Изобретение относится к области вычислительной техники и может быть использовано в высокопроизводительных системах обработки больших массивов информации, в том числе, и в режиме реального времени.
Известен компьютер, содержащий процессор, переключатель ввода-вывода, переключатель загрузки команд, память команд, модуль доступа к данным, ассоциативную память и модуль обработки подпрограмм [1].
Недостатком данного компьютера является то, что при выполнении последовательных фрагментов программы в форме тригонометрических или других функций работает только модуль обработки подпрограмм, а процессор простаивает, что ведет к снижению быстродействия. Кроме того, невозможно наращивание производительности системы путем подключения дополнительных блоков.
Наиболее близкой к описываемому изобретению (прототип) является параллельная вычислительные система (процессор) с перепрограммируемой структурой, включающая группу параллельных процессоров (элементов), каждый из которых выполнен в виде матрицы однородных вычислительных ячеек, соединенных с шиной ввода-вывода данных блока управления, содержащего оперативное запоминающее устройство (ОЗУ) и узел загрузки [2].
Существенным недостатком такой системы является жесткая взаимосвязь между собой отдельных параллельных процессоров, что при решении многих задач обусловливает низкую производительность системы в целом, особенно в случае отказов в работе некоторых процессоров, а также затрудняет наращивание производительности системы путем подключения дополнительных блоков. Кроме того, большое число параллельных процессоров, работающих с одним блоком управления, снижает эффективность их использования. Стоит отметить также, что параллельные процессоры неэффективны для задач, при решении которых требуется жестко последовательное выполнение, друг за другом, отдельных модулей и команд программы, реализующих отдельные части задачи.
Увеличение же числа параллельных процессоров наряду с введением в состав каждого параллельного процессора управляющего процессора, введение в состав системы вычислительных узлов, состоящих из процессоров другого типа (последовательных), объединенных одной или несколькими коммуникационными средами, позволяет наиболее быстро и эффективно выполнять сложные программы.
Техническим результатом предлагаемого технического решения является повышение производительности работы вычислительной системы.
Такой технический результат достигается тем, что в известном устройстве, содержащем группу параллельных процессоров, каждый из которых выполнен в виде матрицы однородных вычислительных ячеек, соединенных с шиной ввода-вывода данных блока управления, содержащего ОЗУ, дополнительно введены первая коммуникационная среда и N параллельных процессоров, причем каждый параллельный процессор дополнительно содержит управляющий процессор, системную шину, служебное ОЗУ, буферное ОЗУ и блок загрузки, первая группа входов-выходов которого соединена с первой коммуникационной средой, при этом вторая группа входов-выходов блока загрузки соединена с группой информационных входов-выходов буферного ОЗУ, группа управляющих входов которого соединена с первой группой управляющих выходов блока загрузки, третья группа входов-выходов которого соединена с группой информационных входов-выходов служебного ОЗУ, группа управляющих входов которого соединена со второй группой управляющих выходов блока загрузки, четвертая группа входов-выходов которого соединена с группой информационных входов-выходов ОЗУ, группа управляющих входов которого соединена с третьей группой управляющих выходов узла загрузки, первая группа выходов которого связана с группой информационных входов матрицы процессорных элементов, группа информационных выходов которой связана с группой входов блока загрузки, группа управляющих выходов которого связана с группой управляющих входов матрицы процессорных элементов, группа управляющих выходов которой связана с группой управляющих входов блока загрузки, пятая группа входов-выходов которого соединена с системной шиной, которая также соединяется с группой входов-выходов управляющего процессора.
Кроме того, в вышеописанную параллельную вычислительную систему с программируемой архитектурой могут быть дополнительно введены одна или более коммуникационных сред, а каждый параллельный процессор может дополнительно содержать один или более сетевых адаптеров, при этом первая группа входов-выходов каждого сетевого адаптера соединена с системной шиной параллельного процессора, которому принадлежит сетевой адаптер, а вторая группа входов-выходов каждого сетевого адаптера соединена с одной из коммуникационных сред.
Возможно также в вышеописанную параллельную вычислительную систему с программируемой архитектурой дополнительно ввести один или более вычислительных узлов, каждый из которых содержит последовательный процессор, системную шину и один или более сетевых адаптеров, при этом группа входов-выходов последовательного процессора соединена с системной шиной, с которой также соединена первая группа входов-выходов каждого сетевого адаптера, а вторая группа входов-выходов каждого сетевого адаптера соединена с одной из коммуникационных сред.
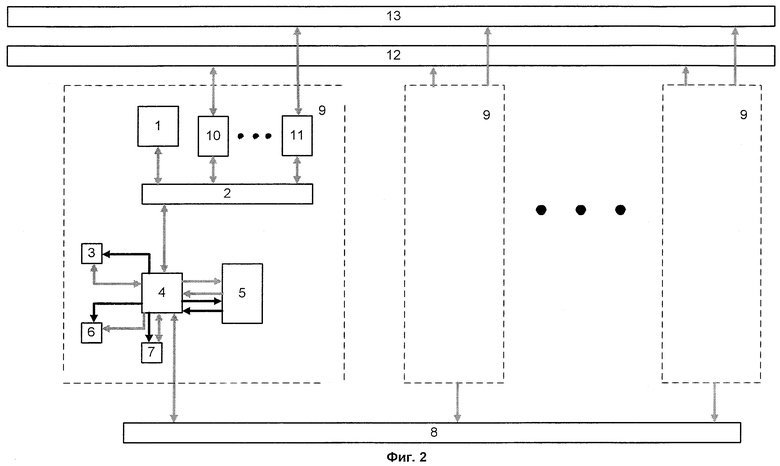
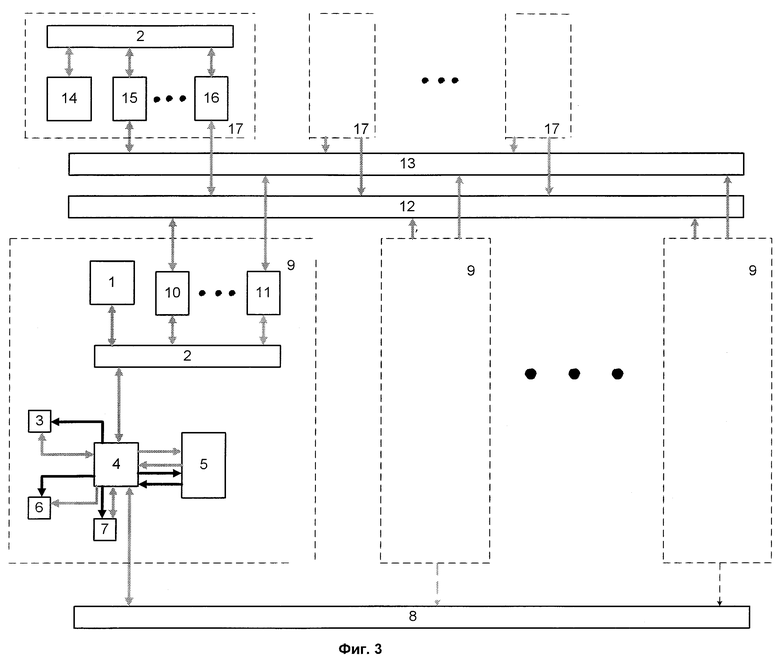
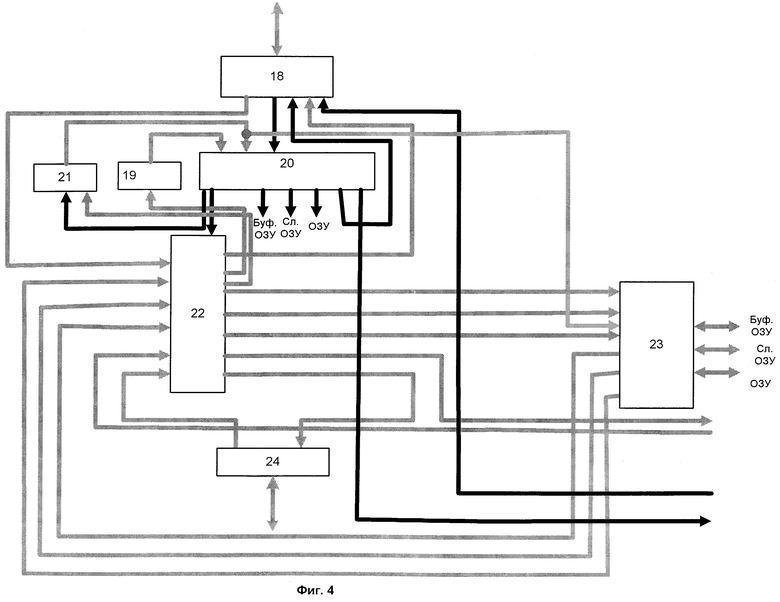
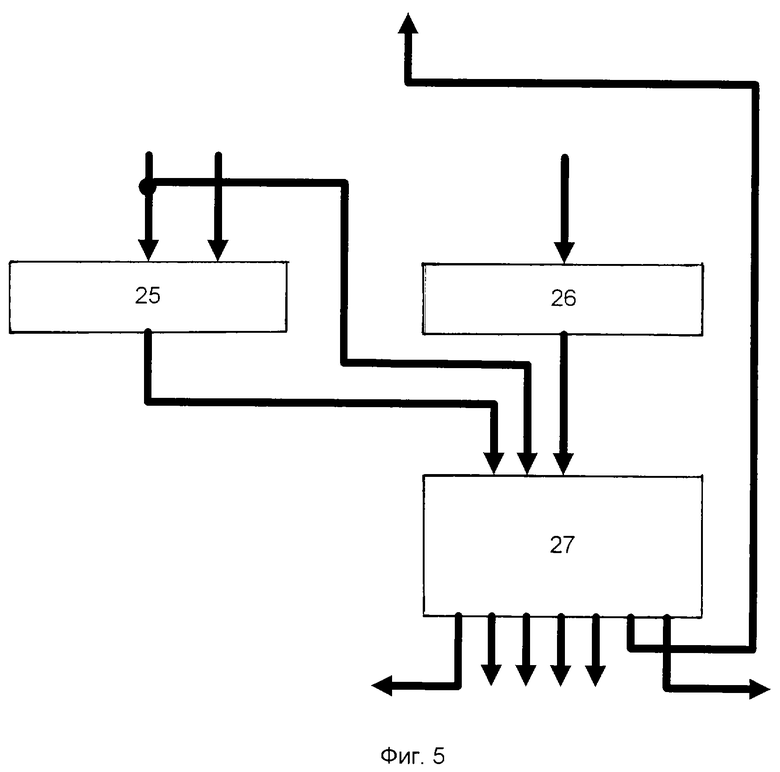
На фиг.1, 2, 3 приведена структурная схема вычислительной системы с программируемой структурой соответственно п.п.1, 2, 3 формулы изобретения; на фиг.4 - структура узла загрузки; на фиг.5 - структура блока команд.
При этом на каждой из фиг.2, 3 изображены две дополнительно введенные коммуникационные среды, хотя их дополнительно может быть введено одна или более. Точно так же на каждой из фиг.2, 3 изображены два дополнительно введенных в параллельный процессор сетевых адаптера, хотя их дополнительно может быть введено один или более, и два дополнительно введенных в вычислительный узел сетевых адаптера, хотя их дополнительно может быть введено один или более.
На фигурах приняты следующие обозначения: 1 - управляющий процессор, 2 - системная шина, 3 - ОЗУ, 4 - узел загрузки, 5 - матрица процессорных элементов, 6 - служебное ОЗУ, 7 - буферное ОЗУ, 8 - первая коммуникационная среда, 9 - параллельный процессор, 10, 11, 15, 16 - сетевые адаптеры, 12 - вторая коммуникационная среда; 13 - третья коммуникационная среда, 14 - последовательный процессор, 17 - вычислительный узел, 18, 23, 24 - блоки шинных формирователей, 19 - регистр настроек, 20 - блок команд, 21 - счетчик адреса, 22 - коммутатор, 25 - компаратор, 26 - регистр, 27 - дешифратор команд. На фиг.1 блоки 1, 2, 3, 4, 5, 6, 7 образуют параллельный процессор 9. На фиг.3 блоки 2, 14, 15, 16 образуют вычислительный узел 17.
Управляющий процессор 1, взаимодействуя с управляющими процессорами 1 других параллельных процессоров 9 и вычислительными узлами 17, получает для выполнения определенные части программы (процессы) и соответствующие данные, инициирует их обработку на матрице процессорных элементов и передает другим процессорам полученные результаты. Он может быть реализован на основе как одиночного стандартного микропроцессора, так и многопроцессорных плат типа SMP [4]. В качестве системной шины используются стандартные шины (например, РСI [4]). ОЗУ 3 предназначено для хранения информации и программ. Служебное ОЗУ 6 предназначено для хранения информации о настройке этого блока на выполнение загружаемого процесса. В некоторых случаях ОЗУ и служебное ОЗУ могут быть совмещены. Буферное ОЗУ 7 служит для обмена данными между параллельными процессорами 9 через первую коммуникационную среду 8 и может быть выполнено как обычное ОЗУ либо в виде набора регистров, являющихся FIFO-буферами.
Матрица процессорных элементов 5 представляет собой набор процессорных элементов, объединенных связями заданного вида (причем каждый из процессорных элементов реализует часть или одну из команд выполняемой программы) и может быть выполнена, например, как в [3] или в виде матрицы, состоящей из ПЛИС (программируемых логических интегральных схем, например, Xilinx [6]). Параллельные процессоры 9 для быстрого обмена данными между собой объединены посредством первой коммуникационной среды 8, представляющей собой набор шин передачи данных, организованных в определенную геометрическую структуру, например, тор [5].
Узел загрузки 4 предназначен для загрузки и выгрузки команд и данных в матрицу процессорных элементов 5 и из нее соответственно. Основные функции, которые он выполняет:
- формирование управляющих сигналов и адресов для ОЗУ, служебного ОЗУ, буферного ОЗУ;
- формирование управляющих сигналов, подаваемых в матрицу процессорных элементов 5;
- коммутация блоков параллельного процессора с целью обмена информацией между ними;
- обмен информацией между блоками параллельного процессора.
Один из возможных вариантов реализации блока загрузки показан на фиг.4. Узел загрузки содержит 18 - блок шинных формирователей, 19 - регистр настроек, 20 - блок команд, 21 - счетчик адреса, 22 - коммутатор, 23 - блок шинных формирователей, 24 - блок шинных формирователей. На фиг.5 показана одна из возможных реализаций блока команд. Блок команд содержит 25 - компаратор, 26 - регистр, 27 - дешифратор команд.
Блоки шинных формирователей 18, 24 обеспечивают связь блоков узла загрузки с системной шиной и первой коммуникационной средой соответственно. Блок шинных формирователей 23 обеспечивает связь блоков узла загрузки с ОЗУ 3, служебным ОЗУ 6 и буферным ОЗУ 7. Блок команд 20 обеспечивает дешифрацию команд, поступающих от управляющего процессора 1 с учетом содержимого регистра настроек 19, который содержит служебную информацию о режимах работы узла загрузки (например, побайтный или пословный обмен информацией, размер передаваемого массива и др.) и выдает управляющие сигналы для работы блоков узла загрузки. Счетчик адреса 21 пересчитывает адреса и выдает их в блок команд 20 и блок шинных формирователей 23. Коммутатор 22 обеспечивает соединение любого своего входа с любым своим выходом. Компаратор 25 производит сравнение текущего адреса, содержащегося в счетчике адресов с конечным адресом массива из регистра настройки 19. Регистр 26 служит для хранения команды, выдаваемой управляющим процессором 1 в узел загрузки 4. Дешифратор команд обеспечивает выдачу управляющих сигналов во все блоки узла загрузки в соответствии с содержимым регистра настройки 19, регистра 26 и выхода компаратора 25.
Узел загрузки работает следующим образом.
Управляющий процессор 1 через системную шину 2 и блок шинных формирователей 18 подает команды на блок команд 20. В соответствии с командами производится настройка коммутатора на передачу команд и данных от одного блока к другому. Затем в регистр настроек 19 записывается информация о режимах работы узла загрузки (например, побайтный или пословный обмен информацией, размер передаваемого массива и др.), а в счетчик адреса 21 подается начальный адрес массива информации. Первоначальные установки счетчика адреса и регистра обеспечиваются сигналами начальной установки (на всех фигурах сигналы начальной установки и их разводка не показаны). Далее счетчик адреса 21 увеличивает свое значение в соответствии с поступаемыми тактовыми импульсами (на всех фигурах генератор тактовых импульсов и разводка тактовых импульсов не показаны) до тех пор, пока компаратор 25, входящий в состав блока команд 20, не выдаст сигнал окончания обмена, который остановит счетчик адреса 21. Коммутатор 22 в соответствии с сигналами, поступающими с блока команд 20, устанавливает связи для передачи данных между блоками узла загрузки 4.
Блоки шинных формирователей 18, 23, 24, регистр настроек 19, счетчик адреса 21 выполнены стандартным образом, например так, как это описано в [7, 8]. Коммутатор 22 может быть выполнен так, как описано в [5, 7]. Блок команд может быть построен так, как это показано на фиг.5. Регистр 26 запоминает входную команду, компаратор 25 сравнивает содержимое счетчика адреса с последним адресом обмениваемого массива, который содержится в регистре настроек 19 и выдает в дешифратор команд 27 сигнал завершения обмена. По завершении обмена дешифратор команд 27 выдает в управляющий процессор 1 сигнал прерывания, после чего управляющий процессор 1 может выдавать другую команду.
Компаратор 25, регистр 26, дешифратор команд 27 выполнены стандартным образом, например так, как это описано в [7, 8].
С целью совмещения во времени процесса вычислений на матрице процессорных элементов 5 и загрузки исходных данных для следующего процесса в ОЗУ 3, в параллельном процессоре может быть введен второй узел загрузки 4. Управление очередностью работы узлов производит управляющий процессор 1.
Сетевые адаптеры 10, 11 предназначены для подключения параллельного процессора к второй 12 и третьей 13 коммуникационным средам с целью обмена информацией с другими параллельными процессорами 9 и вычислительными узлами 17. Сетевые адаптеры 15, 16 предназначены для подключения вычислительного узла 17 ко второй 12 и третьей 13 коммуникационным средам с целью обмена информацией с другими вычислительными узлами 17 и параллельными процессорами 9. В качестве аппаратуры передачи данных могут быть использованы стандартные коммуникационные среды типа SCI, Myrinet или аналогичные им по назначению и характеристикам [5].
Устройство работает следующим образом. Любая программа, описывающая решение какой-либо задачи, состоит из ряда вычислительных процессов (модулей программы), каждый из которых выполняет логически завершенное действие. Последовательные процессы (процессы последовательного типа), все команды которых должны выполняться строго друг за другом, выполняются на вычислительных узлах, каждый из которых состоит из последовательного процессора (процессорах последовательного или фон-неймановского типа) системной шины и одного или нескольких сетевых адаптеров. Параллельные процессы (процессы параллельного типа), команды которых могут выполняться одновременно (полностью или частично), выполняются на параллельных процессорах. Разбиение программы на процессы осуществляется либо программистом, либо транслятором, входящим в состав системного программного обеспечения параллельной вычислительной системы с программируемой архитектурой. При этом управляющий процессор тоже является процессором последовательного типа. Основной его задачей является обеспечение запуска процессов параллельного типа, но в фоновом режиме каждый управляющий процессор может выполнять последовательные процессы. Поэтому параллельная система с программируемой архитектурой для некоторых областей приложений может и не содержать вычислительных узлов.
Выполнение программы начинается с загрузки и запуска на одном из процессоров ее начального процесса. Этот процесс, в соответствии со структурой программы, может запускать на выполнение другие процессы, которые в свою очередь тоже могут запускать новые вычислительные процессы, при этом один процесс может запустить несколько других процессов до момента своего окончания. До тех пор, пока есть свободные процессоры, все процессы сразу же направляются на выполнение. Если же свободных процессоров данного типа нет, то процесс ставится в режим ожидания. Последовательные и параллельные процессы выполняются на процессорах соответствующего типа. Таким образом, в ходе выполнения программы решаемой задачи в системе функционирует максимальное число одновременно выполняемых процессов (не превышающее число вычислительных процессоров в системе), а другая часть готовых к выполнению процессов ожидает освобождения процессоров своего типа.
Способы создания очередей, готовых к выполнению процессов и запуска их на выполнение, определяются программными средствами и здесь не описаны.
Команды на загрузку процессов поступают через коммуникационные среды 8, 12, 13. При наличии свободного от выполнения каких-либо операций процессора и по запросу от него в его память пересылаются команды вычислительного процесса и/или необходимые данные. Пересылка и запуск процессов для последовательных процессоров 14 проводится стандартным способом через посредство соответствующей коммуникационной среды [5]. Для параллельных же процессоров 9 выполнение вычислительных процессов и обмен данными проводится следующим образом.
В случае, когда параллельная вычислительная система с программируемой архитектурой содержит только первую коммуникационную среду 8, к которой каждый параллельный процессор 9 подключается используя узел загрузки 4, при инициализации системы в каждый управляющий процессор 1 записывается программа вызова и получения очередного процесса. Получение процесса и данных, которые он обрабатывает, производится через первую коммуникационную среду 8. То же самое происходит после завершения текущего процесса.
В случае, когда параллельная вычислительная система с программируемой архитектурой содержит одну или более коммуникационных сред (12, 13 на фиг. 3), дополнительно подключаемых к параллельному процессору 9 через сетевые адаптеры 10, 11, при инициализации системы в каждый управляющий процессор 1 записывается программа вызова и получения очередного процесса. Получение процесса и данных, которые он обрабатывает, производится через вторую и/или третью и т.д. коммуникационную среду (12, 13 на фиг.3). То же самое происходит после завершения текущего процесса.
Каждый управляющий процессор 1 через системную шину 2 и узел загрузки 4 записывает команды полученного для выполнения процесса и необходимые для него данные в ОЗУ 3, а также записывает информацию о настройках узла в служебное ОЗУ 6. Последнее содержит данные для настройки узла загрузки 4, а именно начальные адреса соответствующих процессов и их данных в ОЗУ 3, а также тип данных, с которыми работает ОЗУ 3. Это может происходить в разные моменты времени, если набор команд, описывающих процесс, и данные для него передаются из разных процессоров. Как правило, все процессы, выполняемые на параллельных процессорах 9, одновременно загружаются в ОЗУ 3 каждого параллельного процессора 9 перед началом решения задачи, а данные направляются, по мере их готовности, только в ОЗУ 3, принадлежащие параллельным процессорам 9, в которых инициируются процессы, связанные с этими данными. Затем управляющий процессор 1 выдает в узел загрузки команду загрузки программы в матрицу процессорных элементов 5, а потом команду запуска самого вычислительного процесса [3]. В ходе функционирования каждая матрица процессорных элементов 5 считывает через узел загрузки 4 входные данные из ОЗУ 3 и записывает в него же или в буферное ОЗУ 7 результаты выполненной работы. В процессе вычислений каждая матрица процессорных элементов 5 может обмениваться данными с другими матрицами процессорных элементов 5 через узел загрузки 4, буферное ОЗУ 7 и первую коммуникационную среду 8. По окончании работы каждая матрица процессорных элементов 5 через узел загрузки 4 выдает своему управляющему процессору 1 сигнал прерывания, после чего управляющий процессор 1 может передать результаты выполнения вычислительного процесса через одну из коммуникационных сред другому управляющему процессору 1, который находится в ожидании поступления этих данных для выполнения очередного параллельного процесса на параллельном процессоре 9, или через дополнительно введенные вторую 12 (или другие) коммуникационную среду вычислительному узлу 17, который находится в ожидании поступления этих данных для выполнения очередного последовательного процесса.
Если же свободные процессоры отсутствуют, то очередной процесс ожидает освобождения процессора своего типа для своего выполнения. Каждый управляющий процессор 1 и последовательный процессор 14 после окончания выполнения очередного процесса осуществляют поиск на выполнение следующего процесса своего типа путем рассылки по одной из коммуникационных сред управляющих запросов типа "у кого есть для выполнения процесс и/или данные для процесса моего типа?". Функционирование процессоров продолжается до момента времени, когда все процессы заданной программы будут выполнены. В ходе выполнения процессоры обмениваются данными через коммуникационные среды. Наиболее эффективной является специализация коммуникационных сред. При этом обмен данными между параллельными процессорами 9 производится через первую коммуникационную среду 8, обмен управляющими сообщениями, контроль и управление работой всей системы - через вторую коммуникационную среду 12, и загрузка процессов и обмен данными между последовательными процессорами 14 и между последовательными 14 и параллельными 9 процессорами - через третью коммуникационную среду 13. Возможно введение большего количества коммуникационных сред, использующихся для создания сложных многоуровневых сетевых архитектур [5] . В некоторых случаях возможно использование вычислительной системы с программируемой структурой без первой коммуникационной среды, подключаемой через узел загрузки, но при этом система обязательно должна быть снабжена одной или более коммуникационными средами (12, 13 на фиг.3), дополнительно подключаемыми через сетевые адаптеры.
Так как все процессоры имеют одинаковый приоритет по обработке информации и являются равноправными, то в случае отказа какого-либо из них вычислительная система в целом остается работоспособной.
Устройство позволяет существенно повысить скорость обработки информации и увеличить надежность его работы. Также возможно простое наращивание производительности системы путем подключения дополнительных блоков.
Источники информации
1. РСТ Патент WO 99/08172, кл. G 06 F 15/16, 1999.
2. RU Патент 2110088 С1, кл. 6 G 06 F 15/16, 15/00, 1998.
3. RU Патент 2134448 С1, кл. 6 G 06 F 15/16, 7/00, 1999.
4. Корнеев В.В. Современные микропроцессоры. М.: Нолидж, 1999.
5. Корнеев В.В. Параллельные вычислительные системы. М.: Нолидж, 1999.
6. Xilinx. DataBook 2000. http://www.xilinx.com./ partinfo/databook.htm.
7. Угрюмов Е. П. и др. "Цифровая схемотехника", БХВ-Санкт-Петербург, 2000.
8. Хоровиц П., Хилл У.; "Основы схемотехники", Пер. с англ. Б.Н. Бронина и др. - 5-е изд., перераб. - М.: Мир, 1998.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРОЦЕССОР ОДНОРОДНОЙ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2000 |
|
RU2180969C1 |
| ОДНОРОДНАЯ ВЫЧИСЛИТЕЛЬНАЯ СРЕДА С ДВУСЛОЙНОЙ ПРОГРАММИРУЕМОЙ СТРУКТУРОЙ | 1998 |
|
RU2134448C1 |
| ПАРАЛЛЕЛЬНЫЙ ПРОЦЕССОР С ПЕРЕПРОГРАММИРУЕМОЙ СТРУКТУРОЙ | 1994 |
|
RU2110088C1 |
| Процессор для обработки семантических сетей | 1989 |
|
SU1672462A1 |
| Архитектура параллельной вычислительной системы | 2016 |
|
RU2644535C2 |
| ТРЕХКАНАЛЬНАЯ РЕЗЕРВИРОВАННАЯ УПРАВЛЯЮЩАЯ СИСТЕМА | 2008 |
|
RU2387000C1 |
| ПАРАЛЛЕЛЬНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА С ПРОГРАММИРУЕМОЙ АРХИТЕКТУРОЙ | 2012 |
|
RU2486581C1 |
| МУЛЬТИПЛЕКСОР ТЕЛЕКОММУНИКАЦИОННЫЙ МНОГОФУНКЦИОНАЛЬНЫЙ | 2004 |
|
RU2269154C1 |
| МНОГОПРОЦЕССОРНЫЙ МОДУЛЬ | 2008 |
|
RU2397538C1 |
| ЗАЩИЩЕННЫЙ КОМПЬЮТЕР, СОХРАНЯЮЩИЙ РАБОТОСПОСОБНОСТЬ ПРИ ПОВРЕЖДЕНИИ | 2015 |
|
RU2591180C1 |
Изобретение относится к области вычислительной техники и может быть использовано в высокопроизводительных системах обработки больших массивов информации, в том числе и в режиме реального времени. Техническим результатом является повышение производительности работы вычислительной системы. Система содержит N параллельных процессоров, каждый из которых содержит матрицу процессорных элементов, ОЗУ, управляющий процессор, системную шину, служебное ОЗУ, буферное ОЗУ, блок загрузки и одну или более коммуникационных сред. 2 з.п.ф-лы, 5 ил.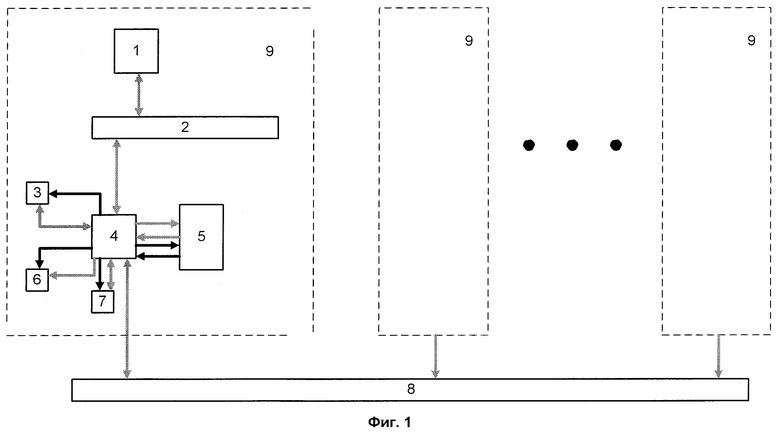
| ПАРАЛЛЕЛЬНЫЙ ПРОЦЕССОР С ПЕРЕПРОГРАММИРУЕМОЙ СТРУКТУРОЙ | 1994 |
|
RU2110088C1 |
| ПАРАЛЛЕЛЬНАЯ ПРОЦЕССОРНАЯ СИСТЕМА | 1991 |
|
RU2084953C1 |
| US 5008815 А, 16.04.1991 | |||
| JP 63163566 А2, 07.07.1988 | |||
| US 5421019 А, 30.05.1995. | |||

