Изобретение относится к области информатики и вычислительной техники и может использоваться для обработки информационных потоков и обнаружения в них заданных эталонных информационных признаков, представленных в различных буквенно-знаковых системах письменности. Способ может быть использован в устройствах контроля информационных потоков для мониторинга информационного трафика.
Известен способ, реализованный в устройстве обработки информации для информационного поиска (патент РФ №2096825, МПК6 G06F 17/00, G06F 17/30, опубликованный 20.11.1997). Данный способ заключается в том, что предварительно формируют базу эталонных информационных значений, подлежащих выявлению в информационном потоке, запоминают их, запоминают количество символов в обрабатываемом текстовом фрагменте (ТФ), запоминают количество символов в словах (словосочетаниях), запоминают количество цифр и специальных символов в ТФ, запоминают предварительно выделенные комбинации символов, соответствующие структурным признакам ТФ, задают правила выделения ТФ из информационного потока. Далее принимают информационный поток, запоминают по предварительно заданным правилам очередной ТФ. Выделяют из ТФ слова и словосочетания, для чего используют предварительно запомненные структурные признаки. Запоминают ТФ, для чего записывают в память слова и словосочетания последовательно, аналогично позициям в выделенном ТФ. Сравнивают запомненные слова и словосочетания с выделенным ТФ, для чего выбирают методом прямого перебора из памяти слова (словосочетания), определяют количество и вид символов в выбранном слове на предмет наличия только цифр и (или) спецзнаков, сравнивают количество символов с эталонным значением и запоминают данные сравнения. Запоминают данные о количестве повторений данного слова в ТФ (о количестве одинаковых слов), запоминают данные о количестве совпадений символьной структуры. Сравнивают выделенный признак с эталонным, содержащимся в базе эталонных информационных признаков. В случае их совпадения считают обнаруженным искомый признак.
Недостатками данного способа являются:
1) относительно низкая скорость обработки информации вследствие использования алгоритмов последовательного поиска;
2) значительные затраты объемов памяти для хранения эталонных информационных признаков.
Второй недостаток объясняется тем, что при повышении интенсивности трафика увеличивается время обработки необходимой текстовой единицы (слова, словосочетания и т.п.), вследствие чего увеличивается общее время обработки всего массива информационных признаков. Увеличение объемов памяти и необходимость увеличения вычислительного ресурса приводит к неоправданным экономическим затратам.
В значительной степени первый недостаток устраняет способ обработки информации для обнаружения идентификационных признаков в информационных потоках (патент РФ №2282889, МПК6 G06F 17/30, опубликованный 27.08.2006. Бюл. №24). Данный способ заключается в том, что предварительно формируют базу эталонных информационных признаков (БЭИП), подлежащих выявлению в информационном потоке, принимают информационный поток, последовательно выделяют и запоминают фрагменты принимаемого информационного потока, из которых выделяют по установленным правилам информационные признаки, сравнивают их с эталонными информационными признаками из БЭИП и по результатам сравнения фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению. Для формирования БЭИП выбирают совокупность из Ni эталонных информационных признаков, выделяют содержащиеся в них и отличающиеся друг от друга символы. Затем из выделенных символов формируют алфавит символов (АС), вычисляют число S содержащихся в нем символов, присваивают j-му, где j=1,2,…,S, символу номер nj его позиции в алфавите символов и рассчитывают для заданного значения коэффициента заполнения K БЭИП ее объем Nk=N/K. После этого для i-го, где i=1, 2,…,N, эталонного информационного признака вычисляют число mi символов, образующих этот признак, и его морфологический коэффициент di, а также рассчитывают с использованием хеш-функции заданного вида f(di) адрес эталонного информационного признака Аi=f(di). Затем запоминают i-й эталонный информационный признак в БЭИП на позиции, соответствующей его адресу Ai. Для выделения из каждого фрагмента принимаемого информационного потока информационных признаков выделяют в нем группу двоичных знаков, находящихся между примыкающими друг к другу двумя пробелами, декодируют ее к виду информационного признака, вычисляют его морфологический коэффициент и адрес. После этого сравнивают выделенный и декодированный информационный признак с эталонным информационным признаком, находящимся по этому адресу в БЭИП.
Для i-го эталонного информационного признака морфологический коэффициент di вычисляют по формуле:
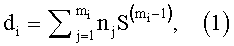
где nj - номер позиции j-го символа в алфавите символов;
mi - число символов, образующих i-й признак;
S - число символов АС;
j=1,2,…,mi - позиция символа в i-ом признаке.
В качестве хеш-функции для вычисления адреса признака Аi=f(di) используют функцию вида:
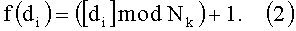
Данный способ является наиболее близким по технической сущности и выбран в качестве прототипа.
Недостатком данного способа-прототипа является ограниченность его применения, выражающаяся в возможности обнаружения информационных признаков, представленных из символов в одном из регистров (только приписные или строчные символы) в одной буквенно-знаковой системе письменности. Кроме того, при необходимости внесения в БЭИП новых информационных признаков, содержащих новые дополнительные символы, не входящие в имеющийся АС, требуется осуществить полный перерасчет всех значений морфологических коэффициентов di, а также новый расчет адресов Аi, соответствующих каждому информационному признаку в БЭИП, при помощи хеш-функций f(di).
Техническим результатом реализации предлагаемого способа является расширение функциональных возможностей в применении способа для обнаружения идентификационных признаков, выраженных в различных буквенно-знаковых системах письменности, а также более эффективное использование памяти для хранения эталонных информационных признаков.
Этот результат достигается тем, что из способа-прототипа исключают процедуру определения морфологического коэффициента di, вместо нее определяют адрес памяти Ai, по которому записывают значение уровня логической единицы для информационного признака, подлежащего обнаружению в информационном потоке. По остальным адресам выделенной памяти записываются значения уровня логического нуля. Адрес памяти искомого идентификационного признака представляет собой трехбайтную последовательность вида:
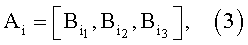
где 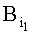 - 1-й байт адреса памяти,
- 1-й байт адреса памяти, 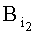 - 2-й байт адреса памяти,
- 2-й байт адреса памяти, 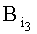 - 3-й байт адреса памяти.
- 3-й байт адреса памяти.
Значению 1-го байта адреса приводят в соответствие бинарное числовое значение кодового знака 1-го символа слова 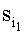 . Значение 2-го байта адреса
. Значение 2-го байта адреса 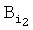 рассчитывают выражением:
рассчитывают выражением:
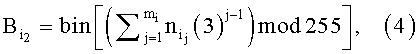
где bin - функция бинарного представления значения числа, представленного в десятичной системе исчисления;
mi - число символов в i-ом идентификационном признаке;
nj - код j-го символа в алфавите символов;
3 - минимальное нечетное простое число;
mod - функция модуля по основанию;
j=1,2,…,mi - позиция символа в i-м идентификационном признаке.
Значение 3-го байта адреса 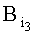 рассчитывают выражением:
рассчитывают выражением:
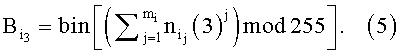
Бинарная последовательность Аi из трех байт определяет адрес выделенной памяти, в которой для эталонных информационных признаков, необходимых для отбора, записывают в память по их рассчитанным адресам значения уровня логической единицы, для остальных информационных признаков, не участвующих в расчете адресов, - значения уровня логического нуля. При мониторинге информационного потока для каждого выделенного из информационного потока слова определяют трехбайтовый адрес и при наличии по данному адресу памяти значения уровня логической единицы принимают решение о наличии эталонного информационного признака в информационном потоке. При добавлении нового эталонного информационного признака определяют его трехбайтный адрес, записывают по данному адресу памяти значение уровня логической единицы и осуществляют дальнейшее обнаружение идентификационных признаков в информационных потоках.
Благодаря новой совокупности существенных признаков заявленного способа достигается более эффективное использование памяти для БЭИП, а также устраняется необходимость дополнительных перерасчетов содержательной части БЭИП при появлении нового информационного признака, представленного в другой буквенно-знаковой системе письменности.
Проведенный анализ уровня техники обработки информации позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам технического решения, отсутствуют в доступных источниках информации, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Введенные в совокупности отличительные признаки: представление информационных признаков различных буквенно-знаковых систем письменности в виде уникальных трехбайтных адресов БЭИП, а также размещение по данным адресам значений минимальной длины (1-го бита информации: 1 или 0), характеризующих наличие или отсутствие по данному адресу эталонного признака, в аналогах не встречаются. Следовательно, заявляемый способ соответствует критерию «изобретательский уровень».
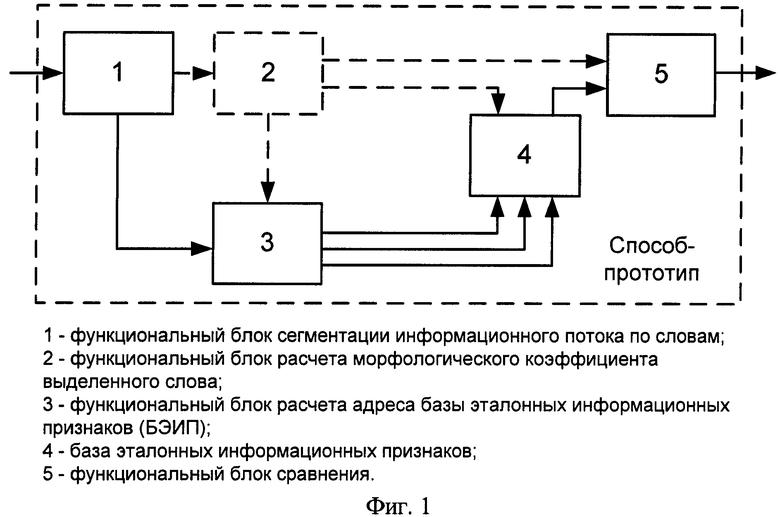
Заявленный способ поясняется чертежами, на которых показаны:
на фиг.1 - блок-схема, поясняющая способ обнаружения идентификационных признаков для различных буквенно-знаковых систем письменности;
на фиг.2 - график зависимости роста количества адресов от количества эталонных информационных признаков по способу-прототипу;
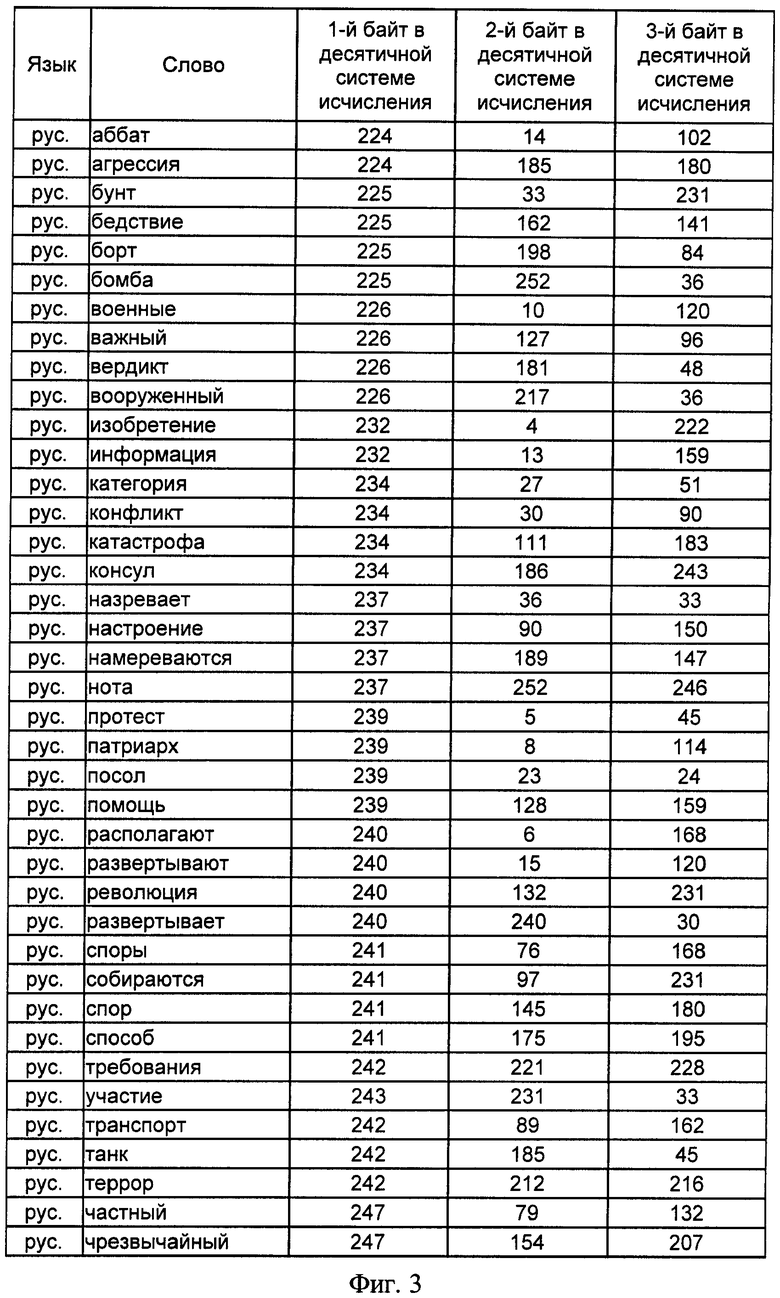
на фиг.3 - сводная таблица словарных признаков отбора, принадлежащих русскому языку, и трехбайтных адресов, им соответствующих, представленных в десятичной системе исчисления;
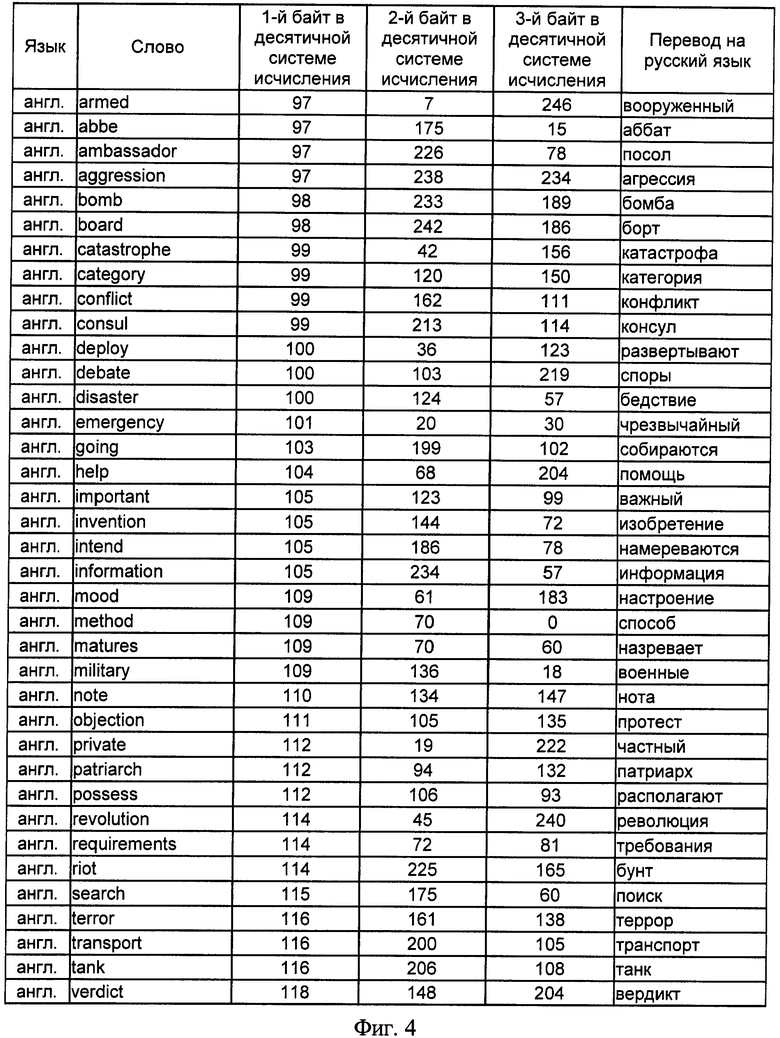
на фиг.4 - сводная таблица словарных признаков отбора, принадлежащих английскому языку, и трехбайтных адресов, им соответствующих, представленных в десятичной системе исчисления;
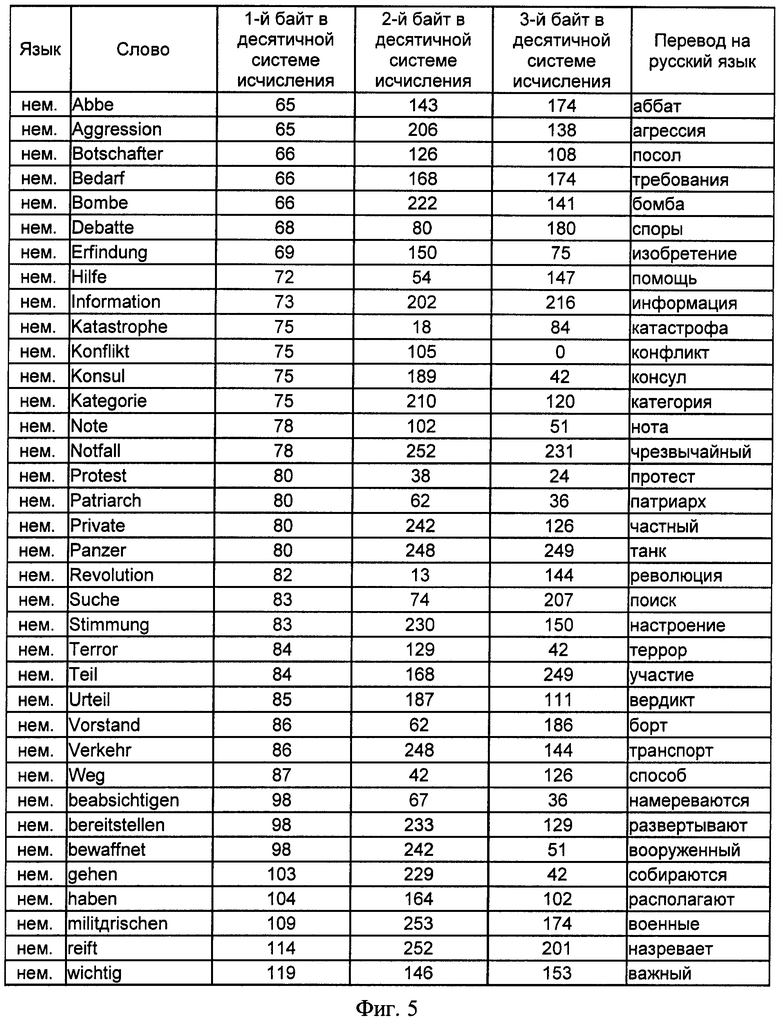
на фиг.5 - сводная таблица словарных признаков отбора, принадлежащих немецкому языку, и трехбайтных адресов, им соответствующих, представленных в десятичной системе исчисления;
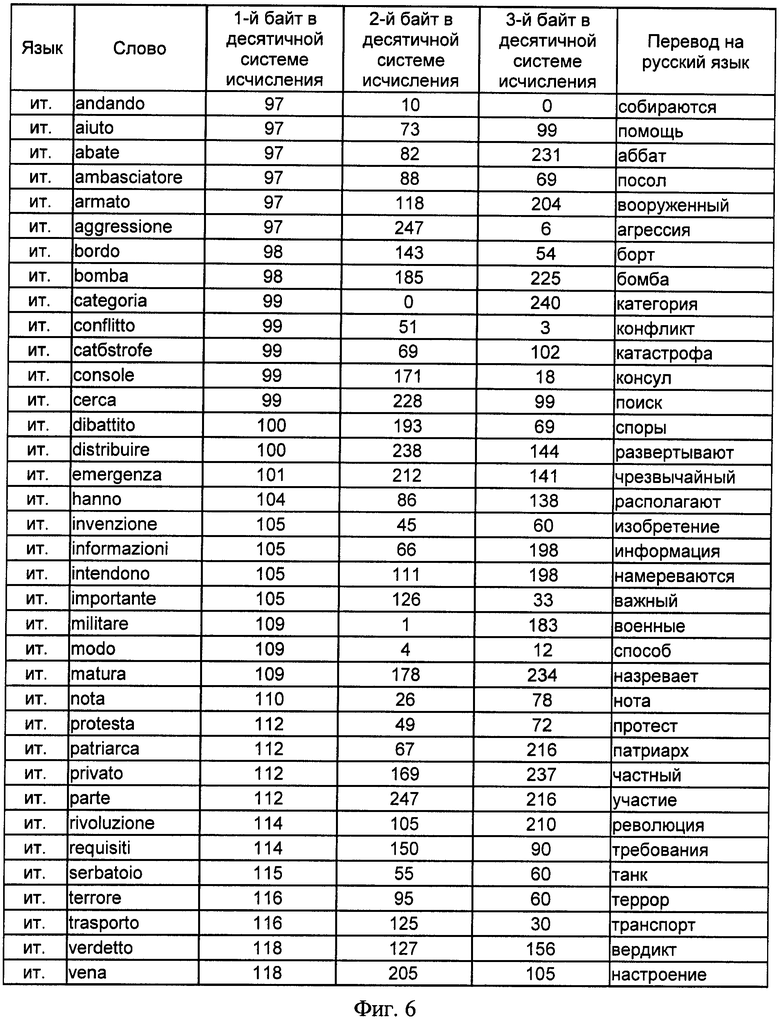
на фиг.6 - сводная таблица словарных признаков отбора, принадлежащих итальянскому языку, и трехбайтных адресов, им соответствующих, представленных в десятичной системе исчисления;
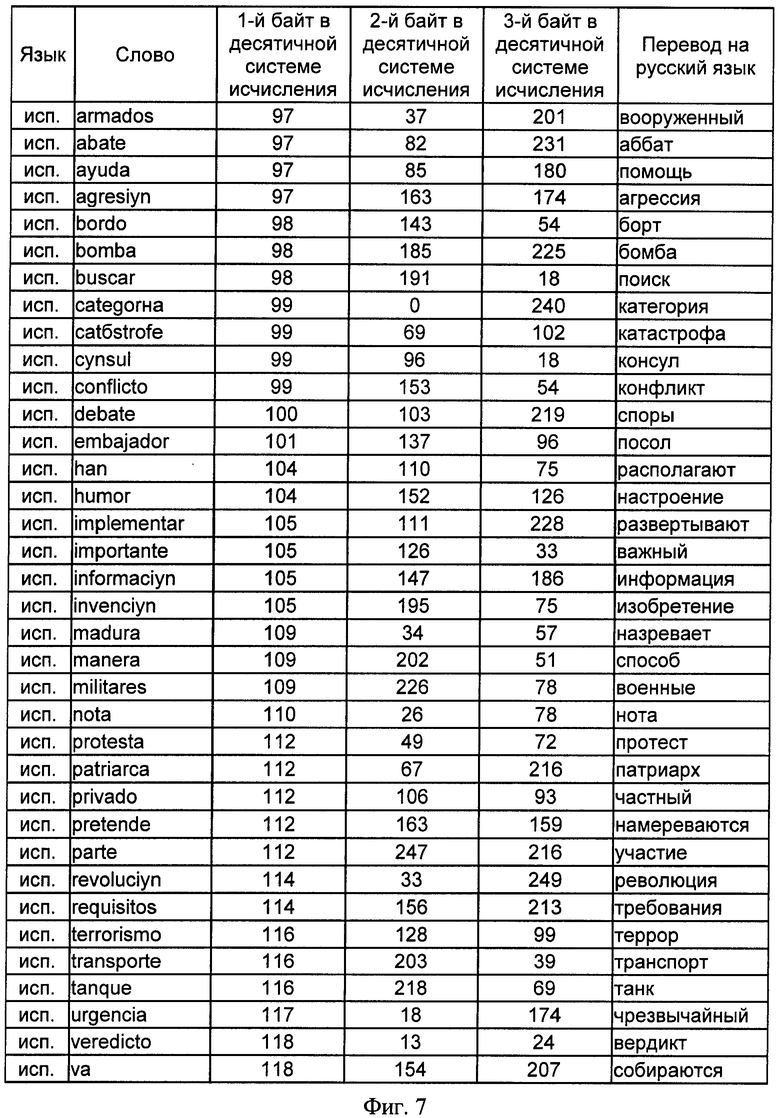
на фиг.7 - сводная таблица словарных признаков отбора, принадлежащих испанскому языку, и трехбайтных адресов, им соответствующих, представленных в десятичной системе исчисления;
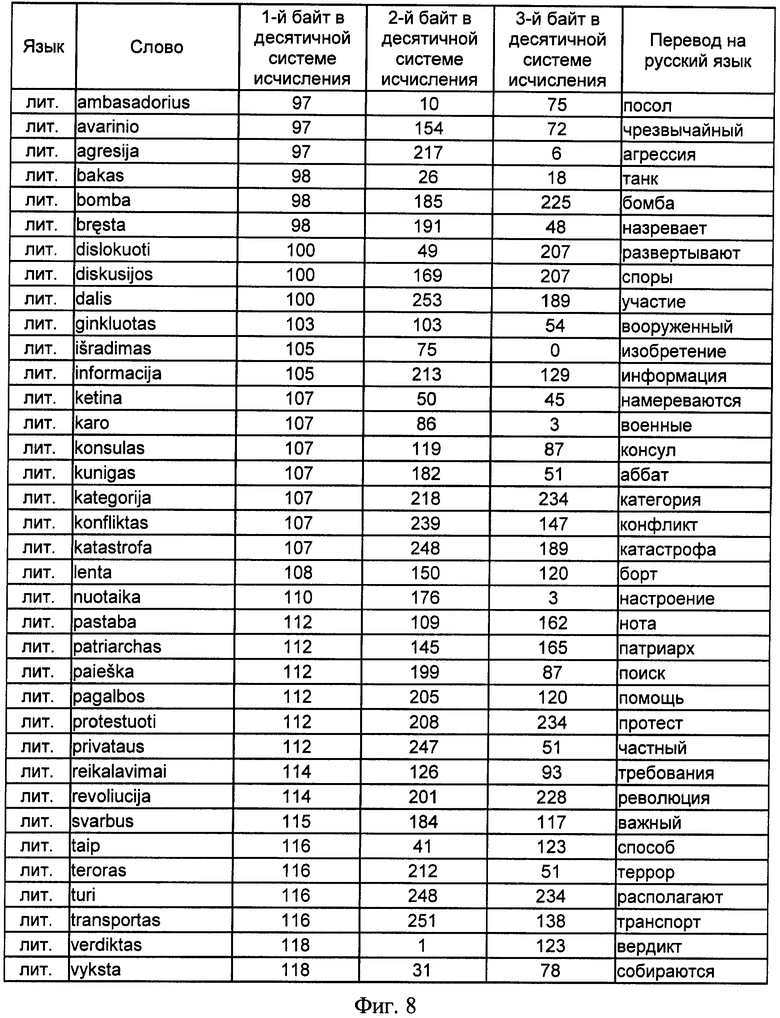
на фиг.8 - сводная таблица словарных признаков отбора, принадлежащих литовскому языку, и трехбайтных адресов, им соответствующих, представленных в десятичной системе исчисления;
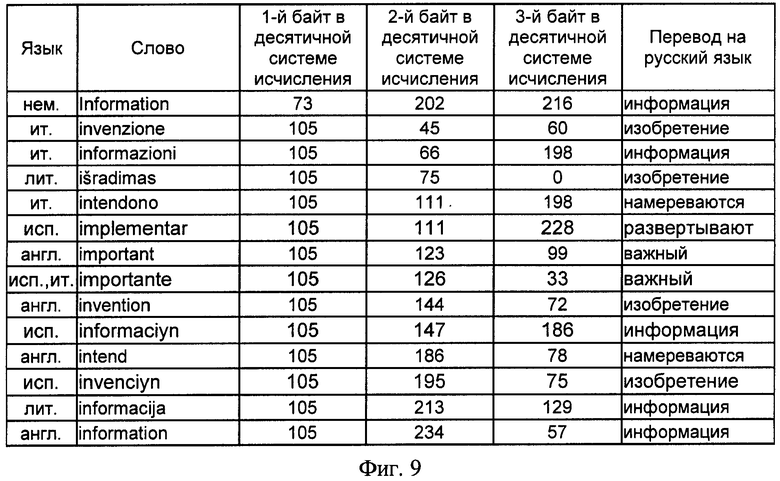
на фиг.9 - сводная таблица словарных признаков отбора с первым символом "i" языков латинской буквенно-знаковой системы письменности и трехбайтных адресов, им соответствующих, представленных в десятичной системе исчисления.
Заявленное техническое решение достигается исключением из способа-прототипа функционального блока расчета морфологического коэффициента выделенного слова и лишних связей между 2 и другими (1, 3, 4, 5) функциональными блоками. На фигуре 1 представлена блок-схема, поясняющая способ обнаружения идентификационных признаков для различных буквенно-знаковых систем письменности. В качестве функциональных блоков блок-схемы прототипа и предлагаемого способа выступают следующие элементы:
1 - функциональный блок сегментации информационного потока по словам;
2 - функциональный блок расчета морфологического коэффициента выделенного слова;
3 - функциональный блок расчета адреса базы эталонных информационных признаков (БЭИП);
4 - база эталонных информационных признаков;
5 - функциональный блок сравнения.
Функциональный блок 2 исключают из способа, так, вместо морфологического коэффициента di, вычисляемого выражением 1, в память БЭИП по адресу, соответствующему конкретному информационному признаку, заносится значение уровня логической единицы, которое является маркером нахождения в информационном потоке эталонного признака. Из предлагаемого способа также исчезают информационные связи между блоками 1, 3, 4, 5 и 2, представленные на фигуре пунктирными линиями.
Функциональный блок 1 полностью реализует действия, описанные в способе-прототипе. В функциональном блоке 1 осуществляется сегментация информационного потока по словам. На вход функционального блока 1 поступают на этапе заполнения БЭИП отобранные словарные признаки, а при контроле информационного графика - информационный поток. На этапе формирования БЭИП по предлагаемому способу функционируют только блоки 1, 3 и 4, а при контроле информационного трафика - блоки 1, 3, 4 и 5. Информационный выход функционального блока 1 является информационным входом функционального блока 3. Для реализации нового технического решения в блоке 3 реализуется отличная от способа-прототипа функция расчета адреса БЭИП. Вместо адреса, достаточного для отображения Nk строк БЭИП по способу-прототипу, для любых по длине слов, представленных в различных буквенно-знаковых системах письменности, в блоке 3 определяется трехбайтный адрес БИЭП для i-го эталонного информационного признака в соответствии с выражениями 3, 4 и 5. Три информационных выхода по количеству байт-адреса являются информационными входами в блок 4. В отличие от способа-прототипа формирование БЭИП в функциональном блоке 4 осуществляется иначе. Вместо записи морфологического коэффициента по рассчитанному адресу Аi осуществляется запись значения уровня логической единицы. Информационный выход функционального блока 4 является информационным входом блока 5. Функциональный блок 5 осуществляет процедуру сравнения только при контроле информационного трафика. В функциональном блоке 5 осуществляется сравнение значения уровня по рассчитанному адресу БЭИП со значением уровня логической единицы, при совпадении этих значений на выход выдается информация о наличии в текущем фрагменте информационного потока необходимого словарного признака.
Рассмотрение заявленного способа целесообразно провести на примере действий, реализованных способом-прототипом, и дополнить необходимыми действиями для получения заявленного технического решения.
Пусть в качестве словарных признаков отбора информационных сообщений выбрано по 39 идентификационных признаков на 6 естественных языках, т.е. N=234 словарных признака, для 2-х различных знаково-буквенных систем письменности (латинского и кириллического написания). В качестве АС используем расширенную кодовую таблицу ASCII, где знаку "пробел" соответствует десятичное значение 32 или бинарное значение 00100000; строчной букве "а" латинской системы письменности (английского, немецкого, испанского, итальянского и литовского языков) соответствует десятичное значение 97 или бинарное значение 01100001; строчной букве "я" кириллической системы письменности соответствует десятичное значение 255 или бинарное значение 11111111. Состав АС содержит совокупность отличающихся символов, достаточных для составления из них любого из N информационных признаков.
По способу-прототипу число строк базы эталонных признаков определяется как Nk=N/K, где K=0,2, соответственно минимальное число строк в базе эталонных информационных признаков будет равно:
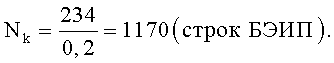
Объем памяти VБЭИП, необходимый для хранения эталонных информационных признаков в БЭИП, по способу-прототипу вычисляется как:
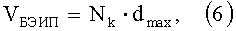
где Nk - число строк в БЭИП; dmax - минимальное количество бит, необходимое для хранения морфологического коэффициента максимальной битовой длины. Так, для словарного признака "информация" в кодировке ASCII десятичная запись кодов, составляющих слово в строчном виде, имеет вид 232 237 244 238 240 236 224 246 232 255. Морфологический коэффициент, рассчитанный по способу-прототипу для слова "информация", имеет вид 963701989565045000000000 в десятичной системе исчисления, что соответствует в бинарном исчислении значению 110001110111000100111010111000000101110000100100101001000000000 и составляет 63 бита необходимого объема памяти. Учитывая тот факт, что морфологические коэффициенты по способу-прототипу имеют различную длину, а следовательно, требуют различные объемы памяти для хранения своих двоичных значений, необходимо определить информационный признак с максимальным значением морфологического коэффициента. Для записи морфологического коэффициента русского слова, не превышающего в своем составе 12 знаков и оканчивающегося на "я", потребуется в пределе 64 бит или 8 байт необходимого объема памяти. Кроме того, для отображения адресов 1170 строк БЭИП необходимо как минимум по 12 бит для адреса на строку. Таким образом, эффективный коэффициент использования памяти η(М1) по способу-прототипу составит 9,5 байт/признак. Изменение количества информационных признаков как в сторону увеличения, так и уменьшения не позволяет использовать расчеты БЭИП, полученные ранее, т.к. каждый адрес БЭИП напрямую зависит от меняющегося значения Nk, которое в свою очередь зависит от количества информационных признаков N. Изменение количества информационных признаков N в сторону увеличения пропорционально увеличению строк в 5 раз, т.к. Nk=N/K, где K=0,2 (по способу-прототипу). Зависимость роста количества строк Nk от количества признаков N представлено на фигуре 2. С увеличением информационных признаков от 1 до 10000 адресное поле должно пропорционально увеличиваться от 3 бит до 2 байт на один адрес.
В предлагаемом способе адрес фиксирован 3 байтами и не зависит от текущего количества информационных признаков. Для 39 идентификационных признаков на 6 естественных языках, т.е. N=234 словарных признака, в двух системах буквенно-знаковых систем письменности (латинской и кириллической) представлены значения трехбайтных адресов и соответствующих им информационных признаков на русском, английском, немецком, испанском, итальянском и литовском языках в таблицах фигур 3, 4, 5, 6, 7 и 8 соответственно.
Так, для словарного признака "информация" адрес в десятичной системе исчисления в результате определения кода 1-го символа слова и вычислений по выражениям 4 и 5 имеет вид: 232 13 159, что соответствует в бинарном исчислении значению 11101000 00001101 10011111. Для латинской буквенно-знаковой системы письменности для английского, немецкого, испанского, итальянского и литовского языков в одну таблицу фигуры 9 выделены информационные признаки, начинающиеся с единого для различных языков символа "i", соответствующего в кодовой таблице ASCII значению 105 в десятичной системе исчисления, исключение составляет существительное немецкого языка "Information", начальный символ которого начинается с прописного знака "i", которому соответствует значение 73 кодовой таблицы ASCII. Данные, представленные на фигуре 9, показывают, что адреса БЭИП являются уникальными для слов, имеющих различное символьное написание, хотя и одинаковое значение на русском языке. Исключением является слово "importante" испанского и итальянского языка, которое имеет одинаковое написание символов в латинской системе письменности, что не влияет на техническое решение заявленного способа.
При появлении нового необходимого для выделения в информационном потоке признака не требуется корректировка и перерасчет старых адресов, а только рассчитывается новый адрес информационного признака и по данному адресу в память записывается 1 бит информации, соответствующий уровню логической единицы. Эффективный коэффициент использования памяти η(M2) по предлагаемому способу для любого информационного признака различных знаково-буквенных систем письменности и любой длины (количества символов в информационном признаке) составляет значение 3,125 байт/признак, т.к. 3 байта составляют адрес поля памяти, а содержательная часть по данному адресу представлена одним битом информации, уровнем логической 1 или 0.
Сравнив коэффициенты использования памяти по способу-прототипу η(М1) и предлагаемому способу η(M2), можно констатировать повышение эффективности использования памяти в 3,04 раза.
Сокращение в способе-прототипе функции расчета морфологического коэффициента при изменении функций определения адреса эталонного информационного признака и заполнения памяти в БЭИП можно реализовать на существующей в настоящее время элементной базе, например, на любых серийно выпускаемых программируемых логических интегральных схемах (ПЛИС).
Таким образом, из рассмотренной сущности заявляемого способа следует, что он обеспечивает обнаружение в информационных потоках заданных эталонных информационных признаков, представленных в различных буквенно-знаковых системах письменности. Это подтверждает положительный эффект технического решения предлагаемого способа.
| название | год | авторы | номер документа |
|---|---|---|---|
| АДРЕСНЫЙ СПОСОБ ОБНАРУЖЕНИЯ ИДЕНТИФИКАЦИОННЫХ ПРИЗНАКОВ В ИНФОРМАЦИОННЫХ ПОТОКАХ | 2009 |
|
RU2409850C1 |
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ИДЕНТИФИКАЦИОННЫХ ПРИЗНАКОВ В ИНФОРМАЦИОННЫХ ПОТОКАХ | 2005 |
|
RU2282889C1 |
| СПОСОБ ЗАВЕРЕНИЯ ДОКУМЕНТА ЦИФРОВЫМ СЕРТИФИКАТОМ ПОДЛИННОСТИ В ОДНОРАНГОВОЙ КОРПОРАТИВНОЙ СЕТИ | 2021 |
|
RU2772557C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ СИГНАЛОВ | 2012 |
|
RU2485586C1 |
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| НАГЛЯДНОЕ ПОСОБИЕ ЧЕЛОВЕК | 2011 |
|
RU2520049C2 |
| УСТРОЙСТВО ПОИСКА ПРОИЗВОЛЬНЫХ ВХОЖДЕНИЙ | 2001 |
|
RU2202823C2 |
| МЕТОД И СИСТЕМА ИЗВЛЕЧЕНИЯ ДАННЫХ ИЗ ИЗОБРАЖЕНИЙ СЛАБОСТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ | 2015 |
|
RU2613846C2 |
| Устройство хранения и передачи данных с системой двухоперационного шифрования | 2022 |
|
RU2813249C1 |
| Устройство хранения и передачи данных с расширенной системой шифрования | 2022 |
|
RU2818177C1 |
Изобретение относится к области информатики и вычислительной техники и может использоваться для обработки информационных потоков и обнаружения в них заданных эталонных признаков, представленных в различных буквенно-знаковых системах письменности. Техническим результатом является расширение функциональных возможностей в применении способа для обнаружения идентификационных признаков, представленных в различных буквенно-знаковых системах письменности, а также повышение эффективности использования памяти для хранения эталонных информационных признаков. Способ заключается в том, что осуществляют расчет уникального трехбайтного адреса базы эталонных информационных признаков (БЭИП) и записывают по данному адресу значение уровня логической единицы. Представление эталонного информационного признака в виде трехбайтного адреса позволяет при необходимости дополнять БЭИП без перерасчета значений адресов и морфологических коэффициентов информационных признаков. Трехбайтные адреса для информационных признаков не зависят от символьной длины словарных признаков. 2 ил., 7 табл.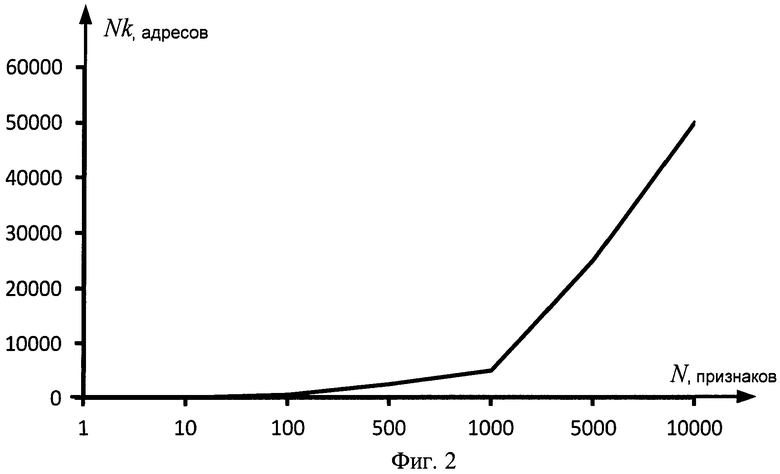
Способ обнаружения идентификационных признаков для различных буквенно-знаковых систем письменности, заключающийся в том, что для формирования базы эталонных информационных признаков, подлежащих выявлению в информационном потоке, выбирают совокупность из Ni, эталонных информационных признаков, формируют алфавит символов, присваивают j-му, где j=1, 2,…, S, символу алфавита nj значение его позиции в алфавите символов, для каждого i-го, где i=1, 2,…, N, эталонного признака вычисляют количественное значение, ему соответствующее, а также рассчитывают с использованием хеш-функции заданного вида адрес эталонного информационного признака, затем запоминают i-й эталонный информационный признак в базе эталонных информационных признаков на позиции, соответствующей его адресу, а для выделения из каждого фрагмента принимаемого информационного потока информационных признаков выделяют в нем группу двоичных знаков, находящихся между примыкающими друг к другу двумя пробелами, декодируют ее к виду информационного признака, рассчитывают численное значение признака и адрес, сравнивают полученное числовое значение информационного признака с числовым значением эталонного информационного признака, хранящимся по схожему адресу в базе эталонных информационных признаков, отличающийся тем, что алфавит символов включает в себя все возможные символы различных буквенно-знаковых систем письменности и соответствует одной из стандартных кодировок символов, i-й идентификационный признак представляют в единой кодировке для различных буквенно-знаковых систем письменности в виде слова из соответствующих кодировке последовательных числовых значений символов nj, слова преобразуют от первого до последнего символа в последовательность из трех байт 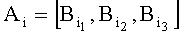 , где
, где 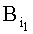 - первый байт, соответствует бинарному числовому значению кодового знака первого символа слова
- первый байт, соответствует бинарному числовому значению кодового знака первого символа слова 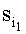 ,
, 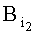 - второй байт, определяется выражением
- второй байт, определяется выражением 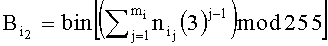 , где bin - функция бинарного представления значения числа в десятичной системе исчисления, mi - число символов в i-м идентификационном признаке, 3 - минимальное нечетное простое число, mod - функция модуля по основанию,
, где bin - функция бинарного представления значения числа в десятичной системе исчисления, mi - число символов в i-м идентификационном признаке, 3 - минимальное нечетное простое число, mod - функция модуля по основанию, 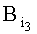 - третий байт, определяется выражением
- третий байт, определяется выражением 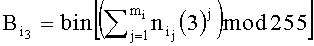 , бинарная последовательность Ai, из трех байт определяет адрес выделенной памяти, в которой для эталонных информационных признаков, необходимых для отбора, записывают в память по их рассчитанным адресам значения уровня логической единицы, для остальных информационных признаков, не участвующих в расчете адресов, - значения уровня логического нуля, при мониторинге информационного потока для каждого выделенного из информационного потока слова определяют трехбайтовый адрес и при наличии по данному адресу памяти значения уровня логической единицы принимают решение о наличии эталонного информационного признака в информационном потоке, при добавлении нового эталонного информационного признака определяют его трехбайтный адрес, записывают по данному адресу памяти значение уровня логической единицы и осуществляют дальнейшее обнаружение идентификационных признаков в информационных потоках.
, бинарная последовательность Ai, из трех байт определяет адрес выделенной памяти, в которой для эталонных информационных признаков, необходимых для отбора, записывают в память по их рассчитанным адресам значения уровня логической единицы, для остальных информационных признаков, не участвующих в расчете адресов, - значения уровня логического нуля, при мониторинге информационного потока для каждого выделенного из информационного потока слова определяют трехбайтовый адрес и при наличии по данному адресу памяти значения уровня логической единицы принимают решение о наличии эталонного информационного признака в информационном потоке, при добавлении нового эталонного информационного признака определяют его трехбайтный адрес, записывают по данному адресу памяти значение уровня логической единицы и осуществляют дальнейшее обнаружение идентификационных признаков в информационных потоках.
| АДРЕСНЫЙ СПОСОБ ОБНАРУЖЕНИЯ ИДЕНТИФИКАЦИОННЫХ ПРИЗНАКОВ В ИНФОРМАЦИОННЫХ ПОТОКАХ | 2009 |
|
RU2409850C1 |
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ИДЕНТИФИКАЦИОННЫХ ПРИЗНАКОВ В ИНФОРМАЦИОННЫХ ПОТОКАХ | 2005 |
|
RU2282889C1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

