Область техники
Настоящее изобретение относится к способу синтезирования монофонического звукового сигнала на основе имеющегося кодированного многоканального звукового сигнала, который содержит, хотя бы для некоторой части звуковой полосы частот, раздельные значения параметров для каждого канала многоканального звукового сигнала. Изобретение в равной степени относится к соответствующему звуковому декодеру, соответствующей системе кодирования и соответствующему компьютерному программному продукту.
Уровень техники
Системы звукового кодирования хорошо известны в современной технике. В частности, они используются для передачи или хранения звуковых сигналов.
Системы звукового кодирования, которые используются для передачи звуковых сигналов, включают в себя кодер на передающем конце и декодер на приемном. Для примера, в качестве передающей и приемной частей могут выступать мобильные терминалы. Сигнал для передачи поступает на кодер. Кодер отвечает за согласование скорости цифрового потока звукового сигнала и скорости передачи в канале, так чтобы соблюсти требования к ширине полосы канала. В идеале в результате процесса кодирования кодер отбрасывает только несущественную информацию звукового сигнала. Затем кодированный сигнал передается передатчиком и принимается приемником системы звукового кодирования. Декодер в приемнике обращает процесс кодирования, чтобы получить декодированный звуковой сигнал, в котором искажения отсутствуют совсем или едва заметны на слух.
Если система звукового кодирования применяется для архивации звуковых данных, то данные, закодированные кодером, помещаются в какое-либо устройство хранения, а декодер, после извлечения их из этого устройства, декодирует и передает их для воспроизведения, например, неким медиа-проигрывателем. В таком случае цель в том, чтобы кодер достиг минимально возможной скорости передачи кодированных данных, для того чтобы сэкономить место в устройстве хранения.
В зависимости от допустимой скорости передачи данных могут применяться разные виды кодирования звукового сигнала.
В большинстве случаев нижняя и верхняя полосы в спектре звукового сигнала взаимосвязаны друг с другом. Обычно в кодеках, работающих по алгоритмам расширения полосы, частотная область, занимаемая сигналом, предназначенным для кодирования, сначала делится на две полосы частот. Нижняя полоса обрабатывается независимо так называемым основным кодеком, в то время как верхняя полоса обрабатывается, с использованием сведения о параметрах кодирования и сигналах нижней полосы. Использование параметров кодирования нижней полосы для кодирования верхней уменьшает скорость передачи данных и приводит к значительному увеличению степени кодирования верхней полосы.
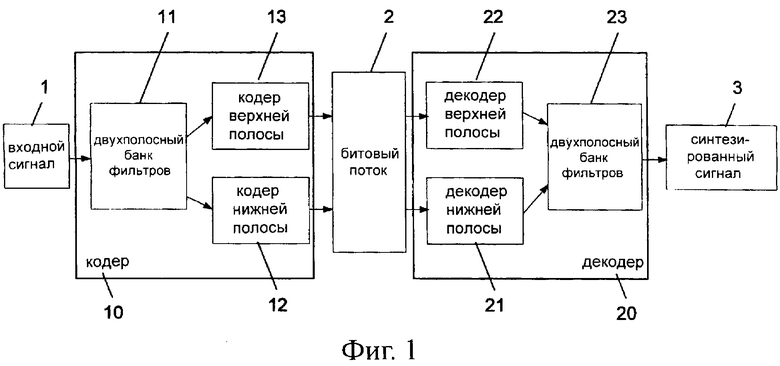
На фиг.1 представлена типичная система кодирования и декодирования с разделением полосы. Система содержит звуковой кодер 10 и звуковой декодер 20. Звуковой кодер 10 включает в себя двухполосный банк фильтров 11 для разложения, кодер 12 нижней полосы и кодер 13 верхней полосы. Звуковой декодер 20 включает в себя декодер 21 нижней полосы, декодер 22 верхней полосы и двухполосный банк фильтров 23 для синтеза. Кодер 12 нижней полосы и декодер 21 могут быть, например, стандартными Адаптивными Широкополосными Многоскоростными (Adaptive Multi-Rate Wideband - AMR-WB) кодером и декодером, а кодер 13 верхней полосы и декодер 22 могут содержать либо независимые алгоритмы кодирования, алгоритмы расширения полосы или их комбинацию. В виде примера предполагается, что в представленной системе в качестве алгоритма кодирования с разделением полосы используется расширенный кодек AMR-WB (AMR-WB+).
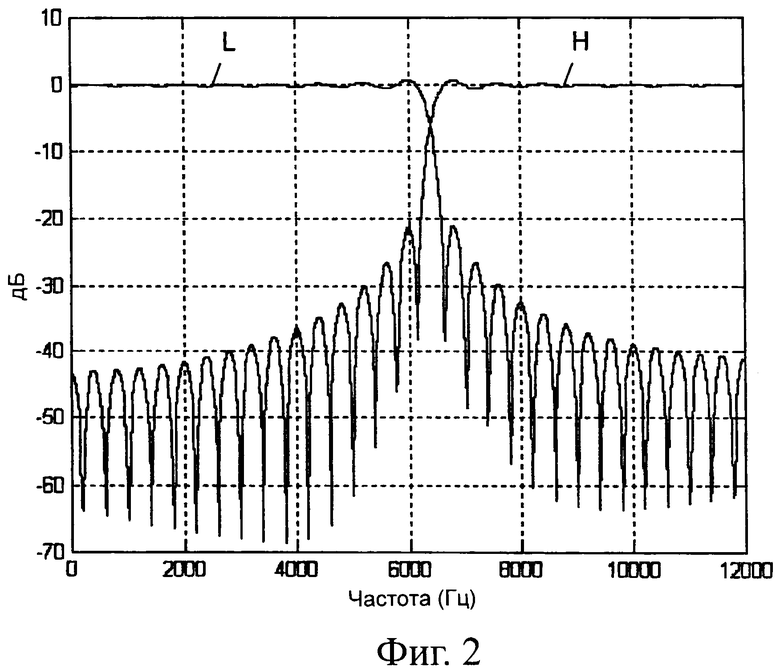
Входной звуковой сигнал 1 сначала обрабатывается двухполосным разлагающим банком фильтров 11, в котором звуковая полоса частот делится на нижнюю и верхнюю полосу частот. В качестве иллюстрации на фиг.2 приведен пример частотной характеристики двухполосного банка фильтров для случая AMR-WB+. Звуковая полоса шириной 12 кГц разделена на полосу L от 0 кГц до 6.4 кГц и полосу Н от 6.4 кГц до 12 кГц. В двухполосном разлагающем банке фильтров 11 для получающихся частотных полос, кроме того, значительно уменьшается частота дискретизации. То есть для нижней полосы частот частота дискретизации уменьшается до 12.8 кГц, а верхняя полоса частот повторно дискретизируется с частотой 11.2 кГц.
Затем нижняя и верхняя полосы частот независимо друг от друга кодируются соответственно кодером 12 нижней полосы и кодером 13 верхней полосы.
Кодер 12 нижней полосы содержит с этой целью полные алгоритмы кодирования для исходного сигнала. Алгоритмы включают алгоритм Линейного Предсказания с Алгебраическим Кодовым возбуждением (algebraic code excitation linear prediction) (ACELP) и алгоритм, основанный на преобразовании. Выбор конкретного алгоритма основан на динамических характеристиках соответствующего входного звукового сигнала. Для кодирования речевых и импульсных сигналов обычно выбирают алгоритм ACELP, а, алгоритмы, основанные на преобразовании, для того чтобы лучше управлять разрешением по частоте, обычно выбирают для кодирования музыки и тональных сигналов.
В кодексе AMR-WB+, кодер 13 верхней полосы использует кодирование с линейным предсказанием (linear prediction coding) (LPC), для формирования спектральной огибающей сигнала верхней полосы частот. После этого верхнюю полосу можно представить с помощью коэффициентов синтезирующего LPC фильтра, которые определяют спектральные характеристики синтезированного сигнала, и коэффициентов усиления для сигнала возбуждения, которые задают амплитуду синтезированного звукового сигнала верхней полосы частот. Сигнал возбуждения верхней полосы дублируется с кодера 12 нижней полосы. Для передачи предусмотрены только LPC коэффициенты и коэффициенты усиления.
Выход кодера 12 нижней полосы и кодера 13 верхней полосы мультиплексируются в один битовый поток 2.
Мультиплексированный битовый поток 2 передается, например, по каналу связи к звуковому декодеру 20, в котором нижняя и верхняя полосы частот декодируются отдельно.
Для синтезирования звукового сигнала нижней полосы в декодере 21 нижней полосы выполняются преобразования, обратные преобразованиям в кодере 12 нижней полосы.
В декодере 22 верхней полосы формируется сигнал возбуждения, посредством повторной дискретизации сигнала возбуждения нижней полосы, поступающего с декодера 21 нижней полосы, и приведения частоты дискретизации, к частоте дискретизации, используемой в верхней полосе частот. Таким образом, сигнал возбуждения нижней полосы частот повторно используется для декодирования верхней полосы частот путем переноса сигнала нижней полосы частот в верхнюю полосу. В качестве альтернативы, можно генерировать случайный сигнал и использовать его в качестве сигнала возбуждения для восстановления сигнала верхней полосы. Затем для восстановления сигнала верхней полосы частот масштабированный сигнал возбуждения фильтруется LPC схемой верхней полосы, которая задается LPC коэффициентами.
Для синтезирования выходного звукового сигнала 3 в двухполосном синтезирующем банке фильтров 23 частоты дискретизации для декодированных сигналов нижней и верхней полосы частот повышаются до первоначальных, и сигналы объединяются.
Входной звуковой сигнал 1, который необходимо кодировать, может быть или монофоническим звуковым сигналом или многоканальным, который содержит по меньшей мере сигнал первого и второго канала. Примером многоканального звукового сигнала является стереофонический звуковой сигнал, который состоит из сигнала левого и правого каналов.
Для работы кодека AMR-WB+ в стереорежиме, входной звуковой сигнал поровну делится в двухполосном разлагающем банке фильтров 11 на сигнал нижней и верхней полосы частот. Кодер 12 нижней полосы генерирует монофонический сигнал, объединяя сигналы нижней полосы частот левого и правого каналов. Монофонический сигнал кодируется так, как описано выше. Кодер 12 нижней полосы дополнительно использует параметрическое кодирование для кодирования различий сигналов левого и правого каналов для монофонического сигнала. Кодер 13 верхней полосы отдельно кодирует левый и правый канал, определяя разные LPC коэффициенты и коэффициенты усиления для каждого канала.
В случае, если входной звуковой сигнал 1 является многоканальным звуковым сигналом, а устройство, которое должно воспроизводить синтезированный звуковой сигнал, не поддерживает многоканальный звуковой выход, входной многоканальный битовый поток 2 нужно преобразовать в монофонический звуковой сигнал с помощью звукового декодера 20. Преобразование многоканального сигнала в монофонический в нижней полосе частот несложно, так как декодер 21 нижней полосы может просто опускать стереопараметры в принятом битовом потоке и декодировать только монофоническую часть. Но для верхней полосы частот требуется больше обработки, так как в битовом потоке монофоническая часть сигнала верхней полосы частот отдельно не доступна.
Обычно стереофонический битовый поток для верхней полосы частот отдельно декодируется для сигналов левого и правого канала, после чего создается монофонический сигнал путем объединения сигналов левого и правого каналов в ходе микширования. Этот подход показан на фиг.3.
Детали декодера 22 верхней полосы на фиг.1 схематически изображены на фиг 3 для случая монофонического звукового выхода. Для этого декодер верхней полосы содержит блок 30 для обработки левого канала и блок 33 для обработки правого канала. Блок 30 для обработки левого канала включает смеситель 31, который соединен с синтезирующим LPC фильтром 32. Блок 33 для обработки правого канала включает такой же смеситель 34, который соединен с синтезирующим LPC фильтром 35. Выход обоих синтезирующих LPC фильтров 32, 35 соединен далее со смесителем 36.
Сигнал возбуждения нижней полосы частот, который вырабатывается декодером 21 нижней частоты, поступает на оба смесителя 31 и 34. Смеситель 31 применяет коэффициенты усиления для левого канала к сигналу возбуждения нижней полосы частот. Затем синтезирующий LPC фильтр 32 восстанавливает сигнал верхней полосы левого канала, в результате того, что схема LPC для верхней полосы, которая определена LPC коэффициентами левого канала, фильтрует масштабированный сигнал возбуждения. Смеситель 34 применяет коэффициенты усиления для правого канала к сигналу возбуждения нижней полосы частот. Затем синтезирующий LPC фильтр 35 восстанавливает сигнал верхней полосы правого канала, в результате того, что схема LPC для верхней полосы, которая определена LPC коэффициентами правого канала, фильтрует масштабированный сигнал возбуждения.
Восстановленные сигналы верхней полосы частот для левого и правого канала затем преобразуются в монофонический сигнал верхней полосы частот смесителем 36, который вычисляет их среднее во временной области.
Это, в принципе, простой и работающий подход. Однако он требует раздельного синтезирования множества каналов, хотя в результате требуется только одноканальный сигнал.
Более того, если входной многоканальный звуковой сигнал 1 несбалансирован, и большая часть энергии многоканального сигнала сосредоточена в каком-то одном из каналов, непосредственное микширование каналов, через вычисление их среднего, приведет к ослаблению объединенного сигнала. В крайнем случае, когда в одном из каналов вообще ничего не передается, это приведет к тому, что уровень мощности объединенного сигнала будет составлять половину мощности активного канала на входе.
Сущность изобретения
Целью изобретения является снижение вычислительной нагрузки, необходимой для синтезирования монофонического звукового сигнала на основе кодированного многоканального звукового сигнала.
Предложен способ синтезирования монофонического звукового сигнала на основе кодированного многоканального звукового сигнала, который содержит раздельные значения параметров по меньшей мере для некоторой части полосы частот исходного многоканального звукового сигнала для каждого из каналов многоканального звукового сигнала. Предложенный способ содержит, по меньшей мере для некоторой части звуковой полосы частот, объединение значений параметров множества каналов в области значений параметров. Кроме того, предложенный способ содержит, для этой звуковой полосы частот, применение объединенных значений параметров для синтезирования монофонического звукового сигнала.
Кроме того, предложен звуковой декодер для синтезирования монофонического звукового сигнала на основе имеющегося кодированного многоканального звукового сигнала. Кодированный многоканальный звуковой сигнал содержит, по меньшей мере для некоторой части полосы частот исходного многоканального звукового сигнала, раздельные значения параметров для каждого канала многоканального звукового сигнала. Предложенный звуковой декодер содержит по меньшей мере один блок выбора параметра, предназначенный для объединения значений параметров для нескольких каналов в области значений параметров по меньшей мере для некоторой части полосы частот многоканального звукового сигнала. Кроме того, предложенный звуковой декодер содержит блок синтеза звукового сигнала, предназначенный для синтезирования монофонического звукового сигнала, по меньшей мере для некоторой части полосы частот многоканального звукового сигнала, на основе объединенных значений параметров, которые поступают от блока выбора параметра.
Дополнительно предложена система кодирования, которая содержит в дополнение к предложенному декодеру звуковой кодер, который выдает кодированный многоканальный звуковой сигнал.
Наконец, предложен компьютерный программный продукт, в котором содержится программный код для синтезирования монофонического звукового сигнала на основе имеющегося кодированного многоканального звукового сигнала. Кодированный многоканальный звуковой сигнал содержит, по меньшей мере для некоторой части полосы частот исходного многоканального звукового сигнала, раздельные значения параметров для каждого канала многоканального звукового сигнала. Во время работы в звуковом декодере предложенный программный код выполняет все этапы предложенного способа.
Кодированный многоканальный звуковой сигнал может быть, в частности, но не только, кодированным стереофоническим звуковым сигналом.
Изобретение исходит из того, что для получения монофонического звукового сигнала можно избежать отдельного декодирования имеющегося множества каналов, если перед декодированием значения параметров для этих нескольких каналов уже объединены в области значений параметров. После этого можно использовать значения параметров для декодирования единственного канала.
Преимуществом изобретения является то, что оно позволяет сократить вычислительную нагрузку в декодере, что уменьшает его сложность. Например, если несколько каналов представляют собой стерео каналы, которые обрабатываются в системе с разделением полосы, можно сэкономить приблизительно половину вычислительной нагрузки, требуемой для фильтрации при синтезе верхней полосы частот по сравнению с выполнением раздельной фильтрации при синтезе верхней полосы частот для обоих каналов и объединения получающихся сигналов левого и правого каналов.
В одной реализации изобретения, параметры содержат коэффициенты усиления и коэффициенты линейного предсказания для каждого из нескольких каналов.
Объединение значений параметров можно производить статическим методом, например, просто вычисляя средние значения имеющихся параметров по всем каналам. Однако, предпочтительно, объединение значений параметров управляется хотя бы для одного параметра на основе информации о соответствующей активности в нескольких каналах. Это позволяет получать монофонический звуковой сигнал со спектральными характеристиками и уровнем сигнала, максимально близкими к спектральным характеристикам и уровню сигнала в соответствующем активном канале, и, соответственно, улучшенным качеством звука синтезированного монофонического звукового сигнала.
Если активность в первом канале значительно выше, чем во втором, можно рассматривать первый канал как активный, а второй как тихий, который, в основном, не обеспечивает заметного на слух вклада в исходный звуковой сигнал. Если присутствует тихий канал, то при объединении значений параметров значения по меньшей мере одного параметра преимущественно полностью игнорируются. В результате синтезированный монофонический сигнал будет аналогичен активному каналу. Во всех других случаях можно объединять значения параметров, например, формируя среднее или весовое среднее по всем каналам. Для весового среднего, вес, присвоенный каналу, растет вместе с относительной активностью канала в сравнении с другим каналом или каналами. Для осуществления объединения можно использовать и другие способы. В равной степени, значения параметра для тихого канала, которые не надо отбрасывать, можно объединить со значениями параметра активного канала через усреднение или любым другим способом.
Информация о соответствующей активности в множестве каналов может формироваться на основе разнообразных видов сведений. Ее можно получить, например, через коэффициент усиления для каждого канала из множества каналов, путем объединения коэффициентов усиления на длительности короткого промежутка времени или коэффициентов линейного предсказания для каждого канала из множества каналов. Информацию об активности в равной степени можно получить на основе уровня мощности в, по меньшей мере, части полосы частот многоканального звукового сигнала для каждого канала из множества каналов или на основе независимой дополнительной информации об активности, полученной от кодирующей стороны, которая выдает кодированный многоканальный звуковой сигнал.
Для получения кодированного многоканального звукового сигнала исходный многоканальный звуковой сигнал можно разделить, например, на сигнал нижней и сигнал верхней полосы частот. Затем сигнал нижней полосы частот можно закодировать стандартным способом. Сигнал верхней частотной полосы также можно закодировать стандартным способом отдельно для всего множества каналов, в результате чего получаются значения параметров для каждого канала из множества каналов. Затем кодированная часть, соответствующая по меньшей мере верхней полосе частот всего кодированного многоканального сигнала, может быть обработана в соответствии с изобретением.
Необходимо понимать, однако, что многоканальные значения параметров, которые соответствуют нижней полосе частот всего кодированного многоканального сигнала, в равной степени могут быть обработаны в соответствии с изобретением, для того чтобы предотвратить дисбаланс между нижней и верхней полосой частот, например дисбаланс в уровне сигнала. В качестве альтернативы, значение параметров для тихих каналов в верхней полосе частот, которые влияют на уровень сигнала, в принципе, можно не отбрасывать, но только те значение параметров тихих каналов, которые влияют на спектральные характеристики сигнала.
Изобретение можно реализовать, например, но не только, в системе кодирования на основе AMR-WB+.
Другие объекты и возможности представленного изобретения станут очевидными из следующего далее подробного описания вместе с сопроводительными чертежами.
Краткое описание чертежей
Фиг.1 - принципиальная блок-схема системы кодирования с разделением полосы;
Фиг.2 - график частотной характеристики двухполосного банка фильтров;
Фиг.3 - принципиальная блок-схема стандартного декодера верхней полосы для преобразования стерео в моно;
Фиг.4 - принципиальная блок-схема декодера верхней полосы для преобразования стерео в моно, в соответствии с первой реализацией изобретения;
Фиг.5 - график, иллюстрирующий частотную характеристику для стереосигналов и моносигнала, получающегося с помощью декодера верхней полосы на фиг.4;
Фиг.6 - принципиальная блок-схема декодера верхней полосы для преобразования стерео в моно, в соответствии со второй реализацией изобретения;
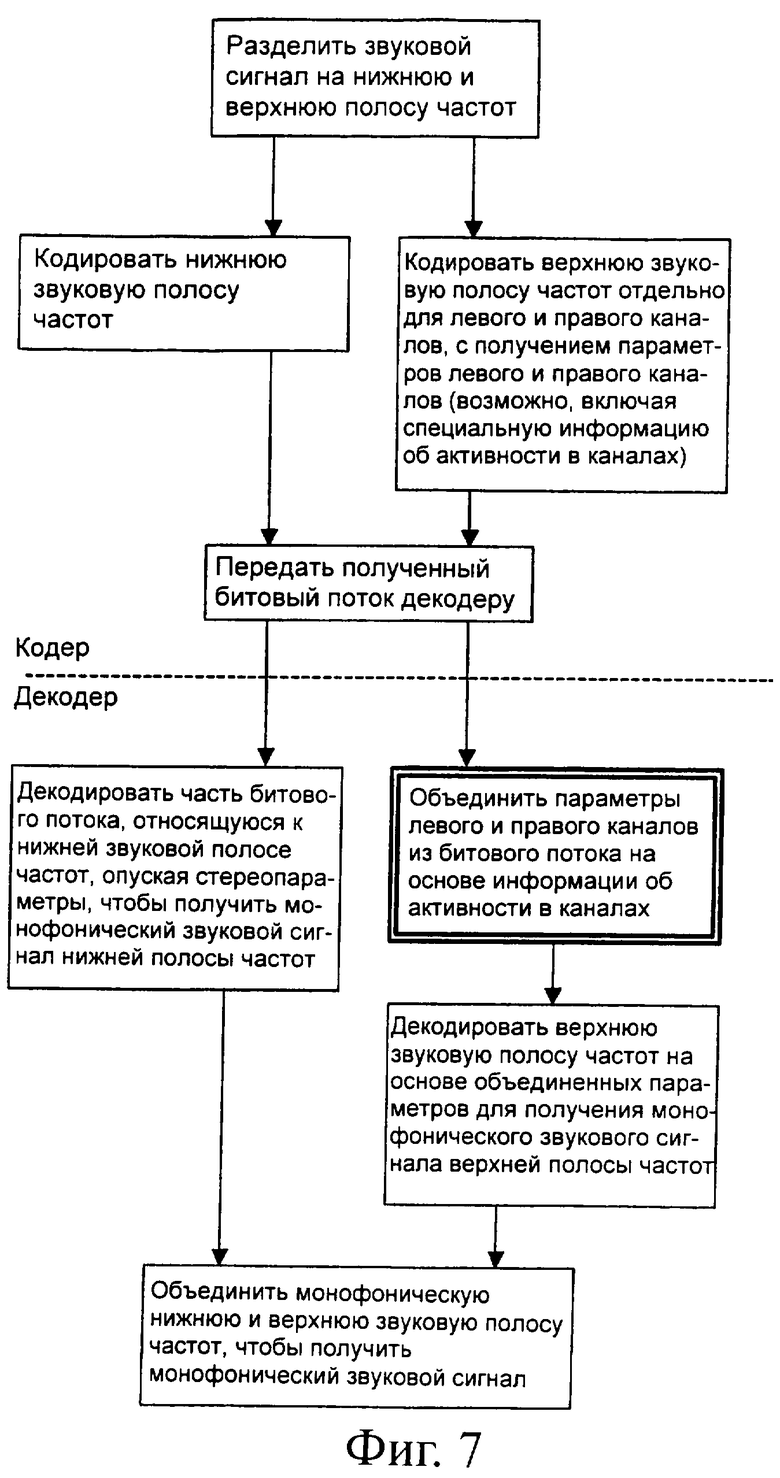
Фиг.7 - схема, иллюстрирующая работу системы, использующей декодер верхней полосы с фиг.6;
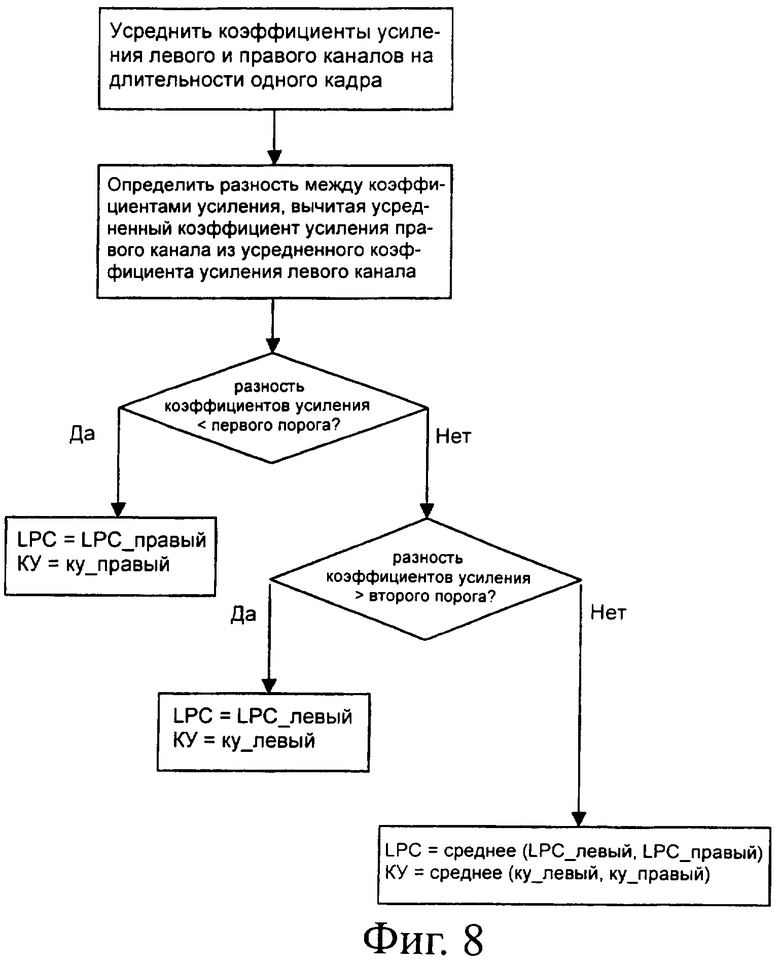
Фиг.8 - схема, иллюстрирующая первый вариант объединения параметров на схеме фиг.7; и
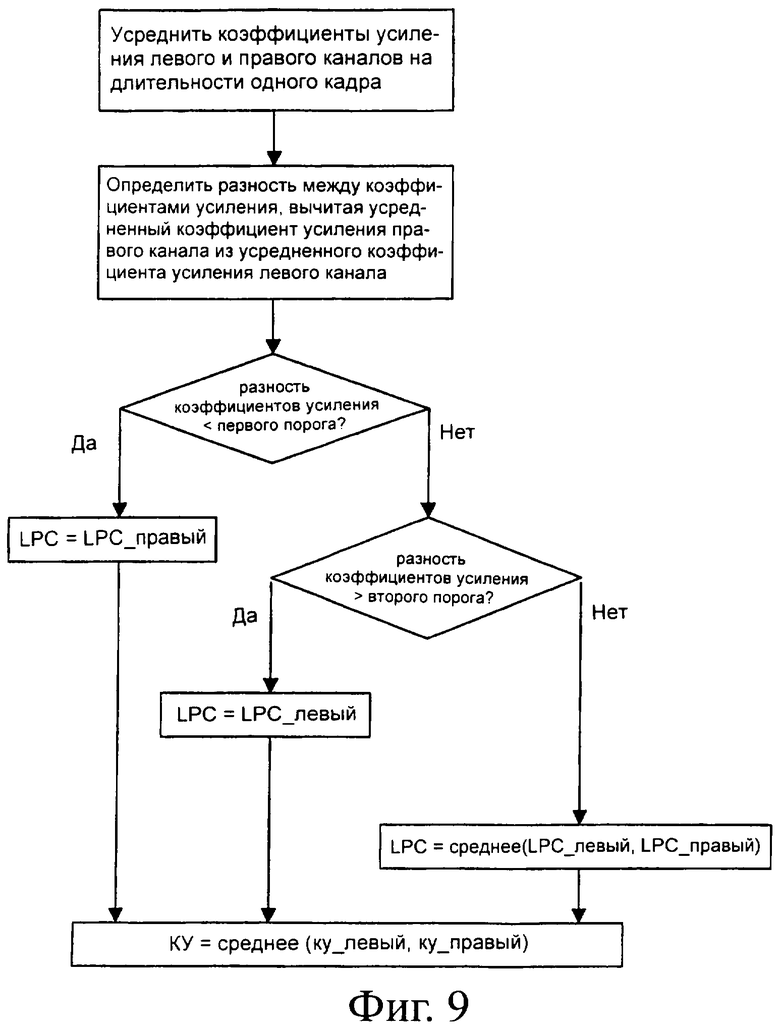
Фиг.9 - схема, иллюстрирующая второй вариант объединения параметров на схеме фиг.7.
Подробное описание изобретения
Предполагается, что изобретение реализовано в системе на фиг.1, поэтому будем ссылаться на нее и далее. Входной стереосигнал 1 поступает для кодирования на звуковой кодер 10, а декодированный монофонический звуковой сигнал 3 должен поступать со звукового декодера 20 для воспроизведения.
Для того чтобы иметь возможность обеспечить такой монофонический звуковой сигнал 3 с низкой вычислительной нагрузкой, можно реализовать декодер 22 верхней полосы системы в соответствии с первой простой реализацией изобретения.
На фиг.4 изображена принципиальная блок-схема такого декодера 22 верхней полосы. Вход возбуждения нижней полосы декодера 22 верхней полосы соединен через смеситель 40 и синтезирующий LPC фильтр 41 с выходом декодера 22 верхней полосы. Декодер 22 верхней полосы дополнительно включает в себя блок 42 для вычисления среднего коэффициента усиления, который подключен к смесителю и блоку 43 вычисления средних коэффициентов LPC, который соединен с синтезирующим LPC фильтром 41.
Система работает следующим образом.
Входной стереосигнал звукового кодера 10 разделяется двухполосным разлагающим банком фильтров 11 на нижнюю и верхнюю полосу частот. Кодер 11 нижней полосы кодирует звуковой сигнал нижней полосы частот, как описано выше. AMR-WB+ кодер 12 верхней полосы кодирует стереосигнал верхней полосы отдельно для левого и правого каналов. Точнее, он определяет коэффициенты усиления и коэффициенты линейного предсказания для каждого канала, как описано выше.
Кодированный монофонический сигнал нижней полосы частот, стереофонические значения параметров нижней полосы частот и стереофонические значения параметров верхней полосы частот передаются в едином битовом потоке 2 к звуковому декодеру 20.
Декодер 21 нижней полосы принимает для декодирования часть битового потока, относящегося к нижней полосе частот. В процессе этого декодирования он опускает стереопараметры и декодирует только монофоническую часть. Результатом является монофонический звуковой сигнал нижней полосы частот.
Декодер 22 верхней полосы принимает, с одной стороны, значения параметров верхней полосы частот из переданного битового потока, а с другой - сигнал возбуждения нижней полосы с выхода декодера 21 нижней полосы.
Параметры верхней частотной полосы включают в себя соответственно коэффициент усиления левого канала, коэффициент усиления правого канала, LPC коэффициенты левого канала и LPC коэффициенты правого канала. В блоке 42 вычисления среднего коэффициента усиления соответствующие коэффициенты усиления для левого и правого каналов усредняются, усредненный коэффициент усиления используется смесителем 40 для масштабирования сигнала возбуждения нижней полосы. Полученный сигнал поступает для фильтрации на синтезирующий LPC фильтр 41.
В блоке 43 вычисления среднего LPC объединяются соответствующие коэффициенты линейного предсказания для левого и правого каналов. В AMR-WB+объединение коэффициентов LPC обоих каналов можно сделать, например, вычисляя среднее для принятых коэффициентов в области Спектральных Пар Иммитанса (Immitance Spectral Pair, ISP). Затем средние коэффициенты используются для настройки синтезирующего LPC фильтра 41, обработке которым подлежит масштабированный сигнал возбуждения нижней полосы.
Масштабированный и прошедший сквозь фильтр сигнал возбуждения нижней полосы формирует требуемый монофонический звуковой сигнал верхней полосы.
Монофонические звуковые сигналы нижней и верхней полосы объединяются в двухполосном синтезирующем банке фильтров 23, а выходным сигналом, предназначенным для воспроизведения, является получающийся синтезированный сигнал 3.
Преимуществом системы, использующей кодер верхней полосы, показанный на фиг.4, по сравнению с системой, использующей кодер верхней полосы, показанный на фиг.3, является то, что ей требуется приблизительно только половина вычислительной мощности для создания синтезированного сигнала, так как он генерируется всего один раз.
Необходимо заметить, что, тем не менее, остается упомянутая выше проблема возможного ослабления объединенного сигнала, если входной звуковой стереосигнал содержит активный сигнал только в одном из каналов.
Кроме того, для входных звуковых стереосигналов, у которых активным является только один из каналов, усреднение коэффициентов линейного предсказания приводит к нежелательному побочному эффекту «выравнивания» спектра результирующего объединенного сигнала. Вместо того, чтобы иметь спектральные характеристики активного канала, объединенный сигнал имеет спектральные характеристики, искаженные некоторым образом из-за сочетания «реального» спектра активного канала и практически плоского или имеющего случайную структуру спектра тихого канала.
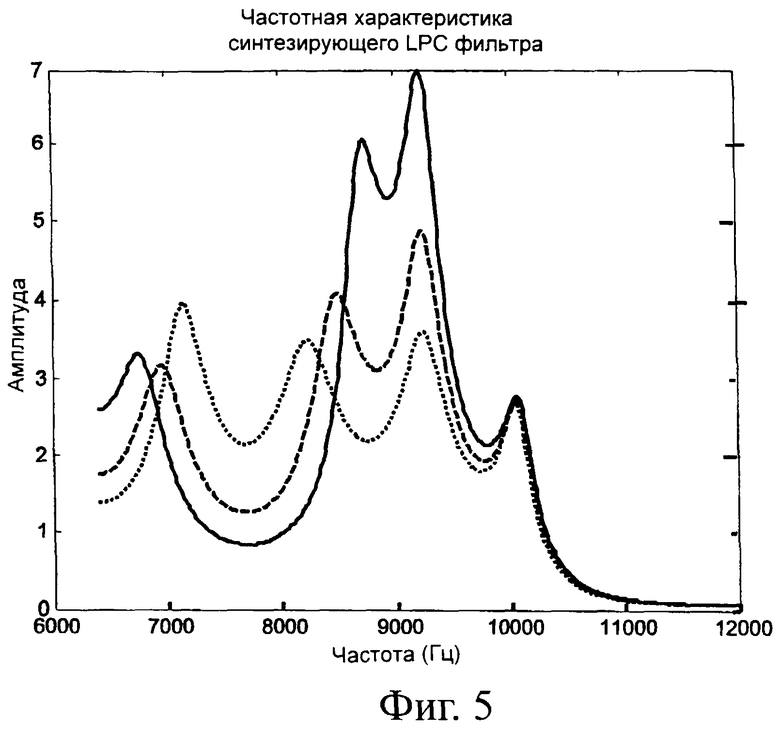
Этот эффект иллюстрируется на фиг.5. Фиг.5 - это график зависимостей амплитуды от частоты, вычисленных в окне длительностью 80 мс для трех разных синтезирующих LPC фильтров. Сплошной линией изображена частотная характеристика синтезирующего LPC фильтра для активного канала. Пунктирной линией изображена частотная характеристика синтезирующего LPC фильтра для тихого канала. Штриховой линией изображена частотная характеристика синтезирующего LPC фильтра, получаемая в результате усреднения LPC блоков в ISP области. Можно видеть, что усредненный LPC фильтр создает спектр, который и близко не напоминает ни один из реальных спектров. На практике этот эффект заметен на слух в виде сниженного качества звука в верхней полосе частот.
Для того чтобы иметь возможность не только обеспечить получение монофонического звукового сигнала 3 при низкой вычислительной нагрузке, но и избежать ограничений, которые свойственны декодеру верхней полосы, показанному на фиг.4, декодер 22 верхней полосы, который содержится в системе, показанной на фиг.1, можно реализовать согласно второму варианту осуществления изобретения.
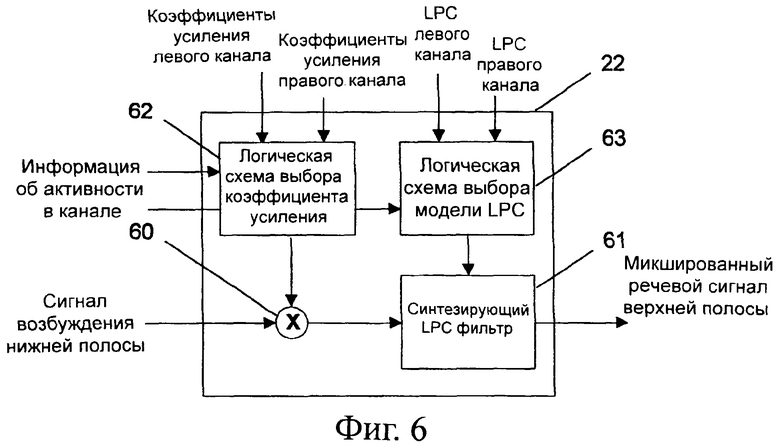
Принципиальная блок-схема подобного декодера 22 верхней полосы представлена на фиг.6. Вход возбуждения нижней полосы декодера 22 верхней полосы соединен с его выходом через смеситель 60 и синтезирующий LPC фильтр 61. Декодер 22 верхней полосы дополнительно содержит логическую схему 62 выбора коэффициента усиления, которая соединена со смесителем 60, и логическую схему 63 для выбора LPC коэффициентов, которая соединена с синтезирующим LPC фильтром 61.
Описывая работу системы, в которой используется кодер 22 верхней полосы, выполненный согласно фиг.6, будем ссылаться к фиг.7. На фиг.7 изображена схема, верхняя часть которой описывает обработку в звуковом кодере 10, а нижняя - в звуковом декодере 20 системы. Верхняя и нижняя часть разделены горизонтальной штрих линией.
Входной звуковой стереосигнал 1 кодера делится двухполосным разлагающим банком фильтров 11 на верхнюю и нижнюю полосу частот. Кодер 12 нижней полосы кодирует нижнюю полосу частот. AMR-WB+ кодер 13 верхней полосы кодирует верхнюю полосу частот отдельно для левого и правого каналов. Если быть более точным, он определяет отдельные коэффициенты усиления и коэффициенты линейного предсказания для обоих каналов в качестве параметров верхней полосы частот.
Кодированный монофонический сигнал нижней частотной полосы, стереофонические значения параметров нижней полосы частот и стереофонические значения параметров верхней полосы частот передаются в едином битовом потоке 2 к звуковому декодеру 20.
Декодер 21 нижней полосы принимает ту часть битового потока 2, которая соответствует нижней полосе частот, и декодирует ее. Декодер 21 нижней полосы в процессе декодирования опускает принятые стереопараметры, а декодирует только монофоническую часть. В результате получается монофонический звуковой сигнал нижней полосы.
Декодер 22 верхней полосы принимает, с одной стороны, коэффициент усиления левого канала, коэффициент усиления правого канала, коэффициенты линейного предсказания левого канала и коэффициенты линейного предсказания правого канала, а с другой стороны - сигнал возбуждения нижней полосы с выхода декодера 21 нижней полосы. В то же время коэффициент усиления левого и правого каналов используются в качестве информации об активности в канале. Необходимо заметить, что вместо этого в качестве дополнительного параметра кодер 13 верхней полосы может предоставить некоторую другую информация об активности в канале, которая показывает распределение активности в верхней частотной полосе левого и правого канала.
Информация об активности в канале оценивается, и в соответствие с оценкой коэффициенты усиления для левого и правого каналов объединяются в один коэффициент логической схемой 62 выбора коэффициента усиления. Потом выбранный коэффициент усиления с помощью смесителя 60 применяется к сигналу возбуждения нижней частотной полосы, который поступает с декодера 21 нижней полосы.
Кроме того, в соответствие с оценкой, LPC коэффициенты для левого и правого канала объединяются логической схемой 63 выбора модели LPC в единственный набор LPC коэффициентов. Объединенная LPC модель поступает в синтезирующий LPC фильтр 61. Синтезирующий LPC фильтр 61 применяет выбранную LPC структуру к масштабированному сигналу возбуждения нижней полосы, который подал смеситель 60.
Затем получающийся звуковой сигнал верхней полосы частот объединяется с монофоническим звуковым сигналом нижней полосы частот в двухполосном синтезирующем банке фильтров 23 в монофонический полнополосный звуковой сигнал, который может быть выходным сигналом, предназначенным для некоего устройства воспроизведения или какого-либо приложения, которое не способно обрабатывать стереофонические звуковые сигналы.
Предложенную оценку информации об активности в канале и последующее объединение значений параметров, которое отмечено на схеме на фиг.7 в виде блока с двойной рамкой, можно реализовать разными способами. Будут представлены два варианта (см. схемы на фиг.8 и 9).
В первом варианте, который изображен на фиг.8, коэффициенты усиления для левого канала сначала усредняются на длительности одного кадра, точно также на длительности одного кадра усредняются коэффициенты усиления для правого канала.
Затем усредненный коэффициент усиления для правого канала вычитается из усредненного коэффициента усиления для левого канала, для каждого кадра получается определенная разность коэффициентов усиления.
В том случае, если эта разность меньше величины первого порога, объединенные коэффициенты усиления для этого кадра устанавливаются равными коэффициентам усиления для правого канала. Дополнительно объединенная LPC модель для этого кадра устанавливается равной LPC модели, предусмотренной для правого канала.
В том случае, если эта разность больше величины второго порога, объединенные коэффициенты усиления для этого кадра устанавливаются равными коэффициентам усиления для левого канала. Дополнительно объединенная LPC модель для этого кадра устанавливается равной LPC модели, предусмотренной для левого канала.
Во всех других случаях объединенные коэффициенты усиления для этого кадра устанавливаются равными среднему между соответствующими коэффициентами усиления для правого и левого канала. Объединенная LPC модель для этого кадра устанавливается равной среднему между LPC моделями, соответствующими левому и правому каналу.
Величина первого и второго порогов выбирается исходя из требуемой чувствительности и типа прикладной задачи, для которой требуется преобразование из стерео в моно. Для примера, подходящими значениями для первого порога являются -20 дБ и 20 дБ для второго.
Таким образом, если в силу большой разности между усредненными коэффициентами усиления на длительности соответствующего кадра один из каналов можно рассматривать как тихий, а другой канал как активный, то на длительности этого кадра пренебрегают коэффициентами усиления и LPC структурой тихого канала. Это становится возможным в силу того, что тихий канал не вносит заметного на слух вклада в выходной микшированный сигнал. Такое объединение значений параметров гарантирует, что спектральные характеристики и уровень сигнала оказываются максимально близкими к соответствующему активному каналу.
Необходимо заметить, что вместо пропуска стереопараметров, декодер нижней полосы также мог бы формировать объединенные значения параметров и применять их к монофонической части сигнала, таким же образом как в описанной обработке верхней полосы частот.
Во втором варианте объединения величин параметров, изображенном на фиг.9, коэффициенты усиления для левого и правого каналов соответственно, тоже усредняются на длительности одного кадра.
Затем усредненный коэффициент усиления для правого канала вычитается из усредненного коэффициента усиления для левого канала, для каждого кадра получается определенная разность коэффициентов усиления.
В том случае, если эта разность меньше величины первого, низкого порога, объединенные LPC структуры для этого кадра устанавливаются равными LPC моделям, предусмотренным для правого канала.
В том случае, если эта разность больше величины второго, высокого порога, объединенные LPC структуры для этого кадра устанавливаются равными LPC моделям, предусмотренным для левого канала.
Во всех других случаях, объединенные LPC структуры для этого кадра устанавливаются равными среднему между LPC моделями, соответствующими левому и правому каналу.
В любом случае объединенные коэффициенты усиления для этого кадра устанавливаются равными среднему между соответствующими коэффициентами усиления для левого и правого канала.
LPC коэффициенты имеют непосредственное влияние только на спектральные характеристики синтезированного сигнала. Таким образом, объединение только LPC коэффициентов приводит к желаемым спектральным характеристикам, но не решает проблему ослабления сигнала. Однако, в том случае, если, в соответствии с изобретением, нижняя полоса частот не микшируется, имеется преимущество в том плане, что сохраняется баланс между нижней и верхней полосой частот. Сохранение уровня сигнала в верхней полосе частот может изменять баланс между нижними и верхними полосами частот, внося относительно слишком громкие сигналы в верхнюю полосу частот, которые приводят к возможному ухудшению субъективного восприятия качества звука.
Необходимо заметить, что описанные конструктивные реализации являются одними из множества вариантов, которые разными способами можно совершенствовать и далее.

Изобретение относится к способу синтезирования монофонического звукового сигнала на основе имеющегося кодированного многоканального звукового сигнала. Кодированный многоканальный звуковой сигнал содержит, по меньшей мере, для верхней частотной полосы частот раздельные значения параметров для каждого канала многоканального звукового сигнала, причем значения параметров множества каналов объединяются в области значений параметров, при этом объединением значений параметров управляют, по меньшей мере, для одного параметра на основе информации о соответствующей активности в упомянутом множестве каналов. После этого объединенные значения параметров используются для синтезирования монофонического звукового сигнала. Изобретение также касается соответствующего звукового декодера и соответствующей системы кодирования. Технический результат - снижение вычислительной нагрузки, необходимой для синтезирования монофонического звукового сигнала на основе кодированного многоканального звукового сигнала. 4 н. и 14 з.п. ф-лы, 9 ил.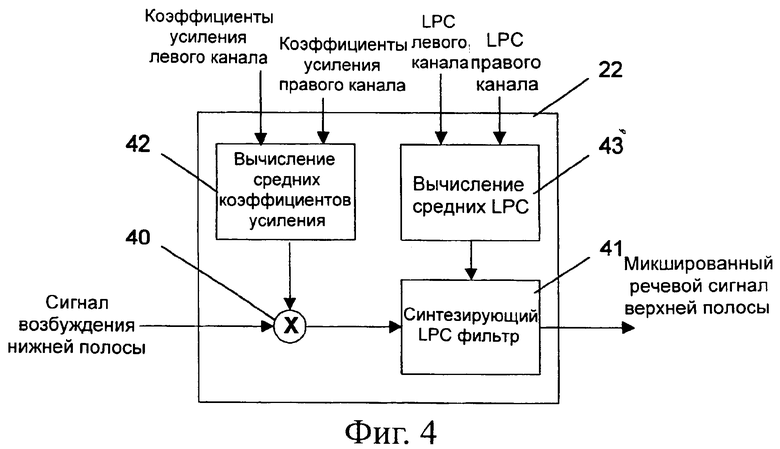
1. Способ синтезирования монофонического звукового сигнала на основе имеющегося кодированного многоканального звукового сигнала, который содержит, по меньшей мере, для верхней частотной полосы многоканального звукового сигнала, раздельные значения параметров для каждого канала упомянутого многоканального звукового сигнала, при этом упомянутый способ включает:
объединение значений параметров множества каналов в области значений параметров, при этом упомянутым объединением значений параметров управляют, по меньшей мере, для одного параметра, на основе информации о соответствующей активности в упомянутом множестве каналов; и
декодирование, по меньшей мере, верхней частотной полосы звукового сигнала на основе объединенных значений параметров и формирование монофонического звукового сигнала в качестве выходного сигнала, предназначенного для воспроизведения.
2. Способ по п.1, в котором упомянутые параметры содержат коэффициенты усиления и коэффициенты линейного предсказания для каждого канала из упомянутого множества каналов.
3. Способ по п.1 или 2, в котором упомянутая информация о соответствующей активности в упомянутом множестве каналов содержит, по меньшей мере, одно из следующего:
коэффициент усиления для каждого канала из упомянутого множества каналов;
объединение коэффициентов усиления за короткий промежуток времени для каждого канала из упомянутого множества каналов;
коэффициенты линейного предсказания для каждого канала из упомянутого множества каналов;
уровень мощности, по меньшей мере, в части полосы частот упомянутого многоканального звукового сигнала для каждого канала из упомянутого множества каналов и
отдельную дополнительную информацию об упомянутой активности, принятую от кодирующей стороны, предоставившей упомянутый выше кодированный многоканальный звуковой сигнал.
4. Способ по п.1 или 2, в котором если упомянутая информация об активности в упомянутом множестве каналов указывает на то, что активность в первом из упомянутого множества каналов существенно ниже, чем, по меньшей мере, в одном другом из упомянутого множества каналов, то пренебрегают значением, по меньшей мере, одного параметра, который имеется для упомянутого первого канала.
5. Способ по п.4, в котором если упомянутая информация об активности в упомянутом множестве каналов указывает на то, что активность в первом из упомянутого множества каналов существенно ниже, чем, по меньшей мере, в одном другом из упомянутого множества каналов, то усредняют значения, по меньшей мере, одного другого параметра, который имеется для упомянутого множества каналов.
6. Способ по п.1 или 2, в котором если упомянутая информация об активности в упомянутом множестве каналов не указывает на то, что активность в одном из упомянутого множества каналов существенно ниже, чем, по меньшей мере, в одном другом из упомянутого множества каналов, то усредняют величины указанных параметров, которые имеются для упомянутого множества каналов.
7. Способ по п.1 или 2, в котором упомянутый многоканальный сигнал является стереофоническим сигналом.
8. Способ по п.1 или 2, включающий предшествующие шаги по разделению исходного многоканального звукового сигнала на сигнал нижней частотной полосы и сигнал верхней частотной полосы, кодирование указанного сигнала нижней частотной полосы и кодирование указанного сигнала верхней частотной полосы для упомянутого множества каналов, в результате чего получаются упомянутые значения параметров для каждого канала из упомянутого множества каналов, причем, по меньшей мере, значения параметров, получающиеся для упомянутого сигнала верхней частотной полосы, объединяются для синтезирования указанного монофонического звукового сигнала.
9. Звуковой декодер для синтезирования монофонического звукового сигнала на основе имеющегося кодированного многоканального звукового сигнала, который содержит, по меньшей мере, для верхней полосы частот исходного многоканального звукового сигнала, раздельные значения параметров для каждого канала упомянутого многоканального звукового сигнала, указанный декодер включает:
по меньшей мере, один блок выбора параметров, предназначенный для объединения значений параметров упомянутого множества каналов в области значений параметров на основе информации о соответствующей активности в упомянутом множестве каналов; и
блок синтеза звукового сигнала, предназначенный для синтезирования монофонического звукового сигнала в качестве выходного сигнала, предназначенного для воспроизведения, причем указанное синтезирование сигнала включает декодирование, по меньшей мере, верхней частотной полосы сигнала на основе объединенных значений параметров.
10. Звуковой декодер по п.9, в котором указанные параметры содержат коэффициенты усиления и коэффициенты линейного предсказания для каждого канала из упомянутого множества каналов.
11. Звуковой декодер по п.9 или 10, в котором упомянутая информация о соответствующей активности в упомянутом множестве каналов включает, по меньшей мере, одно из следующего:
коэффициент усиления для каждого канала из упомянутого множества каналов;
объединение коэффициентов усиления за короткий промежуток времени для каждого канала из упомянутого множества каналов;
коэффициенты линейного предсказания для каждого канала из упомянутого множества каналов;
уровень мощности, по меньшей мере, в части полосы частот упомянутого многоканального сигнала для каждого канала из упомянутого множества каналов и
отдельную дополнительную информацию об упомянутой активности, принятую от кодирующей стороны, предоставляющей упомянутый кодированный многоканальный звуковой сигнал.
12. Звуковой декодер по п.9 или 10, в котором упомянутый блок выбора параметра настроен так, чтобы отбрасывать в процессе упомянутого объединения значение, по меньшей мере, одного параметра, который имеется для первого из упомянутого множества каналов, если упомянутая информация об активности в упомянутом множестве каналов указывает на то, что активность в упомянутом первом канале существенно меньше, чем, по меньшей мере, в одном другом из упомянутого множества каналов.
13. Звуковой декодер по п.12, в котором упомянутый блок выбора параметра настроен для усреднения величин, по меньшей мере, одного другого параметра, которые имеются для упомянутого множества каналов, при упомянутом объединении, если упомянутая информация об активности в упомянутом множестве каналов указывает на то, что активность в первом из упомянутого множества каналов существенно меньше, чем, по меньшей мере, в одном другом из упомянутого множества каналов.
14. Звуковой декодер по п.9 или 10, в котором упомянутый блок выбора параметра настроен для усреднения величин упомянутых параметров, которые имеются для упомянутого множества каналов, если упомянутая информация об активности в упомянутом множестве каналов не указывает на то, что активность в одном из упомянутого множества каналов существенно меньше, чем, по меньшей мере, в одном другом из упомянутого множества каналов.
15. Звуковой декодер по п.9 или 10, в котором упомянутый многоканальный звуковой сигнал является стереофоническим сигналом.
16. Мобильный терминал, содержащий звуковой декодер по одному из пп.9-15.
17. Система кодирования, включающая звуковой кодер, предоставляющий кодированный многоканальный звуковой сигнал, который содержит, по меньшей мере, для верхней полосы частот исходного многоканального звукового сигнала раздельные значения параметров для каждого канала упомянутого многоканального звукового сигнала, и звуковой декодер по одному из пп.9-15.
18. Система по п.17, в которой упомянутый звуковой кодер содержит блок оценки, предназначенный для определения информации об активности в упомянутом множестве каналов и предоставления указанной информации для ее использования упомянутым звуковым декодером.
| US 6021386 А, 01.02.2000 | |||
| Кишечный интубатор | 1986 |
|
SU1377123A2 |
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| ЕР 1376538 A1, 02.01.2004 | |||
| СПОСОБ СОКРАЩЕНИЯ ЧИСЛА ДАННЫХ ПРИ ПЕРЕДАЧЕ И/ИЛИ НАКОПЛЕНИИ ЦИФРОВЫХ СИГНАЛОВ, ПОСТУПАЮЩИХ ИЗ НЕСКОЛЬКИХ ВЗАИМОСВЯЗАННЫХ КАНАЛОВ | 1993 |
|
RU2119259C1 |

