Изобретение относится к области техники связи и, в частности, к системам передачи информации, в которых для ее защиты от искажений в канале связи применяются коды-произведения, представляющие собой каскадные коды с последовательным соединением через перемежитель компонентных циклических линейных блочных кодов. Изобретение может быть использовано в кодеках (кодер-декодер) систем передачи данных, а также в устройствах помехоустойчивого кодирования при передаче и хранении дискретной информации.
Известен способ декодирования каскадных кодов с последовательным соединением через перемежитель компонентных циклических линейных блочных кодов [7], который включает в себя три этапа поиска локализованных ошибок, выполняемых последовательно. На первом и втором этапах выполняется поиск цепочек локализованных ошибок в кодовом слове каскадного кода, которые начинаются с однократной и двукратной ошибки в кодовых словах одного из компонентных кодов соответственно. Далее, цепочки локализованных ошибок объединяются в альтернативные группы локализованных ошибок, для которых на третьем этапе выполняется поиск локализованных ошибок, имеющих конфигурацию кодовых слов одного из компонентных кодов. В качестве оптимального вектора коррекции выбирают ту группу локализованных ошибок, которая имеет «нулевые» и «условно нулевые» синдромы для всех кодовых слов компонентных кодов и имеет наименьший вес.
Недостатком способа [7] является невысокое качество декодирования.
Другим недостатком способа является его большая вычислительная сложность, связанная с формированием большого числа повторяющихся цепочек локализованных ошибок, которые необходимо исключать из рассмотрения.
Декодирование кодового слова кода-произведения начинается с преобразования последовательности элементов, полученной от демодулятора, в кодовые слова компонентных кодов. Для всех кодовых слов компонентных кодов вычисляются синдромы. При наличии «мягкого» решения с выхода демодулятора для вычисления синдромов элементы кодовых слов дополнительно демодулируются с «жестким» решением.
Характерной особенностью декодирования кодов-произведения является то, что подстановка вектора из соответствующего смежного класса векторов ошибок в кодовое слово компонентного кода «зануляет» его синдром и приводит к модификации синдромов кодовых слов других компонентных кодов, на которые указывают единичные биты подставляемого вектора.
Поиск вектора ошибки кодового слова компонентного кода основан на построении в соответствии с его синдромом смежного класса векторов ошибок, упорядоченного в соответствии с возрастанием их веса [6, 7]. Для этого используется расширенная проверочная матрица [6, 7] циклического компонентного кода, согласно которой вычисляется расширенный синдром кодового слова. Модификация синдромов кодовых слов других компонентных кодов зависит от номера кодового слова, в которое выполняется подстановка вектора ошибки. Количество кодовых слов компонентного кода, синдромы которых модифицируются, равно весу подставляемого вектора из смежного класса векторов ошибок.
Техническим результатом является получение качества декодирования, соответствующего способам декодирования по критерию максимального правдоподобия, как с «жестким», так и с «мягким» решениями, а также снижение аппаратной и вычислительной сложности декодирования. Декодер, синтезированный на основе предложенного способа, может успешно применяться для декодирования двух- и трехкомпонентных кодов-произведений и их модификаций, распространенных в цифровых системах связи.
В основе декодирования кодового слова кода-произведения лежит формирование всевозможных цепочек локализованных ошибок, которые начинаются с любого искаженного кодового слова компонентного кода. Формирование цепочек локализованных ошибок кода-произведения заключается в объединении всевозможных различных векторов из упорядоченных по весу смежных классов векторов ошибок кодовых слов компонентных кодов и выполняется строго по шагам, начиная с первого. Порядковый номер шага всегда равен весу всех формируемых на этом шаге цепочек локализованных ошибок. Формирование каждой цепочки локализованных ошибок сопровождается «занулением» синдромов кодовых слов, в которые выполняется подстановка векторов из соответствующих упорядоченных смежных классов векторов ошибок, и модификацией синдромов тех кодовых слов других компонентных кодов, которые однозначно связаны с позициями единичных бит подставляемого вектора ошибки.
Для выполнения способа декодирования кода-произведения с использованием упорядоченного по весу смежного класса векторов ошибок необходимо:
1. Преобразовать принятую демодулированную последовательность элементов в кодовые слова компонентных кодов.
2. Вычислить расширенные синдромы всех кодовых слов компонентных кодов (см. пояснение ниже).
3. Выполнить поиск кодового слова компонентного кода, имеющее «ненулевой» расширенный синдром. Если кодовое слово, имеющее «ненулевой» расширенный синдром, найдено, то перейти к п.4, иначе - к п.7.
4. Сформировать из различных векторов упорядоченных по весу смежных классов векторов ошибок, соответствующих вычисленным расширенным синдромам кодовых слов компонентных кодов, цепочки локализованных ошибок веса t, начинающихся с найденного кодового слова (первоначальный вес t=1).
5. Сохранить в памяти декодера цепочки локализованных ошибок, для которых синдромы всех кодовых слов компонентных кодов становятся «нулевыми».
6. Сформировать наиболее вероятный вектор коррекции из сохраненных цепочек локализованных ошибок (см. пояснение ниже). Если вектор коррекции найден или установлен отказ от коррекции, то перейти к п.7, иначе - увеличить вес t=t+1 и перейти к п.4.
7. Инвертировать элементы систематической части кодового слова кода-произведения, номера которых соответствуют позициям «ненулевых» элементов сформированного вектора коррекции.
Пояснение к п.2 способа: при «мягком» решении для вычисления расширенных синдромов элементы кодовых слов дополнительно демодулировать с «жестким» решением.
Пояснение к п.6 способа:
- при «жестком» решении выбрать вектор коррекции из сохраненной цепочки локализованных ошибок, если цепочка одна. Если в памяти декодера несколько цепочек локализованных ошибок, то установить отказ от коррекции;
- при «мягком» решении выбрать вектор коррекции из сохраненной цепочки локализованных ошибок с максимальной метрикой, вычисляемой для каждой цепочки.
Декодер кода-произведения с использованием упорядоченного по весу смежного класса векторов ошибок содержит:
- блок компоновки кодовых слов 1;
- блок вычисления синдромов 2;
- блок поиска искаженного кодового слова 3;
- блок формирования цепочек локализованных ошибок 4;
- блок хранения цепочек локализованных ошибок 5;
- блок выбора вектора коррекции 6;
- блок формирования декодированной информации 7.
Блок компоновки кодовых слов 1 преобразует элементы демодулированной последовательности в кодовые слова компонентных кодов.
В блоке вычисления синдромов 2 вычисляются расширенные синдромы всех кодовых слов компонентных кодов кода-произведения.
Блок поиска искаженного кодового слова 3 находит кодовое слово одного из компонентных кодов, которое имеет «ненулевой» синдром, и с которого будут начинать формироваться цепочки локализованных ошибок.
Блок формирования цепочек локализованных ошибок 4 выполняет объединение векторов из упорядоченных смежных классов векторов ошибок кодовых слов компонентных кодов в цепочки локализованных ошибок, вес которых равен номеру шага.
Блок хранения цепочек локализованных ошибок 5 запоминает и хранит цепочки локализованных ошибок, подстановка которых в искаженное кодовое слово кода-произведения приводит к «занулению» синдромов всех кодовых слов компонентных кодов.
В блоке выбора вектора коррекции 6 формируется наиболее вероятный вектор коррекции искаженного кодового слова кода-произведения из сохраненных цепочек локализованных ошибок.
В блоке формирования декодированной информации 7 инвертируются элементы в систематической части кодового слова кода-произведения, которые указаны в векторе коррекции, и откорректированная систематическая часть кодового слова передается на выход декодера.
Устройство, реализующее способ, работает следующим образом.
Принятая демодулированная последовательность элементов поступает в блок компоновки кодовых слов 1, в котором она преобразуется в кодовые слова для каждого компонентного кода. В блоке вычисления синдромов 2 для каждого кодового слова компонентных кодов вычисляется расширенный синдром. Вычисленные расширенные синдромы поступают в блок поиска искаженного кодового слова 3.
В блоке поиска искаженного кодового слова 3 выполняется поиск кодового слова одного из компонентных кодов, имеющее «ненулевой» синдром. Если кодовое слово, имеющее «ненулевой» синдром, найдено, то информация об этом передается в блок формирования цепочек локализованных ошибок 4. Если кодовое слово, имеющее «ненулевой» синдром, не найдено, то кодовое слово кода-произведения не искажено и информация об этом сообщается в блок формирования декодированной информации 7, в котором выделяется систематическая часть кодового слова, которая поступает на выход декодера и декодирование завершается.
В блоке формирования цепочек локализованных ошибок 4 выполняется объединение различных векторов из соответствующих расширенным синдромам упорядоченных по весу смежных классов векторов ошибок кодовых слов компонентных кодов в цепочки локализованных ошибок веса t. Объединение векторов ошибок всегда начинается с искаженного кодового слова, найденного в блоке поиска искаженного кодового слова 3, и выполняется строго по шагам. На первом шаге первоначальный вес t=1. Сформированные цепочки локализованных ошибок поступают в блок хранения цепочек локализованных ошибок 5.
В блоке хранения цепочек локализованных ошибок 5 выполняется запоминание и хранение цепочек локализованных ошибок, для которых синдромы всех кодовых слов компонентных кодов становятся «нулевыми». Из блока хранения цепочек локализованных ошибок 5 цепочки передаются в блок выбора вектора коррекции 6.
В блоке выбора вектора коррекции 6 при декодировании с «жестким» решением вектор коррекции формируется из сохраненной цепочки локализованных ошибок, если она одна, или устанавливается отказ от коррекции, если сохранено несколько цепочек локализованных ошибок. При декодировании с «мягким» решением вектор коррекции формируется из сохраненной цепочки локализованных ошибок, имеющей максимальную метрику. Если вектор коррекции сформирован или установлен отказ от коррекции, то информация об этом передается в блок формирования декодированной информации 7. Если вектор коррекции не сформирован, то вес увеличивается на единицу t=t+1 и выполняется следующий шаг - последовательное выполнение блока формирования цепочек локализованных ошибок 4, блока хранения цепочек локализованных ошибок 5 и блока выбора вектора коррекции 6 повторяется. Число выполняемых в способе шагов связано с конфигурацией ошибки и зависит от искажений, полученных в канале связи.
В блоке формирования декодированной информации 7 инвертируются элементы систематической части кодового слова кода-произведения, соответствующие позициям «ненулевых» бит сформированного вектора коррекции. Откорректированная систематическая часть поступает на выход декодера и декодирование кода-произведения завершается.
Реализация описанного устройства может быть аппаратной, программной или аппаратно-программной.
Способ декодирования с использованием упорядоченного по весу смежного класса векторов ошибок может быть применен для кодов-произведений с «расширенными» циклическими компонентными кодами, для которых формирование цепочек локализованных ошибок выполняется с учетом бита четности кодовых слов компонентных кодов.
Способ декодирования с использованием упорядоченного по весу смежного класса векторов ошибок может быть применен для кодов-произведений с «укороченными» компонентными кодами. В этом случае формирование цепочек локализованных ошибок выполняется по векторам ошибок из смежных классов «укороченных» компонентных кодов.
Список литературы
1. Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. М.: Техносфера, 2005. 320 с.
2. Мак-Вильямс Ф.Дж., Слоэн Н.Дж.А. Теория кодов, исправляющих ошибки: пер. с англ. М.: Связь, 1979. 744 с.
3. Berrou С., Glavieux A., Thitimajshima P. Near Shannon limit error correcting coding and decoding: Turbo-codes // Proc. Int. Conf. Communication. May, 1993. P. 1064-1070.
4. Карташевский В.Г., Мишин Д.В. Прием кодированных сигналов в каналах с памятью. М.: Радио и связь, 2004. 239 с.
5. Золотарев В.В., Овечкин Г.В. Помехоустойчивое кодирование. Методы и алгоритмы: справочник. М.: Горячая линия Телеком, 2004. 126 с.
6. Хмельков А.Н. Патент на изобретение «Способ синдромного декодирования циклического кода (варианты)» №2340088, публикация 10.06.2008 года.
7. Хмельков А.Н. Патент на изобретение «Способ декодирования последовательного каскадного кода (варианты)» №2340091, публикация 10.06.2008 года.
8. Хмельков А.Н., Минеев В.А. Оптимальные синдромные декодеры каскадных кодов с последовательным соединением через перемежитель компонентных циклических линейных блочных кодов // Радиотехника. 2007. №12. 77-82 с.
9. Минеев В.А. Анализ синдромных декодеров кодов-произведения с «жестким» решением (тип 2) // Радиотехника. 2008. №12. 85-91 с.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДЕКОДИРОВАНИЯ ПОСЛЕДОВАТЕЛЬНОГО КАСКАДНОГО КОДА (ВАРИАНТЫ) | 2006 |
|
RU2340091C2 |
| СПОСОБ ДЕКОДИРОВАНИЯ ТУРБОКОДА (ВАРИАНТЫ) | 2006 |
|
RU2340090C2 |
| СПОСОБ СИНДРОМНОГО ДЕКОДИРОВАНИЯ ЦИКЛИЧЕСКОГО КОДА (ВАРИАНТЫ) | 2006 |
|
RU2340088C2 |
| СПОСОБ ДЕКОДИРОВАНИЯ ЦИКЛИЧЕСКИХ КОДОВ С "ЖЕСТКИМ" РЕШЕНИЕМ ПО ВЕКТОРУ-УКАЗАТЕЛЮ И УСТРОЙСТВО ЕГО РЕАЛИЗУЮЩЕЕ | 2014 |
|
RU2575394C1 |
| СПОСОБ ДЕКОДИРОВАНИЯ LDPC-КОДОВ И УСТРОЙСТВО ЕГО РЕАЛИЗУЮЩЕЕ | 2014 |
|
RU2575399C1 |
| СПОСОБ СИНДРОМНОГО ДЕКОДИРОВАНИЯ НЕСИСТЕМАТИЧЕСКОГО СВЕРТОЧНОГО КОДА (ВАРИАНТЫ) | 2006 |
|
RU2340089C2 |
| Способ декодирования блочных помехоустойчивых кодов по критерию минимального среднего риска | 2019 |
|
RU2706171C1 |
| УСТРОЙСТВО ПАРАЛЛЕЛЬНОГО ДЕКОДИРОВАНИЯ ЦИКЛИЧЕСКИХ КОДОВ НА ПРОГРАММИРУЕМЫХ ЛОГИЧЕСКИХ ИНТЕГРАЛЬНЫХ СХЕМАХ | 2015 |
|
RU2612593C1 |
| ПАРАЛЛЕЛЬНЫЙ КАСКАДНЫЙ СВЕРТОЧНЫЙ КОД С КОНЕЧНОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ БИТОВ И ДЕКОДЕР ДЛЯ ТАКОГО КОДА | 1997 |
|
RU2187196C2 |
| СПОСОБ СИНДРОМНОГО ДЕКОДИРОВАНИЯ ДЛЯ СВЕРТОЧНЫХ КОДОВ | 2004 |
|
RU2282307C2 |
Изобретение относится к вычислительной технике. Технический результат заключается в повышении качества декодирования. Способ декодирования кода-произведения, в котором принятую демодулированную последовательность преобразуют в кодовые слова компонентных кодов, вычисляют расширенные синдромы кодовых слов компонентных кодов, выполняют поиск кодового слова, имеющего «ненулевой» синдром, начиная с которого, по шагам, из векторов упорядоченных по весу смежных классов векторов ошибок, соответствующих вычисленным расширенным синдромам кодовых слов компонентных кодов, формируют цепочки локализованных ошибок равного веса, сохраняют в памяти те цепочки локализованных ошибок, для которых синдромы всех кодовых слов компонентных кодов становятся «нулевыми», формируют вектор коррекции кода-произведения при декодировании с «жестким» решением из сохраненной цепочки локализованных ошибок, если цепочка одна или устанавливают отказ от коррекции, если имеется несколько сохраненных цепочек локализованных ошибок, инвертируют элементы систематической части кодового слова кода-произведения, номера которых соответствуют позициям «ненулевых» элементов сформированного вектора коррекции. 2 н. и 1 з.п. ф-лы, 1 ил.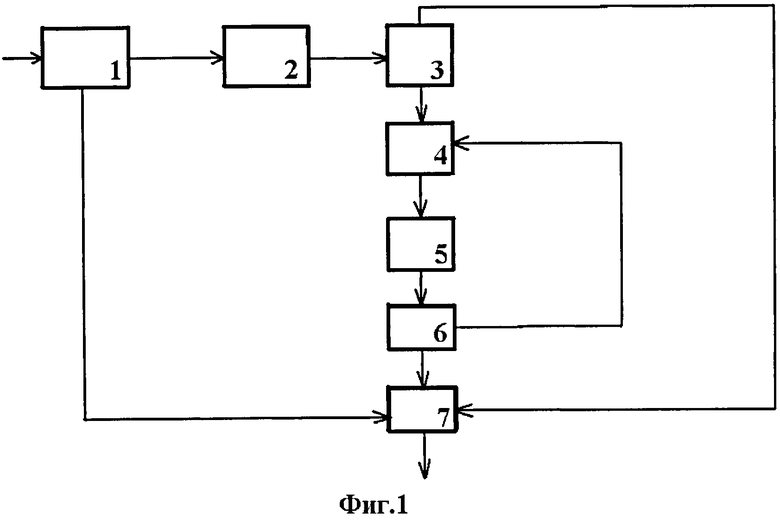
1. Способ декодирования кода-произведения, характеризующийся тем, что принятую демодулированную последовательность преобразуют в кодовые слова компонентных кодов, вычисляют расширенные синдромы кодовых слов компонентных кодов, выполняют поиск кодового слова, имеющего «ненулевой» синдром, начиная с которого, по шагам, из векторов упорядоченных по весу смежных классов векторов ошибок, соответствующих вычисленным расширенным синдромам кодовых слов компонентных кодов, формируют цепочки локализованных ошибок равного веса, сохраняют в памяти те цепочки локализованных ошибок, для которых синдромы всех кодовых слов компонентных кодов становятся «нулевыми», формируют вектор коррекции кода-произведения при декодировании с «жестким» решением из сохраненной цепочки локализованных ошибок, если цепочка одна, или устанавливают отказ от коррекции, если имеется несколько сохраненных цепочек локализованных ошибок, инвертируют элементы систематической части кодового слова кода-произведения, номера которых соответствуют позициям «ненулевых» элементов сформированного вектора коррекции.
2. Способ по п.1, отличающийся тем, что при декодировании с «мягким» решением перед вычислением расширенных синдромов элементы кодовых слов компонентных кодов демодулируют с «жестким» решением и вектор коррекции кода-произведения формируют из сохраненной цепочки локализованных ошибок, имеющей максимальную метрику.
3. Устройство декодирования кода-произведения для реализации способа по пп.1 и 2, состоящее из блока компоновки кодовых слов, блока вычисления синдромов, блока поиска искаженного кодового слова, начиная с которого в блоке формирования цепочек локализованных ошибок выполняется поиск цепочек локализованных ошибок, которые сохраняются в блоке хранения цепочек локализованных ошибок, блока выбора вектора коррекции, блока формирования декодированной информации, при этом блок компоновки кодовых слов имеет вход для искаженного кодового слова кода-произведения, а первый выход соединен с входом блока вычисления синдромов для вычисления синдромов скомпонованных кодовых слов, а второй выход соединен с первым входом блока формирования декодированной информации для коррекции систематической части кодового слова кода-произведения, а выход блока вычисления синдромов соединен с входом блока поиска искаженного кодового слова для поиска искаженного кодового слова, имеющего «ненулевой» синдром, а первый выход блока поиска искаженного кодового слова соединен с первым входом блока формирования локализованных ошибок для формирования цепочек локализованных ошибок, второй выход соединен со вторым входом блока формирования декодированной информации и в случае, если кодовое слово не найдено, то сообщается в блок формирования декодированной информации об отсутствии необходимости в коррекции систематической части кодового слова кода-произведения, а выход блока формирования локализованных ошибок соединен с входом блока хранения цепочек локализованных ошибок для сохранения цепочек, имеющих «ненулевые» синдромы всех кодовых слов компонентных кодов, а выход блока хранения цепочек локализованных ошибок соединен с первым входом блока выбора вектора коррекции для определения наиболее вероятного вектора коррекции и при отсутствии сохраненных цепочек локализованных ошибок для формирования цепочек локализованных ошибок большего веса второй выход соединен со вторым входом блока формирования цепочек локализованных ошибок, а выход блока выбора вектора коррекции соединен со вторым входом блока формирования декодированной информации для хранения сформированной декодированной информации, а также блок формирования декодированной информации имеет выход для передачи откорректированной систематической части кодового слова кода-произведения для дальнейшей обработки.
| СПОСОБ ДЕКОДИРОВАНИЯ ПОСЛЕДОВАТЕЛЬНОГО КАСКАДНОГО КОДА (ВАРИАНТЫ) | 2006 |
|
RU2340091C2 |
| СПОСОБ СИНДРОМНОГО ДЕКОДИРОВАНИЯ ЦИКЛИЧЕСКОГО КОДА (ВАРИАНТЫ) | 2006 |
|
RU2340088C2 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| УСТРОЙСТВО КОДОВОЙ ЦИКЛОВОЙ СИНХРОНИЗАЦИИ С ИНТЕГРИРОВАННЫМИ МЯГКИМИ И ЖЕСТКИМИ РЕШЕНИЯМИ | 2011 |
|
RU2450464C1 |
| US 7185259 B2, 27.02.2007 | |||

