Область техники, к которой относится изобретение
Изобретение в целом относится к способам синтеза речи, а в частности к компилятивным способам синтеза речи на основе текста.
Уровень техники
Устройства для синтеза речи находят широкое применение в различных областях. В частности, они могут быть использованы в автоматизированных информационно-сервисных системах, например при информировании, бронировании, оповещении и т.д., в системах центров обработки звонков и/или заказов, в системах речевого сопровождения, во вспомогательных и адапционных системах для незрячих и слабовидящих людей, а также других категорий людей с ограниченными возможностями, при построении голосовых порталов, в образовательных целях, в телевизионных и рекламных проектах, например для создания презентаций, в системах для подготовки документов и редакционно-издательских системах, в электронных телефонных секретарях, в мультимедийных и развлекательных проектах и в других областях.
Наиболее распростроненным подходом к синтезированию речи, дающим наибольшую приближенность синтезированной речи к естественной, является компилятивный. При реализации компилятивных способов синтезированную речь на основе произвольного текста получают путем соединения блоков предварительно записанной естественной речи различной длины.
Исторически первыми электронными синтезирующими системами стали системы, синтезировавшие речь из фонем. В настоящем описании термин «фонема» означает минимальную единицу звукового строя языка, не имеющую самостоятельного лексического или грамматического значения. Эти системы не требовали баз данных больших объемов, так как количество фонем в конкретном языке обычно не превышает нескольких десятков. Например, согласно различным фонологическим школам, русский язык содержит от 39 до 43 фонем. Однако при синтезировании текста из фонем ввиду разнообразия их сочетаний требуется учитывать коартикуляционные граничные эффекты в местах их соединения. Для учета указанных эффектов использовали обширный набор правил коартикуляции, но даже в этом случае полученная с помощью таких систем речь по качеству была далека от естественной.
Дальнейшие исследования на пути решения коартикуляционных проблем привели к созданию систем, синтезировавших речь из более крупных блоков. Так, были созданы разнообразные системы для дифонного синтеза. Термин «дифон» в настоящем описании понимается как отрезок речи между центрами соседних фонем. Такой подход потребовал увеличения емкости базы данных до 1500-2000 элементов. При этом очевидным преимуществом дифонного синтеза перед фонемным является тот факт, что дифон несет всю информацию, определяющую переход между двумя соседними фонемами. Однако большое количество соединительных точек - по одной на каждый дифон - приводило к необходимости использовать сложные алгоритмы сглаживания для синтеза речи приемлемого качества. Далее, в силу того, что в базе данных обычно сохраняли по одному варианту каждого дифона, синтезируемая речь не обеспечивала просодического разнообразия, и для придания интонационных оттенков необходимо было использовать технологии управления длительностью и высотой звука.
Еще один подход к учету коартикуляционных эффектов состоит в использовании слогов в качестве элементов для синтеза речи. Преимуществом такого решения является то, что большинство коартикуляционных эффектов имеют место внутри слога, а не на его границах. Благодаря этому системы для послогового синтеза обеспечивают лучшее качество синтезируемой речи по сравнению с вышеописанными системами. Однако ввиду большого количества слогов в языке послоговый синтез требует существенного увеличения емкости базы данных. Для уменьшения объема хранимой информации использовали полуслоговый синтез, то есть синтез на основе полуслогов, получаемых разделением слогов по ядру. Однако это автоматически приводило к усложнению соединения речевых блоков при синтезе.
Все вышеупомянутые системы синтезировали однородную речь без интонационного разнообразия, так как из-за ограниченных объема базы данных и производительности вычислительных устройств имели только по одному кандитату на каждый синтезируемый речевой звук или по небольшому количеству кандидатов. Для придания синтезированной речи эмоциональной окраски использовали различные технологии изменения длительности речевых звуков и их высоты, однако качество такой речи было недостаточно высоким. С другой стороны, сравнительно малая длина блоков естественной речи, которые использовали для синтеза, обусловливала большое количество соединительных точек и, следовательно, необходимость применения различных технологий сглаживания и/или коартикуляции, с одной стороны, усложняя синтезирующую систему, а с другой - не позволяя использовать элементы базы данных без обработки, что делало синтезированную речь менее естественной.
С увеличением объема памяти и производительности вычислительных устройств стало возможно работать с более обширными базами данных, содержащими непрерывные и неоднородные образцы речи, и, соответственно, использовать при синтезе более длинные и более разнообразные речевые блоки, что обеспечивает улучшение качества синтезируемой речи как за счет меньшего количества соединительных точек, так и за счет интонационной насыщенности используемых блоков.
Так, в патентной публикации WO 0126091 раскрыт способ получения речи из текста, в соответствии с которым обрабатываемый текст разбивают на слова и сравнивают полученные слова с перечнем слов, предварительно сохраненных в базе данных в виде звуковых файлов. Если для каждого слова, содержащегося в тексте, найден соответствующий звуковой файл, то речь синтезируют в виде последовательности звуковых файлов, включающих все слова текста. Если же для каких-либо слов соответствующий звуковой файл не найден, такие слова разбивают на дифоны и получают требуемое слово путем сочетания требуемых дифонов, также предварительно сохраненных в базе данных. Достоинством этого способа является использование для синтеза речи относительно крупных речевых блоков в виде целых слов, что уменьшает количество соединительных точек и делает получаемую речь более плавной. С другой стороны, возможность использовать сочетание соответствующих дифонов вместо слов позволяет ограничить содержимое базы данных только достаточно употребительными словами и тем самым ограничить ее объем. Однако такой подход не позволяет синтезировать речь, качество которой близко к естественной речи. Это обусловлено тем, что база данных содержит в основном по одному нейтральному варианту звучания каждого слова, в то время как в реальной речи в зависимости от места в предложении и интонации слово может звучать по-разному. В малой степени эту проблему решили путем записи в базу данных дополнительных вариантов произнесения слов, соответствующих конечному положению этих слов в предложении. Однако в целом указанный способ не позволяет синтезировать неоднородную речь с интонационной окраской.
В последние годы усилия разработчиков способов синтеза речи из произвольного текста и соответствующих устройств для синтеза речи были направлены на улучшение естественности синтезируемой речи за счет придания ей просодической гибкости и интонационной окраски.
В патенте США №6665641 описаны варианты синтезатора речи, содержащего, например, речевую базу данных, включающую речевые волны; искатель речевых волн, взаимодействующий с указанной базой данных; и соединитель речевых волн, взаимодействующий с указанной базой данных. Упомянутый искатель выполняет поиск речевых волн в базе данных по конкретным критериям. Такими критериями могут, например, быть схожесть лингвистических и просодических признаков, причем кандидатные звуковые волны должны иметь высоту в пределах диапазона, определенного как функция лингвистических признаков. Упомянутый соединитель далее соединяет найденные речевые волны для получения выходного речевого сигнала. Описанный синтезатор речи обеспечивает получение речи на основе предварительно записанных речевых блоков с отражением различных просодических особенностей, однако здесь не учтена зависимость физических параметров речевой волны от интонации исходного текста и его частей, что не позволяет высокоточно передавать интонационную составляющую речи.
В патентной публикации WO 2008147649 раскрыт способ синтеза речи, использующий в качестве речевых блоков для синтеза речевые микроотрезки. Согласно способу обрабатывают входную текстовую последовательность для получения акустических параметров. Далее выделяют из речевой библиотеки наборы кандидатных речевых микроотрезков в соответствии с полученными акустическими параметрами и определяют для данных акустических параметров предпочтительную последовательность речевых микроотрезков, из которых далее синтезируют речь. Длительность указанных микроотрезков может составлять не более 20 мс, то есть в несколько раз меньше, чем, например, длительность дифона. Это обеспечивает получение более частых акустических изменений в синтезируемой речи по сравнению с синтезом на основе фонем или дифонов, что делает речь более естественной. В патенте описаны различные способы получения акустических параметров на основе обработки входного текста, однако в нем также не предусмотрены механизмы прямой связи этих параметров с интонацией, что в конечном итоге не позволяет получать синтезированную речь с заданной интонационной окраской.
Наиболее близкий аналог предложенного изобретения описан в патенте США №7502739. В этом патенте раскрыто устройство для речевого синтеза, которое предназначено для синтеза речи из текста и в котором реализован способ синтеза речи, включающий
выделение в тексте по меньшей мере одной части;
определение интонации каждой части;
постановку в соответствие каждой части целевых речевых звуков;
определение физических параметров целевых речевых звуков;
нахождение в речевой базе речевых звуков, наиболее близких по физическим параметрам к целевым речевым звукам;
синтез речи в виде последовательности из найденных речевых звуков.
В соответствии с указанным способом дополнительно определяют интонационные модели, находят в базе данных для хранения интонационных шаблонов интонационные шаблоны, соответствующие этим моделям, и соединяют найденные шаблоны для получения интонационного шаблона всего текста, причем синтез речи осуществляют на основе этого интонационного шаблона.
Реализованный в патенте США №7502739 способ позволяет получить широкий спектр интонаций и оттенков речи в зависимости от полноты базы данных для хранения интонационных шаблонов. Однако в соответствии с этим способом интонация синтезируемой речи является результатом обработки речевых блоков интонационным шаблоном и последующего их соединения для выработки речи, соответствующей исходному тексту, что может нарушать естественность звучания синтезированной речи.
Таким образом, несмотря на большое количество разработанных способов, устройств и систем для компилятивного синтеза речи из произвольного текста, реализующих различные решения для учета просодических и интонационных особенностей, задача синтеза речи с улучшенной передачей интонации продолжает оставаться актуальной.
Сущность изобретения
Задачей настоящего изобретения является создание способа синтеза речи на основе текста, в котором достигнуто улучшение качества синтезируемой речи за счет точной передачи интонации.
Указанная задача решена тем, что в способе синтеза речи на основе текста, согласно которому
выделяют в тексте по меньшей мере одну часть;
определяют интонацию каждой части;
ставят в соответствие каждой части целевые речевые звуки;
определяют физические параметры целевых речевых звуков;
находят в речевой базе речевые звуки, наиболее близкие по физическим параметрам к целевым речевым звукам;
синтезируют речь в виде последовательности из найденных речевых звуков,
физические параметры указанных целевых речевых звуков определяют в соответствии с определенной интонацией.
Таким образом, согласно предложенному способу, в соответствии с интонацией речи определяют физические параметры целевых речевых звуков, а не учитывают ее при синтезе уже найденных звуков. Иными словами, интонацию речи учитывают на стадии поиска, а не на стадии синтеза, что позволяет найти наиболее подходящие для синтеза звуки в речевой базе, минимизировать или исключить необходимость последующей обработки полученной речи и, следовательно, сделать ее более естественной и добиться улучшенной передачи интонации.
В соответствии с предложенным способом также целесообразно дополнительно определять лингвистические параметры речевых звуков, соответствующих каждой части, причем при поиске в речевой базе речевых звуков находить в этой базе речевые звуки, наиболее близкие к речевым звукам, соответствующим каждой части, также и по указанным лингвистическим параметрам.
Лингвистические параметры речевого звука в предпочтительном варианте осуществления изобретения включают по меньшей мере один из следующих параметров: транскрипция, речевые звуки, идущие перед указанным речевым звуком и после него, положение указанного речевого звука по отношению к ударной гласной.
По меньшей мере одну часть в тексте обычно выделяют на основе грамматических характеристик слов в тексте и пунктуации в тексте.
Как правило, в соответствии с определенной интонацией выбирают по меньшей мере одну предварительно созданную интонационную модель, определяемую по меньшей мере одним из таких параметров, как наклон траектории основного тона, форма изменения основного тона на ударных гласных, энергия речевых звуков и закон изменения длительности речевых звуков, и определяют физические параметры речевых звуков, соответствующих каждой части, на основе по меньшей мере одного из указанных параметров соответствующей модели.
Форма изменения основного тона на ударных гласных обычно включает изменение на первой ударной гласной, и/или на средней ударной гласной, и/или на последней ударной гласной.
Указанные физические параметры речевых звуков предпочтительно включают по меньшей мере длительность речевых звуков, частоту основного тона речевых звуков и энергию речевых звуков.
Наиболее близкие звуки обычно определяют путем вычисления значения по меньшей мере одной функции, определяющей различие физических и/или лингвистических параметров звука, соответствующего каждой части, и звука из речевой базы,
и/или путем вычисления для каждого звука из речевой базы, который может быть использован при синтезировании, значения по меньшей мере одной функции, характеризующей свойства этого звука,
и/или путем вычисления для каждой пары звуков из речевой базы, которые могут быть использованы при синтезировании каждой последовательной пары звуков, соответствующих каждой части, по меньшей мере одной функции, определяющей качество связи между указанной парой звуков из речевой базы,
причем указанные наиболее близкие звуки определяют как речевые звуки, для последовательности которых, в виде которой синтезируют предварительно определенный фрагмент указанного текста, сумма вычисленных значений указанных функций минимальна.
Предварительно определенный фрагмент текста, как правило, является предложением или абзацем.
В предпочтительном варианте осуществления изобретения вычисляют значение по меньшей мере одной из следующих функций, определяющих различие физического и/или лингвистического параметра речевых звуков:
- контекстной функции, определяющей степень совпадения речевых звуков, идущих до сравниваемых речевых звуков и после них;
- интонационной функции, определяющей соответствие интонационных моделей сравниваемых речевых звуков и их положения по отношению к фразовому ударению;
- функции частоты основного тона, определяющей разность частот основного тона сравниваемых речевых звуков;
- позиционной функции, определяющей различие позиции в слове сравниваемых речевых звуков;
- позиционной функции, определяющей различие позиции в слоге сравниваемых речевых звуков;
- позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством слогов от начала этой части текста;
- позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством слогов до конца этой части текста;
- позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством ударных слогов от начала этой части текста;
- позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством ударных слогов до конца этой части текста;
- функции произнесения, определяющей степень соответствия произнесения речевого звука из речевой базы и идеального произнесения этого звука в соответствии с правилами языка;
- орфографической функции, определяющей орфографическое различие слов, содержащих сравниваемые речевые звуки;
- ударной функции, определяющей соответствие типа ударения сравниваемых речевых звуков;
и/или для каждого звука из речевой базы, которые могут быть использованы при синтезировании, вычисляют значение по меньшей мере одной из следующих функций, характеризующей свойства этого звука:
- функции длительности, определяющей отклонение длительности соответствующего звука от средней по речевой базе длительности одноименных звуков с учетом фразового ударения;
- амплитудной функции, определяющей отклонение амплитуды соответствующего звука от средней по речевой базе амплитуды одноименных звуков с учетом фразового ударения;
- функции максимальной частоты основного тона, определяющей максимальное значение частоты основного тона соответствующего звука;
- функции скачка частоты основного тона, определяющей скачок частоты основного тона на соответствующем звуке;
и/или для каждой пары звуков из речевой базы, которые могут быть использованы при синтезировании каждой последовательной пары звуков, соответствующих каждой части, вычисляют значение по меньшей мере одной из следующих функций, определяющих качество связи между указанными звуками из речевой базы:
- функции связи по частоте основного тона соответствующей пары звуков, определяющей соотношение частоты основного тона на концах звуков пары;
- функции связи по производной частоты основного тона соответствующей пары звуков, определяющей соотношение производной частоты основного тона на концах звуков пары;
- функции связи по коэффициентам MFCC, определяющей соотношение нормированных коэффициентов MFCC на концах звуков пары;
- функции неразрывности, определяющей, составляют ли звуки соответствующей пары единый фрагмент речевого корпуса.
При вычислении суммы значений вышеуказанных функций эти значения обычно берут с различными весами.
Если найденный наиболее близкий звук не удовлетворяет некоторому критерию, то при синтезировании речи предпочтительно его заменяют на речевой звук из базы речевых звуков, удовлетворяющий указанному критерию.
Сведения, подтверждающие возможность осуществления изобретения
Способ синтеза речи в соответствии с настоящим изобретением может быть осуществлен посредством синтезатора речи, реализованного в виде программного продукта, который может быть установлен на вычислительном устройстве, например компьютере.
На чертеже представлена функциональная схема синтезатора речи в соответствии с настоящим изобретением. Необходимо отметить, что в этом варианте осуществления синтезатор предназначен для синтезирования русской речи. Синтезатор содержит блок 1 преобразования текста, включающий N подблоков, каждый из которых предназначен для преобразования текста в соотвествующей кодировке и/или формате, например неформатированного текста, текста в формате word и т.д., в последовательность букв русского текста и цифр без посторонних символов и кодов.
Блок 1 связан с движком 2, который включает последовательность таких подблоков, как лингвистический подблок 2-1, просодический подблок 2-2, фонетический подблок 2-3 и акустический подблок 2-4. Подблок 2-2 взаимодействует с интонационной базой 3, содержащей параметры, определяющие набор интонационных моделей, а подблок 2-4 взаимодействует с речевой базой 4, содержащей неоднородные непрерывные образцы естественной речи, и базой 5 речевых звуков, содержащей все аллофоны русского языка. В настоящем описании под термином «аллофон» понимается конкретная реализация фонемы в речи, обусловленная ее фонетическим окружением.
При синтезировании речи предложенный синтезатор выполняет следующую последовательность операций.
Текст, на основании которого должна быть синтезирована речь, вводят в компьютер, используя стандартные устройства ввода-вывода, например клавиатуру (не показана). Введенный текст поступает на вход блока 1. Блок 1 определяет кодировку и/или формат поступившего текста и в зависимости от них направляет текст на один из своих подблоков, каждый из которых предназначен для преобразования текста в конкретных кодировке и/или формате, например неформатированного текста, текста в формате word и т.п. Соответствующий подблок блока 1 переводит форматированный текст в последовательность букв русского текста и цифр без посторонних символов и кодов.
Данная последовательность далее поступает на движок 2 и проходит последовательную обработку на его подблоках 2-1 - 2-4.
Подблок 2-1 выполняет лингвистическую обработку текста, в частности делит его на слова и предложения, расшифровывает сокращения, расшифровывает аббревиатуры, иноязычные вставки, выполняет поиск слов в словаре для получения их лингвистических характеристик и ударения, исправляет допущенные орфографические ошибки, переводит числительные, записанные цифрами, в словесную форму, решает задачи омонимии, в частности выбирает соответствующее контексту ударение в словах, например зАмок или замОк.
Подблок 2-2 определяет интонацию и расставляет паузы, в частности определяет тип интонационного контура, то есть траектории движения частоты основного тона голоса. Интонационный контур может соответствовать, например, завершенности, вопросу, незавершенности, восклицанию. Подблок 2-2 также определяет положения пауз и их длительность.
Подблок 2-3 преобразует орфографический текст в последовательность фонетических символов, а именно переводит буквы текста в соответствующие фонемы. Указанный подблок, в частности, учитывает вариативность преобразования, т.е. тот факт, что одно и то же по написанию слово может быть произнесено по-разному в зависимости от контекста. Далее этот подблок определяет требуемые физические параметры, соответствующие каждому фонетическому символу, например значения частоты основного тона, длительности, энергии.
Подблок 2-4 формирует последовательность речевых звуков для выходного речевого сигнала. Для этого указанный подблок обращается к базе 4 и выполняет в ней поиск наиболее подходящих по параметрам речевых звуков. Далее подблок 2-4 подгоняет эти звуки друг к другу, при необходимости выполняя их модификацию, в частности изменяет темп, высоту тона, громкость и т.п.
Генерацию звуковой волны речевого сигнала выполняют соответствующие стандартные устройства компьютера (не показаны), например звуковая карта или микросхема на материнской плате и акустическая система.
Ниже более подробно описано функционирование блока 2-2. На первом этапе этот блок на основе проведенного в блоке 2-1 лингвистического анализа текста, в частности анализа грамматических характеристик слов в тексте, например определенных части речи, рода и числа слов, и пунктуации в тексте, проводит анализ связей между словами и выделяет в тексте отдельные части. Например, блок 2-2 может выделять в тексте синтагмы. В настоящем описании под термином «синтагма» понимается возникающее в речи интонационно организованное фонетическое единство, выражающее единое смысловое целое. В частном случае текст может включать только одну синтагму. Далее блок 2-2 определяет интонацию каждой синтагмы. Для этого предварительно все интонационные оттенки речи были сведены в 13 интонационных типов. Для каждого типа интонации были построены математические интонационные модели, задаваемые интонационным контуром и определяемые по меньшей мере одним из таких параметров, как наклон траектории основного тона, начальное значение основного тона, конечное значение основного тона, форма изменения основного тона на ударных гласных, а именно на первой ударной гласной, на средней ударной гласной и на последней ударной гласной, энергия речевых звуков и закон изменения длительности речевых звуков. В описываемом варианте осуществления изобретения в качестве речевых звуков, используемых как минимальная единица при синтезе речи, использованы аллофоны.
Таким образом, интонацию конкретной синтагмы определяют путем отнесения ее к одному из указанных интонационных типов. Далее в соответствии с определенной интонацией для данной синтагмы выбирают соответствующую интонационную модель, список параметров которой предварительно сохранен в базе 3. Эти параметры используют для определения физических параметров целевых аллофонов, соответствующих данной синтагме, то есть аллофонов, которые должны быть произнесены при правильном произнесении синтагмы в соответствии с правилами русского языка, как подробно описано ниже.
Кроме того, на основе лингвистического анализа текста, выполненного блоком 2-1, а также в соответствии с определенной интонацией синтагм блок 2-2 определяет положение пауз в речи и их длительность.
Таким образом, на выход блока 2-2 поступает текст, разбитый на синтагмы и разделенный паузами, которые необходимо учесть при синтезировании речи, а также интонационный контур текста, определяемый конкретными параметрами и полученный путем соединения интонационных контуров каждой синтагмы.
Ниже более подробно описано функционирование подблока 2-3.
Для преобразования букв текста в фонемы подблок 2-3 использует правила транскрипции русского языка. Также учитывают контекст буквы в тексте, то есть буквы, расположенные в тексте перед ней, и положение буквы по отношению к ударной гласной - до нее или после нее. Дополнительно учитывают предварительно составленный список исключений в транскрипции. Например, слово "радио" произносится с ударным "а" и безударным "о".
После определения всех целевых фонем, соответствующих введенному тексту, и, соответственно, всех целевых аллофонов, для которых определены такие лингвистические параметры, как транскрипция, аллофоны, идущие перед данным аллофоном и после него, положение данного аллофона по отношению к ударной гласной, блок 2-3 определяет физические параметры каждого аллофона. Эти параметры зависят от вида интонационного контура соответствующей синтагмы, полученного в блоке 2-2. Например, в тексте была выделена синтагма, и было определено, что она имеет вопросительную интонацию по модели №3. Далее, блок 2-3 определил, что эта синтагма содержит 16 аллофонов. В этом случае блок 2-3 обращается в базу 3, содержащую список параметров для модели №3, раскрытый выше применительно к описанию функционирования блока 2-2, и на основе этих параметров определяет физические параметры каждого из 16 аллофонов в синтагме. Например, на основании начального и конечного значений основного тона в синтагме, наклона траектории основного тона, формы изменения основного тона на ударных гласных может быть определено поведение основного тона на каждом аллофоне, а на основании закона изменения длительности аллофонов в синтагме может быть определена длительность каждого аллофона.
Таким образом, подблок 2-3 для каждого аллофона каждой синтагмы определяет перечень физических параметров, включающих по меньшей мере длительность аллофона, частоту основного тона аллофона и энергию аллофона.
Соответственно, на выход подблока 2-3 поступает последовательность целевых аллофонов, которые соответствуют введенному тексту и для каждого из которых определены вышеуказанные физические и лингвистически параметры.
Эти данные поступают на вход подблока 2-4, функционирование которого более подробно описано ниже.
Для формирования выходного речевого сигнала блок 2-4 обращается к базе 4 и выполняет в образцах естественной речи поиск аллофонов, наиболее близких по физическим и/или лингвистическим параметрам к целевым аллофонам, соответствующим введенному тексту, и определенных блоком 2-3.
Для определения наиболее близких аллофонов вычисляют функцию стоимости, общий вид которой может быть представлен формулой

где Ct - стоимость замены, wt - вес стоимости замены, Cc - стоимость связи, wc - вес стоимости связи, ti - целевой аллофон, ui - аллофон из речевой базы 4.. Аллофон из базы 4 в настоящем описании также может быть назван кандидатным аллофоном или кандидатом.
Стоимость замены для аллофона ui из базы 4 по отношению к целевому аллофону ti, которые сравнивают по p признакам, вычисляют по формуле
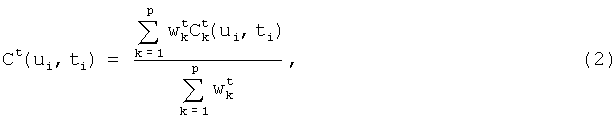
где 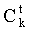 - штраф по k-му признаку,
- штраф по k-му признаку, 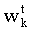 - вес k-го признака.
- вес k-го признака.
При необходимости можно менять признаки, по которым проводят сравнение. Если вес соответствующего признака приравнять к 0, то штраф по этому признаку не будет учтен при вычислении стоимости замены. Значение стоимости замены падает при увеличении сходства сравниваемых аллофонов и обращается в 0, если сравнивают два тождественных по учитываемым признакам аллофона.
Кроме того, уравнение (2) может быть использовано для оценки отклонения значения одного или более признаков аллофона ui, из базы 4 от таких признаков у некоторой совокупности аллофонов, например от усредненного значения конкретного признака у всех аллофонов в базе 4.
Стоимость связи между двумя аллофонами базы ui и ui-1, качество которой оценивают по q признакам, вычисляют по формуле
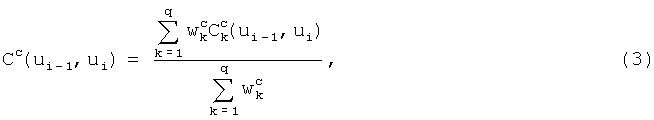
где  - штраф по k-му признаку,
- штраф по k-му признаку, 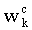 - вес для k-го признака.
- вес для k-го признака.
Стоимость связи показывает качество связи между двумя оцениваемыми аллофонами при их последовательном расположении при синтезе речи, то есть то, насколько хорошо эти аллофоны стыкуются между собой.
При необходимости можно менять признаки, по которым оценивают качество связи. Если вес соответствующего признака приравнять к 0, то штраф по этому признаку не будет учтен при оценке качества связи. Значение стоимости связи падает по мере улучшения качества связи между аллофонами. Нулевое значение обычно соответствует двум аллофонам, которые расположены последовательно в образце естественной речи.
Функцию (1) вычисляют для фрагмента текста, например для предложения или абзаца.
Для сравнения целевого аллофона и аллофона из базы 4 по признакам, определяющим стоимость замены, могут быть вычислены значения по меньшей мере одной из описанных ниже функций, определяющих различие физических и/или лингвистических параметров целевого аллофона и аллофона из базы 4. Значения этих функций представляют собой штраф при соответствующей замене аллофонов и их включают в качестве слагаемых 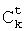 в уравнение (2).
в уравнение (2).
Необходимо отметить, что значения, возвращаемые нижеописанными функциями, были получены посредством различных методов экспертных оценок. Для некоторых функций указаны диапазоны возвращаемых ими значений, а конкретные значения из этих диапазонов определяются применяемым методом экспертной оценки.
В описываемом варианте осуществления изобретения для определения стоимости замены использованы следующие функции.
1. Контекстная функция, определяющая степень совпадения аллофонов, идущих до сравниваемых речевых звуков и после них.
Для вычисления значения функции за неточный правый и/или левый контекст кандидатного аллофона для синтеза устанавливают штрафы в диапазоне от 0 до 100. Штрафы за левый и правый контексты суммируют, а сумму нормируют к 1. Итоговое значение может быть взято с соответствующим весом.
2. Интонационная функция, определяющая соответствие интонационных моделей сравниваемых аллофонов и их положения по отношению к фразовому ударению.
Для вычисления значения функции за замену одного интонационного контура на другой назначают штраф в диапазоне от 0 до 100 и нормируют полученное значение к 1. Далее для кандидата и целевого аллофона определяют их положение по отношению к фразовому ударению: под фразовым ударением, до него или после него. В последних двух случаях дополнительно определяют количество слогов от аллофона до фразового ударения. Далее в зависимости от положения целевого аллофона по отношению к фразовому ударению сумму штрафа вычисляют следующим образом:
А. Если целевой аллофон расположен под фразовым ударением и
a. кандидат расположен под фразовым ударением, то в качестве итогового значения берут штраф за замену интонационного контура;
b. кандидат без фразового ударения, то берут 1.
B. Если целевой аллофон расположен после фразового ударения и
a. кандидат расположен под фразовым ударением, то в качестве итогового значения берут 1;
b. кандидат расположен перед фразовым ударением, то берут значение из диапазона 0,3-0,7.
c. кандидат расположен после фразового ударения, то берут значение, вычисляемое по формуле K*(штраф за замену интонационного контура)+min(L; (количество слогов)*M), где K выбирают из диапазона 0,3-0,7; L выбирают из диапазона 0,25-0,45, M выбирают из диапазона 0,03-0,1.
C. Если целевой аллофон расположен перед фразовым ударением, то итоговое значение штрафа определяют по аналогии с B.
Для согласной итоговый штраф уменьшают в 10 раз. Полученное значение штрафа может быть взято с соответствующим весом.
3. Функция частоты основного тона, определяющая разность частот основного тона сравниваемых аллофонов. Для вычисления значения функции частоту основного тона кандидата сравнивают с предсказанными значениями частоты основного тона целевого аллофона и возвращают максимальное отклонение, деленное на 15. Итоговое значение штрафа может быть взято с соответствующим весом.
4. Позиционная функция, определяющая различие позиции в слове сравниваемых аллофонов. Для вычисления значения функции позицию в слове кандидата сравнивают с позицией в слове целевого аллофона, при этом возможны следующие позиции: начальный аллофон, конечный аллофон, аллофон в середине слова. В случае несовпадения позиций возвращают 1, в противном случае возвращают 0. Итоговое значение может быть взято с соответствующим весом.
5. Позиционная функция, определяющая различие позиции в слоге сравниваемых аллофонов. Для вычисления значения функции позицию в слоге кандидата сравнивают с позицией в слоге целевого аллофона, при этом возможны следующие позиции: начальный аллофон, конечный аллофон, аллофон в середине слога. В случае несовпадения позиций возвращают 1, в противном случае возвращают 0. Итоговое значение штрафа может быть взято с соответствующим весом.
6. Позиционная функция, определяющая различие позиции в синтагме сравниваемых аллофонов, определяемой количеством слогов от начала этой синтагмы. Для вычисления значения функции сравнивают количество слогов до аллофона от начала синтагмы для кандидата и целевого элемента. Если разность равна 0, то возвращают 0; если разность менее 3, или 4, или 5, или 6, то возвращают значение из диапазона 0,2-0,45; если менее 8, или 9, или 10, или 11, или 12, то возвращают значение из диапазона 0,5-0,75; если более 7, или 8, или 9, или 10, или 11, то возвращают 1. Итоговое значение может быть взято с соответствующим весом.
7. Позиционная функция, определяющая различие позиции в синтагме сравниваемых аллофонов, определяемой количеством слогов до конца этой синтагмы. Для вычисления значения функции сравнивают количество слогов от аллофона до конца синтагмы для кандидата и целевого аллофона. Если разность равна 0, то возвращают 0; если разность менее 3, или 4, или 5, или 6, то возвращают значение из диапазона 0,2-0,45; если менее 8, или 9, или 10, или 11, или 12, то возвращают значение из диапазона 0,5-0,75; если более 7, или 8, или 9, или 10, или 11, то возвращают 1. Итоговое значение может быть взято с соответствующим весом.
8. Позиционная функция, определяющая различие позиции в синтагме сравниваемых аллофонов, определяемой количеством ударных слогов от начала этой синтагмы. Для вычисления значения функции сравнивают количество ударных слогов до аллофона от начала синтагмы для кандидата и целевого аллофона. Если разность равна 0, то возвращают 0; если менее 2, или 3, или 4, то возвращают значение в диапазоне 0,2-0,35; если менее 6, или 7, или 8, то возвращают значение в диапазоне 0,5-0,75; если более 5, или 6, или 7, то возвращают 1. Итоговое значение может быть взято с соответсвующим весом.
9. Позиционная функция, определяющая различие позиции в синтагме сравниваемых аллофонов, определяемой количеством ударных слогов до конца этой синтагмы. Для вычисления значения функции сравнивают количество ударных слогов от аллофона до конца синтагмы для кандидата и целевого аллофона. Если разность равна 0, то возвращают 0; если менее 2, или 3, или 4, то возвращают значение в диапазоне 0,2-0,35; если менее 6, или 7, или 8, то возвращают значение в диапазоне 0,5-0,75; если более 5, или 6, или 7, то возвращают 1. Итоговое значение может быть взято с соответствующим весом.
10. Функция произнесения, определяющая степень соответствия произнесения аллофона из базы 4 диктором и идеального произнесения этого аллофона в соответствии с правилами русского языка. Возможные отличия в произнесении обусловлены тем, что в реальной речи диктора заменяет некоторые аллофоны или сливает их с соседними. Для вычисления значения функции сравнивают реальную и идеальную транскрипции кандидата. В случае совпадения возвращают 0; если транскрипции не совпадают, а аллофон редуцированный, то возвращают 1; в противном случае, то есть когда транскрипции отличаются не только степенью редукции, но и наименованием аллофона, кандидат отбрасывают, если только его не берут вместе с соседними аллофонами. Итоговое значение может быть взято с соответсвующим весом.
11. Орфографическая функция, определяющая орфографическое различие слов, содержащих сравниваемые аллофоны. Для вычисления значения функции сравнивают содержащие кандидата и целевой аллофон слова на уровне орфографии. В случае совпадения орфографии возвращают 0, в противном случае - 1. Итоговое значение может быть взято с соответствующим весом.
12. Ударная функция, определяющая соответствие типа ударения сравниваемых аллофонов. Для вычисления значения функции проверяют соответствие по типу ударение кандидата и целевого аллофона. Возможны 3 типа ударения: фразовое ударение, логическое ударение, отсутствие ударения. Если типы совпадают, возвращают 0, в противном случае кандидата отбрасывают.
Альтернативно или дополнительно для вычисления стоимости замены для каждого аллофона из базы 4, который может быть использован при синтезировании, могут быть вычислены значения по меньшей мере одной функции, характеризующей свойства этого аллофона. Значения этих функций представляют собой штраф при соответствующей замене аллофонов, и эти значения включают в качестве слагаемых
в уравнение (2).
В описываемом варианте осуществления изобретения для этого использованы следующие функции.
1. Функция длительности, определяющая отклонение длительности соответствующего аллофона от средней по базе 4 длительности одноименных аллофонов с учетом фразового ударения. Для вычисления значения функции сравнивают длительность кандидатного аллофона и среднее значение длительности по базе 4 для всех аллофонов соответствующей фонемы с учетом фразового ударения, а разность считают по отношению к среднеквадратичному отклонению. Функция является кусочно-линейной. Точки излома и коэффициенты наклона задают в виде строк DurDeviation_x(i)=k(i), где k(i) - коэффициент наклона прямой, соединяющей точки x(i-1) и x(i), a i - номер строки в текстовом файле. Итоговое значение может быть взято с соответствующим весом. Также можно задать пороги минимального и максимального допустимых значений, при превышении которых кандидата отбрасывают.
2. Амплитудная функция, определяющая отклонение амплитуды соответствующего аллофона от средней по базе 4 амплитуды одноименных аллофонов с учетом фразового ударения. Для вычисления значения функции сравнивают амплитуду кандидатного аллофона и среднее значение амплитуды по базе 4 для всех аллофонов соответствующей фонемы с учетом фразового ударения, а разность считают по отношению к среднеквадратичному отклонению. Функция является кусочно-линейной. Точки излома и коэффициенты наклона задают в виде строк AmplDeviation_x(i)=k(i), где k(i) - коэффициент наклона прямой, соединяющей точки x(i-1) и x(i), a i - номер строки в текстовом файле. Итоговое значение может быть взято с соответствующим весом. Также можно задать пороги минимального и максимального допустимых значений, при превышении которых кандидата отбрасывают.
3. Функция максимальной частоты основного тона, определяющая максимальное значение частоты основного тона соответствующего аллофона. Для вычисления значения функции по значениям частоты основного тона кандидата определяют максимальное значение. Если оно не превышает пороговое значение, возвращают значение 0. В противном случае кандидат отбрасывают.
4. Функция скачка частоты основного тона, определяющая скачок частоты основного тона соответствующего аллофона. Для вычисления значения функции по значениям частоты основного тона кандидата определяют скачок частоты основного тона. Если он не превышает пороговое значение, возвращают значение 0. В противном случае кандидата отбрасывают.
Альтернативно или дополнительно для вычисления стоимости связи между двумя последовательными аллофонами для каждой пары аллофонов из базы 4, которые могут быть использованы при синтезировании каждой последовательной целевой пары аллофонов, соответствующих каждой синтагме, может быть вычислена по меньшей мере одна функция, определяющая качество связи между указанной парой аллофонов из базы 4. Значения этих функций представляют собой штраф при использовании при синтезировании речи данной пары аллофонов из базы 4. Эти значения включают в качестве слагаемых 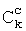 в уравнение (3).
в уравнение (3).
В описываемом варианте осуществления изобретения для этого использованы следующие функции.
1. Функция связи по частоте основного тона пары аллофонов, определяющая соотношение частоты основного тона на концах аллофонов пары. Для вычисления значения функции сравнивают значения частоты основного тона на концах соединяемых аллофонов и возвращают разность этих значений, деленную на пороговое значение JoinF0Threshold. Итоговое значение может быть взято с соответствующим весом. Если разность больше порогового значения, то к значению функции прибавляют дополнительный штраф.
2. Функции связи по производной частоте основного тона пары аллофонов, определяющая соотношение производной частоты основного тона на концах аллофонов пары. Для вычисления значения функции сравнивают значения производной частоты основного тона на концах соединяемых аллофонов и возвращают разность этих значений, деленную на пороговое значение JoinDF0Threshold. Итоговое значение может быть взято с соответствующим весом. Если разность больше порогового значения, то к значению функции прибавляют дополнительный штраф.
3. Функция связи по коэффициентам MFCC, определяющая соотношение нормированных коэффициентов MFCC на концах аллофонов пары.
С помощью коэффициентов MFCC (Mel-frequency cepstral coefficients) может быть описана спектральная огибающая. Каждый аллофон характеризуется частотным спектром слева, то есть в начале, и частотным спектром справа, то есть в конце. Если два аллофона взяты подряд из естественной фразы, то спектр первого аллофона справа точно совпадает со спектром второго аллофона слева. Для вычисления значения функции сравнивают значения нормированных коэффициентов MFCC на концах соединяемых аллофонов. В настоящем варианте осуществления изобретения используют 20 коэффициентов MFCC. Для вычисления разности между двумя векторами, содержащими по 20 коэффициентов, используют евклидову метрику, в соответствии с которой разность между двумя векторами, содержащими 20 коэффициентов, может быть вычислена по формуле:

где xn - координаты одного вектора MFCC, yn - координаты другого вектора MFCC, n=20. Итоговое значение может быть взято с соответствующим весом.
4. Функция неразрывности, определяющая, составляют ли звуки соответствующей пары единый фрагмент речевого корпуса, В том случае, если соединяемые аллофоны не составляют единый фрагмент речевого корпуса, возвращают предварительно определенное значение, в противном случае возвращают 0. Итоговое значение может быть взято с соответствующим весом.
Таким образом, подблок 2-4 формирует последовательность аллофонов из базы 4, для которых для каждого фрагмента текста, например предложения или абзаца, функция стоимости (1) принимает минимальное значение. С помощью соответствующих стандартных устройств компьютера, например звуковой карты или микросхемы на материнской плате и акустической системы, на основании последовательности аллофонов, получаемой на выходе подблока 2-4, проводят генерацию звуковой волны речевого сигнала. Благодаря реализованному в синтезаторе по настоящему изобретению способу синтеза речи за счет учета множества физических и лингвистических параметров целевых аллофонов, соответствующих введенному тексту, и аллофонов из базы 4 обеспечивают использование для синтеза оптимальных по параметрам аллофонов из базы 4. С другой стороны, при прочих равных синтезатор речи по настоящему изобретению выбирает для синтеза речи максимально длинные блоки естественной речи из базы 4, так как это минимизирует функцию стоимости замены (2). Это обеспечивает высокое качество синтезируемой речи и ее близость по звучанию к естественной.
В синтезаторе дополнительно реализована возможность обращения к базе 5, содержащей все аллофоны языка, если ни один из аллофонов базы 4, в том числе аллофон, наиболее близкий по параметрам к целевому аллофону, не удовлетворяет некоторому критерию. В этом случае при синтезировании речи синтезатор вместо указанного наиболее близкого по параметрам аллофона из базы 4 для синтеза соответствующего целевого аллофона использует одноименный ему аллофон из базы 5. Например, указанным критерием может быть точное соответствие фонетического окружения целевого и кандидатного аллофонов. Если в базе 4 отсутствует аллофон с фонетическим окружением, идентичным фонетическому окружению целевого аллофона, синтезатор обращается к базе 5 и использует для синтеза найденный в ней аллофон с идентичным фонетическим окружением. Например, если для синтеза нужен аллофон "И", у которого слева звук "С", а справа звук "М", то синтезатор ищет в базе 4 аллофон "сИм". При ненахождении его в базе 4 синтезатор использует соответствующий аллофон из базы 5.
В настоящем описании принципы изобретения представлены на примере предпочтительного варианта его осуществления. Однако для специалиста очевидно, что возможны и другие варианты осуществления, которые подразумевают изменения и модификации, не выходящие за пределы сущности и объема настоящего изобретения, которые определяются формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| УСТРОЙСТВО СИНТЕЗА РЕЧИ | 2014 |
|
RU2606312C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2011 |
|
RU2460154C1 |
| СПОСОБ ЛЕЧЕНИЯ ЗАИКАНИЯ | 2011 |
|
RU2450835C1 |
| СПОСОБ РЕАБИЛИТАЦИИ И РАЗВИТИЯ СЛУХОРЕЧЕВОЙ ФУНКЦИИ У ПАЦИЕНТОВ С КОХЛЕАРНЫМИ ИМПЛАНТАМИ | 2007 |
|
RU2342109C1 |
| Способ слоговой компиляции речи | 1982 |
|
SU1075300A1 |
| Устройство для вывода речевой информации | 1975 |
|
SU607211A1 |
| СПОСОБ ОБУЧЕНИЯ РЕЗОНАНСНОМУ ПЕНИЮ И ИНСТРУМЕНТАРИЙ ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2001 |
|
RU2202831C2 |
| СПОСОБ РЕАБИЛИТАЦИИ ДЕТЕЙ С НАРУШЕНИЕМ СЛУХА | 2021 |
|
RU2769620C1 |
Изобретение в целом относится к способам синтеза речи, а в частности к компилятивным способам синтеза речи на основе текста. Техническим результатом является улучшение качества синтезируемой речи за счет точной передачи интонации. Указанный технический результат достигается тем, что выделяют в тексте по меньшей мере одну часть, определяют интонацию каждой части, ставят в соответствие каждой части целевые речевые звуки, определяют физические параметры целевых речевых звуков, находят в речевой базе речевые звуки, наиболее близкие по физическим параметрам к целевым речевым звукам, синтезируют речь в виде последовательности из найденных речевых звуков, причем физические параметры указанных целевых речевых звуков определяют в соответствии с определенной интонацией. 11 з.п. ф-лы, 1 ил.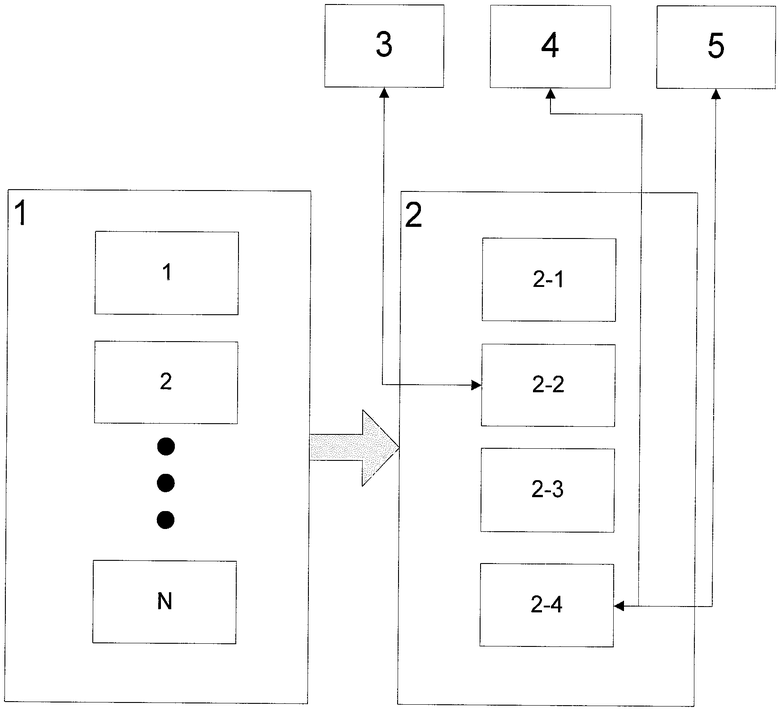
1. Способ синтеза речи на основе текста, согласно которому
выделяют в тексте по меньшей мере одну часть;
определяют интонацию каждой части;
ставят в соответствие каждой части целевые речевые звуки;
определяют физические параметры целевых речевых звуков;
находят в речевой базе речевые звуки, наиболее близкие по указанным физическим параметрам к целевым речевым звукам;
синтезируют речь в виде последовательности из найденных речевых звуков,
отличающийся тем, что
физические параметры целевых речевых звуков определяют в соответствии с определенной интонацией.
2. Способ по п.1, в котором дополнительно определяют лингвистические параметры целевых речевых звуков, причем при поиске в речевой базе речевых звуков находят в этой базе речевые звуки, наиболее близкие к целевым речевым звукам также и по указанным лингвистическим параметрам.
3. Способ по п.2, в котором лингвистические параметры речевого звука включают по меньшей мере один из следующих параметров: транскрипция, речевые звуки, идущие перед указанным речевым звуком и после него, положение указанного речевого звука по отношению к ударной гласной.
4. Способ по п.1, в котором по меньшей мере одну часть в тексте выделяют на основе грамматических характеристик слов в тексте и пунктуации в тексте.
5. Способ по п.1, в котором в соответствии с определенной интонацией выбирают по меньшей мере одну предварительно созданную интонационную модель, определяемую по меньшей мере одним из таких параметров, как наклон траектории основного тона, форма изменения основного тона на ударных гласных, энергия речевых звуков и закон изменения длительности речевых звуков, и определяют физические параметры целевых речевых звуков на основе по меньшей мере одного из указанных параметров соответствующей модели.
6. Способ по п.5, в котором форма изменения основного тона на ударных гласных включает изменение на первой ударной гласной, и/или на средней ударной гласной, и/или на последней ударной гласной.
7. Способ по п.5, в котором указанные физические параметры речевых звуков включают по меньшей мере длительность речевых звуков, частоту основного тона речевых звуков и энергию речевых звуков.
8. Способ по любому из пп.1-7, в котором наиболее близкие звуки определяют путем вычисления значения по меньшей мере одной функции, определяющей различие физических и/или лингвистических параметров целевого звука и звука из речевой базы,
и/или путем вычисления для каждого звука из речевой базы, который может быть использован при синтезировании, значения по меньшей мере одной функции, характеризующей свойства этого звука,
и/или путем вычисления для каждой пары звуков из речевой базы, которые могут быть использованы при синтезировании каждой последовательной пары целевых звуков по меньшей мере одной функции, определяющей качество связи между указанной парой звуков из речевой базы,
причем указанные наиболее близкие звуки определяют как речевые звуки, для последовательности которых, в виде которой синтезируют предварительно определенный фрагмент указанного текста, сумма вычисленных значений указанных функций минимальна.
9. Способ по п.8, в котором предварительно определенный фрагмент текста является предложением или абзацем.
10. Способ по п.8, в котором вычисляют значение по меньшей мере одной из следующих функций, определяющих различие физического и/или лингвистического параметра речевых звуков:
контекстной функции, определяющей степень совпадения речевых звуков, идущих до сравниваемых речевых звуков и после них;
интонационной функции, определяющий соответствие указанных интонационных моделей сравниваемых речевых звуков и их положения по отношению к фразовому ударению;
функции частоты основного тона, определяющей разность частот основного тона сравниваемых речевых звуков;
позиционной функции, определяющей различие позиции в слове сравниваемых речевых звуков;
позиционной функции, определяющей различие позиции в слоге сравниваемых речевых звуков;
позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством слогов от начала этой части текста;
позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством слогов до конца этой части текста;
позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством ударных слогов от начала этой части текста;
позиционной функции, определяющей различие позиции в выделенной части текста сравниваемых речевых звуков, определяемой количеством ударных слогов до конца этой части текста;
функции произнесения, определяющей степень соответствия произнесения речевого звука из речевой базы и идеального произнесения этого звука в соответствии с правилами языка;
орфографической функции, определяющей орфографическое различие слов, содержащих сравниваемые речевые звуки;
ударной функции, определяющей соответствие типа ударения сравниваемых речевых звуков;
и/или в котором для каждого звука из речевой базы, которые могут быть использованы при синтезировании, вычисляют значение по меньшей мере одной из следующих функций, характеризующей свойства этого звука:
функции длительности, определяющей отклонение длительности соответствующего звука от средней по речевой базе длительности одноименных звуков с учетом фразового ударения;
амплитудной функции, определяющей отклонение амплитуды соответствующего звука от средней по речевой базе амплитуды одноименных звуков с учетом фразового ударения;
функции максимальной частоты основного тона, определяющей максимальное значение частоты основного тона соответствующего звука;
функции скачка частоты основного тона, определяющей скачок частоты основного тона на соответствующем звуке;
и/или в котором для каждой пары звуков из речевой базы, которые могут быть использованы при синтезировании каждой последовательной пары целевых звуков, вычисляют значение по меньшей мере одной из следующих функций, определяющих качество связи между указанными звуками из речевой базы:
функции связи по частоте основного тона соответствующей пары звуков, определяющей соотношение частоты основного тона на концах звуков пары;
функции связи по производной частоты основного тона соответствующей пары звуков, определяющей соотношение производной частоты основного тона на концах звуков пары;
функции связи по коэффициентам MFCC, определяющей соотношение нормированных коэффициетов MFCC на концах звуков пары;
функции неразрывности, определяющей, составляют ли звуки соответствующей пары единый фрагмент речевого корпуса.
11. Способ по п.8, в котором при вычислении суммы значений функций эти значения берут с различными весами.
12. Способ по п.8, в котором, если найденный наиболее близкий звук не удовлетворяет некоторому критерию, то при синтезировании речи его заменяют на речевой звук из базы речевых звуков, удовлетворяющий указанному критерию.
| US 2007106514 A1, 10.05.2007 | |||
| US 2005114137 A1, 26.05,2005 | |||
| Устройство для защиты электродов электрохимической ячейки от разрушения при коротких замыканиях | 1983 |
|
SU1221693A1 |
| US 2008294443 A1, 27.11.2008 | |||
| US 2007203703 A1, 30.08.2007 | |||
| JP 2007004011 A, 11.01.2007 | |||
| KR 20060093089 A, 23.08.2006 | |||
| WO 9819297 A1, 07.05.1998 | |||
| СПОСОБ И СИСТЕМА ДИНАМИЧЕСКОЙ АДАПТАЦИИ СИНТЕЗАТОРА РЕЧИ ДЛЯ ПОВЫШЕНИЯ РАЗБОРЧИВОСТИ СИНТЕЗИРУЕМОЙ ИМ РЕЧИ | 2002 |
|
RU2294565C2 |
| Способ компиляционного синтеза речи | 1988 |
|
SU1599888A1 |

