Область техники
[0001] Настоящее изобретение относится к методам обработки информации Интернета, в частности к способу и устройству для определения и оценки значимости слов.
Уровень техники
[0002] С быстрым развитием Интернета проблема "информационной перегрузки" становится все более серьезной. Пользуясь преимуществами, предоставляемыми Интернетом, люди получают информацию в очень большом объеме. При этом актуальной является задача более эффективного и точного извлечения полезной информации из огромного объема данных Интернета.
[0003] В настоящее время имеются Интернет-платформы разных типов. Они предоставляют пользователям большой объем данных. Среди таких Интернет-платформ известны поисковые системы, например Google, Baidu, Soso; существуют также интерактивные платформы Q&A, например, Zhidao, Wenwen, Answers, а также популярные блог-платформы, например Qzone, Sina Blog и прочее.
[0004] Для всех указанных Интернет-платформ требуется метод обработки текста на естественном языке, то есть извлечение полезной информации из большого объема данных для обработки. При обработке текста на естественном языке необходимо провести анализ синтаксиса документа, например, выполнить классификацию, кластеризацию, аннотирование, анализ сходства. Поскольку все документы состоят из слов, в каждом методе обработки текста на естественном языке необходимо обеспечить понимание слов. Таким образом, определение способа точной оценки важности слова в предложении становится важной проблемой, требующей изучения.
[0005] Например, в предложении "Китай имеет долгую историю; Великая стена и Терракотовая армия являются гордостью Китая" слова "Китай", "Великая стена", "Терракотовая армия" и "история", очевидно, более важны, чем другие.
[0006] При определении и оценке значимости слов необходимо выяснить соответствующий уровень значимости слов-кандидатов. Например, может быть три уровня значимости слова - важное, обычное и постоянно используемое. Сначала выбирают важные слова, затем - обычные и постоянно используемые. Таким образом, при анализе документа сначала можно учитывать важные слова. Обычные слова можно использовать в качестве дополнений, а постоянно используемые - полностью отфильтровывать.
[0007] В настоящее время определение и оценку значимости слов на основе данных большого объема, как правило, осуществляют путем вычисления Документной Частоты ДЧ (DF) и Инверсной Документной Частоты ИДЧ (IDF) слова. В частности, слово, не встречающееся постоянно, то есть, слово с низкой частотой употребления, считается неважным. Однако точно определить важность слова на основе вычисленных значений ДЧ (DF) и ИДЧ (IDF) невозможно. Например, на основе корпуса текстов получают следующие результаты: ИДЧ (IDF) слова "освещать" - 2,89, а ИДЧ (IDF) слова "ха-ха" - 4,76. Кроме того, для неструктурированных данных (например, данных платформы Q&A и блоговых данных) слово с низкой частотой может являться ошибочным, например, это может быть ошибочно введенная пользователем строка "асфсдфсфда" или строка "У Гао Ци также" (часть предложения "У Гао Ци также есть надежда на новую династию").
[0008] Кроме того, при классификации документов для оценки вклада слова в ту или иную категорию обычно используют такие методы определения значений признаков, как "Прирост Информации" ПИ (IG) и критерий χ2. Однако в качестве эффективных признаков выбирают только те признаки, значения которых находятся на первых n местах, причем n - целое число, которое можно выбирать в соответствии с требованиями к определению и оценке значимости слов. Затем вычисляют весовой коэффициент категории на основе показателя ЧТ-ИДЧ (TF-IDF), где ЧТ (TF) - частота термина. Методы, основанные на критериях ПИ (IG) и χ2, используют только для выбора характерного слова. Они эффективны для структурированных данных небольшого объема. Однако для неструктурированных данных большого объема такая одноаспектная оценка не может полностью отражать важность слова и не позволяет эффективно ее определять. Например, на основе того же корпуса текстов критерий χ2 слова "из" - 96292,63382, а слова "Цзинчжоу" - только 4445,62836. Однако очевидно, что слово "Цзинчжоу" с более низким критерием χ2 является более важным.
Раскрытие изобретения
[0009] В настоящем изобретении предлагаются способ и устройство определения и оценки значимости слов, которые позволяют точно определить важность слов.
[0010] В настоящем изобретении предложен способ определения и оценки значимости слов. Предлагаемый способ включает в себя следующие этапы: вычисляют Документную Частоту ДЧ (DF) слова в классифицированных данных большого объема;
выполняют совокупность одноаспектных оценок слова согласно ДЧ (DF) слова;
выполняют многоаспектную оценку слова по результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова.
[0011] Кроме того, в настоящем изобретении предлагается устройство определения и оценки значимости слов. Указанное устройство содержит:
блок вычисления ДЧ (DF), выполненный с возможностью вычисления ДЧ (DF) слова в классифицированных данных большого объема;
блок одноаспектной оценки, выполненный с возможностью оценки слова по совокупности отдельных аспектов согласно ДЧ (DF) этого слова;
блок многоаспектной оценки, выполненный с возможностью оценки слова по совокупности аспектов согласно результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова.
[0012] В настоящем изобретении предложено усовершенствованное решение, основанное на теории вероятности и теории энтропии. Входными данными являются классифицированные данные большого объема, а выходными данными - слова высокой значимости. Настоящее изобретение позволяет оценивать важность слов в классифицированных данных большого объема и определять слова высокой значимости посредством комплексной оценки.
[0013] Предлагаемое техническое решение можно использовать в различных сценариях определения и оценки значимости слов. Например, при применении в поисковых системах оно позволяет точно извлекать слова высокой значимости. Слова высокой значимости можно использовать для поиска типа относительности и анализа строк, которые ищут пользователи. Другой пример: при применении в интерактивной платформе, блоговой платформе или новостях предлагаемое техническое решение позволяет точно извлекать конкретное слово в тексте. Таким образом, можно получать точные конкретные слова высокой значимости для анализа действий пользователей, что упрощает обеспечение соответствия их требованиям и предоставление им рекомендаций. Кроме того, при применении при классификации, кластеризации и аннотировании документов данное решение позволяет точно извлекать характерные слова для получения текстовой информации. Данное решение можно также применять при фильтрации ненужной информации и классификации рекламы для эффективного извлечения ключевых слов, относящихся к определенной категории.
Краткое описание чертежей
[0014] На фиг.1 показана блок-схема, иллюстрирующая способ определения и оценки значимости слов согласно настоящему изобретению.
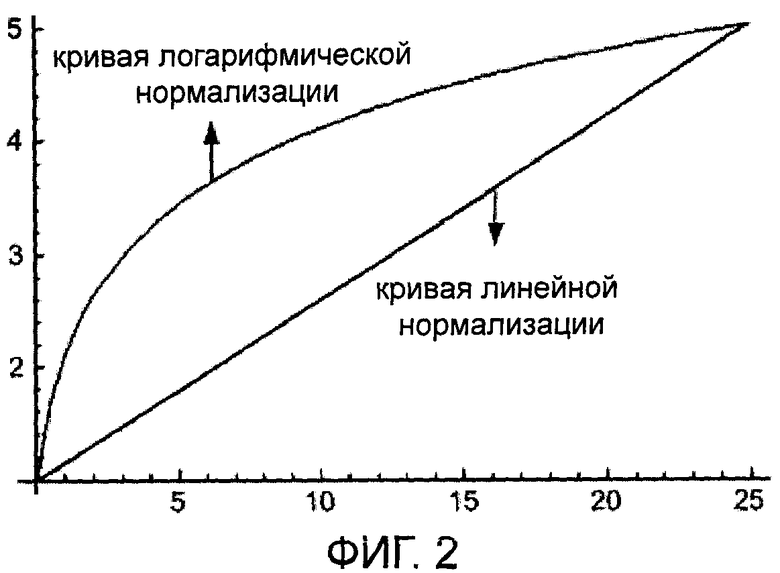
[0015] На фиг.2 на графике для сравнения показаны кривые линейной и логарифмической нормализации согласно настоящему изобретению.
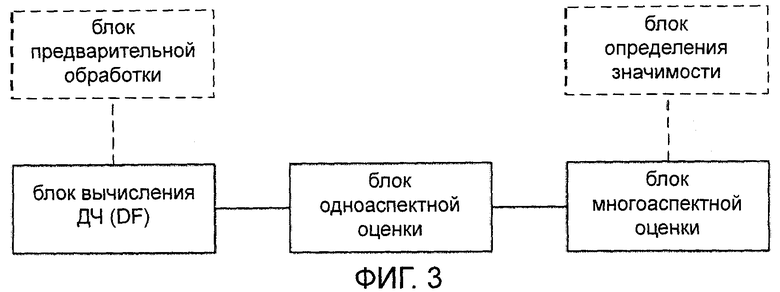
[0016] На фиг.3 показана схема устройства определения и оценки значимости слов согласно настоящему изобретению.
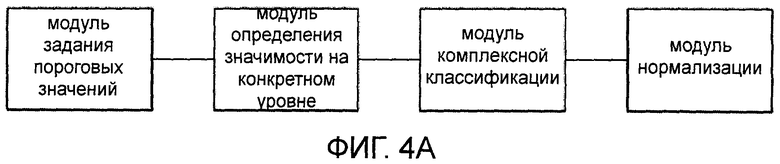
[0017] На фиг.4А схематично показана первая структура блока определения значимости согласно настоящему изобретению.
[0018] На фиг.4В схематично показана вторая структура блока определения значимости согласно настоящему изобретению.
Подробное описание изобретения
[0019] В соответствии с настоящим изобретением вычисляют ДЧ (DF) слова в классифицированных данных большого объема, а также выполняют совокупность одноаспектных оценок указанного слова согласно вычисленной ДЧ (DF) и многоаспектную оценку слова согласно результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова.
[0020] На фиг.1 показана блок-схема, иллюстрирующая способ определения и оценки значимости слов согласно настоящему изобретению. Как видно на данном чертеже, способ включает в себя следующие этапы.
[0021] На этапе 101 вычисляют ДЧ (DF) слова в классифицированных данных большого объема.
[0022] Согласно настоящему изобретению входными данными являются классифицированные данные большого объема. Классифицированные данные большого объема относятся к данным документов большого объема, распределенным по разным категориям. Например, классифицированными данными большого объема могут быть новости, разделенные на следующие категории: новости техники, новости спорта, новости культурных и развлекательных мероприятий. Это могут быть также данные интерактивной платформы Q&A, разделенные на следующие категории: компьютеры, образование и игры.
[0023] Вычисление ДЧ (DF) слова является первым этапом для определения и оценки значимости слова. Цель указанного вычисления состоит в получении статистики, необходимой при последующих расчетах. При вычислении ДЧ (DF) слова в классифицированных данных большого объема выполняют, в основном, следующие действия: вычисляют вектор ДЧ (DF) слова в каждой категории классифицированных данных большого объема и вычисляют ДЧ (DF) слова во всех категориях.
[0024] Перед тем как вычислить ДЧ (DF) слова, слова получают путем сегментирования классифицированных данных большого объема. Для полученных слов можно выполнить некоторую предварительную обработку, например унификацию обычных и упрощенных символов, заглавных и строчных букв, полноширинных и полуширинных символов, чтобы слова, значимость которых определяется и оценивается, имели одинаковый формат.
[0025] Вычисляют вектор ДЧ (DF) слова w в каждой категории классифицированных данных большого объема для получения вектора FW={df1,df2,…,dfn}, где dfi - вектор ДЧ (DF) слова w в категории i, причем i=1, 2, …, n, а n - число категорий. Например, имеются две категории - компьютеры и спортивные соревнования. Векторы ДЧ (DF) слова "компьютер" в указанных категориях имеют значения 1191437 и 48281, соответственно. В этом случае вектор ДЧ (DF) слова "компьютер" выражается в виде {1191437, 48281}.
[0026] Вычисляют ДЧ (DF) слова w во всех категориях. В частности, ДЧ (DF) слова w представляет собой сумму векторов ДЧ (DF) слова w для всех категорий: 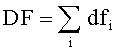
[0027] На этапе 102 выполняют совокупность одноаспектных оценок слова согласно ДЧ (DF) указанного слова.
[0028] После вычисления ДЧ (DF) слова выполняют совокупность его одноаспектных оценок на основе теории вероятности и теории энтропии. В частности, могут быть рассмотрены следующие аспекты.
[0029] ① Инверсная Документная Частота ИДЧ (IDF)
[0030] Показатель ИДЧ (IDF) служит для оценки значимости слова во всех классифицированных данных на основе ДЧ (DF) слова. В частности, показатель ИДЧ вычисляют по следующей формуле: 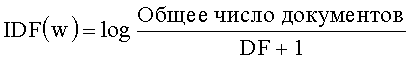
[0031] ② Средняя Инверсная Документная Частота СИДЧ (AVAIDF)
[0032] СИДЧ (AVAIDF) представляет собой среднее значение ИДЧ (IDF) слова в каждой категории, вычисляемое по следующей формуле: 
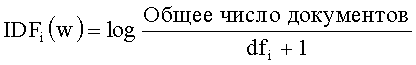
[0033] Проблема, возникающая при использовании методов, основанных на ИДЧ (IDF) и СИДЧ (AVAIDF), заключается в том, что для часто встречающихся слов значения оценки, т.е. IDF(w) и AVAIDF(w), низкие, а для редко встречающихся слов - высокие. Поэтому при определении значимости слов только на основе ИДЧ (IDF) и СИДЧ (AVAIDF) результат оценки будет неточным.
[0034] ③ Хи-квадрат (χ2)
[0035] Критерий χ2 используют для оценки относительности между словом и категорией и вычисляют по следующей формуле:
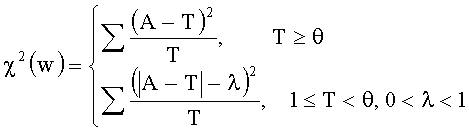
где A - фактическое значение ДЧ (DF) слова w в определенной категории, T - теоретическое значение ДЧ (DF) слова w в этой категории, θ - предельная величина теоретического значения ДЧ (DF), а λ - поправочный коэффициент.
[0036] С учетом этапа 101 dfi представляет собой А. Тогда формула для расчета χ2 выглядит следующим образом:
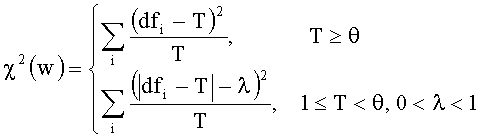
где i=1, 2, …, n, n - число категорий.
[0037] Проблема, возникающая при использовании метода "хи-квадрат", заключается в том, что критерий "хи-квадрат" часто встречающегося слова и критерий "хи-квадрат" редко встречающегося слова несоизмеримы, так как числитель и знаменатель каждого элемента 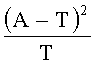
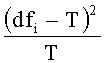
[0038] ④ Прирост Информации ПИ (IG)
[0039] Показатель ПИ (IG) используют для оценки объема информации, предоставляемой словом для категории.
[0040] В универсальную формулу для расчета ПИ (IG) входят два компонента - энтропия всей категории и ожидаемое значение энтропии распределения каждого атрибута признака F: 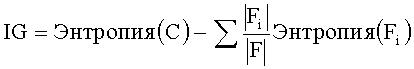
[0041] При использовании метода ПИ (IG) подробный вид формулы следующий: 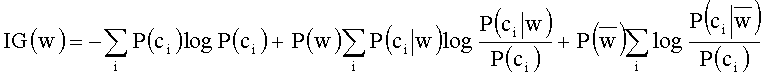
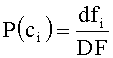
[0042] Формула состоит из трех составляющих. Первая составляющая: 
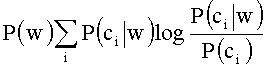
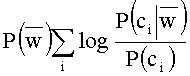
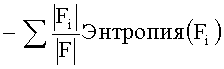
[0043] При использовании метода ПИ (IG) возникает следующая проблема: для очень часто встречающегося слова и очень редко встречающегося слова распределение двух атрибутов {присутствует в категории, отсутствует в категории} имеет серьезный дисбаланс. Оба значения ПИ (IG) близки к 0. Различить два слова просто по значениям ПИ (IG) невозможно. Поэтому с учетом описанной проблемы в настоящем изобретении предлагается улучшенное решение, основанное на принципе сбалансированного распределения атрибутов и корректного отражения важности слова.
[0044] Сначала все слова-кандидаты классифицируют по разным диапазонам согласно ДЧ (DF), причем такая классификация может выполняться по логарифмическому градиенту линейному градиенту экспоненциальному градиенту логарифмическому и линейному градиентам или экспоненциальному и линейному градиентам.
[0045] Ниже в качестве примера для описания классификации слов используется способ классификации по логарифмическому градиенту
[0046] Вектор ДЧ (DF) слова wj в категории ci представляет собой dfi. Вычисляют [log(dfi)] для получения диапазона [[log(dfi)], [log(dfi)]+Шаг], которому сопоставляют слово wj, т.е. wj∈[[log(dfi)], [log(dfi)]+Шаг], где Шаг - это градиент, обычно целое число, которое может быть задано в соответствии с требованием к точности значения ПИ (IG); [x] - округленное в меньшую сторону значение x, т.е. наибольшее целое число, не превышающее х. Таким образом, векторы ДЧ (DF) слов в каждом диапазоне находятся в пределах определенного диапазона.
[0047] После классификации слов на основе ДЧ (DF) вычисляют показатель IG(w) слова на основании каждого диапазона, т.е. расчет IG(w) выполняют не на основании всех классифицированных данных, а только на основании классифицированных данных, соответствующих определенному диапазону.
[0048] И наконец, определяют важность слова на основе диапазона и показателя ПИ (IG) слова, сопоставленного этому диапазону. Показатель ПИ (IG) слова может быть унифицирован в единый диапазон, например [нижний_предел, верхний_предел], согласно важности слова. Таким образом, важность слова можно определить в соответствии с позицией показателя ПИ (IG) в диапазоне.
[0049] Из приведенного выше описания видно, что благодаря классификации слов по диапазонам в зависимости от ДЧ (DF) распределение атрибутов {присутствует в категории, отсутствует в категории} слова становится относительно сбалансированным. Это позволяет определять важность слова более точно.
[0050] ⑤ Взаимная Информация ВИ (MI)
[0051] Показатель ВИ (MI) также используют для оценки относительности между словом и категорией. Его вычисляют по следующей формуле: 
[0052] ⑥ Ожидаемая Перекрестная Энтропия ОПЭ (ЕСЕ)
[0053] Показатель ОПЭ (ЕСЕ) используют для представления разницы между вероятностями распределения по категориям до и после появления слова w. Его вычисляют по следующей формуле: 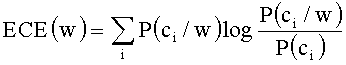

[0054] ⑦ Энтропия ЭНТ (ENT)
[0055] Показатель ЭНТ (ENT) используют для представления степени равномерности распределения слова w по всем категориям. Чем меньше ЭНТ (ENT), тем менее равномерно слово w распределяется по всем категориям. Такое слово, скорее всего, относится к определенной области и, следовательно, является более важным. Формула для вычисления ЭНТ (ENT) имеет следующий вид: 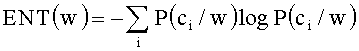
[0056] При использовании методов ВИ (MI), ОПЭ (ЕСЕ) и ЭНТ (ENT) учитывается только различие в распределении слова по категориям, но не учитывается вероятность появления слова. Однако фактически при малом значении ДЧ (DF) слова оно встречается с низкой вероятностью и надежность его распределения по категориям должна быть относительно низкой.
[0057] ⑧ Выборочное Предпочтение ВП (SELPRE)
[0058] Показатель ВП (SELPRE) используют для оценки степени концентрации значения слова, т.е. возможности использования слова с другими словами.
[0059] Как правило, важное слово с концентрированным значением может использоваться только с некоторыми специальными словами, а общее слово может использоваться со многими словами. Поэтому сначала определяют распределение использования слов двух частей речи. Согласно настоящему изобретению можно определить, что существительные могут использоваться с глаголами и прилагательными, прилагательные - с существительными, и глаголы - с существительными. Показатель ВП (SELPRE) слова вычисляют по следующей формуле: 
[0060] При использовании метода ВП (SELPRE) не учитываются различия между категориями. Поэтому по значению ВП (SELPRE) невозможно определить, является ли слово специальным словом определенной области.
[0061] Чем больше значение оценки при использовании описанных выше методов оценки (за исключением метода ЭНТ (ENT)), тем более важным является слово. Из приведенного выше описания следует, что с помощью одного-единственного метода невозможно получить точный результат. Поэтому необходимо эффективно объединять значения одноаспектных оценок. Таким образом, посредством комплексной оценки можно получить весовой коэффициент важности, который может точно отражать значимость слова.
[0062] На этапе 103 выполняют многоаспектную оценку слова по результатам совокупности одноаспектных оценок с тем, чтобы получить весовой коэффициент важности слова.
[0063] В частности, слова-кандидаты классифицируют по различным уровням в зависимости от их ДЧ (DF). В зависимости от уровня каждого слова-кандидата определяют способ его многоаспектной оценки для получения весового коэффициента важности этого слова-кандидата. Ниже приведено подробное описание указанного процесса.
[0064] Сначала слова-кандидаты классифицируют по четырем уровням в зависимости от их ДЧ (DF) во всех классифицированных данных. Используют следующие четыре уровня: уровень очень часто встречающихся слов, уровень часто встречающихся слов, уровень редко встречающихся слов и уровень очень редко встречающихся слов. Очень часто встречающееся слово - это слово с очень высокой ДЧ (DF), которое встречается в большинстве документов. Очень редко встречающееся слово - это слово с очень низкой ДЧ (DF), которое встречается только в очень немногих документах. Часто встречающееся слово - это слово, ДЧ (DF) которого находится в диапазоне между значениями ДЧ (DF) очень часто встречающегося слова и очень редко встречающегося слова. Хотя ДЧ (DF) часто встречающегося слова меньше ДЧ (DF) очень часто встречающегося слова, она является относительно высокой и часто встречающееся слово присутствует во многих документах. Редко встречающееся слово - это слово, ДЧ (DF) которого находится в диапазоне между значениями ДЧ (DF) очень часто встречающегося слова и очень редко встречающегося слова. Хотя ДЧ (DF) редко встречающегося слова относительно небольшая, она все же превышает ДЧ (DF) очень редко встречающегося слова. Редко встречающееся слово присутствует в нескольких документах. Четыре рассмотренных уровня можно обозначить следующим образом: "Очень_Часто", "Часто", "Редко" и "Очень_Редко". Настоящее изобретение не ограничивается четырьмя указанными выше уровнями. После определения уровней согласно ДЧ (DF) можно применять различные способы классификации, например, по логарифмическому градиенту по линейному градиенту, по экспоненциальному градиенту, по логарифмическому и линейному градиентам и по экспоненциальному и линейному градиентам. Разные уровни могут иметь разные пределы.
[0065] Затем слово относят к соответствующему уровню согласно ДЧ (DF) во всех классифицированных данных.
[0066] Далее, применяют метод многоаспектной оценки на основе одноаспектных оценок, полученных на этапе 102.
[0067] Методы ИДЧ (IDF) и СИДЧ (AVAIDF) основаны на использовании ДЧ (DF). Поэтому они не вносят большого вклада в различение важности слов, отнесенных к одному и тому же уровню согласно ДЧ (DF). Однако абсолютное значение разности показателей ИДЧ (IDF) и СИДЧ (AVAIDF), определяемое выражением |IDF(w)-AVAIDF(w)|, может отражать различие в распределении слова по разным категориям, тем самым, указывая, является ли слово важным. Таким образом, получается следующая формула: Diff(w)=|AVAIDF(w)-IDF(w)|. Использование такого способа комплексной оценки позволяет эффективно устранить недостаток способа одноаспектной оценки, с помощью которого невозможно точно определить важность слова на уровнях "Очень_Часто" и "Очень_Редко". Например, для слова "освещать" значение Diff(освещать)=|5.54-2.89|=2.65, а для слова "ха-ха" значение Diff(xa-xa)=|5.16-4.76|=0.4. Это связано с тем, что слово "освещать" в некоторых категориях встречается часто, а в других категориях - редко. Слово "ха-ха" часто встречается во всех категориях. Важное слово может точно определяться по значению Diff(w). Чем больше значение Diff(w), тем более важным является слово.
[0068] Методы ВИ (MI), ОПЭ (ЕСЕ) и ЭНТ (ENT) основаны на вероятности распределения слова в каждой категории. Поэтому эти три метода можно использовать вместе для оценки важности слова. В частности, значения MI(w), ECE(w) и ENT(w) нормализуются линейно. Поскольку значение ЭНТ (ENT) обратно пропорционально важности слова, требуется нисходящая нормализация. В результате получаются значения LineNorm1(MI(w)), LineNorm2(ECE(w)) и LineNormDesc(ENT(w)). В качестве основы для оценки используют линейную комбинацию указанных трех значений: 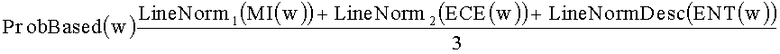
[0069] В методах ПИ (IG) и "хи-квадрат" используют ДЧ (DF) слова и вероятность распределения слова в каждой категории. Поэтому эти два метода можно объединить для определения важности слова. Значения χ2(w) и IG(w) нормализуют логарифмически для получения значений LogNorm(χ2(w)) и LogNorm(IG(w)) и затем объединяют для получения значения 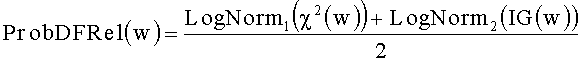
[0070] В методе ВП (SELPRE) учитывается взаимосвязь слов. Этот метод используется как метод независимой оценки. Значение ВП (SELPRE) вычисляют по следующей формуле: SelPre(w)=LineNorm3(SELPRE(w)) после линейной нормализации.
[0071] В некоторых из описанных выше методов используют значения ДЧ (DF), тогда как в других - вероятность распределения слова. Поэтому значения оценки имеют разные диапазоны. Следовательно, их требуется нормализовать в один диапазон. В соответствии с настоящим изобретением применяют способ линейной нормализации и способ логарифмической нормализации. На фиг.2 представлены графики сравнения указанных способов. Как видно на данном чертеже, в своих начальных диапазонах два способа имеют разные тенденции изменения. Если переменная x является функцией логарифма вероятности или логарифма ДЧ (DF), обычно применяют метод линейной нормализации; в противном случае используют метод логарифмической нормализации. Кроме того, метод нормализации можно выбрать в зависимости от опыта анализа данных.
[0072] При линейной нормализации один диапазон сопоставляют другому с помощью линейного метода. Формула следующая: LineNorm(x)=kx+b, где k>0, x - это MI(w), ECE(w) и SELPRE(w). При логарифмической нормализации один диапазон сопоставляют другому с помощью логарифмического метода. Формула следующая: LogNorm(x)=log(kx+b), где k>0, x - это χ2(w) и IG(w). Указанные два метода являются восходящими, т.е. k>0. Если k<0, то метод является нисходящим. В этом случае формула выглядит следующим образом: LineNormDesc(x)=kx+b или LogNormDesc(x)=log(kx+b), где x - это ENT(w). Значения k и b могут быть вычислены в соответствии с конечными значениями диапазона после сопоставления.
[0073] После получения способов комплексной оценки можно определить способ многоаспектной оценки слова в соответствии с уровнем слова. Ниже рассматриваются способы многоаспектной оценки для четырех уровней.
[0074] Для слов на уровнях "Очень_Часто" и "Часто" подходят все указанные выше способы комплексной оценки. Поэтому для многоаспектной оценки может применить линейный подход, формула для которого следующая: Очень_Часто(w)=Часто(w)=Diff(w)*ProbBased(w)*ProbDFRel(w)*SelPre(w).
[0075] Для слов на уровне "Редко" значение ДЧ (DF) небольшое, и существует мало слов, которые могут использоваться вместе. Способ комплексной оценки с использованием показателя SelPre(w) менее надежен. Поэтому формула для способа многоаспектной оценки слов на уровне "Редко" имеет следующий вид: Редко(w)=Diff(w)*ProbBased(w)*ProbDFrel(w)+SelPre(w).
[0076] Для слов на уровне "Очень_Редко" методы ПИ (IG) и "хи-квадрат" менее надежны, и существует очень мало слов, которые могут использоваться вместе. Поэтому метод ВП (SELPRE) не рассматривается. В результате формула для способа многоаспектной оценки слов на уровне "Очень_Редко" имеет следующий вид: Очень_Редко(w)=Diff(w)*(ProbBased(w)+ProbDFRel(w)).
[0077] После определения способа многоаспектной оценки слова в соответствии с его уровнем недостатки одноаспектных оценок, указанные выше при описании этапа 102, устраняются. Далее описывается многоаспектная оценка слов на уровне с высокой частотой употребления (включая уровни "Очень_Часто" и "Часто") и уровне "Очень_Редко", причем установление различий на этих уровнях наиболее сложное.
[0078] На уровне с высокой частотой рассматриваются два слова - освещать" и "ха-ха". Хотя ИДЧ (IDF) этих двух слов близки, слово "освещать" встречается в основном в категории "Игра QQ", а слово "ха-ха" - в равной степени во всех категориях. Следовательно, два слова могут различаться с помощью показателя Diff(w). Кроме того, критерий χ2 слова "освещать" имеет значение 1201744, а критерий χ2 слова "ха-ха" - значение 3412. После нормализации критерия χ2(w) различие между значениями становится еще больше. По существу, такая же картина наблюдается и для метода ПИ (IG). Таким образом, важность двух слов можно также четко различать с помощью показателя ProbDFRel(w). В то же время для определения степени равномерности распределения слова по всем категориям, в основном, используется показатель ProbBased(w). Он также позволяет различать два слова. Согласно показателю SelPre(w), слово "ха-ха" является очень общим и может использоваться вместе со многими словами. Однако слово "освещать" обычно используется в иконках и контексте, связанных с продуктом QQ. Результат многоаспектной оценки слова "освещать" составляет 9,65, а слова "ха-ха" - 1,27. Таким образом, можно сделать вывод о том, что слово "освещать" является словом высокой значимости, а слово "ха-ха" - низкой значимости.
[0079] На уровне "Очень_Редко" рассматриваются слово "Chujiangzhen" (город в провинции Хунань) и случайно введенное слово "фдгфдг". Оба слова имеют очень низкое значение ДЧ (DF), а их значения ИДЧ (IDF) составляют около 14. Однако слово "Chujiangzhen" в основном встречается в категории "регион", а слово "фдгфдг" может встречаться во всех категориях. Таким образом, Diff(Chujiangzhen)=2.12, a Diff(фдгфдг)=1.05. Хотя значения χ2 слова "Chujiangzhen" и слова "фдгфдг" маленькие, эти слова можно различить с помощью значения Diff(w). В то же время очевидно, что значение ProbBased(w) слова "Chujiangzhen" больше значения ProbBased(w) слова "фдгфдг". В результате получается, что значение многоаспектной оценки слова "Chujiangzhen" - 9,71, а слова "фдгфдг" - 1,13. Таким образом, можно сделать вывод о том, что слово "Chujiangzhen" является словом высокой значимости, а слово "фдгфдг" - низкой значимости.
[0080] Согласно приведенному выше описанию, объединение многоаспектной оценки и классификация по уровням на основе ДЧ (DF) позволяют определить важность слова посредством комплексной оценки соответствующего уровня. Указанные выше значения Очень_Часто(w), Часто(w), Редко(w) и Очень_Редко(w), полученные на каждом уровне, представляют весовой коэффициент важности слова на соответствующем уровне и в целом могут выражаться значением WgtPart(w).
[0081] На этапе 104 определяют значимость слова по его весовому коэффициенту важности.
[0082] Получив весовой коэффициент важности слова, можно определить по нему значимость слова. В результате, можно определить слова высокой значимости для последующего использования при обработке документов.
[0083] Ниже описан один из способов обработки.
[0084] Сначала для каждого уровня задают пороговое значение α важности и пороговое значение β постоянного использования. Эти два пороговых значения могут быть заданы в соответствии с требованиями к определению и оценке. Если требуется много важных слов, то для α можно задать меньшее значение, а в противном случае - большее значение. Если к диапазону постоянно используемых слов требуется отнести много слов, то для β можно задать большее значение, а в противном случае - меньшее значение. Если на этапе 103 задано четыре уровня, то для каждого уровня следует задать пару значений α и β. В результате будет четыре пары значений α и β.
[0085] Затем определяют значимость слова на каждом уровне согласно отношению между двумя указанными выше пороговыми значениями уровня и коэффициентом важности слова на этом уровне. Значимость слова на каждом уровне может быть представлена следующим образом:
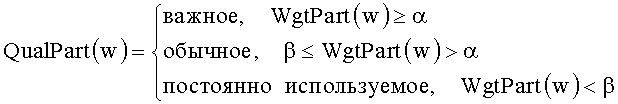
[0086] В результате указанной выше обработки получают только значимость слова на определенном уровне. Однако при анализе документа путем выбора важного и обычного слов для того, чтобы различать функции разных слов, как правило, необходима унифицированная оценка.
[0087] После классификации слов-кандидатов по уровням согласно значениям ДЧ (DF) слова на каждом уровне классифицируют по их важности. Однако предельные значения WgtPart(w) на разных уровнях различны. Поэтому требуется выполнить процесс нормализации, т.е. нормализовать показатель WgtPart(w) каждого уровня, чтобы получить комплексный весовой коэффициент важности Wgt(w) слова. Например, комплексный весовой коэффициент важности Wgt(w)=LineNorm(WgtPart(w)) можно получить посредством линейной нормализации. Для получения комплексного весового коэффициента важности слова можно также использовать логарифмическую нормализацию.
[0088] Наконец, на основе Wgt(w), полученного в результате нормализации, для слов одинаковой значимости на разных уровнях выполняют комплексную классификацию по значимости. Например, на этапе 103, получается четыре уровня. Для слов высокой значимости на этих четырех уровнях выполняют комплексную классификацию по значимости. Для всех уровней после процесса нормализации задают пороговое значение ε1 очень важного слова и пороговое значение ε2 слова обычной важности. Все слова классифицируют по значимости, которая представляется следующим образом:

Аналогично:
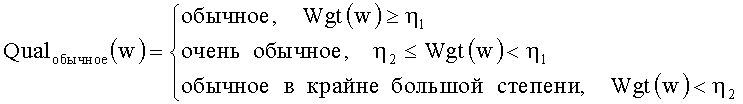

[0089] Ниже описан другой способ обработки.
[0090] Поскольку предельные значения WgtPart(w) на разных уровнях разные, показатели WgtPart(w) слов на разных уровнях несоизмеримы. Поэтому требуется выполнить другой процесс нормализации, т.е. требуется нормализовать показатель WgtPart(w) каждого уровня, чтобы получить комплексный весовой коэффициент важности слова. Например, комплексный весовой коэффициент важности Wgt(w)=LineNorm(WgtPart(w)) слова можно получить посредством линейной нормализации. Для получения комплексного весового коэффициента важности слова можно также использовать логарифмическую нормализацию.
[0091] После выполнения нормализации задают пороговое значение α' важного слова и пороговое значение β' постоянно используемого слова. Выполняют классификацию слова согласно отношению между двумя указанными выше пороговыми значениями и комплексным весовым коэффициентом важности слова:
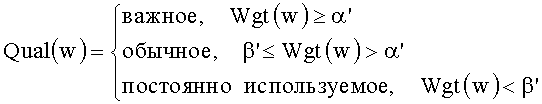
[0092] Описанные выше этапы для определения и оценки значимости слов можно выполнять на любом устройстве (например, на компьютере или веб-сервере), тип которого в настоящем изобретении не ограничивается.
[0093] На фиг.3 показана схема устройства для определения и оценки значимости слов согласно настоящему изобретению. Как видно на данном чертеже, устройство содержит блок вычисления ДЧ (DF), блок одноаспектной оценки и блок многоаспектной оценки. Блок вычисления ДЧ (DF) выполнен с возможностью вычисления ДЧ (DF) слова в классифицированных данных большого объема. Блок одноаспектной оценки выполнен с возможностью оценки слова по одному аспекту согласно ДЧ (DF) этого слова. Блок многоаспектной оценки выполнен с возможностью оценки слова по совокупности аспектов согласно результатам совокупности одноаспектных оценок слова для получения весового коэффициента важности слова.
[0094] В состав устройства может также входить блок предварительной обработки, предназначенный для предварительной обработки слов классифицированных данных большого объема, например для унификации обычных и упрощенных символов, заглавных и строчных букв, полноширинных и полуширинных символов, чтобы стандартизировать слова и сделать их единообразными.
[0095] Устройство может также содержать блок определения значимости, который определяет значимость слова согласно весовому коэффициенту важности слова.
[0096] Блок вычисления ДЧ (DF) содержит: модуль вычисления вектора ДЧ (DF) и модуль вычисления ДЧ (DF). При этом модуль вычисления вектора ДЧ (DF) выполнен с возможностью вычисления вектора ДЧ (DF) слова в каждой категории классифицированных данных большого объема, а модуль вычисления ДЧ (DF) принимает сумму векторов ДЧ (DF) слова в качестве ДЧ (DF) слова во всех классифицированных данных.
[0097] Блок одноаспектной оценки содержит совокупность модулей, каждый из которых используется для выполнения одноаспектной оценки. В состав блока одноаспектной оценки могут входить следующие модули: модуль ИДЧ (IDF), модуль СИДЧ (AVAIDF), модуль "хи-квадрат", модуль ПИ (IG), модуль ВИ (MI), модуль ОПЭ (ЕСЕ), модуль ЭНТ (ENT) и модуль ВП (SELPRE). В частности, модуль ПИ (IG) может содержать модуль деления на диапазоны и модуль вычисления ПИ (IG). Модуль деления на диапазоны выполнен с возможностью распределения всех слов-кандидатов по разным диапазонам в соответствии с их ДЧ (DF). Модуль вычисления ПИ (IG) выполнен с возможностью вычисления ПИ (IG) слова согласно классифицированным данным, соответствующим диапазону слова. Модуль деления на диапазоны классифицирует слова-кандидаты, используя различные способы классификации, например, по логарифмическому градиенту, по линейному градиенту, по экспоненциальному градиенту, по логарифмическому и линейному градиентам и по экспоненциальному и линейному градиентам.
[0098] Блок многоаспектной оценки содержит модуль деления на уровни и модуль определения способа многоаспектной оценки. Модуль деления на уровни предназначен для распределения слов-кандидатов по разным уровням в соответствии со значениями ДЧ (DF) слов. Модуль определения способа многоаспектной оценки предназначен для определения способа многоаспектной оценки слова в соответствии с уровнем слова с тем, чтобы получить весовой коэффициент важности слова на соответствующем уровне. Модуль деления на уровни содержит модуль деления на ряд уровней и модуль классификации слов. Модуль деления на диапазоны предназначен для задания диапазонов согласно значениям ДЧ (DF) слов во всех классифицированных данных. Модуль классификации слов выполнен с возможностью распределения слова на соответствующий уровень согласно ДЧ (DF) слова во всех классифицированных данных.
[0099] Блок определения значимости может содержать: модуль задания пороговых значений, модуль определения значимости на конкретном уровне, модуль нормализации и модуль комплексной классификации (см. фиг.4А). Модуль задания пороговых значений предназначен для задания порогового значения важности и порогового значения постоянного использования для каждого уровня, причем уровень определяется согласно значениям ДЧ (DF) слов во всех классифицированных данных. Модуль определения значимости на конкретном уровне служит для определения значимости слова на конкретном уровне согласно отношению между двумя пороговыми значениями и весовым коэффициентом важности слова на этом уровне. Модуль нормализации предназначен для нормализации весового коэффициента важности слова на каждом уровне с целью получения комплексного весового коэффициента важности слова. Модуль комплексной классификации выполнен с возможностью классификации слов одинаковой значимости на разных уровнях в соответствии с комплексными весовыми коэффициентами важности слов.
[0100] Альтернативно, блок определения значимости может также содержать: модуль нормализации, модуль задания пороговых значений и модуль комплексной классификации (см. фиг.4B). Модуль нормализации выполнен с возможностью нормализации весового коэффициента важности слова на каждом уровне с целью получения комплексного весового коэффициента важности слова, причем уровень задается согласно значениям ДЧ (DF) слов во всех классифицированных данных. Модуль задания пороговых значений предназначен для задания порогового значения важности и порогового значения постоянного использования для каждого уровня. Модуль комплексной классификации предназначен для классификации слова согласно отношению между двумя пороговыми значениями и комплексным весовым коэффициентом важности этого слова.
[0101] Выше был описан предпочтительный пример выполнения настоящего изобретения и некоторые из его вариантов. Использованные термины и приведенные описание и чертежи предназначены только для иллюстрации и не служат в качестве ограничений. Возможны различные модификации, не выходящие за рамки сущности и области применения настоящего изобретения, определяемого представленными ниже пунктами формулы (и их эквивалентами), в которых все термины используются в самом широком подходящем смысле, если не указано иначе.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КЛАССИФИКАЦИИ ДОКУМЕНТОВ ПО КАТЕГОРИЯМ | 2012 |
|
RU2491622C1 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СПОСОБ И СИСТЕМА ДЛЯ КЛАССИФИКАЦИИ ДИСПЛЕЙНЫХ СТРАНИЦ С ПОМОЩЬЮ РЕФЕРАТОВ | 2005 |
|
RU2377645C2 |
| СПОСОБ ПОТОКОВОЙ ОБРАБОТКИ ТЕКСТОВЫХ СООБЩЕНИЙ | 2003 |
|
RU2251148C1 |
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНОГО ПРЕДСТАВЛЕНИЯ ЭЛЕКТРОННОГО ТЕКСТОВОГО ДОКУМЕНТА ДЛЯ КЛАССИФИКАЦИИ ПО КАТЕГОРИЯМ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2021 |
|
RU2775358C1 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СПОСОБ И СИСТЕМА СТАТИЧЕСКОГО АНАЛИЗА ИСПОЛНЯЕМЫХ ФАЙЛОВ НА ОСНОВЕ ПРЕДИКТИВНЫХ МОДЕЛЕЙ | 2020 |
|
RU2759087C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ И ФИЛЬТРАЦИИ ЗАПРЕЩЕННОГО КОНТЕНТА В СЕТИ | 2020 |
|
RU2738335C1 |
| СПОСОБЫ И УСТРОЙСТВО ОБЕСПЕЧЕНИЯ СИСТЕМЫ ПРОГНОЗИРОВАНИЯ ГРУППОВОЙ ТОРГОВЛИ | 2008 |
|
RU2510891C2 |

Изобретение относится к методам обработки информации. Техническим результатом является повышение точности определения важности слов в классифицированных данных большого объема. В предлагаемом способе вычисляют Документную Частоту (ДЧ) слова в классифицированных данных. Затем выполняют одноаспектные оценки слова согласно ДЧ. После чего выполняют многоаспектную оценку слова по результатам одноаспектных оценок для получения весового коэффициента важности слова. Причем перед вычислением ДЧ в классифицированных данных предварительно выполняют обработку указанного слова и (или) после получения коэффициента важности определяют значимость слова согласно его коэффициенту важности. При определении значимости слова по его коэффициенту важности задают пороговое значение важности и пороговое значение постоянного использования для каждого уровня. Определяют значимость слова на уровне согласно отношению между двумя пороговыми значениями и коэффициентом важности. Выполняют нормализацию коэффициента важности на каждом уровне для получения комплексного весового коэффициента. На основе комплексного коэффициента выполняют комплексную классификацию значимости для слов одинаковой значимости на разных уровнях. 4 н. и 20 з.п. ф-лы, 5 ил.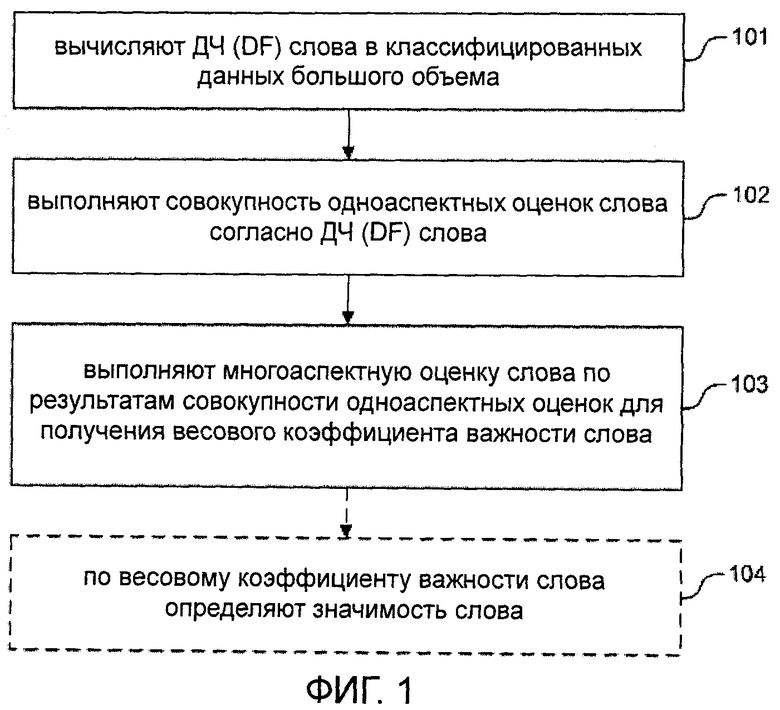
1. Способ определения и оценки значимости слов, включающий в себя следующие этапы:
вычисляют Документную Частоту ДЧ (DF) слова в классифицированных данных большого объема;
выполняют совокупность одноаспектных оценок слова согласно ДЧ (DF) слова;
выполняют многоаспектную оценку слова по результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова;
причем указанный способ дополнительно содержит следующие этапы:
перед вычислением ДЧ (DF) слова в классифицированных данных большого объема предварительно выполняют обработку указанного слова и (или) после получения весового коэффициента важности слова определяют значимость слова согласно его весовому коэффициенту важности;
причем при определении значимости слова по его весовому коэффициенту важности выполняют следующие действия:
задают пороговое значение важности и пороговое значение постоянного использования для каждого уровня, причем уровни определяют согласно значениям ДЧ (DF) слов во всех классифицированных данных; определяют значимость слова на соответствующем уровне согласно отношению между двумя пороговыми значениями и весовым коэффициентом важности слова на этом уровне; выполняют нормализацию весового коэффициента важности слова на каждом уровне для получения комплексного весового коэффициента важности слова; на основе комплексного весового коэффициента важности слова выполняют комплексную классификацию значимости для слов одинаковой значимости на разных уровнях.
2. Способ по п.1, при котором на этапе вычисления ДЧ (DF) слова в классифицированных данных большого объема выполняют следующие действия:
рассчитывают вектор ДЧ (DF) слова в каждой категории классифицированных данных большого объема;
применяют сумму векторов ДЧ (DF) слова во всех категориях в качестве ДЧ (DF) слова во всех категориях.
3. Способ по п.1, при котором одноаспектная оценка предусматривает определение одного или нескольких из следующих показателей: Инверсной Документной Частоты ИДЧ (IDF), Средней Инверсной Документной Частоты СИДЧ (AVAIDF), хи-квадрата, Прироста Информации ПИ (IG), Взаимной Информации ВИ (MI), Ожидаемой Перекрестной Энтропии ОПЭ (ЕСЕ), Энтропии ЭНТ (ENT) и Выборочного Предпочтения ВП (SELPRE).
4. Способ по п.3, при котором при одноаспектной оценке слова используют показатель ПИ (IG) и выполняют следующие действия:
распределяют все слова-кандидаты по диапазонам в соответствии со значениями ДЧ (DF) указанных слов;
вычисляют значение ПИ (IG) слова на основе классифицированных данных, соответствующих диапазону слова.
5. Способ по п.1, при котором на этапе многоаспектной оценки слова согласно результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова выполняют следующие действия:
распределяют слова-кандидаты по уровням согласно значениям ДЧ (DF) указанных слов;
выполняют многоаспектную оценку слова в соответствии с его уровнем для получения весового коэффициента важности слова на этом уровне.
6. Способ по п.5, при котором при распределении слов-кандидатов по уровням согласно значениям ДЧ (DF) выполняют следующие действия:
определяют уровни согласно ДЧ (DF) каждого слова во всех классифицированных данных;
распределяют каждое слово на соответствующий уровень согласно ДЧ (DF) слова во всех классифицированных данных.
7. Устройство определения и оценки значимости слов, содержащее:
блок вычисления ДЧ (DF), выполненный с возможностью вычисления ДЧ (DF) слова в классифицированных данных большого объема;
блок одноаспектной оценки, выполненный с возможностью оценки слова по совокупности отдельных аспектов согласно ДЧ (DF) этого слова;
блок многоаспектной оценки, выполненный с возможностью оценки слова по совокупности аспектов согласно результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова;
причем указанное устройство дополнительно содержит:
блок предварительной обработки, предназначенный для предварительной обработки слова в классифицированных данных большого объема, и (или) блок определения значимости, определяющий значимость слова согласно весовому коэффициенту важности слова;
при этом указанный блок определения значимости содержит:
модуль задания пороговых значений, предназначенный для задания порогового значения важности и порогового значения постоянного использования для каждого уровня, причем уровень определяется согласно значениям ДЧ (DF) слов во всех классифицированных данных;
модуль определения значимости на конкретном уровне, предназначенный для определения значимости слова на конкретном уровне согласно отношению между двумя пороговыми значениями и весовым коэффициентом важности слова на соответствующем уровне;
модуль нормализации, предназначенный для нормализации весового коэффициента важности слова на каждом уровне для получения комплексного весового коэффициента важности слова;
модуль комплексной классификации, предназначенный для выполнения комплексной классификации значимости для слов одинаковой значимости на разных уровнях на основе комплексного весового коэффициента важности слова.
8. Устройство по п.7, в котором блок вычисления ДЧ (DF) содержит:
модуль вычисления вектора ДЧ (DF), выполненный с возможностью вычисления вектора ДЧ (DF) слова в каждой категории классифицированных данных;
модуль вычисления ДЧ (DF), который принимает сумму векторов ДЧ (DF) слова в качестве ДЧ (DF) слова во всех категориях.
9. Устройство по п.7, в котором блок одноаспектной оценки содержит: модуль Инверсной Документной Частоты ИДЧ (IDF), модуль Средней Инверсной Документной Частоты СИДЧ (AVAIDF), модуль "хи-квадрат", модуль Прироста Информации ПИ (IG), модуль Взаимной Информации ВИ (MI), модуль Ожидаемой Перекрестной Энтропии ОПЭ (ЕСЕ), модуль Энтропии ЭНТ (ENT) и модуль Выборочного Предпочтения ВП (SELPRE).
10. Устройство по п.9, в котором модуль ПИ (IG) содержит:
модуль деления на диапазоны, выполненный с возможностью задания диапазонов согласно ДЧ (DF) всех слов-кандидатов; и
модуль вычисления ПИ (IG), выполненный с возможностью вычисления ПИ (IG) слова согласно классифицированным данным, соответствующим диапазону слова.
11. Устройство по п.7, в котором блок многоаспектной оценки содержит:
модуль деления на уровни, выполненный с возможностью задания уровней согласно ДЧ (DF) слов-кандидатов;
модуль многоаспектной оценки, выполненный с возможностью оценки слова по совокупности аспектов в соответствии с уровнем слова для получения весового коэффициента важности слова на указанном уровне.
12. Устройство по п.11, в котором модуль деления на уровни содержит:
модуль деления на ряд уровней, выполненный с возможностью задания уровней согласно ДЧ (DF) слов во всех классифицированных данных;
модуль классификации слов, выполненный с возможностью распределения слова на соответствующий уровень согласно ДЧ (DF) слова во всех классифицированных данных.
13. Способ определения и оценки значимости слов, включающий в себя следующие этапы:
вычисляют Документную Частоту ДЧ (DF) слова в классифицированных данных большого объема;
выполняют совокупность одноаспектных оценок слова согласно ДЧ (DF) слова;
выполняют многоаспектную оценку слова по результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова;
причем указанный способ дополнительно содержит следующие этапы:
перед вычислением ДЧ (DF) слова в классифицированных данных большого объема предварительно выполняют обработку указанного слова и (или) после получения весового коэффициента важности слова определяют значимость слова согласно его весовому коэффициенту важности;
причем при определении значимости слова по его весовому коэффициенту важности выполняют следующие действия:
выполняют нормализацию весового коэффициента важности слова на каждом уровне для получения комплексного весового коэффициента важности слова, причем уровень определяют согласно значениям ДЧ (DF) слов во всех классифицированных данных; задают пороговое значение важности и пороговое значение постоянного использования; выполняют комплексную классификацию значимости слова согласно отношению между двумя пороговыми значениями и комплексным весовым коэффициентом важности.
14. Способ по п.13, при котором на этапе вычисления ДЧ (DF) слова в классифицированных данных большого объема выполняют следующие действия:
рассчитывают вектор ДЧ (DF) слова в каждой категории классифицированных данных большого объема;
применяют сумму векторов ДЧ (DF) слова во всех категориях в качестве ДЧ (DF) слова во всех категориях.
15. Способ по п.13, при котором одноаспектная оценка предусматривает определение одного или нескольких из следующих показателей: Инверсной Документной Частоты ИДЧ (IDF), Средней Инверсной Документной Частоты СИДЧ (AVAIDF), хи-квадрата, Прироста Информации ПИ (IG), Взаимной Информации ВИ (MI), Ожидаемой Перекрестной Энтропии ОПЭ (ЕСЕ), Энтропии ЭНТ (ENT) и Выборочного Предпочтения ВП (SELPRE).
16. Способ по п.15, при котором при одноаспектной оценке слова используют показатель ПИ (IG) и выполняют следующие действия:
распределяют все слова-кандидаты по диапазонам в соответствии со значениями ДЧ (DF) указанных слов;
вычисляют значение ПИ (IG) слова на основе классифицированных данных, соответствующих диапазону слова.
17. Способ по п.13, при котором на этапе многоаспектной оценки слова согласно результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова выполняют следующие действия:
распределяют слова-кандидаты по уровням согласно значениям ДЧ (DF) указанных слов;
выполняют многоаспектную оценку слова в соответствии с его уровнем для получения весового коэффициента важности слова на этом уровне.
18. Способ по п.17, при котором при распределении слов-кандидатов по уровням согласно значениям ДЧ (DF) выполняют следующие действия:
определяют уровни согласно ДЧ (DF) каждого слова во всех классифицированных данных;
распределяют каждое слово на соответствующий уровень согласно ДЧ (DF) слова во всех классифицированных данных.
19. Устройство определения и оценки значимости слов, содержащее:
блок вычисления ДЧ (DF), выполненный с возможностью вычисления ДЧ (DF) слова в классифицированных данных большого объема;
блок одноаспектной оценки, выполненный с возможностью оценки слова по совокупности отдельных аспектов согласно ДЧ (DF) этого слова;
блок многоаспектной оценки, выполненный с возможностью оценки слова по совокупности аспектов согласно результатам совокупности одноаспектных оценок для получения весового коэффициента важности слова;
причем указанное устройство дополнительно содержит:
блок предварительной обработки, предназначенный для предварительной обработки слова в классифицированных данных большого объема, и (или) блок определения значимости, определяющий значимость слова согласно весовому коэффициенту важности слова;
при этом указанный блок определения значимости содержит:
модуль нормализации, предназначенный для нормализации весового коэффициента важности слова на каждом уровне для получения комплексного весового коэффициента важности слова, причем деление на уровни осуществляется согласно ДЧ (DF) слов во всех классифицированных данных;
модуль задания пороговых значений, предназначенный для задания порогового значения важности и порогового значения постоянного использования;
модуль комплексной классификации, предназначенный для выполнения комплексной классификации значимости для всех слов на основе отношения между двумя пороговыми значениями и комплексным весовым коэффициентом важности слова.
20. Устройство по п.19, в котором блок вычисления ДЧ (DF) содержит:
модуль вычисления вектора ДЧ (DF), выполненный с возможностью вычисления вектора ДЧ (DF) слова в каждой категории классифицированных данных;
модуль вычисления ДЧ (DF), который принимает сумму векторов ДЧ (DF) слова в качестве ДЧ (DF) слова во всех категориях.
21. Устройство по п.19, в котором блок одноаспектной оценки содержит: модуль Инверсной Документной Частоты ИДЧ (IDF), модуль Средней Инверсной Документной Частоты СИДЧ (AVAIDF), модуль "хи-квадрат", модуль Прироста Информации ПИ (IG), модуль Взаимной Информации ВИ (MI), модуль Ожидаемой Перекрестной Энтропии ОПЭ (ЕСЕ), модуль Энтропии ЭНТ (ENT) и модуль Выборочного Предпочтения ВП (SELPRE).
22. Устройство по п.21, в котором модуль ПИ (IG) содержит:
модуль деления на диапазоны, выполненный с возможностью задания диапазонов согласно ДЧ (DF) всех слов-кандидатов; и
модуль вычисления ПИ (IG), выполненный с возможностью вычисления ПИ (IG) слова согласно классифицированным данным, соответствующим диапазону слова.
23. Устройство по п.19, в котором блок многоаспектной оценки содержит:
модуль деления на уровни, выполненный с возможностью задания уровней согласно ДЧ (DF) слов-кандидатов;
модуль многоаспектной оценки, выполненный с возможностью оценки слова по совокупности аспектов в соответствии с уровнем слова для получения весового коэффициента важности слова на указанном уровне.
24. Устройство по п.23, в котором модуль деления на уровни содержит:
модуль деления на ряд уровней, выполненный с возможностью задания уровней согласно ДЧ (DF) слов во всех классифицированных данных;
модуль классификации слов, выполненный с возможностью распределения слова на соответствующий уровень согласно ДЧ (DF) слова во всех классифицированных данных.
| US 6473753 B1, 29.10.2002 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| CN 101290626 A, 22.10.2008 | |||
| US 7024408 B2, 04.04.2006 | |||
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ДОКУМЕНТОВ | 2003 |
|
RU2254610C2 |

