Изобретение относится к области электроники и может быть использовано, например, в качестве группового способа верификации компьютерных кодов с соответствующими им оригиналами.
Известен способ верификации компьютерных кодов с соответствующими им оригиналами, включающий преобразование исходной символьной информации оригинала документа в совокупность адекватных ей компьютерных кодов в найденных и отобранных полях документа и сличение оператором соответствия компьютерных кодов с оригиналом.
Известен также способ верификации компьютерных кодов с соответствующими им оригиналами, включающий преобразование исходной символьной информации оригинала документа в совокупность адекватных ей компьютерных кодов в найденных и отобранных полях документа и приведение в соответствие компьютерных кодов с оригиналом, - прототип.
Недостатком известных способов являются относительно низкие их функциональные и технические характеристики, в том числе низкие значения достигаемых скорости верификации ее усредненной точности.
Решаемой изобретением задачей является совершенствование способов верификации компьютерных кодов с соответствующими им оригиналами с достижением технического результата в виде повышения скорости верификации и ее усредненной точности. Скорость верификации определяется как количество верифицируемых символов в единицу времени.
Для удобства и однозначного понимания целесообразно привести расшифровки и определения используемых далее обозначений, символов и/или терминов.
Исходное графическое изображение на материальном носителе - подлежащее вводу в компьютер изображение с целью последующей компьютерной обработки или хранения в машиночитаемом виде.
Графическое изображение, введенное в компьютер, - компьютерное представление некоторого фрагмента графической информации.
Компьютерный код символа - компьютерное представление некоторого фрагмента символьной информации.
Компьютерные коды символов получают в процессе компьютерного распознавания графического изображения, введенного в компьютер, например, с помощью сканера, или его фрагментов.
Процесс верификации - производимое человеком и/или заменяющим его устройством, и/или компьютерной программой сличение (определение адекватности) компьютерных кодов символов с графическим изображением, введенным в компьютер.
Процесс распознавания - процесс обработки системой распознавания введенного в компьютер графического изображения некоторого символа, в результате чего система распознавания приписывает изображению компьютерный код этого символа.
Точность процесса распознавания - усредненный процент правильно распознанных символов по статистически представительному практически релевантному множеству текстов.
Правильно распознанные символы - символы, компьютерный код которых правильно определен системой распознавания.
Неправильно распознанные символы - символы, компьютерный код которых неправильно определен системой распознавания.
Выделенные символы - символы, выделенные в процессе фильтрации для последующей верификации. В идеале выделенные символы должны включать все неправильно распознанные символы.
Цена ошибки - параметр, адекватный величине убытка, причиненного попаданием неправильно распознанного символа в окончательный результат распознавания.
Обозначения:
Nисх - общее число символов в документе,
Nвыд - число символов, выделенное алгоритмом фильтрации,
Nневыд - число символов, не выделенное алгоритмом фильтрации,
Nпр - число правильно распознанных символов,
Nнепр - общее число неправильно распознанных символов,
Nвыд.пр - число выделенных правильно распознанных символов,
Nвыд.непр. - число выделенных неправильно распознанных символов,
Nневыд.пр. - число невыделенных правильно распознанных символов,
Nневыд .непр - число невыделенных неправильно распознанных символов,
верхний индекс C (как в NC) обозначает число символов, которые получили в процессе распознавания компьютерный код C,
A - точность распознавания данного документа,
A=Nпр/Nисх,
Aср - усредненная точность распознавания данного документа: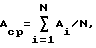
где N - общее число документов в выборке, a i - номер документа в выборке,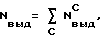
где С - числовое значение компьютерного кода распознанного символа (порядковый номер), выбираемое из всего множества допустимых значений без исключений,
Nгр C - количество сгруппированных для верификации одинаковых компьютерных кодов,
Nэкр - количество графических изображений выводимых на экран одновременно (из общего количества Nгр C).
В качестве кратких сведений, раскрывающих сущность изобретения, следует отметить, что достигаемый технический результат обеспечивают с помощью предложенного группового способа АБИ (ABBYY) верификации компьютерных кодов с соответствующими им оригиналами, включающего преобразование исходной символьной информации оригинала документа в совокупность адекватных ей компьютерных кодов в найденных и отобранных полях документа и приведение в соответствие компьютерных кодов с оригиналом. Отличительные особенности заявленного способа заключаются в том, что в процессе фильтрации выделяют компьютерные коды символов, определяя достоверность распознавания каждого символа на основе результатов распознавания изображения этого символа различными известными способами, сравнения этих результатов между собой и с результатом словарного контроля и выбирая их из исходной последовательности компьютерных кодов символов общим числом Nисх, в количестве Nвыд = F - aNневыд. непр, где а - экспериментальный коэффициент, выбираемый в зависимости от цены ошибки и усредненной точности системы распознавания в пределах: 10-12≤ α ≤ 1015, a F - экспериментальный параметр, выбираемый в зависимости от точности системы распознавания и числа подлежащих распознаванию символов в документе в пределах: 1 ≤F≤1016.
Затем после фильтрации группируют одинаково распознанные компьютерные коды общим числом Nвыд таким образом, что в каждую группу включают Nвыд C одинаковых компьютерных кодов символов, где C - числовое значение верифицируемого компьютерного кода, выбираемое из всего множества допустимых значений, выбирая значение Nвыд C в пределах: 1≤(Nвыд C + Nвыд)/Nвыд ≤2. При этом в каждую группу Nвыд C включают правильно распознанные компьютерные коды символов в количестве Nвыдпр C и неправильно распознанные компьютерные коды символов в количестве Nвыднепр C, а соотношение между Nвыдпр C и Nвыднепр C выбирают в пределах: -0.5≤(Nвыдпр C + Nвыднепр C - bNвыд C)/Nвыдпр C ≤1.5, где b- экспериментальный коэффициент, выбираемый в зависимости от четкости и контрастности исходного графического изображения в пределах: 10-9≤b≤1. Для верификации выбирают количество Nгр сгруппированных одинаковых компьютерных кодов в пределах Nгр= βγN
Группы одинаково распознанных компьютерных кодов выводят для их верификации специализированным устройством или оператором, например, в случайном порядке либо в порядке убывания весовой WC значимости группы компьютерных кодов, которую определяют экспериментально на основе статистической обработки больших массивов информации в зависимости от алфавитного порядка и/или размера группы компьютерных кодов, и/или степени важности данного компьютерного кода для содержания документа и др., исходя из практической значимости достоверности верификации компьютерных кодов, и выбирают в пределах: 10-8≤ WC/Nвыд C≤1016. Производят верификацию, сличая, например, показанное на устройстве отображения визуальной информации изображение, введенное в компьютер, с изображением компьютерного кода символа, для чего одновременно в устройство отображения визуальной информации вводят Nэкр разных графических изображений, предоставляя при этом на верификацию одного изображения промежуток Твер времени, который по отношению к Nэкр выбирают в экспериментально найденных пределах: -20 ≤ log2(αTверNэкр) ≤ 37, где α - экспериментальный коэффициент, выбираемый в зависимости от кинетических характеристик устройства ввода символьной информации в компьютер в пределах 0.2c-1≤ α ≤ 10c-1.
При изложении сведений, подтверждающих возможность осуществления изобретения, целесообразно более детально описать предложенный групповой способ АБИ (ABBYY) верификации компьютерных кодов с соответствующими им оригиналами. При описании способа нецелесообразно детально останавливаться на известных из опубликованных данных особенностях выполнения его операций, в частности, преобразование исходной символьной информации оригинала документа в совокупность адекватных ей компьютерных кодов в найденных и отобранных полях документа и приведение в соответствие компьютерных кодов с оригиналом.
Детально целесообразно остановиться только на отличительных существенных особенностях осуществления операций предложенного способа, заключающихся в том, что в процессе фильтрации выделяют компьютерные коды символов, определяя достоверность распознавания каждого символа на основе результатов распознавания изображения этого символа различными известными способами, сравнения этих результатов между собой и с результатом словарного контроля и выбирая их из исходной последовательности компьютерных кодов символов общим числом Nисх, в количестве Nвыд= F-αNневыд.непр,, где a - экспериментальный коэффициент, выбираемый в зависимости от цены ошибки и усредненной точности системы распознавания в пределах: 1012 ≤ α ≤ 1015, a F - экспериментальный параметр, выбираемый в зависимости от точности системы распознавания и числа подлежащих распознаванию символов в документе в пределах: 1 ≤ F ≤1016. Обычно а выбирают в диапазоне 1 - 105, a F - в диапазоне 10 ≤ F ≤ 106.
В некоторых случаях, в частности, словарный контроль существенно повышает достоверность распознавания отдельных символов, так при этом даже полная невозможность распознания некоторых символов позволяет определить их значение исходя из смыслового содержания слова и месторасположения нераспознанных символов в слове. Если в результате выделения в соответствии с приведенными аналитическими соотношениями необходимых количеств компьютерных кодов получают дробные, отрицательные значения и какие-либо другие значения, некорректные исходя из условий возможности их дальнейшего использования, то их исключают из рассмотрения и/или автоматически удаляют.
Затем группируют после фильтрации одинаково распознанные компьютерные коды общим числом Nвыд таким образом, что в каждую группу включают Nвыд C одинаковых компьютерных кодов символов, где C - числовое значение верифицируемого компьютерного кода из всего множества допустимых значений, выбирая значение Nвыд C в пределах: 1 ≤(Nвыд C + Nвыд)/Nвыд ≤ 2. Определение числового значения C может быть произвольным или в результате, например, последовательно выбора из множества его допустимых значений. При этом в каждую группу Nвыд C включают правильно распознанные компьютерные коды символов в количестве Nвыдпр C и неправильно распознанные компьютерные коды символов в количестве Nвыднепр C, а соотношение между Nвыдпр C и Nвыднепр C выбирают в пределах: -0.5≤ (Nвыдпр C + Nвыднепр C - bNвыд C)/Nвыдпр C≤1.5, где b - экспериментальный коэффициент, выбираемый в зависимости от четкости и контрастности исходного графического изображения в пределах: 10-9≤b≤1. Для верификации выбирают количество Nгр сгруппированных одинаковых компьютерных кодов в пределах: Nгр= βγN
Группы одинаково распознанных компьютерных кодов выводят для их верификации специализированным устройством или оператором, например, в случайном порядке либо в порядке убывания весовой WC значимости группы компьютерных кодов, которую определяют экспериментально на основе статистической обработки больших массивов информации в зависимости от алфавитного порядка и/или размера группы компьютерных кодов, и/или степени важности данного компьютерного кода для содержания документа и др., исходя из практической значимости достоверности верификации компьютерных кодов, и выбирают в пределах: 10-8≤WC/Nвыд C ≤1016. Производят верификацию, сличая, например, показанное на устройстве отображения визуальной информации изображение, введенное в компьютер, с изображением компьютерного кода символа, для чего одновременно в устройство отображения визуальной информации вводят Nэкр разных графических изображений, предоставляя при этом на верификацию одного изображения промежуток Твер времени, который по отношению к Nэкр выбирают в экспериментально найденных пределах: -20 ≤ log2(αTверNэкр)≤ 37, где α - экспериментальный коэффициент, выбираемый в зависимости от кинетических характеристик устройства ввода символьной информации в компьютер в пределах 0.2c-1≤ α ≤ 10-1. Как следует из соотношения, размерность коэффициента α равна величине, обратной секунде.
Достигаемый технический результат, как показали данные экспериментов, может быть реализован только взаимосвязанной совокупностью всех существенных признаков заявленного объекта, отраженных в формуле изобретения. Указанные в ней отличия дают основание сделать вывод о новизне данного технического решения, а совокупность испрашиваемых притязаний в связи с их неочевидностью - о его изобретательском уровне, что доказывается также вышеприведенным их детальным описанием. Соответствие критерию "промышленная применимость" предложенного способа доказывается как его реализацией, так и отсутствием в заявленных притязаниях каких-либо практически трудно реализуемых в промышленных масштабах признаков. Нижние и верхние значения заявленных пределов были получены на основе статистической обработки результатов экспериментальных исследований, анализа и обобщения их и известных из опубликованных источников данных, а также с использованием изобретательской интуиции, исходя из условия достижения указанного технического результата.
Кроме указанного выше технического результата практическое осуществление заявленного объекта позволяет существенно расширить возможности его использования применительно, например, к различным документам, заполняемым рукописными символами.
Изобретение относится к вычислительной технике. Его использование при верификации компьютерных кодов с соответствующими им оригиналами позволяет повысить скорость верификации и ее точность. Способ включает в себя преобразование исходной символьной информации оригинала документа в совокупность адекватных ей компьютерных кодов в найденных и отобранных полях документов и приведение в соответствие компьютерных кодов с оригиналом. Технический результат достигается благодаря тому, что выделяют компьютерные коды символов, определяя достоверность распознавания каждого символа на основе результатов распознавания изображения этого символа известными способами, сравнения этих результатов между собой и с результатом словарного контроля, причем верификацию осуществляют над параллельно выведенными на устройство отображения визуальной информации несколькими графическими изображениями. 1 з.п.ф-лы.
2. Способ по п.1, отличающийся тем, что группы одинаково распознанных компьютерных кодов выводят для их верификации специализированным устройством или оператором в порядке убывания весовой значимости WС группы компьютерных кодов, которую определяют экспериментально на основе статистической обработки больших массивов информации в зависимости от алфавитного порядка, и/или размера группы компьютерных кодов, и/или степени важности данного компьютерного кода для содержания документа, исходя из практической значимости достоверности верификации компьютерных кодов, и выбирают в пределах 10-8 ≤ WС/Nвыд C ≤ 1016.
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Руководство пользователя | |||
| Bit Software, Inc | |||
| - Казань: Казанский производственный комбинат программных средств, 1997 | |||
| US 5544257 A, 06.08.96 | |||
| US 5550931 A, 27.08.96 | |||
| Рабочее колесо турбомашины | 1978 |
|
SU779592A1 |
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |

