Настоящая заявка на патент испрашивает приоритет по предварительной заявке № 60/664749, озаглавленной «Method and Apparatus for Efficient Strongly Ordered Transactions» («Способ и устройство для эффективных строго упорядоченных транзакций»), зарегистрированной 23 марта 2005 г. и переуступленной ее правопреемнику, а настоящим явным образом включенной в материалы настоящей заявки посредством ссылки.
Область техники, к которой относится изобретение
Настоящее раскрытие, в целом, относится к системам обработки, а более точно к способу и устройству для принудительного применения строго упорядоченных запросов в системе слабо упорядоченной обработки.
Уровень техники
Компьютеры и другие современные системы обработки революционизировали электронную промышленность, дав возможность выполнять изощренные задачи лишь несколькими нажатиями клавиатуры. Эти изощренные задачи часто используют некоторое количество устройств, которые поддерживают связь друг с другом быстрым и эффективным образом с использованием шины. Шина обеспечивает совместно используемую линию связи между устройствами в системе обработки.
Типы устройств, присоединенных к шине в системе обработки, могут изменяться в зависимости от конкретного применения. Типично, отправляющими устройствами на шине могут быть процессоры, а принимающими устройствами на шине могут быть устройства памяти или отображаемые в память устройства. В этих системах процессоры часто достигают преимуществ производительности предоставлением возможности операциям с памятью выполняться неупорядоченно. Например, последовательность операций с памятью могла бы переупорядочиваться, чтобы предоставить всем операциям в отношении одной и той же страницы в памяти возможность выполняться до того, как открыта новая страница. Системы обработки, которым предоставлена возможность переупорядочивать операции с памятью, обычно указываются ссылкой как системы «слабо упорядоченной» обработки.
В определенных случаях переупорядочение операций с памятью может непредсказуемо воздействовать на поведение программы. Например, прикладная программа может требовать, чтобы процессор записывал данные в память до того, как процессор осуществляет чтение из этой ячейки памяти. В системе слабо упорядоченной обработки нет гарантии, что это будет происходить. Этот результат может быть неприемлемым.
Различные технологии были применены для выполнения упорядоченных операций с памятью в системе слабо упорядоченной обработки. Одна из технологий состоит в том, чтобы просто задерживать определенные операции с памятью до тех пор, пока не выполнены все операции с памятью перед ними. В предыдущем примере процессор может задерживать выдачу запросов чтения до после того, как он осуществляет запись в ячейку памяти. Другая технология состоит в том, чтобы использовать команду шины, указываемую ссылкой как барьер памяти, когда требуется упорядоченная операция с памятью. «Барьер памяти» может использоваться, чтобы гарантировать, что все запросы доступа к памяти, выданные процессором до барьера памяти, выполняются до всех запросов доступа к памяти, выданных процессором после барьера памяти. К тому же в предыдущем примере барьер памяти мог бы отправляться в память процессором перед выдачей запроса на чтение. Это могло бы гарантировать, что процессор осуществляет запись в память до того, как он осуществляет чтение из той же самой ячейки памяти.
Обе технологии действенны, но неэффективны в отношении производительности системы. Барьер памяти может быть особенно неэффективным в системах обработки с многочисленными устройствами памяти. В этих системах обработки барьеру памяти было бы необходимо выдаваться процессором в каждое устройство памяти, к которому он может осуществлять доступ, чтобы принудительно применять ограничение упорядочения к операциям с памятью. Таким образом, есть сохраняющаяся потребность в более эффективных способах для выполнения упорядоченных операций с памятью в системе слабо упорядоченной обработки.
Сущность изобретения
Раскрыт один из аспектов системы слабо упорядоченной обработки. Система обработки включает в себя множество устройств памяти и множество процессоров. Каждый из процессоров сконфигурирован для формирования запросов доступа к памяти в отношении одного или более устройств памяти, причем каждый запрос доступа к памяти содержит атрибут, который может объявляться, чтобы указывать строго упорядоченный запрос. Система обработки дополнительно включает в себя шинное межсоединение, сконфигурированное для присоединения процессоров к устройствам памяти, шинное межсоединение является дополнительно сконфигурированным для принудительного применения ограничений упорядочения к запросам доступа к памяти на основании атрибутов.
Раскрыт еще один аспект системы слабо упорядоченной обработки. Система обработки включает в себя множество устройств памяти и множество процессоров. Каждый из процессоров сконфигурирован для формирования запросов доступа к памяти в отношении одного или более устройств памяти, причем каждый запрос доступа к памяти содержит атрибут, который может объявляться, чтобы указывать строго упорядоченный запрос. Система обработки дополнительно включает в себя шинное межсоединение, содержащее средство для присоединения процессоров к устройствам памяти, и средство для принудительного применения ограничений упорядочения к запросам доступа к памяти на основании атрибутов.
Раскрыт один из аспектов шинного межсоединения. Шинное межсоединение включает в себя коммутатор шины, сконфигурированный для присоединения множества процессоров к множеству устройств памяти в системе слабо упорядоченной обработки. Каждый из процессоров сконфигурирован для формирования запросов доступа к памяти в отношении одного или более устройств памяти, причем каждый запрос доступа к памяти содержит атрибут, который может объявляться, чтобы указывать строго упорядоченный запрос. Шинное межсоединение дополнительно включает в себя контроллер, сконфигурированный для принудительного применения ограничений упорядочения к запросам доступа к памяти на основании атрибутов.
Раскрыт один из аспектов способа для принудительного применения строго упорядоченных запросов доступа к памяти в системе слабо упорядоченной обработки. Способ включает в себя прием, от множества процессоров, запросов доступа к памяти для множества устройств памяти, один из запросов доступа к памяти содержит атрибут памяти, указывающий строго упорядоченный запрос доступа к памяти. Способ дополнительно включает в себя принудительное применение ограничения упорядочения для строго упорядоченного запроса доступа к памяти по отношению к другим запросам доступа к памяти в ответ на атрибут.
Понятно, что другие варианты осуществления настоящего изобретения станут без труда очевидны специалистам в данной области техники из последующего подробного описания, при этом оно имеет значение различных вариантов осуществления изобретения, показанных и описанных только в качестве иллюстрации. Как будет осознаваться, изобретение является допускающим другие и отличные варианты осуществления, а его некоторые детали являются допускающими модификацию в различных других отношениях, все не выходя из сущности и объема настоящего изобретения. Соответственно, чертежи и подробное описание должны рассматриваться в качестве иллюстративных по характеру, а не в качестве ограничительных.
Краткое описание чертежей
Различные аспекты настоящего изобретения проиллюстрированы в качестве примера, но не в качестве ограничения, на прилагаемых чертежах, на которых:
фиг. 1 - концептуальная структурная схема, иллюстрирующая пример системы слабо упорядоченной обработки;
фиг. 2 - функциональная структурная схема, иллюстрирующая пример шинного межсоединения в системе слабо упорядоченной обработки;
фиг. 3 - функциональная структурная схема, иллюстрирующая пример контроллера в шинном межсоединении для системы слабо упорядоченной обработки;
фиг. 4 - функциональная структурная схема, иллюстрирующая еще один пример контроллера в шинном межсоединении для системы слабо упорядоченной обработки.
Подробное описание
Подробное описание, изложенное ниже в связи с прилагаемыми чертежами, подразумевается в качестве описания различных вариантов осуществления изобретения и не подразумевается для представления единственных вариантов осуществления, в которых изобретение может быть осуществлено на практике. Подобное описание включает в себя характерные детали с целью обеспечения исчерпывающего понимания изобретения. Однако специалистам в данной области техники будет очевидно, что изобретение может быть осуществлено на практике без этих характерных деталей. В некоторых случаях широко известные конструкции и компоненты показаны в виде структурной схемы для того, чтобы избежать затенения концепций изобретения.
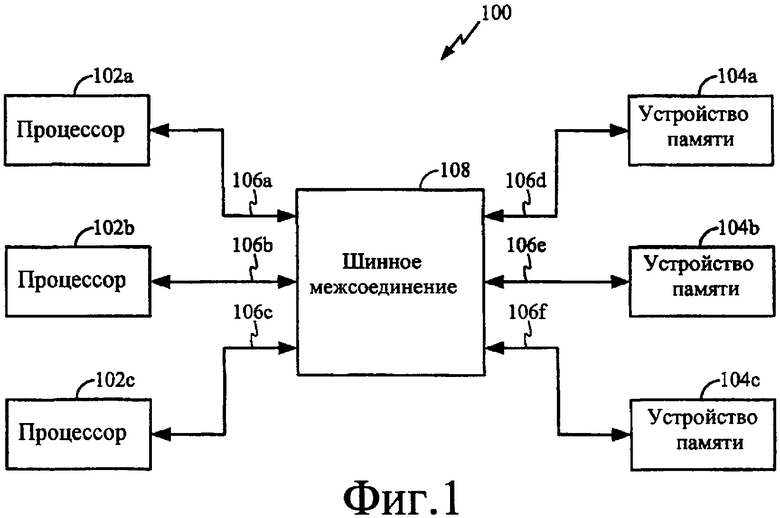
Фиг. 1 - концептуальная структурная схема, иллюстрирующая пример системы слабо упорядоченной обработки. Система 100 обработки может быть компьютером, постоянно находящейся на компьютере или любой другой системой, допускающей обработку, извлечение и сохранение информации. Система 100 обработки может быть автономной системой или, в качестве альтернативы, встроенной в устройство, такое как беспроводной или проводной телефон, персональный цифровой секретарь (PDA), настольный компьютер, дорожный компьютер, игровой пульт, пейджер, модем, камера, автомобильное оборудование, промышленное оборудование, видеоаппаратура, звуковая аппаратура или любое другое подходящее устройство, требующее возможности обработки. Система 100 обработки может быть реализована в виде интегральной схемы, части интегральной схемы или распределена по многочисленным интегральным схемам. В качестве альтернативы, система 100 обработки может быть реализована с помощью дискретных компонентов или любых сочетаний дискретных схем и интегральных схем. Специалисты в данной области техники будут осознавать, каким образом лучше реализовать систему 100 обработки для каждого конкретного применения.
Система 100 обработки показана с многочисленными процессорами 102a - 102c на связи с многочисленными устройствами 104a - 104c памяти через шину 106. Реальное количество процессоров и устройств памяти, требуемых для любого конкретного применения, может изменяться в зависимости от требуемой вычислительной мощности и общих конструктивных ограничений. Шинное межсоединение 108 может использоваться для управления неделимыми операциями шины между процессорами 102a - 102c и устройствами 104a - 104c памяти с использованием двухточечных коммутационных соединений. По меньшей мере в одном варианте осуществления шинного межсоединения 108 многочисленные прямые линии связи могут быть предусмотрены для предоставления возможности происходить одновременно нескольким неделимым операциям шины. В качестве альтернативы, шинное межсоединение 108 может быть сконфигурировано для поддержки совместно используемой шинной компоновки.
Каждый процессор 102a - 102c может быть реализован в виде любого типа устройства управления шиной, в том числе в качестве примера процессора общего применения, цифрового сигнального процессора (ЦСП, DSP), специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA) или другой программируемой логики, дискретного логического элемента или транзисторной логики, дискретной вентильной или транзисторной логики, дискретных аппаратных компонентов или любой другой обрабатывающей сущности или компоновки. Один или более из процессоров 102a - 102c могут быть сконфигурированы для выполнения инструкций под управлением операционной системы или другого программного обеспечения. Инструкции могут находиться в одном или более из устройств 104a - 104c памяти. Данные также могут сохраняться в устройствах 104a - 104c памяти и извлекаться процессорами 102a - 102c для выполнения определенных инструкций. Новые данные, являющиеся следствием выполнения этих инструкций, могут записываться обратно в устройства 104a - 104c памяти. Каждое устройство 104a - 104c памяти может включать в себя контроллер памяти (не показан) и запоминающий носитель (не показан). Запоминающий носитель может включать в себя память ОЗУ (оперативного запоминающего устройства, RAM), память динамического ОЗУ (DRAM), синхронного динамического ОЗУ (SDRAM), флэш-память, память ПЗУ (постоянного запоминающего устройства, ROM), память ППЗУ (программируемого ПЗУ, PROM), память СППЗУ (стираемого и программируемого ПЗУ, EPROM), память ЭСППЗУ (электрически стираемого и программируемого ПЗУ, EEPROM), CD-ROM (ПЗУ на компакт диске), DVD (многофункциональный цифровой диск), регистры, накопитель на жестком диске, съемный диск или любой другой пригодный запоминающий носитель.
Каждый процессор 102a - 102c может быть снабжен выделенным каналом 106a - 106c на шине 106 для поддержания связи с шинным межсоединением 108. Подобным образом, шинное межсоединение 108 может использовать выделенный канал 106d - 106f на шине для поддержания связи с каждым устройством 104a - 104c памяти. В качестве примера, первый процессор 102a может осуществлять доступ к целевому устройству 104b памяти, отправляя запрос доступа к памяти через свой выделенный канал 106a на шине 106. Шинное межсоединение 108 определяет целевое устройство 104b памяти по адресу запроса доступа к памяти и пересылает запрос в целевое устройство 104b памяти через надлежащий канал 106e на шине 106. «Запросом доступа к памяти» может быть запрос на запись, запрос на чтение или любой другой имеющий отношение к шине запрос. Инициирующий процессор 102a - 102c может выдавать запрос на запись в целевое устройство 104a - 104c памяти посредством размещения надлежащего адреса с полезной нагрузкой на шине 106 и установления сигнала разрешения записи. Инициирующий процессор 102a - 102c может выдавать запрос на чтение в целевое устройство 104a - 104c памяти посредством размещения надлежащего адреса на шине 106 и установления сигнала разрешения чтения. В ответ на запрос чтения целевое устройство 104a - 104c памяти будет отправлять полезную нагрузку обратно инициирующему процессору 102a - 102c.
По меньшей мере в одном варианте осуществления системы 100 обработки процессоры 102a - 102c могут передавать «атрибут памяти» с каждым запросом доступа к памяти. «Атрибут памяти» может быть любым параметром, который описывает природу запроса доступа к памяти. Атрибут памяти может передаваться с адресом по каналу адреса. В качестве альтернативы, атрибут памяти может передаваться с использованием сигнализации боковой полосы или некоторой другой методологии. Атрибут памяти может использоваться для указания, является или нет запрос доступа к памяти строго упорядоченным. «Строго упорядоченный» запрос указывает ссылкой на запрос доступа к памяти, который не может выполняться неупорядоченно.
Шинное межсоединение 108 может использоваться для отслеживания атрибута памяти для каждого запроса доступа к памяти от процессоров 102a - 102c. Если атрибут памяти указывает строго упорядоченный запрос доступа к памяти, шинное межсоединение 108 может принудительно применять ограничение упорядочения к такому запросу. В качестве примера, запрос доступа к памяти из первого процессора 102a в целевое устройство 104a памяти может включать в себя атрибут памяти. Шинное межсоединение 108 может использоваться для определения по атрибуту памяти, является ли запрос строго упорядоченным. Если шинное межсоединение 108 определяет, что запрос является строго упорядоченным, оно отправляет барьер памяти в каждое устройство 104b и 104c памяти, к которым способен осуществлять доступ первый процессор 102a, иное чем целевое устройство 104a памяти. Шинное межсоединение 108 также отправляет запрос доступа к памяти в целевую память 104a без барьера памяти, так как целевое устройство 104a памяти будет неявным образом манипулировать им как строго упорядоченным запросом вследствие атрибута памяти, ассоциативно связанного с запросом доступа к памяти.
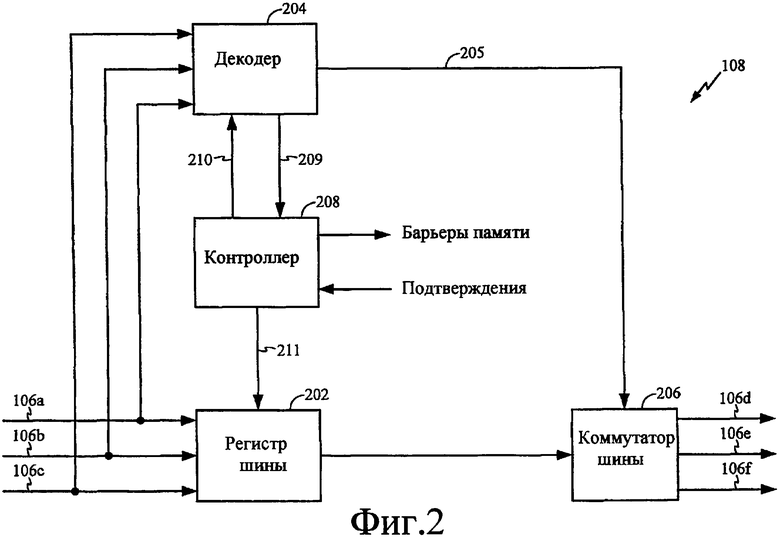
Фиг.2 - функциональная структурная схема, иллюстрирующая пример шинного межсоединения в системе слабо упорядоченной обработки. Способ, которым фактически реализовано шинное межсоединение, будет зависеть от конкретного применения и конструктивных ограничений, накладываемых на всю систему. Специалисты в данной области техники будут осознавать взаимозаменяемость различных конструкций и каким образом лучше реализовать функциональные возможности, описанные в материалах настоящей заявки, для каждого конкретного применения.
Со ссылкой на фиг.2 регистр 202 шины может использоваться для приема и сохранения информации с шины 106. Регистр 202 шины может быть любым типом запоминающего устройства, таким как память обратного магазинного типа (первым вошел - первым вышел, FIFO). Информация, принятая и сохраненная регистром 202 шины, может быть любой имеющей отношение к шине информацией, но типично включает в себя адрес и атрибут памяти для каждого запроса доступа к памяти, а в случае запроса на запись полезную нагрузку. Адрес для каждого запроса доступа к памяти также выдается на декодер 204. Декодер 204 может использоваться для определения целевого устройства памяти для каждого запроса доступа к памяти в регистре 202 шины. Это определение используется для формирования сигнала 205, который управляет коммутатором 206 шины. Коммутатор 206 шины может использоваться для демультиплексирования каждого запроса доступа к памяти в регистре 202 шины в надлежащий канал шины 106 для его целевого устройства памяти. Декодер 208 может использоваться для управления временными характеристиками запросов доступа к памяти, выводимых из регистра 202 шины.
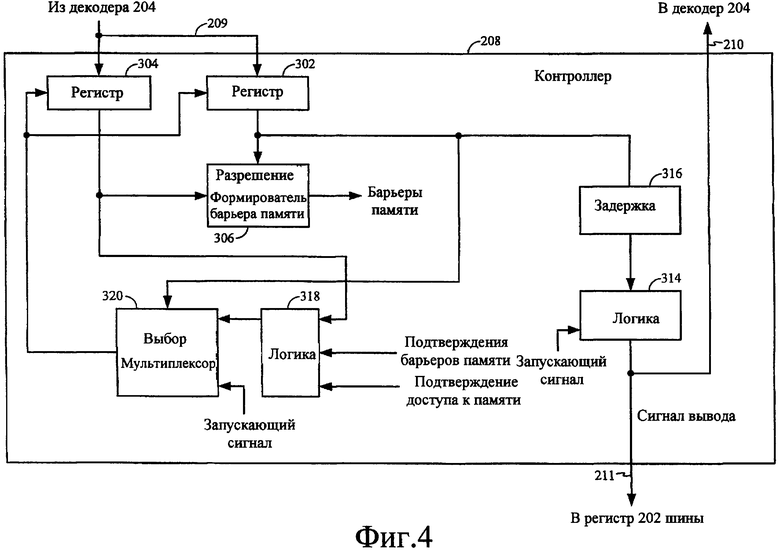
Фиг.3 - функциональная структурная схема, иллюстрирующая пример контроллера в шинном межсоединении для системы слабо упорядоченной обработки. Контроллер 208 ответственен главным образом за принудительное применение ограничений упорядочения к операциям с памятью на основании сигнала 209, который он принимает из декодера 204. Сигнал 209 включает в себя информацию, относящуюся к атрибуту памяти для каждого запроса доступа к памяти, который может быть сохранен в первом регистре 302. Сигнал 209 также включает в себя информацию, которая идентифицирует каждое устройство памяти, иное чем целевое устройство памяти, к которому инициирующий процессор способен осуществлять доступ. Конкретные устройства памяти, открытые для доступа каждым процессором, предварительно конфигурируются во время стадии проектирования, а потому могут быть запрограммированы или аппаратно соединены в декодер. Так или иначе, второй регистр 304 может использоваться для сохранения этих данных. Первый и второй регистры 302, 304 могут быть отдельными регистрами, как показано на фиг. 3 или, в качестве альтернативы, единым регистром. В некоторых вариантах осуществления контроллера 208 информация из декодера 204 может сохраняться в регистрах, совместно используемых при разных функциях шинного межсоединения. Каждый регистр может быть FIFO или другим пригодным запоминающим носителем.
Контроллер 208 принудительно накладывает ограничения упорядочения на операции с памятью, управляя временными характеристиками запросов доступа к памяти, выводимых из регистра 202 шины. Сначала последовательность операций будет описана в связи с атрибутом памяти, который указывает на то, что строго упорядоченный запрос доступа к памяти готов выводиться из регистра 202 шины. В этом случае атрибут памяти выдается первым регистром 302 в формирователь 306 барьера памяти в качестве разрешающего сигнала. Одновременно данные, сохраненные во втором регистре 304, подаются на вход формирователя 306 барьера памяти. Как указано выше, данные, сохраненные во втором регистре 304, включают в себя данные, которые идентифицируют каждое устройство памяти, иное чем целевое устройство памяти, к которому инициирующий процессор способен осуществлять доступ. Когда формирователь 306 барьера памяти разблокируется атрибутом памяти, эта информация используется для формирования барьера памяти для каждого устройства памяти, идентифицированного данными. Каждый барьер памяти может выдаваться в надлежащее устройство памяти посредством выдачи команды шины с атрибутом, идентифицирующим инициирующий процессор, который инициировал строго упорядоченный запрос. В качестве альтернативы, барьеры памяти могут выдаваться в надлежащие устройства памяти с использованием сигнализации боковой полосы или некоторым другим пригодным средством.
Логика 308 в контроллере 208 может использоваться для отслеживания обратной связи из устройств памяти для подтверждений барьера памяти. «Подтверждением барьера памяти» является сигнал из устройства памяти, указывающий, что каждый запрос доступа к памяти, принятый таким устройством памяти из инициирующего процессора, выдавшего строго упорядоченный запрос, который предшествует барьеру памяти, будет вычислен до завершения любого последующего запроса доступа к памяти из инициирующего процессора. Данные из второго регистра 304 используются логикой 308 для определения, каким устройствам памяти необходимо отслеживаться для подтверждений барьера памяти. Когда логика 308 определяет, что все подтверждения барьера памяти были приняты, она формирует запускающий сигнал, который используется для вывода соответствующего запроса доступа к памяти из регистра 202 шины через первое соединение 211. Более точно, атрибут памяти из первого регистра 302 выдается на вход выбора мультиплексора 310. Мультиплексор 310 используется для связывания запускающего сигнала, сформированного логикой 308 с регистром 202 шины, когда атрибут памяти указывает, что запрос доступа к памяти является строго упорядоченным. Запускающий сигнал, выведенный из мультиплексора 310, также связывается с декодером, чтобы синхронизировать временные характеристики коммутатора 206 шины, через второе соединение 210 (смотрите фиг.2).
Как только запрос доступа к памяти выводится из регистра шины, он направляется в целевое устройство памяти через коммутатор 206 шины (смотрите фиг. 2). Второй мультиплексор 312 в контроллере 208 может использоваться для задержки вывода данных из первого и второго регистров 302, 304 до тех пор, пока подтверждение доступа к памяти не принято из целевого устройства памяти, когда атрибут памяти, указывающий строго упорядоченный запрос, прикладывается ко входу выбора. Как обсуждено ранее, атрибут памяти, включенный в запрос доступа к памяти, принудительно применяет ограничение упорядочения к целевому устройству памяти. А именно, целевое устройство памяти выполняет все ожидающие выполнения запросы доступа к памяти, выданные инициирующим процессором, до выполнения строго упорядоченного запроса доступа к памяти. Подтверждение доступа к памяти формируется целевым устройством памяти вслед за выполнением строго упорядоченного запроса. Подтверждение доступа к памяти возвращается на мультиплексор 312 в контроллере 208, где оно используется для формирования запускающего сигнала для вывода новых данных из первого и второго регистров 302, 304, соответствующих следующему запросу доступа к памяти в регистре 202 шины. Если новые данные включают в себя атрибут памяти, указывающий, что соответствующий запрос доступа к памяти в регистре 202 шины является строго упорядоченным, то повторяется та же самая последовательность операций. Иначе, запрос доступа к памяти может быть немедленно выведен из регистра 202 шины.
Контроллер 208 сконфигурирован для немедленного вывода запроса доступа к памяти из регистра 202 шины, когда соответствующий атрибут памяти в первом регистре 302 указывает, что запрос является слабо упорядоченным. В таком случае атрибут памяти используется для блокировки формирователя 306 барьера памяти. В дополнение, атрибут памяти принудительно переводит мультиплексор 310 в состояние, которое связывает внутренне сформированный запускающий сигнал с регистром 202 шины для вывода запроса доступа к памяти через первое соединение 211. Запрос доступа к памяти выводится из регистра 202 шины и связывается с целевым устройством памяти через коммутатор 206 шины (смотрите фиг. 2). Данные, соответствующие следующему запросу доступа к памяти, затем выводятся из первого и второго регистров 302, 304 по сформированному внутри запускающему сигналу, выведенному из второго мультиплексора 312 в контроллере 208.
Фиг.4 - функциональная структурная схема, иллюстрирующая еще один пример контроллера в шинном межсоединении для системы слабо упорядоченной обработки. В этом примере строго упорядоченный запрос доступа к памяти выводится из регистра 202 шины контроллером 208 одновременно с барьерами памяти, которые выдаются в надлежащие устройства памяти. Более точно, атрибут памяти для запроса доступа к памяти в регистре 202 шины выдается первым регистром 302 в формирователь 306 барьера памяти. Если атрибут памяти указывает, что соответствующий запрос доступа памяти является строго упорядоченным, то разблокируется формирователь 306 барьера памяти. Когда формирователь 306 барьера памяти разблокирован, данные во втором регистре 304 используются для формирования барьера памяти для каждого устройства памяти, открытого для доступа инициирующим процессором, иного чем целевое устройство памяти.
С разблокированным формирователем 306 барьера памяти логика 314 в контроллере 208 может использоваться для предохранения запросов доступа к памяти от вывода из регистра 202 шины до тех пор, пока строго упорядоченный запрос выполняется целевым устройством памяти. Задержка 316 может использоваться для предоставления внутренне сформированному запускающему сигналу возможности выводить строго упорядоченный запрос из регистра 202 шины до того, как запускающий сигнал запирается атрибутом памяти. Таким путем запрос доступа к памяти может подаваться в целевое устройство памяти одновременно с барьерами памяти для других устройств памяти, открытых для доступа инициирующим процессором.
Логика 318 может использоваться для отслеживания обратной связи из целевого устройства памяти для подтверждения доступа к памяти, а других устройств памяти, открытых для доступа инициирующего процессора, на подтверждение барьера памяти. Данные из второго регистра 304 используются логикой 318 для определения, каким устройствам памяти необходимо отслеживаться на подтверждение барьера памяти. Когда логика 318 определяет, что различные подтверждения были приняты, она формирует запускающий сигнал для вывода новых данных из первого и второго регистров 302, 304, соответствующих следующему запросу доступа к памяти в регистре 202 шины. Запускающий сигнал связывается через мультиплексор 320, который принудительно переведен в надлежащее состояние атрибутом памяти из первого регистра 202. Если новые данные включают в себя атрибут памяти, указывающий, что соответствующий доступ к памяти в регистре 202 шины является строго упорядоченным, то повторяется та же самая последовательность операций. Иначе, запрос доступа к памяти может быть немедленно выведен из регистра 202 шины с помощью внутренне сформированного запускающего сигнала посредством логики 314. Внутренне сформированный запускающий сигнал также может быть связан через мультиплексор 320 с выводом данных из первого и второго регистров 302, 304 для следующего запроса доступа к памяти в регистре 202 шины.
Предшествующее описание предоставлено, чтобы дать любому специалисту в данной области техники возможность осуществить на практике различные варианты осуществления, описанные в материалах настоящей заявки. Различные модификации в отношении этих вариантов осуществления будут легко очевидны специалистам в данной области техники, а общие принципы, определенные в материалах настоящей заявки, могут применяться к другим вариантам осуществления. Таким образом, формула изобретения не подразумевается ограниченной вариантами осуществления, показанными в материалах настоящей заявки, а должна быть приведена в соответствие с полным объемом, совместимым с изложенной в языковой форме формулой изобретения, в которой ссылка на элемент в единственном числе не подразумевается обозначающей «один и только один», если таковое не указано специально, а скорее «один или более». Все структурные и функциональные эквиваленты по отношению к элементам различных вариантов осуществления, описанных на всем протяжении этого раскрытия, которые известны или станут известны позже специалистам в данной области техники, в прямой форме включены в материалы настоящей заявки посредством ссылки и подразумеваются охваченными формулой изобретения. Более того ничто, описанное в материалах настоящей заявки не подразумевается сделанным общим достоянием независимо от того, изложено ли такое раскрытие в формуле изобретения явным образом. Никакой элемент пункта формулы изобретения не должен истолковываться по условиям §112 раздела 35 Кодекса законов США, шестого пункта, если элемент не перечислен с использованием фразы «средство для» или, в случае пункта формулы изобретения на способ, элемент не перечислен с использованием фразы «этап, на котором».
Изобретение относится к системам обработки, а именно к устройству и способу для принудительного применения строго упорядоченных запросов в системе слабо упорядоченной обработки. Техническим результатом является расширение функциональных возможностей. Система обработки включает в себя множество устройств памяти и множество процессоров. Каждый из процессоров сконфигурирован для формирования запросов доступа к памяти в отношении одного или более устройств памяти, причем каждый запрос доступа к памяти содержит атрибут, который выполнен с возможностью его объявления для указания строго упорядоченного запроса. Система обработки дополнительно включает в себя шинное межсоединение, сконфигурированное для присоединения каждого из множества процессоров к одному или более из множества устройств памяти, шинное межсоединение является дополнительно сконфигурированным для принудительного применения ограничений упорядочения к запросам доступа к памяти на основании атрибутов. Способ описывает работу данной системы. 4 н. и 16 з.п. ф-лы, 4 ил.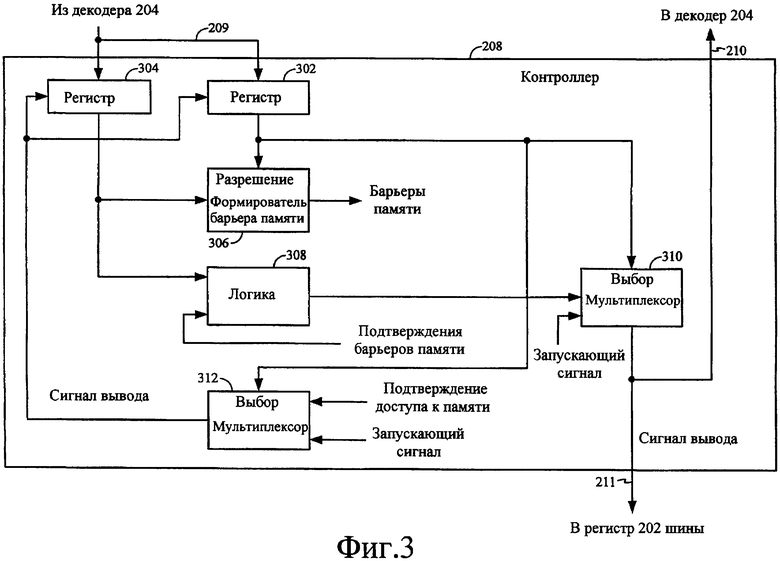
1. Система слабо упорядоченной обработки, содержащая:
множество устройств памяти;
множество процессоров, каждый из процессоров сконфигурирован для формирования запросов доступа к памяти в отношении одного или более устройств памяти, каждый из запросов доступа к памяти содержит атрибут, который выполнен с возможностью его объявления для указания строго упорядоченного запроса; и
шинное межсоединение, сконфигурированное для присоединения каждого из процессоров к одному или более устройствам памяти, шинное межсоединение является дополнительно сконфигурированным для принудительного применения ограничений упорядочения к запросу доступа к памяти на основании атрибутов.
2. Система слабо упорядоченной обработки по п.1, в которой шинное межсоединение дополнительно сконфигурировано для принудительного применения ограничений упорядочения для строго упорядоченного запроса доступа к памяти из инициирующего процессора в целевое устройство памяти посредством отправки барьера памяти в каждое из других устройств памяти, доступных инициирующему процессору.
3. Система слабо упорядоченной обработки по п.2, в которой шинное межсоединение дополнительно сконфигурировано для принудительного применения ограничений упорядочения для упомянутого строго упорядоченного запроса доступа к памяти посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение барьера памяти не принято от каждого из устройств памяти, принимающих барьер памяти.
4. Система слабо упорядоченной обработки по п.1, в которой шинное межсоединение дополнительно сконфигурировано для принудительного применения ограничений упорядочения для строго упорядоченного запроса доступа к памяти из инициирующего процессора в целевое устройство памяти посредством отправки упомянутого строго упорядоченного запроса доступа к памяти с его атрибутом памяти в целевое устройство памяти.
5. Система слабо упорядоченной обработки по п.4, в которой шинное межсоединение дополнительно сконфигурировано для принудительного применения ограничений упорядочения для упомянутого строго упорядоченного запроса доступа к памяти посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение запроса доступа не принято из целевого устройства памяти.
6. Система слабо упорядоченной обработки по п.4, в которой шинное межсоединение дополнительно сконфигурировано для принудительного применения ограничений упорядочения для упомянутого строго упорядоченного запроса доступа к памяти посредством отправки барьера памяти в каждое из других устройств памяти, доступных инициирующему процессору.
7. Система слабо упорядоченной обработки по п.6, в которой шинное межсоединение дополнительно сконфигурировано для принудительного применения ограничений упорядочения для упомянутого строго упорядоченного запроса доступа к памяти посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение барьера памяти не принято от каждого из устройств памяти, принимающих барьер памяти.
8. Система слабо упорядоченной обработки по п.6, в которой шинное межсоединение дополнительно сконфигурировано для принудительного применения ограничений упорядочения для упомянутого строго упорядоченного запроса доступа к памяти посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение запроса доступа не принято из целевого устройства памяти.
9. Система слабо упорядоченной обработки, содержащая:
множество устройств памяти;
множество процессоров, каждый из процессоров сконфигурирован для формирования запросов доступа к памяти в отношении одного или более устройств памяти, каждый из запросов доступа к памяти содержит атрибут, который выполнен с возможностью его объявления для указания строго упорядоченного запроса; и
шинное межсоединение, содержащее средство для присоединения каждого из процессоров к одному или более устройствам памяти, и средство для принудительного применения ограничений упорядочения к запросам доступа к памяти на основании атрибутов.
10. Шинное межсоединение, содержащее:
коммутатор шины, сконфигурированный для присоединения каждого из множества процессоров к одному или более из множества устройств памяти в системе слабо упорядоченной обработки, каждый из процессоров является сконфигурированным для формирования запросов доступа к памяти в отношении одного или более устройств памяти, а каждый из запросов доступа к памяти содержит атрибут, который выполнен с возможностью его объявления для указания строго упорядоченного запроса; и
контроллер, сконфигурированный для принудительного применения ограничения упорядочения к запросам доступа к памяти на основании атрибутов.
11. Шинное межсоединение по п.10, в котором контроллер дополнительно сконфигурирован для принудительного применения ограничений упорядочения для строго упорядоченного запроса доступа к памяти из инициирующего процессора в целевое устройство памяти посредством отправки барьера памяти в каждое из других устройств памяти, доступных инициирующему процессору.
12. Шинное межсоединение по п.11, в котором контроллер дополнительно сконфигурирован для принудительного применения ограничений упорядочения для упомянутого строго упорядоченного запроса доступа к памяти посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение барьера памяти не принято от каждого из устройств памяти, принимающих барьер памяти.
13. Шинное межсоединение по п.10, в котором контроллер дополнительно сконфигурирован для принудительного применения ограничений упорядочения для строго упорядоченного запроса доступа к памяти из инициирующего процессора в целевое устройство памяти посредством отправки упомянутого строго упорядоченного запроса доступа к памяти с его атрибутом памяти в целевое устройство памяти.
14. Шинное межсоединение по п.13, в котором контроллер дополнительно сконфигурирован для принудительного применения ограничений упорядочения для упомянутого строго упорядоченного запроса доступа к памяти посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение доступа к памяти не принято из целевого устройства памяти.
15. Способ для принудительного применения строго упорядоченных запросов доступа к памяти в системе слабо упорядоченной обработки, состоящий в том, что:
принимают от множества процессоров запросы доступа к памяти для множества устройств памяти, один из запросов доступа к памяти содержит атрибут памяти, указывающий строго упорядоченный запрос доступа к памяти; и
принудительно применяют ограничение упорядочения к строго упорядоченному запросу доступа к памяти в отношении других запросов доступа к памяти в ответ на атрибут.
16. Способ по п.15, в котором строго упорядоченный запрос происходит из инициирующего процессора, запрашивающего доступ к целевому устройству памяти, и при этом ограничение упорядочения принудительно применяется посредством отправки барьера памяти в каждое из других устройств памяти, доступных инициирующему процессору.
17. Способ по п.16, в котором ограничение упорядочения принудительно применяется посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение барьера памяти не принято от каждого из устройств памяти, принимающих барьер памяти.
18. Способ по п.15, в котором строго упорядоченный запрос происходит из инициирующего процессора, запрашивающего доступ к целевому устройству памяти, и при этом ограничение упорядочения принудительно применяется посредством отправки строго упорядоченного запроса доступа к памяти с его атрибутом памяти в целевое устройство памяти.
19. Способ по п.18, в котором ограничение упорядочения принудительно применяется посредством задержки передачи последующих запросов доступа к памяти до тех пор, пока подтверждение доступа к памяти не принято из целевого устройства памяти.
20. Способ по п.19, в котором ограничение упорядочения принудительно применяется посредством отправки барьера памяти в каждое из других устройств памяти, доступных инициирующему процессору.
| US 6385705 B1, 07.05.2002 | |||
| US 6038646 A, 14.03.2000 | |||
| US 6088771 A, 11.07.2000 | |||
| КОМПЬЮТЕРНАЯ СИСТЕМА, ИМЕЮЩАЯ ШИННЫЙ ИНТЕРФЕЙС | 1995 |
|
RU2140667C1 |
| АРХИТЕКТУРА ПРОЦЕССОРА ВВОДА-ВЫВОДА, КОТОРЫЙ ОБЪЕДИНЯЕТ МОСТ МЕЖСОЕДИНЕНИЯ ПЕРВИЧНЫХ КОМПОНЕНТ | 1996 |
|
RU2157000C2 |

