Область техники, к которой относится изобретение
Настоящее изобретение относится, в общем, к компьютерным системам, более конкретно к усовершенствованным системе и способу для обнаружения списка в рукописных входных данных.
Предшествующий уровень техники
Способность обнаруживать список является важной для пользователей, чтобы они могли писать и рисовать непосредственно на их компьютерах, используя рукописный ввод или рукописные пометки. Современные аппаратные и программные средства могут обеспечить достаточно приемлемый ввод рукописных входных данных, но на текущий момент они не могут на аналогичном уровне обнаружить и представить смысловое значение рукописных структур, таких как состоящий из пунктов список в рукописных входных данных. В результате, вместо этого пользователи могут использовать основывающиеся на меню прикладные программы для создания структур для текста, таких как список. Разнообразные структуры могут быть представлены пользователю посредством таких прикладных программ для выбора и/или использования при форматировании введенного текста. Например, прикладная программа для обработки текстов может включать в себя опцию меню для форматирования текста в виде промаркированного или пронумерованного списка, состоящего из пунктов.
Исследования, сфокусированные на распознавании рукописных объектов, на текущий момент не дали существенных результатов. Например, использовались инкрементальные алгоритмы распознавания, которые могут распознавать простые геометрические формы, такие как круг или прямоугольник, из заданного количества штрихов, выполненных в конкретном порядке. Однако такие инкрементальные алгоритмы основываются на порядке штрихов и/или предполагают конкретное количество штрихов для распознавания конкретного рукописного объекта. Такой подход не обеспечивает надежности по некоторым причинам. Во-первых, ни один из инкрементальных алгоритмов не решает задачу группирования при принятии решения в отношении того, какой набор штрихов принадлежит единому целому, поскольку эти штрихи представляют определенную структуру или форму. Без этой способности группировать вместе штрихи, которые принадлежат структуре или форме, инкрементальные алгоритмы непригодны для состоящих из множества штрихов структур, таких как списки.
Имеется потребность в способе обнаружения и представления смыслового значения рукописных структур, который будет нечувствителен к порядку ввода штрихов и/или количеству штрихов, требующихся для формирования заданной структуры. Любые подобные система и способ должны быть способны обнаруживать состоящие из множества штрихов рукописные структуры и принимать решение в отношении того, какой набор штрихов принадлежит к единому целому, которое представляет рукописную структуру.
Сущность изобретения
Вкратце, настоящее изобретение обеспечивает систему и способ для обнаружения списка в рукописных входных данных. С этой целью обеспечивается средство обнаружения, которое может обнаружить список, такой как промаркированный или пронумерованный список, состоящий из пунктов, в рукописных входных данных. Средство обнаружения может включать в себя средство обнаружения потенциального списка для выбора группы строк, которая может образовать список в рукописных входных данных, средство обнаружения отступа списка для обнаружения уровня отступа рукописной строки в списке, средство обнаружения маркера в рукописной строке в списке и средство обнаружения структуры строки для обеспечения структуры списка.
Посредством настоящего изобретения можно обнаруживать и представлять смысловое значение рукописной структуры, такой как список, посредством изначального выполнения идентификации потенциального списка для выбора группы строк, которая может образовывать список в рукописных входных данных. Для каждой строки из потенциального списка можно также выполнить кластеризацию по уровню отступа для группирования уровней отступа потенциального списка. Затем можно выполнить обнаружение маркера для идентификации маркера, такого как графический или буквенно-цифровой маркер, в рукописной строке в рукописных входных данных. Наконец, можно определить структуру списка, включая взаимосвязь между пунктами списка, и потенциальный список может быть удостоверен в качестве действительного списка, включающего в себя по меньшей мере два промаркированных пункта.
В одном варианте осуществления обнаружение маркера можно выполнить посредством обнаружения партнеров по маркеру, которые представляют собой пары строк с одинаковым уровнем отступа, которые могут начинаться с потенциальных маркеров с аналогичными признаками. Признаки потенциальных маркеров в упомянутой паре строк можно использовать для определения вероятности того, что эта пара строк может представлять собой партнеров по маркеру. Если вероятность, соответствующая признакам потенциальных маркеров, превосходит пороговое значение, то пара строк может считаться партнерами по маркеру, и потенциальные маркеры можно считать действительными маркерами. В противном случае, потенциальный маркер можно считать действительным маркером, если строка потенциального маркера является членом набора уровня отступа, который имеет поднабор партнеров по маркеру, и определено, что отношение количества строк в упомянутом наборе партнеров по маркеру к количеству строк в наборе уровней отступа превосходит пороговое значения.
Преимуществом является то, что система и способ являются нечувствительными к порядку ввода штрихов и количеству штрихов, которые могут образовывать рукописную структуру. Другие преимущества станут очевидны из нижеследующего подробного описания, приведенного совместно с чертежами.
Перечень фигур чертежей
На чертежах:
Фиг.1 - блок-схема, в общем виде иллюстрирующая компьютерную систему, в которую настоящее изобретение может быть встроено.
Фиг.2 - блок-схема, в общем виде представляющая иллюстративную архитектуру компонентов системы для обнаружения списка в рукописных входных данных, согласно аспекту настоящего изобретения.
Фиг.3 - блок-схема последовательности операций, в общем виде представляющая этапы, выполняемые с целью обнаружения списка в рукописных входных данных и генерирования структуры списка, согласно аспекту настоящего изобретения.
Фиг.4 - иллюстративное изображение, в общем виде представляющее структурную взаимосвязь рукописных объектов в рукописных входных данных для использования при выполнении обнаружения списка, согласно аспекту настоящего изобретения.
Фиг.5 - блок-схема последовательности операций, в общем виде представляющая один вариант осуществления этапов, выполняемых с целью обнаружения списка, согласно аспекту настоящего изобретения.
Фиг.6 - блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых с целью идентификации потенциального списка, согласно аспекту настоящего изобретения.
Фиг.7 - иллюстративное изображение, в общем виде представляющее потенциальные списки, согласно аспекту настоящего изобретения.
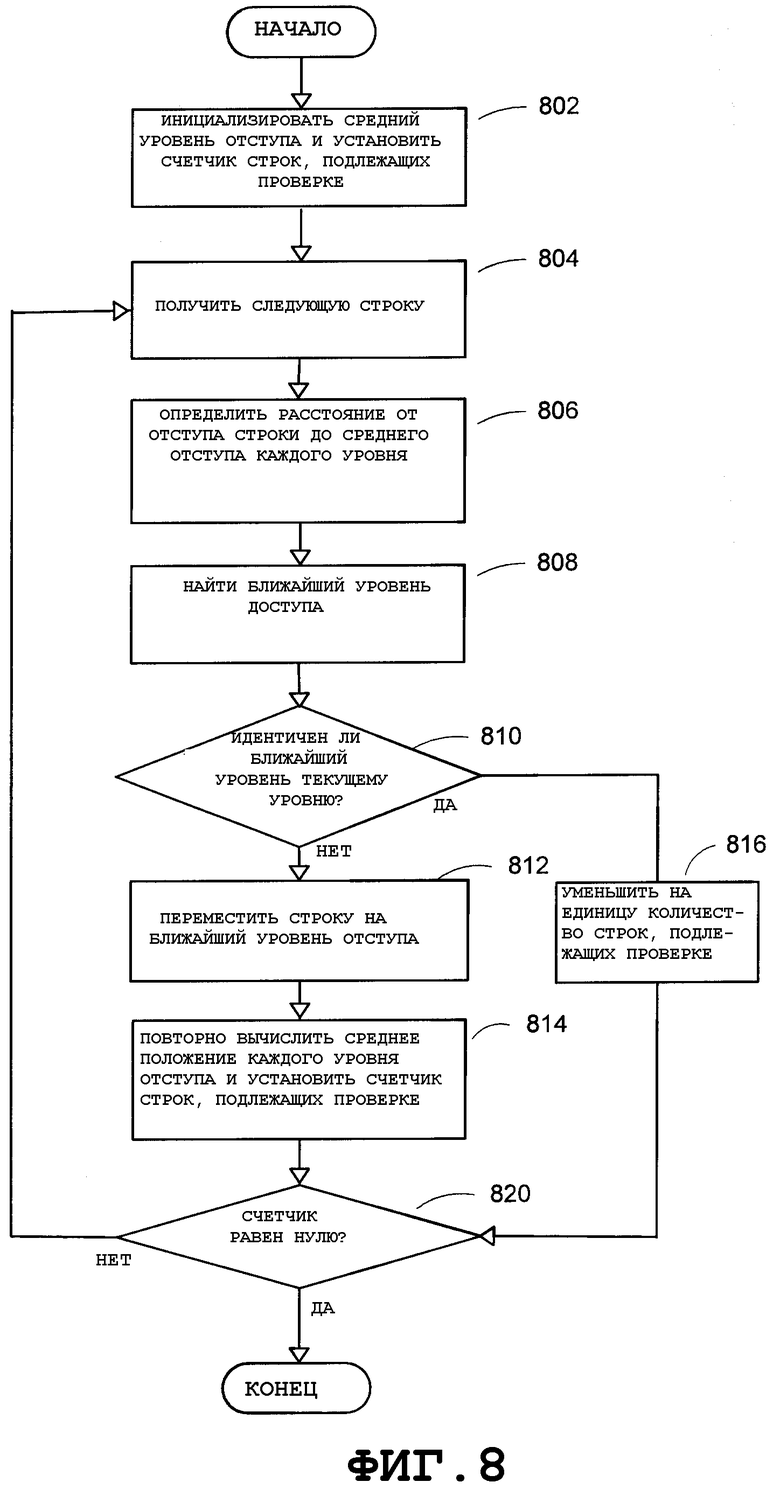
Фиг.8 - блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых с целью кластеризации по уровню отступа, согласно аспекту настоящего изобретения.
Фиг.9 - иллюстративное изображение, в общем виде представляющее потенциальный список после кластеризации по уровню отступа, согласно аспекту настоящего изобретения.
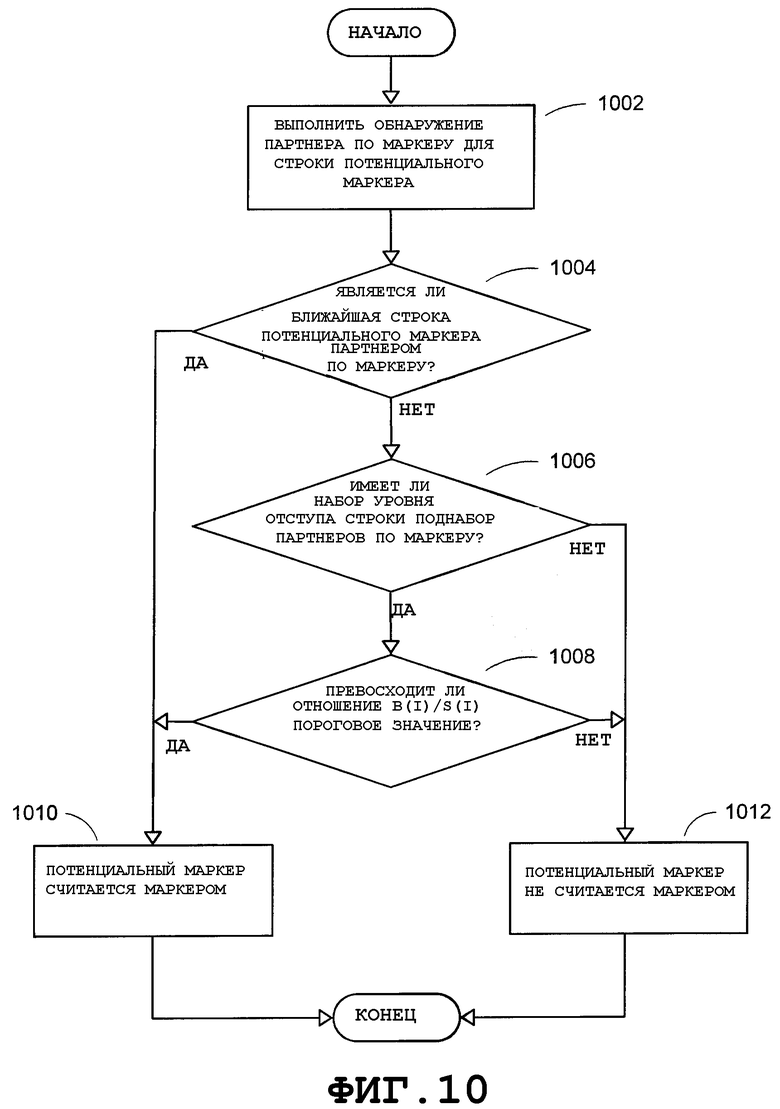
Фиг.10 - блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых с целью выполнения обнаружения маркера, согласно аспекту настоящего изобретения.
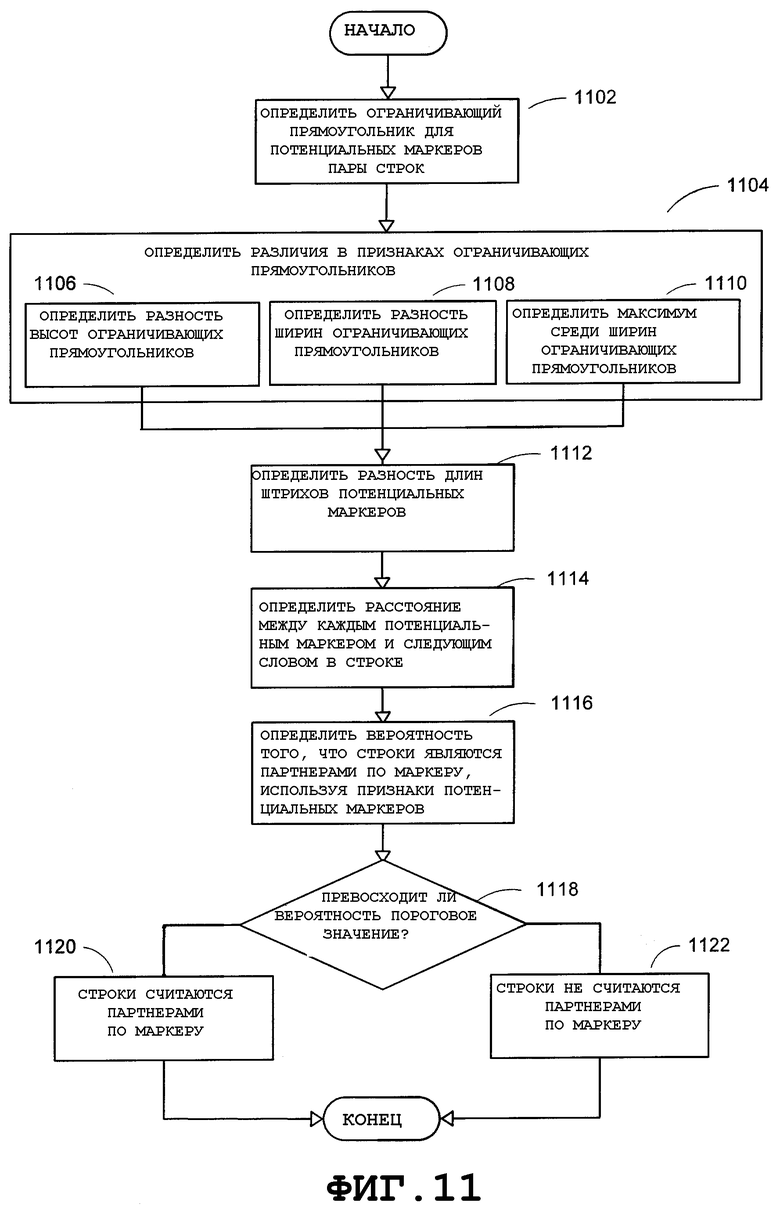
Фиг.11 - блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых с целью выполнения обнаружения партнера маркера, согласно аспекту настоящего изобретения.
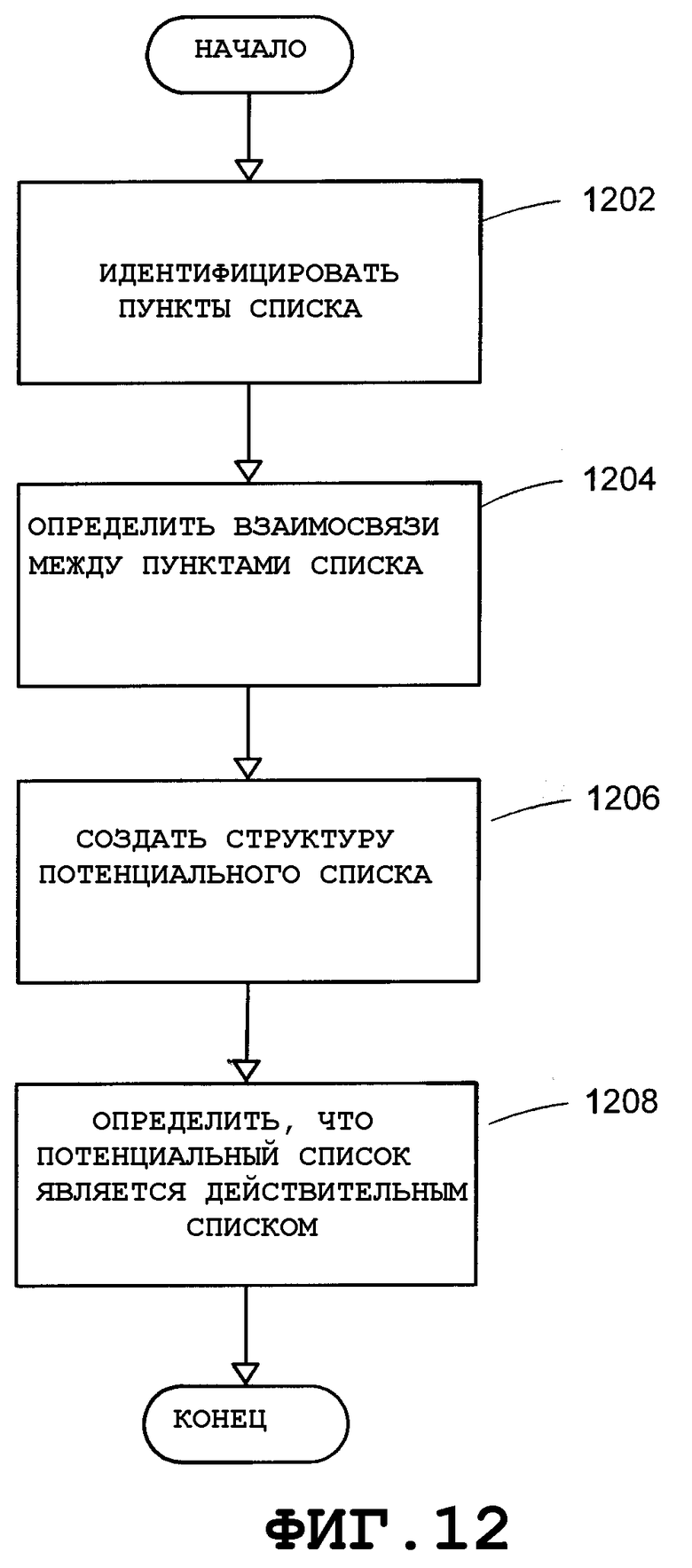
Фиг.12 - блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых с целью определения структуры списка, согласно аспекту настоящего изобретения.
Фиг.13 - иллюстративное изображение, в общем виде представляющее один вариант осуществления структуры потенциального списка, согласно аспекту настоящего изобретения.
Фиг.14 - иллюстративное изображение, в общем виде представляющее структурную взаимосвязь рукописных объектов в рукописных входных данных после выполнения обнаружения списка для объекта-рисунка, согласно аспекту настоящего изобретения.
Подробное описание
Иллюстративная операционная среда
Фиг.1 иллюстрирует пример подходящей среды 100 вычислительной системы, в которой может быть реализовано настоящее изобретение. Среда 100 вычислительной системы представляет собой лишь пример подходящей вычислительной среды, и не подразумевается, что данная среда налагает какое-либо ограничение на объем использования или функциональных возможностей изобретения. Также не следует интерпретировать вычислительную среду 100 как имеющую какую-либо зависимость или требование в отношении какого-либо компонента или их комбинации, проиллюстрированных иллюстративной вычислительной средой 100.
Изобретение также может функционировать с множеством других сред или конфигураций вычислительных систем общего или специального назначения. Примеры широко известных вычислительных систем, сред и/или конфигураций, которые пригодны для практической реализации изобретения, включают в себя, но не в ограничительном смысле, персональные компьютеры, компьютеры-серверы, карманные или переносные устройства, многопроцессорные системы, системы на основе микропроцессоров, телевизионные приставки, программируемую бытовую электронику, сетевые персональные компьютеры (ПК), миникомпьютеры, универсальные компьютеры (мейнфреймы), распределенные вычислительные системы, которые включают в себя любые из вышеперечисленных систем или устройств, и т.п.
Изобретение может быть описано в общем контексте машиноисполняемых команд, таких как программные модули, исполняемые компьютером. В общем случае программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.п., которые выполняют конкретные задания или реализуют определенные абстрактные типы данных. Изобретение также может быть реализовано на практике в распределенных компьютерных средах, где задания выполняются удаленными устройствами обработки данных, которые связаны через сеть связи или другую среду передачи данных. В распределенной вычислительной среде программные модули и другие данные могут быть размещены как на локальных, так и на удаленных компьютерных носителях данных, включая запоминающие устройства.
На Фиг.1 показана иллюстративная система для реализации настоящего изобретения, включающая в себя вычислительное устройство общего назначения в форме компьютера 110. Компоненты компьютера 110 могут включать в себя, но не в ограничительном смысле, процессор 120, системную память 130 и системную шину 121, которая связывает различные компоненты системы, включая системную память 130, с процессором 120. Системная шина 121 может относиться к любому из нескольких типов структур шин, включая шину памяти или контроллер памяти, периферийную шину или порт ускоренной графики, и процессорную или локальную шину, с использованием любой из разнообразия архитектур шин. В качестве примера, а не ограничения, такие архитектуры включают в себя шину архитектуры, соответствующей промышленному стандарту (ISA), шину микроканальной архитектуры (MCA), расширенную шину ISA (EISA), локальную шину ассоциации по стандартам в области видеоэлектроники (VESA) и шину межсоединения периферийных компонентов (PCI), также известную как мезонинная шина.
Компьютер 110 обычно включает в себя разнообразные машиночитаемые носители. Машиночитаемые носители могут представлять собой любой доступный носитель, к которому компьютер 110 может осуществить доступ, и включают в себя как энергозависимые, так и энергонезависимые, как съемные, так и несъемные носители. В качестве примера, а не ограничения, к машиночитаемым носителям относятся компьютерные носители данных и среды передачи. Компьютерные носители данных включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители данных включают в себя, но не в ограничительном смысле, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), электрически стираемое программируемое ПЗУ (EEPROM), флэш-память или память другой технологии, ПЗУ на компакт-диске (CD-ROM), цифровые универсальные диски (DVD) или другой оптический дисковый накопитель, магнитные кассеты, магнитную пленку, магнитный дисковый накопитель или другие магнитные устройства хранения данных, или любой другой носитель, который может использоваться для хранения необходимой информации и к которому компьютер 110 может осуществить доступ. Среды передачи обычно воплощают машиночитаемые команды, структуры данных, программные модули или другие данные в сигнале, модулированном данными, таком как несущая волна или другой механизм транспортировки, и включают в себя любые среды доставки информации. Термин “модулированный данными сигнал” означает сигнал, одна или более характеристик которого установлены или изменены таким образом, чтобы обеспечить кодирование информации в этом сигнале. В качества примера, но не ограничения, среды передачи включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, радиочастотные и другие беспроводные среды. Комбинации любых из вышеприведенных носителей и сред также охватываются понятием “машиночитаемый носитель”.
Системная память 130 включает в себя машиночитаемые носители в форме съемной и/или несъемной, энергозависимой и/или энергонезависимой памяти, например постоянного запоминающего устройства (ПЗУ) 131 и оперативного запоминающего устройства (ОЗУ) 132. Базовая система 133 ввода/вывода (BIOS), содержащая основные процедуры, помогающие переносить информацию между элементами персонального компьютера 130, например, при запуске, хранится в ПЗУ 131. ОЗУ 132 обычно содержит данные и/или программные модули, к которым процессор 120 может осуществить оперативный доступ или которые обрабатываются процессором 120 в текущий момент. В качестве примера, но не ограничения, Фиг.5 иллюстрирует операционную систему 134, прикладные программы 135, другие программные модули 136 и данные 137 программ.
Компьютер 110 может также включать в себя другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных. Исключительно в качестве примера, на Фиг.1 показан накопитель 141 на жестких магнитных дисках, который считывает с несъемных энергонезависимых магнитных носителей или записывает на них, дисковод 151 для магнитного диска, который считывает со сменного энергонезависимого магнитного диска 152 или записывает на него, и дисковод 155 для оптического диска, который считывает со сменного энергонезависимого оптического диска 156, такого как CD-ROM или другой оптический носитель, или записывает на него. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных, которые могут быть использованы в иллюстративной операционной среде, включают в себя, но не в ограничительном смысле, кассеты с магнитной лентой, карты флэш-памяти, цифровые универсальные диски, цифровую видеопленку, твердотельное ОЗУ, твердотельное ПЗУ и т.п. Накопитель 141 на жестких магнитных дисках обычно подключен к системной шине 121 через интерфейс несъемной энергонезависимой памяти, такой как интерфейс 140, а дисковод 151 для магнитного диска и дисковод 155 для оптического диска обычно подключены к системной шине 121 посредством интерфейса съемной энергонезависимой памяти, такого как интерфейс 150.
Дисководы, накопители и соответствующие им компьютерные носители данных, показанные на Фиг.1, обеспечивают хранение машиноисполняемых инструкций, структур данных, программных модулей и других данных для компьютера 110. На Фиг.1, например, накопитель 141 на жестких магнитных дисках показан хранящим операционную систему 144, прикладные программы 145, другие программные модули 146 и данные 147 программ. Следует отметить, что эти компоненты могут либо совпадать с операционной системой 134, прикладными программами 135, другими программными модулями 136 и данными 137 программ, либо отличаться от них. Операционной системе 144, прикладным программам 145, другим программным модулям 146 и данным 147 программ даны здесь другие ссылочные номера с целью иллюстрации того, что, как минимум, они представляют собой другие копии. Пользователь может вводить команды и информацию в компьютер 110 посредством устройств ввода, таких как планшет или электронный цифровой преобразователь 164, микрофон 163, клавиатура 162 и указательное устройство 161, к которому в общем случае относятся мышь, шаровой манипулятор или сенсорная панель. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую панель, спутниковую параболическую антенну, сканер или другие устройства, включая устройство, которое содержит биометрический датчик, датчик состояния окружающей среды, датчик положения или датчик другого типа. Эти и другие устройства ввода подсоединены к процессору 132 посредством интерфейса 160 пользовательского ввода, который подключен к системной шине 121, но могут быть подсоединены посредством других структур интерфейсов и шин, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или устройство отображения другого типа также подсоединены к системной шине 121 через интерфейс, такой как видеоинтерфейс 190. Монитор может быть объединен с панелью сенсорного экрана и т. п. В дополнение к монитору 191, компьютеры часто включают в себя другие периферийные устройства вывода, такие как принтер 196 и громкоговорители 195, которые могут быть подсоединены через периферийный интерфейс 194 вывода.
Компьютер 110 также может работать в сетевой среде, используя логические соединения с одним или более удаленными компьютерами, например удаленным компьютером 180. Удаленный компьютер 180 может представлять собой персональный компьютер, сервер, маршрутизатор, сетевой ПК, одноранговое устройство или другой обычный сетевой узел и обычно включает в себя многие или все элементы, описанные применительно к компьютеру 110, хотя на Фиг.1 показано только запоминающее устройство 181. Логические соединения, показанные на Фиг.1, включают в себя локальную сеть (LAN) 171 и глобальную сеть (WAN) 173, но также могут включать в себя другие сети. Такие сетевые среды обычно имеют место в учреждениях, компьютерных сетях масштаба предприятия, интрасетях и глобальных компьютерных сетях (например, Интернет).
При использовании в сетевой среде LAN компьютер 110 соединен с LAN 171 через сетевой интерфейс или адаптер 170. При использовании в сетевой среде WAN, компьютер 110 обычно включает в себя модем 172 или иное средство для установления связи через WAN 173, такую как Интернет. Модем 172, который может быть внутренним или внешним, подключен к системной шине 121 через интерфейс 160 пользовательского ввода или другой подходящий механизм. В сетевой среде программные модули, показанные применительно к компьютеру 110, или их части, могут храниться в удаленном запоминающем устройстве. В качестве примера, но не ограничения, на Фиг.5 показаны удаленные прикладные программы 185 как находящиеся на запоминающем устройстве 181. Следует понимать, что показанные сетевые соединения являются иллюстративными и могут использоваться другие средства установления линии связи между компьютерами.
Обнаружение списка в рукописных входных данных
Настоящее изобретение в общем ориентировано на систему и способ для обнаружения списка в рукописных входных данных. Пользователь может вычерчивать списки произвольным образом без ограничений в отношении рукописных входных данных. Список может иметь множество штрихов, и порядок ввода штрихов может быть произвольным, так что система и способ могут принимать в качестве входных данных любой рукописный ввод. В настоящем описании под списком понимается структура с по меньшей мере двумя промаркированными пунктами списка, при этом пункт списка включает в себя по меньшей мере одну строку и может включать в себя маркер.
Более конкретно, система и способ могут выбрать группу строк в качестве потенциального списка. Затем для определения структуры списка можно выполнить кластеризацию по уровню отступа и обнаружение маркера. Наконец, можно определить структуру списка, включая взаимосвязь между пунктами списка. Следует понимать, что описываемые здесь разнообразные блок-схемы, схемы последовательности операций и сценарии являются всего лишь примерами и имеется множество других сценариев, к которым применимо настоящее изобретение.
На Фиг.2 показана блок-схема, представляющая в общем виде иллюстративную архитектуру компонентов системы для обнаружения списка в рукописных входных данных. Специалистам в данной области техники должно быть понятно, что функциональные возможности, реализованные в проиллюстрированных на блок-схеме блоках, могут быть реализованы в качестве отдельных компонентов, либо функциональные возможности некоторых или всех из блоков могут быть реализованы в одном компоненте. Например, функциональные возможности средства 206 обнаружения потенциального списка могут быть включены в средство 202 анализа рукописных входных данных. Либо функциональные возможности средства 212 обнаружения структуры списка могут быть реализованы в качестве отдельного компонента.
Средство 202 анализа рукописных входных данных может принимать любые рукописные входные данные, включая рукописные входные данные с объектом-рисунком. Средство 202 анализа рукописных входных данных может включать в себя средство 204 обнаружения списка. В общем, средство 202 анализа рукописных входных данных и средство 204 обнаружения списка могут относиться к исполняемому программному коду любого типа, такому как компонент ядра, прикладная программа, подключаемая библиотека, объект и т. п. Средство 204 обнаружения списка может включать в себя средство 206 обнаружения потенциального списка для выбора группы строк, которые могут образовывать потенциальный список, из рукописных входных данных, средство 208 обнаружения маркера для обнаружения маркера в строке списка, средство 210 обнаружения отступа в списке для обнаружения уровня отступа строки в списке и средство 212 обнаружения структуры списка для обеспечения структуры списка, включая взаимосвязь между пунктами списка. Каждый из этих компонентов также может относиться к исполняемому программному коду любого типа, такому как компонент ядра, прикладная программа, подключаемая библиотека, объект или исполняемый программный код другого типа.
На Фиг.3 показана блок-схема последовательности операций, в общем виде представляющая этапы, выполняемые для обнаружения списка в рукописных входных данных и генерирования структуры списка. На этапе 302 может быть выполнен анализ любых рукописных входных данных, включая рукописные входные данные с рукописной структурой типа списка. Например, в одном варианте осуществления рукописная страница может быть принята в качестве рукописных входных данных и может быть выполнен ее анализ. В этом варианте осуществления средство анализа рукописных входных данных может заранее не иметь информации о рукописных данных на этой странице. Таким образом, могут быть выполнены базовые алгоритмы, такие как алгоритмы группирования слов, классификации письмо/рисунок и группирования рисунков. Для выполнения группирования слов можно сгруппировать штрихи в иерархии слов, строк и блоков. Для этого процесс группирования слов может включать в себя извлечение признаков штрихов для фиксирования расстояния, геометрического несходства и линейности, а также других признаков штрихов. Процесс группирования слов также может включать в себя динамическое программирование для группирования штрихов согласно временной информации. Процесс группирования слов может также включать в себя кластеризацию для группирования штрихов согласно пространственной информации. Слова, строки и блоки, идентифицированные в группах, необязательно должны соответствовать реальным семантическим словам, строкам и блокам. Фактически эти группы могут включать в себя штрихи рукописных структур, таких как список.
Для выполнения классификации письмо/рисунок можно идентифицировать различные признаки, которые могут позволить провести различие между письмом и рисунком. Например, признаки отдельного слова, такие как кривизна, плотность и другие признаки модели рукописного текста, можно использовать для различения письма от рисунка. В одном варианте осуществления контекстные признаки, такие как временные и пространственные контекстные признаки, можно использовать для различения письма от рисунка. Каждый из упомянутых различных признаков можно отобразить на нечеткую функцию, и классификацию между письмом и рисунком можно определить согласно комбинации нечетких функций.
После выполнения группирования слов и классификации письмо/рисунок, штрихи рисунка можно надлежащим образом организовать посредством выполнения группирования рисунка. Для выполнения группирования рисунка штрихи рисунка можно сгруппировать в независимые объекты согласно пространственной связи между ними. Эффективный подход, основывающийся на сетке, можно использовать для аппроксимации рукописных штрихов на сетке изображения с надлежащим размером. Для нахождения соединенных компонентов сетку изображения можно пометить. Каждый соединенный объект может соответствовать объекту-рисунку. Эвристические правила затем могут быть применены для корректировки объектов-рисунков.
Используя строки письма и штрихи рисунка, сгенерированные средством анализа рукописных входных данных, на этапе 304 можно выполнить обнаружение списка с целью определения того, является ли объект-рисунок списком, и если это так, обеспечения структуры списка. При обнаружении списка изначально можно выполнить идентификацию потенциального списка с целью идентификации потенциального списка. Затем также можно выполнить кластеризацию по уровню отступа и обнаружение маркера с целью определения структуры списка. Наконец, можно определить структуру списка. На этапе 306 структура списка может быть сгенерирована в качестве выходных данных. Структура списка может представлять собой иерархическую структуру, например направленный ациклический граф, представляющий структурную взаимосвязь списка.
На Фиг.4 показана иллюстрация, представляющая структурную взаимосвязь рукописных объектов в рукописных входных данных для использования при выполнении обнаружения списка. Корень 402 может представлять рукописные входные данные, такие как рукописная страница, которые могут включать в себя рукописный текст и один или большее количество объектов-рисунков, таких как объекты-рисунки 404 и 406. Структурное представление рукописного текста можно реализовать посредством абзаца 408, который может включать в себя строку 410, имеющую слово 412, сформированное из штрихов 414. Объект-рисунок 404 может иметь связанное с ним содержимое, например текст, структурное представление которого можно реализовать посредством абзаца 408, который может включать в себя строку 410, имеющую слово 412, сформированное из штрихов 414. Рукописная структура, такая как список, может быть обнаружена и ее структура может быть определена в рукописных входных данных 402.
На Фиг.5 показана блок-схема последовательности операций, в общем виде представляющая один вариант осуществления этапов, выполняемых для обнаружения списка. На этапе 502 можно выполнить идентификацию потенциального списка с целью выбора группы строк, которые могут образовывать список в рукописных входных данных. На этапе 504 можно выполнить кластеризацию по уровню отступа для каждой строки потенциального списка для группирования уровней отступа потенциального списка. Отступ строки определяется в настоящем описании как расстояние от левого края строки до левого края списка. Отступы можно группировать по уровням, и отступы на одном уровне являются подобными. Затем, на этапе 506 можно выполнить обнаружение маркера с целью идентификации маркера. Маркер может быть скомпонован из одного или нескольких штрихов и может быть началом строки. В общем случае имеется два типа маркеров: графические маркеры и буквенно-цифровые маркеры. Графические маркеры могут включать в себя точку, тире, кружок, прямоугольник и т. п. Форма графических маркеров обычно является подобной. Буквенно-цифровые маркеры могут включать в себя знак алфавита, число или комбинацию знаков алфавита и/или чисел. Обычно последовательность буквенно-цифровых маркеров является инкрементальной. Маркеры на одном уровне отступа обычно относятся к одному типу. Наконец, структуру списка можно определить на этапе 508, включая взаимосвязь между пунктами списка. Далее потенциальный список может быть утвержден в качестве действительного списка, если он включает в себя по меньшей мере два промаркированных пункта.
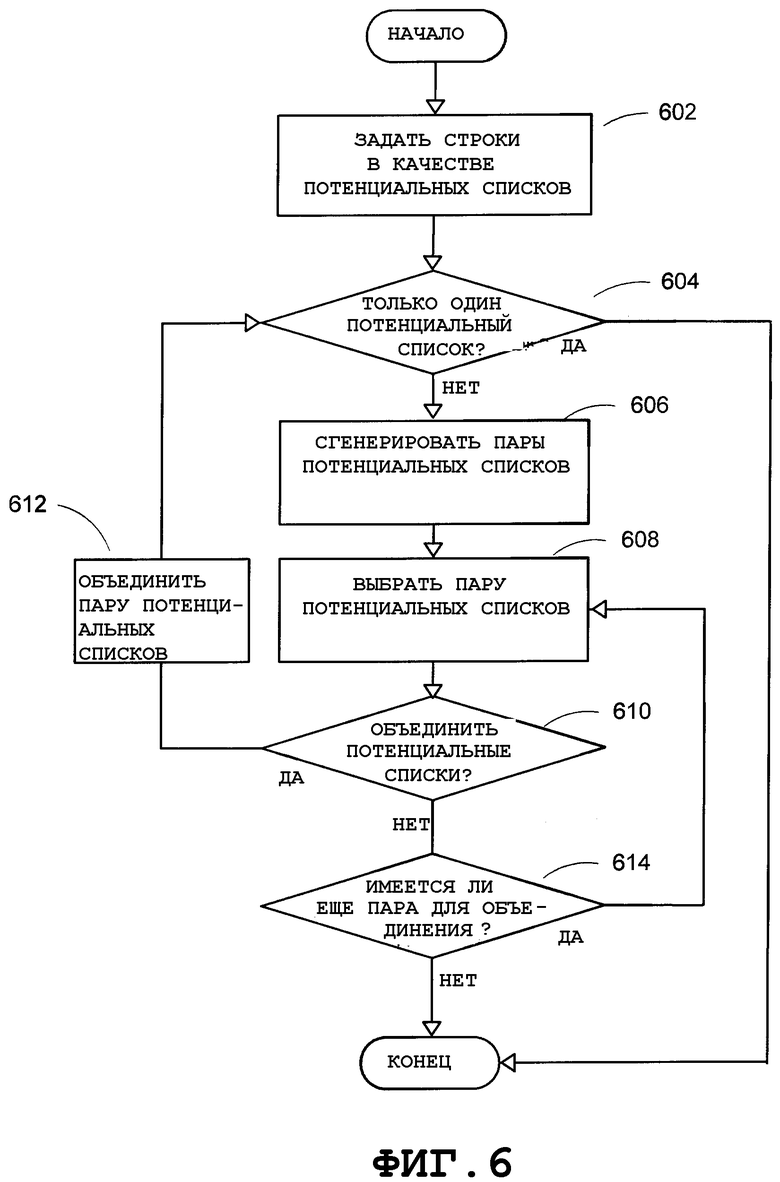
На Фиг.6 показана блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых для идентификации потенциального списка. На этапе 602 каждая из рукописных строк, вводимых в средство обнаружения списка, может быть задана в качестве потенциального списка. В одном варианте осуществления средство обнаружения списка может обрабатывать только одну группу таких строк за раз. На этапе 604 может быть определено, имеется ли в группе строк, заданных в качестве потенциальных списков, только один потенциальный список. Если это так, то идентификацию потенциального списка можно завершить. Если нет, то на этапе 606 можно сгенерировать пары потенциальных списков. На этапе 608 пару потенциальных списков можно выбрать из сгенерированных пар потенциальных списков. Затем может быть определено, следует ли объединить пару потенциальных списков на этапе 610. Если углы строк в обоих списках почти одинаковы и расстояние по вертикали между соседними строками в списках мало, то потенциальные списки можно объединить в новый потенциальный список на этапе 612, после чего процесс может возвратиться на этап 604. В противном случае, может быть определено на этапе 614, имеется ли другая пара потенциальных списков, которые можно объединить. Если это так, то процесс может возвратиться на этап 608 для выбора пары потенциальных списков. Если нет, процесс идентификации потенциального списка можно завершить.
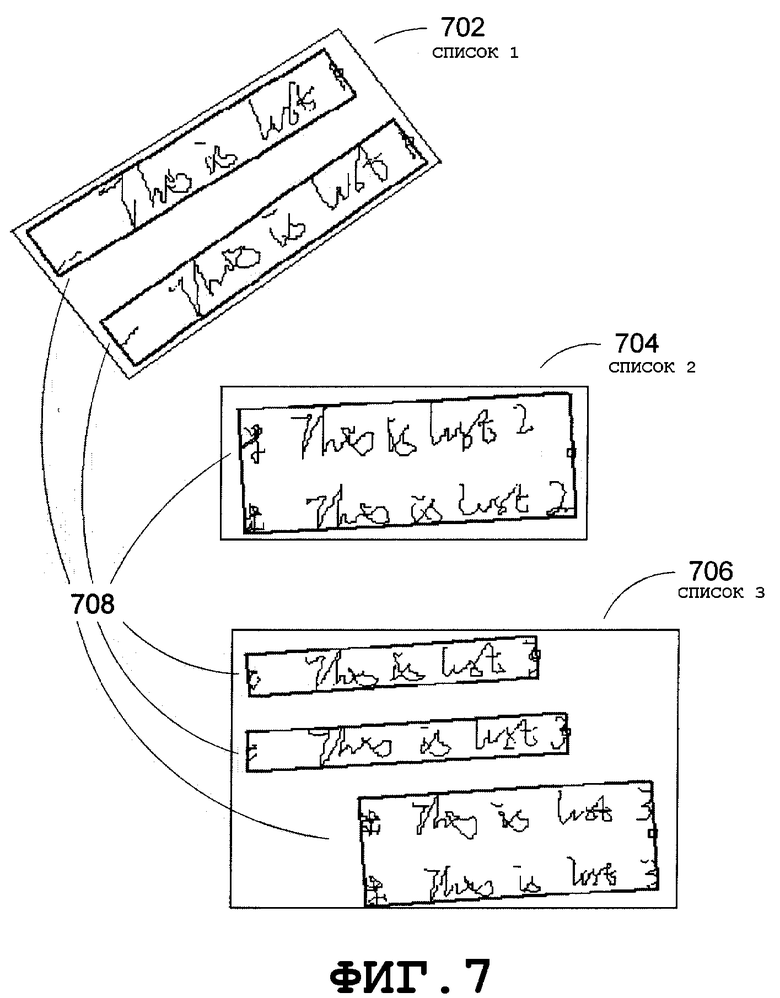
На Фиг.7 приведены примерные иллюстрации, в общем виде представляющие потенциальные списки. Проиллюстрированы три потенциальных списка: список 1 702, список 2 704 и список 3 706. Список 1 702 нельзя объединить со списком 2 704, поскольку слишком велика разность углов строк в обоих списках. Список 2 704 и список 3 706 нельзя объединить, поскольку расстояние по вертикали между последней строкой списка 2 704 и первой строкой списка 3 706 слишком велико. Прямоугольники 708 могут представлять группирование блоков путем группирования слов, выполненного средством анализа рукописных входных данных. Потенциальный список может включать в себя сгруппированные блоки, например три сгруппированных блока в списке 3 706.
На Фиг.8 показана блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых для кластеризации по уровню отступа. Строки потенциального списка можно кластеризовать на группы уровня отступа на основе отступа каждой строки. Для этого отступ каждой строки можно вычислить, а затем отступы можно кластеризовать на несколько групп уровня отступа. Уровень отступа пункта списка может быть равен уровню отступа его первой строки.
В одном варианте осуществления, используемый способ кластеризации по уровню отступа может представлять собой алгоритм кластеризации K-mean (алгоритм, выполняющий разделение на К кластеров таким образом, чтобы сумма расстояний/различий между объектами в пределах одного кластера была минимальна), широко известный в области распознавания образов. Пусть заданы с уровней, m i - средний отступуровня Γi,
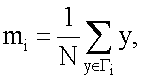
y - отступ строки, N i - количество строк на уровне Γi, J e - сумма квадратичных ошибок всех уровней. Целью кластеризации является минимизация J e, определяемой как
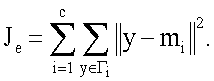
На этапе 802 средний уровень отступа можно инициализировать как  при заданном начальном шаге l отступа, а счетчик подлежащих проверке строк можно установить на количество строк, подлежащих проверке. Для поддержки сценария, согласно которому пользователь может делать рукописные пометки разного размера, в одном варианте осуществления можно использовать нормированный отступ. Например, отступ можно нормировать на среднюю высоту строк в потенциальном списке, в результате чего начальный шаг l отступа может быть равен произведению 1,4 на среднюю высоту строк.
при заданном начальном шаге l отступа, а счетчик подлежащих проверке строк можно установить на количество строк, подлежащих проверке. Для поддержки сценария, согласно которому пользователь может делать рукописные пометки разного размера, в одном варианте осуществления можно использовать нормированный отступ. Например, отступ можно нормировать на среднюю высоту строк в потенциальном списке, в результате чего начальный шаг l отступа может быть равен произведению 1,4 на среднюю высоту строк.
На этапе 804 можно извлечь следующую строку y ∈ Γi. Затем на этапе 806 можно определить расстояние от отступа y до среднего отступа каждой строки. И на этапе 808 можно найти ближайший уровень Γi отступа для y ∈ Γi. На этапе 810, если ближайший уровень отступа равен текущему уровню отступа, то счетчик строк на этапе 816 уменьшается на единицу и для рассматриваемой строки кластеризация по уровню отступа завершается. В противном случае строку можно сместить на ближайший уровень отступа на этапе 812. Затем среднее положение каждого уровня отступа можно вычислить повторно на этапе 814 и счетчик подлежащих проверке строк можно установить равным количеству подлежащих проверке строк. На этапе 820 можно определить, равен ли счетчик строк нулю. Если это так, процесс возвращается на этап 804 для получения следующей строки y ∈ Γi. Если нет, то процесс завершается для отступа на этом уровне.
На Фиг.9 приведена примерная иллюстрация потенциального списка после кластеризации по уровню отступа. Потенциальный список 902 имеет шесть строк. В конце кластеризации по уровню отступа строки 1, 3 и 5 находятся на уровне 1 отступа, а строки 2, 4 и 6 находятся на уровне 2 отступа. Овал 904 окружает маркеры строк на уровне 1 отступа, а овал 906 окружает маркеры строк на уровне 2 отступа.
Обнаружение маркера можно выполнить после кластеризации по уровню отступа. Посредством обнаружения маркера можно обнаружить, включают ли пункты списка маркер. Первое слово каждой строки в списке можно, таким образом, рассматривать как потенциальный маркер для процесса обнаружения маркера. На основе эмпирических наблюдений, если две строки в списке имеют одинаковый уровень отступа и начинаются с маркера, то маркеры этих двух строк обычно представляют собой одинаковые символы, например графические маркеры или буквенно-цифровые маркеры. Следовательно, две строки в списке на одном и том же уровне отступа могут обе, по всей вероятности, начинаться с маркера, если потенциальные маркеры этих двух строк имеют аналогичные признаки. Таким образом, в настоящем описании две строки в списке с одинаковым уровнем отступа, которые начинаются с потенциальных маркеров с аналогичными признаками, определены как партнеры по маркеру. Одна из двух таких строк является партнером по маркеру для другой. Следует отметить, что партнеры по маркеру могут быть соседними строками или не быть таковыми. При обнаружении маркера потенциальные маркеры партнеров по маркеру можно рассматривать как маркеры.
На Фиг.10 показана блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых для обнаружения маркера. На этапе 1002 можно выполнить обнаружение партнеров по маркеру для строки потенциального маркера. На этапе 1004 можно проверить соседние строки потенциального маркера, находящиеся на том же самом уровне отступа, с целью определения того, является ли соседняя строка партнером по маркеру рассматриваемой строки потенциального маркера. Если это так, то потенциальный маркер может считаться маркером на этапе 1010. Если ни один партнер по маркеру не был обнаружен, тогда на этапе 1006 можно определить, является ли строка потенциального маркера членом набора уровня отступа, который имеет поднабор партнеров по маркеру. Если не является, то потенциальный маркер нельзя считать маркером, на что указывается на этапе 1012. Если же строка потенциального маркера является членом набора уровня отступа, который имеет поднабор партнеров по маркеру, и определяемое на этапе 1008 отношение количества строк в наборе партнеров по маркеру к количеству строк в наборе уровня отступа превышает пороговое значение, то потенциальный маркер можно считать маркером, на что указывается на этапе 1010. Если это не так, то потенциальный маркер нельзя считать маркером, на что указывается на этапе 1012. В одном варианте осуществления пороговое значение эмпирически можно установить равным 0,66. Специалистам в данной области техники должно быть понятно, что можно использовать другие пороговые значения.
На Фиг.11 показаны этапы, выполняемые для обнаружения партнеров по маркеру. В одном варианте осуществления при обнаружении партнеров по маркеру можно выполнить проверку в отношении того, является ли каждая пара строк на заданном уровне отступа партнерами по маркеру. Преимуществом является то, что проверка на маркеры парами строк может повысить надежность процесса обнаружения маркеров. Например, если в качестве потенциального маркера попадется плохо сформированный маркер, то это не приведет к сбою в обнаружении других маркеров в этом же списке.
Для повышения скорости анализа, соответствующей процессу обнаружения партнеров по маркеру, можно использовать простые признаки для обнаружения маркера из обычных слов, которые могут появиться в качестве первого слова строки. Эти признаки могут включать в себя использование ширины и высоты ограничивающего прямоугольника вокруг потенциального маркера. Например, размеры ограничивающих прямоугольников графических маркеров и нумерованных маркеров обычно являются одинаковыми, в то время как размеры ограничивающих прямоугольников обычных слов, которые могут появиться в качестве первого слова в строке, могут изменяться в широких пределах. Более конкретно, ограничивающие прямоугольники маркеров зачастую не такие широкие или высокие, как ограничивающие прямоугольники обычных слов, которые могут появиться в качестве первого слова строки. Специалистам в данной области техники должно быть понятно, что можно использовать другие простые признаки, такие как расстояние между потенциальным маркером и следующим словом строки. Обычно расстояние от потенциального маркера до следующего слова строки зачастую больше, чем расстояние между двумя обычными словами в строке.
В одном варианте осуществления следующие пять признаков для обнаружения маркера можно использовать с целью вычисления вероятности того, что две строки могут являться партнерами по маркеру:  ,
,  ,
,  ,
, 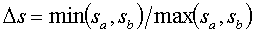 и
и 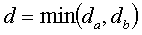 . Для двух потенциальных маркеров a и b ограничивающие прямоугольники, прямоугольник R
a и прямоугольник R
b соответственно могут быть определены на этапе 1102 в угловом положении списка, где встречаются a и b.
. Для двух потенциальных маркеров a и b ограничивающие прямоугольники, прямоугольник R
a и прямоугольник R
b соответственно могут быть определены на этапе 1102 в угловом положении списка, где встречаются a и b.
На этапе 1104 можно определить различия в признаках ограничивающих прямоугольников. Например, на этапе 1106 можно определить разность высот ограничивающих прямоугольников потенциальных маркеров ,
где h(R
a) и h(R
b) - высоты прямоугольника R
a и прямоугольника R
b соответственно. Либо на этапе 1108 можно определить разность ширин ограничивающих прямоугольников потенциальных маркеров , где w(R
a) и w(R
b) - ширины прямоугольника R
a и прямоугольника R
b, соответственно. Либо на этапе 1110 можно определить максимум из ширин ограничивающих прямоугольников потенциальных маркеров .
На этапе 1112 можно определить разность длин штрихов потенциальных маркеров ,
где s
a и s
b представляют собой совокупные длины штрихов потенциальных маркеров a и b соответственно. На этапе 1114 можно определить расстояние до ближайшего слова строки ,
где d a и d b представляют собой расстояния между каждым потенциальным маркером, a и b, и следующим словом соответствующих строк.
Затем на этапе 1116 можно определить вероятность того, что пара строк является партнерами по маркеру, используя признаки потенциальных маркеров. В одном варианте осуществления можно построить нечеткую функцию, которая объединяет признаки, для определения вероятности того, что две строки являются партнерами по маркеру. Эту функцию можно определить следующим образом:
 , α,β,γ,η,κ > 1,
, α,β,γ,η,κ > 1,
где Δh
0, Δw
0, w
0, Δs
0, d
0 представляют собой пороговые значения пяти признаков, а α, β, γ, η, κ можно использовать для регулировки мягкости границы принятия решения. Функция монотонно уменьшается по мере того, как какой-либо признак возрастает от нуля до бесконечности. Если какой-либо признак превосходит свое пороговое значение, то функция будет меньше 0,5. Значение функции равно 1, когда все признаки равны 0, и стремится к нулю, когда какой-либо из признаков стремится к бесконечности. В одном варианте осуществления границу принятия решения можно определить как  . В этом случае
. В этом случае
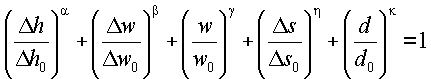 .
.
Далее на этапе 1118 можно определить, превосходит ли вероятность, определяемая нечеткой функцией, пороговое значение, равное 0,5. Если это так, то на этапе 1120 эти две строки можно считать партнерами по маркеру. В противном случае на этапе 1122 эти две строки рассматриваются как не являющиеся партнерами по маркеру.
После обнаружения маркера можно выполнить определение структуры списка, используя результаты кластеризации по уровню отступа и обнаружение маркера. Например, уровень отступа каждой строки можно использовать для определения того, какие строки образуют пункты списка, а также можно использовать для определения взаимосвязи между идентифицированными пунктами списка. Структуру списка также можно определить по наличию маркеров. На Фиг.12 показана блок-схема последовательности операций, в общем виде представляющая вариант осуществления этапов, выполняемых для определения структуры списка.
На этапе 1202 пункты списка идентифицируют посредством определения того, какие строки образуют пункт списка. Для компоновки пункта списка могут быть заданы несколько правил. Например, пункт списка может включать в себя только одну строку, начинающуюся с маркера. Если пункт списка имеет строку, начинающуюся с маркера, то эта строка должна быть первой строкой в пункте списка. Если пункт списка имеет строку с маркером, то уровень отступа строки должен быть меньше или равен уровню отступа любых других строк в пункте списка. Если пункт списка не имеет строки с маркером, то уровень отступа каждой строки в пункте списка может быть одинаковым. Также расстояние по вертикали между соседними строками в пункте списка не должно быть слишком большим.
После идентификации пунктов списка, на этапе 1204 можно определить взаимосвязь между пунктами списка. Существует несколько правил для определения взаимосвязи между пунктами списка. Например, пункт списка может иметь любое количество подпунктов или вообще не иметь их. Уровень отступа пункта списка может быть меньше, чем уровень отступа его подпунктов. Уровень отступа может быть одинаковым для подпунктов пункта списка. Пункт списка может иметь один родительский пункт или вообще не иметь их.
На этапе 1206 можно создать структуру потенциального списка из пунктов списка. Структура потенциального списка может представлять собой иерархическую структуру, такую как ациклический направленный граф или дерево, которая может включать в себя пункт списка конкретного уровня отступа в потенциальном списке на определенном уровне дерева. Наконец, на этапе 1208 может быть определено, что потенциальный список является действительным списком, если в потенциальном списке имеется по меньшей мере два маркера.
На Фиг.13 показана примерная иллюстрация одного варианта осуществления структуры потенциального списка. Структура 1302 потенциального списка включает в себя несколько строк, пронумерованных в верхнем левом углу строк, и иллюстрирует несколько примеров пунктов списка. Например, строка 2 может образовывать пункт 1304 списка. Строки 4 и 5 могут образовывать пункт 1306 списка, поскольку только строка 4 начинается с маркера и строка 4 также является первой строкой в пункте потенциального списка. Помимо этого, уровень отступа строки 4 и строки 5 один и тот же, уровень 2 отступа 1316. Каждая из строк 6 и 7 находятся на одном и том же уровне отступа, уровне 2 отступа 1316, но каждая формирует отдельный пункт списка, 1308 и 1310 соответственно, поскольку каждая из этих строк начинается с маркера, а пункт списка может включать в себя только одну строку, начинающуюся с маркера. Каждая из строк 8 и 9 находится на одном и том же уровне отступа, уровне 3 отступа 1318, и каждая стока сама по себе формирует отдельный пункт списка, 1312 и 1314 соответственно, поскольку каждая из этих строк начинается с маркера, а пункт списка может включать в себя только одну строку, начинающуюся с маркера.
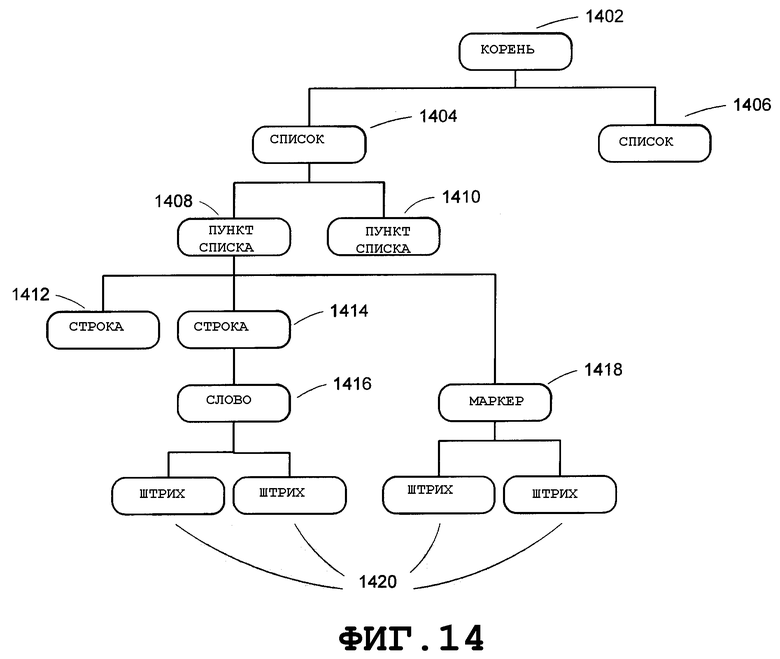
После обнаружения списка и определения его структуры далее может быть выяснена структурная взаимосвязь рукописных объектов. На Фиг.14 приведена примерная иллюстрация, в общем виде представляющая структурную взаимосвязь рукописных объектов в рукописных входных данных после выполнения обнаружения списка в отношении объекта-рисунка. Корень 1402 может представлять собой рукописные входные данные, такие как рукописная страница, которые могут включать в себя одну или большее количество структур, таких как список 1404 и список 1406. Список может включать в себя один или большее количество пунктов 1408 и 1410 списка. Пункт списка может включать в себя одну или большее количество строк, таких как строки 1412 и 1414, и один или большее количество маркеров, например маркер 1418. Каждая строка может включать в себя текст, который структурно может быть представлен одним или большим количеством слов, таких как слово 1416, которое может быть образовано штрихами 1420. Каждый маркер может быть образован штрихами 1420.
После того как все списки обнаружены посредством вышеописанных системы и способа, рукописные объекты в рукописных входных данных могут быть полностью обнаружены и их структуры распознаны. Используя настоящее изобретение, пользователь может вычерчивать списки произвольным образом без каких-либо ограничений в отношении рукописных входных данных. Список может включать в себя множество штрихов, и порядок ввода штрихов может быть произвольным, так что система и способ могут принимать любой рукописный ввод в качестве входных данных. Можно распознать структуру списка, включая взаимосвязь между пунктами списка.
Как следует из вышеприведенного подробного описания, настоящее изобретение предоставляет систему и способ для обнаружения списков. Преимуществом является то, что система и способ являются нечувствительными к порядку ввода штрихов и количеству штрихов, которые могут образовывать рукописный список. Более того, предлагаемые система и способ являются гибкими и расширяемыми. В соответствии с текущим пониманием, настоящее изобретение можно использовать для обнаружения любого списка в рукописных входных данных, такого как промаркированный или пронумерованный список, состоящий из пунктов, включая распознавание структуры списка. Таким образом, способ и система обеспечивают значительные преимущества и выгоды, требующиеся в современных вычислениях.
Хотя настоящее изобретение допускает разнообразные модификации и альтернативные конструкции, подробно описаны и показаны на чертежах определенные иллюстративные варианты его осуществления. Следует однако понимать, что при этом не подразумевается, что настоящее изобретение ограничено конкретными раскрытыми формами, напротив, изобретение охватывает все модификации, альтернативные конструкции и эквиваленты, попадающие в рамки сущности и объема изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ДЛЯ ОБНАРУЖЕНИЯ РУКОПИСНЫХ ОБЪЕКТОВ В РУКОПИСНОМ ВВОДЕ ЧЕРНИЛАМИ | 2004 |
|
RU2373575C2 |
| СИСТЕМА И СПОСОБ ДЛЯ РАСПОЗНАВАНИЯ ФОРМЫ РУКОПИСНЫХ ОБЪЕКТОВ | 2004 |
|
RU2372654C2 |
| СИСТЕМА И СПОСОБ ДЛЯ СОХРАНЕНИЯ ДОКУМЕНТА В ПОСЛЕДОВАТЕЛЬНОМ ДВОИЧНОМ ФОРМАТЕ | 2006 |
|
RU2406142C2 |
| РАЗДЕЛИТЕЛЬ ЧЕРНИЛ И ИНТЕРФЕЙС СООТВЕТСТВУЮЩЕЙ ПРИКЛАДНОЙ ПРОГРАММЫ | 2003 |
|
RU2358316C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2351982C2 |
| СПИСКИ АВТОМАТИЧЕСКОГО ЗАПОЛНЕНИЯ И РУКОПИСНЫЙ ВВОД | 2006 |
|
RU2412470C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2358308C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2008 |
|
RU2485579C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2352981C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2326435C2 |





Изобретение относится к компьютерным системам, а именно к усовершенствованным системе и способу для обнаружения списка в рукописных входных данных. Техническим результатом является возможность обнаруживать список, такой как промаркированный или пронумерованный список, состоящий из пунктов, в рукописных входных данных. Для этого сначала выбирают группу строк в качестве потенциального списка. Затем выполняют кластеризацию по уровню отступа и обнаружение маркера для определения структуры списка. Обнаружение маркера выполняют посредством обнаружения партнеров по маркеру, которые представляют собой пары строк с одинаковым уровнем отступа, которые могут начинаться с потенциальных маркеров с аналогичными признаками. Признаки потенциальных маркеров в паре строк используют для определения вероятности того, что упомянутая пара строк является партнерами по маркеру. В заключение определяют структуру списка, включая взаимосвязь между пунктами списка. 4 н. и 31 з.п. ф-лы, 14 ил.
1. Компьютерная система для обнаружения списка в рукописных входных данных, содержащая:
средство обнаружения списка для приема рукописных входных данных;
средство обнаружения потенциального списка, функционально связанное со средством обнаружения списка и предназначенное для выбора группы строк, которые могут образовывать список в рукописных входных данных;
средство обнаружения отступа, функционально связанное со средством обнаружения списка и предназначенное для обнаружения отступа рукописной строки в рукописных входных данных; и
средство обнаружения маркера, функционально связанное со средством обнаружения списка и предназначенное для обнаружения маркера в рукописной строке в рукописных входных данных.
2. Система по п.1, дополнительно содержащая средство анализа рукописных входных данных, функционально связанное со средством обнаружения списка и предназначенное для посылки рукописных входных данных в средство обнаружения списка.
3. Система по п.1, дополнительно содержащая средство обнаружения структуры списка, функционально связанное со средством обнаружения списка и предназначенное для обеспечения структуры списка в рукописных входных данных.
4. Система по п.1, в которой маркер представляет собой буквенно-цифровой маркер.
5. Система по п.1, в которой маркер представляет собой графический маркер.
6. Машиночитаемый носитель, содержащий машиноисполняемые компоненты, реализующие систему по п.1.
7. Способ обнаружения списка в рукописных входных данных, содержащий этапы, на которых:
принимают рукописные входные данные;
выполняют обнаружение списка в рукописных входных данных путем: выполнения идентификации потенциального списка для выбора группы строк, которые могут образовывать список в рукописных входных данных; выполнения обнаружения отступа для обнаружения отступа рукописной строки в рукописных входных данных, и выполнения обнаружения маркера для идентификации маркера в рукописной строке в рукописных входных данных; и
генерируют структуру списка в качестве выходных данных.
8. Способ по п.7, дополнительно содержащий этап, на котором выполняют анализ рукописных входных данных для проведения различия между письмом и рисунком в рукописных входных данных.
9. Способ по п.7, в котором при выполнении обнаружения списка выполняют определение структуры списка в рукописных входных данных.
10. Способ по п.7, в котором при выполнении идентификации потенциального списка задают каждую строку в группе выбранных строк в качестве потенциального списка.
11. Способ по п.10, в котором при выполнении идентификации потенциального списка выбирают два потенциальных списка для определения того, можно ли объединить два упомянутых потенциальных списка.
12. Способ по п.7, в котором при выполнении идентификации потенциального списка объединяют две строки из группы выбранных строк для формирования потенциального списка.
13. Способ по п.11, в котором при выполнении идентификации потенциального списка объединяют упомянутые два потенциальных списка для формирования нового потенциального списка.
14. Способ по п.13, в котором при выполнении идентификации потенциального списка объединяют новый потенциальный список с другим потенциальным списком.
15. Способ по п.7, в котором при выполнении обнаружения отступа выполняют кластеризацию по уровню отступа для группирования уровней отступа.
16. Способ по п.7, в котором при выполнении обнаружения отступа выполняют кластеризацию по алгоритму K-mean для группирования уровней отступа.
17. Способ по п.7, в котором при выполнении обнаружения отступа определяют расстояние от уровня отступа строки до среднего уровня отступа.
18. Способ по п.7, в котором при выполнении обнаружения отступа выполняют повторное вычисление среднего положения уровня отступа.
19. Способ по п.7, в котором при выполнении обнаружения маркера выбирают первое слово в строке в списке в качестве потенциального маркера.
20. Способ по п.7, в котором при выполнении обнаружения маркера выполняют обнаружение партнера по маркеру для строки.
21. Способ по п.7, в котором при выполнении обнаружения маркера определяют, имеет ли строка соседнюю строку в качестве партнера по маркеру в наборе строк на уровне отступа упомянутой строки, и если это так, считают первое слово строки маркером.
22. Способ по п.7, в котором при выполнении обнаружения маркера определяют, имеет ли строка партнера по маркеру, и, если не имеет, то определяют, имеет ли набор строк на уровне отступа упомянутой строки поднабор партнеров по маркеру.
23. Способ по п.22, дополнительно содержащий этап, на котором определяют, превосходит ли отношение количества строк в поднаборе партнеров по маркеру к количеству строк в наборе уровня отступа пороговое значение, и если это так, считают первое слово в строке маркером.
24. Способ по п.22, дополнительно содержащий этап, на котором определяют, превосходит ли отношение количества строк в поднаборе партнеров по маркеру к количеству строк в наборе уровня отступа пороговое значение, и если это не так, не рассматривают первое слово строки в качестве маркера.
25. Способ по п.20, в котором при выполнении обнаружения партнера по маркеру для строки определяют признаки первого слова в паре строк.
26. Способ по п.25, в котором при определении признаков первого слова в паре строк определяют разности высот и ширин ограничивающих прямоугольников вокруг первого слова в паре строк.
27. Способ по п.26, дополнительно содержащий этапы, на которых определяют максимум среди ширин ограничивающих прямоугольников;
определяют разности длин штрихов первого слова в паре строк;
определяют расстояния между каждым первым словом и следующим словом в паре строк.
28. Способ по п.25, дополнительно содержащий этап, на котором определяют вероятность того, что пара строк является партнерами по маркеру, используя признаки первого слова в упомянутой паре строк.
29. Способ по п.28, дополнительно содержащий этап, на котором определяют, превосходит ли упомянутая вероятность пороговое значение, и если это так, то считают упомянутую пару строк партнерами по маркеру.
30. Способ по п.9, в котором при определении структуры списка в рукописных входных данных выполняют идентификацию пунктов списка.
31. Способ по п.9, в котором при определении структуры списка в рукописных входных данных определяют взаимосвязи между пунктами списка.
32. Способ по п.9, в котором при определении структуры списка в рукописных входных данных создают структуру списка.
33. Способ по п.9, в котором при определении структуры списка в рукописных входных данных определяют на основе структуры списка, что этот список является действительным списком.
34. Способ по п.33, в котором действительный список представляет собой список с, по меньшей мере, двумя маркерами.
35. Машиночитаемый носитель, содержащий машиноисполняемые команды для реализации способа по п.7.
| Автомат для сортировки деталей | 1985 |
|
SU1331592A1 |
| RU 95116654 A, 10.11.1997 | |||
| WO 9534047 A1, 14.12.1995 | |||
| Способ получения листового пористого материала | 1972 |
|
SU667567A1 |

