Уровень техники
Движки распознавания речи (SR) для английского языка нуждаются в мастерах орфографии, в основном вследствие неспособности включения всех или, по существу, всех правильных существительных, в частности имен, в лексикон движка. С другой стороны, набор китайских иероглифов можно считать замкнутым, поскольку все иероглифы включены в лексикон. Не нужно думать или беспокоиться о несловарных иероглифах. Однако основные проблемы в движке SR китайского языка состоят в обобществлении омофона по многим разным иероглифам. Всего в китайском языке существует около 47,000 действительных китайских иероглифов, но существует лишь около 1,600 разных, но фиксированных слогов. Это означает, что, если слоги равномерно распределены по разным иероглифам, каждый слог может соответствовать примерно 23-31 разным иероглифам, многие из которых могут иметь разный смысл.
Фиксированные слоги это набор слогов, связанных с действительными китайскими иероглифами. Например, слог “chu” соответствует иероглифам наподобие  (/ch uh/ в пиньине), но не существует “chiu”, который соответствует каким-либо действительным иероглифам. Вследствие ограниченного количества фиксированных слогов существует значительное количество иероглифов, которые имеют одинаковое произношение. Ниже приведен один пример пятидесяти четырех иероглифов, имеющих одинаковое произношение /l ih/; при этом список для /l ih/ все еще не полон:
(/ch uh/ в пиньине), но не существует “chiu”, который соответствует каким-либо действительным иероглифам. Вследствие ограниченного количества фиксированных слогов существует значительное количество иероглифов, которые имеют одинаковое произношение. Ниже приведен один пример пятидесяти четырех иероглифов, имеющих одинаковое произношение /l ih/; при этом список для /l ih/ все еще не полон:

Следовательно, когда движку не удается правильно распознать слово, пользователи могут безуспешно пытаться исправить его с помощью списка альтернатив, или пытаться повторно произносить нужное слово для распознавания, в силу следующих проблем.
Во-первых, если голосовой аудиосигнал неверно обрабатывается акустической моделью (AM), или AM имеет боле низкий показатель релевантности для нужного слова, чем другие слова, тогда как другие слова имеют более высокие показатели языковой модели (LM), то, независимо от того сколько раз пользователь произносит слово, выход может не быть верным словом из списка альтернатив.
Во-вторых, предположим, что голосовой аудиосигнал правильно обрабатывается AM, но если нужный иероглиф находится в списке, где количество альтернативных элементов превышено и не представлено пользователю, то пользователи не смогут получить слово, не напечатав его. Это весьма вероятно в китайском языке, особенно, когда иероглифы также являются омофонами цифр или чисел, где движок SR также отображает разные форматы результатов ITN (Inversed-Text Normalization, например, нормализующей “twelve” в “12”) для чисел.
В-третьих, хотя для движка SR китайского языка не нужно рассматривать несловарные иероглифы, пользователи могут создавать новые слова, комбинируя разные иероглифы. Помимо новых слов, не существует пробелов между словами для указания границы слова. Для определения границ слова азиатские языки (по меньшей мере, связанные с упрощенным китайским (CHS), традиционным китайским (CHT) и японским (JPN)) требуют разбиения на слова в движке или процессе IME (редактор способов ввода). Следовательно, когда пользователь диктует движку SR китайского языка нужное существительное, например имя собственное, которое, скорее всего, является неизвестным словом, весьма маловероятно, что SR правильно обработает имя, если имя не является распространенным и не входит в обучающие данные. Даже если AM и LM работают безукоризненно, пользователи все же могут принимать выходное имя в виде иероглифов, например  (упор делается на второй иероглиф, где первый иероглиф это фамилия, а второй иероглиф - имя), что отличается от желаемого выхода
(упор делается на второй иероглиф, где первый иероглиф это фамилия, а второй иероглиф - имя), что отличается от желаемого выхода  вследствие вышеописанной проблемы омофонов, т.е.
вследствие вышеописанной проблемы омофонов, т.е.  и
и  являются омофонами, но используются как имена других людей. Это также справедливо для человеческого восприятия при разговоре на китайском, где первый человек называет второму свое имя, и второму человеку приходится спрашивать первого, какие именно иероглифы используются в имени.
являются омофонами, но используются как имена других людей. Это также справедливо для человеческого восприятия при разговоре на китайском, где первый человек называет второму свое имя, и второму человеку приходится спрашивать первого, какие именно иероглифы используются в имени.
Наконец, когда пользователи пытаются исправить иероглифы в слове в процессе SR, существует возможность получить правильный выход, повторно выбирая иероглиф(ы) и/или произнесение иероглифа(ов), чтобы определить, появился ли наконец верный иероглиф в списке альтернатив. Зачастую, когда иероглифы не имеют большого количества омофонов, можно получить верное слово для замены. Однако такого рода исправление производится на основе отдельных иероглифов. Исправление не будет восприниматься в SR, поскольку SR изучает слова, а не отдельные иероглифы. Следовательно, если пользователь хочет использовать иероглиф в документе несколько раз, ему придется повторять процесс исправление process каждый раз при произнесении этого иероглифа. Таким образом, традиционные процессы распознавания громоздки и неэффективны.
Сущность изобретения
Ниже, в упрощенном виде, представлена сводка одного или нескольких вариантов осуществления для обеспечения понимания сущности таких вариантов осуществления. Эта сводка не является обширным обзором и не призвана ни идентифицировать ключевые или критические элементы, ни ограничивать объем вариантов осуществления. Ее единственной целью является представление некоторых концепций одного или нескольких вариантов осуществления в упрощенной форме в качестве прелюдии к более подробному описанию, которое приведено ниже.
Раскрытая архитектура обеспечивает режим проверки орфографии для алгоритмов распознавания азиатской речи. Это облегчает определение границ нового слова и добавление нового слова в лексикон. Следовательно, на основании режима проверки орфографии, исправление слова происходит только один раз, в отличие от традиционных систем, где исправление слова происходит несколько раз.
В частности, применительно к китайским иероглифам, режим проверки орфографии облегчает ввод китайских иероглифов, когда движок распознавания речи возвращает неверные иероглифы при диктовке. Слова, исправленные с использованием режима проверки орфографии, исправляются как единое целое и рассматриваются как слово. Дело в том, что, в отличие от английских слов, например, где границы слова легко распознаются, границы в азиатских языках неочевидны. Таким образом, ввод китайских иероглифов (в этом примере) при работе в режиме проверки орфографии сокращает или исключает неверное распознавание слова при последующей обработке распознавания.
Раскрытый режим проверки орфографии применяется к упрощенному китайскому, традиционному китайскому и/или другим азиатским языкам, например японскому, где иероглифам соответствуют определенные звуки.
Для решения вышеозначенных и родственных задач некоторые иллюстративные аспекты описаны здесь в связи с нижеследующим описанием и прилагаемыми чертежами. Однако эти аспекты представляют лишь некоторые возможные подходы к применению раскрытых здесь принципов и призваны охватывать все подобные аспекты и их эквиваленты. Другие преимущества и признаки новизны следуют из нижеследующего подробного описания, приведенного совместно с чертежами.
Краткое описание чертежей
Фиг. 1 - компьютерная система перевода.
Фиг. 2 - система, которая облегчает обобществление лексикона на основании новых слов, изученных в процессах орфографии/исправления.
Фиг. 3 - система, которая применяет компонент вывода, который облегчает автоматизацию одной или нескольких функций.
Фиг. 4 - один или несколько способов, которые могут применяться раскрытой здесь архитектурой орфографии/исправления.
Фиг. 5 - система, которая применяет произношение слова как способ указания иероглифа.
Фиг. 6 - скриншот диалогового окна орфографии, представляемого, когда пользователю нужны на выходе азиатские иероглифы/слова.
Фиг. 7 - скриншот диалогового окна орфографии, представляемого, когда пользователю нужны на выходе английские слова.
Фиг. 8 - скриншот диалогового окна орфографии, представляемого для обработки команды «омофон».
Фиг. 9 - скриншот диалогового окна режима проверки орфографии, представляемого в ответ на голосовую команду для исправления омофона.
Фиг. 10 - окно, где неверно распознанное слово исправлено, и окно списка очищено в ответ на голосовой выбор индекса.
Фиг. 11 - скриншот диалогового окна орфографии, представляемого для голосового произношения.
Фиг. 12 - скриншот диалогового окна орфографии, представляемого для исправления голосового произношения.
Фиг. 13 - скриншот диалогового окна орфографии, представляемого с пересмотренным окном списка омофонов на основании исправления голосового произношения.
Фиг. 14 - скриншот диалогового окна орфографии, представляемого, когда неверно распознанное слово исправлено, и курсор перемещается к следующему иероглифу для обработки голосового произношения, что позволяет пользователю, при необходимости, продолжать исправление на следующем иероглифе.
Фиг. 15 - система, которая применяет позитивный, нейтральный и негативный смыслы для взвешивания иероглифа в соответствии со вторым способом.
Фиг. 16 - система, которая применяет разложение на слова путем голосового ввода подкомпонентов нужного иероглифа в соответствии с третьим способом.
Фиг. 17 - скриншот диалогового окна орфографии, представляемого для распознавания и обработки японского языка путем голосового/клавиатурного ввода хираганы для получения кандзи.
Фиг. 18 - скриншот диалогового окна орфографии, представляемого для распознавания и обработки японского языка, связанного с получением ромадзи.
Фиг. 19 - способ распознавания речи в соответствии с раскрытой архитектурой.
Фиг. 20 - способ исправления результатов распознавания с использованием мастера орфографии.
Фиг. 21 - способ преобразования фонетического произношения в иероглиф.
Фиг. 22 - способ использования команд разделения в азиатском и английском языках для обработки исправления.
Фиг. 23 - способ использования команд «омофон» в мастере орфографии азиатского языка.
Фиг. 24 - способ применения весовых значений к смыслам слова.
Фиг. 25 - способ обобществления обновленного лексикона.
Фиг. 26 - способ использования разложения на иероглифы для исправления орфографических ошибок.
Фиг. 27A и 27B - способ обработки исправления на основании множественных способов для исправления орфографических ошибок.
Фиг. 28 - блок-схема вычислительной системы, способной осуществлять обработку исправления в соответствии с раскрытой архитектурой.
Фиг. 29 - блок-схема иллюстративной вычислительной среды для обработки исправления в соответствии с раскрытой архитектурой.
ПОДРОБНОЕ ОПИСАНИЕ
Здесь раскрыта архитектура, которая обеспечивает алгоритмы, данные и, по меньшей мере, пользовательский интерфейс (UI), который включает в себя режим проверки орфографии для распознавания азиатской речи и получения новых слов/иероглифов или исправления неверно распознанных иероглифов.
Теперь обратимся к чертежам, снабженным сквозной системой обозначений. В нижеследующем описании, в целях объяснения, многочисленные конкретные детали приведены для обеспечения полного понимания изобретения. Однако очевидно, что новые варианты осуществления можно осуществлять на практике без этих конкретных деталей. В других случаях, общеизвестные структуры и устройства показаны в виде блок-схемы для облегчения их описания.
На фиг. 1 показана компьютерная система перевода 100. Система 100 включает в себя компонент 102 распознавания речи, который принимает голосовой или речевой ввод на азиатском языке и осуществляет обработку распознавания на входном сигнале. В ряде случаев, процесс распознавания будет выводить неверные азиатские иероглифы и/или слова. Соответственно, система 100 дополнительно включает в себя компонент исправления 104 для генерации верного иероглифа и/или слова на основании вывода неверного азиатского иероглифа/слова и/или нового азиатского иероглифа/слова компонентом распознавания речи.
Система 100 будет описана более подробно, по меньшей мере, в контексте UI для взаимодействия с пользователем, UI диалогового окна орфографии с разделением для извлечения английских и азиатских слов, и также для обеспечения и выполнения разных команд для запуска и взаимодействия с окнами UI, и пользовательского режима проверки орфографии для захвата новых слов и определения границ слов. Система 100 также помогает пользователю получать иероглифы путем голосового ввода с использованием произношения, слов, содержащих нужные иероглифы, подкомпонентов нужных иероглифов и выбора из списка омофонов, и затем выбирает нужный иероглиф из преобразованных кандидатов. Предусмотрены хранилища данных, которые содержат данные, которые хранят информацию фонетического расстояния фонем в фонетической системе, и в таблице матрицы неточностей. Эта информация помогает пользователю быстро и легко исправлять неверно распознанное произношение, тем самым снижая вероятность того, что система будет совершать одни и те же ошибки.
Предусмотрено хранилище данных, которое содержит данные, которые содержат частоту использования каждого иероглифа и также возможные категории, в которых может существовать иероглиф, например имена собственные, названия компаний и т.д. Таким образом, при обнаружении ключевого слова активируется соответствующая категория, и иероглифы, используемые для этой категории, продвигаются выше по списку. Чтение ключевых иероглифов в слове и перенастройка списка иероглифов так, чтобы нужный иероглиф оказывался вверху списка для оставшегося исправления, также составляют часть раскрытых здесь способов.
Система 100 облегчает получение иероглифов посредством голосового ввода с использованием слов, которые содержат нужный иероглиф, а также получения иероглифов путем проверки подкомпонента иероглифа. UI системы 100 обрабатывает команды «омофон» для получения верных слов и для избавления от необходимости повторного ввода произношения. Пользователи также могут обобществлять лексикон новых слов и посылать обратно новые слова для оценивания и обновления другого лексикона. Кроме того, другие речевые вводы на азиатских языках (например, японском) могут переключаться между (например, четырьмя) разными системами письма.
На фиг. 2 показана система 200, которая облегчает обобществление лексикона на основании новых слов, изученных в процессах исправления. Система 200 включает в себя компонент 102 распознавания речи и компонент 104 орфографии/исправления, показанный на фиг. 1. Однако выход компонента 104 исправления поступает обратно на компонент распознавания 102 для обновления внутреннего лексикона 202. Заметим, однако, что лексикон 202 может быть внешним по отношению к компоненту распознавания 102.
Система 200 также может включать в себя языковую модель (LM) 204 и акустическую модель (AM) 206, как в традиционных системах распознавания. LM 204 (или файл грамматики) содержит набор вероятностей последовательностей слов. AM 206 характеризует акустическое поведение слов в виде фонем на основании голосовых данных и их транскрипций. AM 206 моделирует звуковые единицы языка на основании векторов признаков, генерируемых из речевого аудиосигнала. Компонент распознавания 102 обрабатывает вход, принятый от LM 204 и AM 206, для обеспечения наилучшего выхода. Однако, как указано, в сложных приложениях, например, для обработки распознавания азиатского языка, обеспечение правильного результата с последующим выявлением неверного результата может быть трудной задачей. Таким образом, при достижении исправленного результата, предпочтительно обновлять (или исправлять) лексикон 202. Эти обновления могут играть важную роль в таких сложных приложениях. Соответственно, при наличии соответствующих проверок безопасности, компонент обобществления 208 облегчает обобществление информации, например лексикона 202, с другими пользователями или системами и/или поставщиком лексикона для распространения нового массива лексикона. Это будет более подробно описано ниже.
На фиг. 3 показана система 300, которая применяет компонент вывода 302, который облегчает автоматизацию одной или нескольких функций. Например, выводы можно делать на основании не только пользователя (например, профилей пользователей), но и речи и действий по исправлению, которые изучает и о которых рассуждает компонент 302. Предположим, что пользователь гораздо лучше знает английский, чем китайский, и что с течением времени компонент вывода 302 узнаёт, что пользователь обычно сталкивается с ошибками распознавания речи, связанными с определенными китайскими иероглифами. Соответственно, компонент 302 может автоматизировать функции UI, чтобы пользователь не делал одни и те же ошибки, представляя интерфейс режима проверки орфографии вместо интерфейса произношения для более эффективной помощи пользователю.
В другом примере, он может узнать, что пользователь обычно предпочитает использовать режим проверки орфографии больше, чем любые другие предусмотренные режимы. Таким образом, при необходимости выбора способа, подлежащего исправлению, компонент 302 будет автоматически представлять UI режима проверки орфографии. Это всего лишь несколько примеров многочисленных выводов, которые можно делать на основании обучения и рассуждения не только о взаимодействиях с пользователем, но и о системных процессах, которые имеют тенденцию повторно происходить, на основании определенных входных критериев.
Компонент вывода 302 может применять машинное обучение и рассуждение (MLR), например, для мониторинга, анализа, вычисления и применения результатов обучения и рассуждения. Заявленная архитектура (например, в связи с выбором) может применять различные схемы на основе MLR для осуществления различных своих аспектов. Например, процесс определения, какой иероглиф или иероглиф в слове следует выбрать и представить, можно облегчить посредством системы и процесса автоматических классификаторов.
Классификатор - это функция, отображающая входной вектор атрибутов, x=(x1, x2, x3, x4, xn), в метку класса class(x). Классификатор также может выводить уверенность в том, что вход принадлежит классу, т.е. f(x)=confidence (class(x)). Такая классификация может применять вероятностный и/или другой статистический анализ (например, анализ, разложимый на утилиты и стоимости анализа для максимизации предполагаемого значения для одного или нескольких людей) для прогнозирования или вывода действия, в отношении которого пользователь желает, чтобы оно осуществлялось автоматически.
Используемый здесь, термин “выводить” или “вывод” относится, в общем случае, к процессу рассуждения о состояниях системы, среды и/или пользователя или их вывода на основании совокупности наблюдений, сделанных на основе событий и/или данных. Вывод можно применять для идентификации конкретного контекста или действия или, например, для генерации распределения вероятности по состояниям. Вывод может носить вероятностный характер, т.е. опираться на вычисление распределения вероятности по нужным состояниям на основании изучения данных и событий. Вывод также может относиться к методам, применяемым для составления событий более высокого уровня из множества событий и/или данных. Такой вывод приводит к построению новых событий или действий из множества наблюдаемых событий и/или сохраненных данных событий, в зависимости от того, коррелируют ли события в тесной временной близости, и от того, приходят ли события и данные из одного или нескольких источников событий и данных.
Метод опорных векторов (SVM) является примером классификатора, который можно применять. SVM осуществляется путем нахождения гиперповерхности в пространстве возможных входов, которая оптимальным образом отделяет инициирующие входные события от неинициирующих событий. Интуитивно, это дает правильную классификацию для данных тестирования, которые близки к обучающим данным, но не идентичны им. Можно применять и другие подходы к классификации направленных и ненаправленных моделей, включая, например, различные формы статистической регрессии, наивные байесовы классификаторы, байесовы сети, деревья решений, нейронные сети, модели на основе нечеткой логики и другие модели статистической классификации, представляющие разные картины независимости. Используемая здесь классификация также включает в себя способы, используемые для назначения ранга и/или приоритета.
Как следует из описания изобретения, заявленная архитектура может применять классификаторы, которые тренируются в явном виде (например, через общие обучающие данные), а также тренируются в неявном виде (например, путем наблюдения поведения пользователя, принимающего внешнюю информацию). Например, SVM конфигурируются на фазе обучения или тренировки в конструкторе классификаторов и модуле выбора признаков. Таким образом, классификатор(ы) можно применять для автоматического изучения и осуществления ряда функций согласно заранее определенным критериям.
Компонент вывода 302 может взаимодействовать с компонентом распознавания 102, компонентом исправления 104, лексиконом 202, LM 204 (соединение не показано), AM 206 и компонентом обобществления 208, например, для мониторинга пользовательских и системных процессов и получения данных. Использование компонента вывода 302 в системе 300 является всего лишь одним примером разнообразных путей применения и соединения вывода (умозаключения). Другими словами, компонент вывода 302 может применяться в подробных иллюстрациях системных компонентов на последующих фигурах.
На фиг. 4 показаны один или несколько способов 400, которые можно применять посредством раскрытой здесь архитектуры исправления. Например, компонент 104 орфографии/исправления может включать в себя способ 402 произношения слова, способ 404 «иероглиф в слове» и способ 406 разложения на иероглифы. Эти способы 400 обеспечивают, по меньшей мере, способы задания иероглифа. Способы задания иероглифа включают в себя задание информации о том, как произносится слово, с помощью локальных фонетических символов (например, способ произношения 402). Способ 404 «иероглиф в слове» включает в себя задание информации о том, как пишется иероглиф, путем задания слов, в которых существует иероглиф. Например, если пользователь указывает  , пользователь может сказать “
, пользователь может сказать “ ”. Это аналогично использованию “a, как в
a
pple” в английском языке.
”. Это аналогично использованию “a, как в
a
pple” в английском языке.
Задание информации о том, как составляется иероглиф (или как его можно разложить), обеспечивается способом разложения 406. Другими словами, пользователь может произносить составные части иероглифа. Например, если пользователь хочет указать  , пользователь может сказать “
, пользователь может сказать “ ”. Все три способа (402, 404, и 406) более подробно описаны ниже.
”. Все три способа (402, 404, и 406) более подробно описаны ниже.
Первый способ, способ произношения 402, можно обеспечить с использованием мастера орфографии, тогда как способы 404 и 406 можно напрямую применять без мастера. Однако следует понимать, что все способы (402, 404 и 406) можно реализовать с использованием мастера, чтобы пользователи могли выбирать один из способов для исправления слова. Также следует понимать, что использование термина “мастер” не следует рассматривать в качестве какого-либо ограничения. Другими словами, может быть представлен ряд диалогов, посвященных небольшой части общего процесса, а не тому, что обычно рассматривает мастер, ведущий пользователя по процессу.
Способ произношения 402 используется, когда пользователи пытаются печатать китайские иероглифы или слова. Использование произношений для азиатских иероглифов широко распространено в некоторых азиатских странах. Однако можно использовать и другие способы ввода вместо произношения в OS с традиционным китайским письмом. С учетом удобства, обеспечиваемого произношением, многие пользователи будут использовать произношение  при печатании иероглифов с помощью клавиатуры. Это особенно актуально для пользователей в Китае при использовании OS с упрощенным китайским письмом, где пиньинь, локальная система произношения, используется для печатания иероглифов с помощью клавиатуры. Тайваньские пользователи (использующие традиционный китайский) напечатают
при печатании иероглифов с помощью клавиатуры. Это особенно актуально для пользователей в Китае при использовании OS с упрощенным китайским письмом, где пиньинь, локальная система произношения, используется для печатания иероглифов с помощью клавиатуры. Тайваньские пользователи (использующие традиционный китайский) напечатают  и пробел для первого аудио тона для получения списка слов, которые используют это произношение, например
и пробел для первого аудио тона для получения списка слов, которые используют это произношение, например  , и выберут одно из слов, например второе слово
, и выберут одно из слов, например второе слово  . Напротив, пользователи в Китае могут напечатать “xun” получить список слов, например
. Напротив, пользователи в Китае могут напечатать “xun” получить список слов, например  , и выбрать одно из слов, например второе слово .
, и выбрать одно из слов, например второе слово .
Однако печатание занимает время и может быть сопряжено с ошибками. Это требует особенно большого времени и труда для тайваньских пользователей, поскольку фонетическая система традиционного китайского отличается от набора из двадцати шести букв (для пиньиня), используемых в континентальном китайском языке. Например, фонетические символы выглядят как  , и первый символ
, и первый символ  можно рассматривать как звук /b/, но задается клавишей 1 (цифра) и ! (восклицательный знак), а не клавишей клавиатуры для буквы b. Таким образом, пользователи должны выучить, где на клавиатуре располагается каждый символ. С другой стороны, пиньинь, используемый в континентальном Китае, состоит из двадцати шести английских букв, что не требует изучения другой раскладки клавиатуры, если пользователи знакомы с расположением двадцати шести английских букв на клавиатуре.
можно рассматривать как звук /b/, но задается клавишей 1 (цифра) и ! (восклицательный знак), а не клавишей клавиатуры для буквы b. Таким образом, пользователи должны выучить, где на клавиатуре располагается каждый символ. С другой стороны, пиньинь, используемый в континентальном Китае, состоит из двадцати шести английских букв, что не требует изучения другой раскладки клавиатуры, если пользователи знакомы с расположением двадцати шести английских букв на клавиатуре.
Мастер орфографии преодолевает это ограничение, позволяя пользователю получать китайские слова с помощью голоса, а не печатания. Это особенно полезно, когда пользователи не знакомы с расположением фонетических символов и/или двадцати шести английских букв на клавиатуре, или не настолько часто имеют дело с символами, чтобы быстро выбирать и вводить символы.
Второй способ (иероглиф в слове) 404 может быть сложнее, чем способ 402 произношения слова, поскольку выбранное слово, которое содержит иероглиф, может быть любым словом, даже именами известных людей. Раскрытая архитектура будет содержать все иероглифы, используемые в китайском языке, но может не содержать все слова, особенно имена наиболее известных людей, которые еще не являются частью обучающих данных.
Пользователи могут выбирать слово, которое содержит нужный иероглиф, но иероглиф может не быть первым иероглифом в слове. Иероглиф может оказаться в середине или в конце слова. Например, пользователь может говорить  , чтобы получить последний (выделенный жирным шрифтом) иероглиф
, чтобы получить последний (выделенный жирным шрифтом) иероглиф  .
.
Для получения хорошей точности распознавания, желательно понимать, слова какого типа люди используют для указания иероглифов, и либо присваивать этим словам более высокие весовые коэффициенты, либо специально обучать этим словам. Правильные сбор и организация данных позволяет повысить точность SR. Кроме того, чем лучше AM для SR, тем лучшие результаты дает этот способ. После этого применять этот способ 404 для исправления неверно распознанных китайских слов может быть проще, чем первый способ 402, поскольку количество этапов для получения верного иероглифа меньше, чем при обеспечении произношения.
Третий способ 406 можно использовать в меньшей степени для немногочисленных легко разложимых слов. Другими словами, количество слов, которые легко разложить и которые широко используются, невелико. Поэтому разложимые слова можно перечислить в грамматике (или LM) для поддержки этого способа 406.
На фиг. 5 показана система 500, которая применяет произношение слова как способ указания иероглифа. Согласно вышесказанному мастер орфографии можно применять для способа произношения. В помощь пользователям, обеспечивающим произношение и выбирающим верные иероглифы, мастер применяет один или несколько файлов данных, которые определяют отображение между иероглифами и произношением. Дополнительно, обеспечивается оптимизированный список слов-омофонов, чтобы пользователи могли быстро получить нужные иероглифы.
Ниже описаны файлы данных для преобразования между фонетическими системами и иероглифами. В этом первом примере фонетическая система описана в CHS/CHT, совместно с обзором иллюстративных файлов данных.
Как описано выше, CHS использует пиньинь, в котором также используется двадцать шесть букв английского языка, но с необязательной тоновой информацией. Напротив, CHT использует чжуинь, который представляет собой набор пиктографических символов, но не стандартный китайский. Чжуинь для CHT аналогичен международному фонетическому алфавиту (IPA) для английского языка. Например, ниже приведены фонетические представления для CHS и CHT для иероглифа  :
:
CHS: tian
CHT: 
В компоненте распознавания 102 на фиг. 5 показана совокупность 502 движков азиатского языка (обозначенных ДВИЖОК SR АЗИАНТСКОГО ЯЗЫКА1, …, ДВИЖОК SR АЗИАНТСКОГО ЯЗЫКАN, где N - положительное целое число). Первый движок 504 из движков 502 использует способ 402 произношения слова, который дополнительно использует три файла данных 506 для обеспечения данных. Каждый движок языка 502 использует три файла данных 506 для процесса преобразования произношения в иероглифы. В первом файле данных 508 хранятся слова в качестве индекса и информация, относящаяся к каждому слову в качестве значения, которое включает в себя произношение, тон, частоту использования и/или возможную категорию. Во втором файле данных 510 хранятся произношение в качестве индекса и все слова с этим произношением в качестве значения, и в порядке на основании частоты использования. Третий файл данных 512 используется для хранения информации матрицы неточностей среди фонем, которая позволяет пользователям эффективно исправлять неверно распознанные фонемы.
Как указано, в первом файле данных 508 хранится информация об иероглифах и произношении, тоне, частоте и/или возможной категории иероглифов. Например,
CHS:

CHT:

Для иероглифов, имеющих разное произношение в разных словах, например  (этот иероглиф используется как 3-й тон в
(этот иероглиф используется как 3-й тон в  (означающий 'очень хороший'); но как 4-й тон в
(означающий 'очень хороший'); но как 4-й тон в 
 (означающий 'излюбленный'), возможные произношения записываются в одной строке, где элементы разделены точкой с запятой (;).
(означающий 'излюбленный'), возможные произношения записываются в одной строке, где элементы разделены точкой с запятой (;).
Согласно последней информации существует около 47,035 действительных китайских иероглифов, большое количество которых редко используются и накопились на протяжении истории. Лишь около 2,000 иероглифов активно используется грамотными людьми в Китае. Следовательно, иероглифы, принадлежащие набору из 2,000 активно используемых иероглифов, можно отображать в первую очередь. Чтобы знать, следует ли отображать иероглифы из активно используемого набора в вершине или вблизи вершины списка, представляемого пользователю, активно используемые иероглифы помечаются цифрой “1”, а остальные - цифрой “2”. Иероглифам, оказавшимся в конкретной категории, например имен собственных, можно назначать код категории, например “n” для имен собственных.
Система 500 также может включать в себя частотный компонент 514 для отслеживания частоты использования иероглифа и/или слова, хранящейся во втором файле данных 510. В этом втором файле данных 510 хранятся произношение и иероглифы, связанные с этим произношением, в порядке частоты появления в разных словах, а также частоты слов или иероглифов. В первом файле данных 508 указано, принадлежит ли слово 2,000 активно используемым иероглифам. В этом втором файле данных 510 иероглифы упорядочены согласно полной активной и/или неактивной частоте и согласно частоте использования, связанной с другими иероглифами-омофонами. Частотную информацию можно получить из существующих обучающих данных. Порядок во втором файле данных 510 можно регулировать на основании обучения и рассуждения о выборах пользователя. Второй файл данных 510 можно генерировать из первого файла данных 508, если более конкретную частотную информацию можно задать в первом файле данных 508. Однако второй файл данных 510 следует генерировать и сохранять в папке пользовательских профилей, чтобы второй файл 510 можно было использовать для сохранения отрегулированного порядка после обучения на основании пользовательского выбора. В нижеприведенном списке указаны произношение и частота слова. Подчеркнутые слова это те, которые редко используются.
CHS


CHT


Для сохранения действительных слогов можно обеспечить контекстно-свободную грамматику (CFG). Для CHS пользователи способны произносить “T I A N” для получения “tian” в фонетической системе CHS, с последующим его преобразованием в список иероглифов, которые используют это произношение. CFG включает в себя другую возможность, которая позволяет пользователям говорить “T I A N” для приема “tian” до преобразования в иероглифы. Этот способ группирует некоторые из дифтонгов или дифтонгов плюс концевые назальные согласно нижеследующему:



Для CHT в грамматике используются только фонемы в чжуине. Произношение, используемое в движке, также будет обеспечено в грамматике для повышения точности SR.

При неверном распознавании произношения мастер позволяет пользователю исправить произношение. После выбора фонемы для исправления мастер показывает список фонем, близких к неверно распознанным фонемам, и список можно упорядочить согласно расстоянию между двумя фонемами, в зависимости, например, от места артикуляции, манеры артикуляции, произнесения, контекста и влияния другого местного диалекта.
Многие тайваньцы говорят на мандаринском и южноминьском диалектах. Звуковая структура южноминьского диалекта оказывает сильное влияние на мандаринский диалект, по нескольким каналам. Большинство людей не отличает  (ретрофлексивные согласные) от
(ретрофлексивные согласные) от  (альвеолярных согласных), и некоторые люди не отличают
(альвеолярных согласных), и некоторые люди не отличают 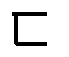 (лабиально-дентальный фрикативный) от
(лабиально-дентальный фрикативный) от 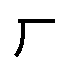 (велярного фрикативного). Для некоторых диалектов в южном Китае, /n/ и /l/ неразличимы и также влияют на продукцию других изученных языков. Расстояние в наборе минимально различимых фонем задается как меньшее расстояние.
(велярного фрикативного). Для некоторых диалектов в южном Китае, /n/ и /l/ неразличимы и также влияют на продукцию других изученных языков. Расстояние в наборе минимально различимых фонем задается как меньшее расстояние.
Контекст указывает, появляются ли две фонемы в одном и том же контексте. Например,  (/b/) и
(/b/) и  (/ph/) ближе в контекстуальном отношении, чем (/b/) и (/f/), поскольку за фонемами могут следовать одни и те же ядерные гласные и кодовые согласные.
(/ph/) ближе в контекстуальном отношении, чем (/b/) и (/f/), поскольку за фонемами могут следовать одни и те же ядерные гласные и кодовые согласные.
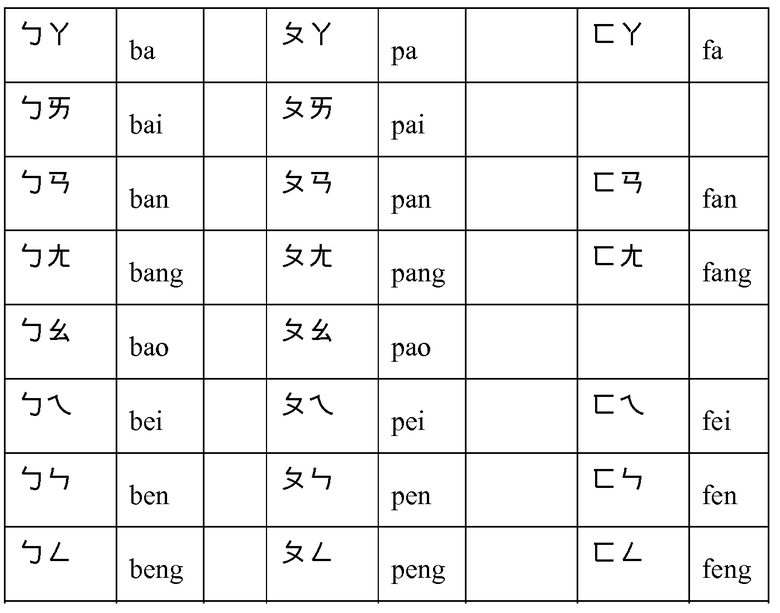



Ниже приведена иллюстративная таблица матрицы неточностей на основании этих признаков для согласных, используемых в CHT. Нижеследующая таблица получена путем вычисления расстояний на основании места артикуляции, манеры артикуляции, произнесения, контекста и влияния других местных диалектов. Матрицу неточностей этого типа также можно генерировать путем автоматического сравнения AM разных фон, которые будут покрывать место артикуляции, манеру артикуляции, произнесение. Матрицу неточностей также можно получить с помощью AM разных фон и регулировать на основании влияния контекста и других диалектов, для окончательной формы. Те же способы можно использовать для генерации матрицы для гласных и тонов для CHT и согласных и гласных для всех остальных азиатских языков.



Можно обеспечить команды разделения для режимов проверки орфографии китайского и английского языков, например, для улучшения результатов распознавания. Например, разделение можно произвести для  (означающего “написание китайских иероглифов/слов”) и
(означающего “написание китайских иероглифов/слов”) и  (означающего “написание английских слов”). Причины этого включают в себя следующее. Когда люди произносят по буквам на английском языке, английская буква может возвращаться напрямую в текст; но при проговаривании на китайском, выводятся фонетические символы, которые затем преобразуются в китайский язык. Таким образом, процесс для двух режимов проверки орфографии различается. Некоторые английские буквы и китайские фонетические символы являются омофонами. Таким образом, разделение двух процессов позволяет избежать путаницы. Кроме того, CFG можно гораздо проще активировать, если разделить процесс. Дополнительно, точность распознавания будет выше. Разделение двух команд наиболее благоприятно для CHS, поскольку фонетические символы в CHS представляют собой те же двадцать шесть английских букв. Если разделение не осуществляется, время для преобразования в китайские иероглифы будет неизвестно. Кроме того, более строгие проверки действительной фонетической последовательности можно не осуществлять, если пользователи намерены использовать пиньинь для китайского языка.
(означающего “написание английских слов”). Причины этого включают в себя следующее. Когда люди произносят по буквам на английском языке, английская буква может возвращаться напрямую в текст; но при проговаривании на китайском, выводятся фонетические символы, которые затем преобразуются в китайский язык. Таким образом, процесс для двух режимов проверки орфографии различается. Некоторые английские буквы и китайские фонетические символы являются омофонами. Таким образом, разделение двух процессов позволяет избежать путаницы. Кроме того, CFG можно гораздо проще активировать, если разделить процесс. Дополнительно, точность распознавания будет выше. Разделение двух команд наиболее благоприятно для CHS, поскольку фонетические символы в CHS представляют собой те же двадцать шесть английских букв. Если разделение не осуществляется, время для преобразования в китайские иероглифы будет неизвестно. Кроме того, более строгие проверки действительной фонетической последовательности можно не осуществлять, если пользователи намерены использовать пиньинь для китайского языка.
Ниже описано несколько окон режима проверки орфографии (скриншотов), которые активируются и отображаются, когда пользователь произносит команды. На фиг. 6 показан скриншот диалогового окна орфографии 600, представляемого, когда пользователю нужны азиатские иероглифы/слова на выходе. Когда пользователь произносит (“написание китайских иероглифов/слов”), окно 600 режима проверки орфографии представляется и включает в себя строку заголовка 602, где указано, что окно 600 является диалоговым окном китайской орфографии, использующим произношение для получения иероглифа или команду «омофон» для изменения иероглифа 604, произношение 606 и кнопки выбора, обозначенные на китайском: кнопку выбора 608 Омофон (H), кнопку выбора 610 Готово (O) и кнопку выбора 612 Отмена (E). Когда пользователь говорит (“написание английских слов”), на фиг. 7 показан скриншот диалогового окна режима проверки орфографии 700, которое представляется, когда пользователю нужны английские слова на выходе. Окно 700 демонстрирует “диалоговое окно орфографии” 702 на китайском, китайскую инструкцию 704 “диктуйте слова отчетливо” (или объявляйте отчетливо), китайскую инструкцию 706 “продиктуйте его снова”, и одну или несколько кнопок выбора, помеченных на китайском: кнопку выбора 708 Готово и кнопку выбора 710 Отмена. Окно 700 также представляет индексированный и упорядоченный список 712 английских букв и/или других знаков (например, @). Хотя в данном варианте осуществления они показаны несколько иными, желательно, чтобы окна 600 и 700 выглядели более похожими для обеспечения более согласованного пользовательского опыта за исключением особенностей, которые присутствуют в одном, но отсутствуют в другом.
На фиг. 8-10 представлены скриншоты, связанные с процессом использования исправления омофона. На фиг. 8 показан скриншот диалогового окна орфографии 800, представляемого для обработки команды «омофон». Команда произносится для получения верного иероглифа, который является омофоном. Отображенное/распознанное слово обеспечивается в виде  (означающий “омофон”) на кнопке 608. Этот интерфейс голосовой команды можно считать более эффективным, чем печатание, поскольку можно избежать повторного печатания фонетических символов. Другими словами, иногда голосовая команда распознается правильно, но пользователю нужен другой иероглиф. Вместо того чтобы предлагать пользователю повторить произношение, команду можно обрабатывать для вывода списка омофонов. Благодаря этой функции исправление голосом обеспечивает повышение удобства пользователя по сравнению с ручным вводом (например, печатанием). Таким образом, когда пользователь вручную вводит произношение путем печатания и выбирает слово из списка омофонов, слово представляется в виде текста, подчеркнутого пунктиром. В этом режиме пользователь все еще может изменять иероглифы из списка.
(означающий “омофон”) на кнопке 608. Этот интерфейс голосовой команды можно считать более эффективным, чем печатание, поскольку можно избежать повторного печатания фонетических символов. Другими словами, иногда голосовая команда распознается правильно, но пользователю нужен другой иероглиф. Вместо того чтобы предлагать пользователю повторить произношение, команду можно обрабатывать для вывода списка омофонов. Благодаря этой функции исправление голосом обеспечивает повышение удобства пользователя по сравнению с ручным вводом (например, печатанием). Таким образом, когда пользователь вручную вводит произношение путем печатания и выбирает слово из списка омофонов, слово представляется в виде текста, подчеркнутого пунктиром. В этом режиме пользователь все еще может изменять иероглифы из списка.
Однако, когда пользователь уверен в словах, пользователь может выбрать кнопку выбора 610 Ввод (или “OK”), чтобы зафиксировать слово в тексте, чтобы система ввода не выполняла автоматическую настройку слова из назначенного показателя LM. Поэтому после того как слово зафиксировано в диалоговом окне 800, если пользователь снова захочет изменить слово, фонетические символы нужно будет перепечатать. Интерфейс голосовой команды избавляет от дополнительных усилий, необходимых для ручного ввода, благодаря распознаванию команды (“омофон”). На первом этапе пользователь выбирает слова, подлежащие исправлению, произнося  (“исправить первый иероглиф”). Затем первый иероглиф 802 выделяется. Затем пользователь может сказать для омофона или выбрать кнопку выбора 608 (“омофон”) для получения иероглифов-омофонов (H) для исходных китайских иероглифов. Окно 800 также представляет кнопки выбора, обозначенные на китайском: кнопку выбора 608 Омофон, кнопку выбора 610 Готово и кнопку выбора 612 Отмена.
(“исправить первый иероглиф”). Затем первый иероглиф 802 выделяется. Затем пользователь может сказать для омофона или выбрать кнопку выбора 608 (“омофон”) для получения иероглифов-омофонов (H) для исходных китайских иероглифов. Окно 800 также представляет кнопки выбора, обозначенные на китайском: кнопку выбора 608 Омофон, кнопку выбора 610 Готово и кнопку выбора 612 Отмена.
Заметим, что исправление посредством команды «омофон» или обеспечения произношения можно осуществлять на любых иероглифах (в полях обозначенных 1, 2 или 3) в окне 800, где 802 представляет собой первый иероглиф. Однако список иероглифов-кандидатов может различаться. Список кандидатов, выдаваемый по команде «омофон», будет содержать иероглифы, которые имеют одинаковый или немного отличающийся тон. Список кандидатов, полученный путем обеспечения произношения, будет содержать иероглифы, которые полностью совпадают с произношением, заданным пользователями. Если пользователь применяет произношение, представляется скриншот, показанный на фиг. 8, где выделен второй иероглиф, а не первый иероглиф 802, как показано на фиг. 10. Затем, после того как пользователь обеспечивает произношение, представляется скриншот, показанный на фиг. 11.
На фиг. 9 показан скриншот диалогового окна режима проверки орфографии 900, представляемого в ответ на голосовую команду для исправления омофона. Произношение исходных иероглифов поддерживается мастером орфографии, благодаря чему индексированный список иероглифов-омофонов представляется в окне 902 списка. Затем пользователь может выбирать нужный иероглиф, произнося соответствующий индексный номер, например  (“один”) или
(“один”) или  (“номер один”) для первого кандидата, или кликая по иероглифу 906, в этом случае. В ответ, окно 900 произношения очищает окно 902 списка, заменяет исходный иероглиф 802 выбранным иероглифом 906, и, как показано на фиг. 10 в виде окна 1000, где окно списка 902 очищено в ответ на голосовой выбор индекса. Затем мастер переводит взаимодействие на второй иероглиф 1002 (во втором поле) для аналогичной обработки, что описано выше в соответствии с иероглифом 802 (в первом поле) на фиг. 8.
(“номер один”) для первого кандидата, или кликая по иероглифу 906, в этом случае. В ответ, окно 900 произношения очищает окно 902 списка, заменяет исходный иероглиф 802 выбранным иероглифом 906, и, как показано на фиг. 10 в виде окна 1000, где окно списка 902 очищено в ответ на голосовой выбор индекса. Затем мастер переводит взаимодействие на второй иероглиф 1002 (во втором поле) для аналогичной обработки, что описано выше в соответствии с иероглифом 802 (в первом поле) на фиг. 8.
Согласно фиг. 10 голосовое исправление можно осуществлять путем обеспечения произношения. Пользователь, в начале, выбирает или осуществляет навигацию к словам, подлежащим исправлению, произнося 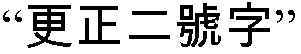 (“исправить второй иероглиф”) для выделения второго иероглифа 1002, если мастер еще не перешел и не выделил второй иероглиф 1002.
(“исправить второй иероглиф”) для выделения второго иероглифа 1002, если мастер еще не перешел и не выделил второй иероглиф 1002.
На фиг. 11 показан скриншот диалогового окна орфографии 1100, представляемого для голосового произношения. Затем пользователь произносит  для произношения, и это произношение представляется обратно пользователю в поле произношения 1102, и мастер вновь обеспечивает индексированный список слов в окне списка 902. В окне списка 902 перечислены слова-кандидаты в порядке от более часто используемых слов в верхней части к менее часто используемым словам в нижней части. Кроме того, когда система диктует, первый иероглиф 802 исправляется ключевым словом, например фамилиями, система обнаружит ключевое слово и отрегулирует исправление нижеследующего списка иероглифов-кандидатов. В этом случае, иероглифы, используемые для имени, будут продвигаться в верхнюю часть списка кандидатов 902 при исправлении остальных иероглифов. Как и раньше, пользователь затем может выбирать нужный иероглиф, произнося соответствующий индексный номер, например
для произношения, и это произношение представляется обратно пользователю в поле произношения 1102, и мастер вновь обеспечивает индексированный список слов в окне списка 902. В окне списка 902 перечислены слова-кандидаты в порядке от более часто используемых слов в верхней части к менее часто используемым словам в нижней части. Кроме того, когда система диктует, первый иероглиф 802 исправляется ключевым словом, например фамилиями, система обнаружит ключевое слово и отрегулирует исправление нижеследующего списка иероглифов-кандидатов. В этом случае, иероглифы, используемые для имени, будут продвигаться в верхнюю часть списка кандидатов 902 при исправлении остальных иероглифов. Как и раньше, пользователь затем может выбирать нужный иероглиф, произнося соответствующий индексный номер, например  (“два”) или
(“два”) или  (“номер два”), связанный со вторыми кандидатами для получения “
(“номер два”), связанный со вторыми кандидатами для получения “ ”. После этого выбранный кандидат заменяет старый иероглиф, окно произношения 1100 очищается, и окно списка 902 удаляется из диалога.
”. После этого выбранный кандидат заменяет старый иероглиф, окно произношения 1100 очищается, и окно списка 902 удаляется из диалога.
Если SR неверно распознает произношение, мастер отображает ближайшие фонемы на основании вышеописанной матрицы неточностей. На фиг. 12 показан скриншот диалогового окна орфографии 1200, представляемого для исправления голосового произношения. Пользователь может взаимодействовать с мастером, произнося фонему, подлежащую исправлению, произнося, например,  (“исправить первую фонему”). Затем выделяется первая фонема 1202. Затем представляется окно 1204 списка фонем со списком фонем, в порядке расстояния фонемы. Затем пользователь может произнести “
(“исправить первую фонему”). Затем выделяется первая фонема 1202. Затем представляется окно 1204 списка фонем со списком фонем, в порядке расстояния фонемы. Затем пользователь может произнести “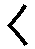 ” (= “qi” в пиньине) для замены первой неверно распознанной фонемы 1202 исправленной фонемой “”, имеющей индекс “1” в окне списка 1204.
” (= “qi” в пиньине) для замены первой неверно распознанной фонемы 1202 исправленной фонемой “”, имеющей индекс “1” в окне списка 1204.
На фиг. 13 показан скриншот диалогового окна орфографии 1300, представляемого с пересмотренным окном списка омофонов 902 на основании исправления голосового произношения. Окно списка иероглифов-омофонов 902 исправляется на основании измененной фонемы. Затем пользователь выбирает первый иероглиф 1402, проиллюстрированный на фиг. 14, произнося соответствующий номер, например (“один”) или (“номер один”), в этом случае. Соответственно, выбранный кандидат заменяет исходный, и поле произношения 1102 очищается, и окно списка 902 удаляется из диалога. На фиг. 14 показан скриншот диалогового окна орфографии 1400, представляемого, когда курсор перемещается к следующему иероглифу для обработки голосового произношения, или когда обработка, показанная на фиг. 13, завершена.
Как описано здесь, имена, скорее всего, потребуют мастера орфографии, поскольку каждый пользователь не знает, какие именно иероглифы используются в именах. Поэтому из имени можно получать и обеспечивать подсказки. Например, в ряде случаев, может быть только несколько сотен рассматриваемого типа фамилии, и, как описано выше, известно, что набор должен быть фиксированным. Таким образом, при выборе фамилии, которая всегда должна быть первым иероглифом строк слов/иероглифов, список иероглифов-кандидатов, отображаемый в окне списка, будет регулироваться. Например, для имени, в котором используется 'fan', иероглиф может представлять собой  (означающий “общий”),
(означающий “общий”),  (“усложненный”),
(“усложненный”),  (“раздражающий”),
(“раздражающий”),  (“варвар”),
(“варвар”),  (“заключенный”) и т.д.
(“заключенный”) и т.д.
Для большинства иероглифов пользователь выбирает для имени позитивный или нейтральный смысл, показанный в первых двух из вышеприведенных примеров. Однако, если большинство обучающих данных получено из газеты, что справедливо для большинства современных систем обучения языку, иероглиф можно связать с последним смыслом (“заключенный”) с очень высокой частотностью. Поэтому, обеспечивая информацию категории в файлах данных, список слов можно регулировать согласно подсказкам. Подсказки, которые можно рассматривать, включают в себя, но без ограничения, имена собственные (например, фамилии), названия улиц (например, с использованием  (“дорога”),
(“дорога”),  (“улица”),
(“улица”),  (“город”) и
(“город”) и  (“страна”)), и названия компаний/организаций (например, с использованием
(“страна”)), и названия компаний/организаций (например, с использованием 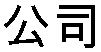 (“компания”) и
(“компания”) и  (“организация”)).
(“организация”)).
Раскрытой системе легче обрабатывать (или распознавать) вышеозначенный сценарий, когда пользователь приобретает опыт в выборе слова с множественными иероглифами, находясь в режиме проверки орфографии и правильно анализируя слово (для границ слова) на основании ограниченной последовательности иероглифов. Если пользователь выбирает только один иероглиф из слова, состоящего из множественных иероглифов, система может потерять информацию о границах слова для нового слова.
Вышеописанный второй способ получает китайские иероглифы путем голосового ввода слов, содержащих нужные иероглифы. На фиг. 15 показана система 1500, которая применяет позитивный, нейтральный и негативный смыслы для взвешивания иероглифа в соответствии со вторым способом. В компоненте распознавания 102, показанном на фиг. 15, показана совокупность 502 движков азиатского языка, где первый движок 504 использует способ 404 «иероглиф в слове», который дополнительно использует файлы данных 1502 для обеспечения данных. Каждый движок языка 502 может использовать файлы данных 1502 для получения иероглифов на основании способа 404 «иероглиф в слове». Первый файл данных 1504 включает в себя слова с позитивным и нейтральным смыслом, а второй файл данных 1506 включает в себя слова с негативным смыслом, и третий файл данных 1508 включает в себя остальные слова в лексиконе, которые не составляют часть файлов данных (1504 и 1506).
В соответствии со способом 404 «иероглиф в слове», и/или дополнительно к обеспечению произношения для получения иероглифов, пользователь также может получать иероглифы, давая другие слова, которые содержат нужный(е) иероглиф(ы). По аналогии с “a, as in apple”, пользователи могут указывать нужный иероглиф, например,  , произнося слово
, произнося слово  , которое содержит иероглиф.
, которое содержит иероглиф.  - это слово, которое содержит нужный иероглиф
- это слово, которое содержит нужный иероглиф  . Слово
. Слово  - это притяжательная форма, указывающая нужный иероглиф, который должен быть в составе слова.
- это притяжательная форма, указывающая нужный иероглиф, который должен быть в составе слова.
Для получения точности распознавания SR желательно иметь информацию или данные о словах, которые люди обычно используют для задания иероглифа. Во многих случаях для указания иероглифов люди обычно используют наиболее часто используемые слова, а также слова с позитивным семантическим смыслом. Ниже представлены подходы к получению слов для CFG. Большой массив имен можно собирать, чтобы получить список иероглифов, которые обычно будут использоваться в таких именах. Кроме того, массив должен быть малым подмножеством действительных иероглифов.
Дополнительно, точность распознавания можно повысить, найдя большой массив слов, которые содержат иероглифы, после чего сгруппировав слова в первую группу или файл 1504, который включает в себя позитивный или нейтральный смыслы, и вторую группу или файл 1506, который включает в себя негативный смысл. Люди обычно используют слова с позитивным или нейтральным смыслами для указания иероглифов, используемых в именах. Система 1500 может включать в себя компонент взвешивания 1510 для назначения словам данных или значений взвешивания. Затем позитивному и нейтральному смыслам можно присваивать более высокое весовое значение, а негативному смыслу присваивать промежуточное весовое значение, и более низкие весовые значения можно присваивать остальным словам в лексиконе, которые не содержат иероглифы, которые люди часто используют в именах. Кроме того, слова в трех группах можно упорядочивать на основании частоты употребления слова с использованием частотного компонента 514, показанного на фиг. 5.
Этот способ применяется к китайскому языку, также, например, к кандзи в японском языке. Способ активируется при наведении курсора UI на один из иероглифов в верхней части (или разделенного или китайского) окна для окон орфографии, например иероглифы в 802, 1002 и 1402. Таким образом, пользователи могут обеспечивать либо произношение, либо слова, содержащие иероглифы, чтобы, в конце концов, получить нужный(е) иероглиф(ы).
Вышеописанный третий способ 406 получает китайские иероглифы путем разложения на слова. На фиг. 16 показана система, 1600 которая применяет разложение на слова путем голосового ввода подкомпонентов нужного иероглифа в соответствии с третьим способом. В компоненте распознавания 102 показана совокупность 502 движков азиатского языка, где первый движок 504 использует способ разложения на иероглифы 406, который дополнительно использует файлы данных 1602 для обеспечения данных. Каждый движок языка 502 может использовать файлы данных 1602 для получения иероглифов на основании способа разложения на иероглифы 406. Первый файл данных 1604 включает в себя разложимые иероглифы, и второй файл данных 1606 включает в себя составные компоненты иероглифов.
Пользователи могут получить нужные иероглифы путем обеспечения подкомпонента(ов) слова, произнося  для указания
для указания  , где
, где  (“лес”) и
(“лес”) и 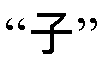 (“сын”) являются символами-подкомпонентами, объединенными для формирования ; это верхний символ иероглифа, и - нижний символ.
(“сын”) являются символами-подкомпонентами, объединенными для формирования ; это верхний символ иероглифа, и - нижний символ.
Следует понимать, что немногие иероглифы являются разложимыми и также широко используемыми пользователями. Следовательно, все иероглифы, которые можно разложить, и разложимые выражения, которые широко используются, будут собраны и включены в грамматику. Аналогично второму способу 404 третий способ 406 может активироваться при наведении курсора на один из иероглифов в верхнем окне из разделенных окон для окон мастера орфографии, например иероглифы в 802, 1002 и 1402. Другими словами, пользователи могут обеспечивать произношение или составные слова, или подкомпоненты, для получения нужных иероглифов. Система 1600 включает в себя компонент популярности 1608 для отыскания, обработки и сохранения популярных иероглифов 1604 и разложения иероглифов на составные компоненты 1606.
Согласно фиг. 2 компонент обобществления 208 позволяет пользователю обобществлять локальный лексикон для повышения точности SR или снижения усилий по исправлению для других пользователей. Когда пользователь работает с аспектами этой архитектуры, пользователь может “обучать” систему, или система может изучать действия пользователя и/или данные/параметры системы (например, используя возможности обучения и рассуждения компонента вывода 302, показанного на фиг. 3). Когда пользователь диктует, вероятность распознанных слов может изменяться, показывая, какие слова используются наиболее часто. Кроме того, если слово отсутствует в стандартном лексиконе 202, показанном на фиг. 2, пользователь может добавить его в задаваемую пользователем часть лексикона. При этом пользователь может “говорить” распознавателю речи 102, где можно найти дополнительные слова (например, в стандартной или пользовательской части) лексикона.
Возможность обобществлять, загружать и выгружать новые лексиконы для множественных пользователей облегчает обеспечение непрерывно улучшаемого распределенного массива. Другими словами, каждый пользователь “учит” компьютеры и способы отдельных пользователей, использующие одинаковые или сходные слова. В групповых или сотруднических вариантах осуществления, например, полезно обмениваться пользовательскими лексиконами. Например, в контексте командного проекта, когда пользователи обновляют соответствующие пользовательские лексиконы новыми словами, обобществление позволяет распространять эти новые слова другим членам команды проекта. Обобществление можно осуществлять по-разному, в том числе из центрального положения, где единый файл обобществляется между множественными пользователями, а также пакетное обобществление против пословного обобществления.
Помимо обобществления с другим пользователем команды, компонент обобществления 208 раскрытой архитектуры включает в себя возможность обеспечения обратной связи в отношении того, что изучил распознаватель речи 102, с сущностью поставщика, чтобы поставщик мог улучшать стандартный лексикон. Для этого распознаватель речи 102 может включать в себя механизм, позволяющий пользователю указывать, можно ли новое слово, добавленное в пользовательский лексикон, сделать общественным достоянием вне системы пользователя, команды проекта и/или границ компании. Если разрешено, распознаватель 102 может направить информацию поставщику для обзора и включения в стандартный лексикон для следующего публичного выпуска или обновлений. Однако, если пользователь запрещает это делать, вновь добавленный термин не направляется поставщику. Примером термина, который можно направить поставщику, является новый промышленный термин, который в последнее время приобрел популярность в сообществе, а примером частного слова может быть название компании или внутреннее название проекта. Следует принимать во внимание вопросы безопасности, чтобы гарантировать, что обобществление не нарушает, например, права интеллектуальной собственности, объем обобществляемого контента и процессы принятия решения на обобществление.
Раскрытая архитектура также облегчает использование и реализацию команд для разных наборов азиатских иероглифов. Например, японский язык имеет четыре разных системы письма: хирагана, катакана, кандзи и ромадзи. Хирагану можно рассматривать как фонетическую систему японского языка и также действительную систему письма (по аналогии с испанским, где слово пишется в соответствии с его звучанием). Катакана является более формальной системой письма, которая находится во взаимно-однозначном соответствии с хираганой. Кандзи часто используется для написания имен. По аналогии с китайским, один набор звуков хираганы может соответствовать множественным омофонам в кандзи. Поэтому те же диалоговые окна и процессы орфографии можно применять для получения кандзи из хираганы.
Кроме того, вместо обеспечения функции омофона, как в китайском, кнопка для хираганы и катаканы задана так, чтобы, если пользователю нужна только хирагана или соответствующая катакана, можно было использовать возможность голосовой команды или кнопки для получения слов в верхнем окне слова способа разделенных окон (1708 на фиг. 17 или 1806 на фиг. 18). Можно предусмотреть кнопку выбора, чтобы пользователь мог выбирать, и/или голосовую команду по названию кнопки для преобразования хираганы в ромадзи. Поскольку один набор хираганы может соответствовать множественным иероглифам ромадзи, когда пользователь произносит произношения хираганы, например,  (“ромадзи”) для запуска преобразования ромадзи, окно списка, используемого для перечисления омофонов кандзи, очищается и повторно наполняется результатами для ромадзи. Затем пользователь может назвать индексный номер, предшествующий нужному иероглифу ромадзи для перемещения этого иероглифа ромадзи в верхнее окно слова (1708 на фиг. 17 или 1806 на фиг. 18).
(“ромадзи”) для запуска преобразования ромадзи, окно списка, используемого для перечисления омофонов кандзи, очищается и повторно наполняется результатами для ромадзи. Затем пользователь может назвать индексный номер, предшествующий нужному иероглифу ромадзи для перемещения этого иероглифа ромадзи в верхнее окно слова (1708 на фиг. 17 или 1806 на фиг. 18).
Например, для иероглифа  (“грязь”), выход для этого иероглифа в четырех системах письма, хирагане, катакане, кандзи и ромадзи, будет следующим:
(“грязь”), выход для этого иероглифа в четырех системах письма, хирагане, катакане, кандзи и ромадзи, будет следующим:
хирагана: 
катакана: 
ромадзи: tsuchi, tuchi, tuti
кандзи:
Существуют другие иероглифы кандзи, которые совместно используют одно и то же произношение, например ту же хирагану,
омофон кандзи: 
На фиг. 17 показан скриншот диалогового окна орфографии 1700, представляемого для распознавания и обработки японского языка путем голосового/клавиатурного ввода хираганы для получения кандзи. Окно 1700 включает в себя строку заголовка, указывающую использование хираганы. В окне списка 1704 показан список омофонов кандзи или 1802 на фиг. 18 для списка слов ромадзи. Строка 1706 предписывает пользователям использовать хирагану в качестве ввода для обработки преобразования в нужные системы письма. Окно слова 1708 сохраняет окончательные иероглифы, подлежащие вводу в приложение текстового редактора. В поле произношения 1710 показан распознанный ввод для обработки. Окно 1700 также включает в себя следующие кнопки выбора: кнопку выбора 1712 ромадзи (R), кнопку выбора 1714 хираганы (H), кнопку выбора 1716 катаканы (K), кнопку выбора 1718 Готово (O) и кнопку выбора 1720 Отмена (E).
Для получения иероглифов кандзи, пользователь может произнести  (“окно ввода хираганы”) для активации диалогового окна 1700 мастера орфографии, затем сказать
(“окно ввода хираганы”) для активации диалогового окна 1700 мастера орфографии, затем сказать  (“грязь” на хирагане), которое представляется в порядке обратной связи пользователю в поле произношения 1710 (после чего окно списка 1704 будет автоматически генерировать список иероглифов-омофонов кандзи, с числовыми индексами, предшествующими каждому иероглифу). Затем пользователь может произнести “1
(“грязь” на хирагане), которое представляется в порядке обратной связи пользователю в поле произношения 1710 (после чего окно списка 1704 будет автоматически генерировать список иероглифов-омофонов кандзи, с числовыми индексами, предшествующими каждому иероглифу). Затем пользователь может произнести “1  ” (“номер один”), чтобы переместить 1-е слово в окне списка 1704 в поля 1708 окна слова. После этого окно списка 1704 больше не представляется. Затем пользователь может сказать “Готово”, чтобы закрыть диалоговое окно орфографии 1700, и слово в окне слова 1708 будет скопировано в документ с использованием любого текстового редактора, применяемого в настоящее время.
” (“номер один”), чтобы переместить 1-е слово в окне списка 1704 в поля 1708 окна слова. После этого окно списка 1704 больше не представляется. Затем пользователь может сказать “Готово”, чтобы закрыть диалоговое окно орфографии 1700, и слово в окне слова 1708 будет скопировано в документ с использованием любого текстового редактора, применяемого в настоящее время.
Для получения хираганы, пользователь может сказать  для запуска диалогового окна орфографии 1700. Когда пользователь говорит
для запуска диалогового окна орфографии 1700. Когда пользователь говорит  , в результате чего представляется в поле произношения 1710, окно списка 1704 будет автоматически генерировать список иероглифов-омофонов кандзи как стандартный список; однако пользователь может по своему выбору игнорировать список. Затем пользователь может произнести
, в результате чего представляется в поле произношения 1710, окно списка 1704 будет автоматически генерировать список иероглифов-омофонов кандзи как стандартный список; однако пользователь может по своему выбору игнорировать список. Затем пользователь может произнести  (“хирагана”), и распознанное в 1710 будет автоматически перенесено в окно слова 1708. Затем окно списка 1704 будет удалено, поскольку оно уже не нужно. Сказав “Готово”, пользователь предписывает закрыть диалоговое окно орфографии 1700, и слово в окне слова 1708 будет скопировано в открытый на данный момент документ.
(“хирагана”), и распознанное в 1710 будет автоматически перенесено в окно слова 1708. Затем окно списка 1704 будет удалено, поскольку оно уже не нужно. Сказав “Готово”, пользователь предписывает закрыть диалоговое окно орфографии 1700, и слово в окне слова 1708 будет скопировано в открытый на данный момент документ.
Для получения катаканы, пользователь может произнести  для запуска диалогового окна орфографии 1700. Когда пользователь говорит , в результате чего представляется в поле 1710 окна произношения, окно списка 1704 будет автоматически генерировать список иероглифов-омофонов кандзи; однако пользователь может по своему выбору игнорировать список. Затем, пользователь может сказать
для запуска диалогового окна орфографии 1700. Когда пользователь говорит , в результате чего представляется в поле 1710 окна произношения, окно списка 1704 будет автоматически генерировать список иероглифов-омофонов кандзи; однако пользователь может по своему выбору игнорировать список. Затем, пользователь может сказать  (“катакана”), и система получит версию катаканы в виде
(“катакана”), и система получит версию катаканы в виде  (“грязь” на катакане), и система напишет непосредственно в окне слова 1708. Затем окно списка 1704 можно закрыть, поскольку оно уже не нужно. Пользователь может выбрать “Готово”, чтобы закрыть диалоговое окно орфографии 1700, и слово в окне слова 1708 будет скопировано в документ с помощью существующего текстового редактора.
(“грязь” на катакане), и система напишет непосредственно в окне слова 1708. Затем окно списка 1704 можно закрыть, поскольку оно уже не нужно. Пользователь может выбрать “Готово”, чтобы закрыть диалоговое окно орфографии 1700, и слово в окне слова 1708 будет скопировано в документ с помощью существующего текстового редактора.
На фиг. 18 показан скриншот диалогового окна орфографии 1800, представляемого для распознавания и обработки японского языка, связанного с получением ромадзи. Для получения ромадзи, пользователь может сказать  , чтобы открыть диалоговое окно орфографии 1800. Когда пользователь произносит , благодаря чему представляется в поле 1804 окна произношения, окно списка 1802 будет автоматически генерировать список иероглифов-омофонов кандзи в окне списка 1802; однако пользователь может игнорировать этот список. Если пользователь произносит
, чтобы открыть диалоговое окно орфографии 1800. Когда пользователь произносит , благодаря чему представляется в поле 1804 окна произношения, окно списка 1802 будет автоматически генерировать список иероглифов-омофонов кандзи в окне списка 1802; однако пользователь может игнорировать этот список. Если пользователь произносит  (“ромадзи”), система преобразует в версию ромадзи. Поскольку существуют множественные кандидаты для версии ромадзи, кандидаты кандзи в окне списка 1802 заменяются кандидатами ромадзи. Затем пользователь может произнести “1
(“ромадзи”), система преобразует в версию ромадзи. Поскольку существуют множественные кандидаты для версии ромадзи, кандидаты кандзи в окне списка 1802 заменяются кандидатами ромадзи. Затем пользователь может произнести “1 ”, чтобы получить 1-е слово в окне списка 1802, благодаря чему “tsuchi” перемещается в окно слова 1806. Затем окно списка 1802 можно закрыть. Если пользователь говорит “Готово”, диалоговое окно орфографии 1800 закрывается, и слово в окне слова 1806 будет скопировано в документ или текстовый редактор, используемый в данный момент.
”, чтобы получить 1-е слово в окне списка 1802, благодаря чему “tsuchi” перемещается в окно слова 1806. Затем окно списка 1802 можно закрыть. Если пользователь говорит “Готово”, диалоговое окно орфографии 1800 закрывается, и слово в окне слова 1806 будет скопировано в документ или текстовый редактор, используемый в данный момент.
Хотя некоторые подходы к отображению информации пользователям показаны и описаны на некоторых фигурах в виде скриншотов, специалистам в данной области техники очевидно, что можно применять различные альтернативы. Термины “экран”, “скриншот”, “веб-страница”, “документ” и “страница” используются здесь взаимозаменяемо. Страницы или экраны сохраняются и/или передаются в качестве описаний дисплея, в качестве графических интерфейсов пользователя, или другими способами отображения информации на экране (например, персонального компьютера, КПК, мобильного телефона или другого подходящего устройства), где схема и информация или контент, подлежащий отображению на странице, сохраняется в памяти, базе данных или другом средстве хранения.
На фиг. 19 показан способ распознавания речи в соответствии с раскрытой архитектурой. Хотя, для простоты объяснения, один или несколько способов, показанные здесь, например, в виде логической блок-схемы или последовательности операций, представлены и описаны как последовательность действий, очевидно, что способы не ограничиваются порядком действий, поскольку некоторые действия могут осуществляться в другом порядке и/или одновременно с другими действиями, иначе, чем показано и описано здесь. Например, специалистам в данной области техники очевидно, что способ можно альтернативно представить в виде ряда взаимосвязанных состояний или событий, например, на диаграмме состояний. Кроме того, не все действия, проиллюстрированные в описании способа, могут потребоваться для новой реализации.
На этапе 1900, движок распознавания речи принимает речевой ввод в виде азиатской речи. На этапе 1902, азиатские голосовые сигналы подвергаются обработке распознавания для вывода результата. На этапе 1904, активируется режим орфографии/исправления для диктовки новых слов или исправления результата. На этапе 1906, написание результата исправляется в один заход на основании фонетического произношения и/или выбора иероглифов. На этапе 1908, исправленный результат выводится в документ или приложение.
На фиг. 20 показан способ исправления результатов распознавания с использованием мастера орфографии. На этапе 2000, движок распознавания принимает речевой ввод на азиатском языке. На этапе 2002, азиатские голосовые сигналы подвергаются обработке распознавания, и режим исправления активируется для исправления результата диктовки. На этапе 2004, мастер орфографии запускается как часть режима исправления. На этапе 2006, азиатские иероглифы вводятся в мастер посредством фонетического произношения. На этапе 2008, орфография исправляется на основании фонетического произношения с помощью мастера.
На фиг. 21 показан способ преобразования фонетического произношения в иероглиф. На этапе 2100, начинается подготовка файла данных для процесса преобразования. На этапе 2102, файл данных создается из индексированных слов и значений слова, причем значения включают в себя произношения, тон, частоту использования и категорию. На этапе 2104, файл данных создается из индексированных произношений и слов, имеющих произношения в качестве значений, упорядоченных по частоте использования. На этапе 2106, файл данных создается из матрицы неточностей расстояний фонем. На этапе 2108, производится доступ к файлам данных для обработки произношения с помощью мастера орфографии.
На фиг. 22 показан способ использования команд разделения в азиатском и английском языках для обработки исправления. На этапе 2200, команды разделения представляются на азиатском и английском языках. На этапе 2202, производится проверка, входить ли в режим исправления орфографических ошибок английского языка. Если да, на этапе 2204, активируется режим проверки орфографии английского языка. На этапе 2206, список иероглифов-кандидатов представляется на основании голосовых сигналов согласно способам, доступным в режиме проверки орфографии. На этапе 2208, новые слова диктуются, или неверно распознанные слова исправляются на основании выбранных кандидатов. Если на этапе 2202 определено, что в режим проверки орфографии английского языка входить нельзя, способ переходит к этапу 2210 для активации режима проверки орфографии азиатского языка и затем к этапу 2206 для продолжения, как описано выше.
На фиг. 23 показан способ использования команд-омофонов в мастере орфографии азиатского языка. На этапе 2300, команды разделения представляются на азиатском и английском языках. На этапе 2302, активируется режим исправления орфографических ошибок азиатского языка. На этапе 2304, принимаются команды «омофон». На этапе 2306, список иероглифов-кандидатов представляется на основании иероглифов-омофонов целевого иероглифа. На этапе 2308, неверно распознанные слова исправляются на основании выбранных кандидатов.
На фиг. 24 показан способ применения весовых значений к смыслам слова. На этапе 2400, инициируется подготовка к исправлению посредством слов, содержащих нужные иероглифы. На этапе 2402, собирается большой массив имен. На этапе 2404, отыскиваются слова, которые содержат иероглифы в именах. На этапе 2406, слова объединяются в файл позитивного и нейтрального смысла. На этапе 2408, слова объединяются в файл негативного смысла. На этапе 2410, большие весовые коэффициенты присваиваются словам в группе позитивного и нейтрального смыслов. На этапе 2412, промежуточные весовые коэффициенты присваиваются словам в группе негативного смысла. На этапе 2414, низкие весовые коэффициенты присваиваются словам, не принадлежащим этим двум группам. На этапе 2416, слова упорядочиваются согласно частоте использования.
На фиг. 25 показан способ обобществления обновленного лексикона. На этапе 2500, инициируется режим исправления. На этапе 2502, новые слова, используемые в режиме исправления, отслеживаются и регистрируются. На этапе 2504, новые слова вводятся в локальный лексикон. На этапе 2506, обновленный лексикон переправляется другим пользователям. На этапе 2508, в необязательном порядке, пользователь может переправить обновленный лексикон поставщику для обновления массива лексикона распространения.
На фиг. 26 показан способ использования разложения на иероглифы для исправления орфографических ошибок. На этапе 2600, инициируется режим исправления орфографических ошибок. На этапе 2602, пользователь произносит символы-подкомпоненты нужного иероглифа. На этапе 2604, способ обращается к соответствующей таблице соотношений между подкомпонентом и соответствующим иероглифом. На этапе 2606, представляются все возможные иероглифы для подкомпонента, при наличии более чем одного совпадения. На этапе 2608, иероглиф-кандидат выбирается на основании подкомпонентов.
На фиг. 27A и 27B показан способ обработки исправления на основании множественных способов для исправления орфографических ошибок. На этапе 2700, движок принимает речевой ввод на азиатском языке. На этапе 2702, распознанные результаты движка представляются в UI. На этапе 2704, система принимает голосовую команду для входа в режим орфографии/исправления (для прямого ввода новых слов). Затем способ переходит к этапу 2706, где те же самые и/или другие иероглифы обрабатываются для контекста слова. Альтернативно, способ может переходить от этапа 2702 к этапу 2708, где система принимает голосовую команду для выбора слова для исправления. На этапе 2710, система принимает голосовую команду для входа в режим проверки орфографии и для выбора и исправления иероглифа. Как и раньше, способ затем переходит к этапу 2706, где те же самые и/или другие иероглифы обрабатываются для контекста слова.
Согласно фиг. 27B, на этапе 2712, осуществляется доступ к списку потенциальных слов на основании вычисленного контекста. Например, контекстом могут быть имена собственные. На этапе 2714, иероглифы из списка слов ранжируются на основании тех же самых и/или других иероглифов. На этапе 2716, производится выбор способа выбора иероглифов. На этапе 2718, способ может переходить к этапу 2720, где выбирается способ произнесения слова, которое содержит иероглиф аналогичного употребления. Альтернативно, на этапе 2722, выбирается способ получения иероглифа путем обеспечения произношения нужного иероглифа. Альтернативно, на этапе 2724, выбирается способ, где слово произносится для получения иероглифа посредством подкомпонентов. Альтернативно, на этапе 2726, выбирается способ произнесения слова(слов) для получения списка омофонов и выбора из списка омофонов. На этапе 2728, добавляется новый иероглиф или неверный иероглиф в неверно написанном слове, затем заменяется выбранным иероглифом. На этапе 2730, голосовое подтверждение правильности всего слова затем принимается от пользователя. На этапе 2732, результат движка корректируется с использованием верного иероглифа.
Используемые в этой заявке термины “компонент” и “система” относятся к компьютерной сущности, которая представляет собой либо оборудование, либо комбинацию оборудования и программного обеспечения, либо программное обеспечение, либо выполняемое программное обеспечение. Например, компонент может представлять собой, но без ограничения, процесс, выполняющийся на процессоре, процессор, привод жесткого диска, множественные приводы (оптического и/или магнитного носителя), объект, выполнимый модуль, поток выполнения, программу и/или компьютер. В порядке иллюстрации, компонентом может быть как приложение, выполняющееся на сервере, так и сам сервер. Один или несколько компонентов могут размещаться с процессе и/или потоке выполнения, и компонент может размещаться на одном компьютере и/или распределяться между двумя или несколькими компьютерами.
На фиг. 28 показана блок-схема вычислительной системы 2800, способной осуществлять обработку исправления в соответствии с раскрытой архитектурой. Для обеспечения дополнительного контекста различных ее аспектов фиг. 28 и нижеследующее описание призваны обеспечивать краткое общее описание пригодной вычислительной системы 2800, в которой можно реализовать различные аспекты. Хотя вышеприведенное описание относится, в целом, к компьютерным инструкциям, которые могут выполняться на одном или нескольких компьютерах, специалистам в данной области техники очевидно, что новый вариант осуществления также можно реализовать совместно с другими программными модулями и/или как комбинацию оборудования и программного обеспечения.
В общем случае, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.д., которые выполняют определенные задачи или реализуют определенные абстрактные типы данных. Кроме того, специалистам в данной области техники очевидно, что способы, отвечающие изобретению, можно осуществлять на практике посредством других конфигураций компьютерной системы, в том числе однопроцессорных или многопроцессорных компьютерных систем, миникомпьютеров, универсальных компьютеров, а также персональных компьютеров, карманных вычислительных устройств, микропроцессорных или программируемых потребительских электронных приборов и пр., каждый их которых может в ходе работы подключаться к одному или нескольким соответствующим устройствам.
Иллюстрируемые аспекты также можно применять на практике в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, связанными друг с другом посредством сети передачи данных. В распределенной вычислительной среде программные модули могут располагаться в локальных и удаленных запоминающих устройствах.
Компьютер обычно включает в себя различные компьютерно-считываемые среды. Компьютерно-считываемые среды могут представлять собой любые имеющиеся среды, к которым компьютер может осуществлять доступ, и включают в себя энергозависимые и энергонезависимые среды, сменные и стационарные среды. В порядке примера, но не ограничения, компьютерно-считываемые среды могут содержать компьютерные носители данных и среды передачи данных. Компьютерные носители данных включают в себя энергозависимые и энергонезависимые, сменные и стационарные носители, реализованные с помощью любого метода или технологии для хранения информации, например компьютерно-считываемых команд, структур данных, программных модулей или других данных. Компьютерные носители данных включает в себя, но без ограничения, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другие оптические диски, магнитные кассеты, магнитную ленту, накопитель на магнитных дисках или другие магнитные запоминающие устройства или любой другой носитель, который можно использовать для хранения полезной информации и к которому компьютер 110 может осуществлять доступ.
Согласно фиг. 28 иллюстративная вычислительная система 2800 для реализации различных аспектов включает в себя компьютер 2802, причем компьютер 2802 включает в себя процессор 2804, системную память 2806 и системную шину 2808. Системная шина 2808 обеспечивает интерфейс для системных компонентов, в том числе, но без ограничения, системной памяти 2806 к процессору 2804. Процессор 2804 может представлять собой любой из различных коммерчески доступных процессоров. В качестве процессора 2804 также можно применять двойные микропроцессоры и другие многопроцессорные архитектуры.
Системная шина 2808 может представлять собой любую из нескольких типов шинных структур и может дополнительно подключаться к шине памяти (с помощью контроллера памяти или без него), периферийной шине и локальной шине с использованием любых разнообразных коммерчески доступных шинных архитектур. Системная память 2806 включает в себя постоянную память (ПЗУ) 2810 и оперативную память (ОЗУ) 2812. Базовая система ввода/вывода (BIOS) хранится в энергонезависимой памяти 2810, например ПЗУ, ЭППЗУ, ЭСППЗУ, причем BIOS содержит основные процедуры, которые помогают переносить информацию между элементами компьютера 2802, например, при запуске. ОЗУ 2812 также может включать в себя высокоскоростное ОЗУ, например статическое ОЗУ для кэширования данных.
Компьютер 2802 дополнительно включает в себя внутренний привод жесткого диска (HDD) 2814 (например, EIDE, SATA), причем внутренний привод жесткого диска 2814 также можно приспособить для внешнего использования в подходящем корпусе (не показан), привод магнитного флоппи-диска (FDD) 2816 (например, для чтения с или записи на сменную дискету 2818) и привод оптического диска 2820, (например, читающий диск CD-ROM 2822 или для чтения с или записи на другие оптические носители высокой емкости, например, DVD). Привод жесткого диска 2814, привод магнитного диска 2816 и привод оптического диска 2820 могут быть подключены к системной шине 2808 посредством интерфейса 2824 привода жесткого диска, интерфейса 2826 привода магнитного диска и интерфейса 2828 оптического привода соответственно. Интерфейс 2824 для реализаций внешнего привода включает в себя, по меньшей мере, одну или обе из технологий универсальной последовательной шины (USB) и интерфейса IEEE 1394.
Приводы и соответствующие компьютерные носители данных обеспечивают энергонезависимое хранилище данных, структур данных, компьютерных инструкций и т.д. Для компьютера 2802 приводы и носители обеспечивают хранение любых данных в подходящем цифровом формате. Хотя вышеприведенное описание компьютерно-считываемых носителей относится к HDD, сменной магнитной дискете и сменным оптическим носителям, например CD или DVD, специалистам в данной области техники очевидно, что другие типы носителей, которые считываются компьютером, например zip-диски, магнитные кассеты, карты флэш-памяти, картриджи и т.п., также можно использовать в иллюстративной операционной среде и, кроме того, что любые такие носители могут содержать компьютерные инструкции для осуществления новых способов раскрытой архитектуры.
На приводах и ОЗУ 2812 может храниться ряд программных модулей, в том числе операционная система 2830, одна или несколько прикладных программ 2832, другие программные модули 2834 и программные данные 2836. Полностью или частично, операционная система, приложения, модули и/или данные также могут кэшироваться в ОЗУ 2812. Также очевидно, что раскрытую архитектуру также можно реализовать с различными коммерчески доступными операционными системами или комбинациями операционных систем.
Пользователь может вводить команды и информацию в компьютер 2802 через одно или несколько проводных/беспроводных устройств ввода, например клавиатуру 2838 и указательное устройство, например мышь 2840. Устройства ввода/вывода могут включать в себя микрофон/громкоговорители 2837 и другое устройство (не показано), например ИК пульт управления, джойстик, игровую панель, перо, сенсорный экран и пр. Эти и другие устройства ввода нередко подключены к процессору 2804 через интерфейс устройств ввода 2842, который подключен к системной шине 2808, но могут подключаться посредством других интерфейсов, например параллельного порта, последовательного порта IEEE 1394, игрового порта, порта USB, ИК интерфейса и т.д.
Монитор 2844 или устройство отображения другого типа также подключен к системной шине 2808 через интерфейс, например видео-адаптер 2846. Помимо монитора 2844, компьютер обычно включает в себя другие периферийные устройства вывода (не показаны), например громкоговорители, принтеры и т.д.
Компьютер 2802 может работать в сетевой среде с использованием логических соединений посредством проводной и/или беспроводной связи с одним или несколькими удаленными компьютерами, например удаленным(и) компьютером(ами) 2848. Удаленный(е) компьютер(ы) 2848 могут представлять собой рабочую станцию, компьютер-сервер, маршрутизатор, персональный компьютер, портативный компьютер, развлекательный прибор на основе микропроцессора, равноправное устройство или другой общий сетевой узел и обычно включает в себя многие или все элементы, описанные выше применительно к компьютеру 2802, хотя, для краткости, показано только запоминающее устройство 2850. Описанные логические соединения включают в себя проводное/беспроводное подключение к локальной сети (LAN) 2852 и/или к более крупномасштабным сетям, например глобальной сети (WAN) 2854. Такие сетевые среды LAN и WAN обычно имеют место в учреждениях и компаниях и обеспечивают компьютерные сети в масштабах предприятия, например интрасети, которые все могут подключаться к глобальной сети связи, например интернету.
При использовании в сетевой среде LAN, компьютер 2802 подключен к локальной сети 2852 через проводной и/или беспроводной интерфейс или адаптер 2856 сети связи. Адаптер 2856 может обеспечивать проводное или беспроводное подключение к LAN 2852, которая также может включать в себя беспроводную точку доступа для связи с беспроводным адаптером 2856.
При использовании в сетевой среде WAN компьютер 2802 может включать в себя модем 2858, или подключаться к серверу связи в WAN 2854, или может иметь другое средство установления связи в WAN 2854, например Интернете. Модем 2858, который может быть внутренним или внешним и проводным и/или беспроводным устройством, подключен к системной шине 2808 через интерфейс 2842 последовательного порта. В сетевой среде программные модули, описанные применительно к компьютеру 2802, или часть из них, могут храниться в удаленном запоминающем устройстве 2850. Заметим, что показанные сетевые соединения являются иллюстративными и можно использовать другие средства установления линии связи между компьютерами.
Компьютер 2802 способен осуществлять связь с любыми беспроводными устройствами или сущностями, оперативно поддерживающими беспроводную связь, например принтером, сканером, настольным и/или портативным компьютером, карманным персональным компьютером, спутником связи, любым оборудованием или установкой, связанной с тегом беспроводной регистрации (например, киоском, новостным табло, комнатой отдыха), и телефоном. Это включает в себя, по меньшей мере, беспроводные технологии Wi-Fi и Bluetooth™. Таким образом, связь может быть заранее заданной структурой, как в традиционной сети, или просто специальным каналом связи между, по меньшей мере, двумя устройствами.
На фиг. 29 показана блок-схема иллюстративной вычислительной среды 2900 для обработки исправления в соответствии с раскрытой архитектурой. Система 2900 включает в себя один или несколько клиент(ов) 2902. Клиент(ы) 2902 может(могут) представлять собой оборудование и/или программное обеспечение (например, потоки, процессы, вычислительные устройства). На клиенте(ах) 2902 могут располагаться, например, куки и/или соответствующая контекстовая информация.
Система 2900 также включает в себя один или несколько серверов 2904. Сервер(ы) 2904 также может представлять собой оборудование и/или программное обеспечение (например, потоки, процессы, вычислительные устройства). На серверах 2904 могут располагаться потоки выполнения передач за счет использования, например, архитектуры. Одной возможной формой связи между клиентом 2902 и сервером 2904 может быть обмен пакетами данных между двумя или более компьютерными процессами. Пакет данных может включать в себя, например куки и/или соответствующую контекстовую информацию. Система 2900 включает в себя инфраструктуру связи 2906 (например, глобальную сеть связи, например, интернет), которую можно применять для обеспечения связи между клиентом(ами) 2902 и сервером(ами) 2904.
Для осуществления связи можно применять проводную (в том числе волоконно-оптическую) и/или беспроводную технологию. Клиент 2902 оперативно подключен к одному или нескольким клиентским хранилищам данных 2908, которые можно применять для хранения информации локально на клиенте(ах) 2902 (например, куки и/или соответствующей контекстовой информации). Аналогично, серверы 2904 оперативно подключены к одному или нескольким серверным хранилищам данных 2910, которые можно применять для хранения информации локально на серверах 2904.
Выше были описаны примеры раскрытой архитектуры. Конечно, невозможно описать все мыслимые комбинации компонентов или способов, но специалисту в данной области техники очевидно, что возможны многие дополнительные комбинации и перестановки. Соответственно, новая архитектура призвана охватывать все такие изменения, модификации и вариации, которые отвечают сущности и объему формулы изобретения. Кроме того, в той степени, в которой термин “включает в себя” используется в подробном описании или в формуле изобретения, такой термин призван быть включенным аналогично термину “содержащий”, поскольку “содержащий” интерпретируется при использовании в качестве переходного слова в формуле изобретения.

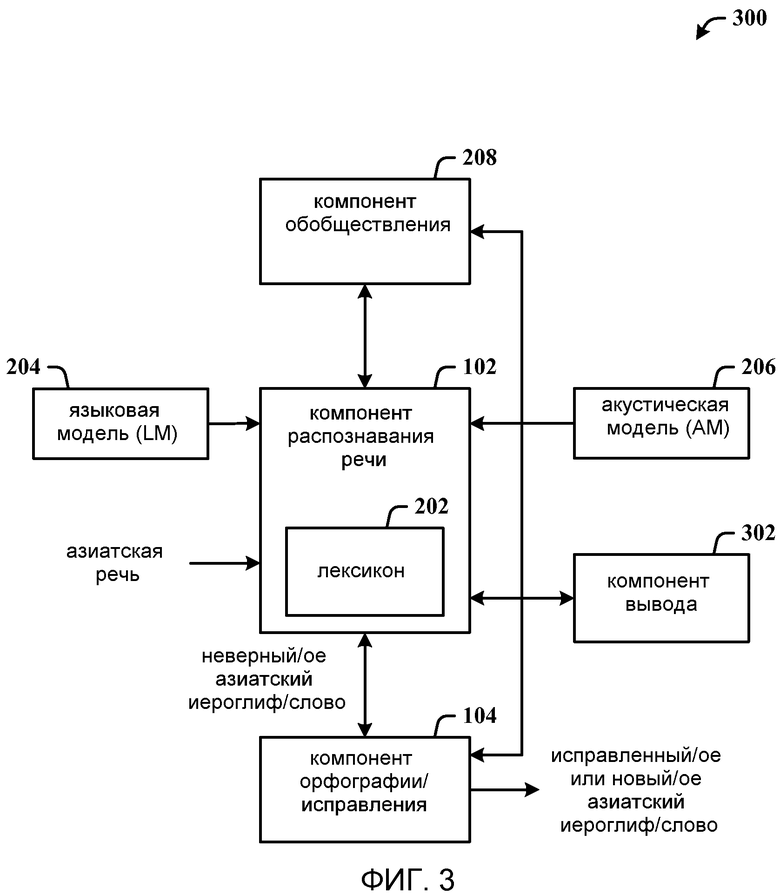
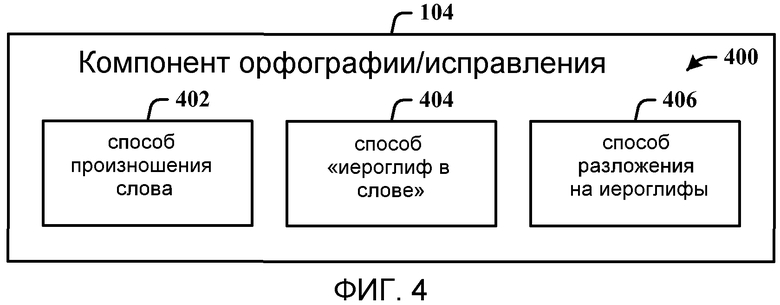
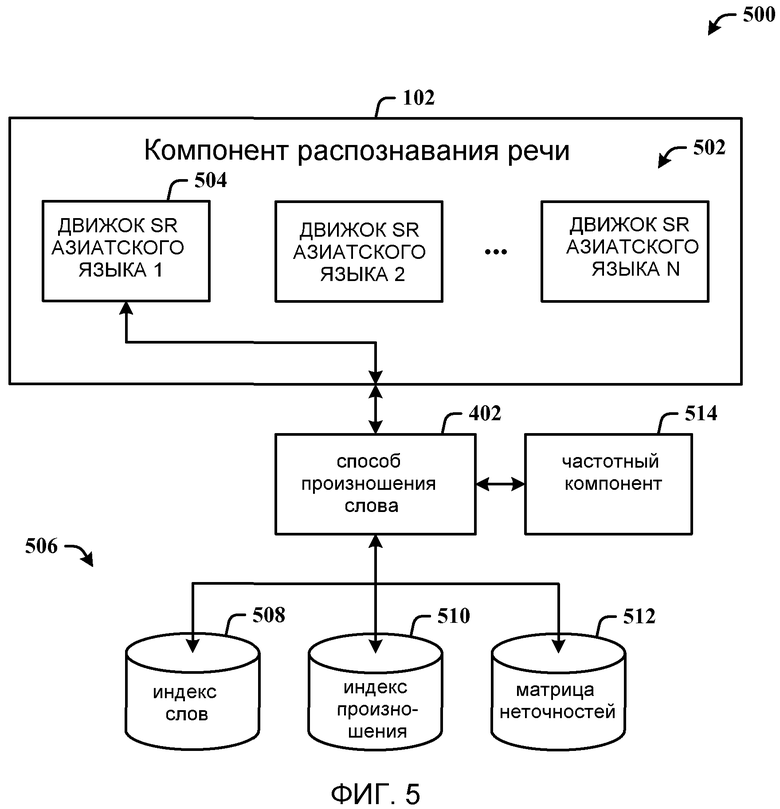
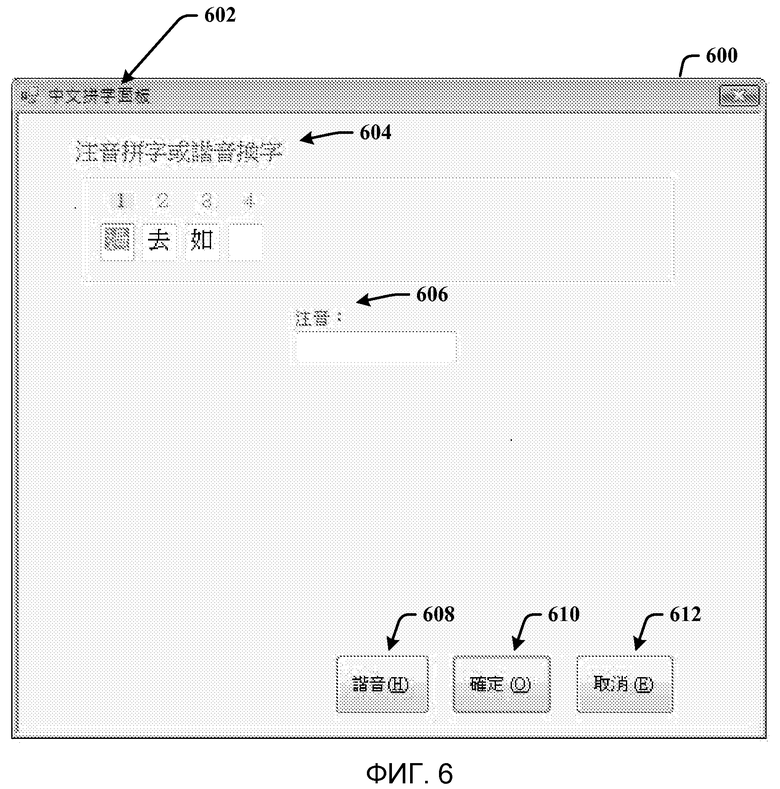

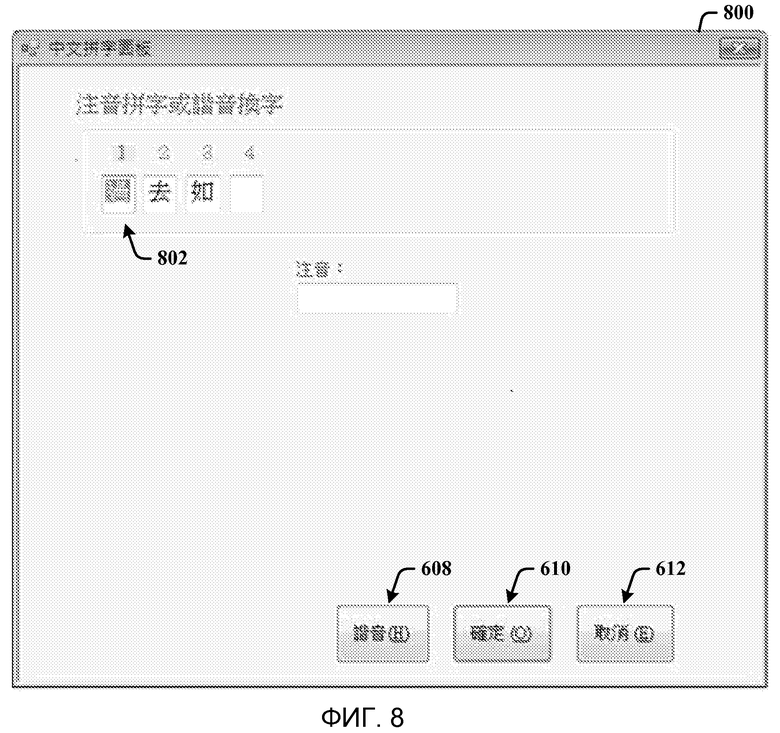
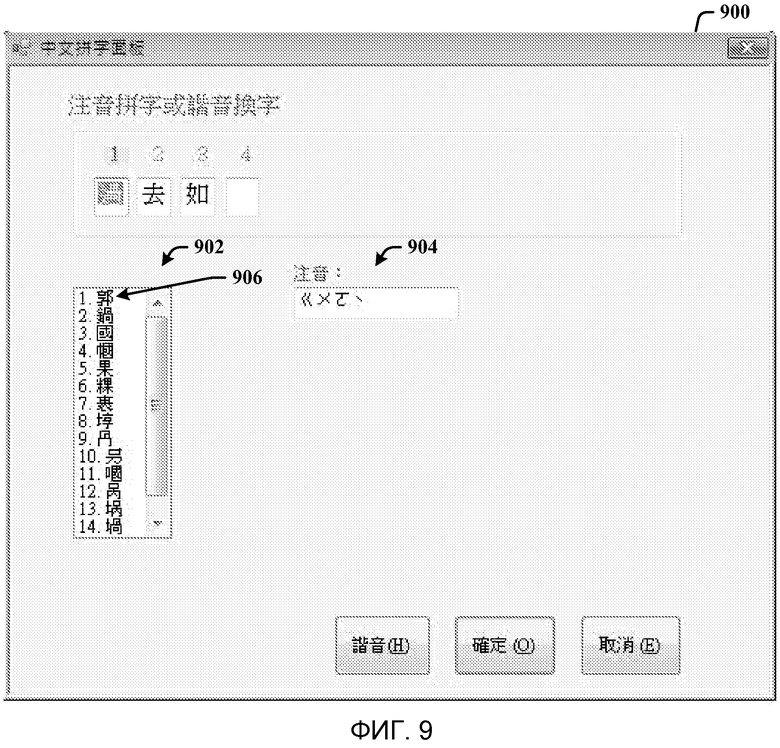
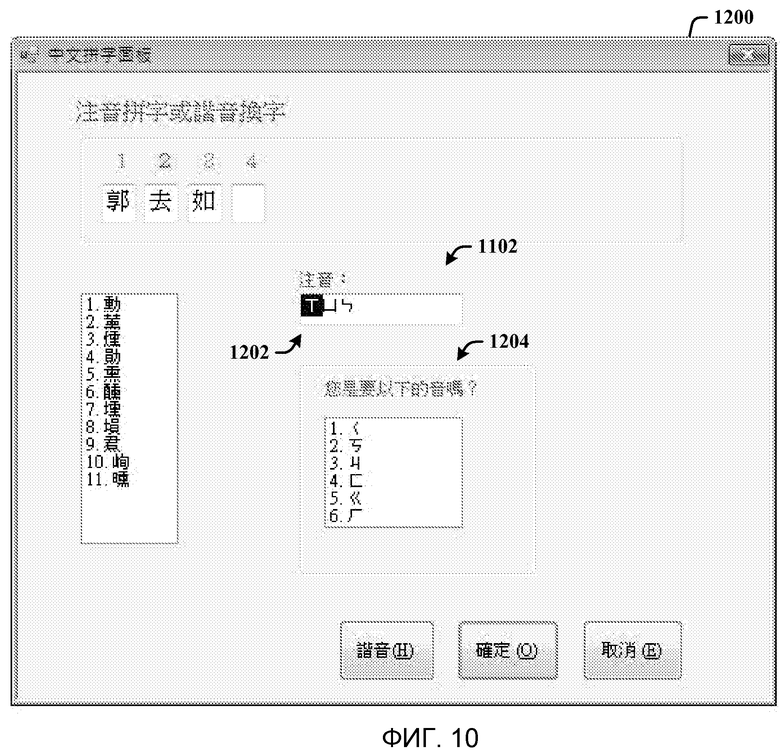


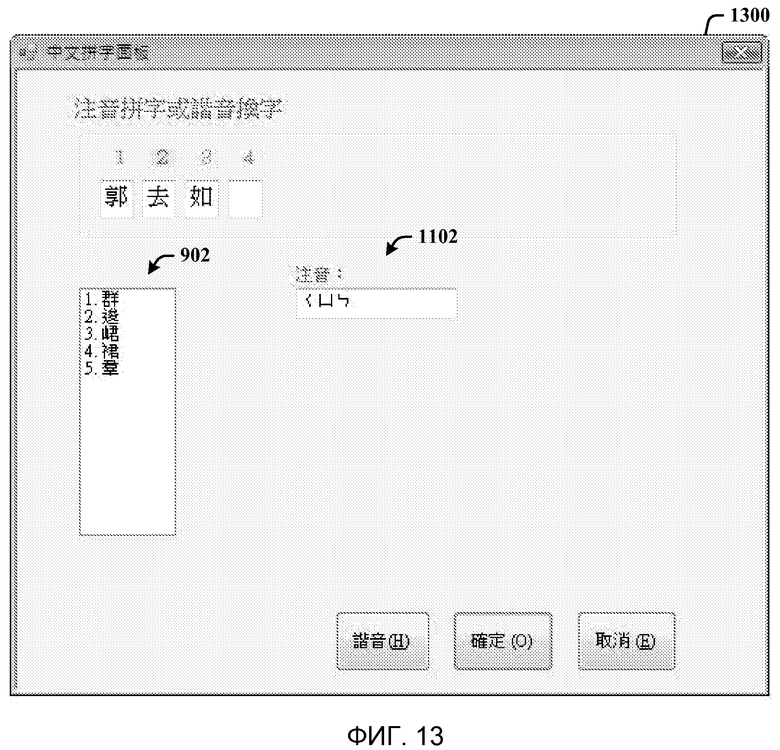


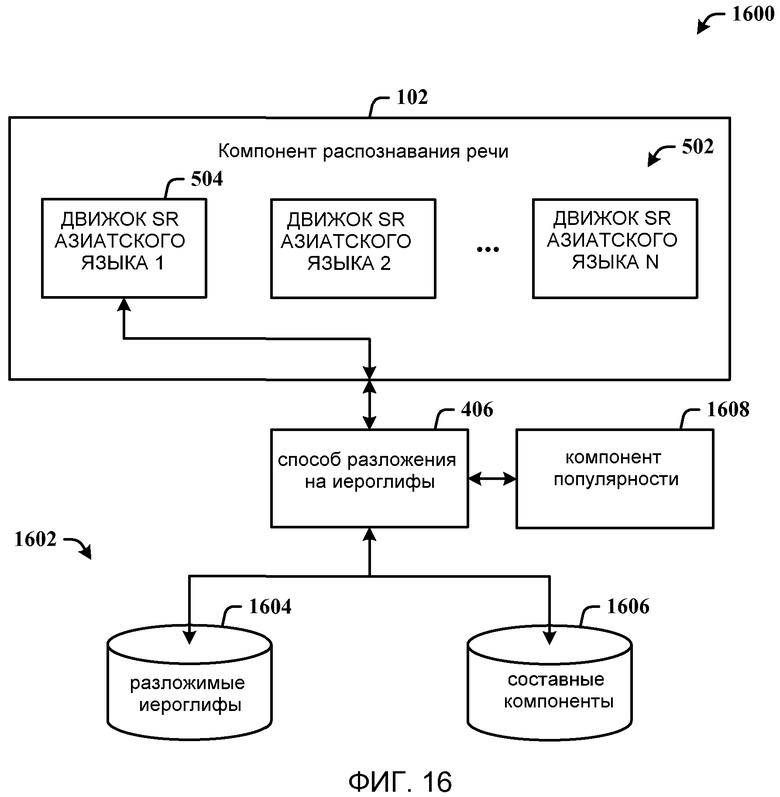

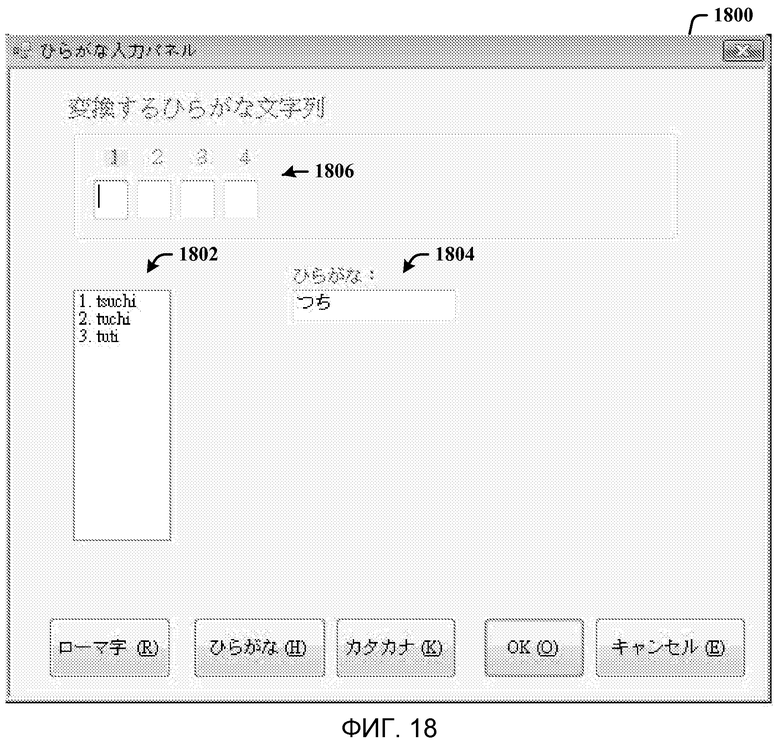

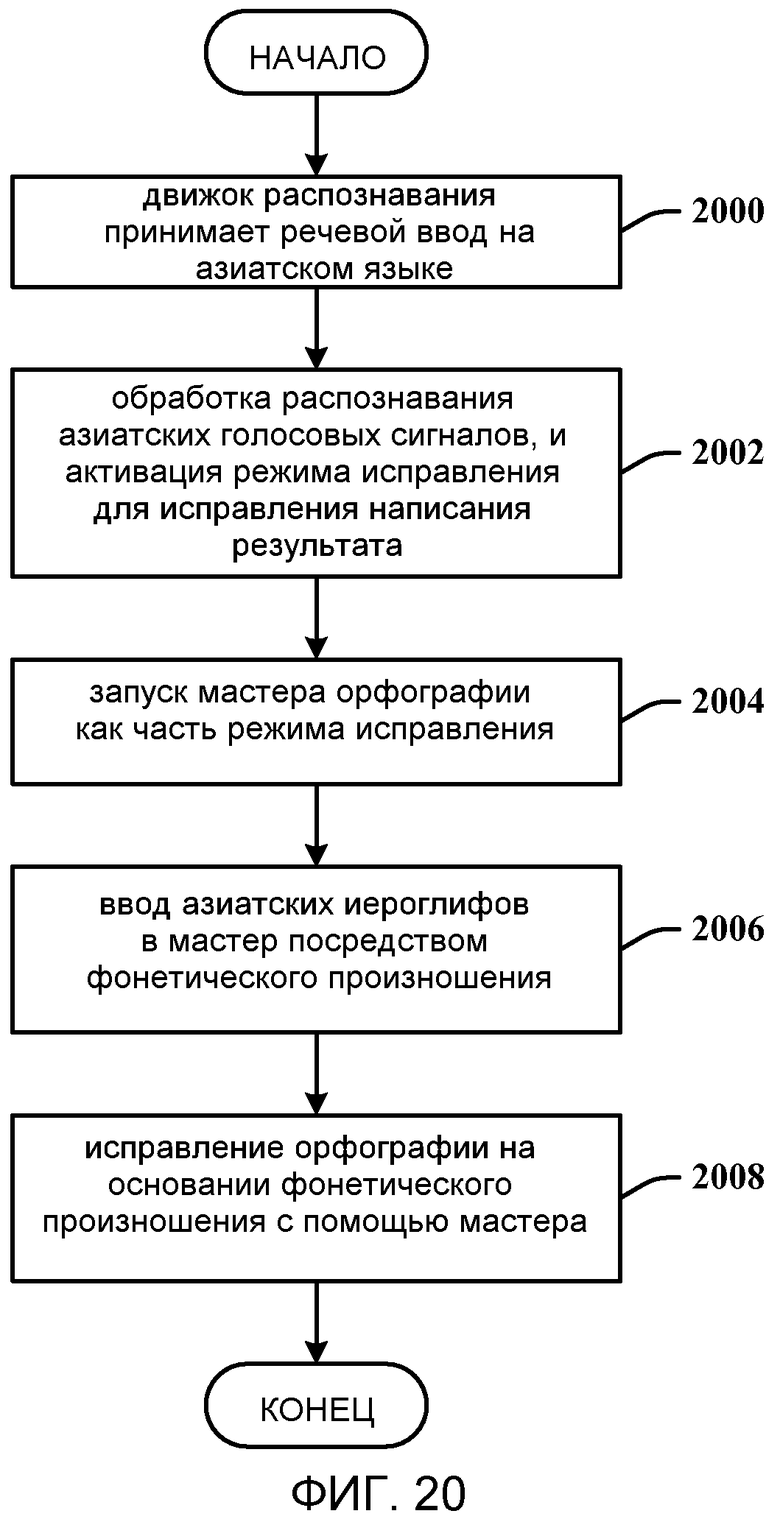


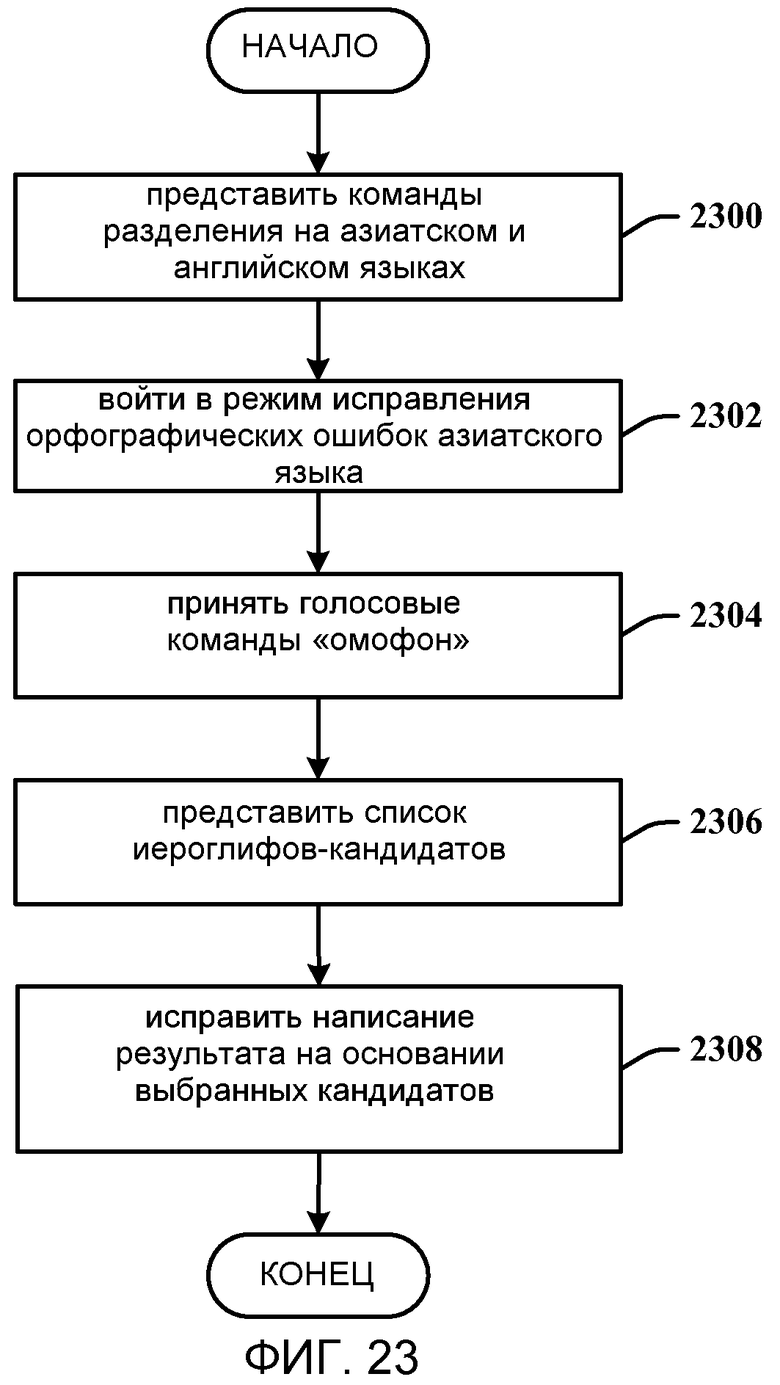


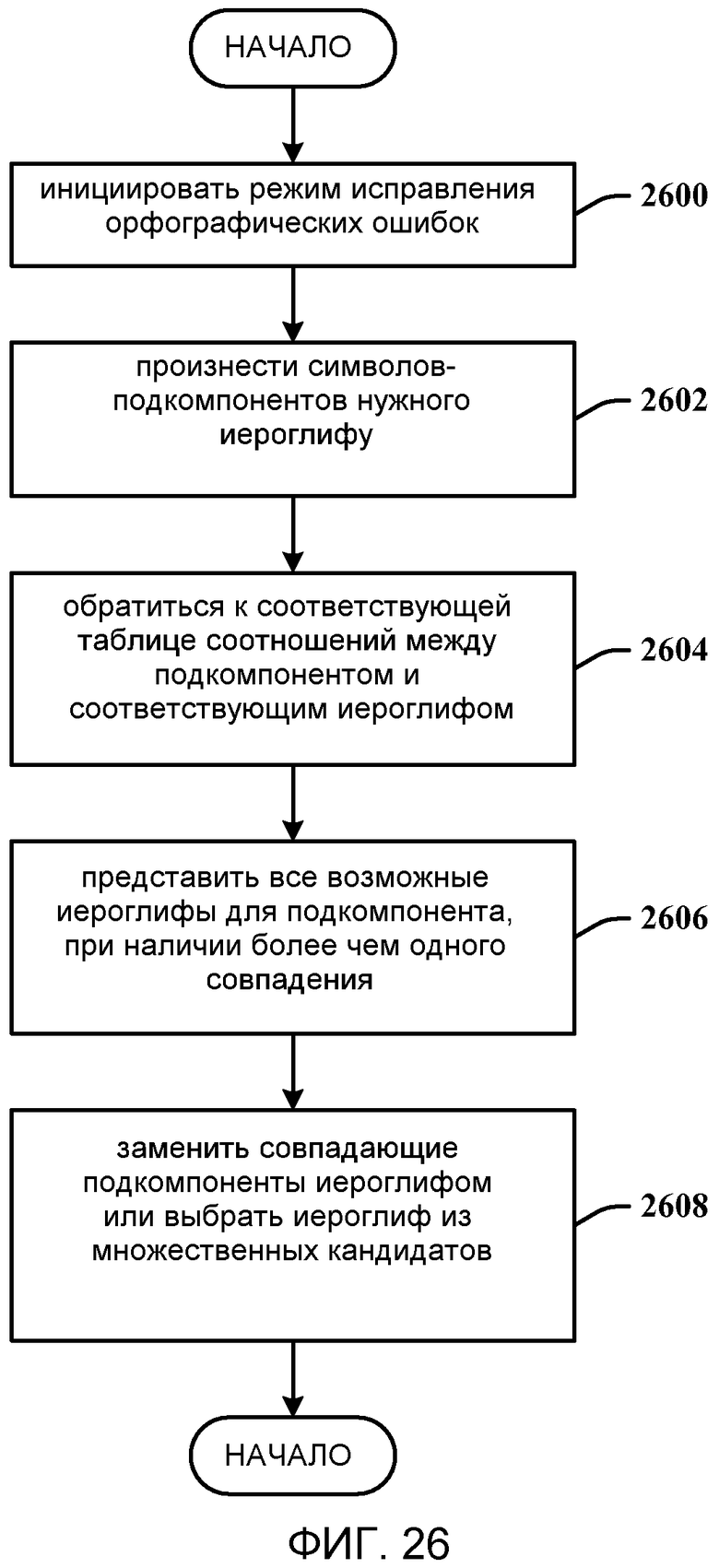


Изобретение относится к распознаванию речи на азиатском языке. Техническим результатом является облегчение ввода иероглифов, когда движок распознавания речи возвращает неверные иероглифы при диктовке, и, соответственно, повышение точности распознавания иероглифов при речевом вводе. Система перевода включает в себя компонент распознавания речи и компонент орфографии/исправления. Компонент распознавания речи выполнен с возможностью переключения между множеством систем письма на основе речевого ввода. Режим проверки орфографии запускают в ответ на прием речевого ввода, причем режим проверки орфографии предназначен для исправления неверного написания результатов распознавания или для генерации новых слов. Исправление получают с использованием речевого и/или мануального выбора и входа. Слова, исправленные с использованием режима проверки орфографии, исправляются как единое целое и рассматриваются как слово. Режим проверки орфографии применяется к языкам, по меньшей мере, азиатского континента, например упрощенному китайскому, традиционному китайскому и/или другим азиатским языкам, например японскому. 3 н. и 15 з.п. ф-лы, 30 ил.
1. Компьютерно-реализованная система перевода, содержащая: исполняемый процессором компонент распознавания речи для вывода азиатского иероглифа на основе речевого ввода, при этом компонент распознавания речи выполнен с возможностью переключения между множеством систем письма на основе языка речевого ввода; и компонент исправления для генерации исправленных выходных данных на основе некорректных выходных данных от компонента распознавания речи, при этом компонент исправления включает в себя мастер проверки орфографии для представления одного или более диалоговых окон для обеспечения пользователю возможности вокального и мануального взаимодействия для выбора и исправления этих некорректных выходных данных, причем упомянутые одно или более диалоговых окон представляются в ответ на голосовую команду.
2. Система по п.1, в которой компонент исправления принимает информацию, связанную с произношением слова, с использованием локальных фонетических символов.
3. Система по п.1, в которой компонент исправления принимает информацию, связанную с тем, как пишется слово, путем обеспечения слов, в которых используется упомянутый иероглиф.
4. Система по п.1, в которой компонент исправления принимает информацию, связанную с тем, как составлен упомянутый иероглиф.
5. Система по п.1, дополнительно содержащая компонент логического вывода, который применяет вероятностный и/или статистический анализ для прогнозирования или логического вывода действия, которое желательно осуществлять автоматически.
6. Система по п.1, дополнительно содержащая компонент совместного использования для совместного использования обновленного лексикона с другими пользователями и поставщиками лексикона.
7. Система по п.1, дополнительно содержащая компонент взвешивания для взвешивания слов на основе смысла.
8. Система по п.1, дополнительно содержащая частотный компонент для сохранения информации частоты использования, при этом компонент исправления использует информацию частоты использования для обеспечения ранжированного списка иероглифов-кандидатов.
9. Система по п.1, в которой упомянутый азиатский иероглиф относится к китайской или японской системе письма и включает в себя пиктограмму, с которой связано фиксированное произношение.
10. Компьютерно-реализуемый способ распознавания речи, содержащий этапы, на которых:
распознают посредством процессора азиатские голосовые сигналы для вывода результата;
переключаются между множеством систем письма на основе языка азиатских голосовых сигналов;
входят в режим проверки орфографии/исправления для исправления написания упомянутого результата, при этом режим проверки орфографии/исправления включает в себя мастер проверки орфографии для представления одного или более диалоговых окон для обеспечения пользователю возможности вокального и мануального взаимодействия для выбора и исправления упомянутого результата, причем эти одно или более диалоговых окон представляются в ответ на голосовую команду; и
исправляют написание упомянутого результата в один заход на основе по меньшей мере одного из фонетического произношения и выбора иероглифов.
11. Способ по п.10, дополнительно содержащий этап, на котором автоматически входят в режим проверки орфографии/исправления в ответ на прием азиатских голосовых сигналов, причем мастер проверки орфографии принимает фонетическое произношение.
12. Способ по п.10, дополнительно содержащий этап, на котором применяют матрицу неточностей, в которой хранятся расстояния между фонемами, используемые для исправления написания.
13. Способ по п.10, дополнительно содержащий этап, на котором написание исправляют с использованием голосовой команды-омофона.
14. Способ по п.10, дополнительно содержащий этап, на котором написание исправляют на основе разложения слов на символы-подкомпоненты.
15. Способ по п.10, дополнительно содержащий этап, на котором разрабатывают новый лексикон при исправлении написания и передают этот новый лексикон другому пользователю.
16. Способ по п.10, дополнительно содержащий этап, на котором выбирают упомянутый иероглиф на основе голосового ввода одного или нескольких слов, которые содержат этот иероглиф.
17. Способ по п.10, дополнительно содержащий этап, на котором генерируют список иероглифов-кандидатов с приоритетами и представляют иероглифы-кандидаты в виде индексированного списка для выбора посредством либо мануального ввода, либо голосовой команды.
18. Компьютерно-реализованная система распознавания речи, содержащая:
компьютерно-реализованное средство для распознавания азиатских голосовых сигналов для вывода результата;
компьютерно-реализованное средство для переключения между множеством систем письма на основе языка азиатских голосовых сигналов;
компьютерно-реализованное средство для входа в режим проверки орфографии/исправления для исправления написания упомянутого результата, при этом режим проверки орфографии/исправления включает в себя мастер проверки орфографии для представления одного или более диалоговых окон для обеспечения пользователю возможности вокального и мануального взаимодействия для выбора и исправления упомянутого результата, причем эти одно или более диалоговых окон представляются в ответ на голосовую команду;
компьютерно-реализованное средство для осуществления поиска по ключевым словам; и
компьютерное средство для исправления написания упомянутого результата в один заход на основе голосовой команды и мануального выбора иероглифов.
| US 6513005 В1, 28.01.2003 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 6067520 A, 23.05.2000 | |||
| US 6018708 A, 25.01.2000 | |||
| KR 19990043026 A, 15.06.1999 | |||
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ РЕЧИ | 2005 |
|
RU2296376C2 |
| КОРОБЧАТАЯ СТАНИНА ДЛЯ ДВИГАТЕЛЕЙ ВНУТРЕННЕГО ГОРЕНИЯ | 1925 |
|
SU4352A1 |

