Область техники
Настоящее изобретение относится к улучшениям, относящимся к обработке больших количеств инструкций в режиме реального времени. Более конкретно настоящее изобретение относится к архитектуре обработки с использованием вычислительных средств, которая специально предназначена для оптимизации обработки сотен инструкций в секунду.
Предпосылки создания изобретения
Существуют различные подходы к решению задачи обработки большого количества инструкций в режиме реального времени. Все эти подходы были успешны при обработке огромного количества таких инструкций, и при этом их эффективность во многом была связана с использованием более мощных и более производительных вычислительных средств. Однако архитектура вычислительного процесса, лежащая в основе этих подходов, имела те или иные ограничения, приводящие к ограничениям максимальной возможной пропускной способности таких систем.
Существует несколько областей применения такой технологии, такие как, например, системы связи, передающие большие массивы данных, и системы обработки данных. Одна из таких систем обработки данных, являющаяся неограничивающим примером такой технологии, может быть использована в системе выполнения расчетных операций, в которой сообщения, содержащие инструкции и представляющие собой соглашения между сторонами, могут быть выполнены для действительного выполнения таких соглашений. В такой системе, вариант которой подробно описан ниже, инструкции (или распоряжения) на компьютере доверенной организации по выполнению расчетов могут быть выполнены только в том случае, если условия (правила), определяемые этим компьютером, позволяют выполнить эти инструкции. Поэтому в качестве первой части процесса необходимо выполнить проверки текущего состояния электронных файлов ресурсных счетов, которые являются объектом соглашения о расчетной операции. Эти проверки позволяют определить приемлемость последствий выполнения инструкции в отношении электронных файлов счетов.
На втором этапе процесса инструкция либо разрешается к выполнению (указывается как "фиксация"), либо отклоняется (указывается как "откат"). Более конкретно, в этом неограничивающем варианте состояния файлов ресурсных счетов обоих участников оцениваются компьютером организации, выполняющей расчетную операцию, для определения возможности выполнения инструкции без возникновения недопустимых состояний электронных файлов счетов. Если условия приемлемы, то инструкция (распоряжение), содержащаяся в записи данных, выполняется, и, соответственно, файлы данных, содержащие текущее состояние ресурсных счетов, обновляются (фиксируются). Если условия неприемлемые, то файлы данных электронных счетов не изменяются, и инструкция в данный момент времени не выполняется. Также имеется возможность обновления всех счетов по умолчанию и отмены обновления (откат), если первый этап показывает, что результирующее состояние электронных файлов счетов будет неприемлемой. Такой алгоритм является предпочтительным вариантом для высокопроизводительных систем. Для инструкций, по которым был выполнен откат, могут быть записаны для повторного выполнения, и позднее делаются попытки повторного выполнения невыполненных инструкций при изменении условий. Все подробности процесса также должны передаваться на компьютеры участников соглашения, чаще всего в режиме реального времени.
Одной из характерных особенностей выполнения вышеуказанной обработки данных, которая ранее ограничивала масштабы применения предложенных решений (их расширяемость), является то, что зачастую количество различных ресурсов, к которым должен быть осуществлен доступ для выполнения этих инструкций, не увеличивается с увеличением количества инструкций. Это связано с тем, что часто имеет место концентрация выполнения инструкций на некотором количестве ресурсов при увеличивающемся количестве инструкций. Такая концентрация представляет собой проблему, поскольку каждая инструкция, которая влияет на величину файла ресурсного счета, должна обновлять эту величину перед выполнением следующей инструкции, которая указывает этот счет для возможной обработки. Обычно это обеспечивается определенной инструкцией, получающей временное исключительно право (блокирование) определенного файла счета, когда она находится в процессе выполнения или проверки и последующего обновления этого файла ресурсного счета. Это необходимое обновление перед обработкой следующей инструкции непосредственно влияет на максимальную скорость, с которой эти увеличившиеся количества инструкций могут быть обработаны. Это серьезная проблема для ресурсов участника, которые являются общими для многих различных типов инструкций. В частности, в тех случаях, когда 50% инструкций обновляют только 5% ресурсных счетов, что считается высокой концентрацией, это особенно серьезная проблема.
В качестве неограничивающего примера такой ситуации можно привести необходимость проверки файла данных, содержащего счет денежной наличности, чтобы удостовериться, что средства, необходимые для выполнения инструкции, имеются. Проверка этого ресурсного счета для каждой инструкции должна выполняться после того, как предыдущая инструкция обновила позицию счета денежной наличности после выполнения этой инструкции. Таким образом, эти процессы должны выполняться последовательно, иначе выполнение одной инструкции, которая может приводить к изменению баланса этого счета, может сделать недействительной какую-либо последующую инструкцию, которой также необходим доступ к этому счету. Это обстоятельство ограничивало максимальную скорость обработки в известных архитектурах (описываются ниже).
Другой проблемой, возникающей в известных системах, в которых используется архитектура параллельной обработки, является "взаимное блокирование". Это проблемное состояние возникает, когда две параллельно выполняемые инструкции обращаются к одним и тем же двум счетам, в результате чего одна инструкция блокирует один ресурсный счет, а другая инструкция блокирует второй ресурсный счет. В этой ситуации каждая инструкция не может получить доступ к другому счету для проверки возможности выполнения инструкции. Обе инструкции будут находиться в состоянии ожидания, в результате чего ими не будет выполняться действие фиксации (выполнения) для обработки инструкции. Необходимо понимать, что хотя откат одной инструкции обеспечит возможность обработки другой, что в принципе всегда возможно, однако такое решение резко снижает производительность при обработке инструкций.
Хотя базовые процессы проверки и обновления электронных файлов счетов являются сравнительно несложными для одной инструкции, однако при обработке миллионов таких инструкций ежедневно решение этой задачи становится нетривиальным. Задачей любой системы, используемой организацией, осуществляющей расчетные операции, является обеспечение наиболее высокой производительности, достижимой в режиме реального времени. Возможность расширения применения любого решения является исключительно важной задачей, поскольку любая небольшая экономия времени на любом этапе обработки увеличивается многократно при массовой обработке инструкций.
Многие известные системы разрабатывались для осуществления таких процедур по выполнению расчетных операций, и типичный пример одной из таких систем будет описан ниже со ссылками на фигуры 1-5.
На фигуре 1 показана типичная система 10 управления централизованными ресурсами, которая должна обеспечивать ежедневно обработку миллионов сообщений, содержащих инструкции. Система 10 соединена с различными каналами 12 связи, которые могут быть арендуемыми выделенными линиями связи или другими каналами защищенной связи. По этим каналам система 10 соединяется со многими серверами различных участников; в данном примере для упрощения система 10 соединяется с сервером 14 участника А и с сервером 16 участника В. Сервер 14 участника А и сервер 16 участника В имеют доступ к соответствующим базам 18 и 20 записей, в которых каждая запись описывает соглашение с другим участником.
Система 10 управления централизованными ресурсами обычно содержит сервер 22 выполнения инструкций, который имеет доступ к главной базе 24 ресурсов, содержащей записи, представляющие ресурсные счета всех участников (а именно участников А и В в настоящем примере).
На фигуре 2 представлена схема структуры главной базы ресурсов для каждого из участников. База 24 данных содержит множество различных файлов 30 ресурсных счетов для каждого участника и указатель 32 агрегированной величины ресурсов для этого участника. В рассматриваемом примере сообщения, содержащие информацию инструкций, относятся к выполнению распоряжения или инструкции по этим файлам 30 счетов, что представляет собой перевод ресурсов со счета одного участника на счет другого участника и соответствующее обновление указателей 32 агрегированной величины ресурсов. Счета являются файлами 30 данных, которые представляют действительные ресурсы участников 14, 16. Ресурсы могут быть любыми ресурсами участника, в частности, в данном примере они представляют все, чем владеет каждый участник и чем он желает торговать. На фигуре 3 представлена в общем виде структура данных или формат сообщения 40, содержащего инструкцию. Сообщение 40 информации инструкции по существу имеет шесть основных полей, которые необходимы для выполнения инструкции. Сообщение 40 содержит поле 42 идентификатора участника для идентификации участников инструкции. В данном варианте сообщение 40 информации инструкции может идентифицировать участника А и участника В. Поле 44 даты выполнения используется для указания даты, в которую эта инструкция 40 должна быть исполнена. Остающиеся четыре поля идентифицируют детали ресурсов, к которым относится инструкция. Первое поле 46 типа ресурса и соответствующее первое поле 48 количества ресурса обеспечивают идентификацию типа ресурса первого участника (например, участника А) и количество этого ресурса, которое необходимо для выполнения инструкции. Второе поле 50 типа ресурса и соответствующее второе поле 52 количества ресурса обеспечивают идентификацию типа ресурса второго участника (например, участника В) и количество этого ресурса, которое необходимо для выполнения инструкции.
Для каждого договора между двумя участниками будет существовать два сообщения 40, содержащие информацию инструкции (одно сообщение для каждого участника).
На фигуре 4 показаны компоненты сервера 22 (см. фигуру 1) выполнения инструкций. Эти компоненты включают модуль 60 проверки достоверности, которое обеспечивает проверку достоверности принятых сообщений 40 информации инструкций и модуль 62 установления соответствия, который устанавливает соответствие двух разных сообщений 40 информации инструкций, относящихся к одному соглашению. Этот модуль 62 также создает инструкцию выполнения расчетной операции для совпавших сообщений 40 информации инструкций. Модуль 64 синхронизации обеспечивает сравнение текущего времени со временем, связанным с созданной инструкцией выполнения расчетной операции. Кроме того, модуль 64 синхронизации может определять, открыто или закрыто временное окно для доступа к файлам 30 ресурсных счетов каждого из участников. Также обеспечивается база 66 данных для хранения инструкций расчетных операций для последующего выполнения. Сервер 22 выполнения инструкций содержит также модуль 68 формирования отчетных сообщений для передачи их соответствующим участникам. И, наконец, центральная часть сервера выполнения инструкций - подсистема 70 выполнения инструкций, проверки и обновления файлов. Модуль 68 формирования отчетных сообщений связан с модулем 60 проверки достоверности инструкций, модулем 62 установления соответствия и подсистемой 70 выполнения инструкций, проверки и обновления файлов. Способ, используемый для обработки инструкций, определяется конкретной архитектурой обработки данных подсистемы 70 выполнения инструкций, проверки и обновления файлов и различается для разных систем (как это описывается ниже).
Работа сервера 22 выполнения инструкций описывается ниже со ссылками на блок-схему алгоритма, приведенную на фигуре 5. Теперь более подробно будут описаны процессы получения, проверки достоверности и установления соответствия сообщений 40, содержащих информацию инструкций, и далее выполнение инструкций (инструкций на выполнение расчетных операций) подсистемой 70 определения позиций и обновления файлов. Более конкретно, процесс 78, осуществляемый известным сервером 22 выполнения инструкций, начинается на стадии 80, когда сервер 22 соединен с каналами 12 связи и готов к получению сообщений 40, содержащих информацию инструкций. Затем на стадии 82 участник А передает в сервер 22 сообщение 40, содержащее информацию инструкции и описывающее соглашение с участником В. Аналогично, на стадии 84 участник В передает в сервер 22 сообщение 40, содержащее информацию инструкции и описывающее соглашение с участником А. Сервер 22 принимает сообщения 40, и модуль 60 проверки достоверности инструкций на стадии 86 обеспечивает обработку каждой полученной инструкции 40 для проверки ее достоверности. Если инструкция 40 на стадии 88 не проходит проверку на достоверность, то на стадии 90 информация о недостоверности инструкции передается в модуль 68, который формирует отчетное сообщение и передает его в источник недостоверного сообщения 40, содержащего информацию инструкции (не показано).
В противном случае, если подтверждается достоверность инструкции 40, то модуль 68 формирования отчетных сообщений на стадии 92 передает в источник инструкции 40 отчет, подтверждающий получение инструкции 40 и ее достоверность.
Сообщения 40, прошедшие проверку на достоверность, поступают в модуль 62 установления соответствия инструкций, и на стадии 94 осуществляется обработка сообщений 40, содержащих инструкции, относящиеся к одному соглашению, для проверки их соответствия друг другу.
Модуль 62 установления соответствия инструкций на стадии 96 проверяет соответствие разных инструкций 40. Если результат установления соответствия на стадии 96 отрицательный, то на стадии 98 информация об отрицательном результате передается в модуль 68, который формирует отчетное сообщение и передает его в источник сообщения 40, для которого не найдено соответствующего сообщения 40, и процесс заканчивается на стадии 100. Случай отрицательного результата сравнения показан в весьма упрощенной форме, чтобы упростить описание существующей системы. Однако на практике вывод об отрицательном результате установления соответствия может быть сделан только после многих попыток сравнения и, возможно, после истечения заданного временного интервала сравнения, который может составлять несколько дней.
Информация о соответствующих инструкциях 40, найденных на стадии 96, передается в модуль 68 формирования отчетных сообщений, который на стадии 102 сообщает о паре соответствующих инструкций 40 источникам этих сообщений (участникам А и В в данном случае). Далее, модуль 62 установления соответствия инструкций на стадии 102 создает инструкцию на выполнение (инструкцию на выполнение расчетной операции) с датой выполнения. Эту дату выполнения получают на стадии 104 из поля даты выполнения одной из инструкций 40, для которой установлено соответствие (поскольку обе соответствующие инструкции 40 содержат одну и ту же дату). Затем дата выполнения инструкции по расчетной операции сравнивается на стадии 104 с текущей датой и с временным окном выполнения (определяемым модулем 64 синхронизации).
Если в результате сравнения на стадии 106 определяется, что инструкция на выполнение расчетной операции не может быть выполнена в настоящий момент, то эта инструкция на стадии 108 записывается в базу 66 данных. База 66 данных, содержащая инструкции, периодически проверяется, и процесс 78 находится в ожидании на стадии 110, пока не наступит дата выполнения, и не будет открыто временное окно выполнения. Обычно окно выполнения может быть открыто каждый день в течение нескольких часов.
В альтернативном варианте, если в результате сравнения на стадии 106 определено, что инструкция на выполнение расчетной операции может быть исполнена сразу же, то процесс 78 продолжается.
Далее, сервер 22 выполнения инструкций в процессе выполнения процесса 78 на стадии 112 передает инструкцию на выполнение расчетной операции в подсистему 70 выполнения инструкций, проверки и обновления файлов (подсистему определения позиций). С подсистемой 70 определения позиций связан набор правил 72 выполнения. Эти правила 72 определяют, может ли быть исполнена инструкция на выполнение расчетной операции, то есть определяют, будет ли допустимым результат выполнения инструкции в отношении файлов 30 ресурсных счетов и агрегированной величины 32 ресурсов. Недопустимый результат может быть получен, например, если определенный файл 30 учетной записи ресурса или агрегированная величина 32 ресурса в результате выполнения инструкции будет иметь величину ниже заданного значения, причем в неограничивающем примере системы выполнения расчетных операций по транзакциям счета ресурсов могут быть счетами наличных средств и счетами ценных бумаг, а агрегированная величина 32 ресурсов может быть максимальной суммой кредита, причем текущая величина ресурсов обеспечивает некоторую величину кредита, поскольку ресурсы выступают в качестве гарантии предоставляемому кредиту.
Подсистема 70 определения позиций на стадии 114 проверяет, будут ли еще выполняться правила 72 после выполнения инструкции, то есть будут ли допустимыми происшедшие в результате изменения файлов 30 ресурсных счетов и агрегированных величин 32 ресурсов обоих участников.
Если указанные правила не выполняются (стадия 116), то на стадии 118 в модуль формирования отчетных сообщений передается соответствующее указание, и этот модуль формирует и передает соответствующие отчетные сообщения относительно невыполненной инструкции обеим сторонам, например участникам А и В. Соответственно, невыполненная инструкция остается на стадии 120 в подсистеме 70 определения позиций, и позже осуществляются повторные попытки ее выполнения (стадии 114-126).
Если же правила 72 выполняются (стадия 116), то инструкция на выполнение расчетной операции выполняется на стадии 122. Затем подсистема 70 определения позиций обновляет на стадии 124 текущие позиции в файлах 30 ресурсных счетов в соответствии с результатами исполненной инструкции, а именно файлы 30 ресурсных счетов и агрегированные величины 32 ресурсов обновляются в соответствии с откорректированными балансами после выполнения перевода ресурсов. И наконец, на стадии 126 в модуль 68 формирования отчетных сообщений передается команда на формирование и передачу сообщения об успешном выполнении расчетной операции обеим сторонам, то есть в рассматриваемом примере участникам А и В.
После успешного выполнения инструкции сервером 22 выполнения инструкций процесс 78 для этой инструкции завершается. Однако, поскольку ежедневно обрабатываются миллионы таких инструкций, то процесс 78 продолжается для других сообщений 40, содержащих инструкции, которые непрерывно поступают от множества серверов других участников.
Как уже указывалось, способ, используемый в существующих системах для обработки инструкций на выполнение расчетных операций, определяется конкретной архитектурой обработки данных подсистемы 70 выполнения инструкций, проверки и обновления файлов и различается для разных систем (как это описывается ниже). По существу применяются два подхода для обработки большого количества инструкций: пакетная обработка (групповой процесс) и параллельная обработка с установлением соответствия на входе, которые будут описаны далее со ссылками на фигуры 6 и 7 соответственно.
Пакетная обработка является стандартным подходом последовательного обновления, в котором инструкции на выполнение записываются для последовательной обработки и исполняются последовательно в автоматическом режиме. Этот процесс 130 иллюстрируется схематично на фигуре 6, где файл 132 новых инструкций, содержащий пакет новых инструкций (последовательный набор), обеспечивается вместе с главным файлом 134, в котором записаны текущие позиции всех файлов 30 ресурсных счетов и агрегированные позиции 32. Каждая инструкция на выполнение расчетной операции идентифицирует двух участников, являющихся сторонами соглашения, файлы 30 ресурсных счетов, количества ресурсов, являющихся предметом соглашения между участниками и время/дату выполнения, как уже описывалось со ссылками на фигуру 3. Ключевой момент этого типа архитектуры обработки заключается в том, что эти инструкции на выполнение расчетных операций должны быть указаны в порядке ресурсного счета 30, к которому они относятся. Как правило, с каждой инструкцией записывается ключ последовательности, с помощью которого осуществляются перекрестные ссылки.
Главный файл 134 задает порядок ресурсных счетов 30 с использованием указанного ключа последовательности. Это соответствие порядка записей в главном файле и файле входных данных является очень важным для пакетной обработки.
Для определения возможности осуществления каждого соглашения путем выполнения соответствующих инструкций используется программа 136 последовательного обновления. Эта программа 136, реализованная в подсистеме обработки (не показана), использует стандартный алгоритм установления соответствия. Как уже указывалось, алгоритм установления соответствия требует, чтобы оба входных файла (существующий главный файл 134 позиций и файл 132 новых инструкций) были записаны в одинаковом порядке ключей последовательностей. Ключи, используемые в файле 132 инструкций, называются "ключами транзакций", а ключи, записанные в существующем главном файле 134, называются "главными ключами".
Программа 136 последовательного обновления определяет логику последовательного считывания обоих файлов 132, 134 до самого их конца. Результаты выполнения программы последовательного обновления записываются в новом главном файле 138, в котором хранятся обновленные позиции всех файлов 30 ресурсных счетов участника и агрегированные позиции 32.
Выполнение программы 136 последовательного обновления начинается считыванием первой инструкции (или записи) каждого из файлов 132, 134. Все инструкции, относящиеся к файлу 30 определенного ресурсного счета, выполняются последовательно, причем каждое изменение величины файла 30 ресурсного счета обновляется в памяти подсистемы обработки, выполняющей алгоритм установления соответствия. После завершения обновления файла 30 определенного ресурсного счета (проявляется в изменении ключа транзакции для следующей инструкции) получившаяся величина файла 30 этого ресурсного счета записывается в новый главный файл 138 вместе любыми обновленными агрегированными позициями 32. Этот процесс повторяется для каждого файла 30 ресурсного счета, пока не будет достигнут конец файла 132 транзакций.
В тех случаях, когда для выполнения инструкции необходимо обновлять несколько ресурсных счетов, используется более сложный подход. Для обеспечения обновления нескольких ресурсных счетов оно разбивается на несколько стадий. Решение заключается в том, что ресурсные счета дебетуются только при первом выполнении (проходе), и затем формируются отчетные сообщения по инструкциям, по которым получено дебетовое сальдо, перед применением кредитования к соответствующим ресурсным счетам. Хотя будут возникать проблемы, связанные с невыполненными инструкциями, поскольку в этом случае кредитование ресурсных счетов задерживается, однако они могут быть разрешены за счет повторения проходов.
Программа 136 последовательного обновления обычно использует нижеуказанную логику обработки инструкций для разных случаев:
После выполнения указанных действий из файла 132 транзакций считывается следующая запись с инструкцией, и процесс применяется снова, пока ключ транзакции не станет больше текущего главного ключа.
В этом алгоритме один процесс обеспечивает многочисленные обновления нового главного файла 138, в результате чего обеспечивается более быстрая обработка инструкций. Ограничение заключается в том, что необходимо группировать и сортировать инструкции перед запуском процесса (пакетная обработка). Кроме того, прежде чем можно будет отправить первое отчетное сообщение участникам с подтверждением выполнения инструкции, должны быть обработаны все инструкции. Кроме того, в процессе пакетной обработки данные недоступны для других процессов при выполнении алгоритма установления соответствия. Для обеспечения доступа к данным в режиме реального времени необходимы обновления базы данных. Если эти обновления базы данных выполнять непосредственно, общая производительность процесса резко упадет. Если эти обновления выполнять на дополнительной стадии после выполнения инструкций (например, с использованием DB2 Load), то на время обновлений блокируются все обращения к базе данных. Таким образом, пакетная обработка очень эффективна при выполнении, однако она не может выполняться в режиме реального времени ввиду требования по группированию и сортировке перед выполнением.
Другой вариант представлен на фигуре 7, а именно вышеупомянутое параллельное установление соответствия входных данных. В этом варианте инструкции на выполнение расчетных операций, которые формируются модулем 62 установления соответствия инструкций, обрабатываются множеством независимых компьютеров 140, 142 (или процессов) обработки инструкций. Кроме того, процесс 144 обработки файла последовательности может обрабатывать пакет инструкций, записанных в базе 66 инструкций. Каждый процесс 140, 142, 144 имеет свою собственную версию программы 146 непосредственного обновления, которая может считывать величину текущего ресурсного счета 30 и агрегированную величину 32 ресурса и создавать инструкцию непосредственного обновления для файлов 30 ресурсных счетов участника в главной базе 24 данных. Для принятия окончательного решения об обновлении базы 24 данных инструкциями, принятыми из процессов 140, 142, 144, используется единственный диспетчер 148 выполнения инструкций. Диспетчер 148 выполнения инструкций использует набор правил 72 выполнения инструкций (см. фигуру 4) для фиксации инструкции на обновление для выполнения или для отката для последующего выполнения.
Одно из правил 72 выполнения инструкций, которые должны быть реализованы в диспетчере 148 выполнения инструкций, касается проблемы взаимного блокирования. Как уже указывалось, взаимное блокирование заключается в том, что доступ к файлу 30 ресурсного счета невозможен, так как он используется другой инструкцией обновления. На практике это означает, что конфликтная ситуация при обновлении некоторого ресурсного счета 30 разрешается путем введения состояний ожидания, пока файл 30 ресурсного счета не будет освобожден предыдущей инструкцией обновления, а именно пока не будет завершена предыдущая инструкция обновления, и, таким образом, диспетчер 143 выполнения инструкций предотвращает ситуацию, при которой две разные инструкции обновления будут одновременно модифицировать один и тот же файл 30 ресурсного счета.
Процессы 140, 142, 144 работают параллельно и обеспечивают большую пропускную способность по сравнению с одним процессом, что в принципе позволяет получить бóльшую производительность. Более конкретно, если обновления распределены по большому числу различных файлов 30 ресурсных счетов, то параллельная система является расширяемой. В таких условиях можно увеличить производительность системы путем обеспечения параллельной работы многих процессов 140, 142, 144 обновления данных. Однако, если распределение обновлений неравномерно, то указанное решение проблемы взаимного блокирования, обеспечивающее целостность данных, быстро ставит предел максимально достижимой производительности системы. После достижения этого предела запуск еще одного процесса обновления не обеспечивает увеличения общей производительности, поскольку в этом случае также увеличивается "состояние ожидания" других инструкций обновления недоступных для них (заблокированных) файлов 30 ресурсных счетов.
Хотя этот подход отлично подходит для обновления в режиме реального времени, однако в большинстве условий работы он не обеспечивает высокой пропускной способности. Невысокая производительность объясняется тем, что обычно обновления не распределены по большому числу различных файлов 30 ресурсных счетов. Напротив, это обычная ситуация во многих приложениях, когда некоторые ресурсные счета интенсивно используются многими инструкциями. Например, при выполнении расчетов по транзакциям ситуация, когда 50% инструкций связаны с 5% имеющихся файлов 30 ресурсных счетов, является достаточно типичной. При таких условиях архитектура, представленная на фигуре 7, имеет неважные характеристики работы в режиме реального времени.
Другой важной проблемой, которую необходимо учитывать, является повторение невыполненной инструкции. Любая инструкция, которая не может быть исполнена в определенный момент времени, поскольку на ресурсных счетах нет требуемых средств для выполнения правил выполнения инструкций, просто сохраняется для попытки ее более позднего выполнения. О каждом событии временного невыполнения инструкции может сообщаться участнику, передавшему инструкцию, для указания, что инструкция может быть выполнена сразу же, как только изменится состояние ресурсного счета. Несколько неудачных попыток выполнения инструкции или истечение отведенного интервала времени могут привести к тому, что по этой инструкции будет передано отчетное сообщение об отказе в выполнении.
Этот известный процесс повторения попыток выполнения инструкции обеспечивает снижение числа новых поступлений инструкций в подсистему для их выполнения. Сохранение инструкции в режиме ожидания повышает вероятность ее обработки при изменении условий. При заданном количестве обрабатываемых инструкций имеется высокая вероятность, что большая часть повторяемых инструкций будет исполнена, и по ним сообщения об отказе в выполнении не будут выдаваться.
Однако эти повторные попытки выполнения, естественно, приводят к снижению пропускной способности подсистемы выполнения инструкций. В частности, когда на вход системы поступают параллельно инструкции, содержащие большие изменения ресурсных счетов, они часто не исполняются, поскольку условия для их выполнения не выполняются на протяжении интервала повторения (до истечения предельного времени ожидания). Когда инструкции поступают на вход системы последовательно, то невыполнение инструкций может приводить к увеличению числа проходов программы, необходимых для обработки неисполненных инструкций.
Различные разработки были выполнены в попытках преодолеть вышеуказанные проблемы. На решение этих проблем было потрачено большое количество денежных средств и ресурсов. Однако несмотря на предпринимаемые усилия проблема производительности при обработке инструкций в режиме реального времени остается.
Ниже указаны публикации, в которых описаны различные технические решения, иллюстрирующие проблему и показывающие, что она была известна в течение достаточно длительного времени, и что за это время не было найдено практически осуществимого решения.
1) Kai Li и др. "Мультипроцессорная обработка транзакций", 19881205; 19881205-19881207, 5 декабря 1988 г., стр.177-187, ХР010280434.
2) Garcia-Molina H. и др. "Система базы данных в оперативной памяти: обзор", IEEE Transactions on Knowedge and Data Engineering, IEEE Service Centre, Las Alamitos, CA, US, том 4, №6, 1 декабря 1992 г., стр.509-516, ХР001167057, ISSN: 1041-4347.
3) Gray J. и др. "Обработка транзакций: принципы и технологии", 1 января 1993 г., Transaction Processing: Concepts and Techniques, стр.249-267, 301, ХР002323530.
4) Gray J. и др. "Обработка транзакций: принципы и технологии", 1 января 1993 г., Transaction Processing: Concepts and Techniques, стр.333-347, 496, ХР002323530.
Целью настоящего изобретения является устранение по меньшей мере некоторых из вышеуказанных проблем и создание улучшенной системы обработки очень больших количеств инструкций в режиме реального времени.
Перед более подробным рассмотрением целей настоящего изобретения важно понять некоторые важные характеристики любой архитектуры, используемой для обработки инструкций, которые изложены ниже.
Каждая новая система будет иметь конкретные требования по пропускной способности. Пропускная способность представляет собой число инструкций, которое система должна исполнять в течение заданного периода времени для выполнения назначения системы. Пропускная способность может быть представлена числом обрабатываемых инструкций в день, в час, в минуту или в секунду. Пропускная способность характеризуется как "высокая пропускная способность", если она превышает 100 инструкций в секунду.
В системах, реализующих архитектуру обработки с одним экземпляром модуля обработки инструкций, этот модуль должен обеспечивать требуемую пропускную способность. Однако в тех случаях, когда требуемой пропускной способности не удается достичь с использованием одного модуля, необходимо использовать несколько экземпляров модулей, обрабатывающих инструкции параллельно. В этом случае общая пропускная способность будет равна сумме пропускных способностей, обеспечиваемых каждым экземпляром модуля. Если процесс выполнения инструкций состоит из множества последовательных стадий, то пропускная способность всего такого процесса определяется пропускной способностью самой медленной стадии (эффект "узкого горлышка").
Время реакции новой системы представляет собой время, прошедшее между получением запроса на выполнение входящей инструкции от сервера третьей стороны и передачей в сервер соответствующего ответа. Система обработки инструкций со временем реакции, не превышающим пять секунд, может быть охарактеризована как система "реального времени". Если в системе работает один экземпляр модуля обработки инструкций, то время реакции может быть измерено как время, затраченное на обработку запроса (считывание запроса и выполнение инструкции) и на отправку ответа (формирование ответа и его передача), причем в том случае, когда интенсивность поступления запросов превышает пропускную способность системы, формируется очередь запросов. В этом случае время, которое запрос будет находиться в очереди, должно считаться частью общего времени реакции на этот запрос. Если процесс обработки инструкций состоит из множества стадий, то общее время реакции системы определяется, как сумма времен реакции на каждой из этих стадий.
Как правило, каждая система обработки инструкций работает с сотнями серверов участников и имеет соответствующие ресурсные счета для каждого участника. Поскольку каждый участник может иметь много ресурсных счетов (могут быть десятки и сотни таких счетов), то возможно, что ресурсные счета, к которым относятся инструкции, равномерно распределены между этими файлами ресурсных счетов. Однако в некоторых специальных применениях системы обработки инструкций требования таковы, что инструкции часто относятся к небольшой части файлов ресурсных счетов, так что эти файлы обновляются с высокой частотой. Концентрация системы обработки инструкций определяет степень, в которой малая часть файлов ресурсных счетов затрагивается обрабатываемыми инструкциями. Система обработки инструкций, в которой 50% инструкций обновляют 5% файлов ресурсных счетов, характеризуется как система с "высокой концентрацией".
С учетом вышеизложенного другой более специальной целью настоящего изобретения является создание системы обработки инструкций, которая работает в режиме реального времени (как это определено выше), имеет высокую производительность (как это определено выше) и может работать в условиях высокой концентрации (как это определено выше).
Краткое описание изобретения
Предпосылки создания изобретения связаны прежде всего с осознанием ограничений известных подходов при попытках получить очень высокую пропускную способность системы обработки инструкций в режиме реального времени, которая может работать в условиях высокой концентрации инструкций. В настоящем изобретении предлагается новая гибридная архитектура обработки данных, которая соединяет скорость распределенной обработки, где это необходимо, и определенность последовательной обработки в других случаях для обеспечения оптимизированной обработки данных для больших количеств инструкций, и которая может работать в условиях высокой концентрации и обеспечивать обработку инструкций в режиме реального времени.
В соответствии с одним из вариантов осуществления настоящего изобретения предлагается система обработки очень больших количеств инструкций в режиме реального времени в течение сеанса обработки, причем в каждой инструкции указываются файлы с информацией ресурсных счетов, относящихся к двум различным объектам, а также количество и тип ресурсов, которыми осуществляется обмен между этими файлами, и система содержит множество модулей предварительной загрузки, каждый из которых предназначен для получения справочных данных, относящихся к инструкциям и содержащих текущие величины каждого из указанных файлов 30 с информацией ресурсных счетов, причем множество модулей предварительной загрузки работает параллельно для чтения справочных данных из главной БД для множества соответствующих полученных инструкций; очередь расширенных инструкций, в которую поступает множество инструкций вместе с относящимися к ним соответствующими предварительно загруженными справочными данными; подсистему выполнения инструкций для последовательного определения с использованием принятых справочных данных возможности выполнения каждой принятой инструкции для текущих величин относящихся к ним файлов ресурсных счетов и формирования команды на обновление для каждой исполнимой инструкции; и модуль обновления, реагирующий на команду на обновление, поступающую из подсистемы выполнения инструкций, для обновления главной БД результатами, полученными для каждой исполнимой инструкции, причем множество модулей обновления и подсистема выполнения инструкций работают независимо друг от друга.
Ниже рассмотрены особенности, являющиеся ключевыми для предлагаемой в изобретении архитектуры обработки инструкций.
Чтобы обеспечить реакцию в режиме реального времени, система обработки инструкций, предлагаемая в настоящем изобретении, должна быть способна обрабатывать и реагировать на индивидуальные запросы. Поэтому невозможно осуществить решение, ориентирующееся исключительно на пакетную обработку, хотя она и является очень эффективной.
Система обработки инструкций по настоящему изобретению должна обеспечивать очень высокую пропускную способность, и в связи с этим большое количество обновлений должно быть выполнено в хранимых файлах ресурсных счетов за очень короткое время. В классической схеме параллельной обработки (описана со ссылками на фигуру 7) обеспечивается работа в режиме реального времени, и может быть достигнута высокая производительность за счет параллельной работы множества экземпляров модуля обработки инструкций. Однако в связи с тем, что система должна работать в условиях высокой концентрации инструкций, использование множества экземпляров модуля обработки инструкций, работающих параллельно, приводит к многочисленным блокированиям, которые серьезно снижают пропускную способность системы.
Было найдено, что использование в известных технических решениях предлагаемой в изобретении специальной комбинации признаков может обеспечить улучшенное решение, которое позволяет достигнуть целей изобретения. Новое гибридное решение устраняет возможность блокирования обработки инструкций за счет использования последовательной обработки. Снижение производительности, которое обычно происходит в этом случае в известных технических решениях, устраняется путем снижения объема обработки до самого минимума, а именно модуль (подсистема) обработки инструкций только принимает решение относительно возможности выполнения принятых инструкций. Функция обновления файлов ресурсных счетов отделена от принятия решения подсистемой обработки инструкций и передана другим компонентам системы, в результате чего повышается производительность подсистемы обработки инструкций. Кроме того, путем предварительной загрузки в инструкции всех данных, которые необходимы для принятия решения о возможности обработки, предотвращаются существенные потери времени на обращения подсистемы обработки инструкций к базе данных.
Поскольку работа предлагаемой в настоящем изобретении системы строится на основе единственной подсистемы последовательной обработки инструкций, то в этом случае требуется предварительно загружать в инструкции справочные данные. Без такой предварительной загрузки единственная подсистема последовательной обработки инструкций, работающая после модулей предварительной загрузки, была бы неспособна обеспечить необходимую высокую пропускную способность. Это связано с необходимостью для подсистемы обработки инструкций считывать многие величины справочных данных для обработки инструкций, и если при этом приходится обращаться к главной БД, то на это будет уходить очень много циклов обработки. Для достижения необходимой общей пропускной способности функция предварительной загрузки осуществляется компонентом, содержащим много экземпляров, то есть предпочтительно для считывания данных из главной БД используется множество модулей предварительной загрузки, по одному на каждую множества инструкций, обрабатываемых параллельно. Кроме того, на входе модулей предварительной загрузки может использоваться множество входных очередей (экземпляров), что помогает разгрузить узкое место системы, причем каждому модулю предварительной загрузки соответствует своя входная очередь. При этом на расширяемость схемы параллельной обработки проблемы блокирования не влияют. Такое влияние отсутствует, поскольку модули предварительной загрузки выполняют только считывание, которое не приводит к возникновению проблем блокирования.
Обновление главной БД выполняется в режиме реального времени только модулем обновления. Поэтому процесс чтения модулями предварительной загрузки не приводит к возникновению ситуации блокирования БД. Чтение, выполняемое модулем предварительной загрузки из файла ресурсного счета, лишь задерживается, если счет закрыт процессом обновления. Пропускная способность процесса предварительной загрузки также увеличивается пропорционально увеличению количества модулей предварительной загрузки, работающих параллельно.
Система содержит также таблицу текущего состояния, которая хранится в подсистеме выполнения инструкций и которая обновляется результатами, полученными при выполнении инструкций в отношении файлов ресурсных счетов, так что величины файлов ресурсных счетов обновляются в режиме реального времени, причем подсистема выполнения инструкций для последующей последовательной обработки инструкций использует информацию, содержащуюся в таблице текущего состояния, вместо справочной информации, получаемой из модулей предварительной загрузки для определенного файла ресурсного счета. Каждый модуль предварительной загрузки содержит блок сбора данных из главной БД, предназначенный для чтения информации из главной БД. Поскольку это асинхронный процесс, то могут возникать ситуации, когда считанные величины справочных данных будут устаревшими. Это не является проблемой, поскольку подсистема выполнения инструкций учитывает, что данные главной БД точны, когда она получает информацию в первый раз, и эта информация записывается в таблицу текущего состояния. Когда выполняется первая инструкция, величины файлов ресурсных счетов в таблице текущего состояния обновляются. Однако для последующих инструкций, для которых также нужны те же самые файлы ресурсных счетов, успешно используются величины в таблице текущего состояния для получения точной обновленной величины определенного файла ресурсного счета, вместо того, чтобы использовать устаревшую величину из главной БД.
Для реализации таблицы текущего состояния с максимально возможной скоростью считывания/записи подсистема выполнения инструкций предпочтительно содержит быстродействующее локальное запоминающее устройство для хранения этой таблицы.
Система может также содержать очередь исходных входных данных, предназначенную для приема инструкций для выполнения в режиме реального времени и инструкций для выполнения в пакетном режиме от различных источников и подачи этих инструкций на входы множества модулей предварительной загрузки. Кроме того, для повышения производительности может использоваться множество экземпляров очереди исходных входных данных. В предпочтительном варианте очереди исходных входных данных обеспечивают присваивание приоритета каждой входящей инструкции.
Инструкция не выполняется, когда результат ее обработки приводит к нарушению набора правил выполнения инструкций. Правила могут устанавливать характеристики или граничные значения для недопустимых результатов обработки. Например, недопустимым результатом выполнения инструкции будет получение отрицательной величины ресурсного счета, относящегося к этой инструкции. Для некоторых ресурсных счетов граничное значение может достигаться, когда агрегированная величина ресурса уменьшается ниже заданного уровня.
Подсистема выполнения инструкций обеспечивает обработку инструкций в соответствии с их приоритетами. Приоритет инструкций также учитывается и в случае невыполненных инструкций, которые могут выполняться повторно. Подсистема выполнения инструкций содержит процесс организации повторного выполнения невыполненных инструкций, которые могут становиться выполнимыми, когда происходит изменение (обычно увеличение) баланса одного из ресурсных счетов, к которым относится инструкция.
Система работает в течение сеанса обработки, обычно один сеанс в день. В этом случае при открытии сеанса запускается выполнение всех накопленных инструкций, которые не могли быть обработаны, когда система была выключена. В этот начальный период времени работа системы более ориентирована на обработку в пакетном режиме. Однако даже в этот период открытия сеанса, когда система получает пакеты инструкций для обработки, она способна обрабатывать в режиме реального времени любые входящие инструкции, не предназначенные для пакетной обработки, присваивать им приоритеты и упорядочивать их для обработки в порядке, соответствующем их приоритетам.
В предпочтительном варианте подсистема содержит модуль организации повторного выполнения, обеспечивающий хранение невыполненных инструкций в быстродействующем локальном запоминающем устройстве и подачу невыполненных инструкция для их повторного выполнения, после того как будет выполнено обновление файлов ресурсных счетов, к которым относятся невыполненные инструкции. В предпочтительном варианте этим невыполненным инструкциям могут быть назначены приоритеты для повышения вероятности их успешного выполнения при повторной попытке. В более предпочтительном варианте система присваивает более высокий приоритет инструкциям, имеющим больший кредит ресурсного счета или большее изменение кредита, по сравнению с инструкциями, имеющими меньшее изменение.
После выполнения массива инструкций сразу после открытия сеанса обработки система обеспечивает обработку инструкций исключительно в режиме реального времени. На этом этапе любое увеличение величины определенного файла ресурсного счета или агрегированной величины определенного ресурса приводит к повторному выполнению всех предыдущих инструкций, по которым не были выполнены расчетные операции, поскольку величина определенного файла ресурсного счета или агрегированная величина определенного ресурса была слишком мала. Это повторное выполнение предпочтительно осуществляется в соответствии с предварительно назначенными приоритетами инструкций, хранящихся для повторного выполнения, как было описано выше.
В предпочтительном варианте модуль организации повторного выполнения обеспечивает хранение невыполненных инструкций в порядке их приоритетов и подает для повторного выполнения прежде всего инструкции, имеющие самый высокий приоритет.
Поскольку подсистема выполнения инструкций хранит в своем запоминающем устройстве все невыполненные инструкции, то любое увеличение величины файла ресурсного счета или агрегированной величины ресурса предпочтительно запускает процесс повторного выполнения всех невыполненных инструкций, ожидающих этого увеличения. В предпочтительном варианте подсистема выполнения инструкций поддерживает в своем локальном запоминающем устройстве перечень невыполненных инструкций, ожидающих увеличения (изменения) справочных данных, и перечень инструкций сравнительно легко обрабатывать в порядке их приоритетов.
Модуль организации повторного выполнения обеспечивает резервирование текущей величины файла ресурсного счета для инструкции в перечне невыполненных инструкций и использует это зарезервированное количество при выполнении потребностей этой инструкции в процессе ее повторного выполнения. Резервирование доступных ресурсов ресурсного счета для инструкции, требующей много ресурсов, чтобы избежать использования этого количества инструкцией, требующей меньшего количества ресурсов, повышает эффективность расчетов при работе процесса повторного выполнения. Например, инструкции необходимо 50 единиц, и баланс счета равен 30. Расчетная операция не выполняется, поскольку не хватает 20 единиц. Резервирование 30 единиц предотвращает выполнение инструкции, для выполнения которой необходимо 20 единиц. Такая логика используется для обеспечения выполнения инструкции, которой необходимо 50 единиц, в случае получения 20 единиц, что может произойти в результате выполнения других инструкций. Эта возможность резервирования поддерживается для невыполненных инструкций. Модуль организации повторения выполнения пытается обеспечить выполнение невыполненных инструкций, которые могли бы увеличить зарезервированную величину, когда увеличение баланса происходит в определенном файле ресурсного счета.
Как уже указывалось, использование процесса повторного выполнения в известных подсистемах выполнения инструкций приводит к снижению общей пропускной способности подсистемы обработки инструкций. Описанный выше динамический процесс повторного выполнения существенно повышает эффективность, так что общая пропускная способность подсистемы выполнения инструкций увеличивается по сравнению с вариантом, в котором процесс повторного выполнения вообще не используется.
Поскольку подсистема выполнения инструкций хранит в своем запоминающем устройстве обновленный точный образ текущих величин файлов ресурсных счетов и агрегированных величин ресурсов, то любое резервирование может быть легко реализовано в самом запоминающем устройстве. Поскольку в работе подсистемы выполнения инструкций параллельная обработка не используется, то инструкции принимаются в порядке их приоритетов, и резервирование осуществляется прежде всего для инструкции, имеющей самый высокий приоритет.
Модуль организации повторения выполнения может обеспечивать подачу невыполненных инструкций для повторного выполнения заданное максимальное число раз, и если инструкция все-таки не будет выполнена, то модуль повторного повторения обеспечивает удаление этой невыполненной инструкции.
Для достижения требуемых целей предлагается система, в которой реализуются принципы настоящего изобретения. Используемая в системе архитектура обеспечивает получение следующих технических характеристик.
Система работает в режиме реального времени. Когда объект (участник) передает инструкцию, он получает ответ (сообщение о выполнении или невыполнении инструкции) обычно в течение трех секунд. Это время состоит из времени, необходимого для транспортировки принятой инструкции и ответного сообщения между инфраструктурой связи объекта и платформой системы, и времени, необходимого для выполнения инструкции. Примерно одна секунда тратится на транспортировку сообщения до платформы обработки, одна секунда уходит на выполнение инструкции внутри платформы обработки, и одна секунда требуется для передачи ответа объекту, передавшему инструкцию. Необходимо понимать, что времена транспортировки могут немного варьироваться, поскольку они зависят от нагрузок сети передачи сообщений и рабочих условий. Соответственно, вышеуказанные времена представляют среднее время транспортировки инструкций.
Система, в которой осуществляется настоящее изобретение, обеспечивает высокую пропускную способность. Более конкретно, система способна обеспечивать обработку 500 инструкций в секунду в пиковые периоды, которые обычно имеют место при открытии сеанса обработки (принимаются пакетные инструкции).
Система, в которой осуществляется настоящее изобретение, обеспечивает так называемое "синхронное завершение". Это означает, что когда подсистема выполнения инструкций обрабатывает инструкцию, обновления всех задействованных ресурсных счетов и агрегированных величин ресурсов участников выполняются как часть одной логической единицы работы.
Система, в которой осуществляется настоящее изобретение, обеспечивает доступ к главной БД величин ресурсных счетов другим приложениям. Эта доступность, когда система активна, полезна для работы внешних систем, которым также необходима информация главной БД.
Архитектура системы по настоящему изобретению позволяет исключить возможность блокирования. Обновления, осуществляемые в главной БД, организуются таким образом, что они не влияют на пропускную способность системы, когда подсистема выполнения инструкций с высокой скоростью обновляет один и тот же файл ресурсного счета. Эта особенность настоящего изобретения является реальным достоинством в условиях высокой концентрации обновлений, например когда некоторая агрегированная величина ресурса может обновляться 50 раз в секунду.
В предпочтительном варианте система содержит также задающий модуль для определения производительности по обработке инструкций подсистемы выполнения инструкций и задания состояний ожидания для процесса подачи инструкций (для очереди) с целью замедления загрузки инструкций, чтобы скорость их загрузки не превышала пропускную способность подсистемы выполнения инструкций. Кроме того, если подсистема выполнения инструкций содержит несколько модулей обработки, каждый из которых содержит множество экземпляров очередей для загрузки инструкций, то задающий модуль задает состояния ожидания для любой очереди любого модуля обработки в подсистеме обработки инструкций для замедления загрузки инструкций, чтобы скорость их загрузки не превышала пропускной способности подсистемы выполнения инструкций.
Организация очередей системы должна исключать накопления слишком большого количества инструкций в любой очереди. Фактически система очередей устроена таким образом, чтобы она обеспечивала транспортировку инструкций, а не накапливала их в очередях, как в контейнерах данных. Контейнером данных в системе является главная БД. Действительно, когда в очередях находится много инструкций, эти очереди не могут хранить их непосредственно в ОЗУ. В этом случае очереди должны будут сбрасывать инструкции на диск. В результате будет существенно снижаться производительность системы.
Для предотвращения накопления в системе слишком большого количества инструкций задающий модуль регулирует скорость, с которой новые инструкции загружаются в систему. Накопление сообщений в очереди происходит, когда скорость загрузки сообщений превышает пропускную способность самого медленного звена системы очередей. Для регулирования скорости загрузки после каждой фиксации может задаваться состояние ожидания, чтобы предотвращать возникновение нагрузки, превышающей заданную скорость.
В предпочтительном варианте подсистема выполнения инструкций содержит модуль формирования отчетных сообщений для уведомления о результатах выполнения полученных инструкций, причем модуль формирования отчетных сообщений формирует команду на обновление по каждой инструкции, для которой определяется, что она может быть выполнена, и команду на уведомление для каждой невыполненной инструкции.
Система может также содержать очередь завершения для приема и организации очереди команд на обновление и уведомление, поступающих из модуля формирования отчетных сообщений.
Развязка процесса обновления главной БД от принятия решений подсистемой выполнения инструкций является основным отличием архитектуры, предлагаемой в настоящем изобретении, от известных технических решений. Помещение в очередь завершения команды на обновление является указанием окончания обработки инструкции. Многие известные системы пакетной обработки работают по принципу "все или ничего". Таким образом, завершение обработки достигалось в конце пакета. Многие известные системы обработки в режиме реального времени считают завершением обработки инструкции фиксацию изменения в главной БД. В настоящем изобретении завершение происходит, как только подсистема выполнения инструкций помещает команду на обновление в очередь завершения. Это означает, что между выполненными инструкциями и относящимися к ним величинами файлов ресурсных счетов в главной БД отсутствует синхронизация в режиме реального времени.
Такая развязка в архитектуре обработки означает, что справочные данных, считанные модулями предварительной загрузки, могут быть устаревшими. В системе по настоящему изобретению, когда справочные данные поступают в подсистему выполнения инструкций в первый раз, величины справочных данных точно отражают действительное текущее состояние величин требуемых ресурсных счетов и агрегированных величин ресурсов. Для этого в системе предпочтительно требуется обеспечить, чтобы все команды на обновление, указывающие на выполнение инструкции, были отражены в главной БД, прежде чем буден запущен сеанс обработки, а именно, до запуска модулей предварительной загрузки и подсистемы выполнения инструкций. Иначе говоря, необходимо обеспечить, чтобы все очереди были пустыми до начала сеанса обработки.
В предпочтительном варианте модуль формирования отчетных сообщений обеспечивает временное хранение множества команд на обновление, пока не будет осуществлена фиксация, и выдачу множества команд на обновление после осуществления фиксации, причем фиксация представляет собой завершение одной физической единицы работы подсистемы выполнения инструкций.
Система обработки осуществляет несколько стадий обработки. Общая пропускная способность (производительность) системы ограничивается самым медленным звеном. Если на какой-то стадии осуществляется параллельная обработка и эта стадия, соответственно, является расширяемой, она не может быть самым медленным звеном (пропускная способность всегда может быть увеличена за счет одновременной работы следующей стадии). В результате, самым медленным звеном системы является подсистема последовательного выполнения инструкций, поскольку это единственный компонент системы, который не поддерживает параллельную обработку.
Для повышения производительности подсистемы выполнения инструкций и, соответственно, всей системы, необходимо сделать все, чтобы в своей работе подсистема обработки инструкций максимально использовала центральный процессор (ЦП) за счет минимизации обращений к внешним данным. Использование множества модулей предварительной загрузки позволяет предварительно загрузить вместе с инструкциями все данные, которые необходимы подсистеме обработки инструкций, и на выходе все команды на обновления, которые должны быть реализованы, упаковываются в одно сообщение команд. И, наконец, обращение к внешним данным подсистемы выполнения инструкций ограничивается одним постоянно поступающим сообщением на входе и одним постоянно выдаваемым сообщением на выходе. Добавление других обращений к данным возможно, однако в результате упадет пропускная способность системы.
Для увеличения пропускной способности необходимо сделать все, чтобы циклы работы ЦП использовались только для непосредственного выполнения инструкций, и не расходовались на выполнение других логических операций. Например, циклы ЦП расходуются бесполезно во время фиксации. Таким образом, подсистема выполнения инструкций осуществляет физическую единицу работы, которая содержит набор логических единиц работы (выполнение множества поступающих инструкций (в локальном запоминающем устройстве) перед выполнением процесса фиксации). При кратности фиксаций, равной 50, производительность 500 инструкций в секунду дает 10 фиксаций в секунду вместо 500! Процесс фиксации для подсистемы выполнения инструкций представляет собой физическую единицу работы. Кратность фиксации, равная 50, означает, что выполняются 50 инструкций, и по ним формируются отчетные сообщения, поскольку вступление в фазу технической фиксации, на которой завершаются все выполняемые обновления (физическое удаление входящей инструкции и физическая запись отчетного сообщения).
В предпочтительном варианте система содержит также структуру маршрутизации, обеспечивающую распределение инструкций среди множества очередей исходных входных данных или среди экземпляров очереди обновления, работающих параллельно. Это дает возможность равномерного распределения инструкций в тех случаях, когда имеется множество различных очередей или обрабатывающих элементов, как в случае модулей предварительной загрузки и модуля обновления.
В предпочтительном варианте структура маршрутизации обеспечивает присвоение инструкции наименования инструкции, описывающего тип информации, к которому относится инструкция, и ключа модуля выравнивания нагрузки, который обеспечивает уникальный ключ, идентифицирующий инструкцию, и в этом случае структура маршрутизации может обеспечивать выбор одной из входных очередей или одного из экземпляров очереди обновления с использованием наименования принятой инструкции и ключа выравнивания нагрузки.
В предпочтительном варианте структура маршрутизации содержит блок выравнивания нагрузки, обеспечивающий вместе со структурой маршрутизации выбор одной из очередей исходных входных данных или одного из экземпляров очереди обновления с помощью наименования принятой инструкции и ключа модуля выравнивания нагрузки.
Для каждого компонента системы, осуществляющего параллельную обработку для обеспечения высокой пропускной способности, такого как модули предварительной загрузки и модуль обновления, нагрузка соответствующим образом распределяется между всеми экземплярами с помощью модуля выравнивания нагрузки и структуры маршрутизации. Однако такое распределение не приводит к какому-либо нарушению правил упорядочивания сообщений, определяющих порядок, в котором должны обрабатываться инструкции.
Структура маршрутизации и модуль выравнивания нагрузки могут распределять нагрузку между множествами очередей, например очередей разделения данных главной БД, и гарантировать направление инструкций, имеющих одинаковый ключ упорядочивания, в одну и ту же очередь. Структура маршрутизации может непосредственно адаптироваться к конфигурации целевого процесса путем анализа количества имеющихся экземпляров и распределения выходных сообщений без нарушений ограничений упорядочивания.
Иначе говоря, модуль выравнивания нагрузки обеспечивает привязку данного ключа модуля выравнивания нагрузки к одному и тому же определенному месту назначения, чтобы все инструкции, относящиеся к определенному файлу с информацией ресурсного счета, всегда направлялись в одну и ту же очередь из множества очередей.
В предпочтительном варианте система содержит также структуру разграничения, которая в ответ на закрытие сеанса обработки в заданное время подает сообщение на вход очереди, предусмотренной на выходе подсистемы выполнения инструкций, и ожидает реакции, а также подает другое сообщение во входную очередь одного из модулей обновления и ожидает его реакции, и принимает последовательные ответы, сообщающие об обновлении главной БД результатами всех инструкций, выполненных до закрытия сеанса обработки.
Если система содержит модуль диспетчера для уведомления о результатах выполнения каждой инструкции, предпочтительно структура разграничения также обеспечивает подачу сообщения во входную очередь модуля диспетчера и ожидает соответствующего ответного сообщения для подтверждения того, что отправлены все отчетные сообщения для инструкций, выполненных до закрытия сеанса обработки.
Иначе говоря, структура разграничения передает сообщение на выход подсистемы выполнения инструкций, а именно в очередь завершения. Как только она получает ответ на сообщение, это будет означать, что все инструкции, накопленные в очереди завершения до прихода сообщения структуры разграничения, обработаны. После этого структура разграничения может передать сообщение в каждый экземпляр диспетчера и ожидает соответствующей реакции от каждого из них. Когда все экземпляры диспетчера передали свои соответствующие ответные сообщения в структуру разграничения, это означает для нее, что все процессы диспетчеризации выполнены. Затем структура разграничения может запустить процесс разграничения в модуле обновления. Это осуществляется путем передачи сообщения в каждый экземпляр модуля обновления данных главной БД и ожидания всех соответствующих ответов.
Когда получены ответы от всех экземпляров модуля обновления данных главной БД, это означает для структуры разграничения, что все обновления, относящиеся к инструкциям, выполненным подсистемой выполнения инструкций перед наступлением крайнего срока, теперь отражены в главной БД. Поток операций структуры разграничения завершен, и диспетчер может формировать отчет об операциях, выполненных во время сеанса обработки инструкций.
В настоящем изобретении также предлагается осуществляемый на компьютере способ обработки в течение сеанса обработки очень больших количеств инструкций в реальном времени, в каждой из которых указываются файлы с информацией ресурсных счетов, относящихся к двум различным экономическим объектам, а также количество и тип ресурсов, которыми осуществляется обмен между этими файлами, причем способ включает получение справочных данных, относящихся к инструкциям, из множества модулей предварительной загрузки, каждый из которых обеспечивает получение справочных данных, которые относятся к инструкциям и которые указывают текущие величины каждого из указанных файлов с информацией ресурсных счетов, причем получение справочных данных включает параллельную работу множества модулей предварительной загрузки по чтению справочных данных из главной БД для множества соответствующих полученных инструкций; помещение множества инструкций вместе с относящимися к ним справочными данными в очередь расширенных инструкций; использование подсистемы выполнения инструкций для последовательного определения с использованием полученных справочных данных возможности выполнения каждой полученной инструкции для текущих величин связанных с ней файлов ресурсных счетов и для формирования команды на обновление для каждой выполнимой инструкции; и выполнение обновления главной БД результатами каждой выполнимой инструкции с использованием множества модулей обновления, которые реагируют на команду обновления, получаемую из подсистемы выполнения инструкций, причем обновление отделено от работы подсистемы выполнения инструкций.
В соответствии с другим вариантом осуществления настоящего изобретения предлагается система обработки очень больших количеств инструкций в режиме реального времени в течение сеанса обработки, причем в каждой инструкции указываются файлы с информацией ресурсных счетов, относящихся к двум различным экономическим объектам, а также количество и тип ресурсов, которыми осуществляется обмен между этими файлами, и система содержит множество модулей предварительной загрузки, каждый из которых предназначен для получения справочных данных, относящихся к инструкциям, причем множество модулей предварительной загрузки работает параллельно для чтения справочных данных из главной базы данных; очередь сообщений, содержащих инструкции, в которую поступает множество инструкций вместе с относящимися к ним соответствующими справочными данными; подсистему выполнения инструкций для последовательного выполнения каждой инструкции, причем подсистема выполнения инструкций определяет возможность выполнения инструкции для текущего состояния относящихся к ним файлов с использованием принятых справочных данных, без обращения к главной БД; и таблицу текущего состояния, которая обновляется результатами, полученными при выполнении инструкций в отношении файлов, так что соответствующие файлы обновляются в режиме реального времени; причем подсистема выполнения инструкций для последующей последовательной обработки инструкций использует информацию, содержащуюся в таблице текущего состояния, вместо справочной информации, получаемой из множества модулей предварительной загрузки для определенного файла с данными, если файл с данными был обновлен подсистемой обработки инструкций в течение сеанса обработки.
Эта особенность настоящего изобретения направлена на то, чтобы предотвращать необходимость обновления главной БД за счет использования обновляемой в режиме реального времени копии самых последних величин ресурсных счетов, размещенной в запоминающем устройстве подсистемы выполнения инструкций. Это важный признак изобретения, который позволяет во многом преодолеть проблемы известных систем, предназначенных для обработки больших количеств инструкций в режиме реального времени.
В соответствии с другим вариантом осуществления настоящего изобретения предлагается система обработки очень больших количеств инструкций в режиме реального времени в течение сеанса обработки, в которой инструкции принимаются асинхронно с разными скоростями, и система содержит множество модулей обработки для выполнения различных типов обработки инструкций, причем один из модулей обработки представляет собой подсистему выполнения инструкций для последовательной обработки инструкций; множество наборов очередей инструкций, причем каждый набор очередей используется для подачи инструкций на вход соответствующего модуля обработки данных; задающий модуль для определения пропускной способности по обработке инструкций подсистемы выполнения инструкций и задания состояний ожидания для любой очереди для замедления загрузки инструкций, чтобы скорость их загрузки не превышала пропускной способности подсистемы выполнения инструкций.
Как уже указывалось, в системе обработки очень больших количеств инструкций в режиме реального времени в течение сеанса обработки, в которой инструкции принимаются асинхронно с разными скоростями, необходимо предотвращать накопление в любой очереди слишком большого количества инструкций. Очереди должны использоваться прежде всего для транспортировки, а не для хранения информации, для чего служит БД; если же количество инструкций в очереди становится слишком большим, они могут сбрасываться на диск, что приводит к большим затратам времени, снижающим пропускную способность системы.
Для предотвращения накопления в системе слишком большого количества инструкций задающий модуль регулирует скорость, с которой новые инструкции загружаются в систему. Накопление сообщений в очереди происходит, когда скорость загрузки сообщений превышает пропускную способность самого медленного звена системы очередей, в данном случае последовательно работающей подсистемы выполнения инструкций. Для регулирования скорости загрузки после каждой единицы времени обработки может задаваться состояние ожидания, чтобы предотвращать возникновение нагрузки, превышающей заданную скорость.
В соответствии с другим вариантом осуществления настоящего изобретения предлагается система обработки очень больших количеств инструкций в режиме реального времени в течение сеанса обработки, причем в каждой инструкции указываются файлы с информацией ресурсных счетов, относящихся к двум различным экономическим объектам, а также количество и тип ресурсов, которыми осуществляется обмен между этими файлами, и система содержит множество модулей предварительной загрузки, каждый из которых предназначен для получения справочных данных, относящихся к инструкциям, причем множество модулей предварительной загрузки работает параллельно для чтения справочных данных из главной базы данных и подачи этих справочных данных вместе с инструкциями в подсистему выполнения инструкций; подсистему выполнения инструкций для последовательного выполнения каждой инструкции, причем подсистема выполнения инструкций определяет возможность выполнения инструкции для текущего состояния относящихся к ним файлов с использованием предварительно загруженных справочных данных, без обращения к главной БД; и быстродействующее локальное запоминающее устройство для хранения таблицы текущего состояния, которая обновляется результатами, полученными при выполнении инструкций в отношении файлов, так что соответствующие файлы обновляются в режиме реального времени; модуль организации повторного выполнения для хранения перечня невыполненных инструкций в быстродействующем локальном запоминающем устройстве и для осуществления операции повторного выполнения, в которой невыполненные инструкции подаются для повторного выполнения после того, как осуществлено обновление в таблице файлов ресурсных счетов, указанных в невыполненной инструкции.
В предпочтительном варианте модуль организации повторного выполнения обеспечивает хранение невыполненных инструкций в порядке их приоритетов и подает для повторного выполнения прежде всего инструкции, имеющие самый высокий приоритет. В этом случае обеспечивается оптимальная обработка различных приоритетов инструкций с максимальной производительностью.
Модуль организации повторного выполнения обеспечивает резервирование текущей величины файла ресурсного счета для инструкции в перечне невыполненных инструкций и использует это зарезервированное количество при выполнении потребностей этой инструкции в процессе ее повторного выполнения. Это обеспечивает выявление возможных потребностей в ресурсах на ранней стадии, что позволяет предотвращать невыполнение важных…. Кроме того, модуль организации повторного выполнения может обеспечивать подачу невыполненных инструкций для повторного выполнения заданное максимальное количество раз, и если инструкция, в конце концов, все-таки не будет выполнена, то модуль повторного повторения может обеспечивать удаление этой невыполненной инструкции. Это предотвращает проблемы с транзакциями, которые намечены для выполнения, связанные с "засорением" системы.
Достоинство этой динамической организации повторения выполнения инструкций, предлагаемой в изобретении, уже описывалось в связи с модулем организации повторения выполнения и здесь не повторяется.
Краткое описание чертежей
Ниже будут описаны конкретные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи, на которых показано:
фигура 1 - архитектура системы обработки инструкций (предшествующий уровень) для выполнения соглашений между участниками А и В;
фигура 2 - схема, иллюстрирующая файлы ресурсных счетов, записанные в главной БД;
фигура 3 - схема информационного содержания сообщения с инструкцией, передаваемой участником;
фигура 4 - блок-схема основных компонентов сервера выполнения инструкций, указанного на фигуре 1;
фигура 5 - общая блок-схема, иллюстрирующая работу платформы обработки инструкций (предшествующий уровень);
фигура 6 - блок-схема, иллюстрирующая стандартный процесс установления соответствия для пакетной обработки (предшествующий уровень);
фигура 7 - блок-схема, иллюстрирующая стандартный процесс установления соответствия для параллельной обработки (предшествующий уровень);
фигура 8 - блок-схема платформы обработки в соответствии с одним из вариантов осуществления настоящего изобретения;
фигура 9 - блок-схема алгоритма работы платформы обработки, представленной на фигуре 8;
фигура 10 - блок-схема алгоритма работы модуля предварительной загрузки платформы обработки, представленной на фигуре 8;
фигура 11 - блок-схема подсистемы определения позиций платформы обработки, представленной на фигуре 8;
фигура 12 - блок-схема алгоритма работы подсистемы определения позиций, представленной на фигуре 11.
Подробное описание изобретения
Ниже со ссылками на фигуры 8-12 описывается платформа 150 обработки в соответствии с одним из вариантов осуществления настоящего изобретения. Платформа 150 обработки реализована на сервере 22 выполнения инструкции, который аналогичен серверу, описанному в разделе "Предпосылки создания изобретения" со ссылками на фигуры 2 и 4 (предшествующий уровень), и функционально в целом ему эквивалентен. Более конкретно платформа 150 обработки в соответствии с рассматриваемым ниже вариантом осуществления настоящего изобретения заменяет подсистему 70 (см. фигуру 4) проверки и выполнения инструкций и обновления файлов.
Как показано на фигуре 8, платформа 150 обработки состоит из четырех основных компонентов: множества модулей 152 предварительной загрузки, подсистемы 154 определения позиций, диспетчера 156 и модуля 158 обновления. Они изображены на фигуре 8 вместе со структурами очередей и другими функциональными модулями, описанными ниже.
Модули 152 предварительной загрузки имеют доступ к главной БД 24, содержащей файлы 30 ресурсных счетов всех участников и к агрегированным величинам 32 ресурсов, только в режиме "чтение". Необходимо учесть, что на фигуре 8 для ее упрощения главная БД 24 показана как часть модуля 152 предварительной загрузки. Необходимо понимать, что модули 152 предварительной загрузки не включают в себя главную БД 24, поскольку в системе существует только одна такая БД. Каждый модуль 152 предварительной загрузки, который обращается к своей собственной очереди 164 исходных входных данных, содержит блок 182 сбора данных главной БД (описано ниже) для получения необходимой информации из главной БД 24 и выдачи результатов в очередь 166 расширенных инструкций. Каждый модуль 152 предварительной загрузки содержит блоки 182 сбора данных главной БД (на фигуре 8 для упрощения показаны только два таких блока). Блоки 182 сбора данных обрабатывают поступающие на вход системы инструкции по расчетным операциям, причем каждая поступающая инструкция назначается одному блоку 182 сбора данных главной БД. Блок 182 сбора данных главной БД считывает из главной БД 24 данных соответствующие данные для поступившей инструкции и объединяет их с исходной инструкцией на выполнение расчетной операции для формирования расширенной инструкции (не показано), которая поступает на выход соответствующего блока 152 предварительной загрузки. Количество блоков 152 предварительной загрузки (и, соответственно, блоков 182 сбора данных главной БД) может быть увеличено, поскольку они выполняют свои действия параллельно без каких-либо конфликтов с БД, таких как взаимное блокирование, поскольку они выполняют только операции чтения из главной БД. Хотя главная БД 24 непрерывно обновляется, однако вышеуказанные проблемы известных решений устраняются за счет разделения функций обновления главной БД и считывания, и, кроме того, после первого считывания в сеансе обработки не требуется точность считываемых величин 30 ресурсных счетов.
Подсистема 154 определения позиций содержит единственный экземпляр логического процессора 184 и таблицу 186 записей обновляемых данных главной БД, которая хранится в его запоминающем устройстве. Таблица 186 обновляемых данных главной БД содержит файлы 30а, соответствующие файлам ресурсных счетов в главной БД. Однако не все файлы 30 ресурсных счетов имеют соответствующие файлы 30а, как это можно видеть на фигуре 11, и будет объяснено ниже.
Логический процессор 184 принимает расширенные инструкции, созданные модулями 152 предварительной загрузки, и обрабатывает их последовательно для определения необходимости фиксации или отката инструкции на выполнение расчетной операции, на основе которой создана расширенная инструкция. По существу, если величины файлов 30 ресурсных счетов и агрегированная величина 32 ресурса для каждого участника будет допустимой после выполнения инструкции по расчетной операции, а именно будут выполняться правила 72 выполнения инструкций, то инструкция по расчетной операции принимается. Для принятия такого решения единственный экземпляр логического процессора 184 непрерывно обновляет соответствующие файлы 30а таблицы 186 обновляемых записей главной БД самыми свежими обновленными величинами каждого из файлов 30 ресурсных счетов, получаемыми в результате выполнения допустимых инструкций по расчетным операциям. Эти обновленные величины файлов 30а ресурсных счетов используются вместо соответствующих величин, содержащихся в полученных расширенных инструкциях. Подсистема 154 определения позиций формирует на выходе перечень инструкций на выполнение расчетных операций, которые поступили на вход подсистемы 154 с указанием допустимости (или недопустимости) инструкции, а именно необходимо ли выполнить фиксацию, или же она недопустима, то есть необходимо выполнить откат. Кроме того, инструкции, по которым должен быть выполнен откат, сохраняются, и по ним могут выполняться повторные попытки выполнения, как это будет подробно описано ниже. Те же файлы 30 ресурсных счетов, которые не являются объектами инструкции, не имеют дубликата в таблице 186 главных записей, находящейся в памяти, и, соответственно, размер памяти меньше размера главной БД.
Диспетчер 156 содержит программный модуль 188 диспетчеризации. Этот модуль 188 принимает перечень обработанных инструкций на выполнение расчетных операций с выхода подсистемы 154 определения позиций и формирует отчетные сообщения о результатах (фиксация или откат) обработки инструкций для передачи соответствующим участникам. Для инструкций, по которым выполнен откат, в отчетных сообщениях указываются причины невыполнения. Для инструкций, по которым выполнена фиксация, формируются отчетные сообщения об успешном выполнении инструкций, и, кроме того, они передаются в модуль 158 обновления.
Модуль 158 обновления содержит множество блоков 190 обновления данных главной БД, каждый из которых имеет доступ к заданной части главной БД 24. Для упрощения схемы на фигуре 8 показаны три блока 190 обновления данных главной БД, имеющих доступ к трем частям 24а, 24b, 24 с главной БД. Однако в этом варианте модуль 158 обновления является расширяемой частью платформы 150, так что может использоваться большое количество блоков 190 обновления главных данных и связанных с ними частей главной БД 24. Подробное описание способа распределения выполненных инструкций между блоками обновления данных главной БД будет приведено ниже.
На входе платформы 150 обработки находятся процессы 160 обработки последовательности файлов, каждый из которых обеспечивает пакеты инструкций на выполнение расчетных операций на входе системы 150, и один или несколько отдельных компьютеров или процессов 162 индивидуальной обработки инструкций (в рассматриваемом варианте используется только один компьютер), обрабатывающие инструкции, получаемые в режиме реального времени, которые должны быть обработаны также в режим реального времени.
Между основными компонентами платформы 150 обработки используются модули организации очередей. Создаваемые очереди, в некоторых случаях, действуют в качестве средств преобразования параллельной обработки в последовательную обработку, и наоборот. В частности, на входе модулей 152 предварительной загрузки используются очереди 164 исходных входных данных, в которые записываются асинхронно инструкции на выполнение расчетных операций, которые могут быть получены из процессов 160 обработки последовательностей файлов и из процессов 162 индивидуальной обработки инструкций. Для упорядочения результатов параллельной работы блоков сбора данных главной БД модулей 152 предварительной загрузки и получения массива данных для последовательной обработки, поступающего на входе подсистемы 154 определения позиций, используется очередь 166 расширенных инструкций. На выходе подсистемы 154 определения позиций используется очередь 168 завершения, из которой данные подаются на вход диспетчера 156. Наконец, между выходом диспетчера 156 и входами модуля 158 обновления используются очереди 170 разделения данных главной БД. На другом выходе диспетчера 156 имеется очередь 172 отчетных сообщений, через которую передаются уведомления в режиме реального времени в процесс 162 индивидуальной обработки инструкций.
Для полной ясности необходимо учитывать, что очередь 164 исходных входных данных, очередь 166 расширенных инструкций, очередь 168 завершения, очереди 170 разделения данных главных БД и очередь 172 отчетных сообщений, могут иметь, как это четко видно на фигуре 8, множество экземпляров, то есть может использоваться множество очередей, работающих параллельно.
Кроме того, используются три дополнительных модуля для улучшения характеристик прохождения потока инструкций через платформу 150 обработки. Скорость, с которой инструкции поступают в очередь из процессов 160 обработки пакетных инструкций для подачи в компонент платформы 150, имеющий наименьшую пропускную способность, регулируется задающим модулем 174. В результате очереди платформы 150 почти всегда практически пусты.
В системе используется структура 175 маршрутизации для направления инструкций в очередь через модуль 176 выравнивания нагрузки. Структура маршрутизации имеет гибкое построение, которое позволяет изменять различные характеристики маршрутизации без изменения упорядочивания принятых инструкций.
Модуль 176 выравнивания нагрузки используется для распределения инструкций по очередям и обеспечения направления инструкций/команд, имеющих одинаковый ключ упорядочивания (описан ниже), в одну и ту же очередь.
Модуль 178 структуры разграничения используется для обеспечения отражения в главной БД 24 и в сообщениях реального времени, подтверждающих обновление, всей обработки, выполняемой подсистемой 154 определения позиций, результаты которой записаны в окончательной очереди 168 к заданному моменту времени и к заданной дате (конечный срок).
Ниже описывается алгоритм 200, блок-схема которого приведена на фигуре 9, работы платформы 150 обработки. Алгоритм 200 начинается с получением на стадии 202 инструкций на выполнение расчетных операций, либо из пакетных файлов 160, обрабатываемых в пакетном режиме, либо из процессов 162 индивидуальной обработки инструкций в режиме реального времени. Пакетные файлы, обрабатываемые не в режиме реального времени, могут быть созданы, например, путем накопления инструкций, которые имеют конкретную дату выполнения в будущем, и пакет формируется для выполнения при наступлении этой конкретной даты. Термин "пакет", как он используется в настоящем описании, не подразумевает, что записи должны быть расположены в каком-либо определенном порядке. Для рассматриваемого варианта порядок расположения инструкций на выполнение расчетных операций внутри пакета не имеет значения. Термин "пакет" используется просто для обозначения совокупности накопленных инструкций на выполнение расчетных операций.
Алгоритм 200 продолжается на стадии 204 записью принятых инструкций в очереди 164 исходных входных данных для их последующего ввода в соответствующие модули 152 предварительной загрузки. Такая организация очередей обеспечивает преобразование асинхронного параллельного входного потока инструкций на выполнение расчетных операций в синхронный последовательный поток. Затем инструкции обрабатываются на стадии 206 модулями 152 предварительной загрузки для получения справочных данных для каждой инструкции из главной БД 24. Этот процесс выполняется параллельно с использованием блоков 182 сбора данных из главной БД, причем в каждом модуле 152 для этого используется один блок 182.
Для каждой инструкции на выполнение расчетной операции полученная информация упорядочивается для формирования на стадии 208 расширенной инструкции, которая содержит эту инструкцию на выполнение расчетной операции и все данные из главной БД, которые необходимы подсистеме определения позиций для определения, может ли эта инструкция быть выполнена с соблюдением правил 72 выполнения инструкций. Все расширенные инструкции помещаются на этой же стадии 208 в очередь 166 расширенных инструкций. Снова, как и в предыдущем случае, очередь 166 обеспечивает преобразование выходной информации блоков 182 сбора данных главной БД, работающих параллельно, в последовательность расширенных инструкций на выполнение расчетных операций, которые должны быть выполнены.
Затем подсистема 154 определения позиций последовательно обрабатывает на стадии 210 каждую расширенную инструкцию в порядке их расположения в очереди. Далее этот процесс будет описан более подробно. На стадии 212 определяется, будут ли соблюдены правила 72 при выполнении инструкции по расчетной операции, и если результат отрицательный, то инструкция на стадии 214 направляется для выполнения повторной попытки ее выполнения, и на стадии 216 формируется сообщение диспетчера уведомлений. В сообщении указывается, что инструкция на выполнение расчетной операции не была исполнена, но позднее может быть выполнена повторная попытка ее выполнения. Если же на стадии 212 получен положительный результат, то инструкция на выполнение расчетной операции выполняется на стадии 218, и соответствующие файлы 30а таблицы 186, содержащей в памяти записанные обновленные данные главной БД, обновляются новыми величинами файлов 30 ресурсных счетов и агрегированной величиной 32 ресурсов для участников, к которым относится инструкция. Затем исполненные инструкции по расчетным операциям на стадии 220 записываются как инструкции выполнения обновления в очередь 168 завершения для подачи в диспетчер 156 и последующей передачи в модуль 153 обновления. На фигуре 9 это не отражено, однако инструкции, направляемые для повторной попытки выполнения, также записываются в очередь завершения. Эти неисполненные инструкции также помещаются в очередь завершения, однако только для целей формирования отчетных сообщений, и они не передаются в модуль 158 обновления.
Диспетчер 156 считывает инструкции, записанные в очереди завершения, и на стадии 222 создает отчетные сообщения, которые должны быть переданы участникам, указанным в инструкции на выполнение расчетной операции, о выполнении или о невыполнении инструкции. Эти сообщения передаются также на стадии 222 в очередь 172 отчетных сообщений для передачи в режиме реального времени в процесс 162 обработки инструкций участникам, указанным в инструкции. После этого сообщения в очереди отчетных сообщений передаются на стадии 224.
Для выполненных инструкций на обновление, записанных в очереди 168 завершения, диспетчер 156 также передает на стадии 226 эти инструкции на обновление в очереди 170 разделения данных главной БД. Этот процесс включает также вход от модуля 176 выравнивания нагрузки и структуры 178 разграничения, как это будет описано ниже более подробно.
И, наконец, части 24а, 24b, 24с главной БД 24, которые назначены каждому блоку 190 обновления главных данных, обновляются на стадии 228 модулем 158 обновления.
Ниже будут описаны более подробно основные компоненты платформы 150 обработки и выполняемые ими функции.
Очереди 164 исходных входных данных представляют собой открытый интерфейс платформы 150. Это позволяет соединять входной поток, поступающий от процессов 162 индивидуальной обработки инструкций, ответ по которым необходим в режиме реального времени, с потоками пакетов, поступающими от процессов 160 обработки файлов последовательностей, по которым необходима очень высокая производительность. Задающий модуль 174 управляет входами в очередях 164 исходных входных данных. Задающий модуль 174 ограничивает нагрузки, создаваемые пакетными инструкциями, пропускной способностью самого медленного компонента платформы, которым обычно является подсистема 154 определения позиций. Для пакетных инструкций нагрузка должна ограничиваться для предотвращения возникновения взаимного блокирования в очередях 164 исходных входных данных. Нагрузка, создаваемая процессами 162 индивидуальной обработки инструкций, ограничивается способностью компьютера пользователя в режиме реального времени вводить новые инструкции. Это управление загрузкой очередей 164 исходных входных данных применяется ко всем очередям платформы 150.
Задающий модель 174 включается при обработке группы инструкций (например, выборки из главной БД или пакетных инструкций). Как показано на фигуре 8, задающий модуль 174 используется в верхней части потока, между последовательными файлами и очередями 164 исходных входных данных. Он действует аналогично системе автоматического поддержания скорости, поскольку ограничивает скорость подачи пакетных инструкций в очереди 164 исходных входных данных для предотвращения возникновения очереди в потоке инструкций (на самом медленном компоненте системы).
Имеются две основные причины необходимости регулирования скорости входного потока из очередей платформы 150. Во-первых, очереди 164, 166, 168, 170 являются эффективным транспортным уровнем, а не контейнерами данных. Количество сообщений или инструкций, которое может быть записано в очередь, ограничено. Возникновение большого количества неисполненных инструкций может приводить к состоянию полного блокирования записи в очередь каким-либо процессом. Кроме того, скорость обработки сообщений в очереди снижается, когда в ней накапливается большое количество сообщений. Это происходит, потому что требуется частый сброс сообщений на жесткий диск.
Во-вторых, необходимо обеспечить положение, при котором инструкции, поступающие из процесса 162 индивидуальной обработки в режиме реального времени, не должны помещаться в очереди позади совокупности пакетных инструкций. Когда запрос на обработку инструкции в режиме реального времени помещается в очередь, время реакции процесса 162 индивидуальной обработки инструкций может не соответствовать требованию реакции в режиме реального времени, которое устанавливает максимальное время ответа, равное двум секундам.
Регулирование скорости входного потока определяется минимальной задержкой между двумя последовательными фиксациями. После выполнения фиксации вычисляется промежуток времени между моментом этой фиксации и моментом предыдущей фиксации.
Пример
Текущая фиксация = 2007-07-01-09.05.04.224335
Предыдущая фиксация = 2007-07-01-09.05.040.100635
Интервал времени между двумя фиксациями равен 0,123700 секунды.
Если заданный темп фиксаций равен 0,5 секунд, то должна быть выполнена задержка в 0,3763 секунды. Если кратность фиксаций равна 50, и заданный темп фиксаций равен 0,5 секунды, то ожидаемая пропускная способность будет равна 100 инструкциям.
Входные потоки в очереди 164 исходных входных данных обрабатываются структурой 175 маршрутизации и модулем 176 выравнивания нагрузки, который влияет на функцию маршрутизации, в которой обеспечивается техническая структура выравнивания нагрузки для равномерного распределения сообщений по очередям 164.
Необходимо понимать, что нет никакого различения между инструкциями, приходящими из процесса 160 пакетных файлов, и инструкциями, приходящими из процесса 162 индивидуальной обработки в режиме реального времени. В момент открытия рабочего временного окна (рабочий сеанс) для платформы 150 все ожидающие обработки инструкции должны быть организованы в форме последовательности и поданы в очереди 164 исходных входных данных. Правило организации последовательности также применяется к инструкциям, поступающим в режиме реального времени, в процессе подачи в очереди инструкции при открытии рабочего временного окна. Инструкции, обрабатываемые в режиме реального времени, должны подаваться в очереди 164 исходных входных данных в соответствии с их приоритетами. После выполнения операций по открытию рабочего временного окна организация последовательности осуществляется в зависимости от времени. Две инструкции, относящиеся к одному и тому же файлу 30 ресурсного счета одного участника, должны подаваться в одну и ту же очередь 164 исходных входных данных (для их последовательной обработки).
Для очередей 164 исходных входных данных, представляющих собой экземпляры программы организации очереди, работающие параллельно, важно, чтобы обрабатывался большой объем исходных инструкций, который может быть, например, при открытии сеанса обработки (рабочего временного окна). При этом загрузка инструкций в очереди 164 исходных входных данных обеспечивается структурой 175 маршрутизации, и это дает возможность модулю 176 выравнивания нагрузки осуществлять равномерное распределение нагрузки между очередями 164.
Каждый модуль 152 предварительной загрузки установлен в системе таким образом, чтобы он считывал инструкции на выполнение расчетных операций из одной соответствующей очереди 164 исходных входных данных. Модуль 152 обеспечивает анализ входящих инструкций на выполнение расчетных операций, чтобы выбрать из главной БД 24 все справочные данные, которые будут необходимы подсистеме 154 определения позиций для определения возможности выполнения инструкции. Такими справочными данными являются текущие величины файлов 30 ресурсных счетов, к которым относится инструкция, и агрегированные величины 32 ресурсов для участников, к которым относится инструкция. Затем выбранные данные используются для формирования расширенных инструкций, содержащих не только входную инструкцию на выполнение расчетной операции, но также все справочные данные, выбранные из главной БД 24.
На фигуре 10 представлена блок-схема алгоритма работы модуля 152 предварительной загрузки. Понятно, что каждый экземпляр модуля 154 предварительной загрузки работает независимо и параллельно для повышения пропускной способности.
Алгоритм 240 работы модуля 154 предварительной загрузки начинается на стадии 242 считыванием инструкции на выполнение расчетной операции из очереди 164 исходных входных данных, которая назначена этому экземпляру модуля 154. После этого блок 182 сбора данных главной БД экземпляра модуля 154 предварительной загрузки определяет на стадии 244, какие файлы 30 ресурсных счетов участников и агрегированные величины 32 ресурсов этих участников должны быть считаны из главной БД. После формирования соответствующих инструкций на считывание на стадии 246 выполняется последовательное считывание. Считанные данные обрабатываются на стадии 248 экземпляром модуля 154 предварительной загрузки для создания упорядоченного образа справочных данных для этой инструкции. Затем полученный образ соединяется на стадии 250 с исходной инструкцией для формирования составной расширенной инструкции. Алгоритм 240 работы модуля предварительной загрузки заканчивается передачей на стадии 252 составной расширенной инструкции на выходе каждого экземпляра модуля 154 в единственную очередь 184 расширенных инструкций.
В подсистеме 154 определения позиций реализуется один из ключевых элементов новой архитектуры по настоящему изобретению, а именно отказ от параллельного выполнения инструкций главным логическим процессором подсистемы 154. Поскольку используется лишь один экземпляр главного логического процессора 184, то именно он должен обеспечивать общую производительность системы. Это обстоятельство повышает значимость выполнения главным логическим процессором 184 операций, критических по времени. Одно из необходимых ограничений, которое применяется для достижения максимально возможной пропускной способности, заключается в требовании запрета доступа к БД, поскольку они снижают пропускную способность. После начальной загрузки, при которой главный логический процессор 184 может выбрать очень часто используемые справочные данные, доступ процессора 184 к внешним данным ограничивается одной входной инструкцией и одним выходным сообщением. Справочные данные, необходимые для обработки инструкции, однако не загруженные на стадии запуска, будут доступны в форме упорядоченного образа справочных данных, входящего в состав каждой расширенной инструкции. Только первый образ справочных данных для данного файла 30 ресурсного счета, полученный из одного из модулей 152 предварительной загрузки, будет записан подсистемой 154 определения позиций в его соответствующем файле 30а таблицы 186 обновляемых записей главной БД. Эта первая копия всегда действительна, поскольку она еще не была модифицирована потоком инструкций, обрабатываемых в режиме реального времени.
После записи в соответствующие файлы 30а таблицы 186 обновляемых записей главной БД образ справочных данных, считанных одним из модулей 152 предварительной загрузки, просто игнорируется, поскольку он может быть обновлен (обновления, подтвержденные подсистемой 154 определения позиций, еще не отражены в главной БД). Поэтому, если справочные данные, относящиеся к величине ресурсного счета, доступны в соответствующих файлах 30а таблицы 186 обновляемых записей главной БД, то они всегда используются вместо образа справочных данных, имеющегося в составе расширенной инструкции.
На фигуре 11 представлена более подробная блок-схема подсистемы 154 определения позиций. Подсистема 154 содержит модуль 260 получения инструкций, предназначенный для считывания расширенных инструкций из очереди 166, и модуль 262 меток времени, предназначенный для записи метки времени в текущей расширенной инструкции. Единственный экземпляр логического процессора 184 подсистемы 154 содержит блок 264 считывания справочных данных и обновления, блок 266 вычисления изменений и внесения обновлений в локальное запоминающее устройство и блок 268 обработки инструкций.
Блок 264 считывания справочных данных и обновления обеспечивает считывание данных, записанных в соответствующих файлах 30а таблицы 186 обновляемых записей главной БД, определение необходимости обновления, и осуществление обновления в случае необходимости. Таблица 186 обновляемых записей главной БД размещается в быстродействующем локальном запоминающем устройстве 270, в результате чего обеспечивается быстрое считывание и запись данных логическим процессором 184 для подсистемы 154 определения позиций. Соответственно, определение выполнения инструкции может осуществляться только путем проверки в быстродействующем локальном запоминающем устройстве, а не проверками во внешней БД, требующими гораздо больших затрат времени. В запоминающем устройстве 270 также сохраняется перечень 272 невыполненных инструкций, которые необходимо попытаться выполнить позднее.
Блок 266 вычисления изменений и обновления данных в локальном устройстве хранения данных предназначен для считывания справочных данных, записанных в соответствующих файлах 30а таблицы 186 обновляемых записей главной БД, для использования информации инструкций с целью определения необходимых изменений этих данных и для записи обновленных справочных данных в таблицу 186 обновляемых записей главной БД.
Модуль 268 обработки инструкций используется для оценки того, что обновленные величины файлов 30 ресурсных счетов и агрегированной величины 32 ресурса формируют допустимую позицию для данных этого ресурса. То есть осуществляется оценка соответствия правилам 72 величин файлов 30 ресурсных счетов и агрегированной величины 32 ресурса.
Для считывания и записи невыполненных инструкций в перечень 272 используется модуль 274 организации повторного выполнения невыполненных инструкций, который обменивается сообщениями с модулем 268 обработки инструкций. Выходная информация логического процессора 184 передается в модуль 276 формирования отчетных сообщений, который передает результаты обработки инструкций в форме инструкций на выполнение обновлений в очередь 168 завершения.
Повторение невыполненных инструкций осуществляется в соответствии с приоритетами входных инструкций. Ранее каждой инструкции был назначен приоритет (например, высший приоритет, обычный приоритет и низкий приоритет). Модуль 274 организации повторения выполнения невыполненных инструкций поддерживает перечень невыполненных инструкций в порядке их приоритетов для осуществления попытки повторения. Порядок определяется прежде всего на основе приоритетов, назначенных каждой инструкции. Затем для определения приоритета используется количество ресурсов, указанных в инструкции. Поддержание приоритетов в перечне повторения выполнения невыполненных инструкций обеспечивает сравнительно простое и потому быстрое их повторное выполнение. Кроме того, процедура повторного выполнения невыполненных инструкций становится динамической за счет того, что порядок повторного выполнения инструкций отражает их приоритеты.
Модуль 274 повторения выполнения невыполненных инструкций также имеет возможность резервировать содержание файла 30 ресурсного счета для обработки с определенной инструкцией. Это происходит, когда количество имеющегося ресурса в файле ресурсного счета должно удовлетворять требованиям инструкции на обработку, записанной в перечне 272. За счет резервирования этого количества модуль 274 повторения выполнения невыполненных инструкций обеспечивает поддержание приоритета и выполнение инструкции с высоким приоритетом раньше выполнения инструкции с низким приоритетом, даже если имеются ресурсы, доступные для выполнения инструкции с низким приоритетом.
Это лучше всего иллюстрируется следующим неограничивающим примером того, как модуль 274 повторного выполнения невыполненных инструкций в подсистеме 154 определения позиций осуществляет резервирование и обработку приоритетов принятых инструкций на обработку.
Пример
Файл Acc/Sed ресурсного счета содержит 50 ценных бумаг.
Инструкции на обработку поступают на вход последовательно и имеют следующее воздействие на Acc/Sec1:
Шаг 1: для выполнения инструкции 1 с наивысшим приоритетом требуется 200 единиц.
Шаг 2: для инструкции 2 с обычным приоритетом требуется 100 единиц.
Шаг 3: для инструкции 3 с обычным приоритетом требуется 150 единиц.
Шаг 4: инструкция 3 со средним приоритетом добавляет 60 единиц.
Шаг 5: инструкция 4 со средним приоритетом добавляет 290 единиц.
Структура памяти, представляющая перечень инструкций, касающихся Acc/Sec1, для повторного выполнения, имеет следующий вид:
После шага 1:
Acc/Sec1
- содержит 50 единиц
- уже зарезервировано
- инструкция 1 для 50 единиц
- перечень невыполненных инструкций <инструкция 1>
После шага 2:
Acc/Sec1
- содержит 50 единиц
- уже зарезервировано
- инструкция 1 для 50 единиц
- перечень невыполненных инструкций <инструкция 1, инструкция 2> (приоритет инструкции 2 ниже приоритета инструкции 1)
После шага 3:
Acc/Sec1
- содержит 50 единиц
- уже зарезервировано
- инструкция 1 для 50 единиц
- перечень невыполненных инструкций <инструкция 1, инструкция 3, инструкция 2> (инструкция 3 имеет такой же приоритет, что и инструкция 2, но размер ее ресурса больше, и поэтому она более важна)
После шага 4: увеличение баланса Acc/Sec1 позволяет выполнить невыполненную инструкцию, в результате чего инструкция 1 добавляет 60 ценных бумаг к зарезервированному количеству. Резервирование не позволяет инструкции 2 (необходимо только 100) использовать 110 ценных бумаг, имеющихся на ресурсном счете.
Acc/Sec1
- содержит 110 единиц
- уже зарезервировано
- инструкция 1 для 110 единиц
- перечень невыполненных инструкций <инструкция 1, инструкция 3, инструкция 2>
После шага 5: Увеличение баланса Acc/Sec1 запускает процесс повторного выполнения невыполненных инструкций.
При запуске этого процесса записи в памяти имеют следующий вид:
Acc/Sec1
- содержит 400 единиц
- уже зарезервировано
- инструкция 1 для 110 единиц
- перечень невыполненных инструкций <инструкция 1, инструкция 3, инструкция 2>
После выполнения невыполненной инструкции 1, которая стоит первой в перечне невыполненных инструкций:
Acc/Sec1
- содержит 200 единиц
- уже зарезервировано
- 0
- перечень невыполненных инструкций <инструкция 3, инструкция 2>
После выполнения невыполненной инструкции 2, которая стоит теперь первой в перечне невыполненных инструкций:
Acc/Sec1
- содержит 50 единиц
- уже зарезервировано
- 0
- перечень невыполненных инструкций <инструкция 2>
Попытка выполнения невыполненной инструкции 2 неудачна (не хватает 50 единиц). Если она не резервируется, то содержание памяти не изменяется. Алгоритм 280 работы подсистемы 154 определения позиций подробно описывается ниже со ссылками на фигуру 12. Алгоритм 280 начинается на стадии 282 считыванием расширенной инструкции из очереди 166 расширенных инструкций. Затем на стадии 284 в считанной инструкции модуль 262 записывает метку времени. С учетом количества инструкций, обрабатываемых в течение одной секунды, метки времени имеют высокое разрешение, и обычно время в них записывается с точностью до микросекунд.
Если, как это определяется на стадии 286, расширенная инструкция с записанной меткой времени содержит новые справочные данные, а именно величины конкретных файлов 30 ресурсных счетов, которые не были записаны в соответствующих файлах 30а таблицы 186 обновляемых данных главной БД, то эти новые справочные данные записываются в таблицу 186. Если справочные данные не новы, то алгоритм 280 просто переходит к локальному обновлению баланса на стадии 290, которое выполняется модулем 266 вычисления изменений и обновления содержимого локального запоминающего устройства. На этой стадии справочные данные считываются из таблицы 186 обновляемых записей главной БД, размещенной в локальном запоминающем устройстве 270, изменение, заданное в инструкции, применяется к считанным справочным данным, и полученная после этого величина справочных данных снова записывается в соответствующие файлы 30а таблицы 186.
Соответственно, после этого модуль 268 обработки инструкций анализирует на стадии 292 текущие величины справочных данных и определяет, соответствуют ли результирующие обновленные величины файлов 30 ресурсных счетов и агрегированная величина 32 ресурса заданным правилам 72, относящимся к допустимым величинам справочных данных. Если результат проверки отрицательный, то выполняются три действия. Во-первых, причина невыполнения инструкции сообщается на стадии 294 через модуль 276 формирования отчетных сообщений. Во-вторых, на стадии 296 восстанавливаются предыдущие величины справочных данных. И, наконец, невыполненная инструкция сохраняется на стадии 298 в перечне 272 невыполненных инструкций для повторной попытки ее выполнения.
Если обновленные справочные данные не нарушают заданные правила 72, то на стадии 300 модуль 276 формирует отчетное сообщение об успешном выполнении инструкции по расчетной операции. В соответствии с этим отчетным сообщением формируются соответствующие сообщения участникам, к которым относится инструкция, и в модуль 158 обновления передается инструкция на обновление главной БД 24. После этого на стадии 302 определяется результирующий баланс, а именно формируются величины изменений ресурсного счета и создаются сообщения обновления баланса. В нижеприведенном примере формирование отчетного сообщения и сообщений обновления баланса описывается в двух стадиях.
Наконец, на стадии 304 запускается процедура выполнения невыполненных инструкций, чтобы определить, позволяют ли измененные справочные данные выполнить какую-либо из ранее невыполненных инструкций.
Конечно, все справочные данные, по которым формируются отчетные сообщения об их обновлении, хранятся в локальном запоминающем устройстве (таблица 186 обновляемых данных главной БД) подсистемы 154 определения позиций, чтобы их можно было многократно использовать при обработке последовательных инструкций на выполнение расчетных операций (заменяя устаревший вариант этих данных, предлагаемый одним из модулей предварительной загрузки), в том числе при повторном выполнении невыполненных инструкций.
Обновленные справочные данные 30, 32, находящиеся в файлах 30а локального запоминающего устройства 270 подсистемы 154, никогда не стираются. В конце периода обработки, например в конце дня, подсистема 154 определения позиций выключается, что приводит к полному сбросу информации в запоминающем устройстве. Такой сброс также происходит в том случае, когда возникает серьезная проблема при работе подсистемы 154. Предусмотрен специальный процесс перезапуска для обеспечения отражения всех конечных обновлений в главной БД 24 и удаления всех инструкций, стоящих в очереди 166 расширенных инструкций перед перезапуском модулей 152 предварительной загрузки (в этот момент главная БД 24 отражает конечный вариант всех балансов).
Ниже приведен неограничивающий пример взаимодействия модулей 152 предварительной загрузки и подсистемы 154 определения позиций.
Пример
Инструкция 1 (Ins1) обрабатывается экземпляром 1 модуля предварительной загрузки (блок 1 сбора данных главной БД). Это инструкция на выполнение расчетной операции между счетом асс1 (участника А) и счетом асс2 (участника В) для типа Sec1 ресурсного счета, в которой 10 ценных бумаг Sec1 обмениваются на 500 единиц Sec2.
Инструкция 2 (Ins2) обрабатывается экземпляром 2 модуля предварительной загрузки (блок 2 сбора данных главной БД). Это инструкция на выполнение расчетной операции между счетом асс3 (участника С) и счетом асс2 (участника В) для типа Sec1 ресурсного счета, в которой 20 ценных бумаг Sec1 обмениваются на 1050 единиц Sec2.
Две инструкции выполняются параллельно.
Экземпляр 1 модуля предварительной загрузки формирует следующее сообщение:
(образ инструкции) + (образ соответствующих балансов: acc1/sec1=1000, acc2/sec1=300, acc1/sec2=25000, acc2/sec2=30000…).
Экземпляр 2 модуля предварительной загрузки формирует следующее сообщение:
(образ инструкции) + (образ соответствующих балансов: асс3/sec1=3000, acc2/sec1=300, acc3/sec2=5000, acc2/sec2=30000…).
Эти два сообщения записываются последовательно в очередь 166 расширенных инструкций подсистемы 154 определения позиций.
Можно видеть, что acc2/Sec1 и acc2/Sec2 указываются дважды с одинаковой величиной. Это уже задача подсистемы 154 определения позиций проанализировать эти величины, когда они принимаются в первый раз (точная величина) и отбросить их при следующем получении (повторное использование вместо этого копии, имеющейся в запоминающем устройстве).
Результат определения позиций будет следующим.
Сначала обработка инструкции, полученной из экземпляра 1 модуля предварительной загрузки (порядок не важен).
Баланс в локальном запоминающем устройстве 186 перед выполнением расчетной операции:
<пусто>
Баланс в запоминающем устройстве после выполнения расчетной операции:
<acc1/sec1>=990 (1000-10)
<acc2/sec1>=310 (300+10)
<acc1/sec2>=25500 (25000+500)
<acc2/sec2>=29500 (30000-500)
Обработка инструкции, полученной из экземпляра 2 модуля предварительной загрузки.
Баланс в запоминающем устройстве перед выполнением расчетной операции (= балансу после выполнения расчетной операции для предыдущей инструкции):
<acc1/sec1>=990 (1000-10)
<acc2/sec1>=310 (300+10)
<acc1/sec2>=25500 (25000+500)
<acc2/sec2>=29500 (30000-500)
Баланс в запоминающем устройстве после выполнения расчетной операции:
<acc1/sec1>=990 (не изменилось)
<acc2/sec1>=330 (310+20: величина 300, полученная модулем предварительной обработки, отбрасывается)
<acc1/sec2>=25500 (не изменилось)
<acc2/sec2>=28450 (29500-1050: величина, полученная модулем предварительной обработки, отбрасывается)
<acc3/sec1>=2980 (3000-20)
<acc3/sec2>=6050 (5000+1050)
Очередь 168 завершения является важной частью рассматриваемого варианта.
Рассмотренный пример иллюстрирует, как разделяется принятие решения подсистемой 154 определения позиций в отношении допустимости данной инструкции (выполнение правил 72) и формирование в режиме реального времени отчетного сообщения о результатах выполнения инструкции вместе с обновлением главной БД 24. Такое разделение дает возможность подсистеме 154 определения позиций минимизировать ее задачи по обработке и, соответственно, обеспечить большую пропускную способность.
Работа подсистемы 154 завершается (на что указывает метка времени, в любом случае подтверждающая инструкцию на выполнение расчетной операции) не отражением получаемых ею обновлений в главной БД 24, а документированием их в инструкции на выполнение обновлений в очередях 168 завершения. Иначе говоря, запись инструкции на завершение (инструкция на выполнение обновления) записывается в очередь 168 завершения, которая является входной очередью для диспетчера 156. При этом исходная инструкция на обработку считается завершенной, то есть выполненной. Задачей диспетчера 156 является формирование уведомлений участникам, указанным в инструкции, и распределение обновлений по различным входным очередям (очередям 170 разделения главных данных) модуля 158 обновления. Основной целью является предотвращение смешивания в одном рабочем логическом блоке действий по формированию отчетных сообщений и обновлений балансов в БД.
Поскольку на выходе подсистемы 154 определения позиций постоянно формируется одно сообщение (содержащее все обновления главной БД, которые должны быть реализованы для завершения порождающей эти обновления инструкции), то диспетчером 156 используется специальный процесс для распределения обновлений и формирования запрошенных отчетных сообщений по выполнению инструкций (например, ответ в процесс 162 индивидуальной обработки инструкций в режиме реального времени). Для одного сообщения, поступившего на вход, диспетчер 156 записывает одно выходное сообщение на каждый обновленный ресурс и одно выходное сообщение на каждый сформированный отчет. Для обеспечения высокой пропускной способности системы в диспетчере осуществляется параллельная обработка. Диспетчер 156 является расширяемым модулем (производительность увеличивается при запуске еще одного экземпляра программы).
Формат отчетного сообщения, формируемого диспетчером 156, представляет собой просто структурированный текст. Однако этот формат может быть изменен в случае необходимости для использования внешнего формата или формата ISO. Кроме того, диспетчер обеспечивает формирование отчетных сообщений о выполнении сессии обработки, в которых указываются все транзакции, поступившие в течение этой сессии, а также изменения величин файлов 30 ресурсных счетов и агрегированных величин 32 ресурсов для каждого вовлеченного в процесс участника, возникшие в результате этих транзакций.
Диспетчер 156 не определяет, в какой из блоков 190 обновления данных главной БД необходимо дать указание на выполнение обновления. Эту функцию выполняют структура 175 маршрутизации и модуль 176 выравнивания потоков операций, описанные ниже.
Структура 175 маршрутизации помогает выровнять потоки операций. Входная информация очередей 164 исходных входных данных и выходная информация программы 188 диспетчера, поступающая в модуль 158 обновления через очереди 170 разделения данных главной БД, передаются через структуру 175 маршрутизации и модуль 178 выравнивания нагрузки. Программа 188 диспетчера передает инструкцию в структуру 175 маршрутизации, не имея информации о точном месте назначения (очередь 170 разделения данных главной БД) этой инструкции. Целью структуры 175 маршрутизации является подготовка инструкции для конкретной маршрутизации к одной из возможных очередей, работающих параллельно на платформе. В рассматриваемом варианте структура маршрутизации подготавливает инструкцию для задания маршрута к одной из очередей 164 исходных входных данных или к одной из очередей 170 разделения данных главной БД, в зависимости от ситуации. Структура 175 маршрутизации добавляет два технологических поля: наименование сообщения и ключ выравнивания нагрузки. Наименование сообщения описывает тип информации, содержащейся в сообщении, и ключ выравнивания нагрузки записывается в идентификатор инструкции для обеспечения правильной последовательности отчетных сообщений о попытках выполнения инструкции, чтобы избежать ситуации, когда после отчета "инструкция выполнена" следует отчет "инструкция не выполнена" из-за проблем с установлением последовательностей сообщений. Это выполняется с помощью внутренней справочной таблицы.
Структура 175 маршрутизации также может добавлять новый процесс в поток инструкций для изменения маршрута инструкции между процессами. Она может также добавить новую инструкцию в поток инструкций, запретить передачу инструкции из процесса и копировать инструкцию, если это необходимо. Затем инструкция с наименованием сообщения и ключом выравнивания нагрузки обрабатывается модулем 176 выравнивания потоков операций (описывается ниже).
При работе платформы 150 задачей структуры 175 маршрутизации является определение адресата, которому должна быть направлена инструкция, в каком формате и в какой экземпляр адресата (при параллельной обработке несколькими экземплярами процессов). Структура 175 маршрутизации используется, чтобы обеспечить положение, при котором отчетное сообщение по одной инструкции следовало бы в потоке после предыдущего отчетного сообщения по этой же инструкции. Например, если предпринималось несколько попыток выполнения инструкции, прежде чем она была, в конце концов, выполнена, то отчетное сообщение о том, что эта инструкция была успешно выполнена, должно следовать после отчетных сообщений о неудачных попытках выполнения этой инструкции. Кроме того, отчетные сообщения по каждой невыполненной инструкции передаются в такой последовательности, которая обеспечивает правильную реакцию участника, передавшего инструкцию, на ее невыполнение.
Пример. Первая попытка выполнения инструкции неудачна по причине того, что уровень ресурсного счета участника А недостаточен для обеспечения инструкции (участник А может предпринять некоторые действия). Затем вторая попытка выполнения инструкции также неудачна по причине того, что уровень ресурсного счета участника В недостаточен для обеспечения инструкции (участник В может предпринять некоторые действия). При передаче отчетных сообщений важно, чтобы сообщение о недостаточности ресурсного счета участника В следовало после сообщения о недостаточности ресурсного счета участника А. Если модуль диспетчера осуществляет параллельную обработку, то в задачи структуры 175 маршрутизации входит обеспечение передачи всех отчетных сообщений по одной инструкции одним и тем же экземпляром модуля 156 диспетчера (выравнивание загрузки по идентификатору инструкции).
Модуль 176 выравнивания нагрузки определяет конечное место назначения инструкции по ее наименованию и ключу выравнивания нагрузки (не показано), которые вместе в соответствии с логикой работы платформы 150 однозначным образом определяют каждую инструкцию. Наименование сообщения используется для идентификации очереди 170 разделения главных данных, информация из которой поступает в определенный блок 190 обновления данных главной БД (ниже описывается, как каждому блоку 190 обновления данных главной БД указывается определенный тип обновления). Ключ выравнивания нагрузки используется для определения конкретного экземпляра (очереди 170 разделения главных данных). Модуль 176 выравнивания нагрузки обеспечивает, чтобы для одного ключа всегда выбирался один и тот же экземпляр (очереди 170 разделения данных главной БД), как это иллюстрируется в нижеприведенном примере.
Пример
наименование сообщения = 'SECURITY_BALANCE_UPDATE' => модуль обновления баланса ценных бумаг
ключ выравнивания нагрузки = идентификатор ценных бумаг=13
Общее число блоков обновления баланса ценных бумаг, работающих параллельно=3.
Выбранный экземпляр=13-(целое (13/3)*3)+1
=13-(4*3)+1
=13-12+1=2
=>всякий раз, когда обновление должно выполняться для идентификатора ценных бумаг, равного 13, будет выбираться экземпляр номер 2 (маршрутизация сообщения).
Каждая очередь 170 разделения главных данных просто принимает инструкции из программы 188 диспетчера, которые специально направляются в эту очередь 170 структурой 175 маршрутизации и модулем 176 выравнивания нагрузки. Каждая очередь 170 разделения главных данных связана с определенным блоком 190 обновления данных главной БД, который работает с определенной частью 24а, 24b, 24с главной БД 24.
Модуль 158 обновления предназначен для отражения в одной из определенных частей 24а, 24b, 24с главной БД 24 инструкции обновления, указанной подсистемой 156 определения как окончательная. Поскольку каждый блок 190 обновления данных главной БД работает независимо с одной определенной частью БД, то при работе блоков 190 обновления не возникают возможные блокирования, которые типичны для других процессов обновления. Более того, поскольку каждый блок 190 обновления осуществляет исключительное обновление некоторой совокупности справочных данных, которыми он управляет, то он может осуществлять взаимный зачет инструкций на обновление БД. Каждый экземпляр модуля обновления работает со своим диапазоном ключей (используемых для идентификации блока обновления, в который направляется инструкция) независимо от того, выделены или нет эти ключи для определенной части главной БД.
Имеются два различных варианта реализации модуля 158 обновления. В одном варианте инструкции на обновление содержат приращения, то есть изменения величин файлов ресурсных счетов. В другом варианте обновления определяются последней величиной файла ресурсного счета. Оба варианта описываются ниже, в частности как они влияют на способ осуществления взаимного зачета.
Когда обновления содержат приращения, алгоритм взаимного зачета (не показан), реализуемый блоком 190 обновления данных главной БД, содержит суммирование изменения каждой инструкции для заданного файла 30 ресурсного счета перед выполнением одного общего обновления этого файла 30 ресурсного счета. Когда обновления определяются последней величиной, алгоритм взаимного зачета содержит хранение величины с самой последней меткой времени обновления и добавление проверки метки времени в операторе "если" процедуры обновления (ниже приводится соответствующий пример).
В частности, в варианте с последней величиной процесс взаимного зачета пытается поддерживать последнее обновление, выполненное подсистемой 154 определения позиций. Поскольку правильная последовательность обновлений не гарантируется, то алгоритм взаимного зачета может принять последнюю величину, относящуюся, например, к 12:45:01 после получения последней величины, относящейся к 12:45:03. Для выполнения обновления должна приниматься во внимание только величина, относящаяся к 12:45:03. Конечно, если допустить, что последняя величина, относящаяся к 12:45:06, уже отражена в базе данных, то величина, относящаяся к 12:45:03, не должна учитываться. Это осуществляется с использованием метки времени при обновлении данных главной БД, как описано ниже.
ЕХЕС SQL UPDATE PP_SEC_BAL
SET BALANCE_VALUE = последняя величина, принятая на входе,
Метка времени баланса = метка времени определения последней величины.
Если идентификатор баланса = идентификатор баланса из запроса на обновление И
Метка времени баланса (в БД) < метка времени определения последней величины.
Сообщения обновления, получаемые блоками обновления, являются окончательными (во всяком случае должны быть применены). Это означает, что они могут быть сгруппированы так, что две последовательные инструкции на обновление для одного ключа преобразуются блоком 190 обновления главных данных в одно физическое обновление.
Ниже приведены примеры алгоритмов обновления с приращениями и с последней величиной.
Пример для последней величины.
Блок обновления принимает следующую последовательность:
Баланс1 10000 2007-08-01-09.01.01.112335 (время с точностью до мкс)
Баланс1 12500 2007-08-01-09.01.02.100475
Баланс1 25000 2007-08-01-09.01.01.875221
Баланс1 12500 2007-08-01-09.01.02.077054
Блок 190 обновления данных главной БД последовательно считывает все обновления.
Для первого обновления он сохраняет величину (баланс указывается первый раз в текущей логической единице работы).
Второе обновление замещает предыдущую величину в памяти (запрос относится к более позднему времени по сравнению с первым запросом).
Третье обновление отбрасывается, поскольку запрос был сформирован по времени перед второй величиной.
Четвертое обновление отбрасывается, поскольку запрос также был сформирован по времени перед второй величиной.
В момент времени фиксации формируется физическое обновление:
ЕХЕС SQL UPDATE SET Величина баланса=12500, метка времени=2007-08-01-09.01.02.100475
Где идентификатор баланса=баланс1 и метка времени < 2007-08-01-09.01.02.100475
Условие временной метки прервет запрос на обновление, если образ в базе данных относится к более позднему времени по сравнению со временем запроса на обновление.
Пример для приращений.
Блок 190 обновления данных главной БД принимает следующую последовательность:
Баланс1 10000 2007-08-01-09.01.01.112335 (время с точностью до мкс)
Баланс1 12500 2007-08-01-09.01.02.100475
Баланс1 25000 2007-08-01-09.01.01.875221
Баланс1 12500 2007-08-01-09.01.02.077054
Блок 190 обновления главных данных последовательно считывает все обновления.
Для первого обновления он сохраняет величину (баланс указывается первый раз в текущей единице работы).
Для второго обновления он добавляет приращение 10000+12500=22500
Для третьего обновления он добавляет приращение 22500+25000=47500
Для четвертого обновления он добавляет приращение 47500+12500=60000.
В момент времени фиксации формируется физическое обновление:
ЕХЕС SQL UPDATE SET Величина баланса = величина баланса+60000
Где идентификатор баланса = баланс1.
Задающий модуль 174 - это не единственное средство регулирования потока инструкций через платформу, которое предотвращает заполнение очередей (очереди почти пусты). При обработке в режиме реального времени структура 178 разграничения обеспечивает правильное отражение в главной БД 24 всех обновлений, выполненных до конца сеанса обработки, чтобы запустить в диспетчере 156 формирование отчетных сообщений в конце сеанса обработки.
Запись инструкции на выполнение обновления в очередь 168 завершения может считаться завершающей операцией по выполнению инструкции платформой 150, даже если обновления главной БД еще не выполнены. Однако с технической точки зрения необходимо еще обеспечить, чтобы инструкции на выполнение обновлений действительно были реализованы в главной БД 24, прежде чем можно будет использовать величины файлов 30 ресурсных счетов главной БД.
Для выполнения этой задачи используется структура 178 разграничения, которая выполняет базовую функцию записи запроса/отчетного сообщения в верхней части очереди завершения. Если отчетное сообщение получено, это означает, что все инструкции, ранее записанные в очередь завершения, выполнены.
Процесс обработки потока инструкций в платформе 150 состоит из ряда процессов, выполняемых последовательно. В частности, очереди 170 разделения главных данных обрабатывают инструкции на обновление только после того, как они пройдут через очередь 168 завершения. Соответственно, как только отчетное сообщение получено из очереди завершения, новый запрос/отчетное сообщение передается последовательно в следующие очереди, именно в очереди 170 разделения данных главной БД. В каждой очереди используется алгоритм FIFO обработки.
Основной задачей структуры 178 разграничения является не проверка того, что в главной БД записаны правильные обновленные данные, а того, что инструкции на выполнение обновлений выполнены поочередно, причем эта проверка выполняется последовательно на различных стадиях обработки в системе.
Если реализована параллельная обработка, то процесс может выполняться параллельно с использованием множества очередей. Чтобы гарантировать, что все очереди обработали содержащиеся в них записи, запрос/отчет должен быть записан во все очереди, а не только в одну из них. Структура 175 маршрутизации должна определять, что сообщение должно быть направлено в n экземпляров процесса, и структура разграничения должна ожидать и не начинать разграничение следующего процесса, пока не будут получены n отчетов.
Нижеприведенный пример иллюстрирует работу структуры 178 разграничения по обеспечению выполнения инструкций на выполнение обновлений модулем 158 обновления после закрытия сеанса обработки.
Пример
В определенное время, например в 16.00, платформа 150 устанавливает крайний срок для выполнения инструкций. При наступлении крайнего срока процесс формирования отчетных сообщений считывает из главной БД все выполненные инструкции для формирования файла отчетных сообщений, который должен быть направлен участнику, заинтересованному в результатах сеанса обработки.
В 16.00 планировщик запускает процесс формирования отчетных сообщений.
На первой стадии выполнения процесса утилита разграничения (не показана, является частью структуры 178 разграничения) используется для формирования и передачи сообщения разграничения в ядро структуры разграничения (не показано, также является частью структуры 178 разграничения). В соответствии с принятым сообщением ядро структуры разграничения начинает записывать сообщения в различные процессы, которые должны быть разграничены, чтобы обеспечить отражение всех обновлений, указанных как окончательные подсистемой 154 определения позиций в главной БД (диспетчер 188 и блоки 190 обновления).
На второй стадии процесса формирования отчетных сообщений выполняется утилита структуры разграничения проверки завершения (не показана, является частью структуры 178 разграничения). Она переводит процесс формирования отчетных сообщений в режим ожидания, пока не будет сообщено, что процесс модуля разграничения завершен ядром структуры разграничения. После этого на следующей стадии выполнение процесса формирования отчетных сообщений возобновляется.
На третьей стадии процесса формирования отчетных сообщений выполняется процесс диспетчера 188 в соответствии с точными данными, находящимися в главной БД.
Задача передачи отчетных сообщений требует от структуры 178 разграничения обеспечить, чтобы инструкции на выполнение обновлений, которые поступили до 16.00, были обработаны диспетчером 156 для целей формирования отчетных сообщений, и что они также отражены в главной БД 24. После этого состояние главной БД 24 отражает все операции по обработке инструкций, подтвержденные до крайнего срока, и могут быть сформированы точные отчетные сообщения, как это было описано выше.
Вышеописанные признаки в отношении варианта, представленного на фигурах 8-12, охарактеризованы в прилагаемой формуле изобретения. Необходимо понимать, что могут быть предложены и другие варианты осуществления настоящего изобретения с использованием лишь части вышеописанных признаков. Например, в некотором варианте можно вместо вышеописанного алгоритма повторного выполнения невыполненных инструкций использовать какой-либо известный алгоритм. Аналогично, задающий модуль может быть изменен или вообще исключен для обеспечения другого решения. Однако при выборе альтернативной архитектуры обработки данных необходимо учитывать ее влияние на пропускную способность системы. В случае настоящего изобретения можно считать, что заявленная архитектура обработки является оптимальной и обеспечивает максимально возможную пропускную способность. Такие признаки, как, например, задающий модуль, просто повышают пропускную способность.
В настоящем описании рассмотрены конкретные предпочтительные варианты осуществления изобретения, однако следует понимать, что рассмотренные варианты являются всего лишь примерами, и различные изменения и модификации могут быть предложены специалистами в данной области техники без выхода за пределы сущности и объема изобретения, определяемого прилагаемой формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| АВТОМАТИЗИРОВАННАЯ ОПЕРАЦИОННО-ИНФОРМАЦИОННАЯ СИСТЕМА СОПРОВОЖДЕНИЯ ПОДГОТОВКИ И ПРОВЕДЕНИЯ ГОЛОСОВАНИЯ | 2005 |
|
RU2303816C2 |
| Индивидуальный диспетчерский тренажер для тренинга оперативно-диспетчерского персонала магистральных нефтепроводов | 2015 |
|
RU2639932C2 |
| РАСЩЕПЛЕННАЯ ЗАГРУЗКА ДЛЯ ЭЛЕКТРОННЫХ ЗАГРУЗОК ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2006 |
|
RU2424552C2 |
| СИСТЕМА ВЗАИМОДЕЙСТВИЯ БАЗ ДАННЫХ АВТОМАТИЗИРОВАННОЙ СИСТЕМЫ УПРАВЛЕНИЯ | 2006 |
|
RU2324974C1 |
| СИСТЕМА ОБЕСПЕЧЕНИЯ КАТАСТРОФОУСТОЙЧИВОСТИ ИНФОРМАЦИОННОЙ ИНФРАСТРУКТУРЫ ПРИЛОЖЕНИЯ И СПОСОБЫ ЕЕ РАЗВЕРТЫВАНИЯ И ФУНКЦИОНИРОВАНИЯ | 2024 |
|
RU2830489C1 |
| СИСТЕМА ПОСТАНОВКИ МЕТКИ КОНФИДЕНЦИАЛЬНОСТИ В ЭЛЕКТРОННОМ ДОКУМЕНТЕ, УЧЕТА И КОНТРОЛЯ РАБОТЫ С КОНФИДЕНЦИАЛЬНЫМИ ЭЛЕКТРОННЫМИ ДОКУМЕНТАМИ | 2017 |
|
RU2647643C1 |
| АППАРАТНАЯ ВИРТУАЛИЗИРОВАННАЯ ИЗОЛЯЦИЯ ДЛЯ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ | 2017 |
|
RU2755880C2 |
| СПОСОБ ФУНКЦИОНИРОВАНИЯ ОПЕРАЦИОННОЙ СИСТЕМЫ ВЫЧИСЛИТЕЛЬНОГО УСТРОЙСТВА ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2626350C1 |
| СРЕДСТВА УПРАВЛЕНИЯ ДОСТУПОМ К ОНЛАЙНОВОЙ СЛУЖБЕ С ИСПОЛЬЗОВАНИЕМ ВНЕМАСШТАБНЫХ ПРИЗНАКОВ КАТАЛОГА | 2011 |
|
RU2598324C2 |
| Система распределенной базы данных и способ ее реализации | 2022 |
|
RU2784208C1 |
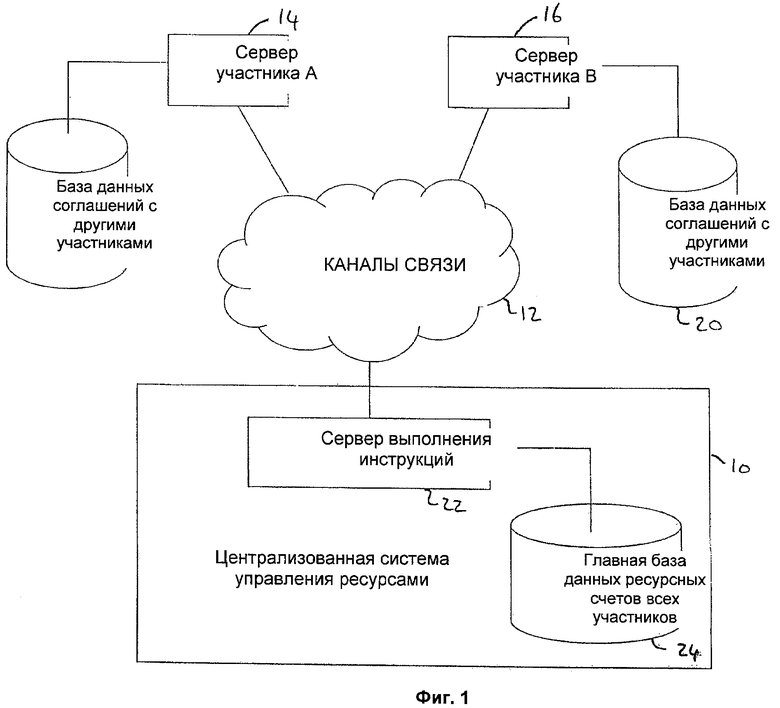
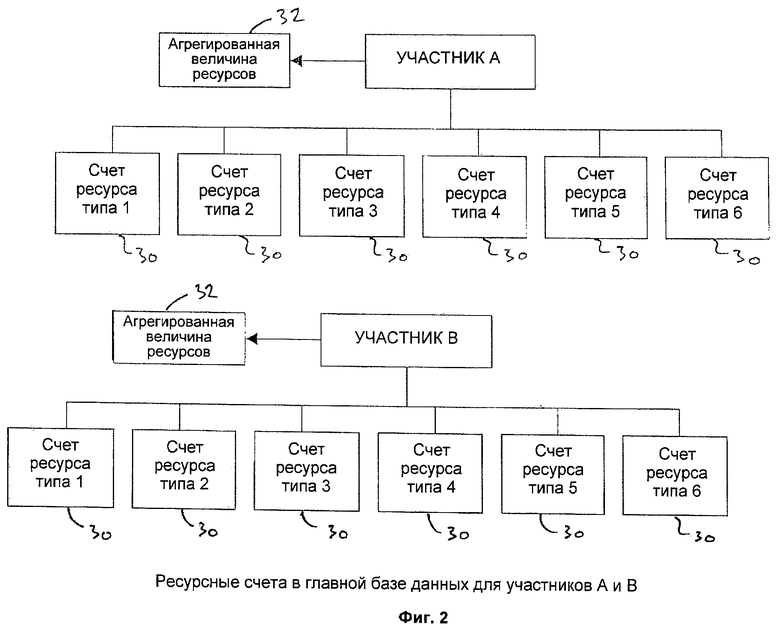
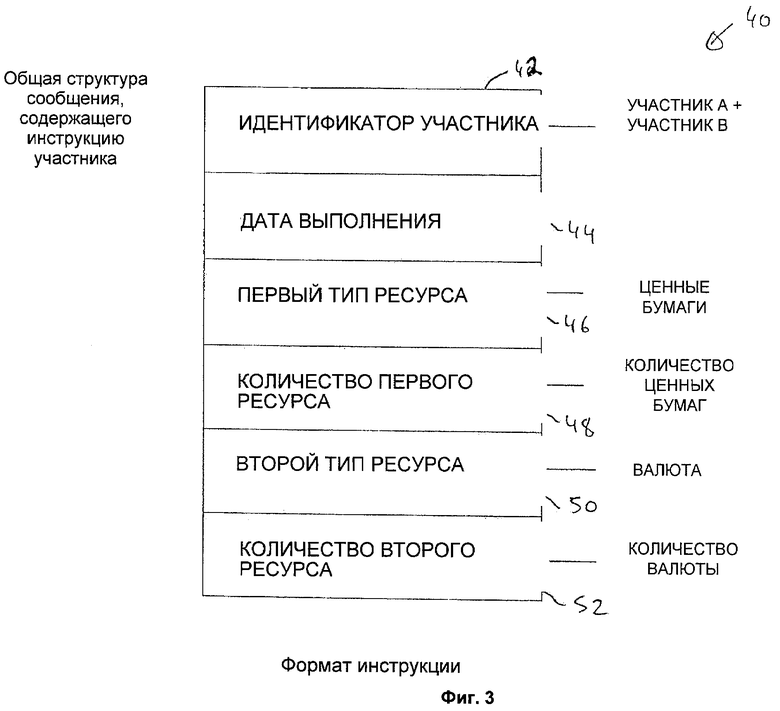
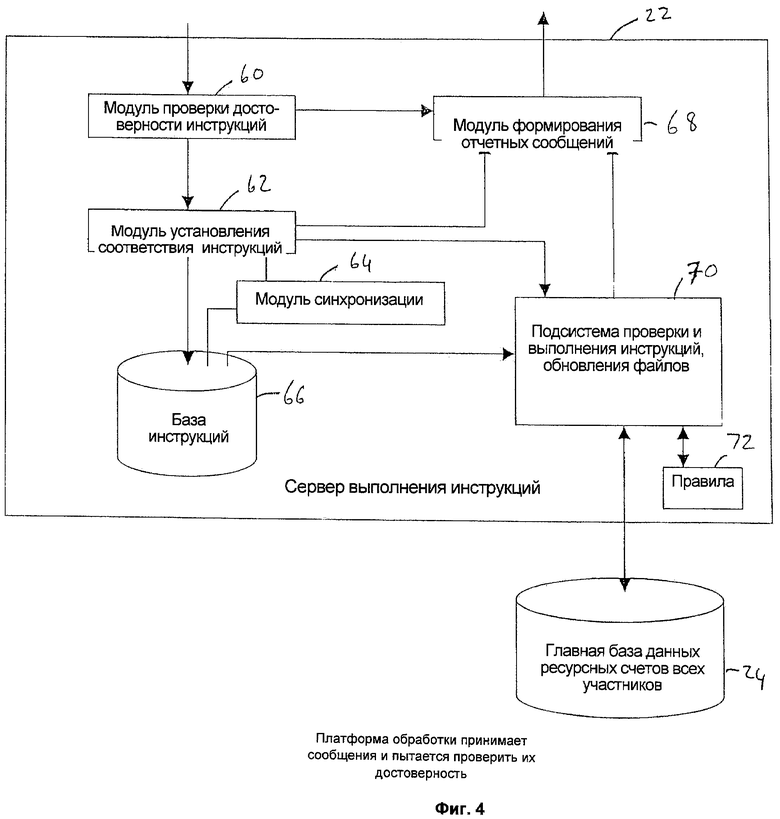
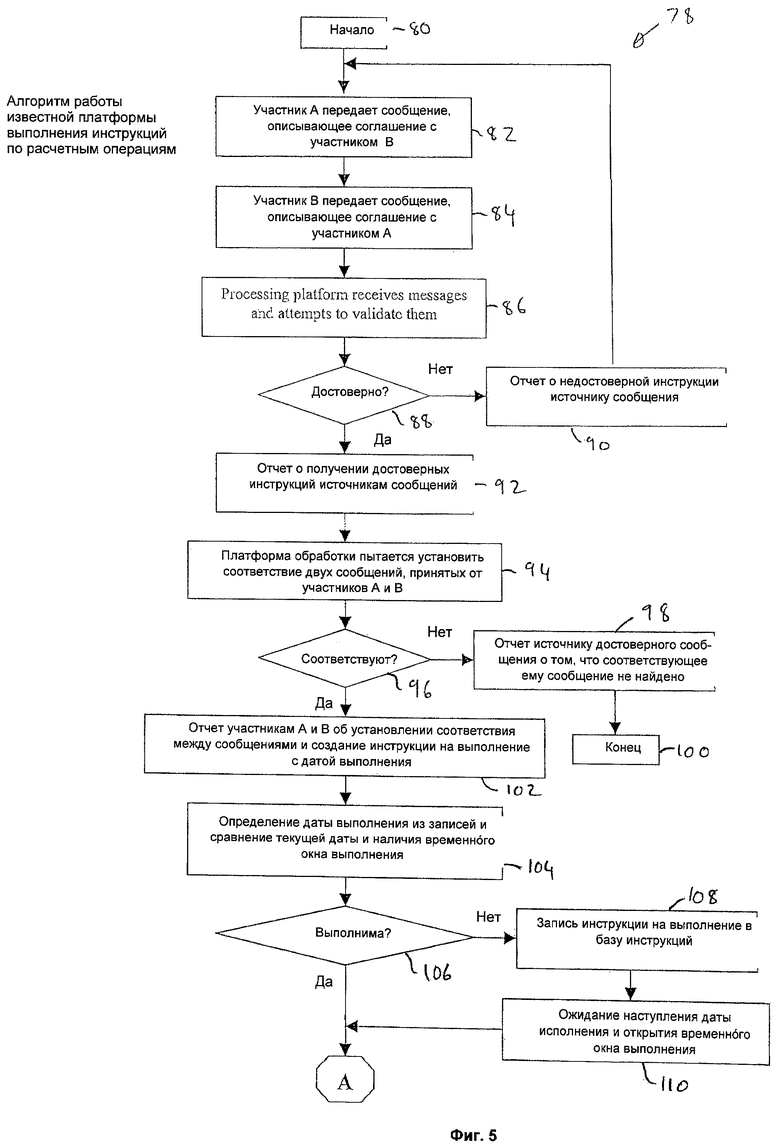
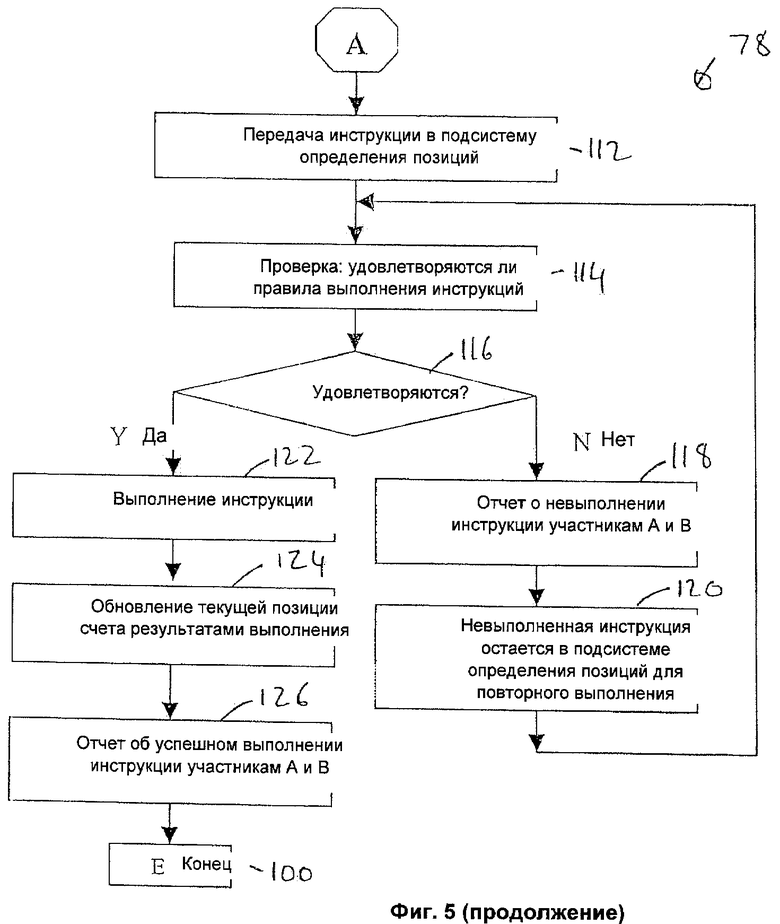
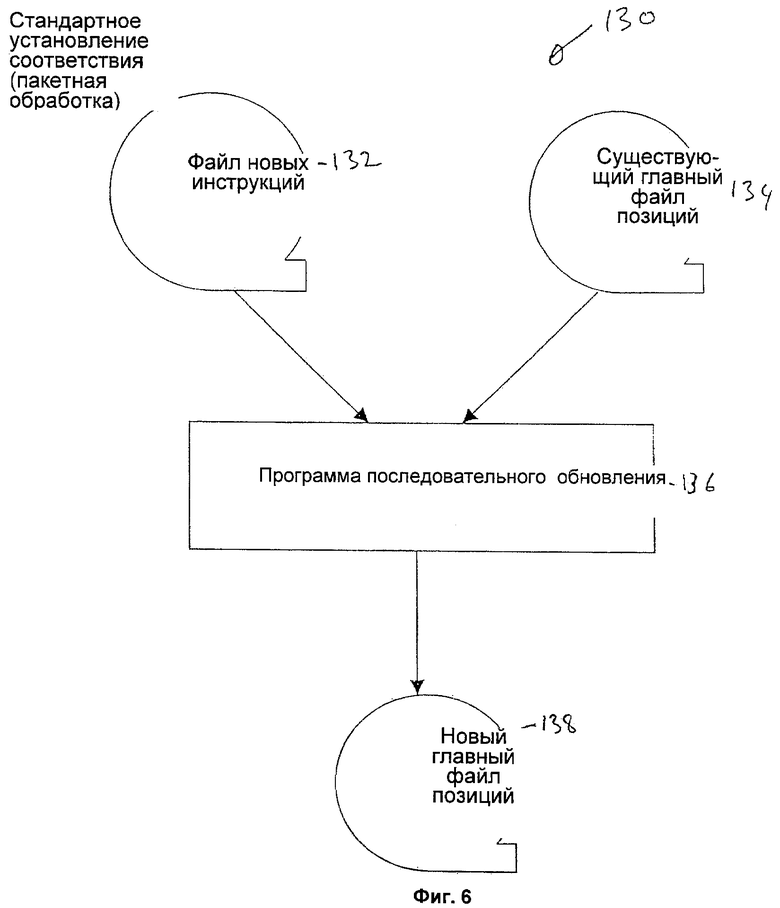
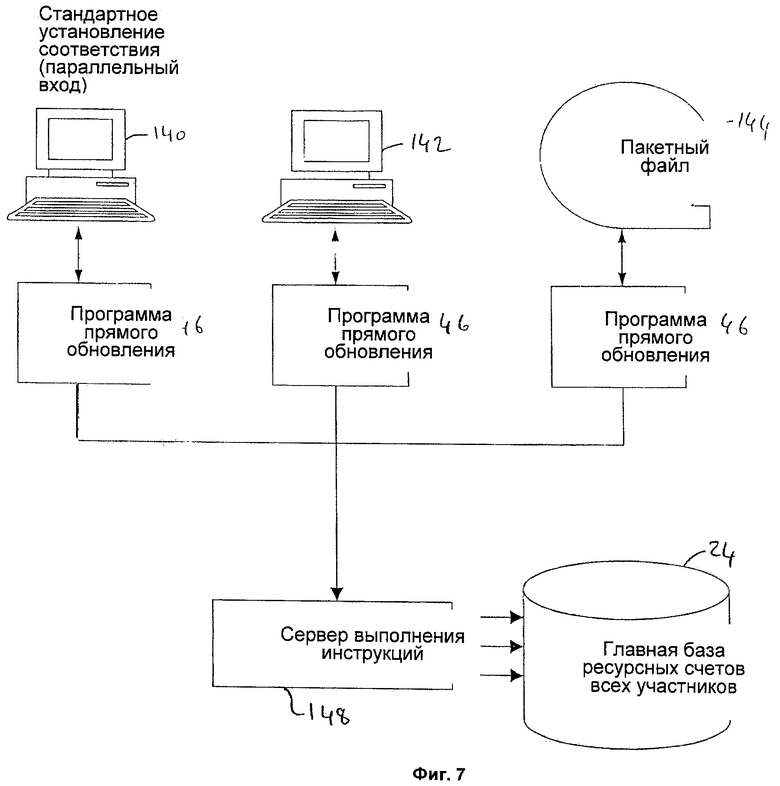
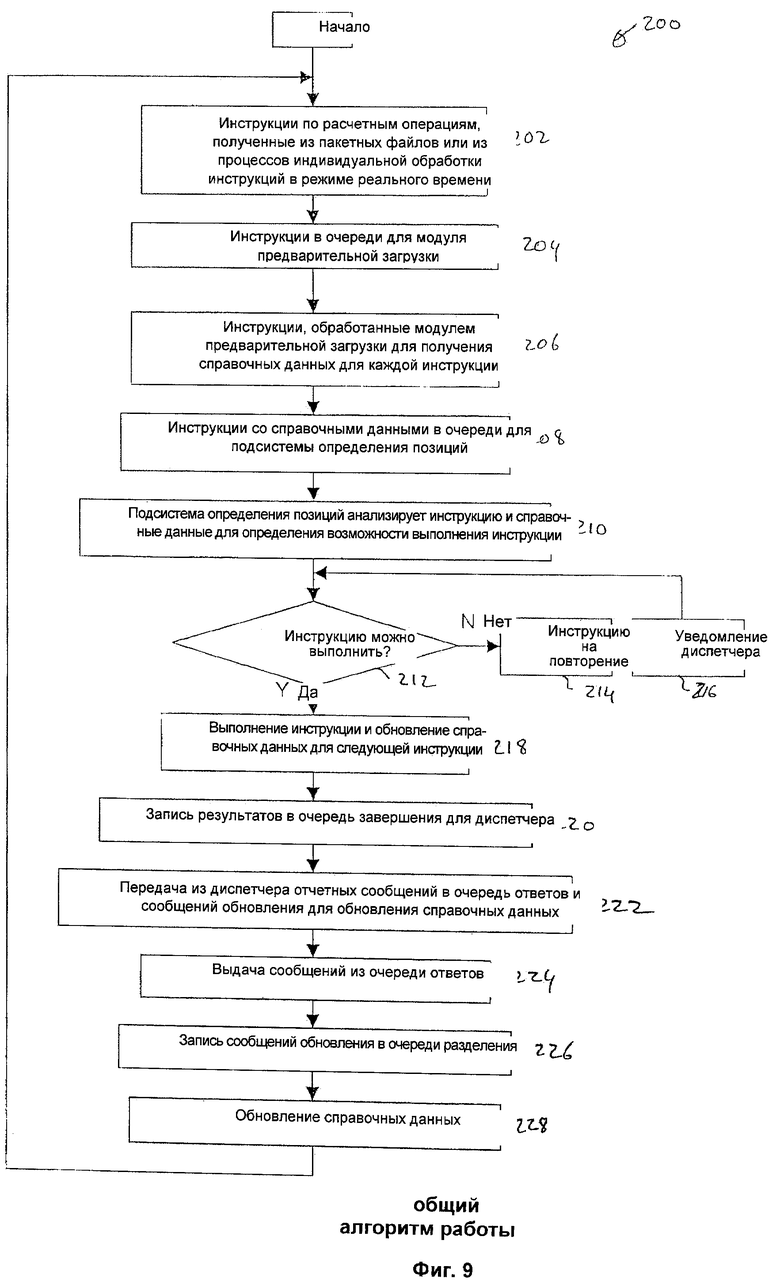
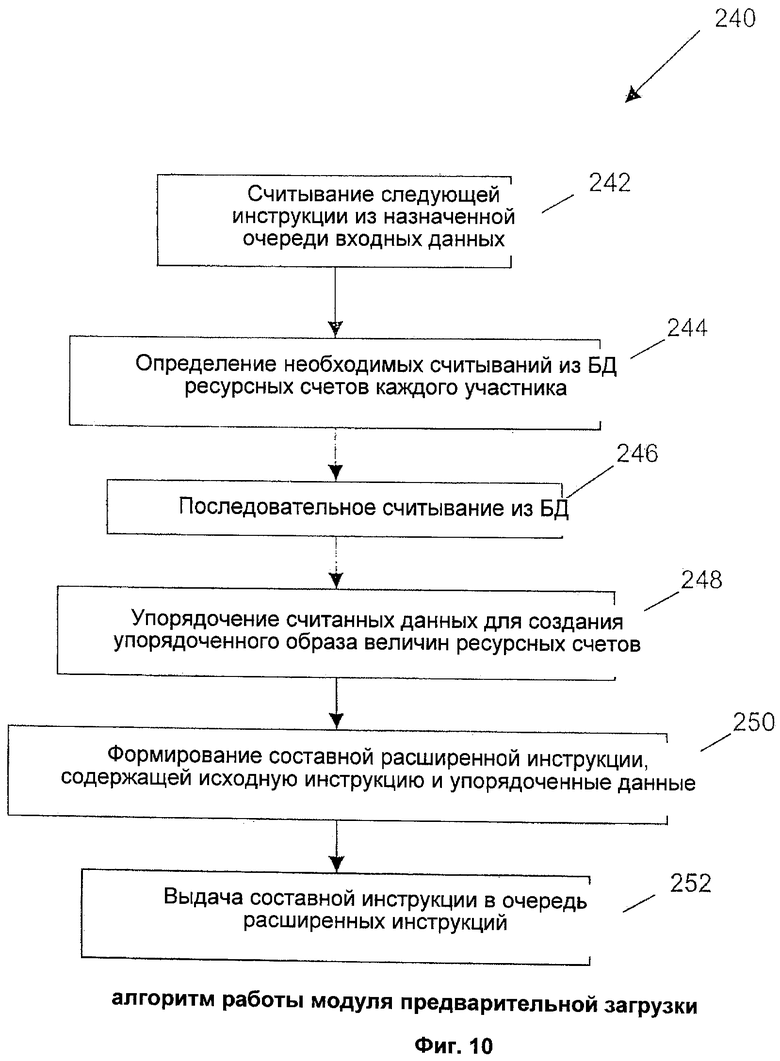
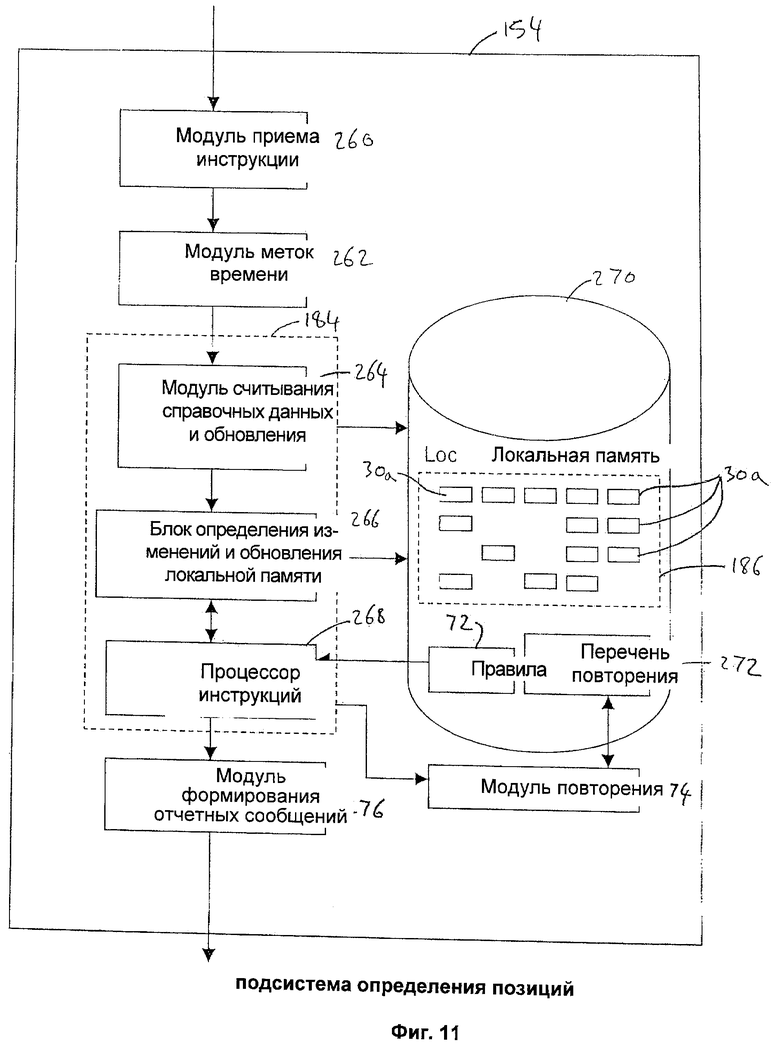
Изобретение относится к архитектуре обработки с использованием вычислительных средств. Техническим результатом является повышение пропускной способности и скорости выполнения большого количества обновлений. Он достигается тем, что система содержит модуль предварительной загрузки для получения справочных данных, относящихся к инструкциям и содержащих текущие величины каждого из указанных файлов с информацией ресурсных счетов; очередь расширенных инструкций, в которую поступает множество инструкций вместе с относящимися к ним соответствующими предварительно загруженными справочными данными; подсистему выполнения инструкций для последовательного определения с использованием принятых справочных данных возможности выполнения каждой принятой инструкции для текущих величин относящихся к ним файлов ресурсных счетов и формирования команды на обновление для каждой исполнимой инструкции; и модуль обновления, реагирующий на команду на обновление, поступающую из подсистемы выполнения инструкций, для обновления главной БД результатами, полученными для каждой исполнимой инструкции, причем множество модулей обновления и подсистема выполнения инструкций работают независимо друг от друга. 26 з.п. ф-лы, 11 ил.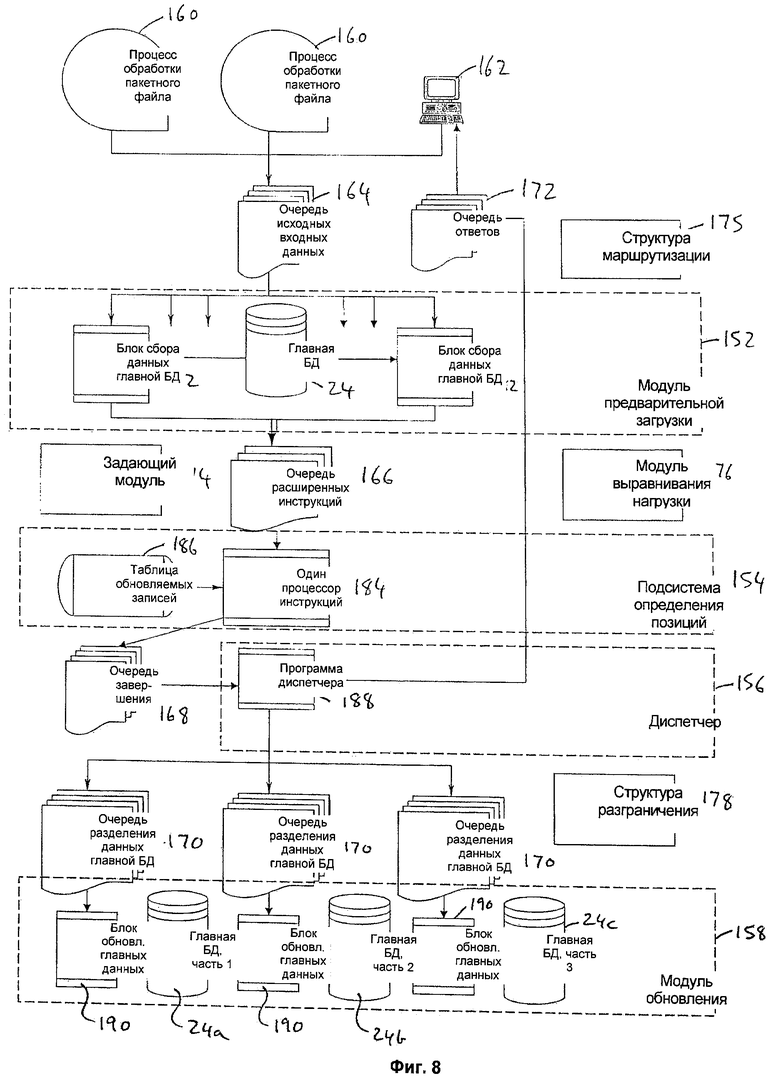
1. Система обработки инструкции в режиме реального времени, в каждой из которых указываются файлы с информацией ресурсных счетов, относящихся к двум различным экономическим объектам, а также количество и тип ресурсов, которыми осуществляется обмен между этими файлами, причем система содержит:
множество модулей предварительной загрузки, обеспечивающих получение справочных данных, относящихся к инструкциям и содержащих текущие величины каждого из указанных файлов с информацией ресурсных счетов, причем множество модулей предварительной загрузки организовано таким образом, чтобы они работали параллельно при считывании справочных данных из главной базы данных (БД) для множества соответствующих принятых инструкций;
очередь расширенных инструкций, в которую поступает множество инструкций вместе с относящимися к ним соответствующими предварительно загруженными справочными данными;
подсистему выполнения инструкций для последовательного определения, с использованием принятых справочных данных, возможности выполнения каждой принятой инструкции для текущих величин относящихся к ней файлов ресурсных счетов и для формирования команды на обновление для каждой исполнимой инструкции; и
множество модулей обновления, реагирующих на команды на обновления, поступающие из подсистемы выполнения инструкций, для обновления главной БД результатами, полученными для каждой исполнимой инструкции, причем множество модулей обновления и подсистема выполнения инструкций работают независимо друг от друга.
2. Система по п.1, содержащая также очередь исходных входных данных, предназначенную для приема инструкций для выполнения в режиме реального времени и инструкций для выполнения в пакетном режиме от различных источников и подачи этих инструкций на входы модулей предварительной загрузки.
3. Система по п.2, в которой очередь исходных входных данных представляет собой множество очередей исходных входных данных, каждая из которых предназначена для подачи исходных входных данных постоянно на вход определенного модуля предварительной загрузки, назначенного для этой очереди.
4. Система по п.2, в которой очередь исходных входных данных обеспечивает назначение приоритета каждой входящей инструкции.
5. Система по п.1, содержащая также таблицу текущего состояния, которая хранится в подсистеме выполнения инструкций и которая обновляется результатами, полученными при выполнении инструкций в отношении файлов ресурсных счетов, так что величины файлов ресурсных счетов обновляются в режиме реального времени, причем подсистема выполнения инструкций для последующей последовательной обработки инструкций использует информацию, содержащуюся в таблице текущего состояния, вместо справочной информации, получаемой из модуля предварительной загрузки для определенного файла с информацией ресурсного счета.
6. Система по п.1, в которой каждый модуль предварительной загрузки содержит блок сбора данных из главной БД, который обеспечивает считывание из главной БД величин файлов ресурсных счетов, указанных в инструкции, а также агрегированных величин ресурсов, объединение информации и выдачу на выходе расширенной инструкции, включающей данные, считанные из главной БД.
7. Система по п.1, в которой подсистема выполнения инструкций содержит быстродействующее локальное запоминающее устройство для хранения таблицы текущего состояния.
8. Система по п.1, в которой подсистема выполнения инструкций обеспечивает определение возможности выполнения текущей инструкции для текущих величин файлов ресурсных счетов, относящихся к этой инструкции, с учетом записанного набора заданных правил.
9. Система по п.1, в которой подсистема выполнения инструкций содержит модуль меток времени для определения времени получения каждой инструкции, формирования метки времени и записи ее в инструкцию.
10. Система по п.1, в которой подсистема выполнения инструкций содержит модуль организации повторного выполнения для хранения перечня невыполненных инструкций в быстродействующем запоминающем устройстве и для осуществления операции повторного выполнения, в которой каждая невыполненная инструкция подается для повторного выполнения после того, как осуществлено обновление файлов ресурсных счетов, указанных в невыполненной инструкции.
11. Система по п.10, в которой модуль организации повторного выполнения обеспечивает хранение невыполненных инструкций в порядке их приоритетов и подает для повторного выполнения прежде всего инструкции, имеющие самый высокий приоритет.
12. Система по п.10, в которой модуль организации повторного выполнения обеспечивает резервирование текущей величины файла ресурсного счета для инструкции в перечне невыполненных инструкций и использует это зарезервированное количество для выполнения запросов этой инструкции в процессе ее повторного выполнения.
13. Система по п.10, в которой модуль организации повторного выполнения обеспечивает подачу невыполненных инструкций для повторного выполнения заданное максимальное число раз, и если инструкция все-таки не будет выполнена, то модуль повторного повторения обеспечивает удаление этой невыполненной инструкции.
14. Система по п.1, в которой подсистема выполнения инструкций содержит модуль формирования отчетных сообщений для уведомления о результатах выполнения каждой из принятых инструкций, причем модуль формирования отчетных сообщений формирует команду на обновление для каждой инструкции, для которой определяется, что она может быть выполнена, и команду на уведомление для каждой невыполненной инструкции.
15. Система по п.14, в которой модуль формирования отчетных сообщений обеспечивает временное хранение множества команд на обновление, пока не будет осуществлена фиксация, и выдачу множества команд на обновление после осуществления фиксации, причем фиксация представляет собой завершение одной физической единицы работы подсистемы выполнения инструкций.
16. Система по п.14, содержащая также очередь завершения, предназначенную для приема и размещения в ней команд на обновление и команд на уведомление, поступающих из модуля формирования отчетных сообщений.
17. Система по п.1, в которой каждый модуль обновления представляет собой множество экземпляров модуля обновления, работающих параллельно, причем эти экземпляры работают с разными, заданными для каждого из них, определенными частями главной БД.
18. Система по п.17, содержащая также очередь разделения входных данных для каждого экземпляра модуля обновления, причем каждая очередь разделения обеспечивает прием множества команд на обновление, относящихся к определенной части главной БД, которая обновляется соответствующим экземпляром модуля обновления.
19. Система по п.18, в которой каждая очередь разделения входных данных обеспечивает взаимный зачет команд на обновление, если команды обновления относятся к одним и тем же файлам ресурсных счетов.
20. Система по п.18, содержащая также модуль диспетчера, который обеспечивает определение маршрута каждой команды на обновление для направления ее к определенной очереди разделения данных и формирование отчетных сообщений для различных экономических объектов, в которых описывается невыполнение или выполнение инструкции.
21. Система по п.18, в которой очередь исходных входных данных представляет собой множество очередей исходных входных данных, каждая из которых предназначена для подачи исходных входных данных постоянно на вход определенного модуля предварительной загрузки, назначенного для этой очереди; и система содержит также
структуру маршрутизации для распределения инструкции среди множества очередей исходных входных данных или очередей разделения входных данных, работающих параллельно.
22. Система по п.21, в которой структура маршрутизации обеспечивает присвоение инструкции наименования инструкции, описывающего тип информации, к которому относится инструкция, и ключ модуля выравнивания нагрузки, который обеспечивает уникальный ключ, идентифицирующий инструкцию.
23. Система по п.22, в которой структура маршрутизации содержит блок выравнивания нагрузки, обеспечивающий вместе с модулем маршрутизации выбор одной из очередей исходных входных данных или одной из очередей разделения входных данных с использованием наименования и ключа модуля выравнивания нагрузки принятой инструкции.
24. Система по п.23, в которой модуль выравнивания нагрузки обеспечивает связь данного ключа модуля выравнивания нагрузки с одним и тем же определенным местом назначения, чтобы все инструкции, относящиеся к определенному файлу с информацией ресурсного счета, всегда направлялись в одну и ту же очередь из множества очередей.
25. Система по п.1, содержащая также структуру разграничения, которая в ответ на закрытие сеанса обработки в заданное время подает сообщение на вход очереди, предусмотренной на выходе подсистемы выполнения инструкций, и ожидает ответа, а также подает другое сообщение во входную очередь одного из модулей обновления и ожидает его ответа, и принимает последовательные ответы, сообщающие об обновлении главной БД результатами всех инструкций, выполненных до закрытия сеанса обработки.
26. Система по п.25, содержащая также модуль диспетчера, который обеспечивает определение маршрута каждой команды на обновление для направления ее в определенную очередь разделения данных и формирование отчетных сообщений для различных экономических объектов, в которых описывается невыполнение или выполнение инструкции; причем
структура разграничения также обеспечивает подачу сообщения во входную очередь модуля диспетчера и ожидает соответствующего ответного сообщения для подтверждения того, что отправлены все отчетные сообщения для инструкций, выполненных до закрытия сеанса обработки.
27. Система по п.1, содержащая также задающий модуль для определения пропускной способности по обработке инструкций подсистемы выполнения инструкций и задания состояний ожидания для любой очереди с целью замедления загрузки инструкций, чтобы скорость их загрузки не превышала пропускной способности подсистемы выполнения инструкций.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 7117165 B1, 03.10.2006 | |||
| Приводной механизм для бабы трамбовальной машины | 1926 |
|
SU6814A1 |

