Изобретение относится к компьютерным системам на микропроцессорной основе, а более конкретно - к многопроцессорным компьютерным системам с возможностью регулирования энергопотребления.
Достижения технологии полупроводников сделали возможным уменьшить размеры элементов интегральных микросхем, что позволило сформировать большее количество транзисторов на одной подложке. Например, изготовляемые в настоящее время наиболее сложные микропроцессоры, обычно состоящие из одной интегральной схемы (IC), содержат несколько миллионов транзисторов. Хотя столь поразительные технологические достижения позволили в огромной степени повысить производительность и улучшить возможности обработки данных в современных компьютерных системах, эти результаты были достигнуты за счет увеличения энергопотребления. Увеличение энергопотребления означает, что увеличивается излучаемое от IC тепло.
Так как излишнее энергопотребление и раcсеяние тепла являются критическими проблемами, с которыми в настоящее время сталкиваются проектировщики компьютеров, используются различные способы уменьшения энергопотребления для уменьшения уровней тока потребляемой энергии в компьютерных системах. Многие из этих способов используют стратегию отключения питания микропроцессора в моменты, когда он не используется, для экономии энергии. Этот подход, однако, не лишен недостатков.
В качестве примера можно привести проблемы, возникающие в микропроцессорных (МР) компьютерных системах, использующих два или более совместно работающих процессора для выполнения задач системы. Если один из процессоров отключается (например, если он завершил выполнение своих текущих задач или если он не используется), то другой микропроцессор системы может продолжать обработку данных по системной шине. Проблема заключается в том, что во время некоторых обращений к шине может предприниматься попытка считывать/записывать данные, сохраненные в измененном состоянии, в отключенном микропроцессоре или в неиспользуемом микропроцессоре. В случае отсутствия некоторого механизма контроля активности шины и изменения ячеек совместно используемой памяти может быть потеряна связность данных. Поэтому МР компьютерные системы нуждаются в механизме, который позволил бы неактивному процессору знать и реагировать на активность шины, которая может предпринимать попытку доступа к устаревшим данным.
Задачей настоящего изобретения является разработка многопроцессорной компьютерной системы, в которой каждый конкретный процессор контролирует трафик шины для поддержания когерентности кэш, работая в режиме уменьшенного энергопотребления. В соответствии с настоящим изобретением неактивный, или отключенный, процессор реагирует на определенные обращения шины путем обратной записи измененных данных в системную шину в режиме уменьшенного энергопотребления. Кроме того, настоящее изобретение работает без простоя или вмешательства со стороны работающей системы. Таким образом, настоящее изобретение предоставляет полностью определенный путь взаимодействия с внешней шиной, минимизируя энергопотребление.
Поставленная задача решается тем, что многопроцессорная компьютерная система согласно изобретению содержит шину, основную память, связанную с шиной, первый процессор, связанный с шиной, для выполнения обмена данными с основной памятью, и второй процессор, имеющий блок шины, связанный с шиной, локальную кэш, имеющую связанный теговый массив, схему фазовой автоматической подстройки частоты (ФАПЧ) для генерирования синхронизирующего сигнала, и при этом второй процессор выполнен с возможностью установления в режим работы с уменьшенным энергопотреблением путем отключения синхронизирующего сигнала от одного или более блока целых чисел, блока с плавающей запятой, ПЗУ управления или локальной кэш, в то время как блок шины остается подключенным к синхронизирующему сигналу, при этом блок шины выполнен с возможностью проверки шины в режиме работы с уменьшенным энергопотреблением и подачи сигнала на первый процессор, сообщающего, что цикл записи по шине, генерируемый первым процессором, выполняется в строку, которая находится в измененном состоянии в локальной кэш второго процессора.
В одном примере осуществления многопроцессорной компьютерной системы второй процессор выполнен с возможностью записи строки в измененном состоянии в основную память по шине после завершения цикла записи первого процессора.
В другом примере осуществления многопроцессорной компьютерной системы первый процессор выполнен с возможностью повторного выполнения исходного цикла записи после того, как второй процессор завершит запись строки в измененном состоянии в основную память.
В следующем примере осуществления многопроцессорной компьютерной системы второй процессор выполняет команду HALT (останов), которая устанавливает второй процессор в режим работы с уменьшенным энергопотреблением каждый раз, когда выполняется эта команда.
В еще одном примере осуществления многопроцессорной компьютерной системы второй процессор содержит внешний вывод, подключенный к ФАПЧ, который при установке вызывает отключение синхронизирующего сигнала от локальной кэш.
Согласно другому варианту изобретения многопроцессорная компьютерная система содержит внешнюю шину, первый и второй процессоры, связанные с внешней шиной, схему фазовой автоматической подстройки частоты (ФАПЧ) для генерирования синхронизирующего сигнала, связанную с первым процессором, механизм разрешения конфликтов, выполненный с возможностью разрешения конфликтов между первым и вторым процессорами для внешней шины, и блок управления прерываниями, связанный с первым и вторым процессорами для управления межпроцессорными прерываниями, причем при установке первого процессора в режим работы с уменьшенным энергопотреблением синхронизирующий сигнал первого процессора отключается от кэш первого процессора, в то время как синхронизирующий сигнал остается подключенным к теговому массиву в первом процессоре, который связан с кэш, при этом первый процессор также содержит регистр, имеющий первый разряд, причем считывание/запись регистра выполняется с помощью программного обеспечения так, что при установке первого разряда отключается режим работы с уменьшенным энергопотреблением.
В одном примере осуществления многопроцессорной компьютерной системы регистр дополнительно содержит второй разряд, при установке которого отключается механизм разрешения конфликтов.
В другом примере осуществления многопроцессорной компьютерной системы регистр дополнительно содержит третий разряд, при установке которого отключается блок управления прерываниями.
В дальнейшем изобретение поясняется подробным описанием конкретного варианта воплощения со ссылками на прилагаемые чертежи, на которых:
фиг. 1 изображает блок-схему микропроцессора согласно изобретению;
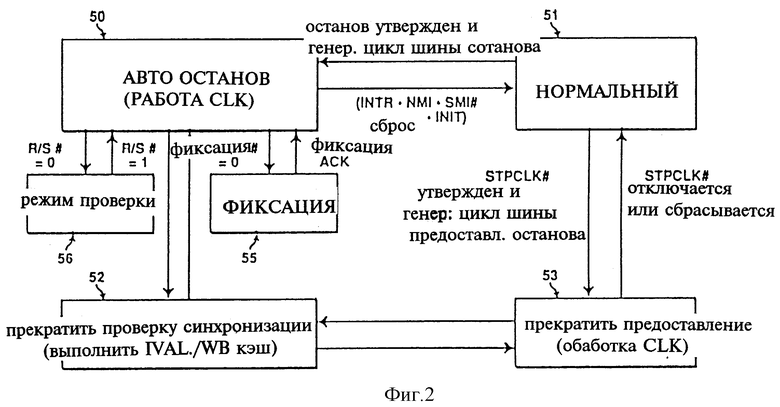
фиг. 2 изображает диаграмму состояния блока управления тактовой частотой согласно изобретению;
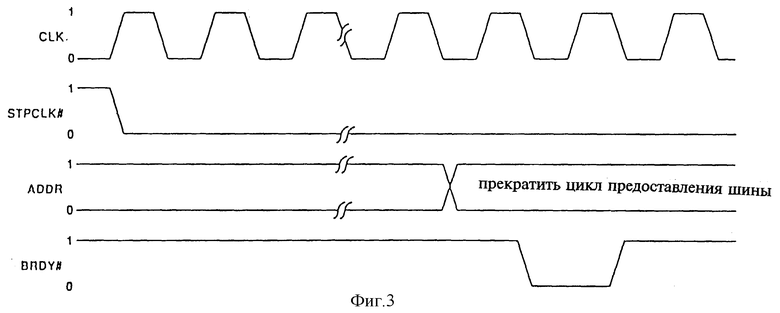
фиг. 3 изображает диаграмму синхронизации согласно изобретению;
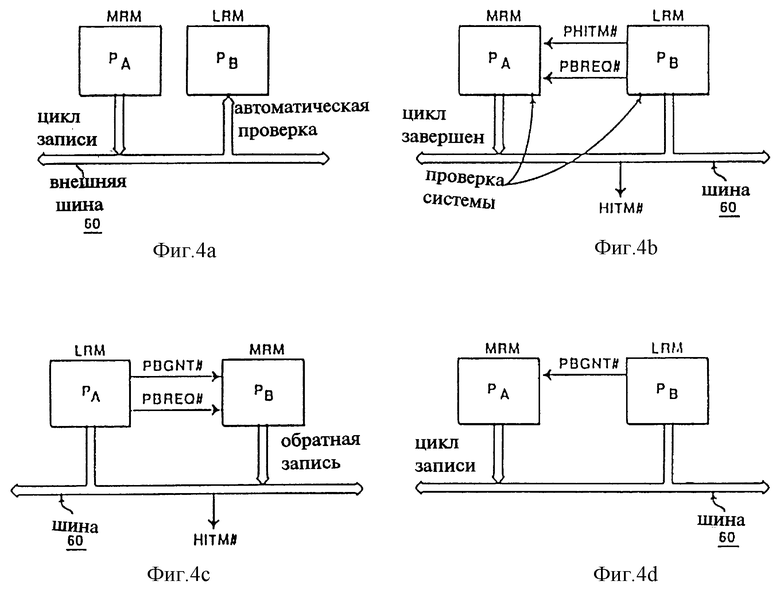
фиг. 4a-d изображает примеры различных режимов работы микропроцессора согласно изобретению;
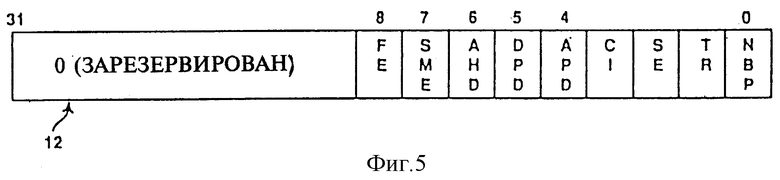
фиг. 5 изображает регистр проверки, который имеет двоичные разряды, позволяющие по программе отключать определенные функции согласно изобретению.
Описание предпочтительных вариантов осуществления изобретения
В настоящем изобретении раскрыта многопроцессорная компьютерная система, поддерживающая когерентность кэш, минимизируя энергопотребление.
На фиг. 1 представлена блок-схема процессора 20, который обладает различными свойствами в соответствии с настоящим изобретением. Процессор 20 содержит усовершенствованный процессор PentiumTM, изготовляемый Intel Corporation в Санта-Кларе (Калифорния). Хотя настоящее изобретение будет описано на примере фиг. 1, но должно учитываться, что в широком понимании настоящее изобретение применимо ко многим другим типам компьютерных систем, включая микропроцессоры, совместимые с процессором Pentium, или в которых используются различные структуры процессоров для обработки данных.
Процессор 20 содержит схему фазовой автоматической подстройки частоты (ФАПЧ) 30, которая вырабатывает внутренний сигнал синхронизации (ICLK), подаваемый по линии 46 на различные функциональные блоки схемы. Например, подаваемый по линии 46 сигнал ICLK передается на большую часть внутренней логики IC, включая кэш команд 25, кэш данных 26, ПЗУ управления 21 и внутреннюю логику, которая содержит блок 22 целых чисел и блок с плавающей запятой (FR) 23 процессора. Сигнал ICLK, кроме того, подается на часть логического блока прерываний 29. Кэш команд 26, кэш данных 26 и блок шины 40 связаны с 64-битной шиной данных 42 и с 32-битной адресной шиной 43.
Кроме сигнала ICLK схема ФАПЧ 30 обеспечивает также и второй сигнал синхронизации (CLK), подаваемый по линии 45 на массивы сравнения тегов кэш команд 25 и на кэш данных 26. Передаваемый по линии 45 сигнал CLK подается также и на часть логического блока прерываний 29 и на блок шины 40. Ниже более подробно описывается различие между сигналами синхронизации ICLK и CLK. Во время нормальной работы процессор 20 работает с тактовой частотой, примерно равной 100 мГц. Различные типы процессора 20 могут поддерживать различные отношения сердечник/шина. Например, в альтернативных исполнениях поддерживаются частоты шины, равные 50 мГц и 60 мГц.
В одном из вариантов выполнения блок шины 40 и логический блок прерываний 29 имеет логическую схему, позволяющую использовать процессор 20 в системе МР. В качестве примера, циклы шины, создаваемые и принимаемые блоком шины 40, а также сигналы прерывания, принимаемые и предоставляемые логическим блоком прерываний 29, совместимы с хорошо известным процессором PentiumTM. Кроме того, процессор 20 имеет логику, которая поддерживает целостность кэш и разрешает конфликты внешней шины.
В одном из исполнений процессор 20 осуществляет также функции управления энергопотреблением, что позволяет устанавливать процессор в состояние уменьшенного рассеяния мощности (т.е. устанавливать режимы работы HALT (останов) или STANDBY (резервирование). Во время работы в нормальном режиме с пиковой мощностью процессор 20 может рассеивать 10 Bт, в режиме работы HALT или STANDBY потребляется всего 700 мBт мощности. Одним из путей ввода процессором 20 функции управления энергопотреблением, а также независимых функций операционной системы является установка режима управления работой системы. Режим управления системой (SMM) состоит из прерывания (SMI), альтернативного адресного пространства и команды (SRET). Прерывание управления системой вызывает фиксирование в логическом блоке 29 запроса на прерывание управления системой. Когда на границе команды обнаруживается защелка SMI#, то для процессора 20 устанавливается режим SMM.
Возможен вариант выполнения, когда процессор 20 имеет внешний вывод, обозначаемый STPCLK# , и связанную схему, которая может использоваться для регулирования потребляемой процессором мощности. Вывод STPCLK# обеспечивает чувствительным к уровню прерыванием SMI, которое устанавливает процессор в низкоуровневое STANDBY состояние. В соответствии с настоящим изобретением процессор 20 реагирует как на внутренние, т.е. ADS#, так и на внешние, т.е. EADS#, запросы проверки в режиме работы STANDBY.
Кроме того, процессор 20 поддерживает механизм, называемый AUTO_HALT, в соответствии с которым процессор устанавливается в режим низкого потребления энергии каждый раз, когда выполняется команда HALT. Процессор 20 реагирует на все события останова и прерывания работы, включая собственные проверки и события межпроцессорных прерываний, которые генерируются во время нахождения процессора в состоянии экономного энергопотребления без установки вывода STPCLK#.
Когда процессор 20 работает в нормальном режиме работы, то отключаются обе линии подачи сигнала синхронизации 46 (ICLK) и 45 (CLK), чтобы на все блоки интегральной схемы подавался внутренний основной сигнал синхронизации. Когда процессор устанавливается в состояние малого энергопотребления или в состояние STANDBY в результате установки вывода STPCLK# или в результате выполнения команды HALT, то отключается сигнал внутренней синхронизации (ICLK), передаваемый по линии 46, и не влияет на непрерывную работу схемы ФАПЧ 30. Другими словами, ФАПЧ 30 продолжает генерировать внутреннюю основную CLK частоту по линии 45, связанной с определенной частью процессора 20. Части процессора 20, которые остаются в рабочем состоянии, т.е. активизируемые посредством CLK, включают ФАПЧ 30, тэговые массивы сравнения блоков кэш 25 и 26, часть логического блока прерываний 29 и блок шины 40. В соответствии с настоящим изобретением подача питания на выбранные части процессора 20 позволяет процессору контролировать и реагировать на трафик внешней шины для поддержания когерентности кэш в системах МР. То есть механизмы разрешения конфликтов шины и обеспечения когерентности кэш умышленно поддерживаются в активном состоянии в режиме работы с уменьшенным энергопотреблением.
На фиг. 2 показана диаграмма состояния, иллюстрирующая определенные ключевые свойства одного из вариантов выполнения настоящего изобретения. В нормальных условиях работы - состояние 51 - процессор 20 находится в активном состоянии, выполняя команды. Это соответствует состоянию подключения полной мощности к процессору, когда как сигналы ICLK, так и сигналы CLK подключаются ко всем частям внутренней логики IC.
В состояние STOP_GRANT - блок 53 - можно войти путем установки внешнего вывода STPCLK# процессора 20. В состоянии STOP_GRANT интегральная схема работает в режиме экономного энергопотребления, когда большинство внутренних функциональных блоков процессора дезактивированы, т. е. ICLK отключен. С другой стороны, блок шины 40, тэговые массивы кэш 25 и 26, ФАПЧ 30 и части логического блока прерываний 29 остаются в активном состоянии. Как только включается цикл шины STOP_GRANT для шины и принимается сигнал BRDY#, процессор устанавливается в состояние STOP_GRANT. Специалисты данной области понимают, что сигнал BRDY# используется для указания, что от внешней системы получены правильные данные по выводам данных в ответ на запрос чтения, или, что внешняя система, например основная память, другой процессор и т.д., приняла данные процессора в ответ на запрос записи. В одном из вариантов выполнения процессор возвращается в состояние нормальной работы примерно в течение десяти тактовых периодов после отключения STPCLK#. Команда RESET тоже выводит процессор из состояния STOP_GRANT, возвращая его в нормальное состояние.
Процессор распознает входную информацию блока шины 40 для поддержания когерентности кэш, например неточности и внешние проверки, путем контроля графика шины во время работы в режиме экономного энергопотребления. Например, в состоянии STOP_GRANT процессор закрепляет преобразования за внешними сигналами прерываний, например SMI#, NMI, INTR, FLUSH#, R/S# и INIT. Все эти прерывания устанавливаются после повторной установки STPCLK#, то есть после повторного входа в нормальное состояние.
Состояние AUTO_HALT - блок 50 устанавливается во время выполнения команды HALT. В состоянии AUTO_HALT внутренний сигнал синхронизации (ICLK) отключается от большей части внутренней логики, в то время как непрерывный сигнал синхронизации CLK поддерживает в рабочем состоянии выбранные функциональные блоки микросхемы. После ввода команд INTR, NMI, SMI# RESET или INIT процессор возвращается к нормальному состоянию работы, т.е. в состояние 51. Как отмечалось ранее, состояние AUTO_HALT приводит к существенному уменьшению энергопотребления благодаря отключению сигнала синхронизации от большей части внутренней логики процессора. Блок шины 40, ФАПЧ 30, теговые массивы, а также логика прерывания остаются активными для поддержания проверок и для обеспечения возможности быстрого перезапуска. Любое внешнее прерывание вызывает выход процессора из состояния AUTO_HALT 50 и его возврат в нормальное рабочее состояние 51. Во время работы в состоянии AUTO_HALT 50 установка сигнала FLUSH# (активного низкого уровня) вызывает фиксацию возникшего события и его обработку - блок 55. В описываемом варианте выполнения сигнала FLUSH# заставляет процессор выполнять обратную запись всех измененных линий в кэш данных 26 и отключать все внутренние кэш. Затем процессором генерируются специальные сигналы подтверждения FLUSH, указывая на завершение операций обратной записи и отмены.
Установка выхода R/S# - активного низкого уровня вызывает завершение нормальной работы процессора и установки его в состояние IDLE. На фиг. 2 показано событие R/S#, вызывающее переход от состояния AUTO_HALT 50 в состояние PROBE_MODE 56. Выход R/S# предоставляется для использования с отладкой процессора совместно со специальным портом отладки. Переход от состояния высокого уровня в низкий уровень вывода R/S# прерывает работу процессора и вызывает завершение работы на границе следующей команды. Повторная установка вывода R/S# вызывает переход от состояния PROBE_MODE 56 обратно в состояние AUTO_HALT 50.
На фиг. 2 тоже показано состояние 52, которое представляет возможность проверки процессора во время работы в режиме экономного энергопотребления, который устанавливается после установки вывода STPCLK# или выполнения команды HALT. Несмотря на уменьшение рассеяния мощности в любом из этих двух состояний, процессор продолжает управлять сигналами шины посредством блока 40, и сохраняется внутреннее машинное состояние процессора. Поддерживаются как собственные, так и межпроцессорные проверки как для циклов отключения кэш, так и для циклов обратной записи. Потребление мощности возрастает на короткий период времени, если для проверки требуется выполнения цикла обратной записи. В соответствии с настоящим изобретением проверки выполняются полностью аппаратным обеспечением без использования микрокодов.
Как в состоянии STOP_ GRANT, так и в состоянии AUTO_HALT процессор 20 поддерживает проверки, включая внутренние и межпроцессорные проверки, поддерживая в активном состоянии логику сравнения тегов блока кэш посредством CLK. Это показано на фиг. 1, где сигнал CLK по линии 45 передается на логику сравнения тегов кэш памятей 25 и 26. С другой стороны, сигнал ICLK отключается от части массива данных кэш для минимизации энергопотребления. Во время выполнения проверки в случае необходимости обновляются MESI, т.е. обновленные, совместно используемые, неправильные двоичные разряды протокола кэш. Части процессора, хотя бы, например, кэш данных, логика управления связанной кэш, а также шины между кэш данных и интерфейсной шиной, отличающиеся от теговых массивов, включаются только, если необходимы циклы обратной записи. В альтернативном варианте выполнения может быть достигнута более жесткая экономия энергии путем отключения логики сравнения тегов в определенной ситуации, например, когда все входы кэш неправильны, или путем отключения питания от теговых массивов до обнаружения обращения, которое возможно проверить, после чего включается состояние медленного повышения мощности для предоставления тегам возможности выполнения операции проверки.
Отметим, что на фиг. 1-4 показан только один пример выполнения настоящего изобретения. Однако возможны более сложные варианты выполнения с разнообразными способами экономии энергопотребления, в соответствии с которыми могут быть использованы разнообразные схемы тактирования. Это же верно и по отношению к конкретному протоколу, используемому после выполнения проверки. Например, вместо выполнения обратной записи данных первым процессором по системной шине первый процессор может удерживать запись и держать засоренной линию. Таким образом, специалисты данной области оценят многие различные способы применения настоящего изобретения.
На фиг. 3 представлена диаграмма синхронизации, показывающая задержку между запросом STPCLK# и циклом шины STOP_GRANT. Отметим, что для иллюстративного исполнения имеется задержка, равная примерно десяти тактам между запросом STPCLK# и циклом шины STOP_GRANT. Эта задержка зависит от текущей команды, количества данных в буферах записи ЦП, а также от характеристик системной памяти.
Кэш данных 26 процессора 20 использует протокол MESI для лучшего поддержания целостности кэш. Линия в кэш данных может быть в обновленном, исключительном, совместно используемом или неправильном состоянии, в то время как линия в кэш команд 25 может быть либо в правильном, либо в неправильном состоянии. В настоящем изобретении рассматриваются ситуации, которые могут возникнуть, когда два или более процессора совместно используют общие данные в компьютерной системе. Локальные кэш процессоров могут предпринимать попытки кэширования данных, когда это возможно. В одном из вариантов исполнения процессора 20 используется механизм обеспечения связности кэш для гарантии совместимости данных, передаваемых между процессорами. Если какие-либо данные были кэшированы в одном из процессоров, а другой процессор предпринимает попытку выполнить доступ к этим данным, то процессор, содержащий данные, сообщает вызывающему процессору, что он кэшировал эти данные. Состояние кэш линии и процессора, содержащего данные, будет изменяться в зависимости от текущего состояния и от типа запроса, выполняемого другим процессором.
В соответствии с настоящим изобретением для основного механизма обеспечения связности необходимо, чтобы не выполняющий цикл процессор, который не использует шину (здесь он упоминается как последний ведущий шины или LRM), проверял бы работу всех MRM шин (MRM упоминается здесь как новый ведущий шины, который использует эту шину). Процессор MRM, использующий цикл шины, затем обращается к процессору LRM для указания, что данные, содержатся в кэш LRM.
Для лучшего понимания работы настоящего изобретения рассмотрим пример разрешения конфликтов интерфейса взаимообмена, представленный на фиг. 4a-d. Предположим, что процессор PB работает в режиме экономного энергопотребления или свободен со стороны внешней шины 60. Это будет выполнено, если процессор PB будет находиться в состоянии AUTO_HALT или STOP_GRANT. Предположим также, что процессор PA в компьютерной системе только что выполнил цикл записи по внешней шине 60. Более того, допустим, что цикл записи по шине выполнялся в линию, которая находилась в измененном состоянии (М) в процессоре PB. Эта ситуация изображена на фиг. 4a. Поскольку как блок шин, так и логика внутренних прерываний и проверок остаются в активном состоянии в процессоре PB, несмотря на то что большинство других внутренних логик отключено, процессор PB автоматически проверяет внешнюю шину 60 для контроля цикла записи, начатого процессором РA.
На фиг. 4b показано, что процессор PB указывает процессору PA, что обращение к записи столкнулось с измененным состоянием кэш линии. Это выполняется посредством установки сигнала PHITM# к процессору PA. Процессор PB тоже устанавливает вывод разрешения внутренних конфликтов BPBREQ# для указания, что процессор PB сгенерировал запрос шины (предполагается, что процессор PA в текущем состоянии использует шину 60). Отметим, что сигнал HITM# тоже подключается к шине 60 для предотвращения доступа к данным со стороны другого ведущего шины до полной обратной записи линии. Затем процессор PA завершает цикл записи по внешней шине 60 так, как если бы процессора PB не существовало.
Внешняя проверка выполняется непосредственно после завершения цикла записи по шине 60, но до момента возникновения у процессора PB возможности записи измененных данных обратно в память системы. На фиг. 4b показано, что процессор PB устанавливает сигнал HITM# для сообщения системе о кэшировании адреса проверки в паре сдвоенных процессоров и о его измененном состоянии. В этом примере внешняя проверка выполняется по той же линии, которая вызвала установку сигнала PHITM#.
На фиг. 4c взаимообмен информацией в процессе разрешения конфликтов был выполнен по внешней шине 60, и теперь процессор PB использует эту шину. В это время процессор PB выполняет обратную запись строки в измененном (М) состоянии. С точки зрения компьютерной системы создается впечатление, что некоторый единый процессор завершил обращение для проверки. Отметим, что на фиг. 4c используются два собственных вывода разрешения конфликтов, связанные с этой парой процессоров для указания, что возможность монопольного использования шины передана процессору PB (или, что процессор PA запросил обратно возможность монопольного использования после завершения операции обратной записи).
Наконец, на фиг. 4d процессор PA повторно выполняет исходный цикл записи после того, как процессор PB передал шину процессору PA. Важно иметь в виду, что процессор PB остается в режиме с уменьшенным энергопотреблением в течение всего процесса проверки и обратной записи (фиг. 4a-d). Это является ключевым свойством настоящего изобретения, т.к. предоставляет существенные преимущества в компьютерных системах, ограниченных требованиями экономии энергии, но для которых необходима когерентность кэш.
На фиг. 5 показан специальный регистр проверки 12, который имеет двоичные разряды, позволяющие программному обеспечению отключать определенные возможности процессора 20. Например, возможность AUTO_HALT может быть отключена путем установки двоичного разряда 6 в регистре 12 в состояние "1". Во время такой установки во время выполнения команды HALT внутренний генератор тактовой частоты (ICLK) не отключается от каких-либо функциональных блоков процессора. В одном из исполнений возможность AUTO_HALT обеспечивается по умолчанию, т. е. 6-й разряд в регистре 12 устанавливается в состояние "0" после выполнения команды RESET (сброс).
Другими свойствами, которые управляются программным обеспечением посредством регистра проверки 12, являeтся управление усовершенствованным программируемым прерыванием (APIC) для многопроцессорных систем. В одном из вариантов выполнения настоящего изобретения процессор обладает усовершенствованным SMI контроллером процессора, который поддерживает прерывание в сложном мультипроцессорном окружении, а также прерываниe в простом однопроцессорном окружении. Модуль контроллера локальных прерываний связан с модулем APIC I/0 (например, модуль N 8259А, выпускаемый Intel Corporation) по 3-проводной последовательной шине. Когда 4-й разряд регистра 12 устанавливается в состояние "1", то свойство APIC полностью отключается. Это означает, что схема APIC не может передавать или получать какие-либо межпроцессорные прерывания. Записываемая или считываемая информация в регистр APIC передается через внешнюю шину. Аппаратное обеспечение разрешения конфликтов дуального процессора тоже может быть отключено в случае установки 5-го разряда регистра 12. Когда этот разряд устанавливается в состояние "1", то отключаются свойства собственного дуального процессора (например, PHIT#, PHITM#, PBREQ#, а также PBGRNT# выводы) как только процессор становится новым ведущим шины (MRM). Если этот разряд впоследствии устанавливается в состояние "0", то повторно включаются свойства DP. Другими свойствами, которые могут быть включены/выключены посредством регистра 12, являются сообщения входа/выхода в SMM (разряд 7), а также сообщения об отслеживании быстрого исполнения (разряд 8).
Изобретение относится к компьютерным системам на микропроцессорной основе, в частности к многопроцессорным компьютерным системам с возможностью регулирования энергопотребления. Техническим результатом является возможность контроля трафика шины каждым процессором для поддержания когерентности кэш при работе в режиме уменьшенного энергопотребления. Каждая из систем содержит два процессора, шину, схему фазовой автоматической подстройки частоты, кэш, теговый массив. Вторая система отличается наличием в ней механизма разрешения конфликтов, блока управления прерываниями и регистра. 2 с. и 6 з.п. ф-лы, 5 ил.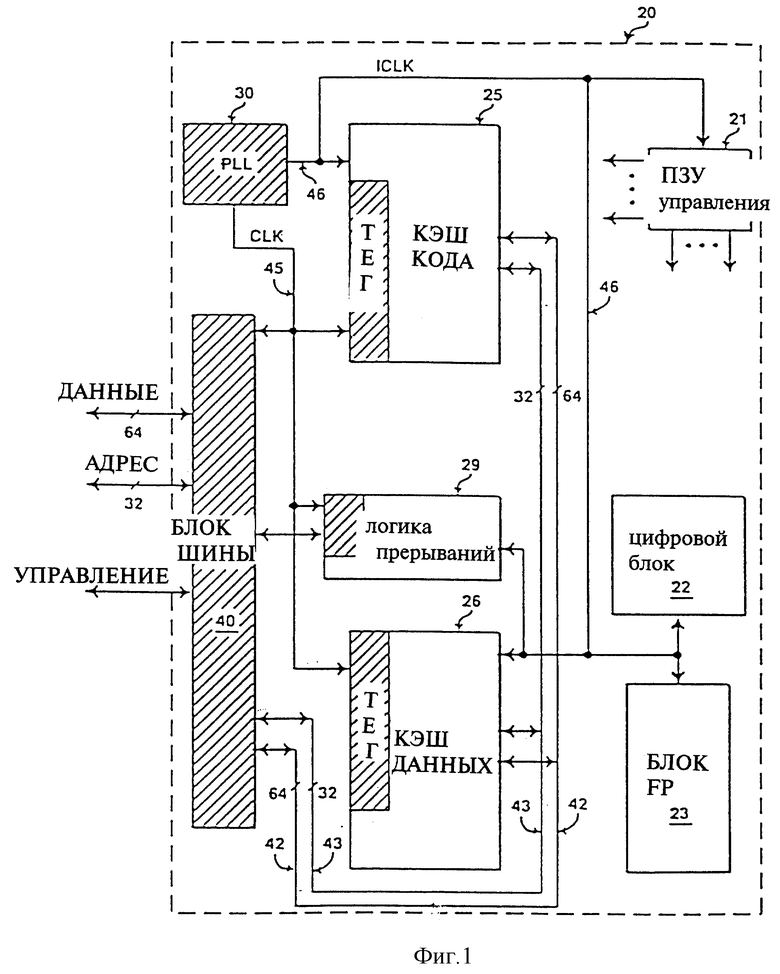
| US 5303362 A, 12.04.1994 | |||
| СХЕМНОЕ УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДВУХ ИЛИ БОЛЕЕ КОМАНД В ЦИФРОВОМ КОМПЬЮТЕРЕ | 1991 |
|
RU2111531C1 |
| US 5119485 A, 20.06.1992 | |||
| US 5228136 A, 13.07.1993 | |||
| US 5297269 A, 22.08.1994 | |||
| US 5167024 A, 24.11.1992 | |||
| US 5287525 A, 15.02.1994. | |||
