Изобретение относится к системам установления или подтверждения личности говорящего. Заявляемые способ и устройство могут быть использованы, например, в системах и устройствах для ограничения несанкционированного доступа к информационным или материальным ресурсам на основе биометрической информации о говорящем.
Известны различные системы, устройства и способы аутентификации личности по голосу на примере частных задач верификации (подтверждения) и идентификации (установления) личности. Остановимся на них подробнее.
Известны способ распознавания диктора и устройство, реализующее этот способ [Патент РФ № 2230375: МПК G10L 15/00, G10L 17/00. Метод распознавания диктора и устройство для его осуществления. - № 2002123509/09; заявл. 03.09.02; опубл. 10.06.04].
Данный способ основан на том, что в качестве параметрических описаний используют соответственно векторы частот формант последовательно расположенных во времени сегментов входного речевого сигнала и эталонов с нефиксированным от сегмента к сегменту количеством формант, а также статистические характеристики спектра мощности входного речевого сигнала и эталонов, вычисляемые для их используемых сегментов. Для сравнения параметрических описаний входного речевого сигнала и эталона используется определенная мера близости между каждой парой сравниваемых сегментов входного речевого сигнала и эталона. При сравнении параметрических описаний входного речевого сигнала и эталона находят для каждого используемого сегмента входного речевого сигнала ближайший по мере близости сегмент каждого выбранного для сравнения эталона, формируют композитные результаты сравнения входного речевого сигнала и каждого из выбранных для сравнения эталонов, в которые соответственно включают взвешенное среднее по всем используемым сегментам входного речевого сигнала значение мер близости между данным используемым сегментом входного речевого сигнала и найденным для него ближайшим сегментом каждого выбранного для сравнения эталона и распознают неизвестного диктора на основе композитных результатов сравнения входного речевого сигнала и упомянутых эталонов. В качестве меры близости пары сравниваемых сегментов используют взвешенный модуль разности векторов формантных частот, для каждого используемого сегмента входного речевого сигнала ближайший по упомянутой мере близости сегмент выбранного для сравнения эталона определяют только среди сегментов эталона, у которых число формант в соответствующем сегменту векторе частот формант равно числу формант в соответствующем векторе частот формант сравниваемого сегмента входного речевого сигнала, а в композитный результат сравнения дополнительно включают коэффициент кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и выбранного для сравнения упомянутого эталона. Также предлагаются процедуры определения эталонов окружающего шума и амплитудно-частотной характеристики (АЧХ) используемого микрофона и процедуры учета при обработке речевого сигнала данных эталонов, которые существенно повышают устойчивость работы метода и устройства распознавания по отношению к искажениям сигнала низкокачественными микрофонами и шумам.
Известное устройство для распознавания диктора включает, в частности, источник речевого сигнала, блок определения параметрического описания речевого сигнала в виде выделителя начала/конца речевого сигнала, сегментатора речевого сигнала на последовательность сегментов, блока умножения на взвешивающее окно, блока добавления к сигналу в сегменте нулей, вычислителя преобразования Фурье, вычислителя спектра мощности сигнала в сегменте и формирователя параметрических описаний входного речевого сигнала, соединенных последовательно, коммутатор, блок сравнения параметрических описаний эталона и входного речевого сигнала, блок принятия решения о распознаваемом дикторе и запоминающее устройство, при этом источник речевого сигнала подключен к блоку определения параметрического описания речевого сигнала, выход которого соединен с входом коммутатора, первый выход которого подключен к первому входу блока сравнения параметрических описаний эталона и входного речевого сигнала, а второй выход соединен со входом запоминающего устройства, выход которого подключен ко второму входу блока сравнения параметрических описаний эталона и входного речевого сигнала, выход которого соединен с входом блока принятия решения о распознаваемом дикторе, выход которого является выходом устройства в целом, блок определения параметрического описания речевого сигнала дополнительно содержит блок определения формантного вектора текущего сегмента и первый сумматор-накопитель статистических характеристик входного речевого сигнала, включенные параллельно друг другу между вычислителем спектра мощности сигнала в сегменте и формирователем параметрических описаний входного речевого сигнала, блок сравнения параметрических описаний эталона и входного речевого сигнала выполнен в виде блока определения формантного расстояния от входного речевого сигнала до эталона и блока определения функции кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и эталона, выходы которых соединены соответственно через первый блок умножения и второй блок умножения со вторым сумматором, а выход второго сумматора соединен с входом блока принятия решения о распознаваемом дикторе.
Недостатки (данного способа и устройства): ограничение надежности распознавания за счет ошибок, появляющихся на этапах оценки параметров речевого сигнала и влияющих на эффективность вычисленных оценок параметров речевого сигнала, здесь можно выделить: ошибки, возникающие при определении границ поиска (примерной полосы) частот формант; ошибки, присутствующие при определении глобальных максимумов спектра мощности в примерной полосе частот, что обусловлено наличием локальных максимумов и минимумов, затрудняющих эффективную оценку формантных частот; ошибки, возникающие при экспериментальном подборе вектора нормализующей функции (на которую покомпонентно умножают входной сигнал спектра мощности сигнала на каждом сегменте), и вектора весовых коэффициентов (для оптимизации вклада каждой формантной частоты в меру близости двух сравниваемых сегментов речевого сигнала).
Известна система для верификации диктора [патент США № 2161336: МПК G10L 17/00. Система для верификации говорящего. - № 98100221/09; заявл. 06.06.96; опубл. 27.12.2000], которая объединяет множество выделенных признаков в множестве классификаторов. Данная система распознавания образов используется для верификации говорящего, при которой признаки выделяются из речи говорящего. Кроме того, выделяемые признаки могут быть сегментированы в полслова. Желательно, чтобы подслово являлось фонемой. Каждое из подслов может быть моделировано по меньшей мере одним классификатором. Результаты классификации объединяются для выявления сходства речи говорящего и речи, заранее запомненной для конкретного говорящего. На основании объединенного результата классификации принимается решение принять или отвергнуть говорящего. Данная система использует линейно предсказанные кепстральные коэффициенты, которые могут быть подвергнуты полосовой фильтрации с использованием окна, для уточнения их оценки. Для классификации речи предлагается применение объединенного классификатора, который использует динамическое предыскажение шкалы времени и нейронную древовидную сеть (или модифицированную нейронную древовидную сеть). Здесь динамическое предыскажение шкалы времени используется для подтверждения достоверности произнесенной парольной фразы, а нейронная древовидную сеть для различения говорящего среди других говорящих (верификации).
Недостатки: эта известная система не обеспечивает высокий уровень надежности верификации дикторов при работе в условиях акустического шума реальных помещений, улицы или транспортных средств, поскольку применяемые в устройстве посегментное, кепстральное временное описание речевых сигналов и динамическое предыскажение шкалы времени подвержены значительному влиянию акустических шумов и естественной изменчивости речи, также недостатком данного устройства является низкая надежность распознавания (высокий процент ложных отказов), вызванная неизбежной индивидуальной вариативностью произнесения одних и тех же слов в разном контексте даже одним и тем же диктором.
Данная известная система для верификации диктора, совпадающая с заявляемым решением по наибольшему числу существенных признаков и принятая за прототип, описана выше. Известное устройство-прототип включает, в частности, речевой источник, модуль выделения признаков, векторы речевых признаков, базу данных для хранения векторов речевых признаков, модуль слияния данных, логический модуль объединения решений. Источник речевого сигнала подключен к модулю выделения признаков, который определяет векторы речевых признаков, представляющие характерные параметры входного речевого сигнала в виде кепстральных коэффициентов линейного предсказания, далее модуль распознавания слова принимает векторы речевых признаков и представляет их в виде данных, которые могут храниться в базе данных. При условии, что принятые модулем распознавания слова векторы речевых признаков согласуются с данными, хранимыми в базе данных, например, соответствуют паролю для заявленной идентичности, модуль верификации говорящего приводится в действие. Если принятые векторы речевых признаков не согласуются с данными, хранимыми в базе данных, например не соответствуют паролю для заявленной идентичности, пользователю предлагается в модуле повторить вызов. При верификации приводится в действие модуль верификации говорящего, в котором используется слияние данных для объединения множества классификаторов с векторами речевых признаков, здесь выходные сигналы, соответствующие объединенным классификаторам, поступают в логический модуль объединения решений, который принимает окончательное решение принять или отвергнуть заявленную идентичность говорящего, тем самым выполняя верификацию заявленного соответствия говорящего.
Технический результат: создание способа верификации диктора и устройства, реализующего этот способ, которые позволили бы повысить потенциальную надежность распознавания, при этом обеспечивая высокую помехоустойчивость распознавания при работе с наличием шумов и при использовании микрофонов низкого качества.
Технический результат достигается за счет того, что заявляемый способ верификации диктора основывается на выделении существенных параметров речевого сигнала, таких как частота основного тона и амплитуды несущих гармоник (на частоте основного тона и нескольких первых обертонов), а также за счет применения метода расчета, имеющего повышенную точность оценки частоты основного тона речевого сигнала, содержащего вокализованные участки речи. В заявляемом способе используются более эффективные методы выделения и оценки параметров речевого сигнала, основанные на математической модели речевого сигнала в виде импульса амплитудно-модулированного (AM) колебания при модуляции нескольких несущих гармоник, а также ее физической интерпретации [Голубинский А.Н. Модель речевого сигнала в виде импульса АМ-колебания с несколькими несущими для верификации личности по голосу / А.Н.Голубинский // Системы управления и информационные технологии. - 2007. - № 4. - С.86-91].
Высокая помехоустойчивость распознавания достигается за счет того, что при работе с наличием шумов и при использовании микрофонов низкого качества рассчитанные параметры входного речевого сигнала и эталона можно нормализовать путем деления амплитуд несущих гармоник на эталон АЧХ микрофона (или на эталон АЧХ микрофона для случая использования помещения с минимальным уровнем шумов) для значений при соответствующих частотах. В заявляемом способе можно предварительно определять и запоминать эталон АЧХ используемого микрофона. При этом эталон частотного коэффициента передачи мощности используемого микрофона определяют путем накопления при непрерывном произнесении в микрофон речи в течение заданного интервала времени среднего значения спектральной плотности мощности данного речевого сигнала и последующего покомпонентного деления полученного среднего значения спектральной плотности мощности на заранее заданное эталонное среднее значение спектральной плотности мощности речевого сигнала (полученное при использовании качественного микрофона с равномерной АЧХ). Амплитудно-частотную характеристику получают путем извлечения квадратного корня из частотного коэффициента передачи мощности.
Суть заявляемого способа заключается в использовании в качестве параметров, характеризующих речевой сигнал, значений частоты основного тона и амплитуд несущих гармоник на частотах основного тона и обертонов. Общеизвестно [McAulay R.J., Quatieri T.F. «Speech analysis/synthesis based on a sinusoidal representation» IEEE Trans. On Acoustics, Speech and Signal Process., 1986, vol. 34 no. 4, pp.744-754] представление речевых сигналов, содержащих вокализованные участки речи, в суммы гармонических составляющих. В заявляемом изобретении впервые предлагается использовать для верификации дикторов параметры речевого сигнала, полученные на основании математической модели в виде импульса АМ-колебания с несколькими несущими частотами. Для оценки частоты основного тона и амплитуд несущих гармоник применяется минимизация невязки между коэффициентами корреляции входного сигнала и модели [Голубинский А.Н. Разработка математической модели речевого сигнала в виде импульса АМ-колебания с несколькими несущими частотами, применительно к задаче верификации личности по голосу / А.Н.Голубинский. - Воронеж, 2008. - 29 с. - Деп. в ВИНИТИ 09.07.08, № 591-В2008]. Вывод расчетных соотношений для частоты основного тона и амплитуд несущих гармоник проводится на основе метода наименьших квадратов. В отличие от известных решений в данном способе верификации и реализующем его устройстве предлагается проводить повышение точности оценки частоты основного тона при помощи использования метода расчета, основанного на математической модели речевого сигнала, построенной на основании физических принципов речеобразования. Для сравнения параметров входного речевого сигнала и эталона используется мера близости между входным речевым сигналом и эталоном, которая определяется, как взвешенная Евклидова невязка параметров входного речевого сигнала и эталона. Существенным отличием от прототипа является то, что формируются существенные параметры, применяемые для верификации личности, которые представляют собой амплитуды и частоты основного тона и обертонов речевого сигнала. Также предлагается использовать процедуру определения эталона АЧХ используемого микрофона, а также процедуру учета соответствующей АЧХ при обработке речевого сигнала данного эталона, которая существенно повышают устойчивость работы метода и устройства распознавания по отношению к искажениям сигнала микрофонами низкого качества.
Поставленная задача в части устройства решается тем, что в устройстве для распознавания диктора, включающем источник речевого сигнала, первый коммутатор, блок определения эталона амплитудно-частотной характеристики микрофона, блок расчета параметров речевого сигнала в виде выделителя начала/окончания речевого сигнала, блока вычисления коэффициентов корреляции речевого сигнала, блока расчета оценки частоты основного тона, блока расчета оценок амплитуд несущих гармоник и блока формирования параметров входного речевого сигнала, соединенных последовательно, второй коммутатор, блок сравнения параметров эталона и входного речевого сигнала, блок принятия решения о распознаваемом дикторе и запоминающее устройство, при этом источник речевого сигнала соединен с входом первого коммутатора, один из выходов которого соединен с первым входом блока определения параметров входного речевого сигнала, а второй выход первого коммутатора подключен ко входу блока определения эталона амплитудно-частотной характеристики микрофона, выход которого соединен с входом запоминающего устройства, подключенного ко второму входу блока расчета параметров входного речевого сигнала, выход блока расчета параметров речевого сигнала соединен с входом второго коммутатора, первый выход которого подключен к первому входу блока сравнения параметров эталона и входного речевого сигнала, а второй выход второго коммутатора соединен со входом запоминающего устройства, выход которого подключен ко второму входу устройства выбора эталона, к первому входу устройства выбора эталона подключено устройство ввода верификационного признака диктора, выход устройства выбора эталона подключен ко второму входу блока сравнения параметров эталона и входного речевого сигнала, выход которого соединен с входом блока принятия решения о распознаваемом дикторе, выход которого является выходом устройства в целом.
Блок расчета параметров речевого сигнала содержит блок оценки начала/окончания речевого сигнала, первый выход которого соединен с блоком вычисления коэффициентов корреляции речевого сигнала, выход которого соединен с блоком расчета оценки частоты основного тона, первый выход которого подключен ко входу блока расчета оценок амплитуд несущих гармоник, выход которого соединен с первым входом блока формирования параметров речевого сигнала, второй выход блока оценки начала/окончания речевого сигнала и второй выход блока расчета оценки частоты основного тона соединены соответственно со вторым и третьим входами блока формирования параметров речевого сигнала.
Блок сравнения параметров эталона и входного речевого сигнала выполнен в виде блока определения взвешенной Евклидовой невязки параметров от входного речевого сигнала до эталона, выход которого соединен с входом блока принятия решения о распознаваемом дикторе.
Блок определения эталона амплитудно-частотной характеристики микрофона может включать последовательно соединенные блок оценки начала/окончания речевого сигнала, блок вычисления коэффициентов корреляции речевого сигнала, блок вычисления среднего значения спектральной плотности мощности с применением методики спектральных окон и блок формирования эталона АЧХ используемого микрофона, включающий делитель на эталон среднего значения спектральной плотности мощности речевого сигнала и запоминающее устройство хранения эталона среднего значения спектральной плотности мощности речевого сигнала, при этом выход блока вычисления среднего значения спектральной плотности мощности сигнала соединен с входом блока формирования эталона АЧХ используемого микрофона.
Заявляемый способ распознавания диктора и устройство для его осуществления поясняются чертежами, где:
на фиг.1 схематически изображены основные блоки устройства для верификации диктора по голосу;
на фиг.2 приведена блок-схема расчета параметров речевого сигнала;
на фиг.3 приведена блок-схема определения эталона АЧХ используемого микрофона.
Устройство, с помощью которого реализуют заявляемый способ распознавания диктора, включает (см. фиг.1) источник речевого сигнала в цифровой форме, например микрофон 1 (М), и аналого-цифровой преобразователь (АЦП) 2, первый коммутатор 3, блок 4 расчета параметров речевого сигнала (БРПРС), блок 5 сравнения параметров эталона и входного речевого сигнала (БСПРС), блок 6 принятия решения верификации (БПРВ), блок 7 запоминания эталона АЧХ микрофона и эталона среднего значения спектральной плотности мощности речевого сигнала (БЗЭМ), блок 8 вычисления эталона АЧХ используемого микрофона (БВЭМ), второй коммутатор 9, блок 10 запоминания параметров эталонов речевого сигнала заранее известных дикторов (БЗЭД), блок 11 ввода верификационного признака диктора (БВВПД) и блок 12 выбора эталона диктора (БВЭД). Микрофон 1 через АЦП 2 соединен с входом первого коммутатора 3, первый выход которого подключен к первому входу БРПРС 4, а второй выход - к БВЭМ 9. Выход БРПРС 4 соединен с входом второго коммутатора 9, первый выход которого подключен к первому входу БСПРС 5, а второй выход соединен с входом БЗЭД 10. Выход БВЭМ 8 подключен к входу БЗЭМ 7, выход которого соединен со вторым входом БРПРС 4. В свою очередь, БВВПД 11 соединен с первым входом БВЭД 12, второй вход которого соединяют с выходом БЗЭД 10, а выход БВЭД 12 подключают ко второму входу БСПРС 5, выход которого соединен с входом БПРВ 6, выход которого является выходом устройства в целом.
Блок 4 расчета параметров речевого сигнала (БРПРС) включает (см. фиг.2) последовательно соединенные блок оценки 13 начала/окончания речевого сигнала (БОНОРС), блок 14 вычисления коэффициентов корреляции речевого сигнала (БВККРС), блок 15 расчета оценки частоты основного тона (БРОЧОТ), блок 16 расчета оценок амплитуд несущих гармоник (БРОАНГ). Выход БРОАНГ 16 соединен с первым входом блока 17 деления амплитуд несущих гармоник на эталон АЧХ используемого микрофона (БДАНГМ), на второй вход БДАНГМ 17 подают сигналы эталона АЧХ микрофона из БЗЭМ 7. Выход БДАНГМ 17 соединен с первым входом блока 18 формирования параметров речевого сигнала (БФПРС). Второй выход БОНОРС 13 и второй выход БРОЧОТ соединены соответственно со вторым и третьем входами БФПРС 18. Вход БОНОРС 13 является входом БРПРС 4, а выход БФПРС 18 - выходом БРПРС 4.
Блок 8 вычисления эталона АЧХ используемого микрофона (БВЭМ) включает (см. фиг.3) последовательно соединенные блок оценки 19 начала/окончания речевого сигнала (БОНОРС), блок 20 вычисления коэффициентов корреляции речевого сигнала (БВККРС), блок 21 вычисления среднего значения спектральной плотности мощности речевого сигнала (БВСЗСПМ). Выход БВСЗСПМ 21 соединен с первым входом блока деления 22 (БД) на эталон среднего значения спектральной плотности мощности речевого сигнала (ЭСЗСПМРС), второй вход БД 22 соединен с выходом блока ЭСЗСПМРС 24. С выхода БД 22 сигнал поступает на вход блока 23 запоминания эталона АЧХ используемого микрофона (ЭАЧХМ).
Верификация диктора по заявляемому способу иллюстрируется на примере работы устройства, реализующего заявляемый способ. Ссылки на блоки устройства даны по фиг.1-3.
Устройство верификации дикторов может работать в различных режимах: режиме обучения и режиме верификации.
В режиме обучения речевой сигнал голосовых паролей, произносимых заранее известными дикторами, подают на вход устройства, например, с микрофона 1 (или выхода магнитофона) через АЦП 2 и коммутатор 3 на вход БРПРС 4. Коммутатор 3 переключает устройство в режим верификации или обучения (нижняя позиция на фиг.1) или в режим настройки технических параметров (верхняя позиция на фиг.1). В качестве голосовых паролей используют отдельные слова. Из речевого сигнала произнесенных паролей в БРПРС 4 формируют параметры речевых сигналов, запоминаемые в БЗЭД 10 в качестве эталонов. При этом коммутатор 9 замыкает вход на второй выход (нижний на фиг.1). На каждое произнесение каждого голосового пароля каждого известного диктора запоминают свой эталон. Число заранее известных дикторов может быть любым: от одного и более. Число использованных голосовых паролей также может быть любым, большим единицы. Для каждого голосового пароля может выполняться несколько его различных произнесений одним и тем же диктором, для каждого из которых формируют отдельный эталон. Эталоны речевого сигнала произнесения голосового пароля запоминают и могут хранить совместно с верифицирующей данного диктора информацией (например, символьно-числовым кодом).
Сохраненные эталоны используют для сравнения с входным речевым сигналом верифицируемого диктора. Выбор эталонов для верификации заявляемого диктора производят блоком БВЭД 12. В режиме верификации неизвестный диктор через блок БВВПД 11 вводит верификационный признак того диктора, тождество с которым он хочет подтвердить своим голосовым паролем. Далее блок БВЭД 12 выбирает для сравнения эталон того диктора, тождество с которым заявил верифицируемый диктор.
С целью повышения надежности распознавания для каждого голосового пароля предлагается иметь несколько эталонов, получаемых при разных произнесениях данного голосового пароля. Дело в том, что ошибки в распознавании дикторов для произвольного метода распознавания отчасти вызваны тем, что речь любого диктора изменяется от произнесения к произнесению даже для одного и того же голосового пароля. Такая естественная вариативность речи велика при длительном перерыве между произнесениями (несколько дней и более), однако мала при быстром повторении одного и того же голосового пароля во время одной сессии обучения. С целью увеличения вариативности речевого сигнала в разных эталонах одного и того же голосового пароля при их запоминании в рамках одной сессии обучения перед повторным произнесением одного и того же голосового пароля известный диктор произносит речевое высказывание с измененным характером артикуляции. Например, очень высоким или очень низким голосом с имитацией состояния страха или угрозы и т.д. Вид изменения характера артикуляции не существенен. Необходимо только лишь функционирование органов артикуляции речи в ненормативном режиме с ненормативным мышечным усилием и ненормативной конфигурацией вокального тракта. После такого высказывания, как показывает практика, вариативность произнесения пароля уже нормальным голосом возрастает, что приводит к большей вариативности речевого сигнала эталонов и к уменьшению ошибки распознавания диктора при использовании нескольких, вышеуказанным образом полученных эталонов. Например, при применении трех эталонов одного голосового пароля с их произнесением по вышеприведенному методу ошибка пропуска своего диктора уменьшается примерно на 5-15% по сравнению с использованием обычного повторного произнесения голосовых паролей при получении эталонов.
В режиме верификации согласно предлагаемому изобретению входной речевой сигнал через блоки 1, 2, 3 в цифровой форме поступает в БРПРС 4, формирующий его параметрическое описание. Далее речевой сигнал поступает в блок БОНОРС 13 (фиг.2), где происходит оценка начала и окончания высказывания, и временные отметки передаются в блок БФПРС 18. Способ оценки начала и окончания высказывания может быть выбран исходя из соображений практического удобства, например, можно воспользоваться вычислением уровня мгновенных энергий речевого сигнала в начале и окончании процесса записи, и сравнения его с соответствующим порогом "молчания". Далее в БВККРС 14 производят вычисление коэффициентов корреляции центрированного (без постоянной составляющей) речевого сигнала:

где Rl - коэффициент корреляции центрированного речевого сигнала; Kl - функция корреляции:
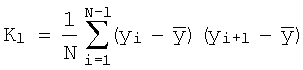 ;
;
 ,
,
N - число отсчетов речевого сигнала; L - число отсчетов коэффициента корреляции (достаточно взять L=200);
 ,
,
где xi - начальные отсчеты речевого сигнала;  - математическое ожидание:
- математическое ожидание:
 .
.
Затем для входного речевого сигнала или эталона рассчитывают параметры соответственно теста или эталона, состоящие из двух частей. Первую часть получают в блоке БРОЧОТ 15, она состоит из оценки частоты основного тона входного речевого сигнала или эталона. В блоке БРОЧОТ 15 производят вычисление оценки частоты основного тона, при помощи методики, основанной на определении минимума невязки коэффициентов корреляции. Невязка определяется между значениями коэффициентов корреляции, полученных на основе экспериментальных данных, и коэффициентами модели речи, содержащей вокализованные участки. Оценка  частоты основного тона f0 определяется как значение аргумента, при котором наблюдается наименьшее значение невязки εR(f0) в диапазоне частот от 50 до 400 Гц:
частоты основного тона f0 определяется как значение аргумента, при котором наблюдается наименьшее значение невязки εR(f0) в диапазоне частот от 50 до 400 Гц:

здесь невязка (ошибка):
 ,
,
где Ra(lΔ, f0) - коэффициент корреляции модели речевого сигнала, применяемый для оценки частоты основного тона, упрощенный вид которого:
 ,
,
где Δ=1/fd интервал дискретизации, при частоте дискретизации fd.
Вторую часть параметров рассчитывают в блоке БРОАНГ 16 для входного речевого сигнала или эталона. Каждый вектор состоит из (К+1)=5 и более (до 6-8) амплитуд гармоник (в том числе с учетом амплитуды низкочастотной составляющей) на частоте основного тона и на частотах нескольких первых обертонов. Для оценки амплитуд несущих гармоник применяется минимизация невязки (на основе метода наименьших квадратов) между коэффициентами корреляции входного сигнала и модели речевого сигнала [Голубинский А.Н. Модель речевого сигнала в виде импульса АМ-колебания с несколькими несущими для верификации личности по голосу / А.Н.Голубинский // Системы управления и информационные технологии. - 2007. - № 4. - С.86-91]. Расчет значений оценок амплитуд гармоник  проводится по формуле (3):
проводится по формуле (3):

при этом Vk - элементы матрицы V - матрица-столбец размером (К+1)×1:
V=A-1B,
где В - матрица-столбец (К+1)×1, с элементами:
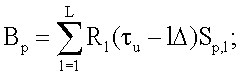
здесь τu - длительность произнесения парольной фразы; А - квадратная матрица (К+1)×(К+1), с элементами:
 ;
;
 ,
,
где F0 - частота модулирующего колебания, значение которой можно принять порядка 10 Гц; Еа - энергия модели речевого сигнала, которую можно отнормировать, приняв, например, 10 В2·с.
Затем амплитуды гармоник поступают на блок БДАНГМ 17, где покомпонентно делятся на эталон АЧХ используемого микрофона ЭАЧХМ 23, который был получен в режиме настройки технических характеристик и был запомнен в БЗЭМ 7. Нормализацию параметров входного речевого сигнала и эталона можно осуществлять путем деления оценок амплитуд  несущих гармоник на эталон АЧХ
несущих гармоник на эталон АЧХ  микрофона для значений при соответствующих частотах (ωk=2πkf0):
микрофона для значений при соответствующих частотах (ωk=2πkf0):

где 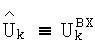 и
и  - соответственно входные и нормализованные амплитуды гармоник;
- соответственно входные и нормализованные амплитуды гармоник;  - частотный коэффициент передачи мощности используемого микрофона KP(ω).
- частотный коэффициент передачи мощности используемого микрофона KP(ω).
Такое деление позволяет сделать параметры обрабатываемого речевого сигнала относительно независимым от АЧХ используемого микрофона и тем самым повысить надежность распознавания.
В блоке БФПРС 18 происходит формирование параметрического описания речевого сигнала, состоящего из оценки частоты основного тона и амплитуд гармоник, вычисление которых для данного высказывания проводится согласно сигналам из блока БОНОРС 13, на протяжении высказывания от его начала до конца.
В режиме верификации коммутатор 9 замыкает вход на первый выход (верхний на фиг.1). БСПРС 5 формирует результат сравнения входного речевого сигнала неизвестного диктора и поступающего из БЗЭД 10 эталона, сравнивая между собой параметры входного речевого сигнала неизвестного диктора и речевого сигнала сравниваемого эталона. Для сравнения параметров входного речевого сигнала и эталона используется мера близости между входным речевым сигналом и эталоном, которая определяется, как взвешенная Евклидова невязка параметров входного речевого сигнала и эталона. Таким образом, мера различия верифицируемого и эталонного дикторов рассчитывается по соотношению:

где ωk, ωf - весовые коэффициенты (их общее количество равно К+2), определяемые на этапе обучения (введения эталонов) системы. Число сравниваемых амплитуд гармоник (К+1) должно быть равно 5 и более.
В системе верификации говорящего, тех говорящих, которые заявляют истинную идентичность, можно называть "Своими", в то время как говорящих, которые заявляют ложную идентичность, можно называть "Чужими". При оценке говорящих система верификации говорящего может делать ошибки двух типов: (а) ложное отклонение и (б) ложный допуск. Ошибка ложного отклонения (ошибка первого рода - вероятность ложной тревоги) имеет место, когда "Свой" заявляет истинную идентичность, но система верификации говорящего его отвергает. Когда "Чужой" получает допуск с помощью системы верификации говорящего, имеет место ошибка ложного допуска (ошибка второго рода - вероятность пропуска цели). Также можно характеризовать обнаружение сигнала средней вероятностью ошибки, которая определяется как половина от суммы ошибок первого и второго рода. Решение принять или отвергнуть идентичность зависит от порога верификации. В зависимости от цены ошибки каждого типа система может быть спроектирована так, чтобы достичь компромисса между одним типом ошибки и другим.
В блоке БПРВ 6 полученная мера различия (близости) сравнивается с заранее заданным значением порога верификации D0. Порог D0 выбирается исходя из ошибок первого и второго рода (или средней вероятностью ошибки) на этапе практического тестирования системы. Возможна ситуация выбора порога верификации, при котором получается равный уровень ошибок обоих родов. Следует отметить, что при удовлетворении условия:

диктор верифицирован (принят), а при условии

не верифицирован (отвергнут).
В заявляемом способе распознавания диктора перед режимами обучения и верификации можно провести процедуру оценки технических характеристик используемого устройства, переключив его в режим настройки технических параметров с помощью коммутатора 3 (верхняя позиция на фиг.1). Во время работы в этом режиме для получения ЭАЧХМ обеспечивается поступление на вход устройства речевого сигнала в течение заранее заданного фиксированного интервала времени. Например, заранее известный диктор до начала сессии обучения непрерывно говорит в используемый микрофон обычно в пределах нескольких секунд.
Речевой сигнал в режиме настройки поступает с используемого микрофона 1 на вход БВЭМ 8. Для этого сигнала в блоке БОНОРС 19 (фиг.3) оцениваются временные интервалы начала и окончания поступления речевого сигнала в устройство. Блок БОНОРС 19 может быть аналогичен блоку БОНОРС 13 в блоке 4 (фиг.2). Далее в БВККРС 20 производят вычисление коэффициентов корреляции центрированного речевого сигнала аналогично БВККРС 14 блока 4. Далее проводят вычисление нормированной спектральной плотности мощности  для используемого микрофона в помещении для верификации:
для используемого микрофона в помещении для верификации:

 ,
,
где V - точка отсечения спектрального окна W(l) для получения состоятельной оценки спектральной плотности мощности. Например, для окна Тьюки:

где точку отсечения можно принять равной, например, V=1600.
Затем в БД 22 полученное среднее значение спектральной плотности мощности речевого сигнала делят на значение соответствующей спектральной компоненты эталона  среднего значения спектральной плотности мощности речевого сигнала, получаемого из ЭСЗСПМРС 24:
среднего значения спектральной плотности мощности речевого сигнала, получаемого из ЭСЗСПМРС 24:

где KP(ω)- частотный коэффициент передачи мощности используемого микрофона. Значения АЧХ получают посредством соотношения

Получаемые значения АЧХ запоминают в БЗЭМ 7 в виде эталона АЧХ используемого микрофона. Среднее значение спектральной плотности мощности эталонного речевого сигнала получают путем измерения среднего спектра речи на большом количестве дикторов и при использовании прецизионного измерительного микрофона и хранят в виде фиксированного набора чисел.
Перед сравнением входного (верифицируемого) речевого сигнала и эталона их параметры можно нормализовать с целью компенсации искажений спектра речевого сигнала, возникающих за счет отличий АЧХ используемого микрофона от идеальной (равномерной). Для этого после вычисления амплитуд гармоник речевого сигнала теста и эталона каждую амплитуду в блоке БДАНГМ 17 (фиг.2) делят на соответствующую компоненту запомненного в режиме настройки технических характеристик эталона АЧХ используемого микрофона. После такого деления амплитуды гармоник нормализованного речевого сигнала уже не содержат информации об АЧХ используемого микрофона и сохраняет информацию только об индивидуальности диктора, что позволяет повысить надежность распознавания диктора.
Также возможен случай определения АЧХ используемого микрофона при учете (вычитании) шума в помещении для верификации, для этого надо провести запись эталона среднего значения нормированной спектральной плотности мощности речевого сигнала  с применением высококачественного микрофона и в шумоизоляционном помещении (с минимальным уровнем шумов), который записывается в ЭСЗСПМРС 24. Повышение точности в режиме настройки технических параметров за счет устранения влияния неравномерности АЧХ используемого микрофона особенно существенно (ошибка распознавания уменьшается на 30-60%) при применении дешевых микрофонов, АЧХ которых имеет сильные отклонения от плоской (обычно до 20 дБ в речевом диапазоне частот).
с применением высококачественного микрофона и в шумоизоляционном помещении (с минимальным уровнем шумов), который записывается в ЭСЗСПМРС 24. Повышение точности в режиме настройки технических параметров за счет устранения влияния неравномерности АЧХ используемого микрофона особенно существенно (ошибка распознавания уменьшается на 30-60%) при применении дешевых микрофонов, АЧХ которых имеет сильные отклонения от плоской (обычно до 20 дБ в речевом диапазоне частот).
Использование заявляемого изобретения обеспечит создание способа верификации диктора и устройства, реализующего этот способ, которые повысят потенциальную надежность распознавания, при этом обеспечивая высокую помехоустойчивость распознавания при работе с наличием шумов и при использовании микрофонов низкого качества. Это достигается за счет использования существенных параметров речевого сигнала, таких как частота основного тона и амплитуды несущих гармоник (на частотах основного тона и обертонов речевого сигнала) модели, за счет адекватности математической модели речевого сигнала (в виде импульса АМ-колебания с несколькими несущими частотами), включающего вокализованные участки речи, а также за счет повышения точности оценки частоты основного тона, которое обусловлено применением метода расчета, основанного на математической модели речевого сигнала при минимизации ошибки (на основе метода наименьших квадратов) между характеристиками модели и экспериментальными данными. При этом использование дополнительной кодовой информации, вводимой верифицируемым диктором, позволяет обеспечить повышенную надежность верификации личности за счет комбинирования биометрического считывателя персональной физиологической характеристики человека - голоса и кода.
Перечень позиций
1 - микрофон (М);
2 - аналого-цифровой преобразователь (АЦП);
3 - коммутатор (низ - верификация или обучение, верх - настройка технических параметров);
4 - блок расчета параметров речевого сигнала (БРПРС);
5 - блок сравнения параметров речевых сигналов (БСПРС);
6 - блок принятия решения верификации (БПРВ);
7 - блок запоминания эталона микрофона (БЗЭМ);
8 - блок вычисления эталона микрофона (БВЭМ);
9 - коммутатор (верх - верификация, низ - обучение);
10 - блок запоминания эталонов дикторов (БЗЭД);
11 - блок ввода верификационного признака диктора (БВВПД);
12 - блок выбора эталона диктора (БВЭД);
13 - блок оценки начала/окончания речевого сигнала (БОНОРС);
14 - блок вычисления коэффициентов корреляции речевого сигнала (БВККРС);
15 - блок расчета оценки частоты основного тона (БРОЧОТ);
16 - блок расчета оценок амплитуд несущих гармоник (БРОАНГ);
17 - блок деления амплитуд несущих гармоник на эталон амплитудно-частотной характеристики используемого микрофона (БДАНГМ);
18 - блок формирования параметров речевого сигнала (БФПРС);
19 - блок оценки начала/окончания речевого сигнала (БОНОРС);
20 - блок вычисления коэффициентов корреляции речевого сигнала (БВККРС);
21 - блок вычисления среднего значения спектральной плотности мощности (БВСЗСПМ);
22 - блок деления (БД);
23 - эталон амплитудно-частотной характеристики микрофона (ЭАЧХМ);
24 - эталон среднего значения спектральной плотности мощности речевого сигнала (ЭСЗСПМРС).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КОНТАКТНО-РАЗНОСТНОЙ АКУСТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 2011 |
|
RU2451346C1 |
| УСТРОЙСТВО АВТОМАТИЧЕСКОЙ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ | 2018 |
|
RU2704723C2 |
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СПОСОБ ОЦЕНКИ ЧАСТОТЫ ОСНОВНОГО ТОНА РЕЧЕВОГО СИГНАЛА | 2012 |
|
RU2546311C2 |
| СПОСОБ ВЕРИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ В СИСТЕМАХ САНКЦИОНИРОВАНИЯ ДОСТУПА | 2007 |
|
RU2351023C2 |
| СПОСОБ ВЫЯВЛЕНИЯ ЭМОЦИОНАЛЬНОГО СОСТОЯНИЯ ЧЕЛОВЕКА ПО ГОЛОСУ | 2012 |
|
RU2553413C2 |
| СПОСОБ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ НА ОСНОВЕ АНАТОМИЧЕСКИХ ПАРАМЕТРОВ ЧЕЛОВЕКА | 2010 |
|
RU2421699C1 |
| СПОСОБ АУТЕНТИФИКАЦИИ ДИКТОРА ПО ГОЛОСУ | 2022 |
|
RU2789689C1 |


Изобретение относится к системам установления или подтверждения личности говорящего. Техническим результатом является повышение потенциальной надежности верификации личности при обеспечении высокой помехоустойчивости верификации при наличии шумов и использовании низкокачественных микрофонов. Указанный технический результат достигается тем, что сравнивают параметры входного речевого сигнала диктора с параметрами выбранного для сравнения эталона диктора путем вычисления меры различия - взвешенной Евклидовой невязки - между параметрами входного и верифицируемого речевых сигналов, и на основании рассчитанной меры различия принимают решение, принять или отвергнуть говорящего. Для этого определяют значения коэффициентов корреляции входного речевого сигнала, вычисляют значения коэффициентов корреляции математической модели речевого сигнала в виде импульса амплитудно-модулированного колебания с несколькими несущими частотами и рассчитывают минимальное значение невязки между коэффициентами корреляции входного речевого сигнала и его математической модели, при котором определяют частоты основного тона и оценки амплитудных значений гармоник на частотах основного тона и обертонов речевого сигнала, являющиеся упомянутыми параметрами. Параметры входного речевого сигнала и эталона могут быть нормализованы путем деления амплитуд несущих гармоник на эталон амплитудно-частотной характеристики микрофона при учете уровня шумов. 2 н.п. и 2 з.п. ф-лы, 3 ил.
1. Способ верификации диктора, включающий сравнение входного речевого сигнала диктора с заранее сохраненными эталонами, представляющими собой речевой сигнал голосовых паролей, произносимых заранее известными дикторами, по меньшей мере один из которых представлен по меньшей мере одним упомянутым эталоном, для чего осуществляют сравнение параметров входного речевого сигнала с параметрами выбранного для сравнения эталона, при этом рассчитывают меру различия между параметрами входного и верифицируемого речевых сигналов, и на основании рассчитанной меры различия принимают решение, принять или отвергнуть указанного говорящего, отличающийся тем, что определяют значения коэффициентов корреляции входного речевого сигнала, вычисляют значения коэффициентов корреляции математической модели речевого сигнала в виде импульса амплитудно-модулированного колебания с несколькими несущими частотами и рассчитывают минимальное значение невязки между коэффициентами корреляции входного речевого сигнала и его математической модели, при котором определяют частоты основного тона и оценки амплитудных значений гармоник на частотах основного тона и обертонов речевого сигнала, являющиеся упомянутыми параметрами, описывающими входной речевой сигнал, а меру различия для сравнения параметров входного речевого сигнала и эталона определяют как взвешенную Евклидову невязку параметров входного речевого сигнала и эталона.
2. Способ по п.1, отличающийся тем, что предварительно определяют и запоминают эталон амплитудно-частотной характеристики используемого микрофона, при этом эталон амплитудно-частотной характеристики используемого микрофона определяют путем накопления при непрерывном произнесении в микрофон речи в течение заданного интервала времени среднего значения спектральной плотности мощности данного речевого сигнала и последующего покомпонентного деления полученного среднего значения спектральной плотности мощности на заранее заданный эталон среднего значения спектральной плотности мощности речевого сигнала.
3. Способ по п.2, отличающийся тем, что параметры входного речевого сигнала и упомянутого эталона нормализуют путем покомпонентного деления амплитудных значений гармоник на эталон амплитудно-частотной характеристики упомянутого микрофона.
4. Устройство верификации диктора, содержащее источник речевого сигнала, соединенный с входом первого коммутатора, один из выходов которого подключен к первому входу блока расчета параметров речевого сигнала, а другой выход первого коммутатора подключен к входу блока вычисления эталона микрофона, выход которого соединен с входом блока запоминания эталона микрофона, выход которого соединен со вторым входом блока расчета параметров речевого сигнала, выход которого соединен с входом второго коммутатора, первый выход которого подключен к первому входу блока сравнения параметров эталона и входного речевого сигнала, выход которого соединен с входом блока принятия решения о распознаваемом дикторе, выход которого является выходом устройства в целом, а второй выход второго коммутатора соединен с входом блока запоминания эталонов дикторов, выход которого соединен со вторым входом блока выбора эталона диктора, первый вход которого соединен с блоком ввода верификационного признака диктора, а выход блока выбора эталона диктора подключен ко второму входу блока сравнения параметров эталона и входного речевого сигнала, при этом блок расчета параметров речевого сигнала содержит выделитель начала/окончания речевого сигнала и блок формирования параметров входного речевого сигнала, а блок вычисления эталона микрофона содержит блок оценки начала/окончания речевого сигнала, блок вычисления среднего значения спектральной плотности мощности речевого сигнала, блок деления на эталон среднего значения спектральной плотности мощности речевого сигнала, блок запоминания эталона среднего значения спектральной плотности мощности речевого сигнала, отличающееся тем, что блок расчета параметров входного речевого сигнала содержит блок вычисления коэффициентов корреляции речевого сигнала, соединенный с блоком расчета оценки частоты основного тона, первый выход которого соединен с первым входом блока формирования параметров входного речевого сигнала, а второй выход подключен ко входу блока расчета оценок амплитуд несущих гармоник, выход которого соединен с первым входом блока деления амплитуд несущих гармоник на эталон амплитудно-частотной характеристики используемого микрофона, выход которого подключен ко второму входу блока формирования параметров входного речевого сигнала, при этом блок запоминания эталона микрофона подключен ко второму входу блока деления амплитуд несущих гармоник на эталон амплитудно-частотной характеристики используемого микрофона, а блок вычисления эталона микрофона дополнительно содержит блок вычисления коэффициентов корреляции речевого сигнала, причем блок оценки начала/окончания речевого сигнала, блок вычисления коэффициентов корреляции речевого сигнала и блок вычисления среднего значения спектральной плотности мощности речевого сигнала соединены последовательно, выход блока вычисления среднего значения спектральной плотности мощности соединен с первым входом блока деления на эталон среднего значения спектральной плотности мощности речевого сигнала, а второй вход блока деления соединен с выходом блока запоминания эталона среднего значения спектральной плотности мощности речевого сигнала, выход блока деления сигнала соединен со входом блока запоминания эталона микрофона, а блок сравнения параметров эталона и входного речевого сигнала выполнен с возможностью вычисления взвешенной Евклидовой невязки параметров входного речевого сигнала и эталона.
| А.Н.ПАВЛОВЕЦ и др | |||
| Гармоническая модель речевого сигнала: определение параметров и их квантование, доклады БГУИР, №4, 2007, с.21-25 | |||
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 1998 |
|
RU2161826C2 |
| Способ идентификации говорящего | 1986 |
|
SU1453442A1 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| Пюпитр для пишущей машины | 1927 |
|
SU9430A1 |
| Способ верификации диктора | 1989 |
|
SU1675936A1 |
| US 4078154 А, 07.03.1978 | |||
| US 4627323 А, 09.12.1986 | |||
| US 5339385 А, 16.08.1994 | |||
| WO 9954868 А1, 28.10.1999. | |||

