Изобретение относится к информационным технологиям, в частности к предварительной обработке текстовой информации, и может быть использовано при распознавании и синтезе речи, аннотировании баз данных, автоматическом синхронном переводе с одного языка на другой, коррекции фонограмм по их тексту, конверсии голоса по исходному тексту и других технических областях, в которых требуется обработка текстовой информации средствами вычислительной техники.
Как известно, эффективность современных систем распознавания речи во многом зависит от степени точности представления фонетических явлений в языке с помощью математических структур. Для этой цели применяются большие звуковые базы данных, содержащие сотни часов записей речи множества дикторов и фонетическую транскрипцию этих записей, которая выполняется автоматически по каноническим правилам. Однако в реальной речи правила могут нарушаться, а значит, математические структуры, полученные в результате обработки таких баз, не будут описывать речевой сигнал с высокой точностью.
Современные аллофонные базы, используемые в синтезе речи по тексту, требуют больших объемов памяти и высокой производительности и скорости обработки информации. Такие базы могут содержать мини-набор аллофонов и макси-набор аллофонов (Национальная Академия Наук Белоруссии, Объединенный институт проблем информатики. Б.М. Лобанов, Л.И.Цирульник. «Компьютерный синтез и клонирование речи», Минск, Белорусская наука, 2008, стр.198-243). Макси-набор аллофонов более подробный, и при обучении систем синтеза требует большого объема текста. Мини-набор аллофонов менее подробный, но при определенных методиках с большой долей вероятности он позволяет получить всю совокупность аллофонов при чтении диктором меньшего количества фраз из текста.
Известен способ компиляционного фонемного синтеза русской речи и устройство для его реализации (RU 2298234). Устройство содержит текстовый процессор, который выполняет следующие функции: нормализация текста; фонетическая транскрипция по разбивке слова на фонетические единицы по принципу приоритетов; идентификация звуковых единиц; селекция фонемосочетаний вида согласная-гласная-согласная-согласная (СГСС) и согласная-гласная-согласная (СГСконечная); организация управления параметрами элементов компиляции и слоговым ударением.
Известный способ реализуется следующим образом. Информация после текстового процессора, освобожденная от цифр и знаков пунктуации, представляет последовательность идентификаторов звуковых единиц, поступающую вместе с признаком ударения на вход акустической базы данных. Одновременно с этим текстовый процессор в результате селекции последовательности типов фонем вида СГСС и СГСконечная вырабатывает признак на формирование фрагмента компиляции СГС, который поступает на блок формирования СГС.
К недостаткам обработки текста по известному способу следует отнести плохое транскрибирование частей слов, т.к. не учитываются соотношения более высокого уровня, следовательно, могут некорректно проставляться словесные ударения, а фразовые просто не проставляются. Отсутствует информация о паузах, без обработки которых точность обработки текстов снижается. Применение изобретения ограничено, т.к. оно направлено лишь на синтез с использованием заданной базы фонемных единиц.
Наиболее близким является способ предварительной обработки текста посредством текстового процессора, включающий приведение исходного текста в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст, членение текста на предложения и слова, маркировку фразовых и словесных ударений, объединение слов в синтагмы с простановкой символов пауз в конце синтагм с последующим транскрибированием синтагм для получения идеальных транскрипций синтагм в терминах фонем и аллофонов (RU, 2386178).
В этом способе к идеальным транскрипциям синтагм применяют правила транскрипционного моделирования, после применения правил транскрипционного моделирования получают дополнительные варианты транскрипций, к которым также применяют правила транскрипционного моделирования, из общего списка исходных и полученных дополнительных вариантов транскрипций исключают одинаковые транскрипции и сохраняют оставшиеся в списке транскрипции для дальнейшего использования.
Изобретение позволяет сформировать максимально возможное количество вариантов произношения для последующего выбора наиболее близкого к реально произнесенному диктором. Транскрипционное моделирование основано на применении правил моделирования, список которых формируется как на основании знаний о допустимых отклонениях реального произношения от произносительной нормы, так и в результате сбора и обработки статистической информации. Такой двойной подход к формулированию правил позволяет строить транскрипции, наиболее близкие к произношениям, встречающимся в реальной жизни.
Ограничение данного способа для использования при распознавании и синтезе речи заключается в том, что в режиме обучения таких систем подбор фраз производится непосредственно диктором, а он не имеет возможности использовать наиболее фонетически соответствующий текст и фразы для представления их своим голосом. Это снижает качество воспроизведения. Кроме того, способ требует для его осуществления высокой производительности оборудования (скорости обработки информации), поскольку в нем требуется неоднократное применение достаточно сложных правил транскрипционного моделирования, и в результате получается множество дополнительных вариантов транскрипций, из которых трудно выбрать нужные, и которые необязательно являются фонетически наиболее характерными (сбалансированными) для произносимого текста.
Известно компьютерное устройство для обработки текста, содержащее блок ввода текста, блок анализа, блок базы данных, блок представления результатов, первый выход блока ввода текста подсоединен к первому входу блока анализа, а выход блока базы данных - к второму входу блока анализа (RU, 2113726).
Это устройство предназначено для использования слепыми и как средство обучения русскому языку. Оно позволяет обеспечить высокое качество синтеза русской речи при воспроизведении плоскопечатных текстов.
Устройство имеет блок ввода текста, который выполнен оптическим, для распознавания плоскопечатного текста, блок анализа, входящий в состав блока синтеза русской речи по орфографическому тексту, блок базы данных и блок представления результатов, выполненный в виде тактильного дисплея. Кроме того, устройство содержит блок формирования аудиосигнала, блок унификации текстового файла, блок сопряжения тактильного дисплея с персональным компьютером и блок интерфейса.
В этом устройстве, также как и в известном способе в процессе обучения должен использоваться голос диктора, и устройству присущи все недостатки, которые были ранее описаны для способа.
Решаемая изобретением задача - улучшение технико-эксплуатационных характеристик.
Технический результат, который может быть получен при осуществлении способа и выполнении заявленного устройства, - повышение качества, увеличение скорости обрабатываемых данных, уменьшение количества информационных ресурсов, упрощение выполнения.
Для решения поставленной задачи с достижением указанного технического результата в известном способе предварительной обработки текста посредством текстового процессора, включающем приведение исходного текста в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст, членение текста на предложения и слова, маркировку фразовых и словесных ударений, объединение слов в синтагмы с простановкой символов пауз в конце синтагм с последующим транскрибированием синтагм и с получением идеальных транскрипций синтагм в терминах фонем и аллофонов, согласно изобретению при получении идеальных транскрипций синтагм в терминах фонем и аллофонов в текстовом процессоре дополнительно формируют базу данных эталонных аллофонов, сравнивают совпадение аллофонов идеальных транскрипций синтагм с эталонными аллофонами и исключают аллофоны идеальных транскрипций синтагм, не совпадающие с эталонными аллофонами, по аллофонам идеальных транскрипций синтагм, совпадающим с эталонными аллофонами, формируют сбалансированные синтагмы текста - имеющие наибольшее число совпадений аллофонов идеальных транскрипций синтагм с эталонными аллофонами.
Возможны дополнительные варианты осуществления способа, в которых целесообразно, чтобы:
- сбалансированные синтагмы формировали в виде таблицы в порядке их сбалансированности;
- ограничивали количество сбалансированных синтагм;
- задавали минимальный процент количества сбалансированных синтагм к общему количеству синтагм;
- производили бы процесс уменьшения базы данных эталонных аллофонов, в котором для наиболее сбалансированной синтагмы текста из базы данных эталонных аллофонов исключают эталонные аллофоны, содержащиеся в наиболее сбалансированной синтагме текста, затем для формируемой следующей по сбалансированности синтагмы текста из базы данных эталонных аллофонов исключают эталонные аллофоны, содержащиеся в ней, процесс уменьшения базы данных эталонных аллофонов повторяют для последующих по сбалансированности синтагм, достигая заданного количества сбалансированных синтагм или заданного процента количества сбалансированных синтагм к общему количеству синтагм.
Для решения поставленной задачи с достижением указанного технического результата в известном компьютерном устройстве для обработки текста, содержащем блок ввода текста, блок анализа, блок базы данных, блок представления результатов, выход блока ввода текста подсоединен к первому входу блока анализа, а выход блока базы данных - к второму входу блока анализа, согласно изобретению введены блок ввода параметров, блок формирования сбалансированных синтагм, выход блока ввода параметров соединен с входом блока базы данных, предназначенным для формирования базы данных эталонных аллофонов, выход блока анализа соединен с вторым входом блока базы данных, выход блока базы данных соединен с входом блока формирования сбалансированных синтагм, - такими, которые имеют наибольшее число совпадений аллофонов текста с эталонными аллофонами, выход которого соединен с входом блока представления результатов.
Указанные преимущества, а также особенности настоящего изобретения поясняются лучшим вариантом его выполнения со ссылками на прилагаемые фигуры.
Фиг.1 изображает функциональную схему устройства;
Фиг.2 - блок-схему алгоритма работы устройства;
Фиг.3 - блок-схему алгоритма блока формирования сбалансированных синтагм;
Фиг.4 - графический интерфейс для ввода текстового файла;
Фиг.5 - графический интерфейс для указания языка текста и пути к его файлу;
Фиг.6 - графический интерфейс для редактирования словаря ударений;
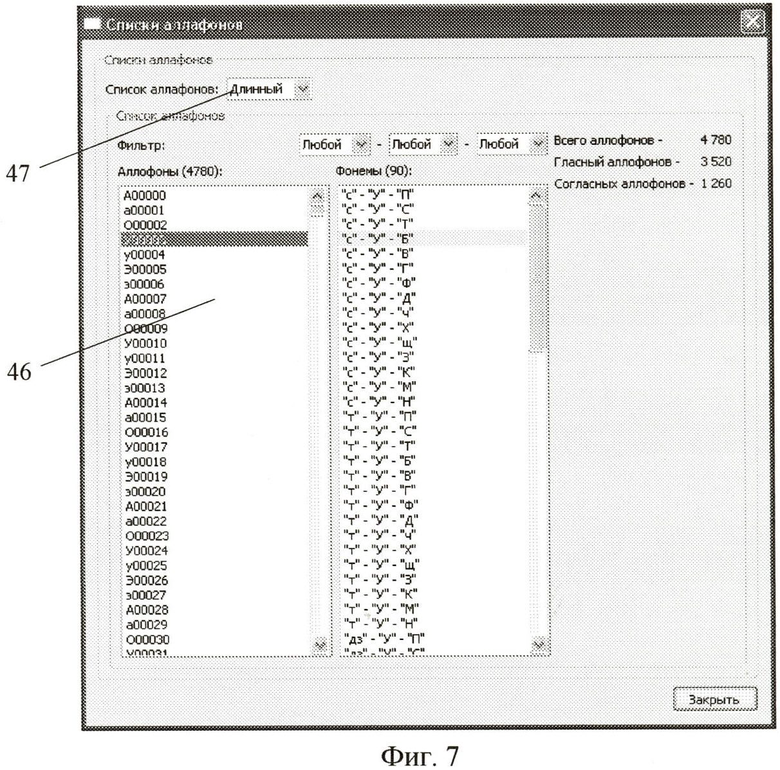
Фиг.7 - графический интерфейс для редактирования списка аллофонов;
Фиг.8 - графический интерфейс для поиска сбалансированных синтагм;
Фиг.9 - графический интерфейс для ввода параметров анализа текста;
Фиг.10 - графический интерфейс сформированных сбалансированных синтагм.
Поскольку заявленный способ реализуется непосредственно при работе компьютерного устройства, то сначала в данном описании оно характеризуется в статике.
Для лучшего понимания изобретения ниже приводится определение терминов, применяемых в описании изобретения.
Синтагма - (от греч. syntagma, буквально - «вместе построенное, соединенное») - фонетическое целое, выражающее единое смысловое целое в процессе речи-мысли. Минимальная единица при членении высказывания интонационными средствами. Может трактоваться как последовательность аллофонов от паузы до паузы. Границами синтагм являются знаки препинания.
Фонема - (от греч. phonema - звук) - это минимальная звуковая единица языка, линейно не членимая, служащая для образования звуковых оболочек значащих единиц и условно связанная со смыслом звукового строя языка, предельный элемент, выделяемый линейным членением речи. Замена символов фонемами осуществляется в соответствии со справочником фонем.
Аллофон - (от греч. allos - иной, другой и phone - звук) - вариант, разновидность фонемы, обусловленная данным фонетическим окружением. Замена фонем на аллофоны осуществляется согласно правил.
Транскрипция (слово «транскрипция» значит "переписывание", от лат.trans-"через, пере-" +scribo "черчу, пишу") - особый вид записи речи, который используется для фиксации на письме особенностей ее звучания. Транскрипция описывает реальную или потенциальную возможную звуковую реализацию текста в терминах фонем и аллофонов. Существуют два основных вида транскрипции - фонематическая и фонетическая; первая отражает фонемный состав слова или последовательности слов, вторая - особенности реализации фонем в разных условиях.
Транскрипционный символ - знак или последовательность знаков, обозначающих фонему, аллофон или паузу в транскрипции синтагм.
Транскрибирование - преобразование текстовой записи речи (например, последовательность слов, образующих синтагму) в последовательность транскрипционных символов (транскрипцию).
Идеальная транскрипция (каноническая) - фонетическая транскрипция, соответствующая произносительной норме языка.
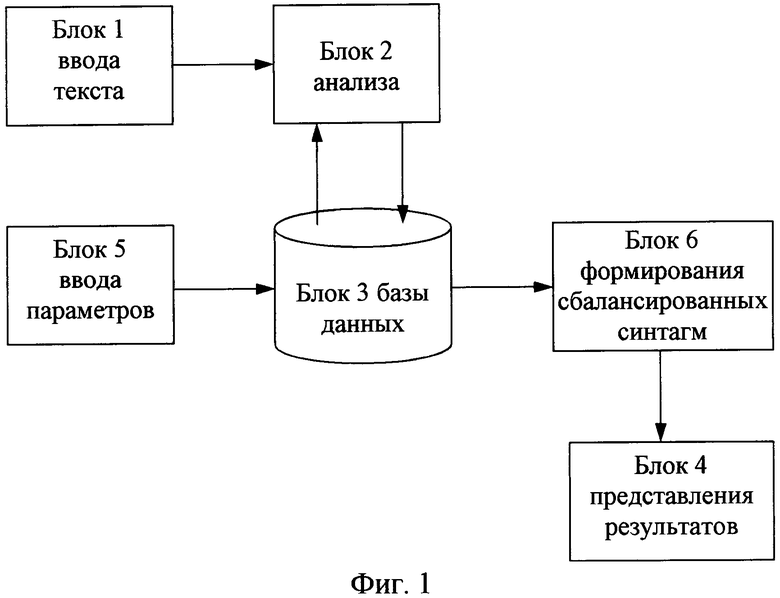
Компьютерное устройство для обработки текста (фиг.1) содержит блок 1 ввода текста, блок 2 анализа, блок 3 базы данных, блок 4 представления результатов. Выход блока 1 ввода текста подсоединен к первому входу блока 2 анализа. Выход блока 3 базы данных подсоединен к второму входу блока 3 анализа. В компьютерное устройство введены блок 5 ввода параметров, блок 6 формирования сбалансированных синтагм. Выход блока 5 ввода параметров соединен с входом блока 3 базы данных. Выход блока 2 анализа соединен с вторым входом блока 3 базы данных. Выход блока базы данных соединен с входом блока 6 формирования сбалансированных синтагм. Выход блока 6 формирования сбалансированных синтагм соединен с входом блока 4 представления результатов.
Блок 1 ввода текста служит для загрузки анализируемого текста из текстового файла или с помощью устройств его ввода (клавиатура, сканер и т.п.).
Блок 2 анализа предназначен для (а) формирования на основе анализируемого текста синтагм; (б) замены (отображения) символов (букв) синтагм на фонемы; (в) замены (отображения) фонем на аллофоны; (г) поиск в тексте аллофонов, совпадающих с эталонными аллофонами; (д) определения количества совпадающих аллофонов в анализируемом тексте (то есть определения набора записей вида: «совпадающий аллофон текста с эталонным» - «их количество в тексте»).
Блок 3 базы данных служит для хранения следующей информации: параметров анализа текста; словаря ударений; списка эталонных аллофонов; списка совпадающих аллофонов - их количество в тексте; результатов анализа текста по совпадающим аллофонам.
Блок 4 представления результатов предназначен для представления пользователю результатов автоматизированного фонетического анализа текста. Результатом анализа текста является выделенный из него набор наиболее фонетически сбалансированных синтагм. Отображение результатов анализа текста пользователю может осуществляться с помощью различных устройств вывода информации (монитор, принтер и т.п.).
Блок 5 ввода параметров служит для ввода пользователем параметров анализа текста с помощью устройства ввода (клавиатуры, «мыши» и т.п.). Параметрами анализа текста являются: количество выводимых в результатах поиска сбалансированных синтагм, минимальный суммарный процент сбалансированности синтагм, алгоритм анализа текста (соответствующее программное обеспечение).
Блок 6 формирования сбалансированных синтагм предназначен для создания по совпадающим аллофонам сбалансированных синтагм - [фраз (предложений)], имеющих наибольшее число совпадений аллофонов текста с эталонными аллофонами блока 3.
Устройство (фиг.1) работает следующим образом.
Анализируемый текст поступает с блока 1 на первый вход блока 2 анализа. С блока 5 ввода параметров в блок 3 базы данных поступают параметры анализа текста, список эталонных аллофонов, словарь ударений, которые сохраняются в блоке 3, и далее поступают на второй вход блока 2 анализа. Блок 2 осуществляет приведение исходного текста в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст. Затем блок 2 производит членение текста на предложения и слова, маркировку фразовых и словесных ударений, объединение слов в синтагмы с простановкой символов пауз в конце синтагм. После формирования синтагм блоком 2 производится их транскрибирование для получения идеальных транскрипций синтагм в терминах фонем и аллофонов. Блок 2 сравнивает совпадение аллофонов исходного текста с эталонными аллофонами, исключает аллофоны текста, не совпадающие с эталонными аллофонами. Затем блок 2 составляет список: совпадающие аллофоны - их количество, который поступает в блок 3. Из блока 3 этот список поступает в блок 6 формирования сбалансированных синтагм, который по существу производит обратное преобразование текста относительно операции транскибирования, осуществляемой блоком 3: из аллофонов формируются фонемы, затем определяются сбалансированные синтагмы - имеющие наибольшее число совпадений аллофонов исходного текста с эталонными аллофонами. На выходе блока 6 по совпадающим аллофонам формируют список фонетически сбалансированных синтагм в зависимости от количества совпадений аллофонов. Под эталонными аллофонами блока 3 в настоящем изобретении понимаются базы данных аллофонов, сформированные в соответствии с методом создания мини-набора аллофонов или макси-набора аллофонов, например, сообразно упомянутому источнику информации: Б.М.Лобанов, Л.И.Цирульник. «Компьютерный синтез и клонирование речи».
Компьютерное устройство (фиг.1) работает в соответствии с алгоритмом (фиг.2).
Блок 10 осуществляет загрузку исходного текста, приведение исходного текста в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст. Затем блок 10 производит членение текста на предложения и слова. Блок 11 производит анализ линейного теста и объединение слов в синтагмы. Синтагмы поступают в блок 12, который производит маркировку фразовых и словесных ударений. Расстановка ударений в символах синтагмы производится в соответствии со словарем ударений, поступающим из базы данных (БД) блока 3, куда он вводится с помощью блока 5 (фиг.1). Блок принятия решения «Расставлены ударения?» (фиг.2) осуществляет проверку выполнения ударений, и если это нужно, то с его выхода «нет» (ударения не расставлены) предложение о расстановке ударений поступает в блок 13, один из выходов которого служит для пропуска слов без ударений, связанным с входом блоком 14 замены символов синтагм на фонемы. Другой выход блока 13 подсоединен к второму входу блока 12, и ударения могут быть расставлены вручную. С выхода «Да» блока принятия решения «Расставлены ударения?» данные синтагм поступают на блок 14 замены символов (букв) синтагм на фонемы.
Далее фонемы в синтагмах поступают на блок 15 замены фонем на аллофоны в соответствии со списком эталонных аллофонов, поступающих из БД блока 3 (фиг.1), куда они вводятся с помощью блока 5. На выходе блока 15 (фиг.2) имеем идеальные транскрипции синтагм в терминах фонем и аллофонов. Блоком принятия решения «Все фонемы заменены аллофонами?» производится сортировка синтагм по совпадающим аллофонам. Если аллофоны синтагм исходного текста не имеют совпадений с эталонными аллофонами, то с выхода «Нет» этого блока принятия решения данные поступают в блок 16 исключения фонем с несовпадающими аллофонами. Если все аллофоны синтагм исходного текста имеют совпадения с эталонными аллофонами, то с выхода этого блока принятия решения данные о совпадающих аллофонах поступают на вход блока 17. Блок 17 формирует список «совпадающие аллофоны: их количество». Этот список поступает в блок 18 формирования сбалансированных синтагм, на который также поступают из БД параметры: исходный текст, минимальный % сбалансированности синтагм или их количество. Блок 18 осуществляет поиск синтагм с наибольшим количеством совпадающих аллофонов, которые соответственно поступают на блок 19 представления результатов и на выход (блок 4 на фиг.1). Для уменьшения («сужения») БД эталонных аллофонов с выхода блока 18 формирования сбалансированных синтагм (на фиг.2 показано пунктиром) список аллофонов может быть дополнительно подан в блок 20 исключения из БД эталонных аллофонов, совпадающих с аллофонами текста для уменьшения базы данных эталонных аллофонов. Этим достигается дополнительное уменьшение информационных ресурсов и ускорение процесса обработки информационных данных. Этот список соответственно передается в БД.
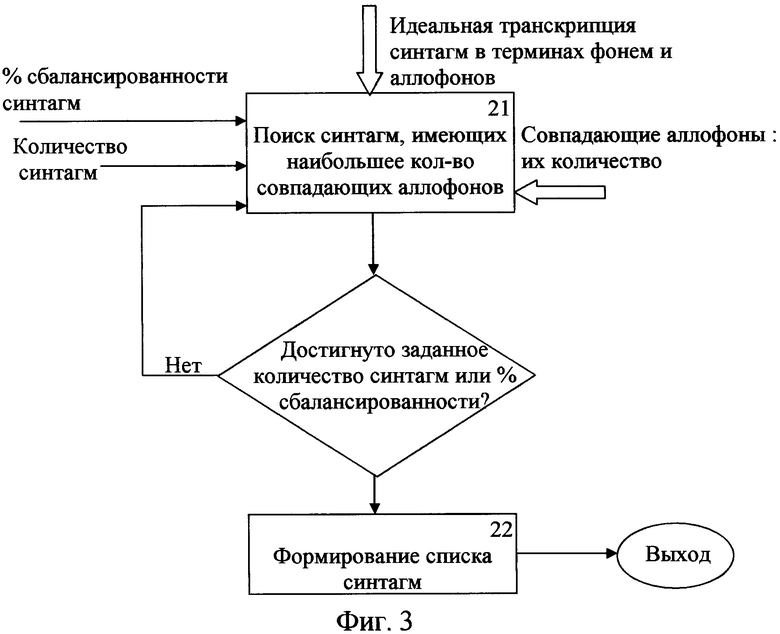
Блок формирования сбалансированных синтагм осуществляет работу в соответствии с алгоритмом (фиг.3).
С выхода блока принятия решения «Все фонемы заменены аллофонами» (фиг.2) через блок 17 поступают идеальные транскрипции синтагм в терминах фонем и аллофонов по совпадающим аллофонам, а также список «совпадающие аллофоны: их количество». Блок 21 (фиг.3) принимает эти данные, а также данные из БД о заданных параметрах минимального % сбалансированности синтагм или минимального количества сбалансированных синтагм на его управляющие входы. Блок 21 осуществляет поиск синтагм, имеющих наибольшее количество совпадающих аллофонов (исходного текста и эталонных). Если не достигнуто заданное количество синтагм или % сбалансированности, то с выхода «Нет» блока принятия решения данные об этом поступают на третий управляющий вход блока 21, а блок 21 осуществляет поиск следующей синтагмы по совпадающим аллофонам. Если достигнуто заданное количество синтагм или минимальный % сбалансированности, то с выхода «Да» блока принятия решения данные поступают в блок 22, который формирует список сбалансированных синтагм.
Таким образом, сбалансированные синтагмы можно формировать в виде таблицы в порядке их сбалансированности, и/или задавать общее количество сбалансированных синтагм, и/или задавать процент количества сбалансированных синтагм к общему количеству синтагм.
Кроме того, для уменьшения баз данных эталонных аллофонов и ускорения процесса формирования сбалансированных синтагм можно для наиболее сбалансированной синтагмы текста из базы данных эталонных аллофонов исключить эталонные аллофоны, содержащиеся в наиболее сбалансированной синтагме текста в блоке 20 (фиг.2). Для следующей по сбалансированности синтагмы текста из базы данных эталонных аллофонов исключают эталонные аллофоны, содержащиеся в ней. Процесс уменьшения базы данных эталонных аллофонов повторяют для последующих по сбалансированности синтагм, достигая заданного количества сбалансированных синтагм или заданного процента количества сбалансированных синтагм к общему количеству синтагм.
Далее, после уже после выявленных сбалансированных синтагм для другого фрагмента текста заявленный способ можно повторить. По сформированной в текстовом процессоре уменьшенной базе данных эталонных аллофонов сравнивают совпадение аллофонов идеальных транскрипций синтагм с эталонными аллофонами и исключают фонемы и аллофоны идеальных транскрипций синтагм, не совпадающие с эталонными аллофонами. По аллофонам идеальных транскрипций синтагм, совпадающим с эталонными аллофонами, формируют сбалансированные синтагмы текста - имеющие наибольшее число совпадений аллофонов идеальных транскрипций синтагм с эталонными аллофонами.
Заявленный способ позволяет наиболее эффективно производить обучение систем. В дальнейшем фразы, соответствующие сбалансированным синтагмам, будет произносить диктор, оставляя образец своего голоса в процессе обучения систем. Эффективным обучением является обучение системы с наилучшим качеством (отсутствие артефактов, естественность речи, хорошая разборчивость) при наименьшей длительности процесса обучения. Как показали испытания, например, для технического решения по патенту RU, №2393548 в режиме обучения этого устройства вместо зачитывания текста из 100 фраз диктору нужно прочесть всего 60÷75 фраз, соответствующих сбалансированным синтагмам, что с одинаковым высоким качеством воспроизведения сокращает произносимый текст обучения системы не менее чем на 25%.
Изобретение иллюстрируется возможными вариантами графических интерфейсов, выводимых на экран монитора компьютерного устройства.
Пользователь запускает специальное программное обеспечение на компьютерном устройстве для обработки текста (фиг.1). Отображается графический интерфейс (фиг.4) в виде диалогового окна, которое содержит инструменты (кнопки) 30, 31, 32, 33, 34. Инструмент 30 «Выделение аллофонов» служит для загрузки исходного текста из текстового файла на диске, инструмент 31 «Настройки» - для редактирования словаря ударений и списка эталонных аллофонов, инструмент 32 «Текст» - для отображения области представления результатов выделения из текста синтагм, фонем и аллофонов, инструмент 33 «Аллофоны» - для отображения области представления таблицы вида «Фонема - Аллофоны - Найденное количество в тексте», инструмент 34 «График» - для визуального графического анализа сбалансированности текста.
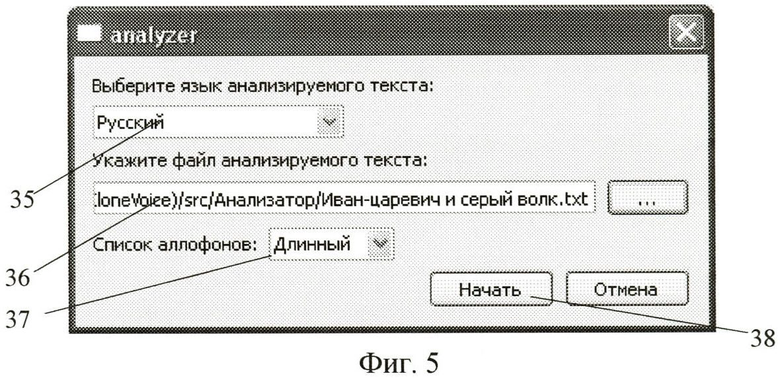
Для загрузки текста из файла пользователь нажимает кнопку «Выделение аллофонов». В отобразившемся окне (фиг.5) пользователь инструментом 35 указывает: язык анализируемого текста в выпадающем списке «Выберите язык», инструментом 36 полный путь к файлу исходного текста в поле данных «Укажите файл». Поле данных списка аллофонов инструмента 37 служит для выбора мини-набора эталонных аллофонов и макси-набора эталонных аллофонов. Инструмент 38 «Начать» служит для применения сделанных установок.
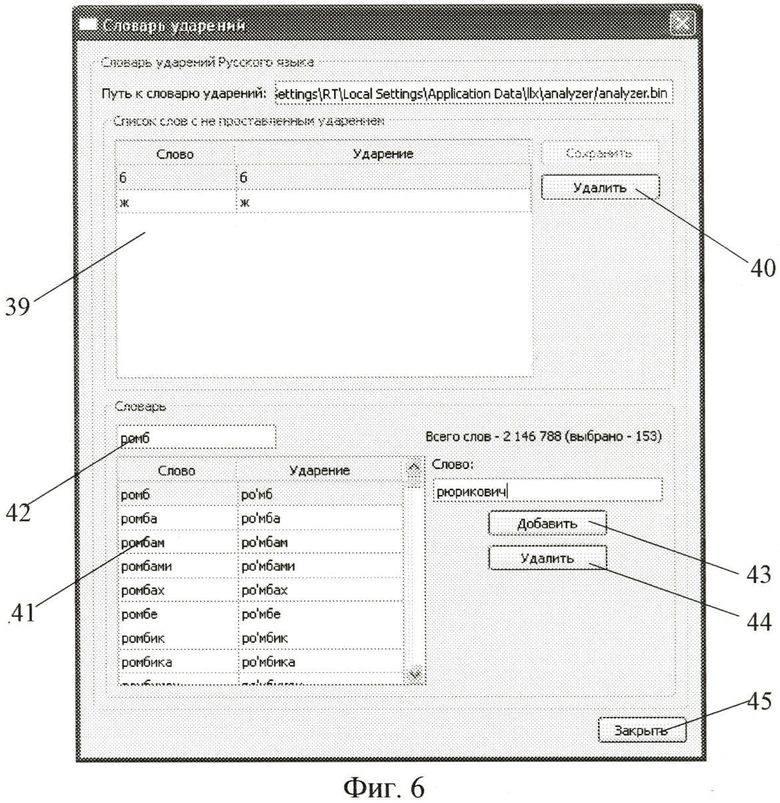
Блок 2 анализа (фиг.1) текста осуществляет разбор введенного пользователем на предыдущем шаге исходного текста на синтагмы. Расставляются ударения в словах, входящих в состав каждой выделенной синтагмы. Расстановка ударений осуществляется с помощью словаря ударений, содержащегося в блоке 3 базы данных. Также словарь ударений может быть отредактирован пользователем. Для редактирования словаря ударений пользователь в отображенном графическом интерфейсе (фиг.4) нажимает инструмент 31 «Настройки» (переход)→«Словарь ударений». В отобразившемся графическом интерфейсе (фиг.6) пользователь осуществляет редактирование словаря ударений. Поле данных 39 служит для составления списка слов с непроставленными ударениями. Инструмент 40 «Удалить» предназначен для удаления слова из поля данных 39 для дальнейшего проставления ударений вручную. Поле данных 41 служит для простановки ударений вручную и составления списка слов для слова введенного поле данных 42. Инструменты 43, 44 служат для добавления слова или его удаления соответственно. Инструмент 45 «Закрыть» предназначен для введения словаря расставленных вручную ударений, в блок 3 базы данных с помощью блока 5 (фиг.1).
Блок 2 анализа текста осуществляет замену символов (букв) синтагмы на фонемы, а фонем на аллофоны. Замена фонем исходного текста на аллофоны осуществляется согласно списку эталонных аллофонов, содержащемуся в блоке 2 базы данных. Список аллофонов может быть также отредактирован пользователем. Для редактирования списка эталонных аллофонов пользователь в графическом интерфейсе (фиг.4) нажимает инструмент 31 «Настройки» (переход)→«Списки аллофонов». В отобразившемся графическом интерфейсе (фиг.7) в поле данных 46 пользователь осуществляет редактирование списка аллофонов при выборе мини-набора эталонных аллофонов или макси-набора эталонных аллофонов в поле данных 47. Результат выделения аллофонов из анализируемого текста пользователь может просмотреть, нажав инструменты 32, 33 «Текст» и «Аллофоны» (фиг.4). Результат выделения синтагм, фонем, аллофонов отображается в графическом интерфейсе (фиг.8) в полях данных 48, 49, 50 соответственно. В поле данных 51 отображается исходный текст. Инструмент 52 «Настройки» служит для редактирования словаря ударений и списка эталонных аллофонов, инструмент 54 «Аллофоны» -для отображения области представления результатов выделения из текста синтагм, фонем и аллофонов, инструмент 55 «График» - для визуального графического анализа сбалансированности текста, инструмент 56 «Выделение аллофонов» - для загрузки исходного текста из текстового файла на диске.
Для поиска сбалансированных синтагм пользователь в отображенном графическом интерфейсе (фиг.8) нажимает инструмент 57 (кнопку) «Поиск сбалансированных синтагм». Отображается графический интерфейс, вид которого представлен на фиг.9.
В отображенном графическом интерфейсе (фиг.9) пользователь указывает следующие параметры анализа текста:
В поле данных 58 - Количество синтагм (с наилучшим фонетическим балансом).
В поле данных 59 - Минимальный суммарный процент сбалансированности синтагм.
В поле данных 60 - Алгоритм анализа текста, (первый или второй, подробнее об алгоритмх смотри ниже).
В поле данных 61 - Суммарное соотношение гласных и согласных аллофонов в найденных синтагмах.
В поле данных 62 - Поле ввода пути и имени файла с исходным текстом.
В поле данных 63 - Таблица вида "Синтагма" - "% согласованности (% гласных, % согласных)".
Инструмент 64 «Подробно» служит для отображения блока "Подробно о синтагме", содержащего: поле "Синтагма", поле "Синтагма с ударениями", поле "Фонемы в синтагме", поле "Аллофоны в синтагме", список "Совпавших аллофонов", список "Не совпавших аллофонов".
Инструмент 65 «График» предназначен для графического представления результатов анализа, инструмент 66 «Сохранить» - для сохранения результата анализа (таблицы сбалансированных синтагм вида "Синтагма" - "% согласованности (% гласных, % согласных)") в текстовом файле на диске, инструмент 67 «Закрыть» - для закрытия окна "Поиск сбалансированных синтагм".
В отображенном графическом интерфейсе (фиг.9) пользователь нажимает инструмент 68 «Запустить».
Данный набор сбалансированных синтагм отображается пользователю на экране монитора компьютерного устройства (фиг.10) в поле данных 69. Функции полей данных 70÷74 и инструментов 75÷78 соответствуют полям данных и инструментам, показанным на фиг.9.
Блок 2 анализа текста (фиг.1) осуществляет определение количества найденных в исходном аллофонов, совпадающих с эталонными аллофонами, их уникальность и частоту появления в тексте. Результатом данного анализа является составленный и сохраненный в базе данных блока 3 список вида: «совпадающие аллофоны» - «их количество в тексте». Блок 6 поиска сбалансированных синтагм осуществляет анализ и выборку из анализируемого текста синтагм, которые являются наиболее сбалансированными и наилучшим образом фонетически характеризуют исходный текст.
Анализ текста может быть выполнен различными способами. Ниже представлены два возможных алгоритма анализа текста.
Первый алгоритм: выделение из текста синтагм с наилучшим фонетическим балансом (то есть содержащие наибольшее количество совпадающих аллофонов) в порядке их сбалансированности. Количество таких синтагм ограничено пользовательской настройкой (количество синтагм) или системой в зависимости от заданного пользователем процента сбалансированности синтагм (минимальный суммарный процент сбалансированности синтагм). Первый алгоритм позволяет получить наилучшее качество воспроизведения диктором исходного текста, но требует большего времени на обработку данных.
Второй алгоритм: анализ процента покрытия базы эталонных аллофонов системы аллофонами, найденными в тексте (отношение количества аллофонов в тексте к количеству эталонных аллофонов в базе системы). Те аллофоны из базы системы, которые отсутствуют в тексте, не учитываются при дальнейшем анализе (база рассматриваемых аллофонов «сужается»). Определяется самая сбалансированная синтагма в тексте (содержащая самый высокий процент эталонных аллофонов из базы). Из базы эталонных аллофонов исключаются аллофоны, содержащиеся в выявленной наиболее сбалансированной синтагме. Далее в тексте определяется следующая по сбалансированности сбалансированная синтагма и аналогичным образом выполняется «сужение» базы эталонных аллофонов. Процесс «сужения» базы эталонных аллофонов повторяется до тех пор, пока не будет достигнуто заданное количество синтагм или минимальный суммарный процент сбалансированности синтагм. Второй алгоритм позволяет сократить время на обработку математически формализованных данных текста.
Специалистами понятно, что могут быть использованы другие алгоритмы.
Наиболее успешно заявленные способ автоматизированной обработки текста и компьютерное устройство для реализации этого способа промышленно применимы для обучения систем распознавания и синтеза речи.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СПОСОБ СИНТЕЗА РЕЧИ | 2009 |
|
RU2421827C2 |
| УСТРОЙСТВО СИНТЕЗА РЕЧИ | 2014 |
|
RU2606312C2 |
| СПОСОБ ОБМЕНА СООБЩЕНИЯМИ И УСТРОЙСТВА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2007 |
|
RU2324296C1 |
| СПОСОБ ПЕРЕОЗВУЧИВАНИЯ АУДИОМАТЕРИАЛОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2012 |
|
RU2510954C2 |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ АНАЛИЗА ТЕКСТА | 2008 |
|
RU2392666C1 |
| Устройство для вывода речевой информации | 1975 |
|
SU607211A1 |




Изобретение относится к информационным технологиям, в частности к предварительной обработке текстовой информации, и может быть использовано при распознавании и синтезе речи и других технических областях, в которых требуется обработка текстовой информации средствами вычислительной техники. Техническим результатом является повышение качества, увеличение скорости обработки и уменьшение количества информационных ресурсов. Указанный результат достигается тем, что способ включает объединение слов в синтагмы с простановкой символов пауз в конце синтагм с последующим транскрибированием синтагм для получения идеальных транскрипций синтагм в терминах фонем и аллофонов. Дополнительно формируют базу данных эталонных аллофонов. Сравнивают совпадение аллофонов идеальных транскрипций синтагм с эталонными аллофонами и исключают аллофоны идеальных транскрипций синтагм, не совпадающие с эталонными аллофонами. По аллофонам идеальных транскрипций синтагм, совпадающим с эталонными аллофонами, формируют сбалансированные синтагмы текста - имеющие наибольшее число совпадений аллофонов идеальных транскрипций синтагм с эталонными аллофонами. Устройство содержит блок ввода текста, блок анализа, блок базы данных, блок представления результатов. Введены блок ввода параметров и блок формирования сбалансированных синтагм. 2 н. и 4 з.п. ф-лы, 10 ил.
1. Способ предварительной обработки текста посредством текстового процессора, включающий приведение исходного текста в нормализованный орфографический текст путем преобразования сокращений и аббревиатур в линейный текст, членение текста на предложения и слова, маркировку фразовых и словесных ударений, объединение слов в синтагмы с простановкой символов пауз в конце синтагм с последующим транскрибированием синтагм - получением идеальных транскрипций синтагм в терминах фонем и аллофонов, отличающийся тем, что в текстовом процессоре дополнительно формируют базу данных эталонных аллофонов, сравнивают совпадение аллофонов идеальных транскрипций синтагм с эталонными аллофонами и исключают аллофоны идеальных транскрипций синтагм, не совпадающие с эталонными аллофонами, по аллофонам идеальных транскрипций синтагм, совпадающим с эталонными аллофонами, формируют сбалансированные синтагмы текста - имеющие наибольшее число совпадений аллофонов идеальных транскрипций синтагм с эталонными аллофонами.
2. Способ по п.1, отличающийся тем, что сбалансированные синтагмы формируют в виде таблицы в порядке их сбалансированности.
3. Способ по п.2, отличающийся тем, что задают количество сбалансированных синтагм.
4. Способ по п.2, отличающийся тем, что задают процент количества сбалансированных синтагм к общему количеству синтагм.
5. Способ по п.2, отличающийся тем, что производят процесс уменьшения базы данных эталонных аллофонов, в котором для наиболее сбалансированности синтагмы текста из базы данных эталонных аллофонов исключают эталонные аллофоны, содержащиеся в наиболее сбалансированной синтагме текста, затем для формируемой следующей по сбалансированности синтагмы текста из базы данных эталонных аллофонов исключают эталонные аллофоны, содержащиеся в ней, процесс уменьшения базы данных эталонных аллофонов повторяют для последующих по сбалансированности синтагм, достигая заданного количества сбалансированных синтагм или заданного процента количества сбалансированных синтагм к общему количеству синтагм.
6. Компьютерное устройство для обработки текста, содержащее блок ввода текста, блок анализа, блок базы данных, блок представления результатов, выход блока ввода текста подсоединен к первому входу блока анализа, а выход блока базы данных - к второму входу блока анализа, отличающееся тем, что введены блок ввода параметров, блок формирования сбалансированных синтагм, выход блока ввода параметров соединен с входом блока базы данных, предназначенным для формирования базы данных эталонных аллофонов, выход блока анализа соединен с вторым входом блока базы данных, выход блока базы данных соединен с входом блока формирования сбалансированных синтагм, такими, которые имеют наибольшее число совпадений аллофонов текста с эталонными аллофонами, выход которого соединен с входом блока представления результатов.
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| Приспособление к ленточному фильтру для снятия осадка с фильтровальной ткани | 1940 |
|
SU61924A1 |
| RU 2004112536 A, 27.03.2005 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 6148285 A, 14.11.2000 | |||
| Пожарный двухцилиндровый насос | 0 |
|
SU90A1 |
| Устройство для контактной сварки | 1940 |
|
SU59880A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

