Область техники
Изобретение относится к области вычислительной техники, в частности к системе обработки информации на основе потока данных и к способу вычислений, использующему поток данных.
Предшествующий уровень техники
Вычислительные системы, управляемые потоком данных, известны несколько десятилетий. В различных странах было создано несколько опытных функционирующих образцов, однако до настоящего времени эти системы не нашли широкого применения. Главным недостатком подобных вычислительных систем является необходимость иметь ассоциативную память большого объема для хранения промежуточных результатов вычислений.
Известна вычислительная система на основе потока данных, содержащая множество одинаковых исполнительных устройств, множество модулей ассоциативной памяти и два коммутатора, один из которых обеспечивает передачу данных из модулей ассоциативной памяти в исполнительные устройства, другой коммутатор - из исполнительных устройств в модули ассоциативной памяти, а также реализованный в ней способ обработки информации на основе потока данных (см. Optical associative memory for high performance digital computers with nontraditional architectures, V.S.Burtsev and V.B.Fyodorov, Optical Computing and Processing, 1991, volume 1, number 4, pages 275-288).
В модулях ассоциативной памяти известной вычислительной системы информация хранится в виде токенов, каждый их которых представляет структуру данных, состоящую из поля данных и поля ключа. Основной операцией в ассоциативной памяти является операция поиска токена, ключ которого совпадает с ключом входного токена. При успешном поиске из входного и найденного токенов формируется пара данных, содержащая ключ и два операнда, один из которых взят из входного токена, а другой - из найденного. На исполнительные устройства информация передается в виде пар данных. Если при операции поиска токен с заданным во входном токене ключом не был найден, то входной токен помещается в ассоциативную память и присоединяется к хранящимся токенам.
Модульность ассоциативной памяти позволяет увеличить темп выполнения операций поиска, так как поиск в различных модулях ассоциативной памяти осуществляется одновременно. Распределение токенов по модулям ассоциативной памяти осуществляется с помощью «вычисления хеш-функции», аргументом которой является ключ токена.
Недостатком известной вычислительной системы и реализованного в ней способа является относительно высокая потребляемая мощность из-за того, что в операции поиск просматривается ассоциативная память в модуле. При этом мощность выделяется из всей ассоциативной памяти. Поскольку при реализации ассоциативной памяти на основе полупроводниковой технологи выделение мощности происходит только в момент поиска, а во время хранения в ассоциативной памяти рассеивается гораздо меньшая мощность, чем при поиске, то имеет смысл организовать поиск таким образом, чтобы поиск происходил только в небольшой части ассоциативной памяти.
По технической сущности наиболее близким к предложенным изобретениям является способ обработки информации на основе потока данных, включающий следующие операции:
«обработка пары данных», представляющей собой набор данных, состоящий из двух операндов и ключа, в котором указаны действия, производимые над операндами при «обработке пары данных», при которой после выполнения указанных в ключе действий и получения результата формируют токен в виде структуры данных, состоящей из поля данных, поля контекста и поля ключа, при этом в поле данных записывают полученный результат, в поле ключа записывают информацию, в которой указаны, какие действия должны быть осуществлены в дальнейшем над результатом, а в поле контекста записывают информацию о контексте, в котором эти действия должны быть произведены;
«вычисление хеш-функции» для сформированного токена, при которой по находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен;
«направление сформированного токена в операцию поиск», где он рассматривается в качестве входного токена;
«поиск» среди сформированных указанным выше образом токенов, называемых в дальнейшем хранящимися токенами, токена, у которого ключ совпадает с ключом входного токена, «поиск» осуществляют путем сравнения ключей в группе хранящихся токенов, номер которой определен в операции «вычисление хеш-функции», при успешном «поиске» из входного и найденного токенов формируют пару данных, содержащую результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной парой данных выполняют действия, указанные в операции «обработка пары данных», при неудачном «поиске» входной токен добавляют к группе хранящихся токенов, в которой производился «поиск»;
а также устройство - система обработки информации на основе потока данных, содержащая один или несколько модулей ассоциативной памяти, каждый из которых выполнен с возможностью:
хранить поступающие в них токены, содержащие поле данных и поле ключа;
отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом входного токена;
запоминать входной токен в модулях ассоциативной памяти в случае неудачного поиска;
формировать пару данных из входного токена и найденного в ассоциативной памяти токена в случае удачного поиска и направлять сформированную пару данных в любое из исполнительных устройств;
одно или несколько исполнительных устройств, выполненных с возможностью:
выполнять инструкции, хранящиеся в доступной для исполнительного устройства памяти команд по адресам, указанным в паре данных;
формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром;
вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти;
направлять сформированный токен в любой номер модуля ассоциативной памяти в соответствии с вычисленной хэш-функцией;
первый коммутатор, выполненный с возможностью направлять токены из любого исполнительного устройства в любой модуль ассоциативной памяти; и
второй коммутатор, выполненный с возможностью направлять пары данных из любого модуля ассоциативной памяти в любое исполнительное устройство;
(см патент США №6,370,634, Data flow computer with two switches. Current U.S. Class 712/10, hitem. class G06F 015/16 of April 9, 2002).
Однако при реализации известной вычислительной системы и используемого в ней способа обработки информации возникают проблемы, связанные с тем обстоятельством, что при работе ассоциативной памяти выделяется гораздо больше энергии, чем при работе обычной памяти с произвольной выборкой (RAM - random access memory) того же объема. Это объясняется тем, что при выполнении типичной операции ассоциативного поиска в ассоциативной памяти переключаются транзисторы во всех ячейках ассоциативной памяти. Так как выделение мощности в КМОП-транзисторах, на основе которых реализована ассоциативная память, происходит только при их переключении, то выделяемая мощность пропорциональна объему ассоциативной памяти, в которой осуществляется поиск. В настоящее время выделяемая в одном кристалле мощность является ограничивающим фактором для дальнейшего увеличения количества транзисторов в одном кристалле. Поэтому проблемы снижения этой мощности являются весьма актуальными и, следовательно, проблемы снижения мощности, выделяемой ассоциативной памятью, также весьма актуальны.
Другим недостатком прототипа является большой объем аппаратных средств, необходимых для передачи информации из модуля ассоциативной памяти в свободное исполнительное устройство. Это удорожает стоимость всей вычислительной системы, увеличивает ее объем, вес и рассеиваемую мощность.
Раскрытие изобретения
Техническим результатом является уменьшение потребляемой мощности и снижение расходов на охлаждение при сохранении объема ассоциативной памяти. Дополнительным техническим результатом является сокращение объема оборудования, необходимого для реализации вычислительной системы и соответствующее сокращение ее общей стоимости.
Достигается это тем, что в способе обработки информации на основе потока данных, заключающемся в выполнении следующих операций:
«обработка пары данных», представляющей собой набор данных, состоящий из двух операндов и ключа, в котором указаны действия, производимые над операндами при «обработке пары данных», при которой после выполнения указанных в ключе действий и получения результата формируют токен в виде структуры данных, состоящей из поля данных, поля контекста и поля ключа, при этом в поле данных записывают полученный результат, в поле ключа записывают информацию, в которой указаны, какие действия должны быть осуществлены в дальнейшем над результатом, а в поле контекста записывают информацию о контексте, в котором эти действия должны быть произведены;
«вычисление хеш-функции» для сформированного токена, при котором по находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен;
«направление сформированного токена в операцию поиск», где он рассматривается в качестве входного токена;
«поиск» среди сформированных указанным выше образом токенов, называемых в дальнейшем хранящимися токенами, токена, у которого ключ совпадает с ключом входного токена, «поиск» осуществляют путем сравнения ключей в группе хранящихся токенов, номер которой определен в операции «вычисление хеш-функции», при успешном «поиске» из входного и найденного токенов формируют пару данных, содержащую результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной парой данных выполняют действия, указанные в операции «обработка пары данных», при неудачном «поиске» входной токен добавляют к группе хранящихся токенов, в которой производился «поиск», согласно изобретению в операции «поиск» каждую группу токенов разбивают на К+1 подгрупп, в каждой из которых может храниться количество токенов, не превосходящее фиксированный для этой группы размер, и нумеруют их от 0 до К;
производят «вычисление номера подгруппы» с использованием метода Н-кодирования путем определения для заданного ключа целого Ц, находящегося в интервале от 0 до К-1;
производят в найденной подгруппе с номером Ц операцию «поиск входного ключа» путем сравнения входного ключа с ключами, хранящимися в этой подгруппе;
одновременно производят операцию «поиск входного ключа» в подгруппе с номером К;
при успешном завершении операции «поиск входного ключа», при котором входной ключ найден либо в подгруппе с номером Ц, либо в подгруппе с номером К, из входного и найденного токенов выполняют операцию «формирование пары данных», которая формирует пару данных, содержащую результат, прикрепленный к входному токену, и результат, прикрепленный к найденному токену, а также ключ, прикрепленный к найденному токену;
над сформированной таким образом парой данных выполняют действия, указанные в операции «обработка пары данных»;
при неуспешном «поиске» входной токен добавляют в группу с номером Ц, а если количество токенов в этой группе равно максимально возможному, то добавляют токен в группу с номером Ц.
Поставленный технический результат по второму изобретению достигается тем, что в системе обработки информации на основе потока данных, содержащей:
один или несколько модулей ассоциативной памяти, каждый из которых выполнен с возможностью:
хранить поступающие в него токены, содержащие поле данных и поле ключа;
отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом поступающего токена;
запоминать поступающий токен в модулях ассоциативной памяти в случае неудачного поиска;
формировать пару данных из поступающего в ассоциативную память токена и найденного в ассоциативной памяти токена в случае удачного поиска и направлять сформированную пару данных в любое из исполнительных устройств;
одно или несколько исполнительных устройств, выполненных с возможностью:
выполнять инструкции, хранящиеся в доступной для исполнительного устройства памяти команд по адресам, указанным в паре данных;
формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром;
вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти;
направлять сформированный токен в любой номер модуля ассоциативной памяти в соответствии с вычисленной хэш-функцией;
первый коммутатор, выполненный с возможностью направлять токены из любого исполнительного устройства в любой модуль ассоциативной памяти; и
второй коммутатор, выполненный с возможностью направлять пары данных из любого модуля ассоциативной памяти в любое исполнительное устройство, согласно изобретению каждый модуль ассоциативной памяти выполнен с возможностью:
хранить токены, в любой из своих К+1 секций, каждая из которых имеет свой фиксированный размер, и пронумерованных от 0 до К;
получать для хранения из исполнительных устройств токен, который в этом случае именуется входным;
вычислять по информации во входном токене целое Ц, находящееся в интервале от 0 до К-1;
осуществлять операцию «поиск входного токена» по ключу входного токена в секциях с номерами Ц и К путем сравнения ключа входного токена с ключами всех хранящихся в секции токенов;
при успешном выполнении операции «поиск входного токена» выполнять операцию «формирование пары данных» и направлять ее в исполнительное устройство через коммутатор 5;
при неуспешном «поиске входного токена» записывать токен в секцию с номером Ц, а в том случае, если количество токенов в этой секции равно максимально возможному для этой секции, записывать токен в секцию с номером К.
Кроме того, в зависимости от специфики конкретного применения в указанные свойства модуля ассоциативной памяти может быть введена возможность начинать выполнение операции «поиск входного токена» над очередным поступающим в модуль ассоциативной памяти входным токеном в секции с номером Ц, не дожидаясь окончания выполнения операций «поиск входного токена» над предыдущими входными токенами, в том случае, если эти операции не выполняются в секции с номером Ц.
В некоторых применениях в качестве среды для хранения токенов предлагается использовать полупроводниковую память с произвольной выборкой, также разбитую на секции, а для сравнения входного токена с хранящимися токенами введено устройство сравнения.
С целью сгладить неравномерность поступления в модуль ассоциативной памяти входных токенов предлагается ввести в модуль ассоциативной памяти буфер входных токенов, выполненный в виде секции ассоциативной памяти.
В тех случаях, когда темп выполнения операций «обработка пары данных» превосходит темп выполнения операций «формирование пары данных», предлагается выполнить второй коммутатор с возможностью направлять пары данных, сформированные в модуле ассоциативной памяти, только в одно или несколько исполнительных устройств, непосредственно связанных только с этим модулем ассоциативной памяти.
Краткое описание чертежей
На Фиг.1 представлена структурная схема известной системы обработки информации, на Фиг.2 приведены структуры данных, используемых в известной и предлагаемой системах, на Фиг.3 приведен алгоритм выполнения операции «поиск» в модуле ассоциативной памяти, на Фиг.4 - состав модуля ассоциативной памяти согласно изобретению, на Фиг.5 - алгоритм выполнения операции поиск в модуле ассоциативной памяти с буфером токенов, на Фиг.6 - структурная схема модуля ассоциативной памяти с дополнительными исполнительными устройствами, на Фиг.7 - схема коммутатора пар данных согласно изобретению, на Фиг.8 - структурная схема вычислительной системы, приближенной к традиционной.
Лучший вариант осуществления изобретений
Известная система 1 обработки информации на основе потока, показанная на Фиг.1, данных содержит один или несколько модулей ассоциативной памяти 22, одно или несколько исполнительных устройств 33, первый коммутатор 4, выполненный с возможностью направлять токены из любого исполнительного устройства 33 в любой модуль ассоциативной памяти 22, и второй коммутатор 5, выполненный с возможностью направлять пары данных из любого модуля ассоциативной памяти 22 в любое исполнительное устройство 33.
Каждый из модулей ассоциативной памяти 22 выполнен с возможностью хранить поступающие в него токены, содержащие поле данных и поле ключа (Фиг.2а),
отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом поступающего токена,
запоминать поступающий токен в модулях ассоциативной памяти 2 в случае неудачного поиска,
формировать пару данных (Фиг.2б) из поступающего в модуль ассоциативной памяти 22 токена и найденного в ассоциативной памяти 22 токена в случае удачного поиска и направлять сформированную пару данных в любое из исполнительных устройств 33.
Каждое исполнительное устройство 33 выполнено с возможностью:
выполнять инструкции, хранящиеся в доступной для исполнительного устройства 33 памяти команд по адресам, указанным в ключе пары данных,
формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром,
вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти,
направлять сформированный токен в модуль ассоциативной памяти с любым номером в соответствии с вычисленной хэш-функцией.
Структура токенов, с которыми оперируют исполнительные устройства 33, и ассоциативная память 22 показана на Фиг.2. Пара данных, структура которой показана на Фиг.2б, формируется в модуле ассоциативной памяти 22 после выполнения операции поиска токена в том случае, если поиск удачен. Здесь поля ДАННЫЕ 1, ДАННЫЕ 2 предназначены для хранения данных, взятых из поля ДАННЫЕ входного токена и поля ДАННЫЕ найденного токена.
Особенностью технического решения устройства является то, что каждый модуль ассоциативной памяти 22 состоит из К+1 секций и устройства, вычисляющего «хэш-функцию» для каждого поступающего в модуль входного ключа. Результатом вычисления «хэш-функции» является целое Ц в диапазоне от 0 до К-1. Это целое определяет номер секции Ц, в которой должен производиться поиск токена, ключ которого совпадает с ключом входного токена. Одновременно с поиском ключа в секции с номером Ц осуществляется поиск того же ключа в секции с номером К. Поиск считается успешным, если ключ найден в секциях с номером Ц или с номером К. При успешном поиске, так же как и в прототипе, формируется пара данных и направляется через коммутатор 5 в одно из исполнительных устройств 33.
При неуспешном поиске производится попытка записи входного токена на свободное место в секцию с номером Ц. Если свободное место в секции Ц отсутствует, то запись входного токена осуществляется на свободное место в секцию с номером К.
Алгоритм выполнения операции «поиск» представлен на Фиг.3.
Предлагаемая организация модуля ассоциативной памяти имеет преимущество перед прототипом в том, что при поиске просматривается только две секции ассоциативной памяти с номерами Ц и К из имеющихся в модуле К+1 секции. В том случае если размер всех секций одинаков, во время выполнения операции «поиск» переключаются транзисторы, количество которых в (К+1)/2 раз меньше, чем в прототипе. При этом рассеивается в (К+1)/2 раз меньше мощности, чем в прототипе.
Дальнейшее уменьшение рассеиваемой мощности может быть получено в том случае, если одновременный поиск в секциях с номерами Ц и К заменить последовательным поиском. Сначала поиск осуществляется в секции с номером Ц, и только при неудачном поиске осуществляется поиск в секции с номером К. Так как вероятность нахождения искомого токена в секции с номером Ц гораздо выше, чем в секции с номером К, то рассеиваемая мощность в этом случае уменьшается еще почти в 2 раза. Правда, при этом в некоторых случаях увеличивается время выполнения операции «поиск».
Значительно увеличить количество хранящихся в модуле ассоциативной памяти токенов можно в том случае, если модуль приспособлен запоминать хранящиеся токены в обычной полупроводниковой памяти с произвольной выборкой (RAM - random access memory). В этом случае модуль ассоциативной памяти состоит из секций с номерами от 0 до К-1, в каждой из которых может храниться не больше некоторого фиксированного количества токенов. Поиск токена в секции с номером Ц состоит в последовательном считывании хранящихся в этой секции токенов в регистр и в сравнении их с ключом входного токена. Организация модуля ассоциативной памяти для простейшего случая, когда в секции может храниться только один токен, показана на Фиг.4. Здесь ключ входного токена поступает на регистр хранения ключа входного токена 11. Ключ из секции с номером Ц из памяти с произвольной выборкой 14 считывается в регистр для хранения ключа 12. Хранящиеся в регистрах 11 и 12 ключи сравниваются на схеме сравнения 13. Одновременно производится поиск входного ключа в ассоциативной памяти 15, которая рассматривается как секция с номером К. Если ключ найден в памяти с произвольной выборкой 14 или в ассоциативной памяти 15, то содержащий этот ключ токен вместе с входным токеном передается на устройство 16 для выполнения операции «формирование пары данных». Если ключ не найден, то производится попытка записать токен в память с произвольной выборкой 14. Если соответствующая секция в этой памяти занята, то запись производится в ассоциативную память 15. Такая организация модуля ассоциативной памяти имеет преимущества, связанные с тем, что, как известно, площадь кристалла, необходимая для хранения одного бита информации в памяти с произвольной выборкой, в несколько раз меньше, чем в ассоциативной памяти. В результате, при использовании памяти с произвольной выборкой на одной и той же площади можно организовать хранение токенов, количество которых в несколько раз больше, чем при использовании ассоциативной памяти.
Рассмотренное техническое решение может быть обобщено следующим образом. Вместо одного блока памяти с произвольной выборкой, в который запись и считывание токенов может происходить только последовательно один токен за другим, предлагается использовать N блоков памяти с произвольной выборкой, в каждый из которых может производиться запись и считывание токенов независимо. В этом случае каждому значению Ц соответствует N токенов по одному в каждом блоке. Аппаратные средства, в которых производится сравнение считанных из каждого блока токенов с входным токеном, приспособлены для одновременной передачи хранящегося в каждом блоке токена на схемы сравнения токенов с входным токеном и одновременного сравнения переданных токенов с входным токеном. В качестве устройства, в котором происходит сравнение ключа входного токена с ключами токенов, считанных и N блоков памяти, предлагается использовать секцию ассоциативной памяти, приспособленную для хранения N токенов. Такое решение позволяет использовать более дешевую и емкую память с произвольной выборкой, которая выполняет все требуемые для рассматриваемого применения функции более дорогой ассоциативной памяти.
В некоторых применениях систему обработки информации на основе потока данных желательно использовать и при традиционных способах обработки информации. Как известно, в современных процессорах используется КЭШ-память, расположенная на одном кристалле вместе в процессором. Это позволяет сократить время доступа к наиболее часто используемым данным и тем самым увеличить скорость обработки информации. Аналогичный прием можно использовать и в каждом модуле ассоциативной памяти. С этой целью в каждый модуль ассоциативной памяти, организованный с использованием памяти с произвольной выборкой, введена дополнительная секция ассоциативной памяти, приспособленная хранить входные токены. Алгоритм работы модуля ассоциативной памяти с такой секцией показан на Фиг.5. Можно убедиться, что дополнительная секция используется в качестве буфера, который сглаживает неравномерность поступления входных токенов в данный модуль ассоциативной памяти.
В некоторых применениях целесообразно выполнять операцию «обработка пары данных» непосредственно в том же модуле ассоциативной памяти, в котором эта пара была получена при выполнении операции «формирование пары данных». С этой целью в каждый модуль 22 ассоциативной памяти 2 предлагается ввести средства для выполнения операции «обработка пары данных». Эти средства могут состоять из одного или нескольких исполнительных устройств 333 (Фиг.6), которые по своим функциональным возможностям аналогичны исполнительным устройствам 33, а по реализации могут значительно отличаться. Например, они могут быть выполнены с привлечением меньшего количества аппаратных средств, иметь меньшую разрядность, скорость выполнения операций и т.п. Токены, полученные на этих исполнительных устройствах, могут снова поступать на секции ассоциативной памяти 222 в этом же модуле ассоциативной памяти 22 либо предаваться в другие модули ассоциативной памяти 22 через блок 66. Для передачи сформированных пар данных из секций 222 на исполнительные устройства 333 в модуль ассоциативной памяти 22 введен коммутатор пар данных 55, а для передачи токенов, полученных на исполнительных устройствах 333, в секции ассоциативной памяти 22 введен коммутатор токенов 44.
Сравнивая Фиг.1 и Фиг.6, можно убедиться, что по своей структуре система обработки информации 1 совпадает с модулем ассоциативной памяти 22. Отличие лишь в том, что система обработки информации может обмениваться информацией с ХОСТ машиной, а модуль ассоциативной памяти может обмениваться информацией с любым из исполнительных устройств 22 через коммутаторы 4 и 5. Таким образом, система обработки информации 1 допускает рекурсивный способ своего построения. В этом случае масштабирование системы, при котором система наилучшим способом приспосабливается к специфике конкретного применения, может осуществляться не только простым изменением количества исполнительных устройств 33 и модулей ассоциативной памяти 22, а совершенствованием модулей (секций) ассоциативной памяти, при котором увеличивается производительность таких секций. Разумеется, рассмотренный прием может быть применен не только к модулям 22, но и к секциям 222, вводя для этой цели подсекции 2222, и т.д.
Рекурсивный способ построения вычислительной системы 1 удачно сочетается со спецификой современной конструктивной базы. Так вычислительная система наиболее низкого уровня может быть реализована в одной интегральной схеме (ИС). Из таких вычислительных систем может быть собрана вычислительная система более высокого уровня, включающая в себя несколько ИС, объединенных печатной платой. В свою очередь несколько печатных плат могут быть объединены в блок, образуя при этом вычислительную систему еще более высокого уровня и т.д.
Рекурсивный способ построения вычислительной системы 1 удачно сочетается также с современными способами разработки программного обеспечение. Например, при восходящем способе разработки программное обеспечение разбивается на несколько уровней. На самом нижнем уровне находятся процедуры, непосредственно взаимодействующие с аппаратурой. Эти процедуры вызываются наиболее часто и к ним предъявляются самые высокие требования по эффективности работы. На более высоком уровне находятся процедуры, которые вызывают процедуры нижнего уровня. К ним предъявляются менее жесткие требования по эффективности работы. Еще на более высоком уровне находятся процедуры, которые вызывают указанные процедуры и т.д. Задержки на передачу информации внутри кристалла значительно меньше, чем при передаче информации между ИС и печатными платами. Это обстоятельство удачно сочетается с требованием, чтобы процедуры наиболее низкого уровня выполнялись с максимальной скоростью.
В некоторых применениях предпочтительно упростить коммутатор пар данных 5 за счет увеличения общего количества исполнительных устройств. Как показано на Фиг.5, из каждого модуля ассоциативной памяти 22 пары данных передаются на одно или несколько исполнительных устройств 23. Возможность передачи данных на эти же устройства из других модулей ассоциативной памяти не предусмотрена. В этом случае коммутатор 5 распадается на К независимых частей, что значительно упрощает его реализацию. В этом случае структура вычислительной системы 1 показана на Фиг.8. Эта структура весьма распространена в многопроцессорных вычислительных системах. Более того, типичный процессорный элемент содержит, кроме исполнительного устройства, КЕШ-память. Известно, что по своим принципам работа КЭШ-памяти близка к ассоциативной. Таким образом, структура процессорного элемента в рассматриваемой системе обработки информации 1 близка к общепринятой. Это дает уверенность, что при реализации системы 1 не может возникнуть непредвиденных проблем.
Изобретение было описано со ссылкой на предпочтительную реализацию. Однако в пределах области действия изобретения возможны многочисленные изменения.
Таким образом, в предложенном техническом решении достигается поставленный технический результат.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ НА ОСНОВЕ ПОТОКА ДАННЫХ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2005 |
|
RU2281546C1 |
| ВЫЧИСЛИТЕЛЬНАЯ МАШИНА | 1997 |
|
RU2130198C1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 1998 |
|
RU2148857C1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 1995 |
|
RU2110089C1 |
| КОМПЬЮТЕР | 1998 |
|
RU2216033C2 |
| УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ИНФОРМАЦИИ | 1991 |
|
RU2029359C1 |
| АССОЦИАТИВНОЕ ЗАПОМИНАЮЩЕЕ УСТРОЙСТВО | 1971 |
|
SU310308A1 |
| Вычислительная система | 1989 |
|
SU1777148A1 |
| СИСТЕМА И СПОСОБ АУГМЕНТАЦИИ ОБУЧАЮЩЕЙ ВЫБОРКИ ДЛЯ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ | 2020 |
|
RU2758683C2 |
| Устройство для управления замещением информации | 1975 |
|
SU651413A1 |
Изобретение относится к области вычислительной техники, в частности к системе обработки информации на основе потока данных и к способу вычислений, использующему поток данных. Способ заключается в выполнении следующих операций «обработка пары данных», «вычисление хеш-функции», «направление сформированного токена в операцию поиск». Операция «обработка пары данных» представляет собой набор данных, состоящий из двух операндов и ключа. После выполнения указанных в ключе действий и получения результата формируют токен в виде структуры данных, состоящей из поля данных, поля контекста и поля ключа. По находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен. Технический результат заключается в уменьшении потребляемой мощности и снижении расходов на охлаждение при сохранении объема ассоциативной памяти. 2 н. и 9 з.п. ф-лы, 8 ил.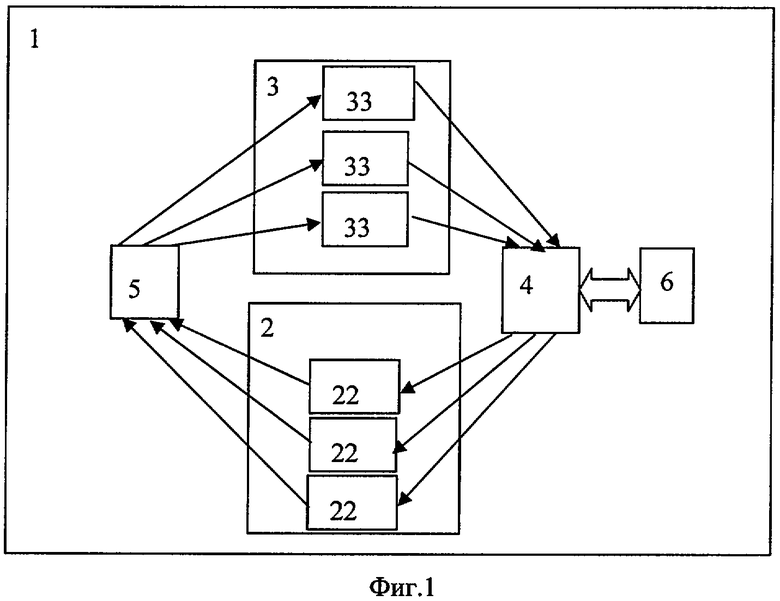
1. Способ обработки информации с использованием подхода, основанного на управлении потоком данных, включающий выполнение операции «обработка пары данных», представляющей собой набор данных, состоящий из двух операндов и ключа, где указаны действия, производимые над операндами при «обработке пары данных», при которой после выполнения указанных в ключе действий и получения результата формируют токен в виде структуры данных, состоящей из поля данных, поля контекста и поля ключа, при этом в поле данных записывают полученный результат, в поле ключа записывают информацию, в которой указаны, какие действия должны быть осуществлены в дальнейшем над результатом, а в поле контекста записывают информацию о контексте, в котором эти действия должны быть произведены, «вычисление хеш-функции» для сформированного токена, при которой по находящемуся в токене ключу определяют номер группы токенов, к которой относится сформированный токен, «направление сформированного токена в операцию «поиск», где он рассматривается в качестве входного токена, «поиск» среди сформированных указанных выше образом токенов, называемых в дальнейшем хранящимися токенами, токена, у которого ключ совпадает с ключом входного токена, «поиск» осуществляют путем сравнения ключей в группе хранящихся токенов, номер которой определен в операции «вычисление хеш-функции» и при успешном выполнении операции «поиск» над входным и найденным токенами - выполнение действия «формирование пары данных», которая содержит данные, прикрепленные к входному токену, и данные, прикрепленные к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной парой данных выполняют действия, указанные в операции «обработка пары данных», при неудачном выполнении операции «поиск» входной токен добавляют к группе хранящихся токенов, в которой производилась операция «поиск», отличающийся тем, что в операции «поиск» каждую группу токенов, среди которых производится поиск, разбивают на К+1 подгрупп, каждая из которых выполнена с возможностью хранения количества токенов, не больше фиксированного для этой группы размера, и нумеруют их от 0 до К, производят вычисление номера подгруппы путем определения для заданного ключа целого Ц, находящегося в интервале от 0 до К-1, производят поиск входного ключа только в найденной подгруппе путем сравнения входного ключа с ключами, хранящимися в этой подгруппе, одновременно производят поиск входного ключа в подгруппе с номером К, при успешном выполнении операции «поиск», при которой входной ключ найден либо в подгруппе с номером Ц, либо в подгруппе с номером К, из входного и найденного токенов формируют пару данных, которая содержит данные, прикрепленные к входному токену, данные, прикрепленные к найденному токену, а также ключ, прикрепленный к найденному токену, над сформированной таким образом парой данных выполняют действия, информация о которых хранится в ключе пары данных, при неуспешном «поиске» входной токен добавляют в группу с номером Ц, а если количество токенов в этой группе равно максимально возможному, то добавляют токен в группу с номером К.
2. Способ по п.1, отличающийся тем, что максимальное количество токенов, которое хранится в каждой из групп с номерами от 0 до К-1, равно целому Т.
3. Способ по п.1, отличающийся тем, что дополнительно вводят подгруппу токенов с номером К+2, в которой количество токенов не больше некоторого фиксированного размера, производят операцию «поиск» ключа входного токена только в подгруппе с номером К+2 путем сравнения входного ключа с ключами, хранящимися в этой подгруппе, при удачном выполнении операции «поиск» над входным и найденным токенами выполняют действие по формированию пары данных и обработке пары данных, при неудачном выполнении операции «поиск» входной токен добавляют в подгруппу с номером К+2 и над ним выполняют все действия, указанные в п.1, после завершения этих действий входной токен исключают из группы с номером К+2 в том случае, если количество находящихся в этой группе токенов превосходит некоторый установленный заранее предел.
4. Система обработки информации с использованием подхода, основанного на управлении потоком данных, содержащая один или несколько модулей ассоциативной памяти, каждый из которых выполнен с возможностью хранить поступающие в них токены, содержащие поле данных и поле ключа, отыскивать среди хранящихся токенов токены, у которых ключ совпадает с ключом поступающего токена, запоминать поступающий токен в модулях ассоциативной памяти в случае неудачного поиска, формировать пару данных из поступающего в ассоциативную память токена и найденного в ассоциативной памяти токена при удачном поиске и направлять сформированную пару данных в любое из исполнительных устройств, одно или несколько исполнительных устройств, выполненных с возможностью выполнять инструкции, хранящиеся в доступной для исполнительного устройства памяти команд по адресам, указанным в паре данных, формировать токен, содержащий поле данных и поле ключа, в котором в поле данных помещается результат выполнения инструкции, а в поле ключа - информация об инструкции, для которой этот результат является параметром, вычислять хэш-функцию, определяющую номер модуля ассоциативной памяти, направлять сформированный токен в любой номер модуля ассоциативной памяти в соответствии с вычисленной хэш-функцией, коммутатора токены для направления токенов из любого исполнительного устройства в любой модуль ассоциативной памяти, и коммутатора пар данных для направления пары данных из любого модуля ассоциативной памяти в любое исполнительное устройство, отличающаяся тем, что каждый модуль ассоциативной памяти выполнен с возможностью хранить токены в любой из своих К+1 секций, каждая из которых имеет свой фиксированный размер и пронумерованных от 0 до К, получать для хранения из исполнительных устройств токен, который в этом случае именуется входным, вычислять по информации во входном токене целое Ц, находящееся в интервале от 0 до К-1, осуществлять операцию «поиск токена» по ключу во входном токене одновременно в секциях с номерами Ц и К путем сравнения ключа входного токена с ключами всех хранящихся в секции токенов, при успешном выполнении операции «поиск токена» направлять найденный токен в устройство, выполняющее операцию «формирование пары данных» и направляющее сформированную пару данных в исполнительное устройство через коммутатор пар данных, при неуспешном выполнении операции «поиск токена» записывать токен в секцию с номером Ц, а в том случае, если количество токенов в этой секции равно максимально возможному для этой секции, записывать токен в секцию с номером К.
5. Система по п.4, отличающаяся тем, что каждая секция модуля ассоциативной памяти приспособлена осуществлять поиск поданного на ее вход входного токена одновременно с аналогичными операциями поиска токена, выполняемыми в других секциях.
6. Система по п.4, отличающаяся тем, что секции с номерами от 0 до К-1 модуля ассоциативной памяти приспособлены для хранения токенов, количество которых не больше фиксированного размера Т, и реализованы на основе полупроводниковой памяти с произвольным доступом и с возможностью одновременно направлять каждый из хранящихся в модуле токенов в дополнительные аппаратные средства, осуществляющие сравнение ключа входного токена с ключом каждого токена, направленного в них из любой секции ассоциативной памяти.
7. Система по п.6, отличающаяся тем, что в каждый модуль ассоциативной памяти введена дополнительная ассоциативная память, выполненная с возможностью хранения токенов, запоминания входных токенов, осуществления поиска ключа входного токена среди хранящихся в ней токенов, выполнения операции «формирование пары данных» при успешном выполнении операции «поиск» и запоминания входного токена при неуспешном выполнении операции «поиск», направления хранящихся в ней токенов в любую секцию модуля ассоциативной памяти и исключения из нее любого из хранящихся токенов.
8. Система по п.4, отличающаяся тем, что секции с номерами от 0 до К-1 модуля ассоциативной памяти выполнены с возможностью хранения N токенов и реализованы на основе N секций полупроводниковой памяти с произвольным доступом с возможностью одновременного направления каждого из хранящихся в секциях токенов в дополнительные аппаратные средства, осуществляющих сравнение ключа входного токена с ключом каждого из направленных в них N токенов.
9. Система по п.4, отличающаяся тем, что в модуль ассоциативной памяти введены исполнительные устройства для выполнения операции «обработка пары данных», коммутатор пар данных, сформированных в любой из секций ассоциативной памяти с номерами от 0 до К-1, в любое исполнительное устройство, и коммутатор токенов, полученных в любом исполнительном устройстве в результате выполнения операции «обработка пары данных», в любую секцию ассоциативной памяти с номерами от 1 до К.
10. Система по п.9, отличающаяся тем, что каждая секция оперативной памяти с номерами от 1 до К-1 совпадает по своей структуре с модулем ассоциативной памяти.
11. Система по п.4, отличающаяся тем, что каждый модуль ассоциативной памяти непосредственно связан с несколькими исполнительными устройствами, к которым может передаваться информация только из него без возможности передачи информации из других модулей ассоциативной памяти.
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 1995 |
|
RU2110089C1 |
| Вычислительная система | 1977 |
|
SU692400A1 |
| US 4366551 A1, 28.12.1982 | |||
| DE 3534026 A, 26.03.1987. | |||

