Область техники
Изобретение относится к системам биометрии человека по индивидуальным характеристикам его голоса в применении к санкционированию доступа, например, к операционной системе, компьютерным ресурсам, банковскому счету или физическому доступу к помещению и тому подобным случаям, требующим санкционированного доступа.
Уровень техники
Верификация диктора по голосу состоит в подтверждении соответствия характеристик его голоса заранее записанным характеристикам при указании диктором своего идентификатора (фамилии, кодового номера и т.п.) неголосовыми средствами (например, набором на клавиатуре) или путем автоматического распознавания произнесенного идентификатора.
Эффективность бизнеса в значительной степени зависит от обеспечения информационной безопасности. Несанкционированный доступ к конфиденциальной информации о финансовой деятельности компании, контрактах и планах чреват не только потерями, но и полным банкротством. Во многих случаях утечка информации происходит изнутри компании. Обман и злоупотребления со стороны своих сотрудников наносят ущерб в размере 6% годовой прибыли, составляя, в среднем, $100000 на каждый случай (в 14.6% случаев потери превысили $1000000) (Association of Certified Fraud Examiners, 2004). В банковской сфере потери от злонамеренной деятельности сотрудников могут достигать огромных величин.
Передаваемые по телефону параметры кредитной карты в 12% случаев подслушиваются с последующим воровством денег с карты (American Bankers Association). Аналогично параметры кредитной карты перехватываются в системах электронной торговли или в банкоматах. Украденные суммы исчисляются сотнями миллионов долларов в год.
Наряду со стандартными методами повышения информационной безопасности (цифровые пароли, специальные аппаратные средства, кадровая политика), все большее применение находят биометрические средства санкционирования доступа по персональным характеристикам пользователя. Среди них наиболее перспективным является подтверждение (верификация) личности по голосу.
Голосовой пароль использует характеристики голоса, присущие только данному человеку. Он является одним из наиболее удобных и надежных средств обеспечения информационной безопасности. Использование голосового пароля не требует аппаратной поддержки, необходимой при распознавании отпечатков пальцев, ладони, радужной оболочки или сетчатки глаза. Индивидуальные характеристики голоса невозможно забыть, потерять, передать другому человеку, украсть, и очень трудно подделать.
Разработка систем верификации диктора по его голосу ведется как крупными корпорациями в США (IBM, Lucent, ATT, Microsoft, Cisco, Nuance), Японии (Hitachi, Fujitsu, Matsushita), Европе (France Telecom, British Telecom, Philips), Корее (Samsung), так и специализированными компаниями, такими как Persay, Sentrycom (Израиль), Diaphonics, VoiceVault, VeriVoice, Quantum Signal (США). Исследованиям в области верификации диктора был посвящен специальный выпуск журнала Speech Communication, 2000, v.31.
Методы верификации диктора разрабатываются уже в течение нескольких десятилетий, однако характеристики предлагаемых систем еще далеки от требований надежности во многих реальных приложениях. Согласно испытаниям, ежегодно проводимым National Institute of Standards and Technologies, USA, эти системы неустойчивы по отношению к типу микрофона и расстоянию до него, шумам и искажениям в канале связи, естественным вариациям речевых характеристик диктора. Такое положение определяется формальным статистическим подходом к анализу речи, крайне чувствительным к различию в условиях обучения системы верификации и распознавания. Характерным признаком таких систем является их независимость от языка и контекста. Известно также, что ошибки, связанные со "старением" обученной модели быстро растут со временем. Поэтому к сообщениям о чрезвычайно высокой надежности верификации следует относиться с большой осторожностью.
Баланс между числом ложного пропуска самозванца и ложным отказом не устраивает подавляющее большинство потенциальных клиентов, и предлагаемые системы верификации востребованы менее чем 1% потенциального рынка (Gartner Research, 2004).
Для достижения максимальной эффективности системы верификации необходимо наложить как можно больше ограничений на условия ее применения, но эти ограничения не должны затруднять ее эксплуатацию. К числу таких ограничений относится использование фиксированного словаря для конкретного языка. В частности, голосовой пароль может быть представлен в виде случайной последовательности и количества слов из ограниченного словаря числительных от 0 до 9. Такая случайная последовательность препятствует попытке обмана системы верификации путем записи и последующего воспроизведения пароля.
Известен способ адаптации к неизвестному каналу связи, описанный в патентах US 6233556 и US 6804647. С этой целью в процессе обучения системы верификации используется несколько различных типов приемника звука, например угольный, электретный микрофон или микрофон мобильного телефона. В процессе верификации сравнивают спектральные характеристики произнесенного слова с запомненными характеристиками этого слова из референтной базы данных. Разница в этих спектральных характеристиках используется для нормализации неизвестного канала связи к одному из каналов, представленных в референтной базе данных. Недостаток известного способа состоит в том, что точность такой нормализации зависит от точности сегментации и определения спектральных характеристик сегментов, которые используются для нормализации. В случае ошибки сегментации вместо нормализации канала произойдет существенное искажение характеристик принятого слова. Поскольку сама сегментация слова на информативные элементы частот сопровождается ошибками, то и процесс нормализации канала связан с ошибками, ухудшающими надежность верификации.
Известен стандартный способ для аппроксимации плотности вероятности в пространстве признаков, который состоит в вычислении параметров небольшого числа нормальных распределений. Этот способ используется, в частности, в патенте US 6411930, в котором плотность вероятности распределения признаков для диктора, подлежащего верификации, описывается лишь одним нормальным распределением. Недостаток такого описания заключается в том, что в силу нелинейных зависимостей параметров друг от друга использование одного нормального распределения сопровождается большой погрешностью аппроксимации и, следовательно, возрастанием ошибок верификации - пропуска самозванца или отказа законному пользователю. Аппроксимация плотности вероятности множества референтных дикторов несколькими нормальными распределениями также ухудшает характеристики системы верификации, поскольку нормальное распределение не ограничено в пространстве аргументов, тогда как реальные значения параметров ограничены как физически, так и по своим диапазонам для каждого диктора.
В патенте US 6496800 слитная последовательность слов в пароле сначала подвергается автоматическому распознаванию независимо от диктора. Затем параметры каждого из распознанных слов сопоставляются с параметрами соответствующего слова этого диктора и дикторов из референтной базы.
Преимущество этого подхода состоит в практической невозможности воспользоваться подслушанным и записанным произнесением пароля. Однако принципиальные недостатки такого подхода не позволяют достичь требуемой надежности верификации. Во-первых, распознавание слов выполняется с заметными ошибками порядка нескольких процентов, и каждая такая ошибка приводит к значительному падению меры сходства произнесенного слова со словами этого диктора, записанными в процессе обучения. Во-вторых, параметры слов в слитном произнесении могут существенно отличаться от параметров слов, которые в процессе обучения должны записываться только в изолированном произнесении. В-третьих, так называемое явление коартикуляции искажает сегменты слов на границе с другими словами вплоть до полной ассимиляции конца или начала слова. В результате параметры слова, выделенного из слитного потока речи, отличаются от параметров, полученных в процессе обучения, и вероятность подтверждения законного диктора падает.
Решаемая техническая задача
Описываемое изобретение решает задачу поиска таких акустических признаков, которые устойчивы к помехам и искажениям в канале связи пользователя с верификатором, сохраняя в то же время индивидуальные особенности, присущие голосу конкретного пользователя. В частности, необходимо было создать способ, с помощью которого вероятность ошибки пропуска самозванца или отказа законному пользователю не превышает 0.05, если количество числительных в пароле не меньше 10 слов, при этом способ должен быть устойчивым к стационарным и нестационарным помехам типа посторонних разговоров и музыки при отношении сигнал/шум от +12 дБ и выше, причем ошибки верификации должны слабо зависеть от типа приемника звука и расстояния до него.
Сущность изобретения
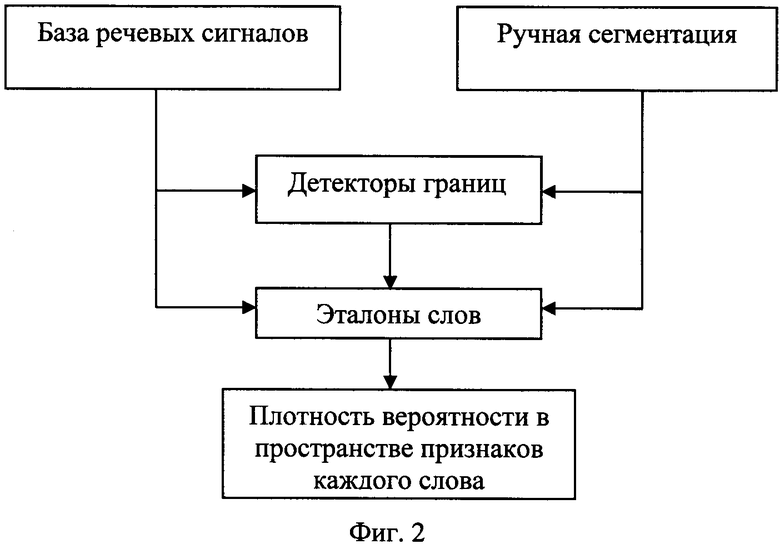
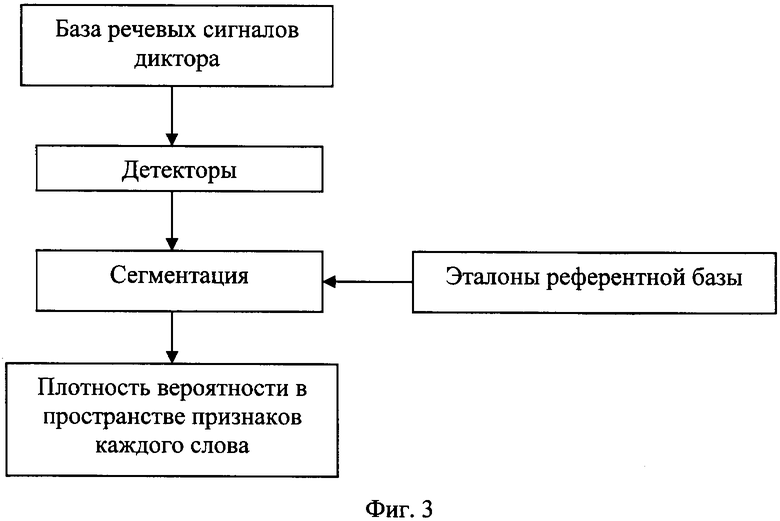
Сущность предлагаемого изобретения состоит в том, что предложен способ верификации пользователя в системах санкционирования доступа, включающий создание референтной базы данных дикторов, создание базы данных пользователей, при этом для верификации пользователя пользователь вводит свой идентификатор, после чего система санкционирования доступа предлагает пользователю произнести пароль из случайной последовательности слов из словаря базы пользователя, после получения звуковых сигналов произнесенного пароля система санкционирования доступа вычисляет вероятность принадлежности произнесенного пароля к голосу пользователя и принимает решение о разрешении доступа или отказе от доступа, при этом для создания референтной базы данных выбирают дикторов, записывают речевые сигналы произнесенных дикторами слов из заданного словаря через основные типы приемников звука и в различных помещениях, вычисляют и запоминают динамические спектры этих речевых сигналов, размечают речевые сигналы на основные типы сегментов, вычисляют и запоминают сигналы динамических детекторов, определяющих возрастание или спад энергии в частотных областях динамического спектра речевого сигнала, вычисляют и запоминают плотность вероятности в пространстве признаков каждого слова, из множества реализации каждого слова по всем дикторам референтной базы отбирают и запоминают эталонные последовательности сегментов, отличающиеся друг от друга хотя бы одним сегментом, при этом для создания базы данных пользователей записывают речевые сигналы произнесенных пользователями слов из заданного словаря, размечают речевые сигналы на основные типы сегментов, вычисляют и запоминают плотность вероятности в пространстве признаков каждого слова, при формировании базы данных пользователя и в процессе его верификации границы сегментов слов предварительно устанавливают в моменты, соответствующие максимумам суммарной по частоте энергии динамических детекторов, при этом признаки сегментов вычисляют как частоты локальных максимумов детекторов спектрально-временных и спектральных неоднородностей, при этом окончательную сегментацию произнесенного слова при верификации выполняют с использованием метода динамической трансформации оси времени с поиском эталона из референтной базы данных, последовательность сегментов и значения признаков которых наиболее близки к признакам сегментов произнесенного слова.
Кроме того, плотность вероятности в пространстве признаков каждого слова для каждого пользователя и диктора могут вычислять, как нормированную суперпозицию нормальных распределений с математическим ожиданием, расположенным в координатах каждого вектора, соответствующего реализации этого слова, а среднеквадратическое отклонение вычисляют пропорционально среднему расстоянию между реализациями данного слова.
Кроме того, вероятность принадлежности произнесенного пароля к голосу пользователя могут вычислять как среднее значение вероятностей принадлежности каждого слова в пароле.
Кроме того, для принятия решения о разрешении доступа или отказе от доступа могут сравнивать вычисленную вероятность с порогом, который устанавливают для каждого пользователя индивидуально путем минимизации ошибки пропуска самозванца при заданной вероятности отказа пользователю.
Достигаемый технический результат
Создан способ, решивший задачу поиска таких акустических признаков, которые устойчивы к помехам и искажениям в канале связи пользователя с верификатором, сохраняя в то же время индивидуальные особенности, присущие голосу конкретного пользователя. Достигнута устойчивость к стационарным и нестационарным помехам типа посторонних разговоров и музыки при отношении сигнал/шум от +12 дБ и выше, причем ошибки верификации слабо зависят от типа приемника звука и расстояния до него. Если количество числительных в пароле не меньше 10 слов, то гарантируется, что вероятность ошибки пропуска самозванца или отказа законному пользователю не превышает 0.05.
Сущность способа и его работа иллюстрируется чертежами.
На Фиг.1 представлены осциллограммы, сонограммы, детектограммы и фонетическая разметка речевых сигналов.
На Фиг.2 показана блок-схема формирования референтной базы данных.
На Фиг.3 показана блок-схема формирования базы данных диктора.
На Фиг.4 показана блок-схема верификации пользователя по последовательности слов в голосовом пароле.
Технический результат достигается за счет максимального использования имеющейся информации. В настоящем изобретении используется изолированное произнесение слов из заданного словаря, причем слово, которое должен произнести пользователь, и последовательность этих слов определяется самой системой верификации. В процессе формирования баз данных для каждого слова находятся сегменты, параметры которых наилучшим образом разделяют пользователя и дикторов, записанных в референтной базе данных. В пространстве этих параметров для каждого сегмента слова выполняется аппроксимация плотности вероятности, а в процессе верификации для сегментов каждого произнесенного слова вычисляется отношение правдоподобия относительно аналогичного сегмента соответствующего слова в референтной базе. Затем с помощью формулы Байеса для каждого пространства вычисляется апостериорная вероятность принадлежности к голосу пользователя, и эти вероятности усредняются по всем словам в пароле. Решение о доступе или отказе принимается по значению этой апостериорной вероятности относительно некоторого порога, индивидуального для каждого пользователя.
В настоящем изобретении для сегментации речевого сигнала на характерные участки, а также для определения признаков голоса диктора используются детекторы спектрально-временных неоднородностей, описанные в статье В.Н.Сорокина и Д.Н.Чепелева "Модель первичного анализа речевых сигналов". Акустический ж., 2005, т.51, №3, с.340-346.
Оператор
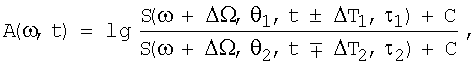
описывает акустические детекторы спектрально-временных неоднородностей сигнала и моделирует многие известные свойства слухового восприятия. Здесь S(ω,t) - динамический спектр мощности принятого сигнала, Δ Ω - сдвиг отсчета спектра по частоте, ΔТ - сдвиг отсчета спектра по времени, θ1 и θ2 - скользящие интервалы сглаживания спектрального разреза по частоте, τ1 и τ2 - постоянные времени сглаживания спектральных компонент фильтром первого порядка, С≥1.
Оператор А(ω,t) обладает рядом важных свойств, необходимых для успешной верификации диктора. Прежде всего он слабо зависит от аддитивных помех и амплитудно-частотной характеристики канала связи, включая характеристики разных типов микрофонов. Это свойство существенно повышает помехоустойчивость верификации. При τ1≠0 и τ2≠0, оператор A(ω,t) оценивает скорость переходных процессов в динамическом спектре речевого сигнала, формируя разнообразные динамические детекторы для различных сочетаний τ1 и τ2. Эти детекторы моделируют явления амплитудно-частотных модуляций в речевом сигнале. При θ1≠0 и θ2≠0, оператор A(ω,t) оценивает неоднородность спектрального профиля в каждый момент времени. При разных значениях параметров θ1 и θ2 формируются детекторы, которые моделируют так называемый эффект латерального торможения в спектральной области.
Детекторы спектральных и спектрально-временных неоднородностей подчеркивают индивидуальные характеристики голоса диктора, поскольку разные размеры речевого тракта влияют на форму мгновенного спектра и скорость движения артикуляторных органов - языка, губ и нижней челюсти.
На Фиг.1 показаны примеры работы детекторов при разных соотношениях их параметров. Вверху приведены осциллограммы последовательности слов "один, шесть, четыре" с разметкой на акустико-фонетические сегменты. Тип сегмента указан на флажке, установленном на границе соответствующего сегмента. Типы сегментов в значительной степени не зависят от конкретного языка, для которого разрабатывается система верификации, хотя и существуют различия, например, в количестве гласных или месте артикуляции некоторых согласных звуков. В системе верификации для русского языка используется более 120 типов сегментов, включающих в себя ударные, безударные и редуцированные гласные, а также огласованные сегменты, не имеющие фонетической классификации, такие как сегменты между согласными и звуком "p" (например, в слове "mъpu"). Кроме границ фонетических элементов - гласных и согласных, необходимо указывать и границы акустических сегментов, таких как шумовые участки речевого сигнала после взрыва смычных согласных. На Фиг.1 такой сегмент в слове "шесть" обозначен флажком с символами Th'.
Под осциллограммами показаны динамические спектры (сонограммы). Под сонограммой показаны отклики динамического детектора (детектограммы), реагирующего на возрастание энергии в данной частотной полосе, а под ним - отклики динамического детектора, реагирующего на спад энергии. И на сонограммах, и на детектограммах амплитуда сигнала в данной частотной полосе отображается степенью черноты изображения. Еще ниже показаны отклики детекторов, описывающих неоднородности спектрального профиля энергетического спектра S при разных параметрах θ1 и θ2.
Энергия каждого динамического детектора в каждый момент времени суммируется по частоте. Максимумы этой функции во времени принимаются за границы сегментов речевого сигнала, а мгновенные или усредненные на квазистационарном сегменте спектральные профили детектограмм используются для вычисления признаков индивидуальности голоса диктора.
В дополнение к свойствам оператора A(ω,t) устойчивость оценки параметров голоса к различным характеристикам акустического и электронного каналов связи достигается еще и тем, что референтная база данных формируется с использованием основных типов приемников звука (направленных и ненаправленных микрофонов, расположенных на разных расстояниях от диктора) и характеристик помещения, в котором производится запись.
При формировании референтной базы данных выполняется ручная разметка речевых сигналов, состоящая в установлении границ между сегментами и маркировке типа сегмента, следующего за границей. На каждой границе считываются амплитуды и частоты локальных максимумов профиля детектограмм, описывающих переходные процессы с возрастанием или спадом энергии в спектре речевого сигнала. Между границами сегментов вычисляются средние частоты локальных максимумов спектра, найденных с помощью детекторов спектральных неоднородностей. Множество динамических и статических параметров сегментов каждого слова формирует пространство признаков этого слова. В отличие от техники нормализации канала связи в данном изобретении в пространстве признаков вычисляется плотность вероятности по всем типам каналов связи и всем дикторам референтной базы данных для каждого слова, используемого в голосовом пароле. Преимущество такого подхода заключается в аппроксимации характеристик каналов связи, находящихся как бы между характеристиками тех типов каналов, которые были использованы в процессе обучения. Кроме того, это позволяет избежать процесса нормализации, чреватого значительными ошибками.
Для наиболее точной аппроксимации плотности вероятности в пространстве признаков вектор признаков каждой реализации слова рассматривается как математическое ожидание некоторой гиперсферы с нормальным распределением. Среднеквадратическое отклонение этого распределения вычисляется пропорционально среднему расстоянию между множеством реализации данного слова для каждого диктора. Затем плотность вероятности в пространстве признаков слова вычисляется как нормированная суперпозиция всех нормальных распределений. Такой подход лишен недостатков, присущих аппроксимации плотности вероятности несколькими или тем более одним нормальным распределением.
Сегментация слова на акустические элементы необходима для установления соответствия параметров слов. Например, на сегментах гласных вычисляются частоты локальных экстремумов спектра, а на сегментах фрикативных звуков - частотные характеристики шумового участка спектра. Ошибка в типе сегмента приводит к падению отношения правдоподобия анализируемого слова. В настоящем изобретении используется оригинальный метод сегментации, не имеющий аналогов в мировой патентной литературе.
Все типы акустических и фонетических сегментов сводятся к 6 основным типам: гласный, назальный, глухая смычка, звонкая смычка, звонкий фрикативный, глухой фрикативный. В процессе обучения системы по всем реализациям каждого слова из заданного словаря формируется кодовая книга, состоящая из множества кодов, представленных в виде последовательности 6 основных типов сегментов. Эти коды служат эталонами, использующимися при сегментации речевых сигналов в процессе верификации пользователя. Каждому эталону соответствует свое пространство признаков, в котором осуществляется аппроксимация плотности вероятности. Все множество эталонов каждого слова формирует общее пространство признаков слова и описывается плотностью вероятности в этом пространстве. Процесс формирования референтной базы данных иллюстрируется блок-схемой на Фиг.2.
При формировании базы данных для диктора, подлежащего верификации, вместо ручной разметки используются эталоны референтной базы данных. Сегментация слов в процессе обучения системы на данного диктора выполняется путем стандартного метода динамического программирования, осуществляющего деформацию временной оси с поиском последовательности сегментов, характеристики которых в терминах некоторого критерия наиболее близки к одному из эталонов референтной базы данных. Затем для каждого произнесенного слова определяется пространство признаков, и в этом пространстве по всем словам, участвовавшим в обучении, формируется плотность вероятности с помощью смеси нормальных распределений. Этот процесс иллюстрируется блок-схемой на Фиг.3.
В процессе верификации каждое произнесенное слово также сегментируется с использованием последовательностей сегментов слов, записанных в референтной базе данных. Затем для полученной последовательности сегментов формируется вектор признаков этого слова, и считываются условные вероятности принадлежности этого вектора к пространству признаков диктора или соответствующего кода в референтной базе. Процесс обработки речевого сигнала и информационные потоки в режиме верификации диктора показаны на блок-схеме (Фиг.4).
Конкретные примеры работы
"Способа верификация пользователя в системах санщионирования доступа".
Способ может быть реализован с помощью аппаратных средств, например, на основе цифрового сигнального процессора или в виде специализированного чипа. Один из вариантов реализации способа может быть представлен как программный модуль, предназначенный для обеспечения доступа к операционной системе Windows в персональных компьютерах. Такой программный модуль был протестирован на обширной речевой базе данных, состоящей из речевых сигналов 420 дикторов разного возраста и пола. Речевые сигналы разных групп дикторов записывались через разные типы приемников звука, включая 2 типа телефонных трубок, 2 типа микрофонов с подавлением шумов, расположенных на головной гарнитуре, 2 типа направленных микрофонов, расположенных на расстоянии 20 см и 80 см от диктора, всенаправленный микрофон и кардиоидный микрофон, расположенный на расстоянии 20 см и 80 см от диктора. Запись речевых сигналов производилась в помещениях различного объема. Каждый диктор произносил каждое числительное от 0 до 9 от 20 до 40 раз.
При тестировании системы верификации поочередно каждый диктор назначался пользователем. Из его произнесений в случайном порядке формировались пароли из 10 числительных, и выполнялась оценка вероятности пропуска самозванца или отказа. Объем тестирования составил более 30 миллионов реализаций, что является вполне представительной выборкой для полученной оценки вероятности ошибок обоего рода, которая оказалась менее 0.05.
При реализации способа эта база данных используется как референтная база. Каждый пользователь производит обучение системы верификации, произнося каждое числительное не менее 20 раз, причем порядок следования числительных определяется системой верификации. Количество произнесений на этапе обучения, а также количество слов в пароле при верификации зависит от требуемого отношения вероятности пропуска самозванца к вероятности отказа законному пользователю. Это отношение устанавливается самим пользователем.
Примеры работы системы верификации при санкционировании доступа иллюстрируются окнами с сообщениями системы. При вызове верификатора появляется окно, в котором пользователю предлагается нажать на клавишу пробела для запуска процесса верификации (Фиг.5). Затем система верификации последовательно высвечивает числительные, которые пользователь должен произнести (Фиг.6). Процесс верификации завершается принятием решения о доступе или отказе от доступа (Фиг.7, 8). В случае отказа от доступа пользователю предоставляется, например, еще две попытки. Если и эти попытки оказались неудачными, то предлагается ввести мастер-ключ (Фиг.9).
Если система верификации предназначена для индивидуального использования, то мастер-ключ известен пользователю. Этот ключ должен храниться отдельно, аналогично ПИН-коду кредитной карты. Если система верификации используется, например, в компании со многими пользователями, то мастер-ключ известен только системному администратору или представителю службы безопасности.



Изобретение относится к системам биометрии человека по индивидуальным характеристикам его голоса к санкционированному доступу, например, к операционной системе, компьютерным ресурсам, банковскому счету или физическому доступу к помещению и к случаям, требующим санкционированного доступа. Сущность изобретения состоит в том, что способ верификации пользователя в системах санкционирования доступа включает создание референтной базы данных дикторов, создание базы данных пользователей, при этом для верификации пользователя пользователь вводит свой идентификатор и произносит пароль из случайной последовательности слов из словаря базы данных пользователя, после получения звуковых сигналов произнесенного пароля вычисляют вероятность принадлежности произнесенного пароля к голосу пользователя и принимают решение о разрешении доступа или отказе от доступа. Технический результат - уменьшение вероятности ошибки пропуска самозванца или отказа законному пользователю при использовании индивидуальных характеристик голоса человека в применении к санкционированию доступа. 9 ил.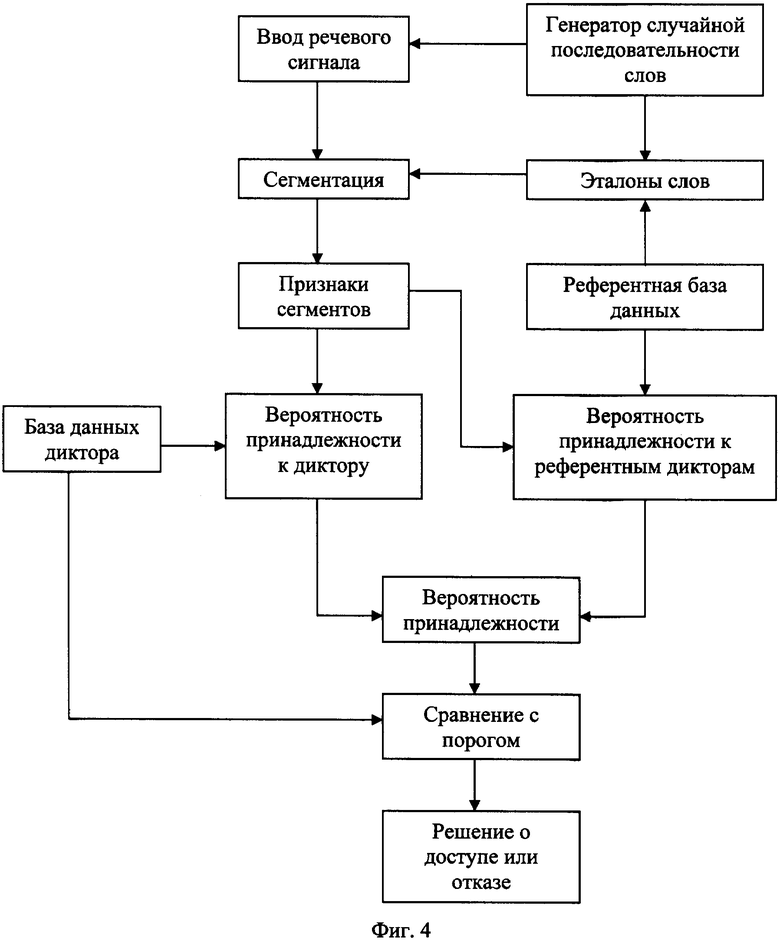
Способ верификации пользователя в системах санкционирования доступа, отличающийся тем, что референтную базу данных дикторов формируют путем записи речевых сигналов через приемники звука основных типов и в различных помещениях, базу данных каждого пользователя формируют путем записи речевых сигналов с многократным произнесением каждого слова из заданного словаря, речевые сигналы в референтной базе данных и базе данных каждого пользователя преобразуют в сигналы от динамических детекторов, определяющих возрастание или спад энергии в спектре речевого сигнала, речевой сигнал для каждого слова сегментируют на последовательность основных типов сегментов, причем границы сегментов слов в референтной базе данных устанавливают в моменты времени, соответствующие локальным пикам суммарной по частоте энергии динамических детекторов, а последовательности сегментов слов в референтной базе данных используют как эталоны для сегментации речевых сигналов пользователя, амплитуды и частоты локальных максимумов профиля динамических детекторов на границах сегментов и средние частоты локальных максимумов спектра используют как признаки для каждого слова, плотность вероятности в пространстве признаков каждого слова в референтной базе и базе каждого пользователя вычисляют как нормированную суперпозицию нормальных распределений с математическим ожиданием, расположенным в координатах каждого вектора, соответствующего реализации этого слова, а среднеквадратическое отклонение вычисляют пропорционально среднему расстоянию между всеми реализациями данного слова в базе данных, при каждом входе в систему санкционирования доступа пользователь вводит свой идентификатор, по которому определяется его база данных, система санкционирования доступа генерирует пароль в виде случайной последовательности слов из заданного словаря, которые пользователь должен произнести поочередно, для сегментов каждого произнесенного слова вычисляют отношение правдоподобия относительно аналогичного сегмента соответствующего слова в референтной базе, затем вычисляют апостериорную вероятность принадлежности к голосу пользователя, и эти вероятности усредняются по всем словам в пароле, для принятия решения о разрешении доступа или отказе от доступа сравнивают вычисленную апостериорную вероятность с порогом, индивидуальным для каждого пользователя.
| US 6496800 B1, 2002.12.17 | |||
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |
| US 6804647 В1, 2004.10.12 | |||
| ПРИБОР ДЛЯ ОПРЕДЕЛЕНИЯ СУММЫ ПОРОКОВ И ЗАСОРЕННОСТИ ХЛОПКА-ВОЛОКНА | 1971 |
|
SU424071A1 |

