Изобретение относится к автоматике и вычислительной технике и может быть использовано в системах понимания речи, системах управления технологическим оборудованием, роботами, средствами вычислительной техники, автоматического речевого перевода, в справочных системах и др.
Известен способ распознавания слов в слитной речи, реализованный в системе автоматического понимания речи английского языка HEARSAY II [1]
Суть способа состоит в том, что периодически с произнесением речевого высказывания берут выборки акустического оцифрованного сигнала этого высказывания через фиксированные интервалы времени с заданной частотой квантования в этом интервале, и по совокупности этих выборок вычисляют функционал, который преобразуют в класс слогов, называемый слоготипом. Затем для каждого слоготипа при построении лексической гипотезы выявляют все слова, которые содержат ударный слог, принадлежащий этому классу слоготипов. Многосложные слова отвергаются, если они плохо согласуются со смежными слоготипами. Определение слоготипов основано на группировании фонем в фонетические классы. Произношение каждого слова, принадлежащего словарю произношений, преобразуется в последовательность слоготипов путем распределения всех фонем по их классам. Последовательности функционалов неизвестного высказывания определяют гипотезы о слоготипах, используемые для построения гипотез о словах.
Особенностью известного способа является то, что вариации произношения слов учитывают путем применения широких классов фонем и включения вариантов произнесения слов в словарь. Классы фонем предполагают, что каждый сологотип принадлежит только к одному классу слоготипов.
Однако этот способ имеет недостатки: невозможно разделить слоги и фонемы строго на классы, так как существуют фонемы, которые можно отнести к двум соседним классам. Это приводит к тому, что различия между классами стираются и уменьшается четкость различения слоготипов, в результате чего снижается точность распознавания слов.
Известен способ распознавания слов в слитной речи, особенность которого состоит в непосредственном переходе от распознанных звуков в высказывании к произношениям слов с учетом изменения этих звуков при коартикуляции. Этот способ реализован в системе автоматического понимания речи DRAGON [2]
Суть способа состоит в том, что периодически с произнесением речевого высказывания берут выборки акустического оцифрованного сигнала этого высказывания через фиксированные интервалы времени с заданной частотой квантования в этом интервале, и по совокупности этих выборок вычисляют функционал, который преобразуют в фонему. После этого формируют последовательность фонем, и, используя сеть лексического декодирования, представляющую собой модель произнесения слова, строят гипотезы о возможных словах в высказывании.
Для построения сети лексического декодирования берут каноническое произношение и применяют к нему фонологические правила, чтобы представить наиболее полную вероятностную модель произношения слова. При использовании словаря канонического произношения (словаря подсетей слова) каждая подсеть слова заменяется до узла. В результате чего получаем сеть, в которой каждый узел представляет собой индивидуальную фонему. Возможные фонетические реализации слова формируются путем неоднократного применения фонологических правил к основному произношению.
Каждое правило обеспечивает альтернативное произношение некоторой последовательности фонем. Для каждого фонологического правила осуществляется просмотр всей сети, чтобы найти любые узлы, которые удовлетворяют условиям контекста. Все это приводит к снижению быстродействия и точности распознавания.
Наиболее близким к предложенному способу, взятому в качестве прототипа, является способ распознавания слов, реализованный в системе CASPERS [3] Суть способа состоит в том, что периодически с произнесением речевого высказывания берут выборки акустического оцифрованного сигнала этого высказывания через фиксированные интервалы времени с заданной частотой квантования в этом интервале, и по совокупности этих выборок вычисляют функционал, которые преобразуют в фонему. После этого формируют последовательность фонем, и, используя лексическую декодирующую схему строят гипотезы о возможных словах в высказывании. При этом лексическая декодирующая схема представляет собой дерево, содержащее все ожидаемые фонетические реализации слов заданного словаря. Слова, имеющие одинаковые первые звуки, помещают в одной и той же начальной точке дерева. Далее, конец каждой ветви дерева, представляющей произношение слова, соединяют со всеми начальными формами слов, применяя при этом набор фонологических правил. В результате создается сеть фонетических последовательностей. Для учета внутрисловарных фонологических явлений, а также изменений окончаний слов из-за влияния предыдущих и последующих слов, ожидаемые фонетические реализации слова представляют путем расширения основного произношения несколькими альтернативными произношениями. Такое расширение словаря производят автоматически, с применением фонологических правил.
Однако, необходимо располагать некоторой эвристической стратегией сравнения для подбора слов, соответствующих фонетической записи неизвестного выражения. Для этого необходимо вводить меру штрафа при ошибочной идентификации, возможных случаев добавления или пропуска акустического состояния так как автоматический фонетический анализатор допускает много ошибок такого типа. Ошибки в фонетической транскрипции могут привести в конечном счете к неустранимому рассогласованию с правильным словом.
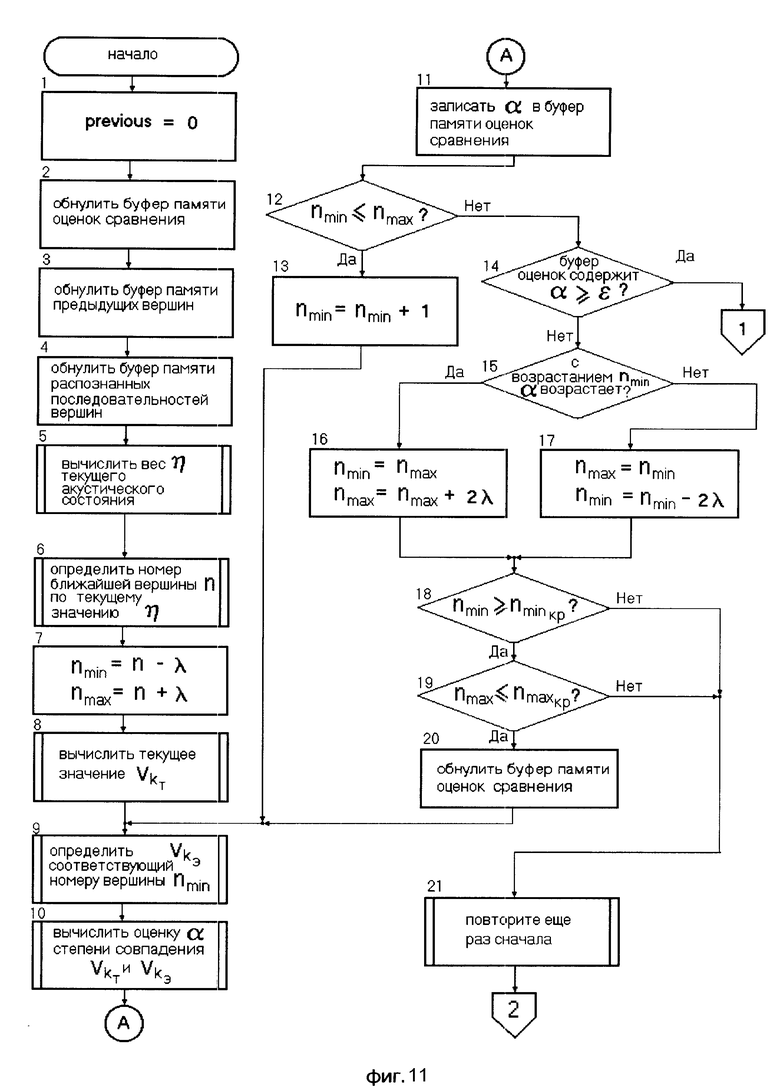
Недостатками вышеперечисленных способов и прототипа являются низкое быстродействие, недостаточная точность распознавания слов, что обусловлено следующим:
фонетическая транскрипция, которая служит входной информацией для построения лексических гипотез, содержит ошибки замещения, лишние звуки и пропуски звуков, уменьшающие сходство распознаваемого слова с правильной гипотезой и увеличивающее сходство распознаваемого слова с ошибочными, особенно при большом объеме словаря;
неоднократное применение фонологических правил к словарю произношений слов влечет за собой замедление процесса распознавания слова;
ожидаемая фонетическая реализация слова зависит от контекста предложения, в котором оно встречается. Границы слов в слитной речи полностью отсутствуют в транскрипции, так как акустические признаки их положений слабо выражены;
положение границы между длительностями фонетических групп зависит от скорости речи, положения синтаксических границ, ударных слогов и локального фонетического окружения.
При распознавании слов в слитной речи возникает задача, суть которой состоит в том, что стратегия принятия решения на фонетическом уровне частично зависит от факторов более высокого уровня, которые не могут быть определены пока не приняты решения на фонетическом уровне. Решение данной задачи сводится к необходимости принятия решения на фонетическом и более высоких уровнях одновременно.
Предлагается способ распознавания слов в слитной речи, который состоит в том, что периодически с произнесением речевого высказывания берут выборки акустического оцифрованного сигнала этого высказывания через фиксированные интервалы времени с заданной частотой квантования в этом интервале и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние.
Способ отличается тем, что минуя уровень фонетического декодирования, одновременно по вычисленным значениям функционала используя сеть лексического декодирования строят гипотезы о возможных словах в высказывании. При этом сеть лексического декодирования представляет собой интегрированную базу знаний, в которой объединены фонетическая транскрипция, фонологические правила и лексика заданного набора слов.
Результатом осуществления изобретения является повышение точности распознавания слов в слитной речи русского языка и обеспечение быстродействия максимально приближенного к реальному времени. Результат достигается использованием сети лексического декодирования (СЛД), лексемы которого представлены в виде последовательности акустических состояний (АС), учитывающей внутрисловарные фонетические явления, а также фонетические явления, возникающие на границах слов.
СЛД создается путем выполнения последовательности операций: представление речи конечным набором слов; представление слова как последовательности конечных акустических состояний; определение акустического состояния как относительно стационарного участка речи; создание базы данных эталонных конечных акустических состояний для фонетического и фонологического описания русских слов. На основе вышесказанного реализуется способ распознавания слов в слитной речи русского языка.
Суть этих операций состоит в следующем.
1) Представляют речь конечным набором слов:
G=Ci}
где
G речь, C слово, i номер слова, i=1, 2,I
2) Представляют слова, как последовательности конечных акустических состояний:
Ci=Cij=[{Vk}j]i,
где C слово, i номер слова, i=1, 2,I,
j номер произношения, j=1, 2,J;
V акустическое состояние;
k число акустических состояний, k=1, 2,K.
3) Определяют акустическое состояние как относительно стационарный участок речи:
Vk=f(x1, x2, x3, xn)
где,
например: x1=F0 частота основного тона; x2=F1, x3=F2, x4=F3, x5=F4, где F1, F2, F3, F4 частоты формант и т.д.
4) Производят описания переходов из конечных акустических состояний, используя набор фонетических и фонологических правил русского языка, а также п. 1, п. 2, п. 3.
5) Создают базу данных эталонных конечных акустических состояний.
6) Каждому элементу базы данных ставят в соответствии весовой коэффициент η
7) Классифицируют базу данных конечных акустических состояний по возрастанию весового коэффициента h
8) Конструируют сеть лексического декодирования с учетом п. 4, п. 5, п. 6, п. 7.
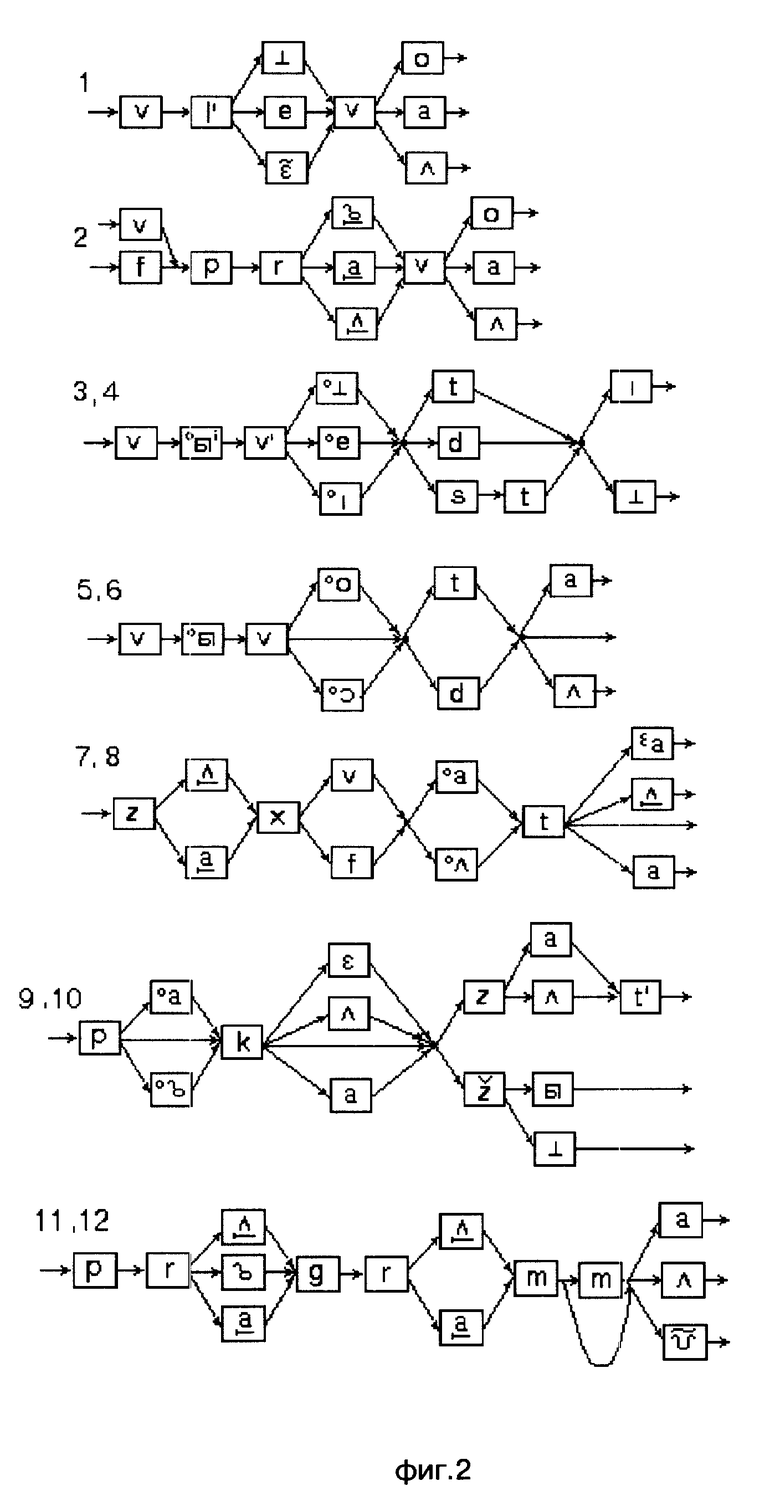
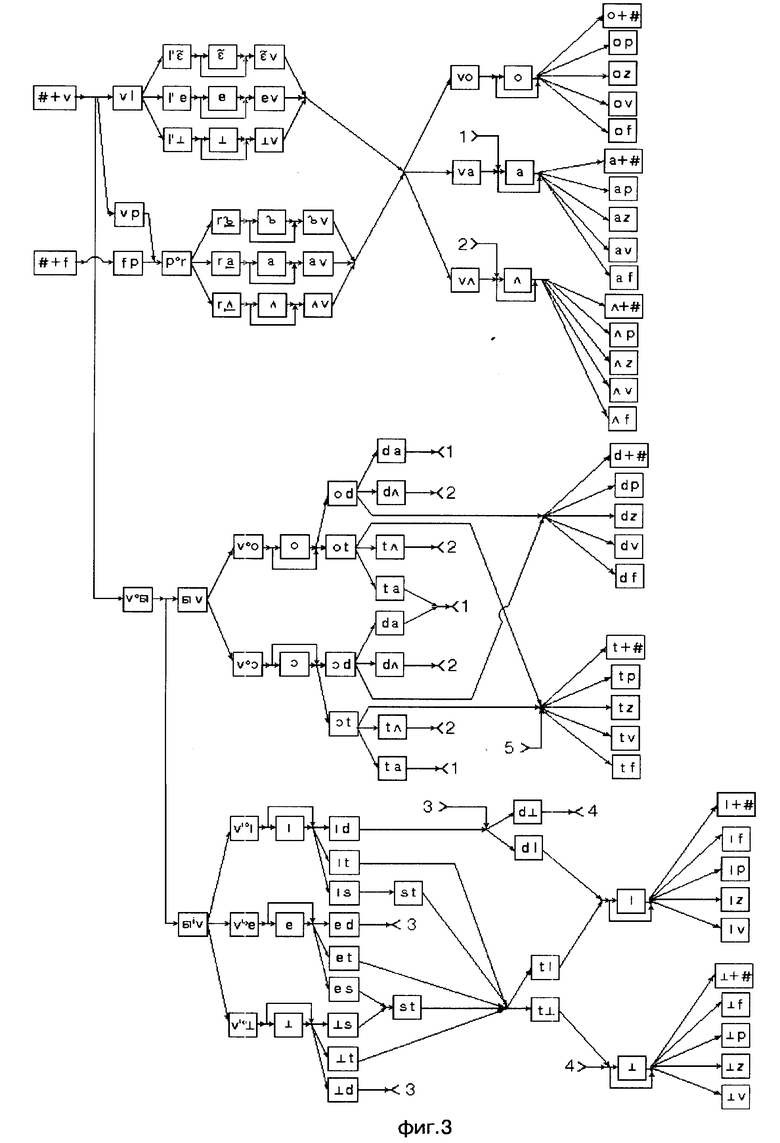
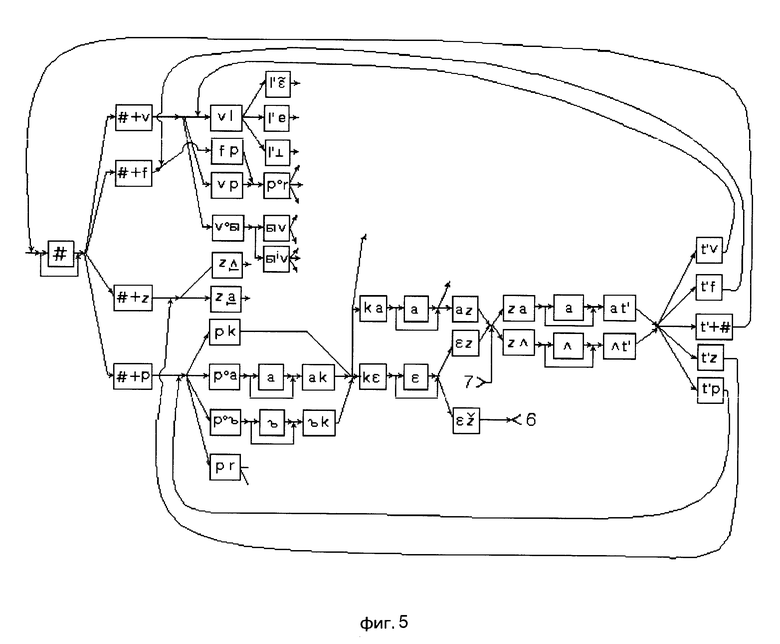
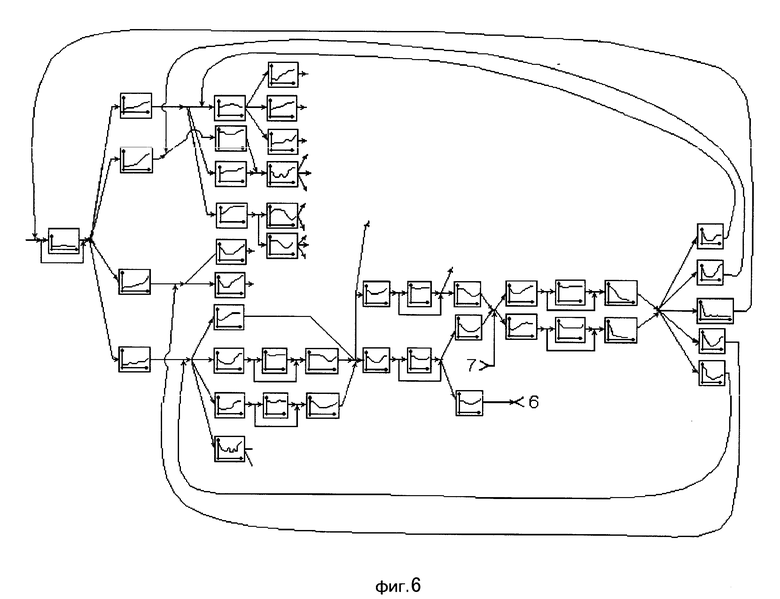
Этапы построения сети лексического декодирования представлены именно фигурами: на фиг. 1 изображены орфографическое и фонемическое представление лексем; на фиг. 2 моделирующий граф, вершинами которого являются фоны, а дугами указатели на следующие возможные фоны; на фиг. 3 и 4 граф альтернативных представлений, вершинами которого являются дифоны и аллофоны, а дугами указатели на следующие возможные дифоны и аллофоны; на фиг. 5 сеть альтернативных представлений, вершинами которой являются дифоны и аллофоны, а дугами указатели на следующие возможные дифоны и аллофоны; на фиг. 6 сеть лексического декодирования, вершинами которой являются акустические состояния, а дугами указатели на последующие возможные акустические состояния.
Этапы построения сети лексического декодирования представлены на примере выражений, применимых для управления движением захвата манипулятора влево и вправо, а также указаний вывода программы захвата. Например, "Выведи захват влево", "Вывод захвата вправо", "Показать программу захвата", "Покажи программу вывода захвата" и т.д.
На первом этапе (фиг. 1) определяют необходимый словарь для речевого общения. Определяют орфографическое и фонемическое представление каждой лексемы. На втором этапе (фиг. 2) для каждой лексемы с возможными окончаниями строят моделирующий граф всех ожидаемых фонетических представлений, вершинами которого являются фоны, а дугами указатели на следующие возможные фоны. На фиг. 2 прямоугольниками обозначены вершины, а цифрами номера лексем, соответствующие номерам лексем на фиг. 1. Далее последовательность фон замещают последовательностью дифонов и аллофонов (фиг. 3 и 4) для всех лексических единиц применяемого словаря и строят их в виде дерева решений. При этом слова, имеющие одинаковые первые звуки, помещают в одной и той же начальной вершине дерева. Например, слова "покажи" и "программа" имеют первый общий звук "п". После этого (фиг. 5) все возможные окончания каждого слова соединяются с корнем дерева и с помощью фонологических правил строится сеть альтернативных фонетических представлений для всех возможных (грамматически правильных и неправильных) последовательностей слов из словаря. На завершающем этапе последовательность дифонов и аллофонов замещается последовательностью акустических состояний (фиг. 6). На фиг. 3 и 6, фиг. 3-6 и фиг. 5 прямоугольниками обозначены вершины, а цифрами разрывы дуговых соединений. Таким образом получают СЛД, которая представляет собой словарь со встроенным фонетическим транскриптором, правилами фонологии и лексикой для заданного набора слов.
В соответствии с фиг. 5 начальная вершина (корень СЛД) представляет собой паузу. Каждая вершина в столбце СЛД представляет собой объект, связанный с одним участком квантованной фразы. Каждая вершина во втором столбце содержит АС, связанное со следующими возможными состояниями и т.д. Каждая вершина допускает переход в самого себя (на фиг. 5 это не показано, чтобы не загромождать схему). Это приводит к тому, что две и более вершины могут быть связаны с одним и тем же АС. Таким образом, в процессе выделения Vk могут возникнуть дополнительные АС, в то время как отсутствие АС приводит к существенным проблемам. Поэтому потенциально отсутствующие АС должны рассматриваться как дополнительные АС в процессе создания СЛД.
Для определения исходного выражения необходимо отыскать оптимальную последовательность (путь) Vk в СЛД. Путь в СЛД продолжается до новой вершины, если акустическое состояние этой вершины соответствует любому АС следующей.
Такая сеть явным образом учитывает коартикуляционные эффекты, возникающие как внутри слов так и на их границах, и позволяет минуя фонетический уровень декодирования строить гипотезы о словах. В СЛД используется такое представление словаря, при котором объединены общие части различных слов. Поэтому процедура просмотра всего словаря легко реализуема с вычислительной точки зрения и не требует отдельного рассмотрения каждого слова. При этом акустико-фонетические знания проявляются в удобной и доступной форме, в результате чего упрощается процесс оптимизации выбора наилучшего пути.
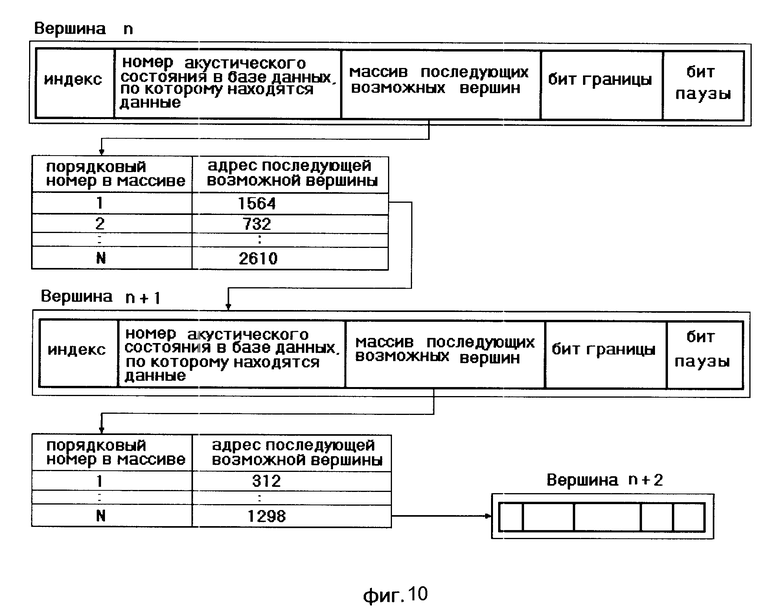
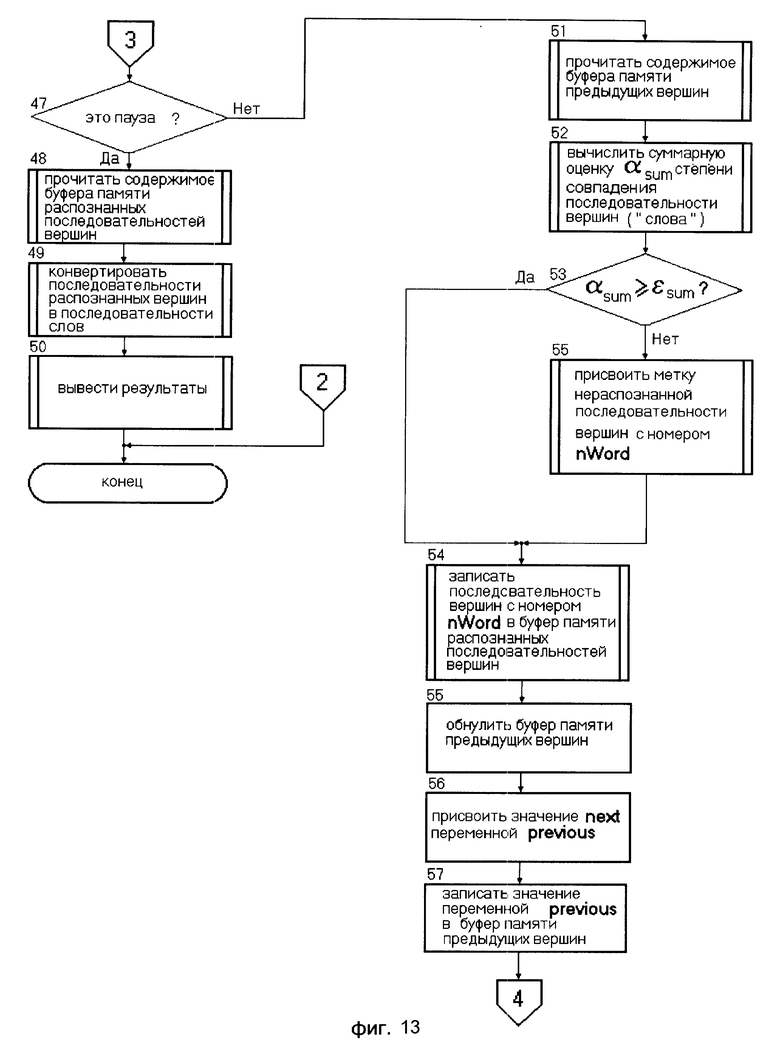
Описание системы распознавания слов в слитной речи русского языка, реализующей предлагаемый способ включает семь фигур: на фиг. 7 изображена структурная схема системы; на фиг. 8 структурная схема блока акустического анализатора; на фиг. 9 структурная схема блока лексического анализатора; на фиг. 10 формат данных системы; на фиг. 11-13 блок-схема алгоритма распознавания.
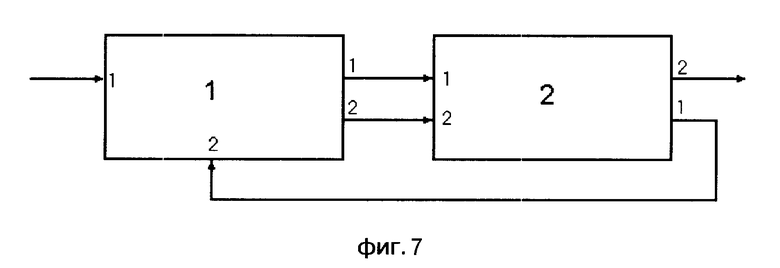
Система распознавания слов в слитной речи, использующая СЛД представлена на фиг. 7. Она состоит из акустического анализатор, представленного блоком 1 и лексического анализатора, представленного блоком 2. Система позволяет формировать транскрипцию входного высказывания на основе информации о последовательности распознанных акустических состояний, по которой определяется последовательность слов входного высказывания.
Блок 1 предназначен для определения акустических состояний в звуковых сигналах и содержит два входа и два выхода.
Блок 2 предназначен для определения слов из лексического словаря акустически схожих с произнесенными и содержит два входа и два выхода. Вход 1 блока 1 соединен с микрофоном, а вход 2 соединен с выходом 1 блока 2. Выходы 1 и 2 блока 1 соединены со входами 1 и 2 блока 2 соответственно. С выхода 2 блока 2 получают искомый результат.
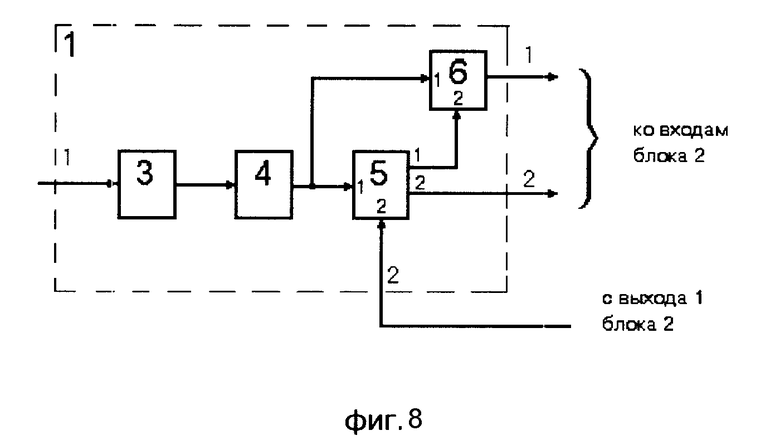
Блок 1, структурная схема которого представлена на фиг. 7 содержит: блок 3 частотный анализатор спектра, блок 4 буфер хранения значений спектра, блок 5 вычислитель весового коэффициента h блок 6 вычислитель текущего акустического состояния Vk.
Блок 2, структурная схема которого представлена на фиг. 8 содержит: блок 7 определитель вершин СЛД, блок 8 хранения базы данных эталонных акустических состояний, блок 9 сравнения текущего значения функционала (акустического состояния) с эталоном, блок 10 буфер памяти оценок сравнения, блок 11 блок управления, блок 12 селектор оптимальной (наилучшей) оценки, блок 13 проверка граничной вершины, блок 14 буфер памяти предыдущих вершин, блок 15 проверки паузы, блок 16 проверки последовательности вершин, блок 17 буфер памяти распознанных последовательностей вершин, блок 18 (устройство) вывода.
Блок 7 представляет собой устройство, в котором хранится информация о сети лексического декодирования.
Блок 9 предназначен для вычисления оценки степени совпадения между акустическими характеристиками ожидаемых эталонов акустических состояний и текущего участка речевого сигнала.
Блок 10 предназначен для запоминания оценок степени совпадения между акустическими характеристиками ожидаемых эталонов акустических состояний и текущего участка речевого сигнала, а также вершин, к которым они принадлежат.
Блок 11 предназначен для обнаружения существования возможных следующих вершин в СЛД, а также управления блоками 7, 10, 14.
Блок 7, блок 8 и блок 11 осуществляют совместный поиск ожидаемых акустических состояний.
Блок 12 предназначен для выбора оптимальной (наилучшей) оценки степени совпадения, имеющейся в блоке 10.
Блок 13 предназначен для обнаружения априорно известных граничных вершин СЛД во входном высказывании.
Блок 14 предназначен для запоминания последовательности распознанных вершин, то есть траектории движения по СЛД, которая представляет собой частичную транскрипцию входного высказывания по сигналам.
Блок 15 предназначен для обнаружения акустических состояний типа "пауза" во входном высказывании и управления блоком 16.
Блок 16 предназначен для проверки последовательности распознанных вершин.
Блок 17 предназначен для запоминания последовательностей распознанных вершин (транскрибированных слов).
Блок 18 предназначен для вывода результатов распознавания.
Работа системы распознавания слов в слитной речи осуществляется следующим образом (см. фиг. 8, 9). Входное высказывание с микрофона поступает на вход блока 3 акустического анализатора 1. Блок 3 с помощью полосовых фильтров выделяет частотный спектр и преобразует его в цифровую форму. Эти оцифрованные сигналы подаются на вход блока 4. Сигналы с выхода блока 4 подаются на вход 1 блока 5 и вход 1 блока 6.
Блок 5 вычисляет весовой коэффициент h по которому определяется индекс вершины, применяемый для поиска входной вершины первого столбца СЛД (см. фиг. 10, фиг. 6). Вычисленное значение весового коэффициента с выхода 2 блока 5 поступает на вход 1 блока 7. Блок 7 по весовому коэффициенту h определяет номер ближайшей возможной вершины. Затем он определяет номера вершин nmin и nmax, обозначающие соответственно верхнюю и нижнюю границы области, в которой необходимо проводить поиск начального акустического состояния. С выхода 1 блока 7 значение nmin поступает на вход 1 блока 8. На выходе 2 блока 7 формируется сигнал разрешения, поступающий на вход 2 блока 5. В свою очередь блок 5 на выходе 1 формирует сигнал разрешения, поступающий на вход 2 блока 6.
Одновременно блок 6 вычисляет текущее значение акустического состояния Vkт, а блок 8 определяет значение эталонного акустического состояния Vkэ, по номеру вершины, поступившему с выхода 1 блока 7. Значение Vkэ, вместе с соответствующим номером вершины, с выхода блока 8 поступает на вход 2 блока 9, а значение Vkт с выхода блока 6 поступает на вход 1 блока 9.
Блок 9 вычисляет оценку a степени совпадения текущего Vkт и эталонного Vkэ акустического состояния. Значение этой оценки, вместе с соответствующим номером вершины, с выхода блока 9 поступает на вход 1 блока 10.
Блок 11 проверяет содержание блока 10 на достижение nmax в блоке 7. Если nmax не достигнута, то происходит дальнейшее сравнение ожидаемых вершин с текущей. Если nmax достигнута, то с выхода 2 блока 11 передаются данные, содержащиеся в блоке 10, которые поступают на вход блока 12.
Блок 12 проверяет данные, поступающие с блока 10 через блок 11 на наличие оценки a превышающей пороговое значение e Если таковой оценки не найдено, то блок 12 анализирует возрастание (убывание) a с возрастанием nmin. После этого на выходе 3 блока 12 формируются сигналы, изменяющие границы области поиска, которые поступают на вход 2 блока 11. Блок 11, изменив границы области поиска, на своем выходе 4 формирует сигнал управления, который поступает на вход 2 блока 10 и производит обнуление содержимого блока 10. Одновременно на выходе 1 блока 11 формируется сигнал управления, поступающий на вход 2 блока 7, который разрешает определение следующей возможной вершины. В случае, когда оценка a превышающая пороговое значение e не найдена и превышены ограничения на допустимую область поиска, то на выходе 5 блока 11 формируется сигнал, поступающий на вход 3 блока 18. На выходе блока 18 формируется сигнал, информирующий оператора о том, что необходимо повторить высказывание.
Если блок 12, проверив содержание блока 10, обнаружил оценку a превышающую пороговое значение e то блок 12 принимает значение a в качестве оптимальной aopt В этом случае блок 12 переопределяет номер вершины, соответствующий αopt как оптимальный nopt и передает его с выхода 2 на вход 2 блока 14.
Блок 14 переопределяет вершину, поступившую с выхода 2 блок 12 как предыдущую previous. Затем блок 14 на выходе 2 формирует сигнал запроса на чтение нового Vkт, который поступает на вход 3 блока 11 вместе со значением вершины previous.
Блок 11 с выхода 1, подготовив сигнал на определение нового Vkт, подает его на вход 2 блока 7 вместе со значением вершины previous. На выходе 2 блока 7 формируется сигнал разрешения, поступающий на вход 2 блока 5. В свою очередь блок 5 на выходе 1 формирует сигнал разрешения, поступающий на входе 2 блока 6.
Одновременно блок 6 вычисляет текущее значение акустического состояния Vkт, а блок 8 определяет значение Vkэ следующее за вершиной previous. Значение Vkэ, вместе с соответствующим номером вершины, с выхода блока 8 поступает на вход 2 блока 9, а значение Vkт с выхода блока 6 поступает на вход 1 блока 9.
Блок 12 с выхода 1, по указанию блока 11 определяет оценку αopt а также nopt, значение которой передает на вход 1 блока 13. Блок 13 проверяет бит границы этой вершины. Если вершина не граничная, то с выхода 2 блока 13 значение nopt передается на вход 1 блока 14. Если вершина граничная, то с выхода 1 блока 13 значение nopt передается на вход 1 блока 15.
Блок 15 проверяет бит паузы у поступившей вершины. Если граничная вершина не пауза, то на выходе 2 блока 15 формируется сигнал, поступающий на вход 2 блока 16, разрешающий блоку 16 проверку содержимого блока 14. Блок 14 с выхода 1 передает на вход 1 блока 16 последовательность распознанных вершин. Проверив содержимое блока 14, блок 16 со своего выхода передает эту последовательность с соответствующими метками на вход блока 17. На выходе 2 блока 17 формируется сигнал запроса на чтение нового Vkт, который поступает на вход 4 блока 11 вместе со значением вершины previous. Если граничная вершина пауза, то на выходе 1 блок 15 формируется сигнал, поступающий на вход 2 блока 18, по которому блок 18 начинает чтение данных, содержащихся в блоке 17. Блок 17 с выхода 1 передает на вход 1 блока 18 последовательности распознанных вершин. Блок 18 преобразует эти последовательности распознанных вершин в последовательности возможных слов и выводит результаты.
Более подробный алгоритм работы системы распознавания слов в слитной речи представлен блок-схемой на фиг. 11-13. Условные обозначения в представленном алгоритме приведены на страницах 15, 16.
Предлагаемая система распознавания слов в слитной речи, использующая СЛД, по своей сути позволяет отслеживать несколько траекторий, из которых можно выбирать наиболее оптимальную. Для этого необходимо модернизировать лексический анализатор путем введения в него блока выбора траектории.
Система ведет поиск, перебирая все допустимые вершины (либо только в выделенной области) содержащие АС, которые могут следовать за начальной. Поиск оптимальной последовательности АС осуществляется в пределах некоторой части СЛД. В связи с тем, что на каждом шаге распознавания перебирается несколько возможных вариантов АС, отпадает необходимость возврата назад.
Преимущества предлагаемой системы состоят в том, что она позволяет с более высоким быстродействием и более высокой вероятностью распознавать слова в слитной речи.
Блока 3 представляет собой стандартный аналого-цифровой преобразователь для ввода акустических сигналов в ЭВМ и набор полосовых, программно реализованных фильтров. Блоки 4-17 могут быть реализованы как аппаратно, так и программно. Программная реализация этих блоков представлена в виде блок-схемы алгоритма работы на фиг. 11-13. Блок 18 представляет собой дисплей.
Условные обозначения следующие:
previous предыдущая вершина;
next следующая вершина;
nPtr индикатор текущей вершины массива следующих возможных вершин, исходящих из предыдущей вершины "previous";
nWord счетчик слов;
n номер ближайшей вершины;
λ коэффициент, определяющий смещение границ области поиска;
nmin номер вершины, обозначающий нижнюю границу области поиска;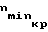 номер вершины, обозначающий критическое значение нижней границы области поиска;
номер вершины, обозначающий критическое значение нижней границы области поиска;
n max номер вершины, обозначающий верхнюю границу области поиска; номер вершины, обозначающий критическое значение верхней границы области поиска;
номер вершины, обозначающий критическое значение верхней границы области поиска;
α оценка степени совпадения текущего и эталонного акустического состояния;
e пороговое значение оценки степени совпадения текущего и эталонного акустического состояния;
aopt оптимальное значение оценки степени совпадения текущего и эталонного акустического состояния;
nopt номер вершины, соответствующий αopt;
αmax максимальное значение оценки степени совпадения текущего и эталонного акустического состояния;
αsum оценка степени совпадения последовательности акустических состояний;
εsum пороговое значение оценки степени совпадения последовательности акустических состояний.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2297676C2 |
| СИСТЕМА И СПОСОБ ПЕРЕВОДА РЕЧЕВОГО СИГНАЛА В ТРАНСКРИПЦИОННОЕ ПРЕДСТАВЛЕНИЕ С МЕТАДАННЫМИ | 2014 |
|
RU2589851C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СПОСОБ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ ЧЕЛОВЕКА С ИСПОЛЬЗОВАНИЕМ АКУСТИЧЕСКИХ СИГНАЛОВ, СНИМАЕМЫХ С ТЕЛА ЧЕЛОВЕКА | 2003 |
|
RU2263358C2 |
| Способ и устройство высокоэффективного сжатия мультимедийной информации большого объема по критериям ее ценности для запоминания в системах хранения данных | 2016 |
|
RU2654126C2 |
| Способ распознавания слитно произнесенных слов и устройство для его осуществления | 1983 |
|
SU1159059A1 |



Изобретение относится к автоматике и вычислительной технике и может быть использовано в системах понимания речи, системах управления технологическим оборудованием, работами, средствами вычислительной техники, автоматического речевого перевода, в справочных системах и др. Суть способа состоит в том, что минуя уровень фонетического декодирования гипотезы о возможных словах в высказывании строят непосредственно из акустического сигнала, при помощи сети лексического декодирования, представляющей собой интегрированную базу знаний, содержащую все ожидаемые акустические представления заданного набора слов, объединяющей фонетическую транскрипцию, фонологические правила и лексику. Техническим результатом изобретения является повышение точности и быстродействия распознавания слов в сметной речи русского языка. Система распознавания слов в слитной речи содержит акустический анализатор 1, лексический анализатор 2, частотный анализатор 3 спектра, буфер 4 хранения значений спектра, вычислитель 5 весового коэффициента η , вычислитель 6 текущего акустического состояния, определитель 7 вершин сети лексического декодирования (СЛД), блок 8 хранения базы данных эталонных акустических состояний, блок 9 сравнения текущего значения функционала с эталоном, буфер 10 памяти оценок сравнения, блок 11 управления, селектор 12 оптимальной оценки, блок 13 проверки граничной вершины, буфер 14 памяти предыдущих вершин, блок 15 проверки паузы, блок 16 проверки последовательности вершин, буфер 17 памяти распознанных последовательностей вершин, блок 18 вывода. 1 з.п. ф-лы, 13 ил.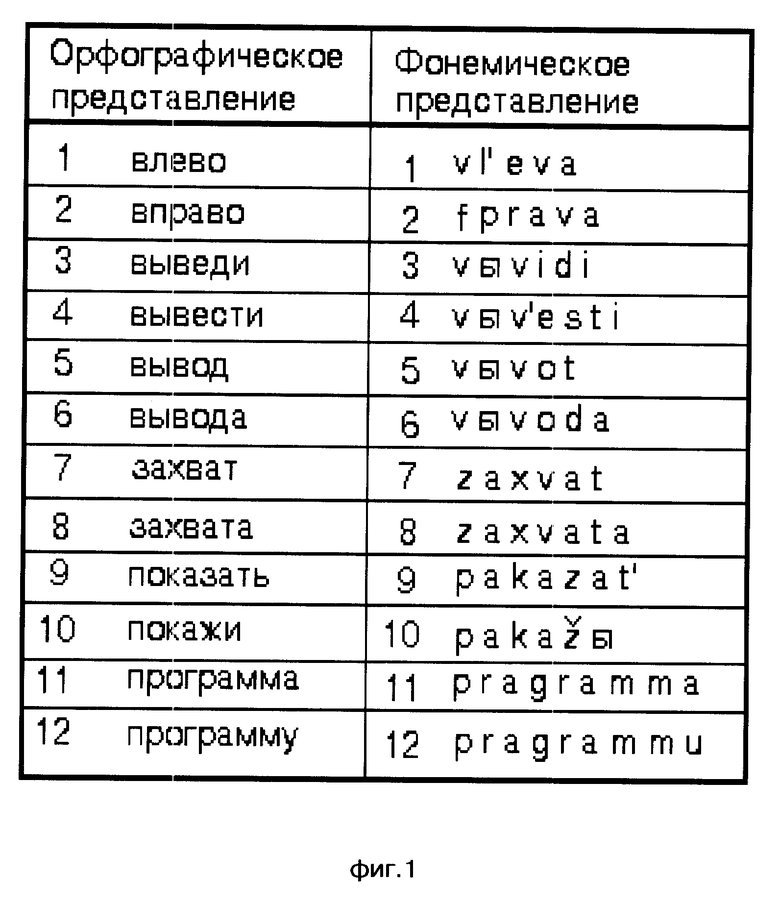
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Lesser V.R., Fennel R.D., Erman L.D., Reddy D.R | |||
| Organization of the HEARSAY II Speech Understanding System | |||
| IEEE Trans | |||
| ASSP, 23, N 1, p.11 - 24, 1975 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Baker J.K | |||
| The DRAGON System | |||
| An obervien | |||
| IEEE Trans | |||
| ASSP, 23, N 1, February, 1975, p.24 - 29 | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Klowstad J.W., Mondshein L.F | |||
| The CASPERS Linguistic Analysus System | |||
| IEEE Trans ASSP, 23, N 1, Februaru, 1975, p.118 - 123. | |||
