Изобретение относится к области информационных технологий, реализующие интерфейс между человеком и компьютером, а именно к сегментации (диаризации) или разделению дикторов в аудио-потоке, представленном в виде файла-записи (фонограммы). Диаризация дикторов является процессом определения, кто из дикторов говорит в какой момент времени. Сегментация речи по принадлежности каждому из двух дикторов обычно используется при дальнейшем автоматическом распознавании речи или идентификации личности по голосу.
Для оценки новизны и технического уровня заявленного решения рассмотрим ряд известных заявителю технических средств аналогичного назначения, характеризуемых совокупностью сходных с заявленным изобретением признаков, известных из сведений, ставших общедоступными до даты приоритета изобретения.
Известен способ распознавания, построенный с использованием методов фонемного анализа (патент США №5315689), в котором применяется двухуровневая обработка речевого сигнала. Блок первого уровня осуществляет распознавание слова (команды) как звукового (слухового) образа в целом. Альтернативный блок второго уровня производит фонемное распознавание звукового сигнала. Недостатком этого способа является снижение степени вероятности правильного распознавания слов (фраз) при увеличении объема словаря распознаваемых слов.
Известен способ обработки речевого сигнала с использованием блока первого уровня, построенного на основании метода динамического программирования, и блока второго уровня, построенного с использованием методов фонемного анализа (патент РФ №2103753). Блок первого уровня отбирает наиболее вероятных кандидатов слов для анализируемого сигнала и выбора на втором уровне наиболее вероятной альтернативы из отобранных кандидатов, отличающийся тем, что результаты распознавания речевого сигнала на первом и втором уровнях анализируют блоком принятия решения и в случае несоответствия указанного результата требованиям блока принятия решения формируют сигнал переспроса блока первого уровня. Данный способ не позволяет добиться высокой степени вероятности правильного распознавания слов (фраз) при увеличении объема словаря распознаваемых слов.
Известен способ дикторонезависимого распознавания звуков речи, включающий в себя предварительную сегментацию речевого сигнала для определения временной длительности звуковых сегментов, определение периодичности каждого сегмента акустических составляющих речевого сигнала для соотнесения звукового сегмента по способу его образования к конкретному виду звуков речи, определение амплитуды и частоты каждой из первых трех формант в спектре звукового сегмента в качестве информативных признаков звуков речи, интеграция упомянутых информативных признаков для каждого звукового сегмента, фонемное распознавание каждого звукового сегмента путем сопоставления интегральных значений его информативных признаков с имеющимся банком данных отдельно для каждого вида звуков речи, принятие решения относительно распознаваемого звука речи и представление его в виде буквенного или транскрипционного обозначения, отличающийся тем, что упомянутое соотнесение звукового сегмента осуществляют к голосовому, шумному или шумно-голосовому виду звуков речи, далее выполняют основную сегментацию речевого сигнала по трем основным режимам в зависимости от ранее найденного вида звукового сегмента, при упомянутом фонемном распознавании сопоставляют интегральные значения информативных признаков каждого звукового сегмента как для каждого упомянутого вида звуков речи, так и для каждого типа в зависимости от числа формант в звуковом сегменте, затем устанавливают временные границы звуков речи в зависимости от изменения фонемной принадлежности звукового сегмента, после чего и принимают упомянутое решение относительно распознаваемого звука речи, см. патент РФ №2234746.
Известно, что при практическом, в частности криминалистическом, исследовании и сравнении фонограмм устной речи, с целью идентификации говорящего, в ряде случаев экспертиза сталкивается с такими затрудняющими принятие решения проблемами, как малая длительность и низкое качество исследуемых фонограмм, различие психофизиологических состояний говорящих в момент произнесения речи на сравниваемых фонограммах, различное словесное содержание и разные языки, на которых произносится речь, различающиеся по типу и уровню помех и искажений каналы звукозаписи и пр. Поэтому в настоящее время актуальной является разработка способов идентификации говорящего по фонограммам произвольной устной речи, в частности, применимых для целей криминалистики и учитывающих указанные выше проблемы, а именно способов, обеспечивающих возможность идентификации говорящих по коротким фонограммам, записанным в различных каналах звукозаписи, с высоким уровнем помех и искажений, по фонограммам, содержащим устную речь, произносимую говорящими в разных психофизиологических состояниях, с различным словесным содержанием, при разных языках произнесения.
Известен способ идентификации дикторов по фонограммам, который проводится путем экстрагирования характерных особенностей диктора из произносимых однотипных фраз (патент Германии №2431458). В данном способе речевой сигнал фильтруют с помощью гребенки из 24 полосовых фильтров, затем детектируют, сглаживают, далее с помощью аналого-цифрового преобразователя и коммутатора сигнал вводят в цифровое обрабатывающее устройство, где автоматически выделяют и сохраняют индивидуализирующие признаки, связанные с интегральным спектром речи. Данный способ идентификации дикторов теряет работоспособность на фонограммах устной речи, полученных в условиях повышенных искажений и помех, из-за ограниченного набора индивидуализирующих признаков. Также этот способ имеет большой процент отказов от решения по идентификации, поскольку он требует фонограмм неизвестного и проверяемого диктора с одинаковым словесным содержанием.
Известен способ, в котором для идентификации личности в речи на сравниваемых фонограммах находятся и сравниваются однотипные ключевые слова (патент США №3466394). В данном способе речевой сигнал подвергается кратковременному спектральному анализу, затем выделяются контуры зависимости особенностей спектра и основного тона голоса от времени. Полученные контуры являются индивидуализирующими признаками. Идентификация дикторов основана на сравнении полученных контуров для фонограмм проверяемого и неизвестного дикторов. Недостатком способа является зависимость результатов идентификации от качества фонограмм, полученных в условиях повышенных искажений и помех. Также этот способ имеет большой процент отказов от решения по идентификации, поскольку он требует фонограмм неизвестного и проверяемого с одинаковыми словами.
Известен способ и устройство распознавания дикторов на основе построения и сравнения чисто статистических моделей кепстральных признаков речевого сигнала известных и неизвестных дикторов (патент США №6411930). В данном способе распознавание диктора выполняют при использовании дискриминантных моделей Гауссовых смесей. Данный способ, как и большинство чисто статистических подходов к распознаванию дикторов, не пригоден для ситуации, когда используемые голосовые сообщения очень короткие (1-10 секунд), состояние дикторов и/или используемые для записи фонограмм каналы существенно различаются по свойствам или дикторы находятся в различных эмоциональных состояниях.
Известен способ распознавания дикторов на основе чисто стохастического подхода (патент США №5995927). В данном способе распознавание диктора выполняют путем построения и сравнения матриц ковариации признаковых описаний входного речевого сигнала и эталонов речевого сигнала известных дикторов. Этот известный способ также не пригоден для ситуации, когда используемые голосовые сообщения короткие (5 секунд и менее), а также очень чувствителен к существенному снижению мощности сигнала на отдельных участках частотного речевого диапазона за счет окружающего шума и низкокачественных микрофонов и каналов звукопередачи и звукозаписи.
Известен способ распознавания изолированных слов речи с адаптацией к диктору (патент РФ №2047912), основанный на дискретизации входного речевого сигнала, его предыскажении, последовательной сегментации речевого сигнала, кодировании сегментов дискретными элементами, вычислении энергетического спектра, измерении формантных частот и определении амплитуд и энергии в различных частотных полосах речевого сигнала, классификации артикуляторных событий и состояний, формировании и сортировке эталонов слов, вычислении расстояний между эталонами слов с реализацией распознаваемого слова, принятии решений о распознавании или отказе от распознавания слова с дополнением словаря эталонов в процессе адаптации к диктору. Предыскажение входного речевого сигнала выполняют во временной области путем дифференцирования со сглаживанием, квантование энергетического спектра выполняют в зависимости от дисперсии шума канала связи, формантные частоты определяют при нахождении глобального максимума логарифмического спектра и вычитании из этого спектра заданной частотно-зависимой функции, при классификации артикуляторных событий и состояний определяют доли периодического и шумового источников возбуждения при сравнении с порогом коэффициентов автокорреляции последовательности прямоугольных импульсов в нескольких частотных полосах, начало и конец артикуляторных движений и соответствующих им акустических процессов определяют при сравнении с порогом функции правдоподобия от значений коэффициентов автокорреляции, формантных частот и энергий в заданных частотных полосах, речевой сигнал сегментируют на интервалы между началом и концом акустических процессов, соответствующих специфическим артикуляторным движениям, и последовательно, начиная с гласных звуков, причем опознавание сегмента производят только в случае совпадения типов переходов на его левой и правой границах и заканчивают сегментацию при опознавании слева и справа по времени сегментов паузы между словами. Эталоны слов формируют в виде матриц с бинарными значениями правдоподобия признаков, а отказ от распознавания осуществляют при нормированной разности расстояния от неизвестной реализации до двух ближайших эталонов, принадлежащих разным словам, меньшей установленного порога. Недостатком данного известного способа распознавания изолированных слов речи с адаптацией к диктору является слабая различительная сила данного способа при его использовании для распознавания дикторов по произнесению произвольной речи, так как данный способ в большинстве случаев не различает дикторов одного пола при произнесении ими сообщений с совпадающим словесным составом.
Известна система для обеспечения секретности на основе распознавания голоса (патент США №5265191), требующая и от обучающего, и от неизвестного диктора обязательного повторного произнесения, по крайней мере, одного речевого сообщения. Система сравнивает параметрические представления повторных произнесений речи неизвестного и известного дикторов и принимает положительное решение о тождестве сравниваемых дикторов только в случае, если каждое произнесение неизвестного диктора достаточно близко произнесениям обучающего диктора, и отрицательное решение, если их представления достаточно далеки друг от друга. Недостатком данной системы является низкая помехоустойчивость в шумах переменного характера (в транспортном средстве, в условиях шума улицы, производственного помещения), а также обязательное требование произнесения сравниваемыми дикторами одинаковых речевых сообщений.
Известен способ автоматической идентификации личности по особенностям произношения парольной фразы этой личностью (патент РФ №2161826), заключающийся в том, что речевой сигнал разбивают на вокализованные зоны, выделяют временные интервалы в вокализованных зонах - в области максимумов интенсивности речевого сигнала, а также в начале первой и в конце последней вокализованных зон. Для выделенных временных интервалов определяют параметры речевого сигнала, сравнивают их с эталонами, которые формируют с учетом математических ожиданий и допустимых разбросов этих параметров, для чего в конце первой, начале последней, в начале и конце остальных вокализованных зон выделяют временные интервалы, длительность временных интервалов устанавливают кратной периоду основного тона речевого сигнала, определяют оценки коэффициентов корреляции параметров речевого сигнала, которые включают в число сравниваемых с эталонами, при формировании эталонов дополнительно учитывают коэффициенты корреляции параметров речевого сигнала. На основании полученных параметров речевого сигнала и соответствующих им статистических характеристик принимают решение по идентификации личности. Недостатком данного известного способа идентификации личности является низкая помехоустойчивость метода, так как для его работы требуется выделение во входном речевом сигнале точного положения границ периодов основного тона голоса, что в условиях наличия акустических и электромагнитных помех (шум офисного помещения, улицы, наводки в каналах речевой связи и т.п.) часто практически невозможно, кроме того, дикторы должны произносить одинаковые голосовые пароли, что на практике не всегда реализуемо.
Известно устройство для верификации диктора на основе измерения расстояния "ближайшего соседа" (патент США №5339385), включающее дисплей, генератор выдачи подсказок по случайному закону, блок распознавания слова, верификатор диктора, клавиатуру и блок первичной обработки сигнала, при этом вход блока первичной обработки сигнала является входом устройства, а его выход соединен с первыми входами распознавателя слов и верификатора дикторов, ко второму входу распознавателя слов подключен первый выход генератора выдачи подсказок, выход которого соединен с дисплеем. Клавиатура подключена к третьему входу распознавателя слов и к третьему входу верификатора дикторов, выход которого является выходом устройства. Верификатор дикторов данного устройства для определения сходства или различия произнесения голосовых паролей использует разбиение входного речевого сигнала на отдельные кадры анализа, вычисление непараметрических речевых векторов для каждого кадра анализа и далее определение близости таким образом полученных описаний речевого сигнала сравниваемых произнесений на основе Эвклидова расстояния ближайшего соседа. Недостатком данного устройства являются низкая помехоустойчивость при работе в акустических шумах офисных помещений и улицы в силу использования непараметрических речевых векторов и Эвклидовой метрики при определении степени сходства/отличия произнесений голосовых паролей, а также низкая надежность распознавания (высокий процент ложных отказов) за счет использования переменных по порядку слов голосовых паролей, вызванная неизбежной индивидуальной вариативностью произнесения одних и тех же слов в разном контексте даже одним и тем же диктором. Кроме того, обеспечение произнесения обоими сравниваемыми дикторами заданного подсказками речевого содержания на практике труднореализуемо.
Известен способ распознавания говорящего (патент США №6389392), включающий сравнивание входного речевого сигнала неизвестного диктора с эталонами, представляющими речь заранее известных дикторов, из которых, по меньшей мере, один представлен, по меньшей мере, двумя эталонами. Последовательные сегменты входного сигнала сравнивают с последовательными сегментами эталона, получая меру близости сравниваемых сегментов входного речевого сигнала и эталона. Для каждого эталона заранее известного диктора, имеющего, по крайней мере, два эталона, формируют композитный результат сравнения данного эталона и входного речевого сигнала на основе выбора для каждого сегмента входного речевого сигнала ближайшего по используемой мере близости сегмента сравниваемого эталона. Далее идентифицируют неизвестного диктора на основе композитных результатов сравнения входного речевого сигнала и эталонов. Этот способ распознавания диктора ограниченно применим на практике, так как обязательное требование наличия для распознаваемого заранее известного диктора не менее двух эталонов на каждое его речевое высказывание не всегда осуществимо в реальных условиях.
Известен способ идентификации личности по фонограммам произвольной устной речи (патент РФ №2107950). Он основан на спектрально-полосно-временном анализе речевого сигнала, выделении характеристик индивидуальности устной речи и сравнении этих характеристик с эталонными, при этом в качестве характеристик индивидуальности устной речи используют акустические интегральные признаки, являющиеся оценками параметров статистического распределения компонент текущего спектра и гистограмм распределения периодов и частот основного тона, измеренных на фонограммах речи как с произвольным, так и фиксированным контекстом, среди которых при адаптивном переобучении выбирают наиболее информативные для речи данного говорящего признаки, независимые от помех и искажений, присутствующих в сравниваемых фонограммах, а также используют лингвистические признаки, фиксируемые экспертом при слуховом анализе фонограмм с применением автоматизированного банка опорных звуковых эталонов диалектных, акцентных и дефектных особенностей устной речи. Данный метод в силу применения интегрального, то есть усредняющего характеристики речевого сигнала, подхода и лингвистического анализа теряет надежность при сравнении дикторов, имеющих короткие сравниваемые фонограммы, а также говорящих на разных языках или находящихся в существенно различных психофизиологических состояниях.
Известен способ распознавания дикторов (патент РФ №2230375), включающий посегментное сравнение входного речевого сигнала диктора с эталонами голосовых паролей, произносимых известными дикторами, и оценку сходства между первой фонограммой говорящего и второй эталонной фонограммой по совпадению значений формантных частот на выбранных для сравнения опорных фрагментах речевого сигнала на первой и второй фонограммах. В этом способе выделяют формантные векторы последовательных сегментов и статистические характеристики спектра мощности входного речевого сигнала и речевого сигнала эталонов, а затем их сравнивают соответственно с формантными векторами последовательных сегментов каждого эталона и со статистическими характеристиками спектра мощности речевого сигнала эталона и формируют композитную метрику сравнения входного сигнала и эталона. В качестве меры близости формантных векторов сегментов используют взвешенный модуль разности частот формантных векторов. Для вычисления композитной метрики сравнения входного сигнала и эталона находят для каждого сегмента входного речевого сигнала ближайший по этой мере близости сегмент эталона с равным числом формант, а в композитную метрику включают взвешенное среднее по всем используемым сегментам входного речевого сигнала значение мер близости между данным сегментом входного речевого сигнала и найденным для него ближайшим сегментом эталона, а также коэффициент кросскорреляции статистических характеристик спектров мощности входного речевого сигнала и эталона. Распознавание диктора выполняют на основе результата сравнения входного речевого сигнала и эталона по композитной метрике. Данный метод не обеспечивает надежное распознавание дикторов при существенно различном звуковом составе входного речевого сигнала и речевого сигнала образцов (например, при коротких сообщениях, при речи во входном сигнале и эталонах на разных языках), а также при существенном различии свойств каналов звукозаписи и различии психофизиологического состояния дикторов, произносящих речь на сравниваемых фонограммах. Эти недостатки обусловлены, во-первых, применением в качестве компонента композитной метрики статистических характеристик спектра мощности, которые существенно зависят от свойств канала записи, состояния диктора и звукового состава речи, а также сегментной меры близости в виде взвешенного среднего по всем используемым сегментам обрабатываемого речевого сигнала, что приводит к усреднению ошибок при сравнении сегментов и подавлению влияния больших межсегментных отклонений, говорящих о различии дикторов даже при малом среднем различии сегментов.
Известен способ идентификации говорящего по фонограммам произвольной устной речи, в котором для сравнения выбирают такие фрагменты речевого сигнала, а для принятия идентификационного решения используют такие индивидуализирующие признаки и методы их сравнения, которые позволяют осуществлять надежную идентификацию говорящего для большинства встречающихся на практике ситуаций, в частности, как для длинных, так и для коротких сравниваемых фонограмм, записанных в различных каналах с высоким уровнем помех и искажений, для фонограмм с произвольной устной речью дикторов, находящихся в различных психофизиологических состояниях, говорящих на разных языках, с тем чтобы расширить область применения способа, в том числе для его использования в криминалистических исследованиях.
Известен способ идентификации говорящего по фонограммам устной речи, включающий оценку сходства между первой фонограммой говорящего и второй, эталонной фонограммой по совпадению значений формантных частот на выбранных для сравнения опорных фрагментах речевого сигнала на первой и второй фонограммах, отличающийся тем, что на первой и второй фонограммах выбирают опорные фрагменты речевых сигналов, на которых присутствуют формантные траектории, по крайней мере, трех формантных частот, из выбранных опорных фрагментов сравнивают между собой опорные фрагменты, в которых совпадают значения, по крайней мере, двух формантных частот, оценивают сходство сравниваемых опорных фрагментов по совпадению значений остальных формантных частот, а сходство фонограмм в целом определяют по суммарной оценке сходства всех сравниваемых опорных фрагментов, см. патент РФ №2419890. В соответствии с этим способом значения формантных частот на каждом выбранном опорном фрагменте вычисляют как средние значения на интервалах времени фиксированной длины, на которых значения частот формант относительно постоянны. Выбирают и сравнивают опорные фрагменты, в которых совпадают значения частот первых двух формант, которые находятся в заданных границах типичной вариативности значений формантных частот для соответствующего типа гласной фонемы для данного языка. Для сравнения на фонограммах выбирают, по крайней мере, два опорных фрагмента речевого сигнала, относящихся к произнесению максимально артикуляторно различных звуков с максимальными и минимальными для данной фонограммы значениями частот первой и второй формант. Перед вычислением значений формантных частот спектр мощности речевого сигнала каждой фонограммы подвергают инверсной фильтрации, при которой для каждой частотной компоненты спектра мощности вычисляют ее среднее по времени значение, по крайней мере, для отдельных фрагментов фонограммы и затем исходное значение спектра мощности сигнала фонограммы для каждой частотной компоненты спектра делят на ее инверсное среднее значение. Перед вычислением значений формантных частот спектр мощности речевого сигнала каждой фонограммы подвергают инверсной фильтрации, при которой для каждой частотной компоненты спектра мощности вычисляют ее среднее по времени значение, по крайней мере, для отдельных фрагментов фонограммы и затем проводят операцию логарифмирования спектров и из логарифма исходного значения каждой частотной компоненты спектра мощности сигнала фонограммы вычитают логарифм ее среднего значения.
Известен BaseLine способ сегментации дикторов в аудио-потоке. Большинство современных систем использует BaseLine-системы диаризации, реализованные в различных комбинациях из: агломеративного иерархического объединения в кластеры с Байесовым Информационным Критерием (BIC) и Гауссовых Моделей Смеси (GMMs) построенных в пространстве кепстральных особенностей (MFCCs), см. Tranter S., Reynolds D. An overview of automatic speaker diarization systems // IEEE Trans. Audio, Speech, Lang. Process. - Sept. 2006 - V. 14 - №5 - P. 1557-1565; D. A. Reynolds and P. Torres-Carrasquillo, "The MIT Lincoln Laboratory RT-04F Diarization Systems: Applications to Broadcast Audio and Telephone Conversations," in Proc. Fall 2004 Rich Transcription Workshop (RT-04), Palisades, NY, November 2004; D. A. Reynolds and P. Torres-Carrasquillo, "Approaches and applications of audio diarization," in Proceedings of the IEEE ICASSP, 2005; R. Sinha, S. E. Tranter, M. J. F. Gales, and P. C. Woodland, "The Cambridge University March 2005 speaker Диаризация system," in Proc. European Conference on Speech Communication and Technology (Interspeech), Lisbon, Portugal, September 2005, pp.2437-2440.
Процесс агломеративного объединения обычно исполняют в нисходящем подходе. То есть начиная от большого количества дикторов, равного вначале числу сегментов речи, последовательно осуществляют попарное слияние кластеров наиболее близких по заданной метрике в сверхкластеры (чаще всего это BIC-критерий) и для модельного отбора останавливают процесс, при достижении некоторого порогового значения. Результатом процесса является разметка исходных речевых сегментов по дикторам. Агломеративное слияние кластеров сопровождается переобучением моделей Гауссовых смесей на кепстральных признаках, используя ЕМ-алгоритм. Каждой последоватльности сегментов речевого файла, которые принадлежат одному диктору, ставится в соответствие своя статистическая модель. Расчет BIC критерия при слиянии кластеров в агломеративной кластеризации производится на основе полученных статистических моделей. После завершения процесса агломеративной кластеризации выполняется заключительная стадия - коррекция положения границ сегментов на основе пересегментации Витерби. Необходимость пересегментации объясняется тем, что для упрощения моделирования изначально все произнесение разбивалось на сегменты с одинаковой длительностью и речь на каждом сегменте приписывалась только одному диктору. Задача пересегментации заключается в том, чтобы более точно определить границы сегментов.
Данный способ включает выполнение следующих стадий.
В блоке выделения речевых признаков с помощью детектора активности речи - VAD (Voice Activity Detector) - происходит определение на фонограмме речевых участков и участков пауз; далее участки пауз изымаются из дальнейшего анализа, и на речевых участках производится расчет акустических признаков - MFCC. Блок диаризации осуществляет процесс НММ-переиндексации. Результат работы основного блока диаризации дает в большинстве случаев точные временные метки для дикторов в записи, но положение этих меток может быть улучшено посредством работы блока пересегментации.
Данный способ не обеспечивает наилучшего по качеству результата сегментации дикторов. Ошибка диаризации (Diarization Error Rate, DER) таких систем для диалога составляет примерно 10%, см. Tranter S., Reynolds D. An overview of automatic speaker diarization systems // IEEE Trans. Audio, Speech, Lang. Process. - Sept. 2006 - V. 14 - №5 - P. 1557-1565. Большинство вышеописанных методов использует локальное ML-обучение на материале тестовой фонограммы, и таким образом, не используют никакой априорной информации о междикторской вариативности. Некоторые авторы пытаются применять априорную информацию на уровне фоновой модели UBM, в этом случае для построения статистичесикх моделей дикторов вместо ML обучения применяется MAP адаптацию от UBM, см D. A. Reynolds, Т. F. Quatieri, and R. В. Dunn. Speaker verification using adapted Gaussian mixture models. Digital Signal Processing, 10(1-3), pp.19-41, 2000.
Хотя такой подход позволяет оперировать априорной информацией, полученной на большой базе обучения, тем не менее его возможности ограничены тем, что данная информация сводится к моделированию распределения акустических признаков, при этом не учитывается междикторская вариативность.
Известно использование априорной информацией о междикторской вариативности посредством метода собственных голосов (eigen voice prior), см. P. Kenny, G. Boulianne, and P. Dumouchel. Eigenvoice modeling with sparse training data. IEEE Trans. Speech Audio Processing, 13(3), 2005.
Учет междикторской вариативности при построении статистической модели диктора является более эффективным способом по сравнению с MAP адаптацией, поскольку в этом случае требуется существенно меньшее число факторов для описания модели (в случае собственных голосов размерность составляет 1CR200, для MAP более 2000). Данная особенность является преимуществом при работе на произнесениях с малым количеством речи, поэтому этот метод позволяет обеспечить хорошую кластеризацию в группы коротких речевых сегментов речи дикторов в низкоразмерном пространстве факторов междикторской вариативности - собственных голосов.
Известен способ сегментация дикторов в аудио-потоке, использующий метод собственных голосов для инициализации основного блока диаризации, см. С.Vaquero, A. Ortega, J. Villalba, A. Miguel, Е. Lleida, "Confidence Measures for Speaker Segmentation and their Relation to Speaker Verification", in Proc InterSpeech, September 2010, Makuhari, Chiba, Japan, pp.2310-2313.
Этот способ решает задачу диаризации для диалога в телефонном канале, поэтому число дикторов S априорно известно (S=2). Он реализуется следующим образом. Сначала производится выделение речевых признаков. Затем, захватывая междикторскую вариативность, моделируют каждого диктора Моделью Гауссовой Смеси (GMM), адаптированной от Универсальной Фоновой Модели (UBM), используя подход собственных голосов согласно формуле:
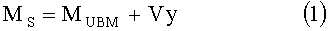
где MS - дикторозависимый супервектор GMM, полученный, связывая все Гауссовы средние,
MUBM - супервектор UBM, V - низко-ранговая eigenvoice матрица,
y - вектор факторов диктора.
Таким образом происходит отображение исходных речевых фрагментов в набор низкоразмерных векторов скрытого пространство диктора размерностью 50. Далее методом Главных Компонент (Principal Component Analisys, РСА) производится преобразование этих 50-мерных векторов в 20-мерные вектора, чтобы получить направление максимальной изменчивости в пространстве факторов диктора. Это ограничение в 20-ть собственных голосов. Затем происходит грубая кластеризация в этом 20-мерном пространстве в два кластера методом K-средних. Далее на основании этой первичной кластеризации производится инициализация НММ-моделей в блоке инициализации НММ-диаризации. Далее в основном блоке диаризации осуществляются НММ-итерации переиндексации сегментов речи. Каждая итерация состоит в шаге локального обучения НММ-модели на материале диаризуемого файла при использовании результата предыдущей сегментации, а также в шаге решения, выполненого в виде прямого прохода Витерби, который дает сегментацию файла. После нескольких итераций в основном блоке результаты диаризации подаются на блок окончательной пересегментации Витерби. Работа этого блока сходна с работой основного блока диаризации, но здесь применяется своя НММ-модель диалога, и используются ранее игнорированные паузы. Задачей этого блока является, не меняя индексов сегментов, немного исправить границы каждого из них, тем самым улучшив итоговую диаризацию.
Данный способ выбран в качестве прототипа заявленного изобретения.
Прототип имеет следующие недостатки. Во-первых, метод собственных голосов имеет один недостаток, выражающийся на практике в возможности рассогласования по условиям записи материала для обучения матрицы собственных голосов и тестовой аудиозаписи, подлежащей диаризации. Это может приводить к существенной деградации эффективности систем диаризации, основанных на этом методе.
С другой стороны, такие генеративные модели, как НММ или GMM, обучающиеся на локальном материале тестовой аудиозаписи, лишены этого недостатка, но сильно зависят от их инициализации (что опять-таки требует знания большой априорной информации о междикторской вариативности), см J. Ajmera and С.Wooters, "A Robust Speaker Clustering Algorithm," in Proc. IEEE ASRU Workshop, St. Thomas, U.S. Virgin Islands, November 2003, pp.411-416; J. Ajmera. Unknown-multiple speaker clustering using HMM. ICSLP, 2002; S. Meignier, J.-F. Bonastre, and S. Igounet, "E-HMM approach for learning and adapting sound models for speaker indexing," in Proc. Odyssey Speaker and Language Recognition Workshop, Chania, Creete, June 2001, pp.175-180.
Учитывая вышеизложенное, известный способ не в состоянии решить поставленную нами задачу.
Задачей изобретения является осуществление диаризации для диалога в телефонном канале, с наибольшим качеством сегментации дикторов, используя итерационную инициализацию основного блока, выполняющего диаризацию.
Сущность заявляемого изобретения как технического решения выражается в следующей совокупности существенных признаков, достаточной для достижения указанного выше обеспечиваемого изобретением технического результата.
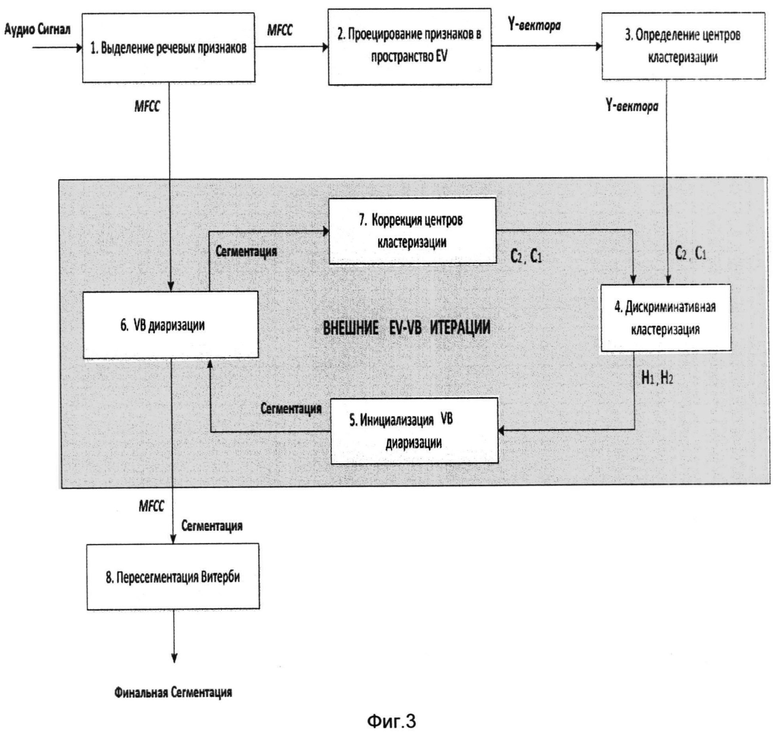
Согласно изобретению способ гибридной генеративно-дискриминативной сегментации дикторов в аудио-потоке, включающий выделеление речевых сегментов и расчет акустических признаков MFCC вектора, проецирование каждого речевого сегмента на пространство EV собственных голосов размерности 10 с получением набора Y-векторов и определение центров кластеризации C1 и C2 Y-векторов, характеризуется тем, что осуществляют дискриминативную кластеризацию путем расчета параметров плоскостей H1, H2 и приближенного определения областей концентрации Y-векторов, однородных по дикторской информации, при этом полученные данные о речевых сегментах используют для инициализации VB диаризации на основе вариационно-байсовского анализа, получают разметки сегментов по дикторам на всем произнесении, на основе чего производят коррекцию центров кластеризации C1 и C2, при этом операции дискриминативной кластеризации, вариационно-байсовского анализа и коррекцию центров кластеризации последовательно осуществляют в несколько итерационных EV-VB этапов, причем на каждом этапе итераций осуществляют анализ полной сегментации по дикторам и при отсутствии изменений сегментации на итерации прекращают, после чего путем пересегментации Витерби получают финальную сегментацию, представляющую собой табличное соответствие между речевыми сегментами входного сигнала и индексом диктора.
Непосредственный технический результат, достигаемый при реализации заявленной совокупности существенных признаков заявленного изобретения, заключается в основном в том, что в заявленном способе применена вариационно-байесова диаризация, которая предполагает использование априорной информации о междикторской вариативности с существенно большим числом факторов - порядка 200-300 голосов, поскольку данный метод оперирует речевыми сегментами на всем произнесении. Увеличение размерности пространства собственных голосов способствует усилению разрешающей способности статистических моделей при идентификации дикторов, что также эффективно для разделения дикторов на фонограмме при диаризации.
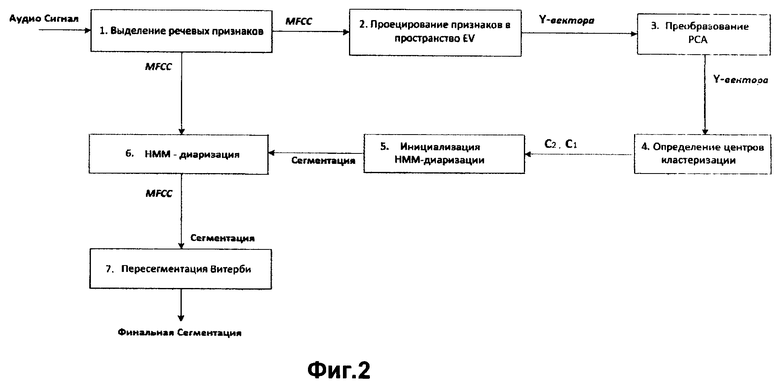
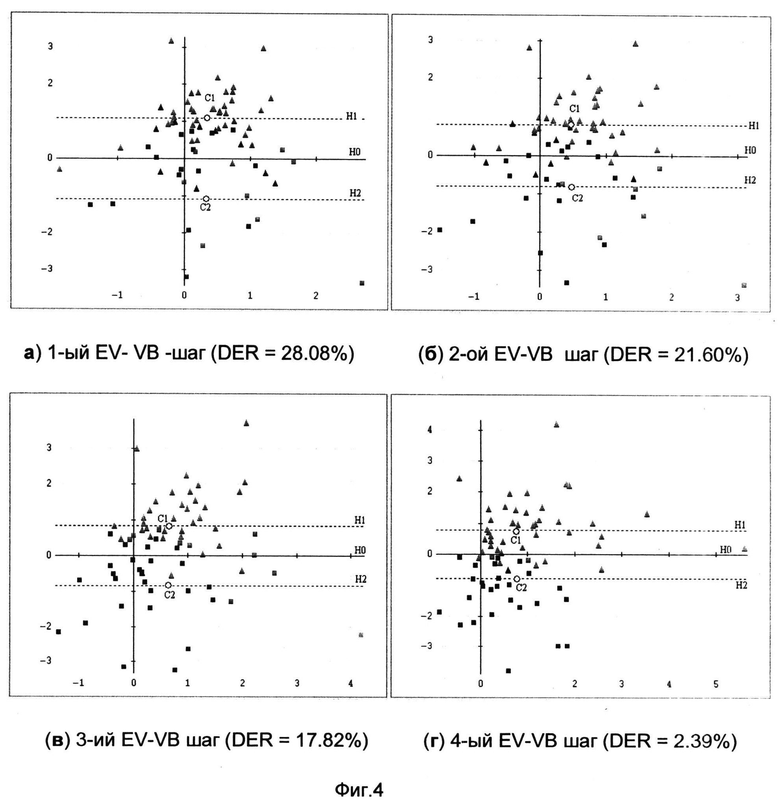
Сущность изобретения поясняется чертежами, где на фиг.1 представлена функциональная схема работы SaseLine разделения дикторов, на фиг.2 - функциональная схема работы EV-HMM-системы разделения дикторов, на фиг 3 - функциональная схема работы заявленного изобретения с гибридным EV-VB-модулем разделения дикторов, на фиг.4а-4г - последовательные (EV-VB)-итерации, выполненные до сходимости. Плоскость наблюдения ортогональна к разделяющей плоскости Н0. Различие в цвете сегментов - информация об идеальной разметке. Различие в форме (треугольники или квадраты) - сегментация, выполненная системой.
Функциональная схема работы заявленного изобретения включает блок 1 выделения речевых признаков, блок 2 проецирования признаков в пространство EV, блок 3 определения центров кластеризации, блок 4 дискриминативной кластеризации, блок 5 инициализации VB диаризации, блок 6 VB диаризации, блок 7 коррекции центров кластеризации, блок 8 пересегментации Витерби.
Заявленный способ использует априорную информацию о междикторской вариативности, но в более сильной форме. Объясняется это тем, что, хотя первичная инициализация у обоих методов производится методом собственных голосов с одинаковой размерностью пространства (число факторов строго варьируется между 10 и 20-ю, так как инициализация у них предусматривает использование стат-независимых коротких 1-2-секундных сегментов речи), тем не менее в блоке диаризации работа описанной схемы с прототипом серьезно отличается. Так, прототип основан на традиционной схеме НММ-диаризации, обучаемой только на акустических признаках, рассчитанных на тестовом файле, тогда как в заявленном способе в блоке 6 используется вариационно-байесова диаризация, см. Kenny P., Bayesian Analysis of Speaker Diarization with Eigenvoice Priors // Technical report, Centre de recherche informatique de Montreal, Montreal, Quebec, Canada - May 2008. Применение вариационно-байесовой диаризации предполагает использование априорной информации о междикторской вариативности с существенно большим числом факторов - порядка 200-300 голосов, поскольку данный метод оперирует речевыми сегментами на всем произнесении. Увеличение размерности пространства собственных голосов способствует усилению разрешающей способности статистических моделей при идентификации дикторов, что также эффективно для разделения дикторов на фонограмме при диаризации.
Кроме того, если инициализация блока 6 диаризации в прототипе производится генеративным образом, просто применяя метод K-средних, то в заявлеенном способе он производится дискриминативным образом - посредством разделяющих плоскостей H1 и Н2 в блоке 4. Данный прием позволяет обеспечить устойчивую инициализацию блока диаризации 6 даже в случае коротких диалоговых произнесений (менее 20 сек чистой речи).
В отличие от прототипа в заявленном способе используются так называемые внешние EV-VB-итерации, осуществляющие взаимодействие между генеративным VB блоком 6 и дискриминативным блоком 4. В данной реализации функциональная взаимосвязь между блоками 6 и 4 позволяет увеличить эффективность работы каждого блока по отдельности. Сказанное иллюстрирется на фиг.4а-4г.
Финальная сегментация, полученная после блока 6, используется для коррекции центров кластеризации C1 и С2 в пространстве собственных голосов, которая произведена в блоке коррекции кластеров 7. Отдельно для каждой из итоговых двух групп сегментов методом K-средних находят новое положение центра (это просто средний вектор в группе), которое передается блоку дискриминативной кластеризации 4. Блок 4 заново строит разделяющие гиперплоскости H1 и Н2 и, соответственно, дает новую инициализацию для генеративного VB-блока. На фиг.4а-4г показаны результаты выполнения таких «внешних» EV-VB-итераций и изменение ошибки сегментации дикторов DER на каждой итерации, см. NIST. Fall 2004 Rich Transcription (RT-04F) evaluation plan. Online: http://www.nist.gov/speech/tests/rt/rt2004/fall/docs/rto4feval-plan-v14.pdf.
Смысл этого итеративного процесса сводится к обмену промежуточной сегментацией между генеративным блоком, работающим в кепстральном пространстве, и дискриминативным блоком, работающим в У пространстве. Как видно из фиг.4а-4г, такой обмен осуществляет повороты в У пространстве, приводящие к все более чистым группам инициализации генеративных моделей, что в свою очередь приводит к сдвигу центров кластеров в сторону их истинных значений и, соответственно, к более оптимальному положению разделяющих H1 и Н2-гиперплоскостей.
Как показали эксперименты, для сходимости такой гибридной схемы требуется менее 10-ти EV-VB итераций. Если на протяжении 2-х итераций итоговая сегментация генеративного блока не изменялась - итерации досрочно прекращались.
Заявленный способ был реализован в виде пакета компьтерных программ и дал следующие результаты своей работы на тестовой диалоговой базе фонограмм NIST-2008 (1171 файлов) и стандартно оценененые по метрике NIST RT в виде ошибки диаризации DER, см. таблицу 1.
В этой же таблице приведены также сравнительные результаты для вышеупомянутых аналога и прототипа. Из таблицы видно, что оба они уступают по качеству диаризации заявленному способу.
Изобретение относится к области информационных технологий, реализующих интерфейс между человеком и компьютером, а именно к сегментации (диаризации) или разделению дикторов в аудио-потоке. Технический результат заключается в повышении точности распознавания диктора для диалога в телефонном канале. Выделяют речевые сегменты. Рассчитывают акустические признаки MFCC вектора. Проецируют каждый речевой сегмент на пространство EV собственных голосов размерности 10 с получением набора Y-векторов. Определяют центры кластеризации C1 и C2 Y-векторов. Осуществляют дискриминативную кластеризацию путем расчета параметров плоскостей H1, H2 и приближенного определения областей концентрации Y-векторов, однородных по дикторской информации. Полученные данные о речевых сегментах используют для инициализации VB диаризации на основе вариационно-байсовского анализа. Получают разметки сегментов по дикторам на всем произнесении, на основе чего производят коррекцию центров кластеризации C1 и C2, при этом операции дискриминативной кластеризации, вариационно-байсовского анализа и коррекции центров кластеризации последовательно осуществляют в несколько итерационных EV-VB этапов. На каждом этапе итераций осуществляют анализ полной сегментации по дикторам и при отсутствии изменений сегментации на итерации прекращают, после чего путем пересегментации Витерби получают финальную сегментацию, представляющую собой табличное соответствие между речевыми сегментами входного сигнала и индексом диктора. 4 ил., 1 табл.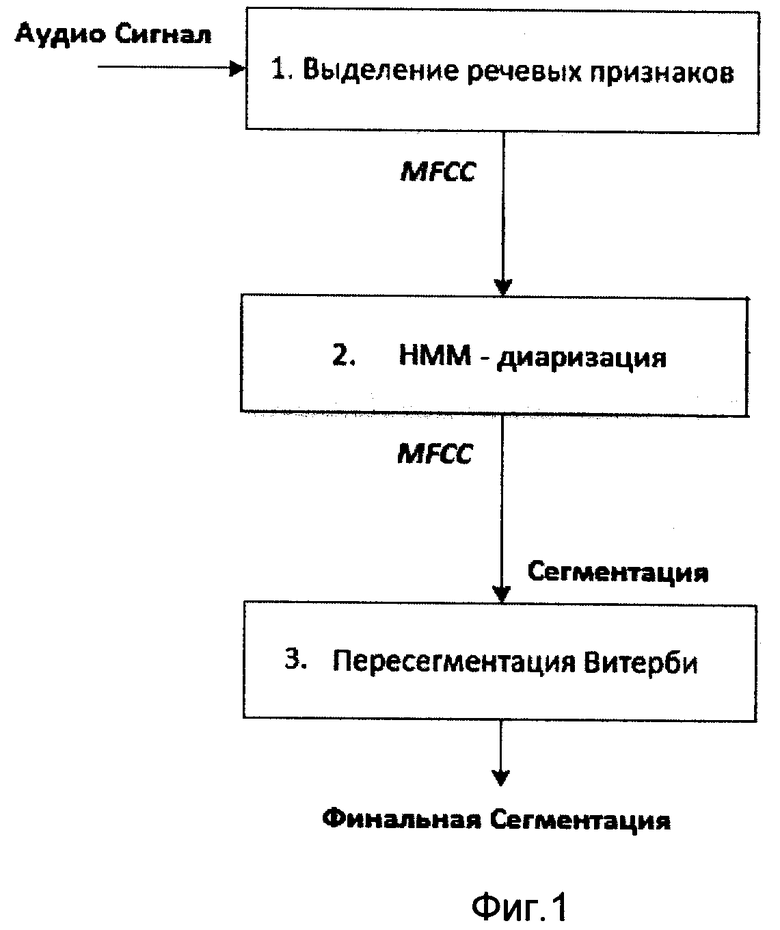
Способ гибридной генеративно-дискриминативной сегментации дикторов в аудио-потоке, включающий выделение речевых сегментов и расчет акустических признаков MFCC вектора, проецирование каждого речевого сегмента на пространство EV собственных голосов размерности 10 с получением набора Y-векторов и определение центров кластеризации C1 и C2 Y-векторов, характеризуется тем, что осуществляют дискриминативную кластеризацию путем расчета параметров плоскостей H1, H2 и приближенного определения областей концентрации Y-векторов, однородных по дикторской информации, при этом полученные данные о речевых сегментах используют для инициализации VB диаризации на основе вариационно-байсовского анализа, получают разметки сегментов по дикторам на всем произнесении, на основе чего производят коррекцию центров кластеризации C1 и C2, при этом операции дискриминативной кластеризации, вариационно-байсовского анализа и коррекции центров кластеризации последовательно осуществляют в несколько итерационных EV-VB этапов, причем на каждом этапе итераций осуществляют анализ полной сегментации по дикторам и при отсутствии изменений сегментации на итерации прекращают, после чего путем пересегментации Витерби получают финальную сегментацию, представляющую собой табличное соответствие между речевыми сегментами входного сигнала и индексом диктора.
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ | 1996 |
|
RU2107950C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| US 5315689 A, 24.05.1994 | |||
| СИСТЕМА ДЛЯ ПРИГОТОВЛЕНИЯ И ПРИВЕДЕНИЯ В ГОТОВЫЙ ВИД ТЕКУЧЕЙ СРЕДЫ, ОБРАЗОВАННОЙ СМЕШИВАНИЕМ СУХОГО ВЕЩЕСТВА И ЖИДКОСТИ | 2006 |
|
RU2431458C2 |
| US 6389392 B1, 14.05.2002 | |||
| US 5995927 A, 30.11.1999 | |||
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| US 4503241 A, 05.03.1985 | |||
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ ЗВУКОВ РЕЧИ | 2002 |
|
RU2234746C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 1998 |
|
RU2161826C2 |
| US 6411930 B1, 25.06.2002 | |||
| US 5265191 A, 23.11.1993 | |||
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ РЕЧЕВЫХ КОМАНД | 1997 |
|
RU2103753C1 |
| US 5339385 A, 16.08.1994 | |||

