ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к способам, устройствам и прикладным программным продуктам, предназначенным для исправления слов в последовательности слов, которая получена при распознавании входной речевой последовательности.
УРОВЕНЬ ТЕХНИКИ
Основные способы распознавания речи известны из компьютерных приложений и также начинают появляться в области персональных мобильных коммуникаций. Пример распознавания речи в мобильном оконечном устройстве может быть представлен набором имени, когда пользователь просто произносит имя человека, которого будет вызывать, и затем мобильное оконечное устройство выполняет распознавание речи, автоматически определяет имя, находит соответствующий номер в адресной книге мобильного оконечного устройства и осуществляет вызов.
Предполагают, что осуществление передовых приложений распознавания речи может быть реализовано в будущих мобильных оконечных платформах, поскольку вычислительная мощность и память непрерывно дешевеют. При поддержке увеличенной вычислительной мощности и памяти, эти передовые приложения распознавания речи могут достичь уровня, приемлемого для пользователей мобильных устройств.
Пример усовершенствованного приложения распознавания речи представляет мобильный речевой ввод. В мобильном речевом вводе пользователь может ввести более длинные фрагменты текста (такого как электронная почта или SMS) в мобильное оконечное устройство, которое, как правило, снабжено клавиатурой небольшого размера или вообще лишено клавиатуры. Высокоэффективная мобильная система речевого ввода может таким способом значительно увеличить скорость и простоту ввода текста.
Недостаток, с которым сталкиваются при мобильном речевом вводе, состоит в том, что средняя точность распознавания слитной речи в настоящее время лежит в пределах от 60% до 95% на уровне слова, в зависимости от языка, произношения, окружающего шума и размера фрагмента речевого ввода. Лучшее распознавание может быть достигнуто при ограничении области речевого ввода (например, при ограничении словаря, который должен быть понят устройством речевого распознавания), путем приведения к сравнительно малой и точной языковой модели, а также при использовании мобильного оконечного устройства в чистой (нешумной) среде.
При распознавании речи, которое все еще остается несовершенным, исправление ошибок необходимо даже в усовершенствованных приложениях распознавания речи, чтобы они могли быть приемлемыми для пользователя. Это исправление ошибок должно быть эффективным и быстрым, потому что в противном случае преимущество во времени, полученное при вводе текста путем распознавания речи, может быть потеряно по причине задержки, необходимой для исправления ошибок.
Заявка на американский патент US 2002/0138265 А1 раскрывает и предлагает технологию исправления ошибок, возникающих в системе распознавания слитной речи. В этой заявке процессор распознает то, что произнес пользователь, путем подбора акустических моделей, которые лучше всего соответствуют цифровым кадрам фрагмента речи, и идентификации текста, который соответствует этим акустическим моделям. Акустическая модель может соответствовать слову, фразе или предписанию словаря. Акустическая модель также может представлять собой звук или фонему, которые соответствуют части слова. В совокупности фонемы, составляющие слово, представляют фонетическую транскрипцию слова. Акустические модели также могут представлять тишину и различные виды окружающего шума. Слова или фразы, соответствующие лучшим акустическим моделям, могут быть названы кандидатами распознавания. Процессор может создать одиночного кандидата распознавания для фрагмента речи или может сформировать список кандидатов распознавания. Механизмы исправления, описанные в US 2002/0138265 А1, включают отображение списка вариантов для каждого распознанного слова и разрешение пользователю исправлять ошибочное распознавание, выбирая слово из списка или печатая правильное слово. Согласно одному варианту системы распознавания речи, описанному в US 2002/0138265 А1, список пронумерованных кандидатов распознавания может быть отображен для каждого слова, произнесенного пользователем, и наилучший кандидат распознавания может быть вставлен в текст, продиктованный пользователем. Если наилучший кандидат распознавания неправилен, пользователь может выбрать кандидата распознавания из списка, произнеся "выбрать N", где "N" представляет номер правильного кандидата. Если правильное слово не включено в список выбора, то пользователь может усовершенствовать список, печатая первые буквы правильного слова или произнося слова (например "альфа", "браво"), ассоциированные с первыми буквами. Если пользователь замечает ошибку распознавания после произнесения дополнительных слов, пользователь может сказать "Ой", вызывая тем самым на дисплей пронумерованный список предварительно распознанных слов. Пользователь затем может выбрать предварительно распознанное слово, произнеся "слово N", где N представляет номер нужного слова. Система затем отвечает отображением списка, связанного с выбранным словом, и разрешает пользователю исправить слово, как описано выше.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Исходя из уровня техники, кроме прочего, цель настоящего изобретения состоит в том, чтобы предложить улучшенные способы, устройства и прикладные программные продукты для исправления ошибок в системах распознавания речи.
Согласно первому аспекту настоящего изобретения, предложен способ для того, чтобы исправлять слова в последовательности слов, которая получена от распознавания входной речевой последовательности. Упомянутый способ включает: представление упомянутой последовательности слов пользователю, причем каждое слово в упомянутой последовательности связано с соответствующим значением достоверности распознавания, при этом по меньшей мере одно слово в упомянутой последовательности автоматически выделено в зависимости от степени достоверности его распознавания; и замену по меньшей мере одного слова в упомянутой последовательности, в случае, если оно было выбрано пользователем для исправления.
Упомянутая входная речевая последовательность может быть рассмотрена как речевое представление одного или более слова, например полное предложение, которое может быть, например, записано с помощью микрофона или восстановлено из памяти. Распознавание речи может быть выполнено в отношении упомянутой входной речевой последовательности, чтобы получить упомянутую последовательность слов, причем необходимо, чтобы упомянутые слова в упомянутой последовательности слов соответствовали словам, которые содержит звуковое представление упомянутой входной речевой последовательности. Несоответствия рассматривают как ошибки, которые необходимо исправить прежде, чем упомянутую последовательность слов подвергнут последующей обработке (например, сохранят в памяти или передадут как сообщение в приемник). Каждое из упомянутых слов в упомянутой последовательности слов связано со степенью достоверности распознавания, которая представляет достоверность того, что упомянутое слово из входной речевой последовательности было распознано правильно. Уровень достоверности распознавания может быть, например, определен речевым устройством распознавания в процессе распознавания речи, но может быть также определен на стадии последующей обработки. Степень достоверности распознавания может также быть основана на информации от устройства речевого распознавания или информации, полученной на стадии последующей обработки. Например, достоверность распознавания может соответствовать акустической оценке в баллах, назначаемой устройством речевого распознавания каждому слову.
С целью исправления ошибок (то есть неправильно распознанных слов), упомянутая последовательность слов может быть представлена пользователю, причем пользователь, например, может быть тем пользователем, который произнес упомянутую входную речевую последовательность. С таким же успехом, входная речевая последовательность может быть предоставлена первым пользователем, а затем может быть откорректирована вторым пользователем. Упомянутое представление, например, может быть выполнено оптически, например, путем отображения и представления последовательности слов пользователю с помощью дисплея, или акустически, например, путем преобразования текста упомянутой последовательности слов в звуковую речь и воспроизведения этой преобразованной речи через громкоговоритель.
В упомянутом представлении последовательности слов, по меньшей мере одно слово этой последовательности выделено в зависимости от степени достоверности его распознавания. Например, слова в упомянутой последовательности, которые связаны с особенно низкой степенью достоверности распознавания (и соответственно с высокой вероятностью потенциальной ошибки), могут быть выделены, чтобы помочь пользователю быстрее обнаружить ошибки, или облегчить их выбор для исправления. Таким способом, в отличие от предшествующих способов исправления ошибок, может быть достигнуто более быстрое и более эффективное исправление ошибок. В этом отношении, способ выделения зависит от способа представления упомянутой последовательности слов. Например, если последовательность слов отображена на дисплее, то выделение может быть реализовано путем изменения вида по меньшей мере одного слова, которое должно быть выделено, например, путем яркостного выделения по меньшей мере одного слова или изменением его шрифта, цвета или стиля.
Если по меньшей мере одно слово упомянутой последовательности слов выбрано пользователем, то по меньшей мере одно слово заменяют. Эта замена может быть выполнена на основе взаимодействия с пользователем или автоматически. Например, пользователь может обеспечить слово замены по меньшей мере для одного выбранного слова, печатая это слово замены, или (опять) вводя речевое представление данного слова, чтобы обеспечить распознавание звукового представления речи на основе уровня достоверности слова, или выбирая слово замены из списка слов-кандидатов, который предоставлен пользователю.
В примере реализации способа, согласно первому аспекту настоящего изобретения, по меньшей мере одно выделенное слово связано с самой низкой степенью достоверности распознавания всех слов в упомянутой последовательности слов. Внимание пользователя в этом случае будет привлечено к тому слову в упомянутой последовательности слов, вероятность ошибочного распознавания которого самая высокая. Пользователь тогда может проверить правильность упомянутого слова, и если это слово признано неправильным, пользователь принимает меры, чтобы исправить упомянутое слово. Выделение только одного одиночного слова избавляет пользователя от переполнения информацией во время представления упомянутой последовательности слов.
Согласно этой иллюстративной реализации, по меньшей мере одно выделенное слово может быть автоматически выделено путем автоматического позиционирования селектора на этом слове. Упомянутым селектором может быть, например, указатель или курсор, которым может управлять пользователь, чтобы выбирать слова в представленной последовательности слов для исправления. Автоматическое позиционирование селектора на упомянутом по меньшей мере одном слове с самой низкой достоверностью распознавания достигает двойной цели. С одной стороны, внимание пользователя будет привлечено к слову, у которого высока вероятность ошибочного распознавания. С другой стороны, нет необходимости для пользователя в перемещении селектора, чтобы выбрать нужное слово для исправления в случае, если это слово, как выяснено, пользователь обозначил как неправильное. Например, может потребоваться только подтверждение пользователем автоматического выбора этого слова, чтобы запустить процесс исправления ошибок.
В другой иллюстративной реализации способа согласно первому аспекту настоящего изобретения, по меньшей мере одно выделенное слово связано со степенью достоверности распознавания, которая ниже заданного порога. Упомянутый порог может, например, быть порогом по умолчанию, или этот порог может быть определен или изменен пользователем. Вместо того, чтобы выделять только слово, связанное с самой низкой степенью достоверности распознавания, могут быть выделены все слова, связанные со степенью распознавания, которая ниже упомянутого заданного порога. В этом случае, пользователь может проверить, что все выделенные слова в упомянутой последовательности, вероятно, содержат ошибки, и потому должны быть тщательно проверены.
Кроме того, согласно первому аспекту настоящего изобретения, предложено устройство для того, чтобы исправлять слова в последовательности слов, которая получена от распознавания входной речевой последовательности. Упомянутое устройство включает средства для представления упомянутой последовательности слов пользователю, причем каждое слово в этой последовательности слов связано с соответствующей степенью достоверности распознавания, и при этом по меньшей мере одно слово в упомянутой последовательности слов автоматически выделено в зависимости от степени достоверности его распознавания; и средства для замены по меньшей мере одного слова в упомянутой последовательности слов, в случае, если оно было выбрано пользователем для исправления.
Упомянутыми средствами для представления упомянутой последовательности слов могут быть, например, дисплей с соответствующей дисплейной логикой или громкоговоритель с соответствующей звуковой логикой. Упомянутые средства для представления упомянутой последовательности слов также могут содержать средства выделения по меньшей мере одного слова. Упомянутые средства для замены по меньшей мере одного слова могут, например, включать пользовательский интерфейс, чтобы взаимодействовать с пользователем, например, предоставлять пользователю возможность выбирать слово замены для по меньшей мере одного выбранного слова из списка или вводить речевое представление по меньшей мере одного слова, а также чтобы выполнить новое распознавание речи или напечатать по меньшей мере одно слово.
В иллюстративной реализации устройства, согласно первому аспекту настоящего изобретения, упомянутым устройством может быть портативное мультимедийное устройство или часть его. Упомянутое устройство, например, может быть мобильным телефоном, личным цифровым помощником, компьютером, цифровым устройством речевого ввода или подобным устройством. Альтернативно, упомянутое устройство также может быть настольным компьютером или частью его.
Кроме того, согласно первому аспекту настоящего изобретения, предложен прикладной программный продукт, включающий носитель данных, содержащий программное приложение для исправления слов в последовательности слов, которая получена при распознавании входной речевой последовательности, осуществленном в нем. Упомянутое программное приложение содержит программный код, чтобы представлять упомянутую последовательность слов пользователю, причем каждое слово в упомянутой последовательности слов связано с соответствующей степенью достоверности распознавания, и при этом по меньшей мере одно слово в упомянутой последовательности слов автоматически выделяется в зависимости от степени достоверности его распознавания; и программный код, чтобы заменять по меньшей мере одно слово в упомянутой последовательности слов, в случае, если оно было выбрано пользователем для исправления.
Упомянутый носитель данных может быть любой энергозависимой или энергонезависимой памятью или запоминающим элементом, таким как постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), флэш-карта или карта памяти, и диск, читаемый оптическим, электрическим или магнитным способами. Упомянутый программный код, включенный в упомянутое программное приложение, может быть осуществлен в процедурном языке программирования высокого уровня или в объектно-ориентированном языке программирования, чтобы управлять компьютерной системой, а также в ассемблере или в машинном языке программирования, чтобы управлять цифровым процессором. В любом случае, упомянутый программный код может быть компилируемым или интерпретируемым кодом.
Согласно второму аспекту настоящего изобретения, предложен способ, чтобы исправлять слова в последовательности слов, которая получена при распознавании входной речевой последовательности, причем каждое слово в упомянутой последовательности связано с набором альтернативных слов-кандидатов. Упомянутый способ включает представление этой последовательности слов пользователю, и замену по меньшей мере одного слова в упомянутой последовательности слов, в случае, если оно было выбрано пользователем для исправления, словом-кандидатом из связанного набора слов-кандидатов, причем упомянутые слова-кандидаты в наборе слов-кандидатов, связанном с упомянутым по меньшей мере одним выбранным словом, упорядочены согласно критерию упорядочивания, основанному на правдоподобии слов-кандидатов, чтобы правильно заменить упомянутое по меньшей мере одно выбранное слово.
Для каждого из слов в упомянутой последовательности слов существует ряд слов-кандидатов. Причем различные наборы слов-кандидатов могут содержать одинаковое количество слов-кандидатов, или различное количество слов-кандидатов. Упомянутые слова-кандидаты могут, например, быть определены устройством распознавания речи в течение упомянутого распознавания речи. Например, устройство распознавания речи может принять упомянутую входную речевую последовательность, которая может быть речевым представлением одного или более слов, и может выполнять распознавание сегментов упомянутой входной речевой последовательности, чтобы определить одно или больше слов, которые представлены упомянутой входной речевой последовательностью. Для каждого из упомянутых сегментов входного речевого фрагмента, которые допущены устройством распознавания речи, чтобы представлять соответствующее слово, устройство речевого распознавания может сформировать ряд возможных результатов распознавания, причем, например, самый вероятный результат распознавания представлен на выходе устройства соответствующим словом, а остальные результаты распознавания представлены соответствующим набором слов-кандидатов (или их поднабором), связанных с упомянутым соответствующим словом.
Упомянутая последовательность слов, полученная после распознавания речи, может быть представлена пользователю, чтобы обеспечить пользователя возможностью корректировать результат распознавания речи. Тогда пользователь может выбрать по меньшей мере одно слово из упомянутой последовательности слов, если он считает, что данное по меньшей мере одно выбранное слово распознано ошибочно. В ответ на такой выбор, по меньшей мере одно выбранное слово может быть заменено словом-кандидатом из набора слов-кандидатов, которые связаны по меньшей мере с одним выбранным словом. Упомянутая замена может быть выполнена автоматически или на основе взаимодействия с пользователем. Согласно второму аспекту настоящего изобретения и в отличие от предшествующих способов исправления ошибок, слова-кандидаты по меньшей мере в упомянутом наборе слов-кандидатов, который связан по меньшей мере с одним выбранным словом, могут быть упорядочены согласно критерию упорядочивания, основанному на правдоподобии слов-кандидатов для правильной замены по меньшей мере одного выбранного слова. Это может значительно ускорить выбор слов-кандидатов в упомянутом наборе слов-кандидатов. Например, если слова-кандидаты упорядочивают в связи с уменьшением их правдоподобия, чтобы правильно заменить по меньшей мере одно выбранное слово, и если набор слов-кандидатов представлен пользователю в форме списка (например, как прокручиваемый список), то пользователю, вероятно, достаточно только прочитать первые записи в списке, пока он не найдет правильную замену для упомянутого по меньшей мере одного выбранного слова. Кроме того, если пользователь должен перемещать селектор по всему списку, чтобы выбрать слово-кандидат, которое может заменить по меньшей мере одно выбранное слово, также может быть минимизировано количество необходимых шагов движения селектора, что обеспечивает более быстрое и эффективное исправление ошибок. Упомянутое упорядочивание слов-кандидатов в наборе слов-кандидатов может быть, например, выполнено только для упомянутого набора слов-кандидатов, которые связаны с упомянутым по меньшей мере одним выбранным словом, например, после выбора по меньшей мере одного слова. Это поможет сэкономить часть вычислительной мощности, затраченной на сортировку. Альтернативно, упомянутое упорядочивание слов-кандидатов может быть выполнено для всех наборов слов-кандидатов, например, в течение или после распознавания речи. Тогда сортировка может быть исключена после выбора по меньшей мере одного слова для исправления, вследствие чего фактический процесс исправления ошибок может быть ускорен.
В иллюстративной реализации способа, согласно второму аспекту настоящего изобретения, критерий упорядочивания основан по меньшей мере на одной из языковых моделей, которая содержит статистику правдоподобия набора слов, включающего по меньшей мере одно слово, существующее в языке, а также на достоверности распознавания слов-кандидатов, причем упомянутая достоверность распознавания выражает, для каждого слова-кандидата в наборе слов-кандидатов, соответствующую достоверность того, что слово-кандидат представляет результат правильного распознавания речи.
Упомянутая языковая модель может, например, быть униграмматической моделью, которая выражает правдоподобие одиночного слова, существующего (или используемого) в языке. Это правдоподобие может быть выражено в форме языкового балла модели, при котором редким словам соответствуют более низкие баллы. С таким же успехом, языковая модель может быть биграмматической моделью, которая рассматривает правдоподобие набора слов, включающего два слова, существующие в языке (или, другими словами, правдоподобие двух слов языка, которые могут следовать друг за другом). Также может быть рассмотрена статистика наборов слов, включающих три или более слов (например, триграмматическая модель и т.д.). Если упомянутый критерий упорядочивания основан на биграмматической языковой модели, то может быть рассмотрено предшествующее слово и/или последующее слово в данной последовательности слов, при упорядочивании слов-кандидатов в наборе слов-кандидатов, связанном со словом, которое стоит между предшествующим словом и последующим словом.
Если упомянутый критерий упорядочивания основан на достоверности распознавания, то степени достоверности распознавания, как, например, определенные устройством речевого распознавания для каждого слова-кандидата в наборе слов-кандидатов, рассматривают при упорядочивании слов-кандидатов в упомянутых наборах слов-кандидатов.
Упомянутый критерий упорядочивания также может быть основан и на языковой модели, и на достоверности распознавания, например, путем назначения каждому слову-кандидату балл языковой модели и степень достоверности распознавания, с последующим комбинированием обоих показателей в комбинированном балле, который может быть рассмотрен при упорядочивании упомянутых слов-кандидатов.
В другой иллюстративной реализации способа, согласно второму аспекту настоящего изобретения, выбор упомянутого слова-кандидата, которое заменяет по меньшей мере одно выбранное слово, из набора слов-кандидатов включает пошаговый перебор слов-кандидатов по принципу «слово-за-словом».
Упомянутый набор слов-кандидатов, например, может быть представлен пользователю в форме списка (например, прокручивающегося списка), а упомянутый пошаговый перебор, например, может быть выполнен с помощью джойстика или клавишей курсора клавиатуры, причем каждое движение джойстика (например, построчная прокрутка упомянутого списка) или каждое нажатие на клавишу курсора продвигает селектор вперед или назад на одно слово-кандидат. Очевидно, упорядочивание слов-кандидатов, например в порядке уменьшения возможности правильной замены ими по меньшей мере одного выбранного слова, согласно второму аспекту настоящего изобретения, может внести свой вклад в сокращение количества шагов, необходимых при выборе заменяющего слова-кандидата, поскольку слова-кандидаты, которые с наибольшей вероятностью подходят для замены упомянутого по меньшей мере одного выбранного слова, расположены в начале упомянутого списка, где также может быть первоначально позиционирован и селектор.
В другой иллюстративной реализации способа, согласно второму аспекту настоящего изобретения, упомянутый критерий упорядочивания по меньшей мере основан на языковой модели, которая содержит статистику правдоподобия по меньшей мере двух слов языка, следующих друг за другом, и этот способ также включает обновление, - в случае, если по меньшей мере одно слово было выбрано и заменено в упомянутой последовательности словом-кандидатом, - порядка слов-кандидатов по меньшей мере в одном наборе слов-кандидатов, связанном с соответствующим словом, соседним, - в пределах данной последовательности слов, - с упомянутым по меньшей мере одним выбранным и замененным словом, при этом упомянутое обновление порядка слов-кандидатов в по меньшей мере одном наборе слов-кандидатов может быть выполнено согласно упомянутому критерию упорядочивания и с учетом данного слова-кандидата, которым было заменено по меньшей мере одно выбранное и замененное слово.
В этом отношении упомянутый критерий упорядочивания может быть основан исключительно на упомянутой языковой модели, которая, например, может быть биграмматической языковой моделью или с таким же успехом может быть основана на дополнительной информации, такой как, например, достоверность распознавания слов-кандидатов. Когда выбранное слово заменено словом-кандидатом из набора слов-кандидатов, который связан с упомянутым выбранным словом, то упорядочивание набора слов-кандидатов, связанных с предыдущим словом и/или последующим словом в данной последовательности слов, может быть обновлено согласно упомянутому критерию упорядочивания. Поскольку порядок слов-кандидатов в упомянутых наборах слов-кандидатов, связанных с предыдущими и последующими словами, зависит от выбранного и замененного слова в силу зависимости упомянутого критерия упорядочивания от языковой модели (например, биграмматической языковой модели), то обновление упомянутых наборов слов-кандидатов улучшает качество упорядочивания наборов слов-кандидатов и, таким способом, помогает осуществлять исправление ошибок, согласно настоящему изобретению, быстрее и более эффективно. Ситуация, при которой порядок слов-кандидатов требует обновления только в одном наборе слов-кандидатов, может возникнуть, если упомянутая последовательность слов включает только два слова, одно из которых выбрано и заменено. Кроме того, если предположить, что слова выбраны пользователем для исправления одно за другим, например, с самого начала упомянутой последовательности слов, то может быть достаточно обновить только порядок слов-кандидатов в наборах слов-кандидатов, связанных со словами, которые можно считать правильными соседями выбранных и замененных слов. Это может значительно сократить издержки сортирования.
Кроме того, согласно второму аспекту настоящего изобретения, предложено устройство для исправления слов в последовательности слов, полученной при распознавании входной речевой последовательности, в котором для каждого слова в упомянутой последовательности слов существует связанный с ним набор альтернативных слов-кандидатов. Упомянутое устройство включает средства, выполненные с возможностью представлять данную последовательность слов пользователю; и средства, выполненные с возможностью заменять по меньшей мере одно слово в упомянутой последовательности слов, - в случае, если оно было выбрано пользователем для исправления, - словом-кандидатом из связанного с ним набора слов-кандидатов, причем упомянутые слова-кандидаты в упомянутом наборе слов-кандидатов, который связан по меньшей мере с одним выбранным словом, упорядочены согласно критерию упорядочивания, сформированному на основе правдоподобия слов-кандидатов, с целью правильной замены упомянутого по меньшей мере одного выбранного слова.
Пример реализации устройства, согласно второму аспекту настоящего изобретения, также содержит средства, выполненные с возможностью пошагового перебора альтернатив выбора по принципу "кандидат-за-кандидатом", с целью выбора слова-кандидата, которое заменяет по меньшей мере одно выбранное слово, из упомянутого набора слов-кандидатов. Такие средства могут, например, включать джойстик или клавиатуру.
Другая иллюстративная реализация устройства, согласно второму аспекту настоящего изобретения, включает средства, выполненные с возможностью обновлять, - в случае, если в данной последовательности слов по меньшей мере одно слово было выбрано и заменено словом-кандидатом, - порядок слов-кандидатов по меньшей мере в одном наборе слов-кандидатов, связанном с соответствующим словом, соседним, - в пределах данной последовательности слов, - с упомянутым по меньшей мере одним выбранным и замененное словом, причем упомянутый критерий упорядочивания по меньшей мере основан на языковой модели, которая содержит статистику правдоподобия по меньшей мере двух слов языка, следующих друг за другом, при этом обновление упомянутого порядка слов-кандидатов по меньшей мере в одном наборе слов-кандидатов может быть выполнено в соответствии с упомянутым критерием упорядочивания и с учетом упомянутого слова-кандидата, которым было заменено по меньшей мере одно выбранное и замененное слово.
Другая иллюстративная реализация устройства, согласно второму аспекту настоящего изобретения, представляет собой портативное мультимедийное устройство или часть его.
Согласно второму аспекту настоящего изобретения, также предложен прикладной программный продукт, включающий носитель данных, содержащий программное приложение для исправления слов в последовательности слов, которая получена после распознавания входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов. Упомянутое программное приложение включает программный код для того, чтобы представлять данную последовательность слов пользователю, и программный код для того, чтобы заменять по меньшей мере одно слово в данной последовательности слов - в случае, если оно было выбрано упомянутым пользователем для исправления, - словом-кандидатом из связанного с ним набора слов-кандидатов, причем слова-кандидаты в упомянутом наборе слов-кандидатов, который связан по меньшей мере с одним выбранным словом, упорядочены согласно критерию упорядочивания, сформированному на основе правдоподобия упомянутых слов-кандидатов, с целью правильной замены по меньшей мере одного выбранного слова.
В иллюстративной реализации прикладного программного продукта, согласно второму аспекту настоящего изобретения, упомянутый критерий упорядочивания по меньшей мере основан на языковой модели, которая содержит статистику правдоподобия следования друг за другом по меньшей мере двух слов языка, и упомянутый прикладной программный продукт также включает программный код для обновления - в случае, если по меньшей мере одно слово выбрано и заменено в данной последовательности слов упомянутым словом-кандидатом, - порядка слов-кандидатов по меньшей мере в одном наборе слов-кандидатов, связанном с соответствующим словом, соседним - в пределах данной последовательности слов, - с упомянутым по меньшей мере одним выбранным и замененным словом, причем такое обновление упомянутого порядка слов-кандидатов по меньшей мере в одном наборе слов-кандидатов может быть выполнено в соответствии с упомянутым критерием упорядочивания и с учетом упомянутого слова-кандидата, которым было заменено по меньшей мере одно выбранное и замененное слово.
Согласно третьему аспекту настоящего изобретения, предложен способ для исправления слов в последовательности слов, которая получена при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов. Этот способ включает представление данной последовательности слов пользователю; и замену по меньшей мере одного слова в данной последовательности слов - в случае, если оно выбрано пользователем для исправления, - словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии по меньшей мере одного выбранного слова, произнесенного пользователем, причем словарь распознавания, который используют при распознавании данной новой входной речевой последовательности, может быть ограничен упомянутым набором слов-кандидатов, связанным по меньшей мере с одним выбранным словом.
Таким способом, если начальное распознавание речи, которое основано на данной входной речевой последовательности и на специальном словаре распознавания (представляющем набор слов, которые при распознавании речи принимают во внимание как возможные результаты распознавания речи), приводит к неправильному распознаванию по меньшей мере одного выбранного слова, то исправление ошибок выполняют, повторяя распознавание на основе новой входной речевой последовательности, которая содержит речевое представление только данной правильной версии по меньшей мере одного выбранного слова, и ограниченного словаря распознавания, включающего только слова-кандидаты из упомянутого набора слов-кандидатов, который связан по меньшей мере с одним выбранным словом. Это может быть полезно в случаях, когда возникают существенные различия между упомянутыми словами-кандидатами с точки зрения акустики, но незначительные различия между упомянутыми словами-кандидатами с точки зрения языковой модели. В отличие от больших словарей распознавания, обычно используемых в предшествующих способах исправления ошибок, упомянутый сокращенный словарь распознавания обеспечивает, согласно третьему аспекту настоящего изобретения, менее сложное и, соответственно, более быстрое и более надежное распознавание речи.
Согласно третьему аспекту настоящего изобретения, также предложено устройство для того, чтобы исправлять слова в последовательности слов, которая получена при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов. Упомянутое устройство включает средства, выполненные с возможностью представления данной последовательности слов пользователю; и средства, выполненные с возможностью замены по меньшей мере одного слова в данной последовательности слов, - в случае, если оно выбрано пользователем для исправления, - словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого по меньшей мере одного выбранного слова, произнесенного пользователем, причем словарь распознавания, используемый в упомянутом распознавании данной новой входной речевой последовательности, ограничен упомянутым набором слов-кандидатов, связанным по меньшей мере с одним выбранным словом.
Иллюстративная реализация устройства согласно третьему аспекту настоящего изобретения представляет собой портативное мультимедийное устройство или часть его.
Согласно третьему аспекту настоящего изобретения, также предложен прикладной программный продукт, включающий носитель данных, содержащий программное приложение для исправления слов в последовательности слов, которая получена при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов. Упомянутое программное приложение содержит программный код для того, чтобы представлять данную последовательность слов пользователю, и программный код для того, чтобы заменять по меньшей мере одно слово в данной последовательности слов, - в случае, если оно выбрано упомянутым пользователем для исправления, - словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого по меньшей мере одного выбранного слова, произнесенного пользователем, причем словарь распознавания, используемый при распознавании данной новой входной речевой последовательности, ограничен упомянутым набором слов-кандидатов, связанным по меньшей мере с одним выбранным словом.
Согласно четвертому аспекту настоящего изобретения, предложен способ для исправления слов в последовательности слов, которая получена при распознавании входной речевой последовательности. Упомянутый способ включает представление данной последовательность слов пользователю; и замену по меньшей мере одного слова в данной последовательности слов, - в случае, если оно выбрано пользователем для исправления, - словом, полученным из новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого по меньшей мере одного выбранного слова, произнесенного пользователем, и представление правильной версии упомянутого по меньшей мере одного выбранного слова, введенного пользователем побуквенно.
Если при начальном распознавании речи, основанном на начальной входной речевой последовательности, может быть сформирована последовательность слов, которая содержит по меньшей мере одно ошибочное слово, то, согласно четвертому аспекту настоящего изобретения, упомянутое по меньшей мере одно слово может быть выбрано пользователем, и затем для упомянутого по меньшей мере одного выбранного слова может быть повторено распознавание речи, основанное на новой входной речевой последовательности, которая содержит только речевое представление правильной версии упомянутого по меньшей мере одного выбранного слова и введенное побуквенно представление этого слова (например, новая входная речевая последовательность "Мемфис, МЕМФИС"). В этом случае распознавание речи должно распознать как речевое представление правильной версии упомянутого по меньшей мере одного выбранного слова, так и речевые представления букв, которые составляют побуквенный ввод правильной версии упомянутого по меньшей мере одного выбранного слова. Затем оба представления могут быть обработаны распознаванием речи совместно, чтобы выполнить правильное распознавание правильной версии упомянутого по меньшей мере одного выбранного слова. Использование побуквенного ввода может быть особенно пригодным для распознавания названий или других редких слов, отсутствующих в словаре распознавания, который используют для распознавания речи.
Согласно четвертому аспекту настоящего изобретения, также предложено устройство для исправления слов в последовательности слов, полученной при распознавании входной речевой последовательности. Упомянутое устройство включает средства, выполненные с возможностью представления данной последовательности слов пользователю; и средства, выполненные с возможностью замены по меньшей мере одного слова в данной последовательности слов, - в случае, если оно было выбрано пользователем для исправления, - словом, полученным из новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого по меньшей мере одного выбранного слова, полностью произнесенного пользователем, и представление правильной версии упомянутого по меньшей мере одного выбранного слова, введенного побуквенно пользователем.
Иллюстративная реализация устройства, согласно четвертому аспекту настоящего изобретения, представляет собой портативное мультимедийное устройство или часть его.
Согласно четвертому аспекту настоящего изобретения, также предложен прикладной программный продукт, включающий носитель данных, содержащий программное приложение для исправления слов в последовательности слов, которая получена при распознавании входной речевой последовательности. Упомянутое программное приложение содержит программный код для того, чтобы представлять данную последовательность слов пользователю, и программный код для того, чтобы заменять по меньшей мере одно слово в данной последовательности слов, - в случае, если оно выбрано упомянутым пользователем для исправления, - словом, полученным из новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого по меньшей мере одного выбранного слова, произнесенного пользователем, и представление правильной версии упомянутого по меньшей мере одного выбранного слова, введенного побуквенно пользователем.
Эти и другие аспекты настоящего изобретения будут очевидны из подробного описания примеров реализаций, приведенного ниже.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На чертежах показаны:
Фиг.1 показывает схематическое представление физических компонентов устройства для исправления ошибок при распознавании речи согласно настоящему изобретению.
Фиг.2а показывает блок-схему, иллюстрирующую функциональные возможности блока распознавания речи с улучшенными возможностями исправления ошибок согласно первому аспекту настоящего изобретения.
Фиг.2b показывает блок-схему, иллюстрирующую функциональные возможности блока распознавания речи с улучшенными возможностями исправления ошибок согласно второму аспекту настоящего изобретения.
Фиг.2с показывает блок-схему, иллюстрирующую функциональные возможности блока распознавания речи с улучшенными возможностями исправления ошибок согласно третьему аспекту настоящего изобретения.
Фиг.2d показывает блок-схему, иллюстрирующую функциональные возможности блока распознавания речи с улучшенными возможностями исправления ошибок согласно четвертому аспекту настоящего изобретения.
Фиг.3а показывает графическую схему шагов, выполняемых предложенным способом для исправления ошибок при распознавании речи согласно первому аспекту настоящего изобретения.
Фиг.3b показывает графическую схему шагов, выполняемых предложенным способом для исправления ошибок при распознавании речи согласно второму аспекту настоящего изобретения.
Фиг.3с показывает графическую схему шагов, выполняемых предложенным способом для исправления ошибок при распознавании речи согласно третьему аспекту настоящего изобретения.
Фиг.3d показывает графическую схему шагов, выполняемых предложенным способом для исправления ошибок при распознавании речи согласно четвертому аспекту настоящего изобретения.
Фиг.4 иллюстрирует последовательность слов с выделенным словом согласно первому аспекту настоящего изобретения.
Фиг.5 иллюстрирует последовательность слов с двумя выделенными словами согласно первому аспекту настоящего изобретения.
Фиг.6 иллюстрирует последовательность слов и сортированного набора слов-кандидатов согласно второму аспекту настоящего изобретения.
Фиг.7 иллюстрирует обновление порядка слов-кандидатов в наборах слов-кандидатов в ответ на замену слова в последовательности слов согласно второму аспекту настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В продолжении этого подробного описания настоящее изобретение будет описано на примере примеров его реализации. В этих примерах, без намерения ограничить возможности применения настоящего изобретения, будут раскрыты предложенные способы исправления ошибок при распознавании речи в контексте мобильного речевого ввода.
Фиг.1 показывает устройство 1 для исправления ошибок при распознавании речи согласно настоящему изобретению. Это устройство 1 способно к осуществлению функциональных возможностей, чтобы выполнить исправление ошибок согласно каждому из четырех предложенных аспектов настоящего изобретения, или любой их комбинации.
Устройство 1 включает центральный процессор 100, который управляет работой всего устройства 1. Упомянутое устройство 1 взаимодействует с памятью 101, которая содержит, кроме прочего, программный код, относящийся к операционной системе 1010 устройства, прикладной программный код 1011, который может быть выполнен центральным процессором 100, чтобы обеспечить заданные функциональные средства пользователю упомянутого устройства, такие, например, как мобильный речевой ввод и соответствующее исправление ошибок, а также программный код 1012, относящийся к функциональным средствам распознавания речи. Устройство 1 также содержит звуковой интерфейс (I/F) 102, чтобы принимать входные речевые последовательности, которые могут быть, например, записаны с помощью микрофона 103 или приняты через внешний вход 104 (такие, например, как входные речевые последовательности, которые записаны во внешнем устройстве и затем переданы в устройство 1). Устройство 1 также содержит контроллер 105 дисплея, чтобы управлять работой дисплея 106, который может быть, например, жидкокристаллическим монитором или ему подобным. Дисплей 106 служит оптическим пользовательским интерфейсом для устройства 1 и позволяет, например, представлять последовательности слов и наборов слов-кандидатов пользователю устройства 1. Устройство 1 также включает контроллер 107 джойстика для того, чтобы принимать входные сигналы от джойстика 108, и контроллер 109 вспомогательной клавиатуры, чтобы принимать входные сигналы от вспомогательной клавиатуры 110. Подразумевается, что использование джойстика носит исключительно характер примера. С таким же успехом могут быть использованы трекбол, шар управления или клавиши курсора, чтобы осуществить их функциональные возможности. Кроме того, благодаря возможности выполнять распознавание речи, устройство 1 может вообще полностью обойтись без вспомогательной клавиатуры 110. Звуковым интерфейсом (I/F) 102, контроллером 107 джойстика, контроллером 109 вспомогательной клавиатуры и контроллером 105 дисплея управляет центральный процессор 100 в соответствии с операционной системой 1010 и/или прикладной программой 1011, которую в настоящее время выполняет центральный процессор 100.
Первый аспект изобретения
Фиг.2а схематично иллюстрирует блок-схему, иллюстрирующую функциональные возможности устройства 2а распознавания речи с улучшенными возможностями исправления ошибок согласно первому аспекту настоящего изобретения. На блок-схеме ядро 200 распознавания речи устройства 2а распознавания речи реализовано с помощью центрального процессора 100 устройства 1 (см. фиг.1), который выполняет программу 1012 распознавания речи, сохраненную в памяти 101, и блок 203 выбора резкости контура в устройстве 2а распознавания речи реализован с помощью центрального процессора 100, выполняющего прикладную программу 1011, сохраненную в памяти 101.
Ядро 200 распознавания речи выполнено с возможностью приема входной речевой последовательности, которая может быть речевым представлением одного или больше слов (например, полного предложения), и выполняет распознавание данной входной речевой последовательности, чтобы определить последовательность слов, которая, в оптимальном случае, совпадает с упомянутым одним или больше словом в данной входной речевой последовательности, которая его представляет. С этой целью, ядро 200 распознавания речи использует языковую модель 201 и словарь 202 распознавания. Упомянутая языковая модель 201, например, может быть сохранена в памяти 101 устройства 1 (см. Фиг.1) и может содержать вероятностную статистику наборов слов, содержащих по меньшей мере одно слово, которое существует в языке. Она, например, может быть униграмматической языковой моделью, отражающей правдоподобие одиночного слова, которое используют в языке, или биграмматической языковой моделью, которая отражает правдоподобие двух слов языка, следующих друг за другом. Также могут быть использованы языковые модели, рассматривающие большее количество следующих друг за другом слов (например, триграмматическая языковая модель и т.д.). Упомянутый словарь 202 распознавания содержит слова, которые могут быть распознаны с помощью упомянутого ядра 200 распознавания речи и которые также могут быть сохранены в памяти 101 устройства 1 (см. фиг.1).
Ядро 200 распознавания речи может, например, выполнить распознавание речи, разделяя данную входную речевую последовательность на сегменты, которые, как предполагается, относятся к одиночным словам, и затем может пытаться распознать упомянутые одиночные слова, например, путем идентифицирования фонем в упомянутых входных речевых сегментах последовательности и сравнивания этих фонем с преобразованием фонема-текст, которое может быть включено в упомянутый словарь 202 распознавания. Это ядро 200 распознавания речи вообще идентифицирует ряд возможных результатов распознавания для каждого входного речевого сегмента последовательности, и каждый из упомянутых возможных результатов распознавания связан со степенью достоверности распознавания, которая отражает достоверность того, что результат распознавания после ядра 200 распознавания речи правилен. Для каждого входного речевого сегмента ядро 200 распознавания речи в этом случае может выводить результат распознавания (слово) с наибольшей степенью достоверности распознавания, приводя к последовательности слов, которая, как полагают, представляет входную речевую последовательность. Распознавание речи в ядре 200 распознавания речи также может быть усовершенствовано путем использования языковой модели 201. Тогда, в дополнение к степеням достоверности распознавания, принимают во внимание вероятность того, что набор из одного или больше количества слов существует в языке, при определении, который из возможных результатов распознавания для каждого входного речевого сегмента последовательности выведен ядром 200 распознавания речи как результат распознавания. Таким образом, в случае биграмматической языковой модели, даже когда возможный результат распознавания отличается высокой достоверностью в отношении акустического пространства, например, в случае слова "фри" в противоположность слову "три", по причине использования биграмматической языковой модели, ядро 200 распознавания речи может, тем не менее, выбрать для слова "три", поскольку упомянутое ядро содержит информацию о контексте, например, слова "в" и "час" в заданной последовательности слов "в три часа". Хотя языковая модель сокращает количество возможных результатов распознавания, произведенная таким способом транскрипция, тем не менее, может содержать ошибки. Таким образом, существует необходимость в исправлении ошибок.
С этой целью последовательность слов, сформированная ядром 200 распознавания речи, затем может быть представлена пользователю. Согласно первому аспекту настоящего изобретения, результатом работы блока 2а распознавания речи может быть представлена не только данная последовательность слов, но также и информация относительно по меньшей мере одного слова в данной последовательности слов, причем это по меньшей мере одно слово должно быть выделено во время упомянутого представления. Это выделенное слово, например, может быть словом, которое отличается наименьшей степенью достоверности распознавания среди всех слов в данной последовательности слов, и, следовательно, среди этих слов отличается самой высокой вероятностью того, чтобы быть неправильно распознанным. С таким же успехом, может быть пригодным выделение всех слов в данной последовательности слов, степень достоверности распознавания которых ниже заданного порога. С этой целью блок 2а распознавания речи может быть обеспечен модулем 203 выбора резкости контура, который принимает последовательность слов как входные данные, причем предполагают, что для каждого слова в данной последовательности слов, связанная с ним степень достоверности распознавания доступна для упомянутого модуля 203 выбора резкости контура. Основанный на этих степенях достоверности распознавания модуль 203 выбора резкости контура затем определяет слова в данной последовательности слов, которые должны быть выделены, и выводит эту информацию, например, в блок представления.
Фиг.3а показывает шаги предложенного способа, выполненные для исправления ошибок при распознавании речи, согласно первому аспекту настоящего изобретения. Эти шаги, например, могут быть выполнены компонентами устройства 1 (см. фиг.1) под управлением центрального процессора 100 устройства 1.
На первом шаге 301 входная речевая последовательность может быть принята через звуковой интерфейс (I/F) 102 устройства 1 (см. фиг.1), или через микрофон 103, или через внешний вход 104. Данная входная речевая последовательность, например, может представлять одно полное предложение, произнесенное пользователем устройства 1 в мобильном приложении речевого ввода. Упомянутое предложение затем может быть помещено в сообщение, такое, например, как сообщения SMS или почтовые сообщения, и передано в удаленный приемник. На втором шаге 302 выполняют распознавание данной входной речевой последовательности, чтобы получить последовательность слов. Это распознавание осуществляет центральный процессор 100, выполняя программу 1012 распознавания речи, сохраненную в памяти 101. На третьем шаге 303 центральный процессор 100 определяет слова в данной последовательности слов, полученной после распознавания речи, которые должны быть выделены во время представления, путем выполнения прикладной программы 1011, сохраненной в памяти 101. Очевидно, что шаги 302 и 303 таким способом реализуют функциональные средства блока 2а распознавания речи, которые были описаны выше со ссылкой на фиг.2а.
На шаге 304 последовательность слов представляют пользователю, причем в упомянутом представлении выделены слова, которые были предназначены для выделения на шаге 303. Это представление инициируют с помощью центрального процессора 100 устройства 1 (см. фиг.1) и выполняют с помощью дисплея 106 под управлением контроллера 105 дисплея.
Фиг.4 показывает, каким способом такое представление последовательности 4 слов с одним выделенным словом может быть продемонстрировано на дисплее 106 (см. фиг.1). Последовательность 4 слов представляет предложение, которое содержит пять слов, причем третье слово (Слово 3) заключено в рамку 40, выполненную штриховой линией. Для этого примера может быть предположено, что слово с наименьшей степенью достоверности распознавания среди всех слов в последовательности слов должно быть выделено, чтобы привлечь внимание пользователя к этому потенциально ошибочно распознанному слову. Кроме того, в примере на фиг.4, предполагают, что рамка 40, выполненная штриховой линией, предназначена не только для выделения, но также представляет селектор, который может быть перемещен пользователем, чтобы выбирать слова, которые распознаны ошибочно, и, следовательно, которые нужно исправить. Упомянутое движение, например, может быть выполнено пословно с помощью джойстика или клавишами курсора, и тогда выбор может быть выполнен нажатием специально предназначенной для этой цели кнопки или ключом (который, например, может быть объединен непосредственно с упомянутым джойстиком или встроен в него). Путем автоматического позиционирования этого селектора на слове с самой низкой степенью достоверности распознавания (Слово 3 в настоящем примере), вместо позиционирования селектора на первом слове (Слово 1) в данной последовательности 4 слов, можно обеспечить значительное сокращение перемещений селектора до ошибочно распознанного слова, и, следовательно, более быстрое и более эффективное исправление ошибок.
Фиг.5 изображает второй пример представления последовательности из 5 слов (полное предложение) с двумя выделенными словами (Слово 3 и Слово 5). Оба слова выделены подчеркиванием. В этом примере предполагается, что все слова в данной последовательности 5 слов, которые связаны со степенью достоверности распознавания ниже заданного порога, должны быть выделены, чтобы предупредить пользователя, что выделенные слова потенциально могут быть ошибочно распознаны и, следовательно, могут потребовать специальной обработки. Очевидно, это также ускоряет исправление ошибок, потому что внимание пользователя обращено к словам, которые отличаются, по меньшей мере среди слов в упомянутом предложении, самой высокой вероятностью ошибочного распознавания. В примере на фиг.5, разумеется, в дополнение к подчеркиванию, можно позиционировать селектор на слово с самой низкой достоверностью распознавания, чтобы ускорить выбор слов для исправления.
Возвращаясь к графической схеме на фиг.3а, на шаге 305, центральным процессором 100 из устройства 1 (см. фиг.1) затем проверяет, выбрал ли пользователь слово в данной представленной последовательности слов для исправления. Такой выбор, например, может быть выполнен пользователем путем пословного перемещения селектора по словам в данной представленной последовательности слов и нажатия кнопки, чтобы подтвердить выбор, причем упомянутое перемещение и упомянутое подтверждение могут быть выполнены с помощью джойстика 108 устройства 1 (см. фиг.1) и переданы в центральный процессор 100 через контроллер 107 джойстика. Если центральный процессор 100 распознает, что слово было выбрано для исправления, то исправленное слово может быть определено на шаге 306. Это может быть достигнуто рядом способов. Исправленное слово может быть введено пользователем путем печатания его на клавиатуре 110, или путем выбора его из списка слов-кандидатов, связанного с выбранным словом, или путем ввода нового речевого представления правильной версии упомянутого выбранного слова. Также можно предположить, что исправленное слово может быть автоматически определено центральным процессором 100, например, путем выбора первого слова-кандидата из набора слов-кандидатов, который связан с упомянутым выбранным словом. После того, как упомянутое исправленное слово определено, выбранное слово может быть заменено исправленным словом, то есть исправленное слово может быть отображено на позиции выбранного слова, вместо этого выбранного слова.
На шаге 308 центральный процессор 100 устройства 1 затем проверяет, закончил ли пользователь речевой ввод, например, путем нажатия заданной клавиши завершения или произнесением команды завершения. Если так, то последовательность слов, включающая замененные (исправленные) слова, может быть сохранена на шаге 311, например, в памяти 101 устройства 1 (см. фиг.1), и процедура приходит к концу. В противном случае, центральный процессор 100 проверяет на шаге 309, происходит ли дальнейший речевой ввод, который указывает на желание пользователя продолжить речевой ввод, не выполняя последующие исправления. Если так, то на шаге 311 последовательность слов, включая замененные (исправленные) слова, может быть сохранена, и процедура переходит в начало, к шагу 301, чтобы принять следующую последовательность слов (например, следующее предложение). Если на шаге 309 определено, что речевого ввода больше нет, то может быть предположено, что пользователь после этого намерен осуществить исправление ошибок, и процедура переходит назад, к шагу 305, чтобы разрешить выбор дальнейших слов для исправления.
Второй аспект изобретения
Фиг.2b изображает схему, иллюстрирующую функциональные средства блока 2b распознавания речи с улучшенными возможностями исправления ошибок, согласно второму аспекту настоящего изобретения. На схеме ядро 200 распознавания речи в устройстве 2b распознавания речи может быть реализовано центральным процессором 100 устройства 1 (см. фиг.1), выполняющим программу 1012 распознавания речи, сохраненную в памяти 101, и упорядочивающий блок 204 блока 2b распознавания речи может быть реализован центральным процессором 100, выполняющим прикладную программу 1011, сохраненную в памяти 101. Функциональные средства ядра 200 распознавания речи в блоке 2b распознавания речи на фиг.2b могут быть те же самые, что и функциональные средства ядра 200 распознавания речи в блоке 2а распознавания речи на фиг.2а, то есть последовательность слов может быть определена в процессе распознавания входной речевой последовательности на основе языковой модели 201 и словаря 202 распознавания. Однако ядро 200 распознавания речи в блоке 2b распознавания речи (см. фиг.2b) выполнено с дополнительной возможностью формировать на выходе, для каждого слова в данной последовательности слов, упомянутый набор альтернативных слов-кандидатов, который может быть сгенерирован в течение процесса распознавания каждого речевого сегмента упомянутой входной речевой последовательности, или их поднабор. Согласно второму аспекту настоящего изобретения, в блоке 204 упорядочивания слова-кандидаты в каждом из упомянутых наборов слов-кандидатов могут быть упорядочены (отсортированы) в соответствии с критерием упорядочивания. Упомянутый критерий упорядочивания может быть связан с упомянутой степенью достоверности распознавания каждого из упомянутых слов-кандидатов на основе языковой модели 201 или на обеих языковых моделях. Например, упомянутые слова-кандидаты в каждом наборе слов-кандидатов можно упорядочить в соответствии с уменьшающейся степенью достоверности распознавания таким способом, чтобы слова-кандидаты с самыми высокими степенями достоверности распознавания были расположены в начале списка. С тем же успехом, упомянутая языковая модель может быть использована для упорядочивания. Например, в случае биграмматической языковой модели, слова-кандидаты в наборе слов-кандидатов, который связан со вторым словом в последовательности слов, могут быть упорядочены в соответствии с их возможностью следовать за первым словом в упомянутой последовательности слов и в соответствии с их возможностью предшествовать третьему слову в упомянутой последовательности слов, и так далее. Упомянутый блок 204 упорядочивания после этого формирует наборы слов-кандидатов, содержащих упорядоченные слова-кандидаты.
Блок 204 упорядочивания также выполнен с возможностью приема информации относительно слов, которые заменены (исправлены) пользователем. Если критерий упорядочивания, примененный в упомянутом блоке 204 упорядочивания, основан (по меньшей мере частично) на упомянутой языковой модели 201, и если упомянутая языковая модель 201 биграмматическая или высокоуровневая языковая модель, то любое изменение слов в данной последовательности слов также может влиять на упорядочивание слов-кандидатов в наборах слов-кандидатов, как будет объяснено ниже более подробно со ссылкой на фиг.6.
Фиг.3b изображает шаги процедуры, выполненные предложенным способом исправления ошибок при распознавании речи, согласно второму аспекту настоящего изобретения. Эти шаги, например, могут быть выполнены компонентами устройства 1 (см. фиг.1) под управлением центрального процессора 100 устройства 1.
На первом шаге 321 входная речевая последовательность может быть принята через звуковой интерфейс 102 устройства 1 (см. фиг.1). Распознавание речи в этом случае может быть осуществлено на шаге 322 центральным процессором 100, который выполняет программу 1012 распознавания речи, сохраненную в памяти 101. Затем на шаге 323 слова-кандидаты в каждом наборе слов-кандидатов, связанном со словами в данной последовательности слов, которая получена при распознавании речи, упорядочивают (сортируют) в соответствии с упомянутым критерием упорядочивания. Таким образом, шаги 322 и 323 отражают функциональные средства блока 2b распознавания речи, раскрытые выше со ссылкой на фиг.2b.
Затем последовательность слов может быть представлена пользователю устройства 1 на шаге 324 с помощью контроллера 105 дисплея и дисплея 106. В упомянутом представлении, разумеется, может быть выделено одно или больше слов, согласно первому аспекту настоящего изобретения, чтобы ускорить исправление ошибок.
Затем на шаге 325 центральный процессор 100 проверяет, выбрано ли слово в данной представленной последовательности слов пользователем для исправления (например, пословным перемещением селектора в данной последовательности слов и нажатием кнопки для подтверждения с помощью джойстика 108). В этом случае на шаге 326 набор слов-кандидатов, который связан с упомянутым выбранным словом, может быть представлен пользователю. Возможный способ достичь этого состоит в том, чтобы представить прокручиваемый список, содержащий слова-кандидаты из набора слов-кандидатов, расположенные одно под другим. Поскольку упомянутые слова-кандидаты упорядочены на шаге 323, то слово-кандидат с самой высокой вероятностью правильной замены выбранного слова расположено на вершине упомянутого прокручивающегося списка, и ниже расположено слово-кандидат, второе по степени правдоподобия, и так далее. Чтобы выбрать одно из упомянутых слов-кандидатов, пользователь может вертикально переместить селектор вниз по упомянутому прокручивающемуся списку и подтвердить свой выбор нажатием кнопки, например, с помощью джойстика 108.
Фиг.6 иллюстрирует такой прокручивающийся список 60 для третьего слова (Слово 3) в последовательности 6 слов. Прокручивающийся список 60 содержит четыре слова-кандидата, которые могут быть упорядочены таким способом, что при произвольном порядке упомянутых слов-кандидатов после распознавания речи на шаге 322, который определяет их нумерацию (Слово-кандидат 1, Слово-кандидат 2, Слово-кандидат 3, Слово-кандидат 4), они после упорядочивания, выполненного в шаге 323, могут быть расположены в другом порядке (Слово-кандидат 2, Слово-кандидат 4, Слово-кандидат 1, Слово-кандидат 3). Селектор 61 может быть автоматически установлен на первую строку в упомянутом прокручивающемся списке 60 и может быть вертикально перемещен на выбранные строки в упомянутом прокручивающемся списке 60.
Как показано на фиг.3b, на шаге 327, центральный процессор 100 устройства 1 (см. фиг.1) проверяет, выбрано ли пользователем слово-кандидат. Если так, то на шаге 328 этим выбранным словом-кандидатом заменяют выбранное (ошибочно распознанное) слово. Если иначе, то шаг 328 пропускают.
Затем на шаге 329 центральный процессор 100 проверяет, должен ли быть закончен речевой ввод. Если должен, то последовательность слов, включая замененное слово (слова), сохраняют на шаге 333, например, в памяти 101 устройства 1. В противном случае на шаге 330 проверяют продолжение дальнейшего речевого ввода, указывающего на желание пользователя продолжить речевой ввод. Если так, то последовательность слов, включая замененное слово (слова), сохраняют на шаге 332, например, в памяти 101 устройства 1, и процедура затем переходит назад, к шагу 321, чтобы принять следующую входную речевую последовательность. В противном случае, опционально может быть выполнен шаг 331 (обозначенный пунктирными линиями), после чего процедура переходит назад к шагу 325, чтобы выполнить исправление других ошибок.
Шаг 331 в блок-схеме на фиг.2b может быть дополнительным, потому что он может быть пригоден, только если критерий упорядочивания, примененный на шаге 323, по меньшей мере частично основан на языковой модели, которая рассматривает вероятность того, что набор из двух или больше слов языка существует в языке. Если так, то следует обновить упорядочивание слов-кандидатов в заданных наборах слов-кандидатов после того, как слово в данной последовательности слов было заменено. Это будет объяснено далее более подробно со ссылкой на фиг.7.
В верхней части фиг.7 изображена последовательность 7 слов, которая представляет полное предложение, содержащее пять слов (Слово 1, Слово 2, Слово 3, Слово 4, Слово 5). Для второго, третьего и четвертого слов также схематично проиллюстрированы связанные с ними наборы 70-2, 70-3 и 70-4 слов-кандидатов. Слова-кандидаты в упомянутых наборах слов-кандидатов упорядочены согласно критерию упорядочивания, который по меньшей мере частично зависит от биграмматической языковой модели. Например, высокая вероятность того, что слово-кандидат 2 в наборе 70-3 следует за вторым словом (Слово 2), и что Слово 4 следует за упомянутым словом-кандидатом 2 в наборе 70-3, предсказанная биграмматической языковой моделью, соответственно, приводит к тому, что слово-кандидат 2 в наборе 70-3 может быть рассмотрено как наиболее вероятная правильная замена для третьего слова (Слово 3).
Теперь может быть рассмотрен случай, когда пользователь выбирает третье слово (Слово 3) в данной последовательности 7 слов, как ошибочно распознанное, и затем выбирает слово-кандидат 2 из набора 70-3 слов-кандидатов (связанного со Словом 3), чтобы заменить Слово 3. Эта замена Слова 3 словом-кандидатом 2 из набора 70-3 не влечет за собой дальнейших последствий, если исправление ошибок в последовательности 7 слов заканчивают после этого исправления. Однако, если необходимо продолжить дальнейшие исправления ошибок в данной последовательности 7 слов, то следует иметь в виду, что по причине зависимости критерия упорядочивания от биграмматической языковой модели порядок слов-кандидатов в наборах 70-2 и 70-4 слов-кандидатов, соответственно связанных со словами Слово 2 и Слово 4, которые являются прямыми соседями замененного Слова 3 в данной последовательности 7 слов, зависит от упомянутого замененного Слова 3. Если дальнейшее исправление ошибок должно обеспечить преимущество на основании порядка слов-кандидатов, и, следовательно, более быстрое распознавание, то необходимо обновить порядок слов в наборах 70-2 и 70-4 слов-кандидатов. Такое обновление проиллюстрировано в нижней части фиг.7. Здесь изображена последовательность 7' слов, которая представляет в основном последовательность 7 слов со Словом 3, замененным на Слово 3'. Кроме того, набор 70-3' слов-кандидатов, связанный со Словом 3', теперь содержит только три слова-кандидата, поскольку одно из первоначальных слов-кандидатов использовано для замены Слова 3. Кроме того, порядок слов-кандидатов в наборах 70-2' и 70-4', связанных со словами Слово 2 и Слово 4, соответственно, должен быть обновлен перед тем, как рассматривать Слово 3'.
В примере на фиг.7, по причине использования биграмматической языковой модели, которая содержит статистику только по двум словам, следующим друг за другом, должны быть обновлены только наборы (70-2 и 70-4) слов-кандидатов, связанные со словами (Слово 2, Слово 4), которые непосредственно соседствуют с замененным словом (чтобы получить наборы 70-2' и 70-4'). Однако, если будет использована триграмматическая языковая модель, то должны быть обновлены также и наборы слов-кандидатов, связанные со Словом 1 и Словом 5.
Кроме того, следует иметь в виду, что с точки зрения сложности может быть предпочтительнее обновлять только слова-кандидаты в наборах слов-кандидатов, связанных со словами, которые соседствуют с замененными словами и следуют за этими замененными словами (соседи справа в примере на фиг.7), в особенности, если выбор слов для исправления выполнен последовательно и начат с первого слова в данной последовательности слов. Вероятность, что исправление ошибок необходимо для слов, которые предшествуют замененным словам, в этом случае низка, и, следовательно, для этих слов нет необходимости в обновлении связанных с ними наборов слов-кандидатов.
Третий аспект изобретения
Фиг.2с изображает блок-схему, иллюстрирующую функциональные средства устройства 2с распознавания речи с улучшенными возможностями исправления ошибок согласно третьему аспекту настоящего изобретения. На схеме ядро 200 распознавания речи в устройстве 2с распознавания речи может быть реализовано с помощью центрального процессора 100 устройства 1 (см. фиг.1), выполняющего программу 1012 распознавания речи, сохраненную в памяти 101, а блок 205 выбора словаря распознавания в устройстве 2с распознавания речи может быть реализован с помощью центрального процессора 100, выполняющего прикладную программу 1011, сохраненную в памяти 101. Функциональные средства ядра 200 распознавания речи в блоке 2с распознавания речи на фиг.2с те же самые, что и функциональные средства ядра 200 распознавания речи в блоке 2b распознавания речи на фиг.2b, то есть при распознавании входной речевой последовательности на основе языковой модели 201 и словаря 202 распознавания может быть определена последовательность слов, и для каждого слова в данной последовательности слов может быть получен связанный с ним набор слов-кандидатов. Однако ядро 200 распознавания речи также выполнено с возможностью приема новой входной речевой последовательности, которая содержит только представление слова, произнесенного пользователем, и распознавания этой новой входной речевой последовательности на основе ограниченного словаря распознавания. Такая новая входная речевая последовательность, например, может быть принята через звуковой интерфейс 102 от микрофона 103 устройства 1 (см. фиг.1), с целью определения слова замены для слова, которое распознано ошибочно, как полагает пользователь устройства 1.
Согласно третьему аспекту настоящего изобретения, распознавание речи таким способом сначала может быть выполнено на уровне последовательности слов (то есть устройство распознавания речи работает на непрерывном уровне и принимает неопределенное количество слов, которые непрерывно произносит пользователь), который, например, может быть уровнем предложения, и затем, если одно или больше упомянутое слов распознано ошибочно, то распознавание речи может быть повторено на уровне слова (то есть на уровне, на котором одновременно может быть распознано только одно слово из входной речи). Таким способом, при распознавании на уровне слова, задача устройства речевого распознавания может быть упрощена. Это означает, что пользователь произносит только одиночное слово, и также границы слова могут быть легко обнаружены. Кроме того, с тем же успехом может быть применима языковая модель, учитывающая слова, которые уже были распознаны при распознавании речи на уровне предложения.
В существующем уровне техники обычно словарь распознавания по умолчанию используют даже для распознавания на уровне слова. Это может помочь в тех случаях, когда ошибочно распознаны редкие слова, которые акустически подобны некоторым более часто используемым словам (например, "solely" вместо "only"). Это происходит вследствие того факта, что правильное моделирование языка для редких слов, как правило, затруднено.
В отличие от этого, согласно третьему аспекту настоящего изобретения, используют ограниченный словарь распознавания для распознавания на уровне слова новой входной речевой последовательности, которая содержит речевое представление правильной версии выбранного (ошибочно распознанного) слова в данной последовательности слов, и этот ограниченный словарь распознавания представляет собой набор слов-кандидатов, который сгенерирован ядром 200 распознавания речи для упомянутого выбранного слова во время распознавания входной речевой последовательности. Этот ограниченный словарь распознавания вообще намного меньше, чем словарь 202 распознавания, принятый по умолчанию. Использование такого сокращенного словаря распознавания особенно полезно в тех случаях, когда существуют (небольшие) акустические различия между словами-кандидатами, которые идентичны с точки зрения моделирования языка. Например, слово "Джонни" может быть ошибочно распознано как "Джон", потому что обеим альтернативам даны названия, которые имеют равную вероятность появления относительно соседних слов. Кроме того, маленький словарь распознавания делает распознавание речи более быстрым и надежным.
Надлежащий выбор правильного словаря распознавания может быть выполнен блоком 205 выбора словаря распознавания, который выбирает либо (стандартный) словарь 202 распознавания (для входной речевой последовательности), либо набор слов-кандидатов, связанный с выбранным словом (для новой входной речевой последовательности, содержащей речевое представление правильной версии упомянутого выбранного слова). Результат действия блока 205 выбора словаря распознавания затем поступает в ядро 200 распознавания речи.
Фиг.3с показывает шаги процедуры, выполняемые в соответствии с предложенным способом исправления ошибок при распознавании речи согласно третьему аспекту настоящего изобретения. Эти шаги, например, могут быть выполнены компонентами устройства 1 (см. фиг.1) под управлением центрального процессора 100 устройства 1.
На первом шаге 341 (начальная) входная речевая последовательность может быть принята через звуковой интерфейс 102, и затем на шаге 342 может быть выполнено распознавание речи, чтобы получить последовательность слов (например, полное предложение), которая представлена данной входной речевой последовательностью. Это распознавание речи основано на словаре распознавания, выбранном по умолчанию (см. словарь 202 распознавания на фиг.2с), причем выбором этого словаря распознавания речи управляет блок 205 выбора словаря распознавания (см. фиг.2с). Как уже изложено выше, и распознавание речи, и выбор словаря распознавания осуществляет центральный процессор 100 устройства 1 (см. фиг.1), выполняя программу 1012 распознавания речи и прикладную программу 1011 соответственно.
Результат распознавания речи затем может быть представлен пользователю с помощью контроллера 105 дисплея и дисплея 106 (см. фиг.1) на шаге 343. В упомянутом представлении, разумеется, может быть ускорено исправление ошибок путем выделения одного или больше слов, согласно первому аспекту настоящего изобретения.
Затем центральный процессор 100 проверяет на шаге 344, было ли выбрано пользователем для исправления одно из упомянутых слов в данной представленной последовательности слов (например, путем перемещения селектора на это слово с помощью джойстика 108 и подтверждения). Если так, то новая входная речевая последовательность может быть принята на шаге 345. Это может быть выполнено, например, путем записи данной новой входной речевой последовательности с помощью микрофона 103 и передачи этой записанной последовательности в центральный процессор 100 через звуковой интерфейс 102. Данная новая входная речевая последовательность содержит только речевое представление правильной версии слова, которое было выбрано пользователем для исправления на шаге 344. Основанное на этой новой входной речевой последовательности, распознавание речи может быть выполнено на шаге 346. На этом шаге под управлением центрального процессора 100, выполняющего прикладную программу 1011 (см. фиг.1), набор слов-кандидатов, связанных с выбранным словом, используют как ограниченный словарь распознавания, чтобы выполнить распознавание речи быстрее и более точно. Затем выбранное на шаге 347 слово заменяют результатом распознавания речи.
На шаге 348 центральный процессор 100 проверяет, намерен ли пользователь закончить речевой ввод. Если так, то последовательность слов, включая замененное слово (слова), может быть сохранена на шаге 351, и процедуру заканчивают. В противном случае, центральный процессор 100 на шаге 349 проверяет, продолжен ли дальнейший речевой ввод. Если так, то данную последовательность слов, включая замененное слово (слова), сохраняют, и процедура переходит назад к шагу 341, чтобы обеспечить прием других входных речевых последовательностей. В противном случае, процедура переходит к шагу 344, чтобы обеспечить исправление других ошибок в данной последовательности слов.
Четвертый аспект изобретения
Фиг.2d показывает блок-схему, иллюстрирующую функциональные средства блока 2d распознавания речи с улучшенными возможностями исправления ошибок согласно четвертому аспекту настоящего изобретения. На этой схеме расширенное ядро 200" распознавания речи, которое теперь также включает распознавание речи для букв, входящее в состав средства 2d распознавания речи, может быть реализовано центральным процессором 100 устройства 1 (см. фиг.1), выполняющим программу 1012 распознавания речи, сохраненную в памяти 101.
Согласно четвертому аспекту настоящего изобретения, расширенное ядро 200' распознавания речи может быть выполнено с возможностью распознавания входной речевой последовательности, чтобы получить последовательность слов, которая представлена данной входной речевой последовательностью, и распознавания новой входной речевой последовательности, которая содержит как речевое представление слова, так и его представление, введенное побуквенно, чтобы получить исправленное слово. Упомянутое слово, представляемое данной новой входной речевой последовательностью, рассматривают как правильную версию ошибочно распознанного слова, которое выбрано пользователем для исправления. Это распознавание речи основано на языковой модели 201 и на расширенном словаре 202' распознавания, который может, в частности, содержать буквы, необходимые расширенному ядру 200' распознавания речи для распознавания букв (словарь распознавания, однако, уже может содержать эти буквы по умолчанию). Расширенное ядро 200' распознавания речи, в этом случае, может использовать новую входную речевую последовательность, которая содержит только речевое представление слова и его представление, введенное побуквенно, например, "Мемфис, МЕМФИС", чтобы получить более точный результат распознавания речи по сравнению со случаем, когда данная входная речевая последовательность представляет ряд слов (например, предложение).
Даже при том, что распознавание символа, как таковое, может быть весьма затруднительным для некоторых языков (например, английский Е-набор), применение побуквенного произнесения обеспечивает хороший способ для исправления ошибок, например, в именах собственных. Некоторые имена людей или названия городов могут отсутствовать в словаре устройства речевого распознавания, и в таких случаях всегда может быть распознано акустически подобное слово. Например "Ньюпорт" может быть ошибочно распознано как "Нью-Йорк" (обработанное как одно слово в словаре распознавания). В этом случае, "НЬЮПОРТ" может быть ясно отличимо от "НЬЮЙОРК”.
Кроме того, слова, распознанные расширенным ядром 200' распознавания речи путем анализа речевого и введенного побуквенно представлений данного слова, могут быть затем сохранены в расширенном словаре 202' распознавания, как обозначает двунаправленная стрелка между полем 200' и полем 202' на фиг.2d.
Фиг.3d изображает шаги процедуры, выполненные в соответствии с предложенным способом исправления ошибок при распознавании речи, согласно четвертому аспекту настоящего изобретения. Эти шаги, например, могут быть выполнены компонентами устройства 1 (см. фиг.1) под управлением центрального процессора 100 устройства 1.
На первом шаге (начальная) входная речевая последовательность может быть принята через звуковой интерфейс 102 устройства 1 (см. фиг.1). Затем на шаге 362 выполняют распознавание этой входной речевой последовательности, чтобы получить последовательность слов, представленных данной входной речевой последовательностью. Данная последовательность слов, например, может быть полным предложением. Затем данная последовательность слов на шаге 363 может быть представлена пользователю с помощью контроллера 105 дисплея и дисплея 106 устройства 1. В упомянутом представлении, разумеется, можно ускорить исправление ошибок путем выделения одного или больше слова, согласно первому аспекту настоящего изобретения.
Затем центральный процессор 100 проверяет на шаге 364, выбрано ли пользователем для исправления одно из упомянутых слов (например, путем перемещения селектора на упомянутое слово с помощью джойстика 108). Если слово было выбрано для исправления, то новая входная речевая последовательность, содержащая только речевое представление правильной версии упомянутого выбранного слова и введенное побуквенно представление упомянутой правильной версии выбранного слова, может быть принята на шаге 365. Эта новая входная речевая последовательность может быть произнесена пользователем в микрофон 103 и передана центральному процессору 100 через звуковой интерфейс 102. На шаге 366 может быть выполнено распознавание новой входной речевой последовательности, то есть как произнесенного представления, так и введенного побуквенно представления правильной версии упомянутого слова, выбранного на шаге 364. Результаты распознавания обоих представлений, например, ряд возможных результатов распознавания слова и ряд наборов букв, введенных побуквенно, могут быть затем проанализированы совместно, чтобы получить окончательный результат распознавания, то есть исправленное слово. На шаге 367 этот результат распознавания сохраняют в расширенном словаре 202' распознавания (см. фиг.2d), например, в форме таблицы соответствия между фонемами и текстом, или тому подобной. Затем на шаге 368 слово, выбранное на шаге 364, может быть заменено исправленным словом, как определено на шаге 366.
На шаге 369 центральный процессор 100 проверяет, намерен ли пользователь закончить речевой ввод. Если так, то последовательность слов, включающую замененное слово (слова), сохраняют на шаге 372 и процедуру заканчивают. В противном случае центральный процессор 100 на шаге 370 проверяет, происходит ли дальнейший речевой ввод. Если так, то последовательность слов, включающую замененное слово (слова) сохраняют, и процедура переходит назад к шагу 361, чтобы обеспечить прием других входных речевых последовательностей. В противном случае процедура переходит к шагу 364, чтобы разрешить исправление других ошибок в данной последовательности слов.
Изобретение было описано выше на примере примеров его реализации. Следует отметить, что возможны альтернативные способы и разновидности настоящего изобретения, очевидные для любого специалиста в этой области техники, которые могут быть осуществлены без выхода за рамки приложенной формулы. В частности, настоящее изобретение не ограничено применением в контексте мобильного речевого ввода. Оно с таким же успехом может быть использовано для повышения скорости и упрощения способа, с помощью которого пользователь взаимодействует с устройством в настольных приложениях (например, для речевого ввода текстов в настольный компьютер). Кроме того, настоящее изобретение для представления результатов распознавания не ограничено устройствами, которые содержат дисплей. Такое представление с тем же успехом может быть выполнено акустическим способом, например, в приложениях для людей со слабым зрением. Вместо того, чтобы выбирать слова и слова-кандидаты джойстиком, с тем же успехом может быть предусмотрены присвоение конкретного номера каждой альтернативе выбора и возможность для пользователя выбирать, вводя соответствующий номер с помощью клавиатуры или просто произнося этот номер голосом. Также следует отметить, что хотя четыре аспекта настоящего изобретения были представлены отдельно, существует возможность комбинировать их (например, первый аспект со вторым, третьим и четвертым аспектом соответственно), чтобы достичь оптимально улучшенного исправления ошибок при распознавании речи.
| название | год | авторы | номер документа |
|---|---|---|---|
| УНИВЕРСАЛЬНЫЕ ОРФОГРАФИЧЕСКИЕ МНЕМОСХЕМЫ | 2005 |
|
RU2441287C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ РАСПОЗНАВАНИЯ РЕЧИ | 2006 |
|
RU2393549C2 |
| АРХИТЕКТУРА РАСПОЗНАВАНИЯ ДЛЯ ГЕНЕРАЦИИ АЗИАТСКИХ ИЕРОГЛИФОВ | 2008 |
|
RU2477518C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОГО ПОИСКА И КОРРЕКЦИИ ОШИБОК В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2021 |
|
RU2785207C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| Система и способ корректировки орфографических ошибок | 2020 |
|
RU2753183C1 |
| ДИАЛОГОВОЕ УПРАВЛЕНИЕ ДЛЯ ЭЛЕКТРИЧЕСКОГО УСТРОЙСТВА | 2003 |
|
RU2336560C2 |
| ЗАКОДИРОВАННЫЕ КОДОВЫМИ КОМБИНАЦИЯМИ СЛОВАРИ | 2006 |
|
RU2421809C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| МАШИННОЕ ОБУЧЕНИЕ | 2005 |
|
RU2391791C2 |
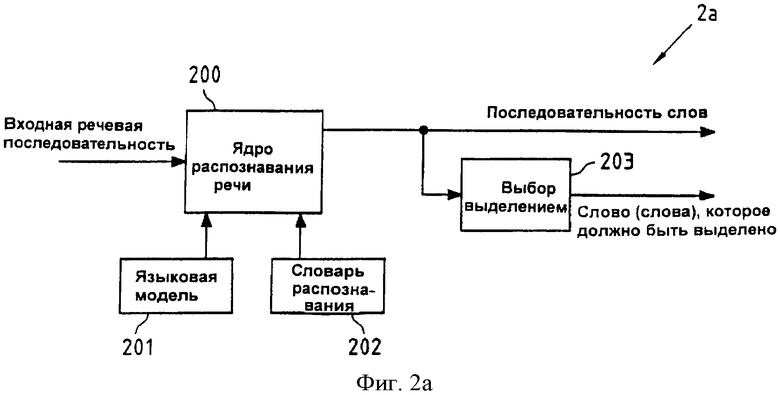
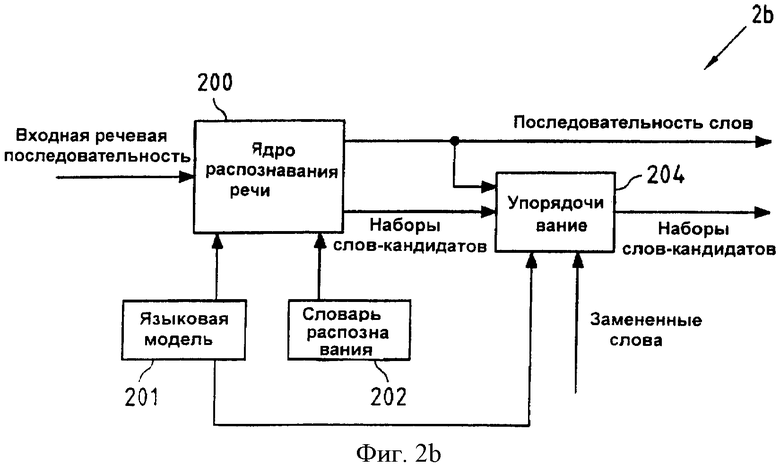
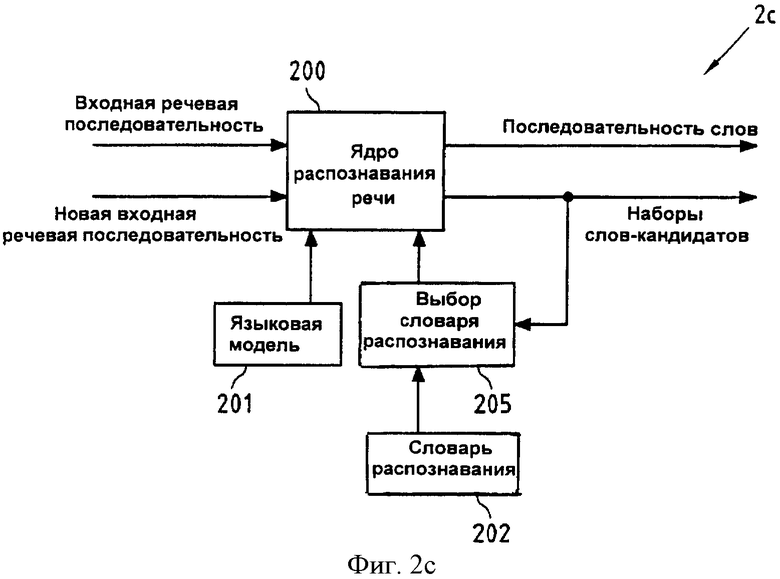
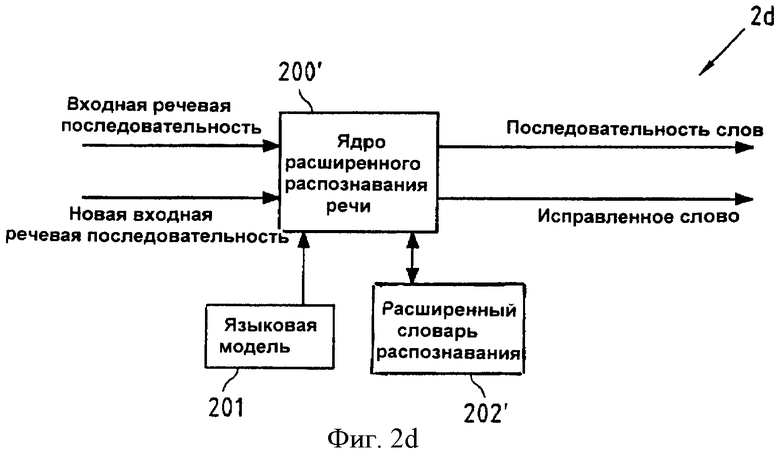
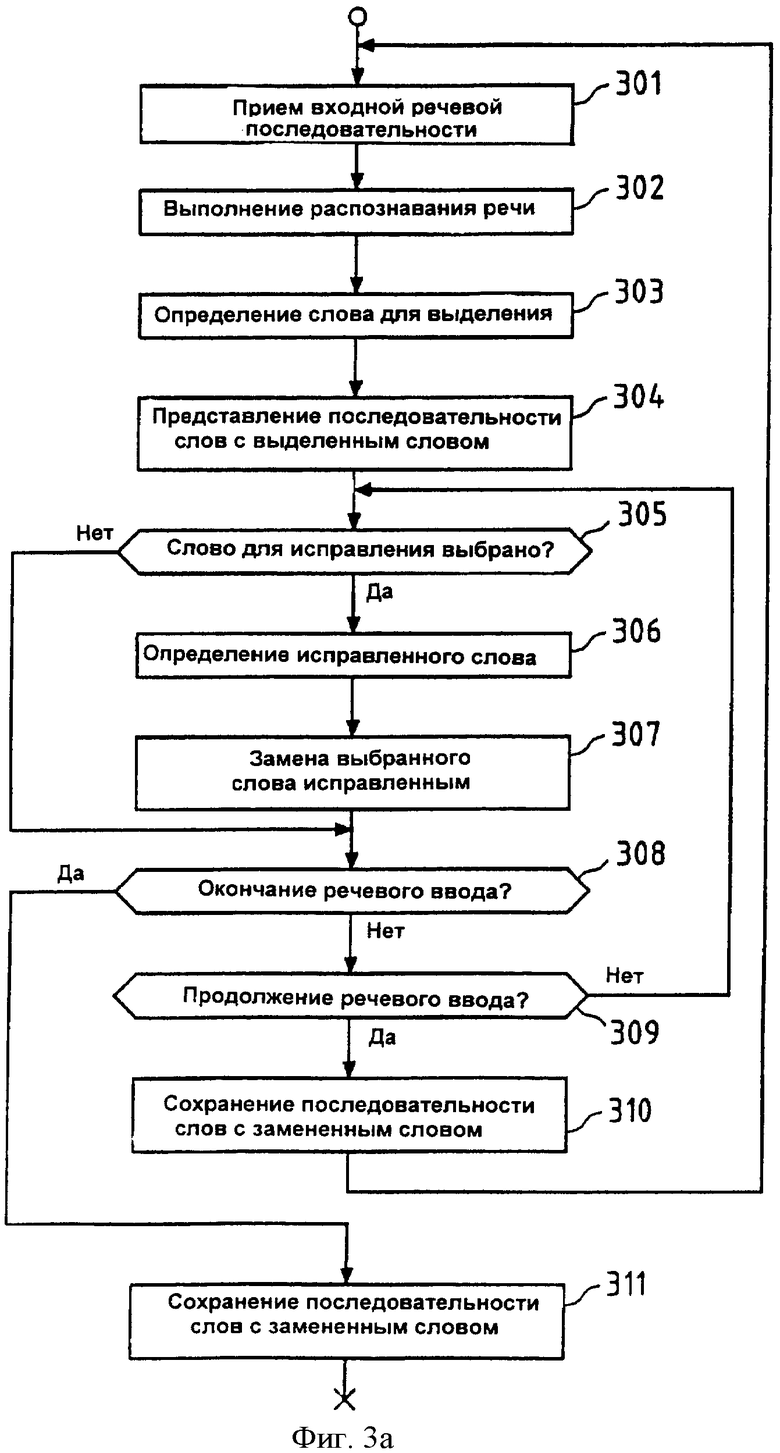
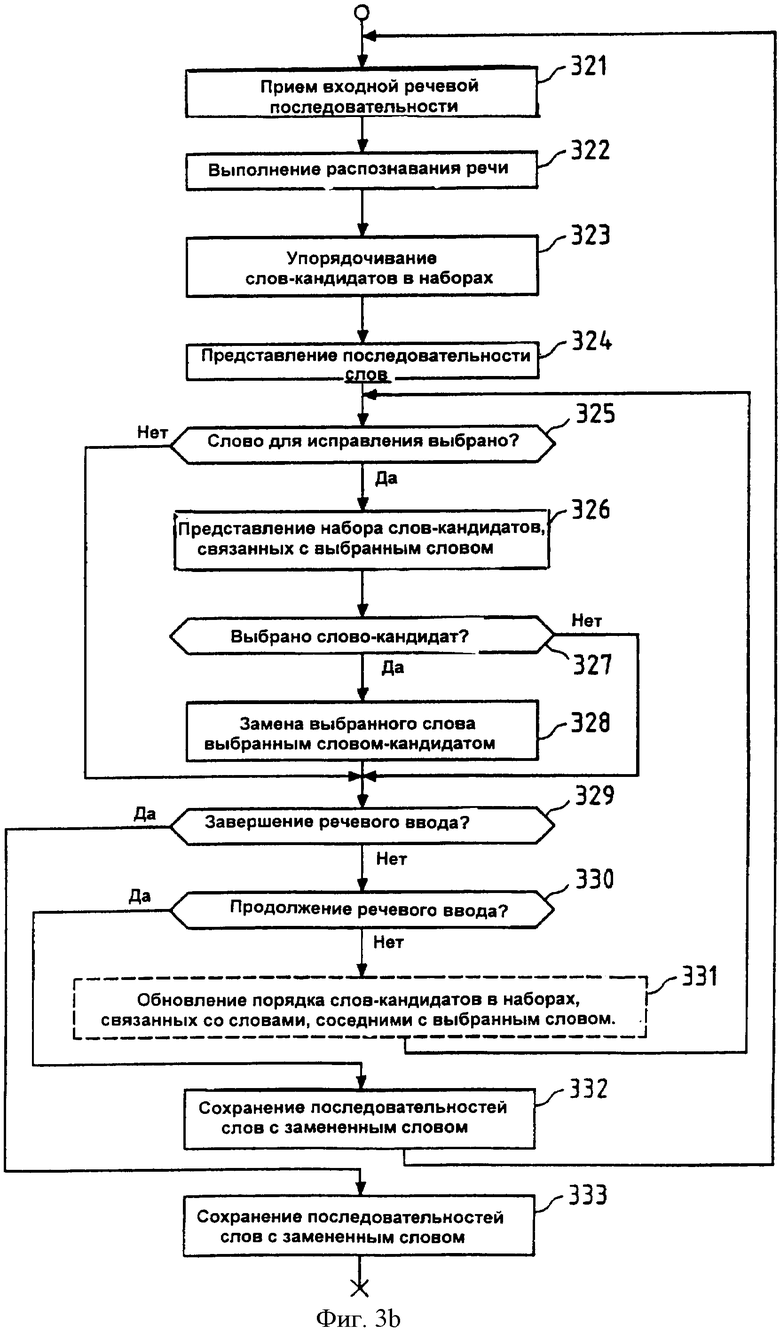
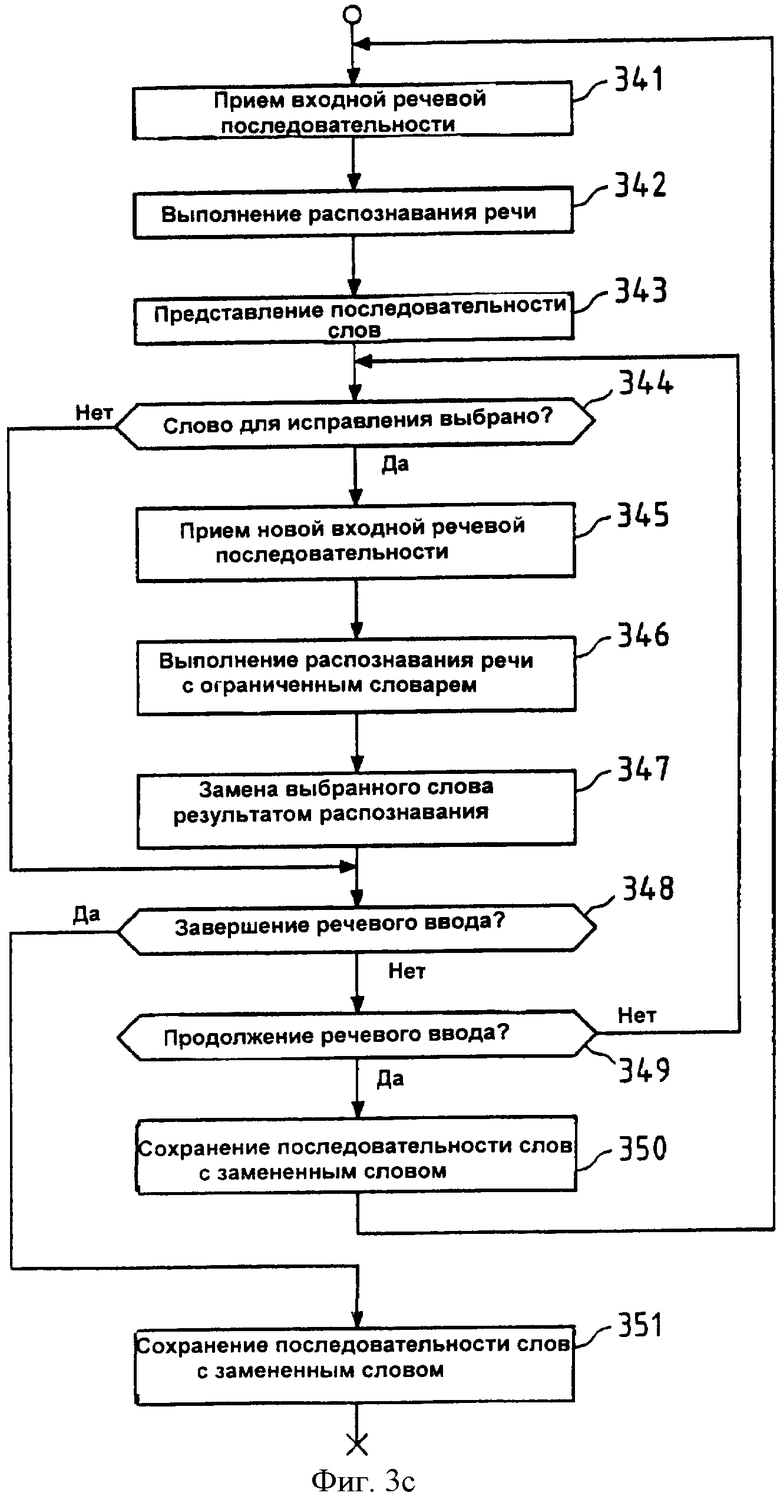
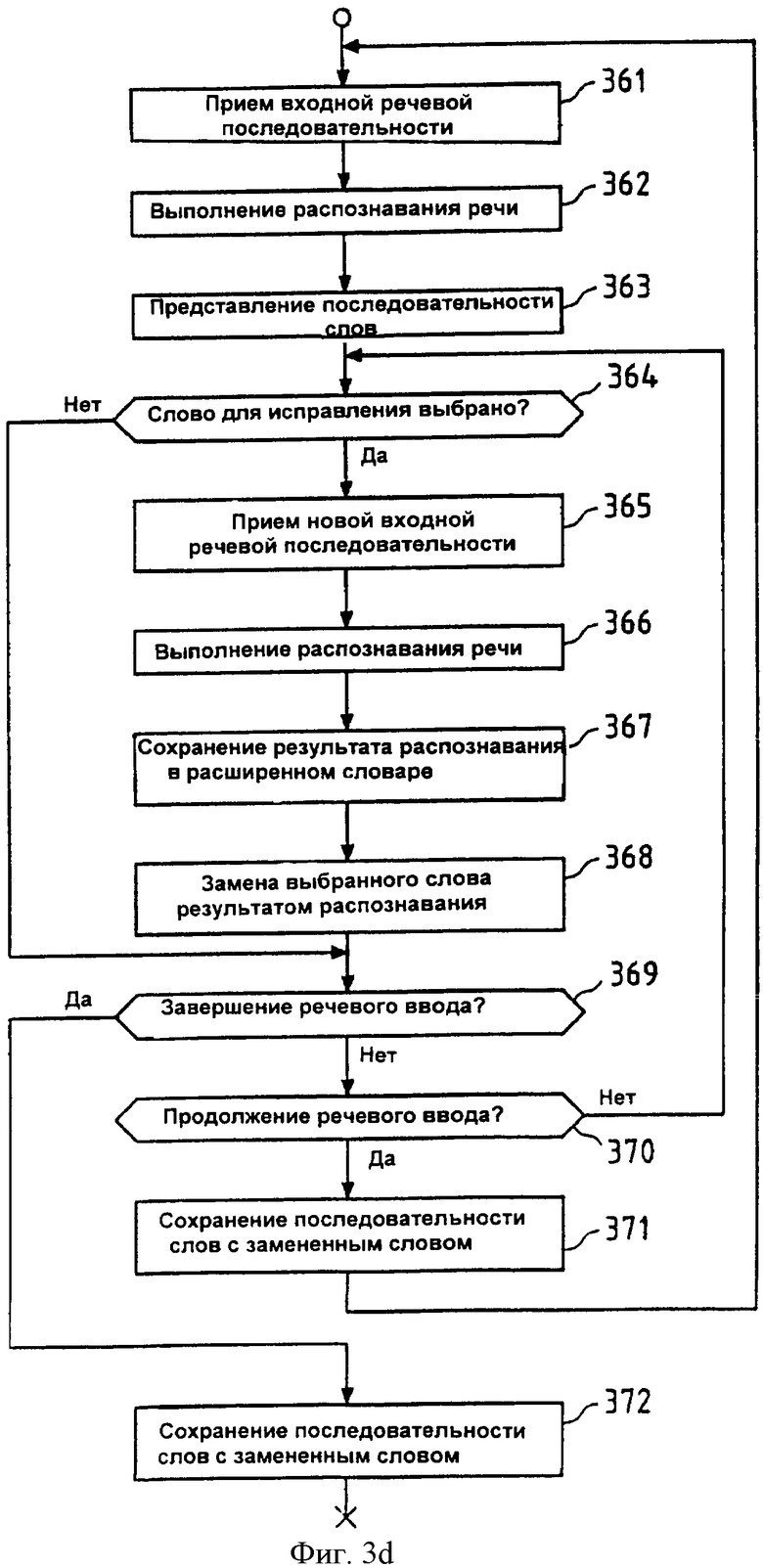
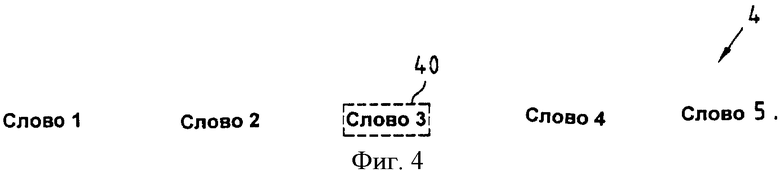
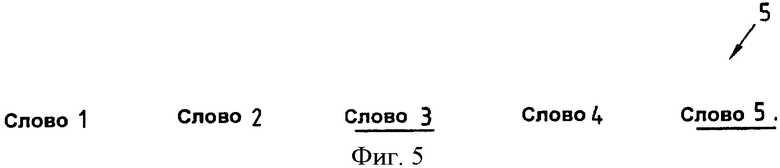
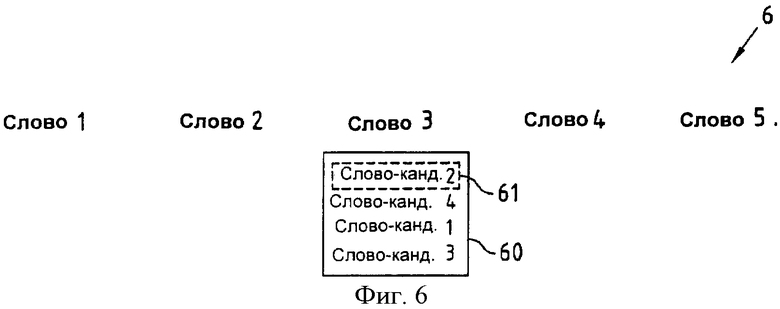
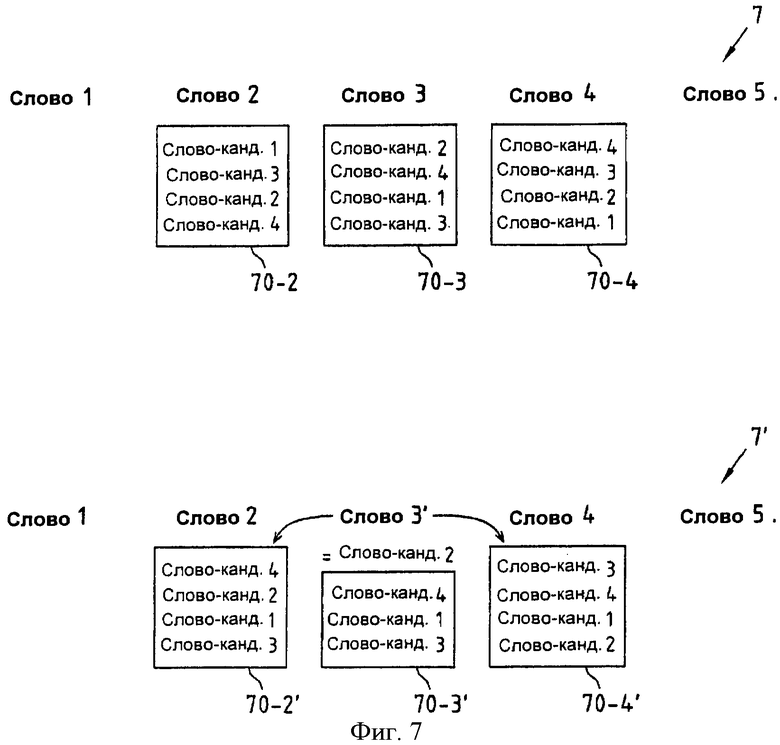
Изобретение относится к прикладным программным продуктам, предназначенным для исправления слов в последовательности слов, которая получена при распознавании входной речевой последовательности. Технический результат - повышение средней точности распознавания слитной речи. Слова в последовательности слов, полученной после распознавания входной речевой последовательности, представляют пользователю, и одно из слов в последовательности слов заменяют, когда оно выбрано пользователем для исправления. Слова с низким значением достоверности распознавания выделяют; альтернативные слова-кандидаты для одного выбранного слова упорядочивают согласно критерию упорядочивания; после замены слова порядок альтернативных слов-кандидатов для соседних слов в последовательности может быть обновлен; слово, которое заменяют, может быть получено из речевого представления одного выбранного слова с помощью распознавания речи с ограниченным словарем; а слово, которое заменяет одно выбранное слово, может быть получено из речевого и побуквенного представления одного выбранного слова. 12 н. и 16 з.п. ф-лы, 13 ил.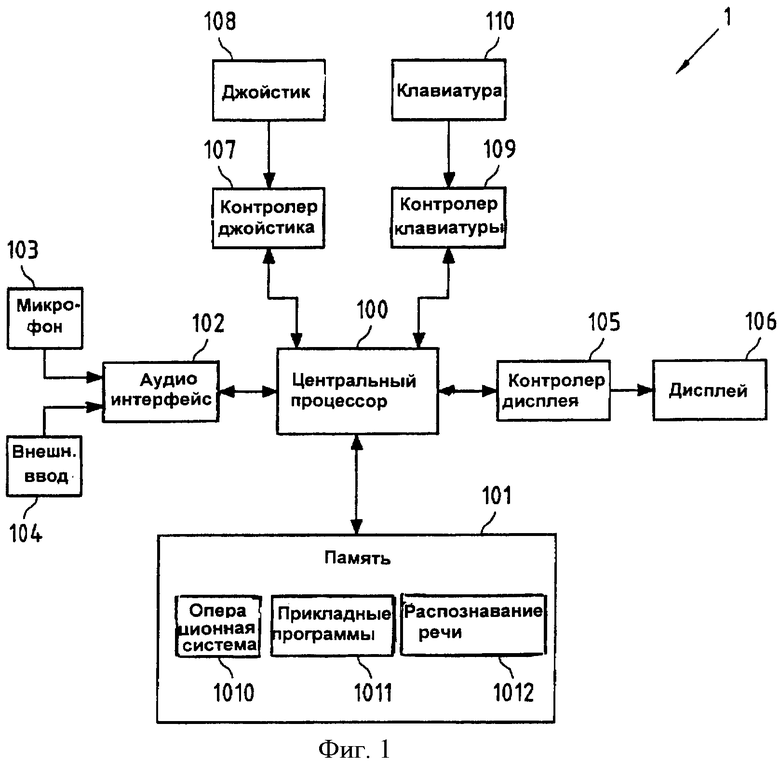
1. Способ исправления слов в последовательности слов, содержащий:
представление пользователю последовательности слов, полученной при распознавании входной речевой последовательности, причем каждое слово в данной последовательности слов связано с соответствующей степенью достоверности распознавания, и, по меньшей мере, одно слово в упомянутой последовательности слов автоматически выделено в зависимости от степени достоверности его распознавания, при этом указанное, по меньшей мере, одно выделенное слово связано с самой низкой степенью достоверности распознавания из всех слов в данной последовательности слов; и
замену, по меньшей мере, одного слова в данной последовательности слов, в случае, если оно выбрано пользователем для исправления.
2. Способ по п.1, отличающийся тем, что, по меньшей мере, одно выделенное слово автоматически выделено путем автоматического позиционирования селектора на этом слове.
3. Способ по п.1, отличающийся тем, что, по меньшей мере, одно выделенное слово связано со степенью достоверности распознавания, которая ниже заданного порога.
4. Способ по п.1, отличающийся тем, что автоматически выделено только одно слово, связанное с самой низкой степенью достоверности распознавания из всех слов в данной последовательности слов.
5. Устройство для исправления слов в последовательности слов, содержащее:
средства для представления пользователю последовательности слов, полученной при распознавании входной речевой последовательности, причем каждое слово в данной последовательности слов связано с соответствующей степенью достоверности распознавания, и, по меньшей мере, одно слово в данной последовательности слов автоматически выделено в зависимости от степени достоверности его распознавания, при этом указанное, по меньшей мере, одно выделенное слово связано с самой низкой степенью достоверности распознавания из всех слов в данной последовательности слов; и
средства для замены, по меньшей мере, одного слова в данной последовательности слов, в случае, если оно было выбрано пользователем для исправления.
6. Устройство по п.5, которое представляет собой портативное мультимедийное устройство или его часть.
7. Устройство по п.5, отличающееся тем, что автоматически выделено только одно слово, связанное с самой низкой степенью достоверности распознавания из всех слов в данной последовательности слов.
8. Устройство по п.5, отличающееся тем, что оно выполнено с возможностью автоматического выделения упомянутого, по меньшей мере, одного выделенного слова путем автоматического позиционирования селектора на этом слове.
9. Устройство по п.5, отличающееся тем, что, по меньшей мере, одно выделенное слово связано со степенью достоверности распознавания, которая ниже заданного порога.
10. Носитель данных с прикладной программой для исправления слов в последовательности слов, содержащий:
программный код для представления пользователю последовательности слов, которая получена при распознавании входной речевой последовательности, причем каждое слово в данной последовательности слов связано с соответствующей степенью достоверности распознавания, и, по меньшей мере, одно слово в упомянутой последовательности слов автоматически выделено в зависимости от степени достоверности его распознавания, при этом указанное, по меньшей мере, одно выделенное слово связано с самой низкой степенью достоверности распознавания из всех слов в данной последовательности слов; и
программный код для замены, по меньшей мере, одного слова в упомянутой последовательности слов, в случае, если оно было выбрано пользователем для исправления.
11. Носитель данных по п.10, отличающийся тем, что автоматически выделено только одно слово, связанное с самой низкой степенью достоверности распознавания из всех слов в данной последовательности слов.
12. Способ исправления слов в последовательности слов, содержащий:
представление пользователю последовательности слов, которая получена при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов; и
замену, по меньшей мере, одного слова в данной последовательности слов, в случае, если оно было выбрано упомянутым пользователем для исправления, словом-кандидатом из связанного с этим словом набора слов-кандидатов, причем упомянутые слова-кандидаты в этом наборе слов-кандидатов, связанном с упомянутым, по меньшей мере, одним выбранным словом, упорядочены согласно критерию упорядочивания, который соответствует правдоподобию упомянутых слов-кандидатов для правильной замены упомянутого, по меньшей мере, одного выбранного слова, при этом выбор упомянутого слова-кандидата, которое заменяет упомянутое, по меньшей мере, одно выбранное слово, из упомянутого набора слов-кандидатов включает пошаговый перебор слов-кандидатов по принципу «слово-за-словом».
13. Способ по п.12, отличающийся тем, что критерий упорядочивания основан, по меньшей мере, на одном из следующего: языковой модели, которая содержит статистику правдоподобия набора слов, содержащего, по меньшей мере, одно слово, существующее в языке, и достоверности распознавания упомянутых слов-кандидатов, причем упомянутая достоверность распознавания выражает, для каждого слова-кандидата в наборе слов-кандидатов, соответствующую достоверность того, что упомянутое слово-кандидат представляет собой результат правильного распознавания речи.
14. Способ по п.12, отличающийся тем, что критерий упорядочивания, по меньшей мере, основан на языковой модели, которая содержит статистику правдоподобия, по меньшей мере, для двух слов языка, расположенных друг за другом, также содержащий:
обновление, в случае, если упомянутое, по меньшей мере, одно слово выбрано и заменено в данной последовательности слов упомянутым словом-кандидатом, порядка слов-кандидатов по меньшей мере в одном наборе слов-кандидатов, связанном с соответствующим словом, которое в пределах данной последовательности слов является соседним с упомянутым, по меньшей мере, одним выбранным и замененным словом, причем такое обновление порядка слов-кандидатов в упомянутом, по меньшей мере, одном наборе слов-кандидатов выполняют согласно упомянутому критерию упорядочивания и с учетом упомянутого слова-кандидата, которым было заменено, по меньшей мере, одно выбранное и замененное слово.
15. Устройство для исправления слов в последовательности слов, содержащее:
средства для представления пользователю последовательности слов, полученной при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов; и
средства для замены, по меньшей мере, одного слова в упомянутой последовательности слов, в случае, если оно выбрано пользователем для исправления, словом-кандидатом из связанного с указанным словом набора слов-кандидатов, причем эти слова-кандидаты в упомянутом наборе слов-кандидатов, связанном, по меньшей мере, с одним выбранным словом, упорядочены согласно критерию упорядочивания, который соответствует правдоподобию упомянутых слов-кандидатов для правильной замены упомянутого, по меньшей мере, одного выбранного слова, при этом устройство также выполнено с возможностью пошагового перебора слов-кандидатов на основе принципа "слово-за-словом", чтобы выбрать упомянутое слово-кандидат для замены упомянутого, по меньшей мере, одного выбранного слова из упомянутого набора слов-кандидатов.
16. Устройство по п.15, также содержащее:
средства для обновления, в случае, если, по меньшей мере, одно слово выбрано и заменено в данной последовательности слов упомянутым словом-кандидатом, порядка слов-кандидатов, по меньшей мере, в одном наборе слов-кандидатов, связанном с соответствующим словом, соседним в пределах данной последовательности слов с упомянутым, по меньшей мере, одним выбранным и замененным словом, причем упомянутый критерий упорядочивания, по меньшей мере, основан на языковой модели, которая содержит статистику правдоподобия, по меньшей мере, для двух слов языка, расположенных друг за другом, при этом такое обновление упомянутого порядка слов-кандидатов в упомянутом, по меньшей мере, одном наборе слов-кандидатов выполняется согласно упомянутому критерию упорядочивания и с учетом упомянутого слова-кандидата, которым было заменено, по меньшей мере, одно выбранное и замененное слово.
17. Устройство по п.15, которое представляет собой портативное мультимедийное устройство или его часть.
18. Устройство по п.15, отличающееся тем, что критерий упорядочивания основан, по меньшей мере, на одном из следующего:
языковой модели, которая содержит статистику правдоподобия набора слов, содержащего, по меньшей мере, одно слово, существующее в языке, и достоверности распознавания упомянутых слов-кандидатов, причем упомянутая достоверность распознавания выражает, для каждого слова-кандидата в наборе слов-кандидатов, соответствующую достоверность того, что упомянутое слово-кандидат представляет собой результат правильного распознавания речи.
19. Носитель данных с прикладной программой для исправления слов в последовательности слов, при этом упомянутая прикладная программа содержит:
программный код для представления пользователю последовательности слов, которая получена при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов; и
программный код для замены по меньшей мере одного слова в данной последовательности слов, в случае, если оно выбрано пользователем для исправления, словом-кандидатом из связанного с указанным словом набора слов-кандидатов, причем эти слова-кандидаты в упомянутом наборе слов-кандидатов, связанном по меньшей мере с одним выбранным словом, упорядочены согласно критерию упорядочивания, который соответствует правдоподобию упомянутых слов-кандидатов для правильной замены упомянутого по меньшей мере одного выбранного слова, при этом выбор упомянутого слова-кандидата, которое заменяет упомянутое, по меньшей мере, одно выбранное слово, из упомянутого набора слов-кандидатов включает пошаговый перебор слов-кандидатов по принципу «слово-за-словом».
20. Носитель данных по п.19, отличающийся тем, что упомянутый критерий упорядочивания, по меньшей мере, основан на языковой модели, которая содержит статистику правдоподобия, по меньшей мере, для двух слов языка, расположенных друг за другом, также содержащий:
программный код для обновления, в случае, если упомянутое, по меньшей мере, одно слово было выбрано и заменено в данной последовательности слов упомянутым словом-кандидатом, порядка слов-кандидатов, по меньшей мере, в одном наборе слов-кандидатов, связанном с соответствующим словом, соседним в пределах упомянутой последовательности слов с упомянутым, по меньшей мере, одним выбранным и замененным словом, причем такое обновление вышеуказанного порядка слов-кандидатов в упомянутом, по меньшей мере, одном наборе слов-кандидатов выполняется согласно упомянутому критерию упорядочивания и с учетом слова-кандидата, которым было заменено, по меньшей мере, одно выбранное и замененное слово.
21. Способ исправления слов в последовательности слов, при этом указанный способ содержит:
представление пользователю последовательности слов, которая получена при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов; и
замену, по меньшей мере, одного слова в упомянутой последовательности слов, в случае, если оно было выбрано пользователем для исправления, словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого, по меньшей мере, одного выбранного слова, произнесенного указанным пользователем, причем словарь распознавания, используемый в этом распознавании новой входной речевой последовательности, ограничен набором слов-кандидатов, связанным с упомянутым, по меньшей мере, одним выбранным словом.
22. Устройство для исправления слов в последовательности слов, содержащее:
средства для представления пользователю последовательности слов, полученной при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов; и
средства для замены, по меньшей мере, одного слова в упомянутой последовательности слов, в случае, если оно выбрано пользователем для исправления, словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого, по меньшей мере, одного выбранного слова, произнесенного указанным пользователем, причем словарь распознавания, используемый в упомянутом распознавании указанной новой входной речевой последовательности, ограничен набором слов-кандидатов, связанным с упомянутым, по меньшей мере, одним выбранным словом.
23. Устройство по п.22, которое представляет собой портативное мультимедийное устройство или его часть.
24. Носитель данных с прикладной программой для исправления слов в последовательности слов, при этом упомянутая прикладная программа содержит:
программный код для представления пользователю последовательности слов, которая получена при распознавании входной речевой последовательности, причем для каждого слова в данной последовательности слов существует связанный с ним набор альтернативных слов-кандидатов,; и
программный код для замены, по меньшей мере, одного слова в данной последовательности слов, в случае, если оно выбрано пользователем для исправления, словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого, по меньшей мере, одного выбранного слова, произнесенного указанным пользователем, причем словарь распознавания, используемый в упомянутом распознавании новой входной речевой последовательности, ограничен набором слов-кандидатов, связанным с упомянутым, по меньшей мере, одним выбранным словом.
25. Способ исправления слов в последовательности слов, содержащий:
представление пользователю последовательности слов, которая получена при распознавании входной речевой последовательности; и
замену, по меньшей мере, одного слова в упомянутой последовательности слов, в случае, если оно было выбрано пользователем для исправления, словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого, по меньшей мере, одного выбранного слова, произнесенного указанным пользователем, и представление упомянутой правильной версии упомянутого, по меньшей мере, одного выбранного слова, введенного указанным пользователем побуквенно.
26. Устройство для исправления слов в последовательности слов, содержащее:
средства для представления пользователю последовательности слов, полученной при распознавании входной речевой последовательности; и
средства для замены, по меньшей мере, одного слова в упомянутой последовательности слов, в случае, если оно выбрано пользователем для исправления, словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого, по меньшей мере, одного выбранного слова, произнесенного указанным пользователем, и представление упомянутой правильной версии упомянутого, по меньшей мере, одного выбранного слова, введенного указанным пользователем побуквенно.
27. Устройство по п.26, которое представляет собой портативное мультимедийное устройство или его часть.
28. Носитель данных с прикладной программой для исправления слов в последовательности слов, причем упомянутая прикладная программа содержит:
программный код для представления пользователю последовательности слов, которая получена при распознавании входной речевой последовательности; и
программный код для замены, по меньшей мере, одного слова в данной последовательности слов, в случае, если оно выбрано пользователем для исправления, словом, полученным при распознавании новой входной речевой последовательности, которая содержит только представление правильной версии упомянутого, по меньшей мере, одного выбранного слова, произнесенного указанным пользователем, и представление упомянутой правильной версии упомянутого, по меньшей мере, одного выбранного слова, введенного указанным пользователем побуквенно.
| US 5799273, А, 25.08.1998 | |||
| US 5864805, А, 26.01.1999 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| EP 1189203, A2, 290.03.2002 | |||
| СПОСОБ НАНЕСЕНИЯ ПОКРЫТИЯ НА ВНУТРЕННЮЮ ПОВЕРХНОСТЬ ТРУБОПРОВОДА | 1998 |
|
RU2148203C1 |
| УСТРОЙСТВО И СПОСОБ МАСКИРОВАНИЯ ОШИБОК | 1994 |
|
RU2120668C1 |
| ИМИТАТОР ВИЗУАЛЬНОЙ ОБСТАНОВКИ АВИАЦИОННОГО ТРЕНАЖЕРА | 2002 |
|
RU2230370C2 |

