Изобретение относится к медицинской технике, а более конкретно к способам и устройствам для автоматической регистрации анатомических точек на медицинских изображениях.
Подобные задачи обычно решаются путем применения методов компьютерного зрения. Некоторые из таких методов используют настроенные вручную алгоритмы для обнаружения специфичных анатомических структур или точек. В других методах используют подход на основе машинного обучения для построения детектора, способного обеспечить обнаружение положения анатомических структур или точек. Типичный способ для осуществления регистрации подобных объектов на изображении заключается в сканировании данного изображения с помощью некоторого окна и решения задачи классификации содержимого окна для каждой его позиции с целью установления нахождения искомой анатомической структуры в вышеуказанной позиции. Для решения задачи классификации подобного рода могут применяться различные известные алгоритмы, например, извлечение признаков общего назначения (таких, как признаки Хаара), использование бустинга, использование Марковских сетей и т.д.
Патент США 8160322 [1] описывает способ регистрации анатомических структур с применением методов машинного обучения. Главная идея способа, описанного в этом патенте, состоит в применении каскада классификаторов к выделенному фрагменту изображения для установления факта присутствия некоторой искомой анатомической точки в конкретной позиции. Классификаторы используют различные фиксированные пространственные признаки. Финальная процедура классификации построена с использованием метода бустинга. После классификации все кандидаты проходят процедуру верификации, которая осуществляется с использованием пространственной статистической информации, извлеченной из обучающей выборки. В дополнение, кандидаты фильтруются по их качеству с использованием фиксированных порогов. Алгоритмы извлечения признаков настраиваются с использованием обучения с учителем.
Патент США 8218849 [2] раскрывает способ автоматической регистрации анатомических точек с помощью объединенного контекста. Под объединенным контекстом подразумевается набор признаков комбинаций некоторых анатомических точек, построенных по возможным позициям отдельно взятых анатомических точек. На первом этапе формирование кандидатов на искомые анатомические точки осуществляют путем применения обучения в ограниченном подпространстве и использования вероятностного бустингового дерева. В данном способе позиция, ориентация и масштаб оцениваются последовательно: а) применяется обученный классификатор для оценки позиции, б) применяется обученный классификатор для оценки позиции и ориентации, в) применяется обученный классификатор для оценки масштаба. В качестве низкоуровневых признаков используют признаки Хаара. Выбор наилучших кандидатов на искомые анатомические точки производят с учетом вероятности появления каждой отдельной точки и вероятности, соответствующей объединенному контексту некоторой комбинации анатомических точек (например, пары точек, в случае, если необходимо найти анатомические точки двух типов). Описанный способ применяется в анализируемом патенте для регистрации вершины сердца и базальной плоскости на магнитно-резонансных изображениях сердца.
Патентная заявка США 20100119137 [3] описывает способ регистрации анатомических точек, схожий со способом, описанным в патенте [2], однако в нем дополнительно используется геометрическая модель, учитывающая относительные позиции анатомических точек. Первоначальную позицию первой анатомической точки оценивают с помощью описанного выше способа, использующего обучение в ограниченном подпространстве. Затем геометрическую модель, обученную на размеченных медицинских изображениях, привязывают к позиции первой анатомической точки. Таким образом, задаются зоны поиска других типов анатомических точек. Позиции остальных анатомических точек определяют внутри полученных зон описанным выше способом, использующим обучение в ограниченном подпространстве. Классификацию производят с использованием вероятностного бустингового дерева. Областью применения являются магнитно-резонансные изображения головного мозга.
Патентная заявка США 20100254582 [4] описывает способ автоматической регистрации анатомических точек в трехмерных медицинских изображениях. В данном способе регистрация производится путем отбора кандидатов на искомые анатомические точки и построения бинарных связей между ними. Регистрацию кандидатов производят с помощью классификации признаков, формируемых на основе пространственных гистограмм. Затем производят определение наилучших кандидатов путем применения модели Марковских сетей к связанному множеству кандидатов.
В качестве недостатков вышеизложенных и похожих на них способов можно выделить несколько аспектов. Большинство алгоритмов способно работать лишь с двумерными медицинскими изображениями. В таких случаях происходит сужение области применимости таких алгоритмов. Некоторые способы оперируют лишь с высококачественными медицинскими изображениями высокого разрешения, которые могут быть сформированы лишь за достаточно длительное время. При этом практически все способы применяют алгоритмы извлечения признаков для решения задачи классификации. Как правило, такие алгоритмы настроены вручную с использованием эмпирической информации. В отдельных случаях используют обученные модели алгоритмов извлечения признаков общего назначения без принятия в расчет специфики используемых данных. В таких ситуациях потенциал подхода машинного обучения реализуется не в полной мере. Также зачастую строится только один уровень признаков, а не многоуровневая иерархия признаков. В некоторых подходах кандидаты на искомые анатомические точки фильтруются с помощью соответствующих порогов, однако такие пороги, как правило, также настраиваются вручную.
Задача, на решении которой направлено заявляемое изобретение, заключается в разработке усовершенствованного подхода к автоматической регистрации анатомических точек в трехмерных медицинских изображениях, который позволил бы определять позиции уникальных искомых точек в рамках каждого типа таких точек, а также позиции нескольких точек для каждого из этих типов.
Технический результат достигается за счет разработки способа и основанной на этом способе системы для автоматической регистрации анатомических точек на объемных (3D) медицинских изображениях.
При этом способ автоматической регистрации анатомических точек в объемных медицинских изображениях предусматривает выполнение таких операций, как получение трехмерного медицинского изображения, определение множества поисковых точек, извлечение признаков указанных точек, формирование множества кандидатов на искомые анатомические точки, фильтрация указанных кандидатов, вывод финальных позиций искомых анатомических точек, и отличается тем, что:
указанное определение множества поисковых точек производят путем задания сетки поисковых точек внутри объемного изображения с использованием статистического атласа, при этом указанный статистический атлас прикрепляют к ограничивающему параллелепипеду, соответствующему исследуемой части тела внутри объемного изображения;
указанное извлечение признаков точек производят путем выделения окружающего контекста для каждой такой точки и применения к нему многослойного алгоритма извлечения признаков;
указанное формирование множества кандидатов производят с помощью вычисления меры качества для каждой поисковой точки и для каждого типа искомых анатомических точек, используя соответствующее выходное значение алгоритма извлечения признаков;
указанную фильтрацию кандидатов производят с помощью статистического атласа и вычисленных заранее порогов для значений меры качества;
указанный вывод финальных позиций производят путем сортировки всех оставшихся после фильтрации кандидатов в рамках каждого типа искомых анатомических точек по мере их качества и вывода кандидатов с наибольшими значениями меры качества или требуемое количество кандидатов с наибольшими значениями меры качества.
Заявляемая система для автоматической регистрации анатомических точек в объемных медицинских изображениях включает в себя:
запоминающее устройство, выполненное с возможностью хранения программы;
связанный с запоминающим устройством процессор, выполненный с возможностью выполнения программы, осуществляющей следующие шаги:
- оценка ограничивающего параллелепипеда исследуемой части тела внутри полученного объемного медицинского изображения,
- прикрепление статистического атласа к ограничивающему параллелепипеду,
- определение сетки поисковых точек внутри объемного медицинского изображения с использованием статистического атласа,
- выделение окружающих контекстов для каждой точки из сетки поисковых точек,
- применение многослойного алгоритма извлечения признаков к выделенным контекстам,
- формирование множества кандидатов на искомые анатомические точки путем вычисления меры качества для каждой поисковой точки и для каждого типа искомых анатомических точек на основе соответствующего выходного значения алгоритма извлечения признаков,
- фильтрация кандидатов с использованием статистического атласа и вычисленных заранее порогов,
- сортировка оставшихся кандидатов в рамках каждого типа искомых анатомических точек по мере их качества,
- вывод кандидатов с наибольшими значениями меры качества или требуемого количества кандидатов с наибольшими значениями меры качества.
Заявляемое изобретение описывает, в отличие от имеющихся прототипов, новый способ, применимый к трехмерным медицинским изображениям с низким разрешением, полученным за короткое время. Главным усовершенствованием, используемым в изобретении, является применение многослойного алгоритма извлечения признаков, полученного в результате обучения без учителя модели алгоритмов на предварительной стадии. Несколько слоев, извлекающих признаки, обеспечивают иерархическое представление входных данных. Подобная декомпозиция на слои ведет к лучшей сепарации данных на составные части и преобразованию разделенных данных таким образом, что по признакам, полученным в последних слоях, могут быть легко сформированы результирующие метки классов, к которым принадлежат входные данные. Также в алгоритме извлечения признаков используются концентрирующие и нормализующие слои для обеспечения различных типов инвариантности признаков относительно входных данных. Преимущество обучения модели алгоритмов извлечения признаков без учителя состоит в том, что она обучается напрямую из данных, и полученный алгоритм способен оптимально описывать скрытые закономерности и специфичную природу используемых данных. Также для такого рода обучения нет необходимости иметь на входе большое множество размеченных данных. Еще одна особенность способа состоит в том, что простой статистический атлас прикрепляется к ограничивающему параллелепипеду для того, чтобы сократить зону поиска. Также преимуществом является вычисление специальных порогов для фильтрации кандидатов на искомые анатомические точки; эти пороги вычисляются заранее путем минимизации некоторой функции потерь, которая включает в себя ошибки классификации первого и второго рода. Заявляемый способ способен выдавать на выход набор искомых анатомических точек для каждого типа, ранжированный по вероятности корректной регистрации.
Способ, описанный в заявляемом изобретении, отличается от других способов автоматической регистрации анатомических точек тем, что в рамках данного способа осуществляется:
оценка ограничивающего параллелепипеда исследуемой части тела для последующего прикрепления к нему статистического атласа;
использование статистического атласа для сокращения зоны поиска;
использование многослойного алгоритма извлечения признаков, включающего в себя слой извлечения признаков, концентрирующие слои и нормализующие слои для построения иерархического представления признаков входных данных;
использование разреженного кодирования для предварительного обучения без учителя модели алгоритмов извлечения признаков для того, чтобы настроить алгоритм, используя лишь небольшое множество размеченных данных;
использование разреженного кодирования для предварительного обучения без учителя модели алгоритмов извлечения признаков для того, чтобы получить алгоритм, способный распознавать скрытые закономерности, типичные для типа используемых входных данных;
использование способа вычисления оптимальных порогов для фильтрации кандидатов на искомые анатомические точки путем снижения общего количества ошибок первого и второго рода.
Далее сущность заявляемого изобретения поясняется чертежами, где:
фиг.1 - основные шаги способа автоматической регистрации анатомических точек.
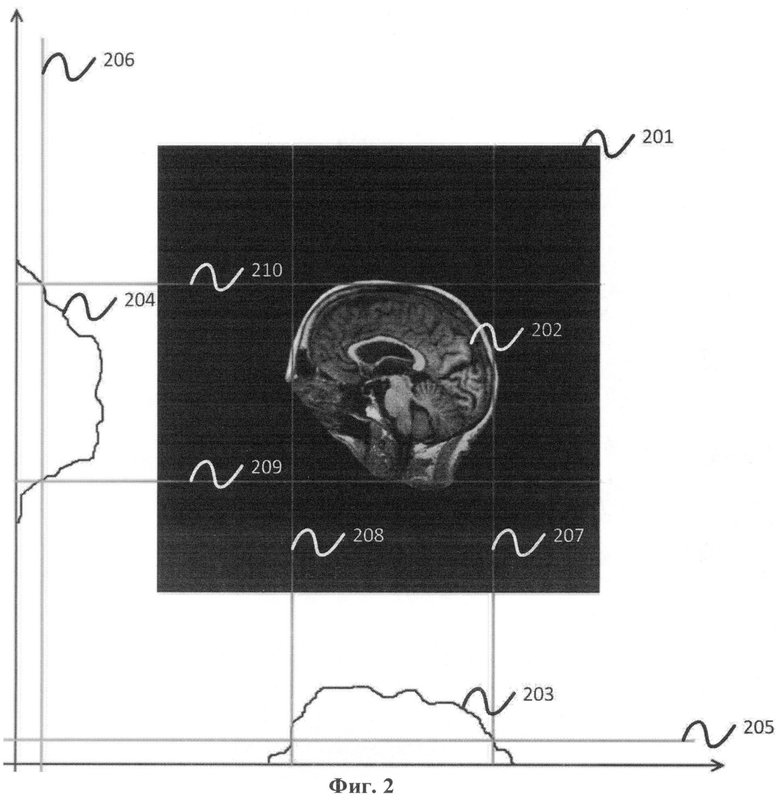
Фиг.2 - оценка ограничивающего параллелепипеда.
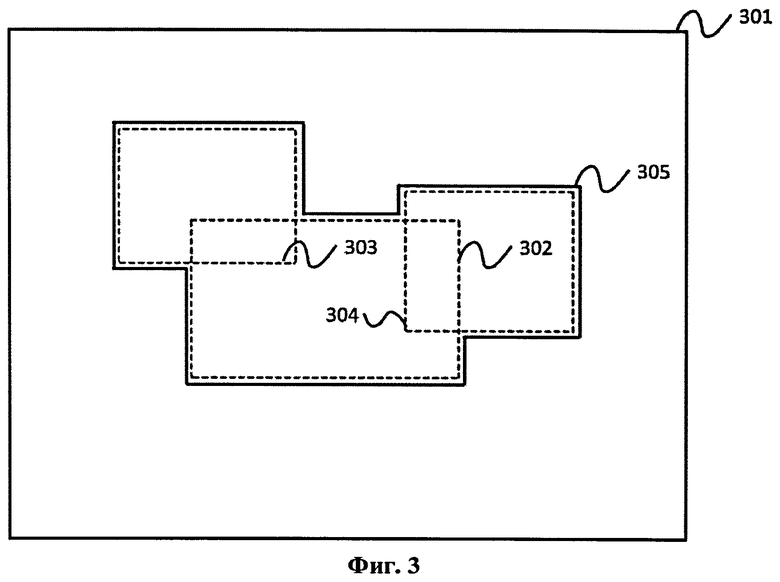
Фиг.3 - область поиска как объединение статистических распределений анатомических точек различных типов.
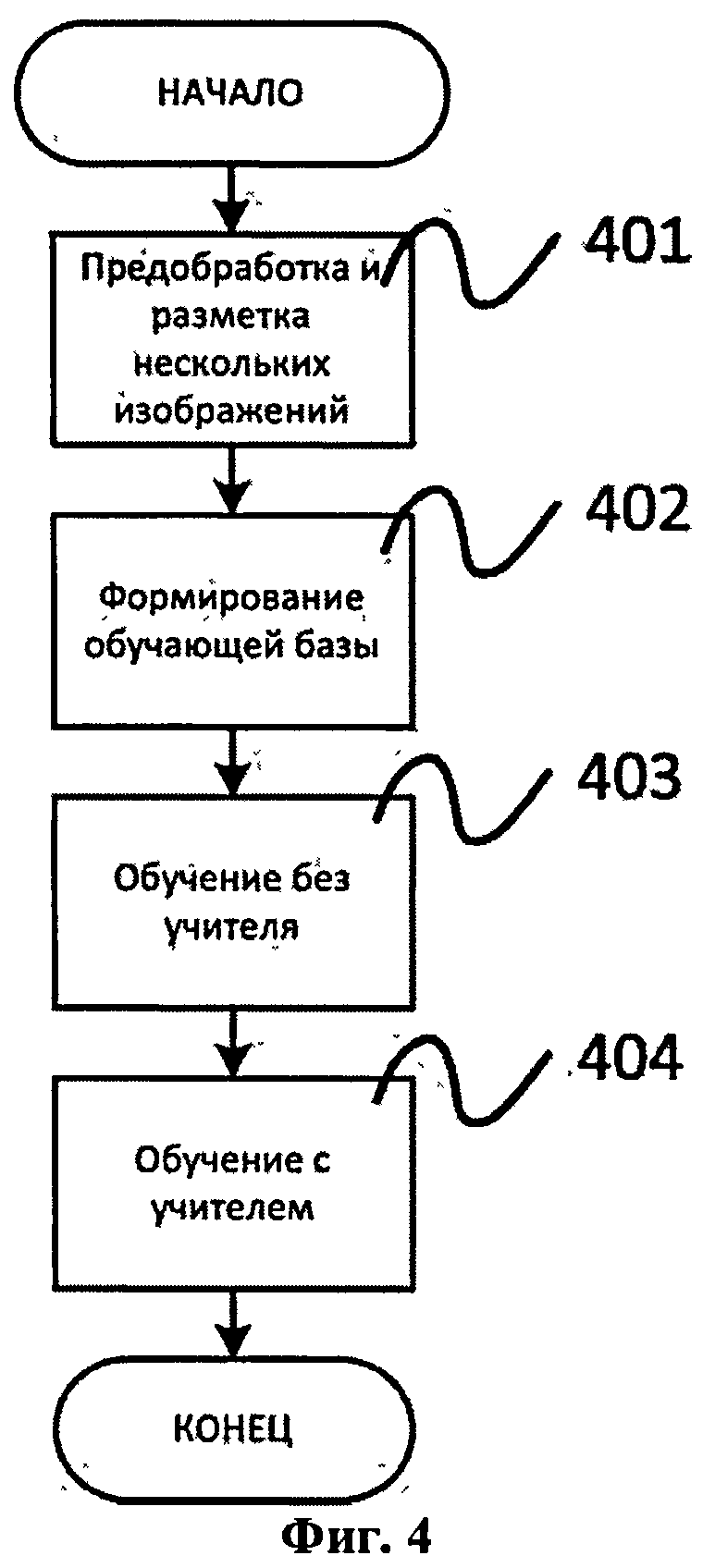
Фиг.4 - основные шаги процедуры обучения многослойной модели алгоритмов извлечения признаков.
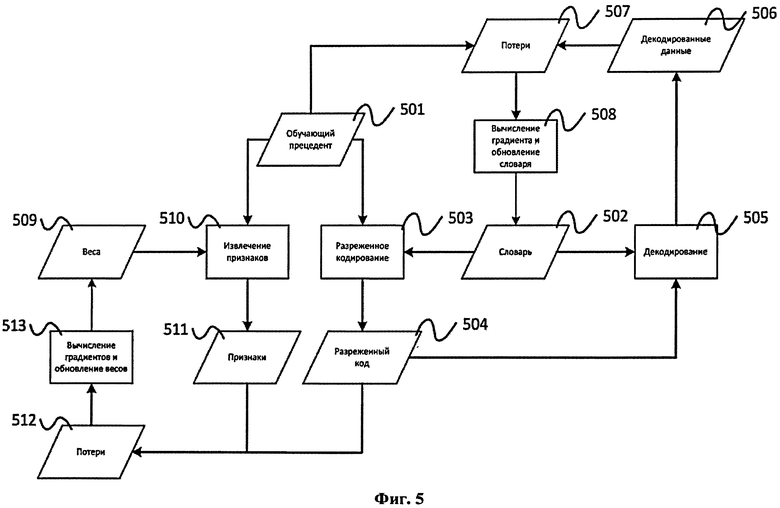
Фиг.5 - схема, иллюстрирующая процедуру обучения без учителя слоев, извлекающих признаки.
Фиг.6 - пример системы, в которой может быть реализовано заявляемое изобретение.
В области обработки медицинских изображений существует множество задач, в которых требуется адекватное распознавание анатомических структур на исследуемом изображении. Одним из способов описания таких структур, а также определения их взаимного расположения является использование специальных анатомических точек, привязанных к вышеуказанным структурам. Автоматическое получение положений таких анатомических точек может являться ключевым моментом во многих процедурах, связанных с исследованием медицинских изображений, таких как планирование видов, сегментация и т.д. Заявляемое изобретение описывает способ автоматической регистрации анатомических точек на трехмерных медицинских изображениях. В качестве результата способ может выдавать позиции уникальных искомых точек в рамках каждого типа, а также позиции нескольких точек для каждого из типов. Заявленный способ включает несколько этапов (шагов), показанных на Фиг.1. На первом шаге 101 осуществляется получение трехмерного медицинского изображения. Затем на шаге 102 производится оценка ограничивающего параллелепипеда для данного изображения. Процедура представляет собой отыскание границ основной части медицинского изображения, при этом пустое пространство по бокам игнорируется. Например, для изображения магнитно-резонансной томографии мозга ограничивающий параллелепипед просто ограничивает голову, игнорируя черные пустоты вокруг нее. На следующем шаге 103 вычисленный заранее статистический атлас привязывается к ограничивающему параллелепипеду. Он используется для генерации на шаге 104 сетки поисковых точек (будущих кандидатов на искомые анатомические точки). Далее начинается основная часть способа. Для каждой точки выбранной сетки (до тех пор, пока вся область не будет просканирована, то есть не будет выполнено условие 105) применяется многослойный алгоритм извлечения признаков (шаг 107). Фактически эта процедура производит классификацию выделенного контекста каждой такой точки (шаг 106) с целью установить, является ли точка искомой анатомической точкой некоторого типа или она соответствует области без искомых анатомических точек. Однако выход алгоритма извлечения признаков нечеток. Выходной вектор признаков может быть интерпретирован как вектор значений, которые связаны с вероятностями того, что данная точка принадлежит тому или иному классу (является искомой анатомической точкой определенного типа или нет). На основе вектора признаков для каждого типа искомых анатомических точек и для ситуации, когда точка не является искомой анатомической точкой, вычисляется мера качества - псевдовероятность того, что эта точка принадлежит одному из этих классов (шаг 108). Затем, после обработки всех точек из зоны поиска все кандидаты на шаге 109 фильтруются с использованием статистического атласа и вычисленных заранее порогов. Далее все кандидаты в рамках каждого типа искомых анатомических точек на шаге 110 сортируются по их мере качества, и предписанное количество кандидатов с наивысшими значениями меры качества выдаются на выход всей процедуры в качестве найденных позиций искомых анатомических точек (шаг 111). В описываемом изобретении применяются методы машинного обучения для построения многослойного алгоритма извлечения признаков. Важной частью всего подхода является процедура обучения модели алгоритмов извлечения признаков (см. Фиг.4). Процедура обучения может быть проведена независимо от основной процедуры регистрации анатомических точек. Более детально упомянутые шаги будут изложены ниже.
Входные данные
Способ, описанный в заявляемом изобретении, способен работать с трехмерными медицинскими изображениями, которые могут быть получены с помощью различных технологий, таких как МРТ (магнитно-резонансная томография), КТ (компьютерная томография), ПЭТ (позитронно-эмиссионная томография) и другие. Способ достаточно устойчив к входным изображениям низкого разрешения. Преимущество этой особенности заключается в том, что изображения с низким разрешением могут быть получены за достаточно короткое время.
Ограничивающий параллелепипед
Способ, описанный в заявляемом изобретении, начинается с оценки ограничивающего параллелепипеда для входного объемного медицинского изображения. Фиг.2 иллюстрирует пример оценки ограничивающего прямоугольника для двумерного случая; в трехмерном случае вычисление производится аналогично. Ограничивающий параллелепипед ограничивает основную часть 202 исследуемого тела. Процедура выполняется путем вычисления интегральных проекций 203-204 всего изображения 201 на оси координат и дальнейшего отыскания областей, где проекция выше некоторых порогов 205-206. Ограничивающий параллелепипед получается как прямое произведение интервалов, чьи граничные точки являются крайними точками пересечений проекций с пороговыми значениями 207-210. Интегральная проекция объема - это одномерная функция, значение которой в данной точке равняется сумме всех значений внутри объема, взятых в точках, одна из координат которых фиксирована и равна данной. Использование ненулевых порогов позволяет обрезать области на краях исследуемого изображения, содержащие лишь шум.
Статистический атлас
Статистический атлас содержит информацию о статистическом распределении искомых анатомических точек внутри исследуемой части тела. Он строится на основе нескольких размеченных объемных медицинских изображений. Ограничивающий параллелепипед используется для сужения области разброса размеченных точек, получающегося вследствие неопределенности позиции исследуемой части тела в рамках исследуемого медицинского изображения. Позиции анатомических точек в некотором объемном медицинском изображении преобразуются в позиции в локальной системе координат, которая привязана к ограничивающему параллелепипеду, а не ко всему объему. Затем на основе позиций анатомических точек, рассчитанных для нескольких размеченных медицинских изображений, оценивается обобщенное пространственное распределение этих анатомических точек. В простейшем случае подобное распределение может быть представлено с помощью выпуклой оболочки всех размеченных точек (для конкретного типа анатомических точек) в единой локальной системе координат.
Генерации сетки поисковых точек
Сетка поисковых точек - это набор точек в объемном медицинском изображении, выделенный контекст которых будет подан в качестве входных данных многослойному алгоритму извлечения признаков. Такая сетка генерируется на основе статистического атласа, вычисленного заранее. Фиг.3 иллюстрирует подобласть всего объемного медицинского изображения 301, из которой берутся поисковые точки. Поисковые точки выбираются из подобласти 305, являющейся объединением подобластей 302-304, которые соответствуют статистическим распределениям искомых анатомических точек для каждого типа искомых точек. Внутри подобласти поисковые точки выбираются с некоторым предопределенным шагом (т.е. расстоянием между соседними точками). Такое сужение области поиска ведет к ускорению вычислений и снижению вероятности появления ошибок первого рода.
Применение многослойного алгоритма извлечения признаков
Основная часть заявленного способа состоит в итеративном применении многослойного алгоритма извлечения признаков к каждой точке из сетки поисковых точек. Операция извлечения признаков заключается в выделении некоторой порции вексельных данных из окружающего контекста текущей точки и дальнейшей подаче этих данных в качестве входных значений многослойного алгоритма извлечения признаков. Многослойный алгоритм извлечения признаков построен с использованием подхода машинного обучения. Для каждого подобного входа алгоритм извлечения признаков генерирует соответствующий выходной вектор. Этот вектор используется для вычисления меры качества для каждого типа искомых анатомических точек и случая, когда данная поисковая точка не принадлежит ни одному типу искомых анатомических точек. Мера качества соответствует вероятности того, что данная поисковая точка представляет собой некоторую искомую анатомическую точку или не представляет ни один из типов искомых анатомических точек. Одна из возможных реализаций вычисления этой меры качества представлена далее. Если тип искомых анатомических точек, для которого производится вычисление, имеет наибольшее значение в выходном векторе алгоритма извлечения признаков, примененного к текущей поисковой точке, то мера качества равна разности между этим значением выходного вектора и вторым по величине значением выходного вектора. В противном случае, если данный тип искомых анатомических точек не имеет наибольшего значения в выходном векторе, то мера качества равна разности между этим значением и наибольшим значением из выходного вектора.
Фильтрация результатов и получение результата
Результатом применения алгоритма извлечения признаков к каждой точке из сетки поисковых точек является набор векторов, элементами которых являются значения описанной выше меры качества. Для каждого типаискомых анатомических точек отбирается множество кандидатов на искомые анатомические точки. Такой кандидат представляет собой объединение позиции анатомической точки и соответствующего значения меры качества. Для полного набора типов искомых анатомических точек кандидаты фильтруются в соответствии с вероятностью появления определенной анатомической точки в данной позиции, принимая во внимание статистический атлас. Также производится дополнительная фильтрация с помощью вычисленных заранее порогов: все кандидаты, для которых значения меры качества оказываются ниже определенного порога, устраняются из рассмотрения. Эти пороги вычисляются заранее на основе множества размеченных объемных медицинских изображений. Вычисление производится путем отыскания порогов, минимизирующих функцию потерь, объединяющую ошибки первого и второго рода. Оптимальные пороги обеспечивают баланс между ошибками первого и второго рода, проявляющимися на этапе тестирования результатов классификации на всем имеющемся множестве размеченных объемных медицинских изображений. Этот баланс может корректироваться с помощью изменения компромиссного параметра в зависимости от типа поставленной задачи. Все оставшиеся кандидаты сортируются по мере качества в рамках одного типа искомых анатомических точек отдельно от других типов. Затем, в зависимости от требований для каждого типа искомых анатомических точек заявленный способ имеет своим выходом наилучшего кандидата (кандидата с наибольшим значением меры качества) или множество кандидатов (кандидатов, оставшихся после фильтрации, или фиксированное количество кандидатов с наибольшими значениями меры качества).
Обучение многослойной модели алгоритмов извлечения признаков
Многослойный алгоритм извлечения признаков используется для получения признаков контекстов поисковых точек. Слои преобразования, заложенного в алгоритм извлечения признаков, содержат набор весов, которые определяют поведение всего алгоритма. Процесс настройки этих весов основан на подходе машинного обучения. Процесс обучения демонстрируется на Фиг.4. Для осуществления этой процедуры необходимо несколько объемных медицинских изображений, из которых будет построена обучающая база. Сначала эти изображения должны быть обработаны некоторым образом и размечены вручную (шаг 401). Доктор или другой специалист должен указать позиции нужных анатомических точек, присутствующий внутри каждого выбранного объемного медицинского изображения. Далее формируется обучающая база (шаг 402). Обучающая база состоит из прецедентов, которые соответствуют некоторым точкам, выбранным из объема.
Прецедент представляет собой комбинацию метки класса и порции вексельных данных, извлеченных из окружающего контекста соответствующей точки в объеме. Обучающая база состоит из прецедентов, соответствующих анатомическим точкам, и прецедентов, соответствующих точкам из объема, в которых нет анатомических структур. Последние прецеденты соответствуют точкам, выбранным из объема случайным образом и достаточно удаленным от интересуемых анатомических точек. Дополнительно к базе добавляются несколько прецедентов, полученных из вышеописанных прецедентов посредством применения к ним пространственных искажений. Это позволяет улучшить инвариантность алгоритма извлечения признаков к вариациям входных данных. Также это помогает разнообразить обучающую базу в случае, когда доступно лишь небольшое количество объемных медицинских изображений. После того как обучающая база сформирована, производятся два этапа обучения модели алгоритмов извлечения признаков.
На первом этапе осуществляется обучение без учителя (шаг 403), с помощью которого инициализируются веса W (элемент 509) слоев, извлекающих признаки. Эта операция производится по отдельности для каждого такого слоя путем решения следующей оптимизационной задачи:
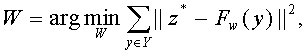
где Y - это обучающая база, y - это вход слоя из обучающей базы, z* - это разреженный код для y, Fw - это функционал, который зависит от W; он преобразовывает вход y в выход слоя.
Оптимизация проводится с помощью стохастического градиентного спуска. Обучающий прецедент (элемент 501) кодируется в разреженный код (элемент 504) с использованием словаря D (элемент 502). После процедуры извлечения признаков (шаг 510) получаются признаки (элемент 511). Значение функции потерь (элемент 512), рассчитанное на основе признаков (элемент 511) и разреженного кода (элемент 504), используется для вычисления градиента (шаг 513) для того, чтобы обновить значения весов W. Вычисление разреженного кода для произвольного входа осуществляется в процессе решения следующей оптимизационной задачи (шаг 503):
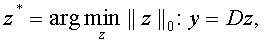
где D - словарь, y - входной вектор, z - кодированный вектор (код), z* - оптимальный разреженный код.
В представленном выше уравнении вход y представлен как линейная комбинация лишь небольшого числа базисных элементов из некоторого словаря D, так что полученный код z (вектор из коэффициентов разложения) является разреженным. Словарь D получается на основе обучающей базы с помощью обучения без учителя (без использования меток прецедентов). Преимущество применения подхода обучения без учителя для отыскания оптимального словаря D состоит в том, что словарь обучается напрямую из данных. При этом D оптимально описывает скрытые закономерности и специфическую природу используемых данных. Еще одно преимущество такого подхода состоит в том, что нет необходимости иметь на входе большое количество размеченный данных для обучения словаря. Отыскание D эквивалентно решению следующей оптимизационной задачи:
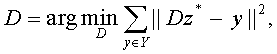
где Y - обучающая база, y - вход слоя из обучающей базы, z* - разреженный код для y, D - словарь.
Оптимизационная задача решается с помощью стохастического градиентного спуска. Декодирование (шаг 505) разреженного кода производится для получения декодированных данных (элемент 506). Значение функции потерь (элемент 507), рассчитанное на основе обучающего прецедента (элемент 501) и декодированных данных (элемент 506), используется для вычисления градиента (шаг 508) для того, чтобы обновить значения словаря D. Процесс корректировки перемежается с отысканием оптимального разреженного кода z* для входа y при фиксированном словаре D. Для всех слоев, кроме первого, набор обучающих прецедентов Y формируется из набора выходов предыдущего слоя. После того как процедура обучения без учителя завершена, полученный алгоритм извлечения признаков настроен на вычисление многоуровневых разреженных кодов, которые являются хорошим, иерархическим признаковым представлением входных данных.
На следующем этапе производится обучение модели алгоритмов извлечения признаков с учителем (шаг 404). В результате алгоритм будет способен выдавать признаки, соответствующие вероятностям появления в данной точке того или иного типа анатомической точки. Обучение проводится путем решения следующей задачи оптимизации:
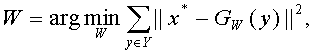
где Y - обучающая база, y - вход алгоритма извлечения признаков из обучающей базы; x* - вектор, построенный на основе метки, соответствующей входу y, Gw зависит от W и определяет полное преобразование входа y в выход алгоритма извлечения признаков.
В процессе такой оптимизации алгоритм извлечения признаков настраивается на выдачу выходов, близких к векторам, предписанным разметкой. Эта оптимизационная задача также решается с помощью стохастического градиентного спуска. В начале процедуры некоторые веса слоев алгоритма инициализируются значениями, вычисленными на этапе предварительного обучения без учителя. Окончательно построенный алгоритм извлечения признаков способен выдавать на выход вектор признаков, который может быть напрямую использован для решения задачи классификации или для привязки к каждому классу вероятности того, что данный вход принадлежит определенному классу.
Система автоматической регистрации анатомических точек
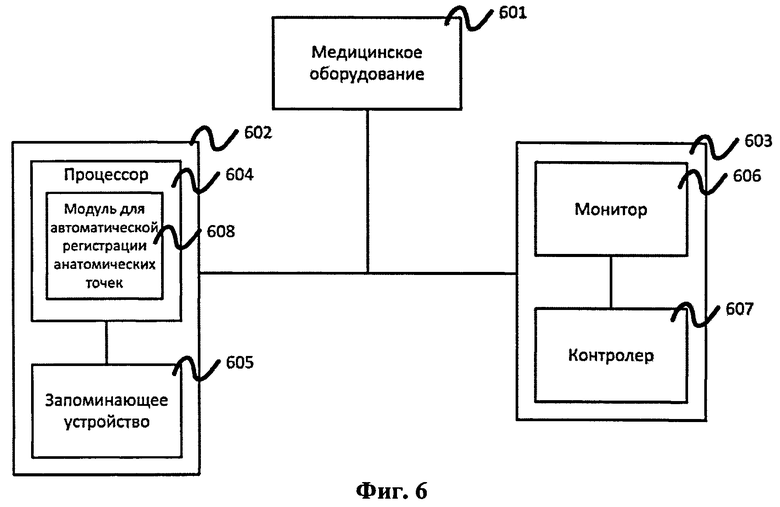
Пример системы, в которой может быть реализовано заявляемое изобретение, представлен на Фиг.6. Система состоит из медицинского оборудования (установки) 601 для получения объемного медицинского изображения, компьютера 602 и операторской консоли 603. После того как объемное медицинское изображение получено с помощью медицинского оборудования, компьютерный файл с изображением сохраняется в памяти 605 компьютера. Оператор, используя контролер 607 консоли, запускает программу, решающую конкретную задачу медицинской диагностики. Программа выполняется на процессоре 604 компьютера и включает в себя модуль автоматической регистрации анатомических точек 608 в качестве подпрограммы. Результат работы программы может быть просмотрен и проанализирован на мониторе 606 консоли.
Способ, описанный в заявляемом изобретении, может быть включен в качестве одного из этапов во многие процедуры, связанные с обработкой медицинских изображений диагностического типа, и может быть реализован в виде программной части или автономной системы в составе используемого медицинского оборудования.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ДЛЯ АВТОМАТИЧЕСКОГО ПЛАНИРОВАНИЯ ДВУХМЕРНЫХ ВИДОВ В ОБЪЕМНЫХ МЕДИЦИНСКИХ ИЗОБРАЖЕНИЯХ | 2013 |
|
RU2526752C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ДИАГНОСТИКИ ТАЗОБЕДРЕННЫХ СУСТАВОВ | 2022 |
|
RU2795658C1 |
| СИСТЕМА И СПОСОБ ДИАГНОСТИКИ ТАЗОБЕДРЕННЫХ СУСТАВОВ | 2022 |
|
RU2801420C1 |
| СИСТЕМЫ И СПОСОБЫ СЕГМЕНТАЦИИ МЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ НА ОСНОВАНИИ ПРИЗНАКОВ, ОСНОВАННЫХ НА АНАТОМИЧЕСКИХ ОРИЕНТИРАХ | 2015 |
|
RU2699499C2 |
| СИСТЕМА И СПОСОБ ДЛЯ АВТОМАТИЧЕСКОГО ПЛАНИРОВАНИЯ ВИДОВ В ОБЪЕМНЫХ ИЗОБРАЖЕНИЯХ МОЗГА | 2013 |
|
RU2523929C1 |
| СЕГМЕНТАЦИЯ ТКАНЕЙ ЧЕЛОВЕКА НА КОМПЬЮТЕРНОМ ИЗОБРАЖЕНИИ | 2017 |
|
RU2654199C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ОЦЕНКИ ОБУЧАЮЩИХ ОБЪЕКТОВ ПОСРЕДСТВОМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2672394C1 |
| СПОСОБ РАЗДЕЛЕНИЯ ТЕКСТОВ И ИЛЛЮСТРАЦИЙ В ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДЕСКРИПТОРА СПЕКТРА ДОКУМЕНТА И ДВУХУРОВНЕВОЙ КЛАСТЕРИЗАЦИИ | 2017 |
|
RU2656708C1 |
| Способ создания многослойного представления сцены и вычислительное устройство для его реализации | 2021 |
|
RU2787928C1 |
| Система и способ диагностики синуситов по рентгеновским изображениям | 2023 |
|
RU2828554C1 |
Изобретение относится к способам и устройствам для автоматической регистрации анатомических точек на медицинских изображениях. Техническим результатом является повышение точности автоматической регистрации анатомических точек в трехмерных медицинских изображениях. Способ предусматривает выполнение таких операций, как получение трехмерного медицинского изображения, определение множества поисковых точек, извлечение признаков указанных точек, формирование множества кандидатов на искомые анатомические точки, фильтрация указанных кандидатов, вывод финальных позиций искомых анатомических точек; определение множества поисковых точек производят путем задания сетки поисковых точек внутри объемного изображения с использованием статистического атласа; извлечение признаков точек производят путем выделения окружающего контекста для каждой такой точки; формирование множества кандидатов производят с помощью вычисления меры качества для каждой поисковой точки и для каждого типа искомых анатомических точек; фильтрацию кандидатов производят с помощью статистического атласа и вычисленных заранее порогов для значений меры качества; вывод финальных позиций производят путем сортировки всех оставшихся после фильтрации кандидатов в рамках каждого типа искомых анатомических точек по мере их качества и вывода кандидатов с наибольшими значениями меры качества или требуемого количества кандидатов с наибольшими значениями меры качества. 3 н. и 39 з.п. ф-лы, 6 ил.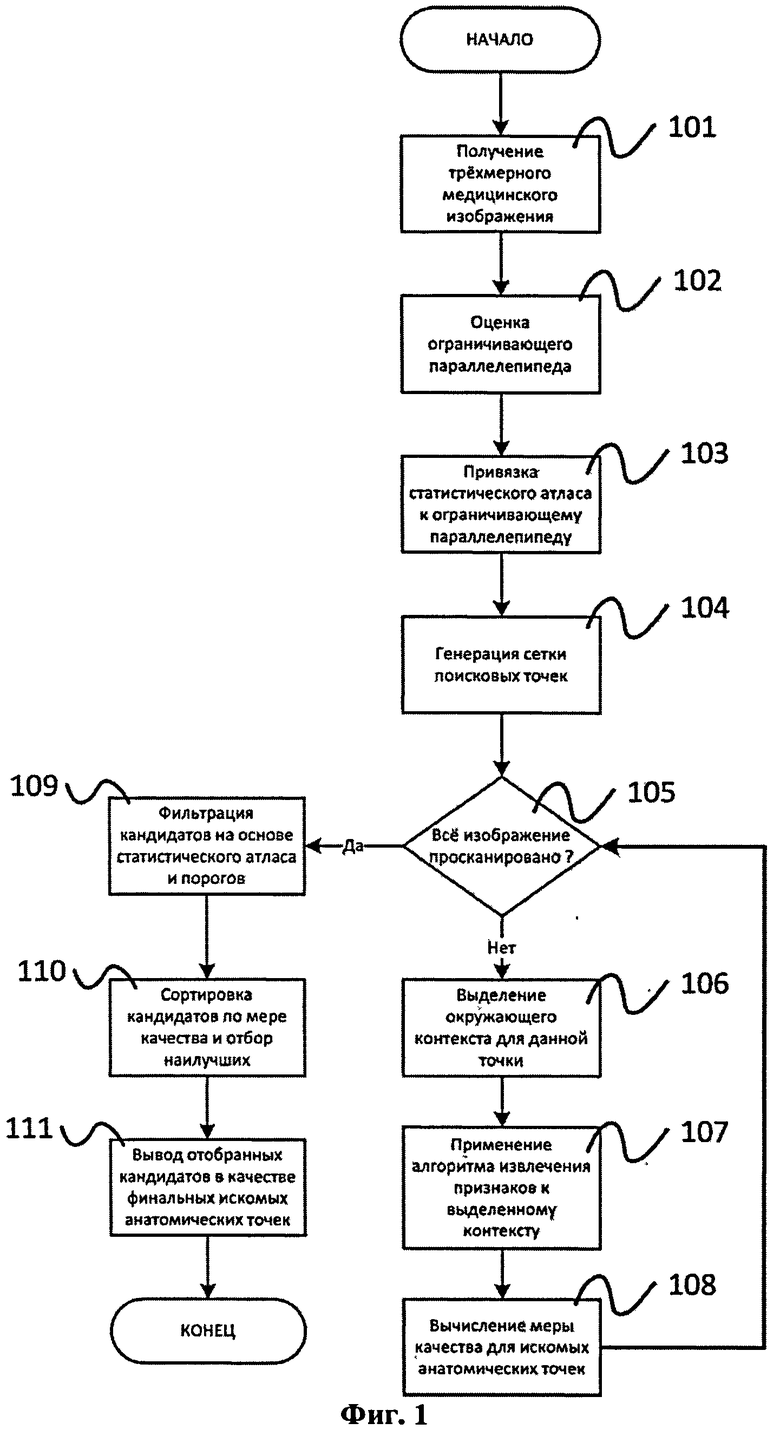
1. Способ автоматической регистрации анатомических точек в объемных медицинских изображениях, предусматривающий выполнение таких операций, как получение трехмерного медицинского изображения, определение множества поисковых точек, извлечение признаков указанных точек, формирование множества кандидатов на искомые анатомические точки, фильтрация указанных кандидатов, вывод финальных позиций искомых анатомических точек, и отличающийся тем, что:
- указанное определение множества поисковых точек производят путем задания сетки поисковых точек внутри объемного изображения с использованием статистического атласа;
указанный статистический атлас прикрепляют к ограничивающему параллелепипеду, соответствующему исследуемой части тела внутри объемного изображения;
- указанное извлечение признаков точек производят путем выделения окружающего контекста для каждой такой точки и применения к нему многослойного алгоритма извлечения признаков;
- указанное формирование множества кандидатов производят с помощью вычисления меры качества для каждой поисковой точки и для каждого типа искомых анатомических точек, используя соответствующий выход алгоритма извлечения признаков;
- указанную фильтрацию кандидатов производят с помощью статистического атласа и вычисленных заранее порогов для значений меры качества;
- указанный вывод финальных позиций производят путем сортировки всех оставшихся после фильтрации кандидатов в рамках каждого типа искомых анатомических точек по мере их качества и вывода кандидатов с наибольшими значениями меры качества илитребуемого количества кандидатов с наибольшими значениями меры качества.
2. Способ по п.1, отличающийся тем, что указанный ограничивающий параллелепипед оценивают с помощью интегральных проекций объемного изображения на оси координат.
3. Способ по п.1, отличающийся тем, что указанный статистический атлас формируют по истинным позициям искомых анатомических точек в размеченных объемных медицинских изображениях.
4. Способ по п.1, отличающийся тем, что указанное выделение окружающего контекста для некоторой точки производят путем выделения подобласти из объемного медицинского изображения, центр которой находится в данной точке.
5. Способ по п.1, отличающийся тем, что указанное выделение окружающего контекста для некоторой точки производят путем выделения трех ортогональных срезов объемного медицинского изображения, которые проходят через данную точку.
6. Способ по п.1, отличающийся тем, что указанный многослойный алгоритм извлечения признаков формируют из слоев извлечения признаков, концентрирующих слоев и нормализующих слоев.
7. Способ по п.1, отличающийся тем, что указанный многослойный алгоритм извлечения признаков получают на основе процедуры обучения.
8. Способ по п.7, отличающийся тем, что указанная процедура обучения включает в себя выполнение следующих операций:
- осуществляют предобработку и разметку нескольких объемных медицинских изображений;
формируют обучающую базу на основе набора размеченных объемных медицинских изображений;
- осуществляют инициализацию слоев, ответственных за извлечение признаков, в алгоритме извлечения признаков с помощью обучения без учителя;
- выполняют обучение с учителем модели алгоритмов извлечения признаков, используя разметку.
9. Способ по п.8, отличающийся тем, что указанное формирование обучающей базы производят путем объединения прецедентов, соответствующих случайно выбранным позициям в объемном изображении, не соответствующим ни одному из типов искомых анатомических точек, и прецедентов, соответствующих истинным позициям искомых анатомических точек в размеченных объемных изображениях.
10. Способ по п.8, отличающийся тем, что указанное формирование обучающей базы включает в себя операцию по вставке в базу прецедентов, полученных путем применения пространственных искажений.
11. Способ по п.8, отличающийся тем, что указанное обучение без учителя производят путем отыскания оптимальных весов слоев, ответственных за извлечение признаков, в алгоритме извлечения признаков таким образом, чтобы их выходы слабо отличались от выходов соответствующих разреженных кодировщиков; указанные разреженные кодировщики получены с помощью подхода разреженного кодирования; указанный подход разреженного кодирования включает в себя отыскание оптимального словаря базисных элементов; указанные разреженные кодировщики выдают разреженные коды, которые являются коэффициентами разложения данного входа по базисным элементам указанного словаря.
12. Способ по п.8, отличающийся тем, что указанное обучение с учителем проводят на основе метода стохастического градиентного спуска.
13. Способ по п.1, отличающийся тем, что указанную фильтрацию кандидатов производят с использованием статистической информации, следующей из статистического атласа.
14. Способ по п.1, отличающийся тем, что указанные пороги для значений меры качества вычисляют путем минимизации некоторой функции потерь, в которую входят ошибки первого и второго рода.
15. Система для автоматической регистрации анатомических точек в объемных медицинских изображениях, состоящая из:
- запоминающего устройства, выполненного с возможностью хранения программы;
- процессора, связанного с запоминающим устройством, выполненным с возможностью выполнения программы, осуществляющей следующие шаги:
- оценка ограничивающего параллелепипеда исследуемой части тела внутри полученного объемного медицинского изображения,
- прикрепление статистического атласа к ограничивающему параллелепипеду,
- определение сетки поисковых точек внутри объемного медицинского изображения с использованием статистического атласа,
- выделение окружающих контекстов для каждой точки из сетки поисковых точек,
- применение многослойного алгоритма извлечения признаков к выделенным контекстам,
- формирование множества кандидатов на искомые анатомические точки путем вычисления меры качества для каждой поисковой точки и для каждого типа искомых анатомических точек, используя соответствующий выход алгоритма извлечения признаков,
- фильтрация кандидатов с использованием статистического атласа и вычисленных заранее порогов,
- сортировка оставшихся кандидатов в рамках каждого типа искомых анатомических точек по мере их качества,
- вывод кандидатов с наибольшими значениями меры качества или требуемого количества кандидатов с наибольшими значениями меры качества.
16. Система по п.15, отличающаяся тем, что указанный ограничивающий параллелепипед оценивается с помощью интегральных проекций объемного изображения на оси координат.
17. Система по п.15, отличающаяся тем, что указанный статистический атлас формируется по истинным позициям искомых анатомических точек в размеченных объемных медицинских изображениях.
18. Система по п.15, отличающаяся тем, что указанное выделение окружающего контекста для некоторой точки производится путем выделения подобласти из объемного медицинского изображения, центр которой находится в данной точке.
19. Система по п.15, отличающаяся тем, что указанное выделение окружающего контекста для некоторой точки производится путем выделения трех ортогональных срезов объемного медицинского изображения, которые проходят через данную точку.
20. Система по п.15, отличающаяся тем, что указанный многослойный алгоритм извлечения признаков состоит из слоев извлечения признаков, концентрирующих слоев и нормализующих слоев.
21. Система по п.15, отличающаяся тем, что указанный многослойный алгоритм извлечения признаков получен на основе процедуры обучения.
22. Система по п.21, отличающаяся тем, что указанная процедура обучения состоит из следующих шагов:
- предобработка и разметка нескольких объемных медицинских изображений;
- формирование обучающей базы на основе набора размеченных объемных медицинских изображений;
- инициализация слоев, ответственных за извлечение признаков, в алгоритме извлечения признаков с помощью обучения без учителя;
- осуществление обучения с учителем модели алгоритмов извлечения признаков, используя разметку.
23. Система по п.22, отличающаяся тем, что указанное формирование обучающей базы производится путем объединения прецедентов, соответствующих случайно выбранным позициям в объемном изображении, не соответствующим ни одному из типов искомых анатомических точек, и прецедентов, соответствующих истинным позициям искомых анатомических точек в размеченных объемных изображениях.
24. Система по п.22, отличающаяся тем, что указанное формирование обучающей базы включает в себя вставку в базу прецедентов, полученных путем применения пространственных искажений.
25. Система по п.22, отличающаяся тем, что указанное обучение без учителя производится путем отыскания оптимальных весов слоев, ответственных за извлечение признаков, в алгоритме извлечения признаков таким образом, чтобы их выходы слабо отличались от выходов соответствующих разреженных кодировщиков; указанные разреженные кодировщики получены с помощью подхода разреженного кодирования; указанный подход разреженного кодирования включает в себя отыскание оптимального словаря базисных элементов; указанные разреженные кодировщики выдают разреженные коды, которые являются коэффициентами разложения данного входа по базисным элементам указанного словаря.
26. Система по п.22, отличающаяся тем, что указанное обучение с учителем основано на методе стохастического градиентного спуска.
27. Система по п.15, отличающаяся тем, что указанная фильтрация кандидатов производится с использованием статистической информации, следующей из статистического атласа, с целью отфильтровать кандидатов со статистически неверными позициями.
28. Система по п.15, отличающаяся тем, что указанные пороги для значений меры качества вычисляются путем минимизации некоторой функции потерь, в которую входят ошибки первого и второго рода.
29. Носитель информации, содержащий выполняемые компьютером инструкции для автоматической регистрации анатомических точек в объемных медицинских изображениях; процессор компьютера в процессе выполнения указанных инструкций реализует следующие шаги:
- оценка ограничивающего параллелепипеда исследуемой части тела внутри полученного объемного медицинского изображения,
- прикрепление статистического атласа к ограничивающему параллелепипеду,
- определение сетки поисковых точек внутри объемного медицинского изображения с использованием статистического атласа,
- выделение окружающих контекстов для каждой точки из сетки поисковых точек,
применение многослойного алгоритма извлечения признаков к выделенным контекстам,
- формирование множества кандидатов на искомые анатомические точки путем вычисления меры качества для каждой поисковой точки и для каждого типа искомых анатомических точек, используя соответствующий выход алгоритма извлечения признаков,
- фильтрация кандидатов с использованием статистического атласа и вычисленных заранее порогов,
- сортировка оставшихся кандидатов в рамках каждого типа искомых анатомических точек по мере их качества,
- вывод кандидатов с наибольшими значениями меры качества или требуемого количества кандидатов с наибольшими значениями меры качества.
30. Носитель информации по п.29, отличающийся тем, что указанный ограничивающий параллелепипед оценивается с помощью интегральных проекций объемного изображения на оси координат.
31. Носитель информации по п.29, отличающийся тем, что указанный статистический атлас формируется по истинным позициям искомых анатомических точек в размеченных объемных медицинских изображениях.
32. Носитель информации по п.29, отличающийся тем, что указанное выделение окружающего контекста для некоторой точки производится путем выделения подобласти из объемного медицинского изображения, центр которой находится в данной точке.
33. Носитель информации по п.29, отличающийся тем, что указанное выделение окружающего контекста для некоторой точки производится путем выделения трех ортогональных срезов объемного медицинского изображения, которые проходят через данную точку.
34. Носитель информации по п.29, отличающийся тем, что указанный многослойный алгоритм извлечения признаков состоит из слоев извлечения признаков, концентрирующих слоев и нормализующих слоев.
35. Носитель информации по п.29, отличающийся тем, что указанный многослойный алгоритм извлечения признаков получен на основе процедуры обучения.
36. Носитель информации по п.35, отличающийся тем, что указанная процедура обучения состоит из следующих шагов:
- предобработка и разметка нескольких объемных медицинских изображений;
- формирование обучающей базы на основе набора размеченных объемных медицинских изображений;
- инициализация слоев, ответственных за извлечение признаков, в алгоритме извлечения признаков с помощью обучения без учителя;
- осуществление обучения с учителем модели алгоритмов извлечения признаков, используя разметку.
37. Носитель информации по п.36, отличающийся тем, что указанное формирование обучающей базы производится путем объединения прецедентов, соответствующих случайно выбранным позициям в объемном изображении, не соответствующим ни одному из типов искомых анатомических точек, и прецедентов, соответствующих истинным позициям искомых анатомических точек в размеченных объемных изображениях.
38. Носитель информации по п.36, отличающийся тем, что указанное формирование обучающей базы включает в себя вставку в базу прецедентов, полученных путем применения пространственных искажений.
39. Носитель информации по п.36, отличающийся тем, что указанное обучение без учителя производится путем отыскания оптимальных весов слоев, ответственных за извлечение признаков, в алгоритме извлечения признаков таким образом, чтобы их выходы слабо отличались от выходов соответствующих разреженных кодировщиков; указанные разреженные кодировщики получены с помощью подхода разреженного кодирования; указанный подход разреженного кодирования включает в себя отыскание оптимального словаря базисных элементов; указанные разреженные кодировщики выдают разреженные коды, которые являются коэффициентами разложения данного входа по базисным элементам указанного словаря.
40. Носитель информации по п.36, отличающийся тем, что указанное обучение с учителем основано на методе стохастического градиентного спуска.
41. Носитель информации по п.29, отличающийся тем, что указанная фильтрация кандидатов производится с использованием статистической информации, следующей из статистического атласа, с целью отфильтровать кандидатов со статистически неверными позициями.
42. Носитель информации по п.29, отличающийся тем, что указанные пороги для значений меры качества вычисляются путем минимизации некоторой функции потерь, в которую входят ошибки первого и второго рода.
| US20100254582 A1, 07.10.2010 | |||
| US20100067764 A1, 18.03.2010 | |||
| US20100119137 A1, 13.05.2010 | |||
| US20090034813 A1, 05.02.2009 | |||
| Трехшарошечное долото для бурения скважин | 1958 |
|
SU120799A1 |

