ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Данное изобретение относится к способу декодирования по меньшей мере одного кодового слова, причем по меньшей мере одно кодовое слово было генерировано кодером, содержащим структуру, обеспечивающую код, представимый множеством переходов от одной ветви к другой в диаграмме матрицы. Далее данное изобретение обеспечивает соответствующий декодер, также как мобильную станцию и базовую станцию в сети связи, применяющей декодер. Кроме того, обеспечена система связи, содержащая базовые станции и мобильные станции.
УРОВЕНЬ ТЕХНИКИ
Кодирование сдвиговых регистров
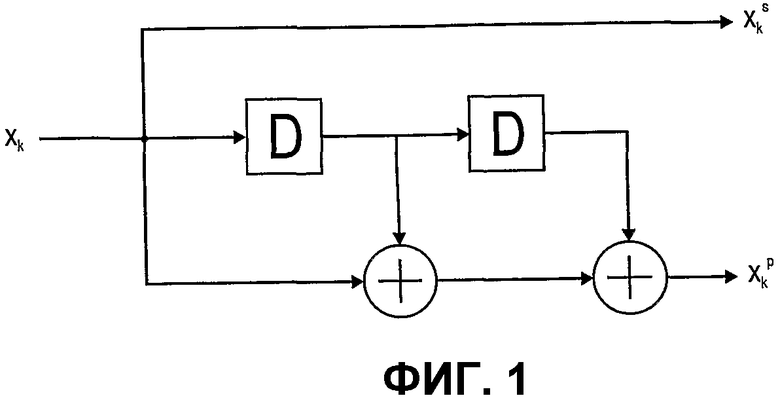
Сверточные коды и связанные коды могут генерироваться посредством одного или нескольких последовательно включенных или каскадно включенных сдвиговых регистров. Для простоты в следующих разделах рассмотрены двоичные сдвиговые регистры. Двоичные сдвиговые регистры способны принимать значение либо двоичное 0, либо двоичное 1. Когда имеет место сдвиг, содержание каждого регистра передается к последующему регистру и становится его новым содержанием. Обычно ввод в кодер используется как новое содержание первого регистра.
Выход кодера с двоичным сдвиговым регистром обычно получается посредством сложения по модулю 2 содержаний нескольких сдвиговых регистров перед сдвигом. В качестве иллюстрации простой кодер двоичного сдвигового регистра показан на фиг.1, где число сдвиговых регистров r=2 и число состояний М=4. Каждый сдвиговый регистр представлен посредством D, и каждый блок сложения по модулю 2 представлен посредством «+». Два выходных бита получаются из одного входного бита: первый выходной бит идентичен входному биту (верхняя ветвь), тогда как второй выходной бит получается посредством сложения по модулю 2 состояний сдвиговых регистров и входного бита (нижняя ветвь).
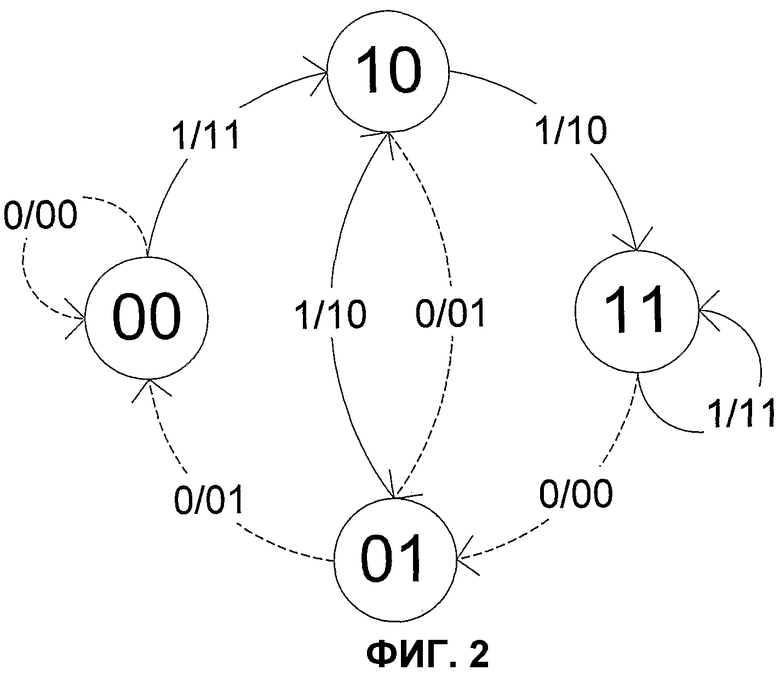
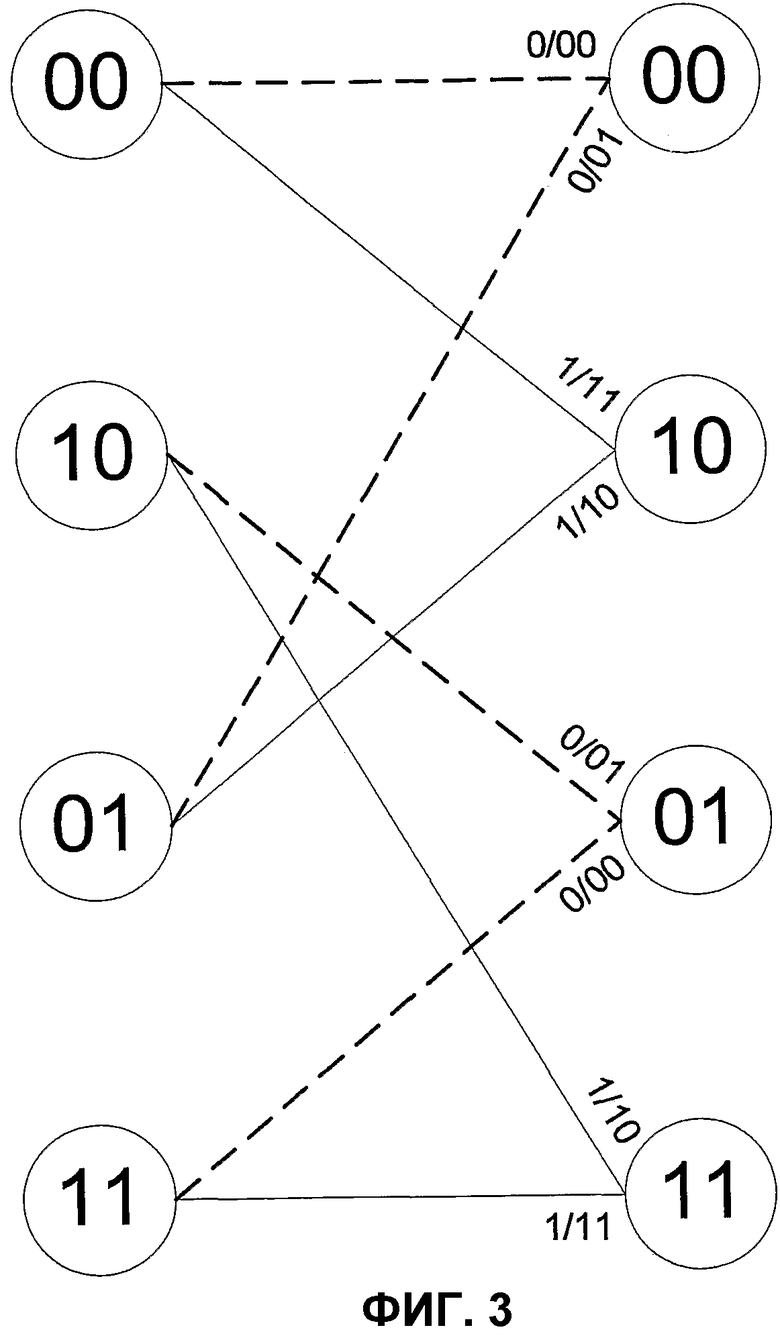
На фиг.2 показана диаграмма перехода состояний для кодера из фиг.1. Каждое состояние представлено значениями сдвигового регистра. Каждый переход представлен ориентированным ребром. Переход, вызванный входным битом нуля, обозначен прерывистым ребром, тогда как переход, вызванный входным битом единицы, обозначен прямым ребром. Каждое ребро далее обозначено входным битом, за которым следуют соответствующие выходные биты. Альтернативным представлением диаграммы перехода состояний является матрица, которая составлена из элементов матрицы, как показано на фиг.3. Дополнительные подробности о кодировании сдвиговых регистров (также известном как сверточное кодирование) могут, например, быть найдены в Lin et al., «Error Control Coding: Fundamentals and Applications», Prentice-Hall Inc., chapter 10.
Сдвиговые регистры обычно используются для сверточных кодов. В последнее время, они также использовались в «турбокодах», достигающих очень низких интенсивностей ошибок, что делает их привлекательными для систем связи.
Популярными алгоритмами декодирования для кодов сдвиговых регистров являются, например, алгоритм Витерби и максимальный апостериорный алгоритм. Хотя первый часто используется для традиционных сверточных кодов, последний является очень популярным для декодирования турбокодов из-за их мягкого выхода апостериорной вероятности.
Максимальный апостериорный алгоритм
Краткое описание максимального апостериорного алгоритма обеспечено в следующих абзацах. Для краткости более подробно рассмотрен двоичный случай. Распространение на недвоичный случай не должно создавать проблем для специалистов в данной области техники. Вообще говоря, в недвоичном случае вероятности событий обычно не могут выражаться посредством отношения логарифмического правдоподобия. Вместо этого может использоваться некоторая (возможно логарифмическая) абсолютная вероятностная мера. Очевидно, все равенства, приведенные далее и включающие отношения логарифмического правдоподобия, должны были бы быть изменены таким образом, чтобы они содержали упомянутые абсолютные вероятностные меры.
Упрощающая характеристика двоичного случая состоит в том, что - так как имеется только два возможных события - вероятности событий могут быть выражены в виде отношения логарифмического правдоподобия (LLR), которое обычно определяется следующим образом:
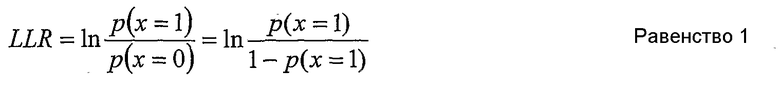
как натуральный логарифм отношения вероятностей того, что х является одним из двух возможных событий.
Следующие символы используются по всему этому документу:
Алгоритм имеет два компонента, обычно называемые прямой и обратной рекурсией. Более конкретно, два распределения, αk и βk, рекурсивно обновляются. Величина αk(Sk) представляет вероятностную меру для нахождения в состоянии Sk=m для информационного бита k, при заданной принятой последовательности y1...yk. Подобным же образом βk(Sk) представляет вероятностную меру для нахождения в состоянии Sk=m для информационного бита k при заданной принятой последовательности yk...yK.
Обе рекурсии могут быть определены на основе так называемой вероятности перехода от одной ветви к другой γk,i(yk,m',m''). Она представляет вероятность перехода между состояниями m' и m'' при заданном наблюдении принятого кодового слова yk, в предположении, что информационный бит, вызывающий этот переход, есть dk=i. Вероятность перехода от одной ветви к другой может быть вычислена как
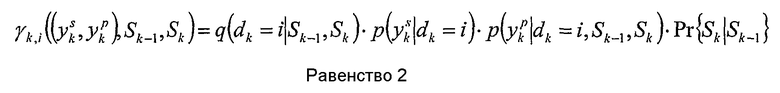
Значение q(dk=I|Sk-1,Sk) есть либо один, либо нуль, в зависимости от того, связан ли бит I с переходом из состояния Sk-1 в состояние Sk или нет. Pr{Sk|Sk-1} является априорной вероятностью информационного бита dk. В контексте турбодекодирования эта вероятность может быть полученной внешней информацией от другого декодера. Другие термины могут быть легко выведены специалистами в данной области техники. Например, если априорная информация не доступна, то вероятности могут быть установлены равными.
Равенство 2 может быть упрощено посредством опускания индекса I, если предполагается, что значения γ существуют только для тех переходов, где q(dk=I|Sk-1,Sk)=1. С использованием этого предположения равенство может быть переписано как
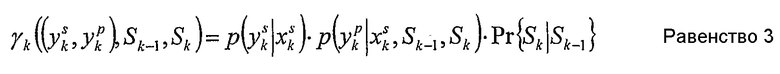
Рассматривая случай, в котором для каждого информационного бита dk на входе кодера имеется два кодированных бита xk=(xs kxp k) на выходе кодера, равенство 3 может быть далее упрощено с получением скорости кода ½. Кроме того, при рассмотрении двоичного случая равенство 3 может быть далее упрощено посредством использования логарифмических выражений:
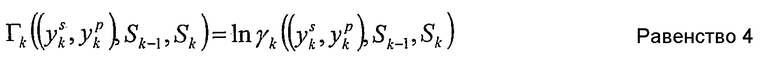
В случае двоичного кода сдвигового регистра число состояний М может быть вычислено как

Инициализация
Для каждого перехода от одной ветви к другой, начинающегося в состоянии Sk-1, оканчивающегося в состоянии Sk, вероятность перехода от одной ветви к другой для случая AWGN (аддитивного белого гауссовского шума) BPSK (двоичной фазовой манипуляции) дается следующим образом:
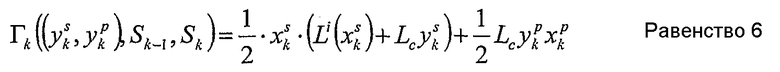
с k, пробегающим от 1 до К.
Поскольку последний член часто используется ниже, равенство 6 может быть переписано как
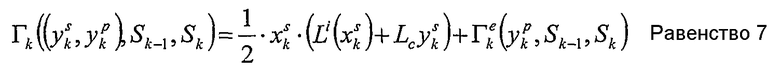
с использованием

Lc - это масштабный коэффициент канала, который может быть выведен из отношения сигнал-шум (SNR), и в этом случае

с σ2, представляющей дисперсию канального шума.
Начальные значения αk и βk могут быть инициализированы согласно системным параметрам. Для кода, который начинается и заканчивается в состоянии m=0, инициализации должны быть таковы

и

Прямая рекурсия
Для каждого состояния Sk, k пробегает от 1 до К, αk может быть вычислено как
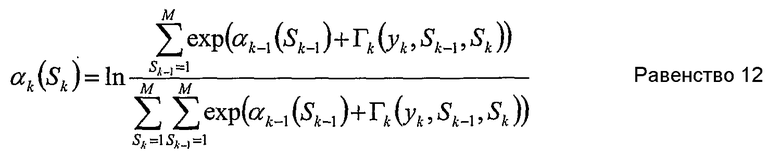
Обратная рекурсия
Для каждого состояния Sk, k пробегает от К-1 до 0, βk может быть вычислено как
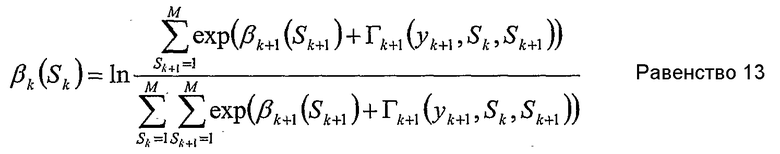
Декодирование
Полный процесс декодирования может состоять из применения прямой и обратной рекурсии. После этих рекурсий можно обновить решение мягкого вывода (то есть апостериорную вероятность) каждого информационного бита:
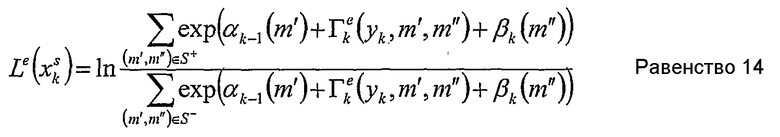

В вышеприведенном равенстве, S+ - множество упорядоченных пар, соответствующих всем переходам из одного состояния в другое m'→m'', которые вызваны входом данных dk=1. S- определяется подобным образом для dk=0.


С использованием равенства 15 значение k-го переданного бита может быть рассчитано как

Следует отметить, что внешняя величина Le, полученная в равенстве 14, может быть использована как внутренняя информация для последующего декодера. Подобным же образом, величина Li в равенстве 15 может быть получена как внутренняя информация из внешней информации другого декодера.
Специалистам в данной области техники будет ясно, что обе величины могут быть также установлены на правильные значения в случае, если от другого декодера нет доступной информации. Дополнительные подробности о применимости алгоритма к турбокодам, внутренней информации и внешней информации даны в Berrou и др. «Near Shannon Limit Error-Correcting Coding and Decoding: Turbo Codes (1)», Proc.IEEE Int.Conf. On Communications, c. 1064-1070, май 1993.
Max-Log-MAP алгоритм
Для упрощения рассматриваемых вычислений, равенства 12 и 13 могут быть приближены и заменены
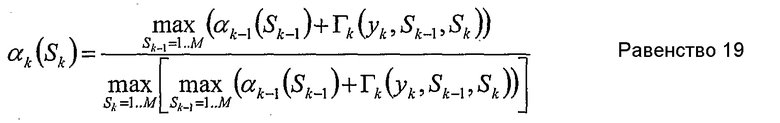
и
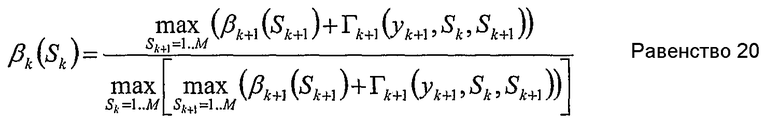
Подобным же образом искомая переменная может быть получена посредством модификации равенства 14 в
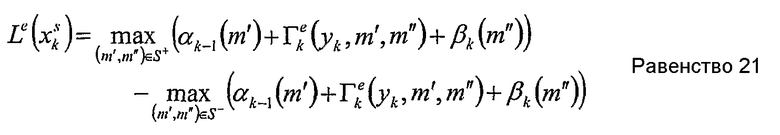
Однако эти приближения могут деградировать эффективность декодирования.
Как будет видно из равенств для прямой и обратной рекурсии, рассматривается информация от бесчисленных величин, которая окончательно выводится из принятого вектора, соответствующего переданному кодовому слову. В шумном окружении канала, высоки шансы того, что несколько принятых величин несут неверную информацию, что означает, что неверная информация может быть получена из этих величин и распространена через итерации декодирования.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Поэтому задачей данного изобретения является уменьшение влияния такой неверной информации.
Эта задача решается содержанием независимых пунктов формулы изобретения. Преимущественные варианты осуществления данного изобретения представлены содержанием зависимых пунктов формулы изобретения.
Согласно одному аспекту данного изобретения не вся информация в прямой и/или обратной рекурсии обрабатывается, как это требовалось бы равенствами соответствующего уровня техники. Согласно этому варианту осуществления данного изобретения некоторые члены вместо этого исключаются. Решение того, какой/какие член/члены исключается/исключаются, может быть, например, определено согласно его/их надежности, то есть член, который создавал бы деградацию эффективности декодирования при использовании в определении прямой и/или обратной рекурсии, опускается в соответствующем равенстве.
В одном из различных примерных вариантов осуществления данного изобретения обеспечен способ декодирования по меньшей мере одного кодового слова, причем по меньшей мере одно кодовое слово было генерировано кодером, содержащим структуру, обеспечивающую код, представимый множеством переходов от одной ветви к другой в диаграмме матрицы.
Согласно этому варианту осуществления этот способ может предусматривать этапы, на которых инициализируют множество вероятностей переходов от одной ветви к другой в декодере на основании принятого кодового слова и структуры кодера, инициализируют первое распределение вероятностей и второе распределение вероятностей согласно начальному состоянию кодера, используемого для кодирования по меньшей мере одного кодового слова, повторно вычисляют значения первого распределения вероятностей на основе начальных значений первого распределения вероятностей и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма, повторно вычисляют значения второго распределения вероятностей на основе начальных значений второго распределения вероятностей и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма и реконструируют декодированное кодовое слово на основе принятого кодового слова и внешней вероятностной меры, вычисленной на основе множества вероятностей переходов от одной ветви к другой, первого и второго распределения вероятностей.
Либо на каждом, либо на обоих этапах повторного вычисления значений первого или второго распределения вероятностей подмножества начальных значений первого распределения вероятностей или второго распределения вероятностей соответственно и подмножества множества вероятностей переходов от одной ветви к другой могут использоваться для повторного вычисления соответствующего распределения вероятностей. Далее используются только значения в подмножествах, удовлетворяющие заданному критерию надежности.
В другом варианте осуществления кодер может быть представлен структурой сдвиговых регистров, содержащей по меньшей мере одно из следующего: математические операции прямой связи и математические операции обратной связи.
Кроме того, в другом варианте осуществления данного изобретения код является подходящим для декодирования посредством применения максимального апостериорного алгоритма.
В другом варианте осуществления данного изобретения способ может дополнительно предусматривать этап, на котором используют внутреннюю вероятностную меру для инициализации множества вероятностей переходов от одной ветви к другой.
Другой вариант осуществления данного изобретения охватывает этап, на котором используют внутреннюю вероятностную меру для реконструкции декодированного кодового слова.
В другой вариации этого варианта осуществления декодер, представимый двумя отдельными экземплярами декодера, используют для декодирования по меньшей мере одного кодового слова на первом этапе декодирования и способ может дополнительно предусматривать этап, на котором используют внешнюю вероятностную меру первого экземпляра декодера как внутреннюю вероятностную меру во втором экземпляре декодера.
В другой вариации этого варианта осуществления способ дополнительно предусматривает этап, на котором выполняют вторую итерацию декодирования в первом экземпляре декодера, причем этот экземпляр декодера использует внешнюю вероятностную меру второго экземпляра декодера как внутреннюю вероятностную меру.
Согласно другому варианту осуществления данного изобретения критерий надежности может быть основан по меньшей мере на одном из: на канальных оценках радиоканала, по которому было принято по меньшей мере одно кодовое слово, абсолютных значениях элементов первого и/или второго распределения вероятностей, количестве выполненных этапов декодирования и случайного процесса. В другой вариации критерий надежности может быть не удовлетворен для элемента первого или второго распределения вероятностей, если отношение сигнал-шум для этого элемента и/или абсолютное значение этого элемента находится ниже заданного порогового значения.
Кроме того, данное изобретение обеспечивает в другом варианте осуществления декодер для декодирования по меньшей мере одного кодового слова, причем по меньшей мере одно кодовое слово было генерировано кодером, содержащим структуру, обеспечивающую код, представимый множеством переходов от одной ветви к другой в диаграмме матрицы.
Декодер может содержать средство обработки для инициализации множества вероятностей переходов от одной ветви к другой в декодере на основании принятого кодового слова и структуры кодера, инициализации первого распределения вероятностей и второго распределения вероятностей согласно начальному состоянию кодера, используемого для кодирования по меньшей мере одного кодового слова, повторного вычисления значений первого распределения вероятностей на основе начальных значений первого распределения вероятностей и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма, повторного вычисления значений второго распределения вероятностей на основе начальных значений второго распределения вероятностей и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма и реконструкции декодированного кодового слова на основе принятого кодового слова и внешней вероятностной меры, вычисленной на основе множества вероятностей переходов от одной ветви к другой, первого и второго распределения вероятностей.
Кроме того, средство обработки может быть выполнено с возможностью использования либо на каждом, либо на обоих этапах повторного вычисления значений первого или второго распределения вероятностей подмножества начальных значений первого распределения вероятностей или второго распределения вероятностей соответственно и подмножества множества вероятностей переходов от одной ветви к другой для повторного вычисления соответствующего распределения вероятностей, причем используются только значения, которые удовлетворяют заданному критерию надежности.
В другом варианте данного изобретения обеспечен декодер, содержащий средства, выполненные с возможностью осуществления вышеупомянутых способов декодирования.
Кроме того, другой вариант осуществления данного изобретения относится к мобильному терминалу в системе мобильной связи, причем мобильный терминал может содержать средство приема для приема по меньшей мере одного кодового слова, средство демодуляции для демодуляции по меньшей мере одного принятого кодового слова и декодер согласно любому из вариантов осуществления данного изобретения.
В другом варианте осуществления мобильный терминал может дополнительно содержать средство кодирования для кодирования данных по меньшей мере в одно кодовое слово и средство передачи для передачи по меньшей мере одного кодового слова, при этом по меньшей мере одно переданное кодовое слово является подходящим для декодирования согласно способам, описанным выше.
В другом варианте осуществления данного изобретения обеспечена базовая станция в системе мобильной связи, причем базовая станция может содержать средство приема для приема по меньшей мере одного кодового слова, средство демодуляции для демодуляции по меньшей мере одного принятого кодового слова и декодер согласно любому из вариантов осуществления данного изобретения.
В другом варианте осуществления базовая станция может дополнительно содержать средство кодирования для кодирования данных по меньшей мере в одно кодовое слово и средство передачи для передачи по меньшей мере одного кодового слова, при этом по меньшей мере одно переданное кодовое слово является подходящим для декодирования согласно способам декодирования, описанным выше.
Кроме того, согласно еще одному варианту осуществления обеспечена система мобильной связи, содержащая по меньшей мере одну базовую станцию согласно любому из вариантов осуществления данного изобретения и по меньшей мере один мобильный терминал согласно любому из вариантов осуществления данного изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Далее данное изобретение описано более подробно со ссылкой на приложенные чертежи. Подобные или соответствующие подробности в чертежах отмечены одними и теми же ссылочными позициями.
Фиг.1 показывает примерную компоновку кодера сдвиговых регистров для систематического кодирования.
Фиг.2 показывает диаграмму переходов от одного состояния к другому кодера, показанного на фиг.1.
Фиг.3 показывает описание сегмента матрицы для кодера, показанного на фиг.1.
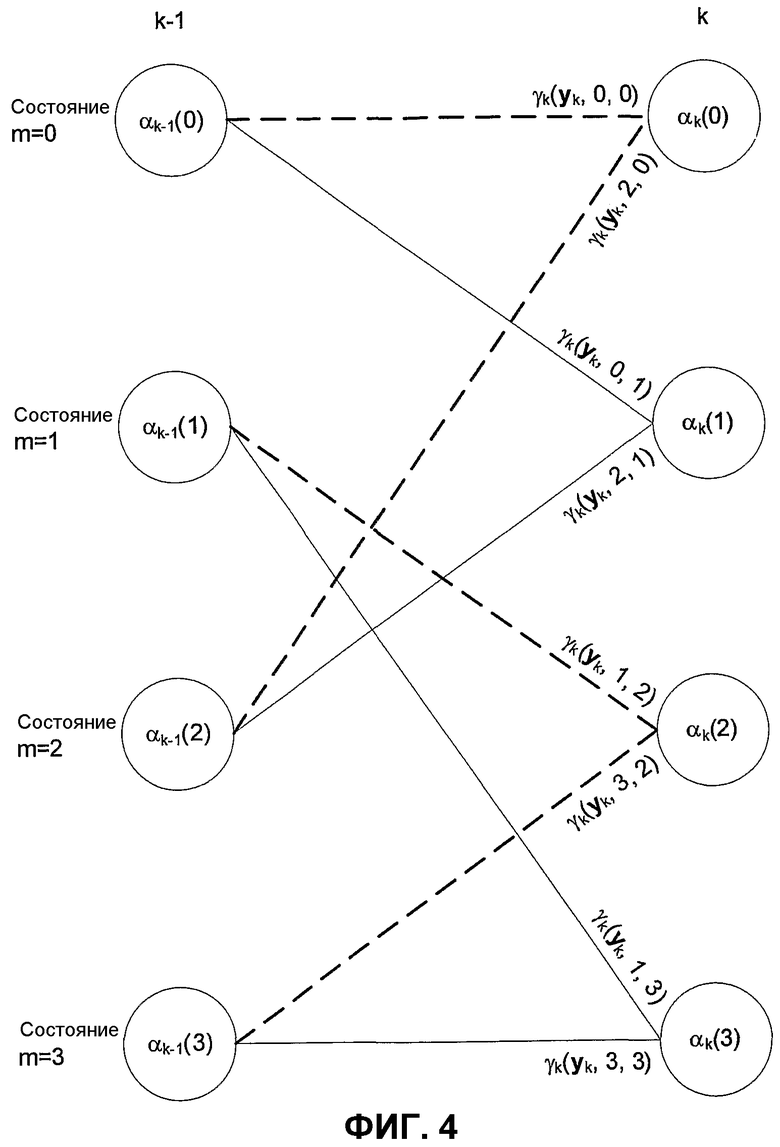
Фиг.4 показывает сегмент матрицы, показывающий переменные для прямой рекурсии.
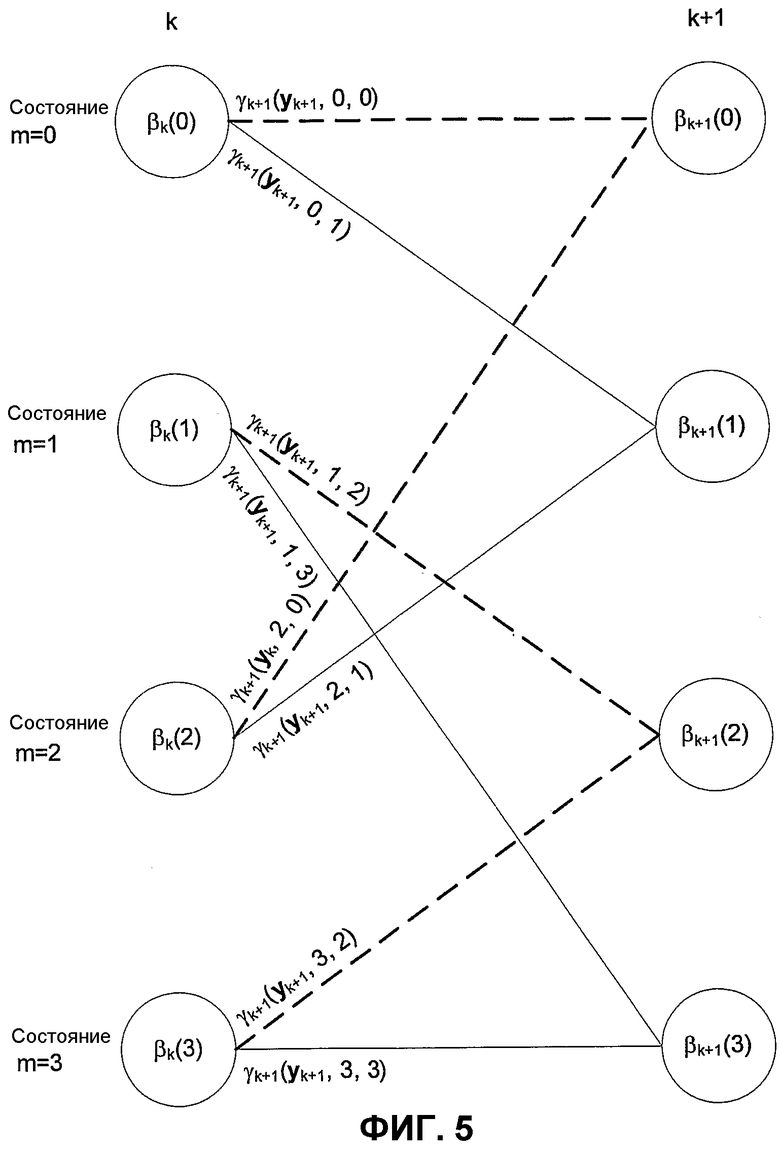
Фиг.5 показывает сегмент матрицы, показывающий переменные для обратной рекурсии.
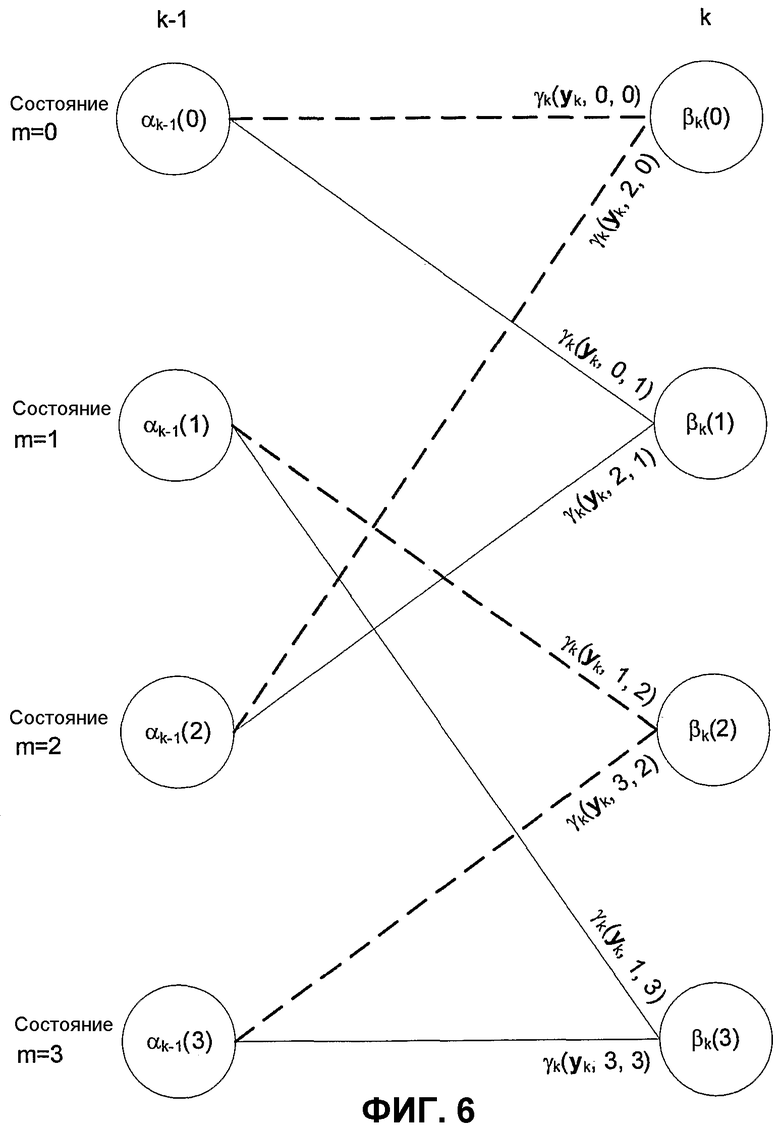
Фиг.6 показывает сегмент матрицы, показывающий переменные для решения.
Фиг.7 показывает блок-схему процесса декодирования согласно одному варианту осуществления данного изобретения.
Фиг.8 и 9 показывают блок-схемы процесса декодирования с использованием турбопринципа согласно различным вариантам осуществления данного изобретения.
Фиг.10 показывает блок передатчика и приемника согласно варианту осуществления данного изобретения.
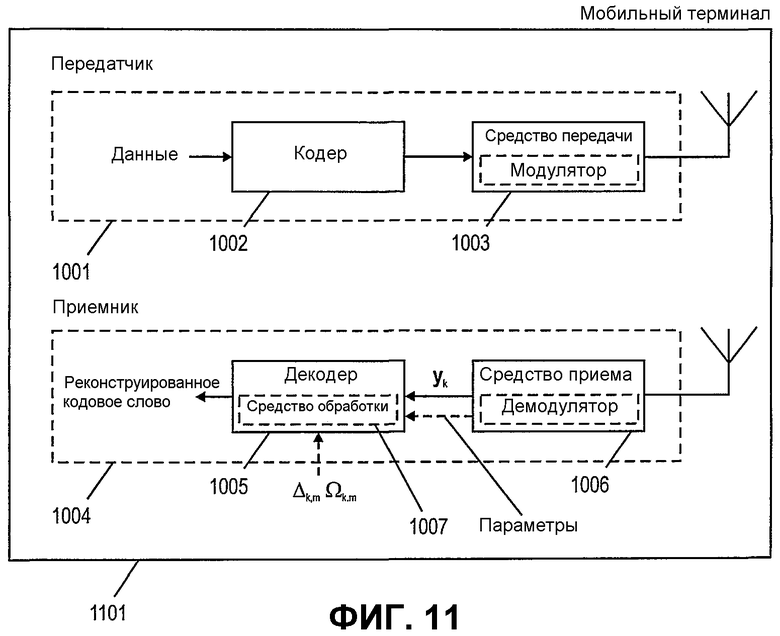
Фиг.11 показывает мобильный терминал согласно варианту осуществления данного изобретения, содержащий передатчик и приемник, показанные на фиг.10.
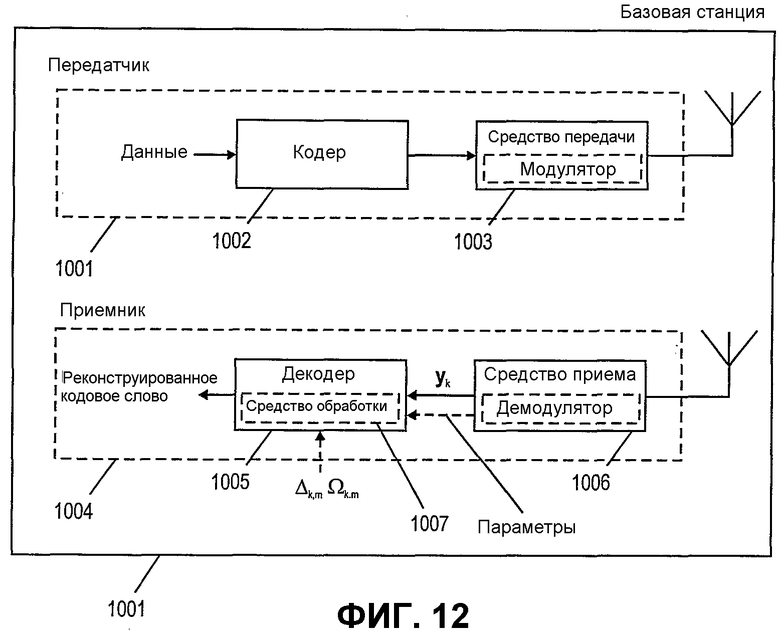
Фиг.12 показывает базовую станцию согласно варианту осуществления данного изобретения, содержащую передатчик и приемник, показанные на фиг.10.
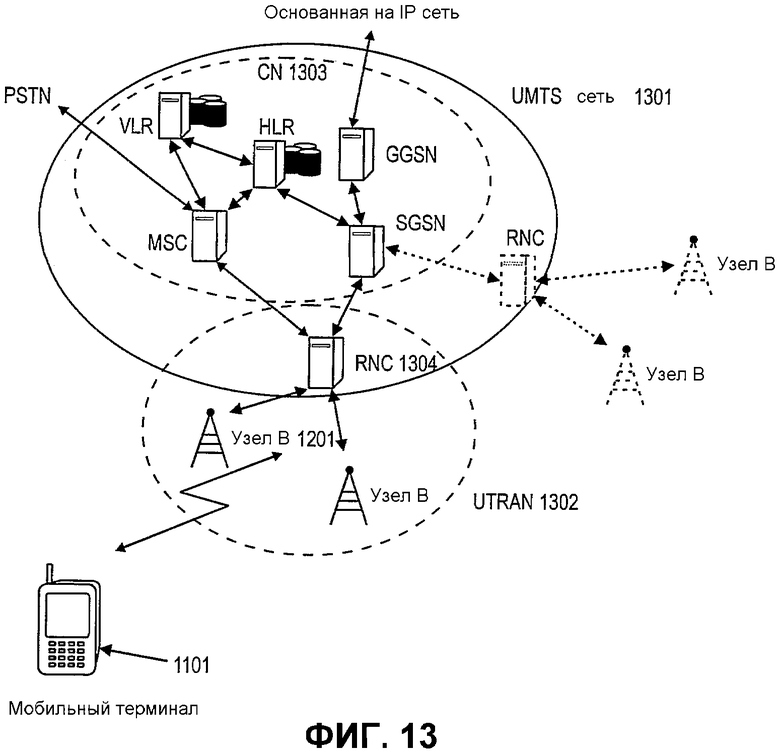
Фиг.13 показывает архитектурный обзор системы связи согласно варианту осуществления данного изобретения, содержащей мобильный терминал, показанный на фиг.11, и базовую станцию (Узел В), показанную на фиг.12.
ПОДРОБНОЕ ОПИСАНИЕ
В следующих абзацах выражение «х∈А\В» означает «х есть элемент множества А без множества В», что эквивалентно «х есть элемент множества А, но не элемент множества В».
Как описано в предыдущих разделах, математические равенства могут быть решены в инициализации, прямой рекурсии, обратной рекурсии и этапа решения максимального апостериорного алгоритма (см., например, равенства 6, 12, 13, 14 и 15).
Обычно эти равенства содержат следующие члены.
- Равенство для инициализации содержат члены, включающие в себя y величин.
- Равенство для прямой рекурсии содержит члены, включающие в себя Г и определенные величины α.
- Равенство для обратной рекурсии содержит члены, включающие в себя Г и определенные величины β.
Числитель равенства 12 для прямой рекурсии может быть интерпретирован как сумма величин для переходов от одного состояния к другому, которые начинаются в состоянии Sk-1 и заканчиваются в состоянии Sk=m. Следовательно, следующее «прямое множество» может быть определено так:

Тk,m является множеством состояний Sk-1, где переходы из состояния Sk-1 в Sk возможны посредством информационного бита dk.
Следовательно,
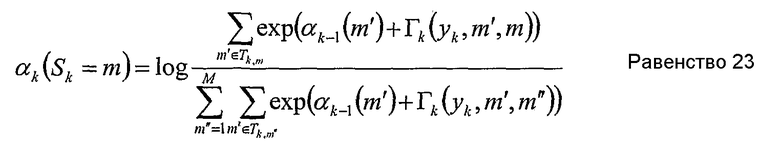
Подобным же образом числитель равенства 13 для обратной рекурсии может быть интерпретирован как сумма величин для переходов от одного состояния к другому, которые начинаются в состоянии Sk+1 и заканчиваются в состоянии Sk=m. Следовательно, второе «обратное множество» может быть определено так:
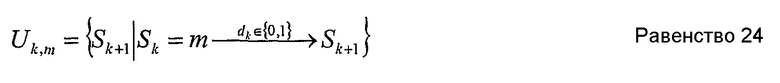
Uk,m является множеством состояний Sk+1, где переходы из состояния Sk в Sk+1 возможны посредством информационного бита dk.
Следовательно,
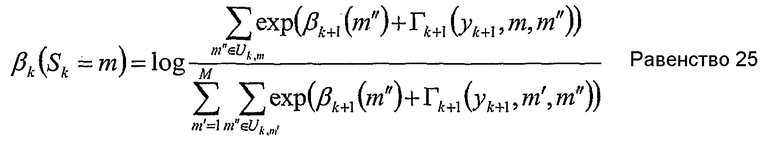
Согласно данному изобретению множества исключения Δk,m и Ωk,m могут быть дополнительно определены для прямой и обратной рекурсии.
Множество исключения Δk,m может указывать те элементы в прямом множестве Тk,m, которые не выполняют конкретный критерий надежности и, следовательно, не могут использоваться на этапе прямой рекурсии. Подобным же образом множество исключения Ωk,m может указывать те элементы в обратном множестве Uk,m, которые не выполняют конкретный критерий надежности и, следовательно, не могут использоваться на этапе обратной рекурсии.
С применением множеств исключения Δk,m и Ωk,m равенства могут, следовательно, быть модифицированы следующим образом.
Новая прямая рекурсия
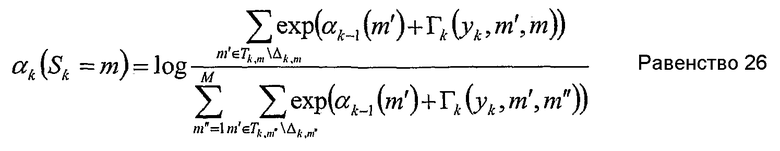
или альтернативно упрощено до
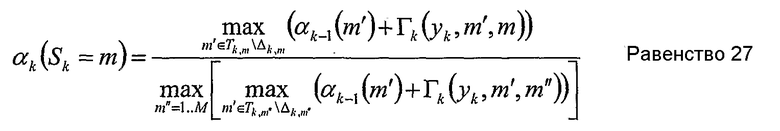
Новая обратная рекурсия
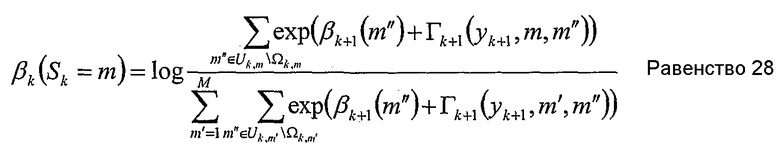
или альтернативно упрощено до
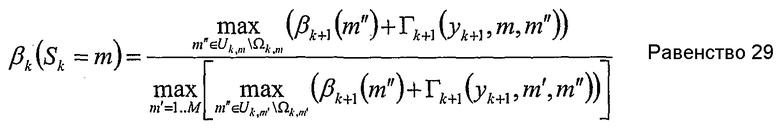
Если оба множества Δk,m и Ωk,m являются пустыми, то дублируется поведение известного уровня техники. Если множество исключения Δk,m содержит те же элементы, что и прямое множество Тk,m, то величина αk(Sk=m) не может быть определена из формулы рекурсии.
В этом случае может быть полезным установить соответствующее αk(Sk=m)=-∞. Подобным же образом βk(Sk=m)=-∞ может быть установлено, когда множество исключения Ωk,m содержит те же самые элементы, что и обратное множество Uk,m.
В случае если для определенного значения k множество исключения равно прямому множеству для всех m=1...M, αk(m) может быть установлено на -lnM, что означает, что все состояния Sk=1...M равноподобны. То же самое применимо к обратному множеству.
Обычно множества исключения могут зависеть от индекса m состояния, для которого решается уравнение, от индекса k информационного бита, для которого решается уравнение, и/или от числа итераций процедуры декодирования (например, в контексте турбодекодирования).
Определение множеств исключения Δk,m и Ωk,m
Как описано выше, множества исключения Δk,m и Ωk,m могут быть определены для того, чтобы исключить данные из равенств (или процесса декодирования), которые предполагаются неверными, или которые, очень вероятно, являются неверными. Если такие данные включены, произведенный выход, вероятно, является также неверным. Следовательно, данное изобретение предлагает отбрасывать такие величины из равенств для преодоления их отрицательных вкладов в выход декодирования.
Как отмечалось выше, множества исключения для этапа новой прямой рекурсии (см. равенства 26 или 27) и этапа обратной рекурсии (см. равенство 28 или 29) могут быть определены таким образом, что ненадежные сообщения исключаются из вычислений. В другом варианте осуществления данного изобретения множества исключения могут, например, быть определенными независимо друг от друга, то есть элемент множества исключения Δk,m необязательно может быть элементом множества исключения Ωk,m.
Подобным же образом в другом варианте осуществления данного изобретения множества исключения Δk,m и Ωk,m могут быть установлены независимо в итерациях декодирования. При увеличении числа итераций общая надежность пропускаемых сообщений может быть увеличена для разумно хороших условий передачи. Это может быть, например, применимо к декодированию турбокодов, когда внешняя информация, обмениваемая между объектами декодирования, возрастает по надежности с увеличенным числом итераций декодирования.
Следовательно, при увеличении числа итераций число элементов множеств исключения может быть уменьшено, так что на поздних этапах (в виде итераций) декодирования множества исключения могут быть пустыми.
В другом варианте осуществления данного изобретения множества исключения могут, например, зависеть как от числа итераций, обработанных до сих пор, так и от максимального числа итераций декодирования, которое может быть параметром, данным системой связи. Это может дать возможность постепенного уменьшения элементов во множествах исключения в зависимости от развития шагов итераций.
Примерным списком возможных критериев, которые могут быть использованы изолированно или в комбинации для определения множеств исключения, являются оценка канала (отношение сигнал-шум), абсолютные значения LLR, число итераций (в контексте турбодекодирования) и/или случайный процесс.
Например, критерий оценки канала дает возможность определения множеств исключения согласно воспринимаемому качеству принятых данных. Преимущество может быть в том, что оценка канала обеспечивает сорт независимой дополнительной информации, известной в декодере для оценки надежности принятой кодированной информации. Однако неоднородность оценки канала может быть ограничена сегментом, который состоит из нескольких битов, так что одна эта мера не может быть применима во всех ситуациях для определения множества исключения.
Критерий абсолютного значения LLR может дать возможность оценки надежности с тонкой неоднородностью. Благодаря определению значения LLR, большие абсолютные значения представляют высокую уверенность. Напротив, малое абсолютное значение представляет низкую уверенность. Поэтому ранжирование абсолютных значений LLR может быть использовано для определения самых малых значений для данного равенства, которые должны быть частью множества исключения. Например, критерий значений LLR может быть использован один или в комбинации с другими критериями для определения элементов во множествах исключения.
Другим возможным критерием может быть критерий случайного процесса. Этот критерий может использоваться либо один, либо в соединении с другими критериями для определения членов множества исключения. Например, из-за оценки канала может предполагаться, что 10% принятой информации является ненадежной. Тогда для каждой части информации может существовать шанс в 10% быть членом множества исключения.
Далее, со ссылкой на фиг. 7, 8 и 9, будут описаны различные варианты осуществления данного изобретения.
Фиг.7 показывает блок-схему процесса декодирования согласно одному варианту осуществления данного изобретения. После приема кодового слова yk через воздушный интерфейс на этапе 701 декодер может генерировать множества исключения Δk,m и Ωk,m на этапе 702.
Для того чтобы генерировать множества исключения, несколько различных параметров решения могут использоваться для решения, какие элементы следует исключить из вычислений на этапах 704, 705 прямой рекурсии и/или обратной рекурсии. Например, приемное средство может обеспечить информацию по качеству канала для приема кодового слова или его индивидуальных битов или даже может обеспечить множества исключения Δk,m и Ωk,m для декодера.
Далее на основе знания структуры кодера и принятого кодового слова yk вероятности Г(yk,Sk-1,Sk) переходов от одной ветви к другой могут быть инициализированы на этапе 703. Также распределения αk и βk вероятностей инициализируются на этапе 704. Это может быть, например, сделано с использованием знания структуры кодера, используемой для генерации принятого кодового слова yk.
После соответствующей инициализации декодера, прямая рекурсия и обратная рекурсия, как, например, определено в равенствах 26-29, могут быть выполнены на этапах 705 и 706. В этих рекурсиях рассматриваются множества исключения Δk,m и Ωk,m, то есть только подмножество величин в распределениях αk, βk и/или Г(yk,Sk-1,Sk) может использоваться для выполнения шагов рекурсии.
После повторного вычисления новых величин αk и βk кодовое слово может быть реконструировано декодером. Этот этап может, например, включать в себя генерацию внешнего LLR Le(xs k) и критерия оценки L(dk) для решения на индивидуальных битах декодированного кодового слова dk.
В другом варианте осуществления может быть далее возможно повторно использовать внешний LLR Le(xs k) или критерий оценки L(dk) как параметр для инициализации вероятностей Г(yk,Sk-1,Sk) переходов от одной ветви к другой следующей процедуры декодирования для последующего кодового слова. Однако это может облегчить распространение ошибок декодирования предыдущего кодового слова на следующее кодовое слово.
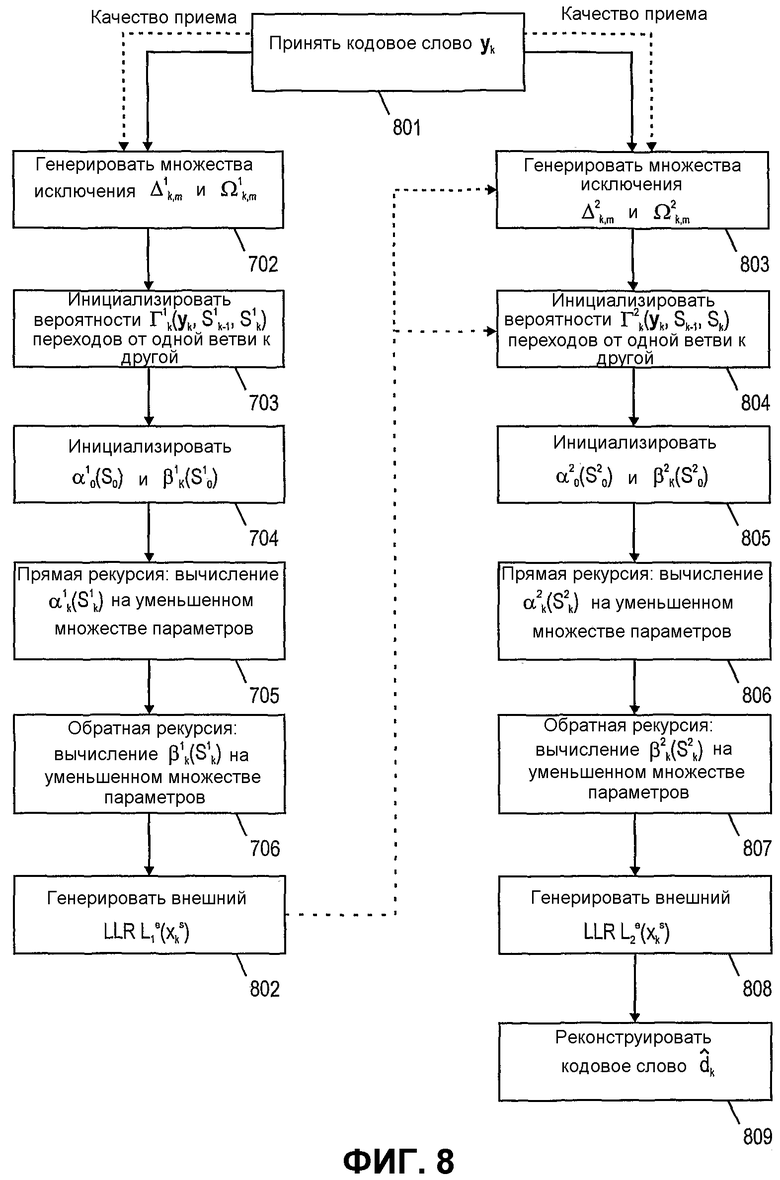
Фиг. 8 и 9 показывают блок-схемы процесса декодирования с использованием турбопринципа согласно другим примерным вариантам осуществления данного изобретения. В этих примерах множественные экземпляры декодера используются в декодере. Например, такая структура может быть применением для использования турбокодеров/декодеров.
Левая ветвь на фиг. 8 и 9 иллюстрирует работу первого экземпляра декодера, тогда как правая ветвь иллюстрирует работу второго экземпляра декодера. Для лучшей дифференциации между параметрами двух различных экземпляров декодера единицы и двойки были добавлены в верхний индекс или нижний индекс.
По существу, этапы, выполняемые обоими экземплярами декодера, подобны соответствующим этапам, описанным со ссылкой на фиг.7. Поэтому в следующем описании фиг.8 и 9 будем фокусироваться на изменениях, примененных к процессу декодирования.
На фиг.8 приемное средство принимает кодовое слово yk на этапе 801 и может обеспечить его для первого экземпляра декодера. После генерации или получения множеств исключения Δ1 k,m и Ω1 k,m (см. этап 702), например, с использованием индикаторов качества приема для индивидуальных битов средства приема вероятности Г1(yk,S1 k-1,S1 k) переходов от одной ветви к другой и величины α1 k и β1 k могут быть инициализированы (см. этапы 703 и 704). Затем выполняется этап 705 прямой рекурсии и этап 706 обратной рекурсии.
Согласно этому варианту осуществления данного изобретения первый экземпляр декодера может генерировать внешний LLR Le 1(xs k) (или альтернативно критерий оценки L1(dk) на его основе) на этапе 802 вместо реконструкции кодового слова dk. Генерируемый внешний LLR Le 1(xs k) (или критерий оценки L1(dk)) может быть отправлен ко второму экземпляру декодера для использования в его процессе декодирования, который будет объяснен далее.
На этапе 803 второй экземпляр декодера принимает кодовое слово yk от средства приема. Затем он может генерировать множества исключения Δ2 k,m и Ω2 k,m или может быть снабжен ими. Альтернативно, например, при использовании результатов первого экземпляра декодера, как указано пунктирной стрелкой, множества исключения Δ2 k,m и Ω2 k,m будут генерироваться на этапе 803. Следует отметить, что рассмотрение результатов обработки первого экземпляра декодера является необязательным на этапе 803.
Затем второй экземпляр декодера может инициализировать вероятности Г2(yk,S2 k-1,S2 k) переходов от одной ветви к другой на этапе 804. Внешний LLR Le 1(xs k) или критерий оценки L1(dk) может быть использован как внутренний LLR Le 2(xs k) в инициализации во втором экземпляре декодера. Далее величины α2 k и β2 k инициализируются подобным же образом, как описано для этапов 703 и 704.
После инициализации Г2(yk,S2 k-1,S2 k), α2 k и β2 k этап 806 прямой рекурсии и этап 807 обратной рекурсии выполняются подобным же образом, как описано со ссылкой на этапы 705 и 706 фиг. 7.
После повторного вычисления распределений вероятностей α2 k и β2 k кодовое слово dk может быть реконструировано. Согласно примерному варианту осуществления фиг.8 внешний LLR Le 2(xs k) может быть генерирован следующим на этапе 808, и на основе этих величин кодовое слово dk может быть реконструировано на этапе 809.
Как стало очевидным, второй экземпляр декодера может работать с задержкой относительно первого экземпляра декодера, так что результаты первого экземпляра декодера могут использоваться в процедуре декодирования второго экземпляра декодера. Следует также отметить, что в альтернативном варианте осуществления первый экземпляр декодера может реконструировать декодированное кодовое слово, которое может быть сравнено с декодированным кодовым словом, полученным от второго экземпляра декодера. В этом случае второй декодер может или не может работать с задержкой от первого экземпляра декодера. Этот процесс будет более точно описан в ссылке на фиг.9 далее.
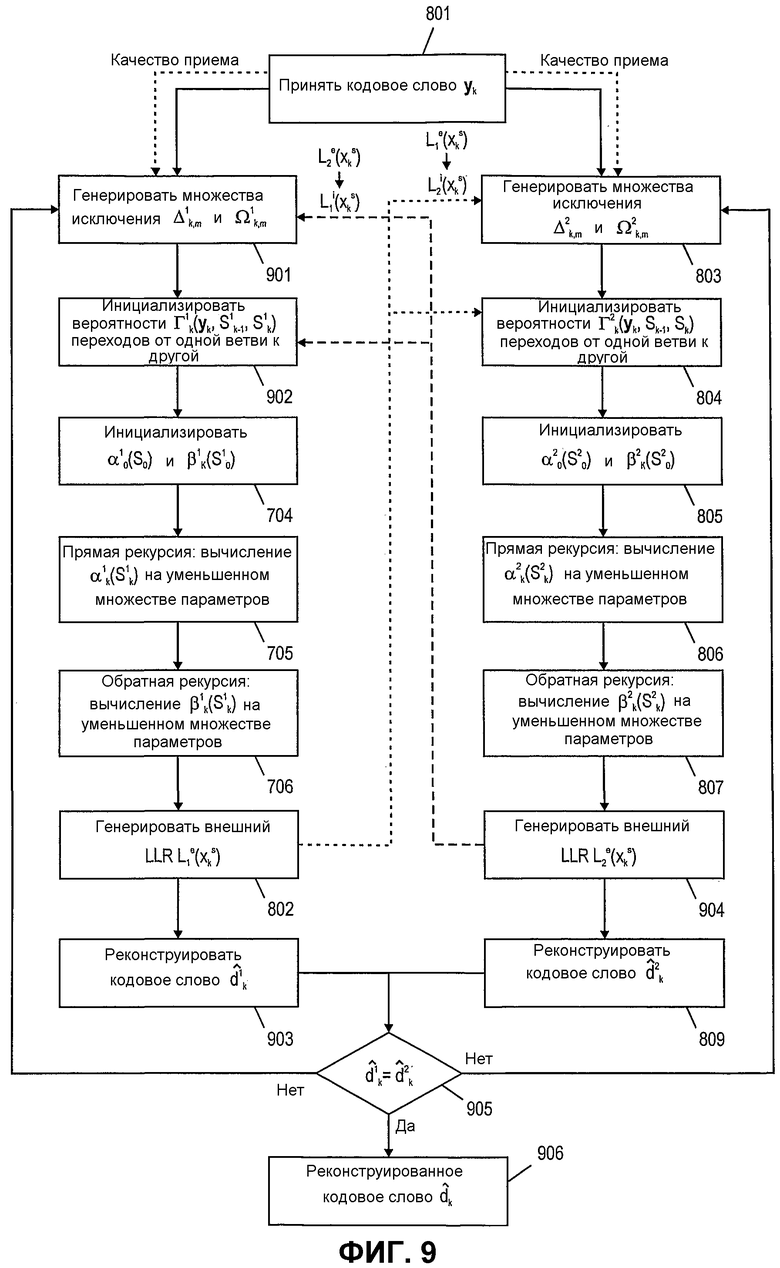
Фиг.9 показывает блок-схему процесса декодирования, использующего турбопринцип согласно другому примерному варианту осуществления данного изобретения. Процессы декодирования в двух экземплярах декодера, показанные в левой и правой ветвях фиг.9, являются почти идентичными. Первая итерация декодирования в первом экземпляре декодера подобна итерации, объясненной со ссылкой на фиг.8, то есть для первой итерации декодирования этапы 901 и 902 подобны этапам 702 и 703 на фиг. 7 и 9.
После инициализации и вычислений прямой рекурсии и обратной рекурсии (см. этапы 704, 705, 706) первый экземпляр декодера генерирует внешний LLR Le 1(xs k), который обеспечен для второго экземпляра декодера. Далее первый экземпляр декодера конструирует декодированное кодовое слово d1 k.
Параллельно или с задержкой, позволяющей использовать результаты первого экземпляра декодера на этапе 804 (и по выбору этапе 803), второй экземпляр декодера может выполнить (этапы 803-807, 809 и 904) подобное декодирование, что и первый экземпляр декодера, или итерацию декодирования, описанную со ссылкой на второй экземпляр декодера на фиг.8.
В конце первой итерации декодирования второй экземпляр декодера генерирует реконструированное кодовое слово d2 k. На этапе 905 два генерированных кодовых слова d1 k и d2 k сравниваются, и если обнаруживается, что они равны, то процесс декодирования заканчивается на этапе 906.
Если, однако, решение на этапе 905 приходит к отрицательному результату, то может быть выполнена дальнейшая итерация декодирования. В этом случае второй экземпляр декодера может обеспечить свой внешний LLR Le 2(xs k) для первого экземпляра декодера (этап 904), как указано пунктирными стрелками. Подобно второму экземпляру декодера первый экземпляр декодера может использовать эту внешнюю информацию как внутреннюю информацию, например внутренний LLR Le 1(xs k), в итерации декодирования. То есть информация второго экземпляра декодера может использоваться для получения заново инициализированного множества вероятностей Г1(yk,S1 k-1,S1 k) переходов от одной ветви к другой на этапе 902 и, по выбору, для определения новых множеств исключения Δ1 k,m и Ω1 k,m на этапе 901.
Таким образом, декодер может выполнять несколько итераций перед получением подобных реконструированных кодовых слов d1 k и d2 k, которые окончат процедуру декодирования для принятого кодового слова yk. Далее, в случае если реконструированные кодовые слова d1 k и d2 k не совпадают после заданного числа итераций, процесс декодирования может быть остановлен и ошибка декодирования может быть передана следующему экземпляру обработки.
Хотя примерная процедура декодирования фиг.9 была описана с обоими экземплярами декодера, реконструировавшими кодовое слово и сравнившими его, следует отметить, что также процедура, предложенная в варианте осуществления, показанном на фиг.8, может быть использована вместе с выполнением нескольких итераций декодирования перед реконструкцией кодового слова.
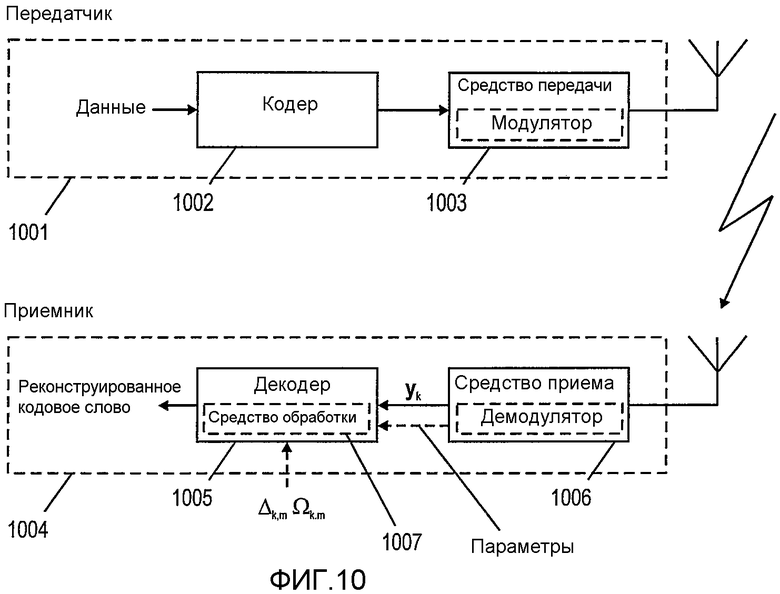
Затем фиг.10 будет обсуждаться более подробно. Фиг.10 показывает блок передатчика и приемника согласно варианту осуществления данного изобретения. Передатчик 1001 содержит кодер 1002 и средство передачи 1003. Средство передачи может содержать модулятор для модуляции сигналов, кодированных кодером 1002. Как указано пунктирной стрелкой, кодер 1002 способен кодировать входные данные в кодовое слово, подходящее для декодирования согласно различным вариантам осуществления процесса декодирования, описанного выше. Модулированные данные могут быть переданы средством 1003 передачи с использованием антенны, как указано.
Приемник 1004, принимающий кодированные сигналы, может содержать средство 1006 приема, которое может содержать демодулятор для демодуляции принятых сигналов. После выделения величин yk и параметров, таких как качество передачи или критерий надежности для каждого бита в принятом кодовом слове yk в средстве 1006 приема, эти данные могут быть обеспечены для декодера 1005, который рассмотрит эти данные для инициализации процесса декодирования, как описано выше.
Декодер 1005 может содержать средство 1007 обработки, приспособленное для декодирования принятых данных согласно способам, описанным выше, для создания реконструированных кодовых слов.
Фиг.11-12 показывают мобильный терминал (UE) 1101 и базовую станцию (Узел В) 1201 согласно различным вариантам осуществления данного изобретения соответственно. Мобильный терминал 1101 и базовая станция могут каждый включать в себя передатчик 1001 и приемник 1004, как показано на фиг.10, для осуществления связи.
Фиг.13 показывает архитектурный обзор системы связи согласно варианту осуществления данного изобретения, содержащей мобильный терминал 1101, показанный на фиг.11, и базовую станцию (Узел В) 1201, показанную на фиг.12.
Этот обзор изображает сеть 1301 UMTS, которая содержит базовую сеть (CN) 1303 и UMTS наземную сеть 1302 радиодоступа (UTRAN). Мобильный терминал 1101 может быть подключен к UTRAN 1302 через беспроводную линию связи к Узлу В 1201. Базовые станции в UTRAN 1302 могут быть далее подключены к контроллеру 1304 радиосети (RNC). CN 1303 может содержать (шлюзовой) центр коммутации мобильной связи (MSC) для подключения CN 1303 к коммутируемой телефонной сети общего пользования (PSTN). Опорный регистр местонахождения (HLR) и визитный регистр местонахождения (VLR) могут использоваться для хранения относящейся к абоненту информации. Далее базовая сеть может также обеспечить подключение к основанной на Интернет протоколе (основанной на IP) сети через обслуживающий узел поддержки GPRS (SGSN) и шлюзовой узел поддержки GPRS (GGSN).
Хотя примерная ссылка на систему мобильной связи была сделана выше, специалисты в данной области техники заметят, что данное изобретение может быть также применимо для использования в сетях беспроводных данных, как, например, IEEE 802.11, в цифровом видеовещании, таком как DVB, или цифровом аудиовещании, как, например, DAB или DRM.
Изобретение относится к способу декодирования по меньшей мере одного кодового слова, причем по меньшей мере одно кодовое слово было генерировано кодером, содержащим структуру, обеспечивающую код, представимый множеством переходов от одной ветви к другой в диаграмме матрицы. Данное изобретение обеспечивает соответствующий декодер, также как и мобильную станцию и базовую станцию в сети связи, использующей декодер. Кроме того, обеспечена система связи, содержащая базовые станции и мобильные станции. Технический результат - уменьшение влияния неверной информации в процессе декодирования путем использования только подмножества надежной информации в прямой и/или обратной рекурсии максимального апостериорного (MAP) алгоритма или Max-Log-MAP алгоритма. 5 н. и 10 з.п. ф-лы, 1 табл., 13 ил.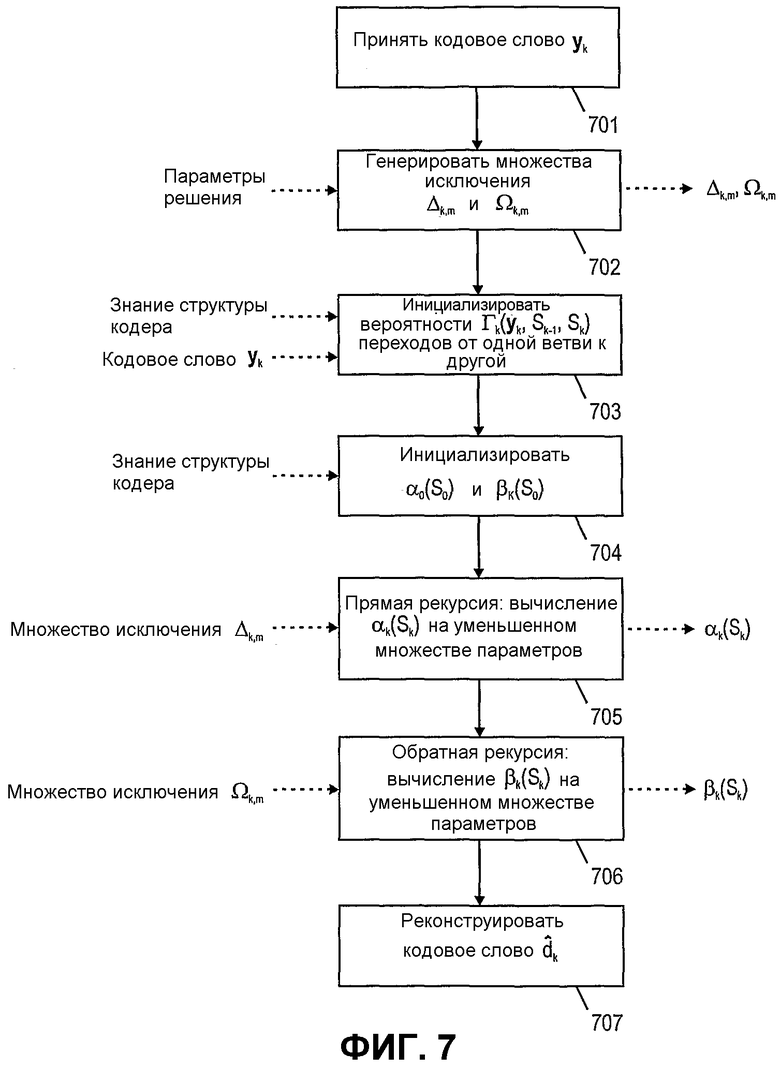
а) инициализируют множество вероятностей переходов от одной ветви к другой в декодере на основании принятого кодового слова и структуры кодера;
b) инициализируют распределение вероятностей прямой рекурсии и распределение вероятностей обратной рекурсии согласно начальному состоянию кодера, используемого для кодирования, по меньшей мере, одного кодового слова;
с) вычисляют значения распределения вероятностей прямой рекурсии на основе начальных значений распределения вероятностей прямой рекурсии и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма;
d) вычисляют значения распределения вероятностей обратной рекурсии на основе начальных значений распределения вероятностей обратной рекурсии и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма; и
е) реконструируют декодированное кодовое слово на основе принятого кодового слова и внешней вероятностной меры, вычисленной на основе множества вероятностей переходов от одной ветви к другой, распределения вероятностей прямой рекурсии и распределения вероятностей обратной рекурсии;
причем либо на каждом, либо на обоих этапах с) и d) подмножество начальных значений распределения вероятностей прямой рекурсии или распределения вероятностей обратной рекурсии, соответственно, и подмножество множества вероятностей переходов от одной ветви к другой используют для вычисления соответствующего распределения вероятностей, и
при этом значения в подмножестве начальных значений распределения вероятностей прямой рекурсии или распределения вероятностей обратной рекурсии соответственно удовлетворяют заданному критерию надежности.
математические операции прямой связи и математические операции обратной связи.
дополнительно используют внешнюю вероятностную меру первого экземпляра декодера как внутреннюю вероятностную меру во втором экземпляре декодера.
первый экземпляр декодера использует внешнюю вероятностную меру второго экземпляра декодера как внутреннюю вероятностную меру.
a) инициализации множества вероятностей переходов от одной ветви к другой в декодере на основании принятого кодового слова и структуры кодера;
b) инициализации распределения вероятностей прямой рекурсии и распределения вероятностей обратной рекурсии согласно начальному состоянию кодера, используемого для кодирования, по меньшей мере, одного кодового слова;
c) вычисления значений распределения вероятностей прямой рекурсии на основе начальных значений распределения вероятностей прямой рекурсии и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма;
d) вычисления значений распределения вероятностей обратной рекурсии на основе начальных значений распределения вероятностей обратной рекурсии и множества вероятностей переходов от одной ветви к другой с использованием рекурсивного алгоритма; и
e) реконструкции декодированного кодового слова на основе принятого кодового слова и внешней вероятностной меры, вычисленной на основе множества вероятностей переходов от одной ветви к другой, распределения вероятностей прямой рекурсии и распределения вероятностей обратной рекурсии;
при этом блок обработки сконфигурирован с возможностью использования либо на каждом, либо на обоих этапах с) и d) подмножества начальных значений распределения вероятностей прямой рекурсии или распределения вероятностей обратной рекурсии, соответственно, и подмножества множества вероятностей переходов от одной ветви к другой для вычисления соответствующего распределения вероятностей, и
значения в подмножестве начальных значений распределения вероятностей прямой рекурсии или распределения вероятностей обратной рекурсии соответственно удовлетворяют заданному критерию надежности.
блок демодуляции, сконфигурированный с возможностью демодуляции, по меньшей мере, одного принятого кодового слова, и
декодер по п.10.
блок приема, сконфигурированный с возможностью приема, по меньшей мере, одного кодового слова,
блок демодуляции, сконфигурированный с возможностью демодуляции, по меньшей мере, одного принятого кодового слова, и
декодер по п.10.
| ОПТИМАЛЬНЫЙ ДЕКОДЕР ПРОГРАММИРУЕМЫХ ВЫХОДНЫХ ДАННЫХ ДЛЯ РЕШЕТЧАТЫХ КОДОВ С КОНЕЧНОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ БИТОВ | 1997 |
|
RU2179367C2 |
| МНОГОСКОРОСТНОЙ ПОСЛЕДОВАТЕЛЬНЫЙ ДЕКОДЕР ВИТЕРБИ ДЛЯ ИСПОЛЬЗОВАНИЯ В СИСТЕМЕ МНОГОСТАНЦИОННОГО ДОСТУПА С КОДОВЫМ РАЗДЕЛЕНИЕМ | 1994 |
|
RU2222110C2 |
| US 6061387 A, 09.03.2000 | |||
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| US 5406570 A, 11.04.1995 | |||
| EP 061198 A1, 17.08.1994. | |||

