ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение в целом относится к программным приложениям распознавания голоса, более конкретно к способу управления характерными особенностями фразы посредством приложения распознавания голоса.
УРОВЕНЬ ТЕХНИКИ
Возможно, речь представляет собой древнейшую форму человеческого общения и многие современные ученые полагают, что способность к речевому общению является неотъемлемым свойством человеческого мозга. Таким образом, давней целью является позволить пользователям общаться с компьютером, используя Естественный Интерфейс Пользователя (ЕИП), такой как речь. Фактически, в последнее время сделаны большие успехи в достижении этой цели. Например, некоторые компьютеры сейчас включают в себя приложения распознавания речи, предоставляющие пользователю возможность устного ввода как команд для управления компьютером, так и преобразования диктовки в текст. Эти приложения, как правило, работают с периодически записываемыми с помощью микрофона звуковыми образцами, анализируя образцы для распознавания фонем, произнесенных пользователем, и определяя слова, состоящие из произнесенных фонем.
В то время как распознавание речи все более становится обычным явлением, по-прежнему есть некоторые неудобства в использовании традиционных приложений распознавания речи, которые приводят к разочарованию опытных пользователей и отпугивают начинающих. Одно такое неудобство касается взаимодействия между говорящим и компьютером. Например, в человеческом общении люди склонны управлять своей речью, основываясь на реакции, которую они ощущают у слушателя. Также, в процессе разговора слушатель может обеспечить обратную связь, кивая или вставляя реплики типа "да" или "угу", показывающие, что он или она понимает то, что им говорится. Кроме того, если слушатель не понимает, что ему говорят, он может выразить недоумение, наклониться вперед или подать другой голосовой или неголосовой сигнал. В ответ на эту обратную связь говорящий, как правило, может изменить особенности его или ее речи и в некоторых случаях может говорить медленнее, громче, с более частыми паузами или иногда повторяя предложение, обычно слушатель даже не осознает, что говорящий меняет особенности своего общения с ним. Таким образом, обратная связь в процессе разговора является очень важным элементом, который информирует говорящего о том, действительно ли слушатель понял его. Однако, к сожалению, традиционные приложения распознавания голоса пока не в состоянии обеспечить такой вид "Естественного Интерфейса Пользователя (ЕИП)", как ответная реакция на речевые входные данные/команды с помощью человеко-машинного интерфейса.
В настоящее время приложения распознавания голоса достигли степени точности примерно 90%-98%. Это значит, что если пользователь диктует документ, используя традиционное приложение распознавания голоса, его речь будет правильно распознана приложением распознавания голоса приблизительно на 90%-98%. Соответственно, из каждой сотни (100) букв, записанных приложением распознавания голоса, приблизительно от двух (2) до десяти (10) букв нужно будет исправить. В частности, существующие приложения распознавания голоса обычно испытывают трудности при распознавании определенных букв, таких как "s" (например, ess) и "f" (например, eff). Один подход, использующийся при обращении к этой проблеме в существующих приложениях распознавания голоса, включает в себя предоставление пользователю возможности использовать заданные мнемоники, чтобы было понятно, какая буква им произносится. Например, пользователь имеет возможность сказать "a as in apple" или "b as in boy", когда диктует.
Однако, к сожалению, этот подход неудобен в связи с тем, что ограничивает для пользователя удобство обращения с приложением распознавания голоса. Одно неудобство касается использования заданных мнемоник для каждой буквы, которые превращаются в стандартный военный алфавит (например, Alpha, Bravo, Charlie …). Дело в том, что даже если пользователю дать перечень мнемосхем для произнесения во время диктовки (например, "I as in igloo"), он имеет склонность к составлению собственного мнемонического алфавита (например, "I as in India") и пренебрегает заданным мнемоническим алфавитом. Так как приложения распознавания голоса не понимают не заданных заранее мнемоник, можно ожидать, что ошибки в распознавании букв станут обычным делом. Другое неудобство заключается в том факте, что тогда как некоторые буквы имеют небольшой набор широко распространенных (т.е. >80%) связанных с ними мнемосхем (A as in Apple, A as in Adam, или D as in Dog, D as in David или Z as in Zebra, Z as in Zulu), другие буквы не имеют доминирующих связанных с ними мнемоник (например, L, P, R и S). Это делает создание пригодной универсальной языковой модели не только очень трудным, но практически невозможным. По существу, язык взаимодействия с программным приложением распознавания речи все еще порождает относительно большое число ошибок и мало того, что эти ошибки вызывают разочарование у постоянных пользователей, они еще и обескураживают новых пользователей, что может привести к их отказу продолжать использование приложения распознавания голоса.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Предлагается способ создания мнемонической Языковой Модели для использования в программных приложениях распознавания речи, при этом способ включает в себя формирование n-граммной Языковой Модели, содержащей заранее заданный большой набор символов, т.е. букв, цифр, знаков и т.д., причем n-граммная Языковая Модель включает в себя, по меньшей мере, один символ из заранее заданного большого набора. Способ дополнительно включает в себя построение новой лексемы Языковой Модели (ЯМ) для каждого, по меньшей мере, одного символа и выделение (извлечение) произношения для каждого, по меньшей мере, одного символа, отвечающего (соответствующего) заранее заданному словарю произношений для получения представления произношения символов. Кроме того, способ включает в себя создание, по меньшей мере, одного альтернативного произношения для каждого, по меньшей мере, одного символа, отвечающего (соответствующего) представлению произношения символа для создания альтернативного словаря произношений и компилирование n-граммной Языковой Модели для использования в программных приложениях распознавания речи, при этом компилирование Языковой Модели соответствует новой лексеме Языковой Модели и альтернативному словарю произношений.
Предлагается способ создания мнемонической Языковой Модели для использования в программных приложениях распознавания речи, при этом способ включает в себя формирование n-граммной Языковой Модели, содержащей заранее заданный большой набор символов, причем n-граммная Языковая Модель включает в себя, по меньшей мере, один символ из заданного большого набора символов. Кроме того, способ включает в себя выделение произношения для каждого, по меньшей мере, одного символа, соответствующего заданному словарю произношений для получения представления произношения символа и создание, по меньшей мере, одного альтернативного произношения для каждого, по меньшей мере, одного символа, соответствующего представлению произношения символа, для создания альтернативного словаря произношений.
Предлагается система, обеспечивающая выполнение способа создания мнемонической Языковой Модели для использования с программным приложением распознавания речи, при этом система включает в себя запоминающее устройство для хранения Программного Приложения Распознавания Речи и, по меньшей мере, одного целевого программного приложения. Система дополнительно включает в себя устройство для голосового ввода данных и команд в систему, устройство отображения, причем устройство отображения включает в себя экран монитора для отображения введенных данных, и устройство обработки. Устройство обработки взаимодействует с запоминающим устройством, устройством ввода и устройством отображения таким образом, что устройство обработки принимает инструкции, чтобы вынудить Программное Приложение Распознавания Речи отображать введенные данные на экране монитора и для манипулирования введенными данными в соответствии с введенными командами.
Предлагается машиночитаемый компьютерный программный код, причем программный код включает в себя инструкции, согласно которым устройство обработки осуществляет способ создания мнемонической Языковой Модели для использования в программном приложении распознавания речи, причем устройство обработки взаимодействует с запоминающим устройством и устройством отображения и при этом запоминающее устройство содержит Программное Приложение Распознавания Речи. Способ включает в себя формирование n-граммной Языковой Модели, содержащей заранее заданный большой набор символов, причем n-граммная Языковая Модель включает в себя, по меньшей мере, один символ из заданного большого набора символов и построение новой лексемы Языковой Модели (ЯМ) для каждого, по меньшей мере, одного символа. Способ дополнительно включает в себя выделение произношения для каждого, по меньшей мере, одного символа, отвечающего заранее заданному словарю произношений, для получения представления произношения символа и создания, по меньшей мере, одного альтернативного произношения для каждого, по меньшей мере, одного символа, отвечающего представлению произношения символа, для создания альтернативного словаря произношений. Более того, способ включает в себя компилирование n-граммной Языковой Модели для использования в программном приложении распознавания речи, причем компилирование Языковой Модели отвечает новой лексеме Языковой Модели и альтернативному словарю произношений.
Предлагается носитель данных с машиночитаемым компьютерным программным кодом, при этом программный код включает в себя инструкции, в соответствии с которыми устройство обработки осуществляет способ создания мнемонической Языковой Модели для использования в программном приложении распознавания речи, причем устройство обработки взаимодействует с запоминающим устройством и устройством отображения и при этом запоминающее устройство содержит Программное Приложение Распознавания Речи. Способ включает в себя формирование n-граммной Языковой Модели, содержащей заранее заданный большой набор символов, причем n-граммная Языковая Модель включает в себя, по меньшей мере, один символ из заданного большого набора символов и построение новой лексемы Языковой Модели (ЯМ) для каждого, по меньшей мере, одного символа. Способ дополнительно включает в себя выделение произношения для каждого, по меньшей мере, одного символа, отвечающего заданному словарю произношений для получения представления произношения символа и создания, по меньшей мере, одного альтернативного произношения для каждого, по меньшей мере, одного символа, отвечающего представлению произношения символа, для создания альтернативного словаря произношений. Более того, способ включает в себя компилирование n-граммной Языковой Модели для использования в программном приложении распознавания речи, причем компилирование Языковой Модели отвечает новой лексеме Языковой Модели и альтернативному словарю произношений.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Вышеизложенные и другие особенности настоящего изобретения будут более понятны из следующего подробного описания иллюстративных вариантов осуществления совместно с прилагаемыми чертежами, в которых одинаковые элементы имеют одинаковые ссылочные позиции на нескольких чертежах:
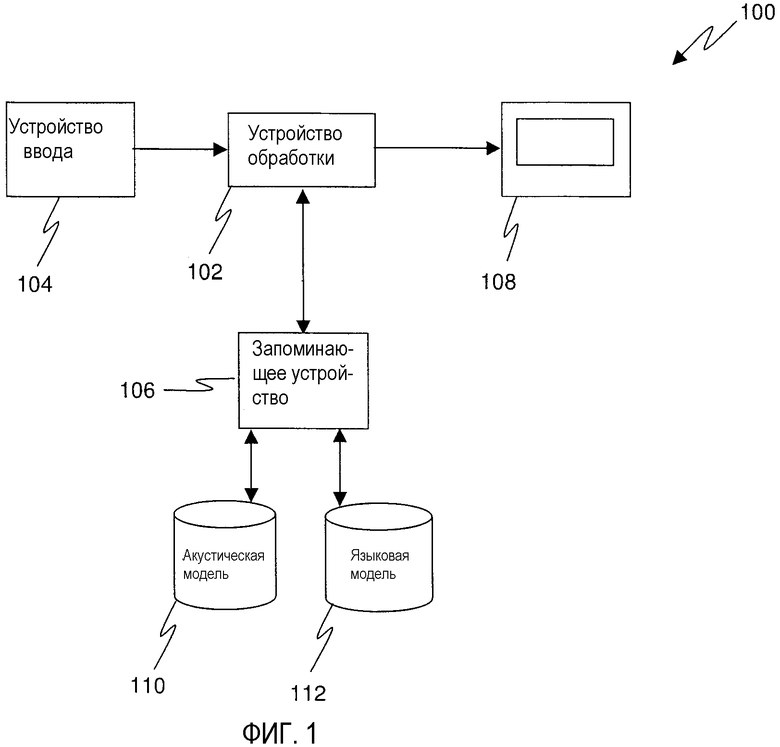
Фиг. 1 - блок-схема, иллюстрирующая обычную систему распознавания речи;
Фиг. 2 - блок-схема, иллюстрирующая систему для осуществления способа создания мнемонической языковой модели для использования в программном приложении распознавания речи в соответствии с иллюстративным вариантом осуществления;
Фиг. 3 - блок-схема, иллюстрирующая способ создания мнемонической языковой модели для использования в программном приложении распознавания речи в соответствии с иллюстративным вариантом осуществления; и
Фиг. 4 - таблица фонем американского варианта английского языка.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Большинство приложений распознавания речи используют модель образцов типичных звуков и образцов типичных слов для того, чтобы определить пословное представление данного фрагмента речи. Эти слова-образцы затем используются приложением распознавания речи и все вместе называются Языковыми Моделями (ЯМ). В сущности, Языковая Модель представляет собой последовательности слов и вероятность появления этой последовательности в данном контексте. Таким образом, для того, чтобы быть эффективной в приложении распознавания речи, Языковая Модель должна быть построена на большом количестве обучающих текстовых данных. Также нужно принять во внимание, что мнемосхемы могут быть более эффективными, если используются для исправления правописания в программных приложениях распознавания речи для настольных систем. Например, один из сценариев может включать в себя пользователя, пытающегося произнести слово по буквам, не используя мнемосхемы и оказавшегося в ситуации, когда программное приложение распознавания речи неверно распознало одну (или более) из произнесенных букв. Использование мнемосхем для повторения буквы значительно увеличивает вероятность того, что пользователь добьется успеха при повторении этой буквы.
На Фиг. 1 показана блок-схема, иллюстрирующая типичную систему 100 распознавания речи, которая включает в себя устройство 102 обработки, устройство 104 ввода, запоминающее устройство 106 и устройство 108 отображения, при этом акустическая модель 110 и Языковая Модель 112 хранятся на запоминающем устройстве 106. Акустическая модель 110 обычно содержит информацию, которая помогает декодеру определять, какие слова были произнесены. Акустическая модель 110 осуществляет это посредством предположения последовательности фонем, основываясь на спектральных параметрах, обеспеченных устройством 104 ввода, где фонема - это наименьшая фонетическая единица в языке, которая способна передать различие в значении и обычно включает в себя использование словаря и скрытых моделей Маркова. Например, акустическая модель 110 может включать в себя словарь (лексикон) слов и соответствующих им фонетических произношений, причем эти произношения содержат индикатор вероятности того, что данная последовательность фонем встретится вместе при построении слова. Дополнительно, акустическая модель 110 может также включать в себя информацию, касающуюся вероятности того, что различающиеся фонемы встречаются в контексте других фонем. Например, "трехзвучие" - это особая фонема, употребляющаяся в окружении одной определенной фонемы слева (предшествующей) и другой определенной фонемы справа (последующей). Таким образом, содержимое акустической модели 110 используется устройством 102 обработки для прогнозирования того, какие слова представлены вычисленными спектральными параметрами.
Кроме того, Языковая Модель 112 (ЯМ) задает, как и с какой частотой слова встречаются вместе. Например, n-граммная Языковая Модель 112 оценивает вероятность того, что слово будет следующим в последовательности слов. Эти вероятностные оценки вместе формируют n-граммную Языковую Модель 112. Затем устройство 102 обработки использует вероятности из n-граммной Языковой Модели 112, чтобы выбрать лучшую из гипотез слов-последовательностей, как идентифицированную, используя акустическую модель 110, для получения наиболее вероятного слова или последовательности слов, представленных спектральными параметрами, причем наиболее вероятные гипотезы могут отображаться с помощью устройства 108 отображения.
Настоящее изобретение, изложенное в данном описании, рассмотрено для варианта автономного и/или встроенного прикладного модуля в компьютерной системе общего назначения, которые используют приложение распознавания речи для приема и распознавания голосовых команд, вводимых пользователем. Как объектно-ориентированное приложение, прикладной модуль может предоставить стандартный интерфейс, к которому клиентские программы могут получать доступ для взаимодействия с прикладным модулем. Прикладной модуль также может давать возможность различным клиентским программам, таким как программа обработки текста, программа настольной издательской системы, прикладная программа и так далее, использовать прикладной модуль локально и/или по сетям, таким как ГВС, ЛВС и/или используя средства передачи данных, основанные на интернет-технологиях. Например, прикладной модуль может быть доступен и используем для любого приложения и/или устройства управления, имеющего текстовое поле, такого как приложения электронной почты или Microsoft® Word, локально или через точку доступа Интернет. Однако, перед изложением аспектов настоящего изобретения, ниже описан один из вариантов осуществления подходящей компьютерной среды, которая может с выгодой включить в себя это изобретение.
На Фиг. 2 показана блок-схема, иллюстрирующая систему 200, обеспечивающую выполнение способа создания мнемонической Языковой Модели 112 для использования в программном приложении распознавания речи, которая включает в себя типовую компьютерную систему 202, включающую в себя устройство 204 обработки, системную память 206 и системную шину 208, причем системная шина 208 соединяет системную память 206 и устройство 204 обработки. Системная память 206 может включать в себя постоянное запоминающее устройство 210 (ПЗУ) и оперативное запоминающее устройство 212 (ОЗУ). Базовая система 214 ввода/вывода (БСВВ), содержащая основные процедуры, которые помогают передавать информацию между элементами внутри основной компьютерной системы 202, например в процессе начальной загрузки, хранится в ПЗУ 210. Основная компьютерная система 202 дополнительно включает в себя запоминающее устройство 216, такое как накопитель 218 на жестком диске, привод 220 магнитных дисков, например для чтения/записи на сменный магнитный диск 222, и привод 224 оптических дисков, например для чтения с компакт-диска 226 или чтения/записи на другие оптические носители. Запоминающее устройство 216 может быть присоединено к системной шине 208 посредством интерфейса запоминающего устройства, такого как интерфейс 230 накопителя на жестком диске, интерфейс 232 привода магнитных дисков и интерфейс 234 оптического привода. Приводы и соответствующие им считываемые компьютером носители обеспечивают энергонезависимое хранение данных для основной компьютерной системы 202. Хотя описанные считываемые компьютером носители относятся к жесткому диску, сменному магнитному диску и компакт-диску, очевидно, что могут использоваться другие типы носителей, которые считываются компьютерной системой и которые применимы для достижения конечного результата, например, магнитные кассеты, карты флэш-памяти, цифровые видеодиски, картриджи Бернулли и тому подобное.
Пользователь может вводить команды и информацию в типовую компьютерную систему 202 посредством традиционного устройства 235 ввода, включающего в себя клавиатуру 236, координатно-указательное устройство 238, например мышь, и микрофон 240, при этом микрофон 240 может использоваться для ввода аудиоинформации, такой как речь, в типовую компьютерную систему 202. Кроме того, пользователь может ввести графическую информацию, такую как рисунок или рукописный текст, в типовую компьютерную систему 202, рисуя графическую информацию на планшете 242 с помощью пера. Типовая компьютерная система 202 может также включать в себя дополнительные устройства ввода, применимые для достижения конечного результата, такие как джойстик, игровой манипулятор, спутниковая тарелка, сканер или подобные. Микрофон 240 может быть связан с устройством 204 обработки посредством звукового адаптера 244, который присоединен к системной шине 208. Более того, другие устройства ввода часто связаны с устройством 204 обработки через интерфейс 246 последовательного порта, который присоединен к системной шине 208, но могут также связываться через другие интерфейсы, например интерфейс параллельного порта, игровой порт или универсальную последовательную шину (USB - universal serial bus).
Устройство 247 отображения, такое как монитор или другой вид устройства 247 отображения, имеющее экран 248 дисплея, также подсоединено к системной шине 208 посредством интерфейса, например видеоадаптера 250. В дополнение к экрану 248 дисплея типовая компьютерная система 202 обычно может еще включать в себя другие периферийные устройства вывода, такие как динамики и/или принтеры. Типовая компьютерная система 202 может функционировать в сетевом окружении, используя логические связи с одной или более удаленными компьютерными системами 252. Удаленная компьютерная система 252 может быть сервером, маршрутизатором, таким же устройством или другим равноправным узлом сети, и может включать в себя некоторые или все элементы, описанные в применении к типовой компьютерной системе 202, несмотря на то, что на Фиг. 2 отображено только удаленное запоминающее устройство 254. Логические связи, как показано на Фиг. 2, включают в себя локальную вычислительную сеть 256 (ЛВС) и глобальную вычислительную сеть 258 (ГВС). Такая сетевая среда является обычным явлением в офисах, корпоративных сетях, интранет-сетях и Интернет.
При использовании в сетевой среде ЛВС типовая компьютерная система 202 подключается к ЛВС 256 посредством сетевого интерфейса 260. При использовании в сетевой среде ГВС типовая компьютерная система 202 обычно включает в себя модем 262 или другие средства установления связи через ГВС 258, такие как Интернет. Модем 262, который бывает внутренним или внешним, может подсоединяться к системной шине 208 посредством интерфейса 246 последовательного порта. В сетевой среде программный модуль, описывающий взаимосвязь с типовой компьютерной системой 202 или ее частями, может храниться на удаленном запоминающем устройстве 254. Следует принять во внимание, что сетевое соединение приведено для примера и могут использоваться другие средства установления канала связи между компьютерными системами. Также следует отметить, что прикладной модуль мог бы равнозначно выполняться на главном компьютере или на сервере, не являющемся типовой компьютерной системой и мог бы равнозначно быть передан в главную компьютерную систему средствами, отличными от компакт-дисков, например через интерфейс 260 сетевого соединения.
Более того, некоторые программные модули могут храниться на накопителях и в ОЗУ 212 типовой компьютерной системы 202. Программные модули управляют функционированием типовой компьютерной системы 202 и взаимодействуют с пользователем, с устройствами ввода/вывода или с другими компьютерами. Программные модули включают в себя процедуры, операционные системы 264, целевые прикладные программные модули 266, структуры данных, средства визуализации, и другие программные или программно-аппаратные компоненты. Способ согласно настоящему изобретению может быть включен в прикладной модуль и прикладной модуль может быть без труда реализован в одном или более программных модулях, например в модуле 270 коррекции речевой системы, на основании способов, изложенных в настоящем описании. Целевые прикладные программные модули 266 могут содержать ряд приложений, использующихся вместе с настоящим изобретением, некоторые из которых показаны на Фиг. 3. Назначение и взаимодействие некоторых из этих программных модулей более полно обсуждаются в описании Фиг. 3. Они включают в себя любое приложение и/или устройство управления, имеющее текстовое поле, например приложение электронной почты, текстовый процессор (такой, как Microsoft® Word, производимый Microsoft Corporation, Редмонд, штат Вашингтон), программу распознавания рукописного текста, модуль 270 коррекции речевой системы и программу, которая принимает вводимые латинские буквы и преобразует их в иероглифы (IME - Input Method Editor).
Следует принять во внимание, что нет описания особого языка программирования, который осуществлял бы различные процедуры, приведенные в подробном описании, поскольку предполагается, что действия, шаги и процедуры, описанные и проиллюстрированные в прилагаемых чертежах, достаточно раскрыты для возможности практического осуществления настоящего изобретения в известном уровне техники. Более того, существует много компьютеров и операционных систем, которые могут быть использованы для практической реализации и, следовательно, нельзя предоставить отдельную компьютерную программу, которая была бы применима для всех этих, во многом различных, систем. Каждый пользователь конкретного компьютера разберется, какой язык и инструменты наиболее полезны для его потребностей и целей.
На Фиг. 3 показана блок-схема, иллюстрирующая способ 300 создания мнемонической языковой модели, используемой в программном приложении распознавания речи, который выполняется типовой компьютерной системой 202 (Фиг. 2), при этом типовая компьютерная система 202 включает в себя устройство 204 обработки, взаимодействующее с устройством 235 ввода, запоминающим устройством 216 и устройством 247 отображения, причем устройство 247 отображения включает в себя экран 248 дисплея, как показано на Фиг. 2. Как описано выше, устройство 235 ввода может быть любым, применимым для достижения конечного результата, например микрофоном. К тому же программное приложение распознавания речи может храниться на запоминающем устройстве 216, что позволяет устройству 204 обработки иметь доступ к программному приложению распознавания речи. Кроме того, по меньшей мере, одно целевое программное приложение 266, такое как Microsoft® Word, тоже может храниться на запоминающем устройстве 216, что позволяет пользователю выполнять целевое программное приложение с помощью инструкций, переданных устройству 204 обработки.
Способ 300 включает в себя формирование n-граммной Языковой Модели 112 для каждого символа и/или строки (последовательности) символов в заданном большом наборе символов и/или строк символов, как показано на этапе 302. Как вкратце описано выше, должна быть установлена вероятность того, что конкретный символ следует за другими символами. Например, рассмотрим событие: буква "a" после последовательности (строки) символов "er" в слове "era". При формировании n-граммной Языковой Модели 112 должна быть определена вероятность P(a|e,r), которая будет присвоена этому событию. Другими словами, вероятность P(a|e,r) должна представлять вероятность появления "a" после буквенной последовательности "er". Следует принять во внимание, что n-граммная Языковая Модель 112 может быть записана в виде файла в формате международного стандарта ARPA (Агентство по перспективным исследовательским проектам) и может быть чувствительной к регистру букв, чтобы учитывать вероятности как для прописных, так и для строчных букв. Способ 300 также включает в себя построение новой лексемы Языковой Модели для каждого символа и/или последовательности символов в заданном большом наборе символов и/или последовательностей символов, как показано на этапе 304. Например, рассмотрим символ "a", причем лексема Языковой Модели уже существует. Новая лексема Языковой Модели, "a-AsIn", строится для использования в произнесении по буквам мнемосхем, в то время, как прежняя лексема Языковой Модели, "a" сохраняется для использования в произнесении по буквам символов. Это позволяет n-граммной Языковой Модели 112 быть реализованной для обычных методик проверки орфографии и мнемонических методик, поддерживая производительность и без увеличения размера Языковой Модели.
Способ 300 дополнительно включает в себя извлечение произношений для каждого символа и/или последовательности (строки) символов, в ответ на заданный словарь произношений, чтобы программное приложение распознавания речи создало альтернативный словарь произношений из представлений произношения символа, как показано на этапе 306. Например, рассмотрим опять символ "a", при этом произношение для слов, начинающихся с "a", взято из словаря произношений программного приложения распознавания речи, используемого для диктовки. Используя этот словарь, получаем, что слово "ARON" имеет произношение "ae r ax n", как показано на Фиг. 4. Для каждого символа и/или последовательности символов в заданном словаре произношений альтернативное произношение может быть создано добавлением перед каждым символом его новой лексемы Языковой Модели и добавлением после символа длинной паузы "sil", как показано на этапе 308. Например, рассмотрим новую лексему Языковой модели "a AsIn" и слово "ARON". В соответствии с вышесказанным альтернативное произношение будет представлено как "ey AAl ey ae z ih n ae r ax n sil", где "ey AA1 ey ae z ih n" - произношение, добавленное спереди к "a AsIn", "ae r ax n" - произношение для "ARON" и "sil" - добавленная в конец длинная пауза. Дополнительно таким же образом рассматриваются прописные буквы. К примеру, рассмотрим фразу "capital a as in ARON". В соответствии с вышесказанным альтернативное произношение будет представлено как "k ae p ih t ax l ey AAl ey ae z ih n ae r ax n sil", где "k ae p ih t ax l" - произношение для прописной буквы, "ey AAl ey ae z ih n" - произношение, добавленное спереди к "a AsIn", "ae r ax n" - произношение для "ARON" и "sil" - добавленная в конец длинная пауза.
Затем стандартным компилятором может быть скомпилирована n-граммная Языковая Модель для использования в распознавателе с большим словарным запасом, как показано на этапе 310, при этом входные данные для компилятора включают в себя n-граммную Языковую Модель (в формате ARPA), построенную на этапе 302, и словарь произношений (в котором закодированы различные варианты произношений для каждой буквы), построенный на этапе 304 и на этапе 306. Нужно принять во внимание, что n-граммная Языковая Модель может быть скомпилирована любым компилятором, пригодным для получения результата, например, Just-In-Time (JIT) (оперативным) компилятором.
Очевидно, что способ 300 облегчает создание основанной на триграммах речевой языковой модели, что дает возможность использовать языковую модель, содержащую более 120,000 мнемоник. Этого можно достичь, кодируя тот факт, что пользователь может произнести одно из 120,000 слов, кодируя произношения слов и кодируя вероятности триграммы - того, что некое слово появится за двумя заданными словами в контексте. Например, дана фраза "this is" и следующее слово, которое произнес пользователь, могло быть словом "near" или "kneel", тогда, поскольку фраза "this is near" - намного более распространенная в английском языке, чем "this is kneel", выбирается слово "kneel". Аналогично, для орфографической языковой модели, термин "слово" фактически относится к символам, где символы включают в себя двадцать шесть строчных букв, двадцать шесть прописных букв, цифры и знаки. Таким образом, раскрытый в настоящем описании способ 300 использует в среднем 5000 произношений для буквы (S as in Salmon = S, S as in Sugar = S, S as in Salamander = S …) и, фактически, каждое из 120,000 слов модели речевого ввода применяется как возможная мнемоника. Каждой мнемонике задан свой вес для каждой буквы или произношения, у некоторых вес больше, чем у других. Например, мнемонической фразе "T as in Tom" придается больший вес, чем "T as in tertiary", из-за вероятности того, что мнемоническая фраза "T as in Tom" используется чаще. Кроме того, последовательности мнемоник также имеют вероятности, например возможность того, что "D" как в Donkey следует за "F" как в Fun меньше, чем возможность того, что "D" как в Donkey следует за "S" как в Sun. Эти вероятности могут быть специально сгенерированы или могут быть получены из простого списка мнемоник (мнемосхем), определенного из исследований. Также следует отметить, что способ 300, как показано здесь, позволяет системе 200 'изучить' дополнительные символы и/или последовательности (строки) символов. Кроме того, хотя способ 300 раскрыт и обсужден здесь применительно к фонемам Американского варианта английского языка, способ 300 может быть использован с фонемами любых языков, например китайского, русского, испанского и французского.
В соответствии с иллюстративным вариантом осуществления, представленная на Фиг. 3 обработка данных может быть осуществлена, полностью или частично, контроллером, работающим в соответствии с машиночитаемой компьютерной программой. Чтобы выполнять предписанные функции и желаемую обработку данных, а также вычисления (например, алгоритм (алгоритмы) управления выполнением (процессы управления описанные выше и т.п.), контроллер может включать в себя, но не ограничиваться ими, процессор (процессоры), компьютер (компьютеры), память, запоминающее устройство, регистр (регистры), синхронизацию, прерывание (прерывания), интерфейс (интерфейсы) связи, интерфейс (интерфейсы) сигналов ввода/вывода, а также сочетание, содержащее, по меньшей мере, одно из перечисленного.
Кроме того, изобретение может быть реализовано в форме процессов компьютера или контроллера. Также изобретение может быть реализовано в виде компьютерного программного кода, содержащего инструкции и выполненного на материальных носителях, таких как дискеты, компакт-диски, жесткие диски и/или других компьютером считываемых носителях, при этом, когда компьютерный программный код загружен и выполнен компьютером или контроллером, компьютер или контроллер становятся устройством, осуществляющим настоящее изобретение. Также изобретение может быть реализовано в виде программного компьютерного кода, записанного на носителе данных, или загружаемого и/или выполняемого компьютером или контроллером, или переданного с помощью каких-нибудь средств передачи данных, например по электрической или кабельной сети, через волоконную оптику или посредством электромагнитного излучения, при этом, когда компьютерный программный код загружен и выполнен компьютером или контроллером, компьютер или контроллер становятся устройством, осуществляющим настоящее изобретение. При выполнении на универсальном микропроцессоре часть компьютерного программного кода может сконфигурировать микропроцессор как устройство, выполненное с возможностью создания специфических логических схем.
Хотя настоящее изобретение было описано в применении к иллюстративному варианту осуществления, специалистам в данной области техники очевидно, что могут быть сделаны различные изменения, опущения и/или дополнения, элементы могут быть заменены их эквивалентами без отклонения от сущности и объема настоящего изобретения. Кроме того, могут быть сделаны многие модификации для приспособления конкретной ситуации или материала к применению настоящего изобретения без отклонения от сущности и объема настоящего изобретения. Следовательно, подразумевается, что настоящее изобретение не ограничено конкретным вариантом осуществления, рассмотренным как лучший способ для осуществления настоящего изобретения, но настоящее изобретение будет включать в себя все воплощения, попадающие в объем прилагаемой формулы изобретения. Кроме того, если специально не оговорено, любое использование терминов первый, второй и т.д. не означает очередность или важность, а скорее термины первый, второй, и т.д. используются, чтобы отличить один элемент от другого.


Изобретение относится к прогаммным приложениям распознавания голоса, более конкретно к способу управления характерными особенностями фразы посредством приложения распознавания голоса. Система и способ создания Языковой Модели мнемосхем предназначены для использования в программном приложении распознавания речи, причем способ включает в себя формирование n-граммной Языковой Модели, содержащей заданный большой набор символов, причем n-граммная Языковая Модель содержит, по меньшей мере, один символ из заданного большого набора символов, построение новой лексемы Языковой Модели (ЯМ) для каждого, по меньшей мере, одного символа, извлечение произношений для каждого, по меньшей мере, одного символа, соответствующего заданному словарю произношений для получения представления произношения символа, создание, по меньшей мере, одного альтернативного произношения для каждого, по меньшей мере, одного символа, соответствующего представлению произношения символа для создания альтернативного словаря произношений и компиляцию n-граммной Языковой Модели для использования в программном приложении распознавания речи, где компиляция указанной Языковой Модели соответствует новой лексеме Языковой Модели и альтернативному словарю произношений. Технический результат - обеспечение увеличения вероятности распознавания речи. 3 н. и 11 з.п. ф-лы, 4 ил.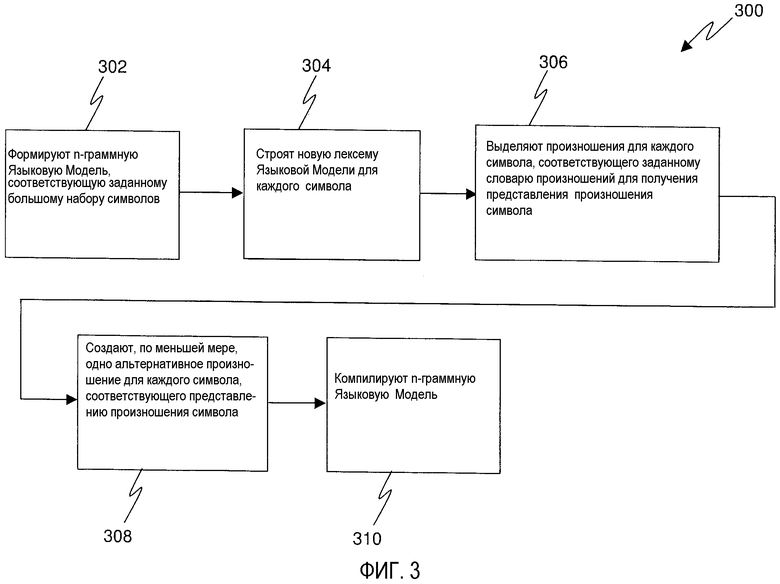
1. Способ приема и распознавания голосовых команд, введенных пользователем, для выполнения по меньшей мере одного целевого программного приложения, причем способ содержит этапы, на которых:
формируют n-граммную Языковую Модель, хранимую на запоминающем устройстве и содержащую заранее заданный большой набор символов, причем указанная n-граммная Языковая Модель включает в себя, по меньшей мере, один символ из указанного заранее заданного большого набора символов;
строят новую лексему Языковой Модели (ЯМ) для каждого из указанных, по меньшей мере, одного символа;
извлекают из запоминающего устройства произношения для каждого из упомянутых по меньшей мере одного символа, соответствующего заданному словарю произношений для получения представления произношения символа;
создают, по меньшей мере, одно альтернативное произношение для каждого упомянутого, по меньшей мере, одного символа, соответствующего указанному представлению произношения символа, для создания альтернативного словаря произношений;
компилируют указанную n-граммную Языковую Модель для использования в программном приложении распознавания речи, причем указанная компиляция упомянутой Языковой Модели отвечает упомянутой новой лексеме Языковой Модели и упомянутому альтернативному словарю произношений,
распознают введенную пользователем голосовую команду программным приложением распознавания речи со скомпилированной n-граммной Языковой Моделью,
выполняют, по меньшей мере, одно целевое программное приложение в ответ на упомянутую распознанную команду.
2. Способ по п.1, в котором заранее заданный большой набор символов включает в себя, по меньшей мере, одно из: букв, включающих в себя строчные буквы и прописные буквы, цифр и графических символов.
3. Способ по п.2, в котором, по меньшей мере, одно из упомянутых заранее заданного большого набора символов, заранее заданного словаря произношений и альтернативного словаря произношений соответствует английскому языку.
4. Способ по п.1, в котором этап построения включает в себя создание лексемы Языковой Модели для каждого, по меньшей мере, одного символа.
5. Способ по п.1, в котором этап построения лексемы включает в себя добавление представления длинной паузы к концу произношения слова для формирования упомянутого альтернативного произношения.
6. Способ по п.1, в котором, если упомянутый символ представляет собой символ в верхнем регистре, то построение лексемы дополнительно включает в себя добавление спереди представления элемента со значением "Заглавный" к лексеме для формирования упомянутого альтернативного произношения.
7. Способ по п.1, в котором n-граммная языковая модель генерируется с использованием формата АКРА.
8. Способ по п.1, в котором выполняемые компьютером команды для выполнения способа сохраняют на считываемом компьютером носителе.
9. Способ по п.1, в котором, по меньшей мере, одно из символа, слова, словаря и альтернативного произношения соответствует разговорному языку.
10. Система для приема и распознавания голосовых команд, введенных пользователем, для выполнения, по меньшей мере, одного целевого программного приложения, причем система содержит:
запоминающее устройство для хранения Программного Приложения Распознавания Речи и, по меньшей мере, одного целевого программного приложения;
устройство ввода для голосового ввода данных и команд в систему;
устройство отображения, причем указанное устройство отображения включает в себя экран монитора для отображения введенных данных; и
устройство обработки, причем упомянутое устройство обработки взаимодействует с упомянутым запоминающим устройством, упомянутым устройством ввода и упомянутым устройством отображения таким образом, что упомянутое устройство обработки принимает инструкции, чтобы вынудить Программное Приложение Распознавания Речи выполнять следующие этапы:
формируют n-граммную Языковую Модель, хранимую на запоминающем устройстве и содержащую заранее заданный большой набор символов, причем указанная n-граммная Языковая Модель включает в себя, по меньшей мере, один символ из указанного заранее заданного большого набора символов;
строят новую лексему Языковой Модели (ЯМ) для каждого из указанных, по меньшей мере, одного символа;
извлекают из запоминающего устройства произношения для каждого из упомянутых, по меньшей мере, одного символа, соответствующего заданному словарю произношений для получения представления произношения символа;
создают, по меньшей мере, одно альтернативное произношение для каждого упомянутого, по меньшей мере, одного символа, соответствующего указанному представлению произношения символа, для создания альтернативного словаря произношений;
компилируют указанную n-граммную Языковую Модель для использования в программном приложении распознавания речи, причем указанная компиляция упомянутой Языковой Модели отвечает упомянутой новой лексеме Языковой Модели и упомянутому альтернативному словарю произношений,
распознают введенную пользователем голосовую команду программным приложением распознавания речи со скомпилированной n-граммной Языковой Моделью,
выполняют, по меньшей мере, одно целевое программное приложение в ответ на упомянутую распознанную команду.
11. Система по п.10, в которой устройство ввода представляет собой микрофон.
12. Система по п.10, дополнительно включающая в себя программный модуль акустической модели и программный модуль Языковой Модели, причем указанный программный модуль акустической модели и указанный программный модуль Языковой Модели размещены на указанном запоминающем устройстве.
13. Система по п.10, дополнительно включающая в себя компилятор, причем указанный компилятор представляет собой стандартный компилятор, допускающий компиляцию в формате АКРА.
14. Машиночитаемый носитель, на котором сохранены считываемые компьютером команды, которые при выполнении их компьютером вынуждают компьютер выполнять способ по любому из пп.1-9.
| US 6694296 B1, 17.02.2004 | |||
| US 2003200508 A, 23.10.2003 | |||
| Приспособление для двойного подгиба среза изделия на швейной машине | 1984 |
|
SU1280069A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| УНИВЕРСАЛЬНАЯ ГЕНЕРИРУЮЩАЯ УСТАНОВКА ТЕПЛОВОГО ГАЗОВОГО ПОТОКА НА ТАНКОВОМ ШАССИ И ПРИВОД УПРАВЛЕНИЯ КРАНОМ ПОДАЧИ ТОПЛИВА ГЕНЕРАТОРА ТЕПЛОВОГО ГАЗОВОГО ПОТОКА | 2007 |
|
RU2353887C2 |
| WO 00/31725 A1, 02.06.2000 | |||
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |

