 сконфигурирован для предоставления набора 402 входных данных для реализуемого компьютером алгоритма 499. Алгоритм 499 может быть сконфигурирован для работы с использованием метода динамического программирования. В широком смысле методы динамического программирования относятся к методам, которые используются для упрощения сложной задачи путем ее рекурсивного разбиения на более простые подзадачи. Хотя некоторые проблемы принятия решений не могут быть разделены таким образом, решения, которые охватывают несколько моментов времени, часто распадаются рекурсивно. Точно так же в информатике, если проблему можно решить оптимально, разбив ее на подзадачи, а затем рекурсивно найдя оптимальные решения подзадач, то говорят, что она имеет оптимальную подструктуру. В контексте настоящей технологии сервер 112 сконфигурирован для выполнения метода динамического программирования для выбора целевого расположения последовательности вторых аудиофрагментов 420 среди множества возможных компоновок 430.
[101] Множество возможных компоновок 430 включает первую возможную компоновку 440, вторую возможную компоновку 450, третью возможную компоновку 460 и четвертую возможную компоновку 480. Первая возможная компоновка 440 содержит второй аудиофрагмент 422, ассоциированный с данными 441 возможной компоновки, второй аудиофрагмент 424, ассоциированный с данными 442 возможной компоновки, и второй аудиофрагмент 426, ассоциированный с данными 444 возможной компоновки. Вторая возможная компоновка 450 содержит второй аудиофрагмент 424, ассоциированный с данными 451 возможной компоновки, второй аудиофрагмент 424, ассоциированный с данными 452 возможной компоновки, и второй аудиофрагмент 426, ассоциированный с данными 454 возможной компоновки. Третья возможная компоновка 460 содержит второй аудиофрагмент 422, ассоциированный с данными 461 возможной компоновки, второй аудиофрагмент 424, ассоциированный с данными 462 возможной компоновки, и второй аудиофрагмент 426, ассоциированный с данными 464 возможной компоновки. Четвертая возможная компоновка 480 содержит второй аудиофрагмент 422, ассоциированный с данными 481 возможной компоновки, второй аудиофрагмент 424, ассоциированный с данными 482 возможной компоновки, и второй аудиофрагмент 426, ассоциированный с данными 484 возможной компоновки. Следует отметить, что данные возможной компоновки, ассоциированные с данным вторым аудиофрагментом, могут содержать возможную временную метку начала данного второго аудиофрагмента в видеофайле и возможный коэффициент сжатия данного второго аудиофрагмента.
[102] Сервер 112 сконфигурирован для генерирования множества оценок 470 потери для множества возможных компоновок 430. Сервер 112 сконфигурирован для генерирования первой оценки 471 потери для первой возможной компоновки 440, второй оценки 472 потери для второй возможной компоновки 450, третьей оценки 473 потери для третьей возможной компоновки 460. Данная оценка потери генерируется на основе (i) временных данных, ассоциированных с последовательностью первых аудиофрагментов 410, (ii) временных данных, ассоциированных с последовательностью вторых аудиофрагментов 420, и (ii) данных возможной компоновки, ассоциирвоанных со вторыми аудиофрагментами в соответствующей возможной компоновке. Сервер 112 сконфигурирован для выбора данной одной из множества возможных компоновок 430 в качестве целевой компоновки для последовательности вторых аудиофрагментов 420 на основе множества оценок 470 потери. Например, сервер 112 может выбрать третье возможную компоновку 460 в качестве целевой компоновки, если третья оценка 473 потери является минимальной оценкой потери среди множества оценок 470 потери. Теперь будет более подробно описано, как сервер 112 сконфигурирован для генерирования данной оценки потери для соответствующей возможной компоновки.
[103] Со ссылкой на фиг. 6 показаны представления 601, 602, 603 и 604 соответствующих возможных компоновок 440, 450, 460 и 480.
[104] Данные 441 возможной компоновки указывают временную метку t0 начала и коэффициент сжатия «1» для второго аудиофрагмента 422. Данные 442 возможной компоновки указывают на временную метку t4 начала и коэффициент сжатия «1» для второго аудиофрагмента 424. Данные 443 возможной компоновки указывают временную метку t9 начала и коэффициент сжатия «1» для второго аудиофрагмента 426. Коэффициент сжатия «1» указывает, что соответствующий второй аудиофрагмент имеет соответствующую исходную продолжительность времени в соответствующей возможной компоновке.
[105] В некоторых вариантах осуществления сервер 112 может быть сконфигурирован для генерирования значений 610-613 потери. Значение 610 потери может указывать на разницу между временной меткой t3 окончания для первого аудиофрагмента и 412 и временной меткой t4 окончания для второго аудиофрагмента 422 в возможной компоновке 440. Значение 611 потери может указывать на разницу между временной меткой t7 окончания для первого аудиофрагмента 414 и временной меткой t10 окончания для второго аудиофрагмента 424 в возможной компоновке 440. Значение 612 потери может указывать на разницу между временной меткой t11 окончания для первого аудиофрагмента 416 и временной меткой t14 окончания для второго аудиофрагмента 426 в возможной компоновке 440. Значение 613 потери может указывать на перекрытие между вторым аудиофрагментом 424 и вторым аудиофрагментом 426 в возможной компоновке 440. В некоторых вариантах осуществления значение 613 потери может быть предварительно определенной оценкой потери, относящейся к возможной компоновке, если определено перекрытие. В других вариантах осуществления значение 613 потери может быть пропорционально степени перекрытия в данной возможной компоновке. Сервер 112 может генерировать оценку 471 потери для возможной компоновки 440 как комбинацию оценок 610-613 потери.
[106] Данные 451 возможной компоновки указывают на временную метку t0 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 422. Данные 452 возможной компоновки указывают на временную метку t4 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 424. Данные 453 возможной компоновки указывают на временную метку t9 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 426. Коэффициент сжатия больше «1» указывает на то, что соответствующий второй аудиофрагмент имеет более короткую продолжительность времени, чем соответствующая исходная продолжительность времени в соответствующей возможной компоновке.
[107] В некоторых вариантах осуществления сервер 112 может быть сконфигурирован для генерирования значений 614-617 потери. Значение 614 потери может указывать степень сжатия для второго аудиофрагмента 422 в возможной компоновке 450. Значение 615 потери может указывать степень сжатия для второго аудиофрагмента 424 в возможной компоновке 450. Значение 616 потери может указывать степень сжатия для второго аудиофрагмента 426 в возможной компоновке 450. Значение 617 потери может указывать на разницу между временной меткой t11 окончания для первого аудиофрагмента 416 и временной меткой t12 окончания для второго аудиофрагмента 426 в возможной компоновке 450. Сервер 112 может генерировать оценку 472 потери для возможной компоновки 450 как комбинацию оценок 614-617 потери.
[108] Данные 461 возможной компоновки указывают на отметку времени t0 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 422. Данные 462 возможной компоновки указывают на временную метку t4 начала и коэффициент сжатия «1» для второго аудиофрагмента 424. Данные 463 возможной компоновки указывают на временную метку t10 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 426.
[109] В некоторых вариантах осуществления сервер 112 может быть сконфигурирован для генерирования значений 618-621 потери. Значение 618 потери может указывать степень сжатия второго аудиофрагмента 422 в возможной компоновке 460. Значение 619 потери может указывать на разницу между временной меткой t7 окончания для первого аудиофрагмента 414 и временной меткой t10 окончания для второго аудиофрагмента 424 в возможной компоновке 460. Значение 620 потери может указывать на разницу между временной меткой t9 начала для первого аудиофрагмента 416 и временной меткой t10 окончания для второго аудиофрагмента 426 в возможной компоновке 460. Значение 621 потери может указывать степень сжатия второго аудиофрагмента 426 в возможной компоновке 460. Сервер 112 может генерировать оценку 473 потери для возможной компоновки 460 как комбинацию значений 618-621 потери.
[110] Данные 481 возможной компоновки указывают на временную метку t0 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 422. Данные 482 возможной компоновки указывают на временную метку t4 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 424. Данные 483 возможной компоновки указывают на временную метку t9 начала и коэффициент сжатия больше «1» для второго аудиофрагмента 426.
[111] В некоторых вариантах осуществления сервер 112 может быть сконфигурирован для генерирования значений 622-626 потери. Значение 622 потери может указывать степень сжатия для второго аудиофрагмента 422 в возможной компоновке 480. Значение 622 потери может указывать на разницу между центральной временной меткой первого аудиофрагмента 414 и центральной временной меткой второго аудиофрагмента 424 в возможной компоновке 480. Значение 624 потери может указывать на разницу между временной меткой t7 окончания первого аудиофрагмента 414 и временной меткой t8 окончания второго аудиофрагмента 424 в возможной компоновке 480. Значение 625 потери может указывать степень сжатия для второго аудиофрагмента 424 в возможной компоновке 480. Значение 626 потери может указывать степень сжатия для второго аудиофрагмента 426 в возможной компоновке 480. Сервер 112 может генерировать оценку 474 потери для возможной компоновки 480 как комбинацию значений 622-626 потери.
[112] Предполагается, что сервер 112 может быть сконфигурирован для генерирования множества значений потери, которые должны использоваться в комбинации при определении оценки потери для данной возможной компоновки вторых аудиофрагментов. Например, данная оценка потери может указывать на разницу между временными метками начала первого аудиофрагмента и соответствующего второго аудиофрагмента в данной возможной компоновке. В другом примере данная оценка потери может указывать на разницу между временными метками окончания первого аудиофрагмента и соответствующего второго аудиофрагмента в данной возможной компоновке. В дополнительном примере данная оценка потери может указывать на разницу между центральными временными метками первого аудиофрагмента и соответствующего второго аудиофрагмента в данной возможной компоновке. В дополнительном примере данная оценка потери может указывать на перекрытие между парой вторых аудиофрагментов в данной возможной компоновке. Например, данная оценка потери может указывать степень сжатия второго аудиофрагмента в данной возможной компоновке.
[113] Предполагается, что сервер 112 может быть сконфигурирован для выбора целевой компоновки для последовательности вторых аудиофрагментов 420 среди возможных компоновок 440, 450, 460 и 480 на основе множества оценок 470 потери. Например, сервер 112 может выбрать целевую компоновку в качестве возможной компоновки с минимальной оценкой потери среди множества оценок 470 потери.
[114] Со ссылкой на фиг. 7 изображен неограничивающий вариант осуществления настоящей технологии, в котором сервер 112 работает в потоковом режиме. Изображены три состояния конвейера потоковой передачи вторых аудиофрагментов, которые должны быть модифицированы сервером 112. Модифицированные вторые аудиофрагменты должны предоставляться пользователю 102 в потоковом режиме. Потоковый конвейер проиллюстрирован в первом состоянии 700 при t=t1, во втором состоянии 700’; при t=t2 и в третьем состоянии 70”; при t=t3.
[115] В первом состоянии 700 при t=t1 сервер 112 может использовать скользящее окно 701 для выбора текущей последовательности вторых аудиофрагментов 710, включающих в себя вторые аудиофрагменты x1, x2 и x3. Сервер 112 сконфигурирован для выбора целевой компоновки 720 текущей последовательности вторых аудиофрагментов 710 аналогично тому, как сервер 112 сконфигурирован для выбора целевой компоновки среди возможных компоновок 440, 450, 460 и 480. В целевой компоновке 720 второй аудиофрагмент x1 является ассоциированными данными 721 целевой компоновки, второй аудиофрагмент x2 является ассоциированными данными 722 целевой компоновки, а второй аудиофрагмент x3 является ассоциированными данными 723 целевой компоновки. В этом варианте осуществления сервер 112 сконфигурирован для модификации первого из последовательности вторых аудиофрагментов 710, x1, в соответствии с данными 721 целевой компоновки. Модифицированный таким образом второй аудиофрагмент x1 предоставляется электронному устройству 104 в сочетании с потоковым видеоконтентом.
[116] Во втором состоянии 700', в момент t=t2, сервер 112 получает новый второй аудиофрагмент x4 и может использовать скользящее окно 701'; для выбора текущей последовательности вторых аудиофрагментов 730, включая вторые аудиофрагменты x2, x3 и x4. Сервер 112 сконфигурирован для выбора целевой компоновки 740 текущей последовательности вторых аудиофрагментов 730 аналогично тому, как сервер 112 сконфигурирован для выбора целевой компоновки среди возможных компоновок 440, 450, 460 и 480. В целевой компоновке 740 второй аудиофрагмент x2 является ассоциированными данными 741 целевой компоновки, второй аудиофрагмент x3 является ассоциированными данными 742 целевой компоновки, а второй аудиофрагмент x4 является ассоциированными данными 743 целевой компоновки. В этом варианте осуществления сервер 112 настроен на модификацию первого из текущей последовательности вторых аудиофрагментов 730, x2, в соответствии с данными 741 целевой компоновки. Модифицированный таким образом второй аудиофрагмент x2 предоставляется электронному устройству 104 в сочетании с потоковым видеоконтентом.
[117] В некоторых вариантах осуществления настоящей технологии сервер 112 сконфигурирован для выполнения способа 800, показанного на фиг. 8. Различные этапы способа 800 теперь будут рассмотрены более подробно.
ЭТАП 802: получение последовательности первых аудиофрагментов
[118] Способ 800 начинается с этапа 802, когда сервер 112 сконфигурирован для получения последовательности первых аудиофрагментов. Данный фрагмент из последовательности первых аудиофрагментов представляет данное предложение на первом языке и ассоциирован с временной меткой в видеофайле.
[119] Например, сервер 112 сконфигурирован для получения входного набора 402, содержащего последовательность первых аудиофрагментов 410. В некоторых вариантах осуществления последовательность первых аудиофрагментов 410 может быть последовательностью первых спектрограмм MEL. В этих вариантах осуществления сервер 112 сконфигурирован для выполнения операции выравнивания 210. В других вариантах осуществления последовательность первых аудиофргаментов 410 может быть последовательностью сигналов первой формы волны. В этих других вариантах осуществления сервер 112 сконфигурирован для выполнения операции выравнивания 208.
Следует отметить, что данный один из последовательности первых аудиофрагментов 410 представляет данное предложение на первом языке. Таким образом, последовательность первых аудиофрагментов 410 содержит первые аудиофрагменты 412, 414 и 416, которые представляют собой три последовательных предложения на первом языке. Каждый из последовательности первых аудиофрагментов 410 ассоциирован с данными временной метки.
ЭТАП 804: получение последовательности вторых аудиофрагментов
[120] Способ продолжается на этапе 804 с сервером 112, сконфигурированным для получения последовательности вторых аудиофрагментов. Данный один из последовательности вторых аудиофрагментов представляет другое данное предложение на втором языке и ассоциирован с продолжительностью времени. Другое данное предложение является переводом данного предложения.
[121] Например, данный один из последовательности вторых аудиофрагментов 420 представляет данное предложение на втором языке. Таким образом, последовательность вторых аудиофрагментов 420 содержит вторые аудиофрагменты 422, 424 и 426, которые представляют три последовательных предложения на втором языке и которые являются соответствующими переводами трех последовательных предложений на первом языке, представленном первыми аудиофрагментами 412, 414 и 416.
[122] Предполагается, что сервер 112 может быть сконфигурирован для генерирования последовательности вторых аудиофрагментов 420 на основе последовательности первых аудиофрагментов 410 с использованием одной или нескольких моделей машинного обучения, как описано выше.
ЭТАП 806: генерирование множества возможных компоновок последовательности вторых аудиофрагментов
[123] Способ 800 переходит к этапу 806 с сервером 112, сконфигурированным для генерирования множества возможных компоновок последовательности вторых аудиофрагментов. Данная возможная компоновка ассоциирована с возможными временными метками в видеофайле и возможными степенями сжатия для соответствующих из последовательности вторых аудиофрагментов.
[124] Например, множество возможных компоновок 430 содержит первую возможную компоновку 440, вторую возможную компоновку 450, и третью возможную компоновку 460, и четвертую возможную компоновку 480.
[125] Первая возможная компоновка 440 содержит второй аудиофрагмент 422, ассоциированный с данными 441 возможной компоновки, вторую аудиочасть 424, связанную с данными 442 подходящей компоновки, и второй аудиофрагмент 426, ассоциированный с данными 444 возможной компоновки.
[126] Вторая возможная компоновка 450 содержит второй аудиофрагмент 424, ассоциированный с данными 451 возможной компоновки, второй аудиофрагмент 424, ассоциированный с данными 452 возможной компоновки, и второй аудиофрагмент 426, ассоциированный с данными 454 возможной компоновки.
[127] Третья возможная компоновка 460 содержит второй аудиофрагмент 422, ассоциированный с данными 461 возможной компоновки, второй аудиофрагмент 424, ассоциированный с данными 462 возможной компоновки, и второй аудиофрагмент 426, ассоциированный с данными 464 возможной компоновки.
[128] Четвертая возможная компоновка 480 содержит второй аудиофрагмент 422, ассоциированный с данными 481 возможной компоновки, второй аудиофрагмент 424, ассоциированный с данными 482 возможной компоновки, и второй аудиофрагмент 426, ассоциированный с данными 484 возможной компоновки.
[129] Следует отметить, что данные возможной компоновки, ассоциированные с данным вторым аудиофрагментом, могут содержать возможную временную метку начала данного второго аудиофрагмента в видеофайле и возможный коэффициент сжатия данного второго аудиофрагмента.
ЭТАП 808: выбор целевой компоновки для последовательности вторых аудиофрагментов
[130] Способ продолжается на этапе 808 с сервером 112, сконфигурированным для выбора целевой компоновки для последовательности вторых аудиофрагментов из множества возможных компоновок. Сервер 112 сконфигурирован для выбора целевой компоновки на основе целевой компоновки, имеющей минимальную оценку потери среди оценок потери, ассоциированных с соответствующими из множества возможных компоновок.
[131] Например, сервер 112 может быть сконфигурирован для генерирования множества оценок 470 потери для множества возможных компоновок 430. Сервер 112 сконфигурирован для генерирования первой оценки 471 потери для первой возможной компоновки 440, второй оценки 472 потери для второй возможной компоновки 450, третьей оценки 473 потери для третьей возможной компоновки 460 и четвертой оценки 474 потери для четвертой возможной компоновки 480.
[132] Данная оценка потери может быть сгенерирована на основе (i) временных данных, ассоциированных с последовательностью первых аудиофрагментов 410, (ii) временных данных, ассоциированных с последовательностью вторых аудиофрагментов 420, и (ii) данных возможной компоновки, ассоциированных со вторыми аудиофрагментами в соответствующей возможной компоновке.
[133] В некоторых вариантах осуществления сервер может быть сконфигурирован для выбора данной одной из множества возможных компоновок 430 в качестве целевой компоновки для последовательности вторых аудиофрагментов 420 на основе множества оценок 470 потери. Например, сервер 112 может выбрать третью возможную компоновку 460 в качестве целевой компоновки, если третья оценка 473 потери является минимальной оценкой потери среди множества оценок 470 потери.
[134] Следует отметить, что оценки потери могут формироваться по-разному. Например, заданная оценка потери для данной возможной компоновки может быть сгенерирована на основе: (i) комбинации различий между временными метками, ассоциированными с соответствующими метками из последовательности первых аудиофрагментов и соответствующими метками из данной возможной компоновки, (ii) наличия перекрытия между данной парой вторых аудиофрагментов, если: вторые аудиофрагменты из последовательности вторых аудиофрагментов скомпонованы в видеофайле в соответствии с возможными временными метками и возможными коэффициентами сжатия.
[135] В других вариантах осуществления данная оценка потери может быть сгенерирована сервером 112 на основе комбинации различий между временными метками начала, ассоциированными с соответствующими фрагментами из последовательности первых аудиофрагментов, и соответствующими возможными временными метками начала из данной возможной компоновки, а также комбинацией различий между временными метками окончания, ассоциированными с соответствующими фрагментами из последовательности первых аудиофрагментов, и соответствующими временными метками окончания из данной возможной компоновки.
[136] В дополнительных вариантах осуществления данная оценка потери может быть сгенерирована сервером 112 на основе комбинации различий между центральными временными метками, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими возможными центральными временными метками из данной возможной компоновки. В дополнительных вариантах осуществления оценка потери может быть сгенерирована сервером 112 на основе комбинации возможных степеней сжатия данной возможной компоновки.
[137] Предполагается, что данная оценка потери может быть сгенерирована как комбинация значений потери. Данное значение потери может быть реализовано как одно из значений 610-626 потери, описанных выше со ссылкой на фиг. 6. Предполагается, что комбинация значений потери может быть взвешена, так что первый тип значений потери может вносить больший вклад, чем второй тип значений потери, в данную оценку потери.
ШАГ 810: генерирование по меньшей мере одного модифицированного аудиофрагмента в качестве перевода аудио данных с использованием целевой компоновки.
[138] Способ 800 переходит к этапу 810 с сервером 112, сконфигурированным для генерирования по меньшей мере одного модифицированного аудиофрагмента для видеофайла в качестве перевода аудиоданных с использованием целевой компоновки.
[139] Предполагается, что сервер 112 может быть сконфигурирован для генерирования по меньшей мере одного модифицированного аудиофрагмента в автономном режиме. Например, перевод аудиоданных может быть сгенерирован сервером 112 и сохранен вместе с видеофайлом в хранилище для будущего предоставления их пользователям сервера 112. В этих вариантах осуществления сервер 112 может быть сконфигурирован для генерирования модифицированных аудиофрагментов для каждого второго аудиофрагмента, сгенерированного из исходных аудиоданных видеофайла. Альтернативно, только фрагменты исходных аудиоданных могут быть переведены, и соответствующие модифицированные аудиофрагменты могут быть сгенерированы сервером 112 и сохранены вместе с видеофайлом в хранилище.
[140] В других вариантах осуществления сервер 112 может быть сконфигурирован для генерирования по меньшей мере одного модифицированного аудиофрагмента в потоковом режиме, при котором видео- и аудиоданные передаются в виде потока на электронное устройство 104. В этих вариантах осуществления по меньшей мере один модифицированный аудиофрагмент может быть первым из последовательности вторых аудиофрагментов, которая была изменена в соответствии с данными целевой компоновки для первого из последовательности вторых аудиофрагментов. Этот модифицированный аудиофрагмент может быть передан на электронное устройство 104 как часть потоковых данных.
[141] Сервер 112 также может быть сконфигурирован на новый первый аудиофрагмент, представляющий дополнительное предложение на первом языке. Сервер 112 также может получить новый второй аудиофрагмент, представляющий другое дополнительное предложение на втором языке. Другое дополнительное предложение является переводом дополнительного предложения. Новый второй аудиофрагмент и подмножество вторых аудиофрагментов из последовательности вторых аудиофрагментов образуют новую последовательность вторых аудиофрагментов. Подмножество вторых аудиофрагментов исключает первую из последовательности вторых аудиофрагментов, которые использовались для генерирования по меньшей мере одного модифицированного фрагмента.
[142] Например, сервер 112 может использовать скользящее окно 701 для выбора текущей последовательности вторых аудиофрагментов 710, включающих в себя вторые аудиофрагменты x1, x2 и x3. Сервер 112 сконфигурирован для выбора целевой компоновки 720 текущей последовательности вторых аудиофрагментов 710. В целевой компоновке 720 второй аудиофрагмент x1 ассоциирован с данными 721 целевой компоновки. Сервер 112 может быть настроен на модифицирование первого из последовательности вторых аудиофрагментов 710, x1, в соответствии с данными 721 целевой компоновки. Модифицированный таким образом второй аудиофрагмент x1 предоставляется электронному устройству 104 в комбинации с потоковым видеоконтентом.
[143] В том же примере сервер 112 может получить новый второй аудиофрагмент x4 и может использовать скользящее окно 701'; для выбора текущей последовательности вторых аудиофрагментов 730, включая вторые аудиофрагменты x2, x3 и x4. Сервер 112 сконфигурирован для выбора целевой компоновки 740 текущей последовательности вторых аудиофрагментов 730. В целевой компоновке 740 второй аудиофрагмент x2 ассоциирован с данными 741 целевой компоновки. Сервер 112 может быть настроен на модифицирование первого из текущей последовательности вторых аудиофрагментов 730, x2, в соответствии с данными 741 целевой компоновки. Модифицированный таким образом второй аудиофрагмент x2 предоставляется электронному устройству 104 в сочетании с потоковым видеоконтентом.
[144] Следовательно, можно сказать, что сервер 112 может генерировать новое множество возможных компоновок для новой последовательности вторых аудиофрагментов и выбрать новую целевую компоновку для новой последовательности вторых аудиофрагментов из нового множества возможных компоновок. Затем сервер 112 может генерировать новый модифицированный аудиофрагмент путем модификации первого из новой последовательности вторых аудиофрагментов в соответствии с новой целевой компоновкой. Затем сервер 112 может передать другую часть видеофайла с новым модифицированным аудиофрагментом на пользовательское устройство.
[145] Модификации и улучшения вышеописанных реализаций настоящей технологии могут стать очевидными для специалистов в данной области техники. Предшествующее описание предназначено для того, чтобы быть примерным, а не ограничивающим. Поэтому предполагается, что объем настоящей технологии ограничен лишь объемом прилагаемой формулы изобретения.
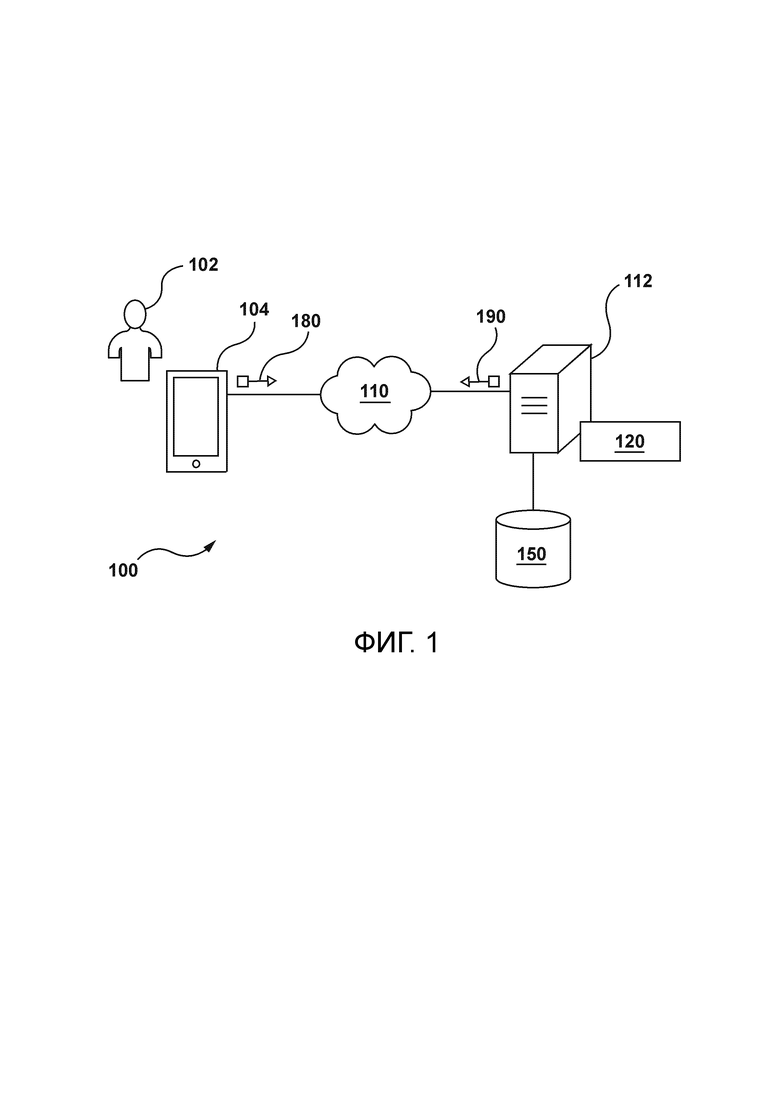
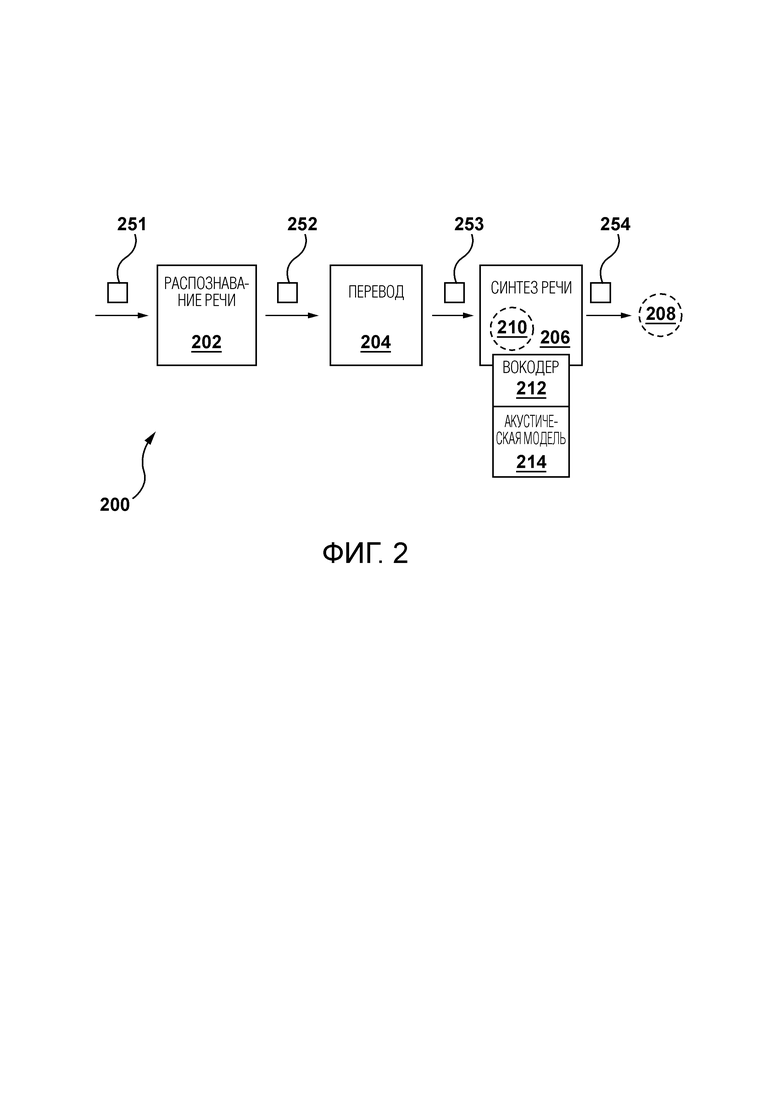
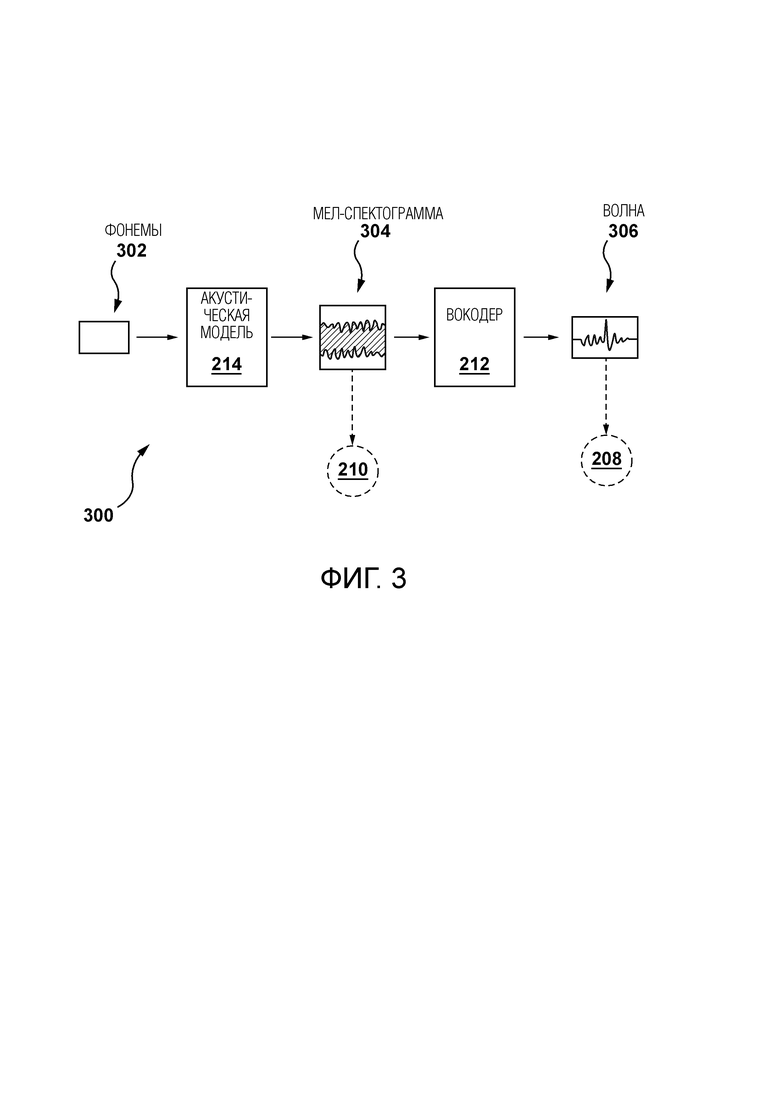
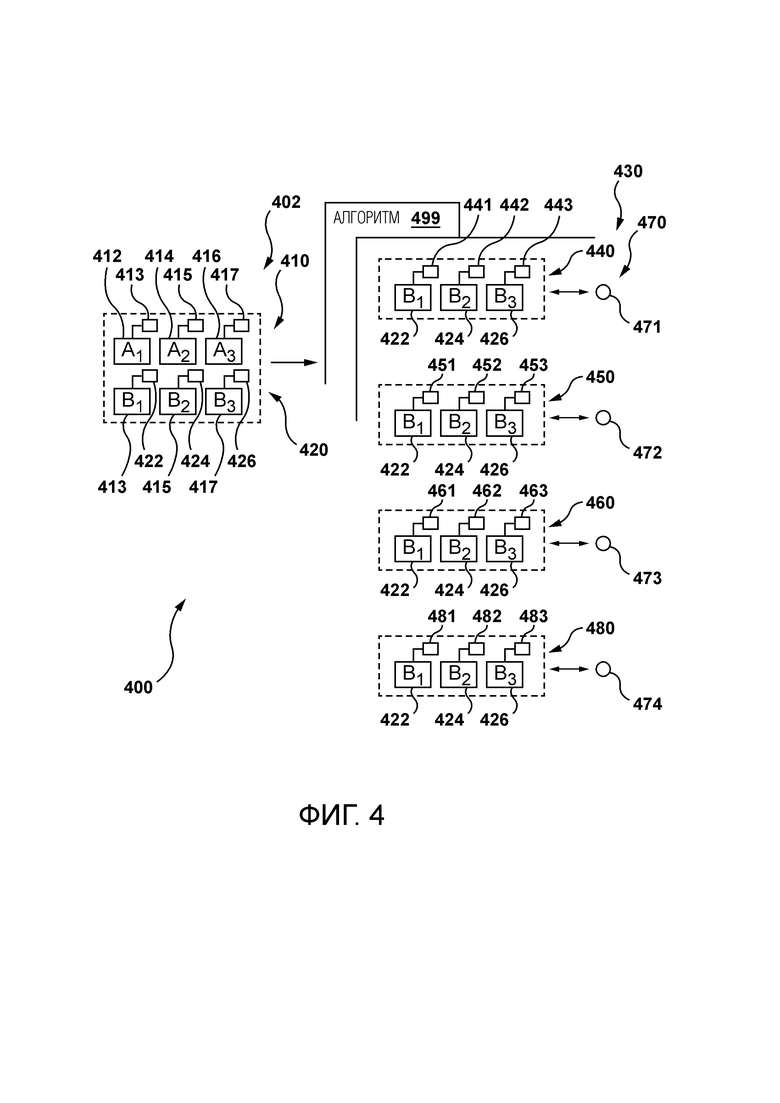
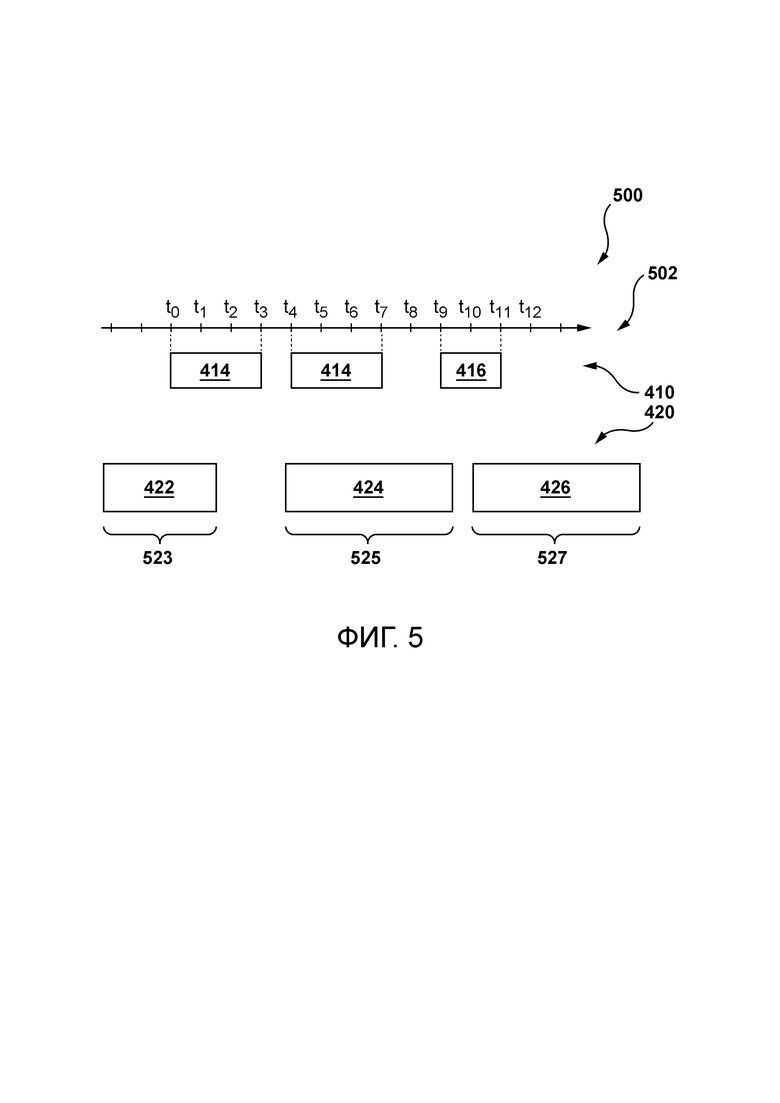
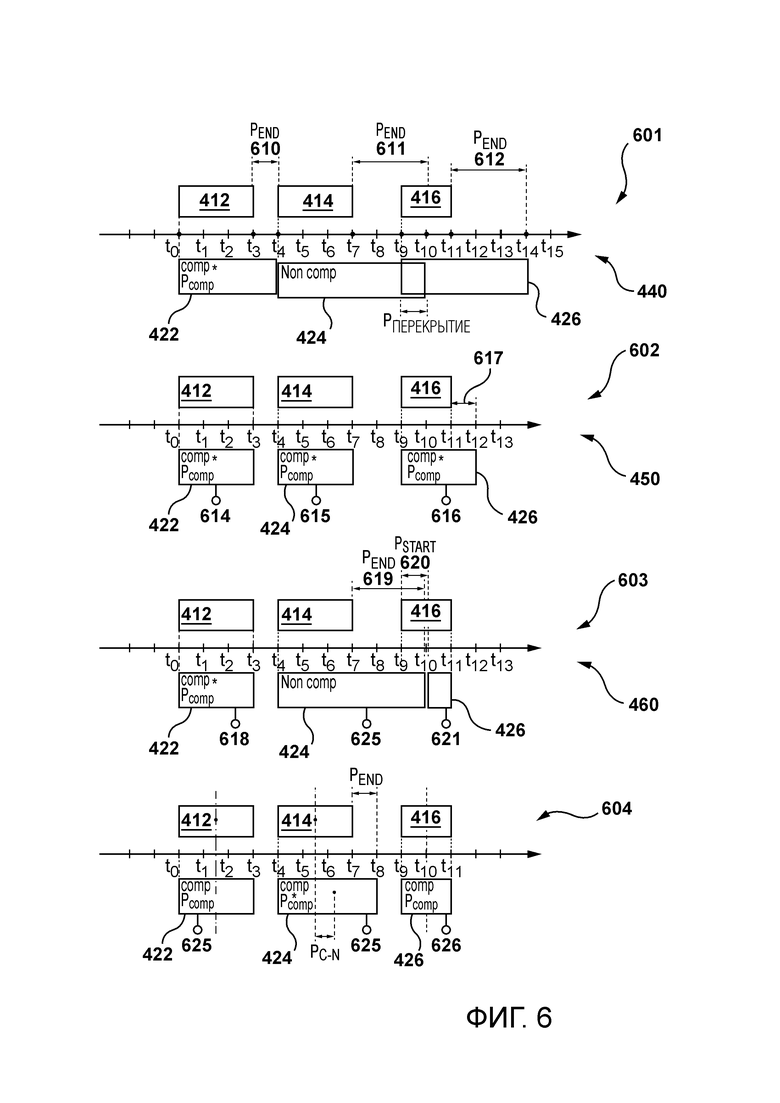
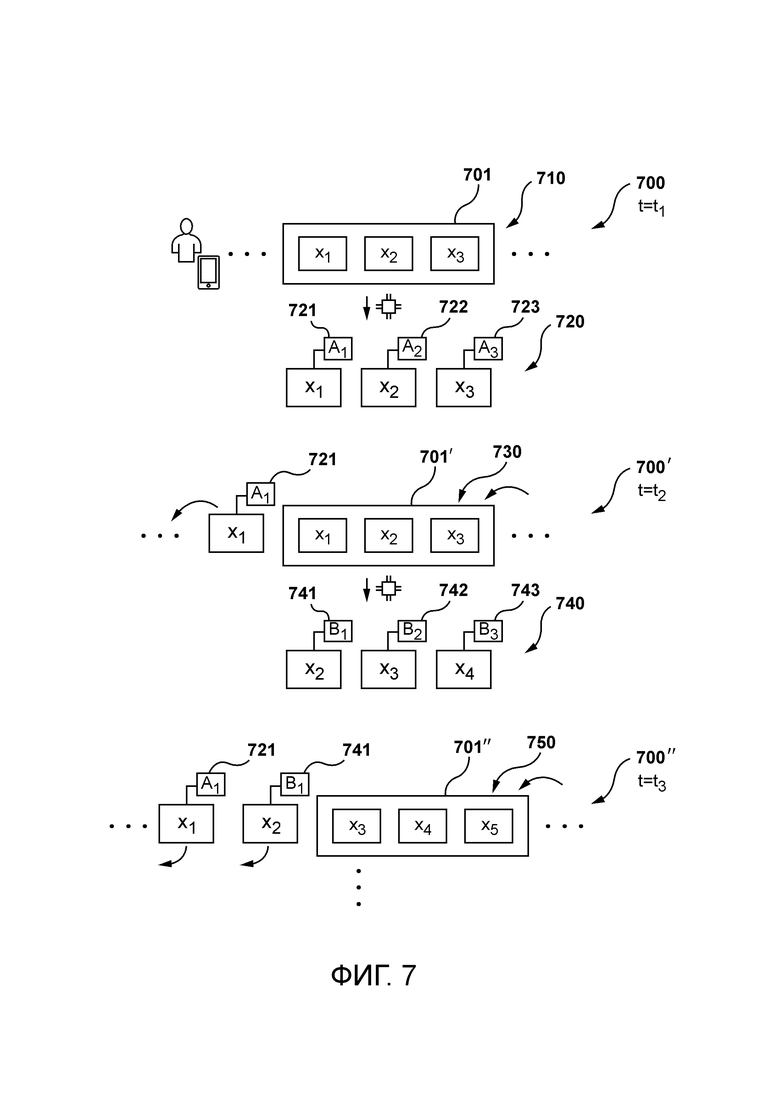
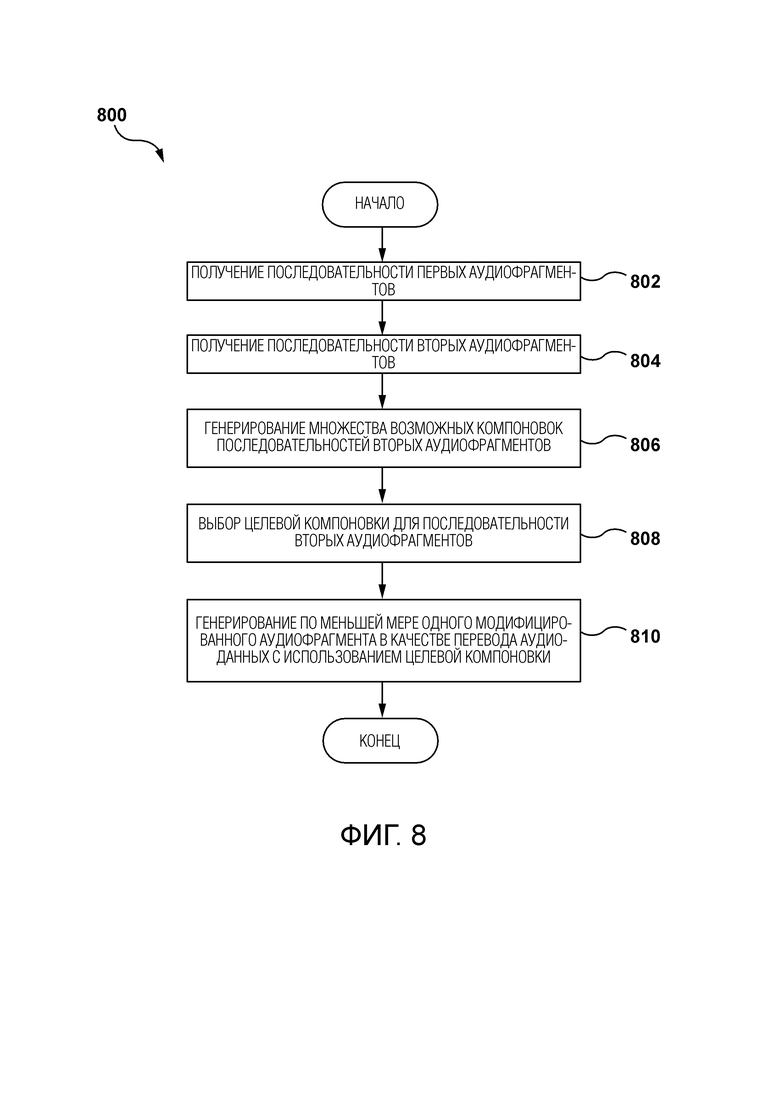
Изобретение относится к средствам для генерирования модифицированных аудиоданных для видеофайла. Технический результат заключается в повышении эффективности генерирования модифицированных аудиоданных. Получают последовательность первых аудиофрагментов и последовательность вторых аудиофрагментов на разных языках. Генерируют множество возможных компоновок последовательности вторых аудиофрагментов, где данная возможная компоновка ассоциирована с возможными временными метками в видеофайле и возможными коэффициентами сжатия для соответствующих из последовательности вторых аудиофрагментов. Выбирают целевую компоновку для последовательности вторых аудиофрагментов из множества возможных. Выбор основан на целевой компоновке, имеющей минимальную оценку потерь среди оценок потерь, ассоциированных с множеством возможных. Генерируют по меньшей мере один модифицированный аудиофрагмент для видеофайла в виде перевода аудиоданных с использованием целевой компоновки. 2 н. и 18 з.п. ф-лы, 8 ил.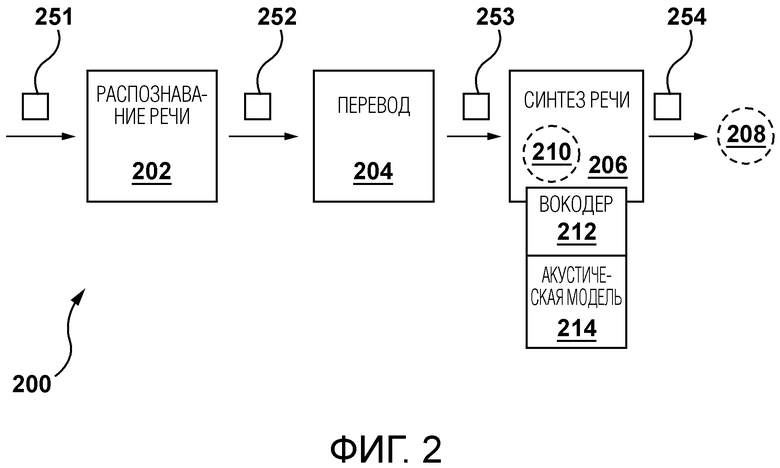
1. Способ генерирования модифицированных аудиоданных для видеофайла, причем видеофайл ассоциирован с аудиоданными, способ, исполняемый сервером, содержит этапы, на которых:
получают сервером последовательность первых аудиофрагментов,
данный фрагмент из последовательности первых аудиофрагментов представляет данное предложение на первом языке и ассоциирован с временной меткой в видеофайле;
получают сервером последовательность вторых аудиофрагментов,
данный фрагмент из последовательности вторых аудиофрагментов представляет собой другое данное предложение на втором языке и ассоциирован с временной продолжительностью, при этом другое данное предложение является переводом данного предложения;
генерируют сервером множество возможных компоновок для последовательности вторых аудиофрагментов,
данная возможная компоновка ассоциирована с возможными временными метками в видеофайле и возможными коэффициентами сжатия для соответствующих из последовательности вторых аудиофрагментов;
выбирают целевую компоновку для последовательности вторых аудиофрагментов из множества возможных компоновок, причем выбор основан на целевой компоновке, имеющей минимальную оценку потери среди оценок потери, ассоциированных с соответствующими из множества возможных компоновок, при этом данная оценка потери данной возможной компоновки генерируется на основе:
(i) комбинации различий между временными метками, ассоциированными с соответствующими из последовательности первых аудиофрагментов и соответствующими из данной возможной компоновки,
(ii) наличия перекрытия между данной парой вторых аудиофрагментов, если: вторые аудиофрагменты из последовательности вторых аудиофрагментов скомпонованы в видеофайле в соответствии с возможными временными метками и возможными коэффициентами сжатия; и
генерируют по меньшей мере один модифицированный аудиофрагмент для видеофайла в качестве перевода аудиоданных с использованием целевой компоновки.
2. Способ по п. 1, в котором данный фрагмент из последовательности первых аудиофрагментов представляет собой аудиосигнал формы волны.
3. Способ по п. 1, в котором данный фрагмент из последовательности первых аудиофрагментов представляет собой мел-спектрограмму.
4. Способ по п. 1, дополнительно содержащий этап, на котором генерируют сервером последовательность вторых аудиофрагментов на основе последовательности первых аудиофрагментов.
5. Способ по п. 1, в котором временная метка, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, является временной меткой начала, а данный фрагмент из последовательности первых аудиофрагментов дополнительно ассоциирован с временной меткой окончания в видеофайле, при этом возможные временные метки данной возможной компоновки включают в себя возможные временные метки начала и возможные временные метки окончания для соответствующих вторых аудиофрагментов из данной возможной компоновки, при этом заданная оценка потери дополнительно генерируется на основе:
комбинации различий между временными метками начала, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими возможными временными метками начала из данной возможной компоновки,
комбинации различий между временными метками окончания, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими временными метками окончания из данной возможной компоновки.
6. Способ по п. 1, в котором временная метка, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, представляет собой центральную временную метку, при этом возможные временные метки данной возможной компоновки включают в себя возможные центральные временные метки для соответствующих вторых аудиофрагментов из данной возможной компоновки, при этом данная оценка потери дополнительно генерируется на основе:
комбинации различий между центральными временными метками, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими возможными центральными метками из данной возможной компоновки.
7. Способ по п. 1, в котором оценка потери дополнительно генерируется на основе комбинации возможных коэффициентов сжатия для данной возможной компоновки.
8. Способ по п. 1, в котором генерирование по меньшей мере одного модифицированного аудиофрагмента выполняется сервером в автономном режиме, и при этом способ дополнительно содержит этап, на котором сохраняют сервером видеофайл с по меньшей мере одним модифицированным аудиофрагментом в хранилище.
9. Способ по п. 1, в котором генерирование по меньшей мере одного модифицированного аудиофрагмента выполняется сервером в потоковом режиме, и при этом способ дополнительно содержит этап, на котором передают сервером видеофрагмент видеофайла с по меньшей мере одним модифицированным аудиофрагментом на пользовательское устройство.
10. Способ по п. 9, дополнительно содержащий этапы, на которых:
получают сервером новый первый аудиофрагмент, представляющий дополнительное предложение на первом языке;
получают сервером новый второй аудиофрагмент, представляющий другое дополнительное предложение на втором языке, причем другое дополнительное предложение является переводом дополнительного предложения,
при этом новый второй аудиофрагмент и подмножество вторых аудиофрагментов из последовательности вторых аудиофрагментов, формирующих новую последовательность вторых аудиофрагментов,
подмножество вторых аудиофрагментов, за исключением первого из последовательности вторых аудиофрагментов, использованных для генерирования по меньшей мере одной модифицированной части;
генерируют сервером новое множество возможных компоновок для новой последовательности вторых аудиофрагментов,
выбирают сервером новую целевую компоновку для новой последовательности вторых аудиофрагментов из нового множества возможных компоновок;
генерируют сервером новый модифицированный аудиофрагмент путем модификации первого из новой последовательности вторых аудиофрагментов в соответствии с новой целевой компоновкой; и
передают сервером другой фрагмент видеофайла с новым модифицированным аудиофрагментом на пользовательское устройство.
11. Сервер для генерирования модифицированных аудиоданных для видеофайла, причем видеофайл ассоциирован с аудиоданными, причем сервер сконфигурирован для:
получения последовательности первых аудиофрагментов,
данный фрагмент из последовательности первых аудиофрагментов представляет данное предложение на первом языке и ассоциирован с временной меткой в видеофайле;
получения последовательности вторых аудиофрагментов,
данный фрагмент из последовательности вторых аудиофрагментов представляет собой другое данное предложение на втором языке и ассоциирован с временной продолжительностью, при этом другое данное предложение является переводом данного предложения;
генерирования множества возможных компоновок для последовательности вторых аудиофрагментов,
данная возможная компоновка ассоциирована с возможными временными метками в видеофайле и возможными коэффициентами сжатия для соответствующих из последовательности вторых аудиофрагментов;
выбора целевой компоновки для последовательности вторых аудиофрагментов из множества возможных компоновок,
при этом сервер сконфигурирован для выбора на основе целевой компоновки, имеющей минимальную оценку потери из числа оценок потери, ассоциированных с соответствующими из множества возможных компоновок, при этом данная оценка потери для данной возможной компоновки генерируется на основе:
(i) различий между временными метками, ассоциированными с соответствующими из последовательности первых аудиофрагментов и соответствующими из данной возможной компоновки, и
(ii) наличия перекрытия между данной парой вторых аудиофрагментов, если: вторые аудиофрагменты из последовательности вторых аудиофрагментов скомпонованы в видеофайле в соответствии с возможными временными метками и возможными коэффициентами сжатия; и
генерирования по меньшей мере одного модифицированного аудиофрагмента для видеофайла в качестве перевода аудиоданных с использованием целевой компоновки.
12. Сервер по п. 11, в котором данный фрагмент из последовательности первых аудиофрагментов представляет собой звуковой сигнал формы волны.
13. Сервер по п. 11, в котором данный фрагмент из последовательности первых аудиофрагментов представляет собой мел-спектрограмму.
14. Сервер по п. 11, который дополнительно сконфигурирован для генерирования последовательности вторых аудиофрагментов на основе последовательности первых аудиофрагментов.
15. Сервер по п. 11, в котором временная метка, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, является временной меткой начала, а данный фрагмент из последовательности первых аудиофрагментов дополнительно ассоциирован с временной меткой окончания в видеофайле, при этом возможные временные метки данной возможной компоновки, включающие в себя возможные временные метки начала и возможные временные метки окончания для соответствующих вторых аудиофрагментов, при этом данная оценка потери дополнительно генерируется на основе:
комбинации различий между начальными временными метками, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими возможными временными метками начала из данной возможной компоновки,
комбинации различий между временными метками окончания, ассоциированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими временными метками окончания из данной возможной компоновки.
16. Сервер по п. 11, в котором временная метка, ассоциированная с данным фрагментом из последовательности первых аудиофрагментов, является центральной временной меткой, при этом возможные временные метки данной возможной компоновки включают в себя возможные центральные временные метки для соответствующих вторых аудиофрагментов, при этом данная оценка потери дополнительно генерируется на основе:
комбинации различий между центральными временными метками, ассцоиированными с соответствующими из последовательности первых аудиофрагментов, и соответствующими возможными центральными временными метками из данной возможной компоновки.
17. Сервер по п. 11, в котором оценка потери дополнительно генерируется на основе комбинации возможных коэффициентов сжатия для данной возможной компоновки.
18. Сервер по п. 11, который сконфигурирован для генерирования по меньшей мере одного модифицированного аудиофрагмента в автономном режиме и дополнительно сконфигурирован для хранения видеофайла с по меньшей мере одним измененным аудиофрагментом в хранилище.
19. Сервер по п. 11, который сконфигурирован для генерирования по меньшей мере одного модифицированного аудиофрагмента в потоковом режиме и дополнительно сконфигурирован для передачи видеофрагмента видеофайла с по меньшей мере одним модифицированным аудиофрагментом на пользовательское устройство.
20. Сервер по п. 19, который дополнительно выполнен с возможностью:
получения нового первого аудиофрагмента, представляющего дополнительное предложение на первом языке;
получения нового второго аудиофрагмента, представляющего другое дополнительное предложение на втором языке, причем другое дополнительное предложение является переводом дополнительного предложения,
при этом новый второй аудиофрагмент и подмножество вторых аудиофрагментов из последовательности вторых аудиофрагментов, формирующих новую последовательность вторых аудиофрагментов,
подмножество вторых аудиофрагментов, за исключением первого из последовательности вторых аудиофрагментов, использованных для создания по меньшей мере одной модифицированной части;
генерирования нового множества возможных компоновок для новой последовательности вторых аудиофрагментов,
выбора новой целевой компоновки для новой последовательности вторых аудиофрагментов из нового множества возможных компоновок;
генерирование нового модифицированного аудиофрагмента путем модификации первого из новой последовательности вторых аудиофрагментов в соответствии с новой целевой компоновкой; и
передачу другого фрагмента видеофайла с новым модифицированным аудиофрагментом на пользовательское устройство.
| US 9734820 B2, 15.08.2017 | |||
| US 8515728 B2, 20.08.2013 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 8250046 B2, 21.08.2012 | |||
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| RU 2016146267 A, 28.05.2018. | |||

