Изобретение относится к области связи и может быть использовано в устройствах передачи дискретной информации в линиях связи с помехами.
Известны способы определения местоположения ошибок в принимаемом коде, основанные на вычислении синдрома порождающего многочлена (см., например, Питерсон У., Уэлдон Э. Коды, исправляющие ошибки. М.: Мир, 1976. 594 с., Мак-Вильямс Ф., Слоэн Н.Дж. Теория кодов, исправляющих ошибки. М.: Связь, 1979. 744 с.).
При реализации алгоритма декодирования по синдрому составляют таблицу, в которой указываются синдромы si и лидеры ei соответствующих им смежных классов. Алгоритм декодирования заключается в следующем:
1. Вычисляют синдром s(u) принятого вектора u.
2. По синдрому s(u)=si определяют лидер ei соответствующего смежного класса.
3. Определяют посланный вектор ν как разность ν=u-еi.
При всей простоте и прозрачности алгоритм синдромного декодирования обладает серьезным недостатком, заключающемся в том, что устройство, реализующее этот способ декодирования, должно хранить информацию о лидерах и синдромах. Объем этой информации оказывается очень большим даже при умеренных длинах кодовых слов (порядка нескольких десятков). Для двоичного (50, 40)-кода получится 1024 лидеров и столько же синдромов, а для (50, 30)-кода число их превзойдет миллион.
Недостатком известных способов декодирования циклических кодов является чрезмерное усложнение аппаратуры для синдромного декодирования.
Наиболее близким к предлагаемому является способ, описанный в книге Шварцман B.C., Емельянов Г.А. Теория передачи дискретной информации. М.: Связь, 1979, с.305-306, принятый за прототип.
Способ-прототип основан на свойстве делимости циклического кода р(х)=f(x)=q(x)·g(x)=xn-km(x)+r(x) без остатка на порождающий многочлен g(x). Остаток от деления принятого многочлена р(х) на порождающий многочлен g(x) называется синдромом. Наличие остатка при делении принятого многочлена р(х) на порождающий многочлен g(x) указывает на наличие ошибки, появившейся при передаче сигнала по каналу связи.
Для исправления обнаруженной ошибки код синдрома строится таким образом, чтобы многочлены ошибок давали при делении на g(x) различные остатки. По коду синдрома определяют положение ошибочного бита в принятом многочлене р(х), возникшего при передаче по двоичному каналу связи.
Недостатком способа-прототипа является исправление не более одного символа принятого циклического кода.
Для устранения указанного недостатка в способе исправления двух ошибок в декодирующем устройстве циклического кода степени n, формируемом в передатчике, основанном на вычислении остатка r(х) от деления принятого сигнала в виде кодового многочлена циклического кода, представляющем собой сумму информационного многочлена А(х), контрольных бит и многочлена ошибок, на порождающий неприводимый многочлен g(x), вычислении адреса ошибочных символов по проверочной матрице Н(х) с последующим инвертированием ошибочных бит принятого сигнала, согласно изобретению вместе с информационным многочленом А(х) и контрольными битами кодового многочлена в передатчике формируют дополнительные контрольные биты b(х), получающиеся как результат деления информационного многочлена А(х) на неприводимый многочлен g1(х)≠g(x), которые при декодировании принятого циклического кода используют для построения дополнительного кодового многочлена F1(x), представляющего сумму контрольных бит b(х), информационных бит А(х) и многочлена ошибок, вычислении дополнительного многочлена r1(х) как остатка от деления многочлена F1(x) на многочлен g1(x), определении столбцов i0 и j0 соответствующих проверочных матриц Н(х) и H1(х) с последующим синхронным циклическим сдвигом столбцов проверочных матриц H(х) и H1(х) на s разрядов до совпадения номеров столбцов проверочных матриц H(х) и H1(х), после чего определяют в кодовом многочлене позиции ошибочных бит i и j из выражений: i≡i0-s(modn) и j≡j0+s(mod n), которые затем инвертируют.
Предлагаемый способ определения местоположения ошибок в принимаемом коде осуществляется следующим образом.
Принимаемый код запоминается в трех регистрах: в первом регистре осуществляется хранение информационной части кодовой последовательности; во втором и третьем регистре осуществляется запоминание порождающих многочленов, где осуществляется деление принятого кода на порождающие многочлены g(x) и g1(x), соответственно. Полученные остатки от деления используются для определения номера столбцов в проверочных матрицах Н(х) и Н1(х) подстановкой в них полученных остатков и сравнения между собой. Далее осуществляется инверсия бит в столбцах, где обнаружены ошибки.
Предлагаемый способ определения местоположения ошибок в принимаемом коде реализуется в следующей последовательности.
Пусть требуется передать по каналу связи, подверженному влиянию помех, кодовое слово, состоящее из k информационных бит, которое представимо в виде многочлена c0

Для циклического кода, имеющего длину n=2m-1, сформируем многочлен
А(x)=a(x)+c0(x)·xm=а(x)+с(х),
где
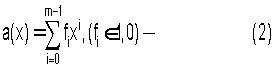
проверочные символы, получающиеся от деления многочлена с(х) на неприводимый многочлен

который является порождающим для данного циклического кода.
Многочлен а(х) также может быть получен с помощью проверочной матрицы размера (n×m)
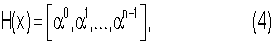
где  (μi∈0,1) - примитивный элемент, степени которого пробегают все поле Галуа GF(2m) по модулю g(x).
(μi∈0,1) - примитивный элемент, степени которого пробегают все поле Галуа GF(2m) по модулю g(x).
Определим дополнительные контрольные символы
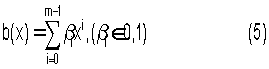
как остаток от деления многочлена с(х) на неприводимый многочлен g1(x)

Заметим, что многочлен b(х) может быть получен также с помощью проверочной матрицы Н1(х)

где 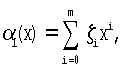 (ζi∈0,1) - примитивный элемент, степени которого пробегают все поле Галуа GF(2m) по модулю g1 (х).
(ζi∈0,1) - примитивный элемент, степени которого пробегают все поле Галуа GF(2m) по модулю g1 (х).
Далее сформируем кодовый многочлен вида
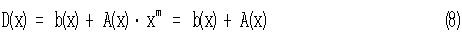
Согласно принятым условиям наличия помех в канале связи, отличным от нуля будет многочлен ошибок

причем, i≠j.
Тогда принятый многочлен D1(x) будет иметь следующий вид:

Нахождение и исправление двух ошибок в кодовом многочлене D1(x) осуществляется следующим образом.
Последовательность символов, представляющая собой кодовый многочлен D1(х) поступает в первый из трех упомянутых регистров, реализующая многочлен. Во второй регистр поступает последовательность символов F(x)=а(х)+с(х)+Е(х), которая содержит информационный многочлен с(х), многочлен ошибок Е(х) и проверочный многочлен а(х), сформированные с помощью проверочной матрицы Н(х). В третий регистр поступает последовательность, реализующая кодовый многочлен F1(х)=b(х)+с(х)+Е(х), которая содержит проверочные символы b(х), полученные с помощью проверочной матрицы Н1(х).
Во втором регистре будет находиться остаток деления многочлена F(x) на неприводимый многочлен g(x) в виде многочлена

где i и j - номера искаженных бит кодового многочлена F(x).
В третьем регистре будет находиться остаток деления многочлена F1(х) на неприводимый многочлен g1(x) в виде многочлена
где i и j - номера искаженных бит кодового многочлена F(x).
В третьем регистре будет находиться остаток деления многочлена F1(х) на неприводимый многочлен g1(х) в виде многочлена

где i и j - номера искаженных бит кодового многочлена F1(х).
Возможны следующие варианты искажений многочлена ошибок: Е(х)=0, Е(х)=хi, Е(х)=хi+xj. Разберем эти случаи.
1. Е(х)=0, тогда можно записать

При этом будем иметь r(х)=r1(х)=0.
2. Е(х)=хi. При этом
а) 2m≤i≤(2m+k-1). Тогда r(α)=αi и  . Степени α и α1 будут равны и указывать на местоположение ошибочного бита;
. Степени α и α1 будут равны и указывать на местоположение ошибочного бита;
б) m≤i≤(2m-1). Тогда получим

Используем следующие выражения для определения ошибочного символа 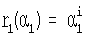 при 0≤i≤(m-1):
при 0≤i≤(m-1):
3. E(x)=xi+xj при i≠j. При этом
а) m≤i≤(2m-1) и 2m≤j≤(2m+k-1), тогда из выражений (11) и (12) определим местоположения ошибочных бит:

Местоположение одного ошибочного бита можно определить из последнего выражения. С помощью матрицы Н(α) можно определить многочлен αj. Определить местоположение второго ошибочного бита можно из уравнения

б) 2m≤i≤2m+k-1 и 0≤j≤m-1. Аналогично предыдущим рассуждениям, получим

в) 2m≤i≤2m+k-1 и 2m≤j≤2m+k-1. Тогда для определения местоположения ошибочных бит воспользуемся выражениями (11) и (12). Умножим обе части этих формул на хs, что соответствует циклическому сдвигу многочленов r(α) и r1(α1) на s позиций. В результате получим

При 0≤i+s≤m-1 выполняется  согласно определению проверочных матриц Н(α) и Н1(α). Рассмотрим случай (i+s)=0, тогда система уравнений (11)-(12) преобразуется к виду
согласно определению проверочных матриц Н(α) и Н1(α). Рассмотрим случай (i+s)=0, тогда система уравнений (11)-(12) преобразуется к виду

где 
Из системы уравнений (19) можно определить положение одного ошибочного бита. Положение второго ошибочного бита определим из выражения

г) 0≤i≤m-1 и m≤j≤2m-1. В этом случае в информационных символах отсутствуют ошибки, поэтому невозможно определить положение ошибочных бит.
Таким образом, при декодировании многочлена D1(x) в нем могут быть определены местоположения любых ошибочных одиночных бит и любые два ошибочных бита при условии, что хотя бы один из них находится в информационных битах.
Предлагаемый способ определения местоположения двух ошибок в принимаемом коде может быть реализован в декодирующем устройстве.
Известны декодирующие устройства, определяющие битовую ошибку в принимаемом коде, см., например, книгу Мак-Вильямс Ф., Слоэн Н.Дж. Теория кодов, исправляющих ошибки. М.: Связь, 1979. С.271, рис.9.5.
Это декодирующее устройство содержит блок задержки, два формирователя для вычисления синдрома, выходы которых соединены с входом устройства, выход блока задержки связан с первым входом блока исправления ошибок, при этом его вход соединен с выходом декодирующего устройства, а второй вход связан с выходом блока определения многочлена локаторов ошибок, а входы соединены с входами формирователя вычислителя синдрома.
Недостатком указанного декодирующего устройства является его сложность, а также для обеспечения возможности исправления двух ошибочных бит при кодировании необходимо уменьшать количество информационных бит в кодовом многочлене за счет увеличения числа проверочных бит.
Наиболее близким по технической сущности к предлагаемому является декодирующее устройство, приведенное в книге Шварцман B.C., Емельянов Г.А. Теория передачи дискретной информации. М.: Связь, 1979, с.309, рис.10.4.
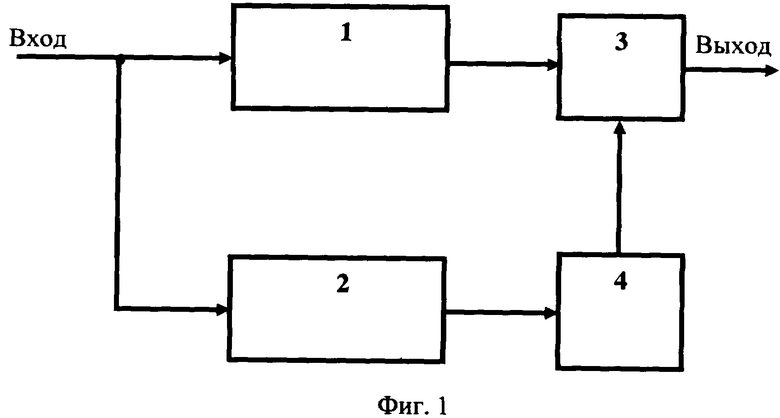
Декодирующее устройство-прототип, схема которого приведена на фиг.1, содержит запоминающий регистр 1, регистр порождающего многочлена 2, входы которых объединены и являются входом декодирующего устройства, выход запоминающего регистра подключен к первому входу блока исправления ошибок 3, выход которого является выходом устройства, второй вход блока исправления ошибок связан с выходом блока определения ошибок 4, вход которого подключен к выходу регистра порождающего многочлена 2.
Устройство-прототип работает следующим образом. На входы запоминающего регистра 1 и регистра порождающего многочлена 2 поступает кодовая последовательность. После числа прихода кодовой последовательности, состоящей из n бит, происходит ее запись в запоминающем регистре 1. В это время параллельно производится деление на порождающий многочлен. В результате чего в регистре порождающего многочлена 2 оказывается записанным синдром. Синдром, дешифрируясь в блоке определения ошибок 4, указывает на место обнаруженной ошибки в кодовой последовательности. При этом на выходе блока определения ошибок 4, который подключен к блоку исправления ошибок 3, устанавливается номер ошибочного бита. Далее происходит сдвиг кодовой последовательности, записанной в запоминающем регистре 1, с суммированием по модулю два сигнала на выходе блока определения ошибок 4. В результате на выходе устройства-прототипа формируется кодовая последовательность с ошибкой, исправленной в одном бите.
Недостатком декодирующего устройства-прототипа является невозможность выявления и исправления более одного ошибочного бита принятого кода, что приводит к низкой помехозащищенности аппаратуры каналов связи.
Для устранения указанных недостатков в декодирующее устройство, содержащее последовательно соединенные запоминающий регистр и блок исправления ошибок, выход которого является выходом устройства, а также первый регистр порождающего многочлена и блок определения ошибок, выход которого соединен со вторым входом блока исправления ошибок, при этом первый вход запоминающего регистра является входом устройства, согласно изобретению введены блок переключения, состоящий из первой и второй схемы «И», первые входы которых подключены к входу устройства, выходы которых подключены к первому и второму регистрам порождающего многочлена, выходы которых подключены к первым входам первого и второго сумматора по модулю два, выходы которых соединены с входами первого и второго дешифраторов соответственно, программируемая логическая матрица (ПЛМ), первый и второй входы которой подключены к выходам первого и второго дешифратора и первому и второму входу блока сравнения, выход которой подсоединен к входу процессора, первый и второй выходы которого соединены с управляющими входами первого и второго регистров порождающего многочлена, третий выход подключен ко второму входу блока определения ошибок, четвертый выход которого подключен к управляющему входу запоминающего регистра, пятый и шестой выходы процессора подключены ко вторым входам схем «И», седьмой выход которого соединен с входом инвертора, выход которого подключен к вторым входам сумматоров по модулю два, и управляющим входом ПЛМ, выход блока сравнения соединен с вторым входом блока определения ошибок.
Схема предлагаемого декодирующего устройства приведена на фиг.2, где обозначено:
1 - запоминающий регистр;
2, 8 - первый и второй регистр порождающего многочлена;
3 - блок исправления ошибок;
4 - блок определения ошибок;
5 - блок переключения;
6, 7 - первая и вторая схема «И»;
9 - процессор;
10 - программируемая логическая матрица;
11, 12 - первый и второй дешифратор;
13, 14 - первый и второй сумматор по модулю два;
15 - инвертор;
16 - блок сравнения.
Предлагаемое декодирующее устройство содержит последовательно соединенные запоминающий регистр 1 и блок исправления ошибок 3, выход которого является выходом устройства, а также первый регистр порождающего многочлена 2 и блок определения ошибок 4, выход которого соединен со вторым входом блока исправления ошибок 3, при этом первый вход запоминающего регистра 1 является входом устройства, блок переключения 5, состоящий из первой 6 и второй 7 схемы «И», первые входы которых подключены к входу устройства, выходы которых подключены к первому 2 и второму 8 регистрам порождающего многочлена, выходы которых подключены к первым входам первого 13 и второго 14 сумматора по модулю два, выходы которых соединены с входами первого 11 и второго 12 дешифраторов соответственно, программируемая логическая матрица (ПЛМ) 10, первый и второй входы которой подключены к выходам первого 11 и второго 12 дешифратора и первому и второму входу блока сравнения 16, выход которой подсоединен к входу процессора 9, первый и второй выходы которого соединены с управляющими входами первого 2 и второго 8 регистров порождающего многочлена, третий выход подключен ко второму входу блока определения ошибок 3, четвертый выход которого подключен к управляющему входу запоминающего регистра 1, пятый и шестой выходы процессора подключены к вторым входам схем «И» 6 и 7, седьмой выход которого соединен с входом инвертора 15, выход которого подключен к вторым входам сумматоров по модулю два 13 и 14, и управляющим входом ПЛМ 10, выход блока сравнения соединен с вторым входом блока определения ошибок 16.
Запоминающий регистр 1 представляет собой двоичный регистр сдвига, представляющий собой соединенные последовательно несколько триггеров, имеющий, по крайней мере, два режима работы: запись информации и сдвиг информации. Управляется сдвиг информации тактовыми импульсами, подаваемыми на вход триггеров.
Регистры порождающего многочлена 2 и 8 представляют собой регистры-делители поступающей на вход последовательности на порождающий многочлен. В результате в регистре записывается остаток от деления, который затем можно сосчитать в параллельном или последовательном коде.
Блок исправления ошибок 3 представляет собой сумматор по модулю два. У него имеются два равнозначных входа, но условно можно считать один вход информационный, а второй управляющий. Если на управляющем входе будет низкий потенциал (логический ноль), то выходной сигнал повторяет входной. Если на управляющем входе будет высокий потенциал (логическая единица), то на выходе сигнал будет инвертирован по отношению к входному. В этом заключается его способность исправлять информационные символы.
Для его работы необходимо устройство управления, которое определяет моменты «исправления» бит принимаемого кода. Эту функцию выполняет блок определения ошибок 4, логическая единица на выходе которого определяет моменты исправления соответствующего бита кодовой последовательности.
Блок переключения 5 представляет собой совокупность двух схем «И» 6 и 7. При подаче на один из входов схемы «И» логического нуля, на выходе также будет нулевой уровень независимо от уровня сигнала на другом входе.
Процессор 9 осуществляет основные функции по переработке информации и управлению ходом вычислительного процесса. Для процессора 9 характерна система команд, организация микропрограммного управления, шинная организация обмена, число и назначение внутренних регистров, обработка прерываний, количество аккумуляторов. Во внутренней структуре процессора выделяют три основные части: устройство управления, арифметическое логическое устройство (АЛУ) с внутренними регистрами, цепи передачи данных, или шины.
Устройство управления процессора обеспечивает синхронизацию и очередность выполнения команд, генерирует управляющие сигналы, определяющие текущие функции АЛУ, обрабатывает сигналы прерываний, вырабатывает информацию о состоянии процессора и др.
ПЛМ 10 запрограммирована выполнять функции, аналогичные проверочным матрицам Н(х) и H1(x), т.е. она содержит номера столбцов и записанные в них векторы, т.е.
номер столбца: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14


Сдвиг на один разряд осуществляется циклическим переходом на соседний столбец, т.е. после достижения столбца на одном краю матрицы последующий находится в начале противоположного края.
В ПЛМ 10 поступают коды с выходов дешифраторов 11 и 12 и управляющие сигналы (выход 7) от процессора 9. Выходной сигнал ПЛМ 10 является входным для процессора 9.
Дешифраторы 11 и 12 представляют собой устройства, обеспечивающие преобразование последовательности поступающих импульсов в отдельные сигналы.
Инвертор 15 осуществляет преобразование логического нуля на входе в логическую единицу и наоборот.
Блок сравнения 16 осуществляет сравнение номеров столбцов ПЛМ 10 или сигналов на выходе дешифраторов. В случае совпадения номеров выдается сигнал.
Рассмотрим работу декодирующего устройства по исправлению ошибочных бит в принятой последовательности двоичных символов.
Вначале осуществляется предварительное обнуление регистров 1, 2 и 8.
При появлении сигнала на входе устройства в процессоре 9 запускается выполнение программы декодирования.
Если принимается кодовое слово с высших разрядов, то на пятом и шестом выходе процессора 9 устанавливается высокий потенциал (логическая единица). Вследствие этого на выходах схем «И» 6 и 7 будут сигналы совпадающими с входным сигналом устройства. По тактовым импульсам, поступающим на первый, второй и четвертый выходы процессора 9 будет записываться информация в регистры 1, 2 и 8. Причем их количество в запоминающий регистр 1 поступит равное сумме степени кодового многочлена и степени порождающего многочлена, а в регистры 2 и 8 только степени кодового многочлена. После принятия информационных импульсов на число тактов, равное произведению длительности одного бита на степень порождающего многочлена, закроется вход схемы «И» 7 (логический ноль на пятом выходе процессора 9) и перестанут поступать тактовые импульсы на первый выход процессора 9. Через промежуток времени, равный произведению длительности одного бита на степень порождающего многочлена, закроется вход схемы «И» 6 (логический ноль на шестом выходе процессора 9) и перестанут поступать импульсы на вход регистра 2. В результате в регистрах 2 и 8 запишутся остатки от деления кодового многочлена на порождающие, а в запоминающем регистре 1 запишется полная кодовая последовательность, сформированная в передатчике с искаженными символами.
При высоком потенциале на седьмом выходе процессора 9 на выходе инвертора 15 установится низкий уровень, который будет на вторых входах сумматоров по модулю два 13 и 14, что обеспечит передачу остатков от деления кодового многочлена на порождающие в регистрах 2 и 8 в дешифраторы 13 и 14. При этом передачу будут сопровождать тактовые импульсы на первом и втором выходах процессора 9. В результате на выходе дешифраторов 11 и 12 установятся коды, обеспечивающие начальный выбор столбцов матриц Н(х) и H1(x) ПЛМ 10, тактовыми импульсами, поступающими с седьмого выхода процессора 9, будет осуществляться сдвиг столбцов матриц Н(х) и H1(х) ПЛМ 10. При этом в блоке сравнения 16 будет осуществляться сравнение получающихся номеров столбцов, как приведено в таблице. В случае совпадения с выхода ПЛМ 10 поступит сигнал на вход процессора 9, где по результатам проделанных операций будет осуществлено определение позиций (бит) принятого кода, где произошло искажение сигнала.
Далее на четвертом выходе процессора 9 появятся тактовые импульсы, в результате чего код, записанный в запоминающем регистре 1, будет поступать на выход через блок исправления ошибок 3. Когда будет формироваться неискаженный бит, на выходе блока определения ошибок 4 установится низкий потенциал. Когда же будет формироваться искаженный бит, на выходе блока определения ошибок 4 установится высокий потенциал. Исправление ошибочных бит в принятой последовательности двоичных символов осуществляется в блоке исправления ошибок 3 (фиг.2).
Если в принятом кодовом многочлене D1(x) помехой искажен только один бит, то при появлении импульса на третьем выходе процессора 9 осуществляется блокирование уровня логической единицы на выходе инвертора 15, выход которого подключен к входам сумматоров по модулю два - 13 и 14 (фиг.2). На выходе схемы сравнения 16, подключенном к первому входу блока определения ошибок 4, появится высокий уровень. Выход блока определения ошибок 4, подключенный к входу блока исправления ошибок 3, обеспечит инвертирование (исправление) ошибочного бита на выходе блока исправления ошибок 3. В результате последовательность символов на выходе блока исправления ошибок 3 (устройства) не будет иметь искаженных бит.
Пример реализации способа определения местоположения двух ошибок в принимаемом сигнале, имеющем 19 бит (n=24-1=15), для которого неприводимые многочлены выбираются по таблице, приведенной в книге Питерсон У., Уэлдон Э. Коды, исправляющие ошибки. М.: Мир, 1976. 594 с.:
g(x)=1+х+х4,
g1(x)=1+x3+x4.
В этом случае проверочными матрицами размера (15×4) будут
Пусть необходимо передать по каналу связи, подверженному воздействию помех, некоторый код с0(х)=х+x4+х10. Тогда для реализации предложенного способа определения местоположения двух ошибок в принимаемом коде необходимо проделать следующие операции:
1. Вычисляем многочлен с(х)=с0(х)·х4, который будет равен с(х)=х5+х8+х14,
2. Используя формулу (2), вычисляем многочлен а(х)=(х+x2)+(1+x2)+(1+х3)=х+х3,
3. Используя формулу (5), вычисляем многочлен b(x)=(1+x+x3)+(x+x2+x3)+(x2+х3)=1+х3,
4. Формируем кодовый многочлен D(x)=1+x3+(х+х3+х5+х8+xl4)·x4=1+х3+х5+х7+х9+х12+х18,
5. Задаем вид многочлена ошибок E(x), который будет содержать два члена Е(х)=х9+х15,
6. Многочлен D1(х), в котором из-за помехи исчез бит х9 и появился бит х15, согласно выражению (10) примет вид
D1(x)=х+х3+х5+х7+xl2+x15+х18,
7. Сформируем многочлены
F(x)=x+x3+x8+x11+x14,
F1(x)=1+x3+x8+x11+х14,
в которых из-за помех отсутствует бит хj=х9-х4=х5 и ошибочно присутствует бит хi=х15-х4=х11.
8. Вычисляем многочлен r(х), являющийся остатком от деления F(x) на g(x)
F(x)=Q(x)·g(x)+r(x),
где r(x)=х3,
9. Вычисляем многочлен r1(х), являющийся остатком от деления F1(x) на g1(x)
F1(x)=Q1(x)·g1(x)+r1(x),
где r1(х)=х+х3,
10. Определяем многочлен r(α) подстановкой α в многочлен r(х)
r(α)=α3,
11. Вычисляем многочлен r1 (α1) подстановкой α1 в многочлен r1(х)

12. Согласно (18) из таблицы определяется значение s, при котором система уравнений примет вид (19)
Из таблицы видно, что s=4, a j1=9,
13. Определяем согласно уравнению (20) местоположение первой ошибки
j=j1-s=5,
14. Из выражения (21) определяем положение второй ошибки
i=-s=11,
Для условия 3.а. возможен многочлен Е(х) вида
5.а. Е(х)=х6+х15.




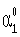
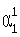

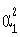

6.a. Многочлен D1(x), в котором из-за помехи появились ошибочные символы х6 и x15, согласно выражению (10) примет вид
D1(x)=1+x3+х5+x6+х7+х9+х12+х15+x18.
7.а. Определяются многочлены
F(x)=x+x2+x3+х5+x8+x11+x14,
F1(x)=1+x3+х5+x8+x11+x14,
в которых из-за помех присутствуют ошибочные биты хj=x6-x4=x2 и xi=х15-х4=x11.
8.а. Вычисляем многочлен r(х), являющийся остатком от деления F(x) на g(x)
F(x)=Q(x)·g(x)+r(x),
где r(х)=х+х3,
9.а. Вычисляем многочлен r1(х), являющийся остатком от деления F1(x) на g1(x)
F1(x)=Q1(x)·g1(x)+r1(x),
где r1(х)=1+х2+х3,
10.а. Определяем многочлен r(α) подстановкой а в многочлен r(х)
r(α)=α9,
11.а. Вычисляем многочлен r1(α1) подстановкой α1 в многочлен r1(х)

Откуда найдем j=11.
12.а. Исходя из системы уравнений (15) определяем
αj=r(α)·αj=α4-α11=α2.
Откуда получим i=2.
Таким образом, предлагаемый способ позволяет определить местоположения двух ошибок в принимаемом коде и с помощью декодирующего устройства исправит два ошибочных бита в принятом кодовом многочлене. Это обеспечивает как повышение исправляющей способности декодирующего устройства, так и увеличение помехозащищенности канала связи.
Технический эффект от использования изобретения: повышение исправляющей способности декодирующего устройства и увеличение помехозащищенности канала связи. В совокупности это означает повышение достоверности доставки кодированных сообщений (информации).
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЕКОДИРОВАНИЯ ЦИКЛИЧЕСКОГО КОДА ХЕММИНГА | 2004 |
|
RU2270521C1 |
| Декодер циклического кода | 1988 |
|
SU1599996A1 |
| СПОСОБ СИНДРОМНОГО ДЕКОДИРОВАНИЯ ДЛЯ СВЕРТОЧНЫХ КОДОВ | 2004 |
|
RU2282307C2 |
| Устройство мажоритарного декодирования кода Рида-Соломона по k-элементным участкам кодовой комбинации | 2015 |
|
RU2613760C2 |
| УСТРОЙСТВО КОДИРОВАНИЯ С ИСПРАВЛЕНИЕМ ОШИБОК И СПОСОБ КОДИРОВАНИЯ С ИСПРАВЛЕНИЕМ ОШИБОК, ИСПОЛЬЗУЕМЫЙ В НЕМ | 2005 |
|
RU2373641C2 |
| УСТРОЙСТВО КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ ИНФОРМАЦИИ | 1994 |
|
RU2115231C1 |
| Логическое запоминающее устройство | 1978 |
|
SU771720A1 |
| Декодирующее устройство | 1989 |
|
SU1644223A1 |
| Устройство для диагностирования цифровых объектов | 1989 |
|
SU1705829A1 |
| Запоминающее устройство с исправлением ошибок | 1984 |
|
SU1226536A1 |
Изобретение относится к области связи и может быть использовано в устройствах передачи дискретной информации в линиях связи с помехами. Техническим результатом является расширение функциональных возможностей за счет выявления и исправления двух ошибок принятого кода, что приводит к повышению помехозащищенности аппаратуры каналов связи. Устройство содержит запоминающий регистр, блок определения ошибок, блок исправления ошибок, блок переключения, состоящий из двух схем «И», два регистра порождающего многочлена, два сумматора по модулю два, два дешифратора, программируемая логическая матрица, блок сравнения, процессор, инвертор. Также раскрыт способ исправления двух ошибок в циклическом коде, реализуемый данным устройством. 2 н.п. ф-лы, 2 ил., 1 табл.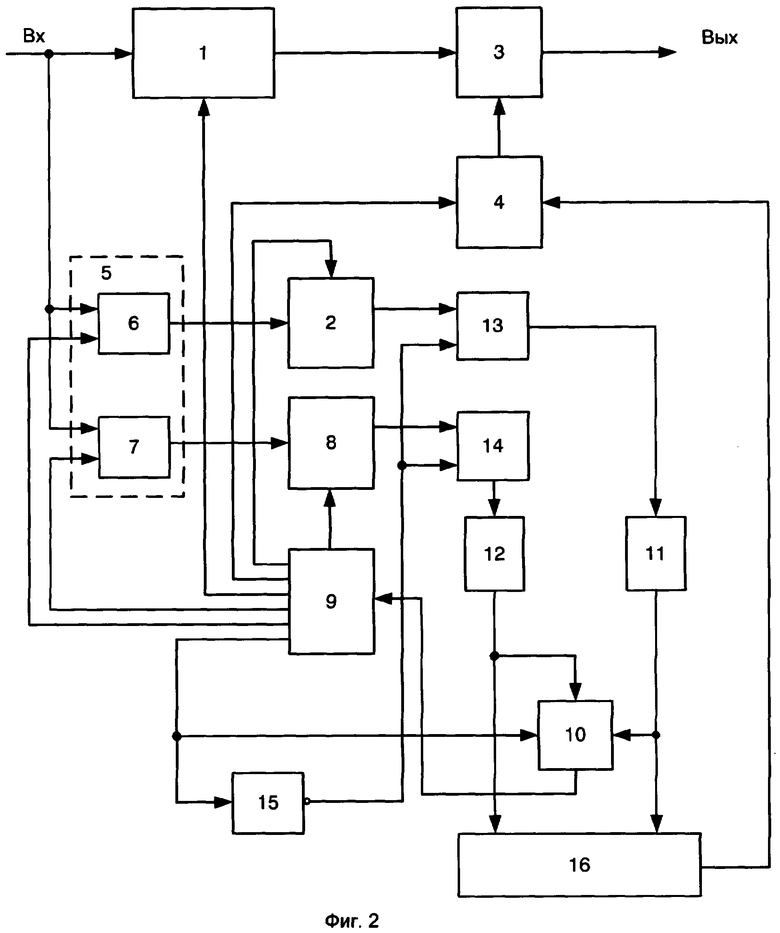
| ШВАРЦМАН B.C | |||
| и др | |||
| Теория передачи дискретной информации | |||
| - М.: Связь, 1979, с.305-306, 309, рис.10.4 | |||
| ВЫЧИСЛИТЕЛЬ ОШИБОК ПОМЕХОУСТОЙЧИВОГО ДЕКОДЕРА | 1999 |
|
RU2152130C1 |
| УСТРОЙСТВО ДЕКОДИРОВАНИЯ ЦИКЛИЧЕСКОГО КОДА ХЕММИНГА | 2004 |
|
RU2270521C1 |
| Устройство для декодирования двоичного циклического кода | 1985 |
|
SU1339901A1 |
| Винтовой грохот | 1987 |
|
SU1468604A1 |
| US 5381423 A, 10.01.1995. | |||

