Изобретение относится к области техники связи, в частности к системам передачи информации, в которых для ее защиты от искажений в канале связи применяются каскадные коды с последовательным соединением через перемежитель циклических линейных блочных кодов, или турбо-коды с компонентными циклическими линейными блочными кодами. Изобретение может быть использовано в кодеках (кодер-декодер) систем передачи данных, а также в устройствах помехоустойчивого кодирования при передаче и хранении дискретной информации.
Известен способ декодирования каскадных кодов с последовательным соединением через перемежитель компонентных циклических линейных блочных кодов [1, 3-5], который включает в себя для двухкомпонентного каскадного кода две процедуры декодирования, представляющие собой модули SISO («мягкий» вход, «мягкий» выход), и две процедуры перемежения для перемешивания «мягкой» информации, которой обмениваются процедуры декодирования. На вход первого SISO модуля поступают две последовательности: априорные сведения о последовательности информационных символов и «мягкий» выход канала связи (демодулятора), а на выходе формируются «мягкие» решения, которые является отношением апостериорных вероятностей информационных элементов кода и которые после перемежения служат априорными сведениями об информационных элементах для второго SISO модуля. Второй SISO модуль уточняет значения анализируемых информационных элементов и вычисляет свои «мягкие» оценки информационных элементов, которые после деперемежения поступают на вход первого SISO модуля, и итерационный процесс продолжается. После каждой итерации увеличивается априорная информация о каждом информационном элементе. Процесс декодирования заканчивается либо после выполнения заданного количества итераций, либо после того, как величина поправки результата декодирования достигнет определенного порогового значения.
Основными недостатками данного способа декодирования являются его большая вычислительная сложность и большое время задержки декодирования, так как декодируется кодовое слово большой длины (несколько десятков тысяч элементов), причем для обработки искаженного кодового слова необходимо выполнить несколько итераций. Кроме того, данный способ декодирования относится к квазиоптимальным способам декодирования.
Целью предлагаемого изобретения является повышение достоверности (качества) декодирования, понижение аппаратной и вычислительной сложности декодирования, уменьшение времени задержки, и, в частности, реализация оптимальной процедуры декодирования как с «мягким», так и с «жестким» решениями.
Для достижения цели предложен способ синдромного декодирования каскадного кода с последовательным соединением через перемежитель циклических линейных блочных кодов, в которых наиболее вероятное значение систематической части кодового слова формируется не в результате итеративной процедуры, включающей в себя циклическую обработку кодового слова с помощью SISO модулей, а в результате поиска оптимального вектора коррекции, который основан на представлении n-разрядного расширенного синдрома s компонентного кода в виде линейных комбинаций строк расширенной проверочной матрицы Нn,n, и представлении вектора ошибки екс, исказившей кодовое слово, в виде совокупности примитивных (неразложимых) векторов коррекции.
Расширенная проверочная матрица Нn,n является транспонированной проверочной матрицей [1], у которой j-я строка состоит из коэффициентов при неизвестном полинома hj(x)=xjh(x)mod(xn+1) (где h(x)=(xn+1)/p(x) - проверочный многочлен циклического (n,k)-кода, р(х) - порождающий многочлен кода, а j=0,1, ... n-1). Транспонированная расширенная проверочная матрица Нn,n отличается от проверочной матрицы Hn,n-k [1] только тем, что в ней добавлено еще k строк, каждая из которых также является циклическим сдвигом предшествующей строки на один разряд направо. Номер строки расширенной проверочной матрицы указывает на номер искаженной позиции принятого искаженного кодового слова.
Примитивные векторы коррекции имеют конфигурацию однократных локализованных ошибок, цепочек локализованных ошибок, а также локализованных ошибок, имеющих конфигурацию кодовых слов компонентных кодов. Однократная локализованная ошибка это такая ошибка в кодовом слове каскадного кода, которая является единственной во всех кодовых словах компонентных кодов, которые она исказила. Цепочка локализованных ошибок - это такая последовательность ошибок в кодовом слове каскадного кода, которая имеет вес не менее двух и которая однозначно определена синдромами тех кодовых слов компонентных кодов, которые она искажает.
Для декодирования каскадного кода с последовательным соединением через перемежитель циклических линейных блочных кодов предлагается способ, заключающийся в следующем.
Для принятой возможно искаженной кодовой реализации каскадного кода (b⊕eкс), кодовое слово которого для двухкомпонентного кода представлено на фиг.1, вычисляют расширенные синдромы для каждого кодового слова компонентных кодов  (где: sj (i) - расширенный синдром j-го кодового слова i-го компонентного кода, bl (i) - j-е кодовое слово i-го компонентного кода, еj (i) - вектор ошибки, исказивший в канале связи - j-е кодовое слово i-го компонентного кода,
(где: sj (i) - расширенный синдром j-го кодового слова i-го компонентного кода, bl (i) - j-е кодовое слово i-го компонентного кода, еj (i) - вектор ошибки, исказивший в канале связи - j-е кодовое слово i-го компонентного кода, 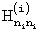 - расширенная проверочная матрица i-го компонентного кода), которые заносятся в таблицу (см. фиг.1). Кроме того, для каждого расширенного синдрома вычисляют вектор HNj (i), элементами которого являются номера строк расширенной проверочной матрицы, которые могли участвовать в формировании одного из (например, крайнего слева) ненулевого элемента расширенного синдрома. В векторе HNj (i) особо помечают номер строки, который соответствует номеру строки расширенного синдрома sj (i) (см. фиг.1). Номер особо помеченной строки указывает на позицию возможной однократной ошибки в bj (i)-м кодовом слове компонентного кода, а каждый непомеченный номер строки указывает на позицию одного из искаженных элементов возможной двукратной ошибки в том же bj (i)-м кодовом слове компонентного кода.
- расширенная проверочная матрица i-го компонентного кода), которые заносятся в таблицу (см. фиг.1). Кроме того, для каждого расширенного синдрома вычисляют вектор HNj (i), элементами которого являются номера строк расширенной проверочной матрицы, которые могли участвовать в формировании одного из (например, крайнего слева) ненулевого элемента расширенного синдрома. В векторе HNj (i) особо помечают номер строки, который соответствует номеру строки расширенного синдрома sj (i) (см. фиг.1). Номер особо помеченной строки указывает на позицию возможной однократной ошибки в bj (i)-м кодовом слове компонентного кода, а каждый непомеченный номер строки указывает на позицию одного из искаженных элементов возможной двукратной ошибки в том же bj (i)-м кодовом слове компонентного кода.
Далее поиск вектора коррекции кодового слова каскадного кода выполняется поэтапно.
На первом этапе выполняется поиск локализованных ошибок в кодовом слове каскадного кода, которые начинаются с однократной ошибки в кодовых словах одного из компонентных кодов.
Для этого выбирают любой i-й компонентный код, и для каждого искаженного кодового слова (sj (i)≠0) в векторе HNj (i) находят номер особо помеченной строки, который указывает на позицию однократной ошибки в j-м кодовом слове i-го компонентного кода. После чего для всех кодовых слов компонентных кодов, которые исказила данная ошибка, сравнивают особо помеченные номера строк вектора HNg (q) с номером позиции рассматриваемой ошибки.
Если номера совпали для всех компонентных кодов, то данная ошибка считается однократной локализованной ошибкой каскадного кода. Она запоминается вместе с номерами кодовых слов компонентных кодов, которые она исказила, а расширенные синдромы этих кодовых слов считаются условно нулевыми (нулевыми только для данной локализованной ошибки).
Если номера не совпали, например, для кодового слова bg (q) q-го компонентного кода, то переходим к поиску цепочек локализованных ошибок, которые возможно имеют двукратную ошибку в данном кодовом слове. Следует учесть, что позиция r первой ошибки двукратной ошибки в кодовом слове bg (q) известна. Она задана позицией однократной ошибки в j-м кодовом слове i-го компонентного кода. Комбинацию двукратной ошибки формируют следующим образом. Для искаженного кодового слова компонентного кода вычисляют текущий расширенный синдром sg (q)=sg (q)⊕hr и соответствующий ему вектор HNg (q), в котором номер особо помеченной строки m расширенной проверочной матрицы указывает на вторую искаженную позицию двукратной ошибки в bg (q) кодовом слове. Таким образом, построена комбинация двукратной ошибки er,g↔em,g в g-том кодовом слове q-го компонентного кода. Причем расширенный синдром sg (q) для искомой цепочки ошибок считается условно нулевым.
Двукратная ошибка er,g↔em,g считается завершенной по m-тому направлению, если расширенные синдромы всех кодовых слов компонентных кодов, откорректированных ошибкой em,g, становятся нулевыми. Цепочку локализованных ошибок формируют до тех пор, пока не будут завершены все направления. После чего цепочка локализованных ошибок запоминается вместе с номерами кодовых слов компонентных кодов, которые она исказила, а расширенные синдромы этих кодовых слов для данной цепочки ошибок считаются условно нулевыми.
Поиск локализованной цепочки ошибок прекращают в том случае, когда вторая ошибка em,g двукратной ошибки попадает в одно из кодовых слов компонентных кодов, которое уже имеет условно нулевой синдром для строящейся цепочки локализованных ошибок.
Если вторая ошибка em,g двукратной ошибки попадает в кодовое слово компонентного кода с нулевым синдромом sf (u)=0, то это кодовое слово возможно искажено ошибкой, которая имеет конфигурацию кодового слова (для циклических кодов Хемминга минимальный вес кодового слова равен трем). В этом случае вектор HNf (u) содержит позиции вторых ошибок искомых трехкратных ошибок, если исключить из рассмотрения особо помеченный номер строки. Следовательно, необходимо рассмотреть w-1 возможных комбинаций трехкратных ошибок (где w - количество ненулевых коэффициентов при неизвестном проверочного многочлена кода), у которых две позиции уже известны. Третью последнюю позицию трехкратной ошибки определяют аналогично рассмотренному выше поиску второй последней позиции двукратной ошибки.
После рассмотрения всех кодовых слов i-го компонентного кода с ненулевыми расширенными синдромами переходим ко второму этапу поиска локализованных ошибок.
На втором этапе выполняется поиск локализованных ошибок в кодовом слове каскадного кода, которые начинаются с двукратной ошибки в кодовых словах i-го компонентного кода. Перед выполнением поиска цепочек локализованных ошибок из векторов HNj (i) всех кодовых слов с sj (i)≠0 исключают особо помеченные номера строк. Таким образом, в векторах HNj (i) остаются только те номера строк расширенной проверочной матрицы, которые указывают на позицию одного из искаженных элементов предполагаемой двукратной ошибки кодового слова. Далее для каждого кодового слова с s(i) j≠0 формируют w-1 возможных пар комбинаций двукратных ошибок, которые могут являться началом предполагаемых цепочек локализованных ошибок. Вторую ошибку находят в соответствии с рассмотренным выше способом. После того, когда определены пары ошибок er,j↔em,j, выполняют поиск цепочек ошибок аналогично поиску локализованных ошибок в кодовом слове каскадного кода на первом этапе. Причем поиск проводят параллельно для ошибок er,j и em,j.
После рассмотрения всех кодовых слов с ненулевым синдромом i-го компонентного кода необходимо среди найденных локализованных ошибок выделить повторяющиеся ep=em и пересекающиеся (один или несколько элементов в выбранной паре локализованных ошибок совпадают) пары локализованных ошибок.
Для определения повторяющихся пар локализованных ошибок ep=em достаточно вычислить NK:
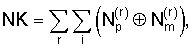
где 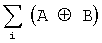 - сумма суммы по mod 2 элементов векторов А и В с одинаковыми индексами i;
- сумма суммы по mod 2 элементов векторов А и В с одинаковыми индексами i;
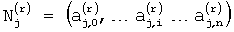 - вектор позиций условно нулевых синдромов r-того компонентного кода для j-ой локализованной ошибки (где j=(p,m)), причем:
- вектор позиций условно нулевых синдромов r-того компонентного кода для j-ой локализованной ошибки (где j=(p,m)), причем:

Если NK=0, то локализованные ошибки ep=em, а если NK≠0, то локализованные ошибки еp≠em.
Для определения пересекающихся локализованных ошибок еp и em достаточно вычислить NN:
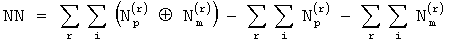
или
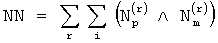 .
.
Если NN=0, то локализованные ошибки ep и em не пересекаются, а если NN≠0, то локализованные ошибки eр и em пересекаются. Позиции пересечения в r-м компонентном коде обозначены в векторе 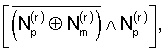 или
или 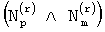 ненулевыми элементами (где (А∧В) - логическое умножение элементов векторов А и В с одинаковыми индексами i).
ненулевыми элементами (где (А∧В) - логическое умножение элементов векторов А и В с одинаковыми индексами i).
Затем среди повторяющихся ошибок оставляем одну из них, а остальные исключаем из рассмотрения.
После чего определяют альтернативные группы локализованных ошибок, в которых пересекающиеся ошибки разнесены в различные группы.
На третьем этапе выполняют поиск локализованных ошибок, имеющих конфигурацию кодовых слов i-го компонентного кода, для каждой альтернативной группы локализованных ошибок. Необходимость выполнения 3-го этапа возникает после завершения 1-го и 2-го этапов, когда все расширенные синдромы i-го компонентного кода каскадного кода становятся нулевыми (как исходно нулевые, так и условно нулевые). В этом случае особо помеченные номера строк векторов HNr (u) ненулевых расширенных синдромов других компонентных кодов либо все, либо группами указывают на одно, либо на группу кодовых слов i-го компонентного кода. Причем позиции, на которые указывают особо помеченные номера строк, образуют цепочки ошибок, имеющие конфигурацию кодового слова. Их и следует выбирать в качестве наиболее вероятных цепочек локализованных ошибок.
В качестве оптимального вектора коррекции выбирают ту группу локализованных ошибок, которая имеет нулевые и условно нулевые синдромы для всех кодовых слов компонентных кодов и имеет наименьший вес.
И в завершении процесса декодирования кодового слова каскадного кода инвертируются те элементы его систематической части, номера которых соответствуют позициям ненулевых элементов в векторе коррекции.
В том случае, когда в качестве компонентных кодов каскадного кода используют «расширенные» циклические коды для декодирования с «жестким» решением, предлагается вариант способа, описанного выше, в котором перед вычислением расширенных синдромов в кодовых словах компонентных кодов удаляют элемент расширения.
В том случае, когда в качестве компонентных кодов каскадного кода используют «укороченные» циклические коды для декодирования с «жестким» решением предлагаются варианты способов, описанные выше, в которых перед декодированием в начало каждого кодового слова «укороченного» компонентного кода добавляют нулевые элементы, количество которых равно величине укорочения. Причем, очевидно, что добавленные в начало нулевые позиции не могут быть искажены в канале связи, так как они по нему не передавались. Этот факт позволяет сократить количество локализованных ошибок, что приводит к уменьшению вычислительной сложности декодирования.
В том случае, когда каскадный код декодируется с «мягким» решением предлагаются варианты способов, описанных выше, в которых для локализованной ошибки еm вычисляют модифицированную метрику vm для всех кодовых слов компонентных кодов, в которые попадают элементы локализованной ошибки em:
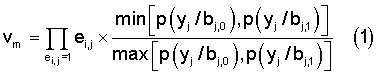
или
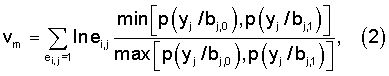
где p(yj/bj,c) - условная вероятность того, что на выходе демодулятора получена величина yj при передаче по каналу связи на j-ой позиции кодового слова компонентного кода элемента с, который для двоичного кода может принимать значение 0 или 1,
еi,j - элемент локализованной ошибки, исказивший j-тый элемент кодового слова i-го компонентного кода.
Модифицированная метрика является отношением общепринятой метрики [1-3] i-го кодового слова к метрике принятого из канала связи с «жестким» решением искаженного кодового слова. Корректируются те элементы принятого с «жестким» решением искаженного кодового слова каскадного кода, которые заданы альтернативной группой локализованных ошибок с максимальной метрикой vm и которая обнуляет все компонентные коды каскадного кода.
В том случае, когда декодируется с «мягким» решением каскадный код с «укороченными» компонентными кодами, предлагается вариант способа, описанного выше, в котором перед декодированием в начало «укороченных» кодовых слов компонентных кодов добавляют нулевые элементы, количество которых равно величине укорочения, с условными вероятностями p(yj/bj,0)=1 и p(yj/bj,1)=0.
Предлагаемые технические решения позволяют решить задачу оптимального синдромного декодирования каскадного кода с последовательным соединением через перемежитель циклических линейных блочных кодов как с «жестким», так и с «мягким» решениями с меньшей вычислительной и аппаратной сложностью, чем известные декодеры [1-5]. Кроме того, предлагаемый способ может быть применен также при синдромном декодировании как с «жестким», так и с «мягким» решением турбо-кодов с компонентными циклическими линейными блочными кодами.
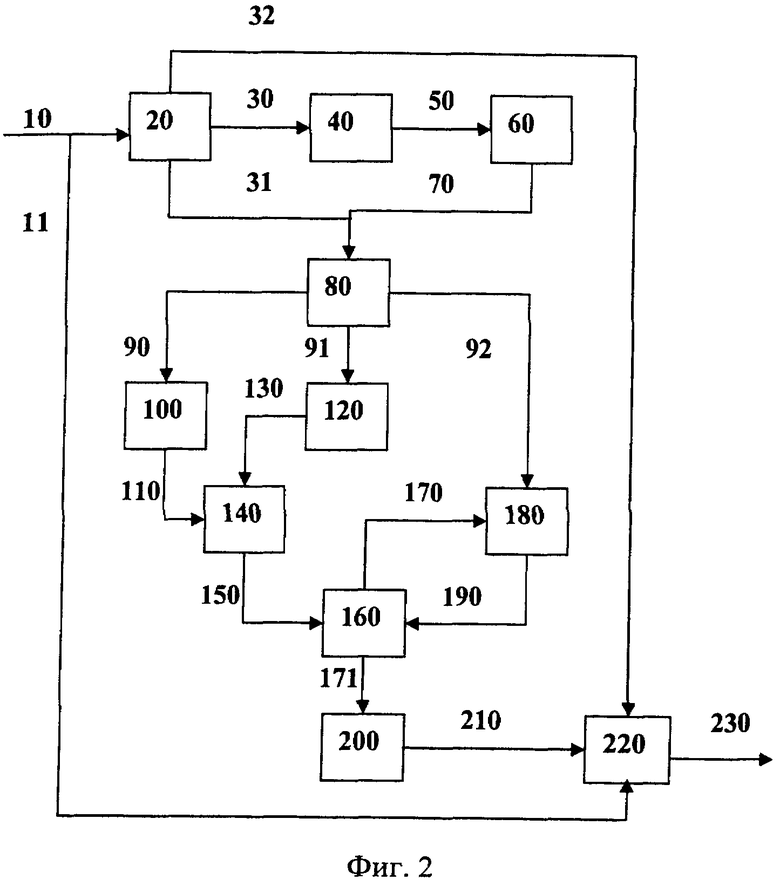
Изобретение поясняется чертежом (фиг.2), на котором изображена структурная схема оптимального синдромного декодера каскадного кода с последовательным соединением через перемежитель циклических линейных блочных кодов.
Синдромный декодер каскадного кода с последовательным соединением через перемежитель циклических линейных блочных кодов содержит: блок вычисления расширенного синдрома 20, блок поиска ненулевого элемента 40, блок формирования номеров строк 60, блок хранения таблицы 80, 1-й блок поиска цепочек локализованных ошибок 100, 2-й блок поиска цепочек локализованных ошибок 120, блок хранения локализованных ошибок 140, блок формирования альтернативных групп локализованных ошибок 160, 3-й блок поиска цепочек локализованных ошибок 180, блок выбора вектора коррекции 200, блок формирования декодированной информации 220.
Блок вычисления расширенного синдрома 20 предназначен для вычисления расширенных синдромов кодовых слов компонентных кодов каскадного кода sr (u) по формуле sr (u)=(br (u)⊕er (u))×Нn,n.
Блок поиска ненулевого элемента 40 предназначен для определения позиции N любого ненулевого элемента расширенного синдрома sr (u). Он может быть реализован в виде сдвигового регистра, у которого анализируется старший разряд на наличие 0. В этом случае в сдвиговый регистр заносится текущий синдром sr (u) и выполняются его сдвиги в сторону старшего разряда до тех пор, пока в нем не появится ненулевой элемент. Количество сдвигов является номером позиции одного из ненулевых элементов N, которое фиксируется счетчиком.
Блок формирования номеров строк 60 предназначен для определения номеров строк расширенной проверочной матрицы Нn,n, у которых один из ненулевых элементов расположен на позиции N. Блок 60 может быть выполнен в виде сдвигового регистра, у которого анализируется старший разряд на наличие 0, и счетчиков номеров строк, количество которых равно w (количество ненулевых коэффициентов проверочного многочлена h(x)). В сдвиговый регистр заносится N-й столбец расширенной проверочной матрицы Нn,n, который сдвигается в сторону старшего разряда до тех пор, пока он не обнулится. Счетчики номеров строк подсчитывают количество сдвигов и при появлении ненулевого элемента в старшем разряде регистра сдвига последовательно отключаются. При обнулении регистра сдвига номера искомых строк расширенной проверочной матрицы соответствуют состояниям счетчиков.
Блок хранения таблицы 80 предназначен для хранения расширенных синдромов sr (u) и соответствующих им векторов HNr (u), в которых указаны номера строк расширенной проверочной матрицы Нn,n, принимавших участие в формировании синдрома sr (u), а при декодировании с «мягким» решением и метрик vr,u. Блок 80 представляет собой оперативное запоминающее устройство, у которого каждая строка состоит из двух (трех) полей для хранения текущих векторов sr (u), HNr (u), а при декодировании с «мягким» решением и метрики vr,u.
1-й блок поиска цепочек локализованных ошибок 100 предназначен для поиска локализованных ошибок в кодовом слове каскадного кода, которые начинаются с однократной ошибки в кодовых словах i-го компонентного кода, в соответствии с действиями, которые предусмотрены для 1 этапа поиска локализованных ошибок предложенного способа.
2-й блок поиска цепочек локализованных ошибок 120 предназначен для поиска локализованных ошибок в кодовом слове каскадного кода, которые начинаются с двукратной ошибки в кодовых словах i-го компонентного кода, в соответствии с действиями, которые предусмотрены для 2 этапа поиска локализованных ошибок предложенного способа.
Блок хранения локализованных ошибок 140 предназначен для хранения локализованных ошибок em и соответствующих им векторов позиций условно нулевых синдромов Nm. Блок 160 может быть реализован в виде оперативного запоминающего устройства, у которого каждая строка состоит из двух (трех) полей для хранения локализованных ошибок em и векторов Nm, а при декодировании с «мягким» решением и метрики vm.
Блок формирования альтернативных групп локализованных ошибок 160 предназначен для выявления и удаления повторяющихся ошибок, выявления пересекающихся локализованных ошибок и формирования альтернативных групп локализованных ошибок, в которых пересекающиеся ошибки разносятся в различные группы. Блок 160 может быть реализован в виде спецвычислителя для определения повторяющихся и пересекающихся локализованных ошибок, содержащего оперативное запоминающее устройство, у которого каждая строка состоит из двух (трех) полей для хранения групп локализованных ошибок, количества условно нулевых расширенных синдромов, соответствующих каждой группе, а при декодировании с «мягким» решением и метрики для каждой из групп.
3-й блок поиска цепочек локализованных ошибок 180 предназначен для поиска локализованных ошибок, имеющих конфигурацию кодовых слов i-го компонентного кода, для каждой альтернативной группы локализованных ошибок, сформированных на втором этапе, в соответствии с действиями, которые предусмотрены для 3 этапа поиска локализованных ошибок предложенного способа.
Блок выбора вектора коррекции 200 предназначен для определения оптимального вектора коррекции искаженного каскадного кода.
Блок формирования декодированной информации 220 предназначен для инвертирования элементов в систематической части кодового слова каскадного кода, которые указаны в векторе коррекции, и передачи на выход декодера откорректированной систематической части кодового слова каскадного кода.
Предлагаемое устройство работает следующим образом.
Принятое, возможно искаженное в канале связи, кодовое слово (b⊕eкс) поступает с выхода канала связи (демодулятора) по шине 10 на блок вычисления расширенного синдрома 20, а по шине 11 на блок формирования декодированной информации 220.
Если все вычисленные синдромы в блоке вычисления расширенного синдрома кодовых слов компонентных кодов 20 равны нулю, то кодовое слово каскадного кода не искажено и информация об этом передается по шине 32 в блок формирования декодированной информации 220, в котором выделяется систематическая часть кодового слова и по шине 230 поступает на выход декодера. На этом процесс декодирования кодового слова заканчивается.
Если же хотя бы один из расширенных синдромов кодовых слов компонентных кодов не является нулевым вектором, то по шине 31 он поступает в блок хранения таблицы 80, а по шине 30 в блок поиска ненулевого элемента 40, в котором определяется любая ненулевая позиция расширенного синдрома и по шине 50 передается в блок формирования номеров строк 60.
Блок формирования номеров строк 60 находит номера тех строк расширенной проверочной матрицы, которые содержат ненулевой элемент в позиции, полученной по шине 50. Сформированный вектор с номерами строк расширенной проверочной матрицы передается по шине 70 в блок хранения таблицы 80.
По завершении вычисления расширенных синдромов для всех кодовых слов компонентных кодов и занесения их вместе со своими векторами с номерами строк расширенной проверочной матрицы в блок хранения таблицы 80 запускается 1-ый блок поиска цепочек локализованных ошибок 100.
1-й блок поиска цепочек локализованных ошибок 100 последовательно считывает по шине 90 расширенные синдромы кодовых слов одного из компонентных кодов и выполняет последовательность действий, которые предусматривает 1 этап поиска локализованных ошибок, изложенный в предложенном выше способе. В результате выявляются локализованные ошибки в кодовом слове каскадного кода, которые начинаются с однократной ошибки в кодовых словах выбранного компонентного кода, которые с вектором позиций условно нулевых расширенных синдромов данной локализованной ошибки передаются по шине 110 в блок хранения локализованных ошибок 140. После того как будет завершен просмотр всех расширенных синдромов кодовых слов выбранного компонентного кода, запускается 2-ой блок поиска цепочек локализованных ошибок 120.
2-й блок поиска цепочек локализованных ошибок 120 последовательно считывает по шине 91 расширенные синдромы кодовых слов выбранного компонентного кода и выполняет последовательность действий, которые предусматривает 2-ой этап поиска локализованных ошибок, изложенный в предложенном выше способе. В результате выявляются локализованные ошибки в кодовом слове каскадного кода, которые начинаются с двукратной ошибки в кодовых словах выбранного компонентного кода. Локализованные ошибки вместе с вектором позиций условно нулевых расширенных синдромов передаются по шине 130 в блок хранения локализованных ошибок 140. После того как будет завершен просмотр всех расширенных синдромов кодовых слов выбранного компонентного кода, запускается блок формирования альтернативных групп локализованных ошибок 160.
Блок формирования альтернативных групп локализованных ошибок 160 по шине 150 последовательно просматривает локализованные ошибки, хранящиеся в блоке хранения локализованных ошибок 140, удаляет повторяющиеся локализованные ошибки и формирует альтернативные группы локализованных ошибок с учетом того, что найденные пересекающиеся ошибки должны входить в различные группы. Для каждой группы локализованных ошибок в блоке 160 вычисляется количество условно нулевых синдромов и их позиции, которые вместе со своей группой локализованных ошибок сохраняются в запоминающем устройстве блока 160..
По завершении формирования альтернативных групп локализованных ошибок запускается 3-ий блок поиска цепочек локализованных ошибок 180. 3-ий блок поиска цепочек локализованных ошибок 180 последовательно считывает по шине 170 из блока формирования альтернативных групп локализованных ошибок 160 группы локализованных ошибок. Для каждой группы локализованных ошибок модифицируется таблица синдромов, поступающая по шине 92 из блока хранения таблицы 80, с учетом условно нулевых синдромов и выполняет последовательность действий, которую предусматривает 3-ий этап поиска локализованных ошибок, изложенный в предложенном выше способе. В результате выявляются локализованные ошибки, которые имеют конфигурацию кодовых слов, в кодовых словах выбранного компонентного кода. Вновь полученные локализованные ошибки включаются в группу и вместе с количеством условно нулевых синдромов по шине 190 возвращаются в блок формирования альтернативных групп локализованных ошибок 160.
После того как будет завершен просмотр всех групп локализованных ошибок, запускается блок выбора вектора коррекции 200, который по шине 171 последовательно считывает группы локализованных ошибок и выбирает при декодировании с «жестким» решением ту, которая содержит все нулевые и условно нулевые синдромы кодовых слов компонентных кодов и имеет наименьший вес. Далее выбранная группа локализованных ошибок по шине 210 поступает в блок формирования декодированной информации 220, в котором инвертируются те элементы в систематической части кодового слова каскадного кода, которые указаны в локализованной группе ошибок. Откорректированная систематическая часть кодового слова каскадного кода по шине 230 поступает на выход декодера.
Для декодирования каскадного кода с «укороченными» кодовыми словами компонентных кодов другим конструктивным вариантом является модификация блока вычисления расширенного синдрома 20, в котором перед вычислением расширенных синдромов «укороченных» кодовых слов компонентных кодов sr (u) в начало каждого кодового слова добавляют нулевые элементы (при декодировании с «мягким» решением с условными вероятностями p(yj/bj,0)=1 и р(yj/bj,1)=0), количество которых равно величине укорочения кода. Кроме того, в 1-м блоке поиска цепочек локализованных ошибок 100, во 2-м блоке поиска цепочек локализованных ошибок 120 и в 3-м блоке поиска цепочек локализованных ошибок 180, учитывается тот факт, что локализованная ошибка не может содержать позиции элементов, добавленных в блоке 20. Данное конструктивное решение позволяет не только декодировать каскадные коды с «укороченными» компонентными кодами, но и повысить быстродействие декодера.
Для декодирования каскадного кода с «расширенными» кодовыми словами компонентных кодов другим конструктивным вариантом является модификация блока вычисления расширенного синдрома 20, в котором перед вычислением расширенных синдромов кодовых слов компонентных кодов sr (u) удаляют последний элемент (элемент расширения или элемент четности кодового слова) в кодовых словах «расширенных» компонентных кодах. При декодировании с «жестким» решение данный элемент более ни в одном из блоков не учитывается. При декодировании с «мягким» решением условные вероятности элемента расширения используются при вычислении метрик в блок формирования альтернативных групп локализованных ошибок 160. Данное конструктивное решение позволяет декодировать каскадные коды с «расширенными» компонентными кодами.
Для декодирования каскадного кода с «мягким» решением другим конструктивным вариантом является модификация блока вычисления расширенного синдрома 20, который перед вычислением расширенных синдромов компонентных кодов формирует кодовое слово каскадного кода с «жестким» решением. В 1-м блоке поиска цепочек локализованных ошибок 100, во 2-м блоке поиска цепочек локализованных ошибок 120 и в 3-м блоке поиска цепочек локализованных ошибок 180, в первую очередь рассматривают наименее достоверные позиции кодовых слов компонентных кодов, что приведет к повышению быстродействия декодера. В блоке формирования альтернативных групп локализованных ошибок 160 вычисляют метрику для каждой альтернативной группы локализованных ошибок, которая является суммой метрик кодовых слов компонентных кодов, искаженных данной группой локализованных ошибок. В блоке выбора вектора коррекции 200 в качестве оптимального вектора ошибки выбирается та группа локализованных ошибок, которая имеет максимальную метрику и имеет все нулевые или условно нулевые синдромы.
Реализация описанного устройства может быть аппаратной, программной или аппаратно-программной и использоваться как для двоичных, так и q-ичных кодов.
Достигаемым техническим результатом предлагаемого способа декодирования каскадного кода с последовательным соединением через перемежитель циклических линейных блочных кодов является повышение достоверности (качества) декодирования с «мягким» решением, повышение его быстродействия, уменьшения аппаратной сложности и уменьшения времени задержки декодирования по сравнению с известными декодерами [1-3], кроме того, он является оптимальным способом декодирования как с «жестким», так и с и «мягким» решением. Предлагаемый синдромный декодер как с «жестким», так и с «мягким» решением может быть с успехом применен для декодирования турбо-кодов с компонентными циклическими линейными блочными кодами.
Список литературы
1. Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение: Пер. с англ. В.Б.Афанасьева. - М.: Техносфера, 2005. - 320 с.
2. Витерби А.Д., Омура Дж.К. Принципы цифровой связи и кодирования: Пер. с англ. - М.: Радио и связь, 1982.
3. Мак-Вильямс Ф.Дж., Слоэн Н.Дж.А. Теория кодов, исправляющих ошибки: Пер. с англ. - М.: Связь, 1979.
4. Карташевский В.Г., Мишин Д.В. Прием кодированных сигналов в каналах с памятью. - М.: Радио и связь, 2004.
5. Золотарев В.В., Овечкин Г.В. Помехоустойчивое кодирование. Методы и алгоритмы: Справочник./Под ред. чл. кор. РАН Ю.Б.Зубарева. - М.: Горячая линия. - Телеком, 2004.
Изобретение относится к области техники связи, в частности к системам передачи информации, в которых для ее защиты от искажений в канале связи применяются каскадные коды с последовательным соединением через перемежитель циклических линейных блочных кодов, и может быть использовано в кодеках систем передачи данных, а также в устройствах помехоустойчивого кодирования. Сущность способа состоит в том, что для принятой кодовой реализации вычисляют расширенные синдромы для каждого кодового слова компонентного кода каскадного кода, и, используя расширенную проверочную матрицу, определяются те наборы строк, которые участвуют в формировании любого ненулевого элемента расширенного синдрома (номера строк расширенной проверочной матрицы, вошедшие в набор строк, соответствуют позициям однократной и двукратных ошибок искаженного кодового слова), затем последовательно просматривая расширенные синдромы одного из компонентных кодов выявляют цепочки локализованных ошибок, которые объединяют в альтернативные группы локализованных ошибок, и при декодировании с «жестким» решением в качестве наиболее вероятного вектора коррекции выбирают ту альтернативную группу, которая имеет наименьший вес и обнуляет все синдромы компонентных кодов, а при декодировании с «мягким» решением выбирают ту альтернативную группу, которая имеет максимальную модифицированную метрику, и инвертируют те элементы систематической части кодового слова инвертируют те элементы систематической части кодового слова каскадного кода, номера которых соответствуют позициям ненулевых элементов в векторе коррекции. Техническим результатом является реализация оптимальной процедуры декодирования как с «жестким», так и с «мягким» решениями, повышение достоверности (качества) декодирования и снижение аппаратной и вычислительной сложности, а также возможность декодирования турбо-кодов с компонентными циклическими линейными блочными кодами. 2 н. и 2 з.п. ф-лы, 2 ил.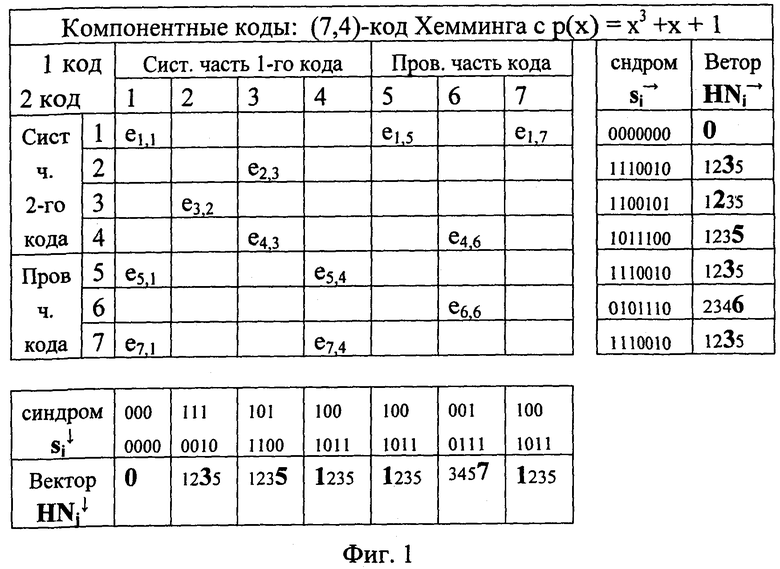
| ПАРАЛЛЕЛЬНЫЙ КАСКАДНЫЙ СВЕРТОЧНЫЙ КОД С КОНЕЧНОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ БИТОВ И ДЕКОДЕР ДЛЯ ТАКОГО КОДА | 1997 |
|
RU2187196C2 |
| СПОСОБ НОРМАЛИЗАЦИИ ЗНАЧЕНИЯ МЕТРИКИ КОМПОНЕНТНОГО ДЕКОДЕРА В СИСТЕМЕ МОБИЛЬНОЙ СВЯЗИ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1999 |
|
RU2214680C2 |
| УСТРОЙСТВО И СПОСОБ КАНАЛЬНОГО КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ ДЛЯ СИСТЕМЫ СВЯЗИ | 1999 |
|
RU2212100C2 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 2004123229 A, 24.06.2004. | |||

