Область техники, к которой относится изобретение
Описанный предмет изобретения относится к обработке данных. Более конкретно, это описание относится к новому и усовершенствованному способу и системе вычисления указателя для масштабируемого, программируемого кольцевого буфера.
Уровень техники
Все в большей степени приложения электронной аппаратуры и поддерживающего программного обеспечения включают в себя обработку сигналов. Домашний кинотеатр, компьютерная графика, обработка изображений в медицине и телекоммуникации, все зависят от технологии обработки сигналов. Обработка сигналов требует быстрых математически сложных, но повторяемых алгоритмов. Многие приложения требуют вычисления в реальном времени, т.е. сигнал является непрерывной функцией времени, которая должна быть квантована и преобразована в цифровую функцию для численной обработки. Таким образом, процессор должен выполнять алгоритмы, выполняющие дискретные вычисления относительно выборок, когда они поступают. Архитектура процессора цифровых сигналов (digital signal processor, сокращенно DSP) оптимизирована, чтобы обрабатывать такие алгоритмы. Характеристики хорошего механизма обработки сигналов обычно могут включать в себя устройства быстрых, гибких арифметических вычислений, неограниченный поток данных в устройства вычислений и из устройств вычислений, увеличенную точность и динамический диапазон в устройствах вычислений, двойные генераторы адресов, эффективное последовательное прохождение программ и простоту программирования.
Одно перспективное приложение технологии DSP включает в себя системы связи, такие как система множественного доступа с кодовым разделением (code division multiple access, сокращенно CDMA), которая поддерживает передачу речи и данных между пользователями через спутниковую или наземную линию связи. Использование способов CDMA в системе связи множественного доступа раскрыто в патенте США №4901307, озаглавленном «Система связи множественного доступа расширенного спектра, использующая спутниковые или наземные ретрансляторы», и в патенте США №5103459, озаглавленном «Система и способ, предназначенные для генерирования форм сигналов в системе сотовых телефонов CDMA», права на оба из которых переданы владельцу заявленного предмета изобретения.
Система CDMA обычно спроектирована с возможностью соответствия одному или более стандартам телекоммуникаций и современного потокового видео. Одним из таких стандартов первого поколения является «Стандарт совместимости терминал-базовая станция TIA/EIA/IS-95 для двухрежимной широкополосной сотовой системы расширенного спектра», далее упоминаемый как стандарт IS-95. Системы CDMA IS-95 могут передавать речевые данные и пакетные данные. Стандарт следующего поколения, который может более эффективно передавать пакетные данные, предложен консорциумом, названным «Проектом партнерства 3-го поколения» (3rd generation partnership project, сокращенно 3GPP), и осуществлен во множестве документов, включая документы под номерами 3G TS 25.211, 3G TS 25.212, 3G TS 25.213 и 3G TS 25.214, которые без труда доступны для общественности. Стандарт 3GPP далее упомянут как стандарт W-CDMA. Также имеются стандарты сжатия видео, такие как MPEG-1, MPEG-2, MPEG-4, H.263 и WMV (Windows Media Video), а также многие другие, которые такие беспроводные телефоны будут использовать все в большей степени.
Во многих приложениях широко используют буферы. Обычным типом является кольцевой буфер, в котором выполняют циклический возврат от конца к началу таким образом, что наименьший пронумерованный элемент концептуально или логически расположен смежным образом к его наибольшему пронумерованному элементу, несмотря на то, что физически они разделены длиной или диапазоном буфера. Кольцевой буфер обеспечивает прямой доступ к буферу таким образом, чтобы дать возможность вызывающей программе составлять выходные данные на месте или выполнять синтаксический анализ входных данных на месте без дополнительного этапа копирования данных в вызывающую программу или из вызывающей программы. Для того чтобы облегчить этот прямой доступ, кольцевой буфер гарантирует, что все ссылки в местоположения буфера либо для вывода, либо для ввода относятся к одному непрерывному блоку памяти. Это исключает проблему, заключающуюся в том, что вызывающая программа, должна иметь дело с разделенными областями буфера, когда зацикливание данных достигает конечного местоположения кольцевого буфера. В результате вызывающая программа может использовать широкое множество имеющихся приложений без необходимости учитывать, что приложения работают непосредственно в кольцевом буфере.
Один тип кольцевого буфера требует, чтобы буфер был одновременно выровнен как степень 2, а также имел длину, которая является степенью 2. В таком кольцевом буфере, вычисление указателя просто включает в себя этап маскировки. Несмотря на то, что это может обеспечить простое вычисление, требование, чтобы длина буфера была равна степени 2, делает такой кольцевой буфер неиспользуемым определенными алгоритмами или приложениями.
При использовании кольцевого буфера длина буфера включает в себя начальное местоположение и конечное местоположение. Для многих приложений было бы желательно, чтобы начальное местоположение и конечное местоположение были определяемыми и программируемыми. С программируемым начальным местоположением и конечным местоположением для кольцевого буфера более широкое множество алгоритмов и процессов могло бы быть использовано в кольцевом буфере. Кроме того, когда различные алгоритмы и процессы изменяются, работа кольцевого буфера могла бы также изменяться таким образом, чтобы обеспечивать увеличенную операционную эффективность и полезность.
При адресации определенного местоположения в кольцевом буфере указатель, который адресует к определенному местоположению буфера, будет перемещаться либо вверх, либо вниз в местоположение буфера. К сожалению, этот процесс является далеко неэффективным. Часто процесс является затруднительным в том, что он требует три операции сложения/вычитания. Первая операция требуется, чтобы генерировать новый указатель буфера с помощью прибавления шага по индексу к текущему указателю буфера. Вторая операция требуется, чтобы определять, достиг ли новый указатель буфера переполнения или отрицательного переполнения диапазона адреса буфера. Затем требуется третья операция, чтобы регулировать новый указатель в случае переполнения или отрицательного переполнения. Эти 3 операции требуют либо 3 отдельных сумматора в точной конвейерной операции, либо, в качестве альтернативы, требуют, чтобы кольцевая адресация стала не конвейерной операцией с множеством циклов. Если было бы возможно уменьшить число этих операций, тогда существенные улучшения DSP могли бы происходить в результате экономии либо области и/или мощности меньшего количества сумматоров, либо улучшения производительности, так как эти операции происходят множество раз во время DSP и других приложений.
Таким образом, существует потребность в способе вычисления указателя, используемого в классе масштабируемых и программируемых кольцевых буферов, причем класс кольцевых буферов поддерживает программируемую длину буфера.
Кроме того, существует потребность в способе вычисления указателя для класса масштабируемых и программируемых кольцевых буферов, который требует как можно меньшего количества сложений, чтобы обнаруживать состояния циклического возврата, и который позволяет регулировать величину указателя в случае, когда временный указатель превышает границы кольцевого буфера.
Раскрытие изобретения
Раскрыты методики, предназначенные для создания и использования способа и системы вычисления указателя для масштабируемого программируемого кольцевого буфера, причем эти методики улучшают как работу процессора цифровых сигналов, так и эффективное использование команд процессора цифровых сигналов для обработки все в большей степени надежных приложений программного обеспечения для персональных компьютеров, персональных цифровых ассистентов, беспроводных телефонов и подобных электронных устройств, а также увеличения скорости и качества обслуживания связанного цифрового процессора.
В соответствии с одним аспектом раскрытого предмета изобретения предоставлены способ и система, предназначенные для определения местоположения указателя кольцевого буфера. Местоположение указателя в кольцевом буфере определяют с помощью установления длины кольцевого буфера, начального адреса, который выровнен по степени 2, и конечного адреса, расположенного удаленным от начального адреса на эту длину и меньше, чем степень 2, большая, чем эта длина.
Способ и система определяют местоположение текущего указателя для адреса в кольцевом буфере, величину шага по индексу бит между начальным адресом и конечным адресом, местоположение нового указателя в кольцевом буфере, которое сдвинуто от местоположения текущего указателя на число бит величины шага по индексу. Местоположение отрегулированного указателя находится в кольцевом буфере с помощью арифметической операции местоположения нового указателя с длиной. В случае положительного шага по индексу местоположение отрегулированного указателя определяют в случае, когда местоположение нового указателя меньше, чем конечный адрес, с помощью регулирования таким образом, что местоположение отрегулированного указателя является местоположением нового указателя. В качестве альтернативы, в случае, когда местоположение нового указателя больше, чем конечный адрес, регулируют отрегулированный указатель с помощью вычитания длины из местоположения нового указателя. Местоположение отрегулированного указателя устанавливают в случае отрицательного шага по индексу в случае, когда местоположение нового указателя больше, чем упомянутый начальный адрес, с помощью регулирования таким образом, что местоположение отрегулированного указателя является местоположением нового указателя. В качестве альтернативы, в случае, когда местоположение нового указателя меньше, чем упомянутый конечный адрес, регулируют отрегулированный указатель с помощью прибавления длины к местоположению нового указателя.
Эти и другие аспекты раскрытого предмета изобретения, а также дополнительные новые особенности будут понятны из описания, предоставленного в настоящей заявке. Целью этого раздела «Раскрытие изобретения» является не исчерпывающее описание заявленного предмета изобретения, а, наоборот, предоставление краткого обзора некоторых функциональных возможностей предмета изобретения. Другие системы, способы, признаки и преимущества, приведенные в настоящем описании, станут понятными специалисту в данной области техники после изучения чертежей и осуществления описания. Предполагается, что все такие дополнительные системы, способы, признаки и преимущества, которые включены в это описание, находятся в рамках сопровождающей формулы изобретения.
Краткое описание чертежей
Признаки, сущность и преимущества раскрытого предмета изобретения станут более понятными из раздела «Осуществление изобретения», приведенного ниже, взятого совместно с чертежами, на которых одинаковые ссылочные символы соответственно указаны по всем чертежам, и на которых:
фиг.1 является упрощенной блок-схемой системы связи, предназначенной для выполнения настоящего варианта осуществления;
фиг.2 иллюстрирует архитектуру DSP, предназначенную для выполнения методик настоящего варианта осуществления;
фиг.3 представляет схему верхнего уровня устройства управления, устройства данных и других функциональных устройств процессора цифровых сигналов в конвейере, использующем раскрытый вариант осуществления;
фиг.4 представляет типичный блок устройства данных, разделенный для раскрытого предмета изобретения, включающий в себя устройство генерирования адреса, предназначенное для осуществления заявленного предмета изобретения;
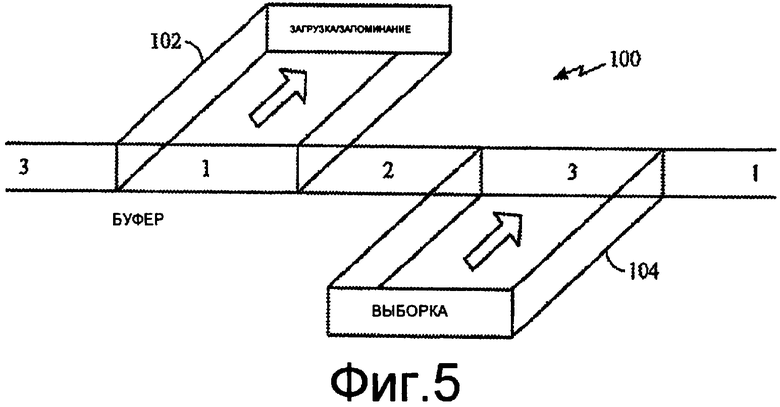
фиг.5 изображает концептуально работу кольцевого буфера, предназначенного для использования с методиками раскрытого предмета изобретения;
фиг.6 предоставляет таблицу, представляющую режимы адресации, выборы сдвигов и эффективные опции выбора адреса, предназначенные для осуществления раскрытого предмета изобретения;
фиг.7 изображает блок-схему способа и системы вычисления адреса для масштабируемого программируемого кольцевого буфера в соответствии с раскрытым предметом изобретения; и
фиг.8 предоставляет вариант осуществления раскрытого предмета изобретения, который может работать в конвейере выполнения связанного DSP.
Осуществление изобретения
Раскрытый предмет изобретения, предназначенный для новых и усовершенствованных способа и системы, предназначенных для масштабируемого программируемого кольцевого буфера, предназначенного для многопоточного процессора цифровых сигналов, имеет приложение в очень широком множестве приложений обработки цифровых сигналов, включающих в себя многопоточную обработку. Одно такое приложение появляется в телекоммуникациях и, в частности, в беспроводных телефонах, которые используют одну или более схем обработки цифровых сигналов. Вследствие этого, фиг.1 является упрощенной блок-схемой системы 10 связи, которая может осуществлять предоставленные варианты осуществления. В устройстве 12 передатчика данные посылают, обычно в множествах, из источника 14 данных в процессор 16 данных передатчика (ТХ), который форматирует, кодирует и обрабатывает данные, чтобы сгенерировать один или более аналоговых сигналов. Затем аналоговые сигналы подают в передатчик 18 (transmitter, сокращенно TMTR), который модулирует, фильтрует, усиливает и преобразует с повышением частоты сигналы основной полосы частот, чтобы сгенерировать модулированный сигнал. Затем модулированный сигнал передают через антенну 20 в одно или более устройств приемника.
В устройстве 22 приемника переданный сигнал принимают с помощью антенны 24 и подают в приемник 26 (receiver, сокращенно RCVR). В приемнике 26 принятый сигнал усиливают, фильтруют, преобразуют с понижением частоты, демодулируют и преобразуют в цифровой вид, чтобы сгенерировать синфазные выборки (I) и (Q). Затем выборки декодируют и обрабатывают с помощью процессора 28 данных приема (RX), чтобы восстановить переданные данные. Декодирование и обработку в устройстве 22 приемника выполняют способом, противоположным кодированию и обработке, выполненным в устройстве 12 передатчика. Затем восстановленные данные подают в приемник 30 данных.
Обработка сигнала, описанная выше, поддерживает передачу речи, видео, пакетных данных, обмен сообщениями и другие типы связи в одном направлении. Система двунаправленной связи поддерживает двухстороннюю передачу данных. Однако обработка сигнала для другого направления не изображена на фиг.1 для простоты. Система 10 связи может быть системой множественного доступа с кодовым разделением (CDMA), системой связи множественного доступа с разделением времени (time division multiple access, сокращенно TDMA) (например, системой GSM), системой связи множественного доступа с частотным разделением (frequency division multiple access, сокращенно FDMA) или другой системой связи множественного доступа, которая поддерживает передачу речи и данных между пользователями через наземную линию связи. В специфичном варианте осуществления система 10 связи является системой CDMA, которая соответствует стандарту W-CDMA.
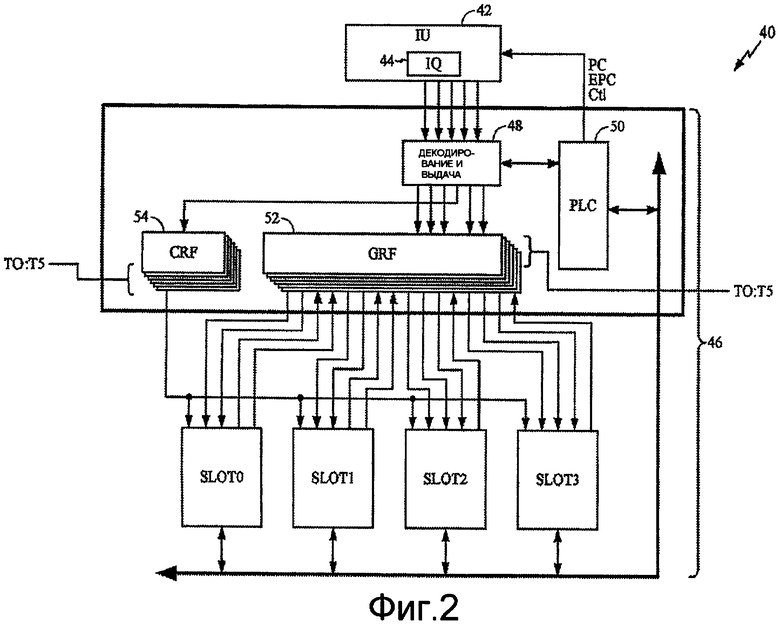
Фиг.2 иллюстрирует архитектуру DSP 40, который может служить в качестве процессора 16 данных передачи и процессора 28 данных приема фиг.1. Понятно, что DSP 40 представляет только один вариант осуществления из очень большого числа возможных вариантов осуществления процессора цифровых сигналов, которые могут эффективно использовать методики и концепции, представленные в настоящем описании. Вследствие этого, в DSP 40 потоки с Т0 по Т5 («Т0:Т5») содержат множества команд из разных потоков. Командное устройство 42 (IU) выбирает команды для потоков Т0:Т5. IU 42 ставит команды с I0 по I3 («I0:I3») в очередь 44 команд (IQ). IQ 44 выдает команды I0:I3 в конвейер 46 процессора. Конвейер 46 процессора включает в себя схемы управления, а также маршрут данных. Из IQ 44 один поток, например поток Т0, может быть выбран с помощью схемы 48 декодирования и выдачи. Логическое устройство 50 управления (PLC) конвейером обеспечивает логическое управление для схем 48 декодирования и выдачи и IU 42.
IQ 44 в IU 42 поддерживает скользящий буфер потока команд. Каждый из шести потоков Т0:Т5, которые поддерживает DSP 40, имеет восьмиэлементную IQ 44, в которой каждый элемент может запоминать один пакет VLIW или до четырех отдельных команд. Логика схем 48 декодирования и выдачи совместно используется всеми потоками для декодирования и выдачи пакета VLIW или до двух суперскалярных команд одновременно, а также для генерирования управляющих каналов и операндов для каждого конвейера SLOT0:SLOT3. Кроме того, схемы 48 декодирования и выдачи выполняют назначение интервала времени и проверку зависимости между двумя самыми старшими действующими командами в элементе IQ 44 для выдачи команды, например, с использованием способов выдачи суперскалярных команд. Логика 50 PLC совместно используется всеми потоками для разрешения исключительных ситуаций и обнаружения состояний срыва конвейера, таких как включение/выключение потока, состояний ответа, поддерживает прохождение программ и т.д.
Во время работы считывают файл 52 главного регистра (GRF) и файл 54 регистра управления (CRF) выбранного потока и считанные данные посылают в маршруты данных выполнения для SLOT0:SLOT3. В этом примере SLOT0:SLOT3 предусматривают комбинацию группировки пакета, используемую в настоящем варианте осуществления. Выходной сигнал из SLOT0:SLOT3 возвращает результаты из операций DSP 40.
Вследствие этого, настоящий вариант осуществления может использовать гибрид неоднородной мультипроцессорной системы (HEP), использующей один микропроцессор до шести потоков Т0:Т5. Конвейер 46 процессора имеет шесть каскадов конвейера, соответствующих минимальному числу циклов процессора, необходимых, чтобы выбирать элементы данных из IU 42. DSP 40 одновременно выполняет команды разных потоков Т0:Т5 в конвейере 46 процессора. То есть DSP 40 обеспечивает шесть независимых программных счетчиков, внутренний механизм тегирования, чтобы различать команды потоков Т0:Т5 в конвейере 46 процессора, и механизм, который инициирует переключение потока. Непроизводительные потери переключения потока изменяются от нуля только до нескольких циклов.
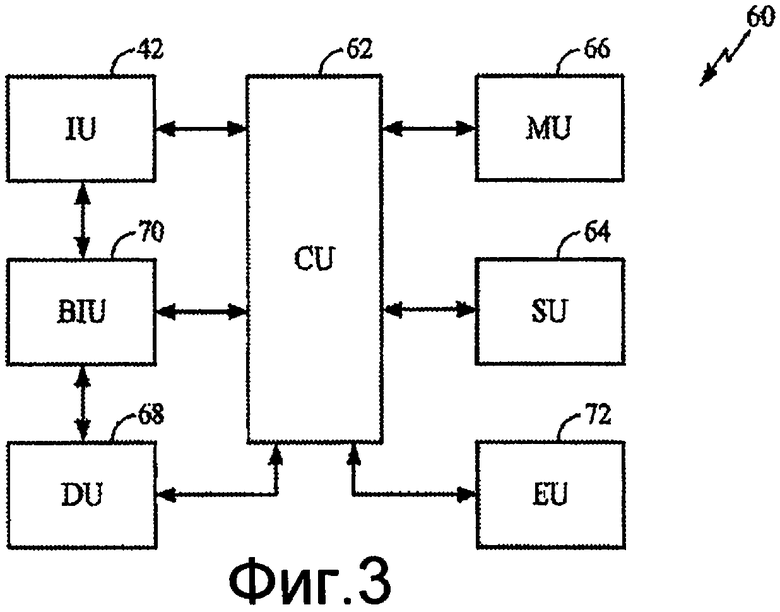
Фиг.3 предоставляет краткий обзор микроархитектуры DSP 40 для одного проявления раскрытого предмета изобретения. Осуществления микроархитектуры DSP 40 поддерживают многопоточную обработку с перемежением (IMT). Предмет изобретения, раскрытый в настоящем описании, имеет дело с моделью выполнения одного потока. Модель программного обеспечения IMT может быть представлена как мультипроцессор с совместно используемой памятью. Один поток видит полный однопроцессорный DSP 40 со всеми доступными регистрами и командами. Посредством функций когерентной совместно используемой памяти этот поток может взаимодействовать и синхронизироваться с другими потоками. Выполняются ли эти другие потоки в том же самом процессоре или в другом процессоре, является в значительной степени прозрачным для программного обеспечения уровня пользователя.
Возвращаясь к фиг.3, настоящая микроархитектура 60 для DSP 40 включает в себя устройство 62 управления (CU), которое выполняет многие из функций управления для конвейера 46 процессора. CU 62 планирует потоки и запрашивает смешанные 16-ти битовые и 32-х битовые команды из IU 42. Кроме того, CU 62 планирует и выдает команды в три устройства выполнения; устройство 64 сдвигового типа (SU), устройство 66 типа умножения (MU) и устройство 68 загрузки/запоминания (DU). CU 62 также выполняет проверку зависимости суперскалярных команд. Устройство 70 интерфейса шины (BIU) согласует IU 42 и DU 68 с системной шиной (на фигурах не показано).
Конвейеры SLOT0 и SLOT1 находятся в DU 68, SLOT2 находится в MU 66, а SLOT3 находится в SU 64. CU 62 подает операнды источника и управляющие каналы в конвейеры SLOT0:SLOT3 и обрабатывает обновления файлов GRF 52 и CRF 54. GRF 52 содержит тридцать два 32-х битовых регистра, доступ к которым может быть осуществлен как к одному регистру, или как к выровненным 64-х битовым парам. Микроархитектура 60 изображает гибридную модель выполнения, которая смешивает преимущества выполнения суперскалярных команд и VLIW. Выдача суперскалярных команд имеет преимущество в том, что не требуется никакая информация о программном обеспечении, чтобы найти независимые команды. Каскад декодирования DE выполняет начальное декодирование команд таким образом, чтобы подготовить такие команды для выполнения и дополнительной обработки в DSP 40. Каскад конвейера файла регистра RF предусматривает обновление регистрового файла. Два каскада конвейера выполнения EX1 и EX2 поддерживают выполнение команды, в то время как третий каскад конвейера выполнения EX3 обеспечивает как выполнение команды, так и обновление файла регистра. Во время выполнения (EX1, EX2 и EX3) и каскадов конвейера обратной записи (WB) IU 42 создает следующий выполняемый элемент IQ 44. Наконец, каскад конвейера обратной записи WB выполняет обновление регистра. Операция записи в шахматном порядке в файл регистра является возможной благодаря микроархитектуре IMT каскадов конвейера обратной записи (WB) и экономит число портов записи на поток. Так как конвейеры имеют шесть каскадов, CU 62 может выдавать до шести разных потоков.
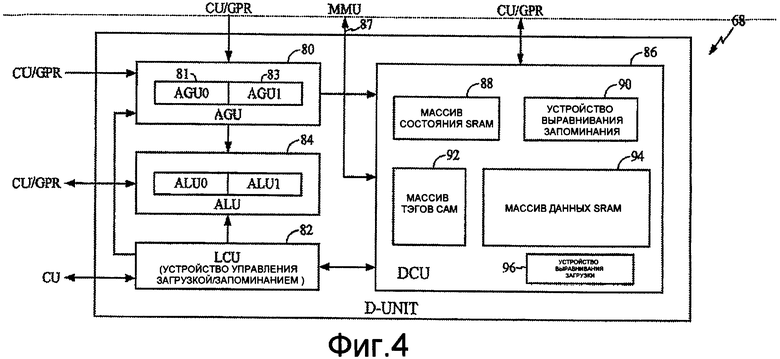
Фиг.4 представляет типичное устройство данных DU 68, разделенное на блоки, в котором можно применить раскрытый предмет изобретения. DU 68 включает в себя устройство 80 генерирования адреса AGU, которое дополнительно включает в себя AGU0 81 и AGU1 83, предназначенные для приема входного сигнала из CU 62. Предмет изобретения, раскрытый в настоящем описании, имеет принципиальное приложение с работой AGU 80. Устройство 82 управления загрузкой/запоминанием LCU также взаимодействует с CU 62 и подает управляющие сигналы в AGU 80 и ALU 84, а также взаимодействует с устройством 86 кэширования данных DCU. ALU 84 также принимает входной сигнал из AGU 80 и CU 62. Выходной сигнал из AGU 80 проходит в CU 62. DCU 86 взаимодействует с устройством 87 управления памятью («MMU») и CU 62. DCU 86 включает в себя схему 88 массива состояния SRAM, схему 90 устройства выравнивания памяти, массив 92 тэгов САМ, массив 94 данных SRAM и схему 96 устройства выравнивания нагрузки.
Чтобы дополнительно объяснить работу DU 68, в котором может работать заявленный предмет изобретения, теперь делается ссылка на основные функции, выполняемые в нем, в соответствии с несколькими разделами следующего описания. В частности, DU 68 выполняет команды типа загрузки, типа запоминания и 32-х битовые команды из ALU 84. Главные признаки DU 68 включают в себя полностью конвейерную работу во всех каскадах конвейера DSP 40, каскадах конвейера DE, RF, EX1, EX2 и WB с использованием двух параллельных конвейеров SLOT0 и SLOT1. DU 68 может принимать либо выдачу команды VLIW, либо выдачу суперскалярной двойной команды. Предпочтительно SLOT0 выполняет команды некэшируемой или кэшируемой загрузки или запоминания, 32-х битовые команды ALU 84 и команды DCU 86. SLOT1 выполняет команды некэшируемой или кэшируемой загрузки или запоминания, 32-х битовые команды ALU 84.
DU 68 принимает до двух декодированных команд на цикл из CU 62 в каскаде конвейера DE, включающем в себя непосредственные операнды. В каскаде конвейера RF DU 68 принимает исходные операнды регистра общего назначения (GRP) и/или регистра управления (CR) из соответствующих регистров специфичного потока. Операнд GRP принимают из файла регистра GRP в CU 62. В каскаде конвейера EX1 DU 68 генерирует действительный адрес (ЕА) команды загрузки или запоминания в памяти. ЕА предоставляют в MMU 87, которое выполняет преобразование виртуального в физический адрес и проверку полномочий уровня страницы и предоставляет атрибуты уровня страницы. Для доступа к кэшируемым местоположениям DU 68 ищет тэг кэш-памяти данных в каскаде конвейера EX2 с помощью физического адреса. Если доступ удается, DU 68 выполняет доступ к массиву данных в каскаде конвейера EX3.
Для кэшируемых загрузок данные, считанные из кэш-памяти, выравнивают с помощью соответствующего размера доступа, расширяют с помощью нуля/знака, как определено, и подают в CU 62 в каскаде конвейера WB, записываемые в GRP, определенное командой. Для кэшируемых запоминаний запоминаемые данные считывают из специфичного регистра потока в CU 62 в каскаде конвейера EX1 и записывают в массив кэш-памяти данных при удачном обращении в каскаде конвейера EX2. Как для загрузок, так и для запоминаний генерируют автоматически возрастающие адреса в каскадах конвейера EX1 и EX2 и подают в CU 62 в каскаде конвейера EX3, записываемые в GRP, определенное командой.
DU 68 также выполняет команды кэш-памяти для управления DCU 86. Команды дают возможность, чтобы специфичные строки кэш-памяти были заблокированы или разблокированы, недействительны и назначены в определенную строку кэш-памяти GRP. Также имеется команда, чтобы глобально сделать недействительной кэш-память. Эти команды являются конвейерными подобно командам загрузки и запоминания. Для загрузок и запоминаний кэшируемых местоположений, которые осуществляют промах кэш-памяти данных, и для некэшируемых доступов DU 68 предоставляет запросы в BIU 70. Некэшируемые загрузки представляют запрос считывания. Удачи запоминания, промахи и некэшируемые запоминания представляют запрос записи. DU 68 отслеживает ожидающие обработки запросы считывания и заполнения строки в BIU 70. DU 68 выдает не блокирующий внутренний поток, т.е. дает возможность доступа с помощью других потоков, пока один или более потоков блокированы, ожидая завершения ожидающих выполнения запросов загрузки.
AGU 80, к которому относится настоящее раскрытие, выдает два одинаковых экземпляра маршрута данных AGU 80, один для SLOT0 и один для SLOT1. Однако следует заметить, что рассматриваемый предмет изобретения может работать и действительно определенно существует и работает в других блоках DU 68, таких как ALU 84. Для иллюстративных целей в понимании функции и структуры раскрытого предмета изобретения внимание, однако, направлено на AGU 80, которое генерирует как действительный адрес (ЕА), так и адрес с автоматическим приращением (AIA) для каждого интервала времени в соответствии с примерными методиками, предоставленными в настоящем описании.
LCU 82 дает возможность выполнений команд загрузки и запоминания, которые могут включать в себя удачные обращения в кэш-память, промахи кэш-памяти и некэшируемые загрузки, а также запоминания инструкций. В настоящем варианте осуществления конвейер загрузки является идентичным для SLOT0 и SLOT1. Выполнение запоминания посредством LCU 82 обеспечивает команду запоминания, команды записи конвейера посредством удачного обращения в кэш-память, команду удачного обращения в кэш-память с обратной записью, команды промаха кэш-памяти, команды некэшируемой записи. Команды запоминания выполняются только в SLOT0 с настоящим вариантом осуществления. При запоминании со сквозной записью запрос записи предоставляют в BIU 70 независимо от состояния удачи. При запоминании с обратной записью запрос записи предоставляют в BIU 70, если имеется промах, а не если имеется успех. При успехе запоминания с обратной записью обновляют состояние строки кэш-памяти. Промах запоминания представляет запрос записи в BIU 70 и не назначает строку в кэш-памяти.
ALU 84 включает в себя ALU0 85 и ALU1 89, одно для каждого интервала времени. ALU 84 содержит маршрут данных, чтобы выполнять операции арифметические/передачи/сравнения (АТС) в DU 68. Они могут включать в себя команды 32-х битового сложения, вычитания, отрицания, сравнения, переноса регистра и мультиплексирования (MUX) регистра. Кроме того, ALU 84 также заканчивает кольцевую адресацию для вычисления AIA.
Фиг.5 изображает концептуально работу кольцевого буфера, предназначенного для использования с методиками раскрытого предмета изобретения. Когда планируют множество потоков выполнения, чтобы выполнять параллельно в DSP 40, они могут взаимодействовать в известном смысле, что увеличивает «дрожание» в их отдельных временах выполнения циклов. Методики предназначены для осуществления детерминистической передачи данных, когда AGU 80 должно передавать большие объемы данных в LCU 82. Для того чтобы исключить потери данных, LCU 82 должно быть способным поддерживать связь с компонентом сбора данных с помощью выборки данных, как только они готовы.
Ссылаясь на фиг.5, изображен кольцевой буфер, который назначает память буфера в некоторое число секций. Во время работы AGU 80 заполняет секцию, например секцию 102 кольцевого буфера 100, в то время как LCU 82 считывает данные как можно быстрее из другой секции, например секции 104. Кольцевой буфер дает возможность как LCU 82, так и AGU 80 осуществлять доступ к данным в буфере одновременно, так как в любой момент времени они считывают и записывают данные в разных секциях буфера. Вследствие этого, кольцевой буфер 100 продолжает запись в начале секции 102, в то же время выполняя считывание, например, из секции 104. Одна обязанность AGU 80 включает в себя поддержание связи с LCU 82 таким образом, чтобы данные никогда не были записаны друг на друга. Механизм синхронизации дает возможность AGU 80 информировать LCU 82, когда имеются новые данные.
Фиг.6 предоставляет таблицу 106, представляющую режимы адресации, выборы сдвигов и опции выбора действительных адресов для одного осуществления раскрытого предмета изобретения. Вследствие этого, таблица фиг.6 перечисляет декодирования главных команд для команд, выполняемых с помощью DU 68. Большая часть функций декодирования находится в CU 62, а декодированные сигналы передают в DU 68 как часть доставки декодированной команды. Таким образом, режим непрямой адресации без автоматического приращения и режим адресации относительно указателя стека используют выбор MUX сдвиг Imm и выбор MUX EA Add. Режим непрямой адресации и режим кольцевой адресации с мгновенным автоматическим приращением используют выбор MUX сдвиг Imm и выбор RF MUX EA. Режим непрямой адресации с регистром автоматического приращения и режим кольцевой адресации с регистром автоматического приращения используют выбор MUX сдвиг М и выбор MUX RF EA. Наконец, режим адресации с инвертированием бит с регистром автоматического приращения использует выбор MUX сдвиг М и BRev или с инвертированием бит, выбор MUX EA. После выполнения различных функций декодирования, описанных в настоящей заявке, настоящий способ и система могут выполнять следующие операции вычисления местоположения указателя, как описано в настоящей заявке.
Фиг.7 изображает вариант осуществления настоящего раскрытия, который, во-первых, включает в себя установление определений для алгоритмического процесса. В рамках таких определений пусть М представляет целое и относится к М битовому сумматору; пусть N является целым, большим, чем 0, и меньшим, чем М, т.е. 0<N<M. Заявитель допускает, что N является масштабируемым и программируемым в пределах 0<N<M. Кроме того, М устанавливают как ссылку в М битовый сумматор. Кольцевой буфер 100 может быть сформирован как базовый указатель, выровненный в 2N, и может иметь программируемую длину L, причем L<2N.
С этими определениями теперь делают ссылку на фиг.7, которая представляет иллюстративную принципиальную блок-схему 110, предназначенную для выполнения настоящего способа и системы вычисления указателя для масштабируемого программируемого кольцевого буфера. Блок-схема 110 включает в себя входные сигналы текущего указателя R в 112, входной сигнал генератора базовой маски в 114, входной сигнал шага по индексу в 116 и направление шага по индексу (либо 0 для положительного направления, либо 1 для отрицательного направления) в 118. Входной сигнал текущего указателя R поступает в вентили 120 и 122 И. Входной сигнал 114 генератора базовой маски поступает в вентиль 122 И и инвертор 124, который подает маску сдвига в вентиль 120 И. На основании величины N генератор 114 базовой маски генерирует маску для бит N-1:0. То есть все биты BM-1:BN могут быть установлены в ноль, в то время как все биты BN-1:B0 могут быть установлены в 1. Выход из вентиля 122 И выдает сдвиг указателя в М битовый сумматор 126.
Входной сигнал 116 шага по индексу поступает в MUX 128 и инвертор 130, который подает инвертированный входной сигнал в MUX 128. Входной сигнал 118 направления шага по индексу также поступает в MUX 128, М битовый сумматор 126, MUX 132 и инвертор 134. Вентиль 122 И выводит сдвиг указателя как побитовую операцию И входного сигнала 112 текущего указателя и базовой маски из генератора 114 базовой маски. Вентиль 120 И выводит базу 136 указателя из логической операции И текущего указателя 112 и маски сдвига из инвертора 124, причем сдвиг маски является инвертированным выходным сигналом из генератора 114 базовой маски.
М битовый сумматор 126 генерирует слагаемое 138 для М битового сумматора 140. Слагаемое получается из суммирования сдвига указателя из вентиля 122 И, мультиплексированного выходного сигнала из MUX 128 и входного сигнала направления 118 шага по индексу. М битовый сумматор 140 выводит суммирование 142 из слагаемого 138, мультиплексированного выходного сигнала из MUX 132 и инвертора 134. Результат суммирования 142 равен слагаемому 138 плюс/минус длина 144 кольцевого буфера. Длина 144 кольцевого буфера выводится из MUX 132 в ответ на входные сигналы из инвертора 146 и входного сигнала 148 длины. Результат суммирования 142, слагаемое 138 и наибольший значащий бит М 183 из М битового сумматора 140 подают в MUX 150, чтобы выдать сдвиг 152 нового указателя. Наконец, вентиль 154 ИЛИ выполняет логическую операцию ИЛИ с использованием мультиплексированного выходного сигнала из MUX 150 и базы 136 указателя, чтобы выдать требуемый новый указатель 156.
Понятные преимущества раскрытого процесса относительно известных способов включают в себя требование только двух сложений, т.е. операций М битовых сумматоров 126 и 140. Также раскрытые процесс и система позволяют изменять N и M, чтобы получать семейство кольцевых буферов. По существу, раскрытый вариант осуществления предусматривает оптимизацию проектирования посредством рассмотрения мощности, скорости и области проектирования. Кроме того, настоящий процесс и система поддерживают сдвиг со знаком и программируемые длины кольцевого буфера. Еще одно преимущество настоящего варианта осуществления включает в себя требование только базовых М битовых сумматоров без необходимых промежуточных элементов переноса бит. Кроме того, раскрытый вариант осуществления может использовать один и тот же маршрут данных как для положительных, так и для отрицательных шагов по индексу.
Чтобы проиллюстрировать преимущественные результаты настоящего способа, предоставлены следующие примеры. Итак, пусть N равно 5, L равно 30 (т.е. В011110), где М равно N+1=6. Текущий указатель Р, текущий шаг по индексу S и знак шага по индексу D, все являются переменными в следующем примере. Результат примеров раскрытого процесса предоставляет различные местоположения нового указателя в кольцевом буфере 100.
В первом примере пусть Р=62 (В111110), S=1 (В000001), а D= положительный (В0) (что является случаем переполнения). В таком случае маска из генератора 114 базовой маски равна 011111, сдвиг указателя из вентиля 122 И равен 011110, а база 136 указателя из вентиля 120 И равна 100000. Слагаемое 138 из М битового сумматора 126 равно 011110+000001=011111. Результат суммирования 142 становится 011111+100001+000001=000001. Сдвиг нового указателя определяют на основании бит 6, являющегося 0 для суммирования 142. Это дает в результате выбор результата суммирования 142, который равен 000001, в качестве сдвига нового указателя. Тогда новый указатель становится 000001+100000=100001.
Во втором примере пусть Р=62 (В111110), S=1 (В000001), а D= отрицательный (В1). В таком случае маска из генератора 114 базовой маски равна 011111, сдвиг указателя из вентиля 122 И равен 011110, а база 136 указателя из вентиля 120 И равна 100000. Слагаемое 138 из М битового сумматора 126 равно 011110+111110+000001=011101. Результат суммирования 142 становится 011101+011110=111011. Сдвиг нового указателя определяют на основании бит 6, являющегося 1 для суммирования 142. Это дает в результате выбор результата суммирования 138, который равен 011101, в качестве сдвига нового указателя. Тогда новый указатель становится 011101+100000=111101.
В третьем примере пусть Р=33 (В100001), S=1 (В000001), а D= положительный (В0). В таком случае маска из генератора 114 базовой маски равна 011111, сдвиг указателя из вентиля 122 И равен 000001, а база 136 указателя из вентиля 120 И равна 100000. Слагаемое 138 из М битового сумматора 126 равно 000001+000001+000010=011101. Результат суммирования 142 становится 000010+100001=100100. Сдвиг нового указателя определяют на основании бит 6, являющегося 1 для суммирования 138. Это дает в результате выбор результат суммирования 138, который равен 000010, в качестве сдвига нового указателя. Тогда новый указатель становится 000010+100000=100010.
В четвертом примере пусть Р=33 (В100001), S=1 (В000001), а D= отрицательный (В1), что является случаем отрицательного переполнения. В таком случае маска из генератора 114 базовой маски равна 011111, сдвиг указателя из вентиля 122 И равен 000001, а база 136 указателя из вентиля 120 И равна 100000. Слагаемое 138 из М битового сумматора 126 равно 000001+111110+000001=011101. Результат суммирования 142 становится 000000+011110=011110. Сдвиг нового указателя определяют на основании бит 6, являющегося 1 для суммирования 142. Это дает в результате выбор результата суммирования 142, который равен 011110, в качестве сдвига нового указателя. Тогда новый указатель становится 011101+100000=111110.
Таким образом, раскрытый предмет изобретения предоставляет способ и систему вычисления указателя для масштабируемого программируемого кольцевого буфера 100, причем начальное местоположение кольцевого буфера 100 выравнивается в степень двух в соответствии с размером кольцевого буфера 100. Отдельный регистр содержит длину кольцевого буфера 100. С помощью выравнивания базы кольцевого буфера 100 раскрытый предмет изобретения требует только операцию вычитания, чтобы достичь местоположения указателя. С помощью такого процесса требуются только два суммирования с использованием двух М битовых сумматоров, как описано в настоящей заявке. Настоящий подход допускает изменение N и М, чтобы получать оптимальное семейство кольцевых буферов 100 по некоторому числу разных показателей мощности, скорости и области. Настоящий способ и система поддерживают сдвиг со знаком и программируемые длины. Кроме того, раскрытый предмет изобретения требует только базовые М битовые сумматоры без промежуточных элементов переноса бит, в то же время использование одного и того же маршрута данных как для положительных, так и для отрицательных шагов по индексу.
Настоящий способ и система имеют дело с начальным местоположением S, которое выровнено в степень двух в соответствии с размером памяти, которая может содержать буфер длины L. Длина буфера L может быть запомнена или необязательно запомнена как состояние в DU 68. Процесс требует некоторого количества бит В, которое равно степени два, большей чем L. Выбирают указатель R, который находится между базой и базой + L. Затем процесс использует компьютерную команду и модифицирует первоначальный указатель R либо с помощью прибавления, либо с помощью вычитания постоянной величины, чтобы получить модифицированный указатель R'. Затем начальное местоположение S регулируют с помощью установки наименьших значащих бит (LSB) из В бит в ноль. Затем процесс определяет конечное местоположение Е с помощью взятия логического ИЛИ от S и L. Если модифицированный указатель R' получают с помощью прибавления константы, процесс включает в себя вычитание конечного местоположения Е из модифицированного указателя R', чтобы получить местоположение нового смещения О. Если местоположение смещения О является положительным, тогда конечный результат получают из взятия логического ИЛИ от определенного начального местоположения S и полученного местоположения смещения О. Если модифицированный указатель R' получают с помощью вычитания константы, тогда процесс включает в себя вычитание модифицированного указателя R' из конечного местоположения Е, чтобы получить местоположение нового сдвига О. Если бит, соответствующий величине В+1 модифицированного указателя R', не равен бит, соответствующему величине В+1 первоначального указателя R, тогда конечный результат равен логической операции ИЛИ от нового начального местоположения S и нового сдвига О для установления местоположения нового указателя R'. Иначе, новый сдвиг О определяет местоположение модифицированного указателя R'.
Варианты раскрытого предмета изобретения могут включать в себя кодирование непосредственно конечного адреса Е вместо кодирования длины определенного числа бит L. Это может предусматривать кольцевой буфер произвольного размера, в то же время уменьшая размер и сложность вычисления кольцевого буфера.
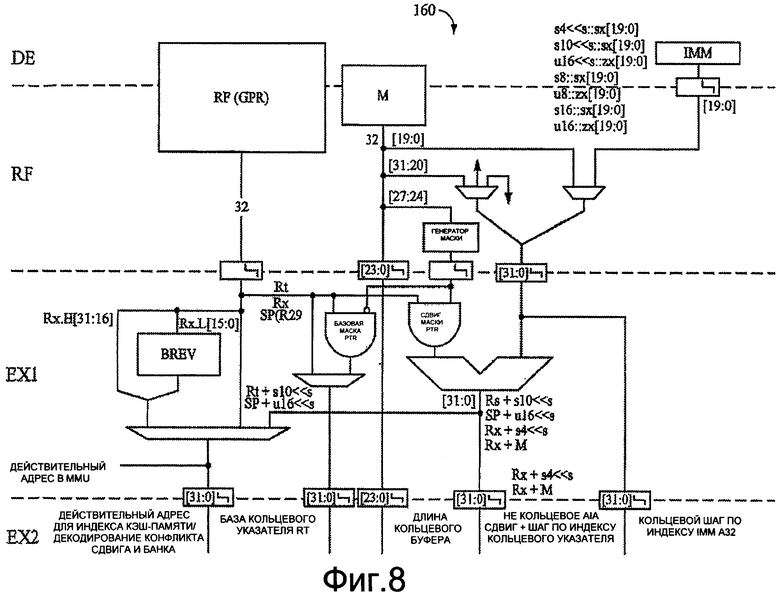
Для иллюстрации еще одного приложения настоящих методик фиг.8 предоставляет альтернативный вариант осуществления раскрытого предмета изобретения, предназначенный для использования в DSP 40 в качестве части AGU 80, которое выдает два одинаковых экземпляра маршрута данных генерирования адреса, один для SLOT0 и один для SLOT1. AGU 80 генерирует как действительный адрес (ЕА), так и адрес с автоматическим приращением (AIA) для каждого интервала времени. Генерирование ЕА основано на режиме адресации и может быть вычислено (а) в режиме регистра, (b) в режиме регистра, дополненного мгновенным сдвигом, и (с) в режиме с инвертированием бит. Маршрут данных, представленный на фиг.8, изображает каждый способ с конечным мультиплексором 3:1 ЕА, описанный следующим образом.
Таким образом, ссылаясь на фиг.8, представлен процесс 160 генерирования адреса. В процессе 160 генерирования адреса предполагают, что мгновенный сдвиг, введенный в AGU 80 из CU 62, расширен с помощью знака/нуля до максимальной длины сдвинутого мгновенного сдвига (19 бит). AGU 80 расширяет с помощью знака/нуля сдвиг до 32 бит.
Вариант осуществления фиг.8 также предоставляет процесс генерирования адреса с автоматическим приращением на основании режима адресации. Процесс генерирования адреса с автоматическим приращением может быть выполнен (а) в режиме регистра, суммируемого с мгновенным сдвигом, (b) в режиме регистра, суммируемого со сдвигом регистра М, и (с) в режиме регистра, суммируемого циклически с мгновенным сдвигом. Процесс 160 генерирования адреса фиг.8 изображает каждый из этих способов.
Следует заметить, что в проиллюстрированном примере не циклическое вычисление адреса с автоматическим приращением выполняют в AGU 80, причем циклическое вычисление адреса с автоматическим приращением также требует ALU 84. Так как обе команды загрузки и запоминания не могут как предварительно получать приращения, чтобы генерировать ЕА, так и получать приращения после, чтобы генерировать AIA, один и тот же сумматор может быть совместно использован как для EA, так и для AIA.
В режиме кольцевой адресации процесс 160 генерирования адреса поддерживает кольцевой буфер 100 с помощью доступа, разделенного с помощью шага по индексу, который может быть либо положительным, либо отрицательным. Текущую величину указателя прибавляют к шагу по индексу. Если результат либо переполняет, либо отрицательно переполняет диапазон адреса кольцевого буфера 100, длину буфера вычитают или прибавляют (соответственно), чтобы иметь указатель, указывающий обратно в местоположение в кольцевом буфере 100.
В DSP 40 начальный адрес кольцевого буфера 100 выравнивают в наименьшую степень 2, большую, чем длина буфера. Если шаг по индексу, который является мгновенным сдвигом, является положительным, тогда суммирование может дать в результате две возможности. Либо сумма находится в пределах длины кольцевого буфера, причем в этом случае она является конечной величиной AIA, либо она больше, чем длина буфера, причем в этом случае длина буфера должна быть вычтена. Если шаг по индексу является отрицательным, тогда суммирование опять может дать в результате два исхода.
Если сумма больше, чем начальный адрес, тогда она является конечной величиной AIA. Если сумма меньше, чем начальный адрес, должна быть прибавлена длина буфера. Маршрут данных в этом случае использует тот факт, что начальный адрес выровнен в 2(К+2), и что требуется, чтобы длина была меньше, чем 2(К+2), где К - мгновенная величина, определенная командой. Величину Rx[31:(К+2)] маскируют в ноль до суммирования. Обратная маска сохраняет биты префикса [31:(К+2)] для дальнейшего использования. Определяют переполнение буфера, когда шаг по индексу (мгновенный сдвиг) является положительным, с помощью прибавления замаскированного Rx к шагу по индексу в сумматоре AGU 80 и вычитания длины из суммы в сумматоре ALU 84. Если результат является положительным, AIA[(K+2)-1:0] поступает из сумматора ALU 84, иначе результат поступает из сумматора AGU 80. AIA[31:(К+2)] равно Rx [31:(К+2)].
Определяют отрицательное переполнение буфера, когда шаг по индексу является положительным, с помощью прибавления замаскированного Rx к шагу по индексу в сумматоре AGU. Если сумма является положительной, тогда AIA[(K+2)-1:0] поступает из сумматора AGU 80. Если сумма является отрицательной, тогда длину прибавляют к сумме в сумматоре ALU 84, и AIA[(K+2)-1:0] поступает из сумматора ALU 84. Опять AIA[31:(К+2)] равно Rx[31:(К+2)].
Следует заметить, что добавляется ли или вычитается длина в ALU 84, определяют с помощью знака сдвига. Результатом опции POR является то, что она добавляет вентиль И, чтобы выполнить маскировку, во входной сигнал Rx сумматора, который находится в критическом маршруте. Альтернативное осуществление происходит следующим образом.
В этом случае Rx прибавляют в шагу по индексу. Сумму сумматора AGU 80 (которая является не критичной к AIA) маскируют таким образом, что только Sum[(K+2)-1:0] предоставляют в качестве выходного сигнала в сумматор ALU 84, в то время как длину ее дополнения к двум предоставляют в качестве другого входного сигнала. Если шаг по индексу является положительным, тогда длину вычитают из замаскированной суммы в сумматоре ALU. Если результат является положительным, тогда AIA[(K+2)-1:0] поступает из сумматора AGU 80, и переполнение не происходит, иначе результат поступает из сумматора ALU (переполнение). AIA[31:(К+2)] всегда равно Rx[31:(К+2)].
Если шаг по индексу является отрицательным, Sum[31:2(К+2)] сумматора AGU сравнивают с Rx[31:(K+2)]. Если биты префикса остаются теми же самыми, это означает, что отрицательное переполнение не произошло.
В этом случает AIA[(K+2)-1:0] поступает из сумматора AGU 80. Если биты префикса отличаются, тогда было отрицательное переполнение. В этом случае длину добавляют в замаскированной сумме в сумматор AGU 80. В этом случае AIA[(K+2):0] поступает из сумматора AGU 80. Опять AIA[31:(К+2)] всегда равно Rx[31:(К+2)]. При этом подходе операцию И маскировки исключают из критического маршрута. Однако добавляют 28-битовый компаратор.
Признаки и функции обработки, описанные в настоящей заявке, могут быть выполнены различными способами. Например, не только DSP 40 может выполнять описанные выше операции, но также настоящие варианты осуществления могут быть выполнены в интегральной схеме прикладной ориентации (ASIC), микроконтроллере, микропроцессоре или других электронных схемах, сконструированных с возможностью выполнения функций, описанных в настоящей заявке. Вследствие этого, предыдущее описание предпочтительных вариантов осуществления предоставлено, чтобы дать возможность любому специалисту в данной области техники создать или использовать заявленный предмет изобретения. Различные модификации в эти варианты осуществления будут без труда понятны специалистам в данной области техники, а базовые принципы, определенные в настоящей заявке, могут быть применены к другим вариантам осуществления без использования новаторской способности. Таким образом, не предполагается, что заявленный предмет изобретения ограничен вариантами осуществления, изображенными в настоящей заявке, а должен соответствовать самым широким рамкам, согласующимся с принципами и новыми признаками, раскрытыми в настоящей заявке.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АДРЕСАЦИИ КОЛЬЦЕВОГО БУФЕРА В ПАМЯТИ МИКРОПРОЦЕССОРА | 2015 |
|
RU2598323C1 |
| СИСТЕМЫ И СПОСОБЫ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОГО ПЕРЕМЕЩЕНИЯ СТЕКА | 2014 |
|
RU2629442C2 |
| КОМАНДА И ЛОГИЧЕСКАЯ СХЕМА ДЛЯ СОРТИРОВКИ И ВЫГРУЗКИ КОМАНД СОХРАНЕНИЯ | 2014 |
|
RU2663362C1 |
| УПРАВЛЕНИЕ СКОРОСТЬЮ, С КОТОРОЙ ОБРАБАТЫВАЮТСЯ ЗАПРОСЫ НА ПРЕРЫВАНИЕ, ФОРМИРУЕМЫЕ АДАПТЕРАМИ | 2010 |
|
RU2526287C2 |
| НЕЧУВСТВИТЕЛЬНЫЙ К ЗАДЕРЖКЕ БУФЕР ТРАНЗАКЦИИ ДЛЯ СВЯЗИ С КВИТИРОВАНИЕМ | 2014 |
|
RU2598594C2 |
| МОДУЛЬ СОПРОЦЕССОРА КЭША | 2011 |
|
RU2586589C2 |
| Связанное с выбранными архитектурными функциями администрирование обработки | 2015 |
|
RU2665243C2 |
| ОПРЕДЕЛЕНИЕ ФОРМАТОВ ТРАНСЛЯЦИИ ДЛЯ ФУНКЦИЙ АДАПТЕРА ВО ВРЕМЯ ВЫПОЛНЕНИЯ | 2010 |
|
RU2556418C2 |
| ОПЕРАЦИОННОЕ УСТРОЙСТВО ДЛЯ ПРОЦЕССОРА С АССОЦИАТИВНОЙ МАТРИЦЕЙ ОДНОРОДНОЙ СТРУКТУРЫ | 1984 |
|
RU2087031C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ИЗВЛЕЧЕНИЯ ДАННЫХ ИЗ БУФЕРА И ЗАГРУЗКИ ИХ В БУФЕР | 2002 |
|
RU2265879C2 |

Изобретения относятся к обработке цифровых сигналов для множества приложений, включая систему связи (например, CDMA). Техническим результатом является повышение скорости обработки цифровых сигналов. Способ определения местоположения указателя в кольцевом буфере включает шаги: устанавливают длину, начальный и конечный адрес кольцевого буфера; определяют местоположение текущего указателя для адреса в кольцевом буфере, формируют базовую маску, определяют маску смещения, определяют базу указателя, определяют смещение указателя, определяют величину шага по индексу бит между начальным и конечным адресом, получают новое смещение указателя, определяют местоположение нового указателя в кольцевом буфере на основании базы указателя и нового смещения указателя. 4 н. и 17 з.п. ф-лы, 8 ил.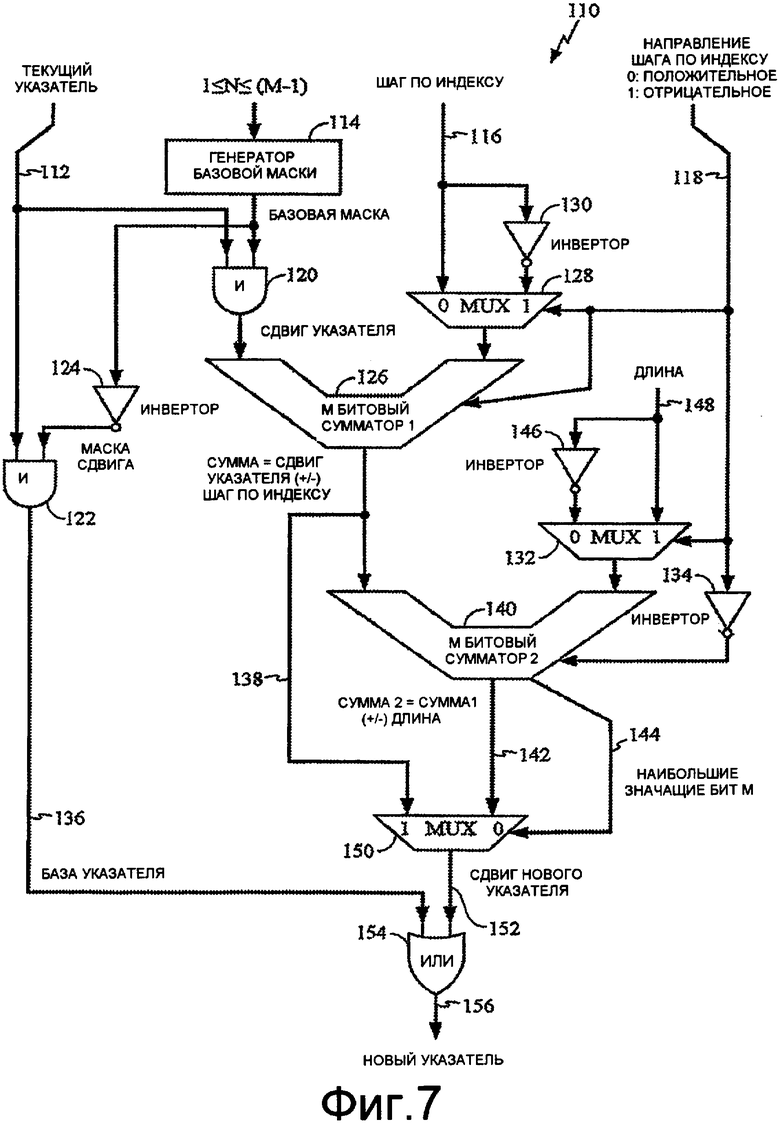
1. Способ адресации кольцевого буфера, содержащий этапы, на которых:
устанавливают длину упомянутого кольцевого буфера, причем упомянутая длина предназначена для ограничения адресуемого диапазона упомянутого кольцевого буфера;
устанавливают начальный адрес для упомянутого кольцевого буфера;
устанавливают конечный адрес для упомянутого кольцевого буфера;
определяют местоположение текущего указателя для адреса в упомянутом кольцевом буфере, причем местоположение упомянутого текущего указателя находится между упомянутым начальным адресом и упомянутым конечным адресом;
формируют базовую маску на основании значений начального и конечного адресов;
инвертируют базовую маску для получения маски смещения;
применяют операцию логического И для местоположения текущего указателя и маски смещения для получения базы указателя;
применяют операцию логического И для местоположения текущего указателя и базовой маски для получения смещения указателя;
определяют величину шага по индексу бит между упомянутым начальным адресом и упомянутым конечным адресом;
получают сумму упомянутого смещения указателя и упомянутого шага по индексу; получают новое смещение указателя на основании мультиплексирования полученной суммы, а также длины кольцевого буфера;
определяют местоположение нового указателя в упомянутом кольцевом буфере посредством логической операции ИЛИ базы указателя и нового смещения указателя.
2. Способ по п.1, дополнительно содержащий этап, на котором устанавливают местоположение отрегулированного указателя в случае положительного шага по индексу: (а) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый конечный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый конечный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью вычитания упомянутой длины из местоположения упомянутого нового указателя.
3. Способ по п.1, дополнительно содержащий этап, на котором устанавливают местоположение отрегулированного указателя в случае отрицательного шага по индексу: (а) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый начальный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый начальный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью прибавления упомянутой длины кольцевого буфера к местоположению упомянутого нового указателя.
4. Способ по п.1, дополнительно содержащий этап, на котором устанавливают наименьшие значащие биты упомянутого начального адреса в ноль до этапа, на котором определяют местоположение упомянутого нового указателя.
5. Способ по п.1, дополнительно содержащий этап, на котором получают местоположение упомянутого отрегулированного указателя в случае положительного шага по индексу с помощью прибавления замаскированного адреса в качестве упомянутого текущего указателя к упомянутому положительному шагу по индексу в устройстве генерирования адреса и вычитания упомянутой длины из суммы в сумматоре арифметического логического устройства.
6. Способ по п.1, дополнительно содержащий этап, на котором получают местоположение упомянутого отрегулированного указателя в случае отрицательного шага по индексу с помощью прибавления замаскированного адреса в качестве упомянутого текущего указателя к упомянутому отрицательному шагу по индексу в устройстве генерирования адреса, в случае отрицательной суммы получают местоположение упомянутого отрегулированного указателя непосредственно из упомянутого устройства генерирования адреса; иначе получают местоположение упомянутого отрегулированного указателя с помощью прибавления упомянутой длины к сумме в арифметическом логическом устройстве и получают местоположение упомянутого отрегулированного указателя из упомянутого арифметического логического устройства.
7. Система для установления адресации кольцевого буфера, содержащая:
кольцевой буфер, причем упомянутый кольцевой буфер содержит:
длину упомянутого кольцевого буфера, причем упомянутая длина предназначена для ограничения адресуемого диапазона упомянутого кольцевого буфера;
начальный адрес для упомянутого кольцевого буфера;
конечный адрес для упомянутого кольцевого буфера;
устройство генерирования адреса, предназначенное для определения местоположения текущего указателя для адреса в упомянутом кольцевом буфере, причем местоположение упомянутого текущего указателя находится между упомянутым начальным адресом и упомянутым конечным адресом;
генератор базовой маски, предназначенный для формирования базовой маски на основании значений начального и конечного адресов;
инвертор для инвертирования базовой маски для получения маски смещения;
первое арифметически логическое устройство И для применения логической операции И к местоположению текущего указателя и маски смещения для получения базы указателя;
второе арифметически логическое устройство И для применения логической операции И для местоположения текущего указателя и базовой маски для получения смещения указателя;
битовый сумматор, предназначенный для получения суммы упомянутого смещения указателя и значения шага по индексу между упомянутым начальным адресом и упомянутым конечным адресом, причем значение шага по индексу определяется из входного сигнала;
мультиплексор, предназначенный для получения нового смещения указателя на основании мультиплексирования полученной суммы, а также длины кольцевого буфера;
арифметически логическое устройство ИЛИ для определения местоположения нового указателя в упомянутом кольцевом буфере посредством применения логической операции ИЛИ к базе указателя и новому смещению указателя.
8. Система по п.7, в которой имеются команды определения местоположения отрегулированного указателя, предназначенные для установки местоположения упомянутого отрегулированного указателя в случае положительного шага по индексу: (а) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый конечный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый конечный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью вычитания упомянутой длины из местоположения упомянутого нового указателя.
9. Система по п.7, в которой имеются команды определения местоположения отрегулированного указателя, предназначенные для установки местоположения упомянутого отрегулированного указателя в случае отрицательного шага по индексу: (а) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый начальный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый начальный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью прибавления упомянутой длины к местоположению упомянутого нового указателя.
10. Система по п.7, в которой имеются команды, предназначенные для установки наименьших значащих бит упомянутого начального адреса в ноль до того, как местоположение упомянутого нового указателя будет определено.
11. Система по п.7, в которой имеются команды для определения местоположения отрегулированного указателя, предназначенные для получения местоположения упомянутого отрегулированного указателя в случае положительного шага по индексу с помощью прибавления замаскированного адреса в качестве упомянутого текущего указателя к упомянутому положительному шагу по индексу в устройстве генерирования адреса и вычитания упомянутой длины из суммы в сумматоре арифметического логического устройства.
12. Система по п.7, в которой имеются команды для определения местоположения отрегулированного указателя, предназначенные для получения местоположения упомянутого отрегулированного указателя в случае отрицательного шага по индексу с помощью прибавления замаскированного адреса в качестве упомянутого текущего указателя к упомянутому отрицательному шагу по индексу в устройстве генерирования адреса, в случае отрицательной суммы получают местоположение упомянутого отрегулированного указателя непосредственно из упомянутого устройства генерирования адреса; иначе получают местоположение упомянутого отрегулированного указателя с помощью прибавления упомянутой длины к сумме в арифметическом логическом устройстве и получают местоположение упомянутого отрегулированного указателя из упомянутого арифметического логического устройства.
13. Процессор цифровых сигналов, предназначенный для обработки цифровых сигналов и содержащий средство управления и адресации кольцевого буфера, содержащий:
средство, предназначенное для установления длины упомянутого кольцевого буфера, причем упомянутая длина предназначена для ограничения адресуемого диапазона упомянутого кольцевого буфера;
средство, предназначенное для установления начального адреса для упомянутого кольцевого буфера;
средство, предназначенное для установления конечного адреса для упомянутого кольцевого буфера;
средство, предназначенное для определения местоположения текущего указателя для адреса в упомянутом кольцевом буфере, причем местоположение упомянутого текущего указателя находится между упомянутым начальным адресом и упомянутым конечным адресом;
средство, предназначенное для формирования базовой маски на основании значений начального и конечного адресов;
средство, предназначенное для инвертирования базовой маски для получения маски смещения;
средство, предназначенное для применения операции логического И для местоположения текущего указателя и маски смещения для получения базы указателя;
средство, предназначенное для применения операции логического И для местоположения текущего указателя и базовой маски для получения смещения указателя;
средство, предназначенное для определения величины шага по индексу бит между упомянутым начальным адресом и упомянутым конечным адресом;
средство, предназначенное для получения суммы упомянутого смещения указателя и упомянутого шага по индексу;
средство, предназначенное для получения нового смещения указателя на основании мультиплексирования полученной суммы, а также длины кольцевого буфера;
средство, предназначенное для определения местоположения нового указателя в упомянутом кольцевом буфере посредством логической операции ИЛИ базы указателя и нового смещения указателя.
14. Процессор цифровых сигналов по п.13, дополнительно содержащий средство, предназначенное для установки местоположения отрегулированного указателя в случае положительного шага по индексу: (а) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый конечный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый конечный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью вычитания упомянутой длины из местоположения упомянутого нового указателя.
15. Процессор цифровых сигналов по п.13, дополнительно содержащий средство, предназначенное для установки местоположения отрегулированного указателя в случае отрицательного шага по индексу: (а) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый начальный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый начальный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью прибавления упомянутой длины к местоположению упомянутого нового указателя.
16. Процессор цифровых сигналов по п.13, дополнительно содержащий средство, предназначенное для установки наименьших значащих бит упомянутого начального адреса в ноль до того, как местоположение упомянутого нового указателя будет определено.
17. Процессор цифровых сигналов по п.13, дополнительно содержащий средство, предназначенное для получения местоположения отрегулированного указателя в случае положительного шага по индексу с помощью прибавления замаскированного адреса в качестве упомянутого текущего указателя к упомянутому положительному шагу по индексу в устройстве генерирования адреса и вычитания упомянутой длины из суммы в сумматоре арифметического логического устройства.
18. Процессор цифровых сигналов по п.13, дополнительно содержащий средство, предназначенное для получения местоположения отрегулированного указателя в случае отрицательного шага по индексу с помощью прибавления замаскированного адреса в качестве упомянутого текущего указателя к упомянутому отрицательному шагу по индексу в устройстве генерирования адреса, в случае отрицательной суммы получают местоположение упомянутого отрегулированного указателя непосредственно из упомянутого устройства генерирования адреса; иначе получают местоположение упомянутого отрегулированного указателя с помощью прибавления упомянутой длины к сумме в арифметическом логическом устройстве и получают местоположение упомянутого отрегулированного указателя из упомянутого арифметического логического устройства.
19. Машиночитаемый носитель, имеющий средство программного кода, выполненного с обеспечением возможности обработки команд в процессоре цифровых сигналов, причем машиночитаемый носитель содержит:
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для установления длины упомянутого кольцевого буфера, причем упомянутая длина предназначена для ограничения адресуемого диапазона упомянутого кольцевого буфера;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для установления начального адреса для упомянутого кольцевого буфера;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для установления конечного адреса для упомянутого кольцевого буфера;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для определения местоположения текущего указателя для адреса в упомянутом кольцевом буфере, причем местоположение упомянутого текущего указателя находится между упомянутым начальным адресом и упомянутым конечным адресом;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для формирования базовой маски на основании значений начального и конечного адресов;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для инвертирования базовой маски для получения маски смещения;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для применения операции логического И для местоположения текущего указателя и маски смещения для получения базы указателя;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для применения операции логического И для местоположения текущего указателя и базовой маски для получения смещения указателя;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для определения величины шага по индексу бит между начальным адресом и упомянутым конечным адресом;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для получения суммы упомянутого смещения указателя и упомянутого шага по индексу;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для получения нового смещения указателя на основании мультиплексирования полученной суммы, а также длины кольцевого буфера;
средство программного кода, доступного для чтения с помощью компьютера, предназначенное для определения местоположения нового указателя в упомянутом кольцевом буфере посредством логической операции ИЛИ базы указателя и нового смещения указателя.
20. Машиночитаемый носитель по п.19, дополнительно содержащий средство программного кода, доступного для чтения с помощью компьютера, предназначенное для установки местоположения отрегулированного указателя в случае положительного шага по индексу:
(а) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый конечный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый конечный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью вычитания упомянутой длины из местоположения упомянутого нового указателя.
21. Машиночитаемый носитель по п.19, дополнительно содержащий средство программного кода, доступного для чтения с помощью компьютера, предназначенное для установки местоположения отрегулированного указателя в случае отрицательного шага по индексу: (а) в случае, когда местоположение упомянутого нового указателя больше, чем упомянутый начальный адрес, с помощью регулирования местоположения упомянутого отрегулированного указателя таким образом, что оно является местоположением нового указателя; и (b) в случае, когда местоположение упомянутого нового указателя меньше, чем упомянутый начальный адрес, с помощью регулирования упомянутого отрегулированного указателя с помощью прибавления упомянутой длины к местоположению упомянутого нового указателя.
| US 5623621 А, 22.04.1997 | |||
| ГЕНЕРАТОР ТОНАЛЬНЫХ СИГНАЛОВ СО ЗВУКОВЫМИ ЭФФЕКТАМИ (ВАРИАНТЫ) | 1995 |
|
RU2143751C1 |
| US 6560691 B2, 06.05.2003 | |||
| US 6604169 B2, 05.08.2003. | |||

