1. Область изобретения
Настоящее изобретение относится к системам распознавания образов и, в частности, к системе проверки личности говорящего, которая использует слияние данных для объединения данных, соответствующих множеству выделенных признаков, и множество классификаторов для точной проверки заявленной идентичности.
2. Описание областей техники, относящихся к изобретению
Распознавание образов относится к идентификации образов, например, речи говорящего или изображения. Идентифицированный речевой образ может быть использован в системе идентификации говорящего для того, чтобы по фрагменту речи определить личность говорящего.
Цель системы для верификации говорящего заключается в подтверждении подлинности личности говорящего по фрагменту его речи. По отношению к вводимой речи система верификации может быть зависящей от текста и не зависящей от текста. Зависящие от текста системы верификации говорящего устанавливают личность говорящего после того, как тот произнесет заранее заданную фразу или пароль. Не зависящие от текста системы верификации говорящего устанавливают личность говорящего независимо от вида произнесенного фрагмента речи. Поскольку не зависящие от текста системы не требуют произнесения пароля, они являются более удобными с точки зрения пользователя.
Извлечение признаков, несущих информацию о говорящем, осуществляется с помощью модуляционной модели, использующей взвешивание адаптивных компонент в каждом речевом кадре, как описано в заявке на патент США N 08/203988 "Speaker Identification Verification System", владельцами которой являются заявители этого изобретения и которая включена в настоящее описание путем ссылки. При адаптивном взвешивании компонент ослабляют неголосовые компоненты тракта и нормализуют речевые компоненты для улучшения распознавания говорящего через канал.
Другие известные способы выделения признаков включают определение кепстральных коэффициентов из частотного спектра или коэффициентов кодирования спектра путем линейного предсказания. Нейронные древовидные сети используют совместно с не зависящими от говорящего данными для определения взаимных параметров говорящих, основанных на различении. Нейронная древовидная сеть является иерархическим классификатором, который сочетает свойства деревьев решений и нейронных сетей, как описано в статье "A. Sankar, R.3. Mammone, Growing and Pruning Neural Tree Networks, IEEE Transactions on Computers, С-42: 221-229, March 1993". Обучающие данные нейронной древовидной сети для распознавания говорящего состоят из данных, соответствующих заданному говорящему, и данных, соответствующих другим говорящим. Нейронная древовидная сеть разбивает пространство признаков на области, которым присваиваются заданные значения вероятностей, отражающие то, насколько вероятно, что говорящий сформировал вектор признаков, который попадает в эту область. Не зависящие от текста системы обладают тем недостатком, что для моделирования и оценки акустических признаков говорящего требуется большого количества данных.
В патенте США N 4957961 описана нейронная сеть, которую можно легко обучить распознаванию связанных слов. Используется способ динамического программирования, при котором входные нейронные блоки входного уровня группируются в многоуровневую нейронную сеть. Для распознавания входного образа компоненты каждого вектора признаков подаются в соответствующие входные нейронные блоки одного из входных уровней, которые выбирают из трех последовательно пронумерованных кадров входного уровня. Промежуточный уровень соединяет входные нейронные блоки по меньшей мере двух кадров входного уровня. Выходной нейронный блок соединен с промежуточным уровнем. Регулирующий блок соединен с промежуточным уровнем для регулирования соединений вход - промежуточный уровень и промежуточный уровень - выход так, чтобы выходной блок вырабатывал выходной сигнал. Нейронная сеть идентифицирует входной образ, как заранее заданный образ, когда регулирующий блок максимизирует выходной сигнал. Для обучения динамической нейронной сети используются около сорока тренировок для каждого речевого образа.
Было обнаружено, что количество данных, необходимых для обучения и тестирования системы верификации, может быть уменьшено при использовании зависящих от текста фрагментов речи говорящего. Одна из известных систем верификации говорящего, зависящих от текста, использует динамическое предыскажение шкалы времени для временного выравнивания оценки признаков на основе искажения, см. "S.Furui. Cepstral Analysis Technique For Automatic Speaker Verification, IEEE Transactions on Acoustics, Speech, and Signal Processing, ASSP-29:254-272, April, 1981". Эталонный шаблон генерируется во время тестирования из пароля, произнесенного несколько раз. Решение принять или отвергнуть заявленную идентичность говорящего принимается на основании того, падает ли искажение, соответствующее речи говорящего, ниже заранее заданного порога. Недостатком такой системы является низкая точность.
Использование скрытых марковских моделей обеспечивает преимущество по сравнению с системами, использующими динамическое предыскажение шкалы времени, как описано в работе "J.J. Naik, L.P. Netsch, G.R. Doddington. Speaker Verification Over Long Distance Telephone Lines, Proceedings ICASSP (1089)". Для зависящей от текста верификации говорящего было использовано несколько форм скрытых марковских моделей. Например, для верификации говорящего рассматривались подсловные модели, как описано в работе "A.E.Rosenberg, С.Н. Lee, F. K. Soong. Subword Unit Talker Verification Using Hidden Markov Models, Proceedings ICASSP, pp.269-272 (1990)", и полнословные модели "A.E.Rosenberg, С.Н. Lee, S. Gokeen, "Connected Word Talker Recognition Using Whole Word Hidden Markov Models, Proceedings ICASSP, pp. 381-384 (1991)". Недостатком способа с использованием скрытых марковских моделей является то, что для адекватной оценки параметров модели требуется большое количество данных. Общим недостатком систем, использующих динамическое предыскажение шкалы времени и скрытые марковские модели, является то, что они моделируют только конкретного говорящего, а не учитывают данных моделирования других говорящих, которые используют эти системы. Сбой при обучении распознаванию дает возможность самозванцу легко проникнуть в систему.
Желательно создать такую систему распознавания образов, в которой для повышения точности распознавания образа множество выделенных признаков могут быть объединены в множестве заранее заданных классификаторов.
Сущность изобретения
Говоря кратко, настоящее изобретение охватывает такую систему распознавания образов, которая объединяет множество выделенных признаков в множестве классификаторов, включающих классификаторы, обученные на различных и перекрывающихся субстратах обучающих данных, например по способу "отбрось один", описанному ниже. Предпочтительно система распознавания образов используется для верификации говорящего, при которой признаки выделяются из речи говорящего. Для классификации выделенных признаков используется множество классификаторов. Результаты классификации объединяются для выявления сходства речи говорящего и речи, заранее запомненной для конкретного говорящего. На основании объединенного результата классификации принимается решение принять или отвергнуть говорящего. Наиболее предпочтительно, чтобы речь классифицировалась посредством объединения классификатора, использующего динамическое предыскажение шкалы времени для подтверждения достоверности произнесенной парольной фразы и классификатора, использующего нейронную древовидную сеть для различения говорящего среди других говорящих. Преимуществом обученного различению классификатора в системе верификации говорящего является повышение точности различения одного говорящего среди других.
Система может также включать предварительное определение, принять или отвергнуть говорящего, основанное на распознавании слова, произнесенного говорящим, то есть на пароле говорящего. Если пароль говорящего подтверждается, разрешается работа классификаторов. Предпочтительно, чтобы классификаторы были обучены посредством подачи на классификатор множества фрагментов речи при одном отброшенном фрагменте. Отброшенный фрагмент может быть подан на классификатор для определения вероятности подтверждения личности говорящего, лежащей между 0 и 1. Вероятности могут сравниваться с порогом классификатора для принятия решения о том, принять или отвергнуть говорящего.
Текст, произносимый говорящим, может быть зависящим от говорящего и не зависящим от говорящего. Кроме того, выделяемые признаки могут быть сегментированы в подслова. Предпочтительно, чтобы подслово являлось фонемой. Каждое из подслов может быть моделировано по меньшей мере одним классификатором. Выходные результаты классификаторов, основанных на подсловах, могут быть объединены для создания верификационной системы, основанной на подсловах.
Предпочтительно признаки можно выделить с помощью полюсной фильтрации для уменьшения влияния канала на речь. Кроме того, выделенные признаки могут быть отрегулированы с помощью афинного преобразования для уменьшения рассогласования между условиями обучения и тестирования.
Изобретение будет описано более подробно со ссылками на прилагаемые чертежи.
Краткое описание чертежей
На фиг.1 изображена блок-схема системы верификации говорящего, выполненной согласно настоящему изобретению,
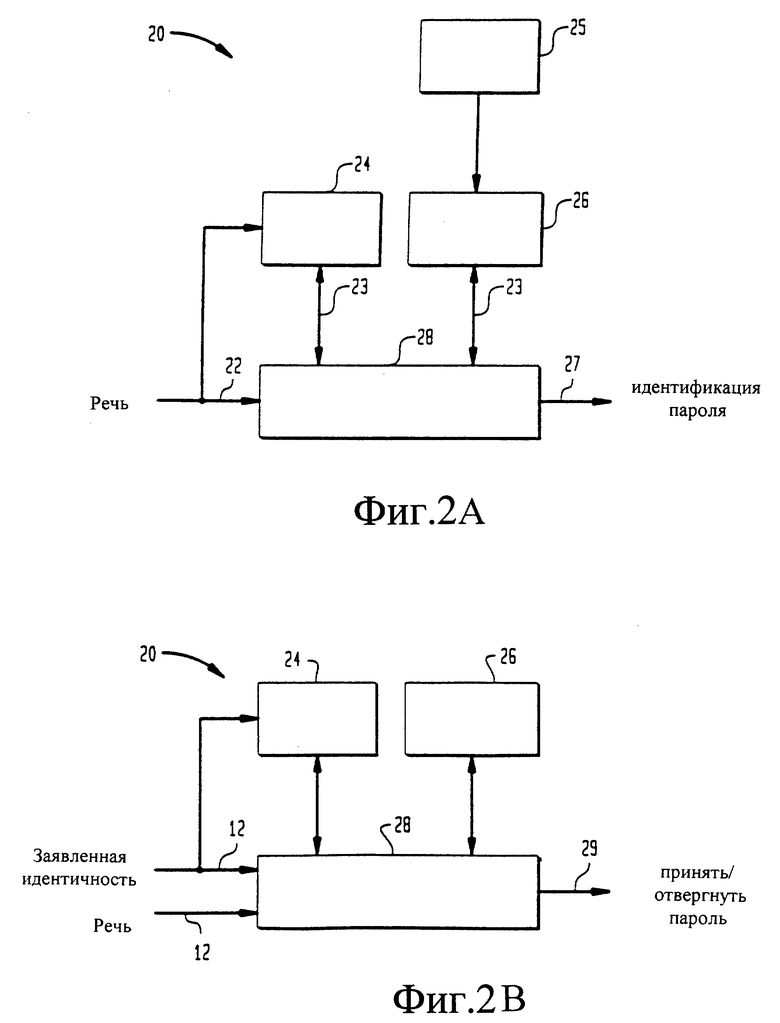
на фиг. 2А изображена блок-схема модуля распознавания слов, показанного на фиг. 1, в процессе обучения системы,
на фиг. 2В изображена блок-схема модуля распознавания слов, показанного на фиг. 1, в процессе тестирования системы,
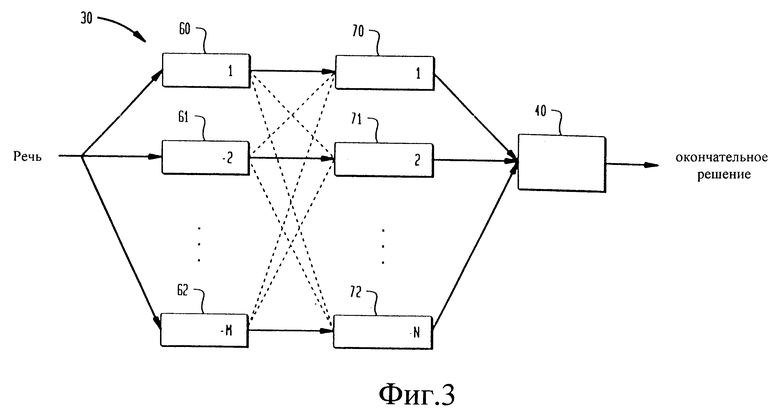
на фиг. 3 изображена блок-схема модуля верификации говорящего, объединяющего множество выделенных признаков с множеством классификаторов,
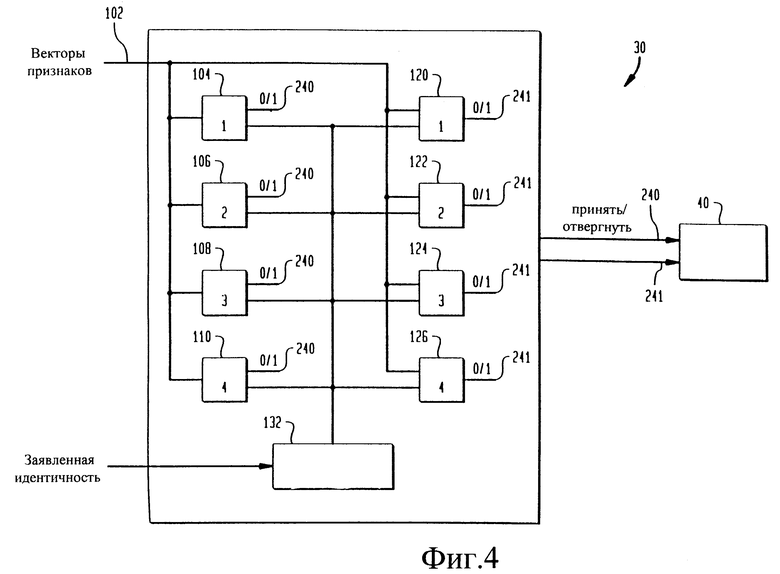
на фиг. 4 изображена блок-схема комбинации классификатора, использующего модифицированную нейронную древовидную сеть, и классификатора, использующего динамическое предыскажение шкалы времени, используемых в модуле верификации говорящего, показанном на фиг. 1,
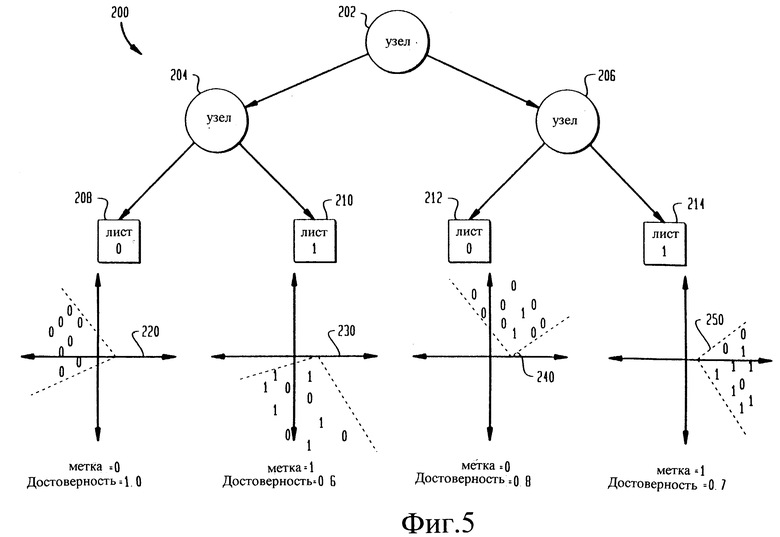
на фиг. 5 изображена блок-схема классификатора на основе модифицированной нейронной древовидной сети, используемого в модуле верификации говорящего, показанном на фиг. 1,
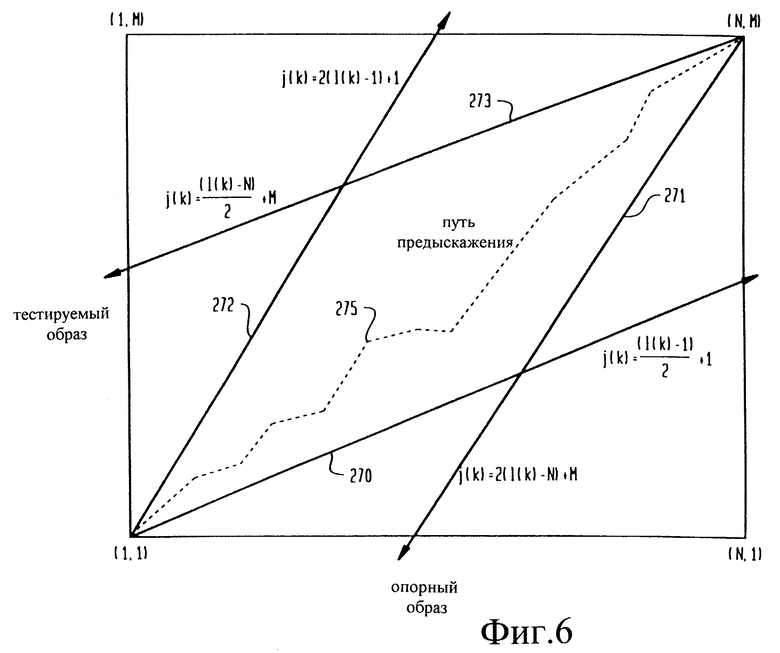
на фиг. 6 схематично изображен классификатор на основе динамического предыскажения шкалы времени, используемый в модуле верификации говорящего, показанном на фиг.1,
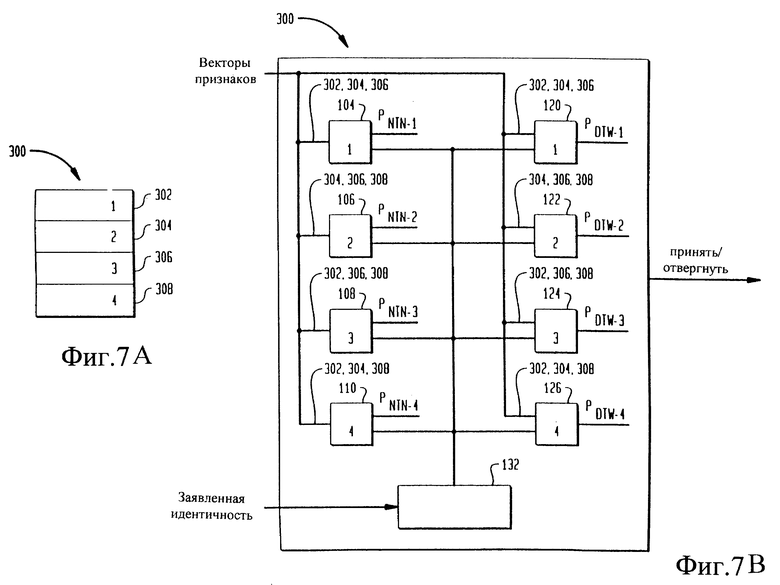
на фиг. 7А схематично изображено множество речевых фрагментов, используемых для обучения модуля верификации говорящего,
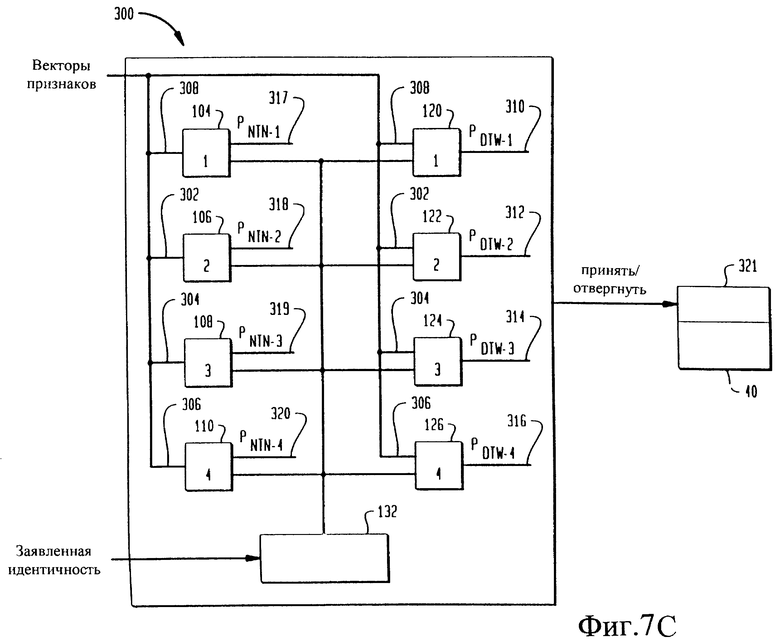
на фиг.7В,С изображена блок-схема использования в модуле верификации говорящего множества речевых фрагментов, показанных на фиг.7А,
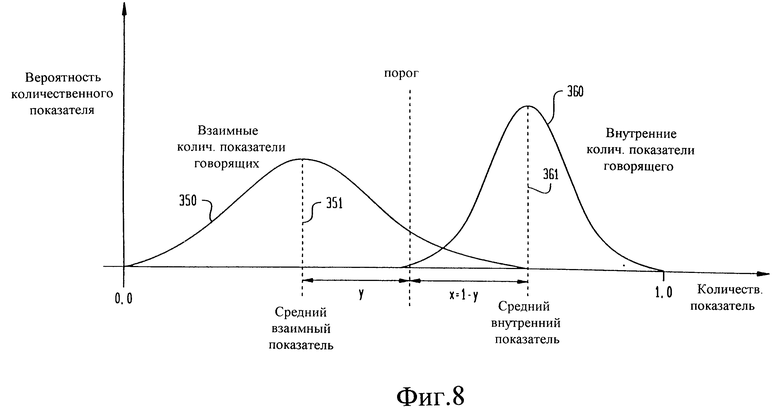
на фиг.8 графически представлены количественные показатели, соответствующие говорящему и другим говорящим,
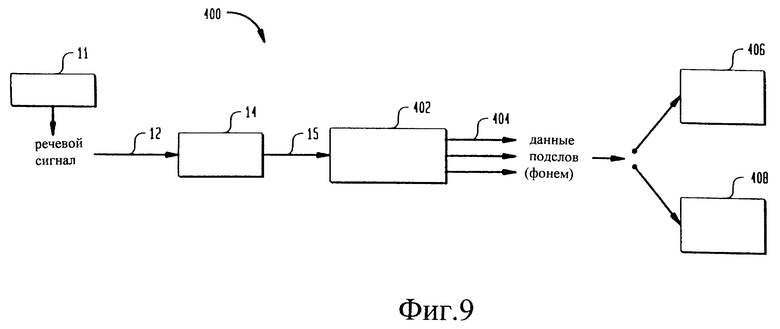
на фиг. 9 изображена блок-схема системы верификации говорящего, основанной на подсловах,
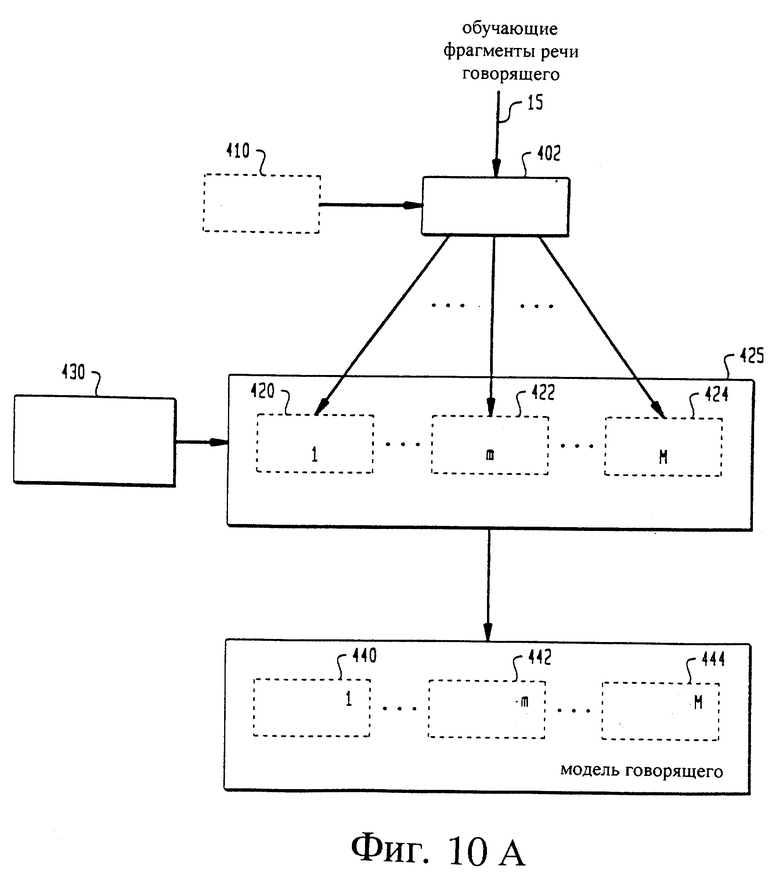
на фиг. 10А изображена блок-схема системы классификации, основанной на подсловах, в процессе обучения,
на фиг. 10В изображена блок-схема системы классификации, основанной на подсловах, в процессе тестирования,
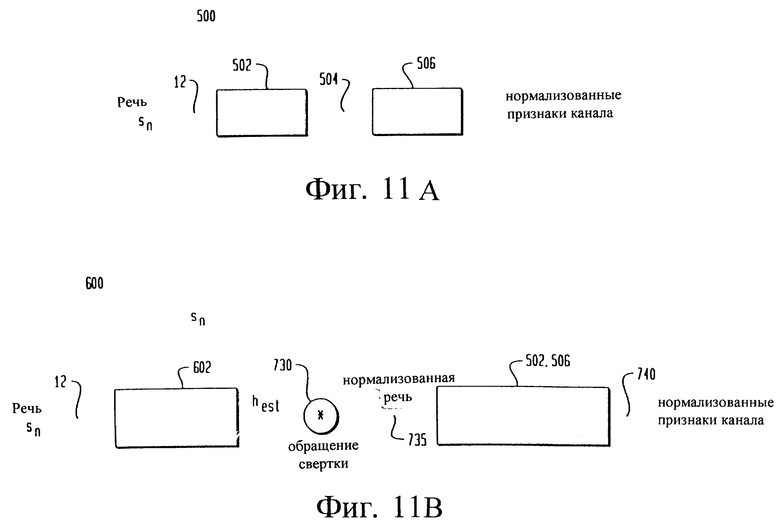
на фиг.11А изображена блок-схема известной системы нормализации канала,
на фиг. 11В изображена блок-схема системы нормализации канала согласно настоящему изобретению,
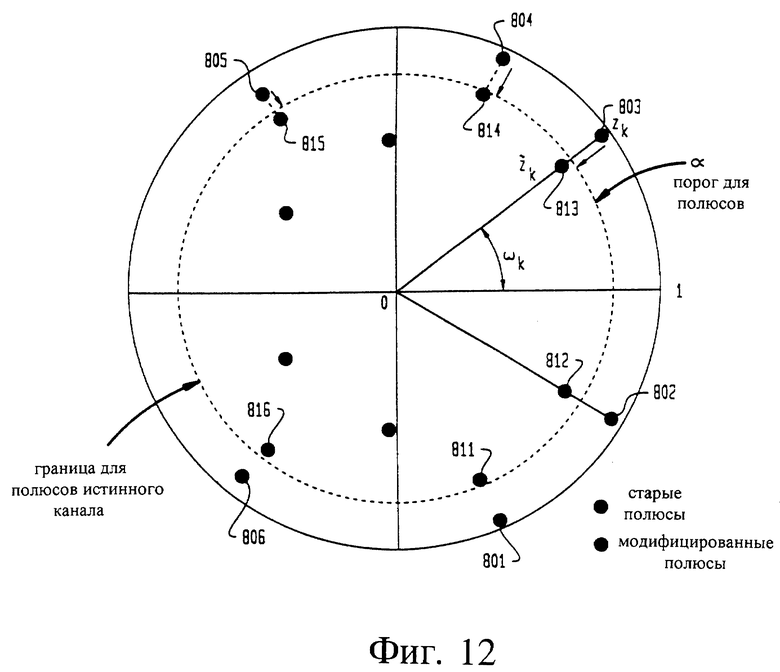
на фиг. 12 графически иллюстрируется нормализация канала с полюсной фильтрацией,
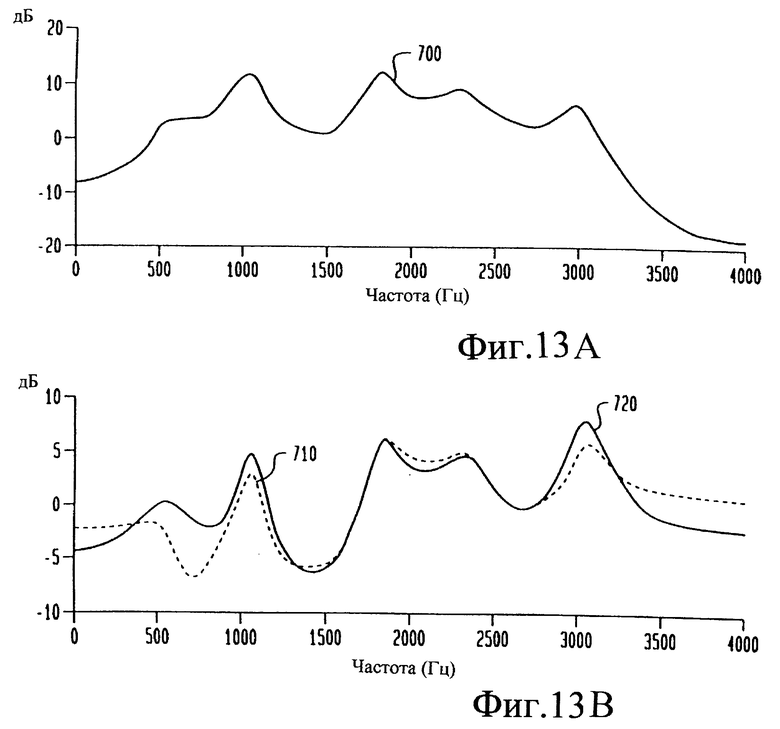
на фиг. 13А изображен график спектра речевого кадра,
на фиг. 13В изображен график спектра речевого кадра для системы нормализации, выполненной согласно настоящему изобретению, по сравнению с кадром для известной системы нормализации,
на фиг. 14 изображена блок-схема системы афинного преобразования.
Подробное описание предпочтительного варианта выполнения изобретения
В этом описании одинаковые позиции обозначают одинаковые элементы на различных чертежах, иллюстрирующих изобретение.
На фиг. 1 изображена блок-схема варианта выполнения системы 10 верификации говорящего в соответствии с настоящим изобретением. Говорящий 11 произносит фрагмент 12 речи. Фрагмент 12 речи в виде входного речевого сигнала 13 подается в модуль 14 выделения признаков. Модуль 14 выделения признаков определяет векторы 15 речевых признаков, представляющие характерные параметры входного речевого сигнала 13. Предпочтительно, чтобы векторы 15 речевых признаков определялись с помощью линейного предсказания для определения кепстральных коэффициентов линейного предсказания. Линейно предсказанные кепстральные коэффициенты могут быть подвергнуты полосовой фильтрации с использованием окна в виде поднятой синусоиды с помощью известных способов, применяемых для улучшенного распознавания кепстральных коэффициентов.
Альтернативно линейному предсказанию или в комбинации с ним модуль 14 выделения признаков может выделять признаки множеством способов. Например, для выделения векторов 15 речевых признаков может быть использован способ адаптивного взвешивания компонент, который описан в вышеупомянутой заявке США N 08/203988. Способ адаптивного взвешивания компонент усиливает выделенные признаки с помощью взвешивания заранее заданных компонент входного речевого сигнала 13 для формирования нормализованного спектра, который усиливает признаки сигнала, связанные с голосовым трактом, при уменьшении влияния неголосовых трактов. Модуль 14 выделения признаков может генерировать также другие признаки, полученные путем линейного предсказания, из коэффициентов линейного предсказания при использовании известных способов, например логарифмического отношения площадей, линейных спектральных пар и коэффициентов отражения. Модуль 14 выделения коэффициентов может также генерировать спектральные признаки путем быстрого преобразования Фурье в линейном и логарифмическом масштабах, фундаментальную частоту (высоту тона), коэффициент громкости и частоту пересечений нулевого уровня.
Модуль 20 распознавания слова принимает векторы 15 речевых признаков и сравнивает их с данными 16, соответствующими векторам 15 речевых признаков. Данные 16 могут хранится в базе 50 данных. Например, говорящий 11 может произнести в качестве фрагмента 12 речи пароль. Векторы 15 речевых признаков представляют фразу пароля для говорящего 11. Конечное множество паролей может быть представлено данными 16 и хранится в базе 50 данных. Конечное множество паролей соответствует множеству индивидуальных говорящих и включает пароль для говорящего 11. При условии, что принятые модулем 20 распознавания слова векторы 15 речевых признаков согласуются с данными 16, хранимыми в базе 50 данных, например соответствуют паролю для заявленной идентичности, модуль 30 верификации говорящего приводится в действие. Если принятые векторы 15 речевых признаков не согласуются с данными 16, хранимыми в базе 50 данных, например не соответствуют паролю для заявленной идентичности, пользователю 11 предлагается в модуле 21 повторить вызов.
В модуле 30 верификации говорящего предпочтительно используется слияние данных для объединения множества классификаторов с векторами 15 речевых признаков, как подробно описано ниже. Выходные сигналы 35, соответствующие объединенным классификаторам, поступают в логический модуль 40 объединения решений. Логический модуль 40 объединения решений принимает окончательное решение принять или отвергнуть заявленную идентичность говорящего 11, тем самым выполняя верификацию заявленной идентичности говорящего.
На фиг. 2А и 2В иллюстрируется модуль 20 распознавания слов в процессе регистрации и тестирования говорящего 11 соответственно. Во время регистрации говорящего 11 в системе 10 верификации говорящий 11 произносит обучающие фразы 22. Например, обучающая фраза 22 может содержать четыре повторения пароля говорящего 11. Каждое из повторений идентифицируется модулем 28 идентификации совпадения слова. Предпочтительно в модуле 28 идентификации совпадения слова для выработки опознанных слов 23 используют алгоритм совпадения с шаблоном, основанный на динамическом предыскажении шкалы времени. Опознанные слова 23 группируются в шаблон 24, зависящий от говорящего. С помощью опознанных слов 23 и данных от повторения той же обучающей фразы 22, произнесенной другими говорящими 25, при использовании системы 10 верификации говорящего можно формировать шаблоны 26, не зависящие от говорящего. Для идентификации пароля 27 пользователя для говорящего 11 может быть использован принцип мажоритарной выборки по словам, идентифицированным модулем 28 идентификации совпадения слов.
Во время тестирования говорящего 11 он произносит речевые фразы 12, которые в модуле 28 идентификации совпадения слов сравниваются с шаблоном 24, зависящим от пользователя, и шаблоном 26, не зависящим от пользователя. Если речевая фраза 12 соответствует паролю 27 говорящего 11 и совпадает или с шаблоном 24 слов, зависящем от говорящего, или шаблоном 26 слов, не зависящим от говорящего, в линию 29 выдается сигнал "Принят". Если речевая фраза 12 не совпадает как с шаблоном 24 слов, зависящим от говорящего, так и с шаблоном 26 слов, не зависящим от говорящего, в линию 29 выдается сигнал "Отвергнут".
Предпочтительно, чтобы модуль 30 верификации говорящего использовал слияние данных для объединения множества выделенных признаков 60, 61 и 62 со множеством классификаторов 70, 71 и 72, как показано на фиг.3. Признаки 60, 61 и 62 могут представлять векторы 15 речевых признаков, выделенные с помощью различных заранее заданных способов, описанных выше. Классификаторы 70, 71 и 72 могут представлять различные заранее заданные способы классификации, например нейронную древовидную сеть, многоуровневый перцептрон, скрытую марковскую модель, динамическое предыскажение шкалы времени, смешанную гауссову модель и векторное квантование. В альтернативном варианте выполнения изобретения признаки 60, 61 и 62 могут представлять собой выделенные признаки альтернативных образов, например речи и изображения, а классификаторы 70,71 и 72 могут представлять заранее заданные способы классификации речевых или зрительных образов. Результаты 73, 74 и 75 из соответствующих классификаторов 70, 71 и 72 могут объединяться в логическом модуле 40 объединения решений для принятия окончательного решения - принять или отвергнуть говорящего 11. Для объединения классификаторов 70, 71 и 72 модуль 40 может использовать известные способы, например линейную совокупность мнений, логарифмическую совокупность мнений, байесовские правила сложения, метод мажоритарной выборки или дополнительные классификаторы. Должно быть понятно, что может быть взято любое количество признаков или классификаторов. Классификаторы могут также включать классификаторы, обучаемые с помощью других или перекрывающихся субстратов обучающих данных, например с помощью способа "отбрось один", описанного ниже.
На фиг. 4 иллюстрируется предпочтительный модуль 30 верификации говорящего для использования в системе верификации говорящего согласно настоящему изобретению. Векторы 102 речевых признаков подаются в классификаторы 104, 106, 108 и 110, использующие нейронную древовидную сеть, и классификаторы 120, 122, 124 и 126, использующие динамическое предыскажение шкалы времени. В процессе классификации каждый классификатор 104, 106, 108 и 110, использующий нейронную древовидную сеть, определяет, превышает ли величина вектора 102 речевых признаков соответствующее заранее заданное пороговое значение "TNTN" для нейронной древовидной сети, хранимое в базе 132 данных. Каждый классификатор 120, 122, 124 и 126, использующий динамическое предыскажение шкалы времени, определяет, превышает ли величина вектора 102 речевых признаков соответствующее заранее заданное пороговое значение "TDTW" для динамического предыскажения шкалы времени, хранимое в базе 132 данных. Если величины векторов 102 признаков превышают соответствующие пороговые значения TNTN и TDTW, то на линии 240 и 241 соответственно выдается двоичная "1". Если величины векторов 102 признаков меньше, чем соответствующие заранее заданные пороговые значения TNTN и TDTW, то на соответствующую линию 240 или 241 выдается двоичный "0".
Во время тестирования говорящего 11 с помощью системы 10 верификации на модуль 40 принятия решения поступают выходные двоичные сигналы с линий 240 и 241. В предпочтительном варианте выполнения модуля 40 может быть произведена мажоритарная выборка выходных двоичных сигналов для определения того, принять или отвергнуть говорящего 11. В этом варианте выполнения изобретения, если большая часть выходных двоичных сигналов представляет собой "1", то говорящий принимается, а если большая часть выходных двоичных сигналов представляет собой "0", то говорящий отвергается.
Предпочтительный классификатор, выполненный в виде модифицированной нейронной древовидной сети 200, может быть использован в модуле 30 верификации говорящего в качестве классификатора, основанного на различении. Модифицированная нейронная древовидная сеть 200 имеет множество соединенных между собой узлов 202, 204 и 206, как показано на фиг. 5. Узел 204 связан с листовым узлом 208 и листовым узлом 210, а узел 206 связан с листовым узлом 212 и листовым узлом 214. В каждом из листовых узлов 208, 210, 212 и 214 используется измерение вероятности за счет "прямой обрезки" дерева путем усечения роста модифицированной нейронной древовидной сети 200 дальше заранее заданного уровня.
Обучение модифицированной нейронной древовидной сети 200 в отношении говорящего 11 производится путем подачи данных 201, соответствующих другим говорящим 25, использующим систему 10 верификации. Векторы 15 выделенных признаков, соответствующие говорящему 11, обозначенные как Si, получают метку "1", а векторы выделенных признаков, соответствующие другим говорящим 25, использующим систему 10 верификации, получают метку "0". Данные 220, 230, 240 и 250 подаются соответственно в листовые узлы 208, 210, 212 и 214 векторов выделенных признаков. В каждом из листовых узлов 208, 210, 212 и 214 производится мажоритарная выборка. Каждому из листьев 208, 210, 212 и 214 присваивается метка в соответствии с мажоритарной выборкой. "Достоверность" определяется как отношение числа большинства меток к общему числу меток. Например, данным 220, которые включают восемь признаков "0", присваивается метка "0" и достоверность "1,0". Данным 230, которые включают шесть признаков "1" и четыре признака "0", присваивается метка "1" и достоверность "0,6".
Обученная модифицированная нейронная древовидная сеть 200 может быть использована в модуле 30 верификации говорящего для определения соответствующего говорящему количественного показателя из последовательности векторов "X" признаков из речевого кадра 12. Соответствующий количественный показатель PMNTN(X/Si) говорящего может быть определен с помощью следующего уравнения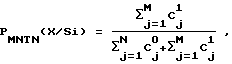
где говорящему 11 соответствует Si, C1 - количественный показатель достоверности для говорящего 11, С0 - количественный показатель достоверности для всех остальных говорящих. М и N соответствуют числу векторов, классифицированных как "1" и "0" соответственно.
Предпочтительный классификатор на основе динамического предыскажения шкалы времени использует подход, базирующийся на внесении искажений, для совмещения во времени двух сигналов или двух образов признаков, как показано на фиг. 6. Сигналы представлены опорными образами векторов 15 речевых признаков по оси X и тестируемыми образами векторов 15 речевых признаков по оси Y, причем N соответствует числу опорных образов, а М - числу тестируемых образов. Глобальные ограничения 270, 271, 272 и 273 соответствуют пределам для пути 275 динамического предыскажения шкалы времени. Путь 275 динамического предыскажения шкалы времени может быть определен известными способами, например, описанными в работе "H.Sakoe and S.Chiba. Dynamic programming algorithm optimization for spoken word recognition, IEEE Trans. on Acoustic, Speech and Signal Processing, vol. ASSP-26, No. 1, pp. 43-49, Feb. 1978".
Предпочтительно объединять классификатор, который основан на внесении искажений, например динамического предыскажения шкалы времени, для получения информации о говорящем, и классификатор, основанный на различении, на нейронной древовидной сети или модифицированной нейронной древовидной сети для получения информации о говорящем относительно других говорящих, использующих систему 10 верификации. Кроме того, преимущество объединения классификатора, использующего динамическое предыскажение шкалы времени, и классификатора, использующего нейронную древовидную сеть или модифицированную нейронную древовидную сеть, заключается в том, что классификатор, использующий динамическое предыскажение шкалы времени, предоставляет временную информацию, которой обычно не имеется в классификаторах, использующих нейронную древовидную сеть или модифицированную нейронную древовидную сеть.
Классификаторы 104, 106, 108 и 110, использующие нейронную древовидную сеть, и классификаторы 120, 122, 124 и 126, использующие динамическое предыскажение шкалы времени, могут быть обучены с помощью обучающего модуля 300, показанного на фиг. 7А и 7В. Обучающий модуль 300 может быть также использован для обучения классификаторов, использующих модифицированную нейронную древовидную сеть, классификаторов, использующих динамическое предыскажение шкалы времени, и других классификаторов, которые могут быть использованы в модуле 30 верификации говорящего. В обучающем модуле 300 предпочтительно используется способ повторной выборки, названный "отбрось один". От говорящего 11 поступает заранее заданное количество речевых фрагментов. В данном варианте выполнения изобретения используются четыре фрагмента, обозначенные как 302, 304, 306 и 308, речи 22, являющиеся паролем говорящего. Комбинация трех из четырех фрагментов при одном отброшенном фрагменте подается в пары классификаторов 104, 106, 108 и 110, использующих нейронную древовидную сеть, и классификаторов 120, 122, 124 и 126, использующих динамическое предыскажение шкалы времени. Три фрагмента используются для обучения классификаторов, а оставшийся фрагмент используется для независимого тестирования. Например, фрагменты 302, 304 и 306 могут быть поданы в классификатор 104, использующий нейронную древовидную сеть, и классификатор 120, использующий динамическое предыскажение шкалы времени, фрагменты 304, 306 и 308 могут быть поданы в классификатор 106, использующий нейронную древовидную сеть, и классификатор 122, использующий динамическое предыскажение шкалы времени, фрагменты 302, 306 и 308 могут быть поданы в классификатор 108, использующий нейронную древовидную сеть, и классификатор 124, использующий динамическое предыскажение шкалы времени, а фрагменты 302, 304 и 308 могут быть поданы в классификатор 110, использующий нейронную древовидную сеть, и классификатор 126, использующий динамическое предыскажение шкалы времени.
После подачи трех соответствующих фрагментов в каждую пару классификаторов 104, 106, 108 и 110, использующих нейронную древовидную сеть, и классификаторов 120, 122, 124 и 126, использующих динамическое предыскажение шкалы времени, отброшенный фрагмент подают в каждую соответствующую пару классификаторов 104, 106, 108 и 110, использующих нейронную древовидную сеть, и классификаторов 120, 122, 124 и 126, использующих динамическое предыскажение шкалы времени, как показано на фиг.7С. Например, фрагмент 308 подают в классификатор 104, использующий нейронную древовидную сеть, и классификатор 120, использующий динамическое предыскажение шкалы времени, фрагмент 302 подают в классификатор 106, использующий нейронную древовидную сеть, и классификатор 122, использующий динамическое предыскажение шкалы времени, фрагмент 304 подают в классификатор 108, использующий нейронную древовидную сеть, и классификатор 124, использующий динамическое предыскажение шкалы времени, а фрагмент 306 подают в классификатор 110, использующий нейронную древовидную сеть, и классификатор 126, использующий динамическое предыскажение шкалы времени. Вычисляют вероятность P, лежащую между 0 и 1 и обозначенную как 310, 312, 314 и 316. Вероятности 310, 312, 314 и 316 сравнивают с порогом TDTW, а вероятности 317, 318, 319 и 320 сравнивают с порогом TNTN в модуле 321 мажоритарной выборки логического модуля 40 объединения решений.
На фиг. 8 представлен график внутренних количественных показателей говорящего относительно других говорящих 25 и взаимных количественных показателей говорящих относительно говорящего 11, который может быть использован для определения порогов классификаторов, применяемых в системе 10 верификации говорящего, например порогов TDTW и TNTN. Взаимные количественные показатели относительно других говорящих для фразы 12 говорящего 11 представлены графиком 350, имеющим средний количественный показатель 351 говорящего. Внутренние количественные показатели других говорящих 25 для фразы 12 представлены графиком 360, имеющим средний количественный показатель 361 говорящего. Порог Т может быть определен из следующего уравнения:
Т = x • взаимн.показатель + у • взаимн. показатель.
Мягкий количественный показатель S может быть определен величиной, на которую речь 12 отклоняется от порога Т в большую или меньшую сторону. Количественный показатель С каждого классификатора лежит между нулем и единицей, причем нуль соответствует наиболее достоверному отклонению, а единица - наиболее достоверному принятию. Достоверность Caccept принятия лежит между порогом Т и единицей и может быть определена как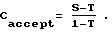
Достоверность Creject отклонения лежит между нулем и порогом Т и может быть определена как: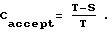
На фиг. 9 иллюстрируется блок-схема системы 400 верификации говорящего, основанная на подсловах. После выделения векторов 15 речевых признаков в модуле 14 выделения признаков эти векторы 15 сегментируются в модуле 402 подсловной сегментации на подслова 404. Предпочтительно, чтобы подслова являлись фонемами. Подслова 404 могут быть поданы на обучаемый модуль 406 говорящего и тестовый модуль 408 говорящего.
На фиг.10А показана блок-схема системы 400 верификации говорящего, основанная на подсловах, при использовании обучаемого модуля 406 говорящего. Выделенные признаки 15 говорящего, описывающие обучающие фрагменты речи говорящего 11, и копию пароля 410 подают в модуль 402 сегментации на уровне подсловных фонем. Копия пароля 410 может быть произнесена говорящим 11, введена с компьютера, считана с карты или введена аналогичным способом. Модуль 402 речевой сегментации сегментирует выделенные признаки 15 говорящего на подслова, от 1 до "М", например подслово "1" в модуль 420, подслово "m" - в модуль 422 и подслово "М" - в модуль 424, где М - число сегментированных подслов. Подслова 420, 422 и 424 могут храниться в базе 425 данных подслов. Контролируемая обучающая схема 430 маркирования векторов определяет метки обучающих речевых векторов для обучающих классификаторов 440, 442 и 444, присваивая им значения "0" и "1". Например, все подслова для других говорящих 25 могут быть помечены как "0", а подслова для говорящего 15 могут быть помечены как "1". Альтернативно ближайшие фонемы можно искать в базе данных 425. Для классификации каждого из подслов 420, 422 и 424 могут использоваться классификаторы 440, 442 и 444 подслов. Предпочтительно, чтобы классификаторы 440, 442 и 444 подслов использовали методы классификации с использованием нейронной древовидной сети и динамического предыскажения шкалы времени.
На фиг. 10В показана блок-схема системы 400 верификации говорящего, основанной на подсловах, при использовании модуля тестирования 408 говорящего. Выделенные признаки 15 говорящего, описывающие тестовые фрагменты речи говорящего 11, и копию пароля 410 подают в модуль 402 сегментации на уровне подсловных фонем. Классификаторы 440, 442 и 444 подслов классифицируют соответствующие подслова 420, 422 и 424, определенные по выделенным речевым признакам 15, описывающим тестовые фрагменты речи говорящего 11. Результат 445 с выхода классификаторов 440, 442 и 444 подается в логический модуль 40 объединения решений для определения, принять или отвергнуть говорящего 11 на основании объединенного результата из классификаторов 440, 442 и 444, полученного на основе вычисленной достоверности Caccept принятия, как описано выше.
В модуле 14 выделения признаков для формирования векторов 15 выделенных признаков, устойчивых по отношению к различиям каналов, может быть использован предпочтительный способ, который можно назвать "полюсной фильтрацией". Полюсная фильтрация осуществляет нормализацию каналов с использованием интеллектуальной фильтрации всеполюсного фильтра линейного предсказания.
Чистый речевой сигнал Cs в канале подвергается свертке с импульсным откликом h, тогда кепстр канала с обычным кепстральным средним может быть представлен как:
CS= Σ
где
SS= Σ
соответствует компоненте кепстрального среднего, обусловленной только исходным чистым речевым сигналом. Компонента, обусловленная чистым речевым сигналом, должна иметь нулевое среднее, чтобы оценка Cs канального кепстра соответствовала кепстральной оценке h действительного исходного сверточного искажения.
Может быть показано эмпирически, что для коротких речевых фрагментов средняя кепстральная компонента, обусловленная чистым речевым сигналом, никогда не равна нулю и может служить для обучения и тестирования системы 10 верификации говорящего.
На фиг. 11А показана известная система 500 нормализации канала, в которой речевой сигнал подается на модуль 502 внутрикадрового взвешивания. Адаптивное взвешивание компонент является примером внутрикадрового взвешивания для нормализации канала. Взвешенный речевой сигнал 504 поступает в модуль 506 межкадровой обработки для удаления дополнительного влияния канала. Одним из известных межкадровых способов устранения влияния каналов является вычитание кепстрального среднего. Поскольку кепстр канала включает общее спектральное распределение, обусловленное как каналом, так и речью, то известное исключение искаженной оценки спектра канала из кепстра каждого речевого кадра фактически соответствует деконволюции (обращению свертки) ненадежной оценки канала.
На фиг. 11В иллюстрируется система 600 нормализации канала согласно настоящему изобретению. Речевой сигнал 12 подается в модуль 602 полюсной фильтрации для оценки канала. Полюсная фильтрация ослабляет вклад инвариантной компоненты, обусловленной речью Ss. Уточненная оценка канала используется для нормализации канала. Предпочтительно уточнение кепстра канала производится итеративным способом.
Оценка кепстра Cs канала зависит от числа речевых кадров в речевом фрагменте. В случае, когда доступный речевой фрагмент имеет достаточную длину, можно получить оценку кепстра канала, которая аппроксимирует истинную оценку h канала. В большей части практических ситуаций длительности речевых фрагментов для обучения или тестирования никогда не являются достаточно большими, чтобы обеспечить Ss, стремящееся к 0. Средняя кепстральная оценка может быть улучшена путем определения доминирования полюсов в речевом кадре и их вклада в оценку кепстра канала.
Влияние каждой моды голосового тракта на кепстральное среднее определяется путем преобразования кепстрального среднего в коэффициенты линейного предсказания и изучения доминирования соответствующих пар комплексно сопряженных полюсов. Спектральная компонента для речевого кадра доминирует в максимальной степени, если она соответствует паре комплексно сопряженных полюсов, ближайших к единичной окружности (минимальная ширина полосы), и доминирует в минимальной степени, если она соответствует паре комплексно сопряженных полюсов, наиболее удаленных от единичной окружности (максимальная ширина полосы).
Наложение ограничений на речевые полюсы для получения более гладкой и, следовательно, более точной оценки обратного канала в кепстральной области соответствует модифицированному кепстральному среднему CS pf, которое ослабляет кепстральное смещение, связанное с инвариантной компонентой, обусловленной речью. Удаление уточненного кепстрального среднего, лишенного компоненты общего спектрального распределения, обусловленной речью, обеспечивает улучшенную схему нормализации канала.
Оценку канала, предпочтительно полученную из модуля 602 полюсной фильтрации канала, объединяют с речевым сигналом 12 в модуле 730 деконволюции во временной области для получения нормализованной речи 735. Для формирования вектора 740 речевых признаков нормализованного канала, к нормализованному речевому сигналу 735 может быть применено известное межкадровое соединение 502 и обработка 506 интерференции. Вектор 740 речевых признаков может быть приложен так же, как векторы 15 речевых признаков, показанные на фиг. 1. Один предпочтительный способ улучшения оценки канала использует кепстральные коэффициенты, обработанные полюсной фильтрацией, причем полоса частот узкополосных полюсов расширяется, в то время как их частоты остаются без изменения, как показано на фиг. 12. Полюсы 801, 802, 803, 804, 805 и 806 перемещены к модифицированным полюсам 811, 812, 813, 814, 815 и 816. Это эквивалентно перемещению узкополосных полюсов внутри единичной окружности вдоль одного и того же радиуса, то есть без изменения частоты, но с расширением полосы частот.
Кепстральные коэффициенты, обработанные полюсной фильтрацией, определяют для речевого сигнала одновременно с векторами 15 речевых признаков. Обработанные полюсной фильтрацией кепстральные коэффициенты определяют, анализируя, имеет ли полюс в кадре 12 полосу частот, меньшую заранее заданного порога t. Если речевой сигнал 12 меньше заранее заданного порога, полосу частот этого полюса ограничивают до порога t. Кепстральные коэффициенты, обработанные полюсной фильтрацией, могут быть использованы для оценки модифицированного кепстрального среднего. Улучшенную оценку обратного фильтра получают с использованием кепстральных коэффициентов, обработанных полюсной фильтрацией, которые лучше аппроксимируют истинный фильтр обратного канала. Вычитание модифицированного кепстрального среднего из кепстральных речевых кадров сохраняет спектральную информацию и при этом точнее компенсирует наклон спектра для этого канала.
На фиг. 13А иллюстрируется образец спектра 700 речевого кадра. На фиг. 13В иллюстрируется спектр 710 известного кепстрального среднего CS, вычитаемый из спектра 700. Спектр 720 соответствует модифицированному кепстральному среднему CS pf при полюсной фильтрации, вычитаемому из спектра 700. Спектр 720 демонстрирует улучшенную спектральную информацию по сравнению со спектром 710.
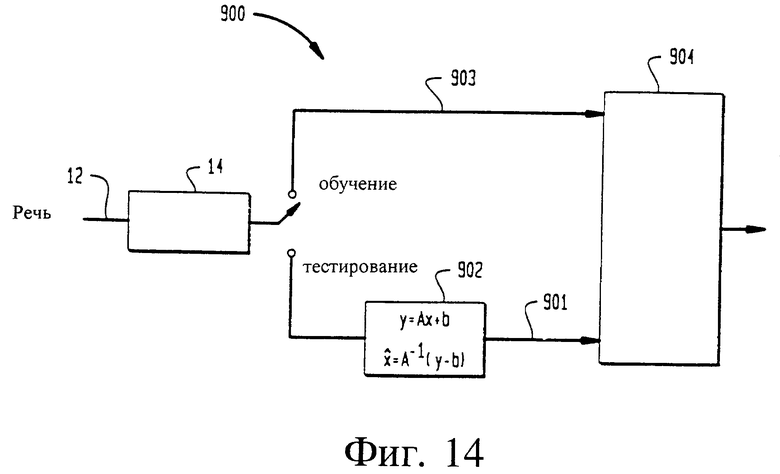
На фиг. 14 иллюстрируется система 900 афинного преобразования, которая может быть использована совместно с системой 10 верификации говорящего при обучении и тестировании. Рассогласование между условиями обучения и тестирования может быть уменьшено с помощью афинного преобразования кепстральных коэффициентов, выделенных в модуле 14 выделения признаков. Афинное преобразование вектора x определяется как
y = Ax + b,
где A - матрица, соответствующая линейному преобразованию, b - ненулевой вектор, соответствующий переносу, y - тестовые данные, а x соответствует обучающим данным. В области обработки речи матрица А моделирует стягивание индивидуальных кепстральных коэффициентов вследствие шума, а вектор b учитывает смещение кепстрального среднего за счет влияния канала.
Сингулярное разложение описывает геометрию афинного преобразования следующим уравнением:
y = UΣVTx+b,
где U и VT - унитарные матрицы, а Σ - диагональ. Геометрический смысл состоит в том, что "x" поворачивается с помощью VT, перемасштабируется с помощью Σ и вновь поворачивается с помощью U. Кроме того, имеется перенос, обусловленный вектором b.
Было обнаружено, что на практике каждый кепстральный коэффициент масштабируется на различную величину, а перемасштабирование кепстральных коэффициентов сопровождается небольшим изменением углов. Кепстральный вектор Cns шума может быть представлен как произведение чистого кепстрального вектора "с" и матрицы, то есть
Cns = Ac
Для одновременного представления искажений, вызванных как каналом, так и шумом, может быть использовано афинное отображение, представленное как
c'= Ac + b
Параметр афинного преобразования "x" определяется афинным преобразованием
x∧ = A-1(y-b),
где x∧ эквивалентно x.
Параметры афинного преобразования А и x могут быть найдены посредством решения вышеприведенного уравнения методом наименьших квадратов на массиве обучающих данных или данных взаимной достоверности.
Во время обучения системы 10 верификации говорящего векторы 15 речевых признаков подают в модуль 902 афинного преобразования, а во время тестирования - через входную линию 901 классификатора подают в классификатор 904. Во время обучения векторы 15 речевых признаков связывают с модулем 902 афинного преобразования и через входную линию 903 классификатора подают в классификатор 904. Предпочтительно, чтобы классификатор 904 представлял собой классификатор с квантованием вектора. Классификатор 904 может соответствовать, например, классификаторам 70, 71 и 72, показанным на фиг. 2, классификаторам 104, 106, 108 и 119, использующим нейронную древовидную сеть, и классификаторам 120, 122, 124 и 126, использующим динамическое предыскажение шкалы времени, показанным на фиг. 4.
В системе 10 верификации говорящего, тех говорящих, которые заявляют истинную идентичность, можно называть истинными говорящими, в то время как говорящих, которые заявляют ложную идентичность, можно называть самозванцами. При оценке говорящих система 10 верификации говорящего может делать ошибки двух типов: (а) ложное отклонение и (б) ложный допуск. Ошибка ложного отклонения имеет место, когда истинный говорящий заявляет истинную идентичность, но система 10 верификации говорящего его отвергает. Когда самозванец получает допуск с помощью системы 10 верификации говорящего, имеет место ошибка ложного допуска. Решение принять или отвергнуть идентичность зависит от порога Т, как описано выше. В зависимости от цены ошибки каждого типа система может быть спроектирована так, чтобы достичь компромисса между одним типом ошибки и другим. Альтернативно для того, чтобы оценить конкурирующие разработки, можно сравнивать равные частоты ошибок в сравниваемых системах. Равные частоты ошибок достигаются тогда, когда оба типа ошибок (ложное отклонение и ложный допуск) происходят с равной вероятностью.
Система верификации говорящего, основанная на подсловах и выполненная согласно настоящему изобретению, была оценена на основе известного собрания речевых данных, называемого YOHO, Консорциума лингвистических данных, Филадельфия. Система верификации говорящего, основанная на подсловах и выполненная согласно настоящему изобретению, продемонстрировала коэффициент равных частот ошибок, равный 0,36%, по сравнению с коэффициентом 1,66%, полученным при тех же условиях для известной скрытой марковской модели.
Преимущество настоящего изобретения заключается в объединении множества свойств различных классификаторов для создания мощной системы распознавания, которая способна точно распознать заданный образ. В варианте выполнения системы верификации классификаторы, основанные на искажении, могут быть объединены с классификаторами, основанными на различении, для объединения признаков, относящихся к говорящему, и признаков, относящихся к говорящему и другим говорящим. Предпочтительно использовать нейронную древовидную сеть для классификации данных, получаемых от говорящего и других говорящих, с уменьшенной обработкой. Модуль разрешения распознавания слова может значительно повысить точность системы верификации и сократить обработку для отвергнутых говорящих. Кроме того, классификаторы могут быть основаны на подсловах, с зависящими и не зависящими от текста данными. Дополнительно для уменьшения объема данных, необходимых для обучения системы, система верификации может быть обучена с помощью способа "отбрось один". Для уменьшения искажения в каналах системы может быть использована полюсная фильтрация. Афинное преобразование выделенных признаков обеспечивает улучшенную корреляцию обучающих и тестовых данных. Чтобы учесть возрастные изменения говорящего, система может также обновлять модель говорящего после того, как верификация завершилась положительно.
Хотя изобретение описано со ссылками на предпочтительные варианты его выполнения, это описание не ограничивает его объем. Специалистам в данной области должно быть понятно, что могут быть сделаны различные модификации изобретения.

Изобретение относится к системам распознавания речи. Его использование в системе проверки личности говорящего позволяет достичь технический результат в виде повышения точности распознавания. Этот технический результат достигается благодаря тому, что в способе верификации говорящего выделяют по меньшей мере один признак из первого речевого фрагмента, произнесенного говорящим, классифицируют этот признак с помощью множества классификаторов для формирования множества результатов классификации, объединяют множество результатов классификации для формирования объединенных результатов классификации, распознают объединенные результаты классификации путем определения сходства объединенных результатов классификации и второго речевого фрагмента, произнесенного говорящим до верификации говорящего, и на основании распознанных объединенных результатов классификации принимают решение принять или отвергнуть говорящего. Реализующая данный способ система содержит средства для выполнения перечисленных операций. 2 с. и 22 з.п.ф-лы, 14 ил.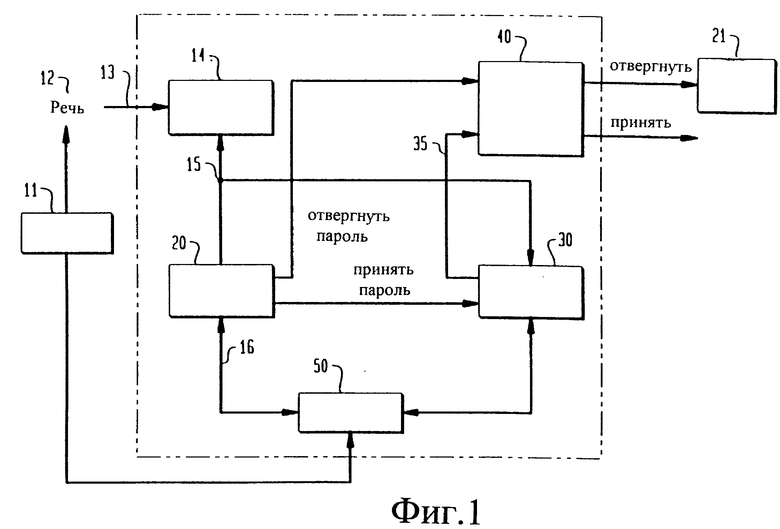
y = Ax + b,
где y - указанное афинное преобразование вектора x;
A - матрица, соответствующая линейному преобразованию;
b - вектор, соответствующий переносу.
| US 5170432 A, 08.12.1992 | |||
| Способ опознания говорящего и устройство для его осуществления | 1983 |
|
SU1117687A1 |
| Способ идентификации говорящего | 1989 |
|
SU1629917A1 |
| ОБЛЕГЧЕННАЯ МЕЖДУЛОПАТОЧНАЯ ПЛОЩАДКА ДЛЯ ОПОРНОГО ДИСКА ЛОПАТОК ВЕНТИЛЯТОРА ТУРБОРЕАКТИВНОГО ДВИГАТЕЛЯ И ОПОРНЫЙ ДИСК ЛОПАТОК | 2004 |
|
RU2343292C2 |
| Устройство для прокатки порошка | 1977 |
|
SU645755A1 |
| DE 4325404 A1, 02.02.1995 | |||
| Кипятильник для воды | 1921 |
|
SU5A1 |

