Изобретение относится к способу цифрового кодирования для передачи и/или накопления акустических сигналов и, в частности, музыкальных сигналов заключающийся в том, что преобразуют временные отсчеты акустического сигнала в последовательность спектральных отсчетов, эти спектральные отсчеты квантуют с требуемой точностью и квантованные спектральные отсчеты по меньшей мере частично кодируют.
Способы согласно ограничительной части основного пункта формулы изобретения известны из патента ФРГ N 3310480 или заявки WO 88/01811. Ниже делается отсылка на указанные публикации для пояснения всех не рассматриваемых подробно понятий.
В частности, изобретение касается OCF - способа (optimum coding frequencies), впервые предложенного в патентной заявке WO 88/01811.
В основу изобретения положена задача, таким образом усовершенствовать способ цифрового кодирования, в частности, известный из патентной заявки WO 88/01811 OCF, чтобы уже при скорости передачи данных приблизительно 2 бита на отсчет было возможно кодирование музыки с качеством, сравнимым с компакт-диском, и при скорости передачи данных 1,5 бита на отсчет было возможно кодирование музыки с качеством хорошей УКВ-радиопередачи. Эта задача решается благодаря тому, что перед квантованием спектрального отсчета вычисляют для него допустимую помеху по большему числу временных отсчетов, чем число временных отсчетов, используемых для получения спектрального отсчета, после чего и осуществляют квантование соответствующего спектрального отсчета с учетом вычисленной для него допустимой помехи. В подпунктах более подробно разъясняется заявленный способ.
Изобретение более подробно поясняется ниже на основании чертежей, где показано:
фиг. 1 - спектр с выраженным максимумом,
фиг. 2 - кодовые слова в фиксированном растре,
фиг. 3 - расположение основных частей сообщения в фиксированном растре,
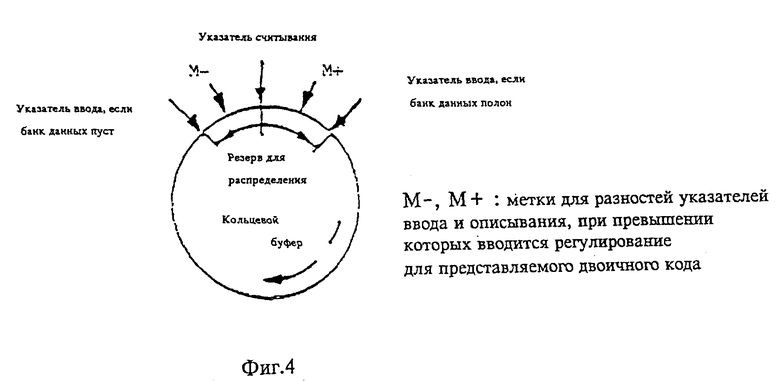
фиг. 4 - схематическое изображение кольцевого буфера, служащего в качестве так называемого "банка данных",
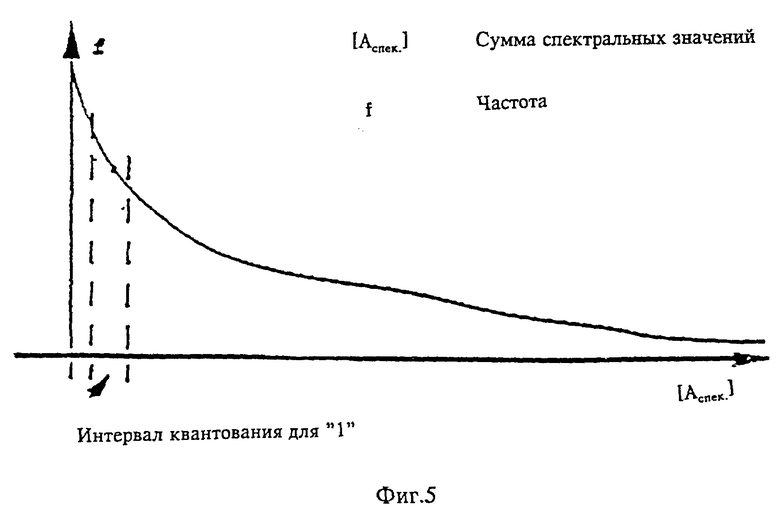
фиг. 5 - функция частотного распределения спектра.
В способах цифрового кодирования для передачи и/или накопления акустических сигналов и, в частности, музыкальных сигналов, в общем случае поступают так, что вначале отсчеты акустического сигнала преобразуют в последовательность вторых отсчетов, которые воспроизводят спектральный состав акустического сигнала. Эту последовательность вторых отсчетов затем соответственно требованиям квантуют с различной точностью и кодируют частично или полностью с помощью оптимального кодирующего устройства. При воспроизведении осуществляют соответствующее декодирование и обратные преобразования.
Преобразование отсчетов акустического сигнала в последовательность вторых отсчетов может при этом осуществляться посредством преобразования или с помощью фильтровального устройства, причем, в данном случае, выходной сигнал фильтровальным устройством дискретизируется (разбивается дискретно на выборки с меньшим интервалом) так что возникает формирование блока как при преобразовании.
Согласно ограничительной части пункта 1 изобретение основано на известном кодирующем устройстве, т.е. схеме присвоения кода, при котором вероятность появления спектральных коэффициентов квантования коррелируется с длиной кода таким образом, что кодовое слово тем короче, чем чаще проявляется спектральный коэффициент. Кодирующие устройства такого типа известны, например, под названием кода Хаффмана.
В соответствии с предлагаемым изобретением измеряют энергию акустического сигнала в различных частотных группах каждого спектрального отсчета и используют измеренное значение энергии сигнала текущего спектрального отсчета и скорректированное с помощью коэффициента забывания измеренное значение энергии сигнала предыдущего спектрального отсчета для вычисления допустимой помехи.
В случае, когда измеренное значение энергии сигнала для текущего спектрального отсчета меньше, чем для предыдущего спектрального отсчета, упомянутое квантование текущего спектрального отсчета осуществляют с меньшей точностью по сравнению с предыдущим спектральным отсчетом. В случае обнаружения в спектральном отсчете резкого подъема энергии в сторону высоких частот уменьшают вычисленную допустимую помеху для частотной группы этого спектрального отсчета, находящейся на оси частот ниже этого подъема энергии.
При квантовании длину кода спектрального отсчета сопоставляют величине, обратной частоте появления этого спектрального отсчета, при этом по меньшей мере одному диапазону значений спектральных отсчетов присваивают общее кодовое слово.
Упомянутое общее кодовое слово присваивают лишь одному диапазону значений спектральных отсчетов, а всем остальным значениям вне этого диапазона присваивают общий идентификатор и специальный код.
Общее кодирование спектральных коэффициентов при этом может осуществляться различными способами: например, оно может быть проведено в частотной области или по оси времени, причем будут кодироваться совместно те же самые коэффициенты из следующих друг за другом блоков (пункт 10 формулы изобретения).
При этом код в общем случае выбирается из таблицы, длина которой соответствует числу кодовых слов. Если большое число кодовых слов с длиной слова, большей его средней длины, обладает сходной длиной слова, то все эти кодовые слова с небольшей потерей эффективности кодирования описываются посредством общего идентификатора и следующего затем специального кода, который соответствует случаю применения. Этим кодом, например, может быть код импульсно-кодовой модуляции (ИКМ). Этот способ особенно эффективен в том случае, если только небольшое число значений обладает большой вероятностью возникновения, как это, например, имеет место при кодировании музыки в спектральном представлении.
В дальнейшем вышеизложенное пояснено на примере. При этом дается следующее распределение вероятностей:
Значение - Вероятность
0 - 50%
1 - 30%
2 - 15%
3 ... 15 - вместе 5%, т.е. каждое 0,38%
Энтропия, то есть возможно короткая средняя длина кода составляет здесь 1,83275 бит.
В подобном случае применения преимущество состоит в том, чтобы определить код Хаффмана, который содержит значения 0, 1, 2 и метку (в дальнейшем она обозначается ESC), в которой кодируются значения от 3 до 15 (см. табл. 1 в конце описания).
При чистом Хаффман-кодировании получают среднюю длину кода, равную 1,89 бит, при кодировании с меткой ESC, например, средняя длина кода составляет 1,9 бит. Эффективность кода при кодировании с меткой ESC хотя и несколько хуже, однако размер таблицы для кодирующего устройства и декодирующего устройства будет в четыре раза меньше, так что скорость процессов кодирования и декодирования значительно повышается.
Если в качестве кода с ESC-значениями используют модифицированный код импульсно-кодовой модуляции, то появляется возможность без изменения средней длины кода кодировать даже значения до 18.
Хаффман-код с меткой ESC
0
10
110
111-0000
111-0001
111-0010
111-0011
111-0100
111-0101
111-0110
111-0111
111-1000
111-1001
111-1010
111-1011
111-1100
111-1101
111-1110
111-0111
Дальнейшее усовершенствование способа, состоит в том, что n спектральных коэффициентов с n ≥ 2 объединяют в одни n - элементный (упорядоченный) набор и совместно кодируют с помощью оптимального кодирующего устройства. Оптимальные кодирующие устройства, которые каждому спектральному значению присваивают одно кодовое слово различной длины, только в исключительном случае являются "оптимальным и в смысле теории информации". Дальнейшее уменьшение избыточности кода посредством предлагаемого по изобретению кодирования согласно пункту 10 формулы изобретения достигают за счет того, что по меньшей мере одной паре спектральных значений присваивают одно кодирующее слово. Уменьшение избыточности получается, во-первых, из того, что оба совместно закодированные спектральные значения статистически не являются независимыми, а во-вторых, из того факта, что при кодировании пар значений может осуществляться более точное согласование книги кодов и соответственно кодовой таблицы со статистическими характеристиками сигналов.
Ниже это поясняется на следующем примере.
Прежде всего рассмотрим кодирующее устройство энтропийного типа (оптимальное кодирующее устройство), которое отдельным значениям присваивает отдельные кодовые слова (см. табл. 2 в конце описания).
Отсюда получается средняя длина кодового слова, равная 1.
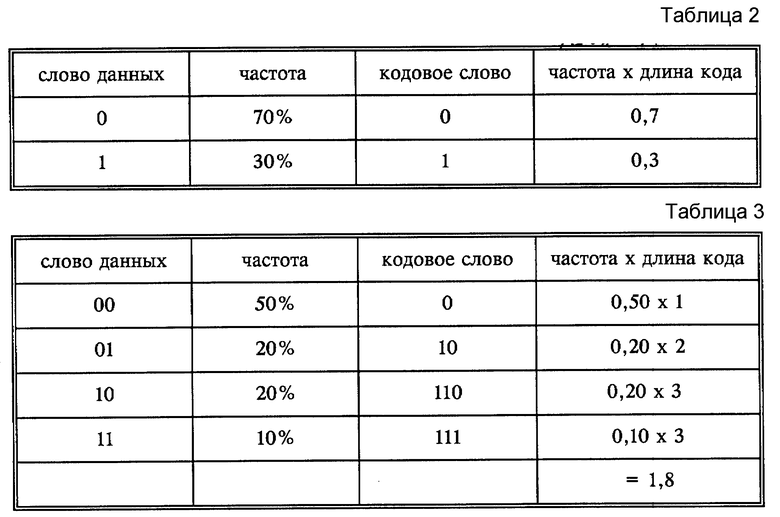
При рассмотрении вероятностей пар отсчетов получается следующее оптимальное кодирующее устройство (см. табл. 3 в конце описания).
Средняя длина кодового слова на отдельное значение получается из суммы членов "частота x длину кодового слова", поделенной на 2 (из-за кодирования пар значений). В вышеприведенном примере она составляет 0,9. Это меньше, чем может быть достигнуто при кодировании отдельных значений при принятии тех же самых статистических характеристик сигналов. Кодирование пар спектральных значений происходит, например, посредством того, что используют соответственно первое спектральное значение в качестве номера строки, а второе значение одной пары в качестве номера столбца, чтобы в кодовой таблице адресовать соответствующее кодовое слово.
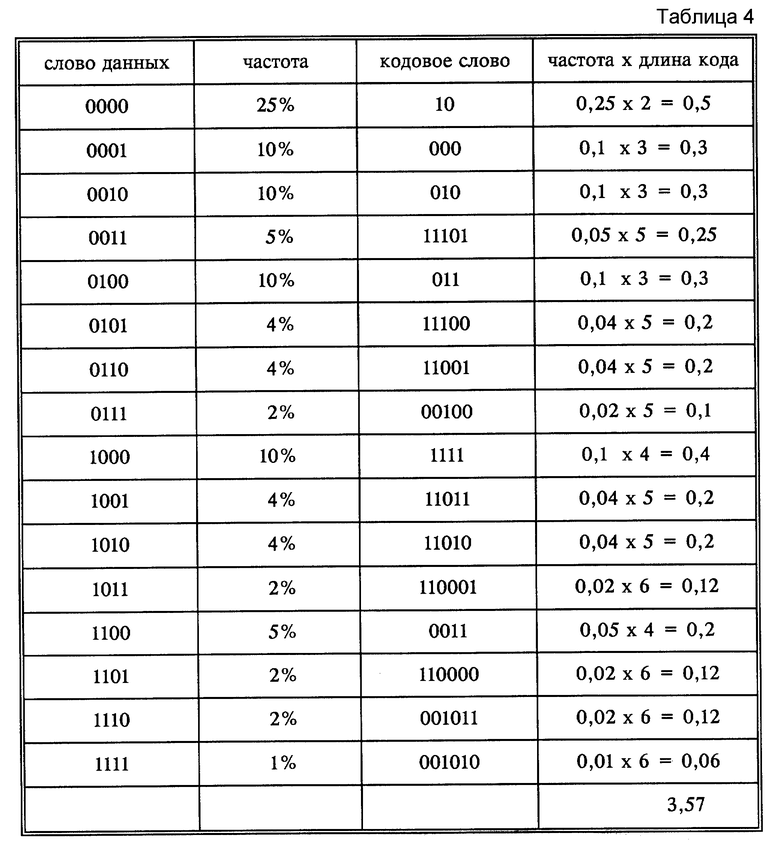
Если и дальше увеличивают количество совместно кодируемых значений, то в среднем получают меньшую длину кода, например, для 4-х элементных наборов, при котором каждое значение возникает из интервала [0,1] (см. табл. 4 в конце описания).
Средняя длина кода составляет в примере таким образом 3,57/4 = 0,89 бит. Далее, возможно также проводить совместное кодирование посредством того, что спектральные коэффициенты с одинаковым номером объединяются из следующих друг за другом блоков и совместно кодируются. Это в дальнейшем поясняется на примере, в котором для упрощения два блока данных кодируются совместно; таким же образом, однако, можно объединять и большее число блоков.
Пусть x(1), x(2). . . x(n) частотные коэффициенты одного блока и y(1), y(2)... y(n) - частотные коэффициенты следующего за этим блока.
1) Подлежащие кодированию спектральные значения двух следующих друг за другом блоков данных кодируются совместно. Для этого из каждого из обоих блоков берется квантованное спектральное значение с одинаковым номером и эта пара кодируется, т.е. значения одинаковой частоты следующие во времени друг за другом, кодируют совместно. Корреляция между этими значениями при квазистационарных сигналах очень большая, т.е. их сумма варьируется только незначительно. Относящаяся к этому информация квантователя требуется для обоих блоков данных только один раз вследствие совместного кодирования.
В этом случае пары (x(1)y(1)), (x(2) y(2)),...,(x(n) y(n)) кодируются совместно.
2) Величины двух следующих друг за другом спектральных значений одного блока при "ровных" спектрах скоррелированы друг с другом. Для таких сигналов целесообразно кодировать совместно два спектральных значения одного блока.
Пары (x(1) x(2)), (x(3) x(4))..., (x(n-1) x(n)) кодируются совместно. В зависимости от преобразования целесообразны также и другие объединения значений.
3) Переключение между 1) и 2) может, например, передаваться через бит идентификации.
Для более чем двух кодируемых совместно значений могут комбинироваться обе возможности: для 4-х элементарных наборов, например, целесообразны следующие возможности:
а) по одному значению из четырех следующих друг за другом блоков;
б) по два значения из двух следующих друг за другом блоков;
в) четыре значения из одного блока.
В случаях а) и б) можно сэкономить дополнительную информацию.
Само собой разумеется, возможно не только, чтобы кодирование происходило посредством образования пар или n-элементных наборов от соответственно одного спектрального значения каждого блока данных или чтобы кодирование осуществлялось посредством образования n-элементных наборов от более чем одного спектрального значения каждого блока данных, но также возможно, чтобы для образования пары или n-элементных наборов спектральных значений происходило переключение между парами или n- элементными наборами последовательных блоков данных и парами или n-элементными наборами спектральных значений, следующих друг за другом при подсчете по значениям частот.
Согласно дальнейшему развитию изобретения дополнительная информация передается следующим образом: в OCF-способе (optimum coding frecquencies), который описан в указанной в вводной части заявки WO 88/01811, осуществляется передача отдельных значений для коэффициента управления по уровням, числа итераций, осуществленных во внутреннем цикле, а также меры для спектрального распределения неравномерности (spectral flatness measure, sfm.) от кодирующего устройства к декодирующему устройству. Согласно изобретению из этих значений определяется "общий коэффициент усиления" и он передается в приемник. Расчет общего коэффициента усиления осуществляется посредством того, что все отдельные значения выражаются как показатели степени определенного числового значения и коэффициенты складываются между собой.
Это поясняется ниже на основе примера:
Пусть возможны следующие операции усиления с сигналом (a, b, c - целые числа):
1) Согласование уровней: ступени усиления с 2a
2) Квантование:
а) начальное значение для квантователя в ступенях по 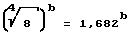
б) укрупнение квантователя в ступенях по 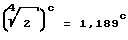
Квантование соответствует делению, т.е. ослаблению. Поэтому полученные коэффициенты должны приниматься отрицательными.
Общий коэффициент, таким образом, составляет 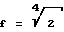
к 1) f4a = 2a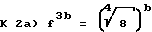
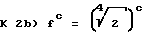
Тем самым общий коэффициент усиления составляет f4a-3b-c, только целочисленный показатель степени передается на декодирующее устройство. Число необходимых бит определяется длиной слова входных данных (в общем случае 16 бит) и длиной преобразования (получается максимальная динамика).
Далее возможно также дополнительной информации присвоить переменную скорость передачи данных.
Поправочные коэффициенты, с помощью которых достигается соблюдение допустимой помехи, должны передаваться к приемнику в качестве дополнительной информации об уровне на каждую частотную группу. Согласно изобретению снижение средней, необходимой для этого скорости передачи данных, достигается посредством того, что в одном управляющем слове кодируется длина следующего слова данных и, смотря по обстоятельствам, применяется только необходимая для передачи длина слова. Это также поясняется ниже с помощью примера.
Принимаем: количество частотных групп = 3,
максимальное число итераций = 8.
Передаваться будет количество усиленийна каждую частотную группу. Без переменной скорости передачи данных дополнительной информации потребовалось бы 3х3 = 9 бит. Максимальное число усилений (в примере) кодировалось бы следующим образом:
отсутствие усиления - 0
максимально одно усиление - 1
максимально три усиления - 2
максимально семь усилений - 3
Соответствующее кодовое слово прямо указывает на число бит, которое необходимо, чтобы закодировать максимальное значение усиления.
Результат психоакустического цикла итераций в примере пусть будет (0 0 2), т. е. частотная группа 3 была дважды усилена, а другие частотные группы нет. Это может быть закодировано следующей последовательностью бит:
10000010, таким образом всего 8 бит.
В изобретении также используют известным способом кодирующее устройство, работающее на основе так называемого кода Хаффмана. Согласно изобретению теперь, однако, применяются n-элементные кодовые таблицы с n ≥ 1 и различной длиной, которые согласованы с соответственно кодируемым акустическим сигналом. Совместно с закодированными значениями передается и соответственно хранится в памяти номер используемой кодовой таблицы.
Средняя кодовая длина кода Хаффмана зависит именно от количества различных символов в коде. Поэтому целесообразно выбрать код Хаффмана, который содержит не более чем необходимое количество значений. Если в качестве критерия выбора кодовой таблицы принимают максимально кодируемое значение, то можно кодировать все фактически встречающиеся значения.
Если имеется в распоряжении несколько кодовых журналов или кодовых таблиц, то на основании подлежащих кодированию значений можно выбрать лучшую таблицу и передать в качестве дополнительной информации номер кодовой таблицы. Предварительный выбор среди кодовых таблиц может происходить с помощью максимально кодируемого значения.
Только в качестве дополнения необходимо упомянуть, что, например, очень неровные спектры в том виде, как они выдаются духовыми инструментами, имеют другую статистику, при которой малые значения встречаются чаще, чем у ровных спектров, создаваемых например, струнными инструментами или духовыми инструментами из дерева.
Дальнейшее развитие изобретения состоит в том, что дополнительно или вместо ранее указанного распределения, различных таблиц различным спектральным областям придаются различные кодовые таблицы. У спектров с выраженным максимумом это дает выигрыш в том, чтобы разделить его на отдельные области и для каждой части участка выбрать оптимальный код Хаффмана.
На фиг. 1 показан подобный спектр, у которого максимум находится почти в середине спектральной области. Здесь можно разделить область, например, на четыре диапазона:
- в первом диапазоне используется код Хаффмана с 16 значениями, во втором диапазоне - код более чем с 32 значениями, в третьем - снова код с 16 значениями и в четвертом диапазоне - код с 8 значениями.
При этом предпочтительно, если для кодовой таблицы с более чем 32 значениями будет применяться таблица согласно пункту 1 формулы изобретения, у которой кодовые слова с большей длиной слов, чем средняя длина слова, описываются общим идентификатором и последующим кодом импульсно-кодовой модуляции. Это обозначается на фигуре 1 посредством "TAB (таблица) с меткой ESC".
Код Хаффмана в обозначенном примере выбирается по максимуму участков, причем код соответственно предоставляется для значений 2, 4, 8 и т.д. Без этого разделения код для более чем 32 значений должен бы применяться на весь общий спектр, так что необходимое число бит для блока было бы значительно выше.
В качестве дополнительной информации должны быть переданы точки разбиения и номера кодовых таблиц для каждого участка.
Выбор кода Хаффмана для каждого участка может, в частности, осуществляться согласно рекомендаций, приведенных в формуле изобретения.
В изобретении рассматривается предпочтительная возможность декодирования уже названного выше кода Хаффмана. Для этого моделируется дерево, которое получается при составлении кода. Вследствие условия, что никакое кодовое слово не может быть началом следующего кодового слова, исходя от "ствола дерева" получается только один возможный путь к соответствующему кодовому слову. Для того, чтобы достичь кодового слова, начиная спереди, используют соответственно один бит кодового слова, чтобы при разветвлениях на дереве установить путь. Практическая реализация осуществляется с помощью таблицы адресных пар, которая всегда отрабатывается, начиная с первой пары. Первое значение пары содержит при этом, в зависимости от обстоятельств, адрес следующего разветвления, которое в случае одного "0" в обстоятельств, адрес следующего разветвления, которое в случае одного "0" в декодируемом значении следует запустить в работу, второе значение содержит адрес разветвления в случае одной "1". Каждый адрес маркируют как таковой. Если подойти к табличному значению без этой маркировки, то кодовое слово достигнуто. Табличное значение соответствует в этом случае декодируемому значению. Следующий декодируемый бит это, следовательно, первый бит следующего кодового слова. Начиная с него осуществляется новый проход таблицы от первой адресной пары.
В дальнейшем это поясняется примером 1 (см. в конце описания)
В случае, если код Хаффмана был составлен для пары значений, то на втором, в указанном примере свободном месте таблицы может размещаться соответствующее второе значение. Этот способ может быть целесообразно применен также для декодирования с кодами Хаффмана, который совместно кодирует более двух значений.
В случае кодирований, при которых начало одного кодового слова определено только концом предыдущего кодового слова (как это, например, имеет место при применении кода Хаффмана) ошибка при передаче приводит к распространению ошибки.
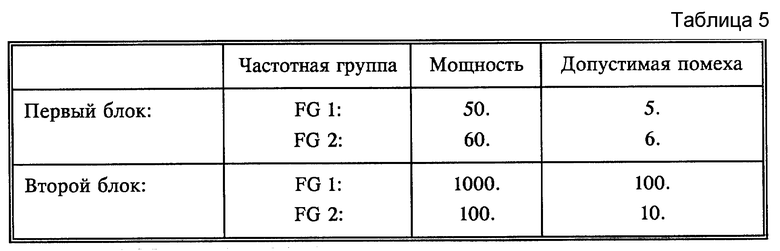
Решение этой проблемы, приведенное в изобретении, разумеется, может быть использовано также независимо от других признаков. Для этого располагают, прежде всего, одну часть кодовых слов в растре, длина которого, например, больше или равна наиболее длинному кодовому слову, в результате для этой части кодовых слов нет никакого распространения ошибки, так как их начало больше не определяется концом предыдущего кодового слова. Остальные кодовые слова распределяются в оставшиеся пробельные промежутки. Пример этого показан на фиг. 2. Если применяемая кодовая таблица будет построена таким образом, что из первых разрядов кодовых слов уже можно делать заключение о диапазоне кодовой таблицы, то длина применяемого растра может быть также меньшей длины наиболее длинного кодового слова. Не вписывающиеся больше в растр разряды распределяются как и остальные кодовые слова в оставшиеся пробельные промежутки. Посредством использования этой более короткой длины растра, предоставляется возможность размещения кодовых слов в этом растре в большем количестве и распространение ошибки ограничивается последними разрядами этих кодовых слов, которые благодаря описанной выше структуре кодовой таблицы имеют только подчиненное значение. Эта пересортировка не приводит к уменьшению эффективности кода.
Это поясняется также на примере 2 (см. в конце описания).
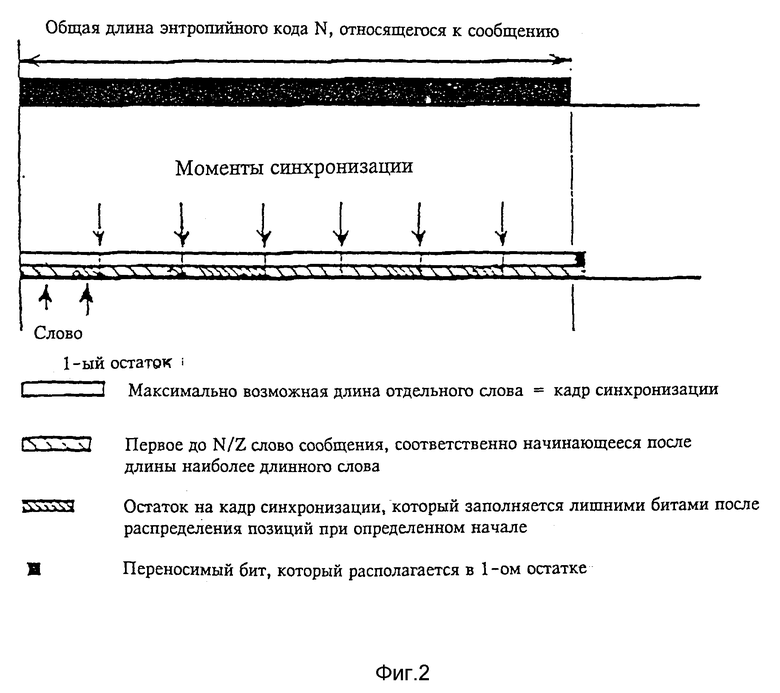
Кроме того, согласно изобретению возможно расположить основные части сообщения в фиксированном растре.
Достоверность передачи непрерывно следующих друг за другом сообщений различной длины с частями сообщений различной важности может быть улучшена следующим образом: средняя длина сообщения непрерывного потока двоичных разрядов представляет интервал между точками эквидистантного растра. Важные части сообщения располагаются теперь в этом фиксированном растре. Дополнительно в этой важной части информации совместно передается позиция соответствующей менее важной части. Благодаря эквидистантному интервалу между важнейшими элементами информации в случае ошибки передачи можно легче обеспечить новую синхронизацию.
В последующем поясняется ограничение ошибки при коде энтропии согласно изобретению.
При битовой ошибке в коде энтропии для случая неисправности теряется, как правило, вся следующая за дефектным местом информация. Посредством маркировки начала блока определенной комбинацией битов и дополнительной передачей длины кода энтропии представляется возможность ограничить возникшую ошибку в пределах того блока сообщения, который содержит битовую ошибку. Это происходит следующим образом.
После правильного декодирования одного сообщения должно бы следовать начало следующего блока сообщения и, тем самым, маркер начала блока. Если это не происходит, то с помощью длины энтропийного кода проверяется, находится ли процесс декодирования на месте, ожидаемом в соответствии с длиной кода энтропии. Если это так, то ошибка предполагается в маркере начала блока и корректируется. Если же это не имеет места, то проверяется, следует ли к указанной посредством длины кода энтропии позиции для двоичной токовой посылки маркер начала блока, который тогда с большой вероятностью будет маркировать начало следующего блока. Если не происходит маркирование начала блока, то имеются, по меньшей мере, 2 ошибки (декодирование/маркер начала блока или длина кода энтропии/декодирование, или маркер начала блока/длина кода энтропии) и при этом нужно вновь осуществить синхронизацию.
Кроме того, согласно изобретению возможно также предусмотреть синхронизационную защиту или же опознавание синхронизации.
При непрерывных потоках данных, которые составлены из блоков различной длины, возникает проблема в том, что синхрослова для идентификации начал блоков могут также случайно находиться в потоке данных. Выбор очень длинных синхрослов хотя и уменьшает эту вероятность, однако не может свести ее совсем к нулю и приводит, с другой стороны, к снижению пропускной способности передачи. Пара схем, которая найденному синхрослову в начале блока присваивает "1" и в пределах блока "0" (или же наоборот, в начале блока "0", а далее "1") известна из литературных источников (например, ИНТЕЛ "Шина для двоичной информации" - кадровый формат). Применение для передачи кодированных музыкальных сигналов осуществляется согласно изобретению. Приспособленное к этому применению "опознание синхронизации" обладает возможностью в областях, в которых ожидается синхрослово, принимать его как таковое, даже если оно из-за ошибки в передаче в некоторых местах было изменено.
Изобретение позволяет также ограничивать максимальное число итераций.
Целью этого является ограничение бита, передаваемого для идентификации квантователя. Исходя из пускового значения квантователя, допускается только ограниченное отклонение от этого стартового значения, которое может быть представлено n битами. Для соблюдения этого условия перед каждым проходом через внешний цикл проверяется, гарантируется ли еще возможность завершения дальнейшего вызова внутреннего цикла с достоверным результатом.
Эта также поясняется ниже на основе следующего примера. Исходя их начального значения квантователя в нем происходят изменения по ступеням 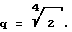 При самом неблагоприятном случае все частотные группы в наружном цикле усиливаются на коэффициент 2. Если еще возможны 4 укрупнения (разбиений) квантователя на
При самом неблагоприятном случае все частотные группы в наружном цикле усиливаются на коэффициент 2. Если еще возможны 4 укрупнения (разбиений) квантователя на 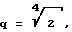 то гарантируется, что внутренний цикл завершается результатом, подходящим для разрешенного битового цикла (кадр). Для передачи предусмотрены 5 бит, для возможного отклонения от начального значения, в результате чего в качестве отклонения от начального значения максимально возможным является число 31. Внутренний цикл таким образом, больше уже не может быть вызван, если уже достигнуто 28 или больше, так как в этом случае уже больше не гарантируется, что блок может быть закодирован разрешенным количеством бит.
то гарантируется, что внутренний цикл завершается результатом, подходящим для разрешенного битового цикла (кадр). Для передачи предусмотрены 5 бит, для возможного отклонения от начального значения, в результате чего в качестве отклонения от начального значения максимально возможным является число 31. Внутренний цикл таким образом, больше уже не может быть вызван, если уже достигнуто 28 или больше, так как в этом случае уже больше не гарантируется, что блок может быть закодирован разрешенным количеством бит.
Заявляется также предпочтительный вариант исполнения, который улучшает психоакустику благодаря тому, что психоакустические мероприятия применяются на нескольких блоках.
Применяемый согласно изобретению способ может быть описан на основе примера. Для того чтобы упростить пример, примем число частотных групп, равное 2. Значения для соответственно допустимой помехи и т.п. также являются примерными значениями, которые в практическом исполнении способа кодирования выбираются по другому.
Пусть допустимая помеха = 0,1 x мощности сигнала по каждой частотной группе. Значения мощности даются без указания размерности. Масштаб может быть выбран произвольно, так как здесь используются данные соотношения, а не абсолютные суммы значений мощности (см. табл. 5 в конце описания).
Пусть коэффициент "забывания", которым учитывается, что мощность сигнала соответственно предыдущего блока меньше входит в расчет действительно допустимой помехи, чем мощность сигнала, действующего в данный момент блока, выбран до 2. Допустимая помеха во втором блоке тогда рассчитывается как минимум вычисленной из данных второго блока допустимой помехи и вычисленной из данных первого блока помехи скорректированного на "коэффициент забывания". В примере для второго блока в частотной группе FG 1 получается:
для FG 1 минимум (2 x 5,100) = 10 и
для FG 2 минимум (2 x 6,10) = 10 как допустимая помеха.
Пункт 26 формулы изобретения характеризует "банк данных". В самом простом случае, как это описано в патентной заявке WO 88/01811, для каждого блока предоставлена в распоряжение определенная скорость передачи данных (число бит). Поскольку не вся скорость передачи данных используется для кодирования блока, то "оставшиеся лишними" биты добавляются к числу бит, находящемуся в распоряжении следующего блока.
В предлагаемом по изобретению расширении этого способа допускаются максимальные нижнее и верхнее суммарные отклонения скорости передачи данных. Суммарное отклонение скорости передачи данных (отклонение сумм двоичных разрядов блоков данных от суммы двоичных разрядов вычисляемой из желаемой постоянной скорости передачи данных), называется "банком данных".
Банк данных заполняется за счет неполного использования соответственно в нормальном режиме действительно имеющегося в распоряжении числа двоичных разрядов. До тех пор, пока не будет достигнута верхняя граница банка данных (= нижней границе отклонения суммарного числа двоичных разрядов), каждому блоку вновь предоставляется в распоряжение лишь рассчитываемое из средней скорости передачи данных число бит, но не бит, "оставшийся лишним" в предыдущем блоке.
Если, например, при сильных возрастаниях уровня сигнала (например, треугольник) для одного блока данных на основании учета допустимой помехи последнего блока данных (см. выше) вычисляется явно меньшая допустимая помеха, чем это имело бы место без учета данных последнего блока, тогда внутреннему итерационному циклу действующего в данный момент блока предоставляется больше бит для кодирования и корректируется значение суммарного отклонения ("банк данных") соответственно. Количество дополнительных бит выбирается таким образом, чтобы не могло быть превышено максимальное суммарное отклонение ("минимальный уровень заполнения банка данных"). В вышеуказанном примере число дополнительных бит может быть, например рассчитано следующим образом.
В первой частотной группе второго блока допустимая помеха пусть равна - 100, если бы данные первого блока не учитывались. Отношение между допустимой помехой с учетом данных последнего блока и без учета этих данных составляет, таким образом 100/12 = 8,33, это приблизительно равно 10xlog (8,33) = 9,2 dB.
Если принять, что шум квантования при квантовании с дополнительным битом на каждое значение уменьшается примерно на 6 dB, тогда на каждое спектральное значение частотной группы необходимо около 1,5 бит, чтобы достичь наименьшей допустимой помехи. Число бит, используемых из банка данных, в данном примере составляет 1,5 количество спектральных значений частотной группы.
Изобретение передусматривает также синхронизацию тактов выходных и входных битов.
У кодирующих систем с произвольным соотношением такта входных битов к такту выходных битов существует проблема, заключающаяся в том, что представляемое число битов может быть бесконечной дробью. Тем самым исключается синхронизация посредством продолжительного усреднения представляемого числа двоичных разрядов, которая была бы возможна при конечной дроби. Рассогласование входа и выхода предотвращается регулированием, которое прослеживает интервал между указателем ввода и вывода буферной памяти. Если интервал уменьшается, то число битов будет уменьшаться и наоборот. При постоянном соотношении между тактами входных и выходных битов или же при соотношении такта входных битов к такту выходных, изменяющемуся на постоянное среднее значение, достаточно предоставляемое двоичное число варьировать соответственно на 1 бит. Максимальное отклонение от среднего значения определяет, однако, предусматриваемую минимальную величину буфера. Это поясняется с помощью фиг.4 на конкретном воплощении способа OCF.
Входные данные являются отсчетами, которые подаются с постоянной частотой. Выход подсоединен к каналу с постоянной скоростью передачи двоичной информации. Тем самым задано постоянное среднее соотношение такта входных битов к такту выходных битов. В кодирующем устройстве передаваемое для каждого блока на выход число битов, обусловленное банком данных, может колебаться. То есть имеются блоки, для которых более или менее среднее, имеющееся в каждом блоке число битов (= такту входных битов/такт выходных битов x длину блока), которое может быть не натуральным числом, передается далее на выход. Это колебание компенсируется на выходе посредством FIFO (кольцевой буфер) (FIFO = "первым пришел - первым обслужен"). Длина FIFO-памяти выбрана соответственно максимальному содержанию банка данных. Если среднее, имеющееся в каждом блоке число бит является не натуральным числом, то должно быть задано для каждого блока либо следующее большее, либо следующее меньшее натуральное число бит. Если выбирается следующее большее или же следующее меньшее, то входной и выходной указатели буферной FIFO-памяти будут сближаться или же расходиться. Относительно заданного интревала теперь определяются заданные в оба направления, при превышении которых осуществляется переключение от ближайшего большего к ближайшему меньшему числу бит (или наоборот). При этом в качестве начального значения для предоставляемого числа бит задается одно из этих приближений. При достаточной величине буфера памяти это регулирование может использоваться также для того, чтобы определить это начальное значение. Во взаимосвязи с банком данных перед сравнением указателей должно быть учтено содержимое банка данных.
Если двоичное число будет варьироваться больше чем на один бит, то этот способ следует применять и в том случае, если и не имеется постоянного среднего значения. Из разности, полученной при сравнении указателей, вычисляется в этом случае поправочное число бит.
Согласно изобретению дальнейший вариант реализации состоит в том, что наряду с другими преимуществами улучшается последующее маскирование. Согласно изобретению для расчета допустимой помехи привлекается энергия сигнала в предыдущих блоках данных, при этом допустимая помеха уменьшается от одного блока данных к следующему с соблюдением всех других параметров для определения фактической допустимой помехи соответственно максимально на определенный коэффициент.
Это также поясняется ниже на основе следующего примера. Пусть допустимая помеха в частотной группе 1 и в блоке 1 равна 20. В блоке 2 мощность сигнала в группе FGI равна 50. При принятой помехе, равной 0,1 x мощность частотной группы, допустимая помеха была бы равна 5. Если "коэффициент последующего маскирования" будет принят как - 3 dB на блок, что соответствует делению пополам мощности, то допустимая помеха в блоке рассчитывается равной 10 (= 0,5 x 20).
Далее возможно предпринять согласование с различными скоростями передачи двоичной информации.
Итерационный блок OCF распределяет имеющееся в распоряжении для блока число бит в соответствии с заданием допустимой помехи на каждую частотную группу. Для оптимизации результата вычисление допустимой помехи согласуется с имеющимся числом битов. Исходным моментом при этом является фактический порог прослушивания, который при допустимой помехе еще не нарушается. Требуемое для определенной скорости передачи двоичных разрядов отношение сигнал/шум выбирается так, чтобы в среднем получался равномерный характер спектра помех. Чем ниже лежит предоставляемое общее число бит, тем меньшее требуется отношение сигнал/шум для каждой группы. При этом, хотя в некотором числе блоков, увеличивающемся с более низкими скоростями передачи битов, рассчитанный порог прослушивания и нарушается, однако в целом достигается равномерный характер прохождения помех. В противоположность этому при высоких скоростях передачи битов может быть достигнут дополнительный интервал безопасности для порога прослушивания, который, например, позволит дополнительную обработку или многократное кодирование/декодирование сигнала.
В качестве дальнейшего мероприятия возможно ограничение ширины полосы частот посредством стирания определенных диапазонов частот перед расчетом допустимой помехи. Это может происходить статически или динамически, если в нескольких блоках последовательно плохо соблюдается требуемое отношение сигнал/шум.
При крутом спаде маскировки в сторону низких частот, то есть при расчете допустимой помехи особенно необходимо учитывать, что существовал только динамически, если в нескольких блоках последовательно плохо соблюдается требуемое отношение сигнал/шум.
При крутом спаде маскировки в сторону низких частот, то-есть при расчете разрешенной помехи особенно необходимо учитывать, что существовал только незначительный эффект маскирования от высоких к низким частотам. Рассчитанная в первом приближении разрешенная помеха в случае сильного нарастания энергии в спектре для частотных групп корректируется поэтому ниже подъема в сторону понижения. Области, в которых "разрешенная помеха" больше энергии сигнала, стирают. Возникающую последовательность стертых значений кодируют одним битом в боковой информации. Возникающую последовательность стертых значений кодируют посредством значения в таблице возможных уровней ступеней квантования для каждой частотной группы в боковой информации.
Далее, согласно изобретению улучшается характеристика квантователя. При квантовании и реконструкции принимается во внимание статистика неквантованных значений. Она строго монотонно убывает по изогнутой графической характеристике. Вследствие этого величина ожидания каждого интервала квантования не лежит в середине интервала, а смещена ближе в сторону к меньшим значениям (фиг. 5).
Для того, чтобы получить наименьшую ошибку квантования возможны два подхода:
a) задание характеристики квантования: на основании характеристики квантования и статического распределения подлежащих квантованию значений для каждого интервала квантования определяется величина ожидания и используется в качестве таблицы для реконструкции в декодирующем устройстве. Преимущество этого подхода заключается в простоте реализации и незначительных затратах на вычисления в кодирующем устройстве;
b) задание характеристики реконструкции: на основании этой характеристики и модели распределения вероятностей входных значений может быть рассчитана характеристика квантователя, у которой величина ожидания каждого интервала квантования точно соответствует реконструируемому значению этого интервала. Это дает то преимущество, что в декодирующем устройстве не требуется никакой таблицы, и характеристика квантования в кодирующем устройстве может быть согласована с фактическими статистическими данными, без того, чтобы это должно быть сообщено декодирующему устройству;
c) задание характеристики квантователя и расчет характеристики реконструкции для каждого значения: при заданной характеристике квантователя и функции распределения вероятностей для входных данных декодирующее устройство может вычислять из этих показателей соответственно реконструкционное значение. Это дает преимущество в том, что для декодирующего устройства не требуются никакие таблицы для реконструкции. Недостаток этого способа заключается в высоких затратах на вычисления в декодирующем устройстве.




Изобретение относится к технике цифрового преобразования сигналов. Его использование позволяет кодировать музыку с хорошим качеством при малых скоростях передачи. Способ заключается в том, что временные отсчеты акустического сигнала преобразуют в последовательность спектральных отсчетов, эти спектральные отсчеты квантуют с требуемой точностью и по меньшей мере частично кодируют квантованные спектральные отсчеты. Технический результат достигается благодаря тому, что перед квантованием спектрального отсчета вычисляют для него допустимую помеху по большему числу временных отсчетов, чем число временных отсчетов, используемых для получения спектрального отсчета, после чего и осуществляют квантование соответствующего спектрального отсчета с учетом вычисленной для него допустимой помехи. 32 з.п.ф-лы, 5 ил. 4 табл.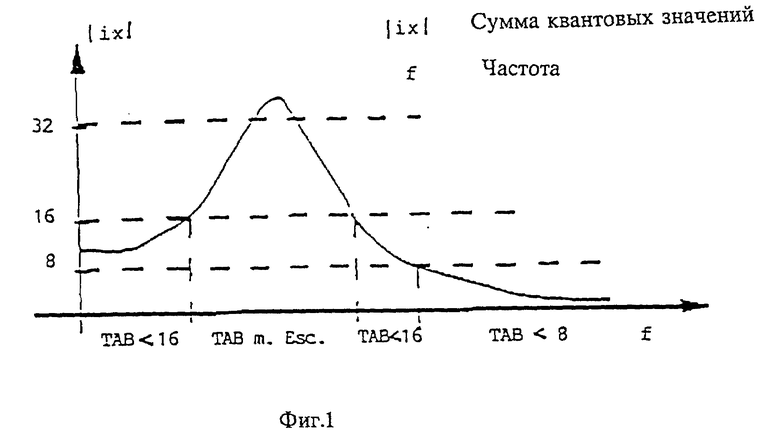
| Шланговое соединение | 0 |
|
SU88A1 |
| US 3717851 A, 20.02.73 | |||
| US 4802222 A, 31.01.89 | |||
| US 4720861 A, 19.01.88 | |||
| DE 3310480 C2, 02.06.86 | |||
| DE 3732047 A1, 06.04.89 | |||
| КЛИНОВОЙ ПРИВОДНОЙ РЕМЕНЬ | 2010 |
|
RU2482348C2 |
| Гибочный автомат для изготовления из проволоки, например дужек ведер и подобных изделий | 1959 |
|
SU124411A1 |
