Изобретение относится к вычислительной технике и может найти променение в цифровых системах управления «жесткого» реального времени.
Основой построения ЭВМ являются принцип программного управления (Чарльз Бэб-бидж - 1861 г.) и принцип хранимой в памяти программы (Джон фон-Нейман - 1942 г.). Известны [1-3] два основных способа организации вычислений: выполнение команд программы в том порядке, в котором они размещены в памяти, начиная с первой, и выполнение команд программы по готовности данных.
Первый способ известен как управление потоком команд (англ. controlf low). Программы, реализующих этот способ вычислительных систем (в дальнейшем по тексту ВС), состоят из линейных последовательностей команд, по шагам описывающих алгоритм решаемой задачи. Существенными признаками реализующих этот способ ВС являются линейно адресуемая память и счетчик адреса команд.
Достоинствами, определившими широкую распространенность ВС controlflow-архитектуры, являются: близость используемых при программировании алгоритмических языков к естественному языку описания алгоритмов решаемых задач (математическому, в частности); глубокая теоретическая проработка процессов алгоритмизации, программирования и проектирования технических средств; наличие проверенного многолетней практикой использования системного программного обеспечения, включая средства оптимизации структур исполняемых программ; относительные простота конструкции технических средств и низкая стоимость.
Недостатками ВС controlflow-архитектуры являются: последовательное выполнение команд программы, большое количество тактов обращения к памяти в цикле работы центрального процессора, что канал «процессор - память» делает «узким местом», ограничивающим быстродействие ВС [1, 7, 14].
Второй способ известен как управление потоком данных (англ. data flow). Основными причинами появления ВС dataflow-архитектуры явились настоятельная необходимость в существенном увеличении производительности и наличие в структуре ВС controlflow-архитектуры «узкого места», препятствующего ее увеличению. Существенными признаками ВС dataflow-архитектуры являются ассоциативная память, отсутствие счетчика адреса команды и описание алгоритма решаемой задачи ярусно-параллельной формой помеченного ориентированного графа потока данных, в вершины которого отображаются операции, а в дуги - отношения между ними по данным и логическим условиям выполнения [4].
Главным достоинством ВС dataflow-архитектуры является врожденный параллелизм обработки данных, а недостатками: кардинальное отличие их программирования от традиционного, сложность процесса формирования командных слов и их буферизация в ассоциативной памяти, непредсказуемая поярусная потребность в операционных устройствах и, как следствие, переменная их загруженность, а также высокая стоимость по сравнению с ВС controlflow-архитектуры.
Попытки увеличения быстродействия ВС controlflow-архитектуры и ее модификаций базировались на совершенствовании элементной и компонентной базы, наращивании тактовой частоты, конвейеризации вычислительного процесса, мультипрограммировании, мультипроцессировании, адаптации систем команд к изобразительным возможностям алгоритмических языков и структурам исполняемых программ, буферизации канала «процессор - память» (кэшировании), адаптации структур программ к многопроцессорной центральной части ВС (мультискалярная архитектура) и топологии центральной части многопроцессорной ВС к структуре исполняемых программ (реконфигурируемые многопроцессорные ВС), выявлении и реализации скрытого параллелизма последовательных программ (суперскалярная, WLIV- и EPIC-архитектуры), увеличении числа одновременного обрабатываемых потоков (мульти- и гипертредовая архитектуры) [5-10].
Основными причинами неполного извлечения из конвейеров команд их потенциальных возможностей явились наличие разгона и выбега, зависимость команд программы по данным и управлению, а также неверные предсказания переходов [6-8, 11, 12].
Быстродействие ВС суперскалярной архитектуры ограничили: малый размер «окна исполнения», неверные предсказания переходов, квадратичный рост сложности ядра, с увеличением числа функциональных устройств в составе центральной части, повышение нагрузки на канал «процессор-память» и переменная степень скрытого параллелизма последовательных программ [7, 12].
«Обозреть» всю программу планировалось при создании мультискалярной архитектуры. Однако при статическом исследовании транслятором программного кода размер окна исполнения фактически определили команды перехода. Функциональные устройства превратились в полнокровные процессоры, а параллелизм уровня команд остался не востребованным [7]. Возросли сложность трансляции и реализуемого операционной системой управления параллельными (последовательными взаимодействующими) процессами, что отрицательно сказалось на цене.
Возможности супер- и мультискалярных микропроцессоров в целом ограничил размер «окна исполнения».
Мультипроцессирование [4, 5, 8] потенциально позволяет не только покрыть все виды параллелизма (от параллелизма независимых задач до параллелизма данных), но и повысить надежность функционирования центральной части ЭВМ за счет выявления отказавших процессорных элементов (ПЭ) и перераспределения их вычислительной нагрузки между исправными ПЭ. Коммуникации между ПЭ строили и продолжают строить по ортогональному принципу (матрица, куб, гиперкуб, тор), что позволяет эффективно реализовать лишь параллелизм слабо зависимых ветвей и параллелизм данных. Эффективно реализовать параллелизм уровня команд в этих топологиях не удается ввиду отсутствия в них диагональных связей [12-14]. В этих условиях, с точки зрения эффективного использования основных вычислительных ресурсов, возможность воссоздания в гиперкубе практически любой топологии [7] выглядит мало привлекательной.
Многопроцессорные ВС с топологией «каждый с каждым» имеют более широкие вычислительные и коммуникационные возможности. Однако квадратичный рост сложности их коммутаторов от числа узлов ставит под сомнение целесообразность создание таких систем с большим числом ПЭ.
Как ни странно, современные многоядерные микропроцессоры наследуют ортогональные топологии (матрицу в частности), что ограничивает возможности использования их основного преимущества - интеграции в одном кристалле обрабатывающих процессоров, их внутренней и общей памяти, средств коммуникации между ПЭ и процессоров ввода-вывода.
Мульти- или гипертредовая, т.е. многопотоковые, архитектуры по сути [7] являются альтернативой кэшированию. Их особенностью является введение в состав центрального процессора n блоков регистров, закрепление их за тредами (подпроцессами) и циклическое переключение процессора с блока на блок. Если время обращения к основной памяти не превышает (n-1) тактов, то проблема «узкого места» успешно решается. Однако и этот способ не идеален. Переключение процессора на новый тред предполагает преемственность состояний. Традиционные запоминание старого и восстановление нового состояния процессора - неприемлемы. Поэтому каждый блок регистров должен иметь довольно емкую служебную часть, хранящую слово состояния процессора в предыдущем шаге реализации закрепленного за ним подпроцесса.
При всем различии подходов к созданию мультитредовых микропроцессоров [7], общим для них является введение множества устройств выборки команд, каждое из которых организует «окно исполнения» для одного подпроцесса. В рамках одного подпроцесса выполняется предсказание переходов, переименование регистров и динамическая подготовка команд к исполнению. Тем самым, общее число находящихся в обработке команд значительно превышает размер окна исполнения однопотокового процессора, с одной стороны, и тактовая частота не лимитируется размером окна исполнения - с другой. Выявление подпроцессов может производиться компилятором на уровне входной (на языке высокого уровня) или выходной (исполняемой) программы. Однако компиляторы не всегда могут разрешить проблемы зависимостей между подпроцессами на уровне регистров и ячеек памяти, проявляющимися в ходе исполнения. Для этого в микропроцессор вводится специальная аппаратура условного исполнения, предусматривающая возврат с отбрасыванием наработанных результатов при обнаружении нарушения зависимостей между подпроцессами по данным.
В целом эта архитектура ориентирована на исполнение не более, чем слабо связанных подпроцессов, порождаемых либо одной программой, либо их совокупностью.
В итоге мульти- или гипертредовые микропроцессоры, наряду с сокращением разрыва между скоростью обработки и временем доступа во внекристальную память, призваны уменьшить простои центрального процессора в ожидании команд или данных. Однако практика показала, что введение двух тредов отнюдь не удваивает производительности. Дополнительная регистровая память и таблицы страниц (англ. аббревиатура TLB), как критические ресурсы, порождают дополнительные «промахи», «лишние» откачки и подкачки блоков, что приводит к неявному увеличению времени переключения процессора с блока на блок [11].
В итоге, несмотря на разработку новых (нефоннеймановских) архитектур и очевидный прогресс в области технологии производства микропроцессоров, ни одно новшество, в том числе параллелизм и многоядерность не дало прироста производительности, пропорционального потребляемой энергии и затрачиваемым системным ресурсам [11].
Перечисленное выше стимулировало дальнейшее совершенствование известных и поиск новых архитектур ВС, реализующих, в том числе, и смешанные способы управления вычислительным процессом.
Известна параллельная вычислительная система с программируемой архитектурой (см. патент RU 2202123 С2, МПК7 G06F 15/16, опубл. 10.04.2003), включающая N параллельных процессоров, каждый их которых содержит матрицу процессорных элементов (ПЭ), управляющий процессор, системную шину, служебное ОЗУ и буферное ОЗУ. При этом каждый параллельный процессор дополнительно содержит один или более сетевых адаптеров, первая группа входов-выходов каждого сетевого адаптера соединена с системной шиной параллельного процессора, которому принадлежит данный сетевой адаптер, а вторая группа входов-выходов каждого сетевого адаптера соединена с одной из коммуникационных сред. Дополнительно к перечисленному в ВС введены один или более вычислительных узлов, каждый из которых содержит последовательный процессор, системную шину и один или более сетевых адаптеров. При этом группа входов-выходов последовательного процессора соединена с системной шиной, с которой также соединена первая группа входов-выходов каждого сетевого адаптера, а вторая группа входов-выходов каждого сетевого адаптера соединена с одной из коммуникационных сред.
Этот аналог имеет следующие недостатки:
- матрица процессорных элементов не позволяет эффективно реализовать параллелизм уровня команд, что отрицательно сказывается на загрузке ПЭ полезной работой,
- дополнительное введение в структуру вычислительной системы сетевых адаптеров и коммуникационных сред усложняет конструкцию и отрицательно сказывается на цене ВС.
Известна также мультипроцессорная система (см. патент RU 2450339 С2, кл. G06F 15/16, опубл. 10.05.2012 Бюл. №13), содержащая множество параллельных процессоров в одном чипе, компьютерную память, расположенную в этом чипе и доступную каждому из упомянутых процессоров, а разрядность этой шины не превышает разрядности одной строки памяти. При этом каждый из этих процессоров выполнен с возможностью обработки набора команд, оптимизированного для параллельной обработки на уровне потоков, который может быть расширен командами оптимизации выполнения последовательностей команд в процессоре. Кроме этого каждый процессор содержит локальную кэш-память, выделенную каждому из, по меньшей мере, трех конкретных регистров в данном процессоре: регистру команды, регистру операнда и регистру результата. Предложен вариант мультипроцессорной системы, содержащей множество параллельных процессоров, связанных с внешним контроллером памяти и внешним процессором и внедренных в кристалл динамической оперативной памяти (DRAM). Предложен также способ параллельной обработки на уровне потоков системой, содержащей главный процессор и компьютерную память в одном чипе, и множество параллельных процессоров, предназначенных для обработки одного потока с использованием минимального набора команд.
Этот аналог имеет следующие недостатки:
- реализуемые мультипроцессорной системой способы включают этап обращения каждого из процессоров к компьютерной памяти, что внутреннюю шину передачи данных превращает в «узкое место», ограничивающее производительность,
- динамическая память, используемая в качестве основы одного из вариантов реализации предложенной мультипроцессорной системы, также ограничивает ее производительность, поскольку для поддержания работоспособности требует периодическоой регенерации,
- введение в структуру каждого процессора локальной кэш-памяти емкостью кратной 1024 байт приносит с собой проблемы перезагрузки страниц и старения данных, решение которых осуществляется с привлечением системных программных средств, что приводит к снижению производительности,
- идентичность архитектуры параллельных процессоров, позволяющая любой из них назначать главным (управляющим всеми остальными), приводит к повышенному расходу площади кристалла и простою части оборудования подчиненных процессоров при выполнении полезной работы,
- применение в операционных устройствах накапливающих сумматоров, требующих последовательной подачи на вход кодов операндов [], не способствует повышению быстродействия процессоров,
- изобретение не использует параллелизма уровня команд, реализация которого вносит наибольший вклад в повышение производительности.
Наиболее близким к заявляемому изобретению по технической сущности и достигаемому техническому результату является асинхронная синергическая вычислительная система (см. патент РФ №2198422 С2, кл.: G06F 9/28, G06F 11/14, G06F 15/76. Опубл. 10.02.2003.), содержащая N функциональных блоков, коммутатор "каждый с каждым", имеющий N информационных входов, 2N адресных входов и 2N информационных выходов. Каждый функциональный блок состоит из устройства управления, устройства памяти команд и операционного устройства, реализующего двуместные и одноместные операции, а также имеет два идентификационных входа аргументов, два входа признаков готовности аргументов, два информационных входа, идентификационный выход аргументов, два выхода признаков аргументов, два адресных выхода, идентификационный выход результата, выход признака результата, информационный выход, выход логического номера, N входов признаков разрешения выбора команд, выход признака разрешения выбора команд, а в коммутатор введены N идентификационных входов результатов, N входов признаков готовности результатов, N идентификационных входов аргументов, 2N входов признаков аргументов, N входов логических номеров, 2N идентификационных выходов аргументов, 2N выходов призраков готовности аргументов. Причем в k-м функциональном блоке (k=1,…,N) первый и второй идентификационные входы аргументов соединены, соответственно, с (2k-1)-м и 2k-м идентификационными выходами аргументов коммутатора, первый и второй входы признаков готовности аргументов соединены, соответственно, с (2k-1)-м и 2k-м выходами признаков готовности аргументов коммутатора, первый и второй информационные входы соединены, соответственно, с (2k-1)-м и 2k-м информационными выходами коммутатора, идентификационный выход аргумента соединен с k-м идентификационным входом аргументов коммутатоpa, первый и второй выходы признаков аргументов соединены, соответственно, с (2k-1)-м и 2k-м входами признаков аргументов коммутатора, первый и второй адресные выходы соединены, соответственно, с (2k-1)-м и 2k-м адресными входами коммутатора. Идентификационный выход результата соединен с k-м идентификационным входом результата коммутатора. Выход признака готовности результата соединен с k-м входом признака готовности результата коммутатора. Информационный выход соединен с k-м информационным входом коммутатора. Выход признака разрешения выбора команд соединен с k-м входом признаков разрешения выбора команд всех функциональных блоков. Кроме того: идентификационные входы аргументов, входы признаков готовности аргументов и информационные входы функционального блока являются соответствующими входами устройства управления, идентификационный выход аргументов, выходы признаков аргументов и адресные выходы функционального блока являются соответствующими выходами устройства управления, третий адресный выход устройства управления соединен с адресным входом устройства памяти команд, командный вход-выход устройства управления соединен с командным входом-выходом устройства памяти команд, идентификационный и управляющий выходы устройства управления соединены, соответственно, с идентификационным и управляющим входами операционного устройства, первый и второй информационные выходы устройства управления соединены, соответственно, с первым и вторым информационными входами операционного устройства, идентификационный выход результата; выход признака результата и информационный выход операционного устройства являются соответствующими выходами функционального блока, выход логического номера, N входов признаков разрешения выбора команд и выход признака разрешения выбора команд функционального блока являются соответствующими выходами и входами устройства управления. Причем устройство управления состоит из блока выбора команд, блока дешифрации команд, блока формирования исполняемой команды, блока управления исполнением команд, блока разрешения выбора команд, регистра информационной связности, имеющего размерность N разрядов, памяти занятых меток, памяти готовности аргументов, буферной памяти кода операции, буферной памяти первого аргумента, буферной памяти второго аргумента, имеющих размер L слов, а адресный выход блока выбора команд является третьим адресным выходом устройства управления, командный выход блока выбора команд является командным выходом устройства управления. Первый идентификационный выход блока выбора команд соединен с адресным входом чтения памяти занятых меток, вход признака занятости метки блока выбора команд соединен с информационным выходом памяти занятых меток, второй идентификационный выход блока выбора команд соединен с идентификационным входом блока дешифрации команд и адресным входом записи памяти занятых меток, выход признака занятости метки блока выбора команд соединен с информационным входом памяти занятых меток, управляющий вход блока выбора команд соединен с управляющим выходом блока дешифрации команд, информационный вход блока выбора команд соединен с третьим информационным выходом блока управления исполнением команд, выход признака разрешения выбора команд блока выбора команд является соответствующим выходом устройства управления. Командный вход блока дешифрации команд является командным входом устройства управления, идентификационный выход аргументов, выходы признаков аргументов, адресные выходы блока дешифрации команд являются соответствующими выходами устройства управления, информационно-управляющий выход блока дешифрации команд соединен с информационно-управляющим входом блока формирования исполняемой команды, идентификационные входы аргументов, входы признаков готовности аргументов и информационные входы которого являются соответствующими входами устройства управления. Первый идентификационный выход блока формирования исполняемой команды соединен с адресным входом памяти готовности аргументов, второй, третий и четвертый идентификационные выходы блока формирования исполняемой команды соединены, соответственно, с адресными входами записи буферной памяти кода операции, буферной памяти первого аргумента и буферной памяти второго аргумента, первый информационный вход-выход блока формирования исполняемой команды соединен с информационным входом-выходом памяти готовности аргументов, второй, третий и четвертый информационные выходы блока формирования исполняемой команды соединены, соответственно, с информационными входами записи буферной памяти кода операции, буферной памяти первого аргумента и буферной памяти второго аргумента, выход признака готовности команды блока формирования исполняемой команды соединен с входом признака готовности команды блока управления исполнением команды, пятый идентификационный выход блока формирования исполняемой команды соединен с идентификационным входом блока управления исполнением команды, первый, второй и третий идентификационные выходы которого соединены, соответственно, с адресными входами чтения буферной памяти кода операции, буферной памяти первого аргумента и буферной памяти второго аргумента, первый, второй и третий информационные входы блока управления исполнением команд соединены, соответственно, с информационными выходами чтения буферной памяти кода операции, буферной памяти первого аргумента и буферной памяти второго аргумента, выход логического номера блока управления исполнением команд является выходом устройства управления, четвертый идентификационный выход блока управления исполнением команд соединен с адресным входом записи памяти занятых меток, выход признака занятости метки блока управления исполнением команд соединен с информационным входом памяти занятых меток, выход установки информационной связности блока управления исполнением команд соединен с входом регистра информационной связности, пятый идентификационный выход блока управления исполнением команд является идентификационным выходом устройства управления, управляющий выход, первый и второй информационные выходы блока управления исполнением команд являются соответствующими выходами устройства управления, выход регистра информационной связности соединен с входом информационной связности блока разрешения выбора команд, выход признака разрешения которого соединен с входом признака разрешения блока выбора команд. N входов признаков разрешения выбора команд блока разрешения выбора команд являются соответствующими входами устройства управления. Коммутатор состоит из N узлов коммутации, каждый из которых включает N устройств выбора, содержащих регистр логического номера, имеющий размерность]Iog2N[разрядов, блок формирования признаков выбора, память признаков выбора, имеющей размер L слов, два буферных блока FIFO-памяти, причем во всех узлах коммутации для k-го устройства выбора (k=1,…,N), k-й информационный вход коммутатора соединен с первыми информационными входами буферных блоков FIFO-памяти, k-й идентификационный вход результата соединен со вторыми информационными входами буферных блоков FIFO-памяти и адресным входом чтения памяти признаков выбора, k-й вход признака готовности результата соединен с сигнальным входом чтения памяти признаков выбора, а во всех устройствах выбора k-го узла коммутации (k=1,…,N) (2k-1)-й адресный вход коммутатора соединен с адресными входами первого аргумента блоков формирования признаков выбора, 2k-й адресный вход коммутатора соединен с адресными входами второго аргумента блоков формирования признаков выбора, (2k-1)-й вход признаков аргументов соединен с входами признака первого аргумента блоков формирования признаков, 2k-й вход признаков аргументов соединен с входами признака второго аргумента блоков формирования признаков, k-й вход логического номера соединен с входами регистров логического номера, k-й идентификационный вход аргумента соединен с адресными входами записи памятей признаков выбора, а также во всех устройствах выбора выход регистра логического номера соединен с входом логического номера блока формирования признаков выбора выход признака наличия аргументов блока формирования признаков выбора соединен с сигнальным входом записи памяти признаков выбора, выходы признаков первого и второго аргументов соединены, соответственно, с первым и вторым информационными входами памяти признаков выбора, первый информационный выход памяти признаков выбора соединен с сигнальным входом записи первого буферного блока FIFO-памяти, второй информационный выход памяти признаков выбора соединен с сигнальным входом записи второго буферного блока FIFO-памяти, кроме того, все первые буферные блоки FIFO-памяти k-го узла коммутации связаны последовательно сигнальным входом чтения в кольцо, а первые информационные выходы первых буферных блоков FIFO-памяти объединены и являются (2k-1)-м информационным выходом коммутатора, вторые информационные выходы первых буферных блоков FIFO-памяти объединены и являются (2k-1)-м идентификационным выходом аргументов коммутатора, выходы признаков готовности первых буферных блоков FIFO-памяти объединены и являются (2k-1)-м выходом признаков готовности аргументов коммутатора, все вторые буферные блоки FIFO-памяти k-го узла коммутации также связаны последовательно сигнальным входом чтения в кольцо, причем первые информационные выходы вторых буферных блоков FIFO-памяти объединены и являются 2k-м информационным выходом коммутатора, вторые информационные выходы вторых буферных блоков FIFO-памяти объединены и являются 2k-м идентификационным выходом аргументов коммутатора, выходы признаков готовности вторых буферных блоков FIFO-памяти объединены и являются 2k-м выходом признаков готовности аргументов коммутатора.
Синергическая вычислительная система принята за прототип заявляемого изобретения.
Общими с заявляемым изобретением признаками прототипа являются:
- наличие памяти команд,
- наличие N функциональных блоков, имеющих информационные входы, входы признаков готовности, информационный выход и выход признака готовности результата и содержащих устройства управления и операционные устройства, реализующие двуместные и одноместные операции,
- активизация операционных устройств готовностью данных.
Изобретение-прототип имеет следующие недостатки:
- необоснованная сложность организации вычислительного процесса,
- высокая сложность конструкции, а также низкая эффективность использования основных вычислительных и коммуникационных ресурсов, что приводит к увеличению стоимости ВС.
Эти недостатки обусловлены следующими причинами.
Последовательное, поэлементное формирование из команд формата controlflow-архитектуры (см. фиг. 2 описания изобретения-прототипа) командных слов dataflow-архитектуры, с буферизацией каждого элемента, последовали: введение в процесс управления идентификаторов аргументов, признаков разрешения выбора команд, признаков (готовности аргументов SA1 и SA2, признаков готовности команд, признаков готовности результатов SR и логических номеров функциональных блоков, а в состав устройств управления каждого функционального блока - памяти команд, блока разрешения выбора команд, блока формирования исполняемой команды, памяти занятых меток, памяти готовности аргументов, буферной памяти кода операции, буферной памяти первого аргумента и буферной памяти второго аргумента, имеющих емкость L слов.
Реализация врожденного параллелизма управления потоком данных выполнена: введением в состав устройств управления каждого функционального блока регистра информационной связности; использованием в качестве коммуникационного устройства коммутатора «каждый с каждым», имеющего N×N=N2 устройств выбора и 2N×N=2N2 буферных блоков FIFO-памяти с двумя информационными входами каждый и, наконец, пятистадийной организацией цикла выполнения команд. При этом на первой стадии осуществляется выбор controlflow-команды, дешифрация кода операции, формирование памяти признаков выбора, формирование заготовки командного слова dataflow-архитектуры, включающее запись соответствующих признаков в память готовности аргументов и буферную память кода операции. На второй стадии производится прием результатов выполнения предшествующих операций и запись их в соответствующие буферные блоки FIFO-памяти в качестве аргументов для выполняемых операций. На третьей стадии производится считывание аргументов из FIFO-памяти и запись их в буферную память первого и второго аргументов. На четвертой стадии производится выбор подготовленных команд dataflow-архитектуры из буферной памяти кода операции, буферной памяти первого и второго аргументов и выдача их на исполнение. На пятой стадии выполняется операция. В результате сложность конструкции обрабатывающей части вычислительной системы оказалась пропорциональной количеству функциональных блоков N, что естественно, а сложность конструкции коммуникационной части - пропорциональной 2N2. При этом, синхронизация только запуска команд (первая стадия циклов их выполнения) и асинхронное выполнение остальных стадий (в зависимости от готовности результатов, аргументов и командных слов) на фоне зависимости единовременной потребности в вычислительных и коммуникационных ресурсах от структуры ярусно-параллельной формы информационного графа исполняемой программы (в описании прототипа такие графы приводятся) эффективность загрузки функциональных блоков собственно вычислительной работой оставляет желать лучшего (выше по тексту работы, направленные лишь на формирование командных слов dataflow-архитектуры выделены косым шрифтом).
Известна [15-18] также потоковая модель последовательной программы в виде композиции двух линейно упорядоченных, помеченных, ориентированных графов, один из которых отображает логическую, а другой - информационную структуру программы. При этом термин «композиция» подчеркивает взаимно однозначное соответствие между парами вершин, одна из которых принадлежит графу переходов, отображающему логическую структуру программы, а другая - информационному графу, отображающему информационную структуру программы. Вершины графа переходов помечаются номерами операторов входной программы или адресами размещения в памяти команд исполняемой программы. Дуги графа переходов отображают порядок перехода между операторами входной программы или командами исполняемой программы. Дуги, отображающие передачи управления помечаются логическими условиями перехода по ним. Вершины информационного графа помечаются операциями, задаваемыми операторами входной программы или командами исполняемой программы, а дуги - результатами выполнения операции и порядком их участия в очередных операциях в качестве операндов.
Известны методы и алгоритмы эквивалентных преобразований потоковой модели, в том числе и распараллеливания, с временной сложностью O(n2), где n - количество операторов или команд в программе. При этом эквивалентность обеспечивается соответствием логических структур исходной (последовательной) и исполняемой (параллельной) программы на уровне линейных участков, разветвлений и циклов, а также сохранением информационных связей «результат - операнд» в пределах перечисленных элементов логической структуры и между ними [18, 19].
Структурные свойства параллельных программ и два способа управления вычислительным процессом (потоком команд и готовностью данных) и положены в основу заявляемого изобретения.
При создании изобретения ставились следующие задачи: повышение производительности параллельной ВС, упрощения ее конструкции и оптимизация архитектуры по критерию минимума отношения «стоимость/производительность».
Поставленные задачи решены благодаря тому, что в ВС, содержащей N функциональных модулей (ФМ), имеющих два информационных входа, два входа признаков готовности, информационный выход и выход признака готовности результата и состоящих из устройств управления и операционных устройств, реализующих двуместные и одноместные операции, количество N ФМ четно, а из состава ВС удалены: коммутатор «каждой с каждым», буферная память кода операции, буферная память первого аргумента, буферная память второго аргумента, память готовности аргументов, память занятых меток, блок формирования исполняемой команды, блок разрешения выбора команд и регистр информационной связности. Устройства памяти команд выведены из состава ФМ в состав ВС с образованием двух устройств с расширенным интерфейсом, доступных со стороны N/2 ФМ каждое. В состав ВС дополнительно введены: локальная шина, системный контроллер, служебная память, память данных с расширенным интерфейсом и адаптер. В состав ФМ введены: коммутатор первого операнда, коммутатор второго операнда, выходной коммутатор, регистры первого и второго операндов, регистр результата операции. В состав устройств управления ФМ введены регистр команд и блок управления потоком данных. Интерфейс ФМ расширен введением четырех информационно-управляющих входов, информационного входа-выхода, информационно-управляющего выхода, управляющего входа-выхода и командного входа-выхода. При этом вход регистра команд соединен с командным входом-выходом ФМ, выходы адресной части регистра команд соединены с блоком управления потоком данных, два выхода которого соединены с адресными входами коммутаторов первого и второго операндов, третий выход соединен с информационным входом-выходом ФМ, четвертый выход соединен с управляющим входом-выходом ФМ, а пятый вход-выход соединен с блоком управления выполнением команд. Выход операционной части регистра команд соединен с входом блока управления выполнением команд, имеющим связи со всеми блоками, устройствами, узлами и коммуникациями интерфейса ФМ. Регистры операндов и регистр результата выполненной операции соединены с операционным устройством способом, известным из уровня техники. Коммутаторы первого и второго операндов имеют: по четыре входа, соединенных с информационно-управляющими входами ФМ; по одному входу, соединенному с информационным входом-выходом ФМ; по адресному входу, соединенному с соответствующим выходом блока управления потоком данных; по информационному выходу, соединенному с входом одноименного регистра операнда, и по выходу готовности, соединенному с соответствующим входом блока управления выполнением команд. Выходной коммутатор имеет: информационный вход, соединенный с выходом регистра результата; вход готовности результата, соединенный с одноименным выходом блока управления выполнением команд; адресный вход, соединенный с соответствующим выходом блока управления выполнением команд и два выхода, один из которых соединен с информационно-управляющим выходом ФМ, а другой - с информационным входом-выходом ФМ. Информационно-управляющие выходы ФМ соединены с информационно-управляющими входами других ФМ с образованием многоуровневой, однонаправленной, замкнутой, вычислительной сети, содержащей два, взаимодействующих по данным и их готовности кольца, количество ФМ в которой определяется из соотношения N>2Тпк/Тфм, где: Тпк - длительность цикла обращения в память команд, а Тфм - длительность цикла выполнения команды ФМ. Выход каждого ФМ соединяется: с первым информационно-управляющим входом следующего ФМ в своей цепи, с вторым информационно-управляющим входом ФМ, следующего через один ФМ в своей цепи, с третьим информационно-управляющим входом следующего ФМ в соседней цепи и с четвертым информационно-управляющим входом ФМ, следующего через один ФМ в соседней цепи. Все управляющие входы-выходы ФМ первого кольца соединены с одним входом-выходом системного контроллера, а все управляющие входы-выходы ФМ второго кольца - с другим входом-выходом системного контроллера. Все командные входы-выходы ФМ первого кольца соединены с входом-выходом первой памяти команд, а все командные входы-выходы ФМ второго кольца - с входом-выходом второй памяти команд; информационные входы-выходы ФМ первого кольца соединены с первым дополнительным портом памяти данных, а информационные входы-выходы ФМ второго кольца - со вторым дополнительным портом памяти данных. Локальная шина соединяет системный контроллер с первой и второй памятью команд, со служебной памятью, с памятью данных и адаптером. Система команд ФМ параллельной вычислительной сети - трехадресная, не содержит команд передачи управления и использует только прямой и регистровый способы адресации. В операционную часть команд дополнительно введен двухразрядный постфиксный указатель, определяющий принадлежность команды к элементам логической структуры исполняемой программы, а функции адресов расширены указанием ФМ-источников операндов (первый и второй адрес) и преемников результата с признаком его готовности (третий адрес). Системное ПО содержит специальное ПО инструментальной ЭВМ и встроенное ПО системного контроллера. При этом в состав специального ПО инструментальной ЭВМ включаются модули подготовки отлаженной последовательной программы к параллельному исполнению, а в состав встроенного ПО системного контроллера - модули, обеспечивающие управление выполнением параллельной программы и ввод/вывод любым из известных способов.
Сущность заявляемого изобретения поясняется схемами, диаграммами и алгоритмами.
На фиг. 1 изображена схема электрическая структурная функционального модуля.
На фиг. 2 изображена схема электрическая структурная параллельной вычислительной сети с параметром k=4.
На фиг. 3 представлена структура параллельной вычислительной системы.
На фиг. 4 представлена архитектура программного обеспечения управляющей параллельной вычислительной системы.
На фиг. 5 представлен пример построения потоковой модели последовательной программы и ее преобразования к ярусно-параллельной форме.
На фиг. 6 представлен алгоритм управления параллельной вычислительной сетью.
На фиг. 7 представлен алгоритм работы функционального модуля.
На фиг. 8 представлена диаграмма работы параллельной вычислительной сети.
На фиг. 9 представлены результаты сравнительной оценки эффективности ВС, управляемой потоком данных, и процессорной матрицы.
На фиг. 10 представлены результаты сравнительной оценки эффективности многопотоковой ВС и ВС заявленной архитектуры.
Согласно изобретению (см. фиг. 1) каждый ФМ содержит: коммутатор первого операнда С.1, коммутатор второго операнда С.2, устройство управления U, регистр первого операнда R.1, регистр второго операнда R.2, операционное устройство IU, регистр результата R.3 и выходной коммутатор С.З. Устройство управления U содержит регистр команд U.1, блок управления потоком данных U.2 и блок управления выполнением команд U.3. Вход регистра команд U.1 соединен с командным входом-выходом 8 ФМ. Выход адресной части регистра команд U.1 соединен с входом блока управления потоком данных U.2, а выход операционной части регистра команд U.1 соединен с входом блока управления выполнением команд U.3. Верхние по схеме выходы блока управления потоком данных U.2 соединены с адресными входами коммутаторов С.1 и С.2, первый по схеме справа сверху выход соединен информационным входом-выходом 5 ФМ, второй по схеме справа сверху выход - с управляющим входом-выходом 7 ФМ, а нижний по схеме вход-выход - с верхним по схеме входом-выходом блока управления выполнением команд U.3, который имеет связи по входу и выходу со всеми блоками, устройствами, узлами и коммуникациями 5, 7 и 8 ФМ. (n+1)-разрядные входы коммутаторов С.1 и С.2 соединены с информационно управляющими входами 1, 2, 3, и 4 ФМ, а также с информационным входом-выходом 5 ФМ. n-разрядные информационные выходы коммутаторов С.1 и С.2 соединены с входами регистров первого операнда R.1 и второго операнда R.2 соответственно, а одноразрядные выходы готовности -с входами блока управления выполнением команд U.3 устройства управления U. Регистры R.1, R.2 и R.3 соединены с операционным устройством Ш способом, известным из уровня техники. Выход регистра R.3 соединен с вторым (слева - направо) входом выходного коммутатора С.3.
Операционное устройство III предпочтительно - совокупность специализированных функциональных устройств, подключаемых к регистрам R.1, R.2 и R.3 по результатам расшифровки кода операции исполняемой команды.
Выходной коммутатор С.3 имеет: информационный вход, соединенный с информационным выходом регистра результата R.3; вход готовности результата ƒ (левый на схеме), соединенный с одноименным выходом блока управления выполнением команд U.3; адресный вход, соединенный с соответствующим выходом блока управления выполнением команд U.3, и два (n+1)-разрядных выхода, один из которых соединен с информационно-управляющим выходом 6 ФМ, а другой - с информационным входом-выходом 5 ФМ.
Информационно-управляющие выходы 6 ФМ (см. фиг. 2) соединены с информационно-управляющими входами других ФМ с образованием многоуровневой, однонаправленной, замкнутой, параллельной вычислительной сети, содержащей два взаимодействующих по данным и их готовности кольца. В каждом из колец информационно-управляющие выходы 6 каждого ФМ соединены: с информационно-управляющим входом 1 следующего ФМ в своей цепи, с информационно-управляющим входом 2 ФМ, следующего через один ФМ в своей цепи, с информационно-управляющим входом 3 следующего ФМ в соседней цепи и с информационно-управляющим входом 4 ФМ, следующего через один ФМ в соседней цепи. Интерфейс вычислительной сети включает элементы 9, 10, 11, 12, 13 и 14. При этом: все управляющие входы-выходы 7 ФМ первого (левого по схеме) кольца соединены с элементом 10 интерфейса, все управляющие входы-выходы 7 ФМ второго (правого по схеме) кольца соединены с элементом 13 интерфейса, все командные входы-выходы 8 ФМ первого (левого по схеме) кольца соединены с элементом 11 интерфейса, все командные входы-выходы 8 ФМ второго (правого по схеме) кольца соединены с элементом 12 интерфейса, все информационные входы-выходы 5 ФМ первого (левого по схеме) кольца соединены с элементом 9 интерфейса, а все информационные входы-выходы 5 ФМ второго (правого по схеме) кольца соединены с элементом 14 интерфейса.
Параллельная вычислительная система (см. фиг. 3) содержит локальную шину S.1, системный контроллер S.2, первую память команд S.3, вторую память команд S.4, служебную память S.5, память данных S.6, параллельную вычислительную сеть S.7 и адаптер S.8.
Системный контроллер S.2 имеет внутренние оперативную и энергонезависимую служебную память, с размещенным в ней встроенным программным обеспечением, и предназначен для управления работой ВС. Через локальную шину S.1 он соединяется:
- односторонней связью по данным, адресам и управлению - с первой памятью команд S.3 и второй памятью команд S.4,
- двусторонней связью по данным, адресам и управлению - со служебной памятью S.5, с памятью данных S.6 и адаптером S.8.
Параллельная вычислительная сеть S.7 двумя двусторонними связями по управлению и односторонними связями по адресам через коммуникации интерфейса 10 и 13 соединена с системным контроллером S.2, двумя двусторонними связями по управлению и односторонними связями по данным через коммуникации интерфейса 11 и 12 - с памятью команд S.3 и памятью команд S.4, и двумя двусторонними связями по данным, адресам и управлению - с памятью данных S.6 через коммуникации интерфейса 9 и 14. Количество N ФМ в замкнутой (см. фиг. 8) по потоку данных параллельной вычислительной сети определяется из соотношения:

где: Тпк - длительность цикла обращения в память команд, а Тфм - длительность цикла выполнения команды ФМ.
Количество N, определенное по формуле (1) обеспечивает исключение простоя ФМ в ожидании команд при работе (см. фиг. 8) в составе замкнутой по потоку данных параллельной вычислительной сети и гарантированную предвыборку очередных команд ФМ, завершившими выполнение текущих команд.
Память команд S.3 и память команд S.4 - равной емкости, энергонезависимые, с расширенным интерфейсом, с двумя видами доступа по порту связи с системной шиной S.1 и одним видом доступа по портам связи с параллельной вычислительной сетью S.7. Первый вид доступа по порту связи с системной шиной S.1 - последовательный, пословный для записи с автоматической инкрементацией кода адреса после каждого обращения, а второй - произвольный по записи в регистры адресов портов связи с параллельной вычислительной сетью S.7 кодов передач управления. Доступ по портам связи с параллельной вычислительной сетью S.7 - последовательный пословный по чтению с последующей автоматической инкрементацией кода адреса. Устройства S.3 и S.4 предназначены для хранения команд ветвей параллельной программы и выдачи команд по запросам параллельной вычислительной сети S.7.
Служебная память S.5 - энергонезависимая, пословная, с произвольным доступом и предназначена для хранения списков смежности вершин графов поярусных переходов исполняемых программ.
Память данных S.6 емкостью 16 слов - регистровая, с расширенным интерфейсом и пословным произвольным доступом к регистрам по всем портам. Она предназначена для: приема, временного хранения и выдачи исходных данных с признаками готовности, поступающих через локальную шину S.1, для приема, временного хранения и выдачи по запросам параллельной вычислительной сети S.7 промежуточных результатов вычислений с признаками их готовности, а также для приема, временного хранения и выдачи окончательных результатов вычислений через локальную шину S.1.
Адаптер S.8 предназначен для обеспечения взаимодействия параллельной вычислительной системы с отладочной платой, а также с устройствами, блоками и узлами системы управления, частью которой она является.
Архитектура системы команд
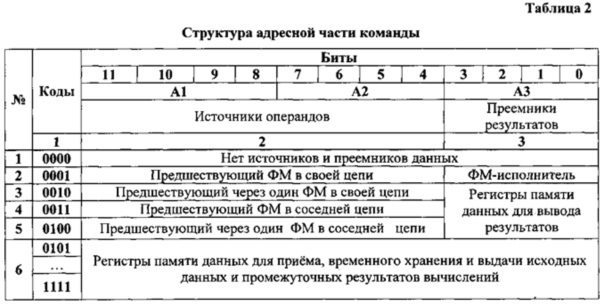
Система команд ФМ параллельной вычислительной сети S.7 не имеет команд передачи управления, использует только прямую и регистровую адресацию и имеет единый трехад-ресный формат, операционная часть которого расширена двухразрядным постфиксным указателем. Операционная часть команд (табл. 1) содержит 7 двоичных разрядов. Из них 5 - используются для кодирования операций, а 2 - для кодирования отношения команды к логической структуре программы. Поле кода операции используется для кодирования арифметических, логических операций, операций сдвигов кода, сравнения кодов и операции вывода.
При этом нулевое поле кода операции соответствует «холостой» команде - не предполагающей активных действий.

Примечание - количество операций в группах определяется требованиями технического задания.
Адресная часть команд (табл.2) содержит 12 бит: по 4 бита в каждом адресе. При этом функции полей адресов, наряду с размещением имен регистров памяти данных S.6, расширена указанием физических устройств источников операндов (поля А1 и А2) и физических устройств преемников результатов выполненных операций (поле A3): память данных или следующие по потоку данных ФМ. Регистры памяти данных с именами 0001, 0010, 0011 и 0100 предназначены только для вывода результатов, а регистры с именами 0101, 0110, ..., 1111 - для приема, временного хранения и выдачи исходных данных и промежуточных результатов вычислений по запросу ФМ.
Способ представления и разрядность данных определяются требованиями технического задания к быстродействию ВС и точности результатов вычислений.
Архитектура программного обеспечения
Архитектура программного обеспечения (далее по тексту ПО) управляющей параллельной вычислительной системы (фиг. 4) включает: специальное ПО инструментальной ПЭВМ и встроенное ПО самой управляющей параллельной вычислительной системы. Специальное ПО инструментальной ЭВМ содержит: модуль M1 построения потоковой модели отлаженной последовательной программы контроля и управления, модуль М2 эквивалентных преобразований этой модели к ярусно-параллельной форме, модуль М3 кодирования графа потока данных системой команд параллельной вычислительной сети с получением параллельной программы, модуль М4 загрузки в память команд S.3 и память команд S.4 взаимодействующих ветвей параллельной программы, а в служебную память S.5 - массива списков смежности вершин графа поярусных переходов исполняемой программы.
Архитектура программного обеспечения
Архитектура программного обеспечения (далее по тексту ПО) параллельной вычислительной системы (фиг. 4) включает: специальное ПО инструментальной ПЭВМ и встроенное ПО самой параллельной вычислительной системы. Специальное ПО инструментальной ПЭВМ содержит: модуль M1 построения потоковой модели отлаженной последовательной программы контроля и управления, модуль М2 эквивалентных преобразований этой модели к ярусно-параллельной форме, модуль М3 кодирования графа потока данных системой команд параллельной вычислительной сети с получением параллельной программы, модуль М4 загрузки в память команд S.3 и память команд S.4 взаимодействующих ветвей параллельной программы, а в служебную память S.5 - массива списков смежности вершин графа поярусных переходов исполняемой программы.
Встроенное ПО параллельной вычислительной системы содержит: модуль контроля М5, модуль инициирования параллельной вычислительной сети М6, модуль ввода исходных данных М7, модуль управления параллельной вычислительной сетью М8 и модуль вывода результатов вычислений М9.
Подготовка к работе
Модуль M1 осуществляет формализацию структуры отлаженной последовательной программы путем построения потоковой модели [] в виде списков смежности линейно упорядоченных, ориентированных, помеченных графов переходов и информационного. В вершины графов отображаются исполняемые операторы (для объектной программы - команды). Вершины графа переходов помечены номерами исполняемых операторов (для объектной программы - действительными адресами команд в памяти). Дуги графа переходов, связывающие соседние вершины, отображают порядок выполнения операторов (команд объектной программы). Дуги, соединяющие не соседние вершины, отображают отклонения от естественного порядка - безусловные передачи управления или передачи управления по условию. Дуги, отображающие передачи управления по условию, помечаются логическими условиями перехода по ним. Вершины информационного графа помечаются операциями. Дуги отображают информационные связи от операторов (команд), получающих результат к операторам (командам), использующих эти результаты в качестве аргументов (операндов). Дуги и их связки (две и более дуг, выходящих из одной вершины) помечаются именами переменных (для объектной программы - действительными адресами размещения их в памяти данных) и порядком участия операндов в операциях.
Модуль М2 осуществляет эквивалентное преобразование графов потоковой модели к ярусно-параллельной форме - осуществляет распараллеливание информационного графа на два взаимодействующих потока с сохранением направления всех дуг и преобразование графа переходов последовательной программы в граф поярусных переходов с сохранением направления помеченных дуг.
Модуль М3 осуществляет кодирование графа потока данных системой команд ФМ параллельной вычислительной сети S.7 (фиг. 3) - переход от модели параллельной программы к самой параллельной программе.
Модуль М4 осуществляет загрузку в служебную память S.5 (фиг. 3) массива списков смежности графа поярусных переходов, а в памяти команд S.3 и S.4 - ветвей параллельной программы.
Пусть одна из отлаженных разработчиком программ управления соответствует позиции 1) на фиг. 5. Результаты ее формализации представлены: на позиции 3 - линейно упорядоченный, ориентированный, помеченный граф переходов, а на позиции 4 - линейно упорядоченный, ориентированный, помеченный информационный граф.
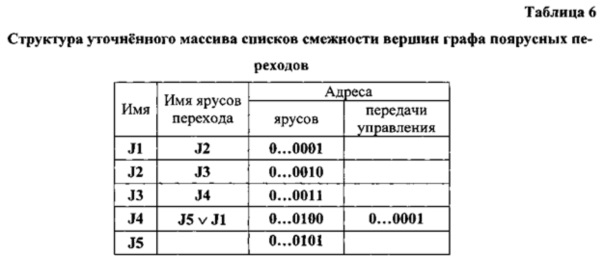
Преобразование исходной модели к параллельному виду сводится [] к оптимальной укладке упомянутого выше информационного графа в плоскую целочисленную решетку с двумя столбцами и соответствующей реструктуризации графа переходов и представлению результатов в памяти в виде массивов списков (см. табл. 3 и 4).



Списки таблицы 3 имеют следующую структуру: имя яруса, пометка первой вершины-операции, координаты (ярус, порядковый номер в ярусе) вершин - источников операндов, пометка второй вершины-операции, координаты (ярус, порядковый номер в ярусе) вершин -источников операндов. Списки таблицы 4 имеют следующую структуру: имя яруса, имена ярусов перехода.
Распределение памяти
Память распределяют на основе таблицы 3 и архитектуры системы команд (см. строку 6 боковика табл. 2).
Память команд распределим следующим образом:
- память команд S.3 - для размещения, начиная с первой ячейки, последовательности команд - образов вершин левой ветви графа потока данных;
- память команд S.4 - для размещения, начиная с первой ячейки, последовательности команд - образов вершин правой ветви графа потока данных.
При этом образуется взаимно одночначное соответствие между ярусами графа потока данных и размещением команд параллельной программы в памяти команд S.3 и S.4: команды-образы вершин первого яруса размещаются в первых ячейках, второго яруса - во вторых и так далее.
Память данных S.6 распределим следующим образом:
- регистр 0101 - для хранения исходного значения переменной «а»,,
- регистр 0110 - для хранения исходного значения переменной «b»,
- регистр 0111 - для хранения значение константы «0,1».
При кодировании системой команд параллельной вычислительной сети коды операций команд определяются вторым и пятым элементами таблицы 3, первый и второй адреса - соответственно третьим, четвертым и шестым, седьмым элементами той же таблицы,. а третьи адреса - с учетом содержимого упомянутых выше элементов последующих списков (информационные связи результат-операнд, входящие в вершины-команды не далее, чем через один следующий ярус, кодируют непосредственными связями между ФМ (см. строки 2÷5 боковика табл. 2), а информационные связи результат-операнд, входящие в вершины-команды через два следующий яруса и более, а также, входящие в вершины-команды предшествующих ярусов, кодируют с использованием памяти данных (см. строку 6 боковика табл.2).
Пример кодирования
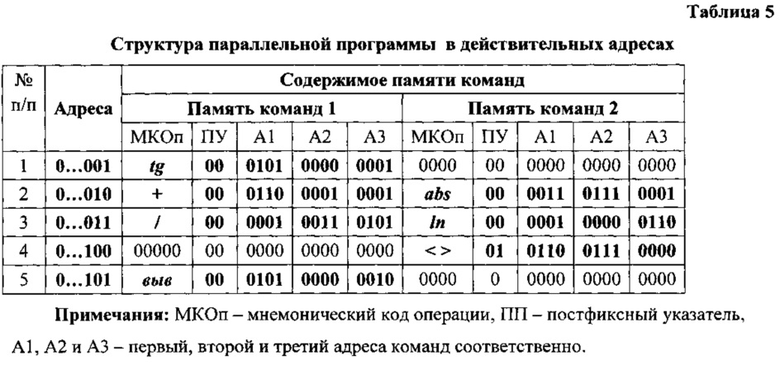
Шаг 1. Элемент J2 списка J1 (первая строка табл. 4) указывает на переход к следующему ярусу. Список J1 смежности вершин графа потока данных (табл. 3) содержит лишь первую половину, второй элемент этого списка (вторая клетка первой строки табл. 3) содержит унарную операцию вычисления тангенса, аргументом вычисляемой функции является переменной «а» или результат выполнения третьей команды той же ветви параллельной программы (третья клетка первой строки табл.3), то с учетом размещения этого значения в регистре 0101 памяти данных S.6, арности заданной операции, использования результата выполнения следующими командами в своей и соседней ветви (см. клетки 2.4 и 2.6 табл.3) и особенностей архитектуры системы команд (см. таблицы 1 и 2) первую команду первой ветви параллельной программы кодируем следующим образом:
tg 00 0101 0000 0001.
В этой команде задана унарная операция, код 00 постфиксного указателя показывает, что эта команда не имеет отношения к передаче управления (изменению естественного порядка выполнения), операнд (поле А1) находится в регистре 0101 памяти данных S.6, а результат выполнения операции (поле A3) используется следующими командами параллельной программы.
Шаг 2. Элемент J3 списка J2 (вторая строка табл. 4) указывает на переход к следующему ярусу. Список J2 смежности вершин графа потока данных (табл. 3) содержит обе половины, второй элемент первой половины этого списка (клетка 2.2 табл. 3) содержит бинарную операцию сложения значения переменной «b» (клетка 2.3 табл. 3) с результатом предшествующей команды в своей ветви параллельной программы (клетка 2.4 табл.3). С учетом размещения значения переменной «b» в регистре 0110 памяти данных, арности заданной операции, использования результата выполненной операции командами следующего яруса и особенностей архитектуры системы команд (см. таблицы 1 и 2) первую команду второго яруса параллельной программы кодируем следующим образом:
+00 0110 0001 0001.
В этой команде код 00 постфиксного указателя показывает, что эта команда не имеет отношения к передаче управления, первый операнд (поле А1) находится в регистре 0110 памяти данных S.6, а результат выполнения операции (поле A3) используется следующими командами параллельной программы.
Второй элемент второй половины рассматриваемого списка (пятая клетка второй строки табл. 3) содержит унарную операцию получения абсолютного значения результата выполнения предшествующей команды соседней ветви (шестая клетка второй строки табл. 3) параллельной программы. С учетом арности заданной операции, использования результата ее выполнения следующими командами параллельной программы и особенностей архитектуры системы команд (см. таблицы 1 и 2) вторую команду рассматриваемого яруса параллельной программы кодируем следующим образом:
abs 00 0011 0000 0001.
В этой команде нулевой постфиксный бит показывает, что эта команда не имеет отношения к передаче управления, операндом (поле А1) является результат первой вершины-команды предшествующего яруса, а результат выполнения операции (поле A3) используется командами следующих ярусов.
Шаг 3. Элемент J4 списка J3 (третья строка табл.4) указывает на переход к следующему ярусу. Список J3 смежности вершин графа потока данных содержит обе половины. Второй элемент первой половины этого списка (вторая клетка третьей строки табл. 3) содержит бинарную операцию деления, делимым является результат выполнения предшествующей команды своей ветви (третья клетка третьей строки табл. 3), а делителем (четвертая клетка третьей строки табл. 3) - результат выполнения предшествующей команды соседней ветви параллельной программы. Результат выполнения кодируемой команды (четвертая клетка первой строки табл. 3) используется в качестве нового значения переменной «а» первой командой своей ветви параллельной программы. С учетом арности заданной операции, особенностей архитектуры системы команд (см. таблицы 1 и 2) и распределения памяти данных первую команду рассматриваемого яруса параллельной программы кодируем следующим образом:
/ 00 0001 0011 0101.
Второй элемент второй половины рассматриваемого списка (пятая клетка третьей строки табл. 3) содержит унарную операцию вычисления натурального логарифма результата выполнения предшествующей команды своей ветви параллельной программы, а результат выполнения операции является новым значением переменной «b». С учетом арности заданной операции, особенностей архитектуры системы команд (см. таблицы 1 и 2) и распределения памяти данных эту команду кодируем следующим образом:
ln 00 0001 0000 0110.
КОп определяет унарную операцию вычисления натурального логарифма, операнд (поле А1) является результатом выполнения предшествующей команды своей ветви параллельной программы, а результат выполнения операции (поле A3) отравляется в регистр 0110 памяти данных.
Шаг 4. Элемент J1 списка J4 (четвертая строка табл. 4) указывает на возможный переход по условию к первому ярусу. Список J4 смежности вершин графа потока данных содержит лишь вторую половину, в которой (пятая клетка четвертой строки табл. 3) содержит операцию сравнения результата выполнения предшествующей команды своей ветви (шестая клетка четвертой строки табл. 3) с константой 0,1 (седьмая клетка четвертой строки табл. 3). При этом значение флага результата сравнения ложность (0) или истинность (1) логического условия перехода к первому ярусу. С учетом выше перечисленного, особенностей архитектуры системы команд (см. таблицы 1 и 2) и распределения памяти данных эту команду рассматриваемого яруса параллельной программы кодируем следующим образом:
<>01 0110 0111 0000.
КОп определяет бинарную операцию сравнения, код постфиксного указателя определяет условный переход, первый операнд (поле А1) находится в регистре 0110 памяти, данных, второй операнд (поле А2) находится в регистре 0111 памяти данных, а результатом сравнения является признак (единица или ноль), определяющий истинность или ложность условия перехода к первому ярусу.
Шаг 5. Отсутствие элемента в списке J5 графа поярусных переходов (пятая строка табл. 4) является признаком завершающей команды параллельной программы. Список J5 смежности вершин графа потока данных содержит лишь первую половину. Второй элемент этого списка (вторая клетка пятой строки табл. 3) содержит унарную операцию вывода значения переменной «а», являющегося (третья клетка пятой строки табл. 3) результатом выполнения предшествующей через одну команду в своей ветви параллельной программы. С учетом особенностей архитектуры системы команд (см. таблицы 1 и 2) и распределения памяти данных эту команду параллельной программы кодируют следующим образом:
выв 00 0101 0000 0010.
КОп определяет унарную операцию вывода, код постфиксного указателя показывает, что эта команда не требует изменения естественного порядка выполнения, операнд (поле А1) находится в регистре 0101 памяти данных, а выводимая переменная отправляется в регистр 0010 памяти данных S.6 и доступна там через верхний по схеме (фиг. 3) порт.
Программа в мнемонических кодах операций с учетом выше описанного распределения памяти команд и данных представлена в таблице 5.
Программа в действительных адресах позволяет уточнить массив списков смежности вершин графа поярусных переходов (таблица 6) адресами ярусов и адресами передач управления.
Управляющая параллельная вычислительная система работает следующим образом.
Исходное положение
Во внутреннюю память системного контроллера S.2 (фиг. 3) загружены (фиг. 4): модуль контроля М5, модуль инициирования параллельной вычислительной сети М6, модель ввода исходных данных М7, модуль управления параллельной вычислительной сетью М8 и модуль вывода результатов вычислений М9. В системную память S.5 загружен массив списков смежности вершин графа поярусных переходов параллельной программы, а в памяти команд S.3 и S.4, начиная с первых адресов, загружены (см. табл. 5) команды ветвей параллельной программы.
Подача питания
С подачей питания контроллер S.2 (фиг. 3) формирует системный сброс (блок 4, фиг. 6) и передает управление модулю М5 (фиг. 4), который (блок 4, фиг. 6) осуществляет контроль работоспособности всех компонентов вычислительной системы, а при успешном его завершении (блок 2, фиг. 6) приводит память S.3, S.4, S.5, S.6 и ФМ параллельной вычислительной сети S.7 (фиг. 2 и 3) в исходные состояния (блок 5, фиг. 6).
В исходном состоянии все регистры ФМ и всех видов памяти находятся в нулевом состоянии. Нулевые состояния регистров команд U.1 ФМ (фиг. 1) соответствуют (см. табл. 1) холостым командам, не предполагающих никаких действий. При этом ни один из входов коммутаторов С.1, С.2 и С.3 не соединен с выходом, блок управления выполнением команд U.3 бездействует, регистры R.1, R.2 и R.3 пусты, операционное устройство IU бездействует, коммуникации интерфейсов ФМ 1,2,…,8 по выходам не активны.
Инициирование
Системный контроллер S.2 передает управление модулю М6 (фиг. 4), который по локальной шине S.1 (фиг. 3) активизирует все виды памяти (блок 7, фиг. 6). При этом регистры адресов памяти команд S.3 и памяти команд S.4 инкрементируются. В результате каждая из них раскодирует полученные адреса, выбирает первую ячейку запоминающего массива в регистр данных и ожидает поступления сигнала «Чтение» по шине управления нижнего по схеме фиг. 3 порта.
Работа
Работа начинается после того, как при исполнении модуля М6 (фиг. 4) системный контроллер S.2 по локальной шине S.1 (фиг. 3), по коммуникациям 10 и 13 интерфейса параллельной вычислительной сети S.7 (фиг. 2 и 3) и коммуникациям 7 интерфейсов ФМ (первая сверху линия на фиг. 1) попарно, последовательно («ФМ0 - ФМ1», «ФМ2 - ФМ3» и так далее (см. фиг. 2) активизирует (блоки 9, 11, 12, 14, фиг. 6) ФМ с задержкой не меньшей, чем длительность полного цикла обращения к памяти команд. При этом, блоки U.3 (фиг. 1) управления выполнением команд ФМ0 и ФМ1 (фиг. 2) по коммуникациям 8 интерфейсов (третья сверху линия на фиг. 1) и далее по коммуникациям 11 и 12 (фиг. 2 и 3) параллельной вычислительной сети S.7 формируют (блок 1, фиг. 7) обращение по чтению: ФМ0 - к памяти команд S.3, а ФМ1 - к памяти команд S.4. При получении сигнала «Чтение» память команд S.3 и S.4 на шины данных нижних по схеме фиг. 3 портов выдают содержимое регистров данных, сопровождая выдачу сигналами «Готов» по шине управления тех же портов и ожидают сигнал подтверждения о приеме. Получив сигнал «Готов» (вторая сверху линия коммуникации 8 интерфейса (фиг. 1), блоки U.3 ФМ0 и ФМ1 на нижние по схеме фиг. 1 входы регистров команд U.1 подают импульсы «Принять». С шин данных (первая сверху линия коммуникации 8 на фиг. 1) коды команд (блок 3, фиг 7) принимаются в регистры команд U.1. В результате (см. строку 1, табл. 5) в регистре команд U.1 ФМ0 оказывается рабочая, а в регистре команд U.1 ФМ1 - холостая команда.
Содержимое регистров команд после завершения активизации всех пар ФМ (уровней параллельной вычислительной сети) представлено в таблице 7.
Приняв коды команд, блоки U.3 ФМ0 и ФМ1 по коммуникациям 8 (нижняя связь по схеме фиг. 1) и коммуникациям 7 (верхняя связь по схеме фиг. 1) интерфейсов выдают (блок 6, фиг. 7) импульсы подтверждения приема кода «Есть прием». Получив подтверждение приема выданного кода, каждая память команд отключается от шины данных, сбрасывает регистр данных, инкрементирует код адреса, декодирует его, выбирает очередную ячейку памяти и принимает ее содержимое в регистр данных, подготавливая выдачу очередной команды. Системный контроллер S.2, получив подтверждение приема кода команд (блок 16, фиг. 6), с использованием списков смежности вершин графа поярусных переходов (см. табл. 6) запоминает (блок 6, фиг. 6) адрес s рабочего уровня параллельной вычислительной сети S.7.
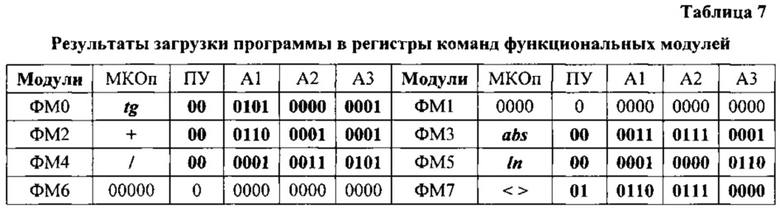
Поскольку ФМ1 принял «холостую» команду, работу продолжает лишь ФМ0 одновременно двумя блоками U.3 и U.2.
С выходов операционной части регистра команд U.1 коды операций (КОп) и постфиксный указатель (ПУ) поступает в блок управления выполнением команд U.3, а коды адресов - в блок управления потоком данных U.2. Блок U.3 анализирует код ПУ (блоки 2, 4, 5, фиг. 7). Поскольку в выполняемой команде ПУ=00, то он приступает к декодированию КОп (блок 12, фиг. 7). Блок U.2 код первого адреса (блок 11, фиг. 7) по левому верхнему по схеме фиг. 1 выходу подает на адресный вход коммутатора С.1, который по результату декодирования этого кода соединяет правый по схеме фиг. 1 вход с выходом. Поскольку на этом входе данные пока отсутствуют, сигнал «1-й готов» на левом по схеме фиг. 1 выходе коммутатора С.1 также отсутствует. Поэтому блок U.3 на нижний по схеме фиг. 1 вход блока U.2 подает команду «Выдать первый адрес в память данных», по которому этот блок по верхнему справа выходу выдает код первого адреса (блок 19, фиг. 7) на адресный (верхний по схеме фиг. 1) вход коммуникации 5 интерфейса ФМ, а блок U.3 по управляющему (нижнему по схеме фиг. 1) входу коммуникации 5 сопровождает код адреса обращением к памяти данных по чтению (блок 22, фиг. 7). Результат чтения - n-раз-рядный код переменной «а», дополненный битом готовности (см. распределение памяти) - по шине данных (средний по схеме фиг. 1 вход коммуникации 5) поступает на правый верхний вход коммутатора С.1. На его левом по схеме фиг. 1 выходе и соответствующем входе блока U.3 появляется сигнал «1-й готов», который по готовности декодирования КОп (блок 15, фиг. 7) сигналами и настраивает (блок 23, фиг. 7) ОпУ IU на выполнение заданной операции. Поскольку декодирована унарная операция (блок 24, фиг. 7), IU запускается (блок 25, фиг. 7). Получив по выходу r ОпУ IU сигнал об окончании выполнения операции и значения связанных с ее результатом флагов блок U.3 по верхнему на схеме фиг. 1 выходу коммуникации 7 интерфейса оповещает об этом (блок 26, 27, фиг. 7) системный контроллер S.2. Далее блок U.3 на управляющий вход регистра R.3 выдает импульс «Принять», а на левый сверху по схеме фиг. 1 вход коммутатора С.3 - признак ƒ готовности результата (блок 28, фиг. 7). В регистре и, следовательно, на входе коммутатора С.3 появляется код результата операции и признак его готовности. Если A3 не больше 0001 (блок 29, фиг. 7) - результат не подлежит записи в память данных S.6 (см. табл. 2), то блок U.3; на адресный (левый по схеме фиг. 1) вход коммутатора С.3 подает код F1(A3) (блок 30, фиг. 7), обеспечивающий соединение входа с левым по схеме фиг. 1 (n+1)-раз-рядным выходом. Код результата и признак его готовности появляются на информационно-управляющем выходе коммуникации 6 интерфейса ФМ. Далее, поскольку в выполняемой команде ПУ=00 и (блок 34, фиг. 7) ФлП=0, осуществляется сброс (блок 37, фиг. 7) и возврат на начало цикла приема и выполнения команд-образов очередного яруса графа потока данных параллельной программы.
Инициирование ФМ следующего уровня (ФМ2 - ФМ3) параллельной вычислительной сети обеспечивает чтение, прием и выполнение описанным выше способом команд-образов второго яруса графа потока данных параллельной программы (см. вторую строку табл. 7). При этом блоки U.2 и U.3 ФМ2 обеспечивают обращение к памяти данных по адресу А1, чтение переменной «b», соединение правого по схеме фиг. 1 входа с выходом коммутатора С.1, прием в регистр R.1 кода переменной «b» по признаку ее готовности. Однако, в отличие от ранее рассмотренного, декодируется бинарная операция, с выходом коммутатора С.2 соединяется его первый вход, по сигналу «2-й готов» (блок 13, фиг. 7) в регистр R.2 принимается результат операции, выполненной ФМ0 (блок 17, фиг. 7), запускается (блок 25, фиг. 7) ОпУ IU, выполняется сложение кодов операндов, по окончании операции (блок 26, фиг. 7) оповещается (блок 27, фиг. 7) системный контроллер S.2, код суммы отправляется в регистр R.3, признак готовности ƒ - на вход коммутатора С.З (блок 28, фиг. 7) и далее совместно с признаком его готовности (блоки 29, 30, 32, фиг. 7) - на информационно управляющий выход 6 коммуникации интерфейса.
Блоки U.2 и U.3 ФМ3 обеспечивают (блоки 11, 14, 18, фиг. 7) соединение третьего по схеме фиг. 1 входа с выходом коммутатора С.1, прием в регистр R.1 кода значения тангенса, получение (блоки 23, 25, 26, фиг. 7) абсолютной величины, отправку (блок 28, фиг. 7) ее кода в регистр R.3 и далее (блоки 29, 30, 32, фиг. 7) совместно с признаком его готовности - на информационно управляющий выход 6 коммуникации интерфейса. Далее, поскольку в выполняемой команде ПУ=00 и (блок 34, фиг. 1) ФлП=0, осуществляется (блок 37, фиг. 7) сброс и возврат на начало цикла приема и выполнения команд-образов очередного яруса графа потока данных параллельной программы.
Инициирование ФМ следующего уровня параллельной вычислительной сети (ФМ4-ФМ5) обеспечивает чтение, прием и выполнение команд-образов третьего яруса графа потока данных параллельной программы (см. третью строку табл. 7). При этом блоки U.2 и U.3 ФМ4 обеспечивают соединение первого по схеме фиг. 1 входа с выходом коммутатора С.1, прием в регистр R.1 кода с выхода 6 интерфейса ФМ2, соединение третьего по схеме фиг. 1 входа с выходом коммутатора С.2, прием в регистр R.2 кода с выхода 6 интерфейса ФМЗ, выполнение деления по сигналу «2-й готов» и получение результата. Однако, в отличие от ранее рассмотренного результатом является новое значение переменной «а», которое требуется передать ФМ предшествующих уровней параллельной вычислительной сети, что не обеспечивается (см. фиг. 2) ее топологией. При известном из распределения памяти месте хранения этой переменной и признаку А3>0001 (блок 29, фиг. 7) блоки U.2 и U.3 ФМ4 обеспечивают (блоки 31 и 33, фиг. 7) запись результата и признака его готовности в память данных, как нового значения переменной «а». Далее, поскольку в выполняемой команде ПУ=00 и (блок 34, фиг. 1) ФлП=0, осуществляется (блок 37, фиг. 7) сброс и возврат на начало цикла приема и выполнения команд-образов очередного яруса графа потока данных параллельной программы.
Инициирование ФМ следующего уровня параллельной вычислительной сети (ФМ6-ФМ7) обеспечивает чтение, прием и выполнение команд-образов четвертого яруса графа потока данных параллельной программы (см. четвертую строку табл.7). Поскольку ФМ6 принял «холостую» команду, работу продолжает лишь ФМ7 также одновременно двумя блоками U.3 и U.2, обеспечивая: соединение первого по схеме фиг. 1 входа с выходом коммутатоpa С.1, прием в регистр R.1 кода с выхода 6 интерфейса ФМ7, чтение из памяти данных и прием в регистр R.2 кода константы 0,1 и признака ее готовности, выполнение сравнения по сигналу «2-й готов» и получение результата. Однако, поскольку (блок 4, фиг. 7) код ПУ=01, системный контроллер S.2 (блок 8, фиг. 7) оповещается о возможной передаче управления по условия (ПУУ), выбирает (блок 13, фиг. 6) по текущему значению s адрес перехода из соответствующего списка (см. четвертую строку табл. 7) смежности вершин графа поярусных переходов (ГПП) и ожидает получение флага перехода (ФлП). Если получен ФлП=1 (блок 15, фиг. 6), то системный контроллер S.2 сбрасывает (блок 17, фиг. 6) все пары ФМ кроме уровня s, через локальную шину S.1 загружает (блок 18, фиг. 6) в регистры адресов (РгА) дополнительных (нижних по схеме фиг. 3) портов памяти команд S.3 и памяти команд S.4 адрес передачи управления (Апер.), попарно, поочередно активизирует ранее сброшенные ФМ (блоки 19÷22, фиг. 6), выдает разрешение (блок 23, фиг. 6 и блок 35, фиг. 7) на завершение цикла выполнения команды ФМ7, который (блок 36, фиг. 7) и также активизируется, осуществляет (блок 37, фиг. 7) сброс и возвращается к чтению и выполнению очередной команды. В результате содержимое регистров команд ФМ параллельной вычислительной сети становится соответствующим табл. 7. Начинается новый цикл работы параллельной вычислительной сети S.7.
Если же ФлП=0 (блок 15, фиг. 6), системный контроллер S.2 (блок 16, фиг. 6) переходит к мониторингу активности ФМ параллельной вычислительной сети S.7, а ФМ ее первого уровня (ФМ0 - ФМ1) - к чтению и выполнению команд-образов пятого яруса графа потока данных параллельной программы (см. пятую строку табл. 5).
Поскольку ФМ1 принял «холостую» команду, работу продолжает лишь ФМ0 одновременно двумя блоками U.3 и U.2. При этом с выходов операционной части регистра команд U.1 коды операций (КОп) и постфиксного указателя (ПУ) поступают в блок управления выполнением команд U.3, а коды адресов - в блок управления потоком данных U.2. Блок U.3 анализирует код ПУ (блоки 2, 4, 5, фиг. 7). Поскольку в выполняемой команде ПУ=00, то он приступает к декодированию КОп (блок 12, фиг. 7). Блок U.2 код первого адреса (блок 11, фиг. 7) по левому верхнему по схеме фиг. 1 выходу подает на адресный вход коммутатора С.1, который по результату декодирования этого кода соединяет правый по схеме фиг. 1 вход с выходом. Поскольку на этом входе данные пока отсутствуют, сигнал «1-й готов» на левом по схеме фиг. 1 выходе коммутатора С.1 также отсутствует. Поэтому блок U.3 на нижний по схеме фиг. 1 вход блока U.2 подает команду «Выдать первый адрес в память данных», по которому этот блок по верхнему справа выходу выдает код первого адреса (блок 19, фиг. 7) на адресный (верхний по схеме фиг. 1) вход коммуникации 5 интерфейса ФМ, а блок U.3 по управляющему (нижнему по схеме фиг. 1) входу коммуникации 5 сопровождает код адреса обращением к памяти данных по чтению (блок 22, фиг. 7). Результат чтения - n-разрядный код переменной «а», дополненный битом готовности (см. распределение памяти) - по шине данных (средний по схеме фиг. 1 вход коммуникации 5) поступает на правый верхний вход коммутатора С1. На левом по схеме фиг. 1 выходе коммутатора С.1 и соответствующем входе блока U.3 появляется сигнал «1-й готов», который по готовности декодирования КОп (блок 15, фиг. 7) сигналами и настраивает ОпУ IU на выполнение сложения. Поскольку декодирована унарная операция (блок 24, фиг. 7), IU запускается (блок 25, фиг. 7). Получив по выходу r ОпУ IU сигнал об окончании выполнения операции и значения связанных с ее результатом флагов блок U.3 по верхнему на схеме фиг. 1 выходу коммуникации интерфейса оповещает об этом (блоки 27, 27, фиг. 7) системный контроллер S.2. Далее блок U.3 на управляющий вход регистра R.3 выдает импульс «Принять», а на левый сверху по схеме фиг. 1 вход коммутатора С.3-признак ƒ готовности результата (блок 28, фиг. 7). В регистре и, следовательно, на его выходе и на входе коммутатора С.3 появляется код результата операции и признак его готовности. Поскольку A3 больше 0001 (блок 29, фиг. 7) блоки U.2 и U.3 ФМ0 обеспечивают (блоки 31 и 33, фиг. 7) запись результата и признака его готовности в память данных. Далее, поскольку в выполняемой команде ПУ=00 и (блок 34, фиг. 7) ФлП=0, осуществляется сброс (блок 37, фиг. 7) и возврат на начало цикла приема и выполнения команд-образов очередного яруса графа потока данных параллельной программы.
Поскольку следующими принимаются только «холостые» команды, работа параллельной вычислительной сети блокируется.
Рассмотренная выше работа покрывает особенности выполнения заявляемой архитектурой распараллеленных линейных участков последовательных программ, ветвей, собственно разветвлений и циклов с постусловием, оставляя за рамками описания возврат на начало тела цикла с предусловием и просто безусловную передачу управления (БПУ), которая осуществляется следующим образом. Если блоком управления выполнением команд U.3 какого-либо ФМ (блок 5, фиг. 7) вскрыт код 10 постфиксного указателя (ПУ), то (блок 9, фиг. 7) системный контроллер S.2 оповещается о безусловной передаче управления (БПУ) (блок 8, фиг. 6), который сбрасывает (блок 17, фиг. 6) все пары ФМ кроме уровня s, через локальную шину S.1 загружает (блок 18, фиг. 6) в регистры адресов (РгА) дополнительных (нижних по схеме фиг. 3) портов памяти команд S.3 и памяти команд S.4 адрес передачи управления (Апер.), попарно, поочередно активизирует ранее сброшенные ФМ (блоки 19÷22, фиг. 6), выдает разрешение (блок 23, фиг. 6 и блок 35, фиг. 7) на завершение цикла выполнения команды, инициировавшей БПУ, обеспечивая переход к выполнению участка параллельной программы, которому передано управление. Проблема сохранения потока данных решается на стадии получения параллельной программы (кодирования графа потока данных системой команд ФМ параллельной вычислительной сети) путем сохранения результата выполнения инициировавшей БПУ команды в памяти данных, - обеспечения его использование в качестве операнда командами, которым передано управление.
Сравнительная оценка (см. фиг. 9 и 10) сверху эффективности заявляемой архитектуры на граф-программе вычисления функции 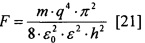 , с. (14-15), показала, что наименее эффективной по критерию минимума отношения «стоимость - производительность» является процессорная матрица (показатель эффективности 10,2 условных единиц), далее следуют: ВС, управляемая потоком данных (показатель эффективности 6,4 условных единицы), многопотоковая ВС (показатель эффективности 3,98 условных единицы) и ВС заявляемой архитектуры (показатель эффективности 3,1 условных единицы).
, с. (14-15), показала, что наименее эффективной по критерию минимума отношения «стоимость - производительность» является процессорная матрица (показатель эффективности 10,2 условных единиц), далее следуют: ВС, управляемая потоком данных (показатель эффективности 6,4 условных единицы), многопотоковая ВС (показатель эффективности 3,98 условных единицы) и ВС заявляемой архитектуры (показатель эффективности 3,1 условных единицы).
Повышение производительности ВС заявленной архитектуры достигнуто: разделением памяти команд, применением регистровой памяти данных с расширенным интерфейсом, предвыборкой команд и упреждающим (до поступления операндов) декодированием кодов операций, уменьшением длительности цикла выполнения команд путем использования только прямой и регистровой адресации операндов, одновременным выполнением независимых по данным и управлению команд, частичного совмещения во времени выполнения зависимых по данным команд и, наконец, запуском операционных устройств готовностью операндов.
Уменьшение сложности конструкции и стоимости ВС достигнуто: удалением из состава ВС-прототипа коммутатора типа «каждый с каждым», буферной памяти кода операции, буферной памяти первого аргумента, буферной памяти второго аргумента, памяти готовности аргументов, памяти занятых меток, блоков формирования исполняемой команды, блоков разрешения выбора команд и регистров информационной связности; заменой N устройств памяти команд двумя устройствами, реализацией структуры параллельной вычислительной сети непосредственными связями между ФМ и управлением активностью связей из адресной части исполняемых команд.
Одновременным повышением производительности и упрощением конструкции ВС достигается минимум отношения «стоимость - производительность».
Источники информации
1. Цилькер Б.Я., Орлов С.А. Организация ЭВМ и систем. СПб.: Питер, 2006. - 668 с.
2. Потоковые вычислительные системы.
URL: http://www.sbras.ru/win/elbib/data/show_page.dhtml?77+861.
3. Потоковые и редукционные вычислительные системы.
URL: http://ilab.xmedtest.net/?q=node/6019.
4. Барский А.Б. Архитектура параллельных вычислительных систем.
URL: www.intuit.ru/department/hardware/paralltech/0/.
5. В. Левин. Некоторые вопросы реализации высокопроизводительных вычислительных систем // Кибернетика и вычислительная техника. М.: Наука. - 1991, стр. 27-35,
6. Корнеев В.В., Киселев А.В. Современные микропроцессоры. Изд. второе. - М.: НОЛИДЖ, 2000. - 320 с, ил.
7. Виктор Корнеев. Эволюция микропроцессорных архитектур // Открытые системы. - 2000, №4.
8. В. Корнеев. Параллельные вычислительные системы. М.: Нолидж. - 1999.
9. В.В. Корнеев. Архитектура вычислительных систем с программируемой структурой. Новосибирск: Наука. - 1985.
10. Виктор Корнеев. Современные подходы к повышению производительности. Открытые системы, 2006, №05.
11. Каляев И.А., Левин И.И., Семерников Е.А., Шмойлов В.И. РЕКОНфИГУРИРУЕМЫЕ МУЛЬТИКОНВЕЙЕРНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СТРУКТУРЫ. Ростов-на-Дону: Изд. ЮНЦ РАН, 2008. - 393 с.
12. Ермишин В.В. Проблемы и перспективы использования основных вычислительных ресурсов // Информационные технологии в естественных науках, экономике и образовании. Труды международной научной конференции. Саратов - Энгельс, 2002. с. 346-352.
13. Ермишин В.В. К проблеме эффективного использования множественных вычислительных ресурсов // Многопроцессорные вычислительные и управляющие системы - 2007. Материалы Международной научно-технической конференции. Т. 1. Таганрог-Москва: Изд-во ТТИ ЮФУ, 2007. с. 60-65.
14. Ермишин В.В. О возможностях принципа программного управления в решении проблемы повышения производительности // Доклады Академии военных наук. 2008, №5(34), с. 119-134.
ISSN 1728-2454.
15. Ермишин В.В. К проблеме создания высокопроизводительных вычислительных систем // Высокопроизводительные вычислительные системы// Материалы Пятой Международной молодежной научной школы. Материалы Международной молодежной научно-технической конференции - Таганрог: Изд-во ТТИ ЮФУ, 2008. С.76-88.
ISBN 978-5-8327-0263-7.
16. Ермишин В.В. К проблеме повышения производительности вычислительных систем // Доклады Академии военных наук. 2011, №5(49), С. 120-145.
ISSN 1728-2454.
17. Ермишин B.B. Модель поведения процессора и ее возможности // Доклады Академии военных наук. Серия "Аналитическая механика. Аналитическая теория автоматического управления". 1999, №1. с. 40-50.
ISBN 5-7933-0564-1.
18. Теоретические основы, методы и алгоритмы оптимизации объектных программ (монография). Саратов. СВВКИУ РВ, 1996. 9,3 п.л. (Деп ЦСИФ МО РФ 2.04.96, инв. Б 2842).
19. Ермишин В.В. К проблеме отображения ехе-программ в множественные вычислительные ресурсы // Доклады Академии военных наук. 2000, №5. с. 102-108.
ISBN 5-93888-002-5.
20. Ершов А.П. Введение в теоретическое программирование, (беседы о методе). - М.: Наука, 1977. - 288 с.
21. Шпаковский Г.И. Организация параллельных ЭВМ и суперскалярных процессоров: Учеб. пособие. - Мн.: Белгосуниверситет, 1996. - 296 с.: ил.
| название | год | авторы | номер документа |
|---|---|---|---|
| Специализированный процессор для вычисления элементарных функций | 1985 |
|
SU1330627A1 |
| АСИНХРОННАЯ СИНЕРГИЧЕСКАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2000 |
|
RU2198422C2 |
| Реконфигурируемый вычислительный модуль | 2018 |
|
RU2686017C1 |
| СИНЕРГИЧЕСКАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2000 |
|
RU2179333C1 |
| СПОСОБ КОДИРОВАНИЯ И ИСПОЛНЕНИЯ КОНТЕКСТНО-ЗАВИСИМОЙ ПРОГРАММЫ МУЛЬТИКЛЕТОЧНЫМ ПРОЦЕССОРОМ, МУЛЬТИКЛЕТОЧНЫЙ ПРОЦЕССОР, КЛЕТКА И КОММУТАЦИОННОЕ УСТРОЙСТВО МУЛЬТИКЛЕТОЧНОГО ПРОЦЕССОРА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 2013 |
|
RU2530690C2 |
| Вычислительная система | 1990 |
|
SU1709331A1 |
| Многопроцессорная вычислительная система | 1982 |
|
SU1168960A1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 1995 |
|
RU2110089C1 |
| УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ИНФОРМАЦИИ | 1991 |
|
RU2029359C1 |
| Способ распределения данных по многофункциональным блокам процессора со сверхдлинной командной строкой | 2024 |
|
RU2818498C1 |
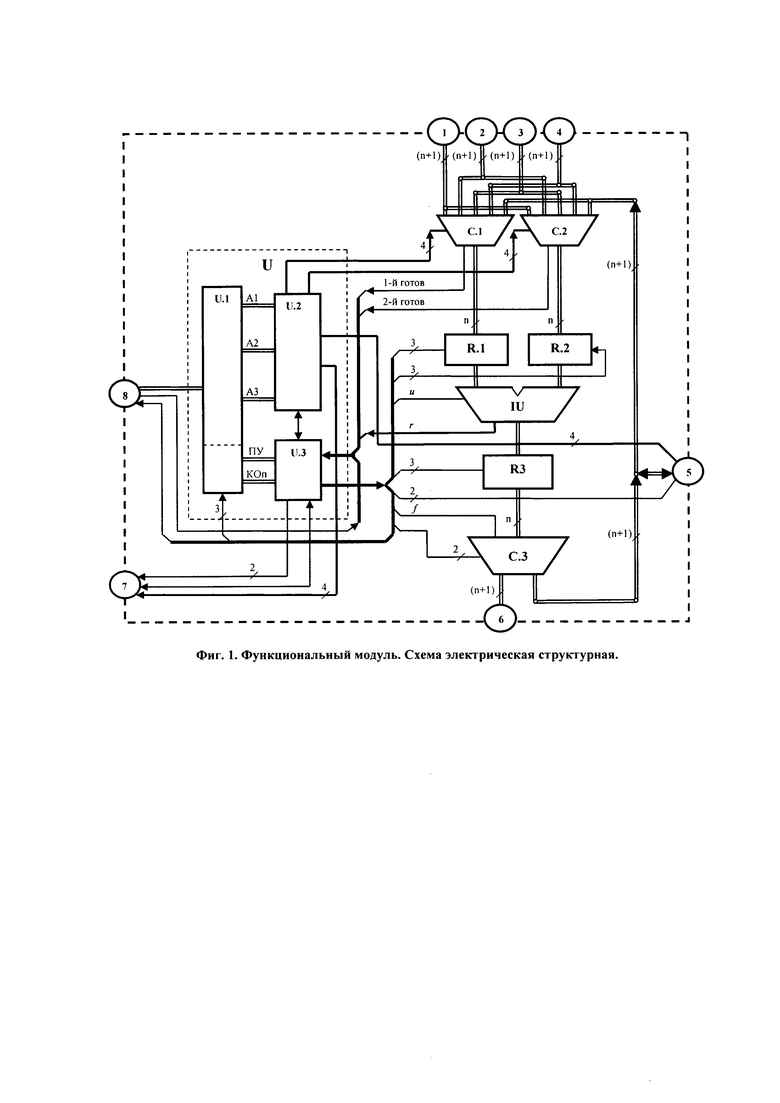

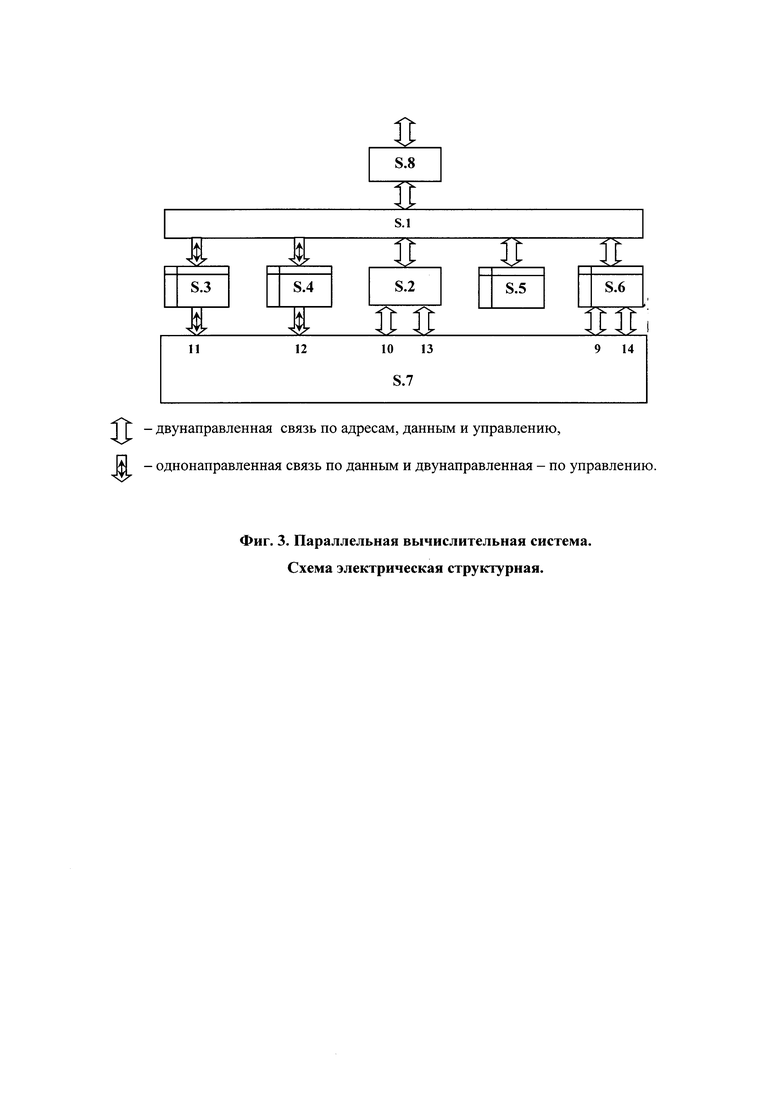

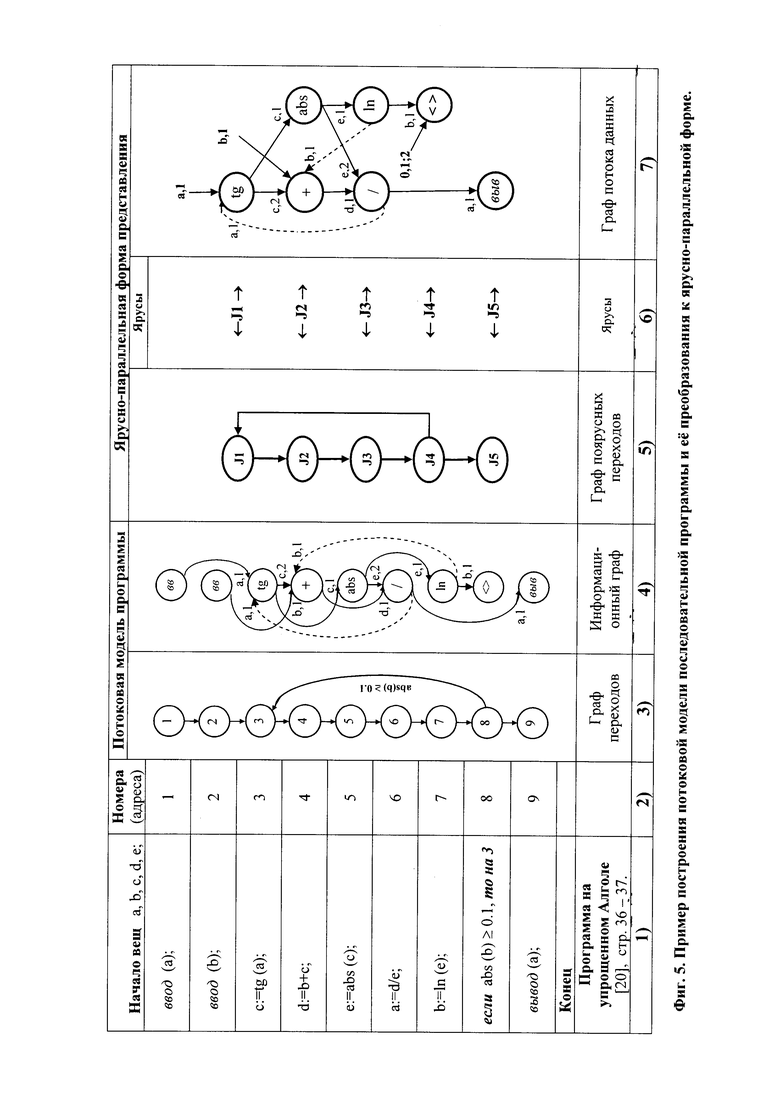
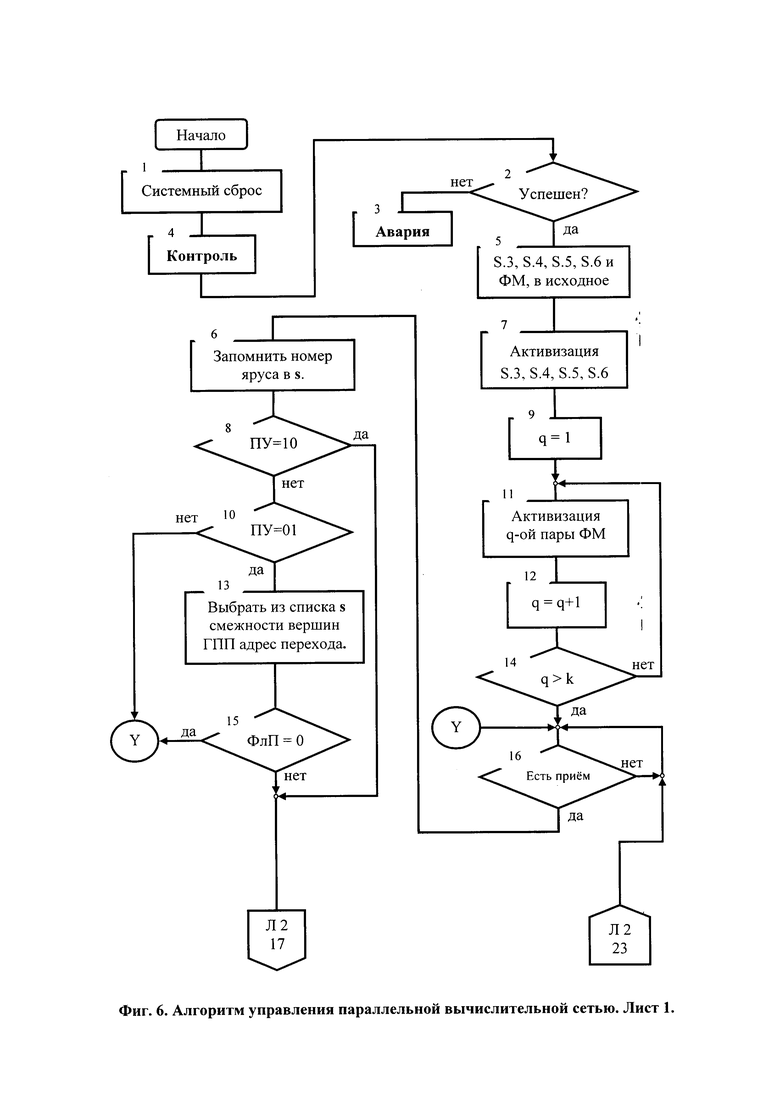
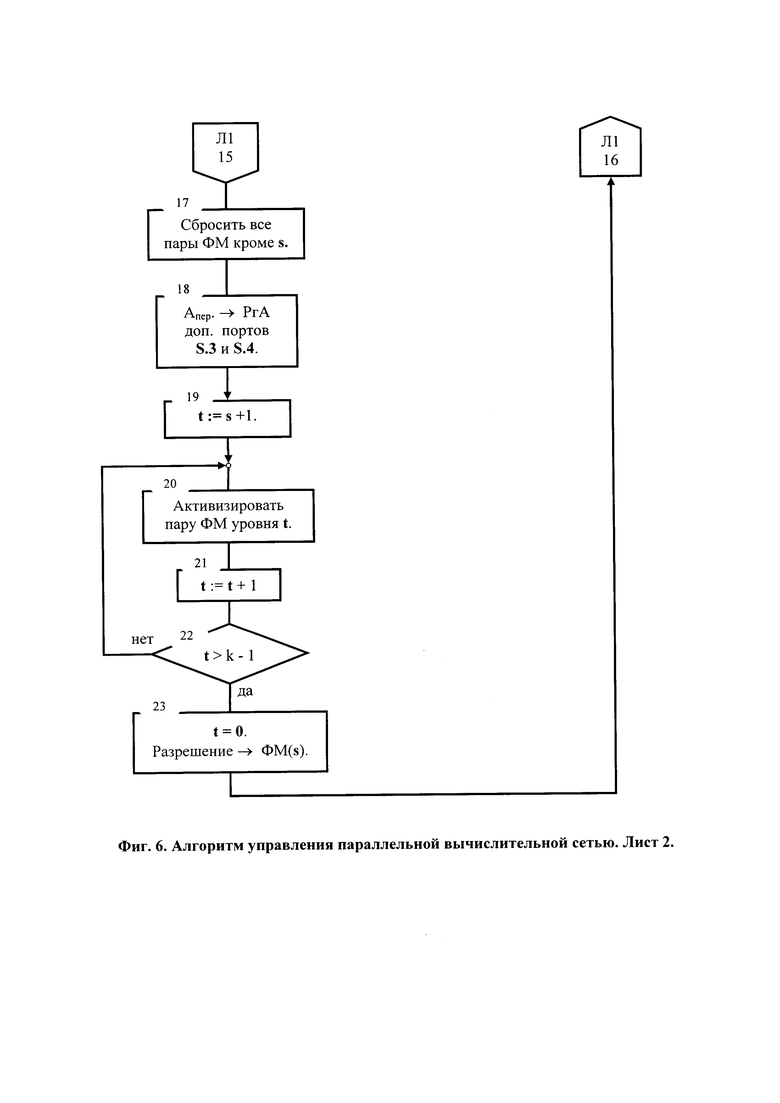

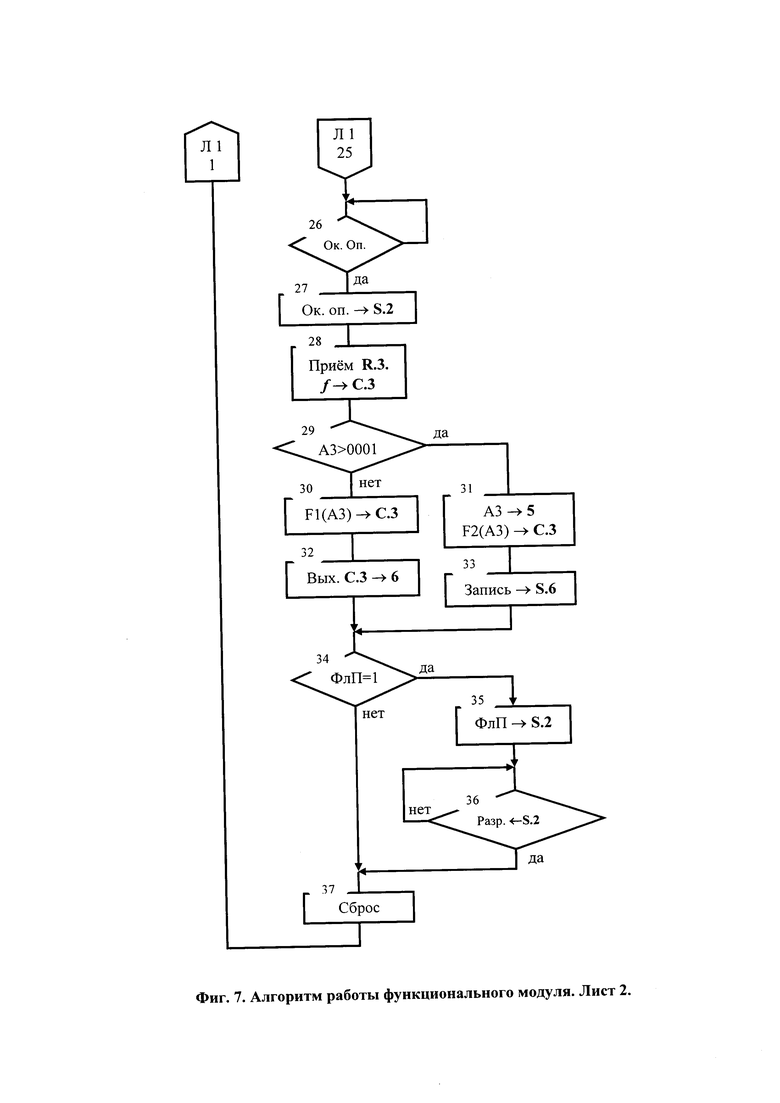
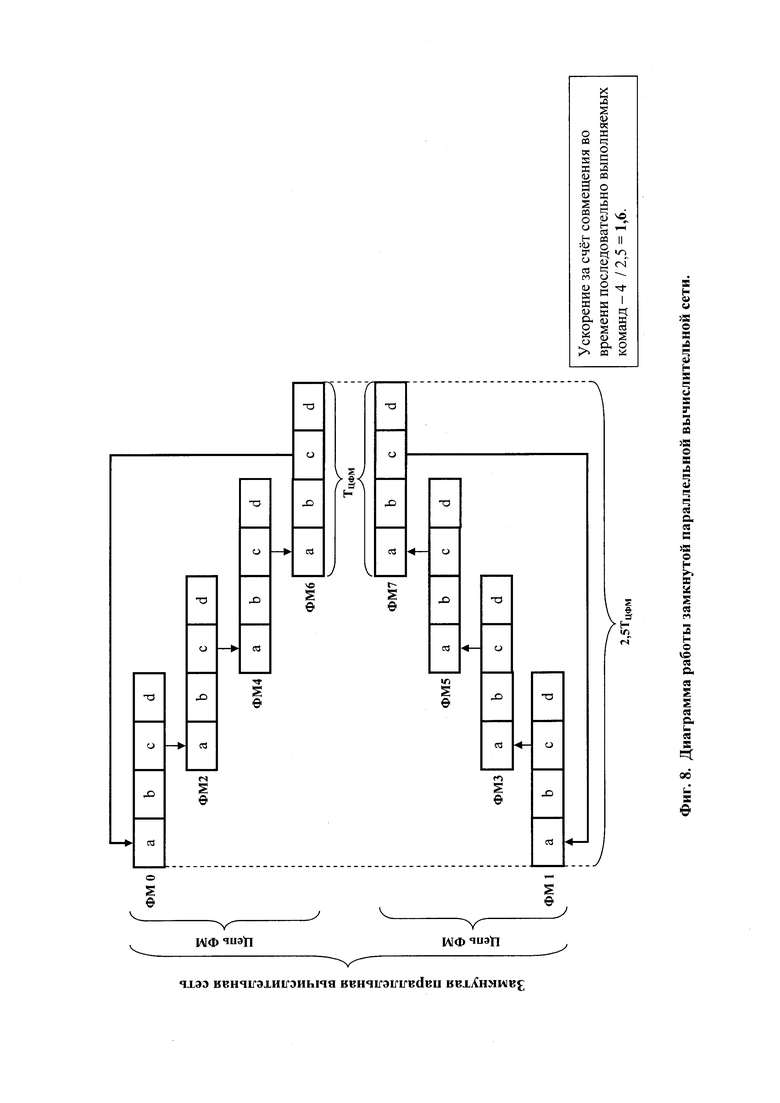
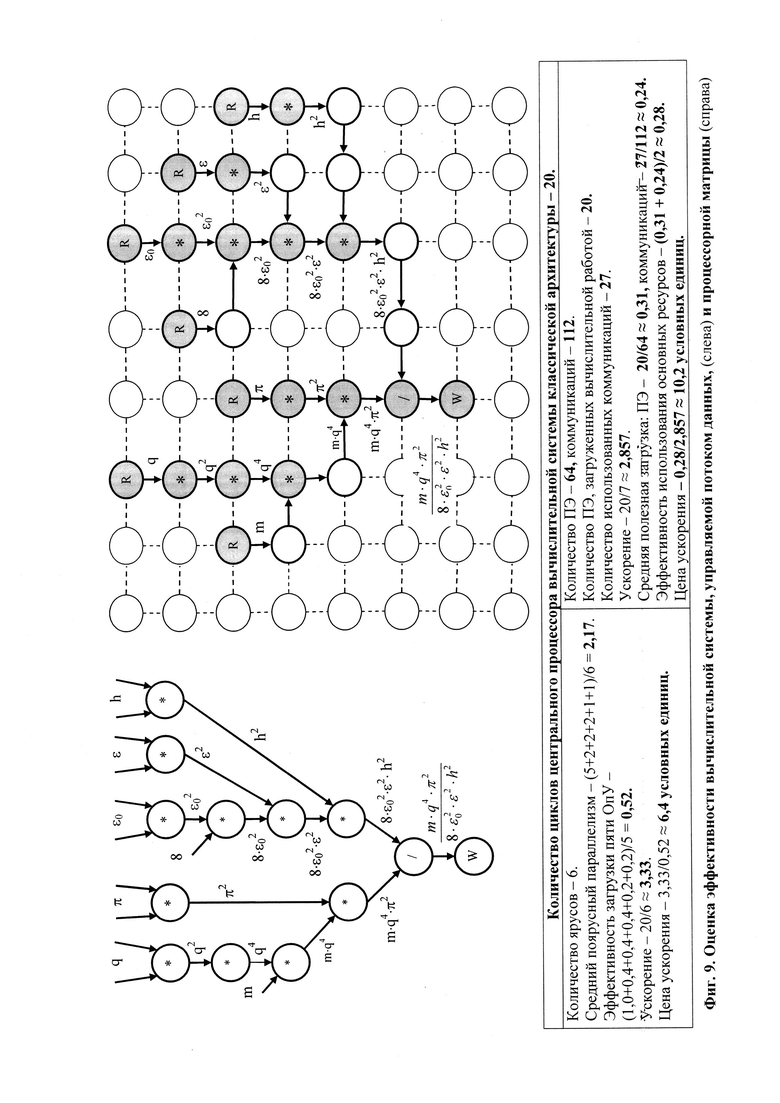
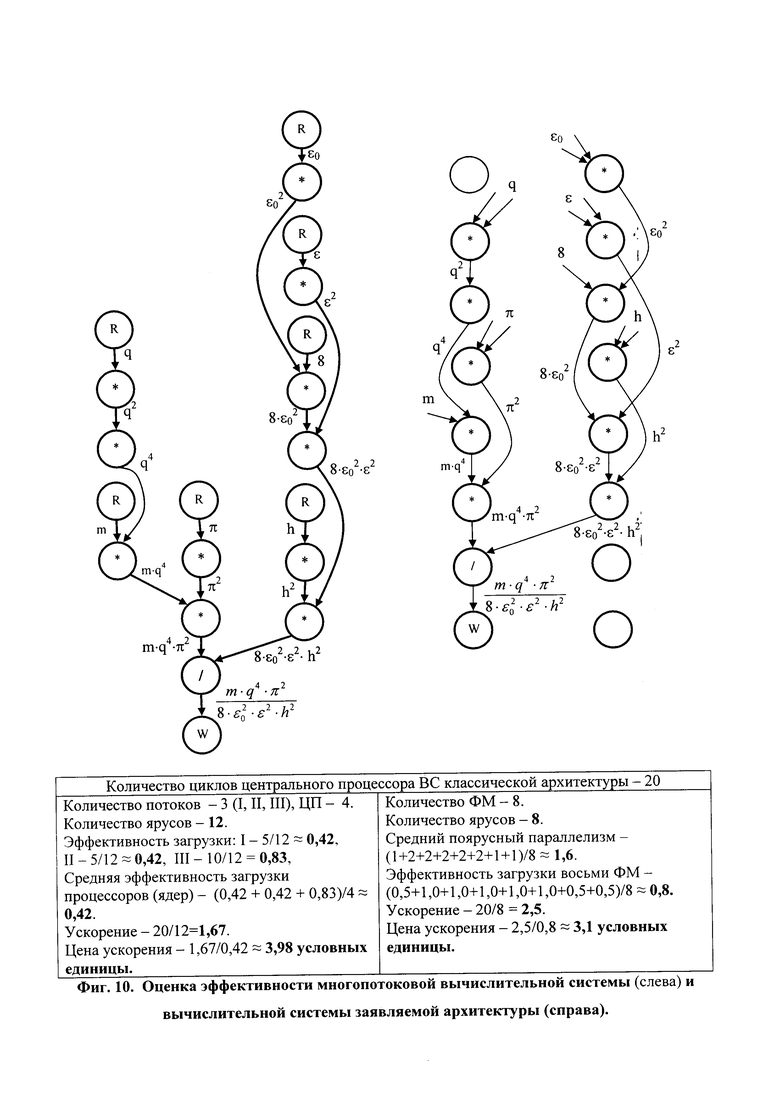
Изобретение относится к технологиям сетевой связи. Технический результат заключается в повышении производительности. Архитектура параллельной вычислительной системы (ВС), содержащей N функциональных модулей (ФМ), имеющих два информационных входа, два входа признаков готовности, информационный выход и выход признака готовности результата и состоящих из устройств управления и операционных устройств, реализующих двуместные и одноместные операции, причем количество N ФМ четно; в состав ВС введены: локальная шина, системный контроллер, служебная память, память данных с расширенным интерфейсом, адаптер и два устройства памяти команд с расширенным интерфейсом, доступных со стороны упомянутого системного контроллера и N/2 ФМ каждое; в состав ФМ введены: коммутатор первого операнда, коммутатор второго операнда, выходной коммутатор, регистры первого и второго операндов и регистр результата операции; устройство управления ФМ содержит регистр команд, блок управления потоком данных и блок управления выполнением команд; интерфейс ФМ представлен четырьмя информационно-управляющими входами, информационным входом-выходом, информационно-управляющим выходом, управляющим входом-выходом и командным входом-выходом. 10 ил., 7 табл.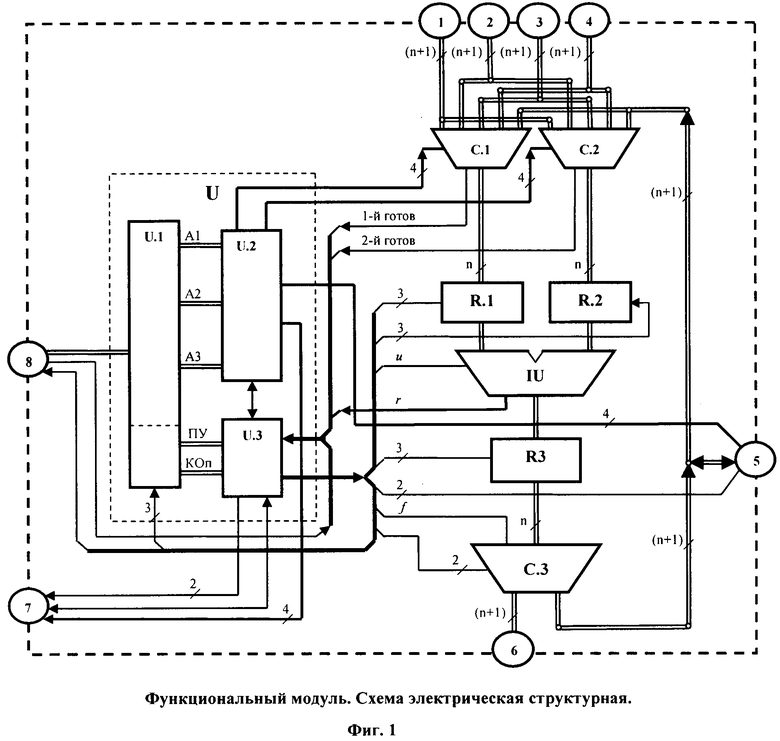
Архитектура параллельной вычислительной системы (ВС), содержащей N функциональных модулей (ФМ), имеющих два информационных входа, два входа признаков готовности, информационный выход и выход признака готовности результата и состоящих из устройств управления и операционных устройств, реализующих двуместные и одноместные операции, отличающаяся тем, что: количество N ФМ четно; в состав ВС введены: локальная шина, системный контроллер, служебная память, память данных с расширенным интерфейсом, адаптер и два устройства памяти команд с расширенным интерфейсом, доступных со стороны упомянутого системного контроллера и N/2 ФМ каждое; в состав ФМ введены: коммутатор первого операнда, коммутатор второго операнда, выходной коммутатор, регистры первого и второго операндов и регистр результата операции; устройство управления ФМ содержит регистр команд, блок управления потоком данных и блок управления выполнением команд; интерфейс ФМ представлен четырьмя информационно-управляющими входами, информационным входом-выходом, информационно-управляющим выходом, управляющим входом-выходом и командным входом-выходом; вход регистра команд соединен с командным входом-выходом ФМ, при этом выходы адресной части регистра команд соединены с блоком управления потоком данных, два выхода которого соединены с адресными входами коммутаторов первого и второго операндов, третий выход соединен с информационным входом-выходом ФМ. четвертый выход соединен с управляющим входом-выходом ФМ, а пятый вход-выход соединен с блоком управления выполнением команд; выход операционной части регистра команд соединен с входом блока управления выполнением команд, имеющим связи со всеми блоками, устройствами, узлами и коммуникациями интерфейса ФМ; коммутаторы первого и второго операндов имеют: по четыре входа, попарно соединенные с четырьмя одноименными информационно-управляющими входами ФМ, по одному входу, соединенному с информационным входом-выходом ФМ и информационным выходом выходного коммутатора, по одному адресному входу, соединенному с соответствующим выходом блока управления потоком данных, по информационному выходу, соединенному с входом одноименного регистра операнда, и по одному выходу готовности, соединенному с соответствующим входом блока управления выполнением команд; выходы регистров операндов соединены с одноименными входами операционного устройства, его выход соединен с входом регистра результата выполненной операции, а его выход соединен с информационным входом выходного коммутатора, который имеет: вход готовности результата, соединенный с одноименным выходом блока управления выполнением команд, адресный вход, соединенный с соответствующим выходом блока управления выполнением команд, и два выхода, один из которых соединен с информационно-управляющим выходом ФМ, а другой - с информационным входом-выходом ФМ и пятыми входами коммутаторов первого и второго операндов; информационно-управляющие выходы ФМ соединены с информационно-управляющими входами других ФМ с образованием многоуровневой, однонаправленной, замкнутой вычислительной сети, содержащей два взаимодействующих по данным и их готовности кольца, количество ФМ в которой определяется из соотношения N>2Тпк/Тфм, где: Тпк - длительность цикла обращения в память команд, а Тфм - длительность цикла выполнения команды ФМ; выход каждого ФМ соединяется: с первым информационно-управляющим входом следующего ФМ в своей цепи, с вторым информационно-управляющим входом ФМ, следующего через один ФМ в своей цепи, с третьим информационно-управляющим входом следующего ФМ в соседней цепи и с четвертым информационно-управляющим входом ФМ, следующего через один ФМ в соседней цепи; все управляющие входы-выходы ФМ первого кольца соединены с одним входом-выходом системного контроллера, а все управляющие входы-выходы ФМ второго кольца - с другим входом-выходом системного контроллера; все командные входы-выходы ФМ первого кольца соединены с входом-выходом первой памяти команд, а все командные входы-выходы ФМ второго кольца - с входом-выходом второй памяти команд; информационные входы-выходы ФМ первого кольца соединены с первым дополнительным портом памяти данных, а информационные входы-выходы ФМ второго кольца - со вторым дополнительным портом памяти данных; локальная шина соединяет системный контроллер с первой и второй памятью команд, со служебной памятью, с памятью данных и адаптером; система команд ФМ параллельной вычислительной сети - трехадресная, не содержит команд передачи управления и использует только прямой и регистровый способы адресации; в операционную часть команд дополнительно введен двухразрядный постфиксный указатель, определяющий принадлежность команды к элементам логической структуры исполняемой программы, а функции адресов расширены указанием ФМ-источников операндов (первый и второй адрес) и преемников результата с признаком его готовности (третий адрес); системное ПО содержит специальное ПО инструментальной ЭВМ и встроенное ПО системного контроллера, при этом в состав специального ПО инструментальной ЭВМ включаются модули подготовки отлаженной последовательной программы к параллельному исполнению, а в состав встроенного ПО системного контроллера - модули, обеспечивающие управление выполнением параллельной программы и ввод/вывод.
| ПАРАЛЛЕЛЬНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА С ПРОГРАММИРУЕМОЙ АРХИТЕКТУРОЙ | 2001 |
|
RU2202123C2 |
| МУЛЬТИПРОЦЕССОРНАЯ АРХИТЕКТУРА, ОПТИМИЗИРОВАННАЯ ДЛЯ ПОТОКОВ | 2008 |
|
RU2450339C2 |
| АСИНХРОННАЯ СИНЕРГИЧЕСКАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2000 |
|
RU2198422C2 |

