Изобретение относится к области техники связи, в частности к системам передачи информации, в которых для ее защиты от искажений в канале связи применяются турбокоды с компонентными рекурсивными систематическими сверточными кодами, и может быть использовано в кодеках (кодер-декодер) систем передачи данных, а также в устройствах помехоустойчивого кодирования при передаче и хранении дискретной информации.
Известен способ декодирования турбокодов с компонентными рекурсивными систематическими сверточными кодами [1, 3-5], который включает в себя для двух компонентного турбокода две процедуры декодирования, представляющие собой модули SISO («мягкий» вход, «мягкий» выход), и две процедуры перемежения для перемешивания «мягкой» информации, которой обмениваются процедуры декодирования. На вход первого SISO модуля поступают две последовательности: априорные сведения о последовательности информационных символов и «мягкий» выход канала связи (демодулятора), на выходе формируют «мягкие» решения, которые является отношением апостериорных вероятностей информационных элементов кода и которые после перемежения служат априорными сведениями об информационных элементах для второго SISO модуля. Второй SISO модуль уточняет значения анализируемых информационных элементов и вычисляет свои «мягкие» оценки информационных элементов, которые после деперемежения поступают на вход первого SISO модуля, и итерационный процесс продолжается. После каждой итерации увеличивается априорная информация о каждом информационном элементе. Процесс декодирования заканчивается либо после выполнения заданного количества итераций, либо после того, как величина поправки результата декодирования достигнет определенного порогового значения.
Основными недостатками данного способа декодирования является большая вычислительная сложность и большое время задержки декодирования, так как декодируется кодовое слово большой длины (несколько десятков тысяч элементов), причем обработка искаженного кодового слова выполняется в течение нескольких итераций. Кроме того, данный способ декодирования относится к квазиоптимальным способам декодирования.
Целью предлагаемого изобретения является повышение достоверности (качества) декодирования, понижение аппаратной и вычислительной сложности декодирования, уменьшение времени задержки, и, в частности, реализация оптимальной процедуры декодирования как с «мягким», так, и с «жестким» решениями.
Для достижения цели предложен способ синдромного декодирования турбокода с компонентными рекурсивными сверточными кодами, в котором наиболее вероятное значение систематической части кодового слова формируется не в результате итеративной процедуры, включающей в себя последовательную обработку компонентных кодов с помощью SISO модулей, а в результате поиска оптимального вектора коррекции, который основан на формировании синдромных последовательностей компонентных кодов, выделении в них локализованных синдромов, которые используют для поиска однократных ошибок, t-кратных локализованных ошибок и локализованных ошибок, имеющих конфигурацию кодовой последовательности. Отметим, что каждому локализованному синдрому соответствует смежный класс векторов ошибок. Затем для каждого вектора ошибки вычисляют метрику, которая при декодировании с «жестким» решением является ее весом, и для исправления наиболее вероятных ошибок в качестве вектора коррекции выбирают тот вектор ошибки, который имеет минимальную метрику и обнуляет локализованные синдромы компонентных кодов. При декодировании с «мягким» решением для каждого вектора ошибки вычисляют модифицированную метрику, и для исправления наиболее вероятных ошибок в качестве вектора коррекции выбирают тот вектор ошибки, который имеет максимальную метрику и обнуляет локализованные синдромы компонентных кодов. В завершении процесса декодирования инвертируют те элементы систематической части турбокода, номера которых соответствуют позициям ненулевых элементов в вектора коррекции систематической части первого компонентного кода.
Локализованная ошибка - это такая ошибка, которая на некотором интервале кодового слова компонентного кода турбокода искажает его первый и последний двухразрядный блок, причем внутри рассматриваемого интервала количество подряд идущих неискаженных блоков меньше защитного интервала τ, а за рассматриваемым интервалом и перед ним следует не мене τ подряд идущих неискаженных блоков. Защитный интервал τ равен кодовому ограничению сверточного кода.
Локализованный синдром - фрагмент синдромной последовательности компонентного кода, который начинается с ненулевого элемента, причем внутри фрагмента отсутствуют серии нулевых элементов длиной более 2(τ-1), а перед и за фрагментом следует серия нулевых элементов длиной не менее 2(τ-1).
Для декодирования турбокода с компонентными рекурсивными систематическими сверточными кодами предлагается способ, заключающийся в следующем.
Для принятой возможно искаженной кодовой реализации турбокода с относительной информационной скоростью R=1/n (фиг.1) вычисляют для каждого из n компонентных кодов синдромную последовательность {si (j)}, элементами которой являются коэффициенты при неизвестном многочлена s(j)(x):
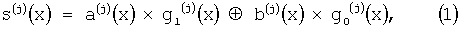
где а(j)(x) - многочлен, коэффициентами при неизвестном которого являются перемеженные j-м перемежителем элементы кодируемого блока информации;
b(j)(x) - многочлен, коэффициентами при неизвестном которого являются проверочные элементы j-го кодера;
g0 (j)(x) - многочлен, задающий обратную связь j-го систематического рекурсивного сверточного кодера;
g1 (j)(x) - порождающий многочлен j-го систематического рекурсивного сверточного кодера.
Затем в каждой синдромной последовательности {si (j)} выделяют локализованные синдромы, которые вместе с номером позиции первого элемента локализованного синдрома заносятся в оперативную память.
Далее поиск локализованных ошибок кодового слова турбокода выполняется поэтапно по мере убывания их вероятности появления.
На первом этапе выполняется поиск однократных локализованных ошибок в кодовой последовательности турбокода (однократная локализованная ошибка это такая ошибка, которая формирует локализованный синдром однократной ошибки во всех компонентных кодах). Конфигурация локализованного синдрома однократной ошибки в перемеженной информационной последовательности j-го компонентного кода соответствует последовательности коэффициентов при неизвестном многочлена g1 (j)(x), начиная с младшей степени. Конфигурация локализованного синдрома однократной ошибки j-го компонентного кода в элементах проверочной последовательности соответствует последовательности коэффициентов при неизвестном многочлена g0 (j)(x), начиная с младшей степени. Причем поиск однократных ошибок выполняется последовательно, начиная с кодовой последовательности первого компонентного кода. Если найдена локализованная однократная ошибка в проверочных элементах, то номер ее позиции заносят в оперативную память, предназначенную для хранения информации об ошибках, а ее локализованный синдром исключают из дальнейшего рассмотрения. Если найдена локализованная однократная ошибка в информационных элементах, то номер ее позиции также заносят в оперативную память, ее локализованный синдром исключают из дальнейшего рассмотрения. Затем корректируют локализованные синдромы других компонентных кодов. Коррекция локализованных синдромов j-го компонентного кода выполняется путем сложения по mod 2 одного из локализованных синдромов с позиции, соответствующей перемеженному номеру однократной ошибки первого компонентного кода, с синдромом однократной ошибки в информационной части данного компонентного кода. Если же синдром однократной ошибки не перекрывает ни одного локализованного синдрома j-го компонентного кода, то тогда синдром однократной ошибки в информационной части j-го компонентного когда добавляют к множеству его локализованных синдромов.
Когда проанализированы все локализованные синдромы первого компонентного кода, выполняют поиск однократных ошибок в других компонентных кодах аналогично рассмотренному, за исключением одного отличия. Оно заключается в том, что если синдром однократной ошибки в информационной части j-го компонентного кода не пересекается ни с одним локализованным синдромом первого компонентного кода, то тогда позиция ошибки не заносится в оперативную память и синдром не исключается из рассмотрения. Кроме того, необходимо заново проанализировать каждый откорректированный локализованный синдром компонентных кодов на наличие однократных ошибок. Если они есть, то необходимо выполнить рассмотренные выше процедуры. После завершения поиска однократных ошибок, если остался хотя бы один локализованный синдром у первого компонентного кода, переходим ко второму этапу. В противном случае переходим к коррекции кодовой последовательности.
На втором этапе выполняется поиск t-кратных локализованных ошибок в кодовой последовательности первого компонентного кода. Поиск ведется только по первому компонентному коду путем представления каждого его локализованного синдрома линейными комбинациями синдромов однократных ошибок в информационной и проверочной последовательностях. Отметим, что каждой линейной комбинации соответствует локализованная ошибка. В качестве оптимального вектора коррекции выбирают ту, которая имеет наименьший вес. Затем приводят в соответствие локализованные синдромы других компонентных кодов в соответствии с инверсией некоторых бит в информационной последовательности компонентных кодов, которые соответствуют откорректированным битам в информационной последовательности первого компонентного кода.
После завершения второго этапа первый компонентный код имеет нулевую синдромную последовательность. Если другие компонентные коды также имеют нулевые синдромные последовательности, то переходим к коррекции кодовой последовательности. Если нет, то в кодовой последовательности первого компонентного кода присутствуют t-кратные локализованные ошибки, которые имеют конфигурацию фрагментов кодовой последовательности. Поэтому переходим к третьему этапу.
На третьем этапе выполняют поиск локализованных ошибок в кодовой последовательности первого компонентного кода, которые имеют конфигурацию фрагментов кодовой последовательности. Для этого определяют по результату разложения оставшихся локализованных синдромов других компонентных кодов такие его локализованные ошибки, которые в первом компонентном коде формируют ошибки, имеющие конфигурацию кодовых последовательностей. Причем найденные ошибки должны обнулить синдромные последовательности всех компонентных кодов. В противном случае найденный вариант ошибок отвергается. Если в результате поиска найден единственный набор локализованных ошибок, то номера их ненулевых позиций заносятся в оперативную память. Если найдено несколько вариантов локализованных ошибок, то в качестве оптимального выбирается тот набор локализованных ошибок, который имеет наименьший вес.
Для завершении процесса декодирования инвертируются те элементы информационной последовательности, номера которых соответствуют позициям, указанным в оперативной памяти для хранения локализованных ошибок.
В том случае, когда декодирование турбокода выполняется с «мягким» решением предлагается вариант способа, описанного выше, в котором для каждой локализованной ошибки вычисляют модифицированную метрику vm:
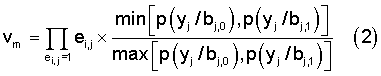
или
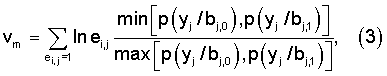
где p(yj/bj,c) - условная вероятность того, что на выходе демодулятора получена величина yj при передаче по каналу связи на j-й позиции кодовой последовательности компонентного кода элемента с, который для двоичного кода может принимать значение 0 или 1,
ei,j - элемент локализованной ошибки, исказивший j-ый элемент кодовой последовательности i-го компонентного кода,
Модифицированная метрика является отношением общепринятой метрики [1-5] i-го фрагмента кодовой последовательности к метрике принятого из канала связи с «жестким» решением искаженного фрагмента кодовой последовательности.
При выполнении 2-го и 3-го этапов поиска локализованных ошибок выбирается та из них, которая имеет наибольшую метрику vm.
Предлагаемые технические решения позволяют решить задачу оптимального синдромного декодирования турбокода как с «жестким», так и с «мягким» решениями с меньшей вычислительной и аппаратной сложностью, а также с меньшим временем задержки декодирования, чем известные декодеры [1, 3-5].
Изобретение поясняется чертежом, на котором изображена структурная схема оптимального синдромного декодера турбокода.
Синдромный декодер турбокода содержит: блоки вычисления синдрома 21÷2n, блоки деперемежения 42÷4n, блоки поиска локализованных синдромов 61÷6n, блоки хранения и обновления локализованных синдромов 81÷8n, блок поиска однократных локализованных ошибок 120, блок поиска локализованных блоков ошибок 140, блок поиска локализованных блоков ошибок, имеющих конфигурацию кодовых последовательностей 160, блок хранения локализованных блоков ошибок 180, блок коррекции 200.
Блоки вычисления синдромов {si (j)} кодовых последовательностей компонентных кодов 21÷2n предназначены для вычисления коэффициентов при неизвестном выражения (1), которые являются элементами синдрома.
Блоки деперемежения 42÷4n предназначены для формирования информационной последовательности компонентных кодов.
Блоки поиска локализованных синдромов 61÷6n предназначены для выявления локализованных синдромов в синдромных последовательностях компонентных кодов. Они могут быть реализованы в виде сдвигового регистра, у которого анализируется старший разряд на наличие 0 и подсчитывается количество подряд идущих нулей. В этом случае в сдвиговый регистр последовательно поступает синдромная последовательность {si (j)} и выполняются ее сдвиги в сторону старшего разряда. При появлении ненулевого элемента номер его позиции фиксируется, и фрагмент синдромной последовательности запоминается до момента прихода серии нулевых элементов длиной более 2(τ-1). После чего процесс поиска очередного локализованного синдрома продолжается аналогичным образом.
Блоки хранения и обновления локализованных синдромов 81÷8n предназначены для хранения локализованных синдромов и номеров позиций их первых ненулевых элементов. Блоки 81÷8n представляют собой оперативное запоминающее устройство, у которого каждая строка состоит из двух полей для хранения номера первой позиции локализованного синдрома и самого синдрома.
Блок поиска однократных локализованных ошибок 120 предназначен для выявления в кодовой последовательности однократных локализованных ошибок в информационной последовательности и в проверочных последовательностях компонентных кодов в соответствии с последовательностью действий, которые предусмотрены для 1-го этапа поиска локализованных ошибок в предложенном выше способе.
Блок поиска локализованных ошибок 140 предназначен для выявления t-кратных ошибок в кодовой последовательности первого компонентного кода в соответствии с последовательностью действий, которые предусмотрены для 2-го этапа поиска локализованных ошибок в предложенном выше способе.
Блок поиска локализованных ошибок, имеющих конфигурацию кодовых последовательностей, 160 предназначен для выявления t-кратных ошибок, имеющих конфигурацию кодовых последовательностей, в кодовой последовательности первого компонентного кода. Поиск выполняется в соответствии с последовательностью действий, которые предусмотрены для 3-го этапа поиска локализованных ошибок в предложенном выше способе.
Блок хранения локализованных ошибок 180 предназначен для хранения локализованных ошибок и номеров позиций их первых ненулевых элементов информационной последовательности и проверочных последовательностях компонентных кодов. Блок 180 представляет собой оперативное запоминающее устройство, у которого каждая строка состоит из двух полей для хранения номера первой позиции локализованного ошибки и самой ошибки.
Блок коррекции 200 предназначен для исправления искаженной информационной последовательности турбокода путем инвертирования тех элементов, на которые указывают ненулевые элементы локализованных ошибок, и передачи откорректированной информации на выход декодера.
Предлагаемое устройство работает следующим образом.
Принятое, возможно искаженное в канале связи, кодовое слово турбокода с n компонентными систематическими рекурсивными сверточными кодами в виде информационной последовательности по шине 10 и n проверочных последовательностей по шинам 11÷1n каждого компонентного кода поступает на соответствующие блоки вычисления синдромов 21÷2n. Кроме того, по шине 10 информационная последовательность поступает на блоки деперемежения 42÷4n и на блок коррекции 200. Затем после деперемежения она поступает по шинам 52÷5n на вход блоков вычисления синдромов 22÷2n.
Вычисленные по формуле (1) синдромы компонентных кодов по шинам 31÷3n поступают в блоки поиска локализованных синдромов 61÷6n. По мере нахождения локализованных синдромов они вместе с номером позиции их первого элемента передаются по шинам 71÷7n в блоки хранения и обновления локализованных синдромов 81÷8n компонентных кодов. Если не найдено ни одного локализованного синдрома, то кодовое слово не искажено. В этом случае блок принятия решения по шине 210 передает информационную последовательность на выход декодера.
После обработки синдромов всех компонентных кодов и заполнении блоков хранения и обновления локализованных синдромов приступает к работе блок поиска локализованных однократных ошибок 120. Блок 120 по шинам 91÷9n последовательно считывает и обрабатывает локализованные синдромы компонентных кодов в соответствии с последовательностью действий, которые предусмотрены для 1-го этапа поиска локализованных ошибок в предложенном выше способе. Номера позиций найденных локализованных однократных ошибок по шине 130 передаются в блок хранения локализованных ошибок 180. Завершив обработку локализованных синдромов компонентных кодов, блок 120 возвращает их по шинам 91÷9n в соответствующие блоки 81÷8n.
После завершения работы блока 120, если в блоке 81 остается хотя бы один локализованный синдром, запускается блок поиска локализованных блоков ошибок 140, который по шинам 101÷10n последовательно считывает и обрабатывает локализованные синдромы 1-го компонентного кода в соответствии с последовательностью действий, которые предусмотрены для 2-го этапа поиска локализованных ошибок в предложенном выше способе. Номера позиций найденных локализованных t-кратных ошибок по шине 150 передаются в блок хранения локализованных блоков ошибок 180. Завершив обработку локализованных синдромов компонентных кодов, блок 140 возвращает их по шинам 101÷10n в соответствующие блоки 81÷8n.
После завершения работы блока 140, если в блоках 82÷8n остались локализованные синдромы, запускается блок поиска локализованных блоков ошибок, имеющих конфигурацию кодовых последовательностей, 160. Блок 160 по шинам 111÷11n последовательно считывает и обрабатывает локализованные синдромы компонентных кодов в соответствии с последовательностью действий, которые предусмотрены для 3-го этапа поиска локализованных ошибок в предложенном выше способе. Номера позиций найденных локализованных ошибок по шине 170 передаются в блок хранения локализованных ошибок 180. Завершив обработку локализованных синдромов компонентных кодов, блок 140 возвращает их по шинам 111÷11n в соответствующие блоки 81÷8n.
После завершения работы блока 160 запускается блок коррекции 200, который устраняет ошибки в информационной последовательности путем инверсии тех ее элементов, номера которых по шине 190 считываются из блока хранения локализованных ошибок 180. После чего откорректированная информационная последовательность по шине 210 передается на выход декодера.
Для декодирования каскадного кода с «мягким» решением другим конструктивным вариантом является модификация блоков вычисления синдромов 21÷2n, которые перед вычислением синдромных последовательностей компонентных кодов формируют кодовые последовательности с «жестким» решением. В блоках поиска однократных локализованных ошибок 120, блоков ошибок 140 и ошибок, имеющих конфигурацию кодовых последовательностей, для каждой формируемой локализованной ошибки вычисляют метрику по формулам (2) или (3) и выбирают ту локализованную ошибку, которая имеет наибольшую метрику vm.
Реализация описанного устройства может быть аппаратной, программной или аппаратно-программной.
Достигаемым техническим результатом предлагаемого способа синдромного декодирования турбокодов с компонентными систематическими рекурсивными сверточными кодами является построение оптимального декодера с «жестким» и «мягким» решениями, а также повышение достоверности (качества) декодирования и его быстродействия, уменьшения аппаратной сложности и уменьшения времени задержки декодирования по сравнению с известными декодерами [1, 3-5]. Предлагаемый способ синдромного декодирования как с «жестким», так и с «мягким» решением может быть с успехом применен для перфорированных турбокодов с компонентными систематическими рекурсивными сверточными кодами.
Литература
1. Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение: Пер. с англ. В.Б.Афанасьева. - М.: Техносфера, 2005. - 320 с.
2. Витерби А.Д., Омура Дж.К. Принципы цифровой связи и кодирования: Пер. с англ. - М.: Радио и связь, 1982.
3. Мак-Вильямс Ф.Дж., Слоэн Н.Дж.А. Теория кодов, исправляющих ошибки: Пер. с англ. - М.: Связь, 1979.
4. Карташевский В.Г., Мишин Д.В. Прием кодированных сигналов в каналах с памятью. - М.: Радио и связь, 2004.
5. Золотарев В.В., Овечкин Г.В. Помехоустойчивое кодирование. Методы и алгоритмы: Справочник / Под ред. чл. кор. РАН Ю.Б.Зубарева. - М.: Горячая линия - Телеком, 2004.
Изобретение относится к области техники связи, в частности к системам передачи информации, в которых для ее защиты от искажений в канале связи применяют турбокоды с компонентными рекурсивными сверточными кодами, и может быть использовано в кодеках систем передачи данных, а также в устройствах помехоустойчивого кодирования. Сущность заявленного способа состоит в том, что для принятой искаженной кодовой реализации турбокода с компонентными рекурсивными сверточными кодами вычисляют синдромные последовательности для каждого компонентного кода, после чего определяются локализованные синдромы, и, используя процедуры формирования смежного класса векторов ошибок, определяют вектор ошибки минимального веса (метрики) при декодировании с «жестким» решением, а при декодировании с «мягким» решением выбирают вектор ошибки, которые имеют наибольшую модифицированную метрику (наиболее вероятную ошибку). Техническим результатом является повышение достоверности (качества) декодирования, снижение аппаратной и вычислительной сложности, а также реализация оптимальной процедуры декодирования, как с «мягким», так и с «жестким» решениями. 2 н.п. ф-лы, 1 ил.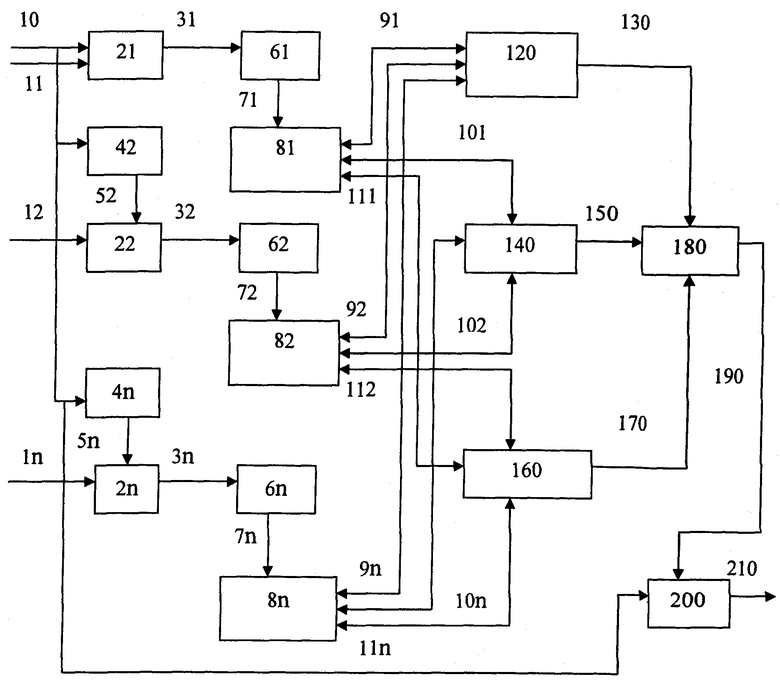
| УСТРОЙСТВО И СПОСОБ ТУРБОКОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ ДЛЯ ОБРАБОТКИ ДАННЫХ КАДРА В СООТВЕТСТВИИ С КАЧЕСТВОМ ОБСЛУЖИВАНИЯ | 1999 |
|
RU2210185C2 |
| УСТРОЙСТВО И СПОСОБ ГЕНЕРИРОВАНИЯ И ДЕКОДИРОВАНИЯ КОДОВ В СИСТЕМЕ СВЯЗИ | 2002 |
|
RU2236756C2 |
| УСТРОЙСТВО И СПОСОБ ФОРМИРОВАНИЯ КОДОВ В СИСТЕМЕ СВЯЗИ | 2002 |
|
RU2251794C2 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| US 5983384 A, 09.11.1999. | |||

