Изобретение относится к области информатики и вычислительной техники и может использоваться для обработки информационных потоков и обнаружения в них заданных эталонных информационных признаков. Способ может быть использован в устройствах контроля информационных потоков для мониторинга информационного трафика.
Известен способ, реализованный в устройстве обработки информации для информационного поиска (Патент РФ №2096825, МПК 6 G06F 17/00, G06F 17/30, опубликованный 20.11.1997). Данный способ заключается в том, что предварительно формируют базу эталонных информационных значений, подлежащих выявлению в информационном потоке, запоминают их, запоминают количество символов в обрабатываемом текстовом фрагменте (ТФ), запоминают количество символов в словах (словосочетаниях), запоминают количество цифр и специальных символов в ТФ, запоминают предварительно выделенные комбинации символов, соответствующие структурным признакам ТФ, задают правила выделения ТФ из информационного потока. Далее принимают информационный поток, запоминают по предварительно заданным правилам очередной ТФ. Выделяют из ТФ слова и словосочетания, для чего используют предварительно запомненные структурные признаки. Запоминают ТФ, для чего записывают в память слова и словосочетания последовательно, аналогично позициям в выделенном ТФ. Сравнивают запомненные слова и словосочетания с выделенным ТФ, для чего выбирают методом прямого перебора из памяти слова (словосочетания), определяют количество и вид символов в выбранном слове на предмет наличия только цифр и (или) спецзнаков, сравнивают количество символов с эталонным значением и запоминают данные сравнения. Запоминают данные о количестве повторений данного слова в ТФ (о количестве одинаковых слов), запоминают данные о количестве совпадений символьной структуры. Сравнивают выделенный признак с эталонным, содержащимся в базе эталонных информационных признаков. В случае их совпадения считают обнаруженным искомый признак.
Недостатками данного способа являются:
1) относительно низкая скорость обработки информации вследствие использования алгоритмов последовательного поиска;
2) значительные затраты объемов памяти для хранения эталонных информационных признаков.
Второй недостаток объясняется тем, что при повышении интенсивности трафика увеличивается время обработки необходимой текстовой единицы (слова, словосочетания и т.п.), вследствие чего увеличивается общее время обработки всего массива информационных признаков. Увеличение объемов памяти и необходимость увеличения вычислительного ресурса приводят к неоправданным экономическим затратам.
В значительной степени первый недостаток устраняет способ обработки информации для обнаружения идентификационных признаков в информационных потоках (Патент РФ №2282889, МПК6 G06F 17/30, опубликованный 27.08.2006, Бюл. №24). Данный способ является наиболее близким по технической сущности и выбран в качестве прототипа.
Способ-прототип заключается в том, что предварительно формируют базу эталонных информационных признаков (БЭИП), подлежащих выявлению в информационном потоке, принимают информационный поток, последовательно выделяют и запоминают фрагменты принимаемого информационного потока, из которых выделяют по установленным правилам информационные признаки, сравнивают их с эталонными информационными признаками из БЭИП и по результатам сравнения фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению. Для формирования БЭИП выбирают совокупность из Ni эталонных информационных признаков, выделяют содержащиеся в них и отличающиеся друг от друга символы. Затем из выделенных символов формируют алфавит символов (АС), вычисляют число S содержащихся в нем символов, присваивают j-му, где j=1, 2, …, S, символу номер nj его позиции в алфавите символов и рассчитывают для заданного значения коэффициента заполнения К БЭИП ее объем Nk=N/K. После этого для i-го, где i=1, 2, …, N, эталонного информационного признака вычисляют число mi, образующих его символов и его морфологический коэффициент di, а также рассчитывают с использованием хеш-функции заданного вида f(di) адрес эталонного информационного признака Ai=f(di). Затем запоминают i-й эталонный информационный признак в БЭИП на позиции, соответствующей его адресу Ai. Для выделения из каждого фрагмента принимаемого информационного потока информационных признаков выделяют в нем группу двоичных знаков, находящихся между примыкающими друг к другу двумя пробелами, декодируют ее к виду информационного признака, вычисляют его морфологический коэффициент и адрес. После этого сравнивают выделенный и декодированный информационный признак с эталонными информационными признаками, запомненными по этому адресу в БЭИП.
Для i-го, где i=1, 2, …, N, эталонного информационного признака вычисляют его морфологический коэффициент di по формуле:
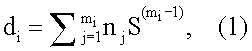
где nj - номер позиции j-го символа в алфавите символов;
mi - число символов, образующих i-й признак;
S - число символов АС;
j=1, 2, …, mi - позиция символа в i-м признаке.
В качестве хеш-функции для вычисления адреса признака Ai=f(di) используют функцию вида
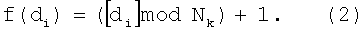
Недостатком данного способа являются значительные затраты объемов памяти для хранения эталонных информационных признаков.
Техническим результатом реализации предлагаемого способа является сокращение объема памяти для хранения эталонных информационных признаков.
Данный технический результат достигается тем, что к функциональным действиям способа-прототипа при формировании БЭИП дополнительно осуществляют сокращение размерности морфологического коэффициента di, представленного в двоичной форме записи, за счет деления на двоичную постоянную R, равную размерности произведения (Nk×10), при этом получают новый морфологический коэффициент сокращенной размерности  , из которого осуществляют расчет вторичной хеш-функции с основанием модуля, равным Nk. Полученное компактное бинарное значение единого размера для любых по символьной длине словарных признаков записывают в БЭИП по адресу Ai=f(di). В дальнейшем при мониторинге информационного трафика фрагменты информационного потока декодируют к виду компактного бинарного значения признака, сравнивают с признаком в двоичной форме записи, хранящимся по адресу Ai=f(di) и по результатам сравнения фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению.
, из которого осуществляют расчет вторичной хеш-функции с основанием модуля, равным Nk. Полученное компактное бинарное значение единого размера для любых по символьной длине словарных признаков записывают в БЭИП по адресу Ai=f(di). В дальнейшем при мониторинге информационного трафика фрагменты информационного потока декодируют к виду компактного бинарного значения признака, сравнивают с признаком в двоичной форме записи, хранящимся по адресу Ai=f(di) и по результатам сравнения фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению.
Благодаря новой совокупности существенных признаков заявленного способа достигается сокращение объема памяти, требуемого для хранения признаков в БЭИП.
Проведенный анализ уровня техники обработки информации позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам технического решения, отсутствуют в доступных источниках информации, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Введенные в совокупности отличительные признаки: сокращение морфологического коэффициента, представленного в двоичной форме, за счет бинарного деления на двоичную постоянную R, равную размерности произведения (Nk×10), а также бинарное вычисление вторичной хеш-функции с основанием модуля, равным Nk, в двоичном представлении от сокращенного морфологического коэффициента 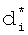 в аналогах не встречаются. Следовательно, заявляемый способ соответствует критерию «изобретательский уровень».
в аналогах не встречаются. Следовательно, заявляемый способ соответствует критерию «изобретательский уровень».
Заявленный способ поясняется чертежами, на которых показаны:
на фиг.1 - блок-схема, поясняющая адресный способ обнаружения идентификационных признаков в информационных потоках;
на фиг.2 - таблица «алфавита символов» и их кодовых значений;
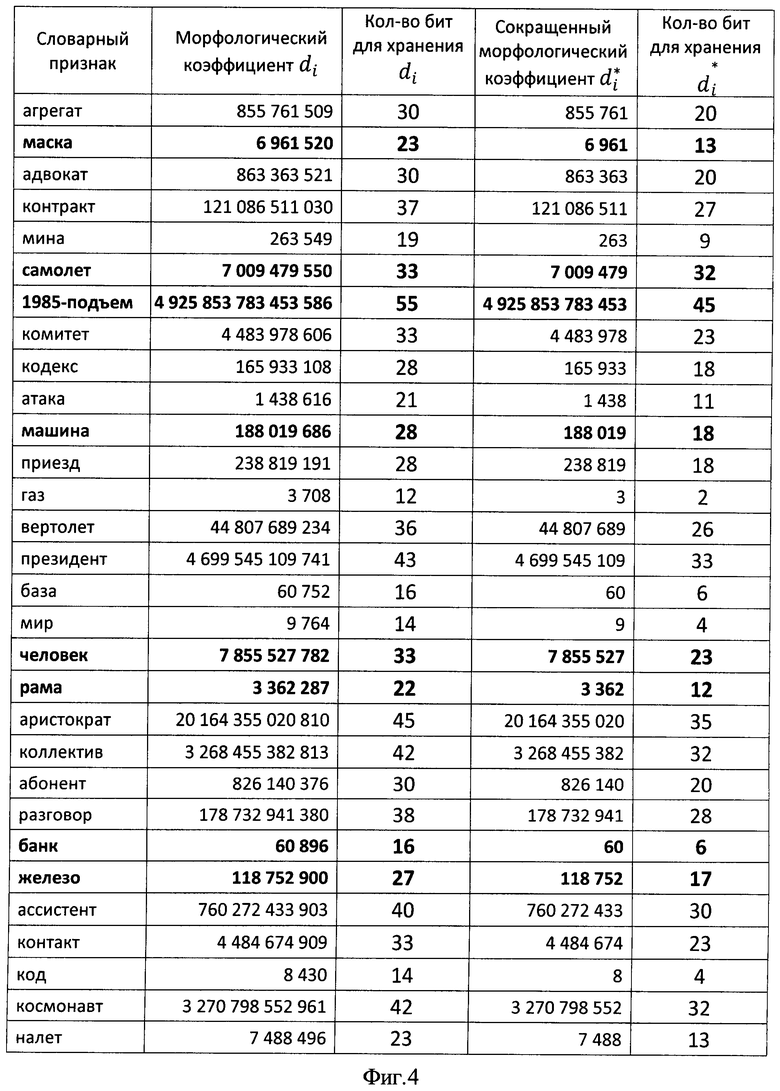
на фиг.3 - сводная таблица словарных признаков отбора, количества символов в том признаке, адресов и морфологических для словарных признаков;
на фиг.4 - сводная таблица словарных признаков с их морфологическими коэффициентами, рассчитанными по способу-прототипу и предлагаемому способу с требуемыми значениями памяти для хранения двоичных последовательностей этих морфологических коэффициентов;
на фиг.5 - сводная таблица словарных признаков, их адресов в десятичной форме записи для адресации в БЭИП, сокращенных по предлагаемому способу морфологических коэффициентов 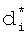 , вторичных хеш-функций от
, вторичных хеш-функций от 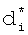 и их двоичное представление для БЭИП.
и их двоичное представление для БЭИП.
Заявленное техническое решение достигается введением в способ-прототип дополнительных функциональных блоков и связей между функциональными блоками. На фигуре 1 представлена блок-схема, поясняющая адресный способ обнаружения идентификационных признаков в информационных потоках. В качестве функциональных блоков данной блок-схемы выступают следующие элементы:
1 - функциональный блок сегментации информационного потока по словам;
2 - функциональный блок расчета морфологического коэффициента выделенного слова;
3 - функциональный блок расчета адреса БЭИП;
4 - функциональный блок сокращения морфологического коэффициента;
5 - функциональный блок расчета компактной записи эталонного информационного признака;
6 - база эталонных информационных признаков (БЭИП);
7 - функциональный блок сравнения информационных признаков.
Функциональные блоки 1, 2, 3, 6, 7 полностью реализуют действия, описанные в способе-прототипе, при этом информационные выходы функционального блока 2 являются по способу-прототипу информационными входами функциональных блоков 6 и 7. Для реализации нового технического решения в блок-схему способа-прототипа дополнительно введены функциональные блоки 4 и 5. В предлагаемом способе на вход функционального блока 1 поступают на этапе заполнения БЭИП отобранные словарные признаки, а при контроле информационного трафика - информационный поток. В функциональном блоке 1 осуществляется сегментация информационного потока по словам. Информационный выход функционального блока 1 является информационным входом функционального блока 2, где осуществляется расчет морфологического коэффициента для выделенного в блоке 1 слова. Информационные выходы функционального блока 2 являются информационными входами функциональных блоков 3 и 4. В функциональном блоке 3 осуществляется расчет адреса БЭИП для представленного из блока 2 морфологического коэффициента. Информационный выход функционального блока 3 является информационным входом блока 6. В функциональном блоке 4 осуществляется сокращение морфологического коэффициента, представленного функциональным блоком 2. Информационный выход функционального блока 4 является информационным входом функционального блока 5, где осуществляется преобразование сокращенного морфологического коэффициента к компактной форме записи в виде двоичной последовательности ограниченного объема. Информационный выход функционального блока 5 является информационным входом блока 6, в который по адресу, рассчитанному в функциональном блоке 3, осуществляется запись значения двоичной последовательности ограниченного объема из функционального блока 5. После заполнения БЭИП система адресного обнаружения идентификационных признаков в информационных потоках готова к использованию. Информационный поток через последовательность функциональных преобразований в функциональных блоках 1, 2, 4, 5 в виде двоичной последовательности ограниченного объема попадает из функционального блока 5 на вход функционального блока 7. Одновременно с этим на вход функционального блока 7 из блока 6 по адресу, рассчитанному в функциональном блоке 2, осуществляется считывание хранящейся в функциональном блоке 6 двоичной последовательности ограниченного объема. В функциональном блоке 7 осуществляется сравнение обеих двоичных последовательностей, и на выход выдается значение о наличии или отсутствии в текущем фрагменте информационного потока отобранных словарных признаков.
Рассмотрение заявленного способа целесообразно провести на примере действий, реализованных способом-прототипом, и дополнить необходимыми действиями для получения заявленного технического решения.
Пусть в качестве словарных признаков отбора информационных сообщений выбрано N=100 словарных признаков. Словарные признаки: "банк", "железо", "маска", "машина", "рама", "самолет", "человек", "1985-подъем", - взяты из способа-прототипа. Из указанных N выбранных признаков выделяют содержащиеся в них и отличные друг от друга символы и формируют «алфавит символов» (АС) с присвоением каждому символу порядкового номера в АС. Будем считать, что в составе всех N признаков содержатся символы, сведенные в таблицу, изображенную на фигуре 2. Каждому символу из АС соответствует кодовое значение номера позиции nj.
Состав АС содержит совокупность отличающихся символов, достаточных для составления из них любого из N предварительно отобранных признаков.
Затем вычисляют для заданного значения коэффициента заполнения К БЭИП ее объем Nk=N/K, т.е. число строк в формируемой БЭИП. По аналогии со способом-прототипом K=0,2 соответственно число строк в базе эталонных информационных признаков будет равно:
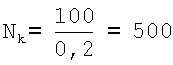 .
.
Далее для каждого 1-го признака вычисляют его морфологический коэффициент di по формуле (1).
Далее с учетом вычисленного значения морфологического коэффициента определяют адрес Ai каждого 1-го признака, используя заданную хеш-функцию (формулу 2), т.е. определяют позицию эталонного признака в БЭИП. Формулу 2 можно упростить до выражения:
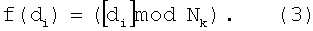
В данном случае адресация в БЭИП в отличие от адресации, рассчитываемой по формуле 2, будет отличаться на постоянную, равную 1, и занимать область адресов с 0 по 499. Обозначим получаемый по формуле 3 адрес как 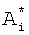 . Так как в морфологическом коэффициенте di уже содержится информация о значении адреса
. Так как в морфологическом коэффициенте di уже содержится информация о значении адреса 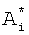 , неэффективно использовать избыточную информацию для хранения в БЭИП. Сократить морфологический коэффициент di предлагается делением морфологического коэффициента на постоянную R, равную размерности произведения (Nk×10). При Nk=500 постоянная R представляется величиной 3-го порядка - 1000 в десятичном представлении или в двоичном представлении - 1111101000. При представлении морфологического коэффициента di в десятичной форме записи для получения сокращенного морфологического коэффициента
, неэффективно использовать избыточную информацию для хранения в БЭИП. Сократить морфологический коэффициент di предлагается делением морфологического коэффициента на постоянную R, равную размерности произведения (Nk×10). При Nk=500 постоянная R представляется величиной 3-го порядка - 1000 в десятичном представлении или в двоичном представлении - 1111101000. При представлении морфологического коэффициента di в десятичной форме записи для получения сокращенного морфологического коэффициента 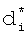 осуществляется деление di на постоянную R, далее дробная часть от деления отбрасывается, а оставляется только целая часть от деления. Так, для словарного признака "маска", занимающего 2-ю позицию словарного признака в таблице фигуры 3, морфологический коэффициент, рассчитываемый по формуле 1, составит в десятичной форме записи значение, равное 6961520. Для данного значения морфологического коэффициента адрес
осуществляется деление di на постоянную R, далее дробная часть от деления отбрасывается, а оставляется только целая часть от деления. Так, для словарного признака "маска", занимающего 2-ю позицию словарного признака в таблице фигуры 3, морфологический коэффициент, рассчитываемый по формуле 1, составит в десятичной форме записи значение, равное 6961520. Для данного значения морфологического коэффициента адрес 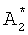 , рассчитываемый по формуле 3, составит значение:
, рассчитываемый по формуле 3, составит значение:
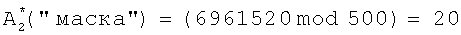
Так как в БЭИП доступно поле адресов от 0 до 499 при Nk=500, то последние значения размерности Nk не несут дополнительной информации, а уже содержатся в значении адреса 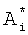 .
.
Для 30 словарных признаков расчеты адресов, морфологических коэффициентов по способу-прототипу и сокращенных морфологических коэффициентов сведены в таблицу фигуры 3.
Расчетные данные необходимого количества бит для хранения морфологических коэффициентов в БЭИП соответствующих словарных признаков сведены в таблицу фигуры 4. Так, для словарного признака "маска" в двоичной форме записи морфологический коэффициент имеет вид 11010100011100101110000, что соответствует 23 битам необходимого объема памяти. Для сокращенного морфологического коэффициента данное значение сократится до 13 бит и составит значение 1101100110001, что следует из решения:
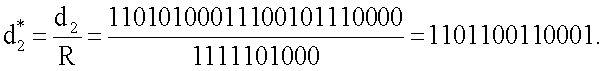
В среднем приведение морфологических коэффициентов к сокращенному виду повышает эффективность использования памяти для хранения эталонных информационных признаков на 10 бит для любого по длине словарного признака.
Учитывая тот факт, что морфологические коэффициенты имеют различную длину, а следовательно, и требуют различные объемы памяти для хранения своих двоичных значений, необходимо привести отображение сокращенных морфологических признаков к компактному виду. При этом компактный вид отображения сокращенных признаков должен быть единого размера для любых по символьной длине словарных признаков. Для этого предлагается осуществить расчет вторичной хеш-функции от сокращенного морфологического коэффициента по формуле:
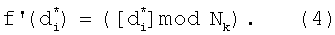
Выбор основания модуля Nk для расчета вторичной хеш-функции основывается на уже реализованной в способе-прототипе функциональным блоком 2 процедуре вычисления хеш-функции. Значение Nk также определяет Vm - необходимое значение объема информации в битах для хранения компактного бинарного значения признака по формуле:

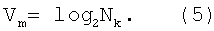
В данном случае значение Vm составляет 8,965784, а при округлении до целого - 9 бит.
Двоичные представления эталонных информационных признаков, записываемых в БЭИП по адресам, соответствующим словарным признакам отбора информации, представлены в таблице фигуры 5.
Обоснование положительного эффекта предлагаемого способа осуществлено следующим образом. Показателем эффективности обнаружения идентификационных признаков в информационных потоках является необходимый объем памяти БЭИП, следовательно, более эффективным является способ, требующий меньший объем памяти для хранения эталонных информационных признаков в БЭИП. Для N словарных признаков, представленных в таблице на фигуре 4, условная эффективность использования памяти для хранения эталонных информационных признаков η(Mi) при реализации Mi способа определяется по формуле:
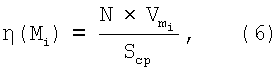
где N - количество словарных признаков;
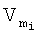 - среднее количество бит, необходимых для хранения одного признака;
- среднее количество бит, необходимых для хранения одного признака;
Scp - среднее количество символов в словарном признаке.
Среднее количество символов для словарных признаков, представленных в таблице на фигуре 3, составляет 6,4 символа на слово при количестве словарных признаков, равном 30.
Для способа-прототипа среднее количество бит, необходимое для хранения одного словарного признака с учетом данных, представленных в таблице фигуры 4, составит значение, равное 29,7 бит/словарный признак. С учетом этого условная эффективность использования памяти для хранения эталонных информационных признаков для способа-прототипа составит:

При представлении в качестве эталонных информационных признаков сокращенных морфологических коэффициентов условная эффективность использования памяти для хранения эталонных информационных признаков составит 92,34375 бит/символ.
При реализации предлагаемого способа условная эффективность использования памяти для хранения эталонных информационных признаков составит:
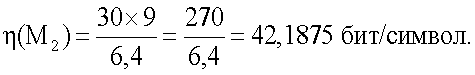
Таким образом, использование памяти для хранения информационных признаков по предлагаемому способу по отношению к способу-прототипу эффективней в 3,3 раза.
Практическая реализация предлагаемого способа не требует больших дополнительных вычислительных затрат, так как вычисление бинарного значения по модулю является бинарной операцией точно так же, как являются бинарными операции сложения и вычитания (Конкретная математика. Основание информатики / Р.Грэхем, Д.Кнут, О.Паташник. Пер. с англ. - 2-е изд., испр. - М.: Мир; БИНОМ. Лаборатория знаний, 2006. - С.104).
Введенные в способ-прототип два дополнительных действия:
1) бинарное деление морфологического коэффициента, рассчитанного по способу-прототипу и представленного в двоичной форме записи, на двоичную постоянную R, равную размерности произведения (Nk×10);
2) бинарное вычисление вторичной хеш-функции с основанием модуля, равным Nk, в двоичном представлении от сокращенного морфологического коэффициента 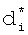 в двоичной форме записи,
в двоичной форме записи,
возможно реализовать на существующей в настоящее время элементной базе, например на любых серийно выпускаемых программируемых логических интегральных схемах (ПЛИС).
Таким образом, из рассмотренной сущности заявляемого способа следует, что он обеспечивает сокращение необходимого объема памяти хранения эталонных информационных признаков. Это подтверждает положительный эффект от внедрения предлагаемого способа.



Изобретение относится к области информатики и вычислительной техники и может быть использовано для контроля информационных потоков при мониторинге информационного трафика. Техническим результатом является сокращение объема памяти для хранения эталонных информационных признаков. Способ включает: для формирования базы эталонных информационных признаков выбирают совокупность из Ni эталонных информационных признаков, выделяют содержащиеся в них и отличающиеся друг от друга символы, формируют из них алфавит символов, вычисляют число содержащихся в нем символов, рассчитывают объем базы эталонных информационных признаков, для i-го эталонного признака вычисляют число mi образующих его символов, его морфологический коэффициент di, рассчитывают с использованием хеш-функции адрес эталонного информационного признака Ai=f(di), сокращают морфологический коэффициент, вычисляют от него вторичную хеш-функцию, запоминают полученное компактное бинарное представление информационного признака в базе эталонных информационных признаков по адресу Аi, для выделения из каждого фрагмента принимаемого информационного потока информационных признаков выделяют в нем группу двоичных знаков, находящихся между двумя пробелами, декодируют ее к виду информационного признака, вычисляют его морфологический коэффициент и адрес, сравнивают полученный морфологический коэффициент с морфологическим коэффициентом, хранящимся по схожему адресу в базе эталонных информационных признаков, фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению. 5 ил.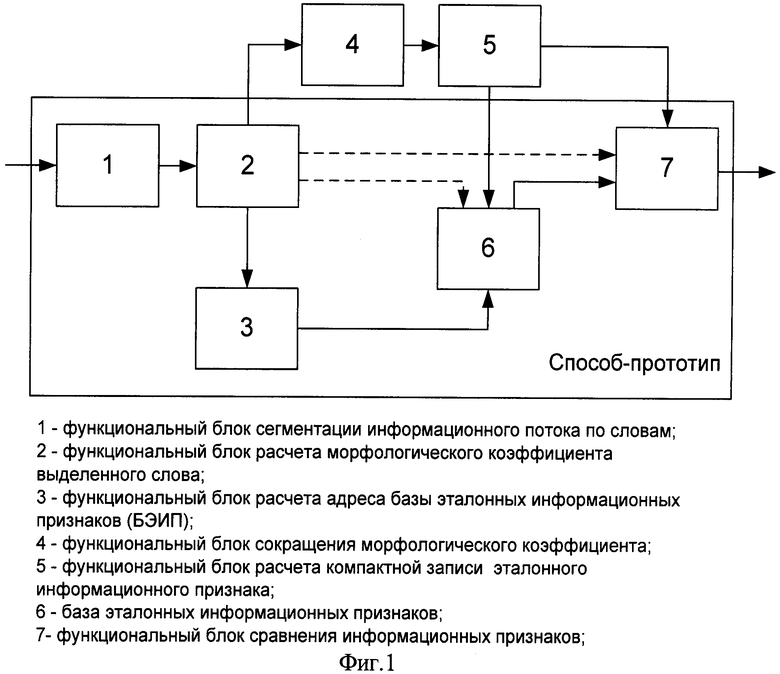
Адресный способ обнаружения идентификационных признаков в информационных потоках, заключающийся в том, что для формирования базы эталонных информационных признаков, подлежащих выявлению в информационном потоке, выбирают совокупность из Ni эталонных информационных признаков, выделяют содержащиеся в них и отличающиеся друг от друга символы, формируют из них алфавит символов, вычисляют число S содержащихся в нем символов, присваивают j-му, где j=1, 2, …, S, символу номер nj его позиции в алфавите символов и рассчитывают для заданного значения коэффициента заполнения К базы эталонных информационных признаков ее объем Nk=N/K, после чего для i-го, где i=1, 2, …, N, эталонного признака вычисляют число mi образующих его символов и его морфологический коэффициент di, а также рассчитывают с использованием хеш-функции заданного вида f(di) адрес эталонного информационного признака Ai=f(di), затем запоминают i-й эталонный информационный признак в базе эталонных информационных признаков на позиции, соответствующей его адресу Аi, а для выделения из каждого фрагмента принимаемого информационного потока информационных признаков выделяют в нем группу двоичных знаков, находящихся между примыкающими друг к другу двумя пробелами, декодируют ее к виду информационного признака, вычисляют его морфологический коэффициент и адрес, сравнивают полученный при декодировании морфологический коэффициент с морфологическим коэффициентом, хранящимся по схожему адресу в базе эталонных информационных признаков, отличающийся тем, что для формирования информационных признаков дополнительно осуществляют сокращение размерности морфологического коэффициента di, представленного в двоичной форме записи, делением на двоичную постоянную R, равную размерности произведения (Nk×10), из морфологического коэффициента сокращенной размерности 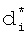 рассчитывают вторичную хеш-функцию с основанием модуля, равным Nk, и записывают полученное компактное бинарное значение в базу эталонных информационных признаков по адресу Ai=f(di), при мониторинге информационного трафика фрагменты информационного потока приводят к виду компактного бинарного значения признака, сравнивают с признаком в двоичной форме записи, хранящимся по адресу Ai=f(di) в базе эталонных информационных признаков, и по результатам сравнения фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению.
рассчитывают вторичную хеш-функцию с основанием модуля, равным Nk, и записывают полученное компактное бинарное значение в базу эталонных информационных признаков по адресу Ai=f(di), при мониторинге информационного трафика фрагменты информационного потока приводят к виду компактного бинарного значения признака, сравнивают с признаком в двоичной форме записи, хранящимся по адресу Ai=f(di) в базе эталонных информационных признаков, и по результатам сравнения фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению.
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ИДЕНТИФИКАЦИОННЫХ ПРИЗНАКОВ В ИНФОРМАЦИОННЫХ ПОТОКАХ | 2005 |
|
RU2282889C1 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| US 2002059281 A1, 16.05.2002 | |||
| US 2008133446 A1, 05.06.2008 | |||
| JP 63170742 A, 14.07.1988. | |||

