Область техники - вычислительная техника, многопроцессорные ЭВМ с распределенной общей памятью.
Область применения глобально адресуемой памяти - высокопроизводительные вычисления, требующие эффективную работу с памятью большого объема.
Известны, например, следующие аналоги.
Первым аналогом является способ организации глобально адресуемой общей памяти заказного суперкомпьютера Cray T3E, информация о котором имеется в статье Synchonisation and Communication in the T3E Multiprocessor (Синхронизация и взаимодействие в суперкомпьютере T3E) [1]. Cray T3E основан на коммерческом суперскалярном процессоре DEC 21164. Механизм аппаратной поддержки глобально адресуемой памяти реализован вне кристалла в виде расширения функциональности процессора. Для обращения в глобально адресуемую память используется большое количество Е-регистров (512 пользовательских + 128 системных) для обеспечения толерантности к большим задержкам, возможны векторные обращения длиной до 8 элементов.
Основные существенные признаки способа организации глобально адресуемой общей памяти Cray T3E:
- трехуровневая сегментно-страничная организация памяти;
- возможность выполнения части этапа трансляции адреса на удаленном узле;
- разделение вопросов защиты и размещения данных;
- универсальный механизм распределения данных, но отсутствует скремблирование;
- существует возможность отображения сегмента на немонотонную последовательность узлов;
- поддерживаются одновременно различные размеры страницы.
Преимущества:
1) гибкий механизм распределения данных и управления задачами за счет отображения на немонотонную последовательность узлов, использования различных размеров страниц;
2) сегментно-страничная трехуровневая схема адресации памяти, обеспечивающая простоту ОС;
3) часть процедуры трансляции выполняется на удаленном узле, что позволяет упростить и децентрализировать организацию ОС, увеличить производительность подсистемы памяти.
Недостаток:
отсутствует организация больших сегментов данных без потерь по промахам в TLB.
Вторым аналогом является способ организации глобально адресуемой общей памяти заказного суперкомпьютера Cray XI, архитектура глобально адресуемой общей памяти которого описана в статье Performance evaluation of the Cray X1 distributed shared-memory architecture (Оценка производительности архитектуры распределенной общей памяти Cray X1) [2]. Cray X1 - суперкомпьютер с векторной архитектурой, кэш-когерентная память внутри одного узла.
Основные существенные признаки способа организации глобально адресуемой общей памяти Cray X1:
- двухуровневая страничная организация памяти;
- возможность выполнения части этапа трансляции адреса на удаленном узле;
- существует возможность отображения сегмента на немонотонную последовательность узлов;
- поддерживаются одновременно различные размеры страницы.
Преимущества:
1) простота виртуальной памяти влечет за собой малое количество требуемых аппаратных ресурсов при реализации;
2) часть процедуры трансляции выполняется на удаленном узле;
3) гибкий механизм распределения данных и управления задачами.
Недостаток:
соединение вопросов защиты и размещения данных, что влечет сложность программ и базового программного обеспечения.
Третьим аналогом является способ организации глобально адресуемой общей памяти суперкомпьютера Cray BlackWidow, которая описана в статье The Cray BlackWidow: A Highly Scalable Vector Multiprocessor (Cray BlackWidow: высоко масштабируемый векторный суперкомпьютер) [3] и американском патенте Remote translation mechanism for a multi-node system (Распределенный механизм трансляции для многоузловой системы) [4]. Cray BlackWidow является заказным суперкомпьютером с векторной архитектурой.
Основные существенные признаки способа организации глобально адресуемой общей памяти Cray BlackWidow:
- двухуровневая организация памяти с виртуальным номером узла непосредственно в адресе;
- возможность выполнения части этапа трансляции адреса на удаленном узле.
Преимущества:
1) простота, и как следствие, низкие затраты аппаратных ресурсов;
2) часть процедуры трансляции выполняется на удаленном узле.
Недостатки:
1) необходимость использовать номера узлов в адресе влечет за собой сложность базового программного обеспечения;
2) сложность базового программного обеспечения неминуемо приведет к усложнению прикладных программ.
Наиболее близким аналогом является способ организации глобально адресуемой общей памяти суперкомпьютера Cray Eldorado (XMT), который описан в статье Eldorado [5], принципы работы которого описаны в документе Cray/MTA Principles of Operation (Принципы работы Cray/MTA) [6]. Cray Eldorado - это заказной суперкомпьютер с мультитредовой архитектурой процессора, причем данный процессор - единственный мультитредовый процессор, который используется для построения суперкомпьютера.
Основные существенные признаки способа организации глобально адресуемой общей памяти Cray Eldorado:
- двухуровневая сегментная адресация памяти;
- работы с сегментами большого объема без увеличения количества TLB-промахов;
- наличие скремблирования с возможностью его отключения. Последовательность виртуальных адресов, следующих с регулярным шагом, скремблирование переводит в псевдослучайную последовательность номеров узлов. Скремблирование позволяет работать с распределенной памятью в стиле UMA (Uniform Memory Access);
- наличие возможности распределения по узлам.
Преимущества:
1) введены суперсегменты как особый тип сегментов, позволяющие работать с увеличенными объемами данных в сравнении с обычными сегментами без потерь по промахам в TLB;
2) отсутствует аппарат страниц, что влечет за собой использование меньшего количества аппаратных ресурсов при реализации.
Недостатки:
1) организация суперсегментов требует большого количества аппаратных ресурсов, например, используются две TLB вместо одной. Эти затраты в частности, связаны с обеспечением преемственности по отношению к ранее выпущенным системам или с необходимостью разработчиков вносить в архитектуру как можно меньше изменений;
2) сегментная организация памяти с двумя уровнями адресации - виртуальными адресами задач и физическими адресами влечет необходимость использования сложных и заведомо неоптимальных подсистем централизованного управления памятью для задач. Управление памятью негибко и неэффективно;
3) для каждого сегмента существует два способа размещения (распределения данных) по физической памяти узлов. Первый способ позволяет располагать сегмент полностью в локальной памяти одного узла. Второй способ позволяет распределять сегмент, но обязательно по физической памяти узлов, количество которых задается уровню системы, и его невозможно изменить для каждого сегмента в отдельности. Включенное при этом скремблирование не учитывает локализацию данных и позволяет отвлечься от расположения данных. Однако при выключенном скремблировании располагать данные близко к конкретному узлу не удается, так как задача может быть запущена на разном количестве узлов, не обязательно совпадающим с максимальным. Поэтому учитывать локализацию оказывается невозможным.
При создании предлагаемой глобально адресуемой общей памяти ставилась цель эффективной работы с глобально адресуемой общей памятью большого объема с уменьшением аппаратных затрат на поддержку суперсегментов, с возможностью управлением локализацией данных, с возможностью эффективного использования и управления системным программным обеспечением локальной памятью каждого узла и всего суперкомпьютера в целом.
Цель достигается следующими приемами:
- за счет введения трехуровневой организации памяти разделены вопросы защиты и размещения данных.
Первый уровень виртуальных адресов позволяет управлять свойствами размещения данных по узлам, второй уровень глобальных виртуальных адресов позволяет для каждого узла управлять размещением необходимой порции данных в его локальной памяти независимо от других узлов. При этом часть этапа трансляции адреса происходит на целевом узле, на котором хранятся данные. Таким образом, при помощи децентрализованной схемы достигается эффективность управления памятью каждого узла;
- суперсегменты введены иначе, чем в прототипе: вместо двух TLB используется одна, что уменьшает количество аппаратных ресурсов без увеличения количества TLB-промахов;
- для каждого сегмента задается количество узлов, на которых распределяются данные сегмента, и способ распределения данных по узлам.
Таким образом, для задач, запускаемых на произвольном количестве узлов, можно задавать узлы, на которых будут лежать данные. Зная способ распределения данных по заданным узлам можно предсказывать, с каких узлов какие обращения в память будут локальными (выполняться без использования сети), а какие глобальными (с использованием коммуникационной сети), и таким образом, управлять локализацией данных. Способов распределения данных по заданным узлам два - блочный и блочно-циклический;
- за счет введения виртуальной нумерации узлов можно загружать задачу на не обязательно монотонную последовательность узлов, что упрощает операционной системе задачу планирования использования узлов для различных задач;
- за счет использования для каждого сегмента независимо от других одного из четырех размеров страниц достигается как эффективность использования памяти при малых размерах страниц, так и повышается производительность за счет уменьшения промахов при больших размерах страниц в зависимости от нужд задачи.
Признак размера страниц устанавливается для всего сегмента целиком и приклеивается к глобальному виртуальному адресу, что позволяет сразу обращаться по глобальному виртуальному адресу к TLB страниц (RPTLB) вне зависимости от того, на каком узле происходит это обращение, что повышает эффективность трансляции.
В контексте мультитредовой архитектуры предлагаемый авторами способ организации глобально адресуемой памяти является новым, так как у ближайшего аналога в Cray XMT отсутствует поддержка страниц и выполнение фазы трансляции на удаленном узле. Также в Cray XMT значительно слабее выражено управление локализацией данных, не столь разнообразны возможности распределения. Если сравнивать в более широком контексте систем, то в них нет поддержки суперсегментов (Cray T3E), а также память имеет более простую страничную организацию (Cray BlackWidow). Также способ организации суперсегментов отличается в сравнении с Cray Eldorado (XMT). Новым является выделение двух аппаратных способов распределения - блочного и блочно-циклического - нет ни в одном суперкомпьютере.
Описание способа организации глобально адресуемой общей памяти в многоядерно-мультитредовом микропроцессоре.
Разработка суперкомпьютера с глобально адресуемой памятью требует решения ряда архитектурных задач, однако главная проблема - обеспечение эффективной работы с памятью в условиях огромной диспропорции задержек выполнения операций в процессоре и памяти. Предлагаемый способ организации глобально адресуемой общей памяти предполагается использовать в суперкомпьютере, в котором для преодоления проблемы диспропорции задержек выполнения операций в процессоре и памяти используется как подход обеспечения толерантности к этим задержкам, так и управляемой локализации вычислений и данных.
Суперкомпьютер, в котором предполагается использовать предлагаемый способ, содержит множество вычислительных узлов, соединенных коммуникационной сетью. Вычислительный узел суперкомпьютера содержит: сетевой адаптер/маршрутизатор; микропроцессор с аппаратной поддержкой трансляции адресов глобально адресуемой памяти и передачи сетевых пакетов, реализующих такие обращения; локальную память на базе стандартных DRAM-модулей.
Каждая задача может использовать для своего выполнения один или более узлов. В каждом из этих узлов в каждом ядре задача представляется одним доменом защиты, который можно рассматривать как виртуальный процессор, выполняющий некоторую часть задачи. Домен защиты содержит дескрипторы данных и программ, дескрипторы тредовых устройств домена защиты и управляющую информацию. Управление доменами защиты производится операционной системой с помощью привилегированных команд.
В каждом домене защиты имеется дескриптор данных домена защиты, находящийся в регистре DDD (Domain Data Descriptor). Регистр DDD содержит адрес и длину таблицы дескрипторов V-сегментов (обычных и суперсегментов), в которых могут находиться данные домена защиты, а также другую управляющую информацию.
Пространство виртуальной памяти в каждом домене защиты свое. Оно состоит в общем случае из множества V-сегментов, каждый из которых имеет свой номер в пределах данного домена защиты. Основные функции V-сегментов - это защита данных, управление использованием областей общей для всех задач распределенной физической памяти, управление распределением блоков памяти по узлам.
В виртуальной памяти по аналогии с Cray XMT присутствуют суперсегменты. В зависимости от бита ST виртуального адреса определяется тип используемого сегмента - суперсегмент или обычный сегмент. В зависимости от этого интерпретируются оставшиеся биты виртуального адреса. Задача может использовать как большое (до 1 млн) количество обычных сегментов (размером от 128 б до 256 Гб), так и небольшое (до 1024) количество суперсегментов (размером от 128 Кб до 256 Тб), что должно соответствовать большему разнообразию требований различных прикладных задач.
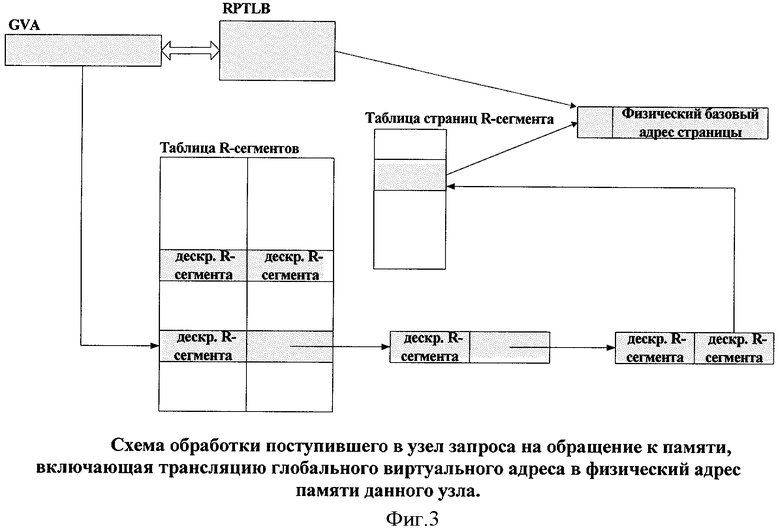
У каждого сегмента (как обычного, так и суперсегмента) есть дескриптор, 64-разрядное слово, описывающее тип, размер и способ распределения сегмента по узлам. Дескрипторы V-сегментов одной задачи хранятся в общей таблице дескрипторов сегментов данных в локальной памяти узла. Расположение и размер этой таблицы определяются с помощью специального регистра, называемого дескриптором данных домена защиты. При этом дескрипторы обычных сегментов располагаются с начала таблицы, а дескрипторы суперсегментов - с конца. С получения дескриптора V-сегмента начинается процедура трансляции виртуального адреса, первая часть которой представлена на фиг.1.
Таблица дескрипторов сегментов кэшируется в кэше VTLB (V-segments Translation Lookaside Buffer), доступ к VTLB осуществляется по физическому адресу дескриптора сегмента. Кэш VTLB используется для обоих типов сегментов, в отличие от системы Eldorado, в которой для суперсегментов используется дополнительная полностью ассоциативная супер-TLB.
На второй фазе трансляции виртуального адреса (фиг.1) происходит контроль различных свойств V-сегмента, определяемых его дескриптором, включая его длину, права доступа и тип сегмента.
Дескриптор V-сегмента позволяет использовать скремблирование. Если последовательно выдаваемые обращения к памяти имеют некоторую регулярность, то возможно попадание в один и тот же модуль памяти. Для снижения вероятности таких конфликтов используется обычно метод "зашумления" или "скремблирования", при котором последовательность виртуальных адресов, следующих с регулярным шагом, скремблирование переводит в псевдослучайную последовательность номеров узлов. Скремблирование по аналогии с Cray XMT можно отключать, если существенна оптимизация за счет локализации данных. Операция скремблирования происходит на третьей фазе трансляции адреса.
Четвертая фаза трансляции носит название распределения, на ней происходит определение номера узла, на котором находятся адресуемые виртуальным адресом данные. В отличие от Cray XMT дескриптор V-сегмента в предлагаемом способе определяет количество узлов, на которых распределен сегмент, что в сочетании с введенными способами распределения позволяет достичь удобной для задачи локализации. Также дескриптор задает номер узла, с которого начинает располагаться сегмент.
Для поддержки языков программирования в подсистему памяти введены два типа распределения - блочное и блочно-циклическое, которые распределяют сегмент по заданным узлам. Возможность размещения массивов на многих узлах позволяет повысить пропускную способность памяти, поскольку это организация расслоения памяти, при котором обращения к отдельным подблокам могут выполняться параллельно. В перспективных языках программирования этим можно управлять из программ. По этой причине такие средства были введены в предлагаемый способ организации общей памяти.
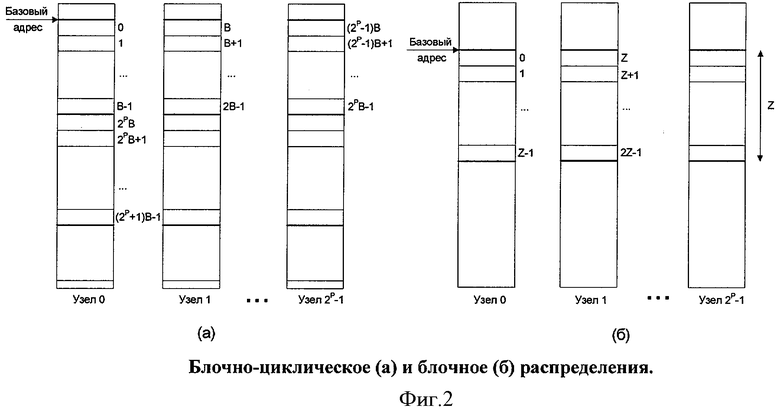
При блочно-циклическом распределении номер узла для физического размещения данных определяется заданным количеством средних разрядов виртуального адреса, оставшиеся разряды задают смещение на локальном узле. Расположение данных на узлах для блочно-циклического распределения указано на фиг.2(а), В - размер блока, а Р - показатель степени, определяющий количество узлов для распределения данных сегмента.
При блочном распределении номер узла для физического размещения данных определяется заданным количеством старших разрядов виртуального адреса, а смещение определяется оставшимися младшими разрядами. Расположение данных на узлах для блочного распределения указано на фиг.2(б), Z - размер блока.
Рассмотрим теперь вопрос расположения данных сегмента на отдельном узле. В предлагаемом способе для каждого сегмента может быть выбрана одна из двух схем: с использованием R-сегментов или без них.
Бит дескриптора V-сегмента указывает, используется ли промежуточное отображение на R-сегменты или нет. Если R-сегменты не используются, то непосредственно в дескрипторе сегмента хранится физический базовый адрес, который указывает начало фрагмента сегмента на каждом из узлов, на которых распределен данный сегмент. К нему в процессе трансляции прибавляется смещение внутри фрагмента сегмента на конкретном узле, полученное с учетом типа распределения. Таким образом, на узле, выдавшем обращение по виртуальному адресу, в данном случае может быть получен физический адрес ячейки данных (физический адрес состоит из номера узла и смещения внутри памяти узла). Характерное для этой схемы размещение сегмента в разных узлах показано на фиг.2, когда все фрагменты сегментов на каждом узле начинаются с одного и того же физического базового адреса. Подобная двухуровневая схема используется в Cray XMT.
Схема без R-сегментов проста, но ее недостатки очевидны: управление памятью должно быть централизованным. Тем не менее схема введена из-за простоты и эффективности.
Теперь рассмотрим более сложную схему организации виртуальной памяти с использованием R-сегментов. Ее особенность - трехуровневая сегментно-страничная модель организации виртуальной памяти.
Пространство виртуальной памяти (также как и в первом случае) состоит из множества V-сегментов, каждый из которых имеет свой номер в пределах данного домена защиты. Основная функция V-сегментов - это защита данных и управление использованием областей общей для всех задач глобальной виртуальной памяти, или иначе, глобального адресного пространства (GVA, Global Virtual Address space). Глобальное адресное пространство состоит из R-сегментов.
Смысл GVA в том, что разделяются вопросы защиты и распределения (размещения) данных. В предлагаемом способе именно R-сегменты отображаются на узлы, а в каждом узле находящийся на нем фрагмент сегмента отображается на страницы, которые находятся в памяти. Вообще говоря, эти страницы могут размещаться и на дисках, как в виртуальной памяти современных систем.
Цель введения трансляции глобального адреса GVA (иначе он называется реальный) на узле с требуемым модулем памяти, а не на узле-источнике обращения, состоит в повышении производительности за счет параллельной трансляции адресов разных обращений и локализации управления распределением памятью. На узле-получателе глобальный виртуальный адрес транслируется в физический. Рассмотрим этот процесс подробнее.
В случае использования R-сегментов в дескрипторе V-сегмента хранится признак размера используемых страниц для всего R-сегмента, а также его номер. В случае удаленного доступа формируется сообщение для коммуникационной сети с номером узла, номером R-сегмента, размером используемых страниц и смещением внутри фрагмента сегмента. В случае локального обращения сообщение в сеть не посылается, трансляция происходит на этом же узле.
Вторая часть схемы трансляции адреса изображена на фиг.3.
В локальной памяти узла хранится единственная для узла таблица R-сегментов, которая является хеш-таблицей с разрешением конфликтов доступа методом цепочек. Каждый элемент таблицы содержит либо два дескриптора (если по ключу конфликтуют не более чем два R-сегмента), либо дескриптор и ссылку на цепочку конфликтующих дескрипторов R-сегментов. Элементы цепочки имеют такой же формат, что и формат элемента таблицы.
Дескриптор R-сегмента содержит адрес таблицы дескрипторов страниц R-сегментов, находящейся в локальной памяти вычислительного узла. В дескрипторе страницы R-сегмента хранится базовый физический адрес страницы, к которому прибавляется смещение внутри страницы.
Для ускорения процедуры трансляции глобального виртуального адреса дескрипторы R-страниц R-сегментов кэшируются в специальной кэш-памяти RPTLB (Real-Page TLB). Кэшируемыми данными (записями) являются дескрипторы R-страниц. Ключ для доступа в RPTLB формируется по значению полей номера R-сегмента из глобального виртуального адреса и номера R-страницы. Так как R-страница может иметь переменную длину 16 Кб, 256 Кб, 4 Мб или 64 Мб, номер R-страницы формируется из старших битов смещения в фрагменте сегмента, причем количество старших битов определяется размером R-страницы. Таким образом, по глобальному виртуальному адресу можно сразу с помощью RPTLB получить физический адрес, избегая обращений в таблицу R-сегментов и таблицу страниц. Именно для эффективного доступа в RPTLB размер страницы для R-сегмента задается в дескрипторе V-сегмента.
В дескрипторе V-сегментов при указании узлов, на которых располагается сегмент можно использовать логический номер узла, то есть общий номер среди всех узлов в системе, если последовательность используемых для этого логических номеров монотонная. Если требуется использовать немонотонную последовательность узлов, то в дескрипторе V-сегмента указывают признак, что используются виртуальные номера узлов.
Принадлежащий задаче вычислительный узел имеет уникальный виртуальный номер в пределах этой задачи, который отображается через некоторую системную таблицу этой задачи на логический номер узла в системе. Такой системной таблицей является таблица VNM (Virtual Node Map), которая имеется у каждой решаемой в системе задачи и находится в локальной памяти каждого узла, на котором решается задача. Таблица задачи VNM содержит номера, логические номера узлов слота отображения (каждый слот отображает 8-элементную монотонную последовательность виртуальных номеров в последовательность логических номеров). Трансляция виртуального номера узла в логический происходит при выдаче сетевого системного сообщения.
Очевидно, что дополнительная схема отображения виртуальных узлов в физические требует накладных расходов на трансляцию, однако позволяет использовать немонотонные последовательности узлов для сегментов задачи.
В настоящее время предлагаемый способ реализуется в ОАО «НИЦЭВТ» в рамках проекта по созданию перспективного суперкомпьютера стратегического назначения. Важность данного проекта по созданию систем с высокой реальной производительностью и эффективной глобально адресуемой памятью, ведущегося в ОАО «НИЦЭВТ», была признана на федеральном уровне. Предложения по данному проекту обсуждались дважды на НТС ВПК, на рабочей группе НТС ВПК. Были приняты положительные решения. В настоящее время решения и рекомендации по проекту находятся в Правительстве РФ, он поддержан Министерством Образования и Науки и Минпромэнерго. Интерес к проекту проявляют ведущие научные центры России.
Литература
1. S.Scott "Synchonisation and Communication in the T3E Multiprocessor", ASPLOS-VII, Cambridge, MA, October 2-4, 1996.
2. Т.Dunigan, J.Vetter, J.White III, P.Worley, "Performance evaluation of the Cray XI distributed shared-memory architecture". Micro, IEEE Volume 25, Issue 1, Jan. - Feb. 2005, Page(s):30-40.
3. D.Abts, A.Batanieh, S.Scott, G.Faanes, J.Scwarzmeier, E.Lundberg, T.Jonson, M.Bye, G.Schwoerer. The Cray BlackWidow: A Highly Scalable Vector Multiprocessor. SC07, November 10-16, 2007.
4. Steven Scott. Remote translation mechanism for a multi-node system. G06F 12/10, US Patent N 6922766 B2, 2002.
5. Cray Eldorado (XMT), статья J.Feo, D.Harper, S.Kahan, P.Konecny, "Eldorado", Cray Inc., 2005.
6. "Cray/MTA Principles of Operation", Cray Inc., 28 November, 2005.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ФОРМИРОВАНИЯ ВИРТУАЛЬНОЙ ПАМЯТИ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2011 |
|
RU2487398C1 |
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2618367C1 |
| ОПРЕДЕЛЕНИЕ ФОРМАТОВ ТРАНСЛЯЦИИ ДЛЯ ФУНКЦИЙ АДАПТЕРА ВО ВРЕМЯ ВЫПОЛНЕНИЯ | 2010 |
|
RU2556418C2 |
| СПОСОБ ОРГАНИЗАЦИИ ПЕРСИСТЕНТНОЙ КЭШ ПАМЯТИ ДЛЯ МНОГОЗАДАЧНЫХ, В ТОМ ЧИСЛЕ СИММЕТРИЧНЫХ МНОГОПРОЦЕССОРНЫХ КОМПЬЮТЕРНЫХ СИСТЕМ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2238584C2 |
| СРАВНЕНИЕ И ЗАМЕНА ПОЗИЦИИ ТАБЛИЦЫ ДИНАМИЧЕСКОЙ ТРАНСЛЯЦИИ АДРЕСА | 2012 |
|
RU2550558C2 |
| ТРАНСЛЯЦИЯ АДРЕСОВ ВВОДА-ВЫВОДА В АДРЕСА ЯЧЕЕК ПАМЯТИ | 2010 |
|
RU2547705C2 |
| СПОСОБ И УСТРОЙСТВО ТРАНСЛЯЦИИ АДРЕСА | 2008 |
|
RU2461870C2 |
| Связанное с выбранными архитектурными функциями администрирование обработки | 2015 |
|
RU2665243C2 |
| АКТИВАЦИЯ/ДЕАКТИВАЦИЯ АДАПТЕРОВ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2010 |
|
RU2562372C2 |
| ПРЕОБРАЗОВАНИЕ ИНИЦИИРУЕМОГО СООБЩЕНИЯМИ ПРЕРЫВАНИЯ В УВЕДОМЛЕНИЕ О ГЕНЕРИРОВАННОМ АДАПТЕРОМ ВВОДА-ВЫВОДА СОБЫТИИ | 2010 |
|
RU2546561C2 |
Изобретение относится к области вычислительной техники и может быть применено при создании многопроцессорных ЭВМ с распределенной общей памятью. Техническим результатом является управление локализацией данных и повышение эффективности использования и управления системным программным обеспечением и локальной памятью каждого узла и всего суперкомпьютера в целом. Способ организации глобально адресуемой общей памяти в многопроцессорной ЭВМ на основе многоядерно-мультитредового микропроцессора с использованием двухуровневой сегментной виртуальной памяти, с использованием сегментов двух типов - обычных сегментов и суперсегментов большого объема, с поддержкой скремблирования, с одновременным с использованием поддержки двухуровневой сегментной виртуальной памяти используют трехуровневую сегментно-страничную организацию памяти с выполнением части этапа трансляции адреса на удаленном узле, при этом для поддержки работы с суперсегментами используется одна TLB, для каждого сегмента или суперсегмента управляют количеством узлов, по которым производится распределение сегмента одним из двух способов - блочным или блочно-циклическим, для каждого сегмента или суперсегмента используют логическую нумерацию узлов или виртуальную нумерацию узлов. 3 ил.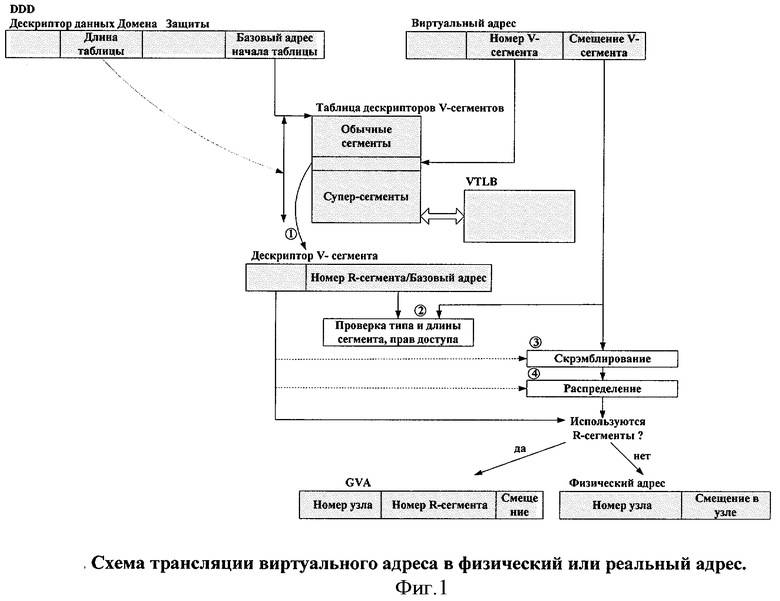
Способ организации глобально адресуемой общей памяти в многопроцессорной ЭВМ на основе многоядерно-мультитредового микропроцессора с использованием двухуровневой сегментной виртуальной памяти, с использованием сегментов двух типов - обычных сегментов и суперсегментов большого объема, с поддержкой скремблирования, то есть отображения последовательности виртуальных адресов одного сегмента, следующих с регулярным шагом, в физические адреса с псевдослучайными номерами узлов, с возможностью распределения виртуальных адресов одного сегмента по физическим адресам разных узлов, отличающийся тем, что, одновременно с использованием поддержки двухуровневой сегментной виртуальной памяти используют трехуровневую сегментно-страничную организацию памяти с выполнением части этапа трансляции адреса на удаленном узле, кроме того, для поддержки работы с суперсегментами используется одна TLB, кроме того, для каждого сегмента или суперсегмента независимо от других сегментов управляют количеством узлов, по которым производится распределение сегмента одним из двух способов - блочным (когда номер узла для физического размещения данных определяется заданным количеством старших разрядов виртуального адреса) и блочно-циклического (когда номер узла для физического размещения данных определяется заданным количеством средних разрядов виртуального адреса), а также для каждого сегмента или суперсегмента используют логическую нумерацию узлов (при этом номера узлов, на которых размещен сегмент, должны быть строго монотонны) или виртуальную нумерацию узлов (которая может отображаться на немонотонную последовательность номеров узлов), также для каждого сегмента или суперсегмената при использовании трехуровневой сегментно-страничной организации памяти указывают один из четырех возможных размеров страниц, после чего производится доступ к TLB страниц.
| Cray/MTA Principles of Operation, Cray Inc., 28 November 2005 | |||
| А.Слуцкин и др | |||
| Российский суперкомпьютер с глобально-адресуемой памятью | |||
| - Открытые системы, №9, 2007 | |||
| DENNIS ABTS et al | |||
| The Cray BlackWidow: A Highly Scalable Vector Multiprocessor, Cray Inc., SC07, November 10-16, 2007 | |||
| J.FEO et al, Cray Eldoralo (XMA), Cray Inc., May 4-6, |

