Областью применения изобретения является автоматическая идентификация личности, используемая для биометрического ограничения несанкционированного доступа (в том числе удаленного) в помещения, к телекоммуникационным и иным системам и устройствам, к средствам электронно-вычислительной техники, к информации конфиденциального характера.
Известны различные системы, устройства и способы идентификации личности по голосу [1, 2, 3]. По публикации [1] для распознавания голоса зарегистрированной личности периодически (на временных интервалах фиксированной длительности) производят определение центра спектра и среднюю амплитуду речевого сигнала. На временном интервале с большой амплитудой вокализованного речевого сигнала положение центра спектра речевого сигнала сравнивают с центром спектра речевого сигнала, хранящегося в запоминающем устройстве в качестве эталона. Формирование эталонного значения центра спектра речевого сигнала производят предварительно на этапе регистрации личности (обучения системы). Далее определяют расхождение положений эталонного значения центра спектра речевого сигнала и центра спектра распознаваемого речевого сигнала и принимают решение по распознаванию голоса путем сравнения величины этого расхождения с заранее заданной величиной. Недостатками данной системы являются малое число контролируемых параметров, их усреднение по фиксированному временному интервалу, вносящее дополнительную погрешность, использование для распознавания только стационарных участков речевого сигнала, а также простое решающее правило определения "свой-чужой", что в совокупности не обеспечивает надежное распознавание голоса.
По публикации [2] выделяют зоны непрерывного речевого сигнала, для каждого временного интервала речевого сигнала внутри зон определяют параметры акустического тракта человека, дополнительно в зонах определяют огибающие интенсивности речевого сигнала. Далее для каждой зоны деформируют контуры параметров акустического тракта идентифицируемого (тестируемого) человека в соответствии с функцией деформации, определенной по эталонному и тестовому произношениям. Так производят нелинейную временную нормализацию, исключающую темповую вариативность произношений. На основании ковариационных матриц деформированных параметров акустического тракта человека, учитывающих их связность между собой, и соответствующих им обратных матриц для каждого временного интервала речевого сигнала вычисляют меру расстояния с последующим усреднением мер расстояний по всему произношению и принятием решения "свой-чужой". Недостатками данной системы являются:
- большая вычислительная нагрузка при определении функции деформации, а также при процедуре обращения матриц параметров акустического тракта человека на каждом временном интервале;
- ограниченное число контролируемых параметров акустического тракта человека, не превышающее 4-5, из-за ограничения размерности обращаемых матриц, не позволяющее существенно повысить надежность идентификации личности относительно достигнутого;
- наличие погрешности определения параметров акустического тракта человека из-за отсутствия синхронизации с периодом основного тона речевого сигнала, ухудшающее надежность идентификации личности;
- отсутствие автоматического выделения вокализованных участков речи на случайных фразах, ухудшающее надежность идентификации личности за счет учета мер расстояний на невокализованных временных интервалах речевого сигнала;
- необходимость достаточно качественных входных данных для процедуры обращения матриц, что не позволяет существенно уменьшить число итераций обучения при формировании эталонов (обучении системы).
Данная система обеспечивает надежное опознавание голоса, но требует длительной фазы обучения и достаточно мощного вычислителя.
Известен "Способ идентификации говорящего" [3], являющийся прототипом предлагаемого способа. Его суть сводится к тому, что произносят парольную фразу, разбивают речевой сигнал фразы на вокализованные зоны, выделяют определенное количество временных интервалов фиксированной длительности. Временные интервалы выделяют в начале первой и в конце последней вокализованных зон парольной фразы, а также в области максимумов интенсивности речевого сигнала. На выделенных временных интервалах определяют параметры речевого сигнала, в качестве которых используют:
- значения длительности интервалов между временными интервалами (T0 - T4, фиг. 2г прототипа),
- число экстремумов речевого сигнала во временных интервалах (N1э - N5э, фиг. 2д прототипа),
- соотношение 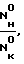 где Nн0 - число нулевых точек первой гармоники речевого сигнала в начальном временном интервале, Nк0 - в конечном временном интервале (фиг. 2е прототипа).
где Nн0 - число нулевых точек первой гармоники речевого сигнала в начальном временном интервале, Nк0 - в конечном временном интервале (фиг. 2е прототипа).
На фиг. 1 показаны матрицы прототипа, столбцы которой определяются временными интервалами, строки - математическими ожиданиями, допустимыми разбросами и параметрами речевого сигнала соответственно. Фактически, эти матрицы можно представить в виде векторов. Формирование эталонных матриц (векторов) математических ожиданий и допустимых разбросов параметров речевого сигнала производят предварительно на этапе формирования эталонов.
При идентификации вектор параметров сравнивают с эталонным вектором математических ожиданий параметров, в результате чего формируют разностный сигнал Δ, который сравнивают с заранее установленным порогом Θ, определенным на основании допустимых разбросов параметров речевого сигнала. Разностный сигнал Δ формируют путем вычисления невзвешенной Евклидовой меры расстояния. При Δ < Θ говорящего идентифицируют как истинное лицо, проводившее обучение, при Δ ≥ Θ - как ложное.
Недостатком описанного выше способа-прототипа является недостаточно надежная идентификация личности, что обусловлено несколькими причинами: малым числом временных интервалов на нестационарных вокализованных участках речи (два временных интервала: в начале и конце парольной фразы), дополнительными погрешностями измерения параметров речевого сигнала из-за фиксированной длительности временных интервалов (некратности их длительности периоду основного тона речевого сигнала), ограниченным количеством параметров речевого сигнала, простым решающим правилом определения "свой-чужой".
Задачей предлагаемого способа является повышение надежности идентификации личности говорящего.
Технический результат, достигаемый способом, заключается в повышении точности определения параметров речевого сигнала и точности формирования эталонов, увеличении числа контролируемых величин, использовании более эффективных методов их обработки.
Указанный результат достигается выделением дополнительных временных интервалов на нестационарных участках речи (в начале и конце каждой вокализованной зоны), синхронизацией длительности временных интервалов с периодом основного тона речевого сигнала, использованием дисперсий, а также в качестве дополнительных контролируемых величин оценок коэффициентов корреляций (коэффициентов корреляций) параметров речевого сигнала использованием нейросети при принятии решения "свой-чужой", использованием дополнительной речевой информации с ларингофона, контактирующего с телом говорящего.
Производят разбиение речевого сигнала парольной фразы на вокализованные зоны. Внутри вокализованных зон выделяют временные интервалы в области максимумов интенсивности речевого сигнала. Дополнительно на нестационарных участках речи (в начале и конце каждой вокализованной зоны) выделяют временные интервалы. На нестационарных участках речи имитация параметров речевого сигнала представляет гораздо большую трудность, чем на стационарных. Навыки произношения любых звуковых форм вырабатываются в течение длительного времени (месяцы и даже годы), поэтому неподготовленный человек не может произвести имитацию всех звуковых форм парольной фразы. Имитация речи профессиональными имитаторами производится в основном на стационарных участках, дающих общую оценку похожести голоса. Взрывные звуковые формы (типа "к", "г", "д"), так же как и гласные на нестационарных участках речи, имитируются с гораздо большим трудом и в общей слуховой оценке похожести голоса участвуют в гораздо меньшей степени, чем стационарные вокализованные звуковые формы (типа "а-а-...", "о-о-...", "е-е-...").
Длительность временных интервалов устанавливают кратной периоду основного тона речевого сигнала, определяемым любым из известных методов, например методом определения функции разности среднего значения, обеспечивающего в условиях тишины наименьшее число ошибок по сравнению с другими методами [4] , или методом определения периода основного тона по пиковым амплитудным значениям речевого сигнала, изложенным в [5]. При кратности длительности временных интервалов периоду основного тона обеспечивается большая точность (уменьшение погрешности) определения параметров речевого сигнала за счет отсутствия краевых эффектов.
При формировании эталонов определяют математические ожидания и дисперсии параметров речевого сигнала, а также коэффициенты корреляции этих параметров. При идентификации параметры речевого сигнала сравнивают с математическими ожиданиями этих параметров, дисперсии параметров речевого сигнала определяют допустимые границы их изменений. Дополнительно сравнивают оценки коэффициентов корреляции с эталонными значениями коэффициентов корреляции, являющимися индивидуальными и постоянными для каждого человека. Повышение надежности идентификации личности достигается за счет фактического увеличения числа контролируемых параметров. При использовании i параметров речевого сигнала добавляется (i2-i)/2 коэффициентов корреляции (оценок коэффициентов корреляции) параметров речевого сигнала, что при i≥3 существенно увеличивает общее число контролируемых величин.
В отличие от прототипа по предложенному способу формируют множество векторов и матриц (смотри фиг. 2), соответствующих своим временным интервалам. Эти векторы, матрицы могут как обрабатываться отдельно для каждого временного интервала с последующим усреднением результата обработки по всему произношению, так и сводиться в единые векторы, матрицы всего произношения для их последующей обработки.
По степени близости (удаленности) контролируемых величин от эталонов, а также учитывая отклик нейросети, делают вывод о принадлежности голоса зарегистрированной личности, производившей обучение. Степень близости может определяться любым из известных методов, например как взвешенной Евклидовой мерой расстояния (типа расстояния Махаланобиса [6]), обеспечивающей достаточно точное разделение областей параметров речевого сигнала зарегистрированного пользователя и имитаторов, так и с использованием невзвешенной Евклидовой меры расстояния. Использование взвешенной Евклидовой меры расстояния дает более точное определение степени близости, но ограничивает размерность обрабатываемых матриц параметров из-за большой вычислительной нагрузки при операции обращения матриц.
В соответствии с п. 2 формулы изобретения идентификацию личности производят с учетом отклика нейросети [7] . На ее входы подают параметры и оценки коэффициентов корреляции параметров речевого сигнала, последние в данном случае также являются контролируемыми параметрами. Использование многослойной нейросети позволяет реализовать решающее правило существенно большей сложности, чем у аналогов, не ограничиваясь размерностью векторов (матриц) параметров речевого сигнала, а также отказаться от процедуры обращения матриц, накладывающей большие ограничения. Использование нейросети позволяет упростить этап обучения, уменьшая в соответствии с требованиями число итераций этого этапа.
В отличие от способа-прототипа использование нейросети предполагает формирование дополнительного неявного эталона в виде нейровесов, получаемых на этапе ее обучения. Одновременно при этом используют обычный эталон в виде математических ожиданий параметров речевого сигнала, их дисперсий, а также коэффициентов корреляции этих параметров.
Недостатком всех аналогов является малая степень защиты от имитации голоса с помощью звуковоспроизводящих устройств типа магнитофонов, CD-проигрывателей, управляемых синтезаторов речи и т.п. В соответствии с п.3 формулы изобретения для защиты от имитации голоса такими устройствами используют дополнительную речевую информацию, вводимую с ларингофона, контактирующего с телом. Речевой сигнал, поступающий с ларингофона, и соответствующие ему параметры речевого сигнала, их коэффициенты коррелляции и оценки коэффициентов корреляции зависят от местоположения ларингофона и не могут быть воспроизведены современными техническими средствами. Сигнал с ларингофона, контактирующего с телом, нельзя описать с достаточной степенью точности современным математическим аппаратом из-за сложности динамических моделей, учитывающих форму и структуру мышц, хрящей, костей и т.п. при их взаимодействии между собой.
На фиг. 1 представлены эталонные матрицы и матрицы идентифицируемого произношения прототипа.
На фиг. 2 представлены эталонные векторы, матрицы и векторы, матрицы идентифицируемого произношения предлагаемого способа.
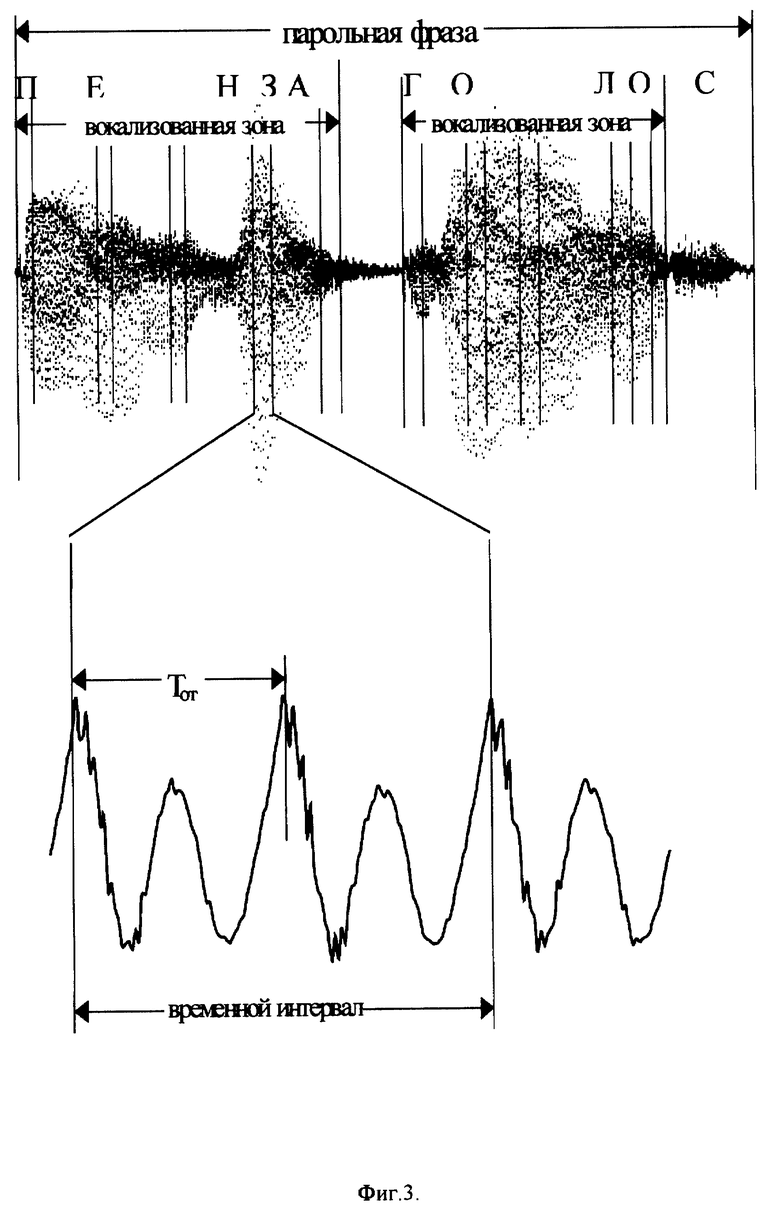
На фиг. 3 представлен пример речевого сигнала парольной фразы "ПЕНЗА-ГОЛОС". Для удобства дается буквенная запись парольной фразы.
На фиг. 4 представлена структурная схема устройства, реализующего способ (пример).
Устройство состоит из блоков:
блока 1 усилителей;
блока 2 разбиения речевого сигнала парольной фразы на вокализованные зоны;
блока 3 долговременного запоминающего устройства для хранения вокализованных зон парольной фразы, а также диалоговых речевых сообщений (в случае их использования);
блока 4 определения периода основного тона речевого сигнала Tот;
блока 5 выделения временных интервалов;
блока 6 определения параметров речевого сигнала;
блока 7 определения математических ожиданий и дисперсий параметров речевого сигнала;
блока 8 определения оценок коэффициентов корреляций и коэффициентов корреляций параметров речевого сигнала;
блока 9 принятия решения "свой-чужой";
блока 10 управления.
Блоки 4-10 могут быть реализованы средствами аналоговой и/или цифровой вычислительной техники.
Входы блока 1 усилителей соединены с микрофоном и ларингофоном, а также с одним из выходов блока 3 долговременного запоминающего устройства (в случае диалога с идентифицируемой личностью). Один из выходов блока 1 усилителей соединен со входом блока 2 разбиения речевого сигнала парольной фразы на вокализованные зоны, другой - с динамиком (телефонным капсюлем) (в случае диалога с идентифицируемой личностью). Выход блока 2 разбиения речевого сигнала парольной фразы на вокализованные зоны соединен со входом блока 3 долговременного запоминающего устройства. Выход блока 3 долговременного запоминающего устройства соединен со входом блока 4 определения периода основного тона речевого сигнала Tот, одним из входов блока 5 выделения временных интервалов, одним из входов блока 6 определения параметров речевого сигнала и обеспечивает подачу на эти блоки вокализованной речи. Выход блока 4 определения периода основного тона речевого сигнала Tот соединен с одним из входов блока 5 выделения временных интервалов для передачи в этот блок значения периода основного тона. Выход блока 5 выделения временных интервалов соединен с одним из входов блока 6 определения параметров речевого сигнала. Выход блока 6 определения параметров речевого сигнала соединен со входом блока 7 определения математических ожиданий и дисперсий параметров речевого сигнала, одним из входов блока 8 определения оценок коэффициентов корреляций и коэффициентов корреляций параметров речевого сигнала, одним из входов блока 9 принятия решения "свой-чужой" для передачи в эти блоки параметров речевого сигнала. Выход блока 7 определения математических ожиданий и дисперсий параметров речевого сигнала соединен с одним из входов блока 8 определения оценок коэффициентов корреляций и коэффициентов корреляций параметров речевого сигнала и с одним из входов блока 9 принятия решения "свой-чужой". Выход блока 8 определения оценок коэффициентов корреляций и коэффициентов корреляций параметров речевого сигнала соединен с одним из входов блока 9 принятия решения "свой-чужой". Выход блока 9 принятия решения "свой-чужой" соединен со входом блока 10 управления для обеспечения возможности анализа выходного сигнала и одновременно является выходом устройства. Выход блока 10 управления соединен с одним из входов блока 9 принятия решения "свой-чужой" для обеспечения возможности его управления.
Работа устройства происходит следующим образом. После воспроизведения хранимого в блоке 3 долговременного запоминающего устройства сообщения через усилитель и динамик (телефонный капсюль) (в случае диалога) идентифицируемый должен прижать ларингофон к телу в определенном месте и произнести соответствующую парольную фразу в микрофон. Речевой сигнал с микрофона и ларингофона через блок 1 усилителей поступает на блок 2 разбиения речевого сигнала парольной фразы на вокализованные зоны, использующий любой из известных методов определения вокализованности речевого сигнала, например аналогичный используемому в устройстве-прототипе и использующий набор узкополосных фильтров. В отличие от вокализованного шумоподобный сигнал имеет более равномерное распределение энергии в частотной области и соответственно более равномерный уровень сигнала на выходах всех фильтров, что позволяет исключить его из дальнейшей обработки.
Вокализованный речевой сигнал сохраняют в блоке 3 долговременного запоминающего устройства и подают на блок 4 определения периода основного тона речевого сигнала Tот. Блок 4 определения периода основного тона аналогичен детектору 8 первой гармоники сигнала прототипа (смотри фиг. 1 прототипа). На блок 5 выделения временных интервалов подают вокализованный речевой сигнал из блока 3 долговременного запоминающего устройства и значение периода основного тона из блока 4 определения периода основного тона речевого сигнала Tот. При выделении временных интервалов их длительность выбирают кратной периоду основного тона речевого сигнала. Внутри вокализованных зон определяют несколько (например, шесть) максимумов интенсивности речевого сигнала и вблизи этих максимумов выделяют временные интервалы. Временные интервалы выделяют также в начале и конце каждой вокализованной зоны.
На основании речевого сигнала из блока 3 долговременного запоминающего устройства и выделенных временных интервалов из блока 5 выделения временных интервалов в блоке 6 определения параметров речевого сигнала вычисляют параметры речевого сигнала pi, в качестве которых могут использоваться любые параметры речевого сигнала, например значения энергии в частотных областях, число переходов речевого сигнала через ноль, значение периода основного тона, коэффициенты линейного предсказания (значимыми являются 10-12 коэффициентов).
При обучении (на N произношениях парольной фразы) полученные параметры речевого сигнала подают на блок 7 определения математических ожиданий и дисперсий параметров речевого тракта для определения их математических ожиданий m(pi), дисперсий σ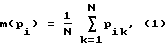
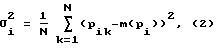
где 1 ≅ k ≅ N - индекс произношения при обучении.
Из блока 7 определения математических ожиданий параметров речевого сигнала и их дисперсий извлекают математические ожидания параметров речевого сигнала и их дисперсии и в блоке 8 определения оценок коэффициентов корреляций и коэффициентов корреляций параметров речевого сигнала вычисляют коэффициенты корреляции Rij и оценки коэффициентов корреляций rij по следующим формулам: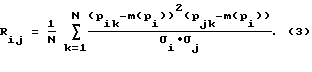
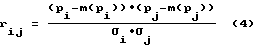
где 1 ≅ k ≅ N - индекс произношения при обучении.
Параметры речевого сигнала и соответствующие им статистические характеристики определяют для каждого временного интервала. На фиг. 2 приведены эталонные векторы, матрицы (вверху) и соответствующие им векторы, матрицы идентифицируемого произношения (внизу).
Параметры речевого сигнала из блока 6 определения параметров речевого сигнала, их математические ожидания и дисперсии из блока 7 определения математических ожиданий и дисперсий параметров речевого сигнала, а также коэффициенты корреляции и оценки коэффициентов корреляции из блока 8 определения оценок коэффициентов корреляций и коэффициентов корреляций параметров речевого сигнала подают на блок 9 принятия решения "свой-чужой". Блок 10 управления формирует решающее правило, используя информацию из блока 9 принятия решения "свой-чужой". Степень близости (удаленности) параметров речевого сигнала от их математических ожиданий и оценок коэффициентов корреляций от коэффициентов корреляций параметров речевого сигнала определяют как невзвешенную Евклидову меру расстояния d, являющуюся среди большого количества мер расстояний наиболее популярной в силу простоты своего вычисления по формуле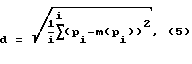
где i - число параметров.
При использовании множества мер расстояний (каждая для соответствующего временного интервала) усреднение мер расстояний по всему произношению производят по следующей формуле: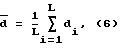
где L - число временных интервалов.
На основании этой меры расстояния, а также с учетом отклика нейросети принимают решение о принадлежности голоса зарегистрированной личности, производившей обучение.
В соответствии с п.2 формулы изобретения в состав блока 9 принятия решения "свой-чужой" входит нейросеть [7]. В основе построения искусственных нейронных сетей лежит модель нейрона. Нейроны соединены друг с другом определенным образом, при этом с выходов других нейронов на вход каждого нейрона поступает множество сигналов, образующих входной вектор. Все сигналы, умноженные на соответствующие весовые коэффициенты, суммируют. Такие коэффициенты образуют весовой вектор, элементы которого соответствуют связям определенных нейронов. Результат суммирования поступает на пороговый элемент, характеризуемый величиной порога и некоторой функцией активации. Существует множество принципов организации нейросетей, которые могут содержать разное число слоев нейронов. Нейроны могут быть связаны как внутри слоев, так и между слоями. Одним из основных свойств нейронных сетей является их способность обучаться. На этапе обучения происходит подстройка нейровесов для получения требуемой реакции нейросети. Эти нейровеса, являющиеся неявным эталоном, формируют блоком 10 управления.
Таким образом, применение нейросети, обеспечивающей сложное решающее правило определения "свой-чужой" и позволяющей отказаться от вычисления взвешенных мер расстояний и операций обращения матриц, увеличивает надежность идентификации личности.
Использование дополнительных параметров речевого сигнала (десяти коэффициентов линейного предсказания) и коэффициентов корреляции (оценок коэффициентов корреляции) параметров речевого сигнала, увеличение числа временных интервалов (для похожей парольной фразы) до 10 увеличивает число контролируемых величин по сравнению с прототипом с 11 до 781, что существенно увеличивает надежность идентификации личности.
По экспертным оценкам специалистов ПНИЭИ вероятность ложной идентификации личности способа-прототипа (или аналогичных ему) составляет порядка 0,1. По экспертным оценкам специалистов ПНИЭИ предложенный способ обеспечивает вероятность ложной идентификации личности не более 0,007, что подтверждено протоколами Предварительных испытаний изделия "Кордон". Копии этих протоколов при необходимости могут быть представлены.
Таким образом, используя большее число нестационарных участков речевого сигнала, синхронизируя временные интервалы с периодом основного тона речевого сигнала, используя дисперсии, коэффициенты корреляции и оценки коэффициентов корреляции параметров речевого сигнала, применяя нейросеть, добиваются уменьшения имитируемости и суммарной погрешности определения параметров речевого сигнала, увеличения числа контролируемых величин и усложнения решающего правила "свой-чужой", что обеспечивает надежное опознавание голоса при незначительных вычислительных затратах и простой процедуре обучения. Использование дополнительной речевой информации с ларингофона, контактирующего с телом говорящего, позволяет обеспечить защиту от имитации голоса с помощью современных звуковоспроизводящих устройств.
Истоники информации
1. US 4078154 A, 07.03.1978.
2. БОЧКАРЕВ С. Л. Система голосовой аутентификации по динамическим параметрам акустического тракта человека. Специальная техника средств связи. Серия системы, сети и технические средства конфиденциальной связи. - Пенза: ПНИЭИ, 1996, вып.1, с.93-102.
3. SU 1453442 A1, 23.01.1989.
4. КОРОТАЕВ Г.А. Анализ и синтез речевого сигнала методом линейного предсказания. Зарубежная радиоэлектроника, 1990, N 3, с.36.
5. US 4627323 A, 09.09.1986.
6. ВЕРХАГЕН К. и др. Распознавание образов. Состояние и перспективы. - М.: Радио и связь, 1985, с.39-45.
7. УОССЕРМЕН Ф. Нейрокомпьютерная техника: теория и практика. - М.: Мир, 1992, с.76.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ОСОБЕННОСТЯМ ПОДПИСИ | 1998 |
|
RU2148274C1 |
| СПОСОБ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ ЧЕЛОВЕКА С ИСПОЛЬЗОВАНИЕМ АКУСТИЧЕСКИХ СИГНАЛОВ, СНИМАЕМЫХ С ТЕЛА ЧЕЛОВЕКА | 2003 |
|
RU2263358C2 |
| СПОСОБ И УСТРОЙСТВО АВТОМАТИЧЕСКОЙ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ | 2008 |
|
RU2399102C2 |
| Способ идентификации говорящего | 1986 |
|
SU1453442A1 |
| СПОСОБ КОНТАКТНО-РАЗНОСТНОЙ АКУСТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 2011 |
|
RU2451346C1 |
| СПОСОБ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ НА ОСНОВЕ АНАТОМИЧЕСКИХ ПАРАМЕТРОВ ЧЕЛОВЕКА | 2010 |
|
RU2421699C1 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЧЕЛОВЕКА ПО ЕГО БИОМЕТРИЧЕСКОМУ ОБРАЗУ | 2005 |
|
RU2292079C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| ТЕКСТОЗАВИСИМЫЙ СПОСОБ КОНВЕРСИИ ГОЛОСА | 2010 |
|
RU2427044C1 |


Изобретение относится к обработке информации и может быть использовано в телекоммуникационных системах. Техническим результатом является повышение надежности идентификации личности. Изобретение основано на том, что в вокализованных зонах речевого сигнала выделяют временные интервалы с определенной длительностью и определяют оценки коэффициентов корреляции параметров речевого сигнала. 2 з.п.ф-лы, 4 ил.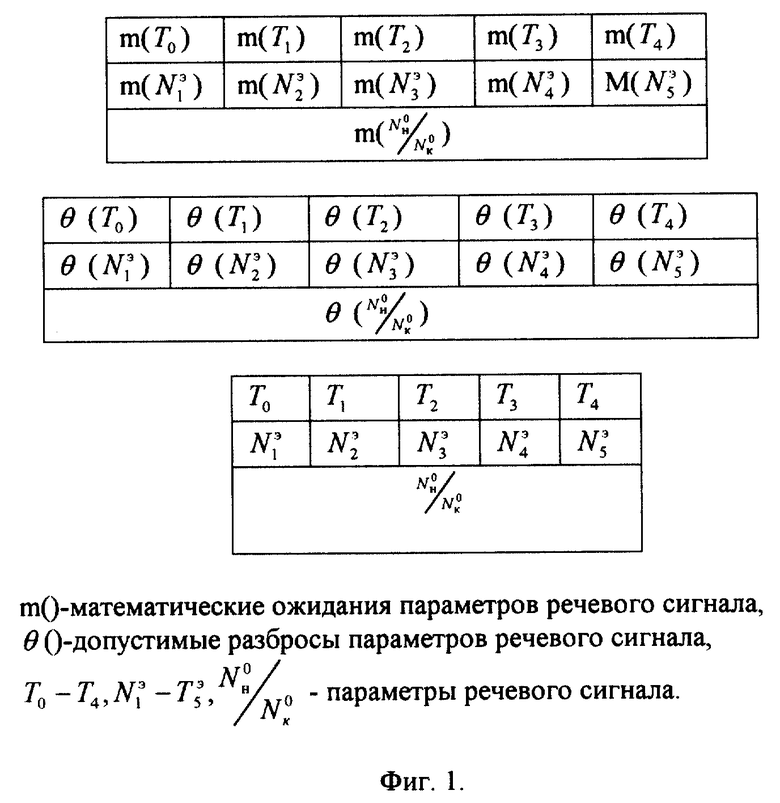
| Способ идентификации говорящего | 1986 |
|
SU1453442A1 |
| US 4078154 A, 07.03.1978 | |||
| БОЧКАРЕВ С.Л | |||
| Система голосовой аутентификации по динамическим параметрам акустического тракта человека | |||
| Специальная техника средств связи | |||
| Серия системы, сети и технические средства конфиденциальной связи | |||
| - Пенза: ПНИЭИ, 1996, вып.1, с.93 - 102 | |||
| КОРОТАЕВ Г.А | |||
| Анализ и синтез речевого сигнала методом линейного предсказания | |||
| Зарубежная радиоэлектроника, 1990, N3, с.36 | |||
| US 4627323 A, 09.09.1986 | |||
| ВЕРХАГЕН К | |||
| и др | |||
| Распознавание образов | |||
| Состояние и перспективы | |||
| - М.: Радио и связь, 1985, с.39 - 45 | |||
| УОССЕРМЕН Ф | |||
| Нейрокомпьютерная техника: теория и практика | |||
| - М.: Мир, 1992, с | |||
| Аппарат, предназначенный для летания | 0 |
|
SU76A1 |
| Способ идентификации говорящего | 1986 |
|
SU1394232A1 |
| Способ идентификации говорящего | 1987 |
|
SU1501139A2 |
| Автоматический огнетушитель | 0 |
|
SU92A1 |
| 1971 |
|
SU411655A1 | |

