Изобретение относится к вычислительной технике, а более точно к высокопроизводительным ЭВМ, предназначенным для обработки информации, в том числе сигнальной, в реальном масштабе времени.
Для таких ЭВМ характерна многоформатность обрабатываемой информации: целочисленный 16-разрядный формат со знаком или без, 32-разрядный формат с фиксированной и плавающей запятой, формат с плавающей запятой с удвоенной точностью (два 32-разрядных числа в форме с плавающей запятой, порядки которых отличаются на число разрядов в мантиссе), комплексные форматы чисел (например, действительная и мнимая части комплексного числа изображаются 32-разрядными числами в форме с плавающей запятой.
Для достижения повышенной производительности в таких ЭВМ часто используются многопроцессорные структуры, причем наибольшей эффективностью по критерию производительность-стоимость здесь обладают многопроцессорные векторные структуры (типа ОКМД). Максимальное количество оборудования, которое можно использовать для создания ЭВМ, ограничено и определяется надежностью технической базы, при этом пиковая производительность пропорциональна среднему объему обрабатывающего оборудования по всем форматам.
Ближайший аналог (прототип) предлагаемого изобретения, ЭВМ М-13, содержит центральную процессорную часть, подсистему ввода-вывода и процессор обработки функций, подключенные через многосвязный 64-байтовый интерфейс к главной внутренней памяти (оперативной и постоянной), а также центральный управляющий процессор, подключенный через многосвязный 8-байтовый управляющий интерфейс ко всем перечисленным подсистемам. Центральная процессорная часть содержит векторное арифметическое устройство, состоящее из 16 многоформатных конвейерных арифметических процессоров, выполняющих в каждом машинном такте одну и ту же операцию с учетом маски и длины обрабатываемого вектора. Каждый арифметический процессор выполняет операции над 1-, 2- и 4-байтовыми операндами, причем в одной операции обрабатывается четыре пары однобайтовых операндов; две пары двухбайтовых операндов или одна пара четырехбайтовых операндов. Четырехбайтовые операнды существуют в форме как с фиксированной, так и с плавающей запятой. Арифметические операции с двойной точностью выполняются с помощью подпрограмм, содержащих от 8 до 25 команд в зависимости от кода операции и точности результата. Процессор обработки функции также включает векторные арифметические устройства, содержащие по 16 арифметических конвейерных процессоров "когерентной обработки", выполняющих в качестве базовой операции двухточечное преобразование Фурье с комплексными операндами в форме с поблочно-плавающей запятой, причем комплексное число представлено в 32-разрядном формате. Синхронизация обработки информации осуществляется с помощью центрального управляющего процессора. В первом такте макроконвейера абоненты реального времени осуществляют ввод информации от объекта управления: сопрягающие процессоры подсистемы ввода-вывода через программируемые абонентские интерфейсы накапливают в своей оперативной памяти 64-байтовые вектора данных и пересылают их в главную внутреннюю память ЭВМ. Адресация главной внутренней памяти осуществляется с точностью до байта, а формат обращения к ней может изменяться от одного до 64 байтов. Один из сопрягающих процессоров получает и обрабатывает сигналы синхронизации. Начало второго такта он сигнализирует по управляющему интерфейсу в центральный управляющий процессор, а тот, в свою очередь, - процессору обработки функций. Процессор обработки функций перекачивает принятый кадр информации в свою память, выполняет сигнальную обработку, результаты помещает в главную оперативную память и сигнализирует завершение по управляющему интерфейсу. Процесс сигнальной обработки может попеременно выполняться на процессоре обработки функций и центральной процессорной части, что потребует дополнительной синхронизации программ. К началу третьего такта макроконвейера сигнальная обработка должна быть завершена и по сигналу центральная процессорная часть начинает вторичную обработку и возможно подготовку выходного кадра, который в четвертом такте может быть передан соответствующему абоненту.
Такая структура ЭВМ и соответствующий ей способ обработки сигнальной информации имеет ряд недостатков;
- операции с двойной точностью выполняются по подпрограммам и имеют производительность на порядок ниже, чем другие операции списка команд;
- форматы комплексных чисел, обрабатываемых процессором обработки функций, не соответствуют форматам информации, обрабатываемой центральной процессорной частью, что требует дополнительных затрат производительности для преобразования форматов;
- процесс сигнальной обработки попеременно выполняется на процессоре обработки функций и на центральной процессорной части, что приводит и дополнительным потерям производительности на синхронизации:
- оперативная память процессора обработки функций недоступна другим процессорам;
- наличие двух типов процессоров при реализации структуры ЭВМ на высокоинтегрированной элементной базе потребует увеличенной номенклатуры больших интегральных схем.
Предлагаемое изобретение позволяет устранить перечисленные недостатки.
Идея данного изобретения заключается в том, чтобы использовать то обстоятельство, что формат 32-разрядного числа с двойной точностью и комплексный формат, когда действительная и мнимая его части изображаются в виде 32-разрядных чисел в формате с плавающей запятой, совпадают, применить для выполнения арифметических операций с двойной точностью аппаратный конвейер, реализующий подпрограмму двойной точности, и на той же аппаратуре реализовать операции над комплексными числами, включая двухточечное преобразование Фурье, и арифметические операции с 32-разрядными и 16-разрядными числами. В этом случае векторное арифметическое устройство будет содержать восемь многоформатных арифметических процессоров, каждый из которых будет выполнять в каждом такте конвейера одну операцию с двойной точностью, одну операцию с комплексными операндами (включая двухточечное преобразование Фурье), две арифметические операции над 32-разрядными числами, четыре - над 16-разрядными.
Такое расширение списка операций центральной процессорной части позволит выполнять на ней обработку кадра информации от начала до конца с автоматической синхронизацией на одном процессоре, без потерь на преобразование форматов, используя общую оперативную память, причем операции с двойной точностью будут выполняться с тем же темпом. Это позволит исключить из состава ЭВМ процессор обработки функций и подключить вместо него вторую центральную процессорную часть. При реализации такой структуры на высокоинтегрированной элементной базе потребное число типов больших интегральных схем существенно сокращается.
Сущность изобретения заключается в том, что многопроцессорная векторная ЭВМ содержит векторную главную внутреннюю память, центральный управляющий процессор, подсистему ввода-вывода и по крайней мере одну центральную процессорную часть, включающую векторное арифметическое устройство, содержащее 2m (m = 0, 1 ..) многоформатных конвейерных арифметических процессоров, каждый из которых содержит узел управления, регистровую память и конвейерное арифметическое устройство и выполняет одновременно с учетом маски операции и длины обрабатываемого вектора две или четыре одно-, двух- или трехместные арифметико-логические операции над N- или N/2-разрядными операндами, соответственно. Многопроцессорная векторная ЭВМ отличается тем, что конвейерное арифметическое устройство для выполнения в каждом многоформатном конвейерном арифметическом процессоре указанных операций, а также для аппаратного выполнения
арифметико-логических операций над действительными 2N-разрядными операндами из старших и младших N-разрядных частей
или арифметических операций над комплексными операндами из N-разрядных вещественных и мнимых частей, содержит
три 2N-разрядных информационных входа, с первого по третий, разделенных каждый на N-разрядные старшую и младшую части, и два 2N-разрядных информационных выхода, первый и второй, разделенных каждый на N-разрядные старшую и младшую части,
тринадцать N-разрядных арифметических схем, с первой по тринадцатую, каждая из которых имеет первые и вторые N-разрядные информационные входы, и по одному информационному N-разрядному выходу,
и связь коммутаторов с первого по седьмой,
причем
арифметические схемы с первой по четвертую одинаковы и являются множительными устройствами, арифметические схемы с пятой по тринадцатую одинаковы и являются суммирующими устройствами,
первый коммутатор имеет четыре N-разрядных выхода, с первого по четвертый, второй коммутатор имеет три N-разрядных выхода, с первого по третий, третий коммутатор имеет три N-разрядных входа с первого по третий, четвертый коммутатор имеет два N-разрядных входа, пятый коммутатор имеет три N-разрядных входа, с первого по третий, шестой коммутатор имеет четыре N-разрядных входа, с первого по четвертый, седьмой коммутатор имеет четыре N-разрядных входа, с первого по четвертый,
первый и второй входы многоформатного конвейерного арифметического процессора подсоединены к первому коммутатору, второй и третий входы многоформатного конвейерного арифметического процессора подсоединены к второму коммутатору, старшая часть первого входа многоформатного конвейерного арифметического процессора подсоединена к первым входам одиннадцатой и двенадцатой арифметических схем и первому входу пятого коммутатора, младшая часть первого входа многоформатного конвейерного арифметического процессора подсоединена к первым входам седьмой и тринадцатой арифметических схем,
выходы первого коммутатора, с первого по четвертый, подсоединены соответственно к первым входам арифметических схем с первой по четвертую, первый выход второго коммутатора подсоединен к вторым входам первой, четвертой, одиннадцатой и двенадцатой арифметических схем, второй выход второго коммутатора подсоединен к вторым входам третьей и тринадцатой арифметических схем, третий выход второго коммутатора подсоединен к второму входу второй арифметической схемы,
выход первой арифметической схемы подсоединен к первому входу третьего коммутатора и второму входу пятого коммутатора, выход второй арифметической схемы подсоединен к первому входу четвертого коммутатора, выход третьей арифметической схемы подсоединен к первому входу пятой арифметической схемы, выход четвертой арифметической схемы подсоединен к второму входу пятой арифметической схемы, выход пятой арифметической схемы подсоединен к третьим входам третьего и седьмого коммутаторов и вторым входам седьмой и восьмой арифметических схем, выход шестой арифметической схемы подсоединен к вторым входам девятой и десятой арифметических схем и к третьему входу шестого коммутатора, выход седьмой арифметической схемы подсоединен к младшей части второго выхода многоформатного конвейерного арифметического процессора, выход восьмой арифметической схемы подсоединен к второму входу седьмого коммутатора, выход девятой арифметической схемы подсоединен к первому входу седьмого коммутатора и старшей части второго выхода многоформатного конвейерного арифметического процессора, выход десятой арифметической схемы подсоединен к второму входу шестого коммутатора, выход одиннадцатой арифметической схемы подсоединен к третьему входу пятого коммутатора, выход двенадцатой арифметической схемы подсоединен к второму входу третьего коммутатора и четвертому входу шестого коммутатора, выход тринадцатой арифметической схемы подсоединен к второму входу четвертого коммутатора и четвертому входу седьмого коммутатора,
выход третьего коммутатора подсоединен к второму входу шестой арифметической схемы, выход четвертого коммутатора подсоединен к первому входу шестой арифметической схемы, выход пятого коммутатора подсоединен к первым входам девятой и десятой арифметических схем, выход шестого коммутатора подсоединен к старшей части первого выхода многоформатного конвейерного арифметического процессора, выход седьмого коммутатора подсоединен к младшей части первого выхода многоформатного конвейерного арифметического процессора.
Следует пояснить, что операции над 2N-разрядными комплексными операндами, включая операции двухточечного преобразования Фурье, и операции сложения и умножения над 2N-разрядными операндами выполняются на нескольких N-разрядных множительных и суммирующих устройствах, что позволяет использовать в конвейерном арифметическом устройстве одну и ту же аппаратуру для выполнения всех указанных операций и применить ограниченное количество указанных множительных и суммирующих устройств, которые могут быть реализованы, например, в виде больших интегральных схем (БИС) всего двух типов. Далее в описании предполагается, что N-разрядные множительные и суммирующие устройства выполнены в виде БИС, хотя это не принципиально. В состав операций с комплексными числами входит операция двухточечного преобразования Фурье, которая представляет собой операцию A+/-P•F, где A, P, F - комплексные операнды.
Устройство и работа предлагаемого изобретения показаны на примере предпочтительного варианта воплощения, который иллюстрируется фиг. 1 - 13.
На фиг. 1 показана блок-схема многопроцессорной векторной ЭВМ; на фиг.2 - подсистема ввода-вывода; на фиг.3 - центральная процессорная часть; на фиг. 4, 5 - конвейерное арифметическое устройство (КАУ); на фиг.6 - узел управления одного АП; на фиг. 7 - блок-схема одного КАУ, настроенного на выполнение операции двухточечного преобразования Фурье; на фиг.8 - блок-схема одного КАУ, настроенного на выполнение операции сложения 2N-разрядных чисел; на фиг.9 - блок-схема одного КАУ, настроенного на выполнение операции умножения 2N-разрядных чисел; на фиг.10 - блок-схема одного КАУ, настроенного на выполнение операции сложения двух комплексных операндов, с N-разрядными вещественными и мнимыми частями; на фиг.11 - блок-схема одного КАУ, настроенного на выполнение операции умножения двух комплексных операндов, с N-разрядными вещественными и мнимыми частями; на фиг.12 - блок-схема AC множительного устройства; на фиг.13 - блок-схема AC суммирующего устройства;
Многопроцессорная векторная ЭВМ на фиг.1 содержит центральный управляющий процессор 1, две одинаковые центральные процессорные части 2 и 3 (может быть одна или больше двух), подсистему ввода-вывода 4 и векторную главную внутреннюю память 5 (ГВП). Подсистемы 1 - 4 ЭВМ связаны с векторной ГВП 5 с помощью многосвязного широкоформатного информационного интерфейса 6, включающего информационные шины и шины адресных требований.
Формат информационных шин интерфейса векторной главной внутренней памяти 5, как правило, равен 2N • 2m, где m = 0, 1, 2, ..., а N/2 - минимальный аппаратно поддержанный дискрет информации в векторной ЭВМ (далее называется позиция), и 2m - количество многоформатных конвейерных арифметических процессоров (АП) в векторном арифметическом устройстве центральной процессорной части ЭВМ 2. Для N в ЭВМ реального времени характерны значения: 16, 24, 32 разряда. Центральный управляющий процессор 1 связан с подсистемами 2 - 5 ЭВМ с помощью многосвязного управляющего интерфейса 7, формат шин которого, как правило, не менее 2N. Центральный управляющий процессор 1 выполняет функции аппаратной поддержки операционной системы реального времени и системы технического обслуживания и интерпретируемого центрального пульта ЭВМ.
Векторная главная внутренняя память 5 позволяет за одно обращение прочитать или записать переменный массив от одной до 4 • 2m позиций. Адресация памяти 5 осуществляется с точностью до одной позиции. Адреса по шинам адресных требований поступают в векторную главную внутреннюю память 5 в физической или виртуальной форме. Обращения по физическим адресам поступают на исполнение, а обращения по виртуальным адресам вызывают обращение к аппаратным таблицам виртуальной памяти, где осуществляется поиск соответствия. Найденное соответствие пересылается по группе шин адресного требования в процессор-источник адресного требования для корректировки адресных ассоциативных регистров процессора. Повторное обращение от процессора-источника имеет физический адрес. В случае отсутствия соответствия в таблицах виртуальной памяти по управляющему интерфейсу поступает прерывание в центральный управляющий процессор 1, который находит соответствие в программных таблицах распределения памяти и корректирует аппаратные таблицы в векторной главной внутренней памяти 5, либо снимает с исполнения дефектный процесс и вступает в диалог с оператором.
Кроме виртуального адреса в адресном требовании поступает "связка ключей доступа", которая сравнивается с замками по записи, чтению и обращению текущего виртуального сегмента. Разрешенные типы обращений также поступают в процессор-источник адресного требования. При обнаружении процессором попытки непредусмотренного обращения формируется прерывание в центральный управляющий процессор 1.
Векторная главная внутренняя память 5 может быть одноуровневой или двухуровневой, причем первый уровень может иметь в своем составе несколько блоков с независимым обращением, часть из которых работает только на считывание и сохраняет информацию при исчезновении питающих напряжений. Обмен между первым и вторым уровнями главной внутренней памяти 5 управляется автоматом обмена, который взаимодействует с центральным управляющим процессором 1 по управляющему интерфейсу. Предусмотрена автоматическая переадресация обращений при обмене.
Подсистема ввода-вывода 5 создает определенное количество программируемых абонентских интерфейсов 8 (фиг. 2); она содержит программно-управляемый или автоматический широкоформатный мультиплексный канал 9 и сопрягающие процессоры 10, связанные между собой системой шин 11. Широкая шина интерфейса главной внутренней памяти 5 делится на 4 • 2m столбов, с форматом N разрядов каждый. К каждому стволу подключается группа из сопрягающих процессоров (как правило, 2k, где k = 0,1...). К абонентским интерфейсам 8 подключаются абонентские устройства общего назначения и абоненты реального времени. Формат информационных шин абонентского интерфейса 8 не должен превышать N разрядов, количество управляющих сигналов не должно превышать N. К одному абонентскому интерфейсу 8 может быть подключено несколько малоформатных абонентов, а один широкоформатный абонент может быть подключен к нескольким абонентским интерфейсам. Сопрягающий процессор 10 обеспечивает логическое сопряжение широкого класса абонентских интерфейсов 8: он формирует стандартные сообщения, выполняет редактирование информации и при подключении к автоматическому широкоформатному мультиплексному каналу 9 выполняют функции подканала мультиплексного канала. Адресные требования подсистемы ввода-вывода могут быть направлены как в первый, так и во второй уровень векторной главной внутренней памяти 5 и обрабатываются по общей схеме. Загрузка подканалов мультиплексного канала 9 и сопрягающих процессоров 10, инициализация их работы и сигнализация в центральный управляющий процессор 1 осуществляются по управляющему интерфейсу 7.
Центральные процессорные части 2 и 3 (фиг. 3) обеспечивают обработку информации, поступившей от абонентов через подсистему ввода-вывода 4 в векторную главную внутреннюю память 5 или из ее второго уровня по программам, транслированным на машинный язык и размещенным в первом уровне векторной главной внутренней памяти 5. Структура команды многопроцессорной векторной ЭВМ, как правило, имеет переменный состав и формат. Семантика команды машинного языка может быть близка к традиционной (IBM-подобной) с необходимыми для выполнения операций под маской над векторами данных или иметь слоговую структуру, при которой каждый слог команды управляет работой своего конвейера арифметических операций, операций управления потоком команд или конвейером обращения к памяти ("широкая команда"). Центральная процессорная часть 2 многопроцессорной векторной ЭВМ включает центральное управление 12 и векторное арифметическое устройство 13. Центральное управление 12 обеспечивает интерпретацию и исполнение команд, поступающих по управляющему интерфейсу 7, и сигнализацию в центральный управляющий процессор 1; интерпретацию и диспетчирование при исполнении команд машинного языка, в том числе: управление конвейерами арифметико-логических операций; выполнение операций над признаками арифметических операций и масками, формирование обобщенного признака передачи управления, управление конвейером масочных операций; формирование адресных требований к памяти, преобразование в ассоциативной памяти виртуальных адресов данных и команд в физические с проверкой типа обращения, управление конвейером обращений в память; формирование адресов чтения команд и данных, автоматическую буферизацию массивов команд и адресов; управление конвейерами операций управления потоком команд и операций преобразования индексов, формирование признака передачи управления по фиксированному числу циклов; обработку и хранение внутренних и внешних прерываний; загрузку и снятие "фотографии" процесса. Список арифметико-логических операций многопроцессорной векторной ЭВМ включает операции над числами с удвоенной точностью и над числами в комплексном формате, где действительная и мнимая части изображаются 32-разрядными числами в форме с плавающей запятой.
Векторное арифметическое устройство 13 многопроцессорной векторной ЭВМ содержит центральное устройство редактирования 14 и многоформатные конвейерные арифметические процессоры 15 (обычно, их число - 2m ). Каждый АП 15 содержит узел управления 16, регистровую память 17, конвейерное арифметическое устройство (КАУ) 18. Регистровые памяти 17 всех АП 15 образуют многопортовую векторную сверхоперативную память, в которой могут размещаться как поименные в команде машинного языка, так и служебные векторные регистры. Векторный регистр может занимать одну или несколько ячеек сверхоперативной памяти. Формат обрабатываемого вектора (формат компоненты и размерность) может формироваться с помощью маскирования арифметико-логической векторной операции и задания формата записи в память результата операции или задеваться в команде (прямо или косвенно). При задании формата вектора в команде аппаратно формируется "маска количества", которая действует совместно с маской операции, предотвращая выработку сигналов прерывания незадействованными арифметическими устройствами и запись в неиспользуемые в операции позиции векторных регистров. Каждый бит маски может воздействовать либо на позицию, либо на компоненту вектора. Для выполнения регистровых векторных операций используются три порта сверхоперативной памяти: два порта чтения и два порта записи. Два порта используются для обмена с векторной главной внутренней памятью 5: один порт чтения и один порт записи и еще два порта используются для выполнения операций в центральном устройстве редактирования 14. Центральное устройство редактирования 14 выполняет операции уплотнение под маской и пересылки компонентов между регистрами; там же осуществляется формирование и буферизации команд и скалярного операнда и пересылка их в центральное управление 12. Центральное управление 12 формирует для АП 15 векторного арифметического устройства 13 код и маску операции, сигналы управления регистровой памятью 17, шины скалярного операнда; признаки арифметической операции и сигналы прерывания поступают в центральное управление 12. Групповой характер операций и возможность считывания за одно обращение к памяти группы команд машинного языка позволяет осуществлять опережающий просмотр команд и осуществлять с помощью аппаратного семафорного механизма динамическую загрузку независимого оборудования центральной процессорной части. При использовании широкой команды загрузка оборудования и разрешение конфликтов на общем оборудовании статически планируется.
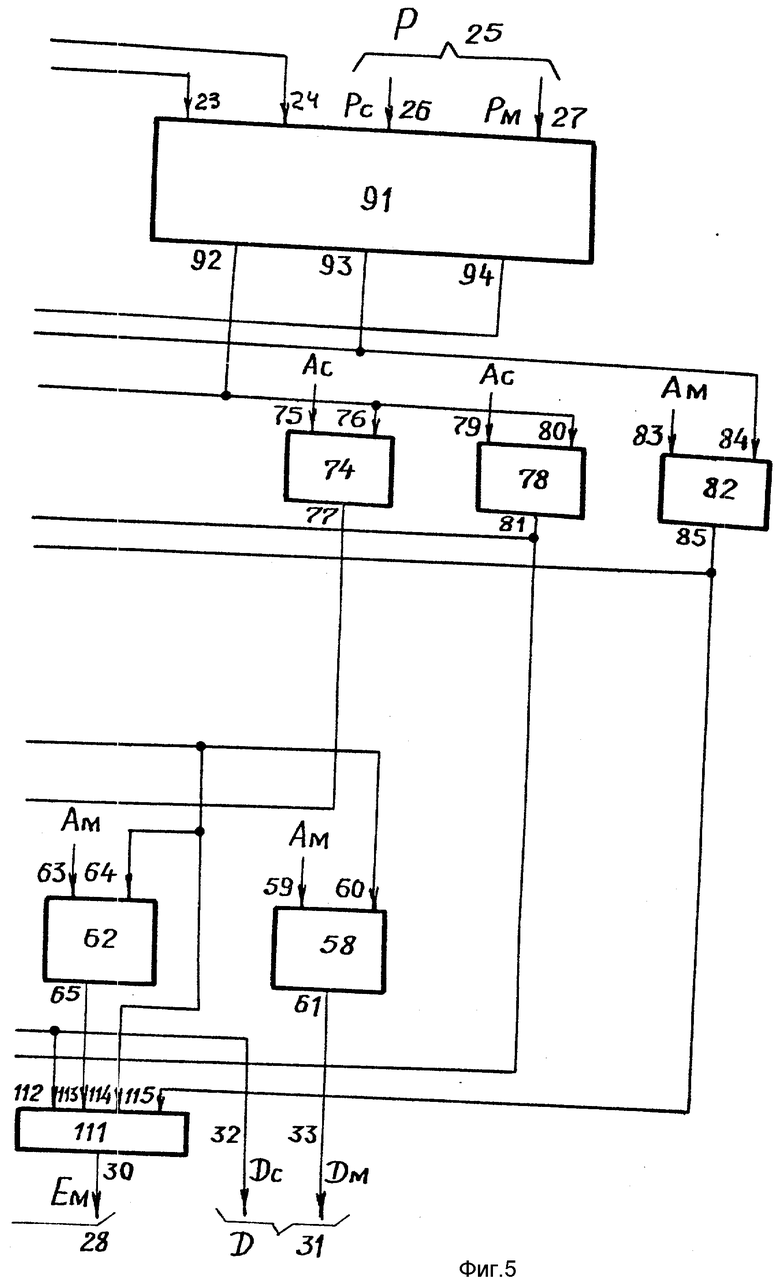
На фиг. 4, 5, показано КАУ 18, которое содержит:
первый 2N-разрядный информационный вход 19, разделенный на N-разрядную старшую 20 и младшую часть 21;
второй 2N-разрядный информационный вход 22, разделенный на N-разрядную старшую 23 и младшую часть 24;
третий 2N-разрядный информационный вход 25, разделенный на N-разрядную старшую 26 и младшую часть 27.
Кроме того, КАУ содержит:
первый 2N-разрядный информационный выход 28, разделенный на N-разрядную старшую 29 и младшую часть 30;
второй 2N-разрядный информационный выход 31, разделенный на N-разрядную старшую 32 и младшую часть 33.
Кроме того, КАУ содержит:
первую N-разрадную АС (Б1) 34, которая имеет первый 35 и второй 36 N-разрядные информационные входы, и один информационный N-разрядный выход 37;
вторую N-разрядную АС (Б2) 38, которая имеет первый 39 и второй 40 N-разрядные информационные входы, и один информационный N-разрядный выход 41;
третью N-разрядную АС (Б3) 42, которая имеет первый 43 и второй 44 N-разрядные информационные входы, и один информационный N-разрядный выход 45;
четвертую N-разрядную АС (Б4) 46, которая имеет первый 47 и второй 48 N-разрядные информационные входы, и один информационный N-разрядный выход 49.
(АС с первой 34 по четвертую 46 одинаковы и являются множительными устройствами).
Кроме того, КАУ содержит:
пятую N-разрядную АС (Б5), которая имеет первый 51 и второй 52 N-разрядный информационные входы, и один информационный N-разрядный выход 53;
шестую N-разрядную АС (Б6) 54, которая имеет первый 55 и второй 56 N-разрядные информационные входы, и один информационный N-разрядный выход 57;
седьмую N-разрядную АС (Б7) 58, которая имеет первый 59 и второй 60 N-разрядные информационные входы, и один информационный N-разрядный выход 61;
восьмую N-разрядную АС (Б8) 62, которая имеет первый 63 и второй 64 N-разрядные информационные входы, и один информационный N-разрядный выход 65;
девятую N-разрядную АС (Б9) 66, которая имеет первый 67 и второй 68 N-разрядные информационные входы, и один информационный N-разрядный выход 69;
десятую N-разрядную АС (Б10) 70, которая имеет первый 71 и второй 72 N-разрядные информационные входы, и один информационный N-разрядный выход 73;
одиннадцатую N-разрядную АС (Б11) 74, которая имеет первый 75 и второй 76 T-разрядные информационные входы, и один информационный N-разрядный выход 77;
двенадцатую N-разрядную АС (Б12) 78, которая имеет первый 79 и второй 80 N-разрядные информационные входы, и один информационный N-разрядный выход 81;
тринадцатую N-разрядную АС (Б13) 82, которая имеет первый 83 и второй 84 N-разрядные информационные входы, и один информационный N-разрядный выход 85.
(АС с пятой по тринадцатую одинаковы и являются суммирующими устройствами).
Кроме того, КАУ содержит:
первый коммутатор (КМ1) 86, который имеет четыре N-разрядных выхода, первый 87, второй 88, третий 89 и четвертый 90;
второй коммутатор (КМ2) 91, который имеет три N-разрядных выхода, первый 92, второй 93, третий 94;
третий коммутатор (КМ3) 95, который имеет три N-разрядных входа, первый 96, второй 97, и третий 98;
четвертый коммутатор (КМ4) 99, который имеет два N-разрядных входа, первый 100 и второй 101;
пятый коммутатор (КМ5) 102 имеет три N-разрядных входа, первый 103, второй 104, и третий 105;
шестой коммутатор (КМ6) 106 имеет четыре N-разрядных входа, первый 107, второй 108, третий 109 и четвертый 110;
седьмой коммутатор (КМ7) 111 имеет четыре N-разрядных входа, первый 112, второй 113, третий 114 и четвертый 115.
Первый 19 и второй 22 входы КАУ подсоединены к первому коммутатору 86, второй 22 и третий 25 входы КАУ подсоединены к второму коммутатору 91, старшая часть 20 первого входа КАУ подсоединена к первому входу 75 одиннадцатой 74 АС, к первому входу 79 двенадцатой АС 78 и первому входу 103 пятого коммутатора 102, младшая часть 21 первого входа КАУ подсоединена к первому входу 59 седьмой АС 58, к первому входу 63 восьмой АС 62 и к первому входу 83 тринадцатой АС 82.
Выходы 87, 88, 89, 90 первого коммутатора 86 соединены соответственно с первыми входами 35, 39, 43, 47 первой 34, второй 38, третьей 42 и четвертой 46 АС. Первый выход 92 второго коммутатора 91 подсоединен к второму входу 36 первой АС 34, к второму входу 48 четвертой АС 46, к второму входу 76 одиннадцатой АС 74 и к второму входу 80 двенадцатой АС 78. Второй выход 93 второго коммутатора 91 подсоединен к второму входу 44 третьей АС 42 и к второму входу 84 тринадцатой АС 82. Третий выход 94 второго коммутатора 91 подсоединен к второму входу 40 второй АС 38.
Выход 37 первой АС 34 подсоединен к первому входу 96 третьего коммутатора 95 и второму входу 104 пятого коммутатора 102. Выход 41 второй АС 38 подсоединен к первому входу 100 четвертого коммутатора 99. Выход 45 третьей АС 42 подсоединен к первому входу 51 АС 50. Выход 49 четвертой АС 46 подсоединен к второму входу 52 пятой АС 50. Выход 53 пятой АС 50 подсоединен к третьему входу 98 третьего коммутатора 95, к третьему входу 114 седьмого коммутатора 111, второму входу 60 седьмой АС 58 и второму входу 64 восьмой АС 62. Выход 57 шестой АС 54 подсоединен к второму входу 68 девятой АС 66, второму входу 72 десятой АС 70 и к третьему входу 109 шестого коммутатора 106. Выход 61 седьмой АС 58 подсоединен к младшей части 33 второго выхода 31 КАУ. Выход 65 восьмой АС 62 подсоединен к второму входу 113 седьмого коммутатора 111. Выход 69 девятой АС 66 подсоединен к первому входу 112 седьмого коммутатора 111 и старшей части 32 второго выхода 31 КАУ. Выход 73 десятой АС 70 подсоединен к второму входу 108 шестого коммутатора 106. Выход 77 одиннадцатой АС 74 подсоединен к третьему входу 105 пятого коммутатора 102. Выход 81 двенадцатой АС 78 подсоединен к второму входу 97 третьего коммутатора 95 и четвертому входу 110 шестого коммутатора 106. Выход 85 тринадцатой АС 82 подсоединен к второму входу 101 четвертого коммутатора 99 и четвертому входу 115 седьмого коммутатора 111.
Выход третьего коммутатора 95 подсоединен к второму входу 56 шестой АС 54. Выход четвертого коммутатора 99 подсоединен к первому входу 55 шестой АС 54. Выход пятого коммутатора 102 подсоединен к первому входу 67 девятой АС 66 и к первому входу 71 десятой АС. Выход шестого коммутатора 106 подсоединен к старшей части 29 первого выхода 28 КАУ. Выход седьмого коммутатора 111 подсоединен к младшей части 30 первого выхода 28 АП.
Каждый коммутатор и каждая АС имеют, кроме перечисленных, входы управления и входы синхронизации, о которых будет сказано ниже. АП содержит также регистровую память (не показана), представляющую собой многопортовую сверхоперативную память. Результаты операции с выхода 31 КАУ 18 поступают в регистровую память.
На фиг. 5 показан узел управления (УУ) 116 арифметического процессора, содержащий восемь регистров: первый 117, второй 118, третий 119, четвертый 120, пятый 121, шестой 122, седьмой 123 и восьмой 124. Кроме того, УУ содержит комбинационную логическую схему (КЛС) 125, вход кода операции 126 и вход управления 127 для выбора операндов, участвующих в операции, из операндов, поступающих на входы 22 и 25 АП. Операнд, поступающий на вход 19 участвует в каждый операции. Входы 126 и 127 УУ подключены к первому регистру 117 УУ. Выходы каждого регистра с первого 117 по седьмой 123 соединены с входом следующего по номеру регистра (соответственно) и с соответствующими входами КЛС 125. Выход последнего восьмого регистра 124 соединен только с соответствующим входом КЛС 125. Выходы КЛС с первого (128) по двадцатый (147) подсоединены к входам управления коммутаторами и АС. Входы управления не показаны, а соединения выходов КЛС с входами управления коммутаторов и АС будут описаны в таблице при описании работы АП. Таким образом, узел управления УУ 116 содержит конвейер (в рассматриваемом примере 8 ярусов регистров 117 - 124), по которому движется команда АП (код операции и код выбора операнда).
Множительные устройства Б1 - Б4 показаны на фиг. 4, 5, под номерами 34, 38, 42, 46. Все они одинаковы.
На фиг. 12 показана блок-схема множительного устройства, которое содержит комбинационную логическую схему (КЛС) 148, регистр 149 и КЛС 150. КЛС 148 имеет информационные входы 151 и 152 и управляющий вход 153. Выход 154 КЛС 148 соединен с входом 155 регистра 149, выход 156 которого соединен с входом 157 КЛС 150. Выход 158 КЛС 150 является выходом множительного устройства.
Суммирующие устройства Б5 - Б13 показаны на фиг. 4, 5, под номерами 50, 54, 58, 62, 66, 70, 74, 78, 82. Все они одинаковы.
На фиг. 13 показана блок-схема суммирующего устройства, которое содержит комбинационную логическую схему (КЛС) 159, регистр 160, КЛС 161, регистры 162 - 167 и коммутаторы 168, 169. Регистр 162 имеет вход 170, а регистр 167 имеет вход 171. Входы 170 и 171 является информационными входами суммирующего устройства. Выход 172 регистра 162 соединен с входом 173 регистра 163. Выход 174 регистра 163 соединен с входом 175 регистра 164. Выход 176 регистра 164 соединен с входом 177 регистра 165. Выход 178 регистра 165 соединен с входом 179 регистра 166. Выход 180 регистра 166 соединен с входом 181 коммутатора 168. Вход 170 соединен с входом 182 коммутатора 168. Выход 172 регистра 162 соединен с входом 183 коммутатора 168. Выход 176 регистра 164 соединен с входом 184 коммутатора 168. Выход 178 регистра 165 соединен с входом 185 коммутатора 168. Выход 186 коммутатора 168 соединен с входом 187 КЛС 159. Выход 188 регистра 167 соединен с входом 189 коммутатора 169. Вход 171 регистра 167 соединен с входом 190 коммутатора 169. Выход 191 коммутатора 169 соединен с входом 192 КЛС 159, выход которой 193 соединен с входом 194 регистра 160. Вход 195 регистра 160 соединен с входом 196 КЛС 161, выход которой 197 является выходом суммирующего устройства.
Работа многопроцессорной векторной ЭВМ (фиг. 1) в целом была уже описана выше при рассмотрении устройства многопроцессорной векторной ЭВМ. Проанализируем работу конвейерного арифметического устройства (КАУ) многопроцессорной векторной ЭВМ.
Программа работы ЦПЧ 2 ЭВМ записана в ГВП 5. Центральное управление 12 центральной процессорной части 2 обеспечивает выборку и расшифровку инструкций для каждого АП 15 векторного арифметического устройства 13.
Все арифметические процессоры 15 могут выполнять одну и ту же команду. Ширина шин управления и шин передачи данных достаточна для передачи операндов и команд АП для всех АП в одном такте. По одной команде АП в нескольких АП может обрабатываться (параллельно) сразу несколько операндов, т.е. вектор.
Для описания работы КАУ рассмотрим выполнение в КАУ следующих операций:
A+/-F•P (операция I двухточечного преобразования Фурье, A, F и P - комплексные операнды, имеющие N-разрядные вещественные и мнимые части) (см. фиг. 7),
A+B (операция II сложения 2N-разрядных действительных операндов) (см. фиг. 8),
A•B (операция III умножения 2N-разрядных действительных операндов) (см. фиг. 9),
A+B (операция IV сложения комплексных операндов, имеющих N-разрядные вещественные и мнимые части) (см. фиг. 10).
A•B (операция V умножения комплексных операндов, имеющих N-разрядные вещественные и мнимые части) (см. фиг. 11).
Под A, F и P имеются ввиду операнды, поступающие соответственно на входы КАУ 19, 22 и 25 (фиг. 4, 5). Под B имеется ввиду операнд, поступающий на входы 22 или 25 в зависимости от сигнала U на входе управления 127 УУ.
АП представляет собой универсальную конвейерную вычислительную схему, настраиваемую для выполнения конкретной вычислительной операции с помощью команды АП, преобразованной в управляющие сигналы узла управления АП, поступающие на коммутаторы и АС КАУ.
Глубина конвейера изменяется в зависимости от выполняемой операции и соответствующей настройки конвейера. Глубина конвейера, в данном случае, - это число, соответствующее общему количеству тактов, необходимых для продвижения промежуточных результатов вычисления по КАУ, начиная с регистра-источника операнда и кончая регистром-приемником результата. Регистры-источники операнда - это регистровая память или регистры для хранения старшей Pс и младшей Pм частей операнда P (не показаны). Для операции двухточечного преобразования Фурье и операции сложения с удвоенной разрядностью глубина конвейера равна 6. Для операции умножения с удвоенной разрядностью глубина конвейера равна 8. Для операции умножения комплексных чисел глубина конвейера равна 4. Для операции сложения комплексных чисел глубина конвейера равна 2.
При выполнении конкретных вычислительных операций иногда используются не все коммутаторы и АС КАУ. НА фиг. 7 - 9 изображены блок-схемы КАУ, настроенного для выполнения указанных выше операций.
Следует повторить, что КАУ с помощью 32-разрядных АС выполняет операции с плавающей запятой над операндами с удвоенной разрядностью (например, 2N = 64 разряда) и над комплексными операндами, в которых вещественные и мнимые части содержат по 32 разряда (т.е. всего тоже 64 разряда). Будем считать, что на первый 32-разрядный вход АС подается число X, а на второй 32-разрядный вход АС подается число Y.
Вычислительные операции КАУ выполняются с помощью микроопераций АС (название "микрооперация" выбрано здесь условно).
Схемы АС с Б1 по Б4 могут выполнять микрооперации умножения трех типов: У, Ус и Ум.
Микрооперация У - умножение двух 32-разрядных операндов с выдачей 32-разрядного округленного результата. (Эта микрооперация обозначается значком "*" или буквой "У"). При микрооперации умножения Ус выдается старшая 32-разрядная часть результата умножения двух 32-разрядных операндов. (Микрооперация Ус обозначается значком "*с" или буквами "Ус", например, X *с Y).
При микрооперации умножения Ум выдается младшая 32-разрядная часть результата умножения двух 32-разрядных операндов. (Микрооперация Ум обозначается значком "*м" или буквами "Ум", например, X *м Y). Сумма результатов микроопераций умножения Ус и Ум, выполненных над одной и той же парой операндов X и Y, с большей точностью равна произведению X • Y, чем результат микрооперации умножения У.
Схемы АС с Б5 по Б13 выполняют микрооперации сложения пяти типов: С, Сс, См, В1 и В2.
Микрооперация С - сложение двух 32-разрядных операндов с выдачей 32-разрядного округленного результата. (Эта микрооперация обозначается значком "+" или буквой "С").
При микрооперации сложения Сс выдается старшая 32-разрядная часть результата сложения двух 32-разрядных операндов.
(Микрооперация Сс обозначается значком "+с" или буквами "Сс", например, X +с Y).
При микрооперации сложения См выдается младшая 32-разрядная часть результата сложения двух 32-разрядных операндов.
(Микрооперация См обозначается значком "+м" или буквами "См", например, X +м Y). Сумма результатов микроопераций сложения Сс и См, выполненных над одной и той же парой операндов X и Y, с большей точностью равна сумме X + Y, чем результат микрооперации сложения С.
Микрооперация В1 - вычитание двух 32-разрядных операндов (X - Y) с выдачей 32-разрядного округленного результата. (Микрооперация В1 обозначается значком "-1" или буквой с индексом "В1").
Микрооперация В2 - вычитание двух 32-разрядных операндов (Y - X) с выдачей 32-разрядного округленного результата. (Микрооперация В2 обозначается значком "-2" или буквой с индексом "В2").
Результаты работы каждой АС при выполнении каждой из операций АП I - V сведены в табл. 1.
Операция двухточечного преобразования Фурье A+/-FP (фиг. 7) состоит в вычислении двух комплексных чисел (E и D)
E = A + F • P,
D = A - F • P,
где
A, F, P - комплексные операнды, приходящие на входы 4, 22 и 25 (фиг. 4, 5). Вещественные и мнимые части операндов A, F, P и результатов E, D обозначены соответственно Aс и Aм, Fc и Fм, Pc и Pм, Ec и Eм, Dc и Dм. Точный алгоритм вычисления E и D можно записать следующим образом:
Eс = Aс + [(Fс • Pс) - (Fм • Pм)],
Eм = Aм + [(Fс • Pм) + (Fм • Pс)],
Dс = Aс - [(Fс • Pс) - (Fм • Pм)],
Dм = Aм - [(Fс • Pм) + (Fм • Pс)].
Этот алгоритм реализуется на АП, настроенном на выполнение операции двухточечного преобразования Фурье и представленном на фиг. 7, из которой видно, на какие входы каких АС поступают вещественные и мнимые части исходных операндов, промежуточных результатов вычисления, и на каких выходах получаются окончательные результаты вычисления. На первом этапе вычисления производится одновременное умножение в четырех АС (Б1-Б4, 34, 38, 42 и 46). Результаты умножения на втором этапе складываются на Б5 (50) и вычитаются на Б6 (54). На третьем этапе производится сложение на АС (Б8 и Б10, 62 и 70) и вычитание на АС (Б7 и Б9, 58 и 66). Прохождение всех операндов в АП определяется настройкой коммутаторов КМ1 - КМ7 под воздействием сигналов управления.
Например, коммутатор КМ1 86 настроен так, что он пропускает часть Fс операнда F с входа 23 на первый вход 35 АС 34 и на первый вход 43 АС 42. Он же пропускает часть Fм операнда F с входа 24 на первый вход 39 АС 38 и на первый вход 47 АС 46.
Коммутатор КМ2 91 настроен так, что он пропускает часть Pс операнда P с входа 26 на второй вход 36 АС 34 и на второй вход 48 АС 46. Он же пропускает часть Pм операнда P с входа 27 на второй вход 40 АС 38 и на второй вход 44 АС 42.
Коммутатор КМ3 95 настроен так, что он пропускает результат с выхода 37 АС 34 на второй вход 56 АС 54.
Коммутатор КМ4 99 настроен так, что он пропускает результат с выхода 41 АС 38 на первый вход 55 АС 54.
Коммутатор КМ5 102 настроен так, что он пропускает часть Aс операнда A с входа 20 на первый вход 67 АС 66 и на первый вход 71 АС 70.
Коммутатор КМ6 106 настроен так, что он пропускает результат с выхода 73 АС 70 на выход 29 АП.
Коммутатор КМ7 111 настроен так, что он пропускает результат с выхода 69 АС 66 на выход 30 АП.
Упомянутые выше этапы вычисления осуществляются ступенями конвейера АП: первая ступень конвейера содержит АС 34, 38, 42, 46, вторая ступень конвейера содержит АС 50, 54, третья ступень содержит 58, 62, 66 и 70. Между ступенями конвейера могут стоять элементы задержки в виде регистров или других схем (входящих, например, в состав АС) для обеспечения временных согласований.
Например, часть Aс операнда A с входа 20 АП должна поступить на АС 66 и 70 одновременно с результатом с выхода 57 АС 54, для чего поступление части Aс в указанные АС задерживается на необходимое число тактов.
Операция A+B (сложение двух операндов с удвоенной разрядностью) состоит в вычислении старшей Eс и младшей Eм частей результата E по следующему алгоритму:
Eс = (Aс +c Bс) +с [(Aс +м Bс) +с (Aм + Bм)],
Eм = (Aс +c Bс) +м [(Aс +м Bс) +с (Aм + Bм)],
где
Aс и Aм - старшая и младшая части операнда A,
Bс и Bм - старшая и младшая части операнда B (B - операнд, выбранный под действием сигнала управления по входу 127 из пары операндов F или P).
Этот алгоритм реализуется на АП, настроенном на выполнение операции сложения с удвоенной разрядностью и представленном на фиг. 8, из которой видно, на какие входы каких АС поступают старшие и младшие части исходных операндов, промежуточных результатов вычисления и на каких выходах получаются окончательные результаты вычисления.
На первом этапе вычисления производится одновременное сложение в трех АС Б11-Б13 (74, 78, 82). Результаты сложения в Б12 (78) и Б13 (82) на втором этапе складываются на Б6 (54). На третьем этапе производится сложение на АС Б9 и Б10 (66 и 70), после чего на выходах АП 29 и 30 получаются соответственно старшая и младшая части результата.
Аналогично выполняются операции вычитания с удвоенной разрядностью X-Y и обратного вычитания Y-X.
Операция A•B (умножение двух операндов с удвоенной разрядностью) состоит в вычислении старшей Eс и младшей Eм частей результата E по следующему алгоритму:
Eс = (Aс *с Bс) +с {(Aс *м Bс) + [(Aс • Bм) + {(Aм • Bс)]},
Eм = (Aс *с Bс) +м {(Aс *м Bс) + [(Aс • Bм) + {(Aм • Bс)]},
где
Aс и Aм - старшая и младшая части операнда A,
Bс и Bм - старшая и младшая части операнда B (B - операнд, выбранный под действием сигнала управления по входу 127 из пары операндов F или P).
Этот алгоритм реализуется на АП, настроенном на выполнение операции умножения операндов с удвоенной разрядностью и представленном на фиг. 9, из которой видно, на какие входы каких АС поступают старшие и младшие части исходных операндов, промежуточных результатов вычисления, и на каких выходах получаются окончательные результаты вычисления.
На первом этапе вычисления производится одновременное умножение в четырех АС Б1-Б4 (34, 38, 42 и 46). Результаты умножения в Б3 (42) и Б4 (46) на втором этапе складываются на Б5 (50). На третьем этапе производится сложение на Б6 (54). На четвертом этапе производится сложение на АС Б9 и Б10 (66 и 70), после чего на выходах АП 29 и 30 получаются соответственно старшая и младшая части результата.
Операция A + B = E (сложение двух комплексных операндов A и B) состоит в вычислении Eс - вещественной N-разрядной части результата E, и Eм - его мнимой N-разрядная часть. Операция производится по следующему алгоритму:
Eс = (Aс + Bс)
Eм = (Aм + Bм)
где
Aс и Aм - вещественная и мнимая части операнда A,
Bс и Bм - вещественная и мнимая части операнда B (B - операнд, выбранный под действием сигнала управления по входу 127 из пары операндов F или P).
Эта операция реализуется на АП, настроенном на параллельное выполнение двух обычных операций сложения. На фиг. 10 видно, на какие входы АС Б12 (78) и Б13 (82) поступают вещественные и мнимые части исходных операндов и на каких выходах получается окончательный результат вычисления. Вычисления производятся одноэтапно в Б12 (78) и Б13 (82), после чего на выходах АП 29 и 30 получаются соответственно вещественная и мнимая части результата.
Операция A • B (фиг. 11) умножения двух комплексных операндов A и B производится в соответствии с формулами:
Eс = (Aс • Bс) - (Aм • Bм),
Eм = (Aс • Bм) - (Aм • Bс).
Индексы "с" и "м" соответствуют вещественной и мнимой частям комплексного числа. Результат (Eс, Eм) рассматривается не как два результата разрядности N, а как одно комплексное число (Ec- его вещественная N-разрядная часть, Em-его мнимая N-разрядная часть).
На первом этапе вычисления производится одновременное умножение в четырех AC Б1-Б4, (34, 38, 42 и 46). Результаты умножения в Б3(42) и Б4(46) на втором этапе складываются на Б5(50). На этом же этапе результаты умножения в Б1(34) и Б2(38) складываются на Б6(54), после чего на выходах АП 29 и 30 получаются соответственно вещественная и мнимая части результата.
Узел управления 116 АП работает следующим образом. Комбинационная логическая схема (КЛС) 125 выдает на свои выходы 128-147 сигналы, показанные в табл.2.
Выходные сигналы узла управления 116 АП, показанные в табл.2, могут принимать значения 0 или 1. Они вырабатываются комбинационной логической схемой 125, реализующей следующие Булевы функции:
1КМ1=(2)[1]+(4)[1]*IC[1]+(5)[1];
1КМ2=(1)[1]+C[1];
1КМ3=(2)[1];
1КМ4=(5)[1];
1КМ7=(4)[1]*IC[1];
1КМ8=(1)[1]+C[1];
1КМ9=(2)[1]+(5)[1];
2КМ1=U[1]*((2)[1]+(3)[1]+(4)[1]*IC[1]+(5)[1]+(6)[1]*IC[1]);
2КМ2=(1)[1]+IU[1]*((2)[1]+(3)[1]+(4)[1]*IC[1]+(5)[1]+(6)[1]*IC[1];
2КМ3=C[1];
2КМ4=U[1]*(2)[1];
2КМ5=U[1]*(5)[1];
2КМ6=IU[1]*(2)[1];
2КМ7=(1)[1]+(5)[1]*IU[1]*C[1];
2КМ9=(1)[1]+C[1]+IU[1]*((2)[1]+(3)[1]+(4)[1]*IC[1]+(5)[1]+6[1]*IC[1];
5КМ1=(1)[1]+С[1];
5КМ2=(2)[2];
5КМ3=(3)[2];
6КМ1=4[2]*IC[2];
6КМ2=(1)[6]+(2)[8]+(3)[6]+C[6];
6КМ3=(5)[4];
6КМ4=(6)[2]*IC[2];
7КМ2=(2)[8]+(3)[6];
7КМ3=(1)[6]+C[6];
1К3=P3[1]*(4)[1];
1К4=P4[1]*(4)[1];
1К5=P5[1]*((4)[1]+C[1]+(2)[1]*IC[1];
1К6=I(4)[1]+P6[1];
1К7=I(4)[1]+P7[1];
2К4=C[1]*P4[1]+IC[1]*(2)[1];
3К5=((4)[1]+C[1])*P5[1];
4К4=C[1]*P4[1];
5К1=C[3]*I(4)[3];
5К2=I(С[3]*I(4)[3];
6К1=((5)[3]+(1)[3])*IC[3]+I(4)[3]*C[3];
7К1=(1)[5]*IC[5]+I(4)[5]*C[5];
7К2=(4)[5]*C[5];
8К1=I(4)[5]*C[5];
8К2=(1)[5]*IC[5]+(4)[5]*C[5];
9K1-(1)[5]+C[5]*P4[5]*IP[5];
9K2=(3)[5]+C[5]*(IP4[5]+P5[5])+(2)[7];
9K4=(3)[5]+C[5]*P4[5]*P5[5]+(2)[7];
9K=C[5]*IP4[5]*P5[5];
10K1=C[5]*P4[5]*IP5[5];
10K2=I(C[5]*P4[5]*IP5[5]);
10K4=C[5]*P4[5]*P5[5];
10K5=(2)[7]+(3)[5]+C[5]*IP4[5]*P5[5];
11K0=C[1]*I(4)[1]*P0[1];
11K1=((3)[1]+C[1])*P1[1];
11K2=((3)[1]+C[1])P2[1];
11K3=P3[1]*IC[1]+(4)[1];
11K4=C[1]*P4[1];
11K5=(3)[1]*IC[1]+C[1]+C[1]*P5[1];
11K6=P6[1]+IC[1]+(4)[1];
11K7=P7[1]+IC[1]+(4)[1];
12K0=((6)[1]+C[1]*I(4)[1]*P0[1];
12K1=((6)[1]+C[1]+(3)[1])*P1[1];
12K2=((6)[1]+C[1]+(3)[1]*P2[1];
12K3=P3[1]+((4)[1]+IC[1])*I(6)[1];
12K4=((6)[1]+C[1])*P4[1]+(3)[1];
12K5=((6)[1]+C[1])*P5[1]
12K6=P6[1]+((4)[1]+IC[1])*I(6)[1];
12K7=P7[1]+((4)[1]+IC[1]*I(6)[1];
13K4=((6)[1]+C[1])*P4[1];
5LO=C[3]+(1)[3]+(2)[3]+(5)[3];
6LO=C[3]+(1)[3]+(2)[5]+(5)[3]+(3)[3];
6L1=(2)[5];
7L1=C[5]+(1)[5];
9LO=(3)[5];
9L1=(1)[5]+(2)[7]+(3)[5]+C[5];
9L2=(2)[7];
11L2=C[1]+(3)[1];
12L2=C[1]+(3)[1]+(6)[1].
В Булевых функциях использованы следующие обозначения:
"I" обозначает инверсию (например, IU означает инверсию U);
"+" обозначает логическое сложение;
"*" обозначает логическое умножение;
"P0-P7" - разряды кода операции (табл. 3);
"U"- поле команды АП, управляющей выбором второго операнда (Y) для всех операций АП, кроме операции двухточечного преобразования Фурье, где используются три операнда. Если U равно 1 (0), то B поступает по входу 22 (25);
"C" несет информацию о виде используемого контроля. (Если C = 0, то контроль сравнением не используется. В заявке аппаратура и работа узла контроля не описана и для простоты изложения "C" принято равным 0);
(1)=P0*P1*P5*IP6*IP7;
(2)=P0*P1*IP3*IP4*IP5*IP7;
(3)=IP0*P3*IP4*IP6*IP7;
(4)=P0*P1*I(IP3*P4*P5)*I(P3*IP4*IP5)*I(IP6*IP7);
(5)=P0*P1*P4*IP6*IP7;
(6)=I(1)[I(2)*I(3)*I(4)*I(5)*IОТСП,
где ОТСОП=IP0*IP1*IP2;
обозначения типа Z[i] были использованы для описания некоторого сигнала или выражения Z, задержанного на i синхронизирующих тактов, т.е. сигнала Z, прошедшего через цепочку из i последовательно соединенных триггеров, на вход синхронизации каждого из которых подан тактовый сигнал. Применение такого обозначения временных сдвигов позволяет не приводить временные диаграммы работы устройства. В ЭВМ используется синхронная временная диаграмма, которая реализуется с помощью единой системы синхронизации. Как было указано, временные согласования работы АС и коммутаторов обеспечиваются сигналами, поступающими из узла управления 116 АП.
Входящие в состав арифметического процессора АС и КМ могут быть выполнены в виде больших интегральных схем или могут располагаться на одном базовом матричном кристалле (БМК), рассчитанном для размещения до 300.000-500.000 эквивалентных вентилей.
АС, в которой реализовано суммирующее устройство (фиг. 13), способна выполнять 9 разновидностей операций сложения/вычитания 32-разрядных операндов X и Y с плавающей запятой. В первом случае, при операциях X + Y, X - Y, Y - X формируется округленная сумма или разность двух этих операндов. Во втором случае, при операциях (X + Y)c и (X + Y)м, а также при операциях (X - Y)c, (X - Y)м и при операциях (Y - X)с, (Y - X)м, формируется результат, являющийся соответственно старшей или младшей частью более точного (в данном случае, приблизительно 64-разрядного) результата (суммы или разности) операции X + Y, X - Y или Y - X, соответственно, чем 32-разрядный результат операции в первом случае. В первом случае (при операциях X + Y, X - Y, Y - X) результат содержит 24-разрядную мантиссу. А во втором случае (при операциях (X + Y)c, (X + Y)м, (X - Y)с, (X - Y)м, (Y -X)c, (Y - X)м) БИС выдает результат в виде старшей или младшей части (с 24-разрядной мантиссой) более точной суммы или разности входных 32-разрядных операндов АС. При операциях с удвоенной разрядностью результат операции АП представляет собой совокупность двух результатов, полученных с двух АС. Поступление операндов на каждое суммирующее устройство должно быть согласовано по времени. Для этого предусмотрены регистры 162 - 167, каждый из которых задерживает операнд на один такт. Управляющие сигналы от узла управления 116, поступающие на входы 198, 199 коммутаторов 168, 169 соответственно выбирают те регистры, с выхода которых операнды через коммутаторы 168, 169 поступают на КЛС 159. На вход 200 КЛС 159 из управления 116 поступает управляющий сигнал, который определяет операцию, выполняемую суммирующим устройством.
АС, в которой реализовано множительное устройство (фиг. 12), способна выполнять 3 разновидности операций умножения 32-разрядных операндов X и Y с плавающей запятой. В первом случае при операции X * Y формируется округленное произведение двух указанных операндов, содержащее 24-разрядную мантиссу. Во втором случае при операциях (X * Y)c и (X * Y)м, формируется результат, являющийся соответственно старшей или младшей частью более точного (в данном случае приблизительно 64-разрядного) результата (произведения) операции X * Y, чем 32-разрядный результат операции в первом случае. Сумма результатов операций (X * Y)c и (X * Y)м при одних и тех же сомножителях X и Y равна точному произведению X * Y, кроме некоторых особых случаев, таких, как, например, выход в меньшую сторону порядка результата операции (X * Y)м из диапазона допустимых порядков. На вход 153 КЛС 148 из узла управления 116 поступает управляющий сигнал, который определяет операцию, выполняемую множительным устройством.
В качестве примера в вышеприведенном описании были рассмотрены пять арифметических операций. В реальном устройстве, конечно, число операций, выполняемых АП, значительно больше, причем выполняются также и логические операции. Эти операции как более простые выполняются описанной аппаратурой без затруднений.
Предложенное изобретение позволяет за счет выполнения дополнительных операций на одной и той же аппаратуре значительно сократить ее объем и ускорить выполнение операций, а за счет широкого применения однотипных БИС уменьшить их стоимость.
| название | год | авторы | номер документа |
|---|---|---|---|
| МАКРОПРОЦЕССОР | 2001 |
|
RU2210808C2 |
| Микропрограммируемый векторный процессор | 1987 |
|
SU1594557A1 |
| РЕВЕРСИВНЫЙ ПРЕОБРАЗОВАТЕЛЬ ДВОИЧНО-ДЕСЯТИЧНОГО КОДА В ДВОИЧНЫЙ | 1990 |
|
RU2022467C1 |
| УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ПРЕДСКАЗАННЫХ СИГНАЛОВ ЧЕТНОСТИ ПРИ СДВИГАХ ДВОИЧНЫХ КОДОВ | 1992 |
|
RU2045772C1 |
| Микропрограммный процессор | 1980 |
|
SU868766A1 |
| СУММИРУЮЩЕЕ УСТРОЙСТВО | 1993 |
|
RU2069009C1 |
| СПОСОБ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2000 |
|
RU2163391C1 |
| УСТРОЙСТВО ДЛЯ ДЕЛЕНИЯ | 1991 |
|
RU2018933C1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА ДЛЯ ИНТЕРВАЛЬНЫХ ВЫЧИСЛЕНИЙ | 1991 |
|
RU2006929C1 |
| УСТРОЙСТВО УМНОЖЕНИЯ | 1998 |
|
RU2148270C1 |













Изобретение относится к вычислительной технике, точнее к построению многопроцессорных векторных ЭВМ. Многопроцессорная векторная ЭВМ содержит один или несколько одинаковых конвейерных арифметических процессоров. Арифметический процессор содержит несколько типовых арифметических схем и коммутаторы. Ариф- метический процессор с помощью одних и тех же суммирующих и множительных N - разрядных арифметических схем выполняет операции сложения и умножения над действительными 2 N -разрядными операндами и операции сложения и умножения над комплексными числами. 13 ил., 3 табл.
Многопроцессорная векторная ЭВМ, содержащая векторную главную внутреннюю память, связанную с помощью многосвязного широкоформатного информационного интерфейса с центральным управляющим процессором, подсистемой ввода вывода и по крайней мере с одной центральной процессорной частью, включающей векторное арифметическое устройство, содержащее 2m (m = 0,1 ...) многоформатных конвейерных арифметических процессоров, каждый из которых содержит узел управления, регистровую память и конвейерное арифметическое устройство и выполняет одновременно, с учетом маски операции и длины обрабатываемого вектора, две или четыре одно-, двух- или трехместные арифметико-логические операции над N- или N/2-разрядными операндами соответственно, отличающаяся тем, что конвейерное арифметическое устройство для выполнения в каждом многоформатном конвейерном арифметическом процессоре указанных операций, а также для аппаратного выполнения арифметико-логических операций над действительными 2N-разрядными операндами из старших и младших N-разрядных частей или арифметических операций над комплексными операндами из N-разрядных вещественных и мнимых частей, содержит три 2N-разрядных информационных входа, с первого по третий, разделенных каждый на N-разрядные старшую и младшую части, и два 2N-разрядных информационных выхода, первый и второй, разделенных каждый на N-разрядные старшую и младшую части, тринадцать N-разрядных арифметических схем, с первой по тринадцатую, каждая из которых имеет первые и вторые N-разрядные информационные входы, и по одному информационному N-разрядному выходу и семь коммутаторов с первого по седьмой, причем арифметические схемы с первой по четвертую одинаковы и являются множительными устройствами, арифметические схемы с пятой по тринадцатую одинаковы и являются суммирующими устройствами, первый коммутатор имеет четыре N-разрядных выхода, с первого по четвертый, второй коммутатор имеет три N-разрядных выхода, с первого по третий, третий коммутатор имеет три N-разрядных входа, с первого по третий, четвертый коммутатор имеет два N-разрядных входа, с первого по второй, пятый коммутатор имеет три N-разрядных входа, с первого по третий, шестой коммутатор имеет четыре N-разрядных входа, с первого по четвертый, седьмой коммутатор имеет четыре N-разрядных входа, с первого по четвертый, первый и второй входы многоформатного конвейерного арифметического процессора подсоединены к первому коммутатору, второй и третий входы многоформатного конвейерного арифметического процессора подсоединены к второму коммутатору, старшая часть первого входа многоформатного конвейерного арифметического процессора подсоединена к первым входам одиннадцатой и двенадцатой арифметических схем и первому входу пятого коммутатора, младшая часть первого входа многоформатного конвейерного арифметического процессора подсоединена к первым входам седьмой, восьмой и тринадцатой арифметических схем, выходы первого коммутатора, с первого по четвертый, подсоединены соответственно к первым входам арифметических схем с первой по четвертую, первый выход второго коммутатора подсоединен к вторым входам первой, четвертой, одиннадцатой и двенадцатой арифметических схем, второй выход второго коммутатора подсоединен к вторым входам третьей и тринадцатой арифметических схем, третий выход второго коммутатора подсоединен к второму входу второй арифметической схемы, выход первой арифметической схемы подсоединен к первому входу третьего коммутатора и второму входу пятого коммутатора, выход второй арифметической схемы подсоединен к первому входу четвертого коммутатора, выход третьей арифметической схемы подсоединен к первому входу пятой арифметической схемы, выход четвертой арифметической схемы подсоединен к второму входу пятой арифметической схемы, выход пятой арифметической схемы подсоединен к третьим входам третьего и седьмого коммутаторов и вторым входам седьмой и восьмой арифметических схем, выход шестой арифметической схемы подсоединен к вторым входам девятой и десятой арифметических схем и к третьему входу шестого коммутатора, выход седьмой арифметической схемы подсоединен к младшей части второго выхода многоформатного конвейерного арифметического процессора, выход восьмой арифмерической схемы подсоединен к второму входу седьмого коммутатора, выход девятой арифметической схемы подсоединен к первому входу седьмого коммутатора и старшей части второго выхода многоформатного конвейерного арифметического процессора, выход десятой арифметической схемы подсоединен к второму входу шестого коммутатора, выход одиннадцатой арифметической схемы подсоединен к третьему входу пятого коммутатора, выход двенадцатой арифметической схемы подсоединен к второму входу третьего коммутатора и четвертому входу шестого коммутатора, выход тринадцатой арифметической схемы подсоединен к второму входу четвертого коммутатора и четвертому входу седьмого коммутатора, выход третьего коммутатора подсоединен ко второму входу шестой арифметической схемы, выход четвертого коммутатора подсоединен к первому входу шестой арифметической схемы, выход пятого коммутатора подсоединен к первым входам девятой и десятой арифметических схем, выход шестого коммутатора подсоединен к старшей части первого выхода многоформатного конвейерного арифметического процессора, выход седьмого коммутатора подсоединен к младшей части первого выхода многоформатного конвейерного арифметического процессора.

