Настоящее изобретение относится, в общем, к системе связи с высокоскоростной передачей пакетных данных и, в частности, к способу и устройству для приема перемеженных данных и деперемежения принятых перемеженных данных в их исходный формат.
Система множественного доступа с кодовым разделением каналов (CDMA), например система стандарта CDMA IS-2000, и система с широкополосным множественным доступом с кодовым разделением (WCDMA), обеспечивающая универсальные мобильные телекоммуникационные услуги (UMTS), поддерживают как речевую связь, так и передачу данных.
В синхронной системе подвижной связи стандарта CDMA2000 Release A/B и асинхронной системе подвижной связи стандарта UMTS для обеспечения надежной передачи мультимедийных данных используются турбокодирование и перемежение. Хорошо известно, что турбокодирование обеспечивает очень высокие возможности восстановления информации с точки зрения коэффициента ошибочных битов (BER) даже при низком отношении сигнал-шум (SNR), а перемежение препятствует концентрации дефектных битов в замирающей среде в одном месте. При перемежении соседние биты подвергаются эффектам замирания случайным образом, что исключает возникновение пакетов ошибок и тем самым повышает эффективность кодирования канала.
Чтобы удовлетворить возрастающую потребность в услугах, требующих высокоскоростной передачи пакетных данных, таких как Интернет и службы передачи мобильного изображения, развитие системы подвижной связи идет в направлении системы, поддерживающей услуги высокоскоростной передачи данных. Согласно стандарту CDMA2000 Release C/D, известному как стандарт Эволюции в передаче данных и речевого сигнала (1xEV-DV), под управлением Программы сотрудничества третьего поколения (3GPP) и Второй программы сотрудничества третьего поколения (3GPP2), базовая станция сегментирует кодовые символы, сформированные путем кодирования потока пакетных данных для передачи канальным кодером, в субблоки заданного размера и перемежает соответствующие сегментированные субблоки. Подвижная станция принимает поток перемеженных субблоков, преобразует принятый поток субблоков в кодовые символы и выполняет деперемежение, т.е. операцию, обратную операции перемежения, которая использовалась в базовой станции, на кодовых символах, чтобы тем самым восстановить принятый поток субблоков в исходный выходной сигнал канального кодера.
В стандарте CDMA2000 Release A/B длина потока кодовых символов, который становится объектом перемежения, должна делиться на степень числа 2. То есть предусмотрено, что длина потока кодовых символов должна быть кратной числу, имеющему 2 в основании, а в качестве его экспоненты - значение сдвига разрядов, одного из параметров перемежения. Что же касается стандарта 1xEV-DV, то в нем длина потока кодовых символов субблока не делится на степень числа 2, т.е. стандарт 1xEV-DV устанавливает правило перемежения, отличное от существующих стандартов. Следовательно, для стандарта 1xEV-DV необходимы методы, которые бы позволили подвижной станции принимать поток данных, перемеженных согласно новому правилу перемежения, и быстро и эффективно выполнять деперемежение принятого потока данных.
В основу настоящего изобретения поставлена задача создания способа и устройства для быстрого восстановления приемником данных, перемеженных передатчиком перед передачей в системе связи.
Следующей задачей изобретения является создание способа и устройства для выполнения деперемежения субблоков на пакетных данных прямой линии связи в приемнике системы связи.
Еще одна задача изобретения - создать способ и устройство для выполнения деперемежения с использованием входного буфера канального декодера в приемнике системы связи.
Изобретение также решает задачу создания способа и устройства для считывания перемеженных данных, записи принятых перемеженных данных и считывания записанных данных в порядке деперемежения в системе связи.
Задачей изобретения является создание способа и устройства для приема перемеженных данных, записи принятых перемеженных данных и считывания записанных данных с использованием адреса считывания, сформированного согласно правилу деперемежения в системе связи стандарта 1xEV-DV.
Для решения перечисленных выше и других задач предложен способ считывания записанных символов посредством деперемежения для декодирования записанного кодирующего пакета в приемнике системы подвижной связи, поддерживающей турбокодирование и перемежение, причем турбокодированный/перемеженный кодирующий пакет имеет значение m сдвига разрядов, верхнее предельное значение J и остаток R, и поток символов кодирующего пакета записан по порядку столбец - строка. Согласно предложенному способу формируют промежуточный адрес посредством инвертирования порядка разрядов (BRO) при допущении, что остаток R равен 0 для принятых символов, вычисляют коэффициент коррекции адреса для коррекции промежуточного адреса с учетом столбца, сформированного с остатком, и формируют адрес считывания путем сложения промежуточного адреса и коэффициента коррекции адреса для требующего декодирования символа, и считывают символ, записанный в сформированном адресе считывания.
Для достижения перечисленных выше и других задач предложено устройство для считывания записанных символов посредством деперемежения в приемнике системы подвижной связи, поддерживающей турбокодирование и перемежение, причем турбокодированный/перемеженный кодирующий пакет имеет значение m сдвига разрядов, верхнее предельное значение J и остаток R, и приемник содержит буфер для записи символов кодирующего пакета по порядку столбец - строка и канальный декодер для декодирования записанного кодирующего пакета. Устройство содержит генератор промежуточного адреса для формирования промежуточного адреса посредством выполнения операции инвертирования порядка разрядов (BRO) на индексе кодового символа, запрашиваемого канальным декодером, без учета последнего столбца символов, записанных в буфер в форме матрицы, корректор адреса для вычисления коэффициента коррекции адреса для коррекции промежуточного адреса с учетом столбца, сформированного из остатка, и сумматор для выработки адреса считывания для считывания кодового символа, запрашиваемого канальным декодером, из буфера путем сложения коэффициента коррекции адреса с промежуточным адресом.
Перечисленные выше и другие задачи, существенные признаки и преимущества настоящего изобретения станут более понятными из приведенного ниже подробного описания со ссылками на прилагаемые чертежи, на которых
фиг.1 изображает структурную схему передатчика базовой станции для формирования передаваемого субпакета путем перемежения пакетных данных для прямого канала передачи пакетных данных,
фиг.2 иллюстрирует операции перемежения субблоков и группировки символов субблока канальным перемежителем,
фиг.3 иллюстрирует конструкцию приемника подвижной станции для получения декодированных данных из субпакета, принятого по прямому каналу передачи пакетных данных,
фиг.4 иллюстрирует процесс перемежения, выполняемый на одном субблоке для NEP=408, в котором процесс перемежения разделен на три этапа,
фиг.5 изображает структурную схему устройства для выполнения деперемежения субблоков на прямом трафике пакетных данных согласно одному варианту настоящего изобретения,
фиг.6 изображает матрицу кодовых символов, образованную с применением размера кодирующего пакета и параметров перемежения, приведенных в примере 1,
фиг.7 иллюстрирует индекс строки, промежуточный адрес, коэффициент коррекции адреса и конечный адрес считывания, сформированные для индекса кодового символа по примеру 1,
фиг.8 иллюстрирует матрицу кодовых символов, образованную с применением размера кодирующего пакета и параметров перемежения, приведенных в примере 2,
фиг.9 иллюстрирует последовательно индекс строки, промежуточный адрес, коэффициент коррекции адреса и конечный адрес считывания, сформированные для индекса кодового символа по примеру 2,
фиг.10 иллюстрирует структурную схему генератора адреса считывания согласно варианту настоящего изобретения для NEP=408, 792, 1560, 3096, 6168 и 12312,
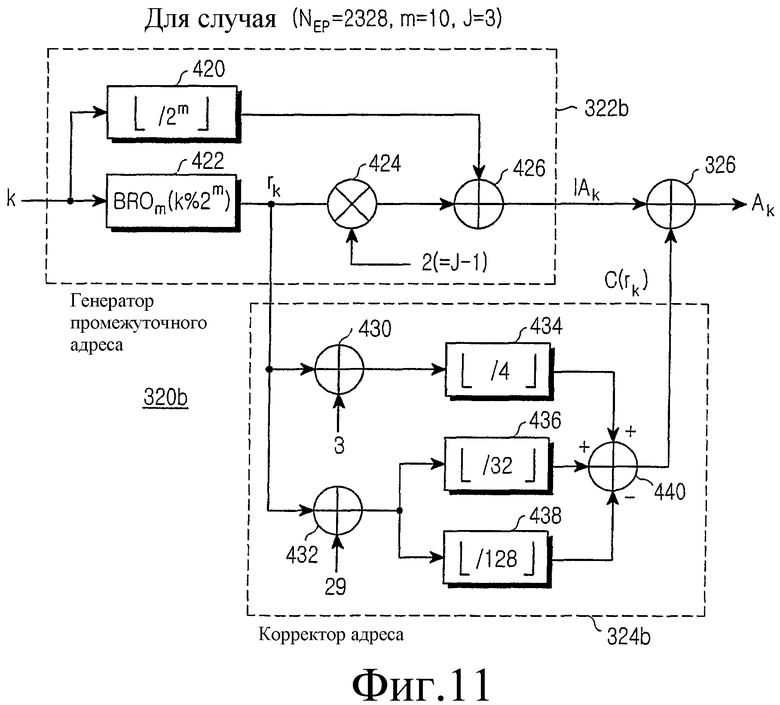
фиг.11 иллюстрирует структурную схему генератора адреса считывания согласно варианту настоящего изобретения для NEP= 3238,
фиг.12 иллюстрирует структурную схему генератора адреса считывания согласно варианту настоящего изобретения для NEP= 3864,
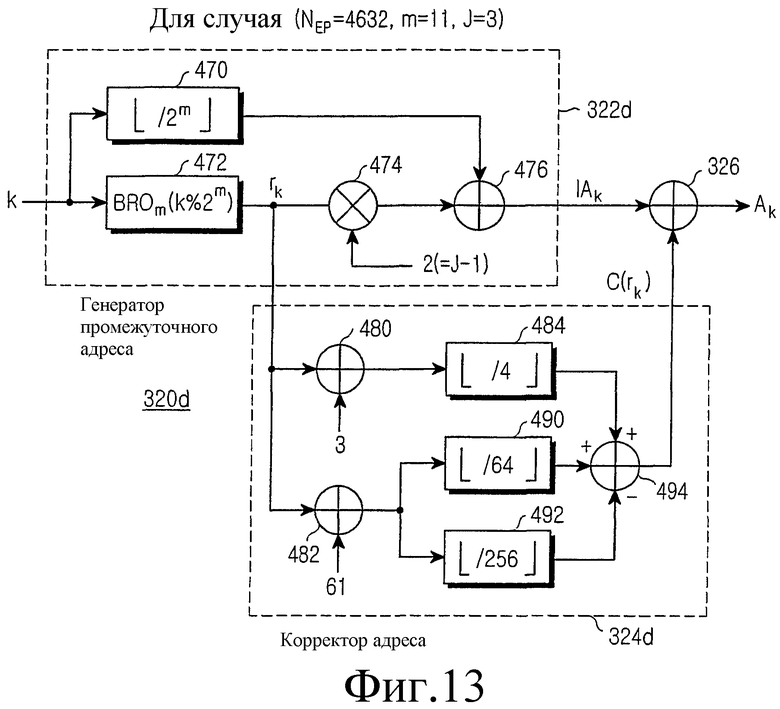
фиг.13 иллюстрирует структурную схему генератора адреса считывания согласно варианту настоящего изобретения для NEP= 4632,
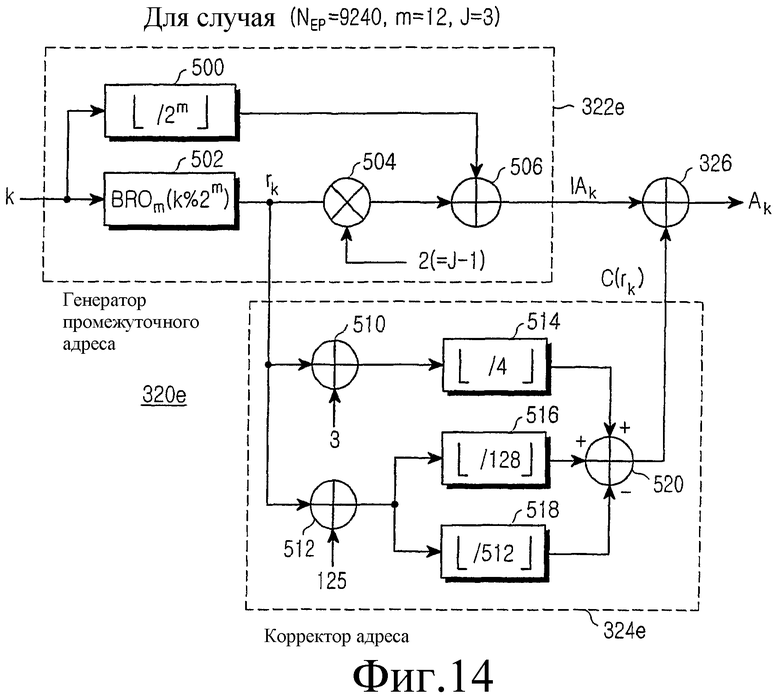
фиг.14 иллюстрирует структурную схему генератора адреса считывания согласно варианту настоящего изобретения для NEP= 9240, и
фиг.15 иллюстрирует структурную схему генератора адреса считывания согласно варианту настоящего изобретения для NEP= 15384.
В дальнейшем будет описано несколько вариантов осуществления настоящего изобретения со ссылкой на прилагаемые чертежи. Одинаковые или подобные элементы обозначены на чертежах одинаковыми ссылочными номерами. Чтобы не усложнять представленное ниже описание, известные функции и конфигурации не будут описываться подробно.
Согласно настоящему изобретению принимают поток перемеженных пакетных данных, и принятый пакет перемеженных данных подвергают деперемежению. В частности, в изобретении подвергают деперемежению поток пакетных данных, которые перемежались согласно стандарту CDMA2000 1xEV-DV (Эволюция в передаче данных и речевого сигнала) для синхронной системы связи CDMA.
Вначале будут описаны структура и операции перемежения потока пакетных данных и деперемежения потока перемеженных данных в системе подвижной связи стандарта CDMA2000 1xEV-DV.
На фиг.1 изображена структурная схема передатчика базовой станции для формирования передаваемого субпакета путем перемежения пакетных данных для прямого канала передачи пакетных данных.
На фиг.1 турбокодер 110 кодирует поток входных пакетных данных кодирующим пакетом с заданной кодовой частотой R и выдает поток кодовых символов. При этом турбокодер 110, имеющий частоту кодирования R=1/5, установленную стандартом 1xEV-DV, состоит из одного турбоперемежителя и двух составляющих кодеров. Теперь будет описана работа турбокодера 110. Входной кодирующий пакет выдается в виде систематического субпакета S как он есть, без изменения, и первый составляющий кодер кодирует входной кодирующий пакет и выдает 2 контрольных (по четности) субблока Р0 и Р1. Турбоперемежитель, входящий в состав турбокодера 110, кодирует входной кодирующий пакет и формирует другой систематический субблок S'. Систематический субблок S', сформированный турбоперемежителем, вводится во второй составляющий кодер. Второй составляющий кодер кодирует систематический субблок S' и выдает другие 2 отличающиеся контрольные субблока Р0' и Р0'. Так как систематический субблок S' не выводится в турбокодер 110, турбокодер 110 выдает 5 субблоков S, Р0, Р1, Р0', Р1', имеющих такой же размер, как и входной кодирующий пакет.
Канальный перемежитель 120 соответствующим образом перемежает кодовые символы на выходе турбокодера 110, так что кодовые символы, составляющие субпакет, гарантируют усиление кодирования на высоком уровне. Кодовые символы, выдаваемые турбокодером 110, имеют правильное размещение. Такое размещение достигается посредством последовательного выполнения разделения символов, перемежения субблоков и группировки символов субблока. В частности, разделитель 122 символов классифицирует 5 видов кодовых символов, выдаваемых турбокодером 110, согласно видам символов, и формирует 5 субблоков. Перемежитель 124 субблоков перемежает каждый из 5 субблоков с выхода разделителя 122 символов согласно такому же правилу перемежения. И, наконец, блок 126 группировки символов субблока попеременно группирует некоторые кодовые символы в перемеженных субблоках.
На фиг.2 проиллюстрированы операции перемежения субблоков и группировки символов субблока канальным перемежителем 120. Как показано на чертеже, 5 субблоков S, Р0, Р0', Р1, Р1' (представленных ссылочными номерами 10-18), разделенные по видам, подвергаются перемежению перемежителем 124 субблоков, а затем выдаются в виде перемеженных субблоков 20-28. После этого блок 126 группировки символов субблока поочередно группирует перемеженные контрольные символы 22-28 без изменения перемеженного систематического субблока 20 среди перемеженных субблоков 20-28. В описании метода группировки кодовые символы перемеженного субблока Р0 (22) и перемеженного субблока Р0' (24) размещаются поочередно, чтобы сформировать первую группу данных 32. Аналогично, кодовые символы перемеженного субблока Р1 (26) и перемеженного субблока Р1' (28) размещаются поочередно, чтобы сформировать вторую группу данных 34.
Блок 130 выбора символов субпакета выбирает некоторые символы из данных, перемеженных канальным перемежителем 120, согласно заданному шаблону выбора и формирует передаваемый субпакет. Сформированный субпакет модулируется с помощью заданной схемы модуляции, а затем передается в подвижную станцию посредством известной процедуры, такой как расширение и преобразование частоты.
Подвижная станция, принимающая высокоскоростные пакетные данные, передаваемые базовой станцией по прямому каналу передачи пакетных данных, принимает декодированные данные посредством обратного выполнения операции, показанной на фиг.1.
На фиг.3 проиллюстрирована конструкция приемника подвижной станции для получения декодированных данных из субпакета, принятого по прямому каналу передачи пакетных данных.
На фиг.3 блок 210 вставки нуля в субпакет вставляет "0" в заданную позицию принятого субпакета во взаимодействии с блоком 140 выбора символа передатчика базовой станции. Канальный деперемежитель 220 передатчика подвижной станции, соответствующий канальному перемежителю 120 приемника базовой станции, выполняет последовательно дегруппировку символов субблока, деперемежение субблока и обратное разделение символов.
Более конкретно, блок 22 дегруппировки символов субблока разделяет субблоки с выхода блока 210 вставки нуля в субпакет по их видам и выдает 5 перемеженных субблоков. Деперемежитель 224 субблоков деперемежает каждый перемеженный субблок согласно правилу деперемежения, соответствующему правилу перемежения, используемому в перемежителе 124 субблоков передатчика базовой станции. И, наконец, блок 226 обратного разделения символов разделяет деперемеженный вывод и выдает его в канальный декодер 230. Канальный декодер 230 декодирует деперемеженный выход с той же частотой кодирования, что и турбокодер 110 передатчика базовой станции, и формирует декодированные данные.
В приемнике подвижной станции, работающей по описанному методу, деперемежение субблоков следует выполнять путем отражения правила перемежения, используемого для перемежения субблоков, и другая сложность такого деперемежения обусловлена зависимостью от длины входной последовательности, которая становится объектом перемежения.
Для уменьшения сложности приемника подвижной станции и повышения скорости обработки данных можно выполнять деперемежение субблоков с применением следующих двух методов. Первый метод состоит в том, чтобы выполнять деперемежение при записи кодовых символов во входной буфер канального кодера, и в этом случае адреса записи во входной буфер для записи кодовых символов создаются с учетом правила деперемежения. Второй способ состоит в том, чтобы выполнять деперемежение, когда канальный декодер считывает кодовые символы из входного буфера, и в этом случае адреса считывания из входного буфера для считывания кодовых символов создаются с учетом правила деперемежения.
Первый из этих методов должен отражать не только деперемежение субблоков, но также и обратное перетасовывание, сопровождающееся процессом демодуляции, при формировании адресов записи. Следовательно, требуется дополнительное управляющее устройство в зависимости от вида схемы модуляции и шаблона обратного перетасовывания, что приводит к увеличению сложности. Поэтому в настоящем изобретении предложен способ формирования адресов считывания для считывания кодовых символов из входного буфера канального декодера при выполнении деперемежения субблоков.
Согласно стандарту 1хEV-DV имеется 11 размеров кодирующего пакета (ЕР), доступных для трафика, передающего канал пакетных данных (PDCH), которые приведены в представленной ниже таблице 1. Кодовые символы с выхода канального кодера перемежаются согласно субблокам, и в этом случае, поскольку размер каждого субблока идентичен размеру кодирующего пакета, длина потока кодовых символов, который стал объектом перемежения/деперемежения, также идентична размеру кодирующего пакета.
В таблице 1 показаны размеры кодирующего пакета, установленные стандартом 1хEV-DV, и соответствующие параметры перемежения/деперемежения субблоков. В таблице 1 значение m сдвига разрядов и верхнее предельное значение J соответственно связаны с количеством строк и количеством столбцов, когда поток кодовых символов, имеющих размер NEP, располагается в форме матрицы, а остаток R означает количество элементов в последнем столбце матрицы.
В результате, отношение между размером NEP кодирующего пакета и параметрами перемежения/деперемежения определяется как

Чтобы описать правило деперемежения согласно настоящему изобретению, сначала будет подробно описан в виде примера формат потока перемеженных данных.
На фиг.4 проиллюстрирован процесс перемежения, выполняемый на одном субблоке для NEP = 408, где процесс перемежения разделен на три этапа.
Как показано на чертеже, на этапе 40 в буфер последовательно записываются 408 кодовых символов в соответствии с индексом k (k=0, 1, 2, ..., 407) выходного кодового символа канального декодера. Стрелки показывают порядок, в котором записываются кодовые символы (вниз→ влево), и кодовые символы записываются в порядке столбец→строка, как показано на чертеже. То есть кодовые символы в первом столбце записываются в направлении строки, кодовые символы во втором и третьем столбцах записываются тем же самым методом, и, наконец, записываются остальные кодовые символы в четвертом столбце. На этапе 42 записанные кодовые символы переставляются для каждого столбца посредством инвертирования порядка разрядов (BRO) номера столбца. В данном контексте под "инвертированием порядка разрядов" подразумевается изменение порядка разрядов на обратный порядок. Например, на фиг.4 номер строки "1" выражается в двоичном коде как "0000001". Это сделано потому, что количество элементов, которое можно включить в каждый столбец, равно 128, так как размер кодирующего пакета равен 408, а верхнее предельное значение установлено на 4. То есть, чтобы выразить 128, требуется 7 двоичных разрядов. Поэтому номер строки "1" выражается как "0000001", и номер строки "1" инвертируется в операции BRO в "1000000". То же самое можно выразить номером строки "64" в десятичной системе. Согласно настоящему изобретению генерируется адрес считывания. На этапе 44 переставленные кодовые символы выдаются из буфера в порядке строка→столбец по строке BRO согласно сформированному адресу считывания. Стрелка показывает порядок, в котором записаны кодовые символы (вправо→ вниз).
На фиг.4 матрица кодовых символов, записанных в буфер, состоит из 27 строк и 4 столбцов, причем последний 4-й столбец имеет всего 24 элемента. Если бы 4-й столбец не содержал ни одного элемента, т.е. при R=0, перемежение субблоков в передатчике базовых станций можно было бы осуществить простой генерацией адреса считывания Bi i-го кодового символа (где i=0, 1, 2, ..., 407) в соответствии с уравнением (2), с последующим считыванием кодового символа в соответствующий адрес из буфера.
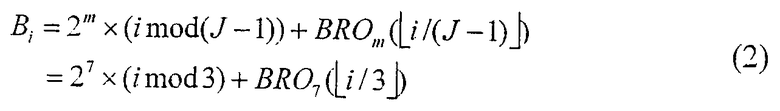
В уравнении (2) "i" означает индекс выходного кодового символа перемежителя субблоков, "mod" означает операцию по модулю, "BRO7(.)" означает 7-разрядную операцию BRO и 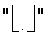 указывает максимальное целое число, не превышающее ввод ".".
указывает максимальное целое число, не превышающее ввод ".".
Тем временем, кодовые символы, перемеженные в базовой станции, передаются в сторону подвижной станции посредством известной процедуры, такой как модуляция и расширение. Кодовые символы, принятые подвижной станцией, записываются во входной буфер канального декодера в порядке перемежения субблоков. Поэтому перемежение субблоков можно обеспечить путем генерации адреса считывания Ak k-го кодового символа для индекса k (k=0, 1, 2, ..., 407) входного кодового символа канального декодера в соответствии с обратной функцией уравнения (2), приведенного выше, и считывания кодового символа в соответствующий адрес из канального декодера. Представленное ниже уравнение (3) является выражением для генерации адреса считывания Ak с использованием обратной функции Bi из уравнения (2).
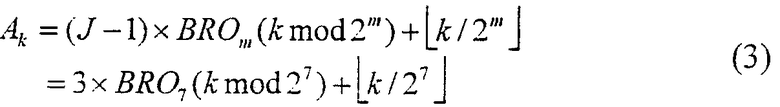
Уравнение (2) и уравнение (3) рассматривались для R=0. Однако, так как R имеет ненулевые значения для всех размеров кодирующих пакетов, указанных в таблице 1, включая NEP=408, выражение для генерации адреса считывания для перемежения субблоков не такое простое, как уравнение (3).
Поэтому в варианте осуществления настоящего изобретения процесс генерации адреса считывания для входного буфера канального декодера разделен на три этапа: генерацию промежуточного адреса, коррекцию адреса и суммирование. В данном контексте под "промежуточным адресом" подразумевается адрес считывания, сгенерированный при допущении, что R=0, а "коррекция адреса" означает операцию генерации коэффициента коррекции адреса для генерации конечного адреса считывания путем коррекции промежуточного адреса.
На фиг.5 проиллюстрировано устройство для выполнения деперемежения субблоков на прямом трафике пакетных данных согласно варианту осуществления настоящего изобретения. Показанное устройство выполняет деперемежение субблоков на каждом перемеженном субблоке с выхода блока 222 дегруппировки символов субблока в приемнике подвижной станции, изображенном на фиг.3.
На фиг.5 перемеженные кодовые символы одного субблока записываются во входной буфер 310 для канального декодера 330 в перемеженном порядке. При этом структура памяти входного буфера 310 построена в форме матрицы памяти 2mxJ согласно размеру NEP кодирующего пакета, и кодовые символы записываются в матрицу памяти в порядке столбец→строка, как было описано этапом 40 на фиг.4. Генератор 320 адреса деперемежения генерирует адрес считывания для считывания кодовых символов из входного буфера 310 согласно правилу деперемежения, соответствующему правилу перемежения, использованному в передатчике базовой станции.
Уравнение (4), приведенное ниже, иллюстрирует выражение для генерации адреса считывания в генераторе 320 адреса деперемежения.
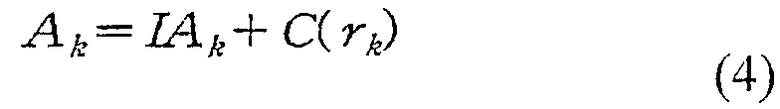
В данном случае "k" - индекс кодового символа, который запрошен канальным декодером 330, "Ak" - адрес считывания из входного буфера 310, в котором было отражено перемежение субблока, "IAk" - промежуточный адрес, "C(rk)" - коэффициент коррекции адреса для промежуточного адреса, и "rk" индекс строки матрицы перемеженных кодовых символов.
Более конкретно, генератор 323 промежуточного адреса принимает индекс k кодового символа из канального декодера 330 и генерирует промежуточный адрес IAk, для которого не рассматривался последний столбец, и индекс строки rk для k. Корректор 324 адреса принимает индекс строки rk и генерирует коэффициент коррекции адреса C(rk) для соответствующей строки, а сумматор 326 суммирует коэффициент коррекции адреса C(rk) соответствующей строки с промежуточным адресом IAk и посылает конечный адрес считывания Ak во входной буфер 310.
Затем входной буфер 310 выдает кодовый символ, соответствующий адресу считывания Ak в канальный декодер 330. Цикл этих процедур продолжается до тех пор, пока не будут считаны все кодовые символы, записанные во входном буфере 310.
Теперь будет более подробно описана генерация промежуточного адреса генератором 322 промежуточного адреса. Изображенный на фиг.5 генератор 322 промежуточного адреса принимает индекс k кодового символа, который запрошен для приема канальным декодером 330, и выдает промежуточный адрес IAk и соответствующий индекс строки rk. Допустим, что матрица памяти входного буфера 310 для записи перемеженных кодовых символов одного субблока имеет формат матрицы, показанной на этапе 44 на фиг.4, тогда индекс строки rk k-го кодового символа можно просто вычислить как

где "m" указывает величину сдвига разрядов, показанную в таблице 1.
Как отмечалось выше, промежуточным адресом является промежуточный адрес считывания, сгенерированный при допущении, что остаток R в таблице 1 равен 0 или общему количеству (=2m) строк. В этом случае перемеженные кодовые символы, записанные во входной буфер 310, образуют идеальную матрицу 2mx(J-1) или 2mxJ.
Согласно таблице 1 для 5 видов кодирующих пакетов с NEP ≤3096, R меньше, чем 2m-1, что равно половине общего количества строк, тогда как для кодирующих пакетов с NEP=3864, R больше, чем 2m-1. Когда R меньше, чем половина количества строк, если используется матрица 2mx(J-1), только R элементов можно рассматривать дальше во время коррекции адреса. И напротив, когда R больше, чем половина количества строк, если используется матрица 2mxJ, только (2m-R) элементов исключаются во время коррекции адреса. Поэтому выражение для генерации промежуточного адреса в целях дополнительного упрощения работы корректора 324 адреса делится на два типа в зависимости от величины остатка R, как показано уравнением (6) ниже.
 (6)
(6)
Далее будет более подробно описана коррекция адреса корректором 324 адреса. Корректор 324 адреса принимает индекс строки rk из генератора 322 промежуточного адреса и выдает коэффициент коррекции адреса C(rk). Как отмечалось выше, если остаток R по размеру кодирующего пакета меньше, чем половина, т.е. 2m-1, количества строк, то коэффициент коррекции адреса повышается на единицу каждый раз, когда возникает элемент, который следует рассматривать дополнительно. И напротив, если остаток R больше, чем половина количества строк, то коэффициент коррекции адреса уменьшается на единицу каждый раз, когда генерируется элемент, подлежащий исключению.
Принцип генерации коэффициента коррекции адреса будет описан ниже со ссылкой на следующие два примера.
Пример 1: NEP=20, m=4, J=2 и R=4
В примере 1 остаток R меньше, чем 8(=2m-1), составляющее половину числа строк.
На фиг.6 показана матрица кодовых символов, сформированная с применением размера кодирующего пакета и параметров перемежения, приведенных в примере 1. Как показано, первый столбец имеет все 16 элементов, но второй столбец имеет только 4 элемента.
В матрице перед операцией BRO кодовые символы последнего столбца располагаются в индексах строк 0, 1, 2 и 3, но после операции BRO кодовые символы последнего столбца равномерно рассеиваются, сохраняя при этом одинаковое расстояние 4 (=16/4) и сдвигаясь тем самым к соответствующим индексам строк 0, 4, 8 и 12. Такая дисперсия возникает в результате особенности операции BRO, при этом понятно, что при использовании такой особенности коэффициент коррекции адреса для R<2m-1 увеличивается на единицу в каждой 4-й строке после того, как кодовый символ впервые появляется в последнем столбце.
На фиг.7 проиллюстрированы последовательно индекс строки rk, промежуточный адрес IAk, коэффициент коррекции адреса C(rk) и конечный адрес считывания Ak, сгенерированный для индекса k кодового символа в примере 1. Как показано, конечный адрес считывания Ak - это значение, определенное путем прибавления коэффициента коррекции адреса C(rk) к промежуточному адресу IAk, и коэффициент коррекции адреса C(rk) увеличивается на единицу в следующих строках каждый раз, когда кодовый символ появляется в последнем столбце, потому что если вставить кодовый символ, подлежащий дальнейшему учету для последнего столбца, который не был учтен во время генерации промежуточного адреса, то дополнительно размещается адрес считывания для вставленного кодового символа, и в результате следующие за ним промежуточные адреса должны сдвигаться вперед на единицу.
Это значит, что коэффициент коррекции адреса C(rk) можно вычислить путем определения строки матрицы, к которой принадлежит кодовый символ, записанный во входной буфер 310, имеющий индекс k, запрошенный канальным кодером 330, и определения количества строк, в которые вставлены кодовые символы, не учтенные во время генерации промежуточного адреса перед строкой, к которой принадлежит соответствующий кодовый символ.
Например, поскольку индекс строки кодового символа с индексом k=10 равен 5, а количество строк, в которые вставлены кодовые символы, не учтенные во время генерации промежуточного адреса до этой строки, равно 2 (индекс строки = 0,4), коэффициент коррекции адреса для индекса 10 кодового символа становится 2. Процесс вычисления коэффициента коррекции адреса определяется как

В данном случае, "d" - это значение, определенное путем деления общего количества строк на количество кодовых символов, подлежащих вставке, или количества строк, в которые следует вставить кодовые символы, и означает межстрочное расстояние кодовых символов, принадлежащих последнему столбцу. Далее, "r" означает индекс строки, в которой расположен первый вставленный кодовый символ из оставшихся кодовых символов, вставленных в последнем столбце. Так как кодовый символ, вставленный первым в последний столбец, всегда располагается в индексе строки 0 из-за особенности операции BRO, r+ равно 0. Однако если существует кодовый символ, который уже был вставлен в последний столбец согласно остатку R и количеству строк, то определяется индекс строки r+ первого кодового символа, дополнительно вставленного согласно индексу строки уже вставленного кодового символа. В коэффициенте коррекции адреса Cd + по уравнению (7) знак "+" служит для указания, что кодовый символ "вставлен" в последний столбец", а "d" указывает отношение количества строк, в которые вставляются кодовые символы, к общему количеству строк.
Если уравнение (7) применить к примеру 1, то выражение для генерации коэффициента коррекции адреса будет иметь форму

Пример 2: NEP=20, m=4, J=2 и R=12
В примере 2 остаток R больше, чем 8 (=2m-1), составляющее половину количества строк.
На фиг.8 показана матрица кодовых символов, построенная с применением размера кодирующего пакета и параметров перемежения, заданных в примере 2. Как показано, первый столбец имеет все 16 элементов, но из второго столбца следует исключить 4 элемента.
В матрице перед операцией BRO на строках кодовые символы, подлежащие исключению из последнего столбца, располагаются в индексах строк 12, 13, 14 и 15, но кодовые символы, подлежащие исключению после операции BRO, рассеяны, сохраняя при этом одинаковое межстрочное расстояние 4 (=16/4), так что они сдвинуты к соответствующим индексам строк 3, 7, 11 и 15. Такая дисперсия возникает из-за особенности операции BRO, но при этом понятно, что при использовании этой особенности коэффициент коррекции адреса для R≥2m-1 уменьшается на единицу в каждой 4-й строке после того, как кодовый символ впервые исключается из последнего столбца.
На фиг.9 последовательно проиллюстрированы индекс строки rk, промежуточный адрес IAk, коэффициент коррекции адреса C(rk) и конечный адрес считывания Ak, сгенерированный для индекса k кодового символа в примере 2. Как показано, конечный адрес считывания C(rk) является значением, определенным путем суммирования отрицательного коэффициента коррекции адреса C(rk) и промежуточного адреса IAk, и коэффициент коррекции адреса C(rk) уменьшается на единицу в следующих строках каждый раз, когда кодовый символ исключается из последнего столбца. Это происходит потому, что если вставляется кодовый символ, который не должен был рассматриваться и который рассматривался во время генерации промежуточного адреса, то необходимо удалить адрес считывания, выделенный для исключенного кодового символа, в результате следующие за ним промежуточные адреса должны сдвинуться назад на единицу.
То есть коэффициент коррекции адреса C(rk) можно вычислить путем определения строки матрицы, к которой принадлежит кодовый символ, записанный во входной буфер 310, имеющий индекс k, запрошенный канальным кодером 330, и определения количества строк, в которые вставляются кодовые символы, которые рассматривались во время генерации промежуточного адреса перед строкой, к которой принадлежит соответствующий кодовый символ.
Например, так как индекс строки кодового символа с индексом кодового символа k=13, запрошенного канальным декодером 330 на фиг.5, равен 11, а количество строк, из которых исключены кодовые символы, которые рассматривались во время генерации промежуточного адреса этой строки, равно 2 (индекс строки=3,7), коэффициент коррекции адреса для индекса 13 кодового символа становится -2. Процесс вычисления коэффициента коррекции адреса определяется как
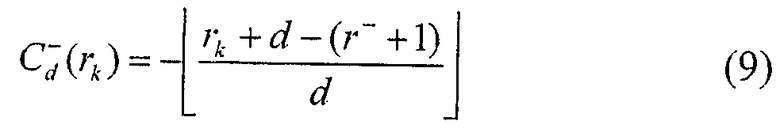
В данном случае "d" - это значение, определенное путем деления общего количества строк на количество кодовых символов, подлежащих исключению, или количества строк, из которых должны быть исключены кодовые символы, и оно означает межстрочное расстояние кодовых символов, подлежащих исключению из последнего столбца. Кроме того, "r-" означает индекс строки, в которой расположен первый исключенный кодовый символ. Так как кодовый символ, первым исключенный из последнего столбца, всегда расположен в индексе строки d-1 в свете особенности операции BRO, r- = d-1. Однако когда существует кодовый символ, который уже был исключен в состоянии, когда последний столбец не заполнен полностью согласно остатку R и количеству строк, определяется индекс строки r- первого кодового символа, дополнительно исключенного согласно индексу строки ранее исключенного кодового символа. В коэффициенте коррекции адреса Cd - уравнения (9) "-" служит для указания, что кодовый символ "исключается" из последнего столбца, а "d" служит для указания отношения количества строк, из которых исключены кодовые символы, к общему количеству строк.
Если уравнение (9) применить к примеру 2, то выражение для генерации коэффициента коррекции адреса для примера 2 будет иметь форму

Описанная со ссылкой на пример 1 и пример 2 процедура вычисления коэффициента коррекции адреса представлена отдельно для случая, когда вставляются кодовые символы, и для случая, когда исключаются виртуальные кодовые символы. При этом отношение d количества строк, в которые вставляются или из которых исключаются кодовые символы, к общему количеству строк представляет собой расстояние между строками, к которым принадлежат кодовые символы, которые должны вставляться или исключаться, и оно определяется как:

При этом, если "d" не является натуральным числом, то выражения для генерации коэффициента коррекции адреса с использованием особенности операции BRO, описанной в связи с примером 1 и примером 2, становятся некорректными. Так как в уравнении (11) общее количество строк, которое является числителем, всегда является степенью числа 2, количество строк вставки или исключения, которое является знаменателем, также должно быть всегда степенью числа 2, чтобы d было натуральным числом. В таблице 1 остаток R представляет количество строк, в которые должны вставляться или из которых должны исключаться символы, и для всех размеров кодирующего пакета ни один из остатков R не является степенью числа 2. Однако даже в этом случае, если R выражено суммой степеней числа 2, можно применить уравнение (7) или уравнение (8).
Далее будет описан принцип генерации коэффициента коррекции адреса для действительного применения к каждому из следующих размеров кодирующего пакета NEP = 408, 792, 1560, 2338, 3096, 3864, 6168 и 12312.
А. Генерация коэффициента коррекции адреса для NEP=408, 792, 1560, 3096, 6168 и 12312 (R=24).
Прежде всего, будет описан способ генерации коэффициента коррекции адреса для кодирующего пакета с размером NEP=408. В данном случае перемеженные кодовые символы считываются из матрицы, показанной на этапе 44 на фиг.4, по порядку строка→столбец, а затем записываются во входной буфер канального декодера.
408 кодовых символов, входящих в один субблок, образуют матрицу, имеющую 128 (=27) строк, и последний столбец в этой матрице имеет 24 кодовых символа, которые не были учтены во время генерации промежуточного адреса. Так как 24 можно выразить в виде степени числа 2 как 24+23, эти 24 кодовых символа будут разделены на 16 высших кодовых символов и 8 низших кодовых символов.
То есть 16 высших кодовых символов размещаются в 0-й, 8-й, 16-й, ..., 104-й, 112-й и 120-й строках, разнесенных на заданное межстрочное расстояние 8 (=128/16), начиная с самой верхней строки, а оставшиеся 8 низших кодовых символов размещаются в 4-й, 20-й, 36-й, ..., 84-й, 100-й и 116-й строках, разнесенных на заданное межстрочное расстояние 16 (=128/8), начиная с 4-й (=8/2) строки.
Из 24 кодовых символов 16 кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 8, а остальные 8 кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 16, так что можно считать, что 24 кодовых символа идентичны по своим шаблонам вставки периоду 16. Поэтому можно считать, что вставка 24 кодовых символов в 128 строк эквивалентна вставке 3 (=24/8) кодовых символов через каждые 16 (=128/8) строк.
Число 3 кодовых символов, подлежащих вставке, можно выразить в виде степени числа 2 как 3=2+1 или 3=4-1. Для этих двух случаев коэффициент коррекции адреса можно вычислить следующим образом.
Если 3 выразить как 2+1, то сначала вставляются 2 кодовых символа в 16 строк, а затем надо вставить один кодовый символ. В этом случае d равно 8 (=16/2) во время первой вставки, и d равно 16 (=16/1) во время второй вставки. Следовательно, коэффициент коррекции адреса C(rk) вычисляется следующим образом:

В уравнении (12) для d=8 сначала вставляются 2 кодовых символа с межстрочным расстоянием 8 в последний столбец в состоянии, когда последний столбец матрицы не имеет кодового символа, так что индекс строки первого вставленного кодового символа равен 0. Поэтому в данный момент r+ равно 0. Далее, для d=16 дополнительно вставляется один кодовый символ в состоянии, когда последний столбец матрицы уже имеет 2 кодовых символа с межстрочным расстоянием 8. В этом случае прибавленный кодовый символ вставляется между уже вставленными 2 кодовыми символами с учетом особенности операции BRO. Следовательно, в этот момент r+ становится 4 (=(0+8)/2).
Если 3 выразить как 4-1, то сначала вставляются 4 кодовых символа в 16 строк, а затем один из этих вставленных кодовых символов исключается. В этом случае d равно 4 (=16/4) во время вставки, и d равно 16 (=16/1) во время удаления. Следовательно, коэффициент коррекции адреса C(rk) вычисляется как

В уравнении (13) для d=4 индекс строки r+ кодового символа, вставленного первым в последний столбец матрицы, равен 0, а для d=16 индекс строки r- кодового символа, удаленного первым из последнего столбца, равен 12. В силу особенности операции BRO первым должен быть исключен кодовый символ в последней строке из 4 символов, которые уже были вставлены в последний столбец. То есть, поскольку число кодовых символов, которые уже были вставлены в последний столбец, равно 4, а их межстрочное расстояние равно 4, индекс r- последней строки равен 12 (=0+3х4).
Уравнение (12) совершенно равно уравнению (13) по результату операции. С точки зрения сложности реализации корректора 324 адреса аппаратными средствами уравнение (13), которое требует наличия всего одного сумматора для прибавления 3 к rk, более эффективно, чем уравнение (12), которое требует наличия двух сумматоров для прибавления разных значений 7 и 11 к rk.
В тех случаях, когда размер кодирующего пакета NEP=792, 1560, 3096, 6168 и 12312, число строк, образующих матрицу, возрастает в 2, 4, 8, 16 и 32 раза соответственно по сравнению со случаем, когда размер кодирующего пакета NEP = 408, но число кодовых символов, которые не учитываются во время генерации промежуточного адреса, равно 24 во всех случаях. Поэтому в этих случаях коэффициент коррекции адреса можно вычислить с помощью выражения для генерации, обобщенного таким образом, чтобы иметь значение m битового сдвига в качестве параметра при использовании уравнения (13). Приведенное ниже уравнение (14) иллюстрирует выражение для генерации коэффициента коррекции адреса, примененное для NEP=408, 792, 1560, 3096, 6168 и 12312 и, как показано в таблице 1, для данных размеров кодирующего пакета m равно 7, 8, 9, 10, 11 и 12 соответственно.

При этом индекс k кодового символа k=0, 1, ..., NEP=1, а индекс rk строки rk=0, 1,..., 2m-1.
В. Генерация коэффициента коррекции адреса для NEP=2328 (R=280)
Если размер кодирующего пакета равен 2328, то 2328 кодовых символов, входящих в один субблок, образуют матрицу, имеющую 1024 (=210) строк, и последний столбец этой матрицы имеет 280 кодовых символов, которые не были учтены во время генерации промежуточного адреса. Так как 280 можно выразить в виде степени числа 2 как 28+24+23, эти 280 кодовых символов будут разделены на 256 высших кодовых символов, следующие 16 кодовых символов и остальные 8 кодовых символов.
То есть 256 высших кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 4 (=1024/256), следующие 16 кодовых символов периодически вставляются каждый раз, когда индекс строки становится 64 (=1024/16), и остальные 8 кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 128 (=1024/8). Таким образом, можно считать, что 280 кодовых символов идентичны по своим шаблонам вставки через периоды индекса строки 128. Поэтому можно считать, что вставка 280 кодовых символов в 1024 строках эквивалентна вставке 35 (=280/8) кодовых символов через каждые 128 (=1024/8) строк.
Число 35 кодовых символов, подлежащих вставке, можно выразить в виде степени числа 2 как 35=32+2+1 или 35=32+4-1. Для этих двух случаев коэффициент коррекции адреса можно вычислить отдельно. Однако, как отмечалось выше, при R=24, когда 35 выражено как 32+2+1, требуется один дополнительный сумматор при реализации корректора адреса. Поэтому принцип генерации коэффициента коррекции адреса будет описан только для случая, когда 35 выражено как 32+4-1.
Когда 35 выражено как 32+4-1, сначала вставляются 32 кодовых символа в 128 строк, затем вставляются 4 кодовых символа, и затем удаляется один вставленный кодовый символ. В этом случае d равно 4 (=128/32) во время первой вставки, d равно 32 (=128/4) во время второй вставки, и d равно 128 (=128/1) во время удаления.
Для d=4 сначала вставляются 32 кодовых символа с межстрочным расстоянием 4 в последний столбец в состоянии, когда последний столбец матрицы не имеет ни одного кодового символа, так что индекс строки первого вставленного кодового символа равен 0. Следовательно, в данный момент r+ равно 0. Для d=32 дополнительно вставляются 4 кодовых символа в состоянии, когда последний столбец матрицы уже имеет 32 кодовых символа с межстрочным расстоянием 4. В этом случае первый вставляемый кодовый символ вставляется между первыми двумя кодовыми символами из уже вставленных 32 кодовых символов с учетом особенности операции BRO. Поэтому в данный момент r+ становится 2 (=(0+4)/2). И, наконец, для d=128 надо исключить один кодовый символ с высшим индексом строки из уже вставленных кодовых символов. В этом случае исключаемым кодовым символом становится кодовый символ в последней строке из вставленных во второй операции 4 кодовых символов из-за особенности операции BRO, так что r- становится 98 (=2+3х32).
В результате, при использовании уравнения (7) и уравнения (9) выражение для генерации коэффициента коррекции адреса применительно к NEP=2328 определяется как

С. Генерация коэффициента коррекции адреса для NEP=3864 (R=1816)
Если размер кодирующего пакета равен 3864, то 3864 кодовых символа, входящих в один субблок, образуют матрицу, имеющую 2048 (=211) строк, и 232 (=2048-1816) кодовых символов, которые рассматривались вместе во время генерации промежуточного адреса, должны быть исключены из последнего столбца этой матрицы. Так как 232 можно выразить в виде степени числа 2 как 27-+26+25+23, 232 кодовых символа будет разделено на 128 кодовых символов, 64 кодовых символа, 32 кодовых символа и 8 кодовых символов.
То есть из 232 кодовых символов последние 8 кодовых символов периодически исключаются каждый раз, когда индекс строки становится кратным 256 (=2048/8), значит, шаблоны исключения 232 кодовых символа идентичны шаблону исключения с периодом 256. Следовательно, можно считать, что исключение 232 кодовых символов из 2048 строк эквивалентно исключению 29 (=232/8) кодовых символов из каждых 256 строк.
Число 29 кодовых символов, подлежащих исключению, можно выразить в виде степени числа 2 как -29=-16-8-4-1 или -29=-32+4-1. Для этих двух случаев коэффициент коррекции адреса можно вычислить отдельно. Однако, если -29 выразить как -16-8-4-1, потребуется несколько дополнительных сумматоров при реализации корректора адреса. Поэтому принцип генерации коэффициента коррекции адреса будет описан только для случая, когда -29 выражено как -32+4-1.
Когда -29 выражено как -32+4-1, сначала исключаются 32 кодовых символа, затем вставляются 4 кодовых символа, и затем исключается один кодовый символ. В этом случае d равно 8 (=256/32) во время первого исключения, d равно 64 (=256/4) во время вставки и d равно 256 (=256/1) во время второго исключения.
Для d=8 сначала исключаются 32 кодовых символа с межстрочным расстоянием 8 из последнего столбца в состоянии, когда последний столбец матрицы полностью заполнен кодовыми символами, так что индекс строки первого исключаемого кодового символа равен d-1 в свете особенности операции BRO. Поэтому в данный момент r- равно 7 (=8-1). Далее, для d=64 восстанавливаются 4 кодовых символа с межстрочным расстоянием 64 из исключенных 32 кодовых символов. В этом случае первый восстановленный кодовый символ - это кодовый символ с самым низким индексом строки из исключенных 32 кодовых символов в свете особенности операции BRO. Поэтому в данный момент r+ становится 7 (=8-1). И, наконец, для d=256 снова исключается один кодовый символ с самым высоким индексом строки из восстановленных 4 кодовых символов, так что r- становится 199 (=7+3х64).
В результате при использовании уравнения (7) и уравнения (9) выражение для генерации коэффициента коррекции адреса применительно к NEP=3864 определяется как
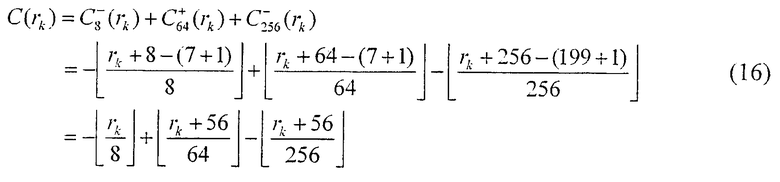
D. Генерация коэффициента коррекции адреса для NEP=4632 (R=536)
Если размер кодирующего пакета равен 4632, то 4632 кодовых символа, входящие в один субблок, образуют матрицу, имеющую 2048 (=211) строк, и последний столбец этой матрицы имеет 536 кодовых символов, которые не были рассмотрены во время генерации промежуточного адреса. Так как 536 можно выразить в виде степени числа 2 как 29 +24+23, 536 кодовых символа будет разделено на 512 высших кодовых символов, следующие 16 кодовых символа и остальные 8 кодовых символов.
То есть 512 высших кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 4 (=2048/512), следующие 16 кодовых символа периодически вставляются каждый раз, когда индекс строки становится кратным 128 (2048/16), и остальные 8 кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 256 (2048/8), то есть можно считать что шаблоны вставки 526 кодовых символов идентичны шаблонам вставки с периодами индексов строки 256. Следовательно, можно считать, что вставка 536 кодовых символов в 2048 строк эквивалентна вставке 67 (=536/8) кодовых символов в каждые 256 (2048/8) строк.
Число 67 кодовых символов, подлежащих вставке, можно выразить в виде степени числа 2 как 67=64+2+1 или 67=64+4-1. Для этих двух случаев можно отдельно вычислить коэффициент коррекции адреса. Однако, как отмечалось выше, при R=24, если 67 выразить как 64+2+1, потребуется один дополнительный сумматор при реализации корректора адреса. Поэтому принцип генерации коэффициента коррекции адреса будет описан только для случая, где 67 выражено как 64+4-1.
Когда 67 выражено как 64+4-1, сначала вставляются 64 кодовых символа в 256 строк, затем вставляется 4 кодовых символа и затем исключается один вставленный кодовый символ. В этом случае d равно 4 (=256/64) во время первой вставки, d равно 64 (=256/4) во время второй вставки и d равно 256 (=256/1) во время исключения.
Для d=4 сначала вставляются 64 кодовых символа с межстрочным расстоянием 4 в последний столбец в состоянии, когда последний столбец матрицы не имеет ни одного кодового символа, так что индекс строки первого вставленного кодового символа равен 0. Поэтому в данный момент r+ равно 0. Далее, для d=64 дополнительно вставляются 4 кодовых символа в состоянии, когда последний столбец матрицы уже имеет 64 кодовых символа с межстрочным расстоянием 4. В этом случае первый вставляемый кодовый символ вставляется между первыми двумя кодовыми символами из уже вставленных 64 кодовых символов в свете особенности операции BRO. Поэтому в данный момент r+ становится 2 (=(0+4)/2). И, наконец, для d=256 надо исключить один кодовый символ с самым высоким индексом строки из уже вставленных кодовых символов. В этом случае исключаемым кодовым символом становится кодовый символ в последней строке из вторично вставленных 4 кодовых символов в свете особенности операции BRO, так что r- становится 194 (=2+3х64).
В результате, при использовании уравнения (7) и уравнения (9) выражение для генерации коэффициента коррекции адреса применительно к NEP=4632 определяется как
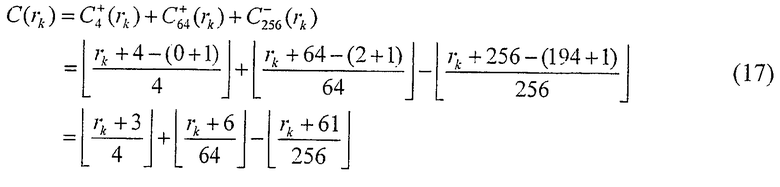
Е. Генерация коэффициента коррекции адреса для NEP=9240 (R=1048)
Если размер кодирующего пакета составляет 9240, то 9240 кодовых символа, входящих в один субблок, образуют матрицу, имеющую 4096 (=212) строк, и последний столбец этой матрицы имеет 1048 кодовых символа, которые не были рассмотрены во время генерации промежуточного адреса. Так как 1048 можно выразить в виде степени числа 2 как 210-+24+23, то 1048 кодовых символа будет разделено на 1024 высших кодовых символов, следующие 16 кодовых символа и остальные 8 кодовых символов.
То есть 1024 кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 4 (=4096/1024), следующие 16 кодовых символа периодически вставляются каждый раз, когда индекс строки становится кратным 256 (4096/16), и остальные 8 кодовых символов периодически вставляются каждый раз, когда индекс строки становится кратным 512 (4096/8), следовательно, можно считать, что шаблоны вставки 1048 кодовых символов идентичны шаблонам вставки с периодами индекса строки 512. Таким образом, можно считать, что вставка 1048 кодовых символов в 4096 строк эквивалентна вставке 131 (=1048/8) кодовых символов в каждые 512 (4096/8) строк.
Число 131 кодовых символов, подлежащих вставке, можно выразить в виде степени числа 2 как 131=128+2+1 или 131=128+4-1. Для этих двух случаев можно отдельно вычислить коэффициент коррекции адреса. Однако, как отмечалось выше, если при R=24 выразить 131 как 128+2+1, то потребуется еще один дополнительный сумматор при реализации корректора адреса. Поэтому принцип генерации коэффициента коррекции адреса будет описан только для случая, когда число 131 выражено как 128+4-1.
Когда число 131 выражено как 128+4-1, сначала вставляются 128 кодовых символов в 512 строк, затем вставляется 4 кодовых символа и затем исключается один вставленный кодовый символ. В этом случае d равно 4 (=512/128) во время первой вставки, d равно 128 (=512/4) во время второй вставки и d равно 512 (=512/1) во время исключения.
Для d=4 сначала вставляются 128 кодовых символа с межстрочным расстоянием 4 в последний столбец в состоянии, когда последний столбец матрицы не содержит ни одного кодового символа, так что индекс строки первого вставленного кодового символа равен 0. Поэтому в данный момент r+ равно 0. Для d=128 дополнительно вставляются 4 кодовых символа в состоянии, когда последний столбец матрицы уже имеет 128 кодовых символов с межстрочным расстоянием 4. В этом случае первый вставляемый кодовый символ вставляется между первыми двумя кодовыми символами из уже вставленных 128 кодовых символов в свете особенности операции BRO. Поэтому в данный момент r+ становится 2 (=0+4/2). И, наконец, для d=512 надо исключить один кодовый символ с самым высоким индексом строки из уже вставленных кодовых символов. В этом случае исключаемым кодовым символом становится кодовый символ в последней строке из вставленных во втором случае 4 кодовых символов в свете особенности операции BRO, так что r- становится 386 (=2+3х128).
В результате, при использовании уравнения (7) и уравнения (9) выражение для генерации коэффициента коррекции адреса применительно к NEP=9240 определяется как

F. Генерация коэффициента коррекции адреса для NEP=15384 (R=7192)
Если размер кодирующего пакета равен 15384, то 15384 кодовых символа, входящие в один субблок, образуют матрицу, имеющую 8192 (=213) строк, и 1000 (=8192-7192) кодовых символов, которые рассматривались вместе во время генерации промежуточного адреса, необходимо исключить из последнего столбца этой матрицы. Так как 1000 можно выразить в видестепени числа 2 как 29+28+27+26+25+23, то 1000 кодовых символа будет разделено на 512 кодовых символов, 256 кодовых символов, 128 кодовых символов, 64 кодовых символа, 32 кодовых символа и 8 кодовых символов.
То есть из 1000 кодовых символов последние 8 кодовых символов периодически исключаются каждый раз, когда индекс строки становится кратным 1024 (=8192/8), Следовательно, шаблоны исключения для 1000 кодовых символов идентичны шаблонам исключения с периодом 1024. Поэтому можно считать, что исключение 1000 кодовых символов из 8192 строк эквивалентно исключению 125 (=1000/8) кодовых символов в каждых 1024 строках.
Число 125 кодовых символов, подлежащих исключению, можно выразить как -125=-64-32-16-8-4-1 или -125=-128+4-1 в виде степени числа 2. Для этих двух случаев можно отдельно вычислить коэффициент коррекции адреса. Однако, если -125 выразить как -64-32-16-8-4-1, то потребуется несколько дополнительных сумматоров при реализации корректора адреса. Поэтому принцип генерации коэффициента коррекции адреса будет описан только для случая, когда -125 выражено как -128+4-1.
Когда -125 выражено как -128+4-1, сначала исключаются 128 кодовых символа, затем вставляются 4 кодовых символа и затем исключается один кодовый символ. В этом случае d равно 8 (=1024/128) во время первого исключения, d равно 256 (=1024/4) во время вставки и d равно 1024 (=1024/1) во время второго исключения.
Для d=8 сначала исключаются 128 кодовых символов с межстрочным расстоянием 8 из последнего столбца в состоянии, когда последний столбец матрицы полностью заполнен кодовыми символами, так что индекс строки первого исключенного кодового символа равен d-1 в свете особенности операции BRO. Поэтому в данный момент r- равно 7 (=8-1). Далее, для d=256 восстанавливаются 4 кодовых символа с межстрочным расстоянием 256 из исключенных 128 кодовых символов. В этом случае первым восстанавливаемым кодовым символом является кодовый символ с самым низким индексом строки из исключенных 128 кодовых символов в свете особенности операции BRO. Поэтому в данный момент r+ становится 7 (=8-1). И, наконец, для d=1024 снова исключается один кодовый символ с самым высоким индексом строки из восстановленных 4 кодовых символов, так что r- становится 775 (=7+3х256).
В результате при использовании уравнения (7) и уравнения (9) выражение для генерации коэффициента коррекции адреса применительно к NEP=15384 определяется как

Как было описано выше, в подвижной станции, поддерживающей стандарт 1xEV-DV, перемежение субблоков для прямого трафика пакетных данных выполняется таким образом, что когда генератор 322 промежуточного адреса генерирует промежуточный адрес согласно уравнению (5) и уравнению (6), корректор 324 адреса генерирует коэффициент коррекции адреса, используя одно из уравнений (14), (15), (16), (17), (18) и (19), и сумматор 326 генерирует адрес считывания путем вычисления уравнения (4).
Следовательно, если уравнение (6) и одно из уравнений (14), (15), (16), (17), (18) и (19), выбранное в зависимости от размера пакета, подставить в уравнение (4), то можно получить приведенные ниже уравнения (20), (21), (22), (23), (24) и (25). Уравнение (20) представляет собой выражение для генерации адреса считывания из входного буфера 310 для NEP=408 (m=7), 792 (m=8), 1560 (m=9), 3096 (m=10), 6168 (m=11) и 12312 (m=12). Уравнение (21) представляет собой выражение для генерации адреса считывания из входного буфера 310 для NEP=2328. Уравнение (22) представляет собой выражение для генерации адреса считывания из входного буфера 310 для NEP=3864. Уравнение (23) представляет собой выражение для генерации адреса считывания из входного буфера 310 для NEP=4632. Уравнение (24) представляет собой выражение для генерации адреса считывания из входного буфера 310 для NEP=9240. Уравнение (25) представляет собой выражение для генерации адреса считывания из входного буфера 310 для NEP=15384.




На фиг.10 представлена структурная схема генератора 320 адреса деперемежения, который генерирует адрес для считывания кодовых символов, записанных во входном буфере 310, для NEP=408 (m=7), 792 (m=8), 1560 (m=9), 3096 (m=10), 6168 (m=11) и 12312 (m=12) и J=4. Эта конструкция представляет собой аппаратное средство для реализации уравнения (20).
Как показано на чертеже, если индекс k требуемого кодового символа поступает из канального декодера 330 в генератор 322а промежуточного адреса, делитель 400 выдает максимальное целое число, не превышающее частное, полученное при делении индекса k кодового символа на 2m. Целое число с выхода делителя 400 подается в сумматор 406. Оператор BRO 402 группирует биты, полученные при делении индекса k кодового символа на 2m, выполняет операцию BRO на индексе строки для символов каждой группы на m битах, и вычисляет индекс строки rk для индекса k кодового символа. То есть для 408 бит, биты от 0-го до 127-го образуют первую группу, биты от 128-го до 255-го образуют вторую группу, и биты от 256-го до 383-го образуют третью группу. Символы, имеющие одинаковый индекс строки в каждой группе, одинаково подвергаются операции BRO. Такая группировка одинаково применяется к различным вариантам, приведенным ниже. Умножитель 404 умножает индекс rk строки на 3 (=J-1) и выдает результат в сумматор 406. Затем сумматор 406 вычисляет промежуточный адрес IAk путем прибавления вывода 3rk умножителя 404 к выводу k/2m делителя 400.
Если индекс строки rk подается в корректор 324а адреса, сумматор 410 прибавляет 2m-5-1 к индексу строки rk и передает результат в делители 412 и 414. Делитель 412 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+2m-5-1' сумматора 410 на 2m-5, а делитель 414 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+2m-5-1' сумматора 410 на 2m-3. Сумматор 416 вычисляет коэффициент коррекции адреса C(rk) путем вычитания вывода делителя 414 из вывода делителя 412. И, наконец, сумматор 326 вычисляет адрес считывания Ak путем прибавления коэффициента коррекции адреса C(rk) к промежуточному адресу IAk.
На фиг.11 показана структурная схема генератора 320 адреса деперемежения, который генерирует адрес для считывания кодовых символов, записанных во входном буфере 310, для NEP=3238 (m=10 и J=3). Эта конструкция представляет собой аппаратное средство для реализации уравнения (21).
Как показано, если индекс k требуемого кодового символа подается из канального декодера 330 в генератор 322b промежуточного адреса, делитель 420 выдает в сумматор 426 максимальное целое число, не превосходящее частное, полученное при делении индекса k кодового символа на 2m. Оператор 422 BRO группирует биты, полученные при делении индекса k кодового символа на 2m, выполняет операцию BRO на индексе строки для символов каждой группы на m бит, и вычисляет индекс rk строки для индекса k кодового символа. Умножитель 424 умножает индекс rk строки на 2 (=J-1) и выдает результат в сумматор 426. Сумматор 426 затем вычисляет промежуточный адрес IAk путем прибавления вывода 3rk умножителя 424 к выводу k/2m делителя 420.
Если индекс rk строки подается в корректор адреса 324b, то сумматор 430 прибавляет 3 к индексу rk строки, и делитель выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+3' сумматора 430 на 4. Сумматор 432 прибавляет 29 к индексу rk строки и передает результат в делители 436 и 438. Делитель 436 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+29' сумматора 432 на 32, а делитель 438 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+29' сумматора 432 на 128. Сумматор 440 вычисляет коэффициент коррекции адреса C(rk) путем сложения вывода делителя 436 с выводом делителя 434 и последующего вычитания вывода делителя 438 из результата сложения. И, наконец, сумматор 326 вычисляет адрес Ak считывания путем сложения коэффициента коррекции адреса C(rk) с промежуточным адресом IAk.
На фиг.12 показана структурная схема генератора 320 адреса деперемежения, который генерирует адрес для считывания кодовых символов, записанных во входном буфере 310, для NEP=3864 (m=11 и J=2). Эта конструкция представляет собой аппаратное средство для реализации уравнения (22).
Как показано, если индекс k требуемого кодового символа поступает из канального декодера 330 в генератор 322с промежуточного адреса, делитель 450 подает в сумматор 456 максимальное целое число, не превышающее частное, полученное при делении индекса k кодового символа на 2m. Оператор 452 BRO группирует биты, полученные при делении индекса k кодового символа на 2m, выполняет операцию BRO на индексе строки для символов каждой группы на m бит, и вычисляет индекс rk строки для индекса k кодового символа. Умножитель 454 умножает индекс rk строки на 2 (=J) и выдает результат в сумматор 456. Сумматор 426 затем вычисляет промежуточный адрес IAk путем прибавления вывода 2rk умножителя 454 к выводу k/2m делителя 450.
Если индекс rk строки подается в корректор 324с адреса, делитель 462 выдает максимальное целое число, не превышающее частное, полученное при делении индекса rk строки на 8. Сумматор 460 прибавляет 56 к индексу rk строки и передает результат в делители 464 и 466. Делитель 464 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+56' сумматора 460, на 64, а делитель 466 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+56' сумматора 460 на 256. Сумматор 468 вычисляет коэффициент коррекции адреса C(rk) путем вычитания вывода делителя 462 и вывода делителя 466 из вывода делителя 464. И, наконец, сумматор 326 вычисляет адрес Ak считывания путем сложения коэффициента коррекции адреса C(rk) с промежуточным адресом IAk.
На фиг.13 показана структурная схема генератора 320 адреса деперемежения, который генерирует адрес для считывания кодовых символов, записанных во входном буфере 310, для NEP=4632 (m=11 и J=3). Эта конструкция представляет собой аппаратное средство для реализации уравнения (23).
Как показано, если индекс k требуемого кодового символа подается из канального декодера 330 в генератор 322d промежуточного адреса, делитель 470 подает в сумматор 476 максимальное целое число, не превышающее частное, полученное при делении индекса k кодового символа на 2m. Оператор 422 BRO группирует биты, полученные при делении индекса k кодового символа на 2m, выполняет операцию BRO на индексе строки для символов каждой группы на m бит, и вычисляет индекс rk строки для индекса k кодового символа. Умножитель 474 умножает индекс rk строки на 2 (=J-1) и выдает результат в сумматор 476. Сумматор 476 затем вычисляет промежуточный адрес IAk путем прибавления вывода 2rk умножителя 474 к выводу k/2m делителя 470.
Если индекс rk строки подается в корректор 324d адреса, сумматор 480 прибавляет 3 к индексу rk строки, и делитель 484 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+3' сумматора 480 на 4. Сумматор 482 прибавляет 61 к индексу rk строки и выдает результат в делители 490 и 492. Делитель 490 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+61' сумматора 482 на 64, а делитель 492 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+61' сумматора 482 на 256. Сумматор 494 вычисляет коэффициент коррекции адреса C(rk) путем прибавления вывода делителя 484 к выводу делителя 490 с последующим вычитанием вывода делителя 492 из результата сложения. И, наконец, сумматор 326 вычисляет адрес Ak считывания путем сложения коэффициента коррекции адреса C(rk) с промежуточным адресом IAk.
На фиг.14 показана структурная схема генератора 320 адреса деперемежения, который генерирует адрес для считывания кодовых символов, записанных во входном буфере 310, для NEP=9240 (m=12 и J=3). Эта конструкция представляет собой аппаратное средство для реализации уравнения (24).
Как показано, если индекс k требуемого кодового символа поступает из канального декодера 330 в генератор 322е промежуточного адреса, делитель 500 подает в сумматор 506 максимальное целое число, не превышающее частное, полученное при делении индекса k кодового символа на 2m. Оператор 502 BRO группирует биты, полученные при делении индекса k кодового символа на 2m, выполняет операцию BRO на индексе строки для символов каждой группы на m бит, и вычисляет индекс rk строки для индекса k кодового символа. Умножитель 504 умножает индекс rk строки на 2 (=J-1) и выдает результат в сумматор 506. Сумматор 506 затем вычисляет промежуточный адрес IAk путем прибавления вывода 2rk умножителя 504 к выводу k/2m делителя 500.
Если индекс rk строки подается в корректор 324e адреса, сумматор 510 прибавляет 3 к индексу rk строки, а делитель 514 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+3' сумматора 510 на 4. Сумматор 512 прибавляет 125 к индексу rk строки и передает результат в делители 516 и 518. Делитель 516 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+125' сумматора 512 на 128, а делитель 518 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+125' сумматора 512 на 512. Сумматор 520 вычисляет коэффициент коррекции адреса C(rk) путем сложения вывода делителя 514 с выводом делителя 516 и последующего вычитания вывода делителя 518 из результата сложения. И, наконец, сумматор 326 вычисляет адрес Ak считывания путем сложения коэффициента коррекции адреса C(rk) с промежуточным адресом IAk.
На фиг.15 показана структурная схема генератора 320 адреса деперемежения, который генерирует адрес для считывания кодовых символов, записанных во входном буфере 310, для NEP=15384 (m=13 и J=2). Эта конструкция представляет собой аппаратное средство для реализации уравнения (25).
Как показано, если индекс k требуемого кодового символа поступает из канального декодера 330 в генератор 322f промежуточного адреса, делитель 530 выдает в сумматор 536 максимальное целое число, не превышающее частное, полученное при делении индекса k кодового символа на 2m. Оператор 532 BRO группирует биты, полученные при делении индекса k кодового символа на 2m, выполняет операцию BRO на индексе строки для символов каждой группы на m бит, и вычисляет индекс rk строки для индекса k кодового символа. Умножитель 534 умножает индекс rk строки на 2(=J) и выдает результат в сумматор 536. Сумматор 526 затем вычисляет промежуточный адрес IAk путем прибавления вывода 2rk умножителя 534 к выводу k/2m делителя 530.
Если индекс rk строки подается в корректор 324f адреса, сумматор 542 выдает максимальное целое число, не превышающее частное, полученное при делении индекса rk строки на 8. Сумматор 540 прибавляет 248 к индексу rk строки и передает результат в делители 544 и 546. Делитель 544 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+248' сумматора 540 на 256, а делитель 546 выдает максимальное целое число, не превышающее частное, полученное при делении вывода 'rk+248' сумматора 540 на 1024. Сумматор 548 вычисляет коэффициент коррекции адреса C(rk) путем вычитания вывода делителя 542 и вывода делителя 546 из вывода делителя 544. И, наконец, сумматор 326 вычисляет адрес Ak считывания путем сложения коэффициента коррекции адреса C(rk) с промежуточным адресом IAk.
Данный вариант осуществления настоящего изобретения обладает следующими преимуществами. В системе подвижной связи, использующей правило деперемежения, установленное стандартом 1xEV-DV, настоящее изобретение позволяет выполнять деперемежение потока перемеженных данных с высокой скоростью для восстановления исходного кодирующего пакета. В частности, согласно настоящему изобретению в память записываются субблоки принятых кодовых символов, считываются кодовые символы согласно адресам считывания, сгенерированным согласно правилу деперемежения, и считанные кодовые символы выдаются в декодер, что позволяет минимизировать необходимую емкость памяти и количество аппаратных элементов, необходимых для вычисления адресов считывания. Это гарантирует миниатюризацию и снижение мощности приемника. Кроме того, в настоящем изобретении деперемежение выполняется на субблоках раздельно, так что декодер может одновременно декодировать множество субблоков, что также позволяет повысить скорость декодирования и обеспечить высокоскоростную передачу данных.
Несмотря на то, что изобретение было описано и проиллюстрировано со ссылкой на его конкретные варианты, специалистам будет понятно, что можно внести различные изменения в форму и детали изобретения, не выходя за рамки объема притязаний, охарактеризованных в прилагаемой формуле изобретения.










Изобретение относится к системе связи с высокоскоростной передачей пакетных данных и, в частности, к способу и устройству для приема перемеженных данных и для считывания записанных символов посредством перемежения в приемнике системы подвижной связи. Сущность изобретения заключается в том, что перемеженный кодирующий пакет имеет значение m сдвига разрядов, верхнее предельное значение J и остаток R, и поток символов кодирующего пакета записывают по порядку столбец - строка, при этом формируют промежуточный адрес посредством инвертирования порядка разрядов при допущении, что остаток R равен 0 для принятых символов, вычисляют коэффициенты коррекции адреса для коррекции промежуточного адреса с учетом столбца, сформированного с остатком, и формируют адрес считывания путем сложения промежуточного адреса с коэффициентом коррекции адреса для требуемого декодирования символа, и считывают символ, записанный в сформированном адресе считывания. Технический результат - одновременное декодирование множества субблоков позволяет повысить скорость декодирования и обеспечить высокоскоростную передачу данных. 4 н. и 28 з.п. ф-лы, 15 ил., 1 табл.
формируют коэффициент коррекции адреса, используя остаток R, и
формируют адрес считывания для входного буфера посредством сложения промежуточного адреса с коэффициентом коррекции адреса для кодового символа, и считывают кодовый символ, записанный в сформированном адресе считывания.
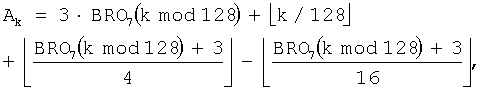
где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и  указывает максимальное целое число, не превышающее ввод ".".
указывает максимальное целое число, не превышающее ввод ".".
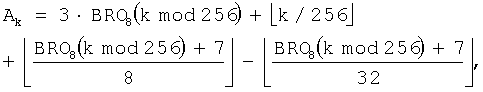
где Ak - адрес считывания, k -индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".
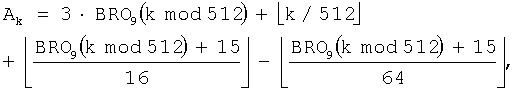
где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".

где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".

где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".
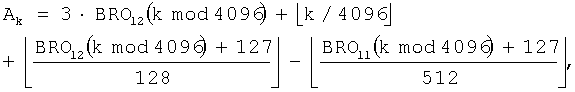
где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".

где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".
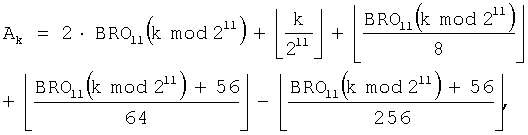
где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".

где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".

где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".

где Ak - адрес считывания, k - индекс кодового символа, BRO означает операцию BRO, mod означает операцию по модулю, и указывает максимальное целое число, не превышающее ввод ".".
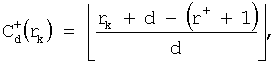
где «d» - значение, полученное посредством деления общего количества строк на количество кодовых символов, подлежащих вставке, «r+» - индекс строки, в которой расположен первый вставленный кодовый символ из оставшихся кодовых символов, вставляемых в (J+1)-ый столбец, и «+» в коэффициенте коррекции адреса  указывает, что кодовый символ «вставлен» в (J+1)-ый столбец.
указывает, что кодовый символ «вставлен» в (J+1)-ый столбец.

где «d» - значение, полученное посредством деления общего количества строк на количество кодовых символов, подлежащих исключению, «r-» - индекс строки, в которой расположен первый исключенный кодовый символ, и «-» в  указывает, что кодовый символ «исключен» из (J+1)-ro столбца.
указывает, что кодовый символ «исключен» из (J+1)-ro столбца.
складывают обработанный операцией BRO индекс столбца с индексом столбца индекса кодового символа.
генератор промежуточного адреса считывания для выполнения операции BRO на индексах столбцов индексов кодовых символов, и сложения обработанных операцией BRO индексов столбцов с индексом столбца индексов кодовых символов,
вычислитель коэффициента коррекции адреса для формирования коэффициента коррекции адресов считывания для коррекции адресов оставшихся символов из индекса кодового символа (J+1)-го столбца, и
сумматор для сложения вывода генератора промежуточного адреса считывания с выводом вычислителя коэффициента коррекции адреса.
Приоритет по пп.1-7, 10, 11, 15-21, 23-24, 28-32 - 29.10.2002;
приоритет по пп.8, 9, 12-14, 22, 25-27 - 24.09.2003.
| УСТРОЙСТВО ОБРАЩЕНИЯ ЦИКЛИЧЕСКОГО СДВИГА И ОБРАЩЕННОГО ПЕРЕМЕЖЕНИЯ ДАННЫХ | 1997 |
|
RU2189629C2 |
| US 6233711 А, 15.05.2001 | |||
| Установка для исследования волн | 1980 |
|
SU952673A1 |
| КОНТАКТНЫЙ ПАЛЕЦ ДЛЯ ЭЛЕКТРИЧЕСКИХ АППАРАТОВ | 1930 |
|
SU35102A1 |
| WO 9925069 А1, 20.05.1999. | |||

