Изобретение относится к области опознавания говорящего по голосу, в частности к автоматическим, автоматизированным и экспертным способам идентификации говорящего по фонограммам произвольной устной речи, предназначенным в том числе для криминалистических исследований.
Известно, что при практическом, в частности криминалистическом, исследовании и сравнении фонограмм устной речи, с целью идентификации говорящего, в ряде случаев, экспертиза сталкивается с такими затрудняющими принятие решения проблемами, как малая длительность и низкое качество исследуемых фонограмм, различие психофизиологических состояний говорящих в момент произнесения речи на сравниваемых фонограммах, различное словесное содержание и разные языки, на которых произносится речь, различающиеся по типу и уровню помех и искажений каналы звукозаписи и пр.
Поэтому в настоящее время актуальной является разработка способов идентификации говорящего по фонограммам произвольной устной речи, в частности, применимых для целей криминалистики и учитывающих указанные выше проблемы, а именно способов, обеспечивающих возможность идентификации говорящих по коротким фонограммам, записанным в различных каналах звукозаписи, с высоким уровнем помех и искажений, по фонограммам, содержащим устную речь, произносимую говорящими в разных психофизиологических состояниях, с различным словесным содержанием, при разных языках произнесения.
Известен способ идентификации дикторов по фонограммам, который проводится путем экстрагирования характерных особенностей диктора из произносимых однотипных фраз (патент DE №2431458, МПК G10L 1/04, 05.02.1976).
В данном способе речевой сигнал фильтруют с помощью гребенки из 24 полосовых фильтров, затем детектируют, сглаживают, далее с помощью аналого-цифрового преобразователя и коммутатора сигнал вводят в цифровое обрабатывающее устройство, где автоматически выделяют и сохраняют индивидуализирующие признаки, связанные с интегральным спектром речи.
Данный способ идентификации дикторов теряет работоспособность на фонограммах устной речи, полученных в условиях повышенных искажений и помех, из-за ограниченного набора индивидуализирующих признаков. Также этот способ имеет большой процент отказов от решения по идентификации, поскольку он требует фонограмм неизвестного и проверяемого диктора с одинаковым словесным содержанием. Известен способ, в котором для идентификации личности в речи на сравниваемых фонограммах находятся и сравниваются однотипные ключевые слова (патент US №3466394, МПК H04M 1/24).
В данном способе речевой сигнал подвергается кратковременному спектральному анализу, затем выделяются контуры зависимости особенностей спектра и основного тона голоса от времени. Полученные контуры являются индивидуализирующими признаками. Идентификация дикторов основана на сравнении полученных контуров для фонограмм проверяемого и неизвестного дикторов.
Недостатком способа является зависимость результатов идентификации от качества фонограмм, полученных в условиях повышенных искажений и помех. Также этот способ имеет большой процент отказов от решения по идентификации, поскольку он требует фонограмм неизвестного и проверяемого с одинаковыми словами. Известен способ идентификации дикторов, основанный на спектрально-полосно-временном анализе произвольной устной речи (Рамишвили Г.С., Чикоидзе Г.Б. Криминалистическое исследование фонограмм речи и идентификация личности говорящего. Тбилиси: "Мецниереба", 1991, с.265).
Для исключения зависимости результатов идентификации от смыслового содержания произносимого текста из речевого сигнала выделяют участки звонкой речи, усредняют по времени их существования значения энергии в каждом из 24 спектральных фильтров в области высших формантных участков. Основной тон определяют на основе выделения первой гармоники сигнала в спектре. Также определяют темп речи. Перечисленные параметры используют в качестве индивидуализирующих признаков.
Данный способ неработоспособен на фонограммах устной речи, полученных в условиях повышенных искажений в канале звукозаписи и различий в состоянии дикторов, из-за потери надежности выделения набора индивидуализирующих признаков.
Известен способ и устройство распознавания дикторов на основе построения и сравнения чисто статистических моделей кепстральных признаков речевого сигнала известных и неизвестных дикторов (патент US №6411930, МПК G10L 15/08). В данном способе распознавание диктора выполняют при использовании дискриминантных моделей Гауссовых смесей.
Данный способ, как и большинство чисто статистических подходов к распознаванию дикторов, не пригоден для ситуации, когда используемые голосовые сообщения очень короткие (1-10 секунд), состояние дикторов и/или используемые для записи фонограмм каналы существенно различаются по свойствам или дикторы находятся в различных эмоциональных состояниях.
Известен способ распознавания дикторов на основе чисто стохастического подхода (патент US №5995927, МПК G10L 9/00).
В данном способе распознавание диктора выполняют путем построения и сравнения матриц ковариации признаковых описаний входного речевого сигнала и эталонов речевого сигнала известных дикторов.
Этот известный способ также не пригоден для ситуации, когда используемые голосовые сообщения короткие (5 секунд и менее), а также очень чувствителен к существенному снижению мощности сигнала на отдельных участках частотного речевого диапазона за счет окружающего шума и низкокачественных микрофонов и каналов звукопередачи и звукозаписи.
Известен способ распознавания изолированных слов речи с адаптацией к диктору (патент RU №2047912, МПК G10L 7/06), основанный на дискретизации входного речевого сигнала, его предыскажении, последовательной сегментации речевого сигнала, кодировании сегментов дискретными элементами, вычислении энергетического спектра, измерении формантных частот и определении амплитуд и энергии в различных частотных полосах речевого сигнала, классификации артикуляторных событий и состояний, формировании и сортировке эталонов слов, вычислении расстояний между эталонами слов с реализацией распознаваемого слова, принятии решений о распознавании или отказе от распознавания слова с дополнением словаря эталонов в процессе адаптации к диктору. Предыскажение входного речевого сигнала выполняют во временной области путем дифференцирования со сглаживанием, квантование энергетического спектра выполняют в зависимости от дисперсии шума канала связи, формантные частоты определяют при нахождении глобального максимума логарифмического спектра и вычитании из этого спектра заданной частотно-зависимой функции, при классификации артикуляторных событий и состояний определяют доли периодического и шумового источников возбуждения при сравнении с порогом коэффициентов автокорреляции последовательности прямоугольных импульсов в нескольких частотных полосах, начало и конец артикуляторных движений и соответствующих им акустических процессов определяют при сравнении с порогом функции правдоподобия от значений коэффициентов автокорреляции, формантных частот и энергий в заданных частотных полосах, речевой сигнал сегментируют на интервалы между началом и концом акустических процессов, соответствующих специфическим артикуляторным движениям, и последовательно, начиная с гласных звуков, причем опознавание сегмента производят только в случае совпадения типов переходов на его левой и правой границах и заканчивают сегментацию при опознавании слева и справа по времени сегментов паузы между словами. Эталоны слов формируют в виде матриц с бинарными значениями правдоподобия признаков, а отказ от распознавания осуществляют при нормированной разности расстояния от неизвестной реализации до двух ближайших эталонов, принадлежащих разным словам, меньшей установленного порога.
Недостатком данного известного способа распознавания изолированных слов речи с адаптацией к диктору является слабая различительная сила данного способа при его использовании для распознавания дикторов по произнесению произвольной речи, так как данный способ в большинстве случаев не различает дикторов одного пола при произнесении ими сообщений с совпадающим словесным составом.
Известна система для обеспечения секретности на основе распознавания голоса (патент US №5265191, МПК G10L 005/00), требующая и от обучающего, и от неизвестного диктора обязательного повторного произнесения, по крайней мере, одного речевого сообщения. Система сравнивает параметрические представления повторных произнесений речи неизвестного и известного диктора и принимает положительное решение о тождестве сравниваемых дикторов только в случае, если каждое произнесение неизвестного диктора достаточно близко произнесениям обучающего диктора, и отрицательное решение, если их представления достаточно далеки друг от друга.
Недостатком данной системы является низкая помехоустойчивость в шумах переменного характера (в транспортном средстве, в условиях шума улицы, производственного помещения), а также обязательное требование произнесения сравниваемыми дикторами одинаковых речевых сообщений.
Известен способ автоматической идентификации личности по особенностям произношения парольной фразы этой личностью (патент RU №2161826, МПК G10L 17/00), заключающийся в том, что речевой сигнал разбивают на вокализованные зоны, выделяют временные интервалы в вокализованных зонах - в области максимумов интенсивности речевого сигнала, а также в начале первой и в конце последней вокализованных зон. Для выделенных временных интервалов определяют параметры речевого сигнала, сравнивают их с эталонами, которые формируют с учетом математических ожиданий и допустимых разбросов этих параметров, для чего в конце первой, начале последней, в начале и конце остальных вокализованных зон выделяют временные интервалы, длительность временных интервалов устанавливают кратной периоду основного тона речевого сигнала, определяют оценки коэффициентов корреляции параметров речевого сигнала, которые включают в число сравниваемых с эталонами, при формировании эталонов дополнительно учитывают коэффициенты корреляции параметров речевого сигнала. На основании полученных параметров речевого сигнала и соответствующих им статистических характеристик принимают решение по идентификации личности.
Недостатком данного известного способа идентификации личности является низкая помехоустойчивость метода, так как для его работы требуется выделение во входном речевом сигнале точного положения границ периодов основного тона голоса, что в условиях наличия акустических и электромагнитных помех (шум офисного помещения, улицы, наводки в каналах речевой связи и т.п.) часто практически невозможно, кроме того, дикторы должны произносить одинаковые голосовые пароли, что на практике не всегда реализуемо.
Известно устройство для верификации диктора на основе измерения расстояния "ближайшего соседа" (патент US №5339385, МПК G10L 9/00), включающее дисплей, генератор выдачи подсказок по случайному закону, блок распознавания слова, верификатор диктора, клавиатуру и блок первичной обработки сигнала, при этом вход блока первичной обработки сигнала является входом устройства, а его выход соединен с первыми входами распознавателя слов и верификатора дикторов, ко второму входу распознавателя слов подключен первый выход генератора выдачи подсказок, выход которого соединен с дисплеем. Клавиатура подключена к третьему входу распознавателя слов и к третьему входу верификатора дикторов, выход которого является выходом устройства. Верификатор дикторов данного устройства для определения сходства или различия произнесения голосовых паролей использует разбиение входного речевого сигнала на отдельные кадры анализа, вычисление непараметрических речевых векторов для каждого кадра анализа и далее определение близости таким образом полученных описаний речевого сигнала сравниваемых произнесений на основе Эвклидова расстояния ближайшего соседа.
Недостатком данного устройства являются низкая помехоустойчивость при работе в акустических шумах офисных помещений и улицы в силу использования непараметрических речевых векторов и Эвклидовой метрики при определении степени сходства/отличия произнесений голосовых паролей, а также низкая надежность распознавания (высокий процент ложных отказов) за счет использования переменных по порядку слов голосовых паролей, вызванная неизбежной индивидуальной вариативностью произнесения одних и тех же слов в разном контексте даже одним и тем же диктором. Кроме того, обеспечение произнесения обоими сравниваемыми дикторами заданного подсказками речевого содержания на практике труднореализуемо.
Известен способ распознавания говорящего (патент US №6389392, МПК G10L 17/00), включающий сравнивание входного речевого сигнала неизвестного диктора с эталонами, представляющими речь заранее известных дикторов, из которых, по меньшей мере, один представлен, по меньшей мере, двумя эталонами. Последовательные сегменты входного сигнала сравнивают с последовательными сегментами эталона, получая меру близости сравниваемых сегментов входного речевого сигнала и эталона. Для каждого эталона заранее известного диктора, имеющего, по крайней мере, два эталона, формируют композитный результат сравнения данного эталона и входного речевого сигнала на основе выбора для каждого сегмента входного речевого сигнала ближайшего по используемой мере близости сегмента сравниваемого эталона. Далее идентифицируют неизвестного диктора на основе композитных результатов сравнения входного речевого сигнала и эталонов.
Известный способ распознавания диктора ограниченно применим на практике, так как обязательное требование наличия для распознаваемого заранее известного диктора не менее двух эталонов на каждое его речевое высказывание не всегда осуществимо в реальных условиях. Кроме того, данный способ не обеспечивает высокий уровень надежности распознавания дикторов при работе в условиях акустического шума реальных офисных помещений, улицы или транспортных средств, при различии эмоционального состояния дикторов, поскольку используемое в способе посегментное параметрическое описание речевых сигналов подвержено сильному влиянию аддитивных акустических шумов и естественной вариативности речи. Кроме того, низкая надежность работы метода в шумах связана с тем, что ближайший по используемой мере близости сегмент сравниваемого эталона ищут для каждого сегмента входного речевого сигнала, что приводит к наличию среди найденных близких по мере сегментов большого числа чисто шумовых сегментов, соответствующих сегментам речевых пауз и в эталоне, и во входном речевом сигнале.
Известен способ идентификации личности по фонограммам произвольной устной речи (патент RU №2107950, МПК G10L 5/06). Он основан на спектрально-полосно-временном анализе речевого сигнала, выделении характеристик индивидуальности устной речи и сравнении этих характеристик с эталонными, при этом в качестве характеристик индивидуальности устной речи используют акустические интегральные признаки, являющиеся оценками параметров статистического распределения компонент текущего спектра и гистограмм распределения периодов и частот основного тона, измеренных на фонограммах речи как с произвольным, так и фиксированным контекстом, среди которых при адаптивном переобучении выбирают наиболее информативные для речи данного говорящего признаки, независимые от помех и искажений, присутствующих в сравниваемых фонограммах, а также используют лингвистические признаки, фиксируемые экспертом при слуховом анализе фонограмм с применением автоматизированного банка опорных звуковых эталонов диалектных, акцентных и дефектных особенностей устной речи.
Данный метод в силу применения интегрального, то есть усредняющего характеристики речевого сигнала, подхода и лингвистического анализа теряет надежность при сравнении дикторов, имеющих короткие сравниваемые фонограммы, а также говорящих на разных языках или находящихся в существенно различных психофизиологических состояниях.
Известен способ распознавания дикторов (патент RU №2230375, МПК G10L 15/00, G10L 17/00), имеющий наибольшее количество совпадающих с заявляемым способом признаков изобретения и выбранный в качестве прототипа, включающий посегментное сравнение входного речевого сигнала диктора с эталонами голосовых паролей, произносимых известными дикторами, и оценку сходства между первой фонограммой говорящего и второй эталонной фонограммой по совпадению значений формантных частот на выбранных для сравнения опорных фрагментах речевого согнала на первой и второй фонограммах.
В известном способе выделяют формантные векторы последовательных сегментов и статистические характеристики спектра мощности входного речевого сигнала и речевого сигнала эталонов, а затем их сравнивают соответственно с формантными векторами последовательных сегментов каждого эталона и со статистическими характеристиками спектра мощности речевого сигнала эталона и формируют композитную метрику сравнения входного сигнала и эталона. В качестве меры близости формантных векторов сегментов используют взвешенный модуль разности частот формантных векторов. Для вычисления композитной метрики сравнения входного сигнала и эталона находят для каждого сегмента входного речевого сигнала ближайший по этой мере близости сегмент эталона с равным числом формант, а в композитную метрику включают взвешенное среднее по всем используемым сегментам входного речевого сигнала значение мер близости между данным сегментом входного речевого сигнала и найденным для него ближайшим сегментом эталона, а также коэффициент кросскорреляции статистических характеристик спектров мощности входного речевого сигнала и эталона. Распознавание диктора выполняют на основе результата сравнения входного речевого сигнала и эталона по композитной метрике.
Данный метод не обеспечивает надежное распознавание дикторов при существенно различном звуковом составе входного речевого сигнала и речевого сигнала образцов (например, при коротких сообщениях, при речи во входном сигнале и эталонах на разных языках), а также при существенном различии свойств каналов звукозаписи и различии психофизиологического состояния дикторов, произносящих речь на сравниваемых фонограммах. Эти недостатки обусловлены, во-первых, применением в качестве компонента композитной метрики статистических характеристик спектра мощности, которые существенно зависят от свойств канала записи, состояния диктора и звукового состава речи, а также сегментной меры близости в виде взвешенного среднего по всем используемым сегментам обрабатываемого речевого сигнала, что приводит к усреднению ошибок при сравнении сегментов и подавлению влияния больших межсегментных отклонений, говорящих о различии дикторов даже при малом среднем различии сегментов.
Задачей настоящего изобретения является создание способа идентификации говорящего по фонограммам произвольной устной речи, в котором для сравнения выбирают такие фрагменты речевого сигнала, а для принятия идентификационного решения используют такие индивидуализирующие признаки и методы их сравнения, которые позволяют осуществлять надежную идентификацию говорящего для большинства встречающихся на практике ситуаций, в частности, как для длинных, так и для коротких сравниваемых фонограмм, записанных в различных каналах с высоким уровнем помех и искажений, для фонограмм с произвольной устной речью дикторов, находящихся в различных психофизиологических состояниях, говорящих на разных языках, с тем чтобы расширить область применения способа, в том числе для его использования в криминалистических исследованиях.
Поставленная задача решается тем, что в способе идентификации говорящего по фонограммам устной речи, включающем оценку сходства между первой фонограммой говорящего и второй эталонной фонограммой по совпадению значений формантных частот на выбранных для сравнения опорных фрагментах речевого сигнала на первой и второй фонограммах, согласно предлагаемому изобретению, в речевых сигналах первой и второй фонограмм выбирают опорные фрагменты, на которых присутствуют формантные траектории, по крайней мере, трех формантных частот, осуществляют сравнение между собой опорных фрагментов первой и второй фонограмм, в которых совпадают значения, по крайней мере, двух формантных частот, оценивают сходство сравниваемых опорных фрагментов по совпадению значений остальных формантных частот, а сходство фонограмм в целом определяют по суммарной оценке сходства всех сравниваемых опорных фрагментов.
Основанием для создания данного способа идентификации говорящего послужил тот экспериментальный факт, что низкочастотные резонансы вокального тракта (форманты) человека при изменении артикуляции меняются по частоте взаимно согласовано. В частности, это верно для первых по частоте 3-5 резонансов, в зависимости от длины вокального тракта. Если меняется частота хотя бы одной из первых четырех формант, то, в большинстве ситуаций на практике, обязательно одновременно меняется и значение частоты одной или нескольких других низкочастотных формант данного диктора. Данное изменение обусловлено акустической взаимосвязью резонансов вокального тракта и анатомической ограниченностью возможности произвольного изменения поперечной площади вокального тракта диктора. Теоретическое обоснование такого факта имеется в научной литературе (Г.Фант. Акустическая теория речеобразования. - М.: Наука. 1964, В.Н.Сорокин. Теория речеобразования. - М.: Радио и связь. 1985).
В заявляемом способе при сравнении фонограмм в качестве индивидуализирующих признаков говорящих используют резонансные параметры акустики вокального тракта, определяемые как характеристические значения частот на формантных траекториях, задающих воспринимаемое качество каждого речевого звука. Эти признаки помехоустойчивы для фонограмм, записанных в условиях высоких шумов и искажений записываемого сигнала.
Экспериментально выявлено, что наличие трех и более траекторий формант внутри спектрограммы опорного фрагмента в большинстве ситуаций позволяет однозначно определить характеристические значения формантных частот и обеспечить на основе их сравнения надежную идентификацию дикторов.
Для обеспечения дополнительной помехоустойчивости выделяемых признаков в аддитивных широкополосных шумах значения формантных частот на каждом выбранном опорном фрагменте вычисляют как средние значения на интервалах времени фиксированной длины, на которых значения частот формант относительно постоянны. При этом на каждом опорном фрагменте речевого сигнала для сравнения используют конкретные жестко зафиксированные значения формантных частот, относящихся к заданному временному интервалу, - формантные вектора.
Для обеспечения надежности идентификации целесообразно сравнивать опорные фрагменты, в которых совпадают значения частот первых двух формант, которые находятся в границах стандартной вариативности значений формантных частот для выбранного типа звука из фиксированного набора гласноподобных звуков.
Опорные фрагменты при сравнении фонограмм сопоставляют между собой, если они соответствуют участкам речевого сигнала на фонограммах, на которых реализуются сопоставимые артикуляторные события, то есть произносятся звуки, при которых резонансная структура спектра сигнала ярко выражена и совпадает по частотам двух или более частот резонансов (формант), независимо от того, каким фонемам в тексте речевого сообщения данные звуки соответствуют. Указанные участки встречаются на речевых фрагментах, на которых дикторы произносят как одинаковые, так и различающиеся фонемы. Сопоставляемые по значениям формант речевые фрагменты в экспертной литературе принято называть «формантно-выровненными» фрагментами речи.
Для принятия синтезирующего общего идентификационного решения на фонограммах выбирают, по крайней мере, два опорных фрагмента речевого сигнала, относящихся к произнесению максимально артикуляторно различных звуков с максимальными и минимальными для данной фонограммы значениями частот первой и второй формант.
Для обеспечения высокой надежности идентификации сравнение опорных фрагментов производят для нескольких максимально артикуляторно различных звуков, то есть максимально различающихся вариантов реализации геометрической формы вокального тракта.
Благодаря тому, что для сравнения выбирают формантно-выровненные фрагменты речи, соответствующие разным не обязательно тождественным звукам, обеспечивается возможность идентификации говорящего в ситуациях, когда звуковое содержание фонограмм существенно различается, в частности, и для длинных, и для коротких фонограмм, для фонограмм, содержащих речь дикторов, находящихся в различных психофизиологических состояниях, а также говорящих на одном и том же или разных языках.
Для обеспечения повышенной надежности идентификации говорящего в условиях сильного искажения речевого сигнала за счет существенно неравномерной АЧХ каналов звукозаписи, не совпадающей для сравниваемых фонограмм, предпочтительно перед вычислением значений формантных частот спектр мощности речевого сигнала каждой фонограммы подвергать инверсной фильтрации, при которой для каждой частотной компоненты спектра мощности вычисляют ее среднее по времени значение, по крайней мере, для отдельных фрагментов фонограммы и затем исходное значение спектра мощности сигнала фонограммы для каждой частотной компоненты спектра делят на ее инверсное (инвертированное) среднее значение.
Возможно также реализовать инверсную фильтрацию вместо деления спектров путем применения операции логарифмирования спектров и вычитания из логарифма мощности спектра исходного сигнала фонограммы логарифма мощности среднего спектра для каждой частотной компоненты.
В дальнейшем предлагаемое изобретение будет более подробно раскрыто на конкретном примере его выполнения со ссылками на чертежи, на которых изображены:
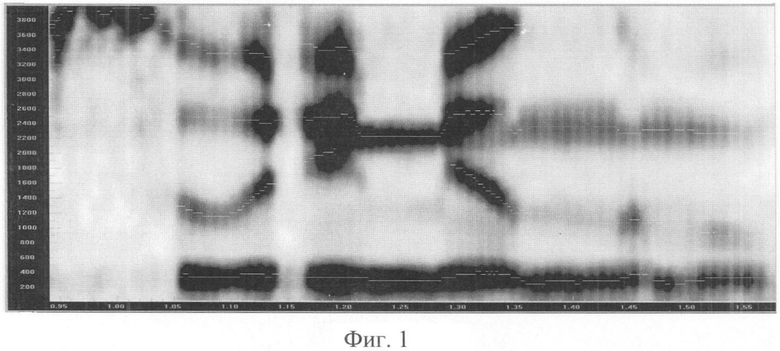
Фиг.1 - пример спектрограммы с наложенными формантными траекториями для слога «тэ»;
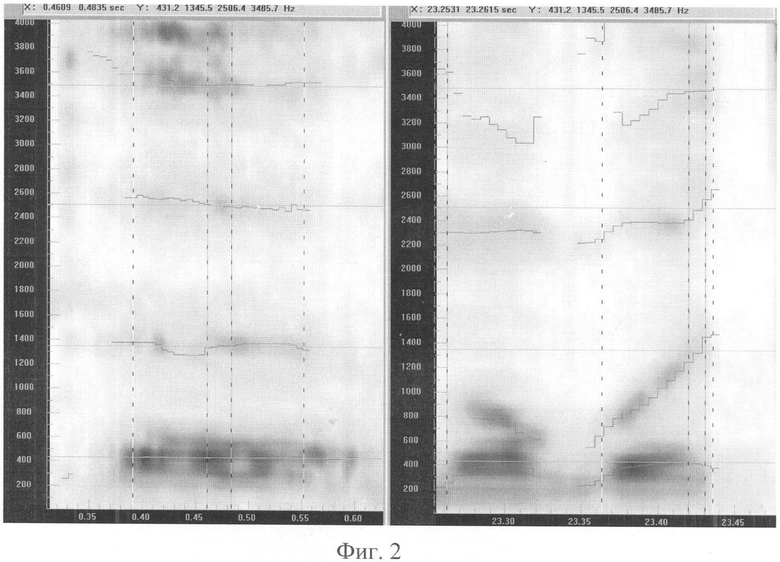
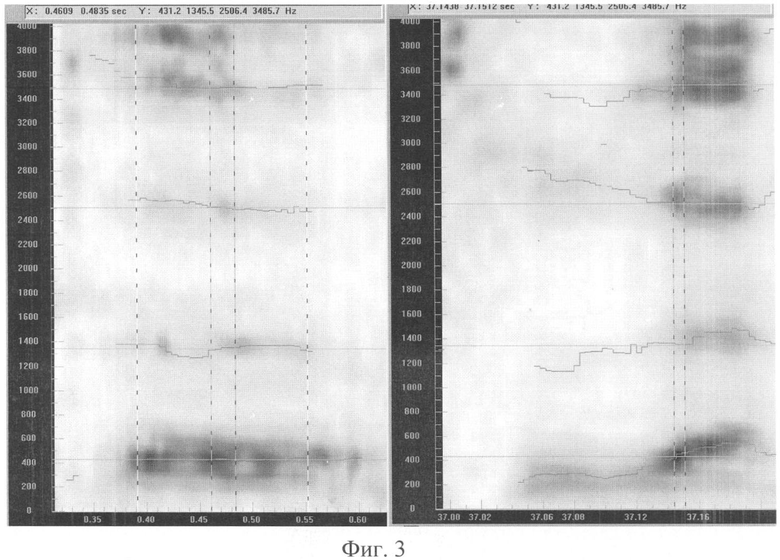
Фиг.2-3 - примеры сравнения спектрограмм с наложенными формантными траекториями для совпавших дикторов для звуков типа «Э»;
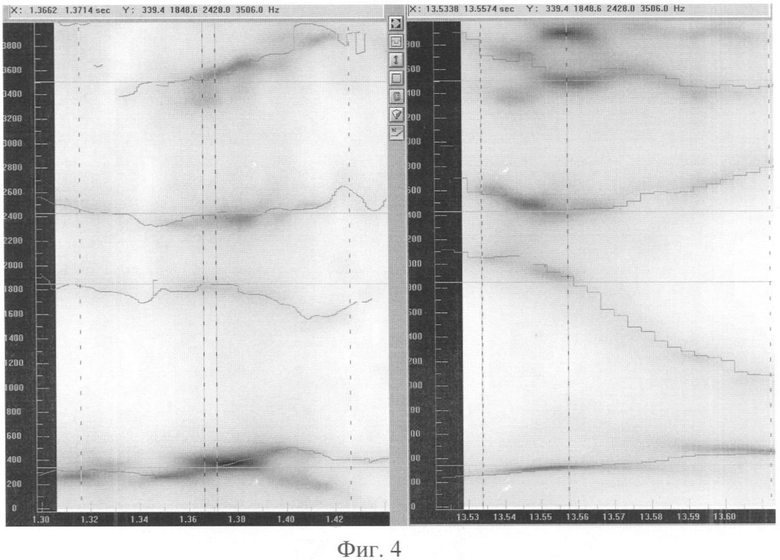
Фиг.4 - пример сравнения спектрограмм с наложенными формантными траекториями для совпавших дикторов для звуков типа «Е»;
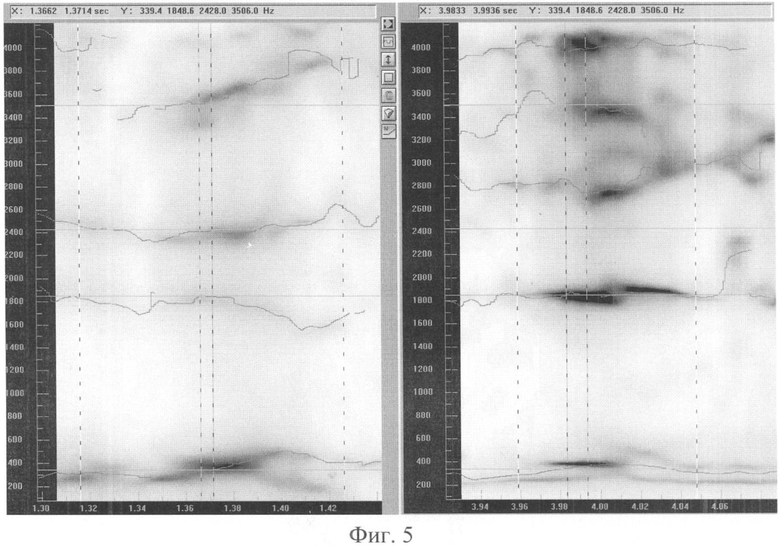
Фиг.5 - пример сравнения спектрограмм с наложенными формантными траекториями для не совпавших дикторов для звука типа «Е»;
Фиг.6 - пример сравнения трех спектрограмм одного и того же речевого сигнала диктора (опорный фрагмент со слогом «На») до и после инверсной фильтрации;
Фиг.7 - пример сравнения средних спектров мощности речевого сигнала трех фонограмм на Фиг.6;
Фиг.8 - пример сравнения спектров формантных векторов, выделенных на спектрограммах на Фиг.6.
Заявленный способ включает сравнение, по крайней мере, двух фонограмм произвольной устной речи. В частности, для целей криминалистического исследования одной из фонограмм может быть фонограмма речи проверяемого говорящего, а второй - фонограмма речи неизвестного лица (эталонная). Целью такого исследования является установление идентичности или различия лиц, голос которых записан на сравниваемых фонограммах.
Сравниваемые фонограммы преобразуют в цифровую форму и хранят их оцифрованные образы в памяти ПЭВМ в виде цифровых файлов звукового сигнала.
Оцифрованные образы с помощью ПЭВМ подвергают спектральному анализу в соответствии с общепринятыми процедурами спектрального анализа сигналов (Марпл С.Л. Цифровой спектральный анализ и его приложения Мир, 1990), вычисляют их динамические спектрограммы и по ним - формантные траектории как линии последовательного изменения во времени значений резонансных частот вокального тракта, отражающихся на спектрограммах в виде локальных максимумов спектра. Формантные частоты при необходимости корректируют путем наложения их на спектрограмму и исправления видимых отличий в движении формант.
На спектрограммах первой и второй сравниваемых фонограмм выбирают опорные фрагменты, на которых осуществляют сравнение формантных частот.
Формантные частоты сами по себе в момент произнесения конкретных звуков испытывают влияние многих случайных факторов, в силу чего на некоторых сегментах могут «исчезать», а также «дрожать» от сегмента к сегменту. Кроме того, поскольку во время речеобразования геометрия вокального тракта постоянно меняется, то и формантные частоты постоянно плавно переходят от одних значений к другим, образуя формантные траектории. В то же время для сравнения формантных частот на каждом опорном фрагменте речевого сигнала должны быть выбраны их конкретные жестко зафиксированные значения.
С целью обеспечения указанного условия в заявляемом варианте реализации способа идентификации выбор значений формантных частот, по которым проводят сравнение опорных фрагментов и фонограмм, осуществляют следующим образом.
Первоначально на спектрограммах первой и второй фонограмм отбирают опорные фрагменты, которые удовлетворяют двум критериям:
(1) наличие на опорном фрагменте формантных траекторий трех или более формант;
(2) значения частот первых двух формант указанных формантных траекторий находятся в пределах стандартной вариативности для одного из заданных типов звука из фиксированного набора гласноподобных звуков.
Экспериментально выявлено, что для частотного диапазона телефонного канала число формантных траекторий на выбранном опорном фрагменте обычно должно быть равно четырем для дикторов мужчин и трем для женщин.
Далее на каждом выбранном опорном фрагменте для последующего сравнения формантных частот выбирают формантные векторы, на которых значения формантных частот вычисляют как средние значения на интервалах времени фиксированной длины, на которых значения частот формант относительно постоянны.
Использование формантных векторов внутри каждого опорного фрагмента для сравнения формантных частот позволяет в наборе «дрожащих» по частоте и иногда «исчезающих» значений формант выбрать участки, на которых интерполированные, сглаженные и по частоте, и по времени частоты формант образуют участки с относительно стабильными значениями, пригодными для уверенной фиксации и последующего сравнения, и тем самым обеспечить дополнительную помехоустойчивость индивидуализирующих признаков в аддитивных широкополосных шумах.
Экспериментально выявлено, что наличие трех и более траекторий формант внутри спектрограммы опорного фрагмента в большинстве ситуаций позволяет однозначно определить значение формантных частот для хотя бы одного формантного вектора внутри опорного фрагмента и при последующем сравнении обеспечить надежную идентификацию дикторов.
Длительность опорного фрагмента определяют по границам участка речевого сигнала, для которого однозначно определяются формантные траектории для тех формант, которые затем используются для выбора положения формантных векторов. Длительные и существенно неоднородные по звуковому составу участки речевого сигнала, подходящие для использования в качестве опорных фрагментов, разбивают на несколько опорных фрагментов, для каждого из которых первые две форманты, в основном, не выходят за типовые границы вариативности формантных частот для одного типа гласной фонемы для данного языка.
Пример такой спектрограммы с наложенными формантными траекториями приведен на Фиг.1.
Спектрограмма на Фиг.1 представляет собой спектрограмму слога «Тэ» в произнесении диктора-мужчины. По горизонтальной оси отложено время в секундах. По вертикальной - частота в Гц. Степень зачернения спектрограммы соответствует мощности сигнала в данной точке частоты и времени. Тонкие темные линии отмечают автоматически выделенные значения формантных частот, образующие формантные траектории. Вертикальные линии отмечают границы выделенного опорного фрагмента и формантного вектора для сравнения. Формантный вектор - это узкий интервал в границах опорного фрагмента, внутри которого значение формантной частоты относительно постоянно. Горизонтальные курсоры отмечают положение частот формант. На спектрограмме Фиг.1 они приблизительно равны: 430, 1345, 2505 и 3485 Гц.
После того, как для сравниваемых речевых сигналов первой и второй фонограмм выбраны опорные фрагменты и в них определены формантные векторы, для каждого опорного фрагмента и формантного вектора речевого сигнала первой фонограммы в речевом сигнале на второй фонограмме для сравнения выбирают опорный фрагмент и в нем формантный вектор так, чтобы у сравниваемых формантных векторов совпали значения частот, по крайней мере, двух формант. Если это не удается сделать, то опорные фрагменты считаются не сопоставимыми и в дальнейшем их сравнение между собой не проводится.
Такой выбор сравниваемых опорных фрагментов и формантных векторов соответствует выбору и сравнению участков речевого сигнала на первой и второй фонограммах, на которых реализуются сопоставимые артикуляторные события, то есть говорящими произносятся звуки, при которых резонансная структура спектра сигнала ярко выражена, а частоты двух или более резонансов (формант) совпадают независимо от того, какие фонемы в данный момент произносили дикторы.
Как указывалось ранее, такие речевые фрагменты, сопоставляемые по значениям части частот формант, в экспертной литературе принято называть «формантно-выровненными речевыми фрагментами». Указанные формантно-выровненные речевые фрагменты встречаются на речевых участках, на которых дикторы произносили как одинаковые, так и различающиеся фонемы. Например, на первой фонограмме в качестве опорного фрагмента для сравнения может быть выбран фрагмент произнесения стационарной гласной, а на второй фонограмме - фрагмент произнесения быстрого перехода от одной фонемы к другой, на котором имеется участок, где не менее двух значений формантных частот совпадает с соответствующими значениями формантных частот стационарной гласной на первой фонограмме.
Совпадение или несовпадение формантных частот проводится в соответствии с известным пороговым методом. Сами пороги допустимого отклонения зависят от качества сигнала, записанного на конкретной фонограмме (от соотношения сигнал/шум, типа и выраженности шумов и искажений, физического и психофизиологического состояния диктора), и определяются, исходя из естественной вариативности частот формант каждого диктора внутри данной фонограммы, для звуков данного типа для каждой форманты отдельно. Эту вариативность и соответствующие пороги, например, определяют путем поиска и сравнения между собой опорных фрагментов и формантных векторов внутри фонограммы, то есть для речевого сигнала каждой из фонограмм.
На формантно-выровненных речевых фрагментах сравнивают значения частот других не выровненных формант. По совпадению или несовпадению значений этих частот определяют совпадение/несовпадение данных сравниваемых опорных фрагментов (определенных фрагментов речи). Например, в типовых практических ситуациях отличие в 3% считают допустимым, а в 10% - недопустимым.
Если значения частот формантных векторов совпадают, то считают, что для данного типа звуков дикторы тождественны. Такая ситуация соответствует тому, что для произнесений звуков данного типа в сопоставляемые моменты времени у сравниваемых дикторов совпадают основные геометрические размеры вокальных трактов, характеризуемых своими акустическими резонансами.
Решение о совпадении или несовпадении формантно-выровненных фрагментов фонограмм принимается для каждого выбранного опорного фрагмента первой фонограммы. Для надежности принимаемого решения по каждому типу звуков необходимо сравнивать несколько (обычно 3-5) опорных фрагментов, соответствующих по формантным частотам данному типу звука.
Если во второй фонограмме для выбранного опорного фрагмента первой фонограммы найден формантно-выровненный опорный фрагмент, не совпадающий по частотам формант соответствующих формантных векторов с опорным фрагментом первой фонограммы, то следует провести обратный поиск форманто-выровненного фрагмента с такими же формантными частотами в первой фонограмме. Только если совпадающего вектора найти не удается, то принимается решение о несовпадении формантных векторов двух фонограмм для звука данного типа и, следовательно, о различии дикторов для данного типа фрагментов. Такая ситуация соответствует тому, что для произнесений звуков данного типа в сопоставляемые моменты времени у сравниваемых дикторов не совпадают характеризуемые своими акустическими резонансами основные геометрические размеры вокальных трактов для сопоставимых артикуляций.
Благодаря тому, что для идентификации говорящего выбирают формантно-выровненные фрагменты, соответствующие разным не обязательно тождественным звукам, обеспечивается возможность идентификации говорящего в ситуациях, когда звуковое содержание фонограмм существенно различается. В частности, именно благодаря такому подходу обеспечивается возможность идентификации дикторов для коротких фонограмм, для фонограмм, содержащих речь дикторов, находящихся в различных психофизиологических состояниях, а также говорящих на одном и том же или разных языках.
Автором экспериментально выявлено, что для обеспечения высокой надежности идентификации для дикторов-мужчин в большинстве практических ситуаций предпочтительно выравнивать (подбирать равными) значения частот трех формант и сравнивать значение четвертой форманты. Для женских и детских голосов желательно также выравнивать три форманты, но во многих практических ситуациях это не удается и возможно выравнивать (подбирать равными) значения частот двух формант и сравнивать значение третьей форманты.
Для принятия синтезирующего общего идентификационного решения необходимо провести на фонограммах поиск и сравнение сопоставимых формантно-выровненных фрагментов для представительного набора максимально различающихся типов артикуляции, то есть для максимально различающихся вариантов геометрии вокальных трактов сравниваемых дикторов. Эти типы артикуляции, как известно из теории (Бондарко Л.В., Вербицкая Л.А., Гордина М.В. Основы общей фонетики. - СПб.: СПбГУ, 2004, Г.Фант. Акустическая теория речеобразования. - М.: Наука. 1964, В.И.Сорокин. Теория речеобразования. - М.: Радио и связь. 1985), соответствуют гласным в вершинах так называемого «фонетического треугольника», то есть гласным звукам с максимальными и минимальными значениями частот первой и второй формант для всего диапазона встречающихся изменений первых двух формантных частот.
Например, для русского языка типичным является требование выбора в представительный набор опорных фрагментов звуков, близких по формантным частотам к средним значениям для гласных типа А, О, У, Э, И. Для английского языка - для гласных типа A, O, U, Е, I.
Например, для большинства языков различных типов по значениям формантных частот звуки в представительном наборе опорных фрагментов для дикторов-мужчин должны иметь значения формантных частот в следующих типовых областях с отклонением - около + или - 20%.
Желательно выбирать опорные фрагменты, близкие по формантным частотам для всех типов указанных в таблице звуков. При этом предпочтительно выбирать для каждого типа звука несколько опорных фрагментов. Экспериментально выявлено, что для каждого типа звука, для надежности принимаемого идентификационного решения достаточно найти в каждой из сравниваемых фонограмм 3-4 опорных фрагмента. В целом, для принятия окончательного синтезирующего идентификационного решения целесообразно использовать 4-8 типов различных звуков. Таким образом, в сравниваемых фонограммах целесообразно использовать 12-32 опорных фрагмента, в зависимости от качества речевого сигнала.
В случае малого объема речевого материала фонограмм минимально необходимым набором звуков является наличие в нем опорных фрагментов, близких по формантным частотам хотя бы к трем различным типам звуков в таблице.
Для опорных фрагментов каждого типа звука (обычно не менее трех) применяется описанная процедура формантного выравнивания и сравнения значений формант и по каждому типу звука принимается частное идентификационное решение о совпадении или несовпадении формант для каждого типа звука. По совокупности решений по формантно-выровненным опорным фрагментам для каждого типа звука принимают решение о совпадении формантных частот для звука данного типа, которому принадлежат сравниваемые опорные фрагменты. Решение принимается положительным, если для всех формантно-выровненных фрагментов данного типа имеется совпадение формантных частот всех рассматриваемых формант. Решение может быть вероятным, если качество фонограммы низкое и не позволяет определять положение формант с достаточной точностью. Решение может быть неопределенным, если качество и количество речевого материала фонограмм недостаточно для надежного выделения опорных фрагментов и формантных векторов на них.
По совокупности частных идентификационных решений для разных типов звуков принимается синтезирующее общее идентификационное решение о тождестве или различии дикторов, речь которых записана на сравниваемых фонограммах. Категорическое положительное синтезирующее решение обычно принимается при положительных частных идентификационных решениях для не менее чем 5 различных звуков при общем количестве сравниваемых опорных фрагментов не менее 15 и при отсутствии исключающих тождество дикторов частных отрицательных идентификационных решений. Отрицательное идентификационное решение принимается при наличии хотя бы одного категорического отрицательного частного идентификационного решения для одного типа звука. Решение может быть вероятным, если качество фонограммы низкое и не позволяет выделить достаточное количество опорных фрагментов, а положение формант определить с достаточной точностью.
Реализация способа подтверждается приведенными ниже примерами сравнения спектрограмм с наложенными формантными траекториями для совпавших и не совпавших дикторов.
На Фиг.2-4 приведены примеры сравнения спектрограмм с наложенными формантными траекториями для совпавших формантных частот для звуков типа «Э» (Фиг.2, 3), для звука типа «Е» (Фиг.4) и не совпавших формантных векторов для звука типа «Е» (Фиг.5).
Фиг.2 - спектрограммы с наложенными формантными траекториями для звуков типа «Е» слога «тэ» (в левой части чертежа) и слова «могут» (в правой части чертежа) в произнесении одного и того же диктора-мужчины. По горизонтальной оси отложено время в секундах. По вертикальной - частота в Гц. Степень зачернения спектрограммы соответствует мощности сигнала в данной точке частоты и времени. Тонкие темные линии отмечают автоматически выделенные значения формантных частот, образующих траектории формант. Вертикальные линии отмечают границы выбранных для сравнения опорных фрагментов и формантных векторов внутри них. Горизонтальные курсоры отмечают совпадающее положение частот формант. Они приблизительно равны: 430, 1345, 2505 и 3485 Гц. На отмеченных формантных векторах разные фонемы имеют совпадающие значения частот (середина ударного «Э» и самый конец заударного «У»).
Фиг.3 - спектрограммы с наложенными формантными траекториями для совпавших дикторов для звуков типа «Е» слога «тэ» (в левой части чертежа) и центрального участка слога «суда» из слова «Государство» (в правой части чертежа) в произнесении одного и того же диктора-мужчины. По горизонтальной оси отложено время в секундах. По вертикальной - частота в Гц. Степень зачернения спектрограммы соответствует мощности сигнала в данной точке частоты и времени. Тонкие темные линии отмечают автоматически выделенные формантные частоты, образующие траектории формант. Вертикальные линии отмечают границы выбранных для сравнения опорных фрагментов и формантных векторов внутри них. Горизонтальные курсоры отмечают совпадающее положение частот формант.Они приблизительно равны: 430, 1345, 2505 и 3485 Гц. На отмеченных формантных векторах разные фонемы имеют совпадающие значения частот (середина ударного «Э» и начало предударного «У»).
Фиг.4 - спектрограммы с наложенными формантными траекториями для произнесения совпадающими дикторами для звуков типа «Е» слога «ре» из слова «интересный» (в левой части чертежа) и слога «ше» из слова «решение» (в правой части чертежа) в произнесении одного и того же диктора-мужчины. По горизонтальной оси отложено время в секундах. По вертикальной - частота в Гц. Степень зачернения спектрограммы соответствует мощности сигнала в данной точке частоты и времени. Тонкие темные линии отмечают автоматически выделенные значения формантных частот, образующих траектории формант. Вертикальные линии отмечают границы выбранных для сравнения опорных фрагментов и формантных векторов внутри них. Горизонтальные курсоры отмечают совпадающее положение значений частот формант для формантных векторов ударных фонем «Е». Они приблизительно равны: 340, 1850, 2430 и 3505 Гц.
Фиг.5 - спектрограммы с наложенными формантными траекториями для не совпавших дикторов для произношения звуков типа «Е» слога «ре» из слова «интересный» (в левой части чертежа) и слога «де» из слова «утверждение» (в правой части чертежа) в произнесении разными дикторами-мужчинами. По горизонтальной оси отложено время в секундах. По вертикальной - частота в Гц. Степень зачернения спектрограммы соответствует мощности сигнала в данной точке частоты и времени. Тонкие темные линии отмечают автоматически выделенные значения формантных частот, образующих траектории формант. Вертикальные линии отмечают границы выбранных для сравнения опорных фрагментов и формантных векторов внутри них. Горизонтальные курсоры отмечают совпадающее положение значений частот трех формант. Они приблизительно равны: 340, 1850 и 3505 Гц. Вместо третьей форманты у диктора на спектрограмме слева 2430 Гц у диктора на спектрограмме справа есть третья форманта в районе 2800 Гц.
Для повышенной надежность идентификации в условиях сильного искажения речевого сигнала за счет существенно неравномерной АЧХ каналов звукозаписи, не совпадающей для сравниваемых фонограмм, предлагается вариант реализации способа идентификации дикторов, в котором перед выполнением всех стадий описанного выше способа проводят инверсную фильтрацию речевого сигнала сравниваемых фонограмм.
Перед выполнением вычисления спектрограмм и формантных частот спектр сигнала каждой фонограммы подвергается инверсной фильтрации, при которой для фонограммы в целом или ее отдельных фрагментов вычисляют средний по времени спектр, а далее исходное значение мощности спектра сигнала обрабатываемой фонограммы для каждой частоты делят на инверсное значение мощности среднего спектра для данной частоты. Инверсным значением мощности считается значение мощности спектра, полученное при делении единицы на данное значение.
Процедура инверсной фильтрации может быть реализована не путем деления, а с помощью логарифмирования и вычитания соответствующих спектров. В этом случае перед выполнением вычисления спектрограмм и формантных частот спектр сигнала каждой фонограммы переводится в форму логарифма спектра, для фонограммы в целом или ее отдельных фрагментов вычисляют средний по времени логарифм спектра, а далее из исходного значения логарифма мощности спектра сигнала обрабатываемой фонограммы для каждой частоты вычитают логарифма мощности среднего спектра для каждой частоты.
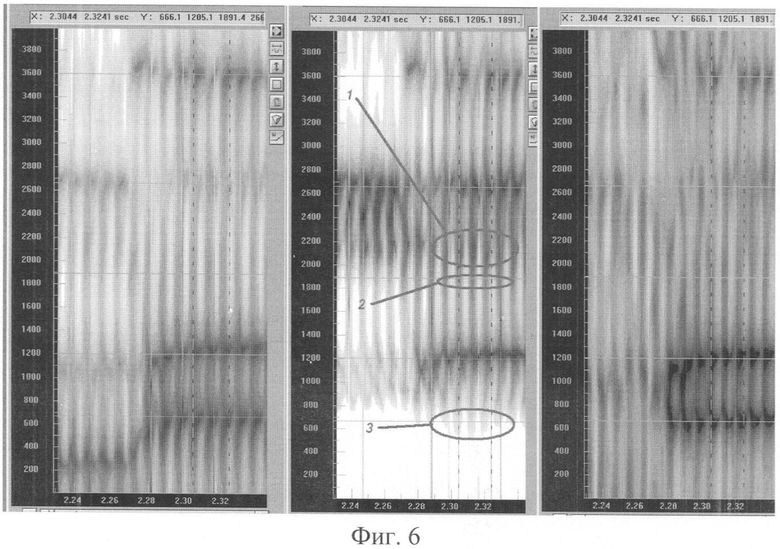
Фиг.6-8 иллюстрируют пример применения инверсной фильтрации при определении значений частот формант для выбранного формантного вектора.
На Фиг.6 приведены три спектрограммы одного и того речевого сигнала диктора (опорный фрагмент со слогом «На»):
- спектрограмма в левом окне относится к оригинальному речевому сигналу, записанному через высококачественный микрофон;
- спектрограмма в центральном окне относится к тому же речевому сигналу, записанному через низкокачественный телефонный тракт;
- спектрограмма в правом окне относится к тому же речевому сигналу, записанному через низкокачественный телефонный тракт после применения к нему инверсной фильтрации согласно предлагаемым вариантам реализации способа.
На каждой спектрограмме на Фиг.6 по горизонтальной оси отложено время в секундах от начала фонограммы, по вертикальной оси - частота в Гц. Степень зачернения спектрограммы пропорциональна мощности спектра сигнала в данной точке частоты и времени. Горизонтальные курсоры отмечают для оригинальной фонограммы значения частот пяти низкочастотных резонансов вокального тракта диктора для формантного вектора, отмеченного вертикальными курсорами.
На центральной фонограмме овалами с цифрами 2 и 3 отмечены области спектра, в которых отсутствуют следы проявления формант F1 и F3, присутствующие на оригинальной фонограмме. Овал с отметкой 1 показывает ложную формантную частоту, появившуюся только на спектрограмме 2 благодаря влиянию низкокачественного телефонного канала.
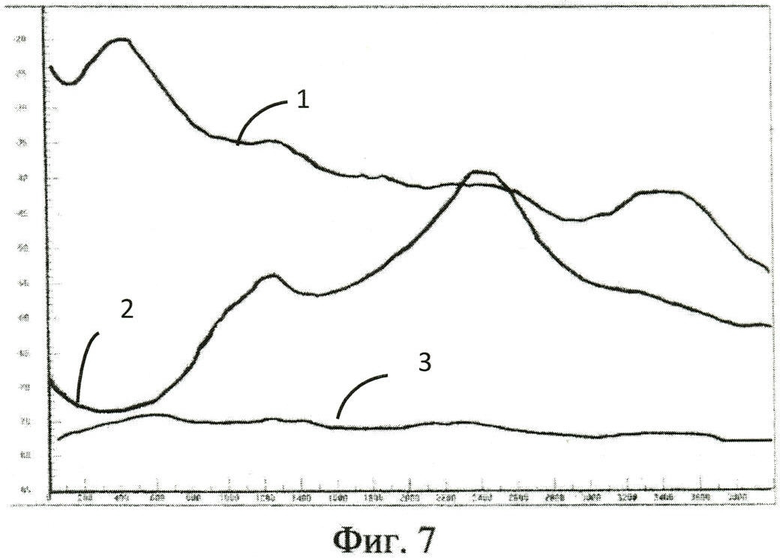
На Фиг.7 показаны: кривая (1) - средний спектр мощности оригинального речевого сигнала всей фонограммы, спектрограмма которого показана в левом окне на Фиг.6; кривая (2) - средний спектр мощности речевого сигнала фонограммы, спектрограмма которого показана в центральном окне на Фиг.6; кривая (3) - средний спектр мощности речевого сигнала фонограммы, спектрограмма которого показана в правом окне на Фиг.6.
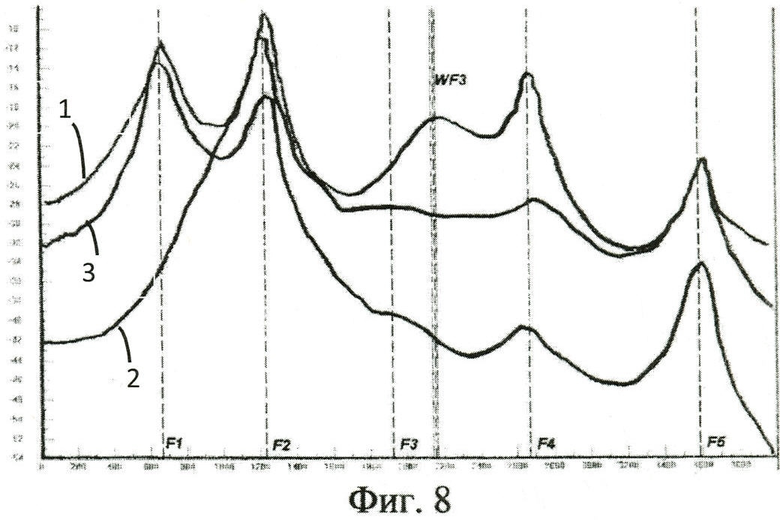
На Фиг.8 показаны усредненные спектры и отмеченные формантные частоты для формантного вектора, выделенного на спектрограммах на Фиг.6. Кривая (1) изображает средний спектр формантного вектора для оригинальной спектрограммы, показанной в левом окне на Фиг.6, кривая (2) - для той же фонограммы, пропущенной через низкокачественный телефонный тракт (соответствует центральному окну на Фиг.6), кривая (3) - для фонограммы, пропущенной через низкокачественный телефонный тракт и подвергнутой инверсной фильтрации (правое окно на Фиг.6). Вертикальные курсоры отмечают форманты F1, F2, F3, F4, F5, совпадающие для оригинальной фонограммы (левое окно на Фиг.6) и фонограммы после инверсной фильтрации (правое окно на Фиг.6). Форманты F1 и F3 на кривой 2 не видны. На кривой 2 отчетливо видна дополнительная ложная форманта WF3, отсутствующая у данного формантного вектора на оригинальной фонограмме.
Таким образом, в области спектра речевого сигнала, записанного через низкокачественный телефонный тракт, в которой отсутствуют следы проявления формант F1 и F3 (отмечены овалами с цифрами 2 и 3 на спектрограмме центрального окна на Фиг.6), на Фиг.8 указанные форманты F1 и F3 отмечены как имеющиеся на оригинальной фонограмме (кривая 1) и фонограмме после инверсной фильтрации (кривая 3). На фонограмме после низкокачественного телефонного тракта они отсутствуют (кривая 2 на Фиг.8). В то же время на фонограмме 2 присутствует ложная форманта WF3.
Приведенные примеры показывают, что предлагаемая инверсная фильтрация позволяет восстановить оригинальную формантную структуру фонограммы, нарушенную в случае прохождения фонограмм через низкокачественные каналы связи.
При этом экспериментально авторами выявлено, что инверсная фильтрация, реализованная как делением, так и с помощью логарифмирования и вычитания соответствующих спектров, дает практически эквивалентный результат.
Предлагаемый способ может быть реализован с помощь известных аппаратных средств.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СПОСОБ КОНТАКТНО-РАЗНОСТНОЙ АКУСТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 2011 |
|
RU2451346C1 |
| СПОСОБ И УСТРОЙСТВО АВТОМАТИЧЕСКОЙ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ | 2008 |
|
RU2399102C2 |
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| Способ дикторонезависимого распознавания фонемы в речевом сигнале | 2021 |
|
RU2763124C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ | 1996 |
|
RU2107950C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| Биометрический способ идентификации абонента по речевому сигналу | 2020 |
|
RU2742040C1 |
| СПОСОБ ОЦЕНКИ ВАРИАТИВНОСТИ ПАРОЛЬНОЙ ФРАЗЫ (ВАРИАНТЫ) | 2013 |
|
RU2598314C2 |
Изобретение относится к области опознавания говорящего по голосу, в частности к способам идентификации говорящего по фонограммам произвольной устной речи, предназначенным в том числе для криминалистических исследований. Сущность способа состоит в том, что идентификацию говорящего по фонограммам устной речи осуществляют путем оценки сходства между первой фонограммой говорящего и второй эталонной фонограммой. Для указанной оценки на первой и второй фонограммах выбирают опорные фрагменты речевых сигналов, на которых присутствуют формантные траектории, по крайней мере, трех формантных частот, сравнивают между собой опорные фрагменты, в которых совпадают значения, по крайней мере, двух формантных частот, оценивают сходство сравниваемых опорных фрагментов по совпадению значений остальных формантных частот, а сходство фонограмм в целом определяют по суммарной оценке сходства всех сравниваемых опорных фрагментов. Технический результат - обеспечивают надежную идентификацию говорящего как для длинных, так и для коротких фонограмм, фонограмм, записанных в различных каналах с высоким уровнем помех и искажений, а также фонограмм с произвольной устной речью дикторов, находящихся в различных психофизиологических состояниях, говорящих на разных языках. 5 з.п. ф-лы, 8 ил.
1. Способ идентификации говорящего по фонограммам устной речи, включающий оценку сходства между первой фонограммой говорящего и второй, эталонной фонограммой по совпадению значений формантных частот на выбранных для сравнения опорных фрагментах речевого сигнала на первой и второй фонограммах, отличающийся тем, что на первой и второй фонограммах выбирают опорные фрагменты речевых сигналов, на которых присутствуют формантные траектории, по крайней мере, трех формантных частот, из выбранных опорных фрагментов сравнивают между собой опорные фрагменты, в которых совпадают значения, по крайней мере, двух формантных частот, оценивают сходство сравниваемых опорных фрагментов по совпадению значений остальных формантных частот, а сходство фонограмм в целом определяют по суммарной оценке сходства всех сравниваемых опорных фрагментов.
2. Способ по п.1, отличающийся тем, что значения формантных частот на каждом выбранном опорном фрагменте вычисляют как средние значения на интервалах времени фиксированной длины, на которых значения частот формант относительно постоянны.
3. Способ по п.1, отличающий тем, что выбирают и сравнивают опорные фрагменты, в которых совпадают значения частот первых двух формант, которые находятся в заданных границах типичной вариативности значений формантных частот для соответствующего типа гласной фонемы для данного языка.
4. Способ по п.1, отличающийся тем, что для сравнения на фонограммах выбирают, по крайней мере, два опорных фрагмента речевого сигнала, относящихся к произнесению максимально артикуляторно различных звуков с максимальными и минимальными для данной фонограммы значениями частот первой и второй формант.
5. Способ по пп.1-4, отличающийся тем, что перед вычислением значений формантных частот спектр мощности речевого сигнала каждой фонограммы подвергают инверсной фильтрации, при которой для каждой частотной компоненты спектра мощности вычисляют ее среднее по времени значение, по крайней мере, для отдельных фрагментов фонограммы и затем исходное значение спектра мощности сигнала фонограммы для каждой частотной компоненты спектра делят на ее инверсное среднее значение.
6. Способ по пп.1-4, отличающийся тем, что перед вычислением значений формантных частот спектр мощности речевого сигнала каждой фонограммы подвергают инверсной фильтрации, при которой для каждой частотной компоненты спектра мощности вычисляют ее среднее по времени значение, по крайней мере, для отдельных фрагментов фонограммы и затем проводят операцию логарифмирования спектров и из логарифма исходного значения каждой частотной компоненты спектра мощности сигнала фонограммы вычитают логарифм ее среднего значения.
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| US 6389398 B1, 14.05.2002 | |||
| СПОСОБ АВТОМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 1998 |
|
RU2161826C2 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |
| WO 00/77772 A2, 21.12.2000 | |||
| US 6411930 B1, 25.06.2002. | |||

