ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к технике улучшения речевых сигналов для улучшения связи в присутствии фонового шума. В частности, но не исключительно, настоящее изобретение относится к системе уменьшения шума, которая уменьшает уровень фонового шума в речевом сигнале.
УРОВЕНЬ ТЕХНИКИ
Уменьшение уровня фонового шума очень важно для многих систем связи. Например, мобильные телефоны используются во многих средах, в которых имеется высокий уровень фонового шума. Такие окружающие среды включают использование телефонов в автомобилях (речь идет о телефонах, которые все успешнее позволяют оставлять руки свободными) или на улице, когда система связи должна работать в присутствии высокого уровня автомобильных шумов или уличных шумов. В офисных приложениях, например при проведении видеоконференций и в Интернет-приложениях, оставляющих руки свободными, система должна эффективно справляться с шумами в офисе. На практике можно встретиться и с другими типами фоновых шумов. Уменьшение шумов, известное также как подавление шумов, или выделение речевого сигнала из шумов, становится важным для этих приложений, причем часто требуется работать при малых отношениях сигнал/шум (SNR - signal-to-noice ratio). Уменьшение шумов важно также в системах автоматического распознавания речи, которые все более широко используются в различных реальных средах. Уменьшение шумов улучшает рабочие характеристики алгоритмов кодирования речевых сигналов или алгоритмов распознавания речи, обычно используемых в вышеуказанных приложениях.
Одним из наиболее часто встречающихся способов уменьшения шумов является вычитание спектров (см. S.F.Boll, "Suppression of acoustic noise in speech using spectral subtraction" ["Подавление акустического шума в речи с использованием вычитания спектров"], IEEE Trans. Acoust., Speech, Signal Processing, vol. ASSP-27, p.p.113-120, Apr. 1979). При вычитании спектров делается попытка оценить кратковременную спектральную амплитуду речи путем вычитания оценки энергии шумов из речи с шумами. Фазу речи с шумами не обрабатывают, предполагая, что фазовые искажения не воспринимаются человеческим ухом. На практике вычитание спектров осуществляют путем формирования функции передачи на основе отношения сигнал/шум из оценок спектра шумов и спектра речи с шумами. Эту функцию передачи умножают на входной спектр, чтобы подавить частотные составляющие с низким отношением сигнал/шум. Главное неудобство при использовании обычных алгоритмов вычитания спектров заключается в том, что в результате образуется остаточный шум, состоящий из "музыкальных тонов", раздражающий слушателя, а также мешающий последующим алгоритмам обработки сигналов (например, при кодировании речи). Музыкальные тоны возникают, главным образом, вследствие дисперсии при оценках спектра. Для решения этой задачи было предложено сглаживание спектров, что приводит к уменьшению дисперсии и к хорошему разрешению. Другой известный способ уменьшения музыкальных тонов заключается в использовании коэффициента сверхвычитания в комбинации со спектральным порогом (см. М.Berouti, R.Schwartz, and J.akhoul, "Enhancement of speech corrupted by acoustic noise" ["Повышение разборчивости речи, искаженной акустическим шумом"] in Proc. IEEE ICASSP, Washington, DC, Apr. 1979, pp.208-211). Недостатком этого способа является деградация речи при значительном уменьшении музыкальных тонов. Другие подходы относятся к мягкому подавлению шумов (см. R.J.McAulay and M.L.Malpass, "Speech enhancement using a soft decision noise suppression filter" ["Повышение разборчивости речи с использованием фильтра мягкого подавления шумов"] IEEE Trans. Acoust, Speech, Signal Processing, vol. ASSP-28, pp.137-145, Apr. 1980) и нелинейному вычитанию спектров (см. Р.Lockwood and J.Boudy, "Experiments with a nonlinear spectral subtracter (NSS), hidden Markov models and projection, for robust recognition in cars" ["Эксперименты с нелинейным вычитанием спектра, скрытыми марковскими моделями и отображениями для устойчивого распознавания в автомобилях"] Speech Commun., vol.11, pp.215-228, June 1992).
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В своем первом аспекте настоящее изобретение предлагает способ подавления шумов в речевом сигнале, включающий:
проведение спектрального анализа для создания спектрального представления речевого сигнала, содержащего множество частотных бинов, и
группировку частотных бинов в множество полос частот,
отличающийся тем, что, когда в речевом сигнале обнаруживают вокализованную речевую активность, для первого количества полос частот подавление шумов выполняют по частотным бинам, а для второго количества полос частот подавление шумов выполняют по полосам частот.
В другом аспекте настоящего изобретения предложено устройство для подавления шумов в речевом сигнале, выполненное с возможностью:
проведения спектрального анализа для создания спектрального представления речевого сигнала, содержащего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающееся тем, что оно выполнено с возможностью обнаруживать вокализованную речевую активность и, при обнаружении в речевом сигнале вокализованной речевой активности, выполнять для первого количества полос частот подавление шумов по частотным бинам, а для второго количества полос частот - подавление шумов по полосам частот.
В еще одном своем аспекте настоящее изобретения предлагает речевой кодер, включающий устройство для подавления шумов, выполненное с возможностью:
проведения спектрального анализа для создания спектрального представления речевого сигнала, включающего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающийся тем, что указанное устройство выполнено с возможностью обнаруживать вокализованную речевую активность и, при обнаружении в речевом сигнале вокализованной речевой активности, выполнять для первого количества полос частот подавление шумов по частотным бинам, а для второго количества полос частот - подавление шумов по полосам частот.
В еще одном своем аспекте настоящее изобретение предлагает систему автоматического распознавания речи, включающую устройство для подавления шумов, выполненное с возможностью:
проведения частотного анализа для создания спектрального представления речевого сигнала, включающего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающуюся тем, что указанное устройство выполнено с возможностью обнаруживать вокализованную речевую активность и, при обнаружении в речевом сигнале вокализованной речевой активности, выполнять для первого количества полос частот подавление шумов по частотным бинам, а для второго количества полос частот - подавление шумов по полосам частот.
В еще одном своем аспекте настоящее изобретение предлагает мобильный телефон, включающий устройство для подавления шумов, выполненное с возможностью:
проведения частотного анализа для создания спектрального представления речевого сигнала, включающего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающийся тем, что указанное устройство выполнено с возможностью обнаруживать вокализованную речевую активность и, при обнаружении в речевом сигнале вокализованной речевой активности, выполнять для первого количества полос частот подавление шумов по частотным бинам, а для второго количества полос частот - подавление шумов по полосам частот.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Вышеописанные и другие признаки, преимущества и особенности настоящего изобретения станут понятнее из последующего не ограничивающего изобретение описания иллюстративного варианта его осуществления, данного в качестве примера со ссылками на сопровождающие чертежи, где:
на фиг.1 схематично показана работа системы передачи речи, включающая подавление шумов;
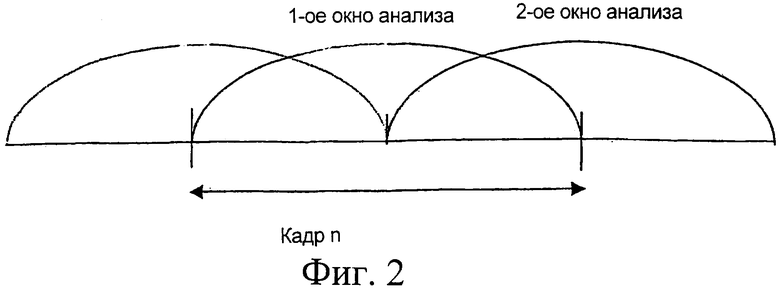
на фиг.2 показано формирование окон анализа при спектральном анализе;
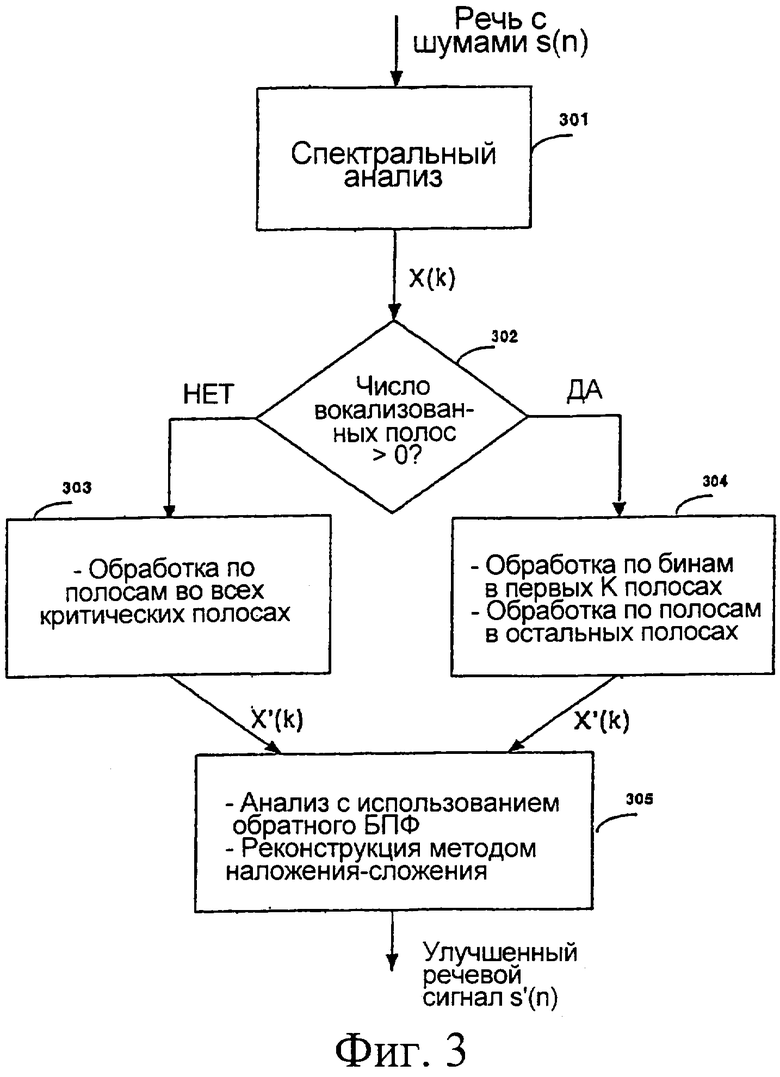
на фиг.3 показана схема примера алгоритма подавления шумов; и
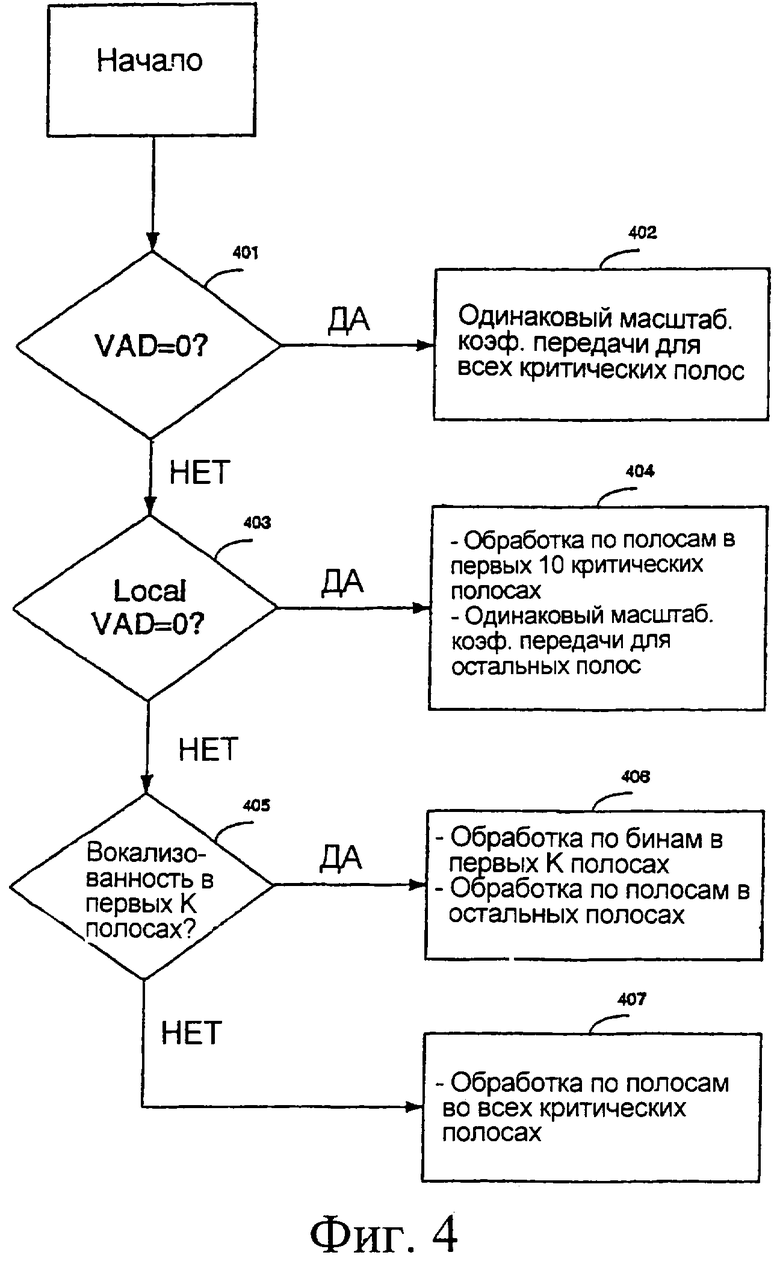
на фиг.4 схематично показана последовательность операций для иллюстративного варианта осуществления подавления шумов по классам, в котором алгоритм подавления зависит от природы обрабатываемого речевого кадра.
ПОДРОБНОЕ ОПИСАНИЕ ИЛЛЮСТРАТИВНЫХ ВАРИАНТОВ
ОСУЩЕСТВЛЕНИЯ НАСТОЯЩЕГО ИЗОБРЕТЕНИЯ
В настоящем описании раскрыты эффективные способы подавления шумов. Эти способы, по меньшей мере частично, базируются на разделении амплитудного спектра на критические полосы и вычислении функции передачи на основе отношения сигнал/шум в критической полосе, аналогично подходу, используемому в улучшенном речевом кодеке с переменной скоростью передачи [Enhanced Variable Rate Codec - EVRC] (см. 3GPP2 C.S0014-0 "Enhanced Variable Rate Codec (EVRC) Service Option for Wideband Spread Spectrum Communication Systems" ["Сервисная опция улучшенного кодека с переменной скоростью передачи для систем широкополосной связи"], 3GPP2 Technical Specification, December 1999). Например, описаны признаки, использующие различную технику обработки на основе природы обрабатываемого речевого кадра. В кадрах с глухими звуками используется обработка по полосам частот для целого спектра. В кадрах, где до определенной частоты обнаружена вокализованность, используется обработка по частотным бинам в нижней части спектра, где обнаружена вокализованность, а в остальных полосах используется обработка по полосам частот. В случае кадров с фоновыми шумами постоянный минимальный уровень шумов удаляют с использованием того же самого масштабирующего коэффициента передачи, что и для целого спектра. Кроме того, раскрыта техника, в которой сглаживание масштабирующего коэффициента передачи в каждой полосе или в каждом частотном бине выполняют с использованием коэффициента сглаживания, который находится в обратной зависимости от фактического масштабирующего коэффициента передачи (сглаживание сильнее для малых коэффициентов передачи). Этот подход предотвращает искажение в речевых сегментах с высоким отношением сигнал/шум, которым предшествуют кадры с малым отношением сигнал/шум, как это имеет место, например, в случае звонких начальных согласных слога.
Один из дополнительных аспектов настоящего изобретения предполагает создание новых способов уменьшения шумов на основе способов вычитания спектров, где способ уменьшения шумов зависит от природы обрабатываемого речевого кадра. Например, в вокализованных кадрах обработка ниже определенной частоты может быть выполнена на базе частотных бинов.
В иллюстративном варианте осуществления настоящего изобретения уменьшение шумов выполняют в системе кодирования речи с целью уменьшения уровня фонового шума в речевом сигнале перед кодированием. Раскрытые методы могут быть применены для узкополосных речевых сигналов с дискретизацией 8000 отсчетов/с, для широкополосных речевых сигналов с дискретизацией 16000 отсчетов/с или при любой другой частоте отсчетов. Кодер, используемый в этом иллюстративном варианте осуществления настоящего изобретения, основан на кодеке AMR-WB (Adaptive Multi-Rate Wideband - адаптивный многоскоростной широкополосный кодек) (см. S.F.Boll, "Suppression of acoustic noise in speech using spectral subtraction" ["Подавление акустического шума в речи с использованием вычитания спектров"] IEEE Trans. Acoust, Speech, Signal Processing, vol. ASSP-27, pp.113-120, Apr. 1979), в котором используется внутреннее преобразование частоты отсчетов сигнала до 12800 отсчетов/с (при работе с шириной полосы 6,4 кГц).
Таким образом, раскрытая в этом иллюстративном варианте осуществления настоящего изобретения техника уменьшения шумов работает или с узкополосными, или с широкополосными сигналами после преобразования частоты отсчетов до 12,8 кГц.
В случае широкополосных входных сигналов входной сигнал прореживают с преобразованием из 16 кГц в 12,8 кГц. Это прореживание выполняют, сначала повышая дискретизацию в 4 раза, а затем фильтруя выходной сигнал через фильтр нижних частот с частотой отсечки 6,4 кГц. Затем сигнал преобразуют с понижением частоты дискретизации в 5 раз. Задержка при фильтровании составляет 15 отсчетов при частоте отсчетов 16 кГц.
В случае узкополосных входных сигналов их необходимо преобразовать с повышением частоты дискретизации от 8 кГц до 12,8 кГц. Это выполняют сначала первым преобразованием с повышением дискретизации в 8 раз, а затем пропусканием выходного сигнала через фильтр нижних частот с частотой отсечки 6,4 кГц. Затем сигнал преобразуют с понижением частоты дискретизации в 5 раз. Задержка при фильтровании составляет 8 отсчетов при частоте отсчетов 8 кГц.
После преобразования частоты дискретизации до процесса кодирования к сигналу применяют две функции предварительной обработки: фильтрование верхних частот и внесение предыскажения.
Фильтр верхних частот служит мерой предосторожности против нежелательных низкочастотных компонент. В данном иллюстративном варианте осуществления настоящего изобретения используется фильтр с граничной частотой 50 Гц, это описывается функцией

Для предыскажения используется фильтр верхних частот первого порядка, чтобы поднять верхние частоты, это описывается функцией
Hpre-emph(z)=1-0.68z-1
Предыскажение используется в кодеке AMR-WB для улучшения рабочих характеристик кодека на верхних частотах и улучшения перцепционного взвешивания в процессе минимизации погрешности, используемом в кодере.
В остальной части этого иллюстративного варианта осуществления настоящего изобретения сигнал на входе алгоритма уменьшения шумов преобразуется к частоте отсчетов 12,8 кГц и подвергается вышеописанной предварительной обработке. Однако раскрытые методы могут быть одинаково применены к сигналам с другими частотами следования отсчетов, например 8 кГц или 16 кГц, с предварительной обработкой и без нее.
Ниже подробно описан алгоритм уменьшения шумов. Кодер речи, в котором используется алгоритм уменьшения шумов, работает с кадрами длиной 20 милисекунд, содержащими 256 отсчетов с частотой отсчетов 12,8 кГц. Кроме того, при анализе кодер использует опережающий просмотр будущих кадров на интервал 13 мс. Уменьшение шумов следует той же структуре кадров. Однако можно ввести некоторый сдвиг между кадрированием кодера и кадрированием при уменьшении шумов, чтобы максимально использовать опережающий просмотр. В настоящем описании индексы отсчетов отражают кадрирование, используемое при уменьшении шумов.
На фиг.1 обобщенно показана система передачи речи, включающая уменьшение шумов. На шаге 101 производят предварительную обработку, как в примере, описанном выше.
На шаге 102 проводят спектральный анализ и обнаружение речевой активности (voice activity detection - VAD). В каждом кадре проводят два спектральных анализа с использованием окон длительностью 20 мс с 50%-ым перекрытием. На шаге 103 уменьшение шумов применяют к спектральным параметрам, а затем используют обратное дискретное преобразование Фурье для преобразования улучшенного сигнала обратно во временную область. Затем для реконструкции сигнала используют операцию наложения-сложения.
На шаге 104 используют анализ с линейным предсказанием (LP) и анализ основного тона без обратной связи (обычно как часть алгоритма кодирования речевых сигналов). В этом иллюстративном варианте осуществления настоящего изобретения параметры, определяемые на шаге 104, используют для принятия решения об обновлении оценки шума в критических полосах (шаг 105). Решение об обнаружении речи также может использоваться для принятия решения об обновлении оценки шумов. Оценки энергии шумов, обновленные на шаге 105, используют в следующем кадре при уменьшении шумов (шаг 103) для вычисления масштабирующего коэффициента передачи. На шаге 106 выполняют кодирование речи для улучшенного сигнала. В других приложениях шаг 106 может относиться к работе системы автоматического распознавания речи. Следует отметить, что функции, выполняемые на шаге 104, могут быть встроены в алгоритм кодирования речи.
Спектральный анализ
Для проведения спектрального анализа и оценки энергии спектра используется дискретное преобразование Фурье (ДПФ). Спектральный анализ проводится дважды за кадр с использованием быстрого преобразования Фурье (БПФ) для 256 точек с 50-процентным перекрытием (как показано на фиг.2). Окна анализа размещены так, чтобы полностью использовать опережающий просмотр. Начало первого окна размещено в 24 отсчетах от начала текущего кадра кодера речи. Второе окно размещено на 128 отсчетов дальше. При спектральном анализе для взвешивания входного сигнала используется квадратный корень окна Ханна (что эквивалентно синусоидальному окну). Это окно особенно хорошо подходит для методов "наложения-сложения" (overlap-add) (таким образом, этот конкретный спектральный анализ используется в алгоритме подавления шумов, основанном на вычитании спектров и анализе/синтезе методом наложения-сложения). Квадратный корень окна Ханна задается следующим выражением:
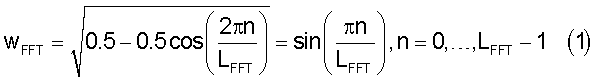
где LFFT=256 - размерность быстрого преобразования Фурье. Следует отметить, что вычисляют и сохраняют только половину окна, поскольку оно симметрично (от 0 до LFFT/2).
Пусть s'(n) обозначает сигнал, а индекс 0 соответствует первому отсчету в кадре уменьшения шумов (в данном иллюстративном варианте осуществления настоящего изобретения он находится на 24 отсчета дальше, чем начало кадра кодера речи). Сигнал в пределах окна для обоих спектральных анализов получают в виде:
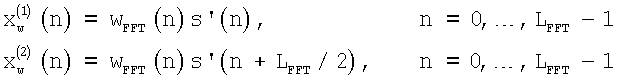
где s'(0) - первый отсчет в имеющемся кадре уменьшения шумов.
Быстрое преобразование Фурье выполняют на обоих сигналах, обработанных окном, чтобы получить два набора спектральных параметров на кадр:
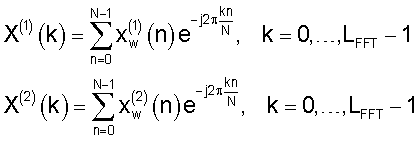
На выходе после быстрого преобразования Фурье получаются действительная и мнимая части спектра, обозначенные XR(k), k=0...128 и Xl(k), k=1...127. Отметим, что ХR(0) соответствует спектру при 0 Гц (сигнал постоянного тока), а ХR(128) соответствует спектру при 6400 Гц. Спектр в этих точках имеет только действительную составляющую, и его при последующем анализе обычно игнорируют.
После анализа с использованием быстрого преобразования Фурье полученный в результате спектр разделяют на критические полосы с использованием интервалов, имеющих следующие верхние границы (20 полос в частотном диапазоне 0-6400 Гц):
Критические полосы = {100,0; 200,0; 300,0; 400,0; 510,0; 630,0; 770,0; 920,0; 1080,0; 1270,0; 1480,0; 1720,0; 2000,0; 2320,0; 2700,0; 3150,0; 3700,0; 4400,0; 5300,0; 6350,0} Гц.
См. D.Johnston, "Transform coding of audio signal using perceptual noise criteria" ["Кодирование сигнала звуковой частоты с преобразованием с использованием перцепционных критериев шумов"], IEEE J.Select. Areas Commiin., vol.6, pp.314-323, Feb. 1988.
Быстрое преобразование Фурье для 256 точек дает разрешающую способность по частоте 50 Гц (6400/128). Таким образом, игнорируя постоянную компоненту спектра, количество частотных бинов (частот анализа ДПФ) на критическую полосу равно МCB={2, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4, 5, 6, 6, 8, 9, 11, 14, 18, 21}, соответственно.
Среднюю энергию в критической полосе вычисляют согласно следующему выражению:
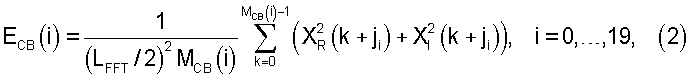
где ХR(k) и Xl(k) - соответственно действительная и мнимая части k-го частотного бина, а ji - индекс первого бина в i-ой критической полосе, задаваемый как ji={1, 3, 5, 7, 9, 11, 13, 16, 19, 22, 26, 30, 35, 41, 47, 55, 64, 75, 89, 107}.
Модуль спектрального анализа вычисляет также энергию на частотный бин, EBIN(k), для первых 17 критических полос (74 бина за исключением постоянного компонента)

Наконец, модуль спектрального анализа вычисляет среднюю полную энергию для обоих анализов быстрого преобразования Фурье в кадре длиной 20 мс, складывая средние энергии критических полос ЕCB. Таким образом, энергию спектра для некоторого спектрального анализа вычисляют как
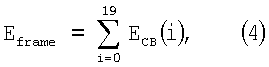
и полную энергию кадра вычисляют как среднее от энергий спектра для обоих спектральных анализов в кадре. То есть
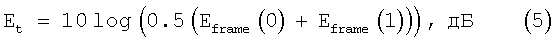
Выходные параметры модуля спектрального анализа, то есть средняя энергия на критическую полосу, энергия на частотный бин и полная энергия, используются в модулях обнаружения речевой активности, подавления шумов и выбора скорости.
Следует отметить, что для узкополосных входных сигналов с частотой отсчетов 8000 отсчетов/с после преобразования частоты отсчетов до 12800 отсчетов/с оба края спектра не несут информации, таким образом, первая наиболее низкочастотная критическая полоса, а также три последние высокочастотные полосы при вычислении выходных параметров не учитываются (учитываются только полосы от i=1 до 16).
Обнаружение речевой активности
Вышеописанный спектральный анализ выполняют дважды за кадр. Пусть 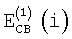 и
и 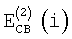 обозначают информацию об энергии на критическую полосу для первого и второго спектрального анализа соответственно (вычисленные согласно уравнению (2)). Среднюю энергию на критическую полосу для целого кадра и части предыдущего кадра вычисляют как
обозначают информацию об энергии на критическую полосу для первого и второго спектрального анализа соответственно (вычисленные согласно уравнению (2)). Среднюю энергию на критическую полосу для целого кадра и части предыдущего кадра вычисляют как
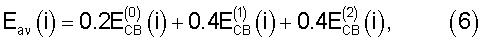
где 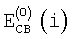 обозначает информацию об энергии, приходящейся на критическую полосу, при втором анализе предыдущего кадра. Отношение сигнал/шум (SNR) в критический полосе затем вычисляют как
обозначает информацию об энергии, приходящейся на критическую полосу, при втором анализе предыдущего кадра. Отношение сигнал/шум (SNR) в критический полосе затем вычисляют как
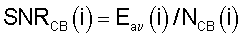 с ограничительным условием
с ограничительным условием 
где NCB(i) - оцененная энергия шумов в критической полосе, вычисление которой будет описано в следующем разделе. Среднее отношение сигнал/шум в кадре тогда вычисляют как
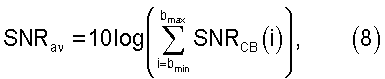
где bmin=0 и bmax=19 в случае широкополосных сигналов, и bmin=1 и bmax=16 в случае узкополосных сигналов.
Активность речи обнаруживают, сравнивая среднее отношение сигнал/шум в кадре с определенным порогом, который зависит от долговременного отношения сигнал/шум. Долговременное отношение сигнал/шум дается выражением

где  и
и 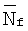 вычисляют с использованием уравнений (12) и (13) соответственно, которые приведены ниже. Исходное значение
вычисляют с использованием уравнений (12) и (13) соответственно, которые приведены ниже. Исходное значение  равно 45 дБ.
равно 45 дБ.
Порог представляет собой кусочно-линейную функцию долговременного отношения сигнал/шум. Используются две функции: одна для чистой речи и одна для речи с шумами.
Для широкополосных сигналов, если SNRLT<35 (речь с шумами), то
thVAD=0.4346SNRLT+13.9575
в противном случае (чистая речь),
thVAD=1.0333SNRLT-7
Для узкополосных сигналов, если SNRLT<29.6 (речь с шумами), то
thVAD=0.313SNRLT+14.6
в противном случае (чистая речь),
thVAD=1.0333SNRLT-7
Кроме того, при принятии решения об обнаружении речи добавляют гистерезис, чтобы предотвратить частое переключение в конце периода речевой активности. Это применяют в случае, когда кадр относится к периоду "мягкого" поддержания в силе решения об обнаружении речевой активности или если последний кадр является кадром активной речи. Период "мягкого" поддержания в силе решения об обнаружении речевой активности состоит из первых 10 кадров после каждой последовательности кадров активной речи длиной более 2 последовательных кадров. В случае речи с шумами (SNRLT<35) гистерезис уменьшает порог принятия решения об обнаружении речи следующим образом
ihVAD=0.95thVAD
В случае чистой речи гистерезис уменьшает порог принятия решения об обнаружении речи следующим образом
ihVAD=thVAD-11
Если среднее отношение сигнал/шум в кадре больше, чем порог принятия решения об обнаружении речи, то есть если SNRaν>thVAD, то кадр объявляется кадром активной речи, а флаг обнаружения речи (VAD) и локальный флаг обнаружения речи (Local VAD) устанавливают равными 1. В противном случае флаг обнаружения речи и локальный флаг обнаружения речи устанавливают на 0. Однако в случае речи с шумами флаг обнаружения речи принудительно устанавливают равным 1 в кадрах "жесткого" поддержания в силе решения об обнаружении речевой активности, то есть в одном или двух неактивных кадрах, следующих после периода речи продолжительностью более чем 2 последовательных кадра (локальный флаг обнаружения речи при этом равен 0, однако флаг обнаружения речи принудительно установлен на 1).
Первый уровень оценки и обновления шумов
В этом разделе поясняется вычисление полной энергии шумов, относительной энергии в кадре, обновление долговременного среднего значения энергии шумов и вычисление долговременной средней энергии в кадре, среднее значение в критический полосе и коэффициент коррекции шумов. Ниже поясняется задание начального значения энергии шумов и обновление.
Полная энергия шумов в кадре дается выражением
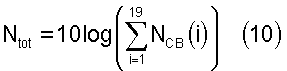
где NCB(i) - оцененная энергия шумов в критической полосе.
Относительная энергия в кадре дается разностью между энергией в кадре в дБ и долговременной средней энергией. Относительная энергия в кадре дается выражением

где Et дается уравнением (5).
Долговременная средняя энергия шумов или долговременная средняя энергия в кадре обновляется в каждом кадре. В случае кадров активной речи (флаг обнаружения речи VAD=1) долговременную среднюю энергию в кадре обновляют с использованием соотношения
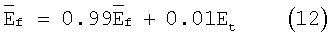
с начальным значением 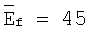 дБ.
дБ.
В случае кадров без речевой активности (флаг обнаружения речи VAD=0) значение долговременной средней энергии шумов обновляют согласно следующему выражению
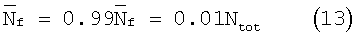
Начальное значение 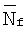 устанавливают равным Ntot для первых 4 кадров. Затем в первых 4 кадрах значение
устанавливают равным Ntot для первых 4 кадров. Затем в первых 4 кадрах значение  ограничивают условием
ограничивают условием 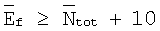 .
.
Энергия кадра на критическую полосу, инициализация шума и обновление шума по нисходящей
Энергию на критическую полосу для целого кадра вычисляют путем усреднения энергий, полученных в обоих спектральных анализах в кадре. Таким образом,
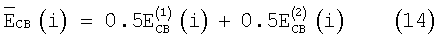
Энергию шумов в критической полосе NCB(i) изначально полагают равной 0,03. Однако в первых 5 субкадрах, если энергия сигнала не слишком высока или если сигнал не имеет сильных высокочастотных составляющих, то энергию шумов инициализируют с использованием энергии в критической полосе, чтобы алгоритм уменьшения шумов мог быть эффективным с самого начала обработки. Вычисляют два высокочастотных отношения: r15,16 - отношение между средней энергией в критических полосах 15 и 16 и средней энергией в первых 10 полосах (среднее по результатам обоих спектральных анализов), и r18,19 - аналогично для полос 18 и 19.
В первых 5 кадрах, если Et<49, r15,16<2 и r18,19<1.5, то для первых 3 кадров
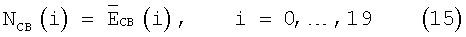
а для следующих двух кадров NCB(i) обновляют так:
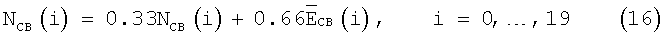
Для последующих кадров на данном этапе обновляют только энергию шумов по нисходящей для критических полос, в результате чего эта энергия меньше, чем энергия фонового шума. Сначала вычисляют временную обновленную энергию шумов:

где 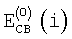 соответствует результату второго спектрального анализа для предыдущего кадра.
соответствует результату второго спектрального анализа для предыдущего кадра.
Затем для i от 0 до 19, если Ntmp(i)<NCB(i), то NCB(i)=Ntmp(i).
Второй уровень обновления шумов выполняют позже, устанавливая NCB(i)=Ntmp(i), если кадр декларирован как неактивный. Причина для разделения обновления энергии шумов на две части заключается в том, что обновление энергии шумов может быть выполнено только в течение неактивных речевых кадров, а следовательно, нужны все параметры, необходимые для принятия решения о наличии речи. Однако эти параметры зависят от анализа линейного предсказания и анализа основного тона без обратной связи, выполняемых на обесшумленном речевом сигнале. Для алгоритма уменьшения шумов, чтобы иметь как можно более точную оценку энергии шумов, обновление оценки энергии шумов обновляют, таким образом, по нисходящей перед выполнением уменьшения шумов и по восходящей позже, если кадр является неактивным. Обновление шумов по нисходящей безопасно и может быть сделано независимо от наличия речевой активности.
Уменьшение шумов
Операцию уменьшения шумов применяют к сигнальной области, а затем обесшумленный сигнал восстанавливают с использованием метода наложения-сложения. Уменьшение шумов выполняют, масштабируя спектр в каждой критической полосе с использованием масштабирующего (взвешивающего) коэффициента передачи, ограниченного между gmin и 1 и полученного из отношения сигнал/шум (SNR) в этой критической полосе. Новая особенность подавления шумов состоит в том, что для частот ниже, чем определенная частота, связанная с вокализованностью сигнала, обработку выполняют на основе частотных бинов, а не на основе критических полос частот. Таким образом, к каждому частотному бину применяют масштабирующий коэффициент передачи, полученный из отношения сигнал/шум в этом бине (отношение сигнал/шум вычисляют с использованием энергии бина, деленной на энергию шумов в критической полосе, включающей этот бин). Эта новая особенность позволяет сохранять энергию на частотах, близких к гармоникам, предотвращая искажения, и при этом сильно уменьшать шум между гармониками. Эта особенность может использоваться только для вокализованных сигналов и, при заданной разрешающей способности по частоте в используемом спектральном анализе, для сигналов с относительно коротким периодом основного тона. Однако именно для таких сигналов шум между гармониками наиболее заметен.
На фиг.3 обобщенно показана предлагаемая процедура. В блоке 301 проводится спектральный анализ. Блок 302 проверяет, больше ли нуля количество критических вокализованных полос. Если да, то уменьшение шумов производится в блоке 304, где проводится обработка по частотным бинам первых К вокализованных полос, а обработка по полосам частот производится в оставшихся полосах. Если К=0, то обработка по полосам частот применяется ко всем критическим полосам. После уменьшения шумов в спектре блок 305 выполняет обратное дискретное преобразование Фурье и использует операцию наложения-сложения для реконструкции улучшенного речевого сигнала, как будет описано ниже.
Минимальный масштабирующий коэффициент передачи, gmin, выводят из максимального разрешенного уменьшения шумов в дБ, NRmax. Максимальное разрешенное уменьшение по умолчанию имеет значение 14 дБ. Таким образом, минимальный масштабирующий коэффициент передачи имеет вид
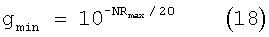
и равен 0,19953 для значения по умолчанию 14 дБ.
В случае неактивных кадров с VAD=0, то же самое масштабирование применяется к целому спектру и задается выражением gs=0.9gmin, если подавление шумов активизировано (если gmin меньше 1). Таким образом, масштабированные действительная и мнимая составляющие спектра равны
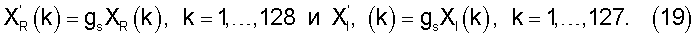
Отметим, что для узкополосных входных сигналов верхние пределы в уравнении (19) устанавливают равными 79 (до 3950 Гц).
Для активных кадров масштабирующий коэффициент передачи вычисляют на основе отношения сигнал/шум в критической полосе или по частотным бинам для первых вокализованных полос. Если КVOIC>0, то осуществляют подавление по частотным бинам на первых КVOIC полосах. Подавление шумов по полосам частот используется в остальных полосах. В случае, если KVOIC=0, подавление шумов по полосам частот используется на всем спектре. Значение KVOlC обновляют, как будет описано ниже. Максимальное значение KVOlC равно 17, поэтому обработку по бинам можно использовать только в первых 17 критических полосах, что соответствует максимальной частоте 3700 Гц. Максимальное количество бинов, для которых можно использовать обработку по бинам, равно 74 (количество бинов в первых 17 полосах). Исключение делается для кадров "жесткого" поддержания в силе решения об обнаружении речевой активности, как будет описано ниже в этом разделе.
В альтернативной реализации значение KVOIC может быть фиксированным. В этом случае во всех типах речевых кадров обработку по бинам выполняют до определенной полосы, а к другим полосам применяют обработку по полосам частот.
Масштабирующий коэффициент передачи в определенной критической полосе или для определенного частотного бина вычисляют как функцию отношения сигнал/шум следующим образом
 с ограничением
с ограничением 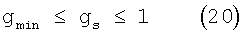
Значения ks и cs определяют так, что gs=gmin для отношения сигнал/шум SNR=1 и gs=1 для SNR=45. Таким образом, для отношений сигнал/шум от 1 дБ и ниже масштабирование ограничено gs, а для отношений сигнал/шум от 45 дБ и выше в данной критической полосе никакого подавления шумов не выполняют (gs=1). Таким образом, при этих двух заданных конечных точках значения ks и cs в уравнении (20) даются следующими выражениями
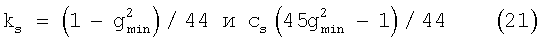
Переменная SNR в уравнении (20) равна либо SNR в критической полосе, SNRCB(i), или SNR в частотном бине, SNRBIN(k), в зависимости от типа обработки.
Отношение сигнал/шум SNR в критической полосе в случае первого спектрального анализа в кадре вычисляют как
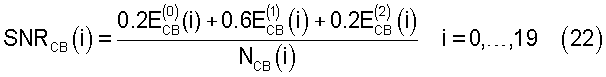
а для второго спектрального анализа SNR вычисляют как

где 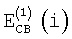 и
и 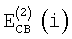 обозначают информацию об энергии, приходящейся на критическую полосу, для первого и второго спектрального анализа соответственно (вычисленные согласно уравнению (2)); обозначает информацию об энергии, приходящейся на критическую полосу, полученную в результате второго анализа в предыдущем кадре, а NСВ(i) обозначает оценку энергии шумов в критической полосе.
обозначают информацию об энергии, приходящейся на критическую полосу, для первого и второго спектрального анализа соответственно (вычисленные согласно уравнению (2)); обозначает информацию об энергии, приходящейся на критическую полосу, полученную в результате второго анализа в предыдущем кадре, а NСВ(i) обозначает оценку энергии шумов в критической полосе.
Отношение сигнал/шум SNR в критическом бине в определенной критической полосе i в случае первого спектрального анализа в кадре вычисляют как

а для второго спектрального анализа SNR вычисляют как
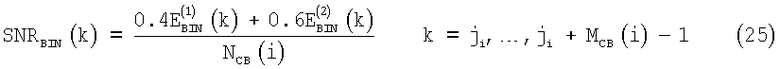
где 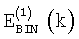 и
и 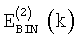 обозначают энергию, приходящуюся на частотный бин, для первого и второго спектрального анализа соответственно (вычисленные согласно уравнению (3));
обозначают энергию, приходящуюся на частотный бин, для первого и второго спектрального анализа соответственно (вычисленные согласно уравнению (3)); 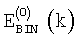 обозначает энергию, приходящуюся на частотный бин и полученную в результате второго анализа в предыдущем кадре, а NСВ(i) обозначает оценку энергии шумов в критической полосе, ji - индекс первого бина в i-ой критической полосе и МСВ(i) - количество бинов в критической полосе i, определенное выше.
обозначает энергию, приходящуюся на частотный бин и полученную в результате второго анализа в предыдущем кадре, а NСВ(i) обозначает оценку энергии шумов в критической полосе, ji - индекс первого бина в i-ой критической полосе и МСВ(i) - количество бинов в критической полосе i, определенное выше.
В случае обработки в критической полосе для полосы с индексом i после определения масштабирующего коэффициента передачи согласно уравнению (22) и при использовании отношения сигнал/шум SNR, определенного согласно уравнениям (24) или (25), фактическое масштабирование выполняют с использованием сглаженного масштабирующего коэффициента передачи, обновляемого при каждом спектральном анализе как

В настоящем изобретении используется новый признак, заключающийся в том, что коэффициент сглаживания адаптивен и находится в обратной зависимости от самого коэффициента передачи. В этом иллюстративном варианте осуществления настоящего изобретения коэффициент сглаживания дается выражением αgs=1-gs. Таким образом, сглаживание будет сильнее для меньшего коэффициента передачи. Этот подход предотвращает искажения в сегментах речи с большим отношением сигнал/шум, которым предшествуют кадры с низким отношением сигнал/шум, как имеет место в случае звонких начальных согласных слога. Например, в невокализованных речевых кадрах отношение сигнал/шум мало; поэтому используется большой масштабирующий коэффициент передачи, чтобы уменьшить шум в спектре. Если звонкие начальные согласные слога следуют за невокализованным кадром, отношение сигнал/шум выше, и если сглаживание предотвращает быстрое обновление масштабируемой передачи, то вероятно использование сильного масштабирования в начале слога, что приведет к плохому качеству. В предложенном подходе процедура сглаживания способна быстро адаптироваться и использовать меньший масштабирующий коэффициент передачи в начале слога.
Масштабирование в критической полосе выполняют как
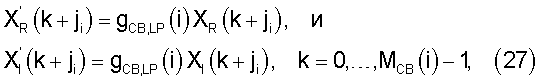
где ji - индекс первого бина в критической полосе i, а МСВ(i) - количество бинов в этой критической полосе.
В случае обработки по частотным бинам в полосе с индексом i после определения масштабирующего коэффициента передачи согласно уравнению (20) и при использовании отношения сигнал/шум SNR согласно уравнениям (24) или (25) фактическое масштабирование выполняют с использованием сглаженного масштабирующего коэффициента передачи, обновляемого при каждом спектральном анализе как
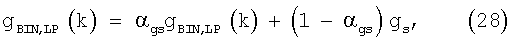
где αgs=1-gs аналогично уравнению (26).
Временное сглаживание коэффициентов передачи предотвращает слышимые колебания энергии, в то время как управление сглаживанием с использованием αgs предотвращает искажение в речевых сегментах с большим отношением сигнал/шум, которым предшествуют кадры с малым отношением сигнал/шум, как имеет место, например, в случае звонких согласных в начале слога.
Масштабирование в критической полосе i выполняют как
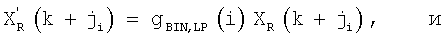
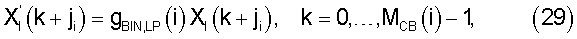
где ji - индекс первого бина в критической полосе i, а МCB(i) - количество бинов в этой критической полосе.
Сглаженные масштабированные коэффициенты передачи gBIN,LP(k) и gCB,LP(i) изначально устанавливают равными 1. Каждый раз, когда обрабатывается неактивный кадр (VAD=0), gmin вновь устанавливается равным значениям коэффициентов передачи, определенным в уравнении (18).
Как сказано выше, если KVOIC>0, то подавление шумов по частотным бинам выполняют в первых KVOIC полосах, а подавление шумов по полосам частот выполняют в оставшихся полосах с использованием вышеописанных процедур. Следует отметить, что при каждом спектральном анализе сглаженные масштабируемые коэффициенты передачи gCB,LP(i) обновляют для всех критических полос (даже для вокализованных полос, обработанных по частотным бинам - в этом случае gCB,LP(i) обновляют на среднее значение gBlN,LP(k), относящееся к полосе i). Точно так же масштабируемые коэффициенты передачи gBlN,LP(k) обновляют для всех частотных бинов в первых 17 полосах (до бина 74). Для полос, обработанных по полосам частот, эти коэффициенты обновляют, устанавливая их равными gCB,LP(i) в этих 17 специфических полосах.
Следует отметить, что в случае чистой речи подавления шумов в кадрах активной речи (VAD=1) не выполняют. Эту ситуацию выявляют, определяя максимальную энергию шумов во всех критических полосах, max(NCB(i)), i=0,...19, и если эта величина меньше или равна 15, то подавления шумов не производят.
Как сказано выше, для неактивного кадра (VAD=0) применяют масштабирование 0,9gmin всего спектра, что эквивалентно удалению постоянного минимального уровня шумов. Для речевых кадров, соответствующих короткому периоду поддержания в силе решения об обнаружении речевой активности (VAD=1 и local VAD=0), обработку по полосам частот применяют к первым 10 полосам, как описано выше (соответствует 1700 Гц), а для остальной части спектра вычитают постоянный минимальный уровень шумов путем масштабирования остальной части спектра постоянным значением gmin. Эта мера уменьшает значительные колебания высокочастотной энергии шумов. Для этих полос выше десятой сглаженные коэффициенты масштабируемой передачи gCB,LB(i) не возвращают к старым значениям, а обновляют с использованием уравнения (26) как gs=gmin, а сглаженные по частотным бинам масштабируемые коэффициенты передачи gBlN.LP(k) обновляют, полагая их равными gCB,LB(i) в соответствующих критических полосах.
Процедуру, описанную выше, можно рассматривать как уменьшение шумов, специфическое для данного класса, когда алгоритм уменьшения шумов зависит от природы обрабатываемого речевого кадра. Это иллюстрируется на фиг.4. На шаге 401 проверяют, равен ли флаг VAD нулю (нет речевой активности). Если да, то из спектра удаляют постоянный минимальный уровень шумов, применяя один и тот же масштабирующий коэффициент передачи ко всему спектру (шаг 402). В противном случае (шаг 403) проверяют, соответствует ли кадр периоду поддержания в силе решения об обнаружении речевой активности ("VAD hangover"). Если да, то обработку по полосам частот применяют для первых 10 полос, а для остальных полос используют тот же самый масштабирующий коэффициент передачи (шаг 406). В противном случае (шаг 405) проверяют, обнаружена ли вокализованность в первых полосах спектра. Если да, то в первых К речевых полосах выполняют обработку по бинам, а обработку по полосам частот выполняют в оставшихся полосах (шаг 406). Если вокализованные полосы не обнаружены, то обработку по полосам частот выполняют во всех критических полосах (шаг 407).
В случае обработки узкополосных сигналов (преобразованных с повышением частоты дискретизации до 12800 Гц) подавление шумов выполняют в первых 17 полосах (до 3700 Гц). Для оставшихся пяти частотных бинов между 3700 Гц и 4000 Гц спектр масштабируют с использованием последнего масштабирующего коэффициента передачи gs для бина на 3700 Гц. Для оставшегося спектра (от 4000 Гц до 6400 Гц) спектр обнуляют.
Восстановление обесшумленного сигнала
После определения масштабированных спектральных компонент, X'R(k) и X'I(k), к масштабированному спектру применяют обратное быстрое преобразование Фурье для получения обработанного окном обесшумленного сигнала во временной области.
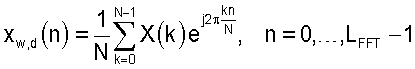
Эту процедуру повторяют для обоих спектральных анализов в кадре, чтобы получить обработанные окном обесшумленные сигналы  и
и 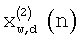 . Для каждого полукадра сигнал реконструируют с использованием операции наложения-сложения для перекрывающихся частей анализа. Поскольку до спектрального анализа в отношении исходного сигнала используется квадратный корень окна Ханна, то же самое окно применяют и на выходе обратного быстрого преобразования Фурье до операции наложения-сложения. Таким образом, дважды обработанный окном обесшумленный сигнал имеет вид:
. Для каждого полукадра сигнал реконструируют с использованием операции наложения-сложения для перекрывающихся частей анализа. Поскольку до спектрального анализа в отношении исходного сигнала используется квадратный корень окна Ханна, то же самое окно применяют и на выходе обратного быстрого преобразования Фурье до операции наложения-сложения. Таким образом, дважды обработанный окном обесшумленный сигнал имеет вид:
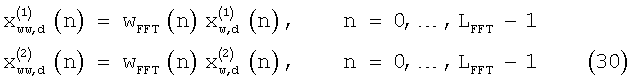
Для первой половины окна анализа операцию наложения-сложения для построения обесшумленного сигнала выполняют следующим образом:
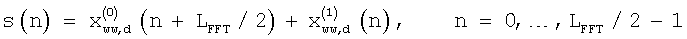
а для второй половины окна анализа операцию наложения-сложения для формирования обесшумленного сигнала выполняют следующим образом:
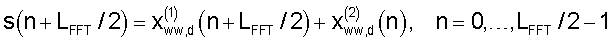
где 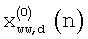 - обесшумленный сигнал после двойного оконного преобразования, полученный в результате второго анализа в предыдущем кадре.
- обесшумленный сигнал после двойного оконного преобразования, полученный в результате второго анализа в предыдущем кадре.
Отметим, что при операции наложения-сложения, поскольку имеется сдвиг на 24 отсчета между кадром речевого кодера и кадром уменьшения шумов, обесшумленный сигнал может быть реконструирован до 24-отсчетного из опережающего просмотра в дополнение к текущему кадру. Однако все еще необходимы 128 отсчетов, чтобы получить полный опережающий просмотр, необходимый кодеру речи для анализа с линейным предсказанием (LP) и анализа основного тона без обратной связи. Эту часть временно получают обратным оконным преобразованием второй половины обесшумленного сигнала 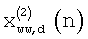 , подвергнутого оконному преобразованию, без выполнения операции наложения-сложения. То есть:
, подвергнутого оконному преобразованию, без выполнения операции наложения-сложения. То есть:
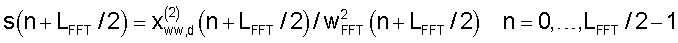
Отметим, что эта часть сигнала должным образом повторно вычисляется в следующем кадре с использованием операции наложения-сложения.
Обновление оценок энергия шумов
В этом модуле обновляют оценки энергии шумов в критической полосе с целью подавления шумов. Обновление выполняют в течение неактивных периодов речи. Однако решение об обнаружении речевой активности, сделанное выше и основанное на отношении сигнал/шум в критической полосе, не используется для того, чтобы определить, обновляются ли оценки энергии шумов. Принимают другое решение на основе других параметров, не зависящих от отношения сигнал/шум в критической полосе. Параметры, используемые для принятия решения об обновлении энергии шумов, - это стабильность основного тона, нестационарность сигнала, вокализованность и отношение между энергиями остаточной ошибки линейного предсказания 2-го и 16-го порядка, - в общем случае они обеспечивают низкую чувствительность к вариациям уровня помех.
Причина того, чтобы не использовать решение кодера об обнаружении речи для обновления оценки энергии шумов, состоит в том, чтобы сделать оценку энергии шумов устойчивой к быстро меняющемуся уровню шумов. Если бы для обновления энергии шумов использовалось решение кодера об обнаружении речевой активности, то внезапное увеличение уровня шумов привело бы к увеличению отношения сигнал/шум даже для неактивных кадров речи, не давая устройству оценки энергии шумов произвести обновление, что, в свою очередь, привело бы к сохранению высокого отношения сигнал/шум в следующих кадрах и т.д. Следовательно, обновление энергии шумов было бы заблокировано и для возобновления подстройки под уровень шумов необходимо было бы применить какую-нибудь другую логику.
В этом иллюстративном варианте осуществления настоящего изобретения анализ основного тона без обратной связи выполняют в кодирующем устройстве для вычисления без обратной связи трех оценок основного тона на кадр: d0, d1 и d2, соответствующих первому полукадру, второму полукадру и опережающему просмотру соответственно. Счетчик стабильности основного тона вычисляют как
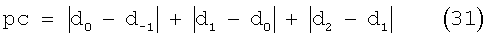
где d-1 - сдвиг, соответствующий второму полукадру из предыдущего кадра. В этом иллюстративном варианте осуществления настоящего изобретения для задержек основного тона более чем на 122, модуль поиска основного тона без обратной связи устанавливает d2=d1. Таким образом, для таких задержек величину рс в уравнении (31) умножают на 3/2, чтобы компенсировать отсутствие третьего члена в уравнении. Стабильность основного тона считается истиной, если значение рс меньше 12. Далее, для кадров с низкой вокализованностью величину рс устанавливают равной 12, чтобы указать на нестабильность основного тона. То есть
Если 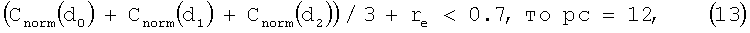
где Cnorm(d) - нормализованная необработанная корреляция, а rе - опциональная коррекция, добавляемая к нормализованной корреляции для компенсации уменьшения нормализованной корреляции в присутствии фонового шума. В этом иллюстративном варианте осуществления настоящего изобретения нормализованную корреляцию вычисляют на основе прореженного взвешенного речевого сигнала Swd(n) согласно выражению:
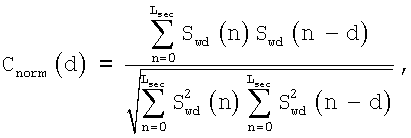
где предел суммирования зависит от самой задержки. В этом иллюстративном варианте осуществления настоящего изобретения взвешенный сигнал, используемый при анализе основного тона без обратной связи, прорежен вдвое, и пределы суммирования даются следующими выражениями:
Lsec=40 для d=10,...,16
Lsec=40 для d=17,...,31
Lsec=62 для d=32,...,61
Lsec=40 для d=62,...,115
Оценку нестационарности сигнала выполняют на основе произведения отношений энергии в критической полосе к средней долговременной энергии в критической полосе.
Среднюю долговременную энергию в критической полосе обновляют следующим образом:
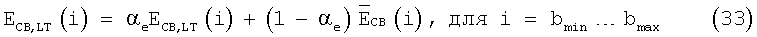
где bmin=0 и bmax=19 в случае широкополосных сигналов и bmin=1 и bmax=16 в случае узкополосных сигналов, a 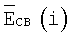 - энергия кадра на критическую полосу, определяемая уравнением (14). Коэффициент обновления αе является линейной функцией полной энергии кадра, определяемой уравнением (5), и задается следующим образом:
- энергия кадра на критическую полосу, определяемая уравнением (14). Коэффициент обновления αе является линейной функцией полной энергии кадра, определяемой уравнением (5), и задается следующим образом:
Для широкополосных сигналов: αe=0,0245Etot-0,235 с границами 0,5<αе<0,99.
Для узкополосных сигналов: αе=0,00091Еtot-0,3185 с границами 0,5<αе<0,999.
Нестационарность кадра определяется произведением отношений энергии кадров и средней долговременной энергии в критической полосе. То есть:
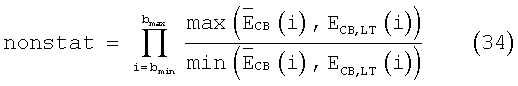
Коэффициент вокализованности для обновления энергии шумов дается выражением

Наконец, отношение между остаточными энергиями при линейном предсказании (LP) после анализа 2-го порядка и 16-го порядка дает
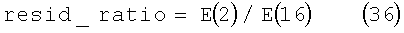
где Е(2) и Е(16) - остаточные энергии при линейном предсказании (LP) после анализа 2-го порядка и 16-го порядка, вычисленные рекурсивным методом Левинсона-Дарбина, как хорошо известно специалистам в данной области техники. Это отношение отражает тот факт, что для представления спектральной огибающей сигнала для речевого сигнала обычно необходим более высокий уровень линейного предсказания, чем для шума. Другими словами, различие между Е(2) и Е(16) предполагается более низким для шума, чем для активной речи.
Решение об обновлении принимают на основе переменной noise_update, которая изначально установлена равной 6, и ее уменьшают на 1, если обнаружен неактивный кадр, и увеличивают на 2, если обнаружен активный кадр. Кроме того, переменная noise_update ограничена значениями 0 и 6. Энергии шумов обновляют только тогда, когда noise_update=0.
Значение переменной noise_update обновляют в каждом кадре следующим образом:
Если (nonstat>thstat) ИЛИ (рс<12) ИЛИ (voicing>0.85) ИЛИ (resid_ratio>thresid)
noise_update=noise_update+2
В противном случае
noise_update=noise_update-1
при этом для широкополосных сигналов thstat=350000 и thresid=1,9, а для узкополосных сигналов thstat=500000 и thresid=11.
Другими словами, кадры объявляют неактивными для обновления шумов, когда
(nonstat≤thstat) И (рс>12) И (voicing<0,85) И (resid_ratio<thresid), и перед обновлением шумов используют задержку (поддержание в силе решения об обнаружении речевой активности) из 6 кадров.
Таким образом, если noise_update=0, то для i=от 0 до 19 NCB(i)=Ntmp(i),
где Ntmp(i) - временно обновленная энергия шумов, уже вычисленная согласно уравнению (17).
Обновление граничной частоты вокализованности
Граничную частоту, ниже которой сигнал считается вокализованным, обновляют. Эта частота используется для определения количества критических полос, для которых подавление шумов выполняют с использованием обработки по бинам.
Сначала вычисляют меру вокализованности:
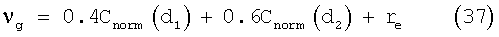
а граничная частота вокализованности задается следующим выражением:
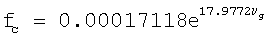 с ограничением
с ограничением 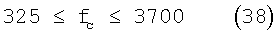
Затем определяют количество критических полос, KVOlC, имеющих верхнюю частоту, которая превышает fc. Границы 325≤fc≤3700 установлены так, что обработку по бинам выполняют минимально на 3 полосах и максимально на 17 полосах (см. верхние границы критических полос, определенные выше). Отметим, что при вычислении меры вокализованности больший вес дается нормализованной корреляции опережающего просмотра, поскольку полученное количество речевых полос будет использовано в следующем кадре.
Таким образом, в следующем кадре для первых KVOlC критических полос подавление шумов будет использовать обработку по бинам, как описано выше.
Отметим, что для кадров с низкой вокализованностью и для больших задержек основного тона используют только обработку по критическим полосам и, таким образом, KVOIC приравнивают 0. Используется следующее условие:
Если (0.4Cnorm(d1)+0.6Cnorm(d2)≤0.72) ИЛИ (d1>116) ИЛИ (d2>116), то KVOIC=0.
Конечно, возможны другие многочисленные изменения и модификации. С учетом вышеописанного иллюстративного подробного описания вариантов осуществления настоящего изобретения и соответствующих чертежей такие изменения и модификации будут очевидны для специалистов в данной области техники. Кроме того, должно быть понятно, что такие модификации могут быть реализованы без выхода за рамки настоящего изобретения.
Изобретение относится к технике улучшения речевых сигналов для улучшения связи в присутствии фонового шума. В одном варианте изобретения предлагается способ подавления шумов в речевом сигнале, согласно которому для речевого сигнала, имеющего спектральное представление в виде множества частотных бинов, определяют значения масштабирующего коэффициента передачи по меньшей мере для некоторых из указанных частотных бинов и вычисляют значения сглаженных масштабирующих коэффициентов передачи. Вычисление значений сглаженных масштабирующих коэффициентов передачи включает, по меньшей мере для некоторых из частотных бинов, комбинирование текущего значения масштабирующего коэффициента передачи и ранее определенного значения сглаженного масштабирующего коэффициента передачи. В другом варианте способ включает разделение множества частотных бинов на первый набор смежных частотных бинов и второй набор смежных частотных бинов, между которыми лежит граничная частота, которая разделяет области применения различных методов подавления шумов, а изменение значения граничной частоты является функцией спектрального состава речевого сигнала. Технический результат - обеспечение эффективного подавления шумов путем уменьшения уровня фонового шума в речевом сигнале. 5 н. и 74 з.п. ф-лы, 4 ил.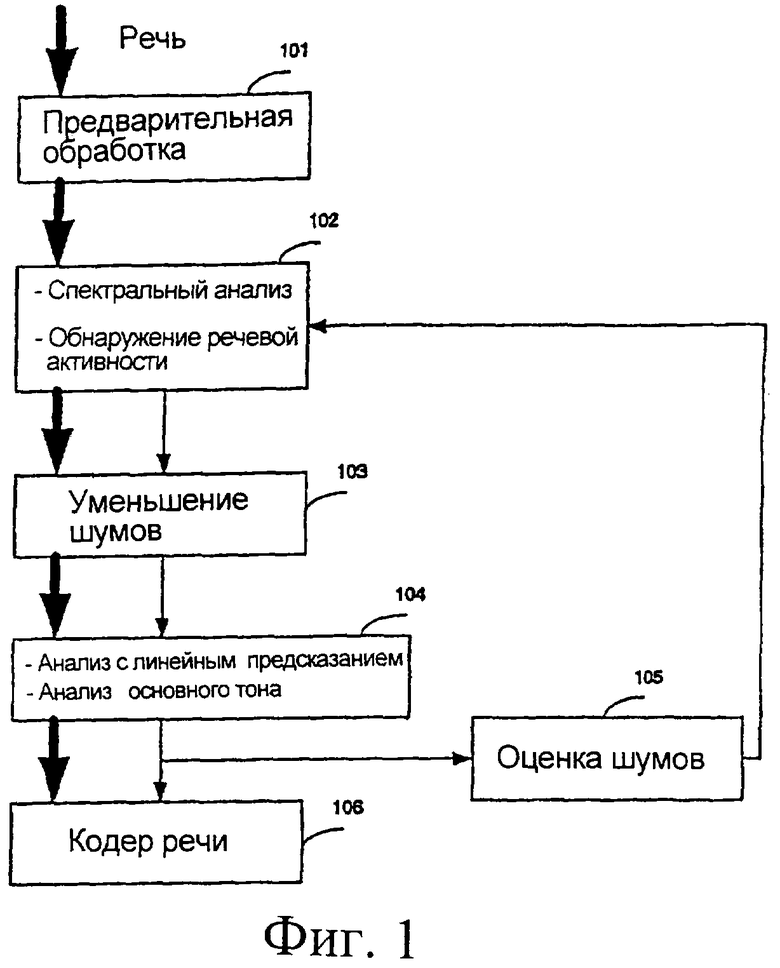
проведение двух спектральных анализов с использованием перекрывающихся окон для создания спектрального представления речевого сигнала, содержащего множество частотных бинов, и
группировку частотных бинов в множество полос частот,
отличающийся тем, что для подавления шума в речевом кадре, когда в речевом кадре обнаруживают вокализованную речевую активность, для первой части полос частот подавление шумов выполняют по частотным бинам, а для второй части полос частот подавление шумов выполняют по полосам частот, и
когда в речевом кадре не обнаруживают вокализованную речевую активность, подавление шумов выполняют по полосам частот для всех полос частот.
проведения двух спектральных анализов с использованием перекрывающихся окон для создания спектрального представления речевого сигнала, содержащего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающееся тем, что оно выполнено с возможностью обнаруживать вокализованную речевую активность и при обнаружении в речевом кадре вокализованной речевой активности выполнять для первой части полос частот подавление шумов по частотным бинам, а для второй части полос частот - подавление шумов по полосам частот,
а когда в речевом кадре не обнаружена вокализованная речевая активность, - выполнять подавление шумов по полосам частот для всех полос частот.
проведения двух спектральных анализов с использованием перекрывающихся окон для создания спектрального представления речевого сигнала, содержащего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающийся тем, что указанное устройство выполнено с возможностью обнаруживать вокализованную речевую активность и при обнаружении в речевом кадре вокализованной речевой активности выполнять для первой части полос частот подавление шумов по частотным бинам, а для второй части полос частот - подавление шумов по полосам частот,
а когда в речевом кадре не обнаружена вокализованная речевая активность, - выполнять подавление шумов по полосам частот для всех полос частот.
проведения двух спектральных анализов с использованием перекрывающихся окон для создания спектрального представления речевого сигнала, содержащего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающаяся тем, что указанное устройство выполнено с возможностью обнаруживать вокализованную речевую активность и при обнаружении в речевом кадре вокализованной речевой активности выполнять для первой части полос частот подавление шумов по частотным бинам, а для второй части полос частот - подавление шумов по полосам частот,
а когда в речевом кадре не обнаружена вокализованная речевая активность, - выполнять подавление шумов по полосам частот для всех полос частот.
проведения двух спектральных анализов с использованием перекрывающихся окон для создания спектрального представления речевого сигнала, содержащего множество частотных бинов, и
группировки частотных бинов в множество полос частот,
отличающийся тем, что указанное устройство выполнено с возможностью обнаруживать вокализованную речевую активность и при обнаружении в речевом кадре вокализованной речевой активности выполнять для первой части полос частот подавление шумов по частотным бинам, а для второй части полос частот - подавление шумов по полосам частот,
а когда в речевом кадре не обнаружена вокализованная речевая активность, - выполнять подавление шумов по полосам частот для всех полос частот.
| US 2003023430 А, 30.01.2003 | |||
| US 5963901 A, 05.10.1999 | |||
| US 4630305, 16.12.1986 | |||
| СПОСОБ И УСТРОЙСТВО ОСЛАБЛЕНИЯ ШУМА В РЕЧЕВОМ СИГНАЛЕ | 1996 |
|
RU2121719C1 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ ОБЕСПЕЧЕНИЯ КОМФОРТНОГО ШУМА В СИСТЕМАХ СВЯЗИ | 1998 |
|
RU2220510C2 |
| RU 21445737 C1, 20.02.2000. | |||

