Область техники, к которой относится изобретение
Настоящее изобретение относится к командам загрузки/перемещения и копирования для процессора.
Предшествующий уровень техники
В системной архитектуре предусмотрены режимы работы процессора и механизмы, предназначенные для поддержки операционной системы, и она включает системно-ориентированные регистры и структуры данных, а также системно-ориентированные команды. Системная архитектура также предоставляет механизмы, необходимые для переключения между режимами реальной адресации и защищенными режимами.
Введение в системную архитектуру технологии одного потока команд и множества потоков данных (SIMD) обеспечивает возможность проведения параллельных вычислений в отношении упакованных целочисленных данных, содержащихся в 64-битовых регистрах. SIMD обеспечивает повышение производительности процессора, например, в усовершенствованной среде обработки информации, в прикладных программах, предназначенных для обработки изображений и сжатия данных.
Перечень фигур чертежей
Фиг.1 - блок-схема процессора.
Фиг.2 - блок-схема среды выполнения.
Фиг.3 - схема порядка расположения байтов в данных фундаментального типа.
Фиг.4 - формат данных с плавающей запятой.
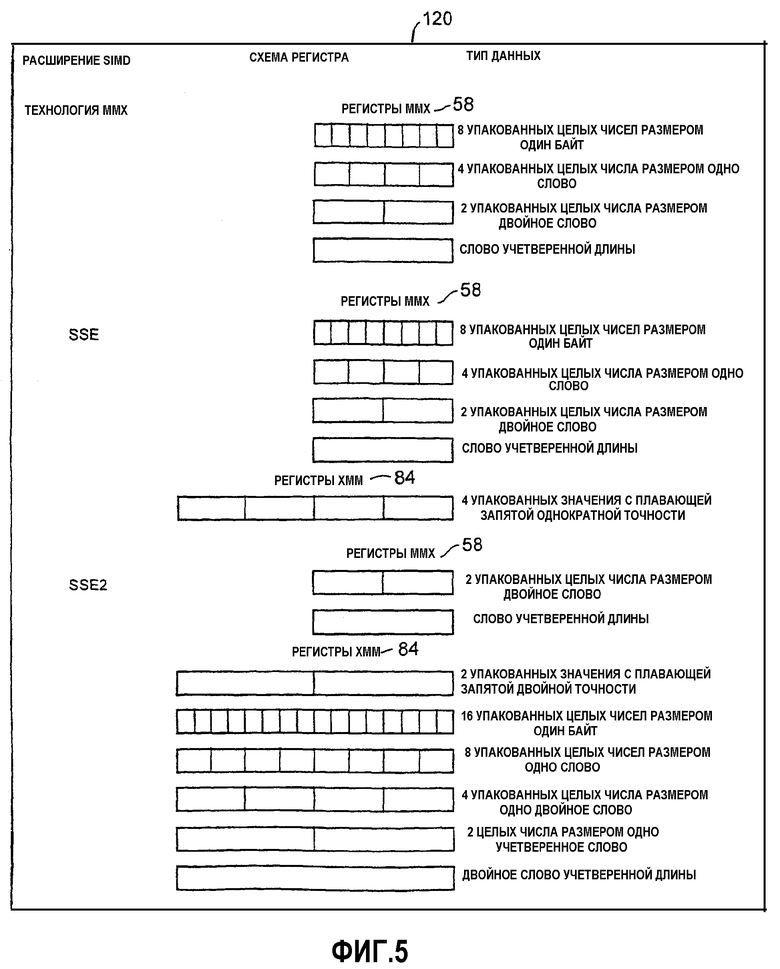
Фиг.5 - таблица, в которой сведены различные расширения SIMD, типы данных и то, каким образом типы данных упакованы в регистры.
Подробное описание изобретения
На фиг.1 показан процессор 10. Процессор 10 представляет собой процессор тройной суперскалярной конвейерной архитектуры. Благодаря использованию технологий параллельной обработки данных процессор 10 обычно позволяет декодировать, осуществлять диспетчеризацию и завершать выполнение (пересылать результаты в регистры) трех команд за цикл тактовой частоты. Для обеспечения возможности обработки команд с такой пропускной способностью в процессоре 10 используют несвязанный, двенадцатиэтапный конвейер, который обеспечивает выполнение команд с изменением их очередности. Микроархитектура конвейера процессора 10 разделена на четыре секции, то есть кэш 12 первого уровня и кэш 14 второго уровня, процессор 16 предварительной обработки, ядро 18 выполнения команд с изменением их очередности и секцию 20 пересылки результатов в регистры. Команды и данные поступают на эти блоки через блок 22 интерфейса шины, который обеспечивает сопряжение с системной шиной 24. Процессор 16 предварительной обработки передает команды в порядке, заданном программой, в ядро 18 выполнения команд с изменением их очередности, которое имеет очень большую пропускную способность исполнения и позволяет выполнять основные операции с целыми числами с задержкой, равной половине цикла такта частоты. Процессор 16 предварительной обработки производит выборку команд и выполняет их декодирование в простые операции, называемые микрооперациями (μ-ops). Процессор 16 предварительной обработки позволяет генерировать множество микроопераций в течение цикла в исходном порядке следования, заданном программой, подавая их в ядро 18 выполнения команд с изменением их очередности. Процессор 16 предварительной обработки выполняет несколько основных функций. Например, процессор 16 предварительной обработки выполняет команды упреждающей выборки, для которых существует вероятность выполнения, команды выборки, для которых еще не была проведена упреждающая выборка, команды декодирования в микрооперации, генерирует микрокод для комплексных команд и код специального назначения, передает декодированные команды из кэша 26 трассирования выполнения и выполняет прогнозирование переходов с использованием современных алгоритмов в блоке 28 прогнозирования переходов.
Процессор 16 предварительной обработки из состава процессора 10 разработан для решения некоторых общих проблем в высокоскоростных микропроцессорах с конвейерной обработкой. Две из этих проблем, например, составляют основной источник задержек. К этим источникам относятся время, требуемое для декодирования команд, выбранных из адреса перехода, и неэффективное использование пропускной способности декодирования из-за расположения перехода или адреса перехода в середине строки кэша.
Кэш 26 трассировки выполнения позволяет решить обе эти проблемы путем сохранения декодированных команд. Средство преобразования (не показано) производит выборку и декодирование команд, которые встраиваются в последовательности микроопераций, называемые трассами. Эти трассы микроопераций записывают в кэш 26 трассирования. Команды наиболее вероятного адреса перехода немедленно следуют по этому переходу, безотносительно непрерывности адресов команд. После того как трасса будет построена, в кэше 26 трассирования выполняют поиск команды, которая следует по этой трассе. Если этой командой оказывается первая команда в существующей трассе, то выборку и декодирование команд 30 из иерархии памяти прекращают и кэш 26 трассирования становится новым источником команд.
Кэш 18 трассирования выполнения и средство преобразования (не показано) содержат взаимодействующее с ними аппаратное средство прогнозирования переходов. При этом адреса переходов прогнозируют на основе их линейных адресов с использованием буферов 28 адресов перехода (BTB) и их выборку выполняют при первой возможности. Выборку адресов перехода выполняют из кэша 26 трассирования, если они действительно содержатся в нем; в противном случае, их выборку выполняют из иерархии памяти. Информацию прогнозирования перехода, соответствующую средству преобразования, используют для формирования трасс вместе с наиболее вероятными путями.
Ядро 18 выполняет команды с изменением их очередности, что позволяет процессору 10 изменять порядок следования команд так, что если одна микрооперация будет задержана на время ожидания данных или из-за конкуренции с исполнительным ресурсом, выполнение других микроопераций, которые в соответствии с порядком выполнения программы следуют после нее, может быть продолжено в обход этой микрооперации. В процессоре 10 используется несколько буферов, предназначенных для сглаживания потоков T-операций (T-ops). Это подразумевает, что когда в одной части конвейера происходит задержка, эта задержка может быть компенсирована параллельным выполнением других операций или выполнением микроопераций, которые ранее были поставлены в очередь в буфере.
Ядро 18 разработано так, что оно обеспечивает параллельное выполнение операций. Ядро 18 позволяет передавать до шести микроопераций за цикл; следует отметить, что это превышает возможности кэша 26 трассирования и требования в отношении обеспечения пропускной способности для 20 микроопераций. Большинство конвейеров могут начинать выполнение новой микрооперации в каждом цикле так, что для каждого конвейера в любое время обеспечивается возможность обработки нескольких команд. В течение цикла могут начинаться две команды арифметико-логического устройства (АЛУ, ALU), и многие команды, связанные с вычислениями с плавающей запятой, могут начинаться через каждые два цикла. Наконец, выполнение микроопераций может начинаться в произвольном порядке, как только для них будут готовы входные данные и будут доступны соответствующие ресурсы.
Секция 20 пересылки результатов в регистры принимает результаты выполненных микроопераций из ядра 18 выполнения и обрабатывает эти результаты так, что требуемое состояние архитектуры обновляется в соответствии с исходным порядком выполнения программы. Для семантически правильного выполнения операций результаты выполнения команд передают в исходном порядке программы перед отправкой результатов в регистры. При этом при пересылке результатов в регистры команд могут возникнуть исключения. Таким образом, исключения не могут возникать произвольно. Они возникают в правильном порядке, и процессор 10 может правильно возобновить свою работу после их выполнения.
Когда микрооперация заканчивается и ее результат записан в место назначения, выполняют пересылку ее результатов в регистры. За один цикл может быть выполнена пересылка в регистры результатов до трех микроопераций. Буфер переупорядочения (ROB) (не показан) в секции 20 пересылки результатов в регистры представляет собой блок в процессоре 10, который выполняет буферизацию завершенных микроопераций, обновляет состояние архитектуры в требуемом порядке и управляет упорядочением исключений.
Секция 20 пересылки результатов в регистры также поддерживает трассирование переходов и отправляет обновленную информацию об адресе перехода в BTB 28 для обновления хронологии переходов. Таким образом, ненужные больше трассы могут быть удалены из кэша 26 трассирования и может быть выполнена выборка новых путей переходов на основе обновленной информации хронологии переходов.
На фиг.2 показана среда 50 выполнения. Для любой программы или задачи, выполняемой в процессоре 10 (по фиг.1), выделяют набор ресурсов для выполняемых команд и для сохранения кода, данных и информации о состоянии. Эти ресурсы составляют среду 50 выполнения для процессора 10. Прикладные программы и операционная система или исполняемые программы, выполняемые в процессоре 10, совместно используют среду 50 выполнения. Среда 50 выполнения включает в себя базовые регистры 52 выполнения программы, пространство 54 адресов, регистры 56 блока для выполнения операций с плавающей запятой (FPU), регистры 58 мультимедийного расширения (MMX) и регистры 60 расширения SIMD (SSE (расширение SIMD для обработки потоков данных) и SSE2).
Любое задание или программа, выполняемая в процессоре 10, может обращаться к базе 54 линейных адресов, имеющей объем до четырех гигабайт (232 байт), и пространству физических адресов, имеющему объем до 64 гигабайт (236 байт). Пространство 54 адресов может быть построено со сплошной адресацией или сегментированным. Благодаря использованию механизма расширения физических адресов можно осуществлять адресацию в пространстве физических адресов 236-1.
Базовые регистры 52 выполнения программы включают в себя восемь регистров 62 общего назначения, шесть сегментных регистров 64, регистр 66 EFLAGS и регистр 68 EIP (указатель команды). Базовые регистры 52 выполнения программы образуют базовую среду выполнения, в которой выполняется набор команд общего назначения. Эти команды обеспечивают выполнение основных арифметических действий с целыми числами длиной байт, слово и слово двойной длины, выполняют управление потоком данных программы, оперируют численностью битов и байтов и выполняют адресацию памяти.
Регистры 56 FPU включают в себя восемь регистров 70 данных FPU, регистр 72 управления FPU, регистр 74 статуса, регистр 76 указателя команды FPU, регистр 78 указателя операнда данных FPU, регистр 80 дескриптора FPU и регистр 82 кода операции FPU. Регистры 56 FPU образуют среду выполнения для работы с величинами с плавающей запятой одинарной точности, двойной точности и расширенной двойной точности, с целыми числами, состоящими из одного слова, двойного слова и учетверенного слова, и двоично-десятичными числами (BCD).
Восемь регистров 58 мультимедийного расширения поддерживают выполнение одиночных команд, операций с множеством потоков данных (SIMD) над 64-битными упакованными целыми числами размером один байт, одно слово и одно двойное слово.
Регистры 60 расширения SIMD (SSE и SSE2) включают в себя восемь регистров 84 расширенных мультимедийных данных (XMM) и регистр 86 MXCSR. Регистры 60 расширения SIMD (SSE и SSE2) поддерживают выполнение операций SIMD над 128-битовыми упакованными значениями с плавающей запятой одинарной точности и двойной точности и над 128-битовыми упакованными целыми числами размером один байт, одно слово, одно двойное слово и одно учетверенное слово.
Стек (не показан) поддерживает вызовы процедур или подпрограмм и передачу параметров между процедурами или подпрограммами.
Регистры 62 общего назначения доступны для записи операндов и указателей. Сегментные регистры 64 содержат до шести селекторов сегмента. Регистры 66 EFLAGS (статус программы и управления) представляют информацию о статусе выполняемой программы и позволяют выполнять ограниченное (на уровне программного приложения) управление процессором. Регистр 68 EIP (указателя команды) содержит 32-битный указатель на следующую выполняемую команду.
32-битовые регистры 62 общего назначения предназначены для записи операндов, необходимых для выполнения логических и арифметических операций, операндов для вычислений адреса и указателей памяти. Сегментные регистры 64 содержат 16-битовые селекторы сегментов. Селектор сегмента представляет собой специальный указатель, который идентифицирует сегмент в памяти. Для осуществления доступа к конкретному сегменту в памяти селектор сегмента для этого сегмента должен присутствовать в соответствующем сегментном регистре 64.
При написании кода приложения программисты обычно получают селекторы сегментов с помощью директив и символов ассемблера. Ассемблер и другие инструментальные средства затем генерируют действительные значения селектора сегмента, связанные с этими директивами и символами. При написании системного кода программистам может понадобиться непосредственно генерировать селекторы сегментов.
Способ использования сегментных регистров 64 зависит от типа модели управления памятью, которую использует операционная система или исполняемая программа. При использовании модели памяти со сплошной (несегментированной) адресацией в сегментные регистры 64 загружают селекторы сегментов, которые указывают на перекрывающиеся сегменты, каждый из которых начинается с нулевого адреса линейного пространства линейных адресов. Эти перекрывающиеся сегменты, кроме того, включают пространство линейных адресов для программы. Обычно определены два перекрывающихся сегмента: один для кода и другой для данных и стеков. Сегментный регистр CS (не показан) сегментных регистров 64 указывает на сегмент кода, и все другие сегментные регистры указывают на сегмент данных и сегмент стека.
При использовании модели сегментированной памяти в каждый сегментный регистр 64 обычно загружают различные селекторы сегментов так, что каждый сегментный регистр 64 указывает на отличающийся сегмент в пределах пространства линейных адресов. В любой момент времени при этом для программы обеспечивается доступ до шести сегментов в пространстве линейных адресов. Для осуществления доступа к сегменту, на который не указывает ни один из сегментных регистров 64, программа вначале загружает селектор сегмента, к которому осуществляется доступ, в сегментный регистр 64.
32-битовый регистр 66 EFLAGS содержит группу флагов статуса, флаг управления и группу системных флагов. Некоторые из флагов в регистре 66 EFLAGS могут быть непосредственно изменены при использовании команд специального назначения. Эти команды не позволяют непосредственно проверять или модифицировать весь регистр 66. Однако нижеследующие команды можно использовать для перемещения группы флагов в процедурные стеки или в регистр общего назначения и из них: LAHF, SAHF, push-F, push-FD, pop-F и pop-FD. После того, как содержимое регистра 66 EFLAGS будет передано в процедурный стек или регистр общего назначения, флаги могут быть проверены и модифицированы с использованием команд процессора 10, предназначенных для манипуляции битами.
При приостановке выполнения задания процессор 10 автоматически сохраняет состояние регистра 66 EFLAGS в сегменте (TSS) (не показан) для задания, выполнение которого было приостановлено. В начале выполнения нового задания процессор 10 загружает в регистр 66 EFLAGS данные из регистра (PSS) (не показан) состояния программы нового задания.
Когда выполняют вызов процедур прерывания или обработки исключений, процессор 10 автоматически сохраняет состояние регистра 66 EFLAGS в процедурном стеке.
Когда прерывание или исключение обрабатывают с использованием переключателя заданий, состояние регистра 66 EFLAGS сохраняется в TSS для задания, выполнение которого было приостановлено.
Фундаментальными типами данных, используемыми в процессоре 10, являются байт, слово, двойное слово, учетверенное слово и двойное учетверенное слово. Байт содержит восемь битов, слово состоит из двух байтов (16 битов), двойное слово состоит из четырех байтов (32 битов), учетверенное слово состоит из восьми байтов (64 битов) и двойное учетверенное слово состоит из шестнадцати байтов (128 битов).
На фиг.3 показан порядок байтов для каждого из фундаментальных типов данных, когда они представляют собой операнды в памяти. Младший байт (биты 0-7) каждого типа данных занимает самый младший адрес в памяти, и этот адрес также представляют собой адрес операнда.
Слова, двойные слова и учетверенные слова не требуется размещать в памяти с совмещением по естественным границам. Естественные границы для слов, двойных слов и учетверенных слов представляют собой адреса с четными номерами, адреса, делящиеся без остатка на 4, и адреса, делящиеся без остатка на 8, соответственно. Однако для повышения эффективности выполнения программ всегда, когда это возможно, структуры данных (в особенности стеки) должны быть размещены с совмещением по естественным границам. Причина этого состоит в том, что для выполнения доступа к данным, размещенным в памяти без совмещения, процессор 10 должен выполнять два доступа к памяти, в то время как для выполнения доступа к данным, размещенным в памяти с совмещением, требуется выполнять один доступ. Операнд размером одно слово или двойное слово, который пересекает границу 4 байтов, или операнд размером четыре слова, который пересекает границу 8 байтов, считается несовмещенным и доступ к нему требуется выполнять за два отдельных цикла тактовой частоты шины памяти. Слово, которое начинается с нечетного адреса, но не пересекает границу слова, считается совмещенным и доступ к нему может быть обеспечен за один цикл тактовой частоты шины.
Для выполнения некоторых команд, которые оперируют двойными учетверенными словами, требуется обеспечить совмещение операндов в памяти по естественным границам. Эти команды генерируют общее исключение защиты (#GP), если задан несовмещенный операнд. Естественная граница для двойного учетверенного слова представляет собой любой адрес, делящийся без остатка на 16. Другие команды, оперирующие двойными учетверенными словами, позволяют выполнять доступ в случае отсутствия совмещения без генерирования общего исключения защиты, однако при этом требуются дополнительные циклы тактовой частоты шины памяти для обеспечения доступа к данным, размещенным без совмещения в памяти.
Хотя байты, слова и двойные слова представляют собой данные фундаментальных типов процессора 10, некоторые команды поддерживают дополнительную интерпретацию этих типов данных, для обеспечения возможности выполнения операций с числовыми типами данных. Например, для процессора 10 определены два типа целых чисел: числа без знака и со знаком. Целые числа без знака представляют собой обычные двоичные значения в диапазоне от нуля до максимального положительного числа, которое может быть закодировано в выбранном размере операнда. Целые числа со знаком представляют собой двоичные значения, представляющие поразрядное дополнение до двух, которые можно использовать для представления как положительных, так и отрицательных целочисленных значений.
Для процессора 10 определены три типа данных с плавающей запятой, которыми он оперирует: число с плавающей запятой однократной точности, число с плавающей запятой двойной точности и число с плавающей запятой с расширенной двойной точностью. Форматы данных этих типов непосредственно соответствуют формату, определенному стандартом IEEE 754 для двоичной арифметики с плавающей запятой.
Указатели представляют собой адреса ячеек памяти. Для процессора 10 определены два типа указателей: ближний указатель (32-битовый) и дальний указатель (48-битовый). Ближний указатель представляет собой 32-битовое смещение (также называемое эффективным адресом) в пределах сегмента. Ближние указатели используют для всех ссылок в памяти для модели памяти со сплошной адресацией или для ссылок для модели с сегментированной адресацией, когда подразумевается уникальность сегмента, к которому осуществляют доступ. Дальний указатель представляет собой 48-битовый логический адрес, состоящий из 16-битового селектора сегмента и 32-битового смещения. Дальние указатели используют для ссылок в памяти и для модели памяти с сегментированной адресацией, где уникальность сегмента, доступ к которому производится, должна быть указана явным образом.
Поле битов представляет собой непрерывную последовательность битов. Оно может начинаться в любом положении бита любого байта в памяти и может содержать до 32 битов. Строки представляют собой непрерывные последовательности битов, байтов, слов или двойных слов. Строка битов может начинаться в любом положении бита любого байта и может содержать до 232-1 битов. Строка байтов может содержать байты, слова или двойные слова и может содержать от нуля до 232-1 байтов (четыре гигабайта).
Двоично-десятичные целые числа (целые BCD числа) представляют собой четырехбитовые целые числа без знака с разрешенными значениями в диапазоне от 0 до 9. Для процессора 10 определены операции над целыми BCD числами, размещенными в одном или нескольких регистрах 62 общего назначения или в одном или нескольких регистрах 56 FPU.
Как показано на фиг.4, вещественные числа представлены в формате 100 с плавающей запятой в регистрах 70 с плавающей запятой FPU 56. Формат с плавающей запятой содержит три части, а именно знак 102, значащую часть 104 числа и экспоненту 106. Знак 102 представляет собой двоичное значение, которое показывает, является ли число положительным (0) или отрицательным (1). Значащая часть 104 числа содержит две части: 1-битовое двоичное целое число 108 (также называемое J-битом) и двоичную дробь 110. Целочисленный бит 108 часто не представлен и вместо него используется подразумеваемое значение. Экспонента 106 представляет собой двоичное целое число, которое представляет степень основания 2, на которое следует умножать значимую часть 104 числа.
Для процессора 10 определен набор 64-битных и 128-битных типов упакованных данных, которыми он оперирует, предназначенный для использования в операциях SIMD. Эти типы данных включают в себя фундаментальные типы данных (упакованные байты, слова, двойные слова и учетверенные слова) и числовые интерпретации фундаментальных типов данных для использования в операциях с упакованными целыми числами и упакованными числами с плавающей запятой.
64-битовыми типами данных SIMD оперируют, прежде всего, в 64-битовых регистрах 58 мультимедийного расширения. Фундаментальные 64-битовые типы упакованных данных представляют собой упакованные байты, упакованные слова и упакованные двойные слова. При выполнении цифровых операций SIMD над этими типами данных в регистрах 58 мультимедийного расширения данные этих типов интерпретируют как содержащие целочисленные значения размером байт слово или двойное слово.
128-битовые типы упакованных данных SIMD используются, прежде всего, в 128-битовых регистрах 84 расширенных мультимедийных данных (XMM) и в памяти 54. Фундаментальные 128-битовые упакованные типы данных представляют собой упакованные байты, упакованные слова, упакованные двойные слова и упакованные слова учетверенной длины. При выполнении операций SIMD над этими фундаментальными типами данных в регистрах 84 расширенных мультимедийных данных (XMM) эти типы данных интерпретируют как содержащие упакованные или скалярные величины с плавающей запятой с однократной точностью или с плавающей запятой с двойной точностью, или как содержащие упакованные целые значения размером байт слово, двойное слово или слово учетверенной длины.
На фиг.5 показана таблица 120, представляющая краткое содержание различных расширений SIMD, типов данных, над которыми выполняются операции, и каким образом эти типы данных упакованы в регистры 58 мультимедийного расширения и регистры 84 расширенных мультимедийных данных (XMM).
Как описано выше, команды мультимедийного расширения оперируют упакованными целочисленными операндами размером байт, слово, двойное слово или слово учетверенной длины, содержащимися в памяти 54, в регистрах 58 мультимедийного расширения и/или в регистрах 62 общего назначения. Команды мультимедийного расширения включают в себя команды передачи данных, команды преобразования, упакованные арифметические команды, команды сравнения, логические команды, команды сдвига и циклического сдвига и команды управления состоянием.
Команды расширения SIMD (SSE и SSE2) разделяют на несколько групп, например на четыре группы: команды SIMD однократной точности с плавающей запятой, которые оперируют с регистрами 84 расширенных мультимедийных данных (XMM), команды MXSCR, которые работают с регистром 86 MXCSR, 64-битовые целочисленные команды SIMD, которые работают с регистрами 58 MXX, и команды управления занесением данных в кэш, упреждающей выборки и команды определения порядка команд.
Один из классов команд представляет команды типа перемещения/загрузки и копирования. Эти команды называются "комбинированными" командами, поскольку они устраняют необходимость выполнения явно заданной операции над загруженным значением для получения, например, копии битов. Данная архитектура включает в себя команду MOVDDUP, команду MOVSHDUP и команду MOVSLDUP. Эти команды поддерживают выполнение сложных арифметических действий с типами упакованных данных с плавающей запятой с однократной и двойной точностью. Эти команды можно использовать для различных целей. Например, эти команды позволяют повысить эффективность работы прикладных программ обработки сигналов, которые обеспечивают обработку естественных типов данных.
Команда MOVDDUP представляет собой команду SSE2, по которой выполняется перемещение и копирование одного числа с плавающей запятой двойной точности, которая загружает/перемещает 64-бита (биты [63-0], если источник представляет собой регистр). Выполнение команды MOVDDUP возвращает одни и те же 64 бита, как в нижнюю, так и в верхнюю половины одного и того же регистра результата, то есть копирует 64 бита источника. Таким образом, если источник содержит компоненты 1/0, то адресат информации будет содержать 1/0/1/0. Команда MOVEDDUP имеет следующий формат:
MOVEDDUP назначение, источник
где операндом источника является ячейка 54 памяти или второй регистр 84 расширенных мультимедийных данных (XMM), и операндом назначения является первый регистр 84 расширенных мультимедийных данных (XMM). Источник содержит данные типа числа с плавающей запятой двойной точности.
При выполнении работы, если операндом источника является адрес в памяти, то биты [63-0] первого регистра расширенных мультимедийных данных (XMM) загружают битами [63-0], соответствующими этому адресу в памяти, а биты [127-64] первого регистра расширенных мультимедийных данных (XMM) загружают битами [63-0] ячейки памяти. Если операнд источника находится во втором регистре расширенных мультимедийных данных (XMM), то биты [63-0] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [63-0] второго регистра расширенных мультимедийных данных (XMM) и биты [127-64] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [63-0] второго регистра расширенных мультимедийных данных (XMM).
Линейный адрес соответствует адресу младшего значимого байта данных в памяти, к которым обращаются. Когда указан адрес в памяти, то загружают или записывают 16 байтов данных в соответствующую ячейку памяти. Когда используют операцию в форме регистр-регистр, то содержимое 128-битового регистра источника копируют в 128-битовый регистр назначения.
Команда MOVSHDUP представляет собой команду SSE2, по которой выполняется перемещение и копирование старшей значимой части упакованного числа с плавающей запятой однократной точности, которая загружает/перемещает 128 битов и копирует компоненты 1 и 3 в регистр результата. В примере регистра источника шириной 128-битов каждый компонент составляет 32 бита. В частности, когда источник содержит компоненты 3/2/1/0 (0 представляет младший значимый компонент с однократной точностью и 3 представляет старший значимый компонент с однократной точностью), в регистр результата после выполнения команды MOVSHDUP будут записаны дублированные компоненты 3 и 1 для получения компонентов 3/3/1/1. Команда MOVSHDUP имеет следующий формат:
MOVSHDUP назначение, источник
где операндом источника является ячейка 54 памяти или второй регистр 84 расширенных мультимедийных данных (XMM), и операндом назначения является первый регистр 84 расширенных мультимедийных данных (XMM). Операнд источника содержит данные типа упакованного числа с плавающей запятой однократной точности.
При выполнении работы, если операндом источника является адресом в памяти, то биты [31-0] первого регистра расширенных мультимедийных данных (XMM) загружают битами [63-32], соответствующими этому адресу в памяти, биты 63-32 первого регистра расширенных мультимедийных данных (XMM) загружают битами [63-32], соответствующими этому адресу в памяти, биты [95-64] первого регистра расширенных мультимедийных данных (XMM) загружают битами [127-96], соответствующими этому адресу в памяти и биты [127-96] первого регистра расширенных мультимедийных данных (XMM) загружают битами [127-96], соответствующими этому адресу в памяти.
Если операндом является второй регистр расширенных мультимедийных данных (XMM), то биты [31-0] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [63-32] второго регистра расширенных мультимедийных данных (XMM), биты [63-32] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [83-32] второго регистра расширенных мультимедийных данных (XMM), биты [95-64] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [127-96] второго регистра расширенных мультимедийных данных (XMM) и биты [127-96] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [127-96] второго регистра расширенных мультимедийных данных (XMM).
Линейный адрес соответствует адресу младшего значимого байта данных в памяти, к которым обращаются. Когда указан адрес в памяти, загружают или записывают 16 байтов данных в соответствующую ячейку памяти. Когда используют операцию в форме регистр-регистр, содержимое 128-битового регистра источника копируют в 128-битовый регистр назначения.
Команда MOVSLDUP представляет собой команду SSE2, по которой выполняется перемещение и копирование младшей значимой части упакованного числа с плавающей запятой однократной точности, которая загружает/перемещает 128 битов и копирует компоненты 0 и 2. В частности, когда источник содержит компоненты 3/2/1/0 (0 представляет младший значимый компонент с однократной точностью), в регистр результата будут записаны компоненты 2/2/0/0. Команда MOVSLDUP имеет следующий формат:
MOVSLDUP назначение, источник
где операндом источника является ячейка 54 памяти или второй регистр 84 расширенных мультимедийных данных (XMM), и операндом назначения является первый регистр 84 расширенных мультимедийных данных (XMM). Операнд источника содержит данные типа упакованного числа с плавающей запятой однократной точности.
При выполнении работы, если операндом источника является адрес в памяти, то биты [31-0] первого регистра расширенных мультимедийных данных (XMM) загружают битами [31-0], соответствующими этому адресу в памяти, биты [63-32] первого регистра расширенных мультимедийных данных (XMM) загружают битами [31-0], соответствующими этому адресу в памяти, биты [95-64] первого регистра расширенных мультимедийных данных (XMM) загружают битами [95-64], соответствующими этому адресу в памяти, и биты [127-96] первого регистра расширенных мультимедийных данных (XMM) загружают битами [95-64], соответствующими этому адресу в памяти. Если операндом источника является регистр, то биты [31-0] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [31-0] второго регистра расширенных мультимедийных данных (XMM), биты [63-32] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [31-0] второго регистра расширенных мультимедийных данных (XMM), биты [95-64] первого регистра расширенных мультимедийных данных (XMM) устанавливают равными битам [95-64] второго регистра расширенных мультимедийных данных (ХММ) и биты [127-96] первого регистра расширенных мультимедийных данных (ХММ) устанавливают равными битам [95-64] второго регистра расширенных мультимедийных данных (ХММ).
Линейный адрес соответствует адресу младшего значимого байта данных в памяти, к которым обращаются. Когда указан адрес в памяти, загружают или записывают 16 байтов данных в соответствующую ячейку памяти. Когда используют операцию в форме регистр-регистр, содержимое 128-битового регистра источника копируют в 128-битовый регистр назначения.
Таким образом, из вышеизложенного следует, что настоящее изобретение предоставляет возможность использовать единую команду перемещения/загрузки, которая обеспечивает загрузку и последующее копирование совокупности битов операнда источника в регистр назначения.
Соответственно, другие варианты выполнения находятся в пределах объема, определяемого следующей формулой изобретения.



Изобретение относится к вычислительной технике. Техническим результатом является обеспечение возможности использования единой команды перемещения/загрузки, которая обеспечивает загрузку и последующее копирование совокупности битов операнда источника в регистр назначения. Процессор содержит первое логическое средство для сохранения совокупности групп бит в несмежные группы ячеек хранения и второе логическое средство для сохранения копии совокупности несмежных групп битов. Согласно способу сохраняют совокупность групп битов в совокупность несмежных групп ячеек хранения и копируют совокупность несмежных групп битов в остальные группы ячеек хранения битов. Система содержит память и процессор для сохранения первой группы битов в первой и второй группах ячеек хранения и сохранения второй группы битов в третьей и четвертой группах ячеек хранения. Устройство содержит модуль исполнения для сохранения битов [31-0] в положениях [31-0] и [62-32], битов [95-64] в положениях [95-64] и [127-96] битов регистра назначения. 4 н. и 16 з.п. ф-лы, 5 ил.
первое логическое средство для сохранения совокупности групп битов из источника в совокупность несмежных групп ячеек хранения битов регистра назначения в качестве реакции на выполнение первой команды,
второе логическое средство для сохранения копии упомянутой совокупности несмежных групп битов в регистре назначения в остальные группы ячеек хранения битов регистра назначения в качестве реакции на выполнение первой команды.
сохраняют совокупность групп битов из источника в совокупность несмежных групп ячеек хранения битов регистра назначения и
копируют упомянутую совокупность несмежных групп битов в регистре назначения в остальные группы ячеек хранения битов в регистре назначения.
память для хранения первой команды и
процессор для осуществления выборки первой команды из памяти и сохранения первой группы битов источника в первой и второй группах ячеек хранения битов регистра назначения и сохранения второй группы битов источника в третьей и четвертой группах ячеек хранения битов регистра назначения в качестве реакции на выполнение процессором первой команды, причем первая группа ячеек хранения битов и третья группа ячеек хранения битов регистра назначения являются несмежными.
| Муфта переключения | 1976 |
|
SU743594A3 |
| US 5995748 А, 30.11.1999 | |||
| US 5613121 A, 18.03.1997 | |||
| Двухуровневое устройство для управления памятью микрокоманд | 1987 |
|
SU1513448A1 |
| Запоминающее устройство | 1980 |
|
SU928408A1 |

