Заявляемые способ и устройство относятся к анализу речи, могут быть использованы, в частности, в различных системах и устройствах для ограничения несанкционированного доступа к материальным или информационным ресурсам на основе биометрической информации о говорящем.
Известны способы и устройства распознавания дикторов на основе построения и сравнения чисто статистических моделей известных и неизвестных дикторов, например [1]. В известном способе распознавание диктора выполняют при использовании дискриминантных моделей Гауссовых смесей.
Данный способ, как и большинство чисто статистических подходов к распознаванию дикторов, не пригоден для ситуации, когда используемые голосовые сообщения (пароли) очень коротки (1-3 секунды), а используемые микрофоны имеют низкое качество (высокую вариативность частотного отклика).
Известен способ распознавания дикторов на основе чисто стохастического подхода [2]. В данном способе распознавание диктора выполняют путем построения и сравнения матриц ковариации признаковых описаний входного речевого сигнала и эталонов речевого сигнала известных дикторов.
Этот известный способ также не пригоден для ситуации, когда используемые голосовые сообщения (пароли) очень коротки (5 секунд и менее), а также очень чувствителен к пропаданию сигнала на отдельных участках частотного речевого диапазона за счет окружающего шума и низкокачественных микрофонов.
Известен способ распознавания изолированных слов речи с адаптацией к диктору [3], основанный на обработке с предискажениями входного речевого сигнала, дискретизации и последовательной сегментации речевого сигнала, кодировании сегментов дискретными элементами, вычислении энергетического спектра, измерении формантных частот и определении амплитуд и энергии в различных частотных полосах речевого сигнала, классификации артикуляторных событий и состояний, формировании и сортировке эталонов слов, вычислении расстояний между эталонами слов с реализацией распознаваемого слова, принятии решений о распознавании или отказе от распознавания слова с дополнением словаря эталонов в процессе адаптации к диктору. Предискажение входного речевого сигнала выполняют во временной области при дифференцировании со сглаживанием, квантование энергетического спектра выполняют в зависимости от дисперсии шума канала связи, формантные частоты определяют при нахождении глобального максимума логарифмического спектра и вычитании из этого спектра заданной частотно-зависимой функции, при классификации артикуляторных событий и состояний определяют доли периодического и шумового источников возбуждения при сравнении с порогом коэффициентов автокорреляции последовательности прямоугольных импульсов в нескольких частотных полосах, начало и конец артикуляторных движений и соответствующих им акустических процессов определяют при сравнении с порогом функции правдоподобия от значений коэффициентов автокорреляции, формантных частот и энергий в заданных частотных полосах, речевой сигнал сегментируют на интервалы между началом и концом акустических процессов, соответствующих специфическим артикуляторным движениям, и последовательно, начиная с гласных звуков, причем опознавание сегмента производят только в случае совпадения типов переходов на его левой и правой границах и заканчивают сегментацию при опознавании слева и справа по времени сегментов паузы между словами. Эталоны слов формируют в виде матриц с бинарными значениями правдоподобия признаков, а отказ от распознавания осуществляют при нормированной разности расстояния от неизвестной реализации до двух ближайших эталонов, принадлежащих разным словам, меньшей установленного порога.
Недостатками данного известного способа распознавания изолированных слов речи с адаптацией к диктору является слабая различительная сила данного способа при его использовании для распознавания дикторов по произнесению голосового пароля, так как данный способ не различает дикторов при произнесении ими паролей с совпадающим словесным составом.
Известна система для обеспечения секретности на основе распознавания голоса [4], требующая и от обучающего и от неизвестного диктора обязательного повторного произнесения, по крайней мере, одного из паролей. Система сравнивает параметрические представления повторных произнесений пароля неизвестного и известного диктора и принимает положительное решение о тождестве сравниваемых дикторов только в случае, если каждое произнесение неизвестного диктора достаточно близко произнесениям обучающего диктора, в то же время если их представления достаточно далеки друг от друга.
Данная известная система достаточно устойчива к использованию магнитофона вместо реального диктора в качестве источника речевого сигнала, в то же время ее недостатком является низкая помехоустойчивость в шумах переменного характера (в транспортном средстве, в условиях шума улицы, производственного помещения).
Известен способ автоматической идентификации личности по особенностям произношения парольной фразы этой личностью [5], заключающийся в том, что речевой сигнал разбивают на вокализованные зоны, выделяют временные интервалы в вокализованных зонах - в области максимумов интенсивности речевого сигнала, а также в начале первой и в конце последней вокализованных зон. Для выделенных временных интервалов определяют параметры речевого сигнала, сравнивают их с эталонами, которые формируют с учетом математических ожиданий и допустимых разбросов этих параметров, для чего в конце первой, начале последней, в начале и конце остальных вокализованных зон выделяют временные интервалы, длительность временных интервалов устанавливают кратной периоду основного тона речевого сигнала, определяют оценки коэффициентов корреляции параметров речевого сигнала, которые включают в число сравниваемых с эталонами, при формировании эталонов дополнительно учитывают коэффициенты корреляции параметров речевого сигнала. На основании полученных параметров речевого сигнала и соответствующих им статистических характеристик принимают решение по идентификации личности.
Недостатком известного способа идентификации личности является низкая помехоустойчивость метода, так как для его работы требуется выделение во входном речевом сигнале точного положения границ основного тона голоса, что в условиях наличия акустических помех (шум большого офисного помещения, улицы и т.п.) практически невозможно.
Известно устройство для верификации диктора на основе измерения расстояния “ближайшего соседа” [6], включающее дисплей, генератор выдачи подсказок по случайному закону, блок распознавания слова, верификатор диктора, клавиатуру и блок первичной обработки сигнала, при этом вход блока первичной обработки сигнала является входом устройства, а его выход соединен с первыми входами распознавателя слов и верификатора дикторов, ко второму входу распознавателя слов подключен первый выход генератора выдачи подсказок, выход которого соединен с дисплеем. Клавиатура подключена к третьему входу распознавателя слов и к третьему входу верификатора дикторов, выход которого является выходом устройства. Верификатор дикторов данного устройства для определения сходства различия произнесения голосовых паролей использует разбиение входного речевого сигнала на отдельные кадры анализа, вычисление непараметрических речевых векторов для каждого кадра анализа и далее определение близости таким образом полученных описаний речевого сигнала сравниваемых произнесений на основе Эвклидова расстояния ближайшего соседа.
Недостатком данного устройства являются низкая помехоустойчивость при работе в акустических шумах офисных помещений и улицы в силу использования непараметрических речевых векторов и Эвклидовой метрики при определении степени сходства/отличия произнесений голосовых паролей, а также низкая надежность распознавания (высокий процент ложных отказов) за счет использования переменных по порядку слов голосовых паролей, вызванная неизбежной индивидуальной вариативностью произнесения одних и тех же слов в разном контексте даже одним и тем же диктором.
Известен способ распознавания говорящего [7], включающий сравнивание входного речевого сигнала неизвестного диктора с эталонами, представляющими речь заранее известных дикторов, из которых, по меньшей мере, один представлен, по меньшей мере, двумя эталонами. Последовательные сегменты входного сигнала сравнивают с последовательными сегментами эталона, получая меру близости сравниваемых сегментов входного речевого сигнала и эталона. Для каждого эталона заранее известного диктора, имеющего, по крайней мере, два эталона, формируют композитный результат сравнения данного эталона и входного речевого сигнала на основе выбора для каждого сегмента входного речевого сигнала ближайшего по используемой мере близости сегмента сравниваемого эталона. Далее идентифицируют неизвестного диктора на основе композитных результатов сравнения входного речевого сигнала и эталонов.
Известный способ распознавания диктора ограниченно применим на практике, так как обязательное требование наличия для распознаваемого, заранее известного диктора не менее двух эталонов не всегда осуществимо в реальных условиях. Кроме того, данный способ не обеспечивает высокий уровень надежности распознавания дикторов при работе в условиях акустического шума реальных офисных помещений, улицы или транспортных средств, поскольку используемое в способе чисто посегментное параметрическое описание речевых сигналов подвержено сильному влиянию аддитивных акустических шумов и естественной вариативности речи. Кроме того, низкая надежность работы метода в шумах связана с тем, что ближайший по используемой мере близости сегмент сравниваемого эталона ищут для каждого сегмента входного речевого сигнала, что приводит к наличию среди найденных ближайших сегментов большого числа близких чисто шумовых сегментов, соответствующих сегментам речевых пауз и в эталоне и во входном речевом сигнале.
Известно устройство для распознавания диктора, совпадающее с заявляемым решением по наибольшему числу существенных признаков и принятое за прототип, описано в [7]. Известное устройство-прототип включает, в частности, источник речевого сигнала, блок определения параметрического описания речевого сигнала в виде выделителя начала/конца речевого сигнала, сегментатора речевого сигнала на последовательность сегментов, блока умножения на взвешивающее окно, блока добавления к сигналу в сегменте нулей, вычислителя преобразования Фурье, вычислителя спектра мощности сигнала в обрабатываемом сегменте, вычислителя кепстральных коэффициентов речи и формирователя параметрических описаний входного речевого сигнала, соединенных последовательно, коммутатор, блок нелинейного выравнивания временной оси сравниваемых слов, блок сравнения параметрических описаний эталона и входного речевого сигнала, блок принятия решения о распознаваемом дикторе и запоминающее устройство. Источник речевого сигнала подключен к блоку определения параметрического описания речевого сигнала, выход которого соединен с входом коммутатора, первый выход которого подключен к первому входу блока нелинейного выравнивания временной оси сравниваемых слов, а второй выход соединен с входом запоминающего устройства, выход которого подключен ко второму входу блока нелинейного выравнивания временной оси сравниваемых слов, выходы блока нелинейного выравнивания временной оси сравниваемых слов соединены со входами блока сравнения параметрических описаний эталона и входного речевого сигнала, выход которого соединен с входом блока принятия решения о распознаваемом дикторе, выход которого является выходом устройства в целом.
Известное устройство распознавания диктора ограниченно применимо на практике, так как обязательное требование наличия для распознаваемого, заранее известного диктора не менее двух эталонов не всегда реализуемо на практике. Известное устройство для распознавания диктора не обеспечивает высокий уровень надежности распознавания дикторов при работе в условиях акустического шума реальных офисных помещений, улицы или транспортных средств, поскольку используемые в устройстве чисто посегментное, кепстральное временное описание речевых сигналов и нелинейное выравнивание временной оси сравниваемых слов подвержены сильному влиянию аддитивных акустических шумов и естественной вариативности речи. Кроме того, низкая надежность работы устройства в шумах связана с тем, что ближайший по используемой мере близости сегмент сравниваемого эталона ищут для каждого сегмента входного речевого сигнала, что приводит к наличию среди найденных ближайших сегментов большого числа близких чисто шумовых сегментов, соответствующих речевым паузам и в эталоне и во входном речевом сигнале.
Задачей настоящего изобретения являлось создание такого способа распознавания диктора и такого устройства, реализующего этот способ, которые, при сохранении достоинств прототипа, позволили бы повысить надежность распознавания, а также обеспечить высокую помехоустойчивость распознавания при работе в шумах и при использовании низкокачественных микрофонов.
Поставленная задача решается тем, что заявляемый способ распознавания диктора включает сравнение входного речевого сигнала неизвестного диктора с заранее сохраненными эталонами, представляющими собой речевой сигнал голосовых паролей, произносимых заранее известными дикторами, по меньшей мере, один из которых представлен, по меньшей мере, одним эталоном, для чего осуществляют посегментное сравнение параметрических описаний входного речевого сигнала с параметрическими описаниями каждого из выбранных для сравнения эталонов. В заявляемом способе в качестве параметрических описаний используют соответственно векторы частот формант последовательно расположенных во времени сегментов входного речевого сигнала и эталонов с не фиксированным от сегмента к сегменту количеством формант, а также статистические характеристики спектра мощности входного речевого сигнала и упомянутых эталонов, вычисляемые для их используемых сегментов. Для сравнения параметрических описаний входного речевого сигнала и эталона используется определенная мера близости между каждой парой сравниваемых сегментов входного речевого сигнала и эталона. При сравнении параметрических описаний входного речевого сигнала и эталона находят для каждого используемого сегмента входного речевого сигнала ближайший по мере близости сегмент каждого выбранного для сравнения эталона, формируют композитные результаты сравнения входного речевого сигнала и каждого из выбранных для сравнения эталонов, в которые соответственно включают взвешенное среднее по всем используемым сегментам входного речевого сигнала значение мер близости между данным используемым сегментом входного речевого сигнала и найденным для него ближайшим сегментом каждого выбранного для сравнения эталона, и распознают неизвестного диктора на основе композитных результатов сравнения входного речевого сигнала и упомянутых эталонов. В качестве меры близости пары сравниваемых сегментов используют взвешенный модуль разности векторов формантных частот, для каждого используемого сегмента входного речевого сигнала ближайший по упомянутой мере близости сегмент выбранного для сравнения эталона определяют только среди сегментов эталона, у которых число формант в соответствующем сегменту векторе частот формант равно числу формант в соответствующем векторе частот формант сравниваемого сегмента входного речевого сигнала, а в композитный результат сравнения дополнительно включают коэффициент кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и выбранного для сравнения упомянутого эталона.
Голосовые пароли заранее известные дикторы могут произносить, по меньшей мере, два раза, при этом перед повторным произнесением пароля диктор произносит речевое высказывание с существенно измененным характером артикуляции.
В качестве используемых сегментов входного речевого сигнала и эталонов могут быть выбраны только сегменты, у которых число формант в соответствующем векторе частот формант составляет 3 и более.
В качестве статистических характеристик спектра мощности входного речевого сигнала и эталонов может быть использован первый статистический момент спектра мощности их используемых сегментов в интервале времени произнесения соответственно входного речевого сигнала и эталонов.
Можно дополнительно определять для каждого используемого сегмента, выбранного для сравнения эталона, ближайший по мере близости сегмент входного речевого сигнала, а в композитный результат сравнения можно дополнительно включать взвешенное среднее по всем используемым сегментам каждого эталона значение мер близости между данным используемым сегментом эталона и найденным для него ближайшим сегментом входного речевого сигнала, при этом для каждого используемого сегмента эталона ближайший по упомянутой мере близости сегмент входного речевого сигнала определяют только среди сегментов входного речевого сигнала, у которых число формант в соответствующем сегменту векторе частот формант равно числу формант в соответствующем векторе частот формант сравниваемого сегмента упомянутого эталона.
Из композитного результата сравнения входного речевого сигнала и выбранного для сравнения эталона дополнительно можно вычитать взвешенное среднее по всем используемым сегментам этого эталона значение меры близости между данным используемым сегментом эталона и найденным для него ближайшим сегментом этого эталона, не тождественным данному используемому сегменту, а также взвешенное среднее по всем используемым сегментам входного речевого сигнала значение меры близости между данным используемым сегментом входного речевого сигнала и найденным для него ближайшим сегментом входного речевого сигнала, не тождественным данному используемому сегменту.
В заявляемом способе можно предварительно определять и запоминать эталон окружающего шума и эталон амплитудно-частотной характеристики используемого микрофона. При этом эталон окружающего шума определяют путем накопления в течение заданного интервала времени среднего спектра мощности сигнала окружающего шума без присутствия речевого сигнала, а эталон амплитудно-частотной характеристики используемого микрофона определяют путем накопления при непрерывном произнесении в микрофон речи в течение заданного интервала времени среднегеометрического значения спектра мощности данного речевого сигнала и последующего покомпонентного деления полученного среднегеометрического значения спектра мощности на заранее заданный эталонный средний спектр речевого сигнала.
В качестве используемых сегментов входного речевого сигнала и эталонов можно выбирать сегменты, у которых усредненная по компонентам относительная энергия разности их спектра мощности и эталона окружающего шума превышает заранее заданное пороговое значение.
Параметрическое описание каждого сегмента входного речевого сигнала и эталона можно нормализовать путем покомпонентного деления спектра мощности данного сегмента на эталон амплитудно-частотной характеристики микрофона.
Суть заявляемого способа заключается в использовании в качестве параметрического описания речевого сигнала сочетания сильно отличающихся по различительным свойствам сегментных признаков векторов формант и статистических характеристик речевого сигнала всего произнесения пароля в целом, а также в использовании нестандартной неевклидовой меры близости при сравнении форматных векторов двух отдельных сегментов с последующим ее применением к определению статистического сходства сегментных формантных структур речевого сигнала сравниваемых произнесений на основе поиска наилучшего приближения. Общеизвестно (см., например, Чистович Л.А. и др. - Физиология речи. Восприятие речи человеком. - Л.: Наука, 1976), что формантное описание речевого сигнала является наиболее помехоустойчивым и информативным при решении задач распознавания речевых образов. До сих пор его реально редко использовали на практике в силу отсутствия способов надежного выделения формант в зашумленном речевом сигнале, вариативности числа формант, выделяемых на отдельном сегменте, нестабильности формантного описания при изменении громкости произнесения и психофизиологического состояния диктора. В заявляемом изобретении впервые предлагается использовать для распознавания дикторов векторы формантных частот с допустимо различным числом выделенных формант на конкретном сегменте. Описанный ниже способ выделения формант обеспечивает их высокую надежность выделения даже в условиях окружающего шума. Предложенная в изобретении метрика сравнения сегментов не привязана к конкретной временной позиции сегмента в высказывании и позволяет найти похожие по реализации сегменты речевого сигнала во всем произнесении, а не только в примерно том же месте относительно начала высказывания и во входном речевом сигнале и в эталоне. Сочетание разнородного описания речевого сигнала (и формантного и статистического) позволяет избежать недостатков использования чисто формантного описания и, в частности, уменьшить ошибки распознавания, связанные с внутренней вариативностью речевого сигнала за счет различной громкости произнесения, изменения эмоционального и физического состояния диктора, Ломбард-эффекта и т.д. В отличие от известных решений в данном способе распознавания и реализующем его устройстве предлагается симметризованная метрика сравнения эталона и входного речевого сигнала на основе посегментного наилучшего приближения с возможным вычитанием из нее объектной дисперсии данной меры близости. Существенным отличием от прототипа является то, что ближайшие к данному сегменту входного речевого сигнала сегменты эталона ищутся не среди всех сегментов сравниваемого эталона, а только среди сегментов, имеющих совпадающее число компонент вектора формантных частот. Дополнительные пункты изобретения предлагают процедуры определения эталонов окружающего шума и АЧХ используемого микрофона, а также процедуры учета при обработке речевого сигнала данных эталонов, которые существенно повышают устойчивость работы метода и устройства распознавания по отношению к искажениям сигнала низкокачественными микрофонами и шумам.
Поставленная задача в части устройства решается тем, что в устройстве для распознавания диктора, включающем источник речевого сигнала, блок определения параметрического описания речевого сигнала в виде выделителя начала/конца речевого сигнала, сегментатора речевого сигнала на последовательность сегментов, блока умножения на взвешивающее окно, блока добавления к сигналу в сегменте нулей, вычислителя преобразования Фурье, вычислителя спектра мощности сигнала в сегменте и формирователя параметрических описаний входного речевого сигнала, соединенных последовательно, коммутатор, блок сравнения параметрических описаний эталона и входного речевого сигнала, блок принятия решения о распознаваемом дикторе и запоминающее устройство, при этом источник речевого сигнала подключен к блоку определения параметрического описания речевого сигнала, выход которого соединен с входом коммутатора, первый выход которого подключен к первому входу блока сравнения параметрических описаний эталона и входного речевого сигнала, а второй выход соединен со входом запоминающего устройства, выход которого подключен ко второму входу блока сравнения параметрических описаний эталона и входного речевого сигнала, выход которого соединен с входом блока принятия решения о распознаваемом дикторе, выход которого является выходом устройства в целом, блок определения параметрического описания речевого сигнала дополнительно содержит блок определения формантного вектора текущего сегмента и первый сумматор-накопитель статистических характеристик входного речевого сигнала, включенные параллельно друг другу между вычислителем спектра мощности сигнала в сегменте и формирователем параметрических описаний входного речевого сигнала, блок сравнения параметрических описаний эталона и входного речевого сигнала выполнен в виде блока определения формантного расстояния от входного речевого сигнала до эталона и блока определения функции кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и эталона, выходы которых соединены соответственно через первый блок умножения и второй блок умножения со вторым сумматором, а выход второго сумматора соединен с входом блока принятия решения о распознаваемом дикторе.
Блок определения формантного расстояния от входного речевого сигнала до сравниваемого эталона может включать блок задания сравниваемых сегментов входного речевого сигнала, подключенный к блоку выбора сравниваемых сегментов эталона, выход которого соединен с входом блока определителя меры близости между 3-формантными векторами пары сравниваемых сегментов, входом блока определителя меры близости между 4-формантными векторами пары сравниваемых сегментов и входом блока определителя меры близости между 5-формантными векторами пары сравниваемых сегментов, выходы которых через соответственно первый, второй и третий блоки поиска наименьшей для заданного сегмента входного речевого сигнала меры близости по всем сегментам эталона, сумматор-накопитель средних наименьших мер близости по всем 3-формантным сегментам эталона, сумматор-накопитель средних наименьших мер близости по всем 4-формантным сегментам эталона, сумматор-накопитель средних наименьших мер близости по всем 5-формантным сегментам эталона соединены соответственно с первыми входами третьего, четвертого и пятого блоков умножения, вторые входы которых подключены к запоминающему устройству весовых коэффициентов, а выходы блоков умножения соединены с третьим сумматором.
Блок сравнения параметрических описаний эталона и входного речевого сигнала может дополнительно содержать блок определения формантного расстояния от сравниваемого эталона до входного речевого сигнала, соединенный через шестой блок умножения со вторым сумматором.
Блок определения формантного расстояния от сравниваемого эталона до входного речевого сигнала может включать блок задания сравниваемых сегментов эталона, подключенный к блоку выбора сравниваемых сегментов входного речевого сигнала, выход которого соединен с входом блока определителя меры близости между 3-формантными векторами пары сравниваемых сегментов, входом блока определителя меры близости между 4-формантными векторами пары сравниваемых сегментов и входом блока определителя меры близости между 5-формантными векторами пары сравниваемых сегментов, выходы которых через соответственно четвертый, пятый и шестой блоки поиска наименьшей для заданного сегмента эталона меры близости по всем сегментам входного речевого сигнала, сумматор-накопитель средних наименьших мер близости по всем 3-форматным сегментам входного речевого сигнала, сумматор-накопитель средних наименьших мер близости по всем 4-формантным сегментам входного речевого сигнала, сумматор-накопитель средних наименьших мер близости по всем 5-формантным сегментам входного речевого сигнала соединены соответственно с первыми входами седьмого, восьмого и девятого блоков умножения, вторые входы которых подключены к запоминающему устройству весовых коэффициентов, а выходы упомянутых блоков умножения соединены с четвертым сумматором.
Блок сравнения параметрических описаний входного речевого сигнала и эталона дополнительно может содержать блок определения формантного расстояния от сегментов эталона до эталона в целом и блок определения формантного расстояния от сегментов входного речевого сигнала до входного речевого сигнала в целом, соединенных через соответственно десятый и одиннадцатый блоки умножения со вторым сумматором.
Блок определения формантного расстояния от сегментов эталона до эталона в целом может включать соединенные последовательно блок задания сравниваемых сегментов эталона, блок удаления выбранного для сравнения сегмента (блок модификации эталона), блок выбора сравниваемых сегментов модифицированного эталона, выход которого соединен с входом блока определителя меры близости между 3-формантными векторами пары сравниваемых сегментов, входом блока определителя меры близости между 4-формантными векторами пары сравниваемых сегментов и входом блока определителя меры близости между 5-формантными векторами пары сравниваемых сегментов, выходы которых через соответственно седьмой, восьмой и девятый блоки поиска наименьшей для заданного сегмента эталона меры близости по всем сегментам модифицированного эталона, сумматор-накопитель средних наименьших мер близости по всем 3-формантным сегментам модифицированного эталона, сумматор-накопитель средних наименьших мер близости по всем 4-формантным сегментам модифицированного эталона, сумматор-накопитель средних наименьших мер близости по всем 5-формантным сегментам модифицированного эталона соединены соответственно с первыми входами двенадцатого, тринадцатого и четырнадцатого блоков умножения, вторые входы которых подключены к запоминающему устройству весовых коэффициентов, а выходы упомянутых блоков умножения соединены с пятым сумматором.
Блок определения формантного расстояния от сегментов входного речевого сигнала до входного речевого сигнала в целом может включать соединенные последовательно блок задания сравниваемых сегментов входного речевого сигнала, блок удаления выбранного для сравнения сегмента (блок модификации входного речевого сигнала), блок выбора сравниваемых сегментов модифицированного входного речевого сигнала, выход которого соединен с входом блока определителя меры близости между 3-формантными векторами пары сравниваемых сегментов, входом блока определителя меры близости между 4-формантными векторами пары сравниваемых сегментов и входом блока определителя меры близости между 5-формантными векторами пары сравниваемых сегментов, выходы которых через соответственно десятый, одиннадцатый и двенадцатый блоки поиска наименьшей для заданного сегмента входного речевого сигнала меры близости по всем сегментам модифицированного входного речевого сигнала, сумматор-накопитель средних наименьших мер близости по всем 3-формантным сегментам модифицированного входного речевого сигнала, сумматор-накопитель средних наименьших мер близости по всем 4-формантным сегментам модифицированного входного речевого сигнала, сумматор-накопитель средних наименьших мер близости по всем 5-формантным сегментам модифицированного входного речевого сигнала соединены соответственно с первыми входами пятнадцатого, шестнадцатого и семнадцатого блоков умножения, вторые входы которых подключены к запоминающему устройству весовых коэффициентов, а выходы упомянутых блоков умножения соединены с шестым сумматором.
Блок определения функции кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и эталона может включать первый, второй и третий блоки покомпонентного умножения, которые последовательно соединены соответственно с седьмым, восьмым и девятым сумматорами, выход седьмого сумматора соединен с первым входом делителя, ко второму входу которого через блок умножения и блок извлечения квадратного корня подключены выходы восьмого и девятого сумматоров.
Устройство для распознавания диктора дополнительно может содержать второй коммутатор, блок определения эталона шума и эталона амплитудно-частотной характеристики микрофона, при этом источник входного речевого сигнала соединен с входом второго коммутатора, один из выходов которого соединен с первым входом блока определения параметрического описания входного речевого сигнала, а второй выход второго коммутатора подключен ко входу блока определения эталона шума и эталона амплитудно-частотной характеристики микрофона, выход которого соединен с входом запоминающего устройства, подключенного ко второму входу блока определения параметрического описания входного речевого сигнала.
Блок определения эталона шума и эталона амплитудно-частотной характеристики микрофона может включать последовательно соединенные блок выделения начала/конца речевого сигнала, сегментатор речевого сигнала на последовательность сегментов, блок умножения на взвешивающее окно, блок добавления к сигналу в сегменте нулей, вычислитель преобразования Фурье, блок вычислителя спектра мощности сигнала в сегменте, а также переключатель режима работы (получения эталона шума или получения эталона АЧХ используемого микрофона), сумматор-накопитель покомпонентного среднего значения последовательности сегментных спектров и блок формирования эталона АЧХ используемого микрофона, включающий последовательно соединенные блок умножителя-накопителя, блок выделения корня n-ой степени из результата работы предыдущего блока, делитель на эталонный средний спектр речевого сигнала и запоминающее устройство хранения эталонного среднего спектра речевого сигнала, при этом выход блока вычислителя спектра мощности сигнала в сегменте соединен с входом переключателя режима, первый выход которого подключен к первому входу сумматора-накопителя покомпонентного среднего значения последовательности сегментных спектров, а второй выход переключателя соединен с первым входом блока формирования эталона АЧХ используемого микрофона, второй выход блока выделения начала/конца речевого сигнала подключен ко второму входу упомянутого сумматора-накопителя и второму входу блока формирования эталона АЧХ используемого микрофона, третий вход которого соединен с запоминающим устройством.
Устройство для распознавания диктора дополнительно может содержать устройство для ввода идентификатора диктора и устройство выбора эталона, при этом устройство для ввода идентификатора диктора подключено к первому входу устройства выбора эталона, второй вход которого соединен с запоминающим устройством, а выход устройства выбора эталона подключен ко второму входу блока сравнения параметрических описаний эталона и входного речевого сигнала.
Заявляемый способ распознавания диктора и устройство для его осуществления поясняются чертежами, где
на фиг.1 схематически изображены основные блоки устройства для распознавания диктора;
на фиг.2 приведена схема блока определения параметрического описания речевого сигнала;
на фиг.3 дана схема блока сравнения параметрических описаний эталона и входного речевого сигнала;
на фиг.4 приведена схема блока определения формантного расстояния от входного речевого сигнала до эталона;
на фиг.5 показана схема блока определения формантного расстояния от эталона до входного речевого сигнала;
на фиг.6 дана схема блока определения формантного расстояния от сегментов эталона до эталона в целом;
на фиг.7 показана схема блока определения формантного расстояния от сегментов входного речевого сигнала до входного речевого сигнала в целом;
на фиг.8 приведена схема блока определения эталона шума и эталона АЧХ используемого микрофона;
на фиг.9 дана схема блока определения функции кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и эталона (Xi - статистические характеристики спектра мощности входного речевого сигнала; Ti - статистические характеристики спектра мощности эталона; КК - значение функции кросс-корреляции);
на фиг.10 показана первая часть последовательности операций определения формантного вектора текущего анализируемого сегмента (ВНФ - вектор нормализующей функции спектра мощности, u обозначает операцию сглаживания);
на фиг.11 приведена вторая часть последовательности операций определения формантного вектора текущего анализируемого сегмента; где ВЧФ - вектор частотных формант; ГФД - границы формантных диапазонов; L и Н - соответственно нижняя и верхняя граница текущего диапазона поиска формант; Lk и Hk - соответственно нижняя и верхняя граница каждого формантного диапазона для каждой компоненты ВЧФ; Ti - величина порога отбрасывания слабых максимумов, Т2 - величина заданного порога близости формант; Q - максимально допустимое число формантных компонент.
Устройство, с помощью которого реализуют заявляемый способ распознавания диктора, включает (см. фиг.1) источник речевого сигнала в цифровой форме, например микрофон 1 (М) и аналого-цифровой преобразователь (АЦП) 2, первый коммутатор 3, блок 4 определения параметрического описания речевого сигнала (БОПОРС), второй коммутатор 5, блок 6 сравнения параметрических описаний эталона и входного речевого сигнала (БСПО), блок 7 принятия решения о распознаваемом дикторе (БПР), первый блок 8 запоминающего устройства для хранения эталонов параметрического описания речевого сигнала заранее известных дикторов, векторов нормализующей функции спектра мощности, границ формантных диапазонов и порогов (ЗУЭД). В устройство могут быть дополнительно введены: блок 9 определения эталона шума и эталона амплитудно-частотной характеристики (АЧХ) используемого микрофона (БОЭШМ) и второй блок 10 запоминающего устройства для хранения эталона шума, эталона АЧХ микрофона, порога шума, эталонного спектра речевого сигнала (ЗУЭШМ). В случае использования устройства для верификации диктора в устройство дополнительно вводят устройство 11 для ввода идентификатора диктора (УВИД) и устройство 12 выбора эталона (УВЭ). Микрофон 1 через АЦП 2 соединен с входом первого коммутатора 3, первый выход которого подключен к первому входу БОПОРС 4, а второй выход - к БОЭШМ 9. Выход БОПОРС 4 соединен с входом второго коммутатора 5, первый выход которого подключен к первому входу БСПО 6, а второй выход соединен с входом ЗУЭД 8. Выход БОЭШМ 9 подключен к входу ЗУЭШМ 10, выход которого соединен со вторым входом БОПОРС 4. В случае верификации диктора УВИД 11 подключают к первому входу УВЭ 12, второй вход которого соединяют с выходом ЗУЭД 8, а выход УВЭ 12 подключают ко второму входу БСПО 6, выход которого соединен с входом БПР 7, выход которого является выходом устройства в целом. Если верификацию диктора не проводят, то выход ЗУЭД 8 непосредственно соединяют со вторым входом БСПО 6.
Блок 4 определения параметрического описания речевого сигнала (БОПОРС) включает (см. фиг.2) последовательно соединенные блок выделения 13 начала/конца речевого сигнала (ВНКРС), сегментатор 14 речевого сигнала на последовательность сегментов (СРС), блок 15 умножения на взвешивающее окно (БУВО), блок 16 добавления к сигналу в сегменте нулей (БДН), вычислитель 17 преобразования Фурье (ВПФ) и блок 18 вычислителя спектра мощности сигнала в сегменте (ВСМ). В случае использования эталона шума (ЭШ) и эталона АЧХ микрофона (ЭАЧХ) блок 4 дополнительно включает вычитатель-компаратор 19 (К), определяющий превышение порога шума (ПШ) по отношению к эталону шума (ЭШ), и блок 20 умножения (УСЭМ) спектра мощности текущего сегмента анализа на эталон АЧХ используемого микрофона (ЭАЧХ). Выход ВСМ 18 соединен в этом случае с первым входом УСЭМ 20, выход которого подключен к первому входу К 19. Выходы К 19 подключены соответственно к входу сумматора-накопителя 21 статистических характеристик входного речевого сигнала (C1) и к первому входу блока 22 определения формантного вектора текущего сегмента (ОФВ), выходы которых соединены соответственно с первым и вторым входами формирователя 23 параметрических описаний входного речевого сигнала (ФПОРС), к третьему входу которого подключен второй выход ВНКРС 13. Второй, третий и четвертый входы ОФВ 22 соединены с выходами ЗУЭД 8, а второй вход УСЭМ 20 и второй и третий входы К 19 подключены к выходам ЗУЭШМ 10. На УСЭМ 20 подают сигнал эталона АЧХ микрофона из ЗУЭШМ 10 (см. фиг.2), а на К 19 подают сигналы эталона шума и порога шума. Если эталоны шума и АЧХ микрофона не используют, то выход ВСМ 18 непосредственно соединяют с первым входом ОФВ 22 и входом C1 21 (на фиг.2 эти связи показаны пунктирными линиями). Вход ВНКРС 13 является входом БОПОРС 4, а выход ФПОРС 23 - выходом БОПОРС 4.
Блок 6 сравнения параметрических описаний входного речевого сигнала и эталона (БСПО) (см. фиг.3) включает, по меньшей мере, блок 24 определения формантного расстояния от входного речевого сигнала до сравниваемого эталона (БОФР1), блок 25 определения функции кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и эталона (БОФКК), выходы которых соединены соответственно через первый блок 26 умножения (BУ1) и второй блок 27 умножения (БУ2) с сумматором 28 (С2). Дополнительно БСПО 6 может включать блок 29 определения формантного расстояния от сравниваемого эталона до входного речевого сигнала (БОФР2), соединенный через блок 30 умножения (БУ6) с сумматором 28. БСПО может также включать блок 31 определения формантного расстояния от сегментов эталона до эталона в целом (БОФР3) и блок 32 определения формантного расстояния от сегментов входного речевого сигнала до этого речевого сигнала в целом (БОФP4), которые соединены через соответственно блок 33 умножения (БУ10) и блок 34 умножения (БУ11) с С2 28. На входы БОФP1 24, БОФКК 25, БОФР2 29, БОФР3 31 и БОФP4 32 подают параметрическое описание входного речевого сигнала (ПОС) из БОПОРС 4 и параметрическое описание эталона (ПОЭ) из ЗУЭД 8. На вторые входы БУ1 26, БУ2 27, БУ6 30, БУ10 33 и БУ11 34 подают значения весовых коэффициентов соответственно W1, W2, W3, W4 и W5 из блока 35 запоминающего устройства весовых коэффициентов (ЗУВК). Выход С2 28 соединен с входом БПР 7.
Блок 24 (см. фиг.4) определения формантного расстояния от входного речевого сигнала до эталона (БОФР1) включает блок 36 задания сравниваемых сегментов входного речевого сигнала (БЗСС), блок 37 выбора сравниваемых сегментов эталона (БВСЭ), блок 38 определителя меры близости между 3-формантными векторами пары сравниваемых сегментов (ОМБ3Ф), блок 39 определителя меры близости между 4-формантными векторами пары сравниваемых сегментов (ОМБ4Ф), блок 40 определителя меры близости между 5-формантными векторами пары сравниваемых сегментов (ОМБ5Ф), три блока 41, 42 и 43 поиска наименьшей для данного, заданного БЗСС 36 сегмента входного речевого сигнала меры близости по всем сегментам эталона, соответственно БПMБ1, БПМБ2 и БПМБ3, сумматор 44 - накопитель средних наименьших мер близости по всем 3-формантным сегментам эталона (СН3ФЭ), сумматор 45 - накопитель средних наименьших мер близости по всем 4-формантным сегментам эталона (СН4ФЭ), сумматор 46 - накопитель средних наименьших мер близости по всем 5-формантным сегментам эталона (СН5ФЭ), три блока 47, 48, 49 умножения, соответственно БУ3, БУ4, БУ5, и сумматор 50 (С3). Вход БЗСС 36 соединен с выходом БОПОРС 4, а выход подключен к первому входу БВСЭ 37, на второй вход которого подают ПОЭ из ЗУЭД 8 (см. фиг.1). Выход БВСЭ 37 подключен в входам ОМБ3Ф 38, ОМБ4Ф 39 и ОМБ5Ф 40. Выход ОМБ3Ф 38 через БПМБ1 41, СН3ФЭ 44 и БУ6 47 подключен ко входу С3 50, к которому также подключены ОМБ4Ф 39 через БПМБ2 42, СН4ФЭ 45 и БУ7 48 и ОМБ5Ф 40 через БПМБ3 43, СН5ФЭ 46 и БУ8 49. На вторые входы БУ3 47, БУ4 48 и БУ5 49 подают значения весовых коэффициентов соответственно W6, W7 и W8 из ЗУВК 35. Выход С3 50 соединен с входом БУ1 26 (см. фиг.3).
Блок 29 (см. фиг.5) определения формантного расстояния от эталона до входного речевого сигнала (БОФР2) включает блок 51 задания сравниваемых сегментов эталона (БЗСЭ), блок 52 выбора сравниваемых сегментов входного речевого сигнала (БВСС), блок 53 определителя меры близости между 3-формантными векторами пары сравниваемых сегментов (ОМБ3Ф), блок 54 определителя меры близости между 4-формантными векторами пары сравниваемых сегментов (ОМБ4Ф), блок 55 определителя меры близости между 5-формантными векторами пары сравниваемых сегментов (ОМБ5Ф), три блока 56, 57 и 58 поиска наименьшей для данного, заданного БЗСЭ 51 сегмента эталона меры близости по всем сегментам входного речевого сигнала, соответственно БПМБ4, БПМБ5 и БПМБ6, сумматор 59 - накопитель средних наименьших мер близости по всем 3-формантным сегментам входного речевого сигнала (СН3ФС), сумматор 60 - накопитель средних наименьших мер близости по всем 4-формантным сегментам входного речевого сигнала (СН4ФС), сумматор 61 - накопитель средних наименьших мер близости по всем 5-формантным сегментам входного речевого сигнала (СН5ФС), три блока 62, 63, 64 умножения, соответственно БУ7, БУ8, БУ9, и сумматор 65 (С4). Вход БЗСЭ 51 соединен с выходом ЗУЭД 8, а выход подключен к первому входу БВСС 52, на второй вход которого подают ПОС из БОПОРС 4 (см. фиг.1). Выход БВСС 52 подключен в входам ОМБ3Ф 53, ОМБ4Ф 54 и ОМБ5Ф 55. Выход ОМБ3Ф 53 через БПМБ4 56, СН3ФС 59 и БУ9 62 подключен к входу С4 65, к которому также подключены ОМБ4Ф 54 через БПМБ5 57, СН4ФС 60 и БУ10 63 и ОМБ5Ф 55 через БПМБ6 58, СН5ФС 61 и БУ11 64. На вторые входы БУ7 62, БУ8 63 и БУ9 64 подают значения весовых коэффициентов соответственно W6, W7 и W8 из ЗУВК 35 (см. фиг.3).
Блок 31 (см. фиг.6) определения формантного расстояния от сегментов эталона до эталона в целом (БОФР3) включает блок 66 задания сравниваемых сегментов эталона (БЗСЭ), блок 67 удаления уже выбранного для сравнения сегмента (БУВС) из набора всех сегментов эталона, блок 68 выбора сравниваемых сегментов модифицированного эталона (БВСМЭ), блок 69 определителя меры близости между 3-формантными векторами пары сравниваемых сегментов (ОМБ3Ф), блок 70 определителя меры близости между 4-формантными векторами пары сравниваемых сегментов (ОМБ4Ф), блок 71 определителя меры близости между 5-формантными векторами пары сравниваемых сегментов (ОМБ5Ф), три блока 72, 73 и 74 поиска наименьшей для данного, заданного БЗСЭ 66 сегмента эталона меры близости по всем сегментам модифицированного эталона, соответственно БПМБ7, БПМБ8 и БПМБ9, сумматор 75 - накопитель средних наименьших мер близости по всем 3-формантным используемым сегментам модифицированного эталона (СН3ФЭ), сумматор 76 - накопитель средних наименьших мер близости по всем 4-формантным используемым сегментам модифицированного эталона (СН4ФЭ), сумматор 77 - накопитель средних наименьших мер близости по всем 5-формантным используемым сегментам модифицированного эталона (СН5ФЭ), три блока 78, 79, 80 умножения, соответственно БУ12, БУ13, БУ14, и сумматор 81 (C5). Вход БЗСЭ 66 соединен с выходом ЗУЭД 8, а выход через БУВС 67 подключен к первому входу БВСМЭ 68, на второй вход которого подают ПОС из ЗУЭД 8 (см. фиг.1). Выход БВСМЭ 68 подключен в входам ОМБ3Ф 69, ОМБ4Ф 70 и ОМБ5Ф 71. Выход ОМБ3Ф 69 через БПМБ7 72, СН3ФЭ 75 и БУ12 78 подключен к входу С5 81, к которому также подключены ОМБ4Ф 70 через БПМБ8 73, СН4ФЭ 76 и БУ13 79 и ОМБ5Ф 71 через БПМБ9 74, СН5ФЭ 77 и БУ14 80. На вторые входы БУ12 78, БУ13 79 и БУ14 80 подают значения весовых коэффициентов соответственно W6, W7 и W8 из ЗУВК 35 (см. фиг.3).
Блок 32 (см. фиг.7) определения расстояния от сегментов входного речевого сигнала до этого речевого сигнала в целом (БОФР4) включает блок 82 задания сравниваемых сегментов входного речевого сигнала (БЗСС), блок 83 удаления выбранного для сравнения сегмента (БУВС), блок 84 выбора сравниваемых сегментов модифицированного входного речевого сигнала (БВСМС), блок 85 определителя меры близости между 3-формантными векторами пары сравниваемых сегментов (ОМБ3Ф), блок 86 определителя меры близости между 4-формантными векторами пары сравниваемых сегментов (ОМБ4Ф), блок 87 определителя меры близости между 5-формантными векторами пары сравниваемых сегментов (ОМБ5Ф), три блока 88, 89 и 90 поиска наименьшей для данного, задаваемого БЗСС 82 сегмента входного речевого сигнала меры близости по всем сегментам модифицированного входного речевого сигнала, соответственно БПМБ10, БПМБ11 и БПМБ12, сумматор 91 - накопитель средних наименьших мер близости по всем 3-формантным используемым сегментам модифицированного входного речевого сигнала (СН3ФС), сумматор 92 - накопитель средних наименьших мер близости по всем 4-формантным используемым сегментам модифицированного входного речевого сигнала (СН4ФС), сумматор 93 - накопитель средних наименьших мер близости по всем 5-формантным используемым сегментам модифицированного входного речевого сигнала (СН5ФС), три блока 94, 95, 96 умножения, соответственно БУ15, БУ16, БУ17, и сумматор 97 (С6). Вход БЗСС 82 соединен с выходом БОПОРС 4, а выход через БУВС 83 подключен к первому входу БВСМС 84, на второй вход которого подают ПОС из БОПОРС 4 (см. фиг.1). Выход БВСМС 84 подключен в входам ОМБ3Ф 85, ОМБ4Ф 86 и ОМБ5Ф 87. Выход ОМБ3Ф 85 через БПМБ10 88, СН3ФС 91 и БУ15 94 подключен к входу С6 97, к которому также подключены ОМБ4Ф 76 через БПМБ11 89, СН4ФС 92 и БУ16 95 и ОМБ5Ф 87 через БПМБ12 90, СН5ФС 93 и БУ17 96. На вторые входы БУ15 94, БУ16 95 и БУ17 96 подают значения весовых коэффициентов соответственно W6, W7 и W8 из ЗУВК 35 (см. фиг.3).
Блок 9 определения эталона шума и эталона амплитудно-частотной характеристики (АЧХ) используемого микрофона (БОЭШМ) включает (см. фиг.8) последовательно соединенные блок выделения 98 начала/конца речевого сигнала (ВНКРС), сегментатор 99 речевого сигнала на последовательность сегментов (СРС), блок 100 умножения на взвешивающее окно (БУВО), блок 101 добавления к сигналу в сегменте нулей (БДН), вычислитель 102 преобразования Фурье, блок 103 вычислителя спектра мощности сигнала в сегменте (ВСМ), а также переключатель режима 104 (получение эталона шума / получение эталона АЧХ микрофона), сумматор 105 - накопитель покомпонентного среднего значения последовательности сегментных спектров (СН) и блок 106 формирования эталона АЧХ используемого микрофона (ФЭМ), включающий последовательно соединенные блок 107 умножителя-накопителя (БУН), блок 108 выделения корня n-ой степени из результата работы БУН и делитель 109 (Д) на эталонный средний спектр речевого сигнала (ЭССС), хранящийся в блоке 110 запоминающего устройства. Выход ВСМ 103 соединен с входом переключателя режима 104, первый выход которого подключен к первому входу СН 105, а второй выход - к первому входу ФЭМ 106. Второй выход ВНКРС 98 соединен со вторым входом СН 105 и вторым входом ФЭМ 106, третий вход которого подключен к блоку 110 запоминающего устройства. С выхода СН 105 поступает эталон шума (ЭШ), а с выхода ФЭМ 106 - эталон амплитудно-частотной характеристики микрофона (ЭАЧХ).
Блок 25 определения функции кросс-корреляции статистических характеристик спектра мощности входного речевого сигнала и эталона (БОФКК) (см. фиг.9) включает первый блок 111 покомпонентного умножения (БПУ1), второй блок 112 покомпонентного умножения (БПУ2), третий блок 113 покомпонентного умножения (БПУ3), которые последовательно соединены соответственно с сумматорами С7 114, C8 115 и С9 116, последовательно подключенные блок 117 умножения (БУ18), блок 118 извлечения квадратного корня (БИКК) и делитель 119 (Д1). Выход С7 114 соединен с первым входом Д1 119, а выходы C8 115 и С9 116 подключены ко входам БУ18 117, выход которого через БИКК 118 соединен с вторым входом Д1 119.
Распознавание диктора по заявляемому способу иллюстрируется на примере работы устройства, реализующего заявляемый способ. Ссылки на блоки устройства даны по фиг.1-11.
Устройство распознавания дикторов может работать в различных режимах: режиме обучения и режиме распознавания. Кроме того, заявляемое устройство может быть использовано для настройки технических параметров.
В режиме обучения речевой сигнал голосовых паролей, произносимых заранее известными дикторами, подают на вход устройства, например, с микрофона 1 (или выхода магнитофона) через АЦП 2 и коммутатор 3 на вход БОПОРС 4. Коммутатор 3 переключает устройство в режим работы или обучения (верхняя позиция на фиг.1), или в режим настройки технических параметров (нижняя позиция на фиг.1). В качестве голосовых паролей используют отдельные слова или фразы. Из речевого сигнала произнесенных паролей в БОПОРС 4 формируют параметрические описания, запоминаемые в ЗУЭД 8 в качестве эталонов. При этом коммутатор 5 замыкает вход на второй выход (нижний на фиг.1). На каждое произнесение каждого голосового пароля каждого известного диктора запоминают свой эталон. Число заранее известных дикторов может быть любым: от одного и более. Число использованных голосовых паролей также может быть любым, большим единицы. Для каждого голосового пароля может выполняться несколько его различных произнесений одним и тем же диктором, для каждого из которых формируют отдельный эталон. Эталоны речевого сигнала произнесения голосового пароля запоминают и могут хранить совместно с идентифицирующей данного диктора информацией (например, его именем или PIN-кодом).
Сохраненные эталоны используют для сравнения с тестом - входным речевым сигналом неизвестного, подлежащего распознаванию диктора. Выбор эталонов для сравнения производят блоком УВЭ 12 или только для заявляемого диктора (режим верификации), или для всех заранее известных дикторов (режим идентификации). В режиме верификации неизвестный диктор через блок УВИД 11 вводит идентификатор того диктора, тождество с которым он хочет подтвердить своим голосовым паролем. Далее блок УВЭ 12 в этом случае выбирает для сравнения только эталон того диктора, тождество с которым заявил неизвестный диктор.
С целью повышения надежности распознавания для каждого голосового пароля предлагается иметь несколько эталонов, получаемых при разных произнесениях данного голосового пароля.
Дело в том, что ошибки в распознавании дикторов для произвольного метода распознавания отчасти вызваны тем, что речь любого диктора изменяется от произнесения к произнесению даже для одного и того же голосового пароля. Такая естественная вариативность речи велика при длительном перерыве между произнесениями (несколько дней и более), однако мала при быстром повторении одного и того же голосового пароля во время одной сессии обучения. С целью увеличения вариативности речевого сигнала в разных эталонах одного и того же голосового пароля при их запоминании в рамках одной сессии обучения перед повторным произнесением одного и того же голосового пароля известный диктор произносит речевое высказывание с измененным характером артикуляции. Например, очень высоким или очень низким голосом с имитацией состояния страха или угрозы и т.д. Вид изменения характера артикуляции не существенен. Необходимо только лишь функционирование органов артикуляции речи в ненормативном режиме с ненормативным мышечным усилием и ненормативной конфигурацией вокального тракта. После такого высказывания, как показывает практика, вариативность произнесения пароля уже нормальным голосом возрастает, что приводит к большей вариативности речевого сигнала эталонов и к уменьшению ошибки распознавания диктора при использовании нескольких, вышеуказанным образом полученных эталонов. Например, при применении трех эталонов одного голосового пароля с их произнесением по вышеприведенному методу ошибка пропуска своего диктора уменьшается на 10% по сравнению с использованием обычного повторного произнесения голосовых паролей при получении эталонов.
В режиме распознавания согласно предлагаемому изобретению входной речевой сигнал через блоки 1, 2, 3 в цифровой форме поступает в БОПОРС 4, формирующий его параметрическое описание. Для речевого сигнала в блок ВНКРС 13 (фиг.2) определяют начало и конец высказывания и временные отметки передают в блок ФПОРС 23. Сам способ определения начала и конца высказывания особой роли не играет и может быть таким, как, например, описано в L.F. Lamel, L.R. Rabiner, A.E. Rosenberg and J.С. Wilpon "An Improved Endpoint Detector for Isolated Word Recognition". - IEEE transactions on Acoustics, Speech and Signal Processing. - Vol. ASSP-29, № 4, pp. 777-785, Aug. 1981 или в J.С. Wilpon, L.F. Lamel, L.R. Rabiner and T. Martin "An Improved Word-Detection Algorithm for Telephone-Quality Speech Incorporating Both Semantic Constraints". - AT&T Bell Laboratories Technical Journal, Vol. 63, № 3, pp.479-497, Mar. 1984. Далее речевой сигнал в сегментаторе речевого сигнала 14 разбивают на последовательность сегментов- отрезков сигнала, следующих друг за другом через фиксированный интервал времени. Длина сегмента особой роли не играет в пределах 20-50 мс со сдвигом от сегмента к сегменту на 2-20 мс. Стандартная длина 256 отсчетов. Далее сигнал на каждом сегменте в БУФО 15 умножают на взвешивающее окно, например окно Хэмминга, с длиной, равной длине сегмента. Далее в БДН 16 с целью увеличения точности вычислений спектра к сигналу добавляют нулевую последовательность, увеличивающую общую длительность сигнала, например, в 2 или 4 раза. Далее в блоке ВПФ 17 производят вычисление преобразования Фурье полученной последовательности значений для всех ее отсчетов. Например, это может быть быстрое преобразование Фурье на 512-1024 отсчетов. Затем в блоке ВСМ 18 вычисляют спектр мощности полученного амплитудного спектра.
Затем в полной версии устройства сигнал поступает на блок УСЭМ 20, где покомпонентно делится на эталон АЧХ используемого микрофона, который был получен в режиме настройки технических характеристик и был запомнен в ЗУЭШМ 10 запоминающего устройства. Такое деление позволяет сделать параметрическое описание обрабатываемого речевого сигнала относительно независимым от АЧХ используемого микрофона и тем самым повысить надежность распознавания.
Далее сигнал поступает на компаратор 19. В нем последовательность поступающих сегментов разбивают на две части: на используемые и не используемые для определения параметрического описания сегменты. На компаратор из ЗУЭШМ 10 поступают эталон шума и значение порога шума. Для каждого сегмента в компараторе вычисляют покомпонентную разность спектра мощности сигнала на данном сегменте и эталона шума ЭШ. Далее определяется средняя энергия полученной разности, которую сравнивают с ПШ. Те сегменты, для которых ПШ превышен, считаются “используемыми” и поступают для дальнейшего построения параметрического описания речевого сигнала. Остальные сегменты исключают из дальнейшего использования.
Затем для всех используемых сегментов входного речевого сигнала или эталона строят параметрическое описание соответственно теста или эталона, состоящее из двух частей. Первую часть получают в блоке ОФВ 22, она состоит из набора векторов формантных частот, определяемых на используемых сегментах теста или эталона.
Формантная частота речевого сигнала на сегменте анализа является устоявшимся понятием в области обработки речевого сигнала (см., например, Г. Фант. - Акустическая теория речеобразования. - М.: Наука, 1964, стр. 32) и соответствует резонансному пику, наблюдающемуся в спектре мощности речевого звука. Число определенных для данного сегмента частот формант может различаться от 1 до 6-7 в полосе частот речевого сигнала. Таким образом, параметрический вектор, описывающий речевой сигнал на сегменте анализа, согласно заявляемому изобретению, может отличаться по числу его компонент. Для получения параметрических описаний, использованных до сих пор в распознавании дикторов, такие описания не применялись (см., например, D. O'Shaughnessy. - Speech Communications. Human and Machine. - New York: IEEE Press, 2000.) Число компонент характеризующего речь вектора признаков параметрического описания для сегмента речевого сигнала обычно используют одно и то же для всех сегментов. В заявляемом способе это число может различаться - число компонент вектора формантных частот (ВФЧ) может быть различным, обычно от 3 до 5 (или 6). Для стабильности оценок параметров речи предлагается считать используемыми сегментами те сегменты входного речевого сигнала или эталона, на которых число определенных формантных частот 3 и более. Сам прием выделения формант для данного способа распознавания дикторов не существенен. Один из приемов выделения формантных частот, применявшийся при реализации и оценке заявляемого способа, описан ниже. Таким образом, первую часть параметрического описания входного речевого сигнала или эталона составляет набор векторов частот формант на используемых сегментах соответственно входного речевого сигнала или эталона. Каждый вектор состоит из Q=3 и более (до 6-8) частот формант.
Вторую часть параметрического описания входного речевого сигнала или эталона образуют статистические характеристики спектра мощности речевого сигнала, полученные на совокупности используемых сегментов соответственно теста или эталона в C1 21. С точки зрения статистики совокупность векторов спектра мощности на всех используемых сегментах речевого сигнала можно рассматривать как многомерную случайную величину, и для описания ее статистических свойств можно использовать общепринятые статистические характеристики, вычисляемые по стандартным общеизвестным процедурам: функцию распределения, математическое ожидание, дисперсию, статистические моменты, характеристические функции (см., например, В.Н. Лавренчик. - Постановка физического эксперимента и статистическая обработка его результатов. - М.: Энергоатомиздат, 1986, глава 2 “Числовые характеристики случайных величин”, стр. 54-76).
Из всей совокупности возможных к применению статистических характеристик спектра мощности входного речевого сигнала или эталона в качестве такой характеристики предлагается использовать, в частности, первый статистический момент спектра мощности (см., например, В.Н. Лавренчик. - Постановка физического эксперимента и статистическая обработка его результатов. - М.: Энергоатомиздат, 1986, глава 2 “Числовые характеристики случайных величин”, стр. 67). Пусть Xi - компоненты спектра мощности речевого сигнала, i=1,..., N. Тогда его первый спектральный момент SM1 находится по формуле
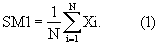
Как показывают практические измерения, применение только одной данной статистической характеристики речевого сигнала совместно с ВФЧ позволило получить достаточно высокий и стабильный процент распознавания дикторов на представительном речевом материале. Отличие заявляемого способа распознавания дикторов от других известных способов состоит, в частности, в том, что в качестве параметрического описания сравниваемых входного речевого сигнала и эталона используют и разноразмерные признаки отдельных сегментов (формантные векторы) и признаки всего произнесения пароля в целом (статистические характеристики). Использование столь разнородных описаний речевого сигнала позволяет учесть вариативность речевых параметров за счет разнообразных причин и добиться высокой надежности распознавания дикторов.
В блоке ФПОРС 23 происходит формирование параметрического описания речевого сигнала, состоящего из статистических характеристик, получаемых в C1 21, вычисление которых для данного высказывания прекращается согласно сигналу из блока ВНКРС 13 и из набора ВФЧ для используемых сегментов на протяжении высказывания от его начала до конца.
В режиме распознавания коммутатор 5 замыкает вход на первый выход (верхний на фиг.1). БСПО 6 формирует композитный результат сравнения входного речевого сигнала неизвестного диктора и каждого поступающего из ЗУЭД 8 эталона, сравнивая между собой параметрические описания входного речевого сигнала неизвестного диктора и речевого сигнала сравниваемого эталона. Сравнение параметрических описаний выполняют раздельно для набора формантных векторов и для статистических характеристик. Наборы формантных векторов сравнивают в БОФр1 24, БОФР2 29, БОФР3 31, БОФР4 32 следующим образом. Сначала сравнивают между собой ВФЧ всех используемых сегментов сравниваемых речевых образов. Для определения степени сходства между собой ВФЧ сравниваемых сегментов речевого сигнала вводится мера близости, которая задается в виде взвешенной суммы модулей разности частот соответствующих по номеру частот формант:
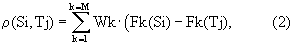
где ρ (Si,Tj) - мера близости двух сравниваемых сегментов речевого сигнала Si и Tj,
Wk - весовые коэффициенты для оптимизации вклада каждой формантной частоты в меру близости,
Fk(Si) и Fk(Tj) - соответственно формантные частоты для к-ой компоненты векторов формантных частот первого сравниваемого сегмента Si и второго сравниваемого сегмента Tj.
Число частот формант в сравниваемых сегментах - М - должно в них совпадать. Для векторов формантных частот с разным числом компонент мера близости не определена, такие сегменты в заявляемом методе считаются несопоставимыми. М должно быть равно 3 и более.
Для сравнения входного речевого сигнала и эталона согласно в БОФР1 24 для каждого используемого сегмента входного речевого сигнала по формуле (2) вычисляют меры близости с каждым используемым сегментом выбранного для сравнения эталона и среди всех сосчитанных мер близости ищется наименьшая по модулю. БЗСС 36 задает текущий сегмент входного речевого сигнала, БВСЭ 37 последовательно перебирает используемые сегменты сравниваемого эталона. В зависимости от числа формант в заданном сегменте входного речевого сигнала в блоках 38, 39 или 40 определяется мера близости между заданным и выбранным для сравнения сегментами. Далее в соответственно БПМБ1 41, БПМБ2 42 или БПМБ3 43 определяется наименьшая мера близости к заданному сегменту среди всех вычисленных мер близости. Все найденные таким образом наименьшие меры близости соответственно в блоках СН3ФЭ 44, СН4ФЭ 45 или СН5ФЭ 46 суммируются и делятся на число соответственно 3-, 4- или 5-формантных используемых сегментов входного речевого сигнала. Далее найденные для 3, 4 и 5 формант в ВЧФ результаты соответственно в БУ3 47, БУ4 48, БУ5 49 умножаются на весовые коэффициенты и суммируются в С3 50, давая в итоге на выходе БОФР 24 d(S,Tm) - формантное расстояние от тестового входного речевого сигнала S до эталона Тm. Здесь индекс m означает, что выбран для сравнения конкретный m-й эталон из всего набора хранящихся эталонов.
Кроме формантного расстояния d(S,Тm) от входного речевого сигнала S до эталона Тm можно в БОФР2 29 определять d(Tm,S) - расстояние от эталона Тm до входного речевого сигнала S. Для его вычисления для каждого используемого сегмента выбранного для сравнения эталона по формуле (2) вычисляются меры близости с каждым используемым сегментом входного речевого сигнала и среди всех сосчитанных мер близости ищется наименьшая по модулю. БЗСЭ 51 задает текущий сегмент сравниваемого эталона, БВСС 52 последовательно перебирает используемые сегменты входного речевого сигнала. В зависимости от числа формант в заданном сегменте сравниваемого эталона в блоках ОМБЗФ 53, ОМБ4Ф 54 или ОМБ5Ф 55 определяется мера близости между заданным и выбранным для сравнения сегментами. Далее в соответственно БПМБ4 56, БПМБ5 57 или БПМБ6 58 определяется наименьшая мера близости к заданному сегменту среди всех вычисленных мер близости. Все найденные таким образом наименьшие меры близости соответственно в блоках СН3ФС 59, СН4ФС 60 или СН5ФС 61 суммируются и делятся на число используемых соответственно 3-, 4- или 5-формантных сегментов эталона. Далее найденные для 3, 4 и 5 формант в ВЧФ результаты умножаются в БУ7 62, БУ8 63, БУ9 64 на весовые коэффициенты и суммируются в С4 65, давая в итоге на выходе БОФР2 29 d(Tm,S) - формантное расстояние от эталона Тm до тестового входного речевого сигнала S. Здесь индекс m означает, что выбран для сравнения конкретный m-й эталон из всего набора хранящихся эталонов. Целесообразность использования такого расстояния связана с тем, что вышеописанным образом определенное расстояние между тестовым входным речевым сигналом и эталоном не обладает свойством математической симметричности для случая, когда статистика распределения формантных частот в сравниваемых произнесениях существенно различается. Для улучшения надежности распознавания и “симметризации” расстояния между тестовым входным речевым сигналом и эталоном и предлагается использовать в композитном результате сравнения тестового входного речевого сигнала и эталона также расстояние от эталона до входного речевого сигнала и от входного речевого сигнала до эталона.
Из композитного результата сравнения кроме d(S,Tm) и d(Tm,S) можно вычитать еще два члена: d(S,S) и d(Tm,Tm) - форматное расстояние от входного речевого сигнала до самого себя и формантное расстояние от сравниваемого эталона Tm до самого себя, то есть эталона Тm. Вычисление этих расстояний со знаком “минус” (то есть инвертированных) производится соответственно БОФР3 31 и БОФР4 32. При определении d(Tm,Tm) для каждого используемого сегмента выбранного для сравнения эталона по формуле (2) вычисляются меры близости с каждым используемым сегментом этого же эталона, кроме того, сегмента, который в данный момент уже выбран, и среди всех сосчитанных мер близости ищется наименьшая по модулю. БЗСЭ 66 задает текущий сегмент сравниваемого эталона, БУВС 67 модифицирует эталон, удаляя из него уже заданный сегмент, БВСМЭ 68 последовательно перебирает используемые сегменты эталона. В зависимости от числа формант в заданном сегменте эталона в блоках ОМБ3Ф 69, ОМБ4Ф 70 или ОМБ5Ф 71 определяется мера близости между заданным и выбранным для сравнения сегментами. Далее в соответственно БПМБ7 72, БПМБ8 73 или БПМБ9 74 определяется наименьшая мера близости к заданному сегменту среди всех вычисленных мер близости. Все найденные таким образом наименьшие меры близости соответственно в блоках СН3ФЭ 75, СН4ФЭ 76 или СН5ФЭ 77 суммируются и делятся на число соответственно 3-, 4- или 5-формантных используемых сегментов эталона. Далее найденные для 3, 4 и 5 формант в ВЧФ результаты соответственно в БУ12 78, БУ13 79 и БУ14 80 умножаются на -1 и весовые коэффициенты и суммируются в C5 81, давая в итоге на выходе БОФР3 31 d(Tm,Tm) - инвертированное формантное расстояние от эталона Tm до эталона Тm. Далее оно умножается на -1 и поступает на умножитель БУ10 33.
При определении d(S,S) - расстояния от тестового входного сигнала S до самого себя, то есть до входного сигнала S, для каждого используемого сегмента тестового входного сигнала по формуле (2) вычисляются меры близости с каждым используемым сегментом этого входного речевого сигнала, кроме того, сегмента, который в данный момент уже выбран, и среди всех сосчитанных мер близости ищется наименьшая по модулю. БЗСС 82 задает текущий сегмент входного речевого сигнала, БУВС 83 модифицирует этот сигнал, удаляя из него уже заданный сегмент, БВСМС 84 последовательно перебирает используемые сегменты тестового входного речевого сигнала. В зависимости от числа формант в заданном сегменте входного речевого сигнала в блоках ОМБ3Ф 85, ОМБ4Ф 86 или ОМБ5Ф 87 определяется мера близости между заданным и выбранным для сравнения сегментами. Далее в соответственно БПМБ10 88, БПМБ11 89 или БПМБ12 90 определяется наименьшая мера близости к заданному сегменту среди всех вычисленных мер близости. Все найденные таким образом наименьшие меры близости соответственно в блоках СН3ФС 91, СН4ФС 92 или СН5ФС 93 суммируются и делятся на число соответственно 3-, 4- или 5-формантных используемых сегментов входного речевого сигнала. Далее найденные для 3, 4 и 5 формант в ВЧФ результаты соответственно в БУ15 94, БУ16 95 и БУ17 96 умножаются на -1 и весовые коэффициенты и суммируются в С6 97, давая в итоге на выходе блока 32 d(S,S) - инвертированное формантное расстояние от входного речевого сигнала S до входного речевого сигнала S. Оба последних расстояния являются оценками степени естественного разброса векторов частот формант для тестового входного речевого сигнала и эталона. Их вычитание (сложение инвертированных расстояний) из композитного результата сравнения входного речевого сигнала и эталона позволяет лучше учесть внутреннюю вариативность речевых параметров и добиться повышения надежности распознавания дикторов, особенно для длительных перерывов между сессиями обучения и распознавания (месяц и более).
Кроме формантных расстояний между параметрическими описаниями сравниваемого эталона и входного речевого сигнала БОФКК 25 определяет меру близости между входящими в параметрическое описание статистическими характеристиками спектра мощности входного речевого сигнала и сравниваемого эталона. Для этого вычисляется коэффициент нормированной кросс-корреляции между входящими в параметрическое описание входного речевого сигнала и эталона статистическими характеристиками спектра мощности входного речевого сигнала Xi, i=1,..., L, и эталона Yi, i=1,..., L. Коэффициент кросс-корреляции ККК получают путем суммирования результатов покомпонентного умножения Xi· Yi по всем компонентам статистических характеристик и последующего деления этой суммы на квадратный корень из произведения сумм квадратов всех компонент Xi и Yi:
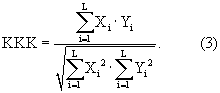
БОФКК 25 реализует вычисление коэффициента кросс-корреляции между статистическими характеристиками входного речевого сигнала и эталона согласно формуле (3) через блоки 111-119, как показано на фиг.9.
Композитный результат сравнения входного речевого сигнала и выбранного для сравнения эталона CR(S,Tm) получается из рассмотренных выше формантных расстояний и коэффициента кросс-корреляции в виде взвешенной суммы. Композитный результат выглядит следующим образом:
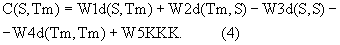
В композитный результат сравнения в заявляемом способе обязательно должны входить только первый и последний члены уравнения:
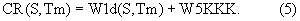
Дополнительно могут входить первый, второй и пятый члены уравнения (3):
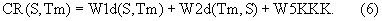
Вычисление по формуле (3) обеспечивает наивысшую надежность распознавания дикторов, хотя для ряда приложений и вычислительно более простые выражения (4) и (5) обеспечивают достаточный уровень надежности распознавания дикторов.
Реализуя формулы (3)-(6) в БСПО 6, результаты на выходе БОФР1 24, БОФР2 29, БОФР3 31, БОФР4 32, БОФКК 25 умножаются на весовые коэффициенты соответственно в умножителях БУ1 26, БУ6 30, БУ10 33, БУ11 34, БУ2 27 и суммируются в С2 28, давая в итоге композитный результат сравнения входного речевого сигнала и выбранного для сравнения эталона.
При идентификации дикторов входной речевой сигнал теста, то есть произнесения голосового пароля неизвестным, подлежащим распознаванию диктором, подается на вход устройства и последовательно сравнивается с эталонами всех заранее известных дикторов, эталоны которых хранятся в ЗУЭД 8. В процессе сравнения входного речевого сигнала и каждого выбранного для сравнения эталона определяют композитный результат их сравнения в виде скалярного числа. Среди всех композитных результатов сравнения входного речевого сигнала с выбранными эталонами в БПР 7 выбирается наименьший результат, который сравнивается с заранее заданным порогом принятия решения, получаемым в процессе статистической обработки результатов распознавания на обучающей базе данных. Если порог не превышен, то неизвестный диктор считается распознанным как диктор, для эталона которого получился наименьший результат сравнения. В противном случае диктор считается неизвестным.
Выбор порога производится из соображений обеспечения необходимого уровня ошибок первого и второго рода (не распознание тождественного диктора и распознание ложного диктора, как известного). Основной характеристикой системы распознавания считается порог, при котором получается равный уровень ошибок обоего рода. Для заявляемого способа распознавания дикторов на базе данных из 100 различных дикторов при 15 тестовых попытках на каждого диктора на 5 различных голосовых паролях получен результат 1,2% равных ошибок распознавания. Для оценок использовалась общедоступная база голосовых паролей (100 дикторов, 5 паролей, 15 произнесений каждого пароля): ELRA-S0050 Russian speech database (STC), 1998, EUROPEAN LANGUAGE RESOURCES ASSOCIATION, ELRA/ELDA 55-57 rue Brillat Savarin, 75013 PARIS, http://www.icp.grenet.fr/ELRA/home.html.
Тестовая версия программы, реализующей заявляемый способ распознавания, доступна на Интернет-сайте заявителя: http://www.speechpro.com.
В заявляемом способе распознавания диктора перед сессиями обучения и распознавания можно провести сессию оценки технических характеристик используемого устройства, переключив его в режим настройки технических параметров с помощью коммутатора 3 (фиг.1). Во время работы в этом режиме для получения эталона шума переключают коммутатор 104 (фиг.8) в режим вычисления эталона шума и обеспечивают поступление на вход устройства только сигнала окружающего шума без присутствия полезного сигнала произнесения голосового пароля в течение фиксированного, заранее определенного интервала времени. Длина интервала существенной роли не играет, типично он выбирается в пределах 30-60 секунд. Звуковой сигнал окружающего шума, соответствующий типичной акустической обстановке в месте размещения микрофона, например, может поступать с используемого микрофона 1 на вход БОЭШМ 9. Для этого сигнала в блоке ВНКРС 98 (фиг.8) выделяются моменты начала и конца поступления шума в устройство и временные отметки передаются в С 105. Блок ВНКРС 98 может быть аналогичен блоку ВНКРС 13 в блоке 4 (фиг.2). Далее звуковой сигнал в СРС 99 разбивают на последовательность сегментов - отрезков сигнала, следующих друг за другом через фиксированный интервал времени аналогично СРС 14 блока 4 Далее сигнал на каждом сегменте в БУВО 100 умножается на взвешивающее окно аналогично БУВО 15. Затем аналогично работе БДН 16 в БДН 101 к сигналу добавляется нулевая последовательность. Далее в ВПФ 102 аналогично блоку ВПФ 17 производится вычисление преобразования Фурье полученной последовательности значений для всех ее отсчетов. Затем в ВСМ 103 вычисляется спектр мощности полученного амплитудного спектра. Далее сигнал через коммутатор 104 поступает в блок сумматора-накопителя 105, где производится вычисление среднего спектра мощности по всем сегментам звукового сигнала за время поступления сигнала окружающего шума (между отметками начала и конца звучания шумового сигнала, поступающими из блока 98). Полученный таким образом эталон окружающего шума, представляющий собой оценку среднего спектра окружающего шума, запоминают в ЗУЭШМ 10 и далее используют для отбрасывания части непредставительных сегментов входного речевого сигнала теста и эталона. При этом используемыми сегментами речевого сигнала могут являться только те сегменты, для которых усредненная по компонентам относительная энергия разности их спектра мощности и соответствующих компонент эталона окружающего шума, вычисляемая в К 19 (фиг.2), не превышает заранее заданного порога, например 10%. Таким образом, из рассмотрения исключаются слабые по энергии, не содержащие достоверной информации о дикторе сегменты речевого сигнала. Оптимальный порог отбрасывания сегментов находится экспериментально во время проверки работы способа на большой выборке реальных произнесений голосовых паролей.
Кроме того, во время работы устройства в режиме настройки технических характеристик может определяться и амплитудно-частотная характеристика (АЧХ) используемого микрофона. Во время работы в этом режиме для получения ЭАЧХ переключают коммутатор 104 (фиг.8) в режим вычисления эталона АЧХ микрофона и обеспечивают поступление на вход устройства речевого сигнала в течение заранее заданного фиксированного интервала времени. Например, заранее известный диктор до начала сессии обучения непрерывно говорит в используемый микрофон 1 минуту. Длина интервала существенной роли не играет, типично он выбирается в пределах 30-90 секунд.
Речевой сигнал, например, может поступать с используемого микрофона 1 на вход БОЭШМ 9. Для этого сигнала в блоке ВНКРС 98 (фиг.8) выделяются моменты начала и конца поступления речевого сигнала в устройство и временные отметки передаются в блок ФЭМ 106. Блок ВНКРС 98 может быть аналогичен блоку ВНКРС 13 в блоке 4 (фиг.2). Далее речевой сигнал в СРС 99 разбивают на последовательность сегментов-отрезков сигнала, следующих друг за другом через фиксированный интервал времени аналогично СРС 14 блока 4. Далее сигнал на каждом сегменте в БУВО 100 умножается на взвешивающее окно аналогично БУВО 15. Затем аналогично работе БДН 16 в БДН 101 к сигналу добавляется нулевая последовательность. Далее в ВПФ 102 аналогично блоку ВПФ 17 производится вычисление преобразования Фурье полученной последовательности значений для всех ее отсчетов. Затем в ВСМ 103 вычисляется спектр мощности полученного амплитудного спектра. Далее сигнал через коммутатор 104 поступает в блок ФЭМ 106. Здесь для каждой компоненты спектра мощности речевого сигнала определяется ее среднегеометрическое значение для всех сегментов сигнала за время его произнесения в рамках данной сессии. Например, для i-ой компоненты N сегментов это значение вычисляется как корень 1/N степени из произведения друг на друга N i-ых компонент каждого сегмента речевого сигнала. БУН 107 производит накопление покомпонентных произведений спектра мощности речевого сигнала на всем его протяжении между метками начала и конца произнесения из блока 98. Далее в блоке 108 из полученных произведений извлекается соответствующий корень (например, путем перехода к логарифму обрабатываемого числа, делением логарифма на N и вычислением экспоненциальной функции от результата). Затем в Д 109 полученное среднегеометрическое значение каждой спектральной компоненты делят на значение соответствующей спектральной компоненты среднего спектра эталонного речевого сигнала, получаемого из ЗУ 110, а получаемые значения запоминают в ЗУЭШМ 10 в виде эталона АЧХ используемого микрофона. Данный средний спектр эталонного речевого сигнала получают путем измерения среднего спектра речи на большом количестве дикторов и при использовании прецизионного измерительного микрофона и хранят в виде фиксированного набора чисел.
Перед сравнением входного речевого сигнала и эталона их параметрические описания можно нормализовать с целью компенсации искажений спектра речевого сигнала, возникающих за счет отличий АЧХ используемого микрофона от идеальной. Для этого после вычисления спектра мощности речевого сигнала на каждом сегменте речевого сигнала теста и эталона каждую компоненту этого спектра в блоке УСЭМ 20 (фиг.2) делят на соответствующую компоненту запомненного в режиме настройки технических характеристик эталона АЧХ используемого микрофона. После такого деления средний спектр нормализованного речевого сигнала уже не содержит информации об АЧХ используемого микрофона и сохраняет информацию только об индивидуальности диктора, что позволяет повысить надежность распознавания диктора. Такое повышение особенно существенно (ошибка распознавания уменьшается на 30-60%) при применении дешевых микрофонов, АЧХ которых имеет сильные отклонения от плоской (типично до 20 дБ в речевом диапазоне частот).
Для выделения вектора форматных частот при реализации заявляемого устройства использовался способ, обеспечивавший достаточно надежное выделение 3-6 формант речевого сигнала для реальных речевых сигналов. Блок-схема его операций приведена на фиг.10 и 11.
Входной сигнал спектра мощности сигнала на сегменте S(i), i=1...N, покомпонентно умножают на нормализующую функцию спектра мощности сегмента G(i):
S*(i)=S(i)· (G(i).
ВНФ - вектор нормализующей функции получают путем экспериментального подбора и хранят в устройстве в зафиксированном виде.
Далее сигнал сглаживают, например, с помощью процедуры скользящего среднего с двумя различными интервалами сглаживания N1 и N2:
S1(i)=S*(i)◆ (N1); S2(i)=S*(i)◆ (N2).
Здесь знак ◆ обозначает процедуру усреднения данных:
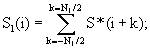
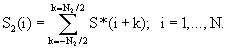
Существенно то, что N1 должно быть в несколько раз больше N2. Например, N1=40, a N2=8.
Далее выполняют вычитание результатов усреднения одного из другого: S3(i)=S2(i)-S1(i); i=1...N.
Затем среди всех полученных значений ищется максимум и запоминается:
МАХ=mах[S3(i)]; i=1...N.
Далее осуществляется поиск первого текущего локального максимума Мс и его расположения Р(Мс) в заданном диапазоне значений текущего индекса i:
Mc=mах[S3(i)]; Р(Мс)=аrg mах[S3(i)]; L<i<H.
ГФД - границы формантных диапазонов задают для каждой форманты в виде двух чисел (верхней и нижней границ допустимости). В начале работы алгоритма текущие границы поиска максимума L и Н устанавливают равными ГФД для первой форманты, затем последовательно изменяются на ГФД для других формант.
Далее выполняется поиск ближайших слева и справа к найденному Мс минимумов M1 и М2:
M1=min[S3(i)]; L<i<P(Mc) М2=min[S3(i)]; Р(Mc)<i<H.
Затем выполняют проверку: превышают ли разности найденного текущего максимума и соседних минимумов, деленные на глобальный максимум МАХ, заданного порога T1.
Если “Нет”, то найденный максимум отбрасывают, левая текущая граница поиска максимумов приравнивается найденному положению текущего максимума, выполняются проверки не превышения левой границы правой границы диапазона и поиск текущего максимума повторяется.
Если “Да”, то выполняется проверка, превышает ли найденный в данном формантном диапазоне текущий максимум прежнего максимума, ранее найденного в данном формантном диапазоне. Если “Нет”, то поиск нового максимума снова повторяется, а если “Да”, то выполняется проверка, превышает ли разность положения двух последовательно расположенных найденных формантных частот заданный порог. Если “Да”, то положение найденного максимума запоминается как соответствующая компонента вектора частот формант. Если "Нет", то поиск текущего максимума возобновляется.
Перед началом нового поиска текущего максимума происходит переприсвоение новых границ поиска часто формант, если диапазон поиска предыдущей форманты уже “пройден”. Кроме того, выполняются проверки: не превышено ли максимальное число формант и были ли в процессе выделения найдены допустимые формантные максимумы вообще.
Литература
1. Патент США №6411930, МПК G 10 L 15/08, 25.06. 2002.
2. Патент США №5995927, МПК G 10 L 9/00, 30.11.1999.
3. Патент РФ №2047912, МПК G 10 L 7/06, опубликован 10.11.1995.
4. Патент США №5265191, МПК G 10 L 005/00, опубликован 23.11.1993.
5. Патент РФ №2161826, МПК G 10 L 17/00, опубликован 10.01.2001.
6. Патент США №5339385, МПК G 10 L 9/00, опубликован 16.08.1994.
7. Патент США №6389392, МПК G 10 L 17/00, опубликован 14.05.2002.
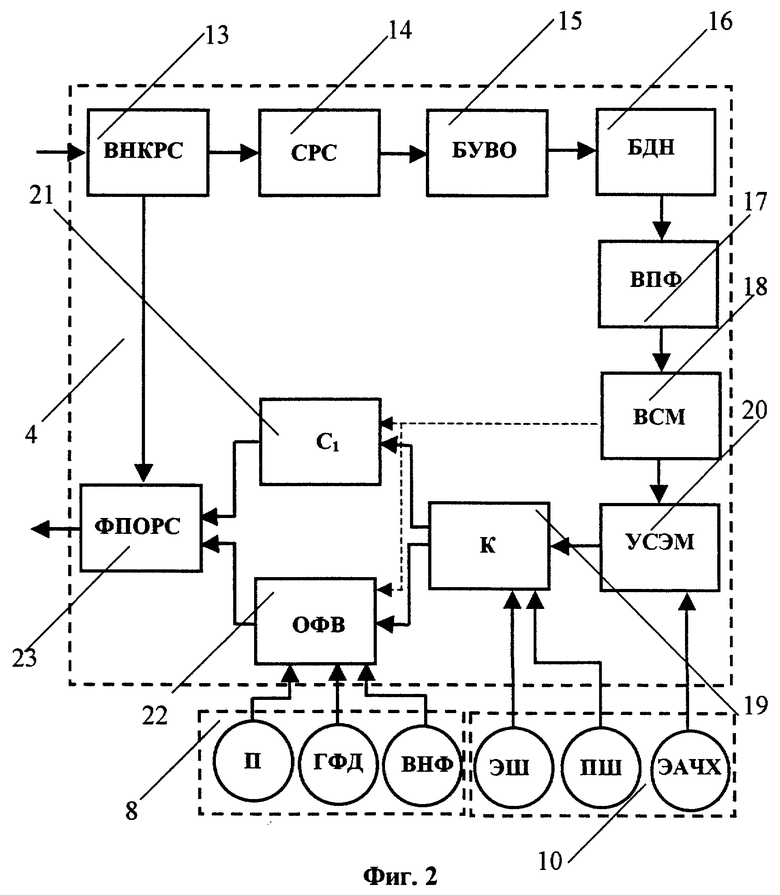
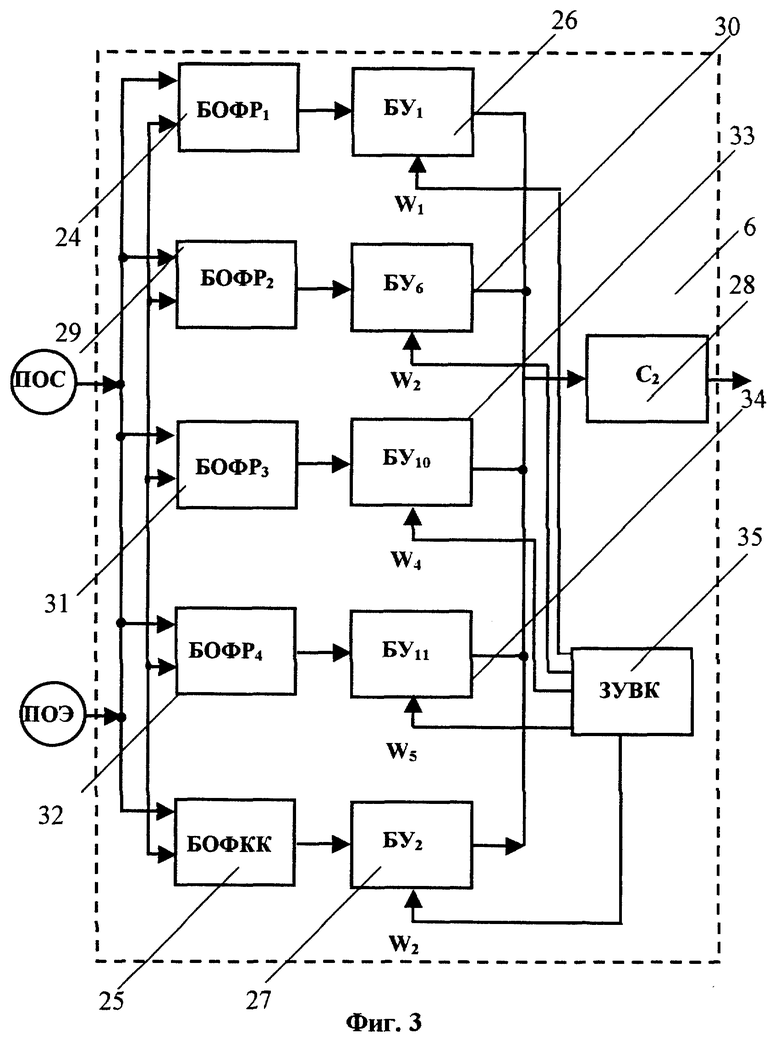
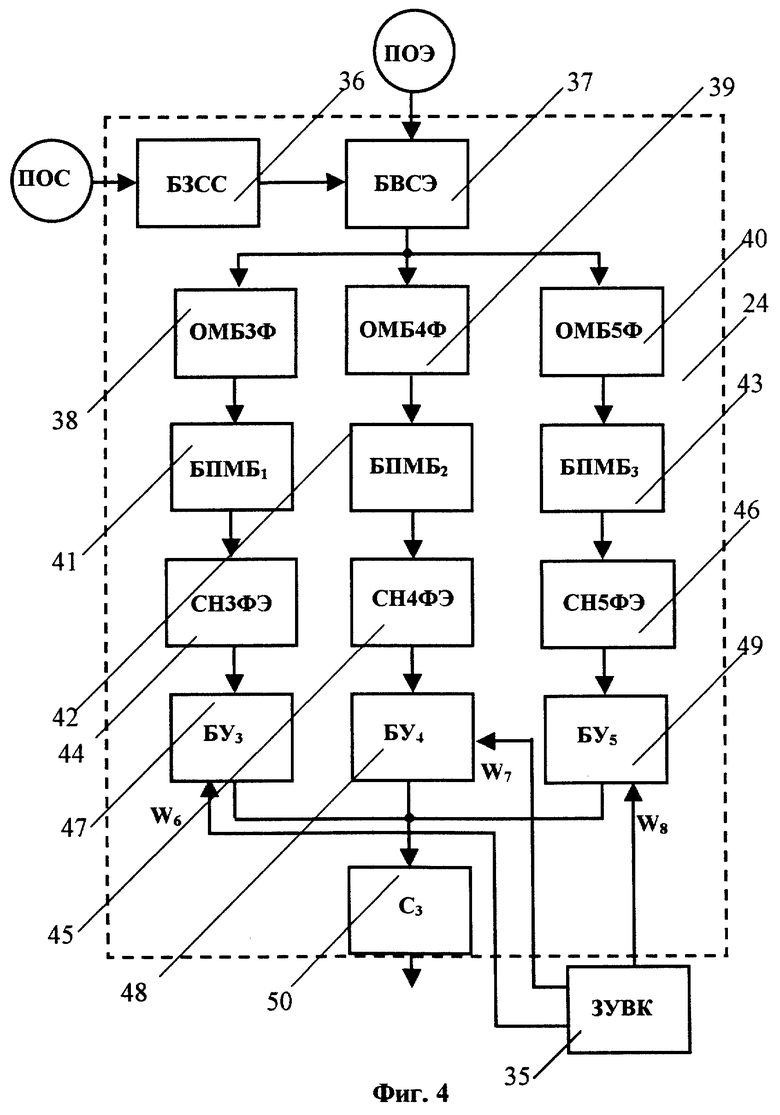
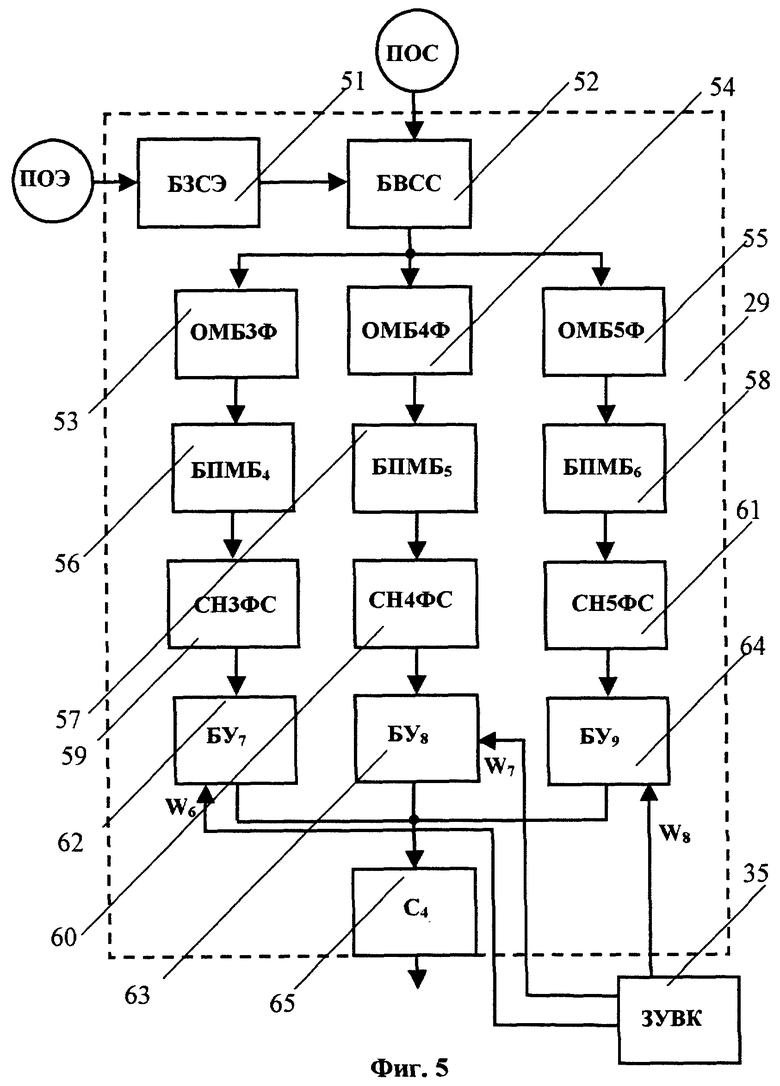
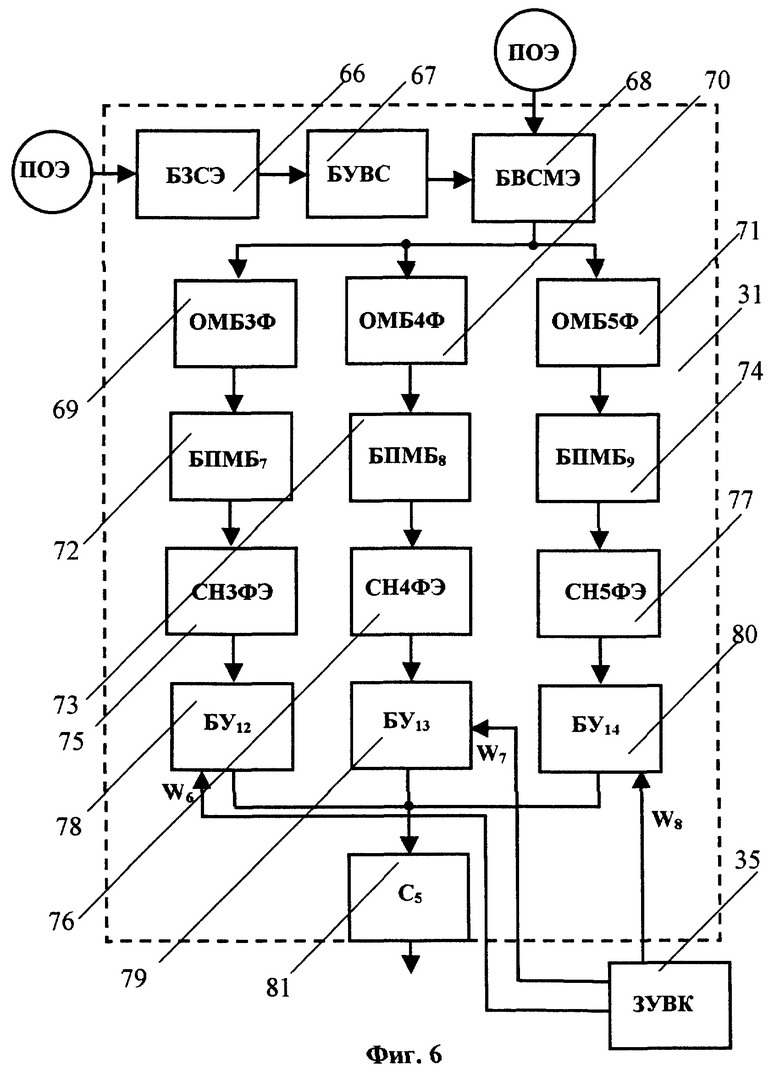
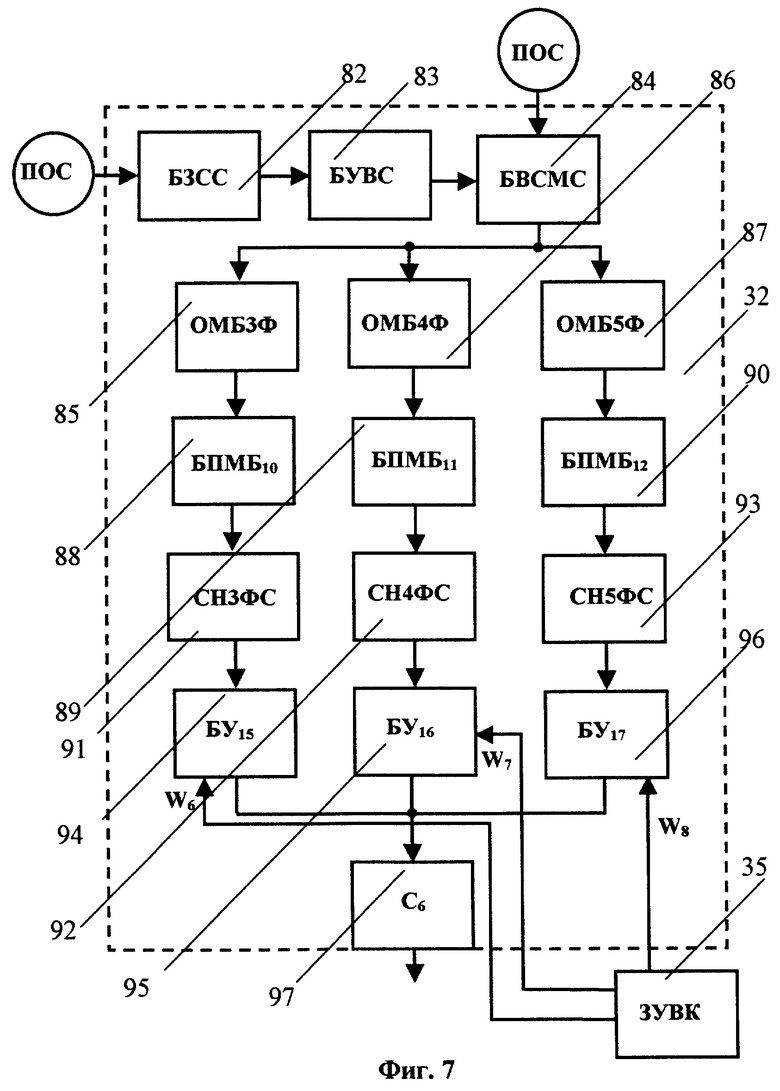
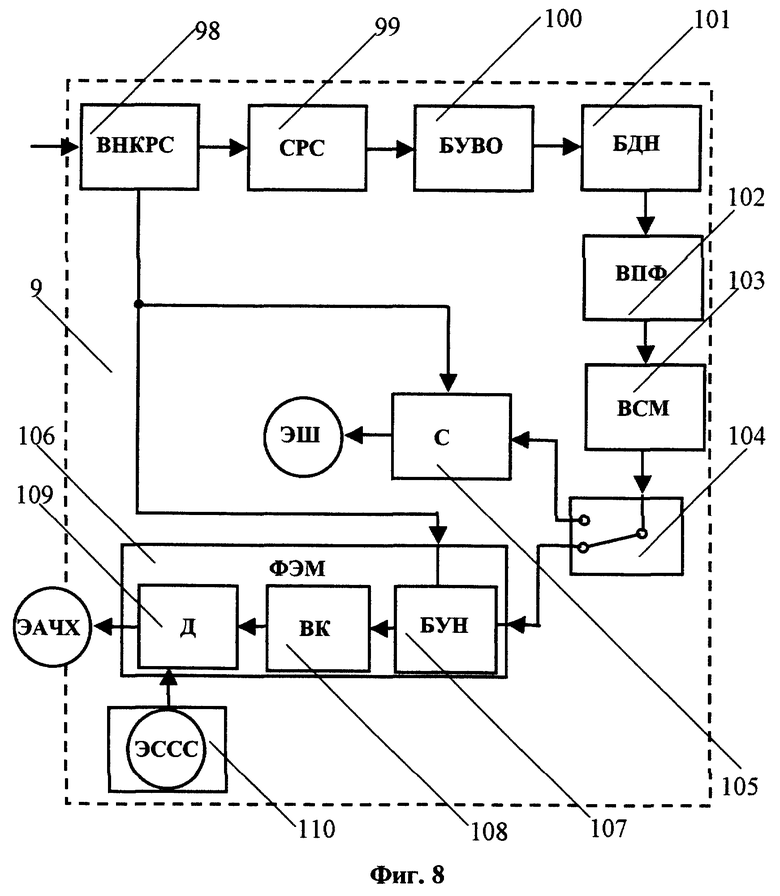
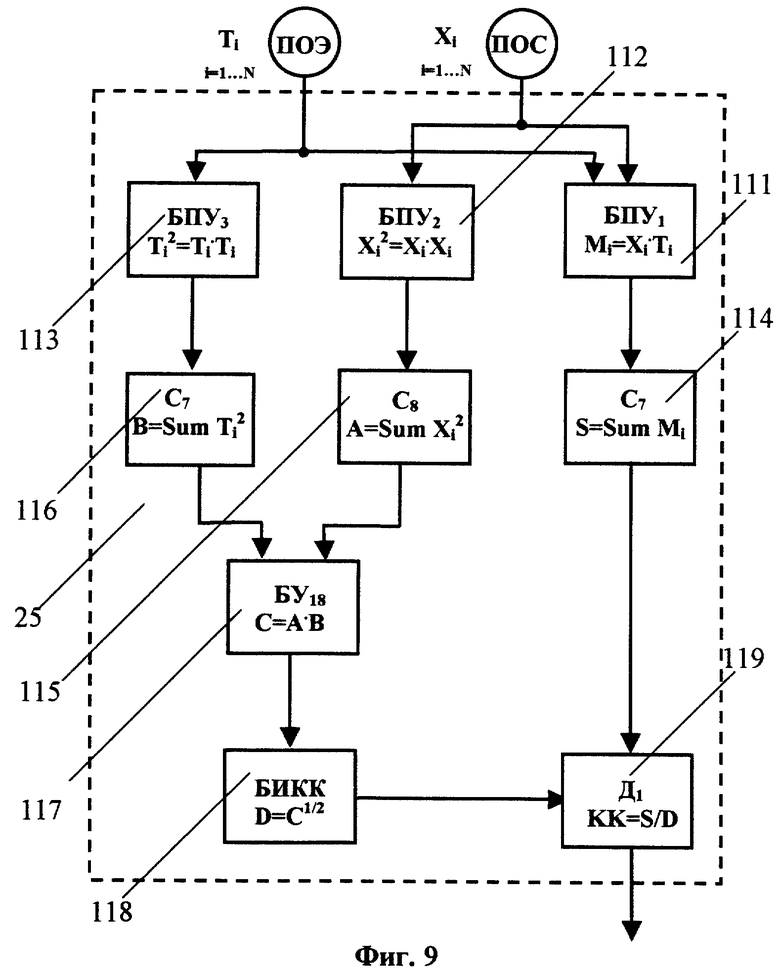
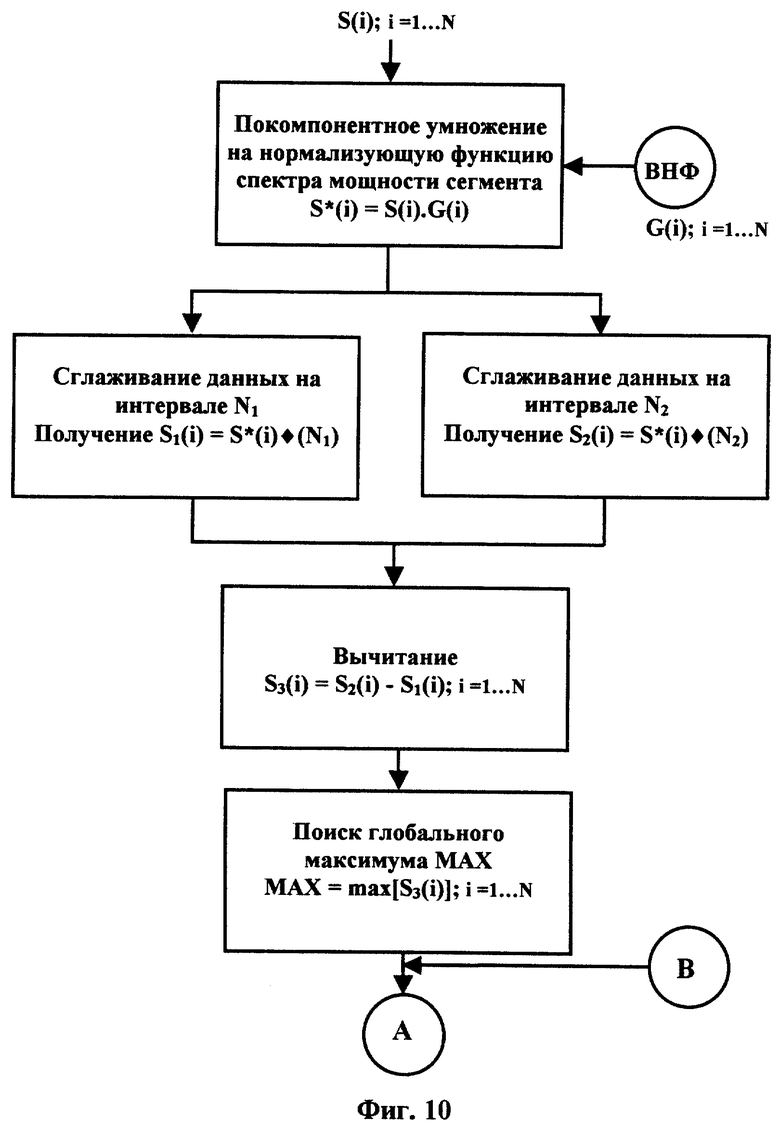
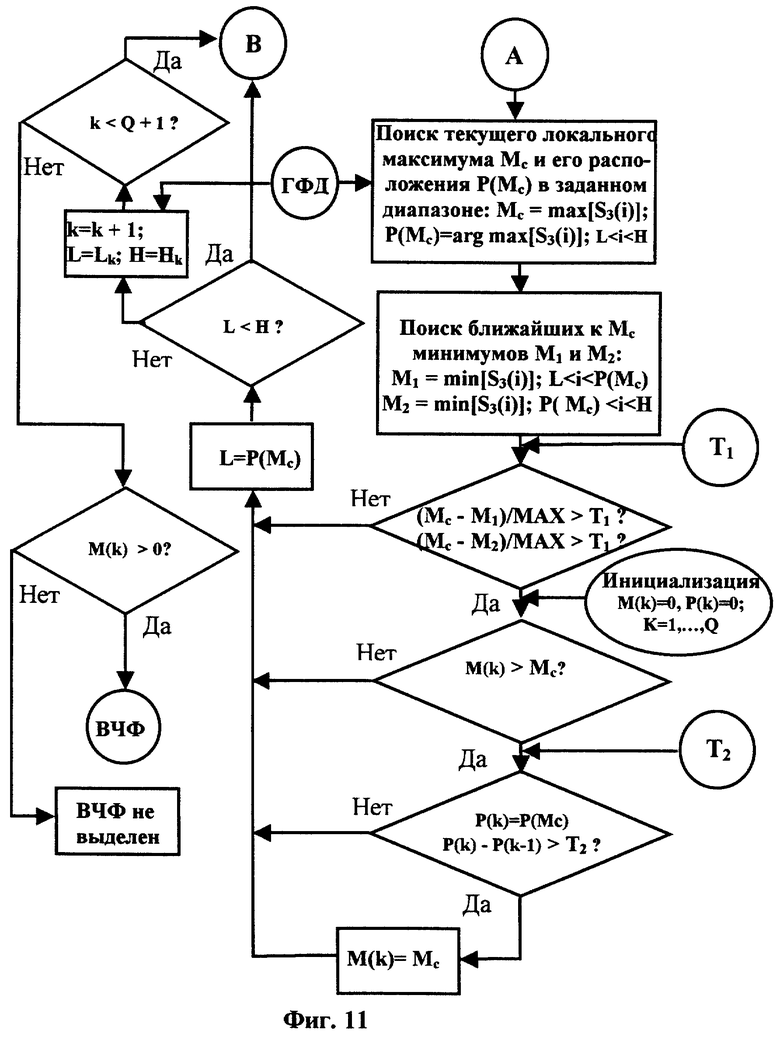
Изобретение относится к области техники анализа речи, в частности к системам ограничения несанкционированного доступа к материальным или информационным ресурсам на основе биометрической информации о говорящем. Техническим результатом является повышение надежности распознавания дикторов и обеспечение высокой помехоустойчивости распознавания при наличии шумов и использовании низкокачественных микрофонов. Технический результат достигается тем, что используют в качестве параметрического описания речевого сигнала сочетания сильно отличающихся по различительным свойствам сегментных признаков векторов формант и статистических характеристик речевого сигнала всего произнесения пароля в целом, а также используют нестандартную неевклидовую меру близости при сравнении формантных векторов двух отдельных сегментов с последующим ее применением к определению статистического сходства сегментных формантных структур речевого сигнала сравниваемых произнесений на основе поиска наилучшего приближения. 2 с. и 18 з.п. ф-лы, 11 ил.
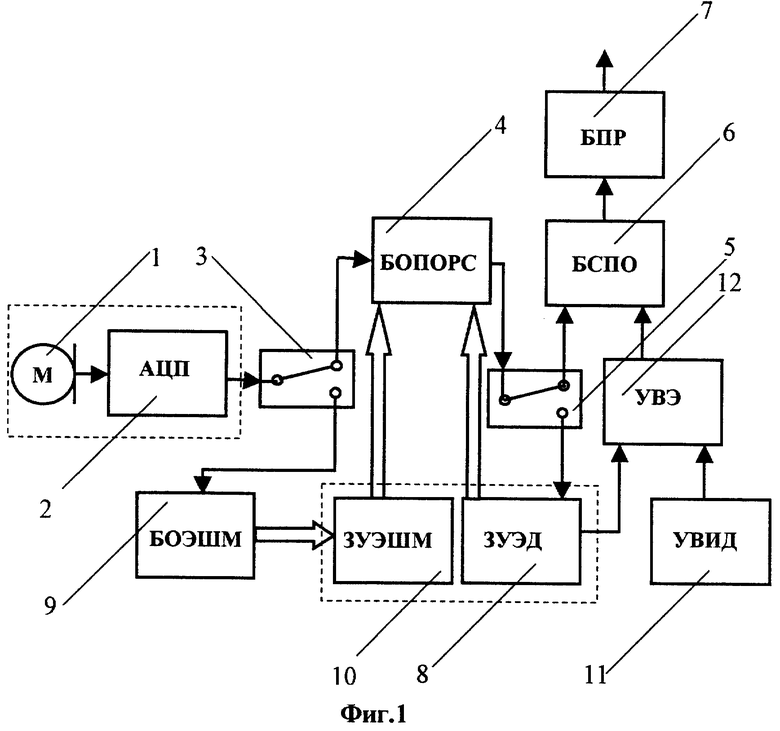
| US 6389398, 14.05.2002 | |||
| СПОСОБ АВТОМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 1998 |
|
RU2161826C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ | 1996 |
|
RU2107950C1 |
| Способ идентификации говорящего | 1986 |
|
SU1453442A1 |
| Работомер, преимущественно для тракторов | 1947 |
|
SU77772A1 |
| WO 9850908, 11.05.1998. | |||
