Областью техники, к которой относится данное изобретение, является автоматическое распознавание человека, используемое для биометрического разграничения и ограничения доступа (в том числе удаленного) к устройствам и системам, к средствам электронно-вычислительной техники, к конфиденциальной информации, в помещения, а также при предоставлении услуг (например, телекоммуникационных или банковских). При этом использование биометрических систем ограничивается рядом причин, например, таких как высокая стоимость некоторых типов биометрических систем, сложная для пользователя процедура формирования эталона(ов) в динамических биометрических системах, зачастую невысокое качество биометрических данных, возможность их фальсификации и, соответственно, невысокие вероятностные характеристики.
Известны различные системы, устройства и способы распознавания человека по голосу [1-6]. Они предполагают выполнение ряда действий, таких как ввод речевого сигнала, определение значений параметров речевого сигнала (например, частотных и/или амплитудных), при необходимости - передача параметров на удаленную сторону, определение значений оценок статистических характеристик речевых параметров с целью формирования эталона(ов), определение степени различий между распознаваемым речевым сигналом и эталоном(ами), принятие решения о принадлежности речевого сигнала лицу, принимавшему участие в формировании эталона(ов).
Одним из основных недостатков аналогов является трудность сохранения в тайне речевого сигнала, как биометрического образа, и малая степень защиты от имитации (фальсификации) голоса с помощью звуковоспроизводящих устройств типа магнитофонов, CD-проигрывателей, управляемых синтезаторов речи и т.п. Это обусловлено тем, что речевой сигнал представляет собой изменения давления воздушной среды его распространения, формируемые речевым трактом человека. Линейная модель речеобразования при ряде допущений позволяет представить речевой тракт человека как систему из резонирующей трубы с несколькими сегментами переменного диаметра, на вход которой подается либо сигнал модулированного воздушного потока в виде импульсов разной амплитуды и формы, либо белый шум. Выходной речевой сигнал является сверткой сигнала возбуждения и импульсного отклика обратного синтезирующего фильтра и выражается следующим образом [7]:
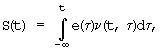
где e(τ) - функция сигнала возбуждения;
ν(t, τ) - отклик голосового тракта в момент t на дельта-функцию, подаваемую на вход фильтра в момент τ.
Такая модель описания речевого тракта человека широко используется во всех современных системах вокодерной связи, а также в ряде биометрических голосовых систем [4].
В публикациях российских авторов (см. [8]) значительное улучшение вероятностных характеристик голосовых биометрических систем предлагается обеспечить за счет увеличения количества слов в неизвестной злоумышленнику парольной фразе. Подобный же способ случайного выбора цепочки парольных фраз был использован в биометрическом фрагменте распознавания по голосу комплекса защиты от НСД к ПЭВМ, разработанного в рамках работ по созданию системы спецсвязи [4]. Однако использование современных скрытных звукозаписывающих и звуковоспроизводящих устройств позволяет злоумышленнику фальсифицировать в процедурах аутентификации биометрический образ зарегистрированного в системе пользователя.
В [6] для защиты от имитации (фальсификации) голоса звуковоспроизводящими устройствами предложено использовать дополнительную речевую информацию, вводимую с ларингофона, контактирующего с телом человека. Речевой сигнал, измеряемый с помощью ларингофона, и соответствующие ему значения параметров речевого сигнала зависят от местоположения ларингофона и не могут быть измерены и воспроизведены современными техническими средствами без непосредственного контакта их измерительного датчика с точкой местоположения ларингофона, т.е. без ведома человека. Вследствие этого попытка фальсификации сигнала с ларингофона, контактирующего с телом человека, другим сигналом, полученным, например, от скрытных радиопередающих и звукозаписывающих устройств, становится крайне затруднительной, если не невозможной.
Развитием способа, предложенного в [6], является способ распознавания человека только по акустическим сигналам, распространяющимся по мягким и твердым тканям тела человека при издании им звуков и наблюдаемым в неизвестной неуполномоченным лицам точке тела.
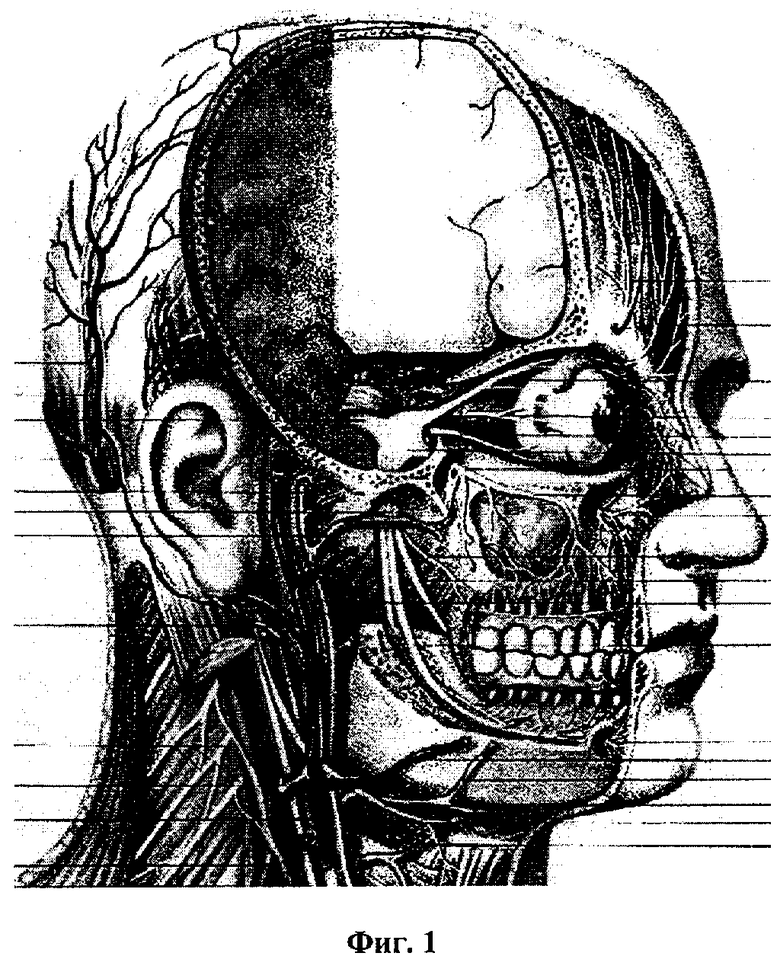
Пример строения твердых и мягких тканей головы человека приведен на фиг.1. В виде модели голову человека можно представить как сложную систему уникальных для каждого человека резонаторов, характеризующихся особенностями строения его мягких и твердых тканей. Так как речевой сигнал возбуждения распространяется не только через резонаторы речевого тракта, но и через резонаторы всех тканей тела человека, то использование датчиков (например, ларингофонного типа) позволяет воспринимать акустические сигналы с тела человека и использовать их в качестве его биометрического образа. Этот образ обладает рядом полезных свойств: уникальностью, стабильностью, неотъемлемостью, устойчивостью к влиянию внешних шумов, тайностью.
Уникальность такого образа определяется уникальностью строения тела человека, например особенностями строения его скелета, мышечной, нервной, лимфатической и других систем, а также уникальностью речевых (разговорных) навыков говорящего. Устойчивость к внешним шумам определяется особенностью ларингофонного датчика воспринимать в основном акустический сигнал, передающийся при непосредственном соприкосновении с телом человека как средой распространения звука. Неотъемлемость образа обеспечивается за счет трудности съема акустического сигнала с тела человека без его ведома. Так как одним из важнейших и необходимых аспектов обеспечения информационной безопасности биометрических голосовых систем является обеспечение сохранения в тайне биометрического акустического образа, это становится возможным в случае съема сигнала с неизвестной злоумышленнику точки тела человека.
На фиг.2 представлена структурная схема устройства, реализующего способ (пример).
Устройство состоит из блоков:
- блока 1 ларингофона;
- блока 2 усилителей;
- блока 3 динамика;
- блока 4 долговременного запоминающего устройства для хранения оцифрованных значений акустических данных с тела человека, а также оцифрованных диалоговых речевых сообщений (в случае их использования);
- блока 5 формирования окон анализа акустического сигнала;
- блока 6 определения параметров акустического сигнала в окнах анализа;
- блока 7 определения оценок математических ожиданий параметров акустического сигнала в окнах анализа, оценок ковариационных матриц параметров акустического сигнала в окнах анализа и оценок обратных ковариационных матриц квадратичной формы;
- блока 8 определения мер расстояний;
- блока 9 принятия решения «свой - чужой»;
- блока 10 управления.
Блоки 4-10 могут быть реализованы средствами аналоговой и/или цифровой вычислительной техники, например, в виде электронно-вычислительного устройства.
Один из входов блока 2 усилителей соединен с выходом блока 1 ларингофона, другой вход - с выходом блока 4 долговременного запоминающего устройства (в случае диалога с распознаваемым человеком). Один из выходов блока 2 усилителей соединен со входом блока 4 долговременного запоминающего устройства, другой - с блоком 3 динамика (телефонного капсюля) (в случае диалога с распознаваемым человеком). Выход блока 4 долговременного запоминающего устройства соединен со входом блока 5 формирования окон анализа акустического сигнала. Выход блока 5 формирования окон анализа акустического сигнала соединен со входом блока 6 определения параметров акустического сигнала в окнах анализа. Один из выходов блока 6 определения параметров акустического сигнала в окнах анализа соединен со входом блока 7 определения оценок математических ожиданий параметров акустического сигнала в окнах анализа, оценок ковариационных матриц параметров акустического сигнала в окнах анализа и оценок обратных ковариационных матриц квадратичной формы, другой выход - с одним из входов блока 8 определения мер расстояний. Выход блока 7 определения оценок математических ожиданий параметров акустического сигнала в окнах анализа, оценок ковариационных матриц параметров акустического сигнала в окнах анализа и оценок обратных ковариационных матриц квадратичной формы соединен с одним из входов блока 8 определения мер расстояний. Выход блока 8 определения мер расстояний соединен с одним из входов блока 9 принятия решения «свой - чужой». Выход блока 9 принятия решения «свой - чужой» соединен со входом блока 10 управления для обеспечения возможности анализа выходного сигнала и одновременно является выходом устройства. Один из выходов блока 10 управления соединен с одним из входов блока 9 принятия решения «свой - чужой» для обеспечения возможности его управления, другой выход - с одним из входов блока 4 долговременного запоминающего устройства.
Работа устройства происходит следующим образом. После воспроизведения через блок 2 усилителя и блок 3 динамика хранимого в блоке 4 долговременного запоминающего устройства сообщения (в случае диалога с распознаваемым человеком) распознаваемый человек j должен прижать блок 1 ларингофона к телу в определенном месте и произнести парольную фразу. Акустический сигнал с ларингофона через блок 2 усилителей поступает на блок 4 долговременного запоминающего устройства. Оцифрованный акустический сигнал сохраняют в блоке 4 долговременного запоминающего устройства и подают в блок 5 формирования окон анализа акустического сигнала. Окна анализа - не перекрывающиеся и могут иметь как одинаковую длительность, так и длительность, кратную периоду основного тона акустического сигнала. Длительность окон анализа выбирают такой, чтобы обеспечить псевдостационарность речевого сигнала. В современных вокодерных системах длительность окон анализа обычно находится в пределах 10-25 миллисекунд, однако может варьироваться как в ту, так и в другую сторону.
В блоке 6 для сформированных окон анализа определяются значения векторов параметров акустического сигнала 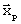 , в качестве которых могут использоваться широко применяемые параметры речевого сигнала, например коэффициенты Фурье-разложения сигнала, число переходов сигнала через ноль, период основного тона, коэффициенты линейного предсказания и т.д.
, в качестве которых могут использоваться широко применяемые параметры речевого сигнала, например коэффициенты Фурье-разложения сигнала, число переходов сигнала через ноль, период основного тона, коэффициенты линейного предсказания и т.д.
В блоке 7 по наблюдениям векторов параметров  человека j для каждого окна анализа m по К произношениям формируется эталон акустического сигнала путем вычисления вектора оценки математических ожиданий параметров
человека j для каждого окна анализа m по К произношениям формируется эталон акустического сигнала путем вычисления вектора оценки математических ожиданий параметров 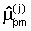 и оценки матрицы квадратичной формы
и оценки матрицы квадратичной формы  определяемой на основании оценки ковариационной матрицы
определяемой на основании оценки ковариационной матрицы 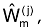 вычисляемой с
вычисляемой с 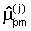 по следующим формулам:
по следующим формулам:
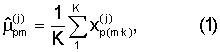
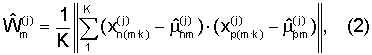
где 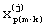 - значение параметра p в окне анализа m для k-го произношения;
- значение параметра p в окне анализа m для k-го произношения;
k - индекс произношения, используемого для формирования эталона, находится в интервале от 1 до К включительно.
Для каждого окна анализа параметры речевого сигнала из блока 6 определения значений параметров речевого сигнала, их математические ожидания и обратные матрицы квадратичной формы из блока 7 определения оценок математических ожиданий параметров акустического сигнала в окнах анализа, оценок ковариационных матриц параметров акустического сигнала в окнах анализа и оценок обратных ковариационных матриц квадратичной формы подают на блок 8 определения мер расстояний.
Определение значений мер расстояний для каждого окна анализа производят по следующей формуле:
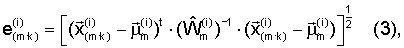
где i неравно j для распознаваемого человека, не формировавшего эталон, i равно j для распознаваемого человека, сформировавшего эталон.
На основании полученных значений по следующей формуле определяется значение совокупной меры расстояния для всего произношения:

где М - количество окон анализа в произношении
Полученное значение используется в блоке 9 принятия решения «свой - чужой» для принятия решения о принадлежности произношения человеку, сформировавшему эталон. Решающее правило использует значение совокупной меры и пороговое значение, разделяющее области «Свой» - «Чужой».
Блок 10 управления формирует решающее правило, используя информацию из блока 9 принятия решения «свой - чужой». Кроме того, сигнал управления подается на блок 4 долговременного запоминающего устройства для хранения оцифрованных значений акустических данных с тела человека, а также оцифрованных диалоговых речевых сообщений (в случае их использования) для управления интерактивным процессом взаимодействия распознаваемого человека с устройством.
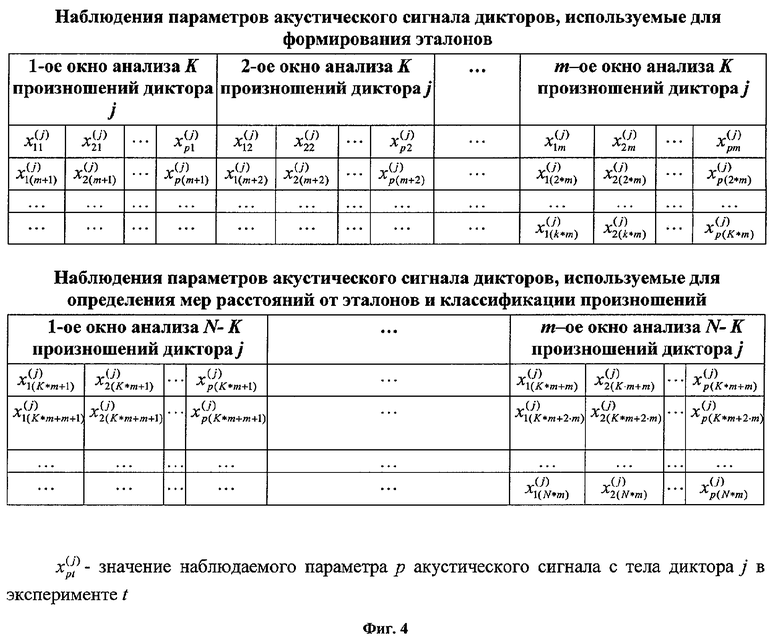
Для экспериментальной проверки предлагаемого способа сформирована база акустических сигналов, наблюдаемых в лобной, челюстной, шейной и ключичной зонах тел семидесяти дикторов по примерно ста произношениям каждого диктора в каждой зоне соответственно. Формат записи акустических сигналов: WAV - формат, частота дискретизации - 8 кГц, разрядность - 16, режим - стерео. В качестве ларингофонного датчика использовался ларингофон ЛА-5, подключенный через малошумящий предварительный усилитель к типовой звуковой карте типа SOUND BLASTER. В стереоканалах попарно записаны сигналы с двух зон съема: лобная зона - челюстная зона, шейная зона - ключичная зона. Вследствие предполагаемой симметричности тела человека точки съема - односторонние (левосторонние). На выборке сигналов из этой базы с применением биометрического фрагмента распознавания по голосу из состава комплекса защиты от НСД к ПЭВМ [4] проведены исследования по оценке возможности распознавания человека по акустическим сигналам, наблюдаемым на его теле. В качестве параметров р использованы кепстральные коэффициенты фильтра акустического тракта [7].
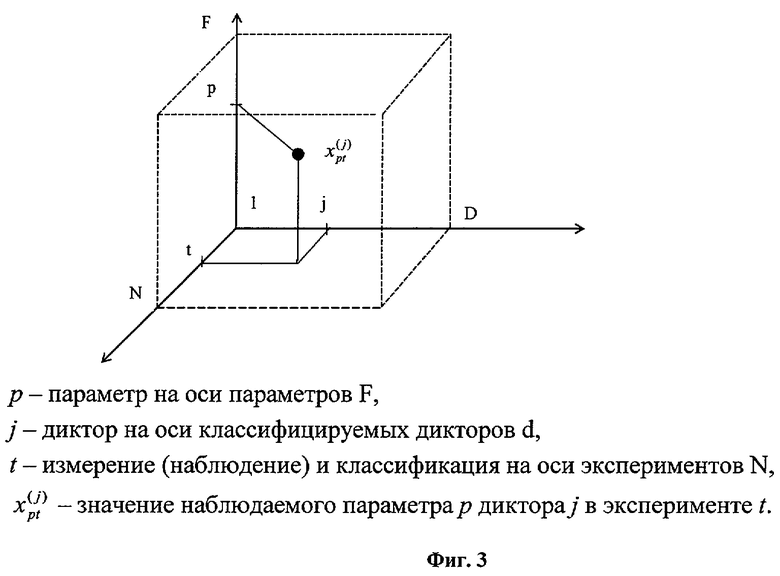
Результаты экспериментальных исследований (см. фиг.3) можно представить в виде куба наблюдений 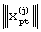 , где
, где 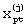 - значение наблюдаемого параметра р акустического сигнала с тела диктора j в эксперименте t. Под экспериментом понимается наблюдение (измерение) параметров акустического сигнала диктора в окне анализа текущего произношения в различных точках наблюдения акустического сигнала. Все эти наблюдения с определенными ограничениями можно представить как частные независимые области куба наблюдений.
- значение наблюдаемого параметра р акустического сигнала с тела диктора j в эксперименте t. Под экспериментом понимается наблюдение (измерение) параметров акустического сигнала диктора в окне анализа текущего произношения в различных точках наблюдения акустического сигнала. Все эти наблюдения с определенными ограничениями можно представить как частные независимые области куба наблюдений.
По К произношениям (см. фиг.4), выбранным в качестве эталонных, в соответствии с формулами 1 и 2 формируются эталоны для каждого окна анализа. В данном случае для формирования эталонов использовались произношения, наблюдаемые в одной точке тела диктора. С целью исключения разной длительности и темповой вариативности произношений используется нелинейная временная синхронизация окон анализа наблюдаемых произношений по отношению к произношению, выбранному в качестве первого эталонного произношения [4].
Оставшиеся N минус К произношения используются для определения мер расстояний от эталонов и классификации произношений (см. фиг.4). Меры расстояний (как для окон анализа, так и для произношений в целом) могут определяться относительно собственных эталонов или эталонов других дикторов, применительно к одним и тем же или различающимся зонам съема акустического сигнала. Определение мер расстояний для окон анализа и произношений в целом производится в соответствии с формулами 3 и 4.
Правило классификации состоит в том, что наблюдения 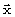 принадлежат диктору j, если выполняется условие по формуле
принадлежат диктору j, если выполняется условие по формуле
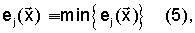
где j находится в интервале от 1 до D включительно.
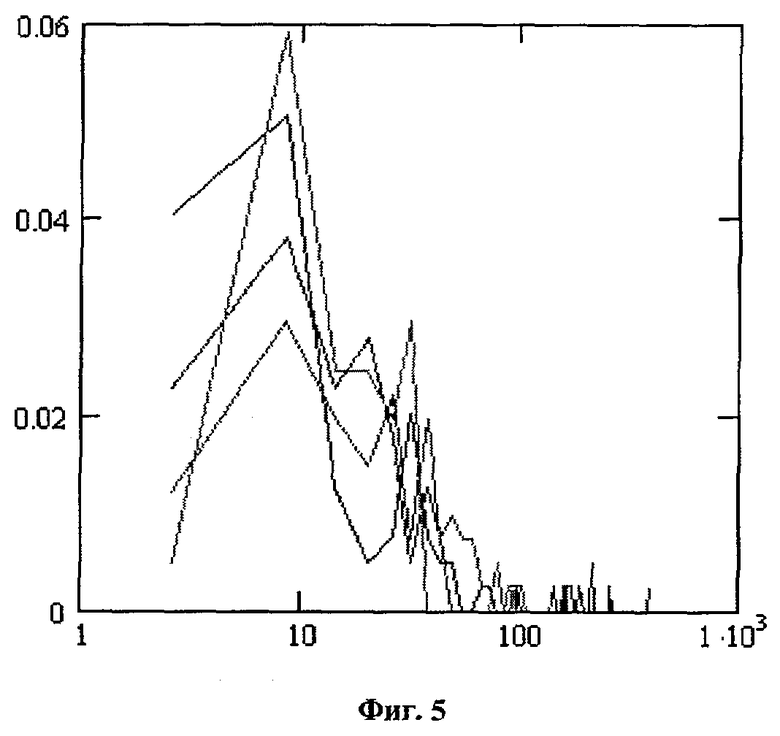
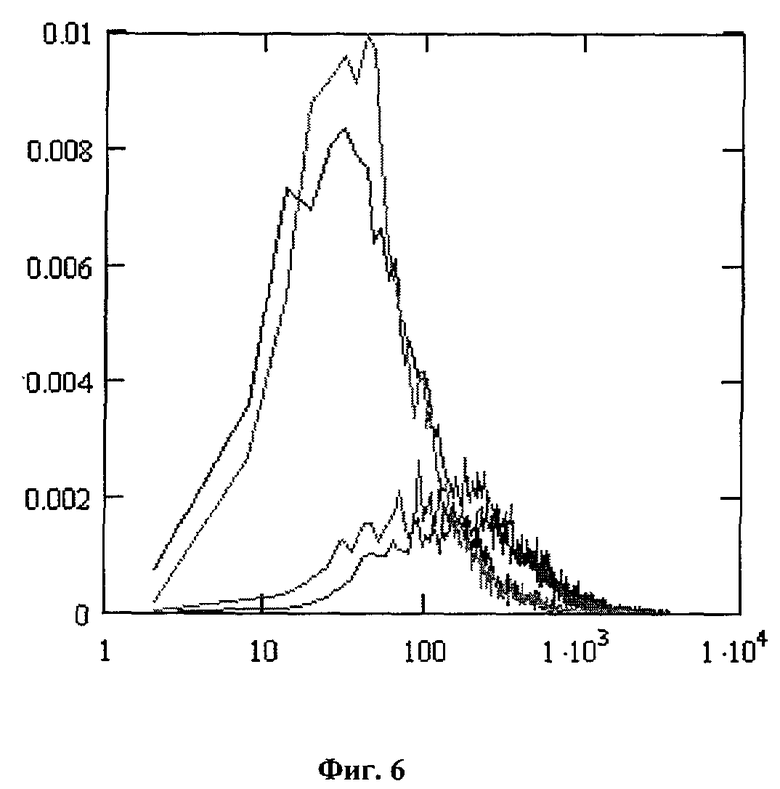
Гистограммы значений квадратичной меры для одного из окон анализа множества произношений относительно собственных (область «Свой 22») и чужих (область «Чужие») эталонов в четырех зонах наблюдения приведены на фиг.5 и 6 соответственно. На основании указанных гистограмм производится оценка вероятности ошибок классификации (ошибок первого и второго рода), которая находится в пределах от 1,2×10-3 до 3,8×10-2, в зависимости от точки наблюдения акустического сигнала. Большой разброс оценки вызван, вероятнее всего, различием в качестве акустического сигнала, наблюдаемого в различных точках тела разных дикторов. Однако при использовании современных специализированных датчиков ларингофонного типа и малошумящих усилителей с большим коэффициентом усиления, а также специальных алгоритмов цифровой обработки акустических сигналов, ошибка классификации для одного окна анализа в любой зоне наблюдения может быть значительно снижена (предположительно до уровня 10-3 и ниже).
Для произношений длительностью около 2 секунд М приблизительно равно 80. С учетом предположения о независимости наблюдений в различных окнах анализа и уменьшения дисперсии совокупной меры примерно в  раз, для произношений длительностью 2-3 секунды предположительно может быть достигнута ошибка классификации, не превышающая 10-4. Кроме того, значительного (до двух порядков и более) уменьшения уровня ошибок можно достигнуть при отсутствии у злоумышленников информации о местоположении точки съема акустического сигнала.
раз, для произношений длительностью 2-3 секунды предположительно может быть достигнута ошибка классификации, не превышающая 10-4. Кроме того, значительного (до двух порядков и более) уменьшения уровня ошибок можно достигнуть при отсутствии у злоумышленников информации о местоположении точки съема акустического сигнала.
Принимая во внимание все вышесказанное, можно сделать вывод о реализуемости предлагаемого способа распознавания человека и достижении при этом хороших вероятностных характеристик (возможно, на уровне лучших статических биометрических систем) и помехоустойчивости.
Используемые источники
1. Патент США №5313556, кл. G 10 L 5/06, опубл. 17.05.94.
2. Патент США №3673331, кл. G 10 L 1/04, опубл. 27.06.72.
3. Патент США №4078154, кл. G 10 L 1/00, опубл. 07.03.78, - том 968, №1.
4. С.Л.Бочкарев // Система голосовой аутентификации по динамическим параметрам акустического тракта человека. // Специальная техника средств связи. Серия Системы, сети и технические средства конфиденциальной связи. - вып.1. - Пенза: ПНИЭИ, 1996, с.93-102.
5. Авт. св. СССР №1453442, кл. G 10 L 9/06, опубл. 23.01.89, бюл. №3.
6. Бочкарев С.Л., Иванов А.И., Андрианов В.В., Бочкарев В.Л., Оськин В.А. Способ автоматической идентификации личности. Патент РФ №RU-2161826.
7. Дж. Д.Маркел, А.Х.Грэй. Линейное предсказание речи. - М: Радио и связь, 1980.
8. А.И.Иванов. Оценка эффекта от использования тайных биометрических образов. //Конфидент, 2002, №4-5.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 1998 |
|
RU2161826C2 |
| СПОСОБ КОНТАКТНО-РАЗНОСТНОЙ АКУСТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 2011 |
|
RU2451346C1 |
| СПОСОБ И УСТРОЙСТВО АВТОМАТИЧЕСКОЙ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ | 2008 |
|
RU2399102C2 |
| СПОСОБ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ НА ОСНОВЕ АНАТОМИЧЕСКИХ ПАРАМЕТРОВ ЧЕЛОВЕКА | 2010 |
|
RU2421699C1 |
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |
| Устройство для распознавания слоев | 1974 |
|
SU516094A1 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧЕВЫХ КОМАНД УПРАВЛЕНИЯ | 2003 |
|
RU2271578C2 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
Изобретение относится к области автоматического распознавания человека по его голосовым характеристикам и может быть использовано для ограничения и разграничения доступа (в том числе удаленного) к устройствам и системам, к средствам электронно-вычислительной техники, к конфиденциальной информации, к услугам (например, телекоммуникационным, информационным, банковским), а также к охраняемым зонам и помещениям. Технический результат заключается в повышении устойчивости голосовых биометрических систем к акустическим помехам и уменьшении возможности фальсификации голосового сигнала. По предлагаемому способу акустический сигнал, наблюдаемый в точке тела человека, неизвестной неуполномоченным (в том числе злоумышленным) лицам, вводят в электронно-вычислительное устройство, определяют значения параметров акустического сигнала, определяют значения оценок статистических характеристик параметров акустического сигнала и формируют на их основе эталон(ы), определяют степень различия между акустическим сигналом и эталоном(ами), на основании степени различия принимают решение о принадлежности акустического сигнала человеку, чьи значения статистических характеристик были использованы при формировании эталона(ов). 6 ил.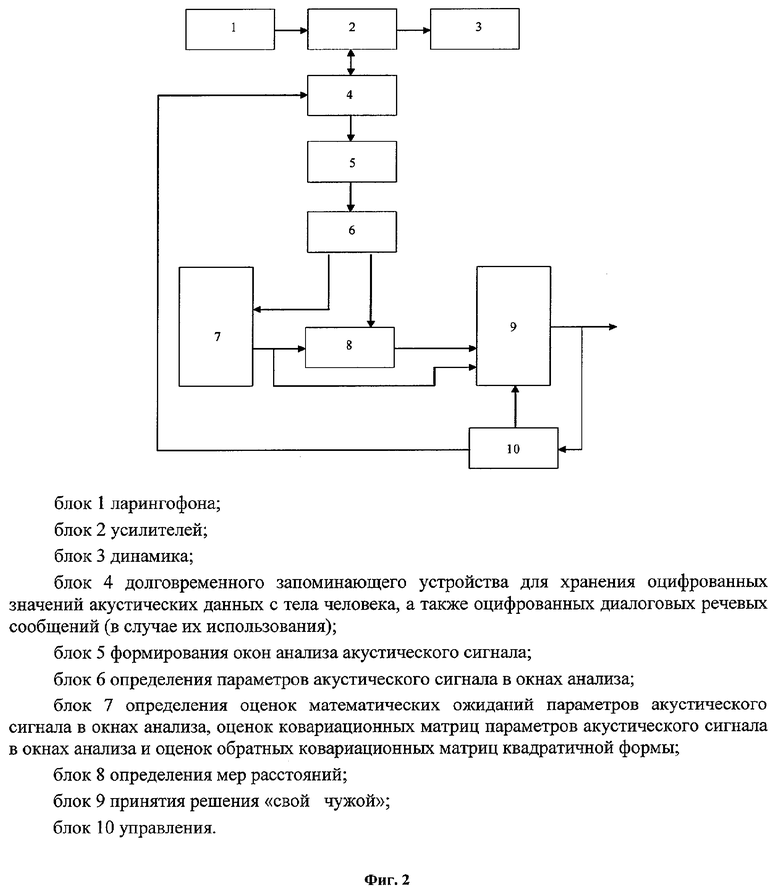
Способ автоматического распознавания человека по речевому сигналу, заключающийся в том, что речевой сигнал вводят при необходимости удаленно в электронно-вычислительное устройство, определяют значения параметров речевого сигнала, определяют значения статистических характеристик параметров акустического сигнала и формируют на их основе эталон или эталоны, определяют степень различия между акустическим сигналом и эталоном или эталонами, на основании степени различия принимают решение о принадлежности акустического сигнала человеку, чьи значения статистических характеристик были использованы при формировании эталона или эталонов, отличающийся тем, что вместо речевого сигнала используется акустический сигнал, измеряемый на теле человека при издании им звуков.
| СПОСОБ АВТОМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 1998 |
|
RU2161826C2 |
| Способ идентификации говорящего | 1986 |
|
SU1453442A1 |
| US 5313556 A, 17.05.1994 | |||
| US 4078154 A, 07.03.1978. | |||

