Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится к области искусственного интеллекта (AI) и нейронного рендеринга и, в частности, к способу создания многослойного представления сцены с использованием нейронных сетей, обучаемых сквозным образом, а также к вычислительному устройству, реализующему данный способ. Многослойное представление сцены можно использовать для синтеза нового вида сцены.
Уровень техники
[0002] В последние годы наблюдается стремительный прогресс в рендеринге на основе изображений и синтезе новых видов с использованием множества разнообразных методов, основанных на принципах нейронного рендеринга. Среди этого разнообразия выделяются подходы, основанные на полупрозрачных многослойных представлениях, благодаря тому, что они сочетают в себе быстроту рендеринга, совместимость с традиционными графическими движками и высокое качество ререндеринга вблизи входных кадров.
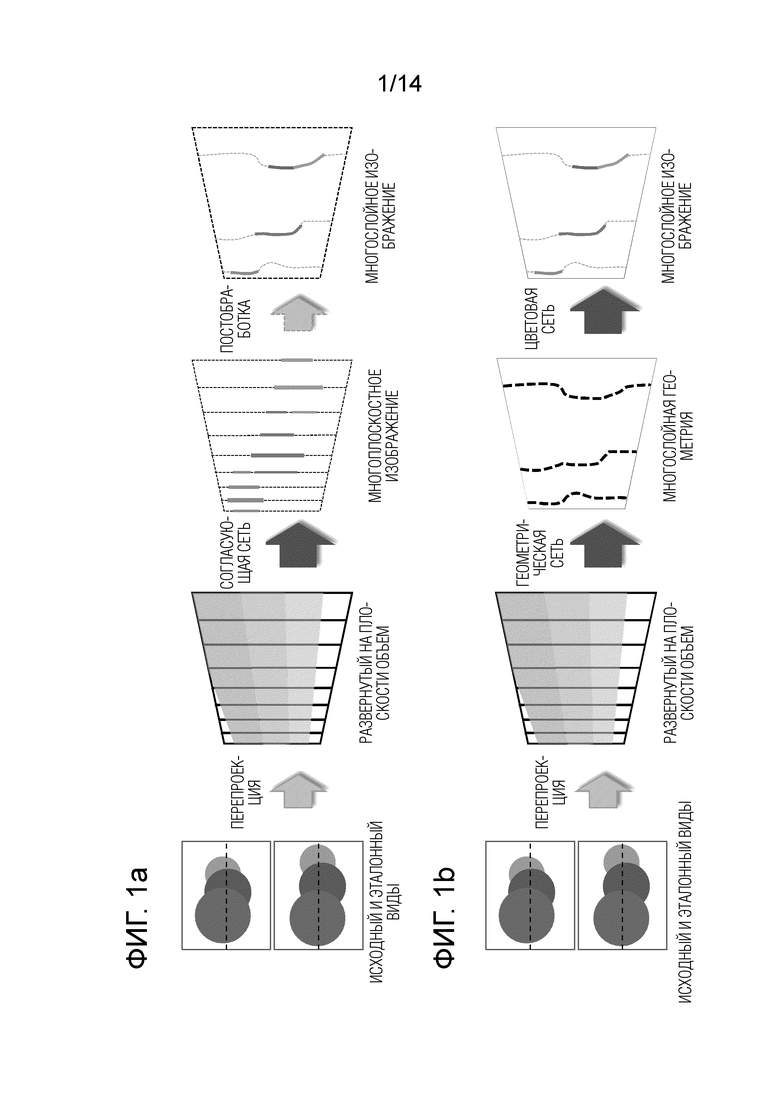
[0003] В существующих подходах многослойные представления строятся на сетках из равноудаленных друг от друга поверхностей, таких как плоскости или сферы, с равномерно изменяющейся обратной глубиной. Поскольку количество слоев обязательно ограничено имеющимися ресурсами и переобучением, оно обычно берется относительно небольшим (например, 32). Поэтому полученное полупрозрачное представление может лишь приблизительно отражать истинную геометрию сцены, что ограничивает обобщение на новые виды и вводит артефакты. В последних работах в данной области используется чрезмерное количество сфер (до 128), а затем полученная геометрия объединяется на этапе необученного слияния при постобработке (см. фиг. 1 (a)). Хотя этап слияния создает адаптированное к сцене компактное геометрическое представление, он не включен в процесс обучения основной согласующей сети и ухудшает качество синтеза новых видов.
[0004] Крупность многослойной геометрии, используемой в многослойных подходах, отличается от более традиционных методов рендеринга на основе изображений, которые начинаются с оценки недискретизированной геометрии сцены в виде сетки, зависимых от вида сеток, однослойной карты глубины. Оценки геометрии могут быть получены на основе согласования многовидового плотного стереоизображения или монокулярной глубины. Все эти подходы обеспечивают более точное приближение к геометрии сцены, хотя многие из них должны использовать относительно медленный этап нейронного рендеринга для компенсации ошибок в оценке геометрии.
Родственные работы
Непатентная литература (НПЛ):
НПЛ1 - M. Broxton, J. Flynn, R. Overbeck, D. Erickson, P. Hedman, M. Duvall, J. Dourgarian, J. Busch, M. Whalen, and P. Debevec. Immersive light field video with a layered mesh representation. In Proc. ACM SIGGRAPH, 2020
НПЛ2 - K.-E. Lin, Z. Xu, B. Mildenhall, P.P. Srinivasan, Y. Hold-Geoffroy, S. DiVerdi, Q. Sun, K. Sunkavalli, and R. Ramamoorthi. Deep multi depth panoramas for view synthesis. In Proc. ECCV, 2020.
НПЛ3 - T. Zhou, R. Tucker, J. Flynn, G. Fyffe, and N. Snavely. Stereo magnification: Learning view synthesis using multiplane images. In Proc. ACM SIGGRAPH, 2018.
[0005] В НПЛ1 и НПЛ2 многослойные представления расширены на более широкие поля зрения путем замены плоскостей сферами. В подходах, раскрытых в НПЛ1 и НПЛ2, предлагается "объединение" (слияние) групп соседних слоев в слои с криволинейной геометрией. В обоих случаях предопределено группирование слоев, а процесс слияния является необучаемым (т.е. выполняется не обученной нейронной сетью) и использует простые эвристики накопления (см. фиг. 1(а)). Поэтому в НПЛ1 сообщается о потере точности синтеза в результате такого слияния. По сравнению с системой StereoMag (НПЛ3), основанной на 32 плоских слоях, предложенное техническое решение обеспечивает более точную реконструкцию новых видов с неплоскими слоями, а также требуется меньшее количество слоев (например, восемь таких неплоских слоев) для достижения более точной реконструкции новых видов по сравнению с НПЛ3.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] Способ согласно варианту осуществления настоящего изобретения (схематически показанный на фиг. 1(b)) начинается с построения геометрического промежуточного представления, которое подгоняется к конкретной сцене. Геометрическое промежуточное представление образовано небольшим количеством слоев сетки с непрерывными значениями координат глубины. На втором этапе для каждого слоя оцениваются прозрачность и цветовые текстуры, в результате чего получается окончательное представление сцены. При обработке новой сцены оба этапа принимают в качестве входных данных одну и ту же пару изображений этой сцены. Для реализации этих двух этапов используются две глубокие нейронные сети, предобученные на наборе данных похожих сцен. Важно, чтобы обе нейронные сети обучались вместе (совместно) сквозным образом, с использованием структуры дифференцируемого рендеринга.
[0007] Раскрытое здесь изобретение сравнивается с ранее предложенными способами, в которых используются равноудаленные друг от друга слои в популярных наборах данных RealEstate10k и LLFF. Кроме того, авторы настоящего изобретения предлагают новый более сложный набор данных для сопоставительного анализа синтеза новых представлений. В обоих случаях использование адаптивной к сцене геометрии, как в настоящем изобретении, приводит к повышению точности синтеза для нового вида сцены. Иными словами, настоящее изобретение обеспечивает лучшее качество синтеза новых изображений.
[0008] Таким образом, настоящая заявка обеспечивает следующие преимущества по сравнению с известными решениями:
Предлагается новый способ геометрической реконструкции сцены из пары изображений (например, стереопары). В способе используется представление, основанное на нескольких адаптивных полупрозрачных слоях сцены из пары изображений.
В отличие от других способов, в предлагаемом способе используется две совместно обучаемые (сквозным образом) глубокие нейронные сети, первая из которых прогнозирует многослойную структуру сцены (т.е. геометрию слоев), а вторая оценивает значения цвета и значения непрозрачности α (т.е. прозрачности) для спрогнозированной многослойной структуры сцены.
- Настоящее изобретение оценивалось на ранее известном наборе данных, а также на новом более сложном наборе данных для обучения и оценки способов синтеза новых видов.
[0009] Таким образом, согласно первому аспекту настоящего изобретения предложен способ создания многослойного представления сцены, заключающийся в том, что: получают пару изображений сцены, в которой одно изображение из пары рассматривается как эталонное изображение, а другое изображение из пары рассматривается как исходное изображение; выполняют операцию перепроецирования в отношении пары изображений для создания развернутого на плоскости объема (plane-sweep volume); прогнозируют, используя геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема; и оценивают, используя цветовую сеть Fc, значения цвета и значения непрозрачности α для спрогнозированной многослойной структуры сцены, чтобы получить многослойное представление сцены; при этом геометрическую сеть и цветовую сеть обучают сквозным образом.
[0010] Согласно второму аспекту настоящего изобретения предложено вычислительное (электронное) устройство, содержащее процессор и память, хранящую исполняемые процессором инструкции, которые при исполнении процессором побуждают процессор выполнять способ согласно первому аспекту или любое дальнейшее развитие первого аспекта, как будет обсуждаться в следующем описании.
[0011] Следовательно, в отличие от большинства предыдущих работ по многослойным полупрозрачным представлениям, конвейер, раскрытый в настоящей заявке, начинается с прогнозирования криволинейного (неплоского, несферического) слоя и только затем оцениваются значения цвета и непрозрачности слоев. Хотя НПЛ1 и НПЛ2 также можно рассматривать как заканчивающиеся криволинейными полупрозрачными слоями в качестве представления, в настоящем изобретении реконструкция выполняется в обратном порядке (сначала прогнозируется геометрия). Что еще более важно, в отличие от НПЛ1 и НПЛ2, в настоящем изобретении геометрия слоев прогнозируется с помощью нейронной сети, и эта сеть обучается совместно с другой цветовой сетью. Сквозное обучение гарантирует, что слои многослойных полупрозрачных представлений являются адаптивными и зависят от представленной пары изображений. Что же касается НПЛ1, то в нем слои получают по определенному алгоритму - эвристике, которая универсальна и может не соответствовать сцене. В настоящем изобретении задачу прогнозирования геометрии и цветов сцены в целом выполняют нейронные сети, что эффективно исключает любые ручные манипуляции с геометрией. Основные различия между настоящим изобретением и известными многослойными подходами (включая НПЛ1 и НПЛ2) показаны на фиг. 1(a). Однако следует отметить, что эти различия, кратко описанные в настоящем абзаце, не являются единственными различиями между настоящим изобретением и НПЛ1 и НПЛ2.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0012] Описанные выше и другие аспекты, существенные признаки и преимущества настоящего изобретения станут более очевидными из следующего подробного описания в совокупности с прилагаемыми чертежами, на которых:
Фиг. 1 (а) иллюстрирует конвейер обработки, известный из предшествующего уровня техники; Фиг. 1 (b) схематически иллюстрирует конвейер обработки согласно варианту осуществления настоящего изобретения.
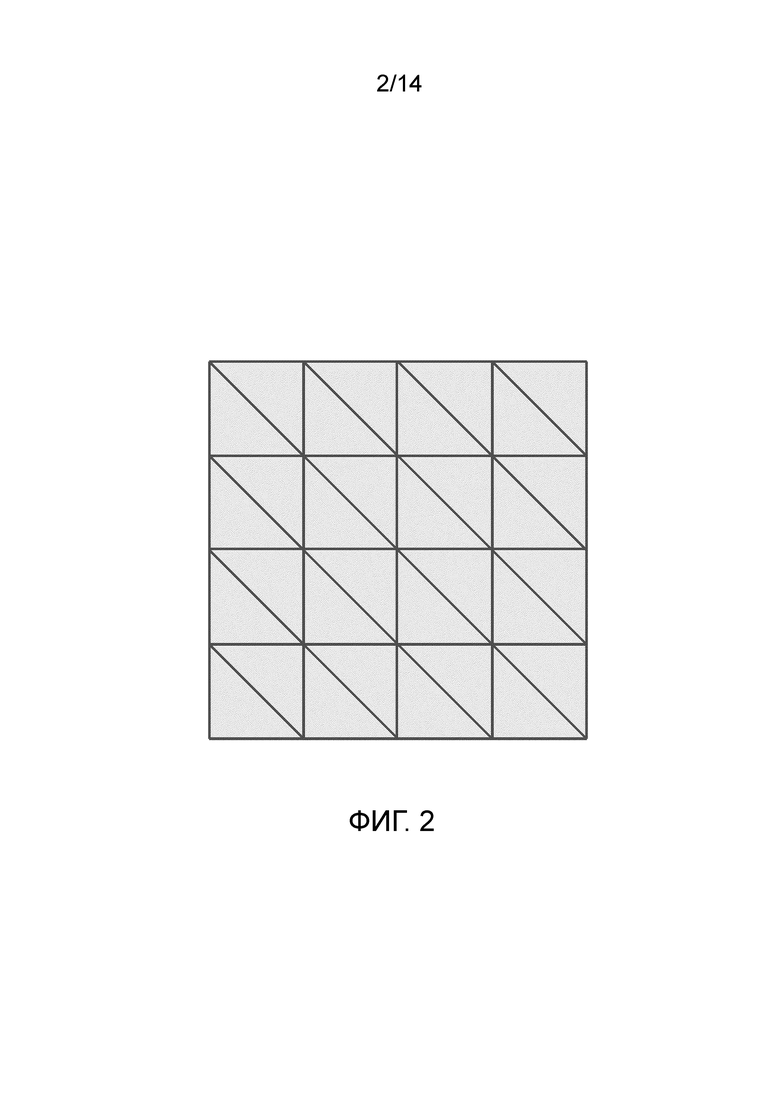
Фиг. 2 иллюстрирует неограничивающий вариант схемы слоя сетки, которая может использоваться для представления каждого слоя спрогнозированной многослойной структуры сцены согласно варианту осуществления настоящего изобретения.
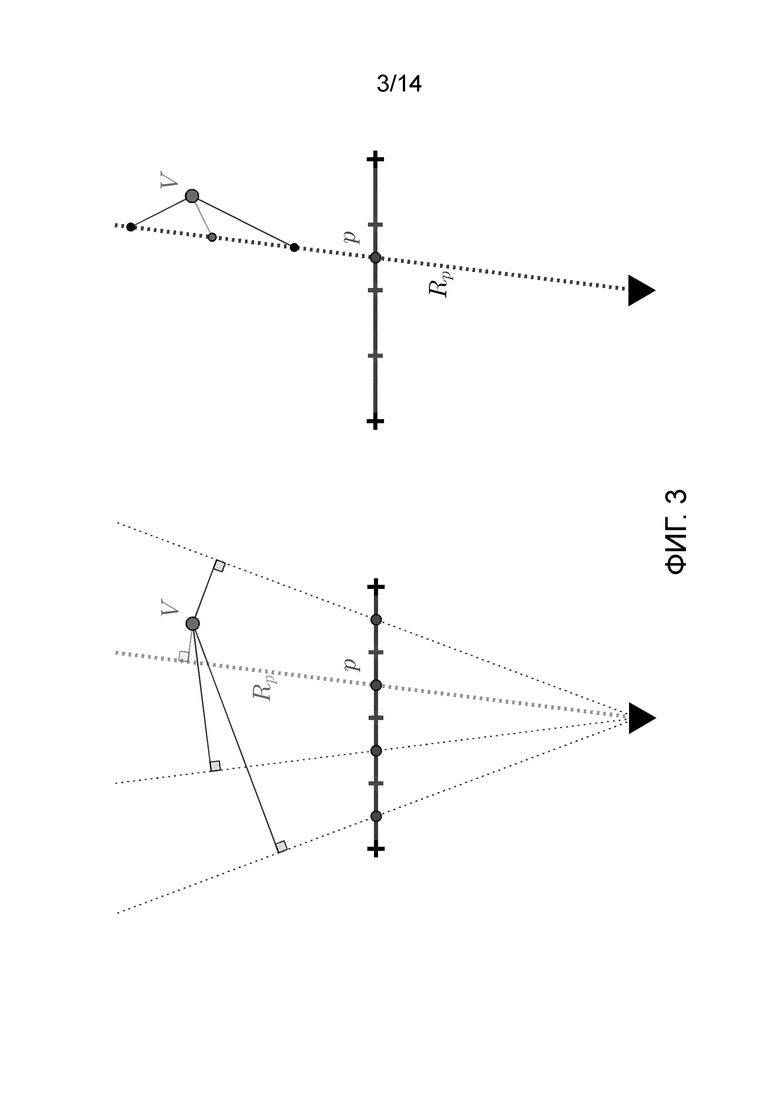
Фиг. 3 иллюстрирует вычисление геометрической потери согласно варианту осуществления настоящего изобретения.
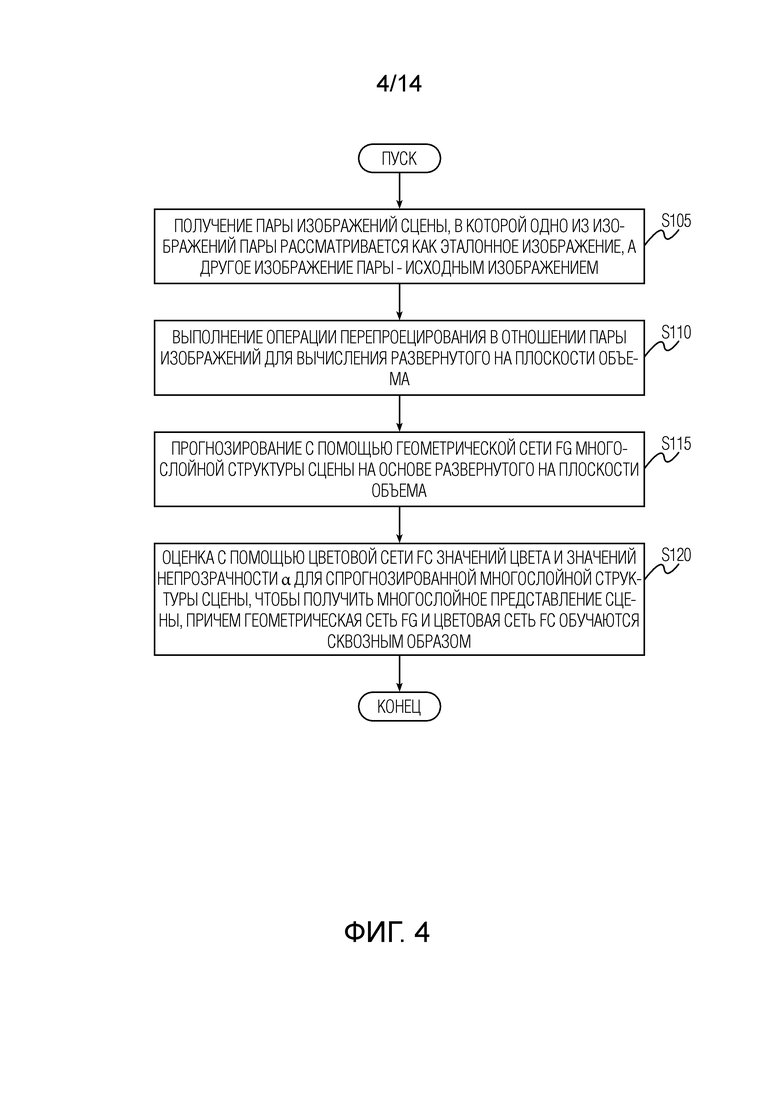
Фиг. 4 иллюстрирует способ создания многослойного представления сцены согласно варианту осуществления настоящего изобретения.
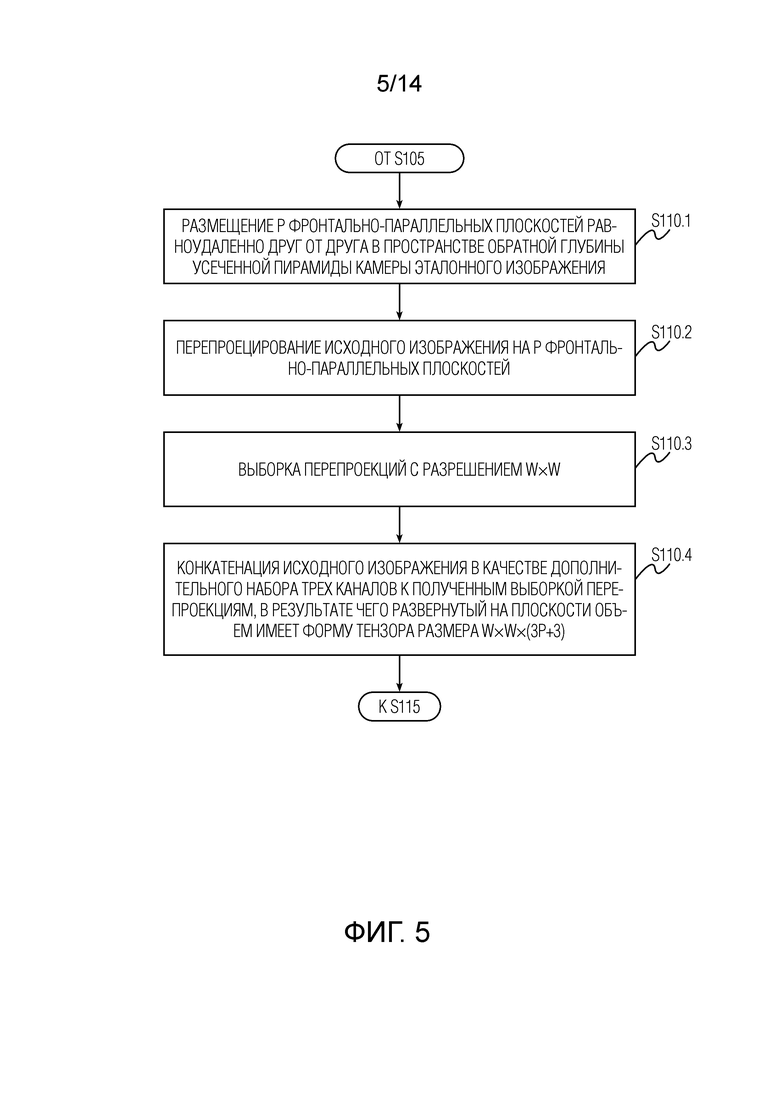
Фиг. 5 иллюстрирует детали этапа выполнения операции перепроецирования в отношении пары изображений для создания развернутого на плоскости объема согласно варианту осуществления настоящего изобретения; этот этап содержится в способе, показанном на фиг. 4.
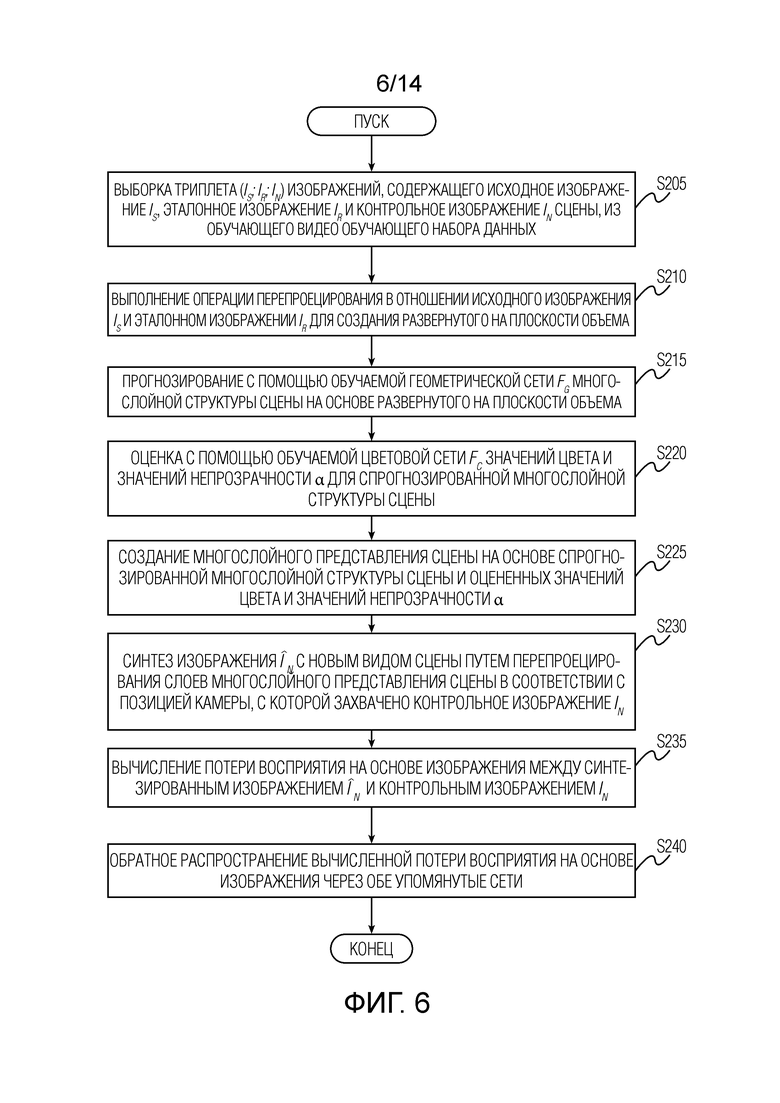
Фиг. 6 иллюстрирует детали этапа вычисления и обратного распространения потери восприятия на основе изображения на этапе обучения геометрической сети и цветовой сети согласно варианту осуществления настоящего изобретения.
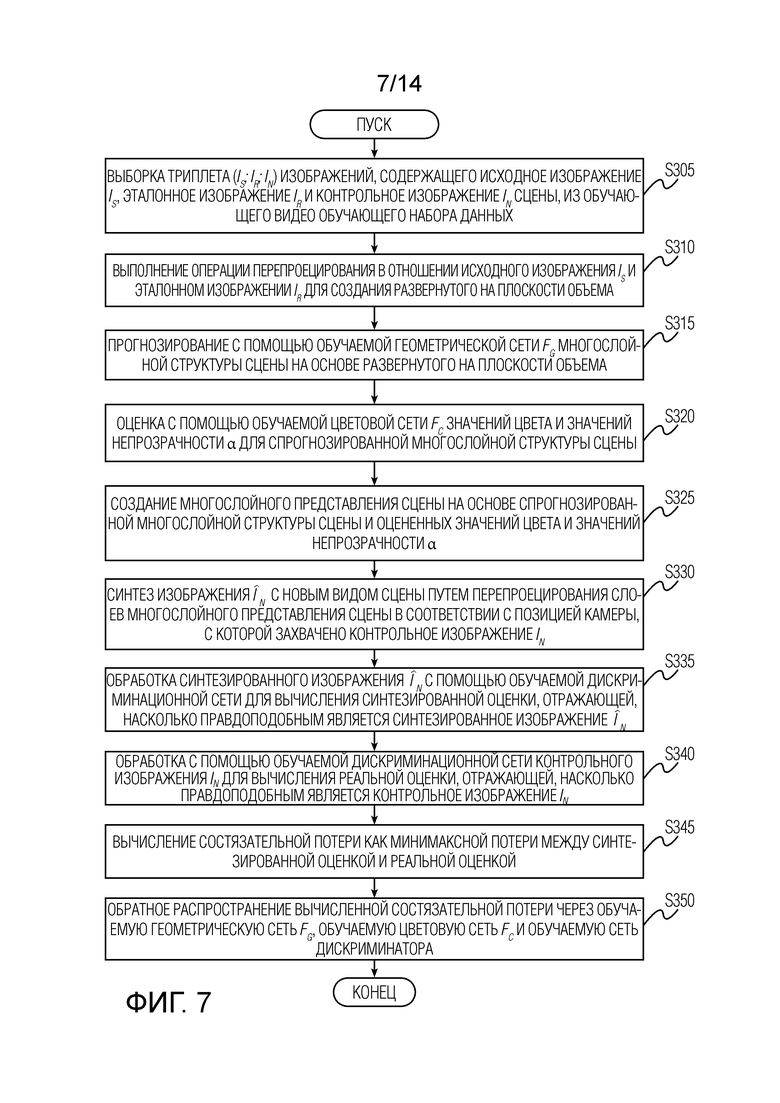
Фиг. 7 иллюстрирует детали этапа вычисления и обратного распространения состязательной потери на этапе обучения геометрической сети, цветовой сети и дискриминационной сети согласно варианту осуществления настоящего изобретения.
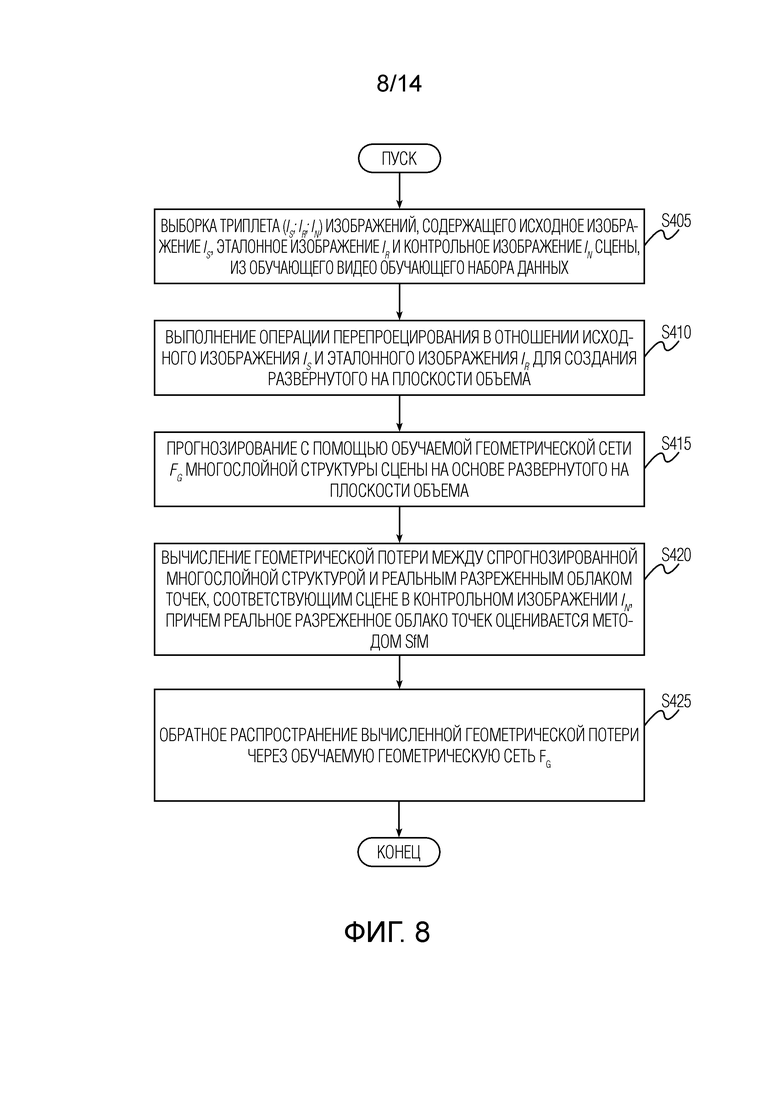
Фиг. 8 иллюстрирует детали этапа вычисления и обратного распространения геометрической потери на этапе обучения геометрической сети согласно варианту осуществления настоящего изобретения.
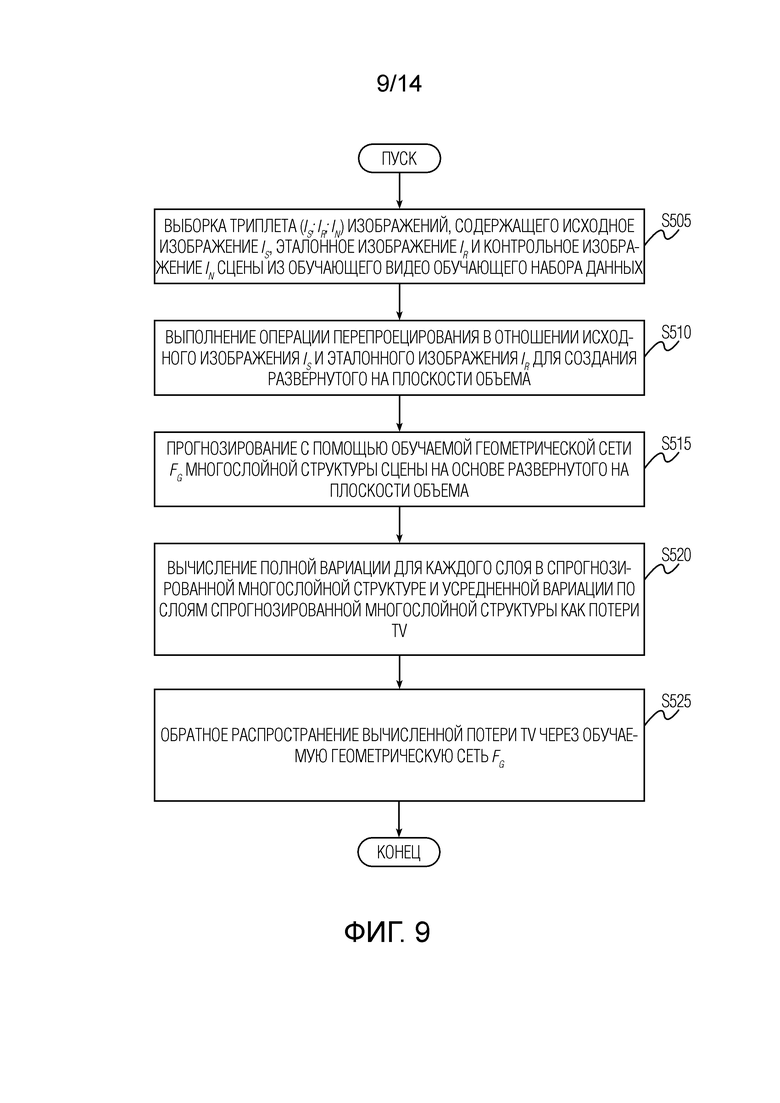
Фиг. 9 иллюстрирует детали этапа вычисления и обратного распространения потери полной вариации (TV) на этапе обучения геометрической сети согласно варианту осуществления настоящего изобретения.
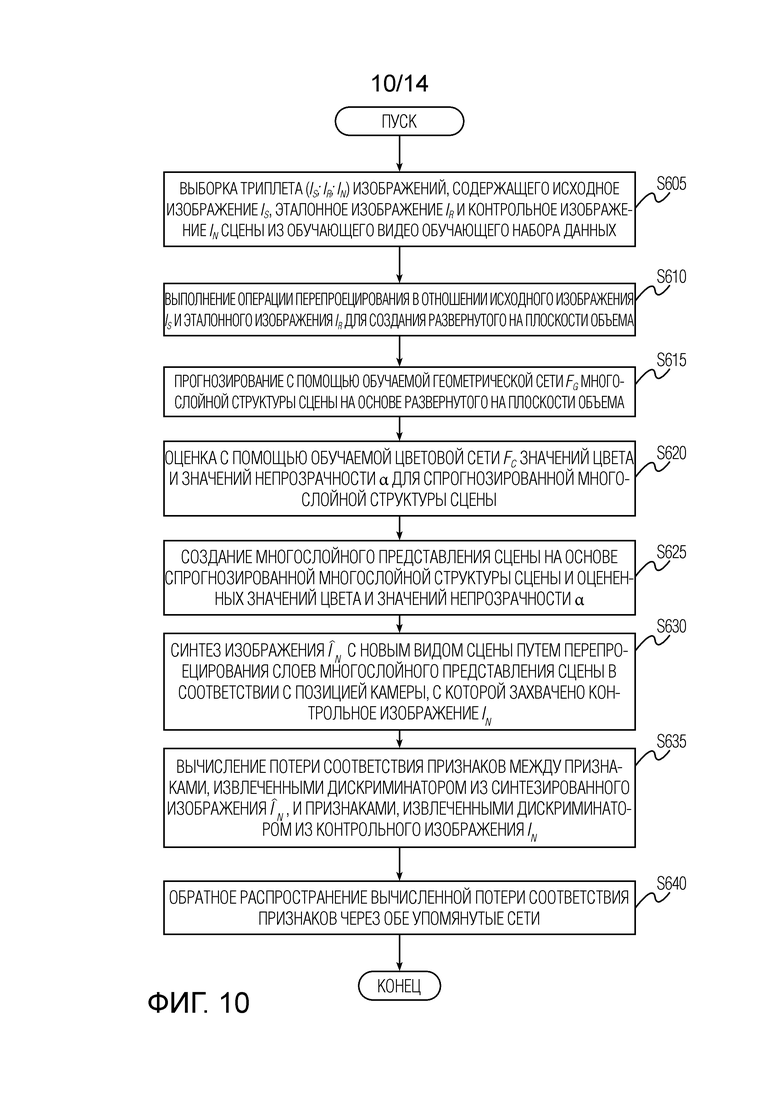
Фиг. 10 иллюстрирует детали этапа вычисления и обратного распространения потери соответствия признаков на этапе обучения геометрической сети, цветовую сеть и дискриминационной сети согласно варианту осуществления настоящего изобретения.
Фиг. 11 иллюстрирует примеры входных изображений (верхний ряд) и соответствующих облаков точек (нижний ряд) из вершин слоев сетки многослойной структуры, спрогнозированной с использованием геометрической сети согласно варианту осуществления настоящего изобретения.
Фиг. 12 иллюстрирует примеры новых видов (экстраполяции представлений), синтезированных для входных изображений (в среднем столбце) с использованием способа, показанного на фиг. 4.
Фиг. 13 иллюстрирует срезы по двум линиям четырех стереопар (показаны только эталонные изображения); каждая вершина сетки показана в виде точки со своим цветом RGBA.
Фиг. 14 схематически иллюстрирует вычислительное устройство согласно варианту осуществления настоящего изобретения.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0013] Сначала будет описана стадия использования (логического вывода) предлагаемого способа, а затем стадия обучения нейронных сетей и другие детали и реализации. На фиг. 4 показан способ создания многослойного представления сцены согласно варианту осуществления изобретения. Способ начинается с этапа S105 получения пары изображений сцены. Эта пара изображений может быть стереопарой, но без ограничения. В качестве альтернативы, пара изображений может быть, но без ограничения, изображениями одной и той же сцены, снятыми под разными углами. Любое одно из изображений пары принимается за эталонное изображение Ir, а другое из изображений пары - за исходное изображение Is. Эталонное изображение Ir и исходное изображение Is могут альтернативно называться эталонным видом и исходным видом, соответственно. Предполагается, что относительная позиция πs камеры исходного изображения относительно эталонного изображения и внутренние параметры Kr и Ks камеры, с которыми снимается стереопара, известны априори, например, определены заранее.
[0014] Изображения могут захватываться любой камерой, например, но без ограничения, обычной цифровой камерой, стереокамерой, 3D-камерой, стереосистемой и т.п., которые могут быть автономным оборудованием или частью электронного вычислительного устройства, такого как, например, смартфон. В качестве альтернативы, если получено разрешение на доступ к памяти электронного вычислительного устройства от пользователя устройства, то пару изображений можно получить из изображений, хранящихся в памяти, или выбрать из видео, хранящегося в памяти, два близких или соседних видеокадра.
[0015] Затем способ переходит к этапу S110 выполнения операции перепроецирования в отношении пары изображений для создания развернутого на плоскости объема (тензора, получаемого операцией "перепроецирования"). Детали этого этапа поясняются со ссылкой на фиг. 5. Этап S110 начинается с подэтапа S110.1 размещения P фронтально-параллельных плоскостей равноудаленно друг от друга в пространстве обратной глубины усеченной пирамиды камеры эталонного изображения. Под "фронтально-параллельными плоскостями" подразумеваются плоскости, по существу параллельные плоскости изображения, захваченного камерой, и расположенные перед камерой, возможно, на разных расстояниях от нее. Затем этап S110 переходит к подэтапу S110.2 перепроецирования исходного изображения на P фронтально-параллельных плоскостей. Проще говоря, на этом этапе выполняется оценка того, какие пиксели были бы видны, если бы на сцену смотрели из другого положения, определенного новыми координатами. Затем этап S110 переходит к подэтапу S110.3 выборки перепроекций с разрешением W×W. Этот этап можно пропустить, если разрешение перепроекции, полученной на предыдущем этапе, уже равно W×W. И наконец, этап S110 переходит к подэтапу S110.4 конкатенации исходного изображения в качестве дополнительного набора трех каналов к полученным выборкой перепроекциям, в результате чего развернутый на плоскости объем имеет форму тензора размера W×W×(3P+3).
[0015] Теперь возвратимся к описанию фиг. 4. После этапа S110 способ переходит к этапу S115 прогнозирования с использованием геометрической сети Fg многослойной структуры сцены на основе развернутого на плоскости объема. Многослойная структура сцены определяет геометрию L слоев сцены. Многослойная структура прогнозируется на этапе S115 геометрической сетью Fg в усеченной пирамиде камеры эталонного изображения. Архитектура геометрической сети Fg аналогична сети предсказания глубины SynSin, но с большим количеством входных и выходных карт признаков. Следовательно, можно сказать, что пара изображений обрабатывается асимметрично, поскольку многослойная структура предсказывается в усеченной пирамиде эталонной камеры, т.е. камеры, используемой для захвата эталонного изображения. Многослойная структура сцены состоит из L слоев, каждый из которых определяется картой глубины w×w, соответствующей глубине вдоль пучка лучей w×w, равномерно разнесенных в координатном пространстве эталонного изображения. Следовательно, такая параметризация позволяет получить неплоскую структуру слоев многослойной структуры. Таким образом, спрогнозированная многослойная структура сцены представляет собой тензор w×w×L, кодирующий геометрию всех L слоев.
[0017] Каждый из спрогнозированных слоев рассматривается как сетка (mesh), получаемая путем соединения каждой вершины с соседними шестью узлами. Таким образом, полученные L сеток (которые также могут называться "многослойной сеткой") представляют геометрию сцены. В общем, количество слоев L сетки может быть меньше количества исходных плоскостей P глубины, что приводит к более компактному и адаптированному к сцене представлению. В качестве неограничивающего примера L может быть равно, например, 4, а P может быть равно, например, 8. Однако также возможен случай, когда, например, P=L=8. Фиг. 2 иллюстрирует неограничивающий вариант схемы слоя сетки, который можно использовать для представления каждого слоя спрогнозированной многослойной структуры сцены. Каждый пиксель представляет собой вершину сетки (точку пересечения линий на рисунке), связанную со своими шестью соседями (вверх и вниз, влево и вправо и двумя соседями по диагонали). Способ также может включать в себя этапы (не показаны) переупорядочивания слоев L прогнозируемой многослойной структуры в соответствии с уменьшающейся средней глубиной, перепроецирования исходного изображения на каждый из L слоев прогнозируемой многослойной структуры сцены, выборки перепроекций с разрешением W×W и конкатенации эталонного изображения в качестве дополнительного набора трех каналов к полученным выборкой перепроекциям, в результате чего получается тензор размера W×W×(3L+3), представляющий спрогнозированную многослойную структуру. Чтобы сделать указанные операции перепроецирования дифференцируемыми относительно геометрии многослойной сетки можно использовать рендерер из PyTorch3D.
[0018] Наконец, после этапа S115, способ переходит к этапу S120 оценки с использованием цветовой сети Fc, значений цвета и значений непрозрачности α для прогнозируемой многослойной структуры сцены, чтобы получить многослойное представление сцены. Значения непрозрачности α используются в качестве весовых коэффициентов для оператора компоновки (Compose-Over), который применяется для синтеза нового вида для многослойного представления. Архитектура цветовой сети может соответствовать сетевой архитектуре, предложенной в НПЛ3. Для выполнения оценки на этапе S120 тензор размера W×W×(3L+3) обрабатывается цветовой сетью Fc, в результате чего получается тензор размера W×W×4L, содержащий оцененные значения цвета и значения непрозрачности α в каждом из положений W×W и на каждом из L слоев. Вычисленные значения цвета и значения непрозрачности α в каждом из положений W×W и на каждом из L слоев прогнозируемой многослойной структуры представляют данное многослойное представление. При оценке используются неплоские слои. Геометрическая сеть Fg, используемая на этапе S115, и цветовая сеть Fc, используемая на этапе S120, обучаются вместе (т.е. сквозным образом) перед стадией использования (логического вывода) предлагаемого способа, описанной выше. Сквозное обучение геометрической сети Fg и цветовой сети Fc будет подробно описано ниже.
[0019] После получения многослойного представления сцены его можно использовать для синтеза нового вида (видов) сцены с повышенной точностью синтеза. Для реализации этой функции способ может дополнительно содержать следующие этапы (не показаны): получение входной информации, определяющей требуемую позицию камеры для нового вида сцены, перепроецирование слоев многослойного представления сцены в соответствии с требуемой позицией камеры и компоновка перепроецированных слоев многослойного представления сцены в обратном порядке с помощью оператора компоновки для синтеза изображения с новым видом сцены. Входная информация содержит параметры камеры, включающие в себя параметры перемещения и поворота, характеризующие требуемую позицию камеры для нового вида сцены. Некоторые примеры новых видов (экстраполяций видов), синтезированных для входных изображений (в среднем столбце) с использованием метода, показанного на фиг. 4, показаны на фиг. 12. В проиллюстрированных примерах базовая модель увеличена в 5 раз. В неограничивающем варианте осуществления пользователь может вводить информацию, характеризующую требуемую позицию камеры для нового вида сцены, посредством сенсорного ввода, например, пользователь может провести вверх, вниз, влево или вправо по экрану электронного вычислительного устройства, отображающему изображение сцены, чтобы синтезировать новые виды сцены, повернутые в соответствующих направлениях вокруг центра сцены. В качестве альтернативы пользователь может ввести позицию и направление камеры для синтеза нового вида непосредственно в пространстве координат.
[0020] Теперь будет описано сквозное обучение геометрической сети Fg и цветовой сети Fc. Геометрическая сеть Fg и цветовая сеть Fc могут обучаться на основе обучающего набора данных из коротких видео статических сцен, для которых последовательности позиций камеры оцениваются методом "структуры из движения" (SfM). Геометрическая сеть Fg и цветовая сеть Fc обучаются сквозным образом путем минимизации взвешенной комбинации одной или нескольких из следующих потерь: потери восприятия на основе изображения, состязательной потери, геометрической потери и потери полной вариации (TV).
[0021] Потеря восприятия на основе изображения. Потеря восприятия на основе изображения - это основная потеря при обучении, которая возникает в результате контроля изображений. Например, при итерации обучения из обучающего видео выбирается триплет изображений (Is;Ir;In), содержащий исходное изображение Is, эталонное изображение Ir и новое (контрольное) изображение In. Учитывая текущие параметры сети (до начала обучения параметры/веса геометрической сети Fg и цветовой сети Fc могут быть инициализированы, например, случайным образом), из (Is;Ir) оцениваются геометрия сцены и текстуры, а затем полученное представление репроецируется на In, в результате чего получается спрогнозированное изображение 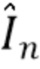 . Затем определяется потеря восприятия [14] между In и и осуществляется обратное распространение через геометрическую сеть Fg и цветовую сеть Fc.
. Затем определяется потеря восприятия [14] между In и и осуществляется обратное распространение через геометрическую сеть Fg и цветовую сеть Fc.
[0022] Фиг. 6 иллюстрирует детали этапа вычисления и обратного распространения потери восприятия на основе изображения на стадии обучения геометрической сети и цветовой сети согласно варианту осуществления настоящего изобретения. Этап вычисления потери восприятия на основе изображения на одной или нескольких итерациях обучения начинается с этапа S205 выборки триплета (Is;Ir;In) изображений, содержащего исходное изображение Is, эталонное изображение Ir и контрольное изображение In сцены, из обучающего видео обучающего набора данных. Затем этап вычисления потери восприятия на основе изображения переходит к этапу S210 выполнения операции перепроецирования в отношении исходного изображения Is и эталонного изображения Ir для создания развернутого на плоскости объема. Затем указанный этап переходит к этапу S215 прогнозирования с помощью обучаемой геометрической сети Fg многослойной структуры сцены на основе развернутого на плоскости объема. Далее упомянутый этап переходит к этапу S220 оценки с помощью обучаемой цветовой сети Fc значений цвета и значений непрозрачности α для спрогнозированной многослойной структуры сцены. Затем упомянутый этап переходит к этапу S225 создания многослойного представления сцены на основе спрогнозированной многослойной структуры сцены и оцененных значений цвета и значений непрозрачности α. На этапах обучения S210, S215, S220 и S225 воспроизводятся этапы использования S110, S115 и S120, проиллюстрированные и описанные выше со ссылкой на фиг. 4. Затем этап вычисления потери восприятия на основе изображения переходит к этапу S230 синтеза изображения с новым видом сцены путем перепроецирования слоев многослойного представления сцены в соответствии с позицией камеры, с которой захвачено контрольное изображение In. В заключение, этап вычисления потери восприятия на основе изображения переходит к этапу S235 вычисления потери восприятия на основе изображения между синтезированным изображением и контрольным изображением In и к этапу S240 обратного распространения вычисленной потери восприятия на основе изображения через обе упомянутые сети.
[0023] Состязательная потеря. К спрогнозированным изображениям 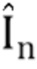 дополнительно применяется состязательная потеря. Основная цель состязательной потери состоит в уменьшении неестественных артефактов, таких как паразитные и дублирующие изображения. Состязательная потеря применяется путем обучения дискриминационной сети параллельно с основными сетями: геометрической сетью Fg и цветовой сетью Fc. Чтобы сделать состязательное обучение более эффективным, в него могут быть включены виртуальные виды. Например, во время одной или нескольких итераций вычисляется виртуальный вид, который отличается от вида In, и прогнозируется вид
дополнительно применяется состязательная потеря. Основная цель состязательной потери состоит в уменьшении неестественных артефактов, таких как паразитные и дублирующие изображения. Состязательная потеря применяется путем обучения дискриминационной сети параллельно с основными сетями: геометрической сетью Fg и цветовой сетью Fc. Чтобы сделать состязательное обучение более эффективным, в него могут быть включены виртуальные виды. Например, во время одной или нескольких итераций вычисляется виртуальный вид, который отличается от вида In, и прогнозируется вид 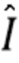 для этой камеры. Этот вид показывается дискриминатору как "фиктивный", и градиенты от дискриминатора используются для получения параметров геометрической сети Fg и цветовой сети Fc. Использование виртуального вида уменьшает переобучение и улучшает обобщение для видов с нехарактерным относительным положением по отношению исходного и эталонного видов (в обучающих данных большинство триплетов принадлежат плавной траектории камеры).
для этой камеры. Этот вид показывается дискриминатору как "фиктивный", и градиенты от дискриминатора используются для получения параметров геометрической сети Fg и цветовой сети Fc. Использование виртуального вида уменьшает переобучение и улучшает обобщение для видов с нехарактерным относительным положением по отношению исходного и эталонного видов (в обучающих данных большинство триплетов принадлежат плавной траектории камеры).
[0024] Фиг. 7 иллюстрирует детали этапа вычисления и обратного распространения состязательной потери на этапе обучения геометрической сети, цветовой сети и дискриминационной сети согласно варианту осуществления настоящего изобретения. Этап вычисления состязательной потери на одной или нескольких итерациях обучения начинается с этапа S305. Этапы S305, S310, S315, S320, S325, S330, проиллюстрированные на фиг. 7, соответствуют этапам S205, S210, S215, S220, S225, S230, соответственно, которые были описаны выше со ссылкой на фиг. 6. Поэтому для краткости здесь опущены повторные описания этапов S305, S310, S315, S320, S325, S330. После этапа S330 этап вычисления состязательной потери переходит к этапу S335 обработки синтезированного изображения с помощью обучаемой дискриминационной сети для вычисления синтезированной оценки, отражающей, насколько правдоподобным является синтезированное изображение , и к этапу S340 обработки с помощью обучаемой дискриминационной сети контрольного изображения In для вычисления реальной оценки, отражающей, насколько правдоподобным является контрольное изображение In. Затем на этапе S345 вычисляется состязательная потеря как минимаксная потеря между синтезированной оценкой и реальной оценкой. В заключение, осуществляют обратное распространение вычисленной состязательной потери на этапе S350 через обучаемую геометрическую сеть Fg, обучаемую цветовую сеть Fc и обучаемую сеть дискриминатора.
[0025] Геометрическая потеря. Хотя потерю на основе изображения можно использовать отдельно для обучения обеих сетей, авторы настоящего изобретения сочли полезным использовать контроль из разреженного облака точек. Практически любой подход SfM создает разреженное облако точек в процессе регистрации видеопоследовательности, поэтому получение разреженного облака точек не требует дополнительных затрат. В частности, было обнаружено, что геометрическая потеря, возникающая в результате таких разреженных облаков точек, может стимулировать обучение, особенно на его ранних стадиях. Геометрическая потеря по существу требует, чтобы спрогнозированные слои покрывали ту часть облака точек, которая попадает в усеченную пирамиду эталонного изображения. Следует отметить, что геометрическая потеря вычисляются на основе вывода геометрической сети Fg и не влияет на цветовую сеть Fc.
[0026] На фиг. 3 представлен пример для визуализации, как вычисляется геометрическая потеря согласно варианту осуществления настоящего изобретения. Проиллюстрирован двухмерный случай. Разрешение геометрии слоев w установлено на 4, а количество слоев L - на 3. Этап 1 (слева на фиг. 3): для каждой точки V направляющего разреженного облака точек ближайший луч Rp определяется как исходящий из эталонной камеры с точечной диафрагмой и проходящий через центр пикселя p эталонного вида. Этап 2 (справа на фиг. 3): его целью является минимизация расстояния между V и ближайшей из L вершин сетки, соответствующих пикселю p на выходе геометрической сети. В качестве альтернативы, в некоторых вариантах может быть предварительно вычислено положение ближайшего пикселя или рассчитана потеря с помощью субдискретизированных карт глубины.
[0027] Фиг. 8 иллюстрирует детали этапа вычисления и обратного распространения геометрической потери на этапе обучения геометрической сети согласно варианту осуществления настоящего изобретения. Этап вычисления геометрической потери на одной или нескольких итерациях обучения начинается с этапа S405. Этапы S405, S410, S415, проиллюстрированные на фиг. 8, соответствуют этапам S205, S210, S215, соответственно, которые были описаны выше со ссылкой на фиг. 6. Поэтому для краткости здесь опущены повторяющиеся описания этапов S405, S410, S415. После этапа S415 этап вычисления геометрической потери переходит к этапу S420 вычисления геометрической потери между спрогнозированной многослойной структурой и реальным разреженным облаком точек, соответствующим сцене в контрольном изображении In, причем реальное разреженное облако точек оценивается методом SfM. В заключение, осуществляют обратное распространение вычисленной геометрической потери на этапе S425 через обучаемую геометрическую сеть Fg.
[0028] Потеря полной вариации (TV). Геометрию слоев можно дополнительно упорядочить, применив потерю TV к глубине каждого слоя (полная вариация вычисляется для каждой из карт w×w, кодирующих глубины). Фиг. 9 иллюстрирует детали этапа вычисления и обратного распространения потери TV на стадии обучения геометрической сети согласно варианту осуществления настоящего изобретения. Этап вычисления потери TV на одной или нескольких итерациях обучения начинается с этапа S505. Этапы S505, S510, S515, проиллюстрированные на фиг. 9, соответствуют этапам S205, S210, S215, соответственно, которые описаны выше со ссылкой на фиг. 6. Поэтому для краткости здесь опущены повторяющиеся описания этапов S505, S510, S515. После этапа S515 этап вычисления потери TV переходит к этапу S520 вычисления полной вариации для каждого слоя в спрогнозированной многослойной структуре и усредненной вариации по слоям спрогнозированной многослойной структуры как потери TV. В заключение, осуществляют обратное распространение вычисленной потери TV на этапе S525 через обучаемую геометрическую сеть Fg.
[0029] Потеря соответствия признаков. Фиг. 10 иллюстрирует детали этапа вычисления и обратного распространения потери соответствия признаков на этапе обучения геометрической сети, цветовой сети и дискриминационной сети согласно варианту осуществления настоящего изобретения. Этап вычисления потери соответствия признаков на одной или нескольких итерациях обучения начинается с этапа S605. Этапы S605, S610, S615, S620, S625, S630 и S640, проиллюстрированные на фиг. 10, соответствуют этапам S205, S210, S215, S220, S225, S230 и S240, соответственно, которые были описаны выше со ссылкой на фиг. 6. Поэтому повторные описания этапов S605, S610, S615, S620, S625, S630 и S640 здесь опущены для краткости. После этапа S630 этап вычисления потери соответствия признаков переходит к этапу S635 вычисления потери соответствия признаков между признаками, извлеченными дискриминатором из синтезированного изображения , и признаками, извлеченными дискриминатором из контрольного изображения In. Упомянутые признаки представляют собой предварительно активированные признаки (карты признаков), соответствующие на выходе (выходах) одного или более сверточных блоков дискриминатора. В заключение, осуществляют обратное распространение вычисленной потери соответствия признаков на этапе S640 через обе упомянутые сети и, при необходимости, через сеть дискриминатора.
[0030] Фиг. 11 иллюстрирует примеры входных изображений (верхний ряд из набора данных LLFF и набора данных SWORD, составленных авторами настоящего изобретения) и соответствующих облаков точек (нижний ряд), скомпонованных из вершин слоев сетки, реконструированных описанным способом. Сцены представлены в виде множества цветных полупрозрачных слоев сетки. Точки с непрозрачностью менее 0,5 опущены для визуализации. На фиг. 13 показаны реальные результаты предложенного способа, когда способ уже оценил как геометрию, так и цвета. Геометрия представлена изогнутыми линиями, которые примерно повторяют объем. Более конкретно, фиг. 13 иллюстрирует срезы по двум линиям четырех стереопар (показаны только эталонные изображения); каждая вершина сетки отображается в виде точки со своим цветом RGBA. Горизонтальная ось соответствует координате пикселя, а вертикальная ось - глубине вершины относительно эталонной камеры. Эти изображения демонстрируют, что обе сети, геометрическая и цветовая, участвуют в моделировании структуры сцены, подбирая значения глубины и непрозрачности для входных пар видов.
[0031] На фиг. 14 представлена схематическая иллюстрация вычислительного устройства 600 согласно варианту осуществления настоящего изобретения. Вычислительное устройство 600 содержит процессор 600.1 и память 600.2, в которой хранятся исполняемые процессором инструкции, которые при их выполнении процессором побуждают процессор выполнять любой или все аспекты раскрытого способа. Вычислительным устройством 600 может быть любое пользовательское электронное устройство, например, смартфон, планшет, ноутбук, умные часы, ПК и так далее. Процессор 600.1 функционально связан с памятью 600.2. Процессор 600.1 может включать в себя один или несколько процессоров. Процессор 600.1 может быть процессором общего назначения, например центральным процессором (CPU), процессором цифровых сигналов (DSP), процессором приложений (AP) или т.п., блоком обработки только графики, таким как графический процессор (GPU), блоком обработки видеоданных (VPU) и/или специализированным процессором AI, таким как нейронный процессор (NPU). Эти процессоры могут быть реализованы в виде специализированной интегральная схемы (ASIC), программируемой вентильной матрицы (FPGA) или системы на кристалле (SoC). Память 600.2 может включать в себя память любого типа, например, оперативную память (RAM) и постоянную память (ROM). Кроме исполняемой процессором инструкции для выполнения любых этапов предложенного способа, память 600.2 может хранить подлежащие обработке изображения, а также параметры и/или веса обученной геометрической сети Fg, обученной цветовой сети Fc, и, при необходимости, дискриминационной сети. Эти вычислительные устройства могут также содержать другие компоненты (не показаны), например (сенсорный) экран, средства ввода-вывода, камеру, средства связи, батарею, необходимые соединения между компонентами и процессором 600.1 и памятью 600.2, и так далее, без ограничений.
[0032] Предлагаемый способ также может быть реализован на машиночитаемом носителе (не показан), на котором хранятся исполняемые процессором инструкции, которые при их исполнении процессором вычислительного устройства побуждают устройство выполнять любой этап (этапы) предлагаемого способа. Интеллектуальные системы, обученные с использованием описанных выше принципов, могут обрабатывать любые типы данных. Фаза обучения может осуществляться в режиме онлайн или автономно. Фазы обучения и использования нейронных сетей могут выполняться на одном устройстве (только если аппаратная конфигурация такого устройства достаточна для выполнения фазы обучения, или на отдельных устройствах (например, сервер для фазы обучения, и смартфон для фазы использования). Обученные нейронные сети (в форме весов и других параметров/исполняемых процессором инструкций) могут передаваться на вычислительное устройство и храниться на нем для последующего использования.
[0033] По меньшей мере один из множества модулей может быть реализован через модель AI. Функция, связанная с AI, может выполняться через энергонезависимую память, энергозависимую память и процессор. Один или несколько процессоров управляют обработкой входных данных в соответствии с заранее определенным рабочим правилом или моделью искусственного интеллекта (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Предварительно определенное рабочее правило или модель искусственного интеллекта предоставляется посредством тренировки или обучения. В данном контексте предоставление посредством обучения означает, что, применяя алгоритм обучения к множеству обучающих данных, создается предварительно определенное рабочее правило или модель AI с требуемой характеристикой. Обучение может выполняться в самом устройстве, в котором выполняется AI согласно варианту осуществления, и/или может быть реализовано на отдельном сервере/системе.
[0034] Модель AI может состоять из множества уровней нейронной сети. Каждый уровень имеет множество значений весов и выполняет операцию уровня посредством вычисления предыдущего уровня и операции множества весов. Примеры нейронных сетей включают, помимо прочего, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети.
[0035] Алгоритм обучения - это метод обучения заранее определенного целевого устройства с использованием множества обучающих данных, чтобы побуждать, разрешать или давать команду целевому устройству выполнять определение или прогнозирование. Примеры алгоритмов обучения включают, без ограничения, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
[0036] Другие детали реализации, наборы данных и экспериментальные данные. Были проанализированы набор данных RealEstate10k, набор данных Local Lightfield Fusion (LLFF), представленный в предыдущих работах, а также предлагаемый новый набор данных SWORD. Подробная информация о трех наборах данных представлена ниже. Набор данных RealEstate10k содержит последовательные кадры из видео о недвижимости с параметрами камеры. Часть набора данных, использованная в экспериментах, состоит из 10 000 сцен для обучения и 7 700 сцен для тестирования. Набор данных RealEstate10k является наиболее популярным эталоном для новых конвейеров синтеза видов. Несмотря на относительно большой размер, разнообразие сцен в наборе данных ограничено. Этот набор данных не содержит достаточного количества сцен с центральными объектами и снимался преимущественно в помещении. Следовательно, модели, обученные на RealEstate10k, плохо обобщаются на сцены на открытом воздухе или сцены с большими близлежащими объектами.
[0037] Набор данных SWORD. Для оценки предложенных (и известных) методов и обучения нейронных сетей с улучшенной производительностью необходимы более разнообразные данные. Авторы настоящего изобретения собрали новый набор данных, который они назвали SWORD (Scenes With Occluded Regions Dataset, Сцены с перекрытыми областями). Новый набор данных содержит около 1500 обучающих сцен и 290 тестовых последовательностей, в среднем по 50 кадров на сцену. Этот набор данных был получен после обработки снятых вручную видеопоследовательностей статических реальных городских сцен.
[0038] Основным свойством этого набора данных является обилие близких объектов и, как следствие, большая распространенность перекрытий. Чтобы доказать это количественно, были рассчитаны площади перекрытий, то есть площади тех областей новых кадров, которые закрыты в эталонных кадрах. Для получения масок для таких регионов использовалась стандартная оценка оптического потока. Согласно этой эвристике, средняя площадь перекрытых частей изображения для SWORD примерно в пять раз больше, чем для данных RealEstate10k (14% против 3% соответственно). Это рационализирует сбор и использование SWORD и объясняет, что SWORD позволяет обучать более мощные модели, несмотря на меньший размер.
[0039] Набор данных LLFF. Набор данных LLFF - это еще один популярный набор данных с центральными объектами, выпущенный авторами Local Lightfield Fusion. Он слишком мал для обучения на нем (40 сцен), поэтому этот набор данных использовался в целях оценки только для тестирования моделей, обученных на двух других наборах данных.
[0040] Детали оценки. В качестве основной базовой модели использовалась система StereoMag (предложенная в НПЛ3). По умолчанию система StereoMag использует 32 равноудаленные друг от друга фронтально-параллельные плоскости (с равномерно разнесенной обратной глубиной), для которых текстуры цвета и прозрачности оцениваются глубокой сетью, работающей на развернутом на плоскости объеме. Исходная система StereoMag использует такую плоскостную геометрию для окончательной визуализации. В сравнениях эта базовая модель указывается как StereoMag-32 или просто StereoMag.
[0041] Кроме того, оценивался вариант Stereo-Mag (обозначенный как StereoMag-P), который объединяет 32 плоскости в восемь неплоских сеток (такое же количество, как в предложенной конфигурации по умолчанию). И наконец, для полноты картины обучася и оценивался вариант StereoMag с восемью плоскостями (StereoMag-8). Хотя система StereoMag была предложена некоторое время назад, она по-прежнему остается самой актуальной для вводов двух изображений, что оправдывает такой выбор базовых моделей.
[0042] Детали обучения. Как отмечалось выше, по умолчанию модель согласно настоящему изобретению обучается с L=8 слоями, если не указано другое число. Все модели обучались на 500 000 итерациях с размером пакета 1 на одном графическом процессоре NVIDIA P40. Для обучения были установлены следующие веса для описанных выше потерь: 1 для потери L1, 10 для потери восприятия, 5 для регуляризации TV, 1 для геометрической потери, 5 для состязательной потери и 5 для потери соответствия признаков. Градиент дискриминатора штрафовался на каждом 16 шаге с весом штрафа R1=0,0001. Большинство экспериментов проводилось с разрешением 256×256, за исключением нескольких экспериментов с высоким разрешением на моделях, которые обучались или применялись с разрешением 512×512. Квалифицированному специалисту должно быть понятно, что этап обучения может выполняться с другими параметрами конфигурации обучения.
[0043] Метрики. Для задачи нового вида и для измерения, насколько этот синтезированный вид похож на эталонное изображение, использовался стандартный оценочный процесс. Для этого вычислялись сходства по пиковому отношению сигнал/шум (PSNR), по структуре (SSIM) и по восприятию (LPIPS) [R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proc. CVPR,2018, Необоснованная эффективность глубинных признаков в качестве метрики восприятия. В Proc. CVPR, 2018]), а также недавно предложенная метрика FLIP [P. Andersson, J. Nilsson, T. Akenine-Moller, M. Oskarsson, K. Astrom, and M.D. Fairchild. FLIP: A Difference Evaluator for Alternating Images. In Proc. ACM SIGGRAPH, 2020. FLIP: Средство оценки различий для чередующихся изображений] между синтезированным изображением и эталонным изображением. Как предложенный способ, так и StereoMag создают сильные артефакты вблизи границ (хотя форма артефактов различается). Поэтому приграничные области были исключены из рассмотрения путем вычисления метрик по центральным частям кадров. Результаты представлены в следующей таблице 1. Как следует из таблицы 1, предложенный способ Ours (8 layers)” и “Ours (4 layers)” превзошел базовые модели для указанных наборов данных, несмотря на то, что в промежуточном представлении сцены было меньше слоев

[0044] В заключение, для определения правдоподобности созданных изображений исследовались человеческие предпочтения на платформе краудсорсинга. Оценка осуществлялась по следующему протоколу: оценщикам показали два коротких видео с виртуальной камерой, перемещающейся по заданной траектории в одной и той же сцене из SWORD (проверочная часть) или LLFF: одно видео было получено с использованием базовой модели, а второе - способом согласно изобретению. Пользователи должны были ответить, какое из двух видео им кажется более реалистичным. В общей сложности было создано 280 пар видео (120 из LLFF и 160 из сцен SWORD), и каждую пару оценивали десять разных участников. Результаты пользовательского исследования представлены в следующей таблице 2.
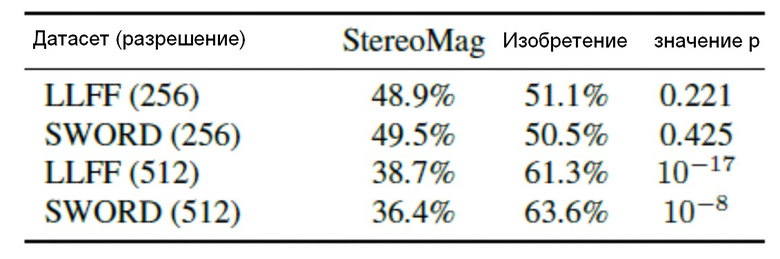
[0045] Столбцы содержат относительное количество пользователей, выбравших соответствующий результат как более реалистичный. Пользователям были показаны видео с движениями панорамирования, по спирали и масштабирования. Для SWORD пользователям также были показаны синтетические видео, соответствующие реальным траекториям. При более низком разрешении (256×256) оценщики не смогли определить победившую модель. При более высоком разрешении 512×512 пользователи явно предпочли результаты предложенного метода, даже если он обучался на более низком разрешении и применялся к более высокому разрешению полностью сверточным образом, тогда как система StereoMag переобучалась на высоком разрешении.
[0046] В настоящем изобретении предложен сквозной конвейер, который восстанавливает геометрию сцены из введенной стереопары, используя фиксированное количество полупрозрачных слоев. Несмотря на использование меньшего количества слоев (восемь против 32 в базовой модели StereoMag), предложенный способ продемонстрировал превосходное качество с точки зрения обычно используемых метрик для задачи синтеза нового вида. Было подтверждено, что предлагаемый метод можно обучать на нескольких наборах данных, он хорошо обобщается на невидимые данные и может применяться с более высоким разрешением. Полученную геометрию сетки можно эффективно визуализировать, используя стандартные графические движки, что делает этот подход привлекательным для мобильной 3D-фотографии. Кроме того, предложен новый сложный набор данных SWORD, содержащий перенасыщенные деталями сцены с сильно перекрытыми областями. Несмотря на то, что SWORD состоит из меньшего количества сцен, чем популярный набор данных RealEstate10K, системы, обученные на SWORD, вероятно, будут лучше обобщаться на другие наборы данных, например, LLFF.
[0047] Следует ясно понимать, что не все технические эффекты, упомянутые в данном документе, необходимо использовать в каждом и любом варианте осуществления настоящего метода. Например, варианты осуществления данного метода могут быть реализованы без получения пользователем некоторых из этих технических эффектов, в то время как другие варианты могут быть реализованы с получением пользователем других технических эффектов или вообще без них.
[0048] Хотя вышеописанные реализации были описаны и показаны со ссылкой на конкретные этапы, выполняемые в определенном порядке, следует понимать, что эти этапы могут быть объединены, разделены на части или переупорядочены без отклонения от сущности настоящего метода. Соответственно, порядок и группировка этапов не являются ограничением данного метода. Термин "содержит" или "включает" предназначен для обозначения открытости перечня перечисленных элементов, то есть означает, что могут содержаться или быть включены другие элементы, не перечисленные явным образом. Указание определенного элемента в единственном числе не означает, что таких элементов не может быть несколько, и наоборот. Конкретные значения параметров, указанные в приведенном выше описании, не следует рассматривать как ограничение раскрытого метода. Вместо этого эти значения можно рассматривать как значения, используемые в предпочтительном варианте осуществления. Однако специалистам в области искусственного интеллекта и архитектур нейронных сетей будет понятно, что такие значения в реальной реализации могут отличаться от предпочтительных значений, например, находиться в диапазоне ±30% от указанных предпочтительных значений.
[0049] Изменения и усовершенствования описанных выше реализаций настоящего метода могут быть очевидными для специалистов в данной области техники. Приведенное описание предназначено скорее для примера, чем для ограничения. Таким образом, объем настоящего изобретения ограничен исключительно объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| Способ построения представления сцены с прямой коррекцией для синтеза изображения в реальном времени | 2022 |
|
RU2799237C1 |
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |
| ГЕНЕРАТОРЫ ИЗОБРАЖЕНИЙ С УСЛОВНО НЕЗАВИСИМЫМ СИНТЕЗОМ ПИКСЕЛЕЙ | 2021 |
|
RU2770132C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| Способ и устройство для коррекции карт глубины для множества видов | 2023 |
|
RU2827434C1 |



Настоящее изобретение относится к способу и устройству для создания многослойного представления сцены. Технический результат заключается в повышении качества синтеза новых изображений. В способе получают пару изображений сцены, в которой одно изображение из пары рассматривается как эталонное изображение, а другое изображение из пары рассматривается как исходное изображение; выполняют операцию перепроецирования в отношении пары изображений для создания развернутого на плоскости объема; прогнозируют, используя геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема, и оценивают, используя цветовую сеть Fc, значения цвета и значения непрозрачности α для спрогнозированной многослойной структуры сцены, чтобы получить многослойное представление сцены; причем геометрическую сеть и цветовую сеть обучают сквозным образом, при этом геометрическую сеть обучают с использованием, по меньшей мере, геометрической потери, вычисляемой между прогнозируемой многослойной структурой и реальным разреженным облаком точек, соответствующим сцене в контрольном изображении, выбираемом из обучающего видео обучающего набора данных. 2 н. и 14 з.п. ф-лы, 14 ил.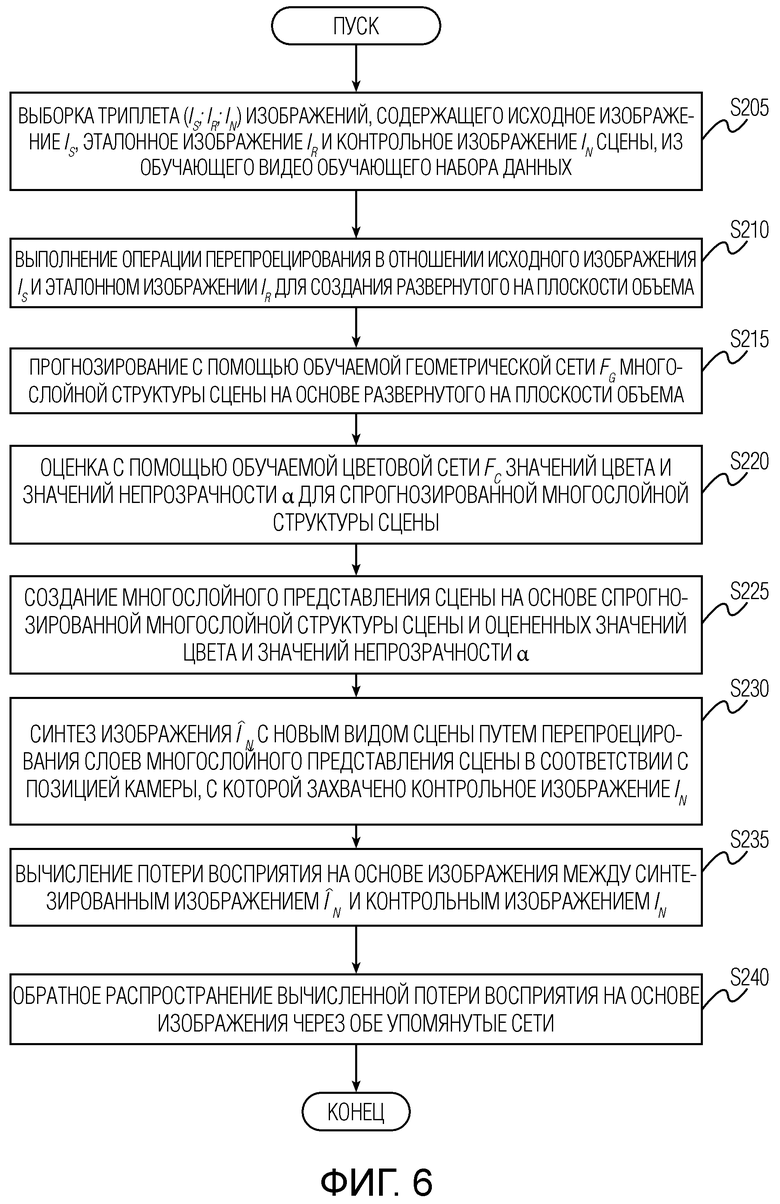
1. Способ создания многослойного представления сцены, заключающийся в том, что:
получают (S105) пару изображений сцены, в которой одно изображение из пары рассматривается как эталонное изображение, а другое изображение из пары рассматривается как исходное изображение;
выполняют (S110) операцию перепроецирования в отношении пары изображений для создания развернутого на плоскости объема;
прогнозируют (S115), используя геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема, и
оценивают (S120), используя цветовую сеть Fc, значения цвета и значения непрозрачности α для спрогнозированной многослойной структуры сцены, чтобы получить многослойное представление сцены;
причем геометрическую сеть и цветовую сеть обучают сквозным образом, при этом геометрическую сеть обучают с использованием, по меньшей мере, геометрической потери, вычисляемой между прогнозируемой многослойной структурой и реальным разреженным облаком точек, соответствующим сцене в контрольном изображении, выбираемом из обучающего видео обучающего набора данных.
2. Способ по п.1, в котором дополнительно:
принимают входную информацию, характеризующую требуемую позицию камеры для нового вида сцены;
перепроецируют слои многослойного представления сцены в соответствии с требуемой позицией камеры, и
компонуют перепроецированные слои многослойного представления сцены в обратном порядке, используя оператор компоновки, для синтеза изображения с новым видом сцены.
3. Способ по п.1, в котором пара изображений представляет собой стереопару,
причем относительная позиция πs камеры исходного изображения относительно эталонного изображения и внутренние параметры Kr и Ks камеры, с которыми захватывается стереопара, известны заранее.
4. Способ по п.1, в котором многослойную структуру прогнозируют (S115), используя геометрическую сеть, в усеченной пирамиде камеры эталонного изображения.
5. Способ по п.1, в котором этап выполнения (S110) операции перепроецирования в отношении пары изображений для создания развернутого на плоскости объема дополнительно содержит этапы, на которых:
размещают (S110.1) P фронтально-параллельных плоскостей равноудаленно друг от друга в пространстве обратной глубины усеченной пирамиды камеры эталонного изображения;
перепроецируют (S110.2) исходное изображение на P фронтально-параллельных плоскостей;
выполняют выборку (S110.3) перепроекций с разрешением W×W; и
конкатенируют (S110.4) исходное изображение в качестве дополнительного набора трех каналов к полученным выборкой перепроекциям, в результате чего получают развернутый на плоскости объем в форме тензора размера W×W×(3P+3).
6. Способ по п.1, в котором многослойная структура сцены содержит L слоев, каждый из L слоев характеризуется картой глубины w×w, соответствующей глубине вдоль пучка w×w лучей, равноудаленных друг от друга в координатном пространстве эталонного изображения, причем спрогнозированная многослойная структура сцены представляет собой тензор w×w×L, кодирующий геометрию всех L слоев.
7. Способ по п.6, в котором слои L спрогнозированной многослойной структуры переупорядочены согласно уменьшающейся средней глубине.
8. Способ по п. 1, дополнительно содержащий этапы, на которых:
перепроецируют исходное изображение на каждый из L слоев спрогнозированной многослойной структуры сцены;
выполняют выборку перепроекций с разрешением W×W, и
конкатенируют эталонное изображение в качестве дополнительного набора трех каналов к полученным выборкой перепроекциям, в результате чего получают тензор размера W×W×(3L+3);
причем этап оценки (S120) с использованием цветовой сети Fc значений цвета и значений непрозрачности α для спрогнозированной многослойной структуры сцены включает в себя этап, на котором:
обрабатывают тензор размера W×W×(3L+3), используя цветовую сеть Fc, для оценки значений цвета и значений непрозрачности α, в результате чего получают тензор размера W×W×4L, содержащий оцененные значения цвета и значения непрозрачности α в каждом из положений W×W и на каждом из L слоев.
9. Способ по п.1, в котором геометрическую сеть Fg и цветовую сеть Fc обучают на основе обучающего набора данных коротких видео статических сцен, для которых последовательности позиций камеры оценивают с помощью метода структуры из движения (SfM).
10. Способ по п.9, в котором геометрическую сеть Fg и цветовую сеть Fc обучают сквозным образом, минимизируя взвешенную комбинацию одной или нескольких из следующих потерь: потери восприятия на основе изображения, состязательной потери, геометрической потери, потери полной вариации (TV) и потери соответствия признаков.
11. Способ по п.10, в котором этап вычисления потери восприятия на основе изображения на одной или нескольких итерациях обучения включает в себя этапы, на которых:
выбирают (S205) триплет (Is;Ir;In) изображений, содержащий исходное изображение Is, эталонное изображение Ir и контрольное изображение In сцены из обучающего видео обучающего набора данных;
выполняют (S210) операцию перепроецирования в отношении исходного изображения Is и эталонного изображения Ir для создания развернутого на плоскости объема;
прогнозируют (S215), используя обучаемую геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема;
оценивают (S220), используя обучаемую цветовую сеть Fc, значения цвета и значения непрозрачности α для спрогнозированной многослойной структуры сцены;
создают (S225) многослойное представление сцены на основе спрогнозированной многослойной структуры сцены и оцененных значений цвета и значений непрозрачности α, и
синтезируют (S230) изображение 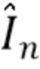 с новым видом сцены путем перепроецирования слоев многослойного представления сцены в соответствии с позицией камеры, с которой захвачено контрольное изображение In, и
с новым видом сцены путем перепроецирования слоев многослойного представления сцены в соответствии с позицией камеры, с которой захвачено контрольное изображение In, и
вычисляют (S235) потерю восприятия на основе изображения между синтезированным изображением и контрольным изображением In;
осуществляют обратное распространение (S240) вычисленной потери восприятия на основе изображения через обе упомянутые сети.
12. Способ по п.10, в котором этап вычисления состязательной потери на одной или нескольких итерациях обучения включает в себя этапы, на которых:
выбирают (S305) триплет (Is;Ir;In) изображений, содержащий исходное изображение Is, эталонное изображение Ir и контрольное изображение In сцены из обучающего видео обучающего набора данных;
выполняют (S310) операцию перепроецирования в отношении исходного изображения Is и эталонного изображения Ir для создания развернутого на плоскости объема;
прогнозируют (S315), используя обучаемую геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема;
оценивают (S320), используя обучаемую цветовую сеть Fc, значения цвета и значения непрозрачности α для спрогнозированной многослойной структуры сцены;
создают (S325) многослойное представление сцены на основе спрогнозированной многослойной структуры сцены и оцененных значений цвета и значений непрозрачности α, и
синтезируют (S330) изображение с новым видом сцены путем перепроецирования слоев многослойного представления сцены в соответствии с позицией камеры, с которой захвачено контрольное изображение In;
обрабатывают (S335), используя обучаемую дискриминационную сеть, синтезированное изображение для вычисления синтезированной оценки, отражающей, насколько правдоподобно синтезированное изображение ;
обрабатывают (S340), используя обучаемую дискриминационную сеть, контрольное изображение In для вычисления реальной оценки, отражающей, насколько правдоподобно контрольное изображение In;
вычисляют (S345) состязательную потерю как минимаксную потерю между синтезированной оценкой и реальной оценкой;
осуществляют обратное распространение (S350) вычисленной состязательной потери через обучаемую геометрическую сеть Fg, обучаемую цветовую сеть Fc и обучаемую дискриминационную сеть.
13. Способ по п.10, в котором этап вычисления упомянутой геометрической потери на одной или нескольких итерациях обучения включает в себя этапы, на которых:
выбирают (S405) триплет (Is;Ir;In) изображений, содержащий исходное изображение Is, эталонное изображение Ir и контрольное изображение In сцены, из обучающего видео обучающего набора данных;
выполняют (S410) операцию перепроецирования в отношении исходного изображения Is и эталонного изображения Ir для создания развернутого на плоскости объема;
прогнозируют (S415), используя обучаемую геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема;
вычисляют (S420) геометрическую потерю между спрогнозированной многослойной структурой и реальным разреженным облаком точек, соответствующим сцене в контрольном изображении In, причем реальное разреженное облако точек оценивают с помощью метода SfM;
осуществляют обратное распространение (S425) вычисленной геометрической потери через обучаемую геометрическую сеть Fg.
14. Способ по п.10, в котором этап вычисления потери TV на одной или нескольких итерациях обучения включает в себя этапы, на которых:
выбирают (S505) триплет (Is;Ir;In) изображений, содержащий исходное изображение Is, эталонное изображение Ir и контрольное изображение In сцены из обучающего видео обучающего набора данных;
выполняют (S510) операцию перепроецирования в отношении исходного изображения Is и эталонного изображения Ir для создания развернутого на плоскости объема;
прогнозируют (S515), используя обучаемую геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема;
вычисляют (S520) полную вариацию для каждого слоя в спрогнозированной многослойной структуре и усредненную вариацию по слоям спрогнозированной многослойной структуры в качестве потери TV; и
осуществляют обратное распространение (S525) вычисленной потери TV через обучаемую геометрическую сеть Fg.
15. Способ по п.10, в котором этап вычисления потери соответствия признаков на одной или нескольких итерациях обучения включает в себя этапы, на которых:
выбирают (S505) триплет (Is;Ir;In) изображений, содержащий исходное изображение Is, эталонное изображение Ir и контрольное изображение In сцены из обучающего видео обучающего набора данных;
выполняют (S610) операцию перепроецирования в отношении исходного изображения Is и эталонного изображения Ir для создания развернутого на плоскости объема;
прогнозируют (S615), используя обучаемую геометрическую сеть Fg, многослойную структуру сцены на основе развернутого на плоскости объема;
оценивают (S620), используя обучаемую цветовую сеть Fc, значения цвета и значения непрозрачности α для спрогнозированной многослойной структуры сцены;
создают (S625) многослойное представление сцены на основе спрогнозированной многослойной структуры сцены и оцененных значений цвета и значений непрозрачности α, и
синтезируют (S630) изображение с новым видом сцены путем перепроецирования слоев многослойного представления сцены в соответствии с позицией камеры, с которой захвачено контрольное изображение In, и
вычисляют (S635) потерю соответствия признаков между признаками, извлеченными дискриминационной сетью из синтезированного изображения , и признаками, извлеченными дискриминационной сетью из контрольного изображения In;
осуществляют обратное распространение (S640) вычисленной потери соответствия признаков через обе упомянутые сети.
16. Вычислительное устройство (600) для создания многослойного представления сцены, содержащее процессор (600.1) и память (600.2), хранящую исполняемые процессором инструкции, которые при исполнении процессором побуждают процессор выполнять способ по любому из пп.1-15.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 11055910 B1, 06.07.2021 | |||
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |

