Изобретение относится к области техники связи и, в частности, к системам передачи информации, в которых для ее защиты от искажений в канале связи применяются LDPC-коды. Изобретение может быть использовано в кодеках (кодер-декодер) систем передачи и хранения дискретной информации.
Известен итеративный способ декодирования LDPC-кодов с «жестким» решением [1], который включает в себя многократно повторяющуюся процедуру коррекции бит искаженного кодового слова. Сначала вычисляется синдром искаженного кодового слова и формируется «вектор взаимосвязи» каждого бита кодового слова с ненулевыми элементами синдрома. Для этого сканируются элементы синдрома, выделяются ненулевые и для каждого из них инкрементируются позиции «вектора взаимосвязи», которые соответствуют ненулевым элементам строки проверочной матрицы. После завершения формирования «вектора взаимосвязи» инвертируются те биты кодового слова, номера которых соответствуют позициям «вектора взаимосвязи», в которых записано число, превышающее выбранный порог (обычно выбирается порог, равный величине, превышающей половину количества «единиц» в столбце проверочной матрицы LDPC-кода). Если откорректированное кодовое слово имеет ненулевой синдром, то процедура коррекции бит повторяется до тех пор, пока синдром откорректированного кодового слова не станет нулевым. В завершении процесса декодирования выполняется отображение откорректированного кодового слова в информационную последовательность, выполняемое путем обратного преобразования согласно правилу кодирования.
К недостаткам итеративного способа декодирования LDPC-кодов с «жестким» решением [1] следует отнести то, что он, во-первых, не относится к классу методов декодирования по критерию максимального правдоподобия. На это указывал Р. Галлагер [1, стр. 64, 94-97], который ввел в рассмотрение LDPC-коды. С его точки зрения у LDPC-кодов достигается разумный компромисс между вычислительной сложностью и достоверностью декодирования. И, во-вторых, некоторые комбинации как исправляемых, так и неисправляемых ошибок приводят к зацикливанию итеративного способа декодирования. Поэтому необходимо вводить ограничение на допустимое количество итераций.
Техническим результатом предлагаемого технического решения является повышение качества декодирования LDPC-кодов.
Для достижения технического результата предложен способ декодирования LDPC-кодов с «жестким» решением, в котором после вычисления синдрома выполняется построение по шагам упорядоченного по весу смежного класса векторов ошибок. На каждом шаге достраиваются, т.е. продолжают формироваться только те фрагменты Vg векторов ошибок, метрика mg которых равна номеру шага t:

где:
Δi - количество ненулевых элементов текущего синдрома при добавлении во фрагмент вектора ошибки Vg очередного элемента на шаге t,
r - количество шагов, за которые был сформирован фрагмент Vg вектора ошибки, при этом r меньше или равно текущему шагу t формирования фрагмента вектора ошибки.
Текущий синдром st каждого вновь формируемого фрагмента вектора ошибки на шаге t определяется в результате сложения по mod 2 исходного синдрома, полученного на (t-1)-шаге, с j-м столбцом проверочной матрицы:

где j - позиция добавленного элемента во фрагмент вектора ошибки.
Построение упорядоченного по весу смежного класса векторов ошибок завершается, когда текущий синдром одного из векторов Vg становится равным нулевому вектору. Этот момент соответствует локализации вектора ошибки, который является либо лидером смежного класса векторов ошибок (исправляемая ошибка), либо одной из ошибок минимального веса в смежном классе векторов ошибок (неисправляемая ошибка).
Рассмотрим регулярный LDPC-код, имеющий в разреженной проверочной матрице l «единиц» в столбце и ρ «единиц» в строке.
Способ декодирования LDPC-кода с использованием упорядоченного по весу смежного класса векторов ошибок:
1. Вычислить синдром декодируемого, возможно искаженного в канале связи, кодового слова. Если синдром равен нулевому вектору, перейти к п. 7.
2. Выбрать любую строку проверочной матрицы, которая соответствует ненулевому элементу синдрома, и определить ρ начальных элементов формируемых фрагментов векторов ошибок смежного класса, которые соответствуют позициям ненулевых элементов в выбранной строке проверочной матрицы. Начальный номер шага t=1.
3. Вычислить метрику mg (1) и определить текущий синдром st(2) для каждого фрагмента векторов ошибок, сформированного на шаге t.
4. Если текущий синдром st одного из векторов ошибок равен нулевому вектору, то сформировать вектор коррекции из данного вектора ошибки и перейти к п. 6.
5. Выбрать любую строку проверочной матрицы, которая соответствует ненулевому элементу текущего синдрома, и определить ρ элементов продолжения формируемых фрагментов векторов ошибок смежного класса для каждого сформированного на текущем шаге t фрагмента векторов ошибок, имеющего метрику, равную номеру шага mg=t. Увеличить номер шага t=t+1 и перейти к п. 3.
6. Сложить по mod 2 принятое искаженное кодовое слово со сформированным вектором коррекции.
7. Сформировать информационную последовательность кодового слова.
При декодировании LDPC-кодов с «мягким» решением необходимо:
- вычислять метрику по формуле:
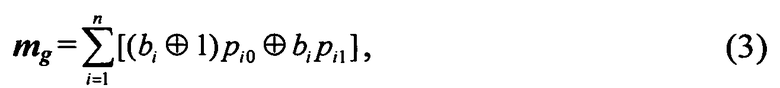
где: bi - значение i-го бита кодового слова LDPC-кода, po0, pi1 - условные вероятности передачи по каналу связи на i-й позиции кодового слова 0 или 1 соответственно.
- на шаге t изменить условие определения вектора коррекции: вектор коррекции - сформированный вектор ошибки смежного класса, текущий синдром которого является нулевым вектором, и который имеет максимальную метрику (3). Для этого необходимо на шаге t последовательно запоминать вектора ошибок с «нулевым» синдромом и вычисленной для него метрикой до тех пор, пока метрика очередного вектора ошибки не начнет уменьшаться.
Декодер LDPC-кода с использованием упорядоченного по весу смежного класса векторов ошибок (фиг.1) содержит:
- блок вычисления синдрома - 1;
- блок формирования начальных элементов векторов ошибок - 2;
- блок вычисления метрики и текущего синдрома - 3;
- блок формирования элементов продолжения векторов ошибок - 4;
- блок формирования вектора коррекции - 5;
- блок коррекции - 6;
- блок формирования информационной последовательности кодового слова - 7;
- оперативное запоминающее устройство - 8.
Блок вычисления синдрома 1 определяет синдром декодируемого кодового слова LDPC-кода.
Блок формирования начальных элементов векторов ошибок 2 определяет исходные ненулевые позиции векторов ошибок смежного класса, соответствующего вычисленному синдрому. Разреженная проверочная матрица позволяет определить ρ начальных ненулевых бит для фрагментов векторов ошибок смежного класса по любому ненулевому элементу синдрома. Выбранные ненулевые начальные значения заносятся в формируемые и хранящиеся в оперативном запоминающем устройстве 8 фрагменты векторов ошибок смежного класса.
Блок вычисления метрики и текущего синдрома 3 последовательно перебирает вновь сформированные фрагменты векторов ошибок, сохраненные в оперативном запоминающем устройстве 8, определяет для каждого из них метрику (1) и текущий синдром (2). Текущий синдром является суммой по mod 2 предшествующего синдрома и столбца проверочной матрицы, номер которого соответствует позиции ошибки, определенной в блоке вычисления метрики и текущего синдрома 3. Сформированный текущий синдром запоминается в оперативном запоминающем устройстве 8 совместно со своим фрагментом вектора ошибки. Если для одного из поступивших в блок фрагмента вектора ошибки определен «нулевой» синдром, то вектор ошибки смежного класса сформирован и передается в блок формирования вектора коррекции 5.
Блок формирования элементов продолжения векторов ошибок 4 последовательно выбирает из оперативного запоминающего устройства 8 сформированные фрагменты векторов ошибок текущего шага t, метрика которых равна номеру шага mg=t, для каждого из выбранных фрагментов по любому ненулевому элементу соответствующего синдрома определяет ρ позиций возможных ошибок, формирует на их основе фрагменты векторов ошибок следующего шага t=t+1 и передает их в блок вычисления метрики и текущего синдрома 3.
Блок формирования вектора коррекции 5 создает вектор коррекции из вектора ошибки, сформированного на шаге t, синдром которого является нулевым вектором.
Блок коррекции 6 исправляет ошибки в искаженном кодовом слове по критерию максимального правдоподобия. Для этого искаженное кодовое слово, поступившее с входа блока вычисления синдрома 1, складывается по mod 2 с вектором коррекции, который сформирован в блоке формирования вектора коррекции 5.
Блок формирования информационной последовательности кодового слова 7 выполняет преобразование, обратное правилу кодирования, откорректированного или неискаженного кодового слова LDPC-кода в информационную последовательность, которая передается на выход для дальнейшей обработки.
Оперативное запоминающее устройство 8 выполняет сохранение текущих синдромов и, соответствующих им, фрагментов векторов ошибок смежного класса.
Предлагаемое устройство работает следующим образом.
Декодируемое кодовое слово, возможно искаженное в канале связи, поступает на вход блока вычисления синдрома 1, в котором определяется синдром.
Если синдром является нулевым вектором, то кодовое слово по критерию максимального правдоподобия не искажено, и управление передается в блок формирования информационной последовательности кодового слова 7.
Если синдром не является нулевым вектором, то синдром передается в блок формирования начальных элементов векторов ошибок 2.
В блоке формирования начальных элементов векторов ошибок 2 по любому ненулевому элементу синдрома с помощью проверочной матрицы определяются позиции, с которых могут начинаться фрагменты векторов ошибок смежного класса. Эти позиции позволяют сформировать ненулевые начальные элементы фрагментов векторов ошибок смежного класса, которые запоминаются в оперативном запоминающем устройстве 8 и управление передается блоку вычисления метрики и текущего синдрома 3.
В блоке вычисления метрики и текущего синдрома 3 для каждого вновь сформированного фрагмента вектора ошибки определяется метрика и текущий синдром, который вместе со своим фрагментом вектора ошибки запоминается в оперативном запоминающем устройстве 8. Если текущий синдром одного из векторов ошибки равен нулевому вектору, то формирование векторов ошибок смежного класса завершается и вектор ошибки с «нулевым» синдромом передается в блок формирования вектора коррекции 5, иначе управление передается блоку формирования элементов продолжения векторов ошибок 4.
Блок формирования элементов продолжения векторов ошибок 4 последовательно выбирает из оперативного запоминающего устройства 8 сформированные фрагменты векторов ошибок текущего шага, метрика которых равна номеру шага, для каждого из которых определяются элементы продолжения вектора ошибки. Они позволяют продолжить формирование векторов ошибок смежного класса, которые передаются в блок определения метрики и текущего синдрома 3.
В блоке формирования вектора коррекции 5 из вектора ошибки с «нулевым» синдромом формируется вектор коррекции.
В блоке коррекции 6 выполняется поразрядное сложение по mod 2 искаженного кодового слова с вектором коррекции.
Откорректированное кодовое слово передается в блок формирования информационной последовательности кодового слова 7, в котором формируется информационная последовательность, передаваемая на выход для дальнейшей обработки.
Декодирование кодового слова LDPC-кода завершено.
Реализация описанного устройства может быть аппаратной, программной или аппаратно-программной.
Способ декодирования LDPC-кодов может быть применен и для декодирования с «мягким» решением. Для этого в блоке вычисления метрики и текущего синдрома 3 при формировании «нулевого» текущего синдрома необходимо определить метрику для откорректированного кодового слова, запомнить ее в оперативное запоминающее устройство 8 вместе со своим текущим синдромом и вектором ошибки. Выполнение блока вычисления метрики и текущего синдрома 3 и блока формирования элементов продолжения векторов ошибок 4 повторяется до тех пор, пока метрика вновь сформированных векторов ошибок с «нулевыми» синдромами не начнет уменьшаться.
Достигаемым техническим результатом предложенного способа декодирования LDPC-кодов с «жестким» и «мягким» решением является повышение качества декодирования LDPC-кодов за счет построения в процессе декодирования упорядоченного по весу смежного класса векторов ошибок, причем предлагаемый способ относится к классу способов декодирования по критерию максимального правдоподобия.
Список литературы
1. Галлагер Р.Дж. Коды с малой плотностью проверок на четность / Пер. с англ. // Под ред. Добрушина Р.Л.: М., Мир, 1966.
Изобретение относится к области техники связи и, в частности, к системам передачи информации, в которых для ее защиты от искажений в канале связи применяются LDPC-коды. Изобретение может быть использовано в кодеках (кодер-декодер) систем передачи и хранения дискретной информации. Техническим результатом, обеспечиваемым способом декодирования LDPC-кода, является получение качества декодирования, соответствующего способам декодирования по критерию максимального правдоподобия, как с «жестким», так и с «мягким» решениями, а также снижение аппаратной и вычислительной сложности декодирования. Технический результат достигается тем, что для принятого, возможно искаженного в канале связи, кодового слова LDPC-кода в процессе поиска вектора коррекции формируется упорядоченный по весу смежный класс векторов ошибок. При декодировании с «жестким» решением в качестве вектора коррекции выбирается первый сформированный вектор ошибки, который является лидером смежного класса векторов ошибок. При декодировании с «мягким» решением в качестве вектора коррекции выбирается вектор ошибки смежного класса, имеющий максимальную метрику. 2 н.п. ф-лы, 1 ил.
1. Способ декодирования LDPC-кода, заключающийся в том, что для принятого возможно искаженного кодового слова определяют синдром и «вектор взаимосвязи» каждого бита кодового слова с ненулевыми элементами синдрома, после этого инвертируют те биты кодового слова, номера которых соответствуют позициям «вектора взаимосвязи», имеющим значения, превышающие выбранный порог, причем определение текущего синдрома, «вектора взаимосвязи» и инверсия бит повторяется до тех пор, пока текущий синдром не станет нулевым вектором, отличающийся тем, что для любого ненулевого элемента синдрома искаженного кодового слова выбирают соответствующую строку проверочной матрицы, по ненулевым элементам выбранной строки определяют начальные элементы фрагментов векторов ошибок смежного класса, формируют эти фрагменты, для каждого из них вычисляют метрику и текущий синдром, далее по шагам для каждого сформированного фрагмента вектора ошибки текущего шага, имеющего метрику, равную номеру шага, по любому ненулевому элементу его текущего синдрома выбирают соответствующую строку проверочной матрицы, по ненулевым элементам которой определяют элементы продолжения фрагментов векторов ошибок смежного класса, формируют новые фрагменты, для которых также вычисляют метрику и текущий синдром, построение смежного класса векторов ошибок завершают тогда, когда текущий синдром одного из векторов ошибок станет нулевым вектором, а при декодировании с «мягким» решением построение упорядоченного по весу смежного класса векторов ошибок завершают тогда, когда сформировано несколько векторов ошибок смежного класса, и в качестве вектора коррекции выбирают вектор ошибки, который имеет максимальную метрику, после чего выполняют коррекцию искаженного кодового слова, из которого формируют информационную последовательность.
2. Устройство декодирования LDPC-кода для реализации способа по п. 1, состоящего из блока вычисления синдрома, блока формирования начальных элементов векторов ошибок, блока вычисления метрики и текущего синдрома, блока формирования элементов продолжения векторов ошибок, блока формирования вектора коррекции, блока коррекции, блока формирования информационной последовательности кодового слова, оперативного запоминающего устройства, при этом блок вычисления синдрома имеет вход для искаженного кодового слова LDPC-кода, а первый выход соединен с первым входом блока формирования информационной последовательности кодового слова для передачи кодового слова, имеющего нулевой синдром, а второй выход соединен с первым входом блока коррекции для передачи искаженного кодового слова, а третий выход соединен с блоком формирования начальных элементов векторов ошибок для передачи искаженного кодового слова и его синдрома, а первый выход блока формирования начальных элементов векторов ошибок соединен с первым входом блока вычисления метрики и текущего синдрома для передачи искаженного кодового слова и сформированных начальных элементов векторов ошибок, а второй выход соединен с оперативным запоминающим устройством для сохранения синдромов и начальных элементов векторов ошибок, блок вычисления метрики и текущего синдрома соединен с блоком формирования элементов продолжения векторов ошибок для передачи текущих синдромов и элементов продолжения векторов ошибок, а также соединен с оперативным запоминающим устройством для сохранения текущих синдромов и считывания элементов продолжения векторов ошибок, блок формирования элементов продолжения векторов ошибок также соединен с оперативным запоминающим устройством для сохранения элементов продолжения векторов ошибок и считывания текущих синдромов сформированных ранее фрагментов векторов ошибок, а третий выход блока вычисления метрики и текущего синдрома соединен с входом блока формирования вектора коррекции для передачи вектора ошибки смежного класса; выход блока формирования вектора коррекции соединен со вторым входом блока коррекции для передачи вектора коррекции; выход блока коррекции соединен со вторым входом блока формирования информационной последовательности кодового слова для передачи откорректированного кодового слова, а также блок формирования информационной последовательности кодового слова имеет выход для передачи откорректированной информационной последовательности кодового слова LDPC-кода для дальнейшей обработки.
| ЭФФЕКТИВНЫЕ ПО ИСПОЛЬЗОВАНИЮ ПАМЯТИ СПОСОБЫ ДЕКОДИРОВАНИЯ КОДОВ С НИЗКОЙ ПЛОТНОСТЬЮ КОНТРОЛЯ ПО ЧЕТНОСТИ (LDPC) И УСТРОЙСТВА ДЛЯ ОСУЩЕСТВЛЕНИЯ ЭТИХ СПОСОБОВ | 2005 |
|
RU2382493C2 |
| СПОСОБЫ И УСТРОЙСТВО LDPC-ДЕКОДИРОВАНИЯ | 2005 |
|
RU2392737C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ LDPC ПАКЕТОВ ПЕРЕМЕННЫХ РАЗМЕРОВ | 2008 |
|
RU2443053C2 |
| СПОСОБ ДИСПЕРГИРОВАНИЯ МАСЛОЖИРОВЫХ СОЕДИНЕНИЙ | 1991 |
|
RU2023492C1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

