Изобретение относится к области информатики и вычислительной техники и может использоваться для обработки информационных потоков и обнаружения в них заданных эталонных информационных признаков. Способ может быть использован в устройствах контроля информационных потоков с целью мониторинга информационного трафика (Трафик - совокупность сообщений, передаваемых по сети электросвязи (Постановление Правительства РФ от 19 октября 1996 г. N 1254 "Об утверждении Правил присоединения ведомственных и выделенных сетей электросвязи к сети электросвязи общего пользования", п.2).
Известен способ, реализованный в устройстве поиска информации по патенту RU №2133500, кл. G 06 F 17/30, заявленный 20.07.1999 г. Известный способ включает следующую последовательность действий. Предварительно запоминают формат блока данных протокола Frame Relay (G), типы передаваемых служебных сообщений Vn=(a,b,c,i, T391), возможные правила использования команд и ответов Р, возможные состояния пользователей Vt=(S1, S2, S3). Принимают информационный поток, выделяют из него блоки данных, определяют тип передаваемого блока данных и формат блока данных. Сравнивают полученную структуру блока данных с эталонной G. На основании этого совпадения делают вывод об использовании или не использовании протокола FR.
Недостатком данного способа является узкая область его применения, т.к. известный способ может работать только со структурами протокола FR и, как следствие, недостаточное быстродействие при последовательном сравнении в случае использования данного способа в системах с большим числом признаков.
Также известен способ, реализованный в устройстве поиска информации по патенту RU №2116670, кл. 6 G 06 F 17/30, заявл. 27.07.98. Известный способ включает следующую последовательность действий. Предварительно запоминают структуру комбинаций начала сообщений (КНС), пороговые значения количества сообщений (Sпв, Sпн), максимальные значения символьной выборки Nmax, принимают информационный поток, выбирают из него некоторую последовательность знаков N<Nmax, выделяют в полученной последовательности КНС, суммируют общее количество КНС, сравнивают сумму со значениями Sпв, Sпн, на основании сравнения делают вывод об изменении интенсивности информационного потока.
Недостатком данного способа является то, что заключение об изменении состояния трафика делается только на основании уменьшения или увеличения числа КНС, что не в полной мере отражает картину изменения интенсивности трафика в канале связи.
Наиболее близким по технической сущности является способ, реализованный в устройстве обработки информации для информационного поиска по патенту РФ №2096825, МПК 6 G 06 F 17/00, G 06 F 17/30, заявл. 20.11.1997. Способ-прототип заключается в том, что предварительно формируют базу эталонных информационных значений, подлежащих выявлению в информационном потоке, запоминают их, запоминают количество символов в обрабатываемом текстовом фрагменте (ТФ), запоминают количество символов в словах (словосочетаниях), запоминают количество цифр и специальных символов в ТФ, запоминают предварительно выделенные комбинации символов, соответствующие структурным признакам ТФ, задают правила выделения ТФ из информационного потока.
Принимают информационный поток, запоминают по предварительно заданным правилам очередной ТФ. Выделяют из ТФ слова и словосочетания, для чего используют предварительно запомненные структурные признаки. Запоминают ТФ, для чего записывают в память слова и словосочетания последовательно, аналогично позициям в выделенном ТФ. Сравнивают запомненные слова и словосочетания с выделенным ТФ, для чего: выбирают методом прямого перебора из памяти слова (словосочетания), определяют количество и вид символов в выбранном слове на предмет наличия только цифр и (или) спецзнаков, сравнивают количество символов с эталонным значением и запоминают данные сравнения. Запоминают данные о количестве повторений данного слова в ТФ (о количестве одинаковых слов), запоминают данные о количестве совпадений символьной структуры. Сравнивают выделенный признак с эталонным, содержащимся в базе эталонных информационных признаков. В случае их совпадения считают обнаруженным искомый признак.
По сравнению с аналогами способ-прототип позволяет несколько повысить производительность поиска информации, выявления наиболее характерных для данного текста слов и словосочетаний, с учетом их повторяемости и позволяет автоматизировать поиск необходимой текстовой информации.
Недостатком прототипа является относительно низкая скорость обработки информации вследствие использования алгоритмов последовательного поиска, что требует для их реализации большого объема памяти и предъявляет высокие требования к вычислительным ресурсам ЭВМ. Это объясняется тем, что при повышении интенсивности трафика увеличивается время обработки необходимой текстовой единицы (слова, словосочетания и т.п.), вследствие чего увеличивается общее время обработки всего массива информационных признаков. Увеличение объемов памяти и необходимость увеличения вычислительного ресурса приводит к неоправданным экономическим затратам.
Целью заявленного технического решения является разработка способа, позволяющего увеличить скорость обработки информации.
Поставленная цель достигается тем, что в известном способе обработки информации, заключающемся в том, что предварительно формируют базу эталонных информационных признаков (БЭИП), подлежащих выявлению в информационном потоке, принимают информационный поток, последовательно выделяют и запоминают фрагменты принимаемого информационного потока, из которых выделяют по установленным правилам информационные признаки, сравнивают их с эталонными информационными признаками из БЭИП и по результатам сравнения фиксируют наличие или отсутствие в каждом фрагменте информационного потока идентификационных признаков, подлежащих выявлению. Новым в заявленном способе является то, что для формирования БЭИП выбирают совокупность из N≥1 эталонных информационных признаков, выделяют содержащиеся в них и отличающиеся друг от друга символы. Затем из выделенных символов формируют алфавит символов (АС), вычисляют число S содержащихся в нем символов, присваивают j-му, где j=1,2,...,S, символу номер nj его позиции в алфавите символов и рассчитывают для заданного значения коэффициента заполнения К БЭИП ее объем Nk=N/K. После этого для i-го, где i=1,2,...,N, эталонного информационного признака вычисляют число mi, образующих его символов и его морфологический коэффициент di, а также рассчитывают с использованием хэш-функции заданного вида f(di) адрес эталонного информационного признака Ai=f(di). Затем запоминают i-й эталонный информационный признак в БЭИП на позиции, соответствующей его адресу Ai. Для выделения из каждого фрагмента принимаемого информационного потока информационных признаков выделяют в нем группу двоичных знаков, находящихся между примыкающими друг к другу двумя пробелами, декодируют ее к виду информационного признака, вычисляют его морфологический коэффициент и адрес. После этого сравнивают выделенный и декодированный информационный признак с эталонными информационными признаками, запомненными по этому адресу в БЭИП.
Для i-го, где i=1,2,...,N, эталонного информационного признака вычисляют его морфологический коэффициент di по формуле:

где nj - номер позиции j-го символа в алфавите символов, mi - число символов, образующих i-ый признак, S - число символов алфавита символов, j=1,2,..., mi - позиция символа в i-м признаке.
В качестве хеш-функции для вычисления адреса признака Ai=f(di) используют функцию вида 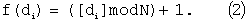
Благодаря новой совокупности существенных признаков заявленного способа достигается сокращение времени идентификации адресов признаков в БЭИП. Время поиска не зависит от объема БЭИП (в отличие от последовательного или итерационного способов), поэтому предельно достижимый выигрыш по времени поиска признака в БЭИП может достигать нескольких порядков (зависит от объема БЭИП). Отмеченное указывает на возможность достижения поставленной цели - увеличение скорости обработки информации.
Проведенный анализ уровня техники обработки информации позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественным всем признакам технического решения, отсутствуют в доступных источниках информации, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежной областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта показали, что они не следуют явным образом из уровня техники. Из уровня техники также выявлена известность влияния предусматриваемых отличительными существенными признаками заявленного изобретения преобразований на достижение указанного технического результата. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Заявленный способ поясняется чертежами, на которых показаны:
на фиг.1 - пример построения БЭИП;
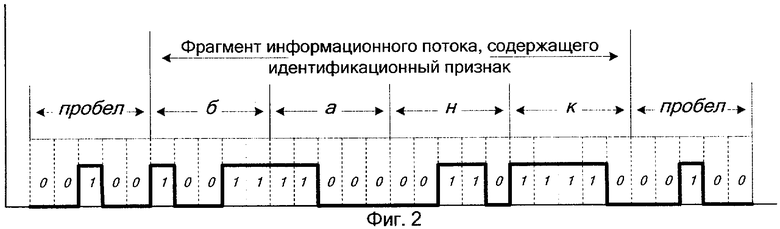
на фиг.2 - пример цифрового информационного потока, содержащего искомый признак.
Используемый в аналогах и прототипе способ поиска информации является последовательным. Процесс поиска сводится к сравнению каждого символа искомого признака последовательно со всеми символами каждого признака в БЭИП, что из-за низкой скорости алгоритма обработки, а также больших объемов баз эталонных информационных признаков, приводит к неоправданному расходу временных ресурсов.
Пусть для формирования базы эталонных информационных признаков выбраны N признаков, каждый длинной М символов. Иными словами, если на одну итерацию затрачивается время t, то на все итерации будет затрачено: Т=N·М·t. При практически используемых в настоящее время БЭИП в десятки тысяч признаков, указанный выше способ, используемый в аналогах, по своей структуре выполнения алгоритма поиска не может обеспечить требуемую на данный момент скорость поиска необходимых признаков.
Рассмотрение заявленного способа целесообразно провести на следующем примере. Пусть для формирования базы эталонных информационных признаков выбраны N=100 признаков, из которых первые семь имеют значение: банк, железо, маска, машина, рама, самолет, человек, а сотый признак имеет значение 1985-подъем. Из указанных N выбранных признаков выделяют содержащиеся в них и отличные друг от друга символы и формируют «алфавит символов» (АС) с присвоением каждому символу порядкового номера в АС. Будем считать, что в составе всех N признаков содержатся символы, сведенные в таблицу 1. Каждому символу из АС присвоен порядковый номер nj. Например, символ «ж» имеет номер n=8, символ «9» имеет номер n=24 и т.д.
Состав АС содержит совокупность отличающихся символов, достаточных для составления из них любого из N предварительно отобранных признаков.
Затем вычисляют для заданного значения коэффициента заполнения К БЭИП ее объем Nk=N/K, т.е. число строк в формируемой БЭИП. Значение коэффициента заполнения БЭИП К выбирают лежащим в пределах [0,2-0,5]. При меньших значениях снижается эффективность использования памяти, при больших - возрастают трудности обеспечения неповторяемости адресов признаков в БЭИП (Кнут Д. Искусство программирования. Т.3. Сортировка и поиск. Пер. с англ. - М.: Издательский дом Вильяме, 2003. - 560 с.).
Полагаем, что в рассматриваемом примере K=0,2, соответственно число строк в базе эталонных информационных признаков будет равно:
Nk=100/0,2=500.
Далее для каждого i-го признака вычисляют его морфологический коэффициент di. В общем случае он может вычисляться различными способами. При использовании десятичной системы для определения адресной позиции эталонного признака в БЭИП, морфологический коэффициент di i-го эталонного признака рассчитывают по формуле (1).
В качестве примера рассмотрим вычисление морфологических коэффициентов признаков «банк» и «1985-подъем».
Для признака «банк»:
D1=3·273+2·272+14·27+11=60896
Для признака «1985-подъем»:
d100=23·2710+24·279+25·278+26·277+27·276+16·275+15·274+6·273+22·272+7·27+13=4925853783453586
Аналогичные расчеты, выполненные для рассматриваемых признаков, сведены в таблицу 2:
Далее с учетом вычисленного значения морфологического коэффициента определяют адрес Ai каждого i-го признака, используя заданную хэш-функцию (формулу (2)), т.е. определяют позицию эталонного признака в БЭИП.
Например, адреса признаков А1("банк") и А100(«1985 - подъем») в БЭИП будут иметь значение:
A1("банк")=(60896 mod 500)+1=396+1=397;
А100("1985-подъем")=(4925853783453586 mod 500)+1=86+1=87.
Аналогичные расчеты, выполненные для рассматриваемых признаков, приведены в таблице на фиг.1.
Затем принимают, например, по телекоммуникационным сетям связи, информационный поток в форме двухбитового цифрового электромагнитного сигнала, содержащего искомые признаки.
Обработку принимаемого цифрового потока выполняют следующим образом.
Выделяют фрагмент цифрового сигнала, находящегося между примыкающими друг к другу пробелами (фиг.2). Символы пробелов в информационном потоке обозначают в виде двоичных международных кодов «00100», рекомендованных к использованию МККТТ (см. например В.А. Григорьев. Передача сообщений по зарубежным информационным сетям. - Ленинград: ВАС, 1989. - 18-19 с.).
Заключенный между ближайшими пробелами признак декодируют к виду искомого информационного признака, например, выявлен признак «банк». Порядок декодирования известен и описан в литературе, например в книге: В.А.Григорьев. Передача сообщений по зарубежным информационным сетям. - Ленинград: ВАС, 1989. - 14-27 с. Затем, аналогично рассмотренному выше примеру, вычисляют его морфологический коэффициент di (по формуле 1) и адрес Аi (по формуле 2), в рассматриваемом случае имеем: d1=60896, A1=397. После чего сравнивают его с эталонными информационными признаками, запомненными по этому адресу в базе эталонных информационных признаков. Из БЭИП (см. фиг.1) выделяют находящийся по найденному адресу А1=397 признак «банк» и сравнивают его с признаком, выделенным из принимаемого цифрового потока (в рассматриваемом примере - признак «банк»). Совпадение сравниваемых признаков дает основание для фиксации присутствия в принимаемом информационном потоке искомого признака.
Таким образом в заявленном способе процесс поиска сводится к выделению из БЭИП признака, находящегося по вычисленному адресу, и последующее сравнение эталонного и выделенного из информационного потока признаков.
Практическая реализация предлагаемого способа не требует высокого быстродействия процессора, так как время поиска не зависит от объема базы эталонных информационных признаков (в отличие от последовательного или итерационного способов), поэтому предельно достижимый выигрыш относительно их может составлять несколько порядков (зависит от объема базы эталонных информационных признаков).
Сравнительная оценка скорости поиска признаков при использовании предлагаемого и способа-прототипа обработки информации для обнаружения идентификационных признаков в информационных потоках может быть рассмотрена на следующем примере.
Предположим, что база эталонных информационных признаков (словарь признаков) имеет N=50000 признаков, каждый длиной М=8 знаков. При обнаружении признака поиск ведется сверху вниз, слева направо. Максимальное количество шагов (итераций) при последовательном способе поиска (прототипе) для случая, если признак находится в строке N:
Rmax=N·М, →Rmax=50000·8=4·105.
Минимальное количество итераций при последовательном способе поиска для случая, если признак находится в первой строке:
Rmin=N·(М-1)+1, →Rmin=50000·(8-1)+1=350001.
При использовании заявленного способа для обнаружения искомого признака максимальное количество операций равно двум.
1. Вычисляют морфологический коэффициент di, и адрес Ai i-го признака.
2. Сравнивают с эталонными информационными признаками, запомненными по этому адресу в базе эталонных информационных признаков.
Если на одну итерацию затрачивается время t=Δt, то на все итерации будет затрачено время: Т=N·М·Δt.
Для ближайшего аналога Тпосл=4·105·Δt.
Для заявленного способа Т3=2·Δt.
Следовательно, относительный выигрыш V по времени, необходимому для поиска признака будет составлять:
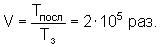
Таким образом, из рассмотренной сущности заявленного способа видно, что он обеспечивает сокращение времени идентификации адресов признаков в БЭИП. Этим достигается сформулированная цель - увеличение скорости обработки информации.
| название | год | авторы | номер документа |
|---|---|---|---|
| АДРЕСНЫЙ СПОСОБ ОБНАРУЖЕНИЯ ИДЕНТИФИКАЦИОННЫХ ПРИЗНАКОВ В ИНФОРМАЦИОННЫХ ПОТОКАХ | 2009 |
|
RU2409850C1 |
| СПОСОБ ОБНАРУЖЕНИЯ ИДЕНТИФИКАЦИОННЫХ ПРИЗНАКОВ ДЛЯ РАЗЛИЧНЫХ БУКВЕННО-ЗНАКОВЫХ СИСТЕМ ПИСЬМЕННОСТИ | 2011 |
|
RU2473964C1 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 2008 |
|
RU2386167C1 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| СПОСОБ ЗАЩИТЫ ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ НА ОСНОВЕ АДАПТИВНОГО ВЗАИМОДЕЙСТВИЯ | 2019 |
|
RU2715165C1 |
| СПОСОБ ЗАЩИТЫ ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ ОТ КОМПЬЮТЕРНЫХ АТАК, НАПРАВЛЕННЫХ НА РАЗЛИЧНЫЕ УЗЛЫ И ИНФОРМАЦИОННЫЕ РЕСУРСЫ | 2021 |
|
RU2782704C1 |
| СПОСОБ ОРГАНИЗАЦИИ ОБМЕНА ИНФОРМАЦИЕЙ МЕЖДУ АБОНЕНТАМИ МОБИЛЬНОЙ СВЯЗИ И СИСТЕМА ДЛЯ ОРГАНИЗАЦИИ ОБМЕНА ИНФОРМАЦИЕЙ МЕЖДУ АБОНЕНТАМИ МОБИЛЬНОЙ СВЯЗИ | 2006 |
|
RU2351980C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИОННЫХ ТЕКСТОВЫХ МАТЕРИАЛОВ | 2003 |
|
RU2242048C2 |
| СПОСОБ ЗАЩИТЫ ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ | 2012 |
|
RU2475836C1 |
| СПОСОБ ЗАЩИТЫ ИНФОРМАЦИОННО-ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ ОТ КОМПЬЮТЕРНЫХ АТАК | 2011 |
|
RU2472211C1 |
Изобретение относится к области информатики и вычислительной техники и может быть использовано в устройствах контроля информационных потоков с целью мониторинга информационного трафика. Техническим результатом является увеличение скорости обработки информации за счет сокращения времени идентификации адресов признаков в базе эталонных информационных признаков. Способ заключается в том, что предварительно формируют базу эталонных информационных признаков, принимают информационный поток, последовательно выделяют и запоминают фрагменты информационного потока, выделяют из них идентификационные признаки, сравнивают их с эталонными. При этом базу эталонных информационных признаков формируют путем вычисления морфологического коэффициента d идентификационного признака и его адреса А с использованием хеш-функции. Для принятых из информационного потока идентификационных признаков также вычисляют морфологические коэффициенты d и идентификационные адреса А, после чего по вычисленному адресу сравнивают выделенный из информационного потока идентификационный признак с эталонным. 3 з.п. ф-лы, 2 ил., 2 табл.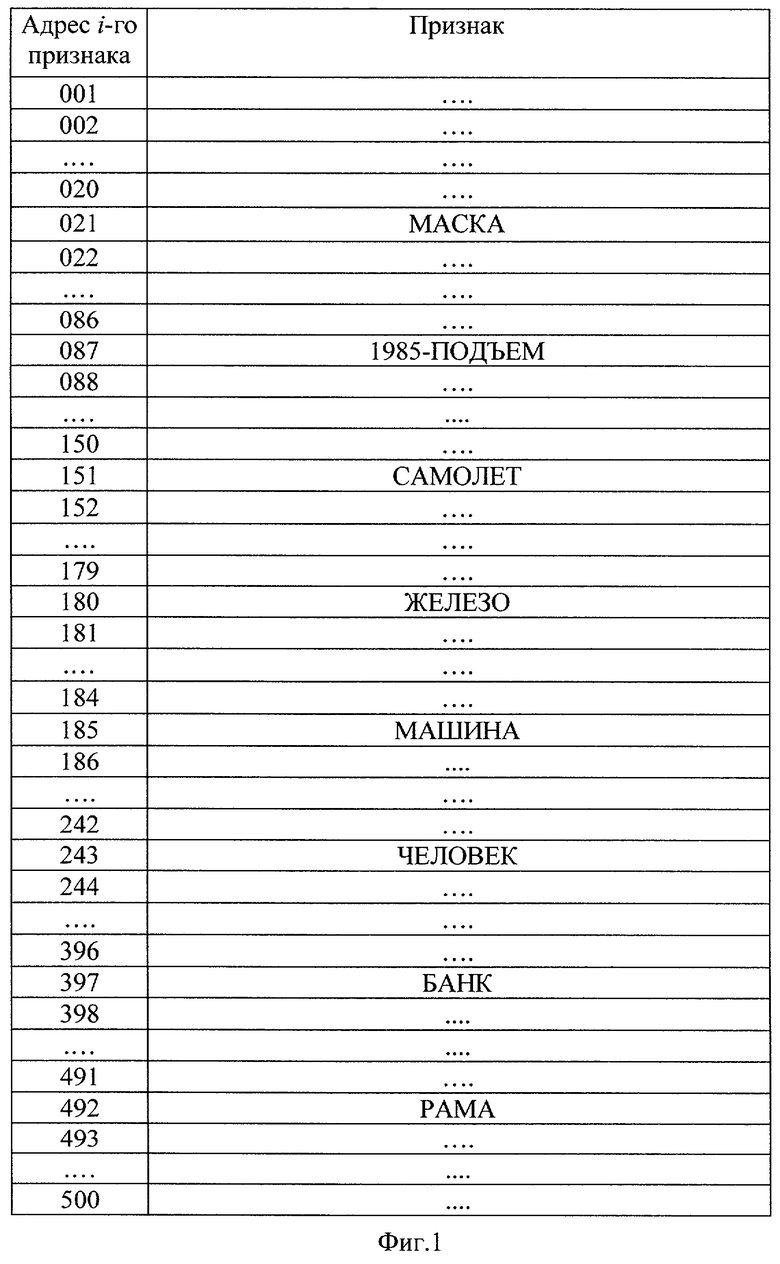
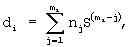
где nj - номер позиции j-го символа в алфавите символов;
mi - число символов, образующих i-й признак;
S - общее число символов в алфавите символов;
j=1,2,...;
mi - позиция символа в i-м признаке.
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| УСТРОЙСТВО ПОИСКА ИНФОРМАЦИИ | 1998 |
|
RU2133500C1 |
| Устройство для поиска информации | 1989 |
|
SU1672471A1 |
| Устройство поиска информации | 1988 |
|
SU1536400A1 |
| US 6574624 А, 03.06.2003 | |||
| US 2003167252 А1, 04.09.2003. | |||

