Изобретение относится к информационным технологиям, в частности к предварительной обработке текстовой информации, и может быть использовано при распознавании и синтезе речи, аннотировании баз данных, а также при автоматическом синхронном переводе с языка на язык и других областях знаний.
Информационные технологии все больше и больше проникают в современную жизнь каждого человека. Особенно активно развиваются системы искусственного интеллекта, связанные с распознаванием образов, анализом изображений и распознаванием и синтезом речи и т.п.
Речевые технологии находят все большее распространение в робототехнике, системах управления оборудованием, средствах коммуникаций и других областях человеческой деятельности.
Распознавание речи - технология, позволяющая использовать естественный для человека речевой интерфейс для взаимодействия с электронной техникой. Технология распознавания речи предоставляет возможность распознавания отдельных слов или слитной человеческой речи, с последующим ее преобразованием в текст либо последовательность команд.
Синтез речи - это технология обработки текстовой или числовой информации согласно установленным правилам произношения для конкретного языка и преобразование ее в синтезированный голос, по звучанию близкий к человеческому.
Эффективность современных систем распознавания речи во многом зависит от степени точности представления фонетических явлений в языке с помощью математических структур. Для этой цели применяются большие звуковые базы данных, содержащие сотни часов записей речи множества дикторов и фонетическую транскрипцию этих записей, которая зачастую порождается автоматически по каноническим правилам. Однако в реальной речи правила могут нарушаться, а значит, математические структуры, полученные в результате обработки таких баз, не будут описывать речевой сигнал с высокой точностью.
Аллофонные звуковые базы, используемые в синтезе речи по тексту, постепенно утрачивают свою актуальность - роль аппаратных ограничений на производительность и доступные объемы памяти снижается, и на первое место выходит качество формируемого звукового сигнала.
Известна система автоматического распознавания русской речи SIRIUS, в которую введен дополнительный уровень представления языка и речи - морфемный уровень. На основе правил словообразования русского языка были разработаны базы данных различных типов морфем, а также методы автоматической обработки текстов. При обработке тестов использовались модули транскрибирования и морфемной сегментации.
Модуль транскрибирования осуществляет преобразование текстов предметной области в фонетическую транскрипцию. На вход модуля поступают: набор предложений, составляющих тексты; словарь слов из этих предложений, разбитый на морфемные единицы; словарь словоформ, полученный из базовых форм слов русского языка с отметкой ударного слога (слогов), используемый фонетический алфавит и фонетические правила. Разбиение слова на морфемы осуществлялось путем подбора различных типов с учетом правил следования морфем в одном слове. Возможные пары типов морфем отмечались знаком «+», а недопустимые пары знаком «-». Отрицательная гипотеза разбиения слова на морфемы отбрасывалась и поиск продолжался дальше, пока не обнаруживался конец слова «STOP».
Разработанные базы данных морфем использовались для создания морфемной модели языка, строящейся на основе статистики встречаемости различных пар морфем (А.Л.Ронжин, А.А.Карпов, И.В.Ли «Система автоматического распознавания русской речи SIRIUS», ЖУРНАЛ «Искусственный интеллект», №3, 2005).
В результате такой обработки скорость распознавания и устойчивость к синтаксическим отклонениям в произнесенной фразе увеличились. Однако высокой точности распознавания достигнуть не удалось из-за собственных ошибок обработки текстов. Разбивка текста на морфемы, которые являются частью слова, затрудняет расстановку пауз. Россия является многонациональной страной, русскоговорящее население которой обладает большой вариативностью национальных акцентов и стилей произношения, что необходимо учитывать при обработке текстов. В системе автоматического распознавания русской речи SIRIUS это не было учтено.
Известен способ компиляционного фонемного синтеза русской речи и устройство для его реализации (патент РФ №2298234). Устройство содержит текстовый процессор, который выполняет следующие функции: нормализация текста; фонетическая транскрипция по разбивке слова на фонетические единицы по принципу приоритетов; идентификация звуковых единиц; селекция фонемосочетаний вида согласная-гласная-согласная-согласная (…СГСС…) и согласная-гласная-согласная (…СГСконечная); организация управления параметрами элементов компиляции и слоговым ударением.
Предлагаемый способ реализуется следующим образом. Информация после текстового процессора, освобожденная от цифр и знаков пунктуации, представляет последовательность идентификаторов звуковых единиц, поступающую вместе с признаком ударения на вход акустической базы данных. Одновременно с этим текстовый процессор в результате селекции последовательности типов фонем вида …СГСС… и …СГСконечная вырабатывает признак на формирование фрагмента компиляции СГС, который поступает на блок формирования СГС.
К недостаткам обработки текста по предложенному способу следует отнести плохое транскрибирование частей слов, т.к. не учитываются соотношения более высокого уровня, следовательно, могут некорректно проставляться словесные ударения, а фразовые просто не проставляются.
Кроме того, отсутствует информация о паузах, без обработки которых точность обработки текстов снижается.
Применение изобретения ограничено, т.к. оно направлено лишь на синтез с использованием заданной базы фонемных единиц.
Наиболее близким техническим решением к заявляемому техническому решению является способ предварительной обработки текста для синтеза украинской речи, который также можно использовать для предварительной обработки текстов и на других славянских или неславянских языках.
На первом этапе осуществляется очистка текстов от служебных знаков, не имеющих отношения к речи (знаки переноса строки, табличные знаки и т.д.), что приводит текст в нормализованный орфографический текст.
На этом этапе осуществляются также следующие преобразования:
- всевозможных сокращений и аббревиатур в линейный текст;
- цифр в их орфографическое представление, например, 28453 преобразуется в двадцать восемь тысяч четыреста пятьдесят три;
- формул (математических, физических, химических и т.д.) в их орфографическое представление.
Основное назначение блока пофразовой обработки текста состоит в его просодической разметке. Вначале осуществляется членение текста на фонетические периоды, затем на фразы и, наконец, на синтагмы. Фонетическим периодом называется наибольший участок речи, который единообразно оформлен с точки зрения интонации и ритмики. Обычно он соответствует такому отрезку текста, который называется в орфографии "абзацем". Далее этот текст делится на фразы. Фразы чаще всего соответствуют предложениям или части сложного предложения. Более сложная задача - членение фразы на синтагмы (если это необходимо, т.к. фраза может состоять только из одной синтагмы). Предложения в тексте могут быть очень длинными, обычно человек читает их не на одном дыхании, а разделяя на какие-то элементы по 3-4 слова, после которых допускается некоторая дыхательная пауза. После членения текста на синтагмы эти синтагмы должны быть промаркированы фразовыми ударениями. В зависимости от того, как разбить фразу на синтагмы, звучание текста может быть самым разным и даже вообще изменить смысл предложения. Поэтому во всех этих блоках желательно использовать всю информацию, весь арсенал лингвистики: лексику (словарь), морфологию, синтаксис и семантику.
На третьем этапе осуществляется обращение не ко всей фразе, а к каждому отдельному слову. Вначале осуществляется расстановка словесных ударений.
После того, как будут проставлены ударения в каждом слове текста, эти ударения нужно промаркировать. Маркировка ударений необходима потому, что, хотя большинство слов имеют полное (сильное) ударение, некоторые, например местоимения, - только частичное (слабое) ударение, некоторые слова, такие как предлоги и частицы, могут вообще не иметь ударений.
После маркировки ударений осуществляется процедура объединения слов в, так называемые, фонетические слова. Эта процедура заключается в объединении безударных слов со словами, у которых есть полное или частичное ударение, т.е. в объединении значащих слов со служебными: предлогами, частицами и союзами.
Последний этап - это фонемное транскрибирование. Оно поддерживается своими правилами. Правила транскрибирования иначе называются правилами преобразования "буква - фонема". При оценке правил преобразования букв в звуки необходимо составить список слов, которые по этим правилам будут иметь неправильное произношение и должны быть представлены в виде словаря исключений. В словарь исключений вносятся и слова-термины. Имена собственные представляют особую проблему, поскольку их произношение часто определяется языком, лежащим в основе их правописания.
На выходе текстового процессора сформирована фонетическая запись транскрипции текста, которая далее оформляется наложением подходящего просодического контура для данного типа предложения на основании синтаксического анализа для разрешения некоторых фонетических неоднозначностей.
Недостатком прототипа является то, что в результате для каждой синтагмы получается один вариант транскрипции (одно произнесение), а для всего предложения используется один вариант расстановки пауз, что сказывается на возможности качественного установления соответствия между транскрипционными символами и звуками, присутствующими в речевом сигнале, при реальном произнесении рассматриваемого фрагмента текста.
При дальнейшем использовании полученных идеальных транскрипций расхождение между реальным звуковым составом фрагмента звукозаписи речи и его идеальной транскрипцией сказывается на качестве распознавания и синтеза речи.
Технической задачей предлагаемого изобретения является устранение недостатков, присущих прототипу, путем введения вариативности в транскрипционное представление, за счет моделирования различных возможных (допустимых) вариантов произношения - транскрипционного моделирования.
Технический результат достигается тем, что в известный способ предварительной обработки текста, включающий приведение его в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст, преобразования формул в их орфографическое представление, членение текста на предложения и слова, маркировку фразовых и словесных ударений, объединение слов в синтагмы с последующим их транскрибированием - получением идеальных транскрипций, внесены дополнительные операции, а именно:
- формируют правила транскрипционного моделирования;
- применяют их к полученным идеальным транскрипциям для получения возможных вариантов транскрипций.
Кроме того, длина синтагм может варьироваться от слова до предложения, а на границах слов могут проставляться символы пауз, с учетом которых формируют правила транскрипционного моделирования.
Необходимость транскрипционного моделирования объясняется тем, что произнесение слов и предложений обладает значительной вариативностью. Одно и то же слово, сказанное одним и тем же человеком, может состоять из разных наборов звуков, а в предложениях - паузы могут быть расставлены разным образом. Причины вариативности произнесения различны. Выделяют такие факторы, как стиль речи, степень формальности речи, наличие акцентов и диалектов, социально-экономические факторы, эмоциональное состояние, анатомические особенности диктора.
Цель транскрипционного моделирования - сформировать максимально возможное количество вариантов произношения, для последующего выбора наиболее близкого к реально произнесенному диктором.
Транскрипционное моделирование основано на применении правил моделирования, список которых формируется как на основании знаний о допустимых отклонениях реального произношения от произносительной нормы, так и в результате сбора и обработки статистической информации. Такой двойной подход к формулированию правил позволяет строить транскрипции, наиболее близкие к произношениям, встречающимся в реальной жизни.
Все применяемые правила делятся на две больших группы: правила пропуска звуков, и правила замен звуков.
Правила пропуска звуков описывают ситуации, когда звук, который должен присутствовать при нормативном произнесении высказывания, не произносится. Правила замены звуков описывают ситуации, когда вместо звука, который должен быть произнесен при нормативном произнесении высказывания, произносится какой-то другой звук.
Можно определить правила вставки звуков, описывающие ситуации, в которых при произнесении высказывания в нем появляются дополнительные звуки, отсутствующие в нормативной реализации высказывания. Однако вставка звуков нехарактерна для русского языка, и правила вставки практически не используются.
Для примера приведем несколько правил пропуска звуков (табл.1) и правил замен (табл.2). Приняты следующие обозначения: гласные: без цифр - ударные, 1 - безударные, @ - вторая степень редукции гласного «а».
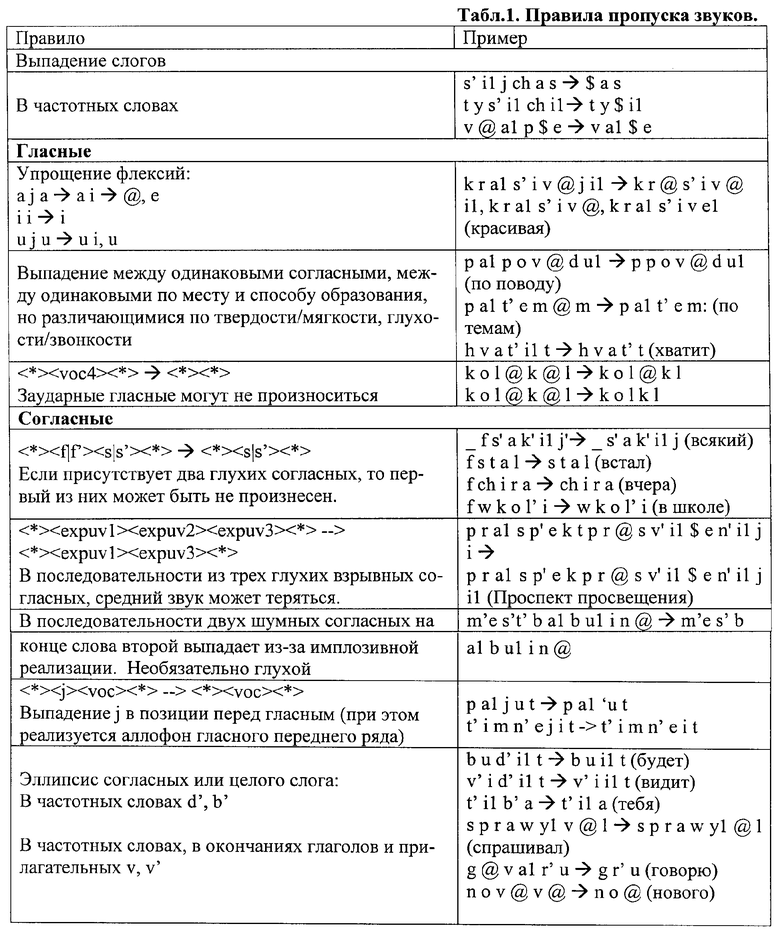

Для моделирования различных способов паузации введена возможность варьирования длины синтагм на этапе обработке текста. Для этих же целей предусмотрена возможность маркировки границ слов, образующих синтагмы, символом паузы. Моделирование паузации позволяет значительно расширить количество вариантов реальных транскрипций. В этом случае требуется дополнение правил транскрипционного моделирования правилами, описывающими возможность различных вариантов расстановки пауз, и обработку сочетаний звуков на стыках слов.
Реализация предлагаемого способа обработки текстов и примеры его применения иллюстрируются следующими чертежами.
На фиг.1 приведена укрупненная блок-схема системы реализации предлагаемого способа. На фиг.2 приведен алгоритм работы блока транскрипционного моделирования. На фиг.3 приведен алгоритм применения правил при транскрипционном моделировании. На фиг.4 приведен алгоритм системы распознавания речи, использующей транскрипционное моделирование, а на фиг.5 - укрупненная блок-схема системы аннотирования речевой звуковой базы с применением транскрипционного моделирования. На фиг.6 показан алгоритм системы синтеза речи с применением транскрипционного моделирования. На фиг.7 приведен алгоритм поиска по звуковой базе, на фиг.8 приведены проценты распознавания речи с применением и без применения транскрипционного моделирования.
Для лучшего понимания ниже приводим определение терминов, применяемых в описании изобретения.
База знаний - один или несколько специальным образом организованных файлов, хранящих систематизированную совокупность понятий, правил и фактов, относящихся к некоторой предметной области.
Основа слова - часть слова, выражающая его лексическое значение, при этом в склоняемых и спрягаемых словах имеются основа и окончание, а остальные слова содержат только основу.
Поисковая система - система, выполняющая автоматический поиск информации по ключевым словам, темам и т.д.
Словосочетание - это синтаксическая единица, образующаяся соединением двух или более слов на основе подчинительной связи - согласования, управления или примыкания - и тех лексико-грамматических отношений, которые порождаются этой связью.
Словоформа - данное слово в данной грамматической форме.
Фонема - (от греч. phonema - звук) - это минимальная звуковая единица языка, линейно не членимая, служащая для образования звуковых оболочек значащих единиц и условно связанная со смыслом звукового строя языка, предельный элемент, выделяемый линейным членением речи.
Аллофон - (от греч. allos - иной, другой и phone - звук) - вариант, разновидность фонемы, обусловленная данным фонетическим окружением.
Синтагма - (от греч. syntagma, буквально - «вместе построенное, соединенное») - фонетическое целое, выражающее единое смысловое целое в процессе речи-мысли. Минимальная единица при членении высказывания интонационными средствами. Может трактоваться как последовательность аллофонов от паузы до паузы.
Транскрипция (слово «транскрипция» буквально значит "переписывание", от лат. trans- "через, пере-" + scribo "черчу, пишу") - особый вид записи речи, который используется для фиксации на письме особенностей ее звучания. Транскрипция описывает реальную или потенциальную возможную звуковую реализацию текста в терминах фонем и аллофонов. Существуют два основных вида транскрипции - фонематическая и фонетическая; первая отражает фонемный состав слова или последовательности слов, вторая - особенности реализации фонем в разных условиях.
Транскрипционный символ - знак или последовательность знаков, обозначающих фонему, аллофон или паузу в транскрипции синтагм.
Транскрибирование - преобразование текстовой записи речи (например, последовательность слов, образующих синтагму) в последовательность транскрипционных символов (транскрипцию).
Идеальная (каноническая) транскрипция - фонетическая транскрипция, соответствующая произносительной норме языка.
Интонационный тип - это тип соотношения тона, тембра, интенсивности и длительности звучащей речи, способный противопоставить несовместимые в одном контексте смысловые различия высказываний с одинаковым синтаксическим строением и лексическим составом или высказываний с разным синтаксическим строением, но одинаковым звуковым составом словоформ.
На фиг.1 показано, что реализация способа предварительной обработки текста осуществляется блоками: 1.1 - текстовый процессор; 1.2 - транскриптор и 1.3 - модуль транскрипционного моделирования.
Исходный текст поступает в текстовой процессор (блок 1.1), в котором происходит предварительная обработка исходного текста, включающая известные операции:
- приведение его в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст;
- преобразования формул в их орфографическое представление;
- членение текста на предложения и слова;
- маркировку фразовых и словесных ударений;
- объединение слов в синтагмы.
Каждая синтагма поступает на вход транскриптора (1.2), переводящего текст из орфографической формы записи в фонетическую транскрипцию, а также формирующего ее просодический образ.
Дополнительно в транскрипторе может быть предусмотрен режим «микропауз», при котором каждое слово, входящее в синтагму, обрабатывается отдельно, как если бы оно было окружено паузами, а в транскрипцию включается дополнительный символ микропаузы. Режим «микропауз» позволяет расширить возможности транскрипционного моделирования.
Процесс транскрипционного моделирования реализуется в блоке 1.3, который осуществляется по заданным правилам моделирования. В результате для каждой идеальной транскрипции формируется список реально возможных транскрипций.
Алгоритм работы блока транскрипционного моделирования приведен на фиг.2. Отдельные операции алгоритма реализуются следующими модулями: 2.1 - загрузки правил транскрипционного моделирования; 2.2 - формирования текущего списка транскрипций; 2.3 - счетчик применяемых правил; 2.4 - проверки обязательности правила; 2.5 - формирования копии текущего списка транскрипций; 2.6 - применения правила к копии списка транскрипций; 2.7 - объединения списков (текущего и копии) транскрипций; 2.8 - применения правила к текущему списку транскрипций; 2.9 - поиска и исключения повторных транскрипций из списка; 2.10 - перевода транскрипций в текстовый формат.
Работа алгоритма транскрипционного моделирования осуществляется следующим образом. Правила моделирования задаются в виде текстового файла, который считывается в память и переводится во внутреннее представление (модуль 2.1). В общем случае каждое правило определяет транскрипционный символ, для которого оно применяется («центральный звук»), а также последовательность транскрипционных символов слева и справа от него. Также правило определяет новую последовательность, заменяющую исходную, смещение этой новой последовательности относительно центрального звука в исходной транскрипции и признак «обязательности» правила.
Последовательность применения правил задается либо специальным списком правил, либо порядком их объявления в файле правил.
Алгоритм транскрипционного моделирования применяется к каждой идеальной транскрипции, сформированной транскриптором. Идеальная транскрипция добавляется в текущий список транскрипций (модуль 2.2), после чего к текущему списку транскрипций по очереди применяются правила моделирования. За один шаг применяется одно правило моделирования. Модуль 2.3 обеспечивает выбор применяемого правила моделирования из списка и выполняет проверку: все ли правила моделирования были применены. Если правило моделирования обязательное (модуль 2.4), то оно применяется непосредственно к текущему списку транскрипций (модуль 2.8), если нет - то создается копия текущего списка транскрипций (модуль 2.5). В этом случае правило применяется к копии списка транскрипций (модуль 2.6), после чего результирующий список транскрипций добавляется к текущему списку (модуль 2.7). По мере применения правил список транскрипций увеличивается, и каждое следующее правило работает с обновленным текущим списком транскрипций.
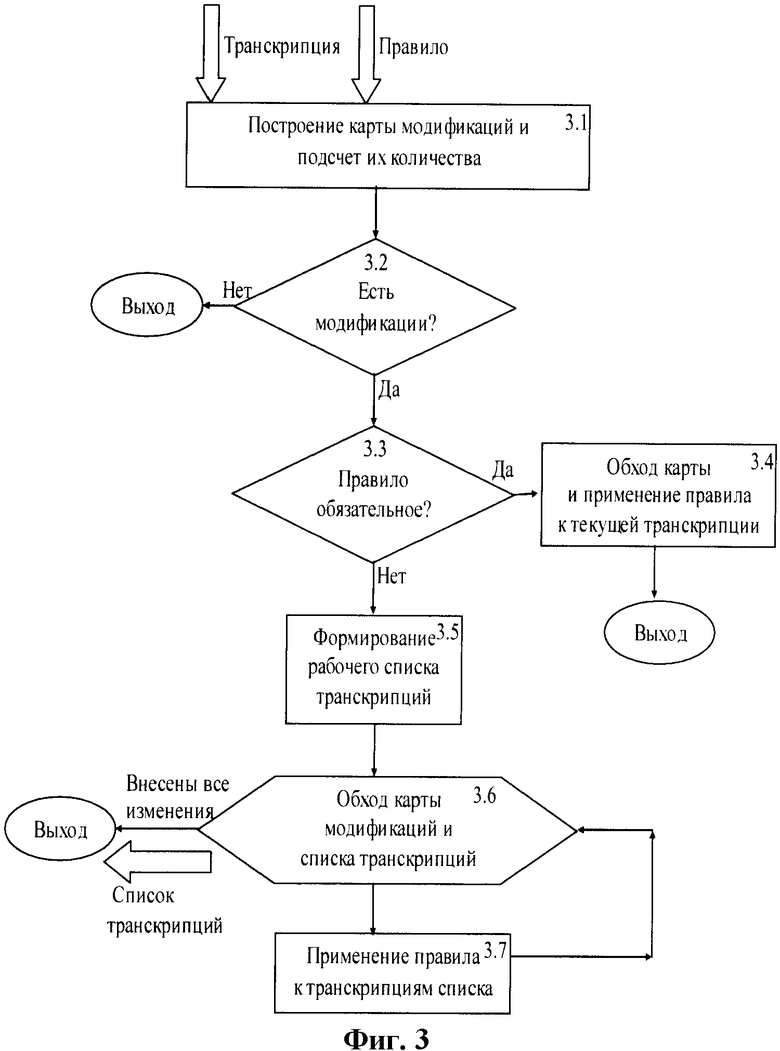
Алгоритм применения правила к каждой транскрипции списка (к копии списка модуль 2.6 и к текущему списку модуль 2.8) показан на фиг.3. На фиг.3 приведены следующие модули, осуществляющие отдельные операции: 3.1 построения карты модификаций; 3.2 проверки наличия модификаций; 3.3 проверки обязательности применяемого правила; 3.4 обхода карты модификаций и применения правила к транскрипции; 3.5 формирования рабочего списка транскрипций; 3.6 организации циклов обхода карты модификаций и рабочего списка транскрипций; 3.7 применения правила к транскрипциям списка.
Алгоритм осуществляется в следующей последовательности.
На вход модуля 3.1 поступает транскрипция и правило транскрипционного моделирования. В модуле 3.1 строится карта применимости правила к транскрипции и подсчитывается количество возможных модификаций. Для этого каждый символ транскрипции сравнивается с центральным звуком правила. Если они совпадают, то выполняется сравнение контекстов. Если и контексты совпадают, то в карте применимости делается соответствующая отметка и увеличивается счетчик модификаций. Карта применимости - это массив флагов. Длина массива равна длине транскрипции. Каждый флаг соответствует траснкрипционному символу транскрипции. Если правило применимо к транскрипционному символу в данной позиции, то флаг установлен, если нет - флаг не установлен.
Если счетчик модификаций равен нулю (модуль 3.2), то работа алгоритма завершается и возвращает пустой список модифицированных транскрипций (выход, переход к фиг.2).
Если правило модификации является обязательным (модуль 3.3), то оно применяется ко всем транскрипционным символам, подлежащим модификации, согласно карте применимости (модуль 3.4), после чего возвращается единственная модифицированная транскрипция (выход, переход к фиг.2).
В модуле 3.5 формируется рабочий список транскрипций, содержащий исходную транскрипцию, в количестве, равном 2 в степени счетчик модификаций.
Далее организуются циклы обхода карты модификаций (просмотра установленных флагов) и рабочего списка транскрипций (модуль 3.6), и производятся изменения транскрипций рабочего списка (модуль 3.7). Когда внесены все изменения во все транскрипции (проверяются условия завершения циклов в модуле 3.6), осуществляется возврат рабочего списка транскрипций (выход, переход к фиг.2).
После того, как применены все правила, из сформированного списка транскрипций исключаются все повторные транскрипции (модуль 2.9). Полученный список транскрипций и является результатом моделирования. Для удобства он может быть преобразован в текстовый вид и сохранен в файл (модуль 2.10).
Если идеальные транскрипции были сформированы в режиме микропауз, то при транскрипционном моделировании есть возможность описать несколько вариантов паузации. Для моделирования паузации требуется подготовить дополнительный комплект правил, обрабатывающий различные варианты расстановки пауз и изменение звуков на стыках слов.
В результате транскрипционного моделирования каждой синтагме будет сопоставлена не одна идеальная транскрипция, а целый список реально возможных транскрипций. Транскрипционное моделирование позволяет выбирать транскрипцию из списка, наиболее соответствующую звуковому сигналу, в то время как в известных решениях отсутствует сама возможность выбора.
Ниже приводятся примеры применения транскрипционного моделирования, которые наиболее очевидны. Это распознавание речи, аннотирование речевых баз данных и синтез речи.
Пример 1. Распознавание речи
Алгоритм работы системы распознавания речи (фиг.4) состоит из следующих блоков: обработки грамматики 4.1; текстового процессора 4.2; транскрипционного моделирования 4.3; формирования моделей высказываний 4.4; блока распознавания 4.5.
Входными данными системы распознавания речи являются: распознаваемая грамматика, база моделей звуков, распознаваемый звуковой сигнал и правила транскрипционного моделирования, которые поступают в соответствующие блоки.
Распознаваемая грамматика представляет собой список слов и список связей между ними. В простейшем случае грамматика представляет собой список отдельных команд. Система распознавания строит список всех возможных высказываний (блок 4.1), соответствующих этой грамматике. Для каждого высказывания с помощью текстового процессора, работа которого была описана (блок 4.2), порождается идеальная транскрипция.
Затем в соответствии с алгоритмом транскрипционного моделирования (блок 4.3) из идеальных транскрипций (полученных ранее) для каждого высказывания формируется множество возможных вариантов транскрипций. Дополнительно транскрипции могут ранжироваться по степени их отклонения от идеального (или нормативного) варианта, чтобы в дальнейшем учитывать еще и вероятности появления каждой транскрипции.
Для каждой транскрипции из базы моделей звуков выбираются необходимые модели, и строится цепочка моделей звуков, образующая модель высказывания (блок 4.4). В результате для каждого возможного высказывания строится несколько моделей, соответствующих различным возможным способам его произнесения.
Далее начинается собственно процесс распознавания (блок 4.5). Звуковой поток разделяется на фреймы, преобразуется в наборы параметров и сравнивается с моделями высказываний. Высказывание, модель которого оказывается наиболее похожей на распознаваемый звук, принимается за результат распознавания.
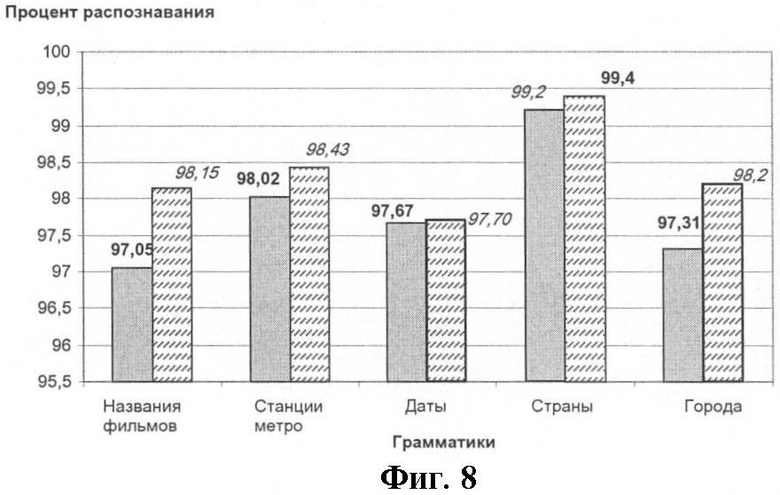
Алгоритм транскрипционного моделирования, включенный в систему распознавания русской речи Vocative Russian ASR Engine (разработанной при участии авторов предлагаемого изобретения), позволяет повысить процент правильного распознавания высказываний.
На диаграмме (фиг.8) представлены проценты правильного распознавания, полученные с применением (штрихованные колонки) и без применения (серые колонки) транскрипционного моделирования для ряда стандартных тестовых грамматик. Видно, что применение транскрипционного моделирования позволяет повысить процент правильно распознанных высказываний.
Пример 2. Аннотирование речевых баз данных
Одним из возможных применений транскрипционного моделирования является его использование в составе системы аннотирования речевой звуковой базы.
Речевой корпус включает десятки (и даже сотни) часов записей диктора (или нескольких дикторов), поэтому аннотирование такой речевой звуковой базы занимает человекогоды и стоит очень дорого.
Автоматизация процесса аннотирования речевых корпусов с применением транскрипционного моделирования позволяет значительно удешевить и ускорить процесс, за счет значительного сокращения доли ручного труда.
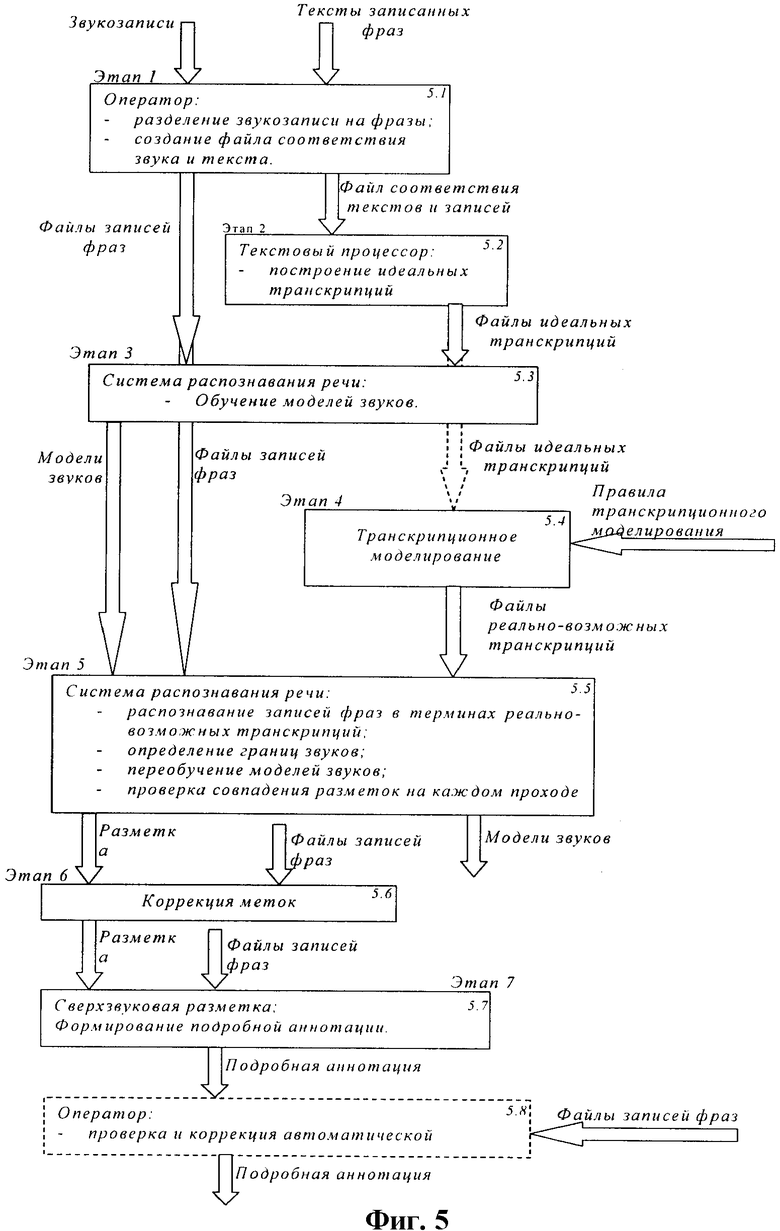
На фиг.5 приведена блок-схема автоматизированной системы аннотирования речевой звуковой базы. Она включает: блок 5.1 предварительной обработки звукозаписей; текстовый процессор 5.2; блок 5.3 обучения моделей звуков; блок транскрипционного моделирования 5.4; систему распознавания речи 5.5; блок 5.6 коррекции меток; блок 5.7 формирования подробной аннотации и блок 5.8 автоматической проверки и коррекции аннотации.
В основе системы аннотирования лежат три основных компонента: система распознавания речи, текстовый процессор и система моделирования транскрипций. Применение транскрипционного моделирования определяется необходимостью построения и выбора транскрипции, наилучшим образом соответствующей звукозаписи речевого сигнала. Обработка речевого корпуса производится в несколько этапов. На вход блока 5.1 поступает звукозапись и тексты записанных фраз.
На первом этапе (подготовительном) звукозапись разделяется на фразы. Каждая фраза записывается в отдельный звуковой файл с уникальным именем и передается на вход блока обучения моделей звуков (блок 5.3). В блоке 5.1 также формируется текстовый файл, в котором устанавливается соответствие между именами звуковых файлов и текстами фраз. Он поступает в текстовый процессор 5.2.
На втором этапе с помощью текстового процессора формируются идеальные транскрипции записанных фраз; транскрипция каждой фразы сохраняется в отдельном файле, с названием, соответствующим названию звукового файла. Параллельно формируются предварительные модели звуков, используемые системой распознавания речи.
На третьем этапе на основе звуковых данных и идеальных транскрипций производится предварительное обучение системы распознавания речи (блок 5.3).
На четвертом этапе запускается алгоритм транскрипционного моделирования, который для каждой идеальной транскрипции формирует множество «реально-возможных» транскрипций (блок 5.4). Транскрипционное моделирование осуществляется по предлагаемому изобретению.
Далее выполняется пятый, циклический этап, который осуществляется системой распознавания речи (блок 5.5) и включает в себя ряд пунктов, а именно:
1) выполняется распознавание каждого звукового файла в терминах реально-возможных транскрипций; для каждого звукового файла определяются наиболее вероятные реально-возможные транскрипции;
2) для полученных результатов распознавания определяются границы отдельных звуков;
3) модели звуков переобучаются на основе звуковых данных, и транскрипций, признанных наиболее вероятными в результате распознавания;
4) если это первый проход, то выполнение продолжается от пункта 1;
5) полученная разметка на звуки сравнивается с разметкой, полученной на предыдущем проходе, если разметка изменилась (критерий совпадения меток - является параметром модуля сравнения), то выполнение продолжается от пункта 1; если нет - считается, что достигнуто оптимальное разделение на звуки.
Обычно требуется от трех до пяти проходов для достижения оптимальной разметки.
На шестом этапе (блок 5.6) выполняется коррекция границ звуков, заключающаяся в переносе меток на начала периодов основного тона для вокализованных звуков, а также в уточнении границ между звонкими и глухими звуками. Коррекция необходима, т.к. система распознавания речи формирует границы с точностью до шага смещения окна.
На последнем (седьмом) этапе формируется подробная аннотация звуковой базы, содержащая не только информацию о разбиении на аллофоны, но и информацию об интонационных контурах (блок 5.7).
При необходимости может быть выполнена дополнительная внутриаллофонная разметка на периоды основного тона, глухие смычки, и т.п., однако, для многих задач синтеза по базе слитной речи, или обучения систем распознавания речи, это излишне.
Дополнительно, на последнем этапе, может быть выполнена ручная проверка и коррекция автоматического разбиения на звуки (блок 5.8).
Пример 3. Синтез речи
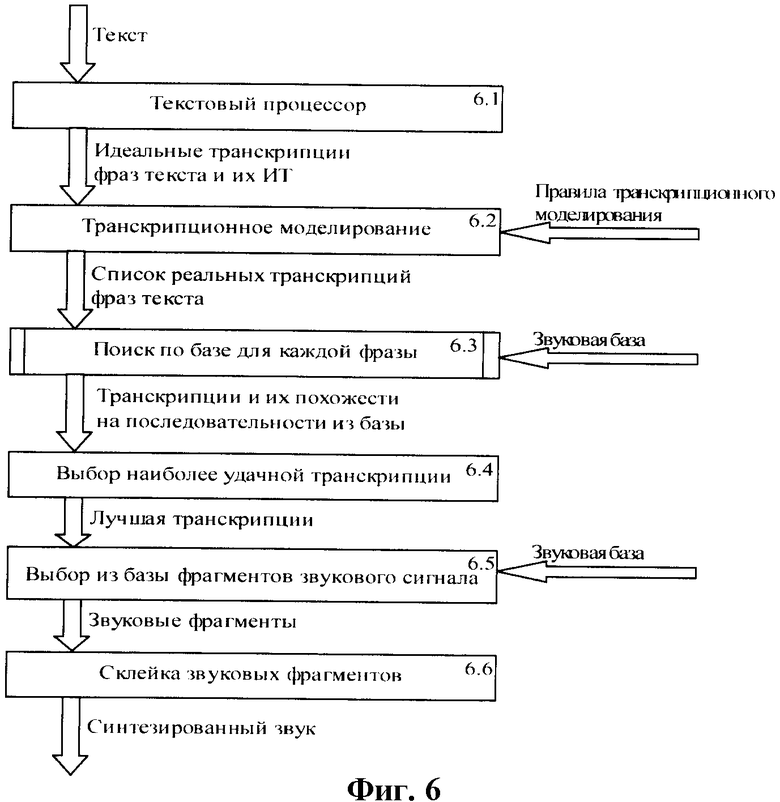
Блок-схема для реализации синтеза речи приведена на фиг.6 и содержит следующие блоки: 6.1 - текстовый процессор; 6.2 - транскрипционного моделирования; 6.3 - поиска по базе для каждой фразы (предложения); 6.4 - выбора наиболее близкой транскрипции; 6.5 - выбора из базы фрагментов звукового сигнала; 6.6 - склейки звуковых фрагментов.
На вход системы синтеза речи (на текстовый процессор - в блок 6.1) подается синтезируемый текст, а на входы блоков 6.3 и 6.5 - размеченная специальным образом звуковая база.
В текстовом процессоре осуществляется предварительная обработка текста и на выходе формируются идеальные транскрипции фраз текста и их интонационные типы. Далее, к полученным идеальным транскрипциям применяется транскрипционное моделирование (блок 6.2), осуществляемое согласно описанию предлагаемого изобретения.
Сформированный в результате транскрипционного моделирования список реальных транскрипций поступает в блок 6.3 - поиск по базе для каждой фразы.
При работе с базой слитной речи основная интеллектуальная нагрузка ложится на алгоритмы поиска и выбора из базы оптимальных фрагментов сигнала. При этом также используется транскрипционное моделирование. Рассмотрим подробнее, как и по каким критериям выполняется выбор звуковых фрагментов из базы.
1. К полученным на выходе текстового процессора идеальным транскрипциям применяется алгоритм транскрипционного моделирования, в результате чего строится список реальных транскрипций (как описано в предлагаемом изобретении).
2. Для каждой транскрипции определяется коэффициент похожести на идеальную транскрипцию. Чем больше отличий, тем похожесть ниже.
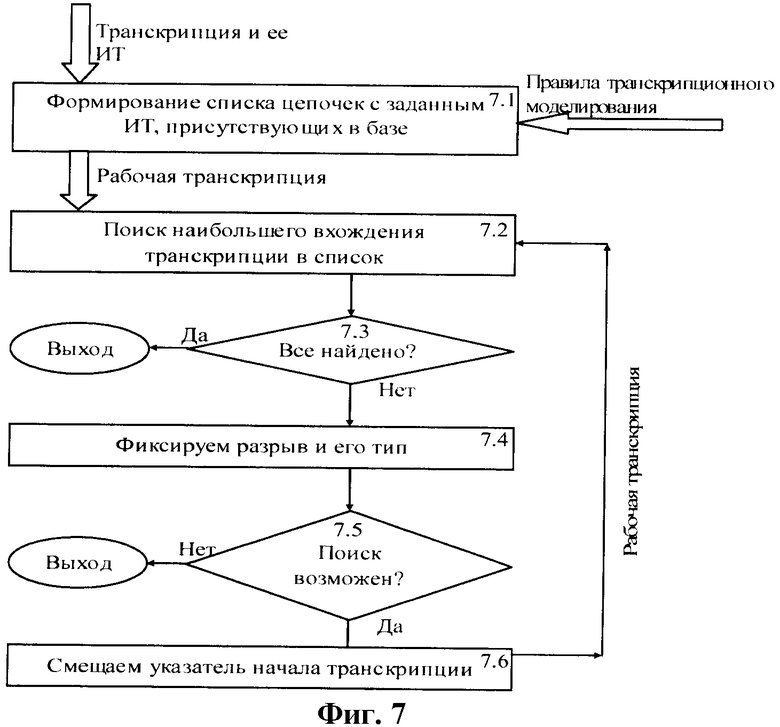
3. Для каждой транскрипции выполняется поиск по базе (блок 6.3), алгоритм которого показан на фиг.7. В результате определяется количество разрывов транскрипции и их качество. Качество разрывов определяется звуками, на которых происходит разрыв. Самое низкое качество у разрыва между гласными, самое высокое (единичное) - на паузе и стыках глухих согласных.
4. Похожести транскрипций умножаются на качество разрывов.
5. Выбирается транскрипция с самой высокой степенью похожести, для которой и формируется результирующий звуковой сигнал (блок 6.4).
6. Если в результате поиска оказывается, что похожести всех транскрипций равны нулю, то строится список транскрипций с минимальным количеством нулевых разрывов.
7. Выбирается транскрипция, наиболее похожая на идеальную транскрипцию по коэффициенту похожести, полученному на шаге 2.
При поиске по базе из просодических характеристик учитываются только инотационные типы (ИТ). Алгоритм поиска приведен на фиг.7.
На фиг.7 показаны модули, реализующие поиск транскрипции по базе: 7.1 - формирования списка цепочек с заданным ИТ; 7.2 - поиск наибольшего вхождения транскрипции в список; 7.3 - проверки нахождения вхождений для всех частей транскрипции; 7.4 - фиксации разрыва, и его типа; 7.5 - проверки возможности продолжения поиска и 7.6 - смещения указателя начала транскрипции.
На вход алгоритма поступает транскрипция и ее интонационный тип. Реализация алгоритма осуществляется следующим образом.
1. Создается список всех элементов базы, имеющих искомый ИТ (блок 7.1).
2. Для каждой транскрипции ищется максимальное вхождение звуков от начала цепочки и от начал элементов списка (блок 7.2). Если найдено полное вхождение транскрипции (блок 7.3), то для нее поиск заканчивается.
3. Если транскрипция найдена частично, то фиксируется разрыв (блок 7.4), и поиск продолжается от точки разрыва, но уже без привязки к началам элементов списка.
4. Пункт 3 повторяется до тех пор, пока не найдены все фрагменты транскрипции или не окажется так, что какой-то фрагмент транскрипции не может быть найден в списке (блок 7.5).
5. Если в транскрипции существует фрагмент, отсутствующий в базе, осуществляется пропуск звука, и фиксируется разрыв с нулевым качеством (блок 7.6), после чего поиск продолжается с пункта 3.
При поиске по базе дополнительно может задаваться ограничение на качество разрывов, однако это может иногда приводить к тому, что ни для одной транскрипции не будет найдено ни одного вхождения. В этом случае следует повторить процедуру поиска с отмененными ограничениями на типы разрывов.
Особенность формирования речевого потока с использованием звуковой базы слитной речи состоит в минимизации изменений фрагментов сигнала, выбираемых из базы. В идеале модификация не требуется вовсе, однако на практике требуется обработка стыков фрагментов, для обеспечения гладкости стыковки.
Простейшим алгоритмом, обеспечивающим такую гладкость, является «морф» стыков, заключающийся в построении плавного перехода от одного фрагмента к другому. Переходный участок строится как сумма отсчетов конца первого сигнала, убывающая по линейному закону, и начала отсчетов второго сигнала, возрастающих по обратному линейному закону. Морф стыков выполняется только при стыковке вокализованных фрагментов сигнала, а длина переходного участка равна средней длине периода основного тона.
Использование базы слитной речи позволяет формировать речевой поток с качеством, значительно превышающим качество речевого потока, формируемого на основе аллофонных баз.
Как видно из примеров применения транскрипционного моделирования, оно значительно сокращает трудоемкость поиска в речевых звуковых базах и повышает качество распознавания и синтеза речи. В настоящее время способ предварительной обработки текста разработан для систем распознавания речи и аннотирования звуковых речевых баз, причем проведенные испытания показали целесообразность применения предлагаемого способа.
Возможности его применения значительно шире и предлагаемое изобретение будет постепенно внедряться в другие области его возможного применения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2011 |
|
RU2460154C1 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СПОСОБ СИНТЕЗА РЕЧИ | 2009 |
|
RU2421827C2 |
| СПОСОБ ОБМЕНА СООБЩЕНИЯМИ И УСТРОЙСТВА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2007 |
|
RU2324296C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| УСТРОЙСТВО СИНТЕЗА РЕЧИ | 2014 |
|
RU2606312C2 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1996 |
|
RU2101782C1 |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2297676C2 |


Изобретение относится к информационным технологиям, в частности к предварительной обработке текстовой информации, и может быть использовано при распознавании и синтезе речи, аннотировании баз данных, а также при автоматическом синхронном переводе с языка на язык и других областях знаний. Изобретение позволяет получить все возможные варианты транскрипций исходного текста, не прибегая к анализу звучания текста. К полученным на основе текста идеальным транскрипциям применяют правила транскрипционного моделирования, получают дополнительные варианты транскрипций, к которым также применяют правила транскрипционного моделирования. Из полученного списка транскрипций исключают одинаковые транскрипции и сохраняют оставшиеся в списке транскрипции для дальнейшего использования. 3 з.п. ф-лы, 8 ил., 2 табл.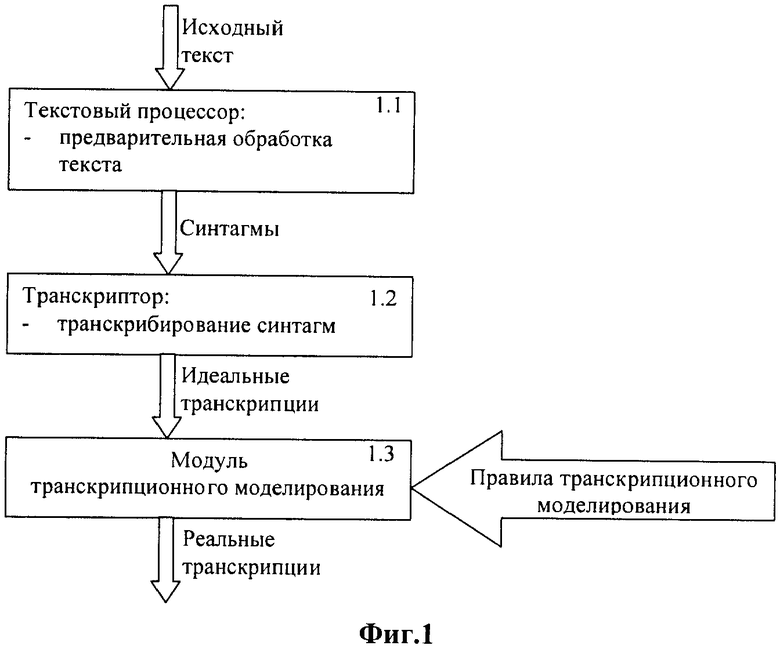
1. Способ предварительной обработки текста посредством текстового процессора, включающий приведение его в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст, преобразования формул в их орфографическое представление, членение текста на предложения и слова, маркировку фразовых и словесных ударений, объединение слов в синтагмы с простановкой символов пауз в конце синтагм с последующим транскрибированием синтагм - получением идеальных транскрипций, отличающийся тем, что к полученным идеальным транскрипциям последовательно применяют правила транскрипционного моделирования, в результате чего получают дополнительные варианты транскрипций, к которым также применяют правила транскрипционного моделирования, из общего списка исходных и полученных дополнительных вариантов транскрипций исключают одинаковые транскрипции и сохраняют оставшиеся в списке транскрипции для дальнейшего использования.
2. Способ по п.1, отличающийся тем, что правила транскрипционного моделирования формируют с учетом правил пропуска и замены символов, отображающих соответствующие звуки, вставки и смещения новой последовательности относительного центрального звука.
3. Способ по п.1, отличающийся тем, что длина синтагм в словах может варьироваться от одного слова до нескольких слов, составляющих предложение.
4. Способ по п.1, отличающийся тем, что если на границах слов, входящих в синтагмы, проставлены символы пауз, они учитываются при формировании правил транскрипционного моделирования.
| Волошин В.Г и др | |||
| Проблемы предварительной обработки орфографического текста для синтеза украинской речи | |||
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| СПОСОБ КОМПИЛЯЦИОННОГО ФОНЕМНОГО СИНТЕЗА РУССКОЙ РЕЧИ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2005 |
|
RU2298234C2 |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |
| US 6342680 В1, 05.06.2001 | |||
| FR 2878990 A1, 09.06.2006. | |||

